A hybrid OSVM-OCNN Method for Crop Classification from Fine Spatial Resolution Remotely Sensed Imagery



Abstract
1. Introduction
2. Method
2.1. Overview of the Support Vector Machine (SVM)
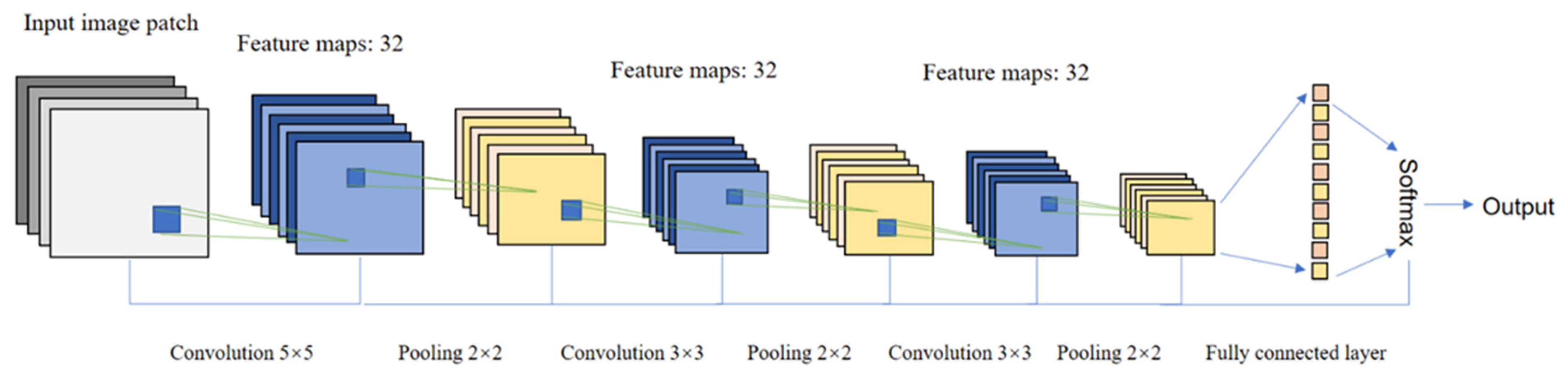
2.2. Overview of Convolutional Neural Networks (CNNs)
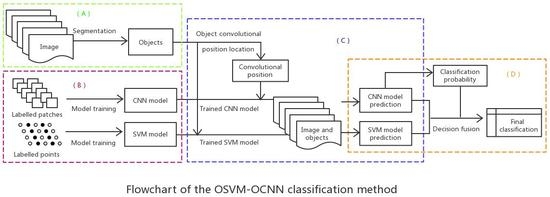
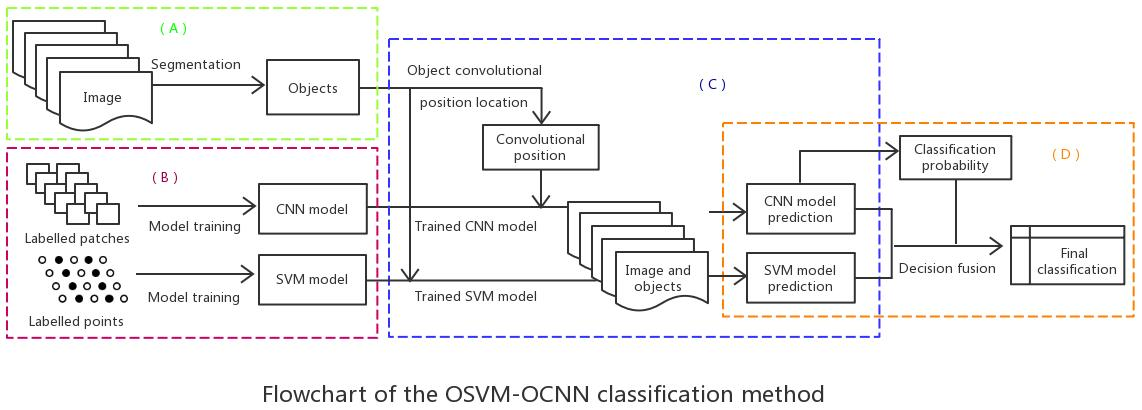
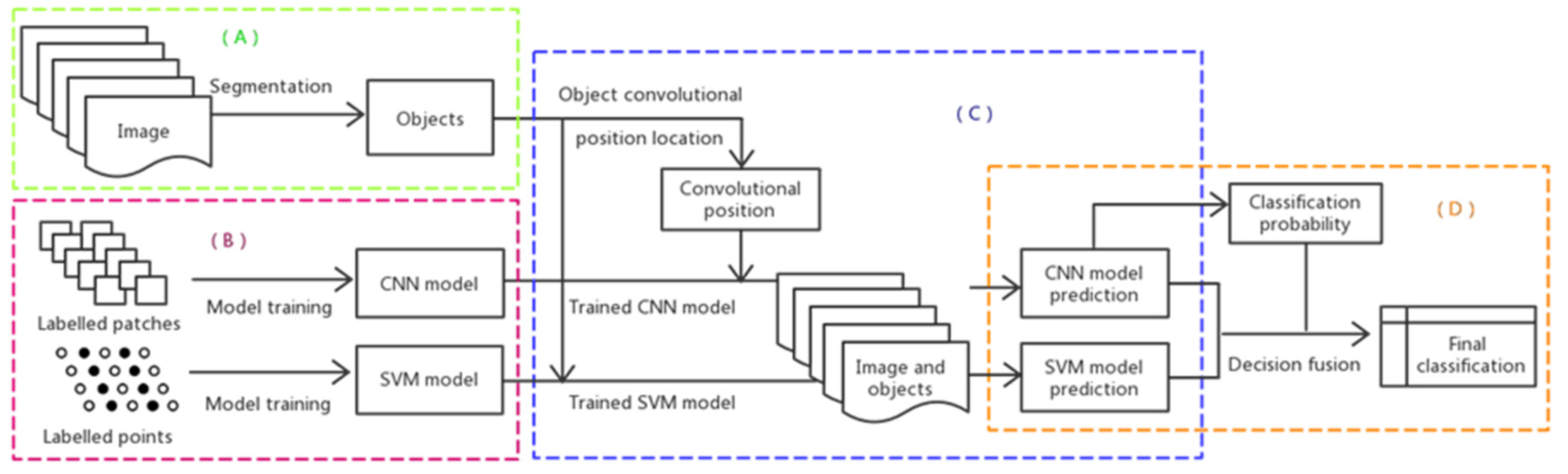
2.3. Hybrid Object-based SVM and CNN (OSVM-OCNN) Approach
2.3.1. Image Segmentation
2.3.2. SVM and CNN Model Training
2.3.3. SVM and CNN Model Inference
2.3.4. Decision Fusion of the SVM and CNN Models
3. Experimental Results
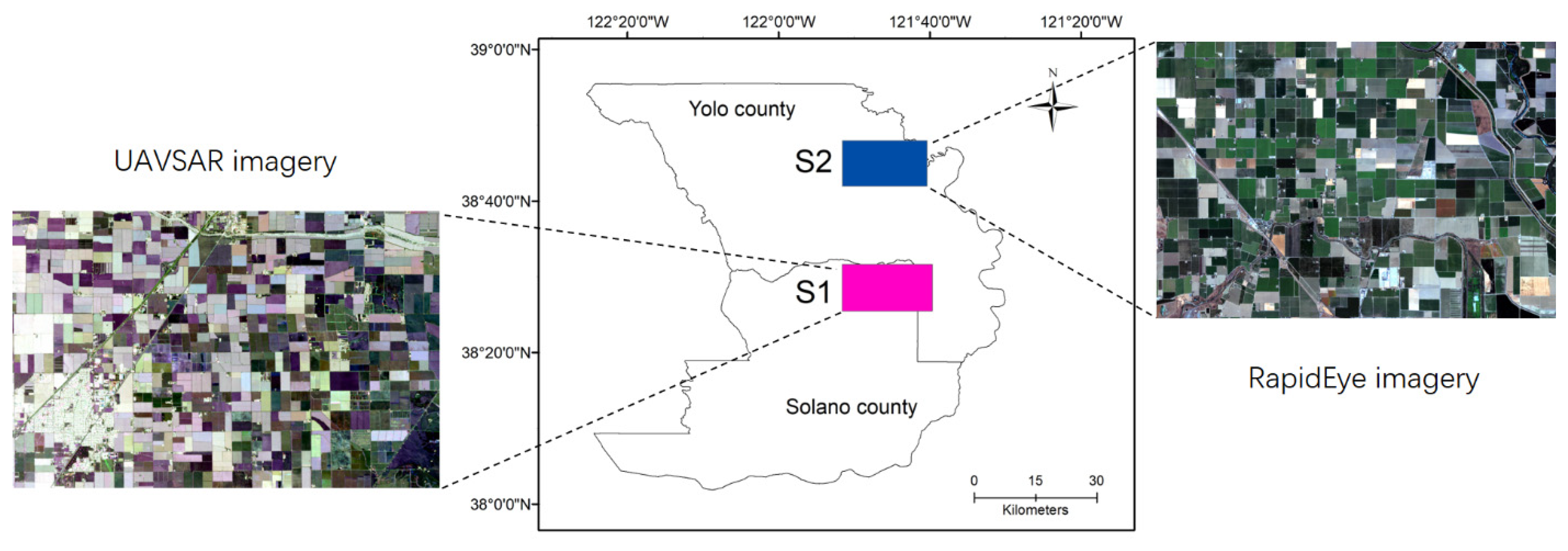
3.1. Study Area and Data
3.2. Model Structure and Parameters
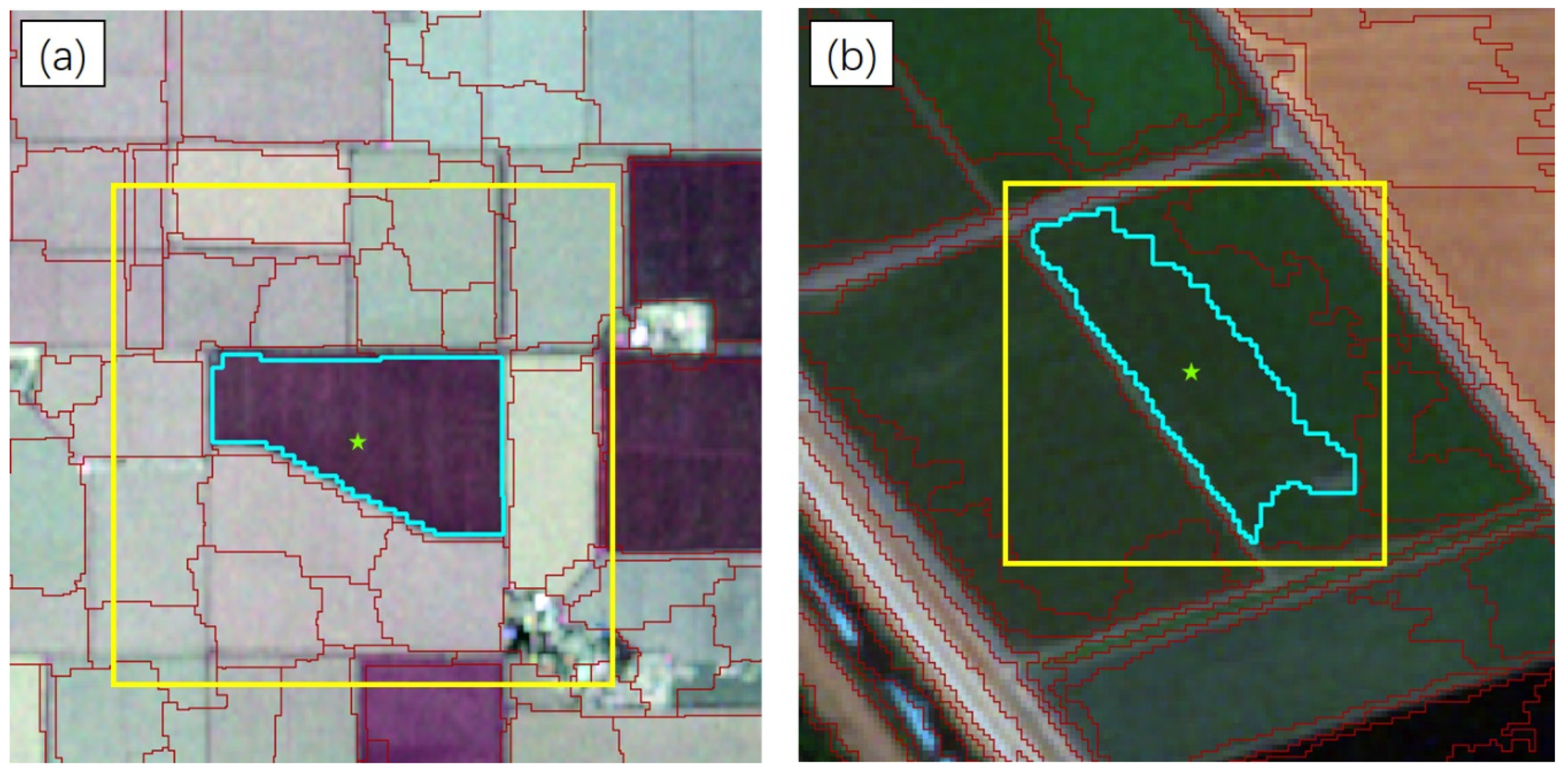
3.2.1. Segmentation Parameter
3.2.2. Model Structure and Parameter Settings
3.2.3. Pixel-wise Classifiers and Their Parameters
3.3. Decision Fusion Parameters
3.4. Results and Analysis
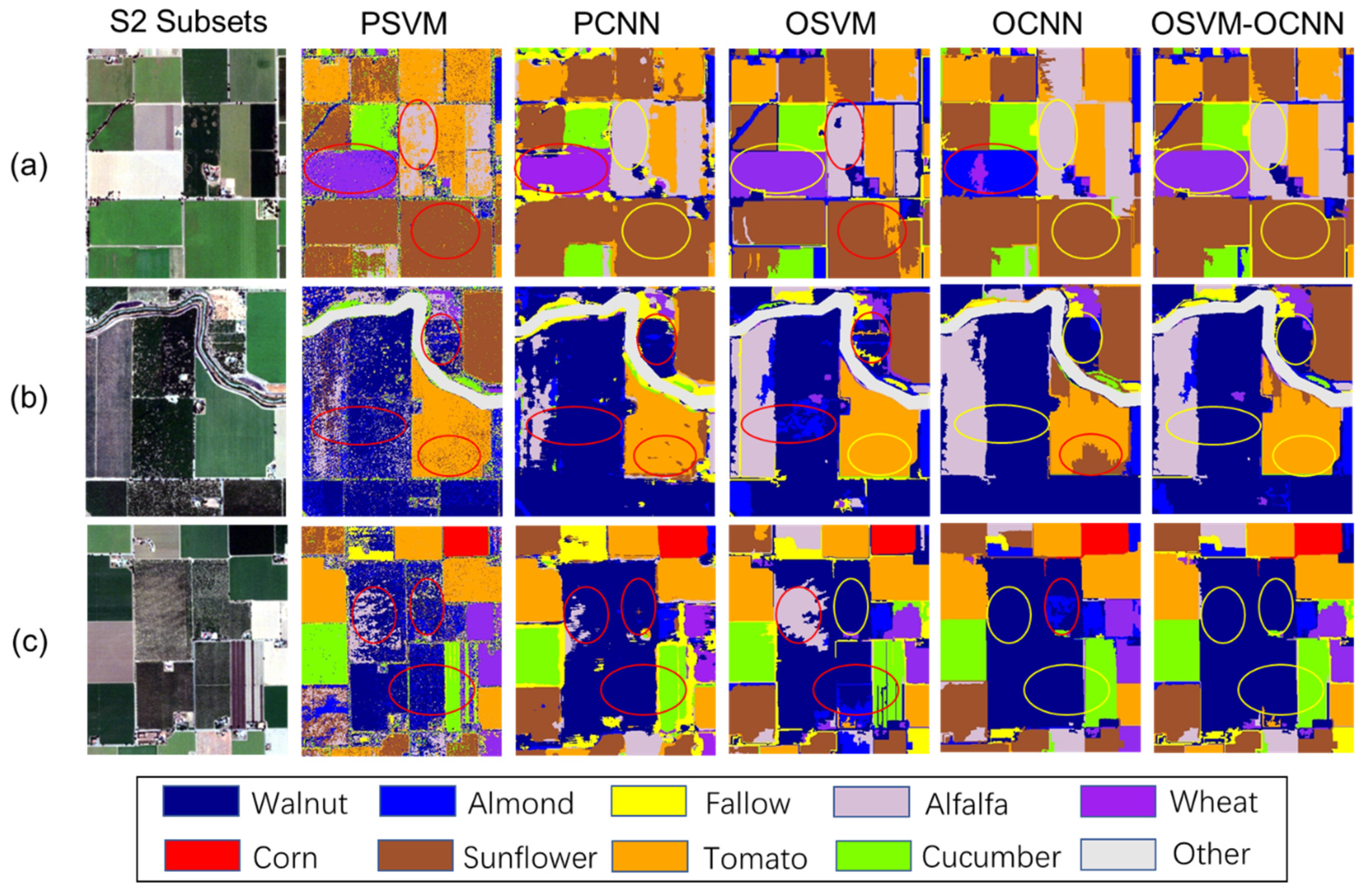
3.4.1. Classification Maps and Visual Assessment
3.4.2. Classification Accuracy Assessment
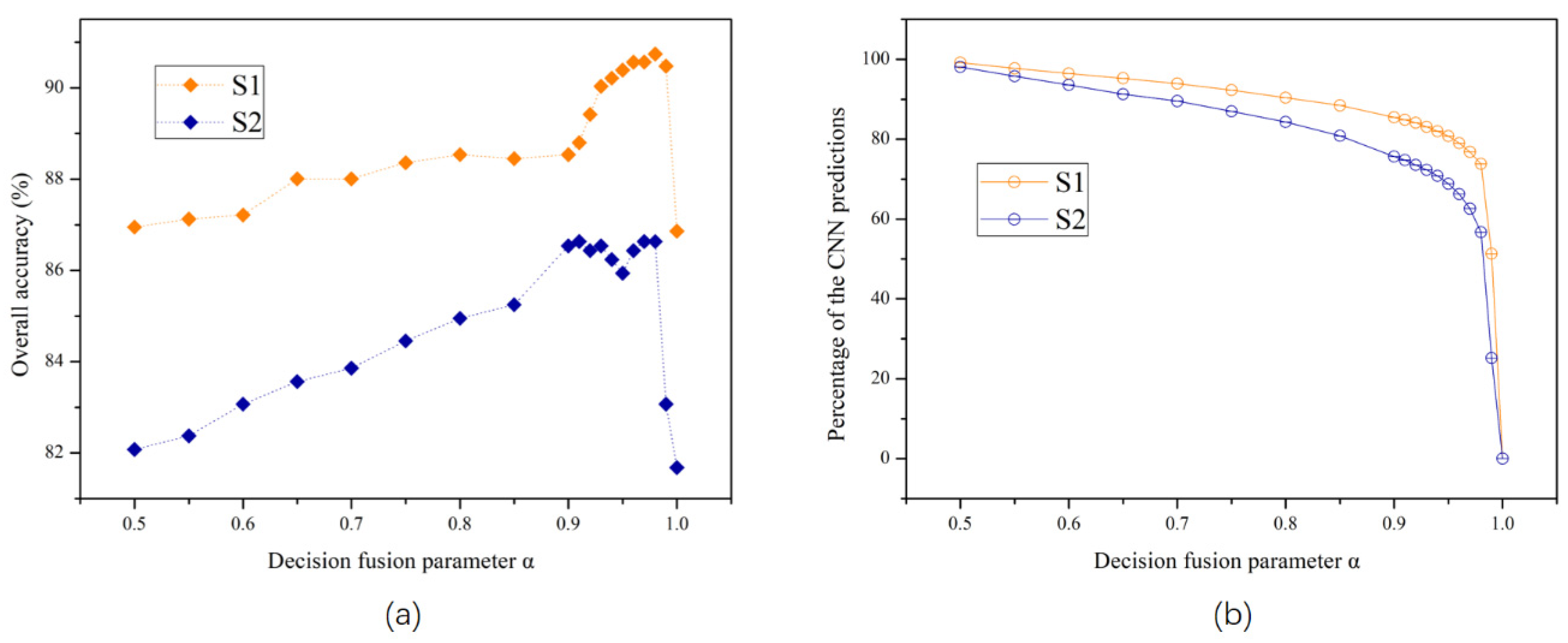
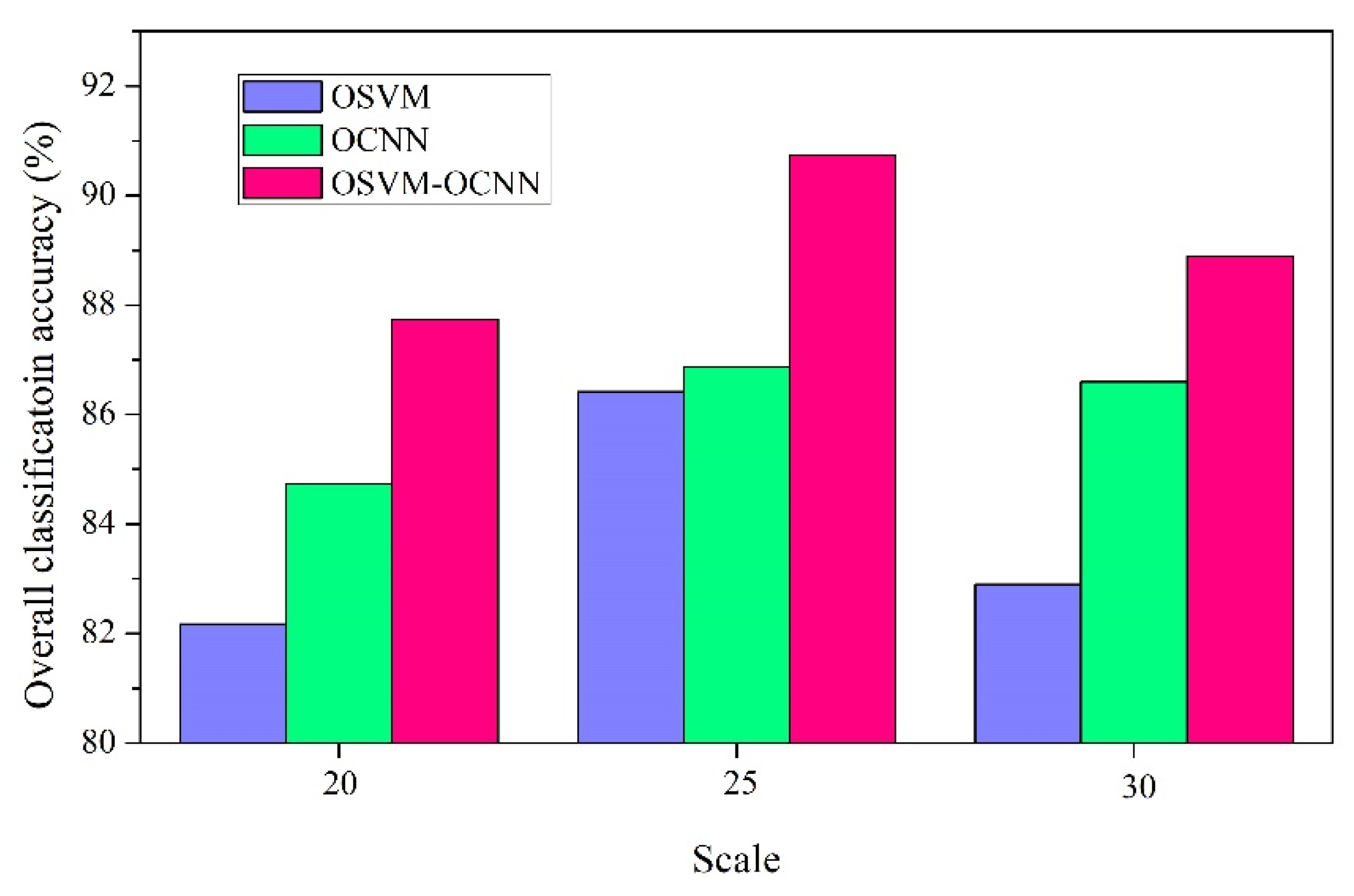
3.5. Influence of the Decision Fusion Parameter
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bastiaanssen, W.G.M.; Ali, S. A new crop yield forecasting model based on satellite measurements applied across the Indus Basin, Pakistan. Agric Ecosyst. Environ. 2003, 94, 321–340. [Google Scholar] [CrossRef]
- Pena-Barragan, J.M.; Ngugi, M.K.; Plant, R.E.; Six, J. Object-based crop identification using multiple vegetation indices, textural features and crop phenology. Remote Sens. Environ. 2011, 115, 1301–1316. [Google Scholar] [CrossRef]
- Zheng, B.J.; Myint, S.W.; Thenkabail, P.S.; Aggarwal, R.M. A support vector machine to identify irrigated crop types using time-series Landsat NDVI data. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 103–112. [Google Scholar] [CrossRef]
- Ramankutty, N.; Evan, A.T.; Monfreda, C.; Foley, J.A. Farming the planet: 1. Geographic distribution of global agricultural lands in the year 2000. Glob. Biogeochem. Cycles 2008, 22, 1. [Google Scholar] [CrossRef]
- Wardlow, B.D.; Egbert, S.L.; Kastens, J.H. Analysis of time-series MODIS 250 m vegetation index data for crop classification in the US Central Great Plains. Remote Sens. Environ. 2007, 108, 290–310. [Google Scholar] [CrossRef]
- Wardlow, B.D.; Egbert, S.L. Large-area crop mapping using time-series MODIS 250 m NDVI data: An assessment for the US Central Great Plains. Remote Sens. Environ. 2008, 112, 1096–1116. [Google Scholar] [CrossRef]
- Conrad, C.; Colditz, R.R.; Dech, S.; Klein, D.; Vlek, P.L.G. Temporal segmentation of MODIS time series for improving crop classification in Central Asian irrigation systems. Int. J. Remote Sens. 2011, 32, 8763–8778. [Google Scholar] [CrossRef]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Mulla, D.J. Twenty five years of remote sensing in precision agriculture: Key advances and remaining knowledge gaps. Biosyst. Eng. 2013, 114, 358–371. [Google Scholar] [CrossRef]
- Li, H.P.; Zhang, C.; Zhang, S.Q.; Atkinson, P.M. Crop classification from full-year fully-polarimetric L-band UAVSAR time-series using the Random Forest algorithm. Int. J. Appl. Earth Obs. 2020. under review. [Google Scholar]
- Li, H.P.; Zhang, C.; Zhang, S.Q.; Atkinson, P.M. Full year crop monitoring and separability assessment with fully-polarimetric L-band UAVSAR: A case study in the Sacramento Valley, California. Int. J. Appl. Earth Obs. 2019, 74, 45–56. [Google Scholar] [CrossRef]
- Atkinson, P.M.; Tatnall, A.R.L. Neural networks in remote sensing—Introduction. Int. J. Remote Sens. 1997, 18, 699–709. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Li, H.P.; Zhang, S.Q.; Zhang, C.; Li, P.; Cropp, R. A novel unsupervised Levy flight particle swarm optimization (ULPSO) method for multispectral remote-sensing image classification. Int. J. Remote Sens. 2017, 38, 6970–6992. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. Isprs J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Vuolo, F.; Neuwirth, M.; Immitzer, M.; Atzberger, C.; Ng, W.-T. How much does multi-temporal Sentinel-2 data improve crop type classification? Int. J. Appl. Earth Obs. Geoinf. 2018, 72, 122–130. [Google Scholar] [CrossRef]
- Immitzer, M.; Vuolo, F.; Atzberger, C. First Experience with Sentinel-2 Data for Crop and Tree Species Classifications in Central Europe. Remote Sens. 2016, 8, 166. [Google Scholar] [CrossRef]
- Defourny, P.; Bontemps, S.; Bellemans, N.; Cara, C.; Dedieu, G.; Guzzonato, E.; Hagolle, O.; Inglada, J.; Nicola, L.; Rabaute, T.; et al. Near real-time agriculture monitoring at national scale at parcel resolution: Performance assessment of the Sen2-Agri automated system in various cropping systems around the world. Remote Sens. Environ. 2019, 221, 551–568. [Google Scholar] [CrossRef]
- Castillejo-Gonzalez, I.L.; Lopez-Granados, F.; Garcia-Ferrer, A.; Pena-Barragan, J.M.; Jurado-Exposito, M.; de la Orden, M.S.; Gonzalez-Audicana, M. Object- and pixel-based analysis for mapping crops and their agro-environmental associated measures using QuickBird imagery. Comput. Electron. Agric. 2009, 68, 207–215. [Google Scholar] [CrossRef]
- Jiao, X.F.; Kovacs, J.M.; Shang, J.L.; McNairn, H.; Walters, D.; Ma, B.L.; Geng, X.Y. Object-oriented crop mapping and monitoring using multi-temporal polarimetric RADARSAT-2 data. Isprs J. Photogramm. Remote Sens. 2014, 96, 38–46. [Google Scholar] [CrossRef]
- Rogan, J.; Franklin, J.; Stow, D.; Miller, J.; Woodcock, C.; Roberts, D. Mapping land-cover modifications over large areas: A comparison of machine learning algorithms. Remote Sens. Environ. 2008, 112, 2272–2283. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Liu, X.L.; Bo, Y.C. Object-Based Crop Species Classification Based on the Combination of Airborne Hyperspectral Images and LiDAR Data. Remote Sens. 2015, 7, 922–950. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.P.; Gardiner, A.; Hare, J.; Atitinson, P.M. An object-based convolutional neural network (OCNN) for urban land use classification. Remote Sens. Environ. 2018, 216, 57–70. [Google Scholar] [CrossRef]
- Chen, Y.S.; Jiang, H.L.; Li, C.Y.; Jia, X.P.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Zhao, L.L.; Yang, J.; Li, P.X.; Zhang, L.P. Characteristics Analysis and Classification of Crop Harvest Patterns by Exploiting High-Frequency MultiPolarization SAR Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 3773–3783. [Google Scholar] [CrossRef]
- Walde, I.; Hese, S.; Berger, C.; Schmullius, C. From land cover-graphs to urban structure types. Int. J. Geogr. Inf. Sci. 2014, 28, 584–609. [Google Scholar] [CrossRef]
- Arvor, D.; Durieux, L.; Andres, S.; Laporte, M.A. Advances in Geographic Object-Based Image Analysis with ontologies: A review of main contributions and limitations from a remote sensing perspective. Isprs J. Photogramm. Remote Sens. 2013, 82, 125–137. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.P.; Gardiner, A.; Hare, J.; Atkinson, P.M. Joint Deep Learning for land cover and land use classification. Remote Sens. Environ. 2019, 221, 173–187. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Niu, X.X.; Suen, C.Y. A novel hybrid CNN-SVM classifier for recognizing handwritten digits. Pattern Recognit. 2012, 45, 1318–1325. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.M.; Chen, Y.J.; Meng, D.Y.; Zhang, L. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed]
- Cheng, G.; Zhou, P.C.; Han, J.W. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Langkvist, M.; Kiselev, A.; Alirezaie, M.; Loutfi, A. Classification and Segmentation of Satellite Orthoimagery Using Convolutional Neural Networks. Remote Sens. 2016, 8, 329. [Google Scholar] [CrossRef]
- Nogueira, K.; Penatti, O.A.B.; dos Santos, J.A. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef]
- Stoian, A.; Poulain, V.; Inglada, J.; Poughon, V.; Derksen, D. Land Cover Maps Production with High Resolution Satellite Image Time Series and Convolutional Neural Networks: Adaptations and Limits for Operational Systems. Remote Sens. 2019, 11, 1986. [Google Scholar] [CrossRef]
- Zhang, C.; Pan, X.; Li, H.P.; Gardiner, A.; Sargent, I.; Hare, J.; Atkinson, P.M. A hybrid MLP-CNN classifier for very fine resolution remotely sensed image classification. Isprs J. Photogramm. Remote Sens. 2018, 140, 133–144. [Google Scholar] [CrossRef]
- Low, F.; Conrad, C.; Michel, U. Decision fusion and non-parametric classifiers for land use mapping using multi-temporal RapidEye data. Isprs J. Photogramm. Remote Sens. 2015, 108, 191–204. [Google Scholar] [CrossRef]
- Clinton, N.; Yu, L.; Gong, P. Geographic stacking: Decision fusion to increase global land cover map accuracy. Isprs J. Photogramm. Remote Sens. 2015, 103, 57–65. [Google Scholar] [CrossRef]
- Du, P.J.; Xia, J.S.; Zhang, W.; Tan, K.; Liu, Y.; Liu, S.C. Multiple Classifier System for Remote Sensing Image Classification: A Review. Sensors 2012, 12, 4764–4792. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Vapnik, V. The Support Vector method of function estimation. In Nonlinear Modeling; Springer: Boston, MA, USA, 1998; pp. 55–85. [Google Scholar]
- Baatz, M.; Schaepe, A. Multiresolution Segmentation: An Optimization Approach for High Quality Multi-Scale Image Segmentation; Herbert Wichmann Verlag: Heidelberg, Germany, 2000. [Google Scholar]
- Cloude, S.R.; Pottier, E. An entropy based classification scheme for land applications of polarimetric SAR. IEEE Trans. Geosci. Remote Sens. 1997, 35, 68–78. [Google Scholar] [CrossRef]
- Freeman, A.; Durden, S.L. A three-component scattering model for polarimetric SAR data. IEEE Trans. Geosci. Remote Sens. 1998, 36, 963–973. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. Isprs J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Zhang, S.Q.; Zhang, J.Y.; Li, F.; Cropp, R. Vector analysis theory on landscape pattern (VATLP). Ecol. Model. 2006, 193, 492–502. [Google Scholar] [CrossRef]
- Hsu, C.; Chang, C.; Lin, C. A Practical Guide to Support Vector Classification; Department of Computer Science and Information Engineering, National Taiwan University: Taipei, Taiwan, 2010. [Google Scholar]
- California Agricultural Statistic, USDA’s National Agricultural Statistics Service. 2011. Available online: www.nass.usda.gov/ca (accessed on 10 February 2018).
- USDA NASS, National Agricultural Statistics Service Cropland Data Layer. 2011. Available online: http://nassgeodata.gmu.edu/CropScape (accessed on 13 February 2018).
- Fore, A.G.; Chapman, B.D.; Hawkins, B.P.; Hensley, S.; Jones, C.E.; Michel, T.R.; Muellerschoen, R.J. UAVSAR Polarimetric Calibration. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3481–3491. [Google Scholar] [CrossRef]
- Dickinson, C.; Siqueira, P.; Clewley, D.; Lucas, R. Classification of forest composition using polarimetric decomposition in multiple landscapes. Remote Sens. Environ. 2013, 131, 206–214. [Google Scholar] [CrossRef]
- RapidEye, Satellite Imagery Product Specifications. 2012. Available online: http://www. rapideye.com (accessed on 16 February 2018).
- Zhong, L.H.; Gong, P.; Biging, G.S. Phenology-based Crop Classification Algorithm and its Implications on Agricultural Water Use Assessments in California’s Central Valley. Photogramm. Eng. Remote Sens. 2012, 78, 799–813. [Google Scholar] [CrossRef]
- Definiens, A.G. Definiens eCognition Developer 8 Reference Book; Definiens AG: München, Germany, 2009. [Google Scholar]
- Huang, C.L.; Wang, C.J. A GA-based feature selection and parameters optimization for support vector machines. Expert Syst. Appl. 2006, 31, 231–240. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Gardiner, A.; Hare, J.; Atkinson, P.M. VPRS-Based Regional Decision Fusion of CNN and MRF Classifications for Very Fine Resolution Remotely Sensed Images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4507–4521. [Google Scholar] [CrossRef]
- Schultz, B.; Immitzer, M.; Formaggio, A.R.; Sanches, I.D.A.; Luiz, A.J.B.; Atzberger, C. Self-guided segmentation and classification of multi-temporal Landsat 8 images for crop type mapping in southwestern Brazil. Remote Sens. 2015, 7, 14482–14508. [Google Scholar] [CrossRef]
- Heumann, B.W. An Object-Based Classification of Mangroves Using a Hybrid Decision Tree-Support Vector Machine Approach. Remote Sens. 2011, 3, 2440–2460. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study Sites | Crop Class | Number of Objects | Training Sample | Testing Sample | Total Sample |
|---|---|---|---|---|---|
| S1 | Walnut | 31 | 112 | 112 | 224 |
| Almond | 33 | 110 | 110 | 220 | |
| Alfalfa | 55 | 125 | 125 | 250 | |
| Hay | 26 | 101 | 101 | 202 | |
| Clover | 41 | 110 | 110 | 220 | |
| Winter wheat | 68 | 120 | 120 | 240 | |
| Corn | 45 | 108 | 108 | 216 | |
| Sunflower | 47 | 122 | 122 | 244 | |
| Tomato | 58 | 120 | 120 | 240 | |
| Pepper | 32 | 106 | 106 | 212 | |
| S2 | Walnut | 39 | 108 | 108 | 216 |
| Almond | 45 | 115 | 115 | 230 | |
| Fallow | 30 | 90 | 90 | 180 | |
| Alfalfa | 35 | 124 | 124 | 248 | |
| Winter wheat | 40 | 116 | 116 | 232 | |
| Corn | 22 | 93 | 93 | 186 | |
| Sunflower | 57 | 130 | 130 | 260 | |
| Tomato | 63 | 141 | 141 | 282 | |
| Cucumber | 21 | 93 | 93 | 186 |
| Study Sites | Imagery | Scale | Colour/Shape | Smoothness/Compactness | Number of Objects | Mean Area of Objects (ha) |
|---|---|---|---|---|---|---|
| S1 | UAVSAR | 25 | 0.8/0.2 | 0.3/0.7 | 4210 | 4.64 |
| S2 | RapidEye | 130 | 0.9/0.1 | 0.2/0.8 | 9192 | 2.95 |
| Crop Type | PSVM | PCNN | OSVM | OCNN | OSVM-OCNN |
|---|---|---|---|---|---|
| Walnut | 80.91 | 87.85 | 84.58 | 91.89 | 96.33 |
| Almond | 76.56 | 88.60 | 86.76 | 91.15 | 95.65 |
| Alfalfa | 72.51 | 88.35 | 84.87 | 88.26 | 89.96 |
| Hay | 62.56 | 77.94 | 76.35 | 89.00 | 87.37 |
| Clover | 71.68 | 90.83 | 91.63 | 91.16 | 94.17 |
| Winter wheat | 70.13 | 64.68 | 83.47 | 80.49 | 83.26 |
| Corn | 83.82 | 88.00 | 89.20 | 95.89 | 96.39 |
| Sunflower | 69.60 | 80.46 | 95.51 | 85.96 | 93.62 |
| Tomato | 74.89 | 74.89 | 89.16 | 81.27 | 87.55 |
| Pepper | 63.16 | 70.71 | 80.18 | 74.40 | 83.10 |
| Overall accuracy (OA) | 72.75 | 81.31 | 86.42 | 86.86 | 90.74 |
| Kappa coefficient (k) | 0.70 | 0.79 | 0.85 | 0.85 | 0.90 |
| Crop Type | PSVM | PCNN | OSVM | OCNN | OSVM-OCNN |
|---|---|---|---|---|---|
| Walnut | 58.71 | 79.28 | 72.95 | 83.66 | 84.82 |
| Almond | 55.11 | 63.54 | 75.34 | 69.38 | 79.65 |
| Fallow | 61.08 | 66.36 | 70.93 | 70.37 | 78.82 |
| Alfalfa | 67.46 | 79.83 | 76.68 | 78.46 | 82.35 |
| Winter wheat | 79.52 | 80.70 | 88.89 | 83.66 | 91.92 |
| Corn | 96.67 | 95.19 | 97.24 | 98.36 | 99.46 |
| Sunflower | 70.64 | 83.02 | 81.66 | 85.07 | 87.69 |
| Tomato | 75.00 | 83.51 | 86.12 | 84.09 | 87.91 |
| Cucumber | 66.67 | 79.00 | 83.33 | 84.69 | 87.50 |
| Overall accuracy (OA) | 70.20 | 79.11 | 81.39 | 81.68 | 86.63 |
| Kappa coefficient (k) | 0.66 | 0.76 | 0.79 | 0.79 | 0.85 |
| Study Sites | Classifiers | Mcnemar Test z-Value | ||||
|---|---|---|---|---|---|---|
| PSVM | PCNN | OSVM | OCNN | OSVM-OCNN | ||
| S1 | PSVM | - | ||||
| PCNN | 5.98 | - | ||||
| OSVM | 8.55 | 3.44 | - | |||
| OCNN | 9.92 | 4.58 | 0.35 | - | ||
| OSVM-OCNN | 12.56 | 7.44 | 4.35 | 4.92 | - | |
| S2 | PSVM | - | ||||
| PCNN | 5.88 | - | ||||
| OSVM | 7.43 | 1.61 | - | |||
| OCNN | 7.40 | 1.80 | 0.21 | - | ||
| OSVM-OCNN | 10.76 | 5.63 | 6.57 | 4.32 | - | |
| Imagery | Date | Accuracy | PSVM | PCNN | OSVM | OCNN | OSVM-OCNN |
|---|---|---|---|---|---|---|---|
| UAVSAR | 03/10/2011 | OA | 57.23% | 68.17% | 67.37% | 68.61% | 70.28% |
| k | 0.52 | 0.65 | 0.64 | 0.65 | 0.67 | ||
| RapidEye | 07/09/2016 | OA | 52.77% | 68.32% | 73.56% | 72.77% | 76.44% |
| k | 0.47 | 0.64 | 0.70 | 0.69 | 0.73 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Zhang, C.; Zhang, S.; Atkinson, P.M. A hybrid OSVM-OCNN Method for Crop Classification from Fine Spatial Resolution Remotely Sensed Imagery. Remote Sens. 2019, 11, 2370. https://doi.org/10.3390/rs11202370
Li H, Zhang C, Zhang S, Atkinson PM. A hybrid OSVM-OCNN Method for Crop Classification from Fine Spatial Resolution Remotely Sensed Imagery. Remote Sensing. 2019; 11(20):2370. https://doi.org/10.3390/rs11202370
Chicago/Turabian StyleLi, Huapeng, Ce Zhang, Shuqing Zhang, and Peter M. Atkinson. 2019. "A hybrid OSVM-OCNN Method for Crop Classification from Fine Spatial Resolution Remotely Sensed Imagery" Remote Sensing 11, no. 20: 2370. https://doi.org/10.3390/rs11202370
APA StyleLi, H., Zhang, C., Zhang, S., & Atkinson, P. M. (2019). A hybrid OSVM-OCNN Method for Crop Classification from Fine Spatial Resolution Remotely Sensed Imagery. Remote Sensing, 11(20), 2370. https://doi.org/10.3390/rs11202370