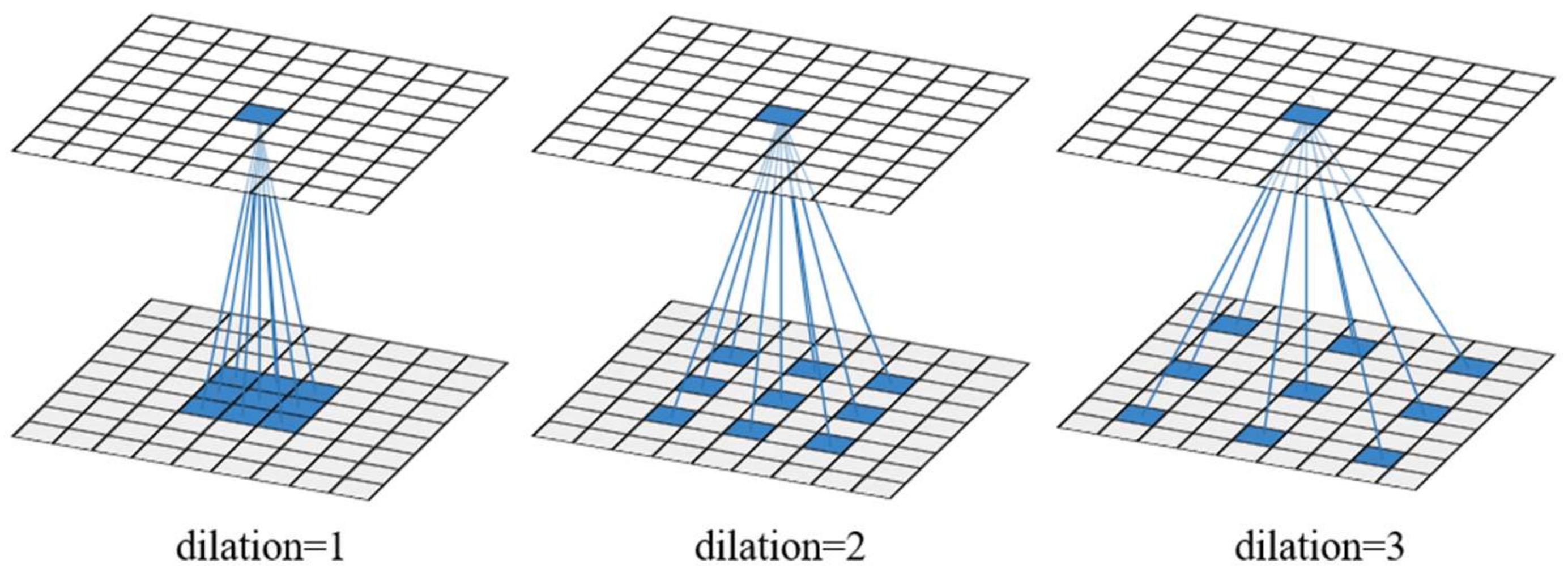
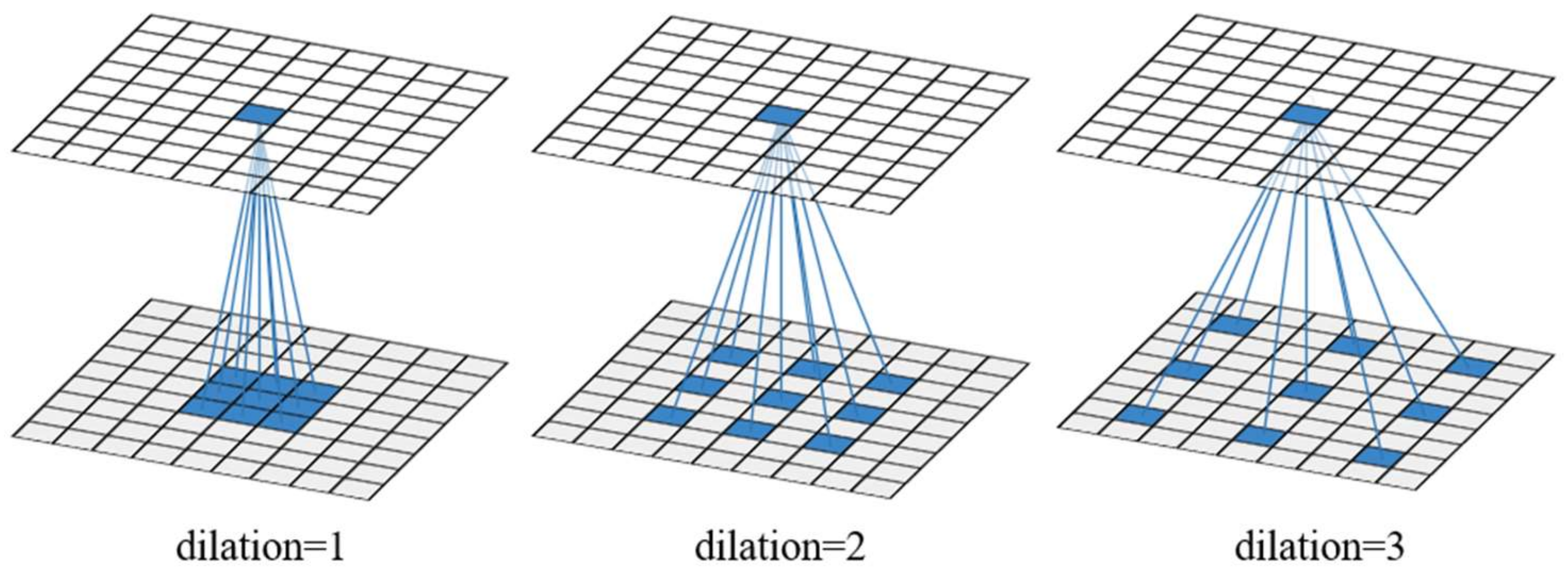
Figure 1.
An illustration of the receptive field for one dilated convolution with different dilation factors. A 3×3 convolution kernel is used in the example.
Figure 1.
An illustration of the receptive field for one dilated convolution with different dilation factors. A 3×3 convolution kernel is used in the example.
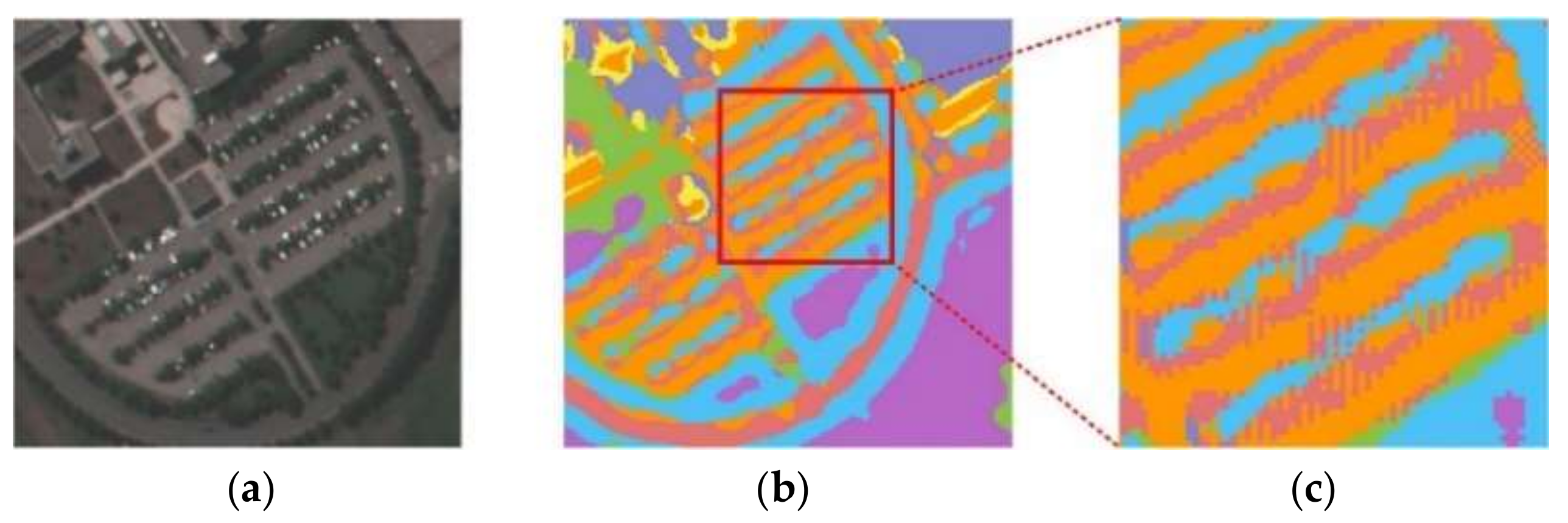
Figure 2.
The gridding problem resulting from dilated convolution. (a) True-color image of Pavia University. (b) Classification results with dilated convolution. (c) Enlarged classification results for (b).
Figure 2.
The gridding problem resulting from dilated convolution. (a) True-color image of Pavia University. (b) Classification results with dilated convolution. (c) Enlarged classification results for (b).
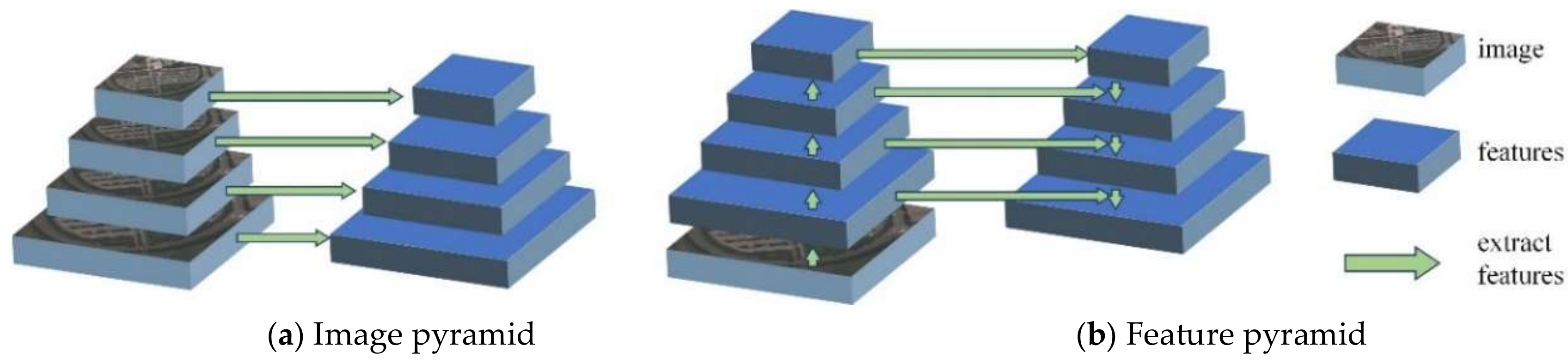
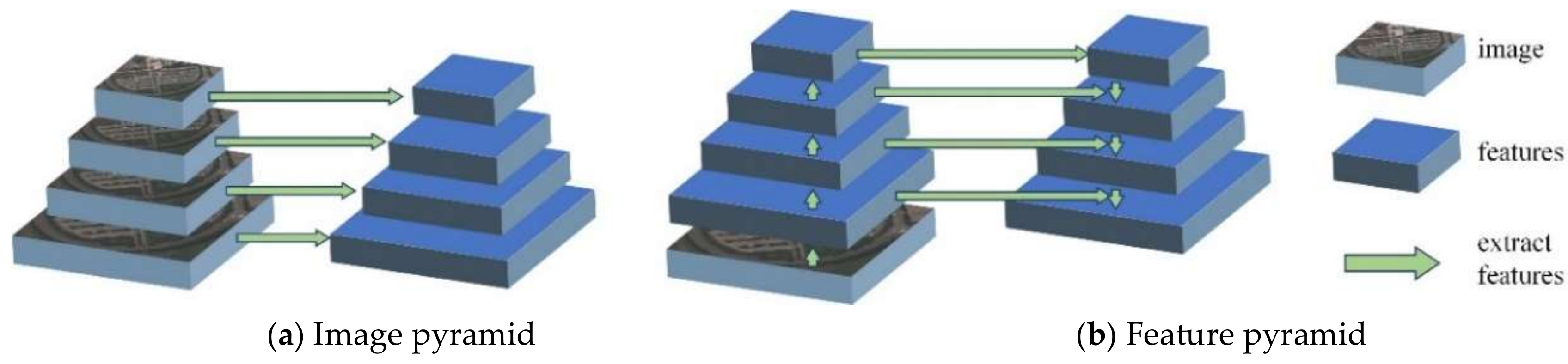
Figure 3.
The image and feature pyramid. (a) The image pyramid independently computes features for each image scale. (b) The feature pyramid creates features with strong semantics at all scales.
Figure 3.
The image and feature pyramid. (a) The image pyramid independently computes features for each image scale. (b) The feature pyramid creates features with strong semantics at all scales.
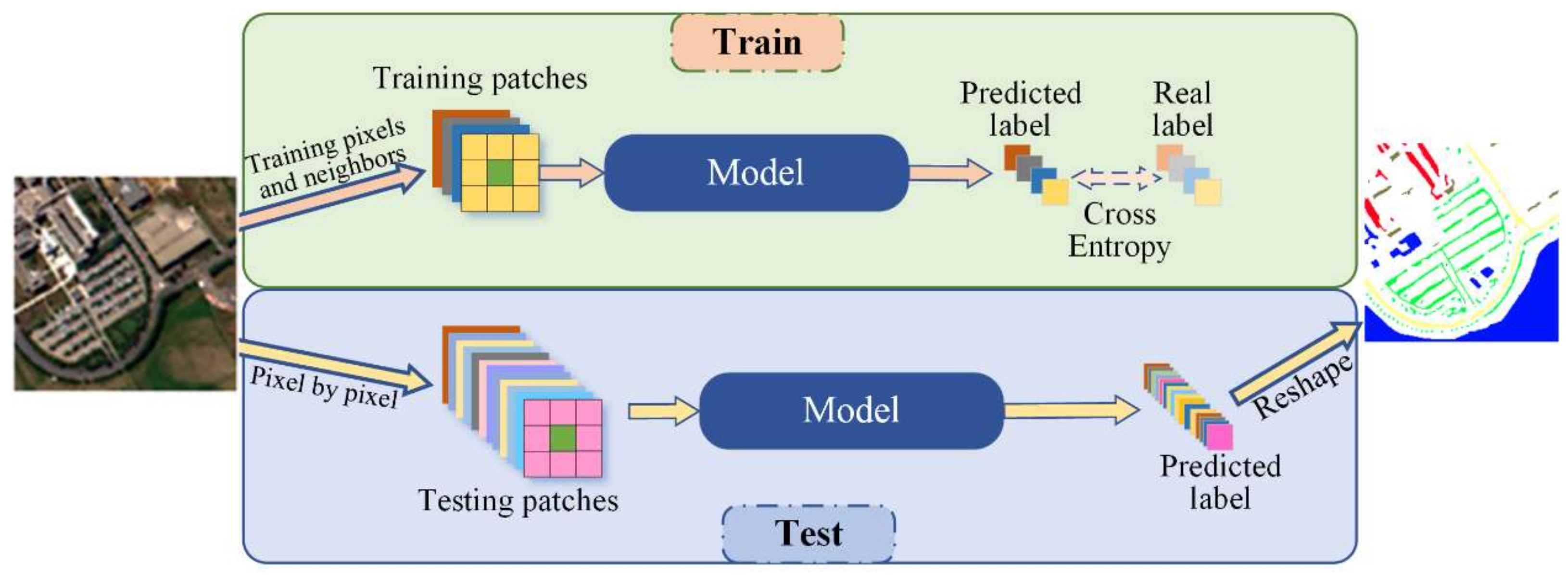
Figure 4.
An illustration of patch-based classification for hyperspectral image (HSI).
Figure 4.
An illustration of patch-based classification for hyperspectral image (HSI).
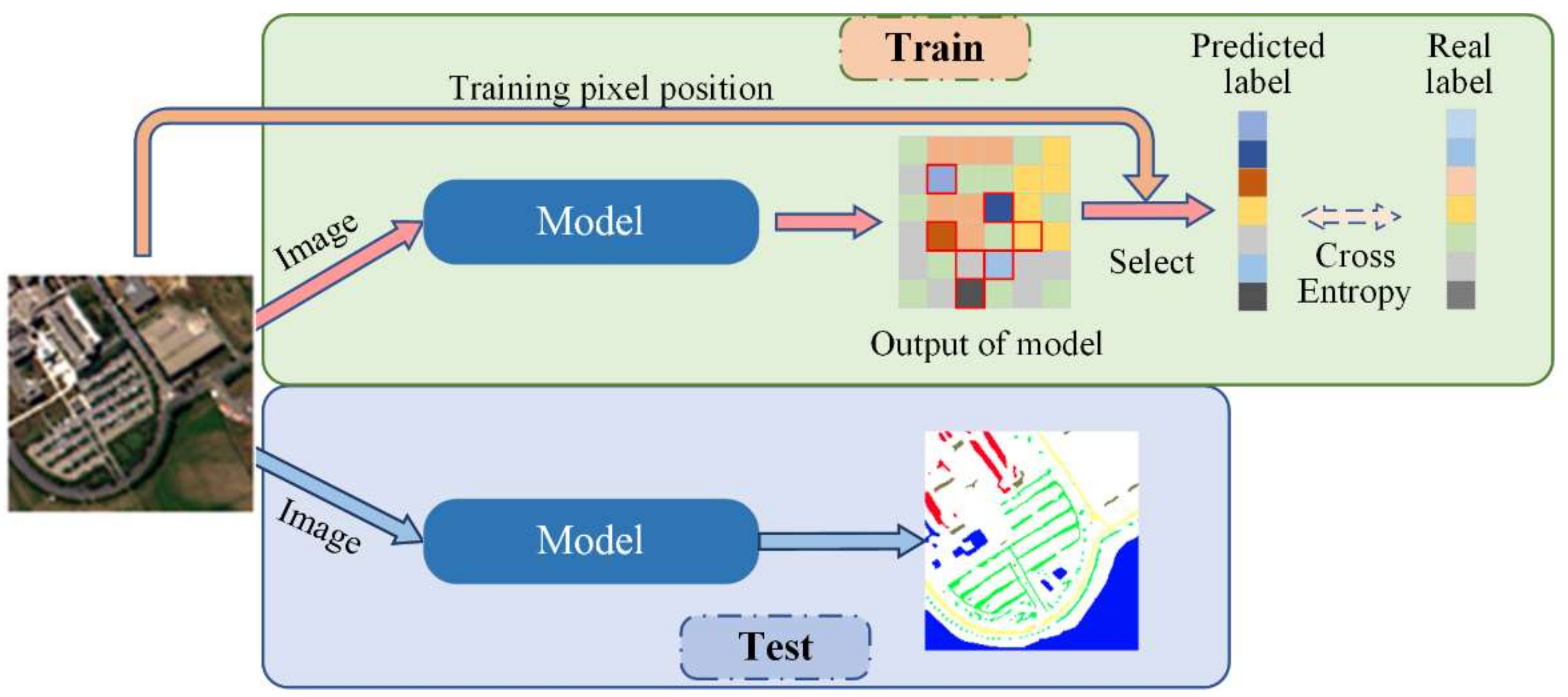
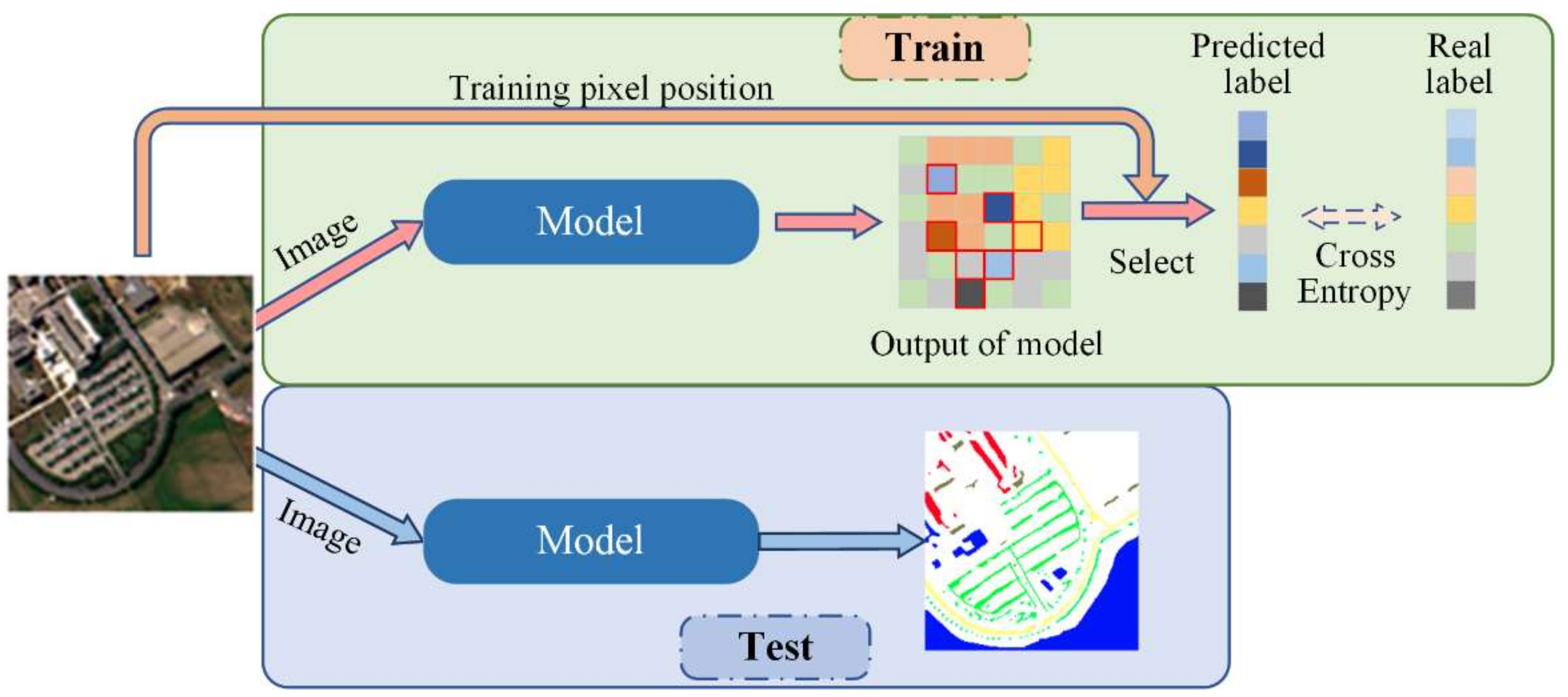
Figure 5.
An illustration of image-based classification for HSI. The model is similar to the segmentation model used in computer vision which takes an input of an arbitrary size and produces an output with a corresponding size. Additionally, the predicted labels should be selected in the output according to the training pixel position during training.
Figure 5.
An illustration of image-based classification for HSI. The model is similar to the segmentation model used in computer vision which takes an input of an arbitrary size and produces an output with a corresponding size. Additionally, the predicted labels should be selected in the output according to the training pixel position during training.
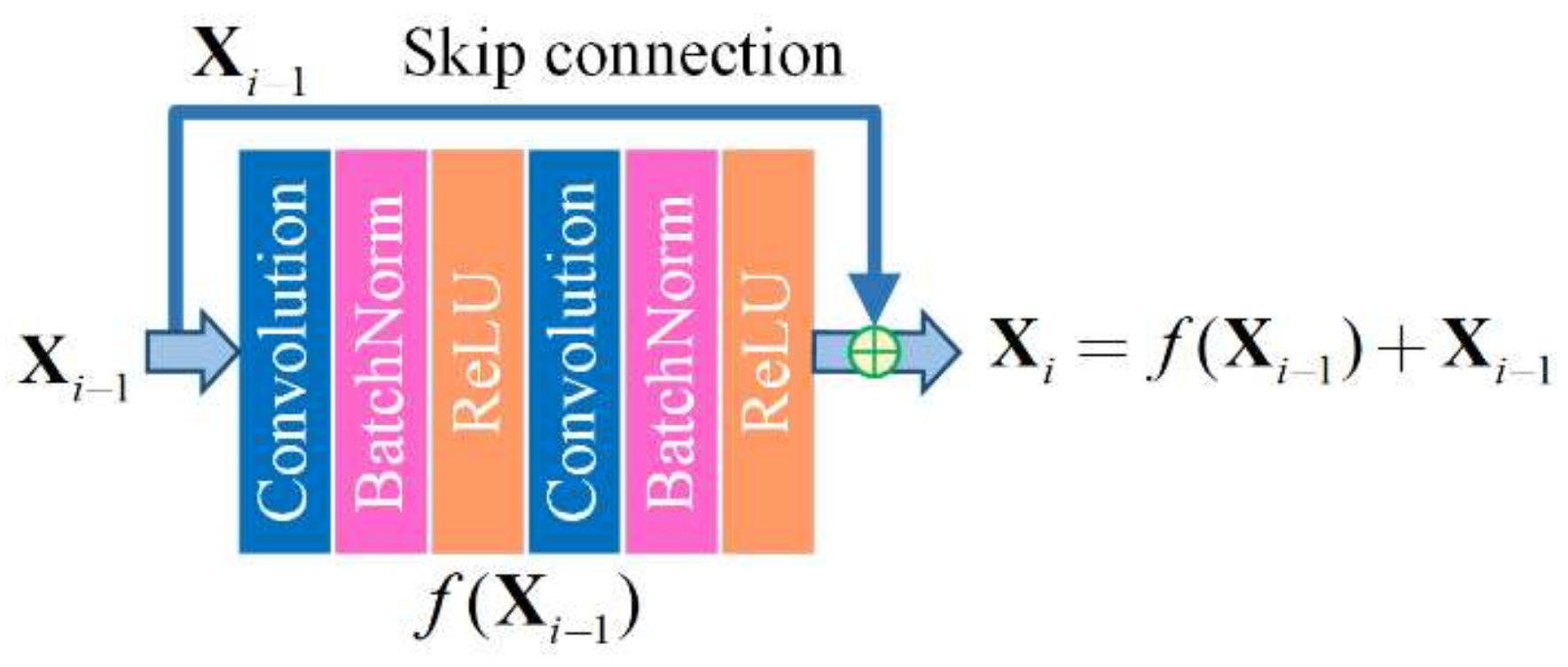
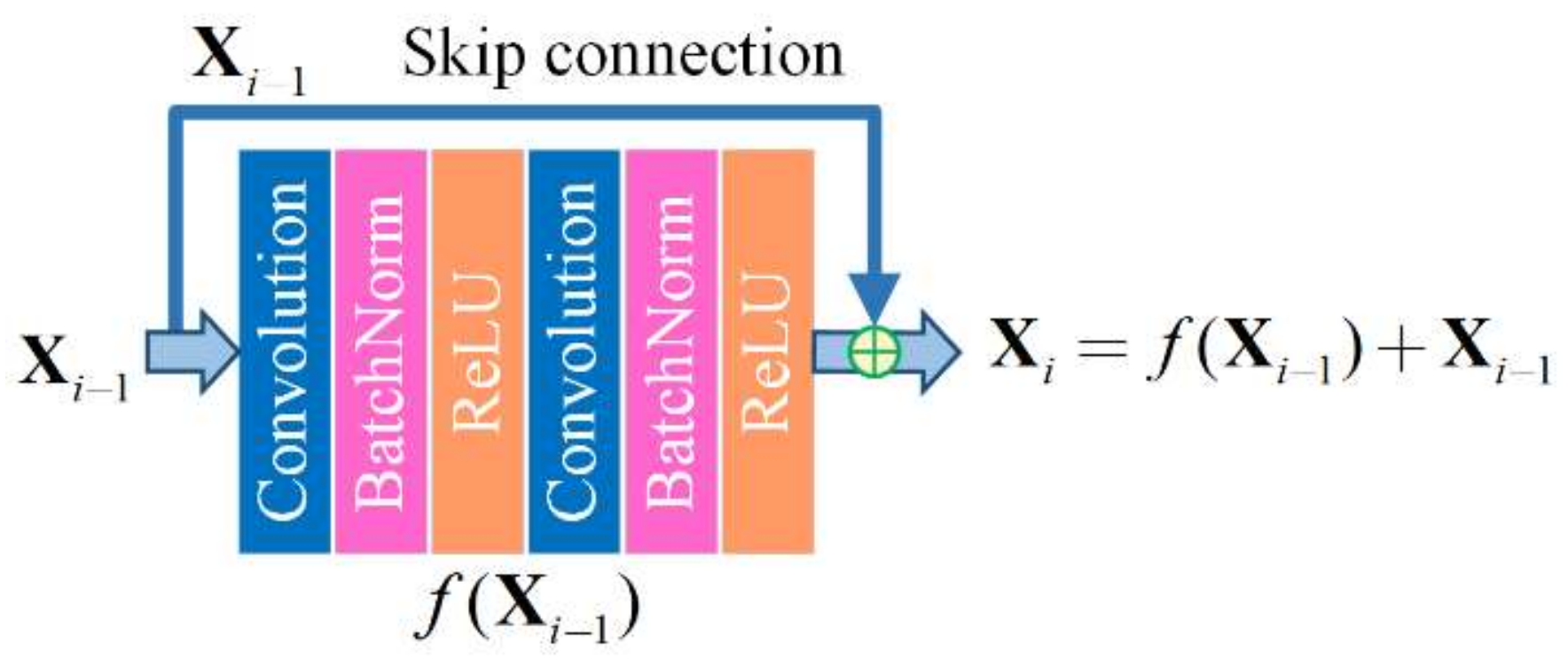
Figure 6.
An illustration of the residual block.
Figure 6.
An illustration of the residual block.
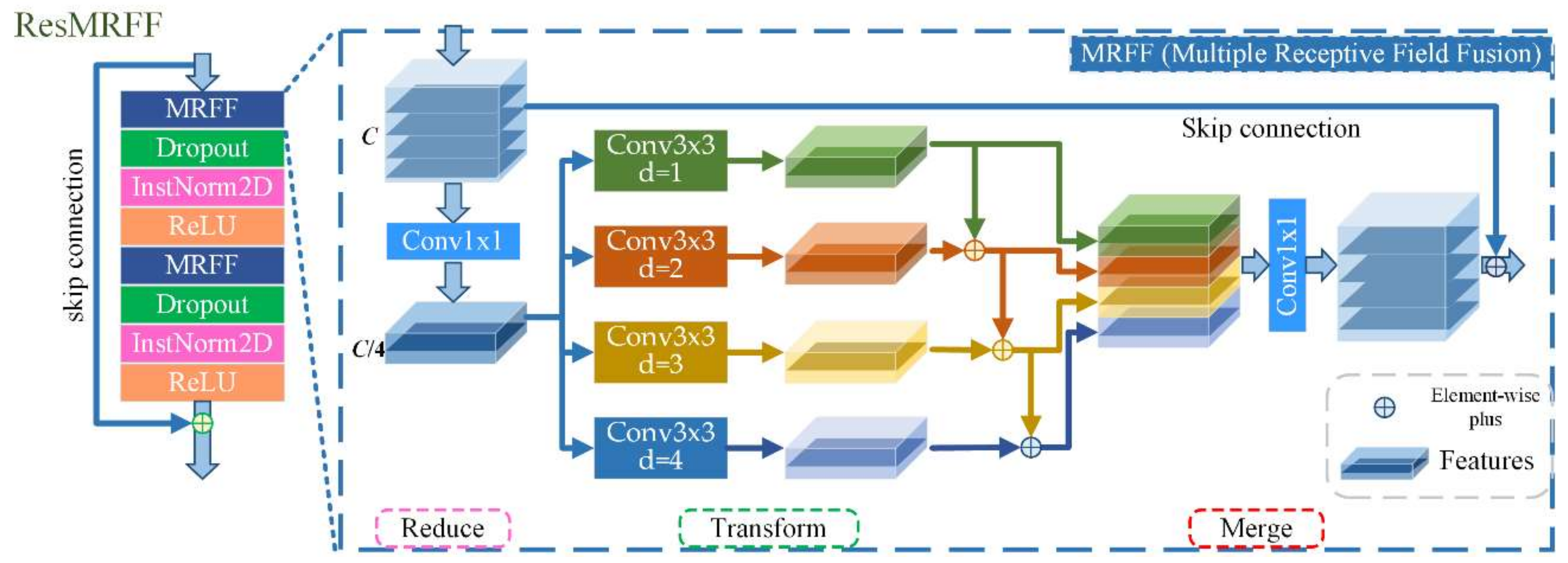
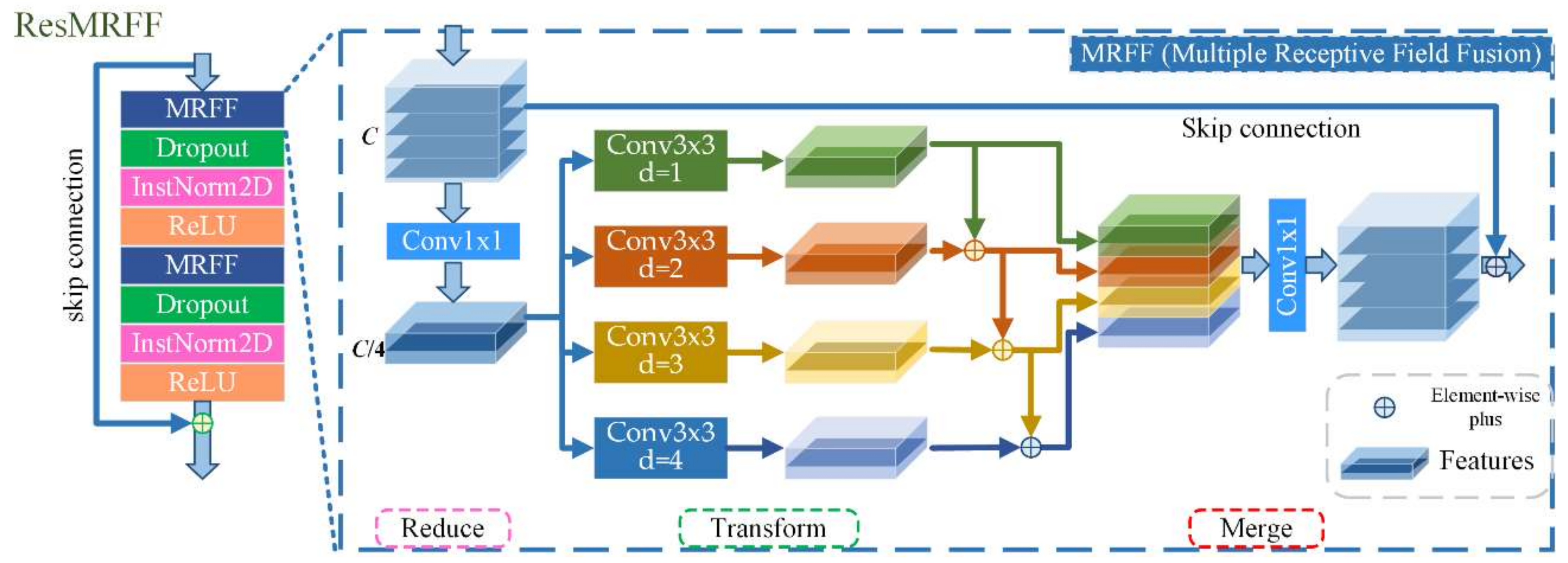
Figure 7.
A schematic of the residual multiple receptive field fusion block (ResMRFF). The basic strategy of the multiple receptive field fusion block is represented as Reduce-Transform-Merge.
Figure 7.
A schematic of the residual multiple receptive field fusion block (ResMRFF). The basic strategy of the multiple receptive field fusion block is represented as Reduce-Transform-Merge.
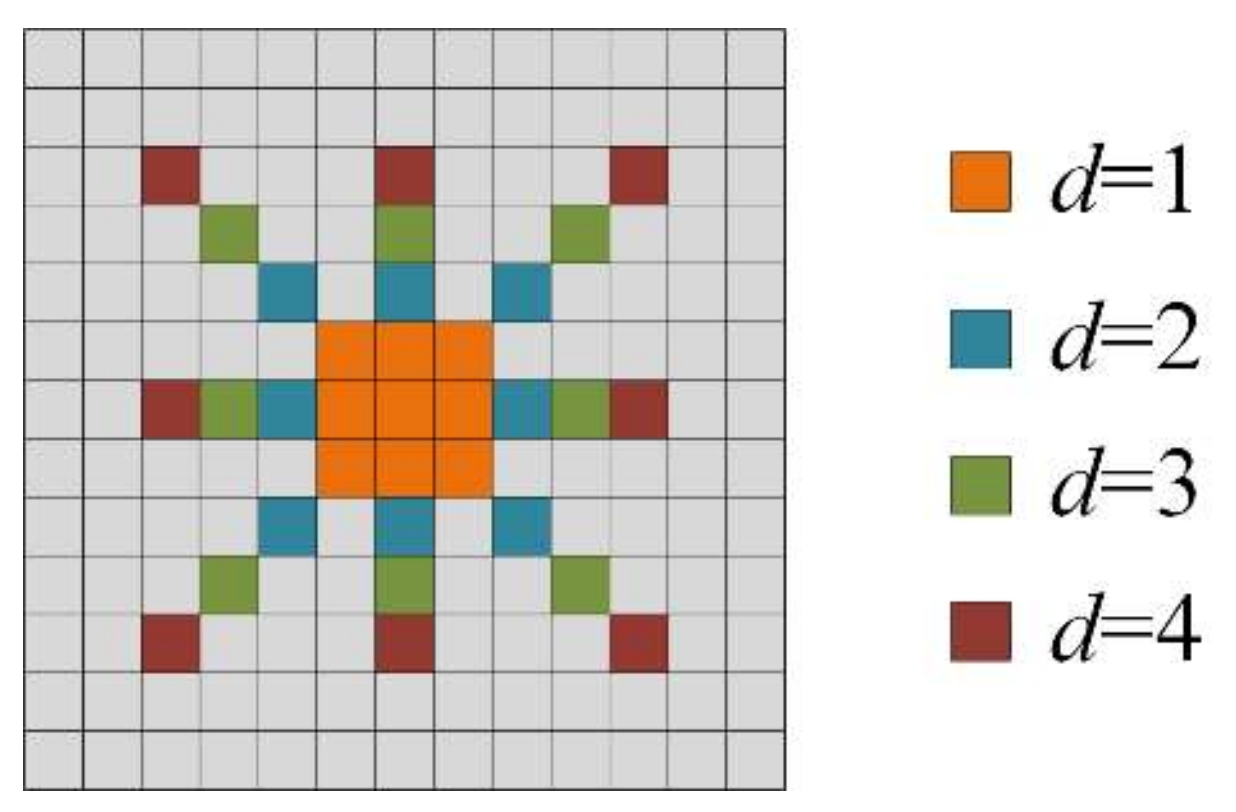
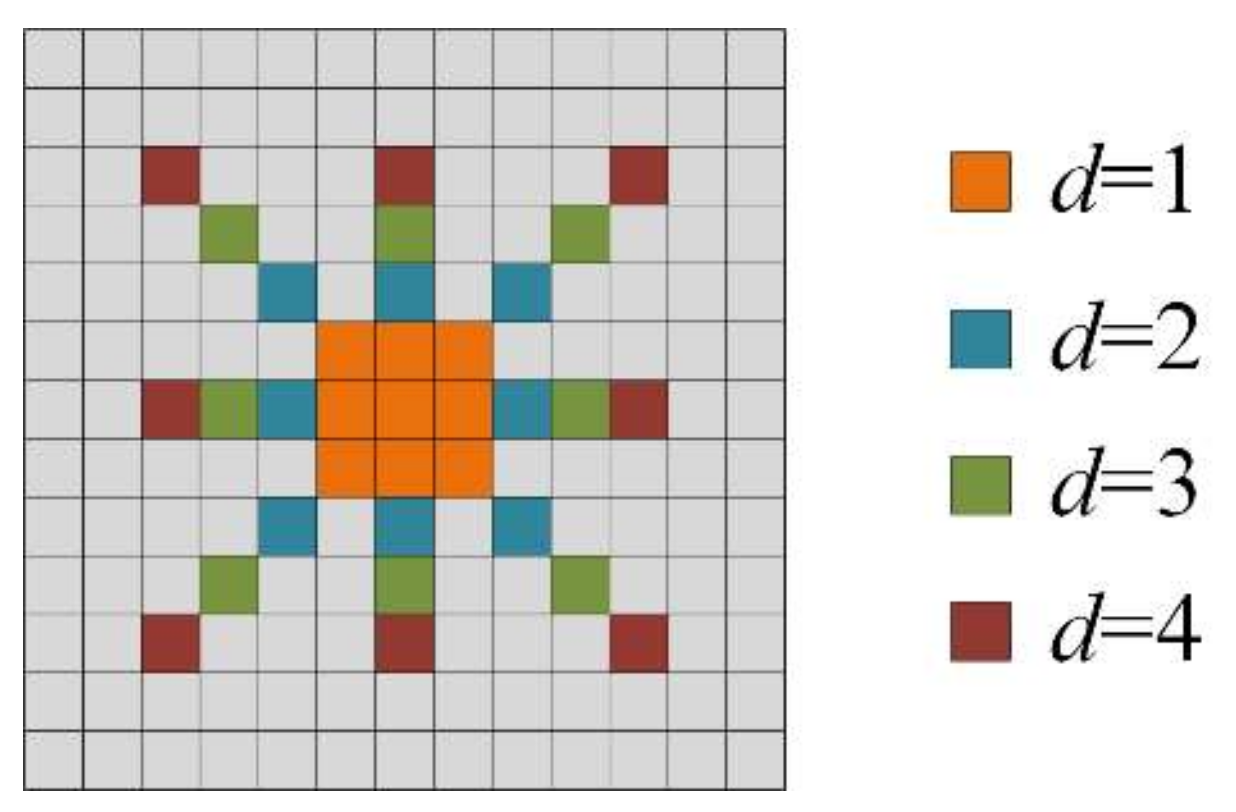
Figure 8.
An illustration of the receptive field for the merged features in one MRFF block.
Figure 8.
An illustration of the receptive field for the merged features in one MRFF block.
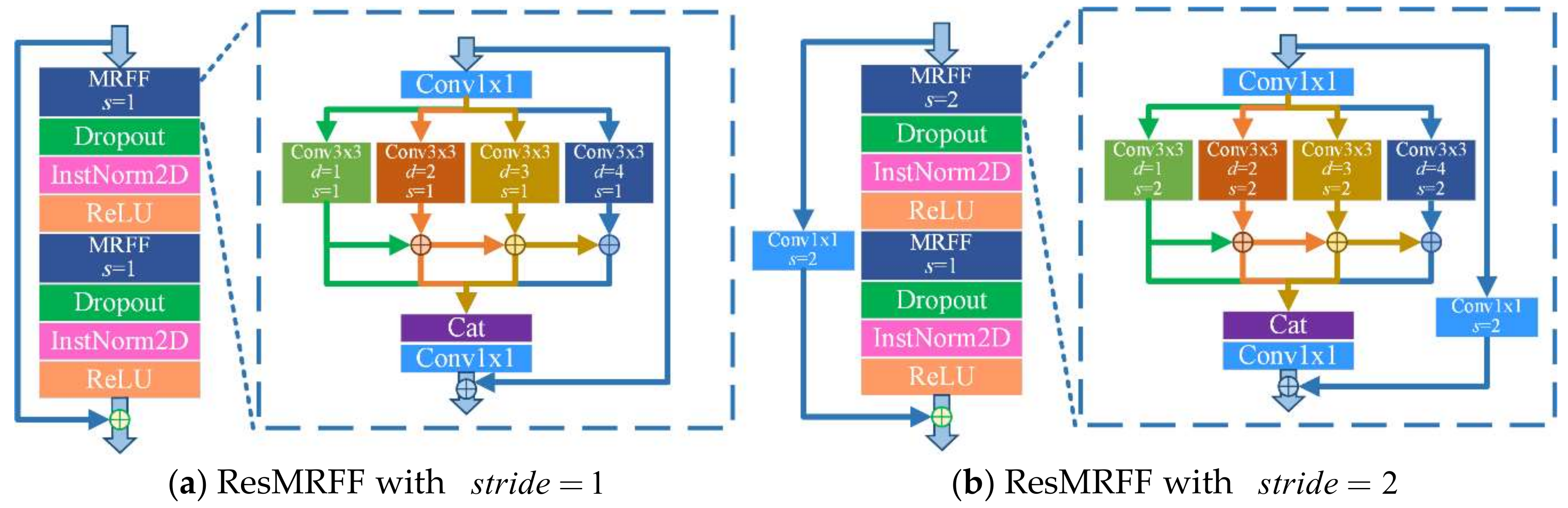
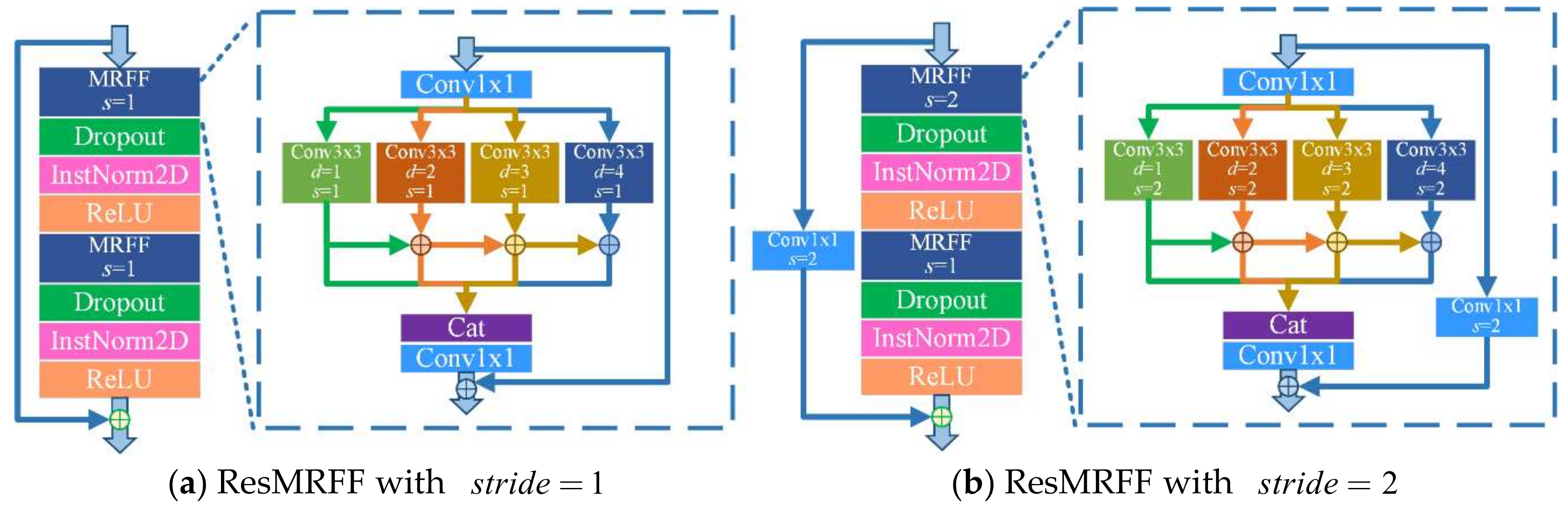
Figure 9.
An illustration of two ResMRFF blocks with different strides, where s refers to the convolution stride and d refers to the dilation factor. (a) refers to the ResMRFF block designed with stride=1, (b) refers to the ResMRFF block designed with stride=2.
Figure 9.
An illustration of two ResMRFF blocks with different strides, where s refers to the convolution stride and d refers to the dilation factor. (a) refers to the ResMRFF block designed with stride=1, (b) refers to the ResMRFF block designed with stride=2.
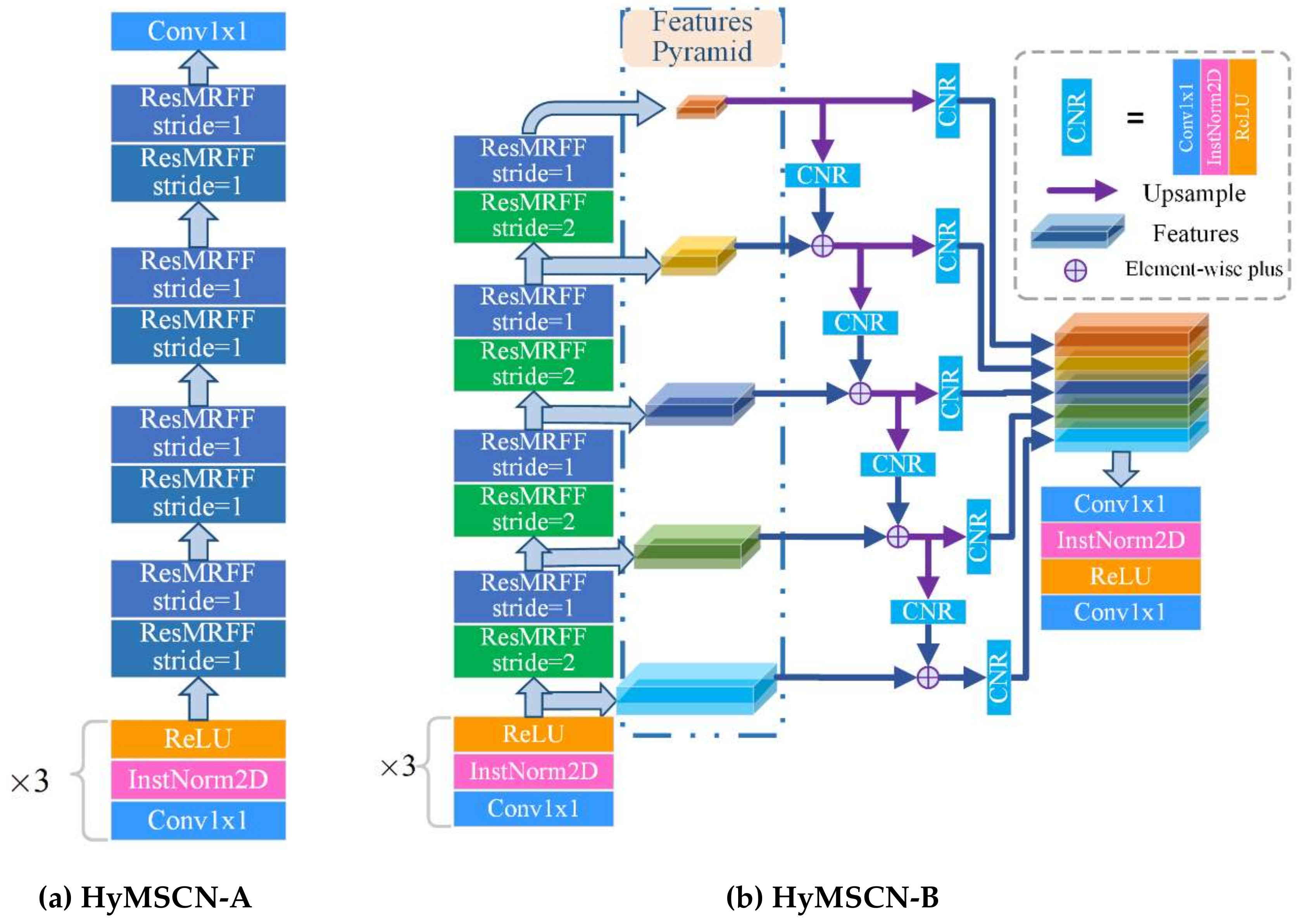
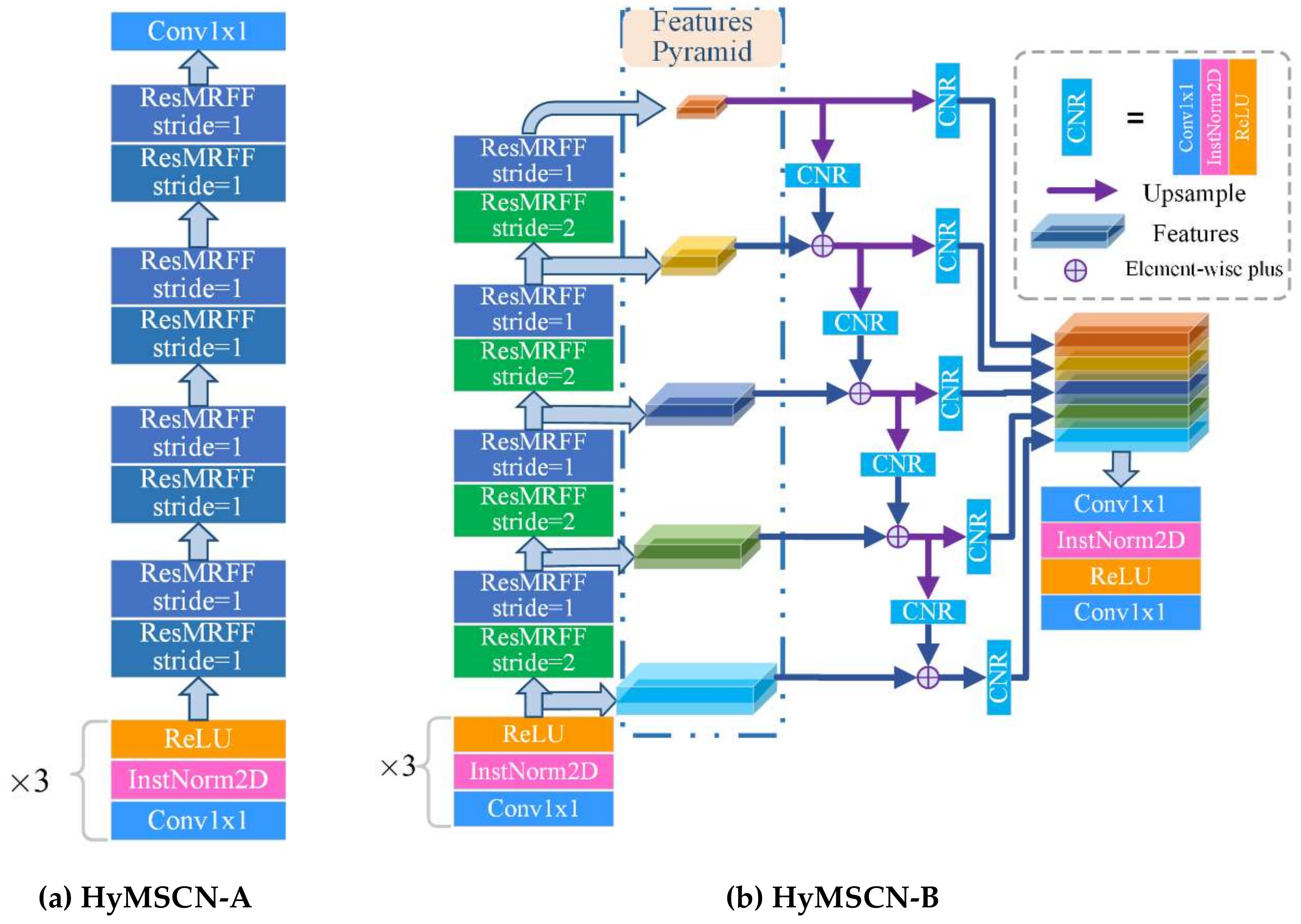
Figure 10.
An illustration of the proposed two networks, (a) HyMSCN-A and (b) HyMSCN-B.
Figure 10.
An illustration of the proposed two networks, (a) HyMSCN-A and (b) HyMSCN-B.
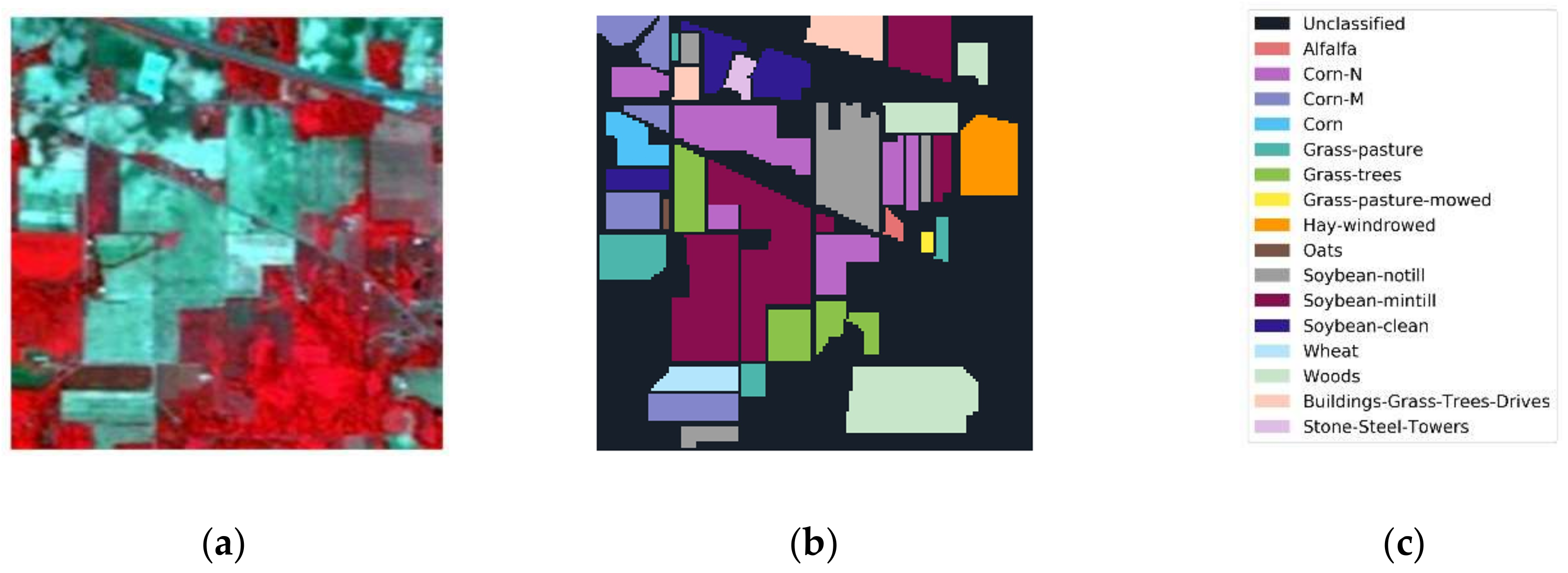
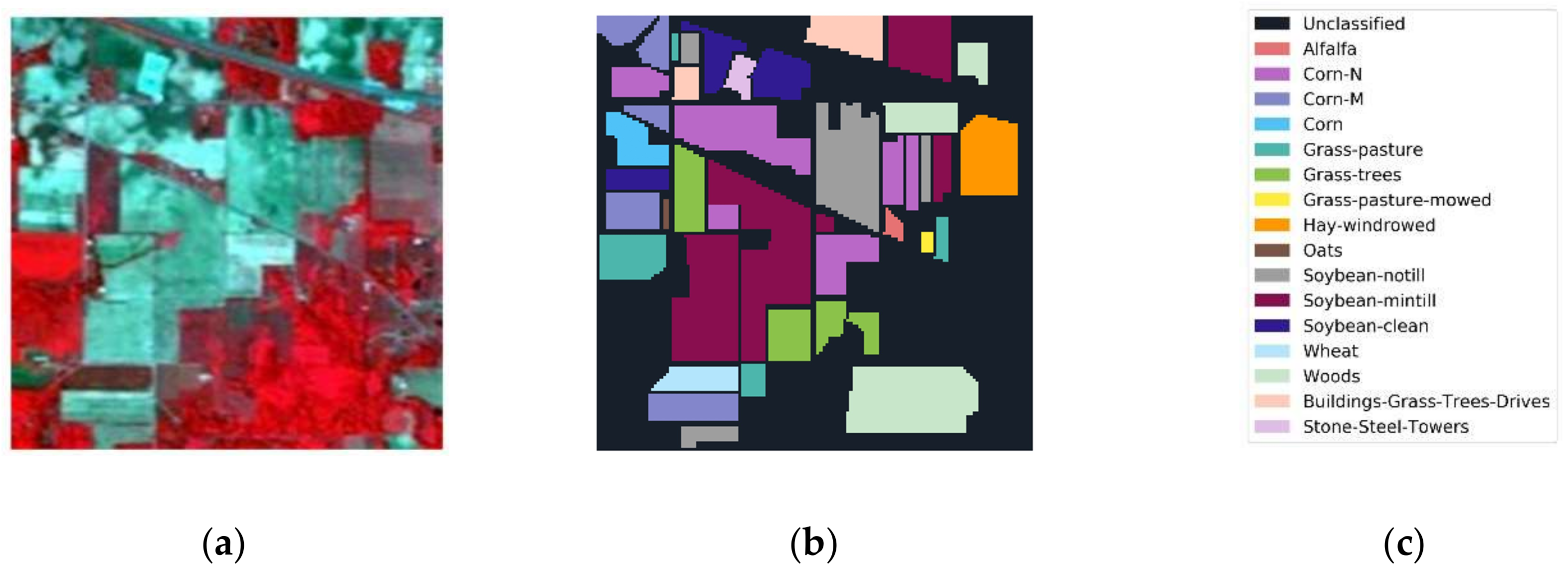
Figure 11.
Indian Pines imagery with (a) color composite, (b) reference data, and (c) class names.
Figure 11.
Indian Pines imagery with (a) color composite, (b) reference data, and (c) class names.
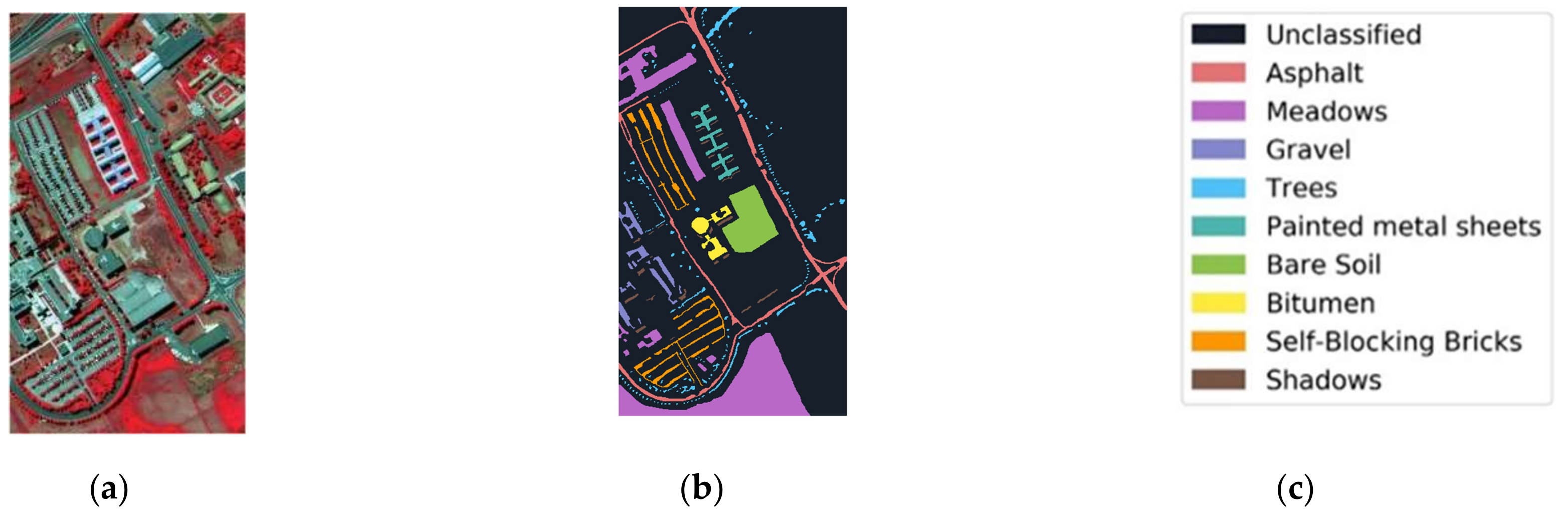
Figure 12.
Pavia University data: (a) color composite, (b) reference data, and (c) class names.
Figure 12.
Pavia University data: (a) color composite, (b) reference data, and (c) class names.
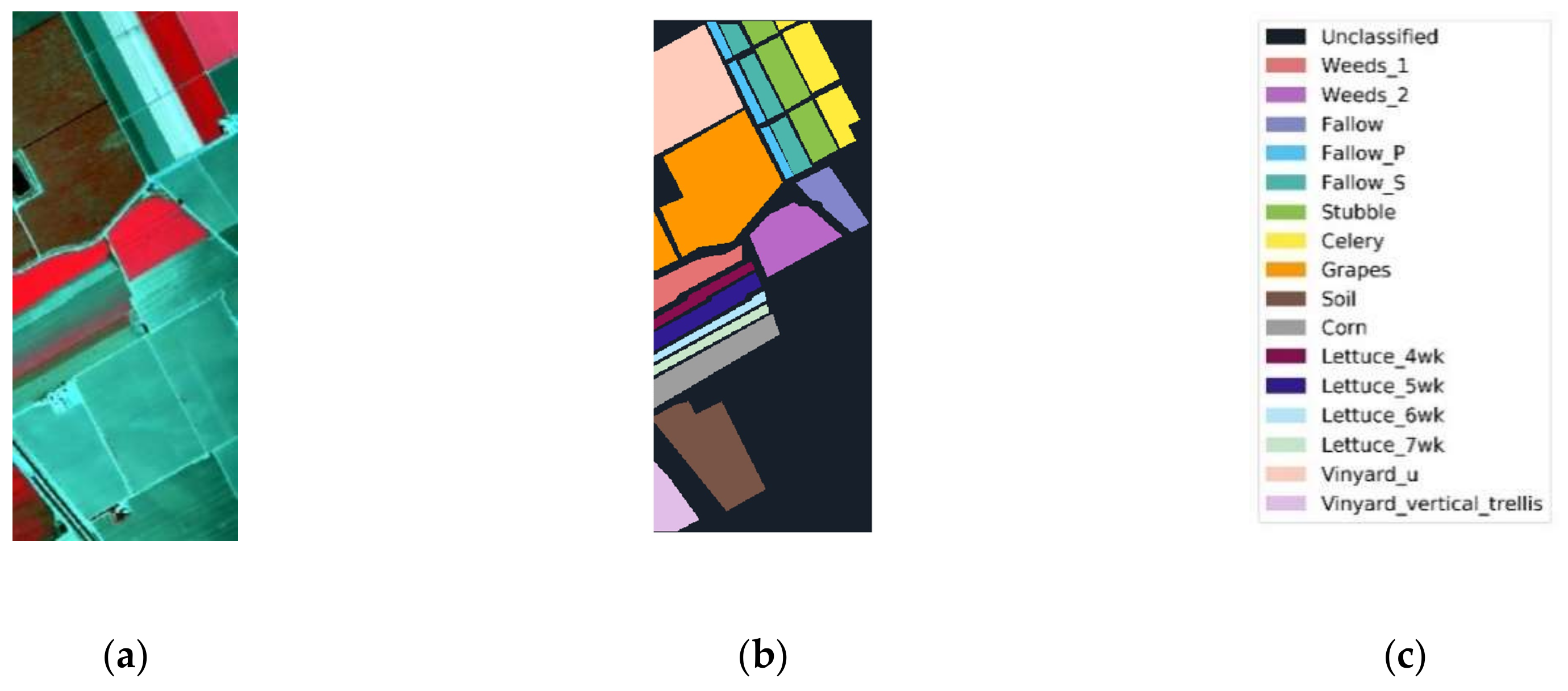
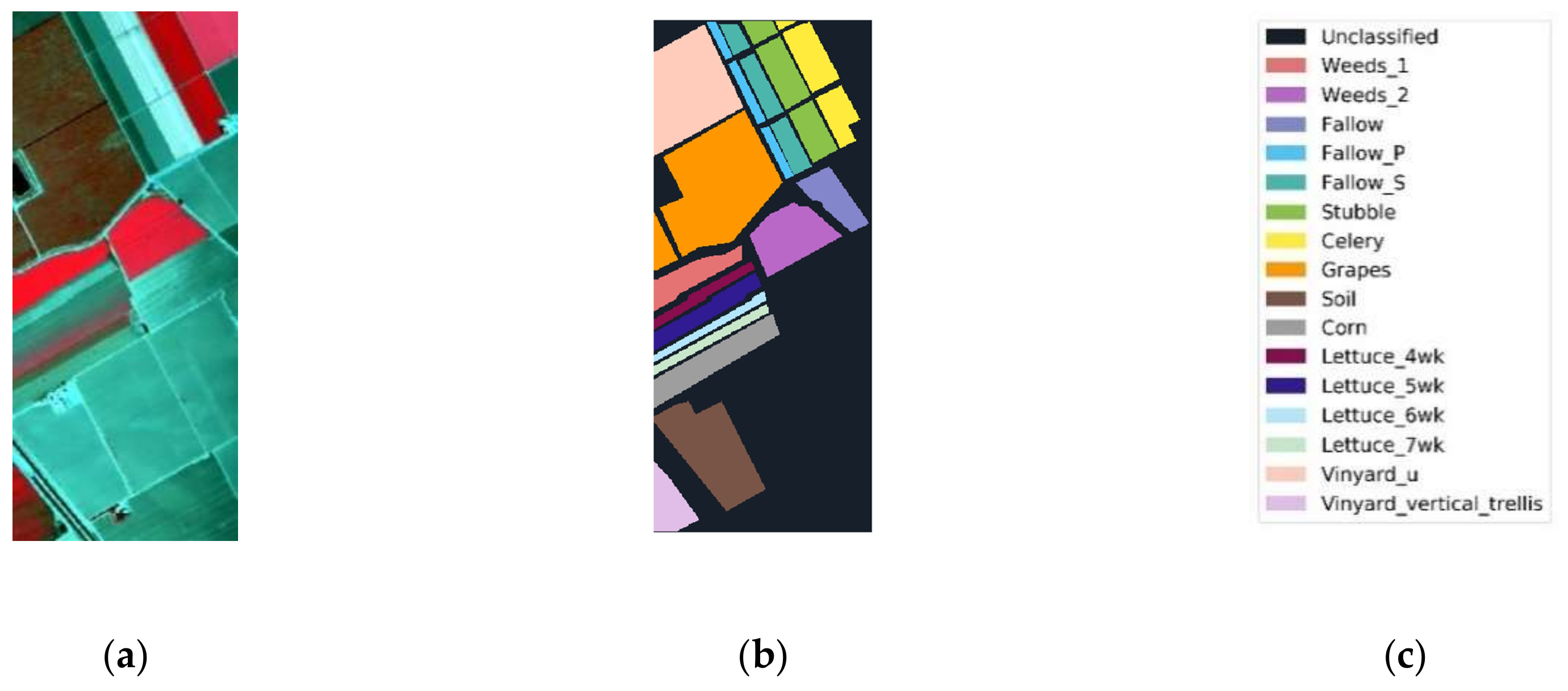
Figure 13.
Salinas data: (a) color composite, (b) reference data, and (c) class names.
Figure 13.
Salinas data: (a) color composite, (b) reference data, and (c) class names.
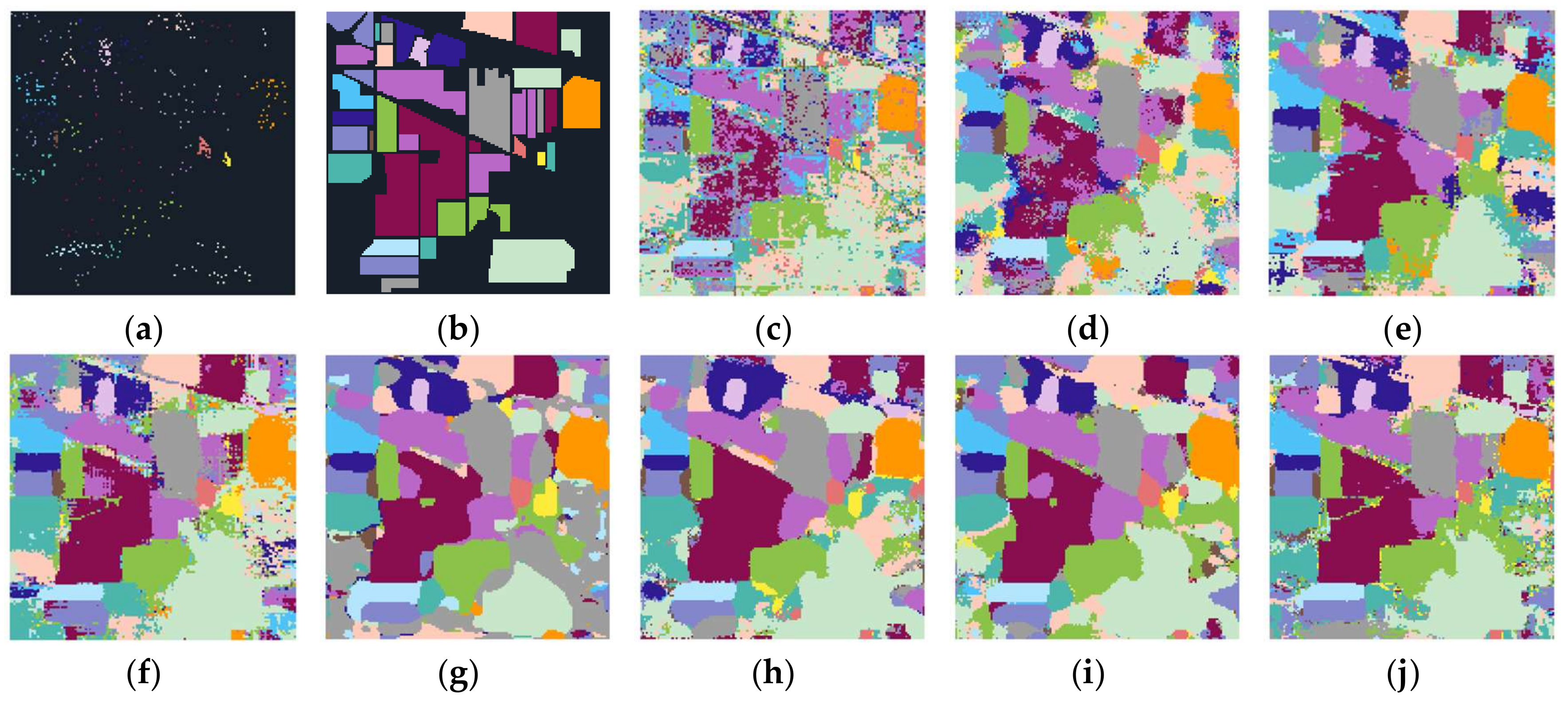
Figure 14.
Classification maps for Indian Pines data with 30 samples per class: (a) training samples, (b) ground truth, and classification maps produced by different methods, including (c) SVM (67.46%), (d) SSRN (78.66%), (e) 3DCNN (86.16%), (f) DCCNN (89.73%), (g) UNet (89.50%), (h) ESPNet (91.80%), (i) HyMSCN-A-128 (92.68%), and (j) HyMSCN-B-128 (93.73%).
Figure 14.
Classification maps for Indian Pines data with 30 samples per class: (a) training samples, (b) ground truth, and classification maps produced by different methods, including (c) SVM (67.46%), (d) SSRN (78.66%), (e) 3DCNN (86.16%), (f) DCCNN (89.73%), (g) UNet (89.50%), (h) ESPNet (91.80%), (i) HyMSCN-A-128 (92.68%), and (j) HyMSCN-B-128 (93.73%).
Figure 15.
Classification map for Pavia University data with 30 samples per class: (a) training samples, (b) ground truth, and classification maps produced by different methods, including (c) SVM (81.40%), (d) SSRN (81.51%), (e) 3DCNN (72.79%), (f) DCCNN (82.19%), (g) UNet (90.64%), (h) ESPNet (91.71%), (i) HyMSCN-A-128 (92.86%), and (j) HyMSCN-B-128 (96.45%).
Figure 15.
Classification map for Pavia University data with 30 samples per class: (a) training samples, (b) ground truth, and classification maps produced by different methods, including (c) SVM (81.40%), (d) SSRN (81.51%), (e) 3DCNN (72.79%), (f) DCCNN (82.19%), (g) UNet (90.64%), (h) ESPNet (91.71%), (i) HyMSCN-A-128 (92.86%), and (j) HyMSCN-B-128 (96.45%).
Figure 16.
Classification maps for Salina data with 30 samples per class: (a) training samples, (b) ground truth, and classification maps produced by different methods, including (c) SVM (88.48%), (d) SSRN (68.55%), (e) 3DCNN (80.99%), (f) DCCNN (82.42%), (g) UNet (84.38%), (h) ESPNet (87.85%), (i) HyMSCN-A-128 (97.05%), and (j) HyMSCN-B-128 (97.31%).
Figure 16.
Classification maps for Salina data with 30 samples per class: (a) training samples, (b) ground truth, and classification maps produced by different methods, including (c) SVM (88.48%), (d) SSRN (68.55%), (e) 3DCNN (80.99%), (f) DCCNN (82.42%), (g) UNet (84.38%), (h) ESPNet (87.85%), (i) HyMSCN-A-128 (97.05%), and (j) HyMSCN-B-128 (97.31%).
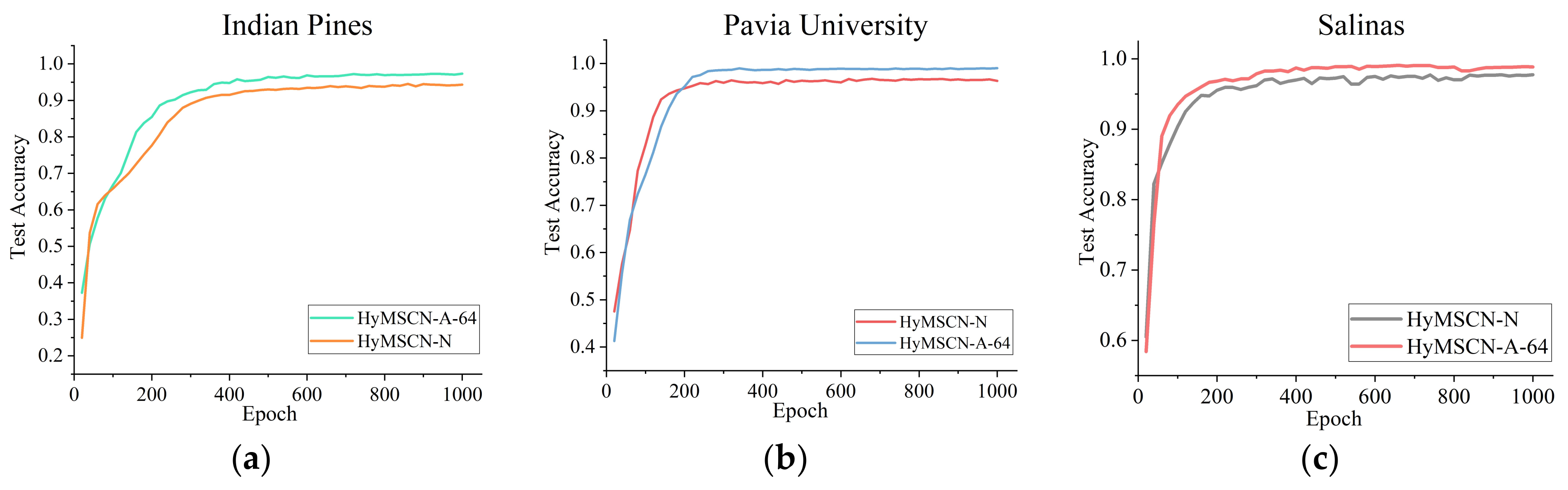
Figure 17.
An evaluation of the overall accuracy for multiple receptive field fusion (MRFF): (a) Indian Pines, (b) Pavia University, and (c) Salinas.
Figure 17.
An evaluation of the overall accuracy for multiple receptive field fusion (MRFF): (a) Indian Pines, (b) Pavia University, and (c) Salinas.
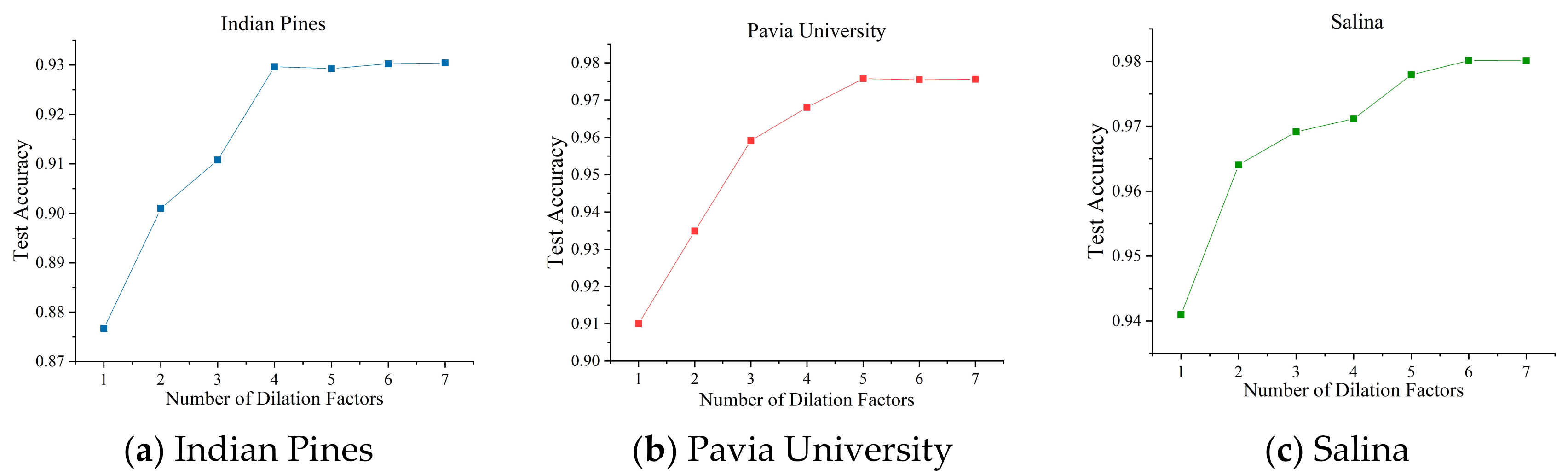
Figure 18.
Test accuracy for the different number of dilation factors in MRFF block. (a) Indian Pines data, (b) Pavia University data, (c) Salina data
Figure 18.
Test accuracy for the different number of dilation factors in MRFF block. (a) Indian Pines data, (b) Pavia University data, (c) Salina data
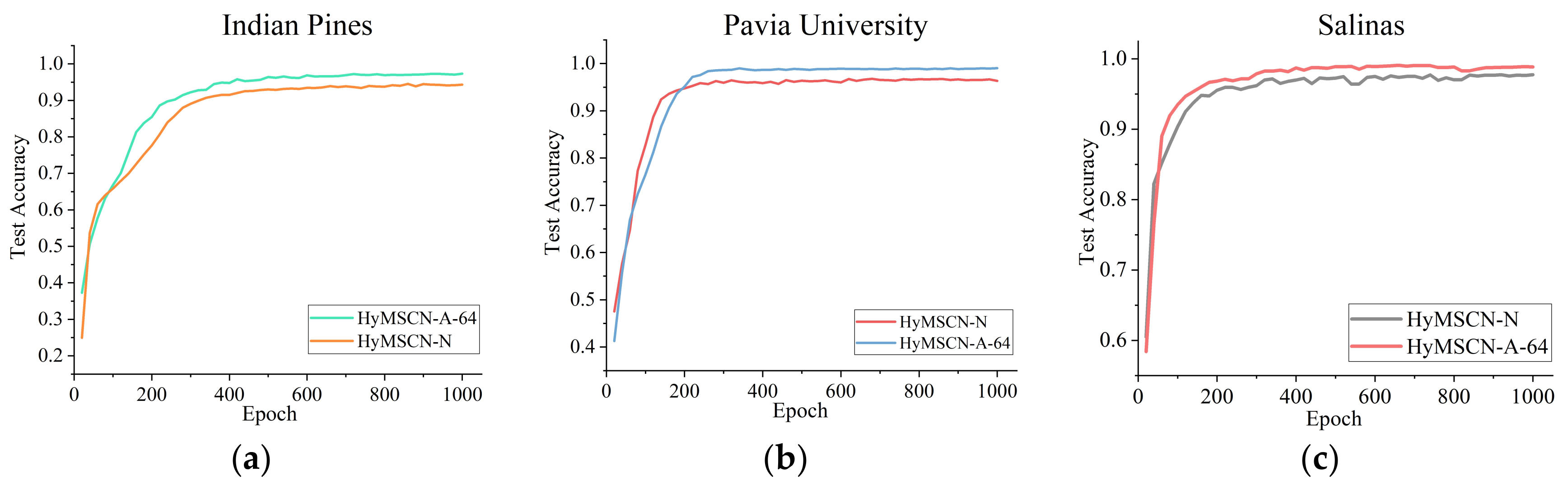
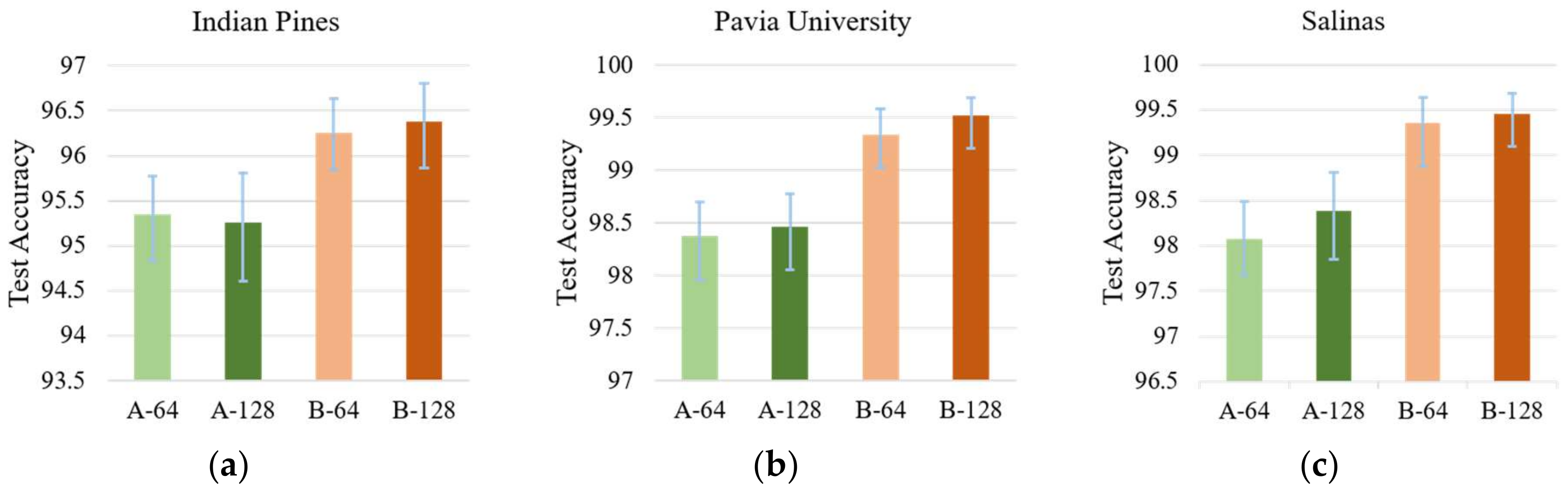
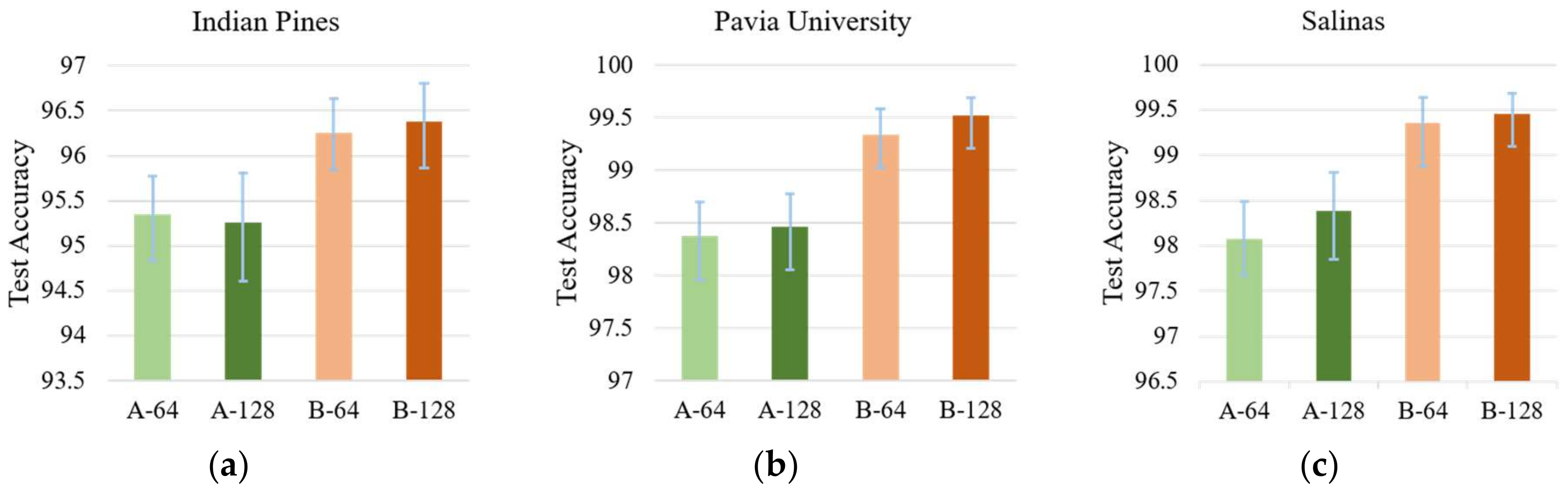
Figure 19.
The overall accuracy for different networks (A-64, A-128, B-64, and B-128 refer to HyMSCN-A-64, HyMSCN-A-128, HyMSCN-B-64, and HyMSCN-B-128, respectively). (a) Indian Pines, (b) Pavia University, and (c) Salinas.
Figure 19.
The overall accuracy for different networks (A-64, A-128, B-64, and B-128 refer to HyMSCN-A-64, HyMSCN-A-128, HyMSCN-B-64, and HyMSCN-B-128, respectively). (a) Indian Pines, (b) Pavia University, and (c) Salinas.
Table 1.
The parameter settings of the proposed networks. The same colors refer to the same pyramid levels.
Table 1.
The parameter settings of the proposed networks. The same colors refer to the same pyramid levels.
| Layer | HyMSCN-A | HyMSCN-B |
|---|
| Output1 | Stride | A-64 Feature | A-128 Feature | Output1 | Stride | B-64 Feature | B-128 Feature |
|---|
| CNR23 | 145 × 145 | 1 | 64 | 64 | 14545 | 1 | 64 | 64 |
| ResMRFF | 145145 | 1 | 64 | 64 | 7373 | 2 | 64 | 64 |
| ResMRFF | 145145 | 1 | 64 | 64 | 7373 | 1 | 64 | 64 |
| ResMRFF | 145145 | 1 | 64 | 64 | 3737 | 2 | 64 | 64 |
| ResMRFF | 145145 | 1 | 64 | 64 | 3737 | 1 | 64 | 64 |
| ResMRFF | 145145 | 1 | 64 | 128 | 1919 | 2 | 64 | 128 |
| ResMRFF | 145145 | 1 | 64 | 128 | 1919 | 1 | 64 | 128 |
| ResMRFF | 145145 | 1 | 64 | 128 | 1010 | 2 | 64 | 128 |
| ResMRFF | 145145 | 1 | 64 | 128 | 1010 | 1 | 64 | 128 |
| CNR | - | - | - | - | 1010 | 1 | 64 | 64 |
| CNR | - | - | - | - | 1919 | 1 | 64 | 64 |
| CNR | - | - | - | - | 3737 | 1 | 64 | 64 |
| CNR | - | - | - | - | 7373 | 1 | 64 | 64 |
| CNR | - | - | - | - | 145145 | 1 | 64 | 64 |
Table 2.
Overall, average, k statistic, and individual class accuracies for the Indian Pines data with 30 training samples per class. The highest accuracies are highlighted in bold.
Table 2.
Overall, average, k statistic, and individual class accuracies for the Indian Pines data with 30 training samples per class. The highest accuracies are highlighted in bold.
| Class | Train
(Test) | SVM | SSRN | 3DCNN | DCCNN | UNet | ESPNet | HyMSC-A1 | HyMSCN-B1 |
|---|
| Alfalfa | 30(46) | 40.17% | 75.41% | 92.00% | 83.64% | 95.83% | 97.87% | 88.46% | 92.00% |
| Corn-no till | 30(1428) | 60.45% | 68.50% | 82.28% | 90.08% | 83.68% | 95.65% | 91.10% | 90.85% |
| Corn-min till | 30(830) | 54.72% | 75.95% | 72.50% | 77.05% | 88.11% | 86.10% | 86.37% | 84.57% |
| Corn | 30(237) | 31.33% | 67.16% | 77.63% | 85.25% | 86.05% | 89.39% | 86.76% | 94.42% |
| Grass-pasture | 30(483) | 78.95% | 77.45% | 91.07% | 91.52% | 94.22% | 99.52% | 94.29% | 95.01% |
| Grass-trees | 30(730) | 90.45% | 81.98% | 97.10% | 93.02% | 96.92% | 98.04% | 94.31% | 96.93% |
| Grass-pasture-m | 14(28) | 76.67% | 96.55% | 37.84% | 30.43% | 40.00% | 47.46% | 29.47% | 62.22% |
| Hay-windrowed | 30(478) | 99.53% | 92.02% | 97.54% | 97.15% | 100.00% | 95.98% | 99.38% | 99.17% |
| Oats | 10(20) | 45.45% | 48.78% | 80.00% | 64.52% | 80.00% | 90.91% | 71.43% | 86.96% |
| Soybean-no till | 30(972) | 51.41% | 68.28% | 73.24% | 79.98% | 73.24% | 80.21% | 81.48% | 88.14% |
| Soybean-min till | 30(2455) | 78.39% | 88.54% | 90.08% | 93.58% | 93.88% | 88.24% | 97.37% | 97.06% |
| Soybean-clean | 30(593) | 62.85% | 64.63% | 94.89% | 91.48% | 88.80% | 100.00% | 97.44% | 86.82% |
| Wheat | 30(205) | 92.61% | 89.04% | 97.10% | 93.58% | 90.71% | 99.03% | 99.51% | 99.03% |
| Woods | 30(1265) | 92.20% | 94.34% | 95.57% | 97.72% | 99.39% | 98.96% | 98.13% | 99.68% |
| Buildings/Grass | 30(386) | 41.78% | 75.08% | 76.56% | 98.21% | 88.40% | 93.90% | 98.44% | 97.72% |
| Stone-Steel-Towers | 30(93) | 98.89% | 68.38% | 92.00% | 76.03% | 93.94% | 89.42% | 96.84% | 97.89% |
| Overall accuracy | 67.46% | 78.66% | 86.16% | 89.73% | 89.50% | 91.80% | 92.68% | 93.73% |
| Average accuracy | 68.49% | 77.01% | 84.21% | 83.95% | 87.07% | 90.67% | 88.17% | 91.78% |
| k statistic | 0.6362 | 0.7596 | 0.8429 | 0.8833 | 0.881 | 0.9065 | 0.9171 | 0.9287 |
Table 3.
The overall accuracies obtained from various classification methods for Indian Pines data using different training samples. The best performances for each group are highlighted in bold.
Table 3.
The overall accuracies obtained from various classification methods for Indian Pines data using different training samples. The best performances for each group are highlighted in bold.
| Sample | Classification Method |
|---|
| (Per Class) | SVM | SSRN | 3DCNN | DCCNN | UNet | ESPNet | HyMSCN-A-128 | HyMSCN-B-128 |
|---|
| 160(10) | 58.42% | 68.79% | 67.58% | 71.84% | 74.03% | 78.95% | 76.22% | 82.29% |
| 320(20) | 63.13% | 73.57% | 79.32% | 86.76% | 85.89% | 86.82% | 87.03% | 87.07% |
| 444(30) | 67.46% | 78.66% | 86.16% | 89.73% | 89.50% | 91.80% | 92.68% | 93.73% |
| 584(40) | 71.95% | 85.35% | 88.79% | 91.53% | 91.69% | 94.40% | 94.13% | 94.59% |
| 697(50) | 72.54% | 89.26% | 90.49% | 94.06% | 94.83% | 95.78% | 95.26% | 96.37% |
Table 4.
Overall, average, k statistic, and individual class accuracy for Pavia University data with 30 training samples per class. The highest accuracies are highlighted in bold.
Table 4.
Overall, average, k statistic, and individual class accuracy for Pavia University data with 30 training samples per class. The highest accuracies are highlighted in bold.
| Class | Train (Test) | SVM | SSRN | 3DCNN | DCCNN | UNet | ESPNet | HyMSCN-A1 | HyMSCN-B1 |
|---|
| Asphalt | 30(6631) | 93.78% | 89.53% | 98.77% | 98.45% | 94.25% | 98.64% | 99.44% | 99.55% |
| Meadows | 30(18649) | 91.07% | 98.54% | 99.66% | 99.36% | 99.85% | 99.51% | 99.99% | 99.67% |
| Gravel | 30(2099) | 71.87% | 56.11% | 39.76% | 57.16% | 56.08% | 68.90% | 89.53% | 95.41% |
| Trees | 30(3064) | 81.36% | 87.17% | 76.80% | 75.25% | 95.50% | 93.22% | 88.55% | 95.86% |
| Painted metal sheets | 30(1345) | 97.38% | 71.01% | 97.39% | 92.00% | 97.96% | 97.25% | 98.75% | 99.78% |
| Bare Soil | 30(5029) | 57.18% | 70.53% | 44.09% | 55.26% | 78.26% | 79.04% | 70.29% | 92.82% |
| Bitumen | 30(1330) | 47.34% | 59.75% | 73.55% | 82.47% | 73.20% | 71.70% | 95.82% | 99.70% |
| Self-Blocking Bricks | 30(3682) | 81.47% | 71.76% | 78.24% | 87.67% | 97.95% | 86.22% | 95.17% | 81.71% |
| Shadows | 30(947) | 99.89% | 77.71% | 97.83% | 98.85% | 93.20% | 96.53% | 100.00% | 99.68% |
| Overall accuracy (OA) | 81.40% | 81.51% | 72.79% | 82.19% | 90.64% | 91.71% | 92.86% | 96.45% |
| Average accuracy (AA) | 80.15% | 75.79% | 78.45% | 82.94% | 87.36% | 87.89% | 93.06% | 96.02% |
| k statistic | 0.7590 | 0.7716 | 0.6722 | 0.7792 | 0.8798 | 0.892 | 0.9078 | 0.9535 |
Table 5.
The overall accuracies produced by various classification methods for Pavia University data using a different number of training samples. The best performances for each group are highlighted in bold.
Table 5.
The overall accuracies produced by various classification methods for Pavia University data using a different number of training samples. The best performances for each group are highlighted in bold.
| Sample | Classification Method |
|---|
| (Per Class) | SVM | SSRN | 3DCNN | DCCNN | UNet | ESPNet | HyMSCN-A-128 | HyMSCN-B-128 |
|---|
| 90(10) | 72.78% | 75.00% | 67.32% | 69.39% | 79.03% | 81.28% | 82.33% | 84.65% |
| 180(20) | 78.33% | 79.81% | 68.91% | 74.62% | 80.75% | 87.11% | 88.90% | 95.80% |
| 270(30) | 81.40% | 81.51% | 72.79% | 82.19% | 90.64% | 91.71% | 92.86% | 96.45% |
| 360(40) | 83.28% | 85.87% | 80.07% | 83.45% | 91.52% | 95.14% | 96.54% | 98.23% |
| 450(50) | 85.64% | 91.73% | 86.57% | 90.44% | 96.36% | 96.77% | 98.46% | 99.50% |
Table 6.
The overall, average, k statistic, and individual class accuracies for the Salina dataset with 30 training samples per class. The best results are highlighted in bold typeface.
Table 6.
The overall, average, k statistic, and individual class accuracies for the Salina dataset with 30 training samples per class. The best results are highlighted in bold typeface.
| Class | Train (Test) | SVM | SSRN | 3DCNN | DCCNN | UNet | ESPNet | HyMSCN-A-128 | HyMSCN-B-128 |
|---|
| Weeds_1 | 30(2009) | 100.0% | 96.08% | 81.75% | 86.04% | 100.00% | 99.95% | 100.00% | 100.00% |
| Weeds_2 | 30(3726) | 98.31% | 84.44% | 63.46% | 66.73% | 99.76% | 100.00% | 100.00% | 99.97% |
| Fallow | 30(1976) | 96.84% | 87.23% | 69.81% | 78.31% | 88.68% | 98.91% | 99.31% | 99.90% |
| Fallow_P | 30(1394) | 94.62% | 93.80% | 96.08% | 96.66% | 48.96% | 61.11% | 90.23% | 96.07% |
| Fallow_S | 30(2678) | 98.82% | 83.29% | 85.24% | 93.72% | 77.14% | 72.03% | 99.69% | 99.47% |
| Stubble | 30(3959) | 99.92% | 84.01% | 90.32% | 94.94% | 99.22% | 99.42% | 100.00% | 99.92% |
| Celery | 30(3579) | 97.86% | 90.24% | 95.48% | 84.94% | 96.94% | 99.62% | 99.69% | 99.11% |
| Grapes | 30(11271) | 77.29% | 74.69% | 85.05% | 88.18% | 87.45% | 87.53% | 99.29% | 98.64% |
| Soil | 30(6203) | 98.79% | 96.89% | 81.87% | 95.62% | 94.74% | 99.73% | 99.92% | 99.53% |
| Corn | 30(3278) | 85.24% | 51.88% | 76.55% | 78.78% | 88.78% | 94.01% | 92.74% | 88.40% |
| Lettuce_4wk | 30(1068) | 79.75% | 28.17% | 62.67% | 63.40% | 93.97% | 91.98% | 87.41% | 86.40% |
| Lettuce_5wk | 30(1927) | 95.71% | 95.09% | 91.82% | 78.29% | 66.33% | 69.13% | 99.64% | 99.84% |
| Lettuce_6wk | 30(916) | 95.75% | 44.04% | 59.17% | 49.56% | 95.31% | 81.21% | 99.46% | 93.27% |
| Lettuce_7wk | 30(1070) | 83.80% | 19.30% | 77.90% | 77.25% | 98.97% | 89.70% | 98.70% | 97.03% |
| Vinyard_u | 30(7268) | 68.96% | 62.33% | 77.70% | 76.61% | 63.16% | 75.37% | 88.83% | 93.62% |
| Vinyard_vertical | 30(1807) | 99.35% | 64.61% | 97.36% | 93.81% | 100.00% | 92.32% | 99.94% | 99.94% |
| Overall accuracy | 88.48% | 68.55% | 80.99% | 82.42% | 84.38% | 87.85% | 97.05% | 97.31% |
| Average accuracy | 91.94% | 72.26% | 80.76% | 81.43% | 87.46% | 88.25% | 97.18% | 97.31% |
| k statistic | 0.8718 | 0.6566 | 0.7892 | 0.8065 | 0.8261 | 0.8649 | 0.9672 | 0.9701 |
Table 7.
The overall accuracies produced by different classification methods for the Salina dataset using a different number of training samples. The best results are highlighted in bold type.
Table 7.
The overall accuracies produced by different classification methods for the Salina dataset using a different number of training samples. The best results are highlighted in bold type.
| Sample | Classification Method |
|---|
| (Per Class) | SVM | SSRN | 3DCNN | DCCNN | UNet | ESPNet | HyMSCN-A-128 | HyMSCN-B-128 |
|---|
| 160(10) | 83.14% | 62.64% | 76.34% | 78.99% | 74.58% | 76.01% | 94.71% | 94.49% |
| 320(20) | 87.11% | 66.16% | 79.05% | 80.12% | 83.63% | 85.15% | 94.82% | 96.51% |
| 480(30) | 88.48% | 68.55% | 80.99% | 82.42% | 84.38% | 87.85% | 97.05% | 97.31% |
| 640(40) | 90.71% | 77.80% | 86.50% | 87.37% | 91.84% | 93.03% | 98.15% | 99.38% |
| 800(50) | 91.23% | 86.05% | 87.41% | 89.96% | 92.79% | 95.48% | 98.38% | 99.45% |
Table 8.
The training and testing times for patch-based and image-based classification. Each control group is highlighted with the same color.
Table 8.
The training and testing times for patch-based and image-based classification. Each control group is highlighted with the same color.
| | Indian Pines | Pavia University | Salinas |
|---|
| SSRN | SSRN | HyMSCN | SSRN | SSRN | HyMSCN | SSRN | SSRN | HyMSCN |
|---|
| Patch Size | 7 | 9 | - | 7 | 9 | - | 7 | 9 | - |
| Train Maximum Batch Size | 510 | 420 | 1 | 450 | 450 | 1 | 620 | 460 | 1 |
| Train Time of One Epoch (s) | 2.76 | 3.13 | 0.34 | 1.35 | 1.36 | 0.62 | 3.12 | 3.28 | 0.56 |
| Test Maximum Batch Size | 680 | 530 | 1 | 2150 | 1580 | 1 | 2150 | 1620 | 1 |
| Test Time of One Epoch (s) | 25.65 | 35.40 | 0.11 | 109.43 | 339.67 | 0.42 | 64.18 | 115.69 | 0.41 |










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}