Land Cover Maps Production with High Resolution Satellite Image Time Series and Convolutional Neural Networks: Adaptations and Limits for Operational Systems


Abstract
1. Introduction
1.1. The Need for Land Cover Mapping
- automation for efficiency and timeliness;
- spatial continuity of the maps;
- temporal coherence between updates of the product;
- reproducibility of the results;
- support of changes of nomenclature without changing the system.
1.2. The State-of-the-Art is Supervised Classification
- Reference data are costly to obtain and one has to rely on existing data bases which contain errors or are out of date.
- Reference data are sparse, only a small amount of the pixels are annotated.
- Large areas may present climatic and topographic variabilities introducing different behaviours for the same class across different landscapes.
1.3. The Promise of Deep Learning
1.4. Semantic Segmentation vs. Patch Based Methods
1.5. Deep Learning on a High Performance Computing Cluster
1.6. Contributions
- a framework of patch generation, data augmentation and patch distribution in a computing cluster that alleviates the very high class imbalance in the dataset;
- a novel adaptation of the U-Net model for dealing with sparse data, while producing detailed and fine-grained class predictions;
- we show results in an operational setting on the country scale for multi-temporal multispectral production-quality data obtained from the Sentinel-2 constellation.
2. Data
2.1. Remote Sensing Imagery
2.2. Reference Data Sources and Nomenclature
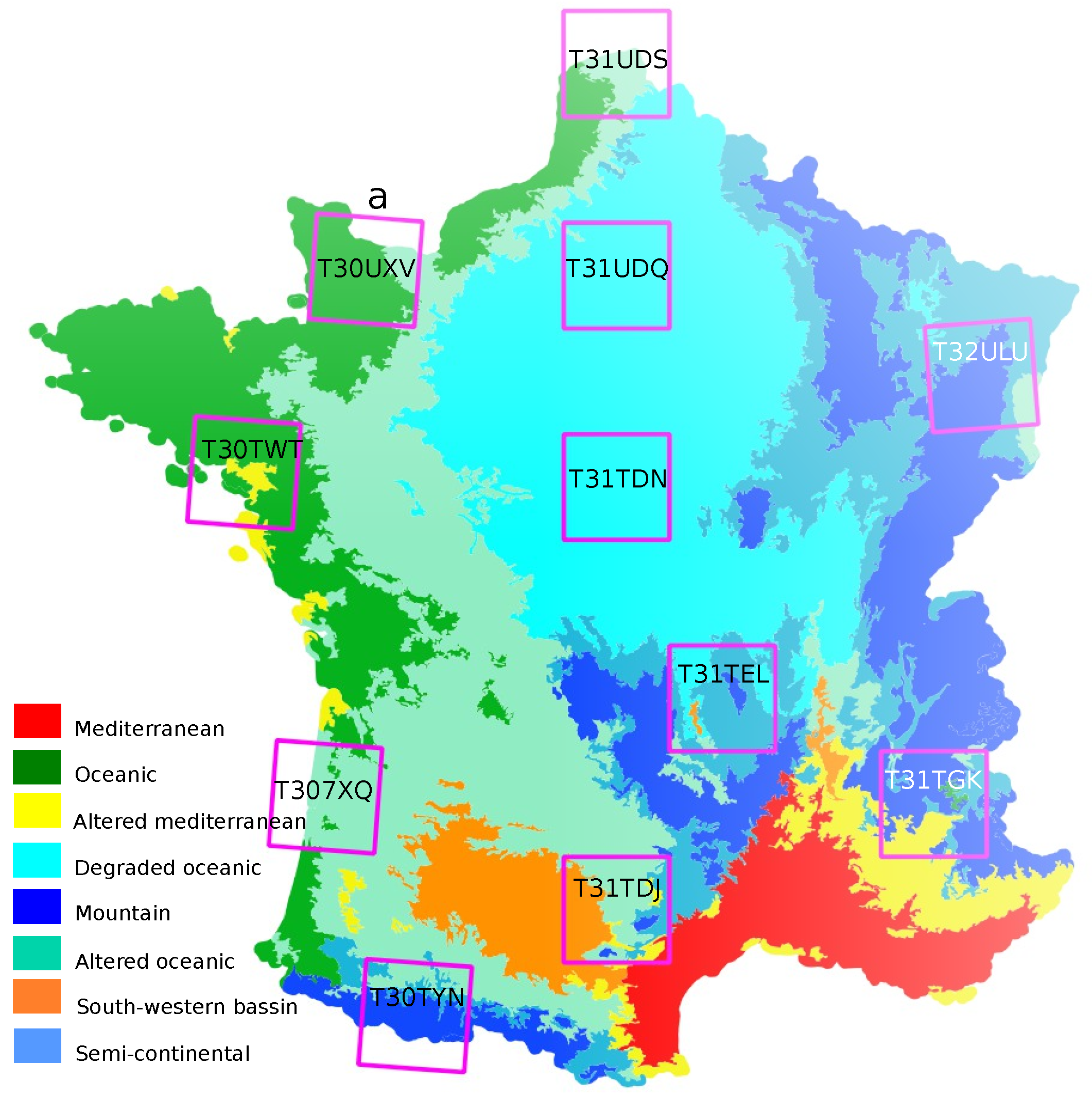
2.3. Training and Test Data
3. Method
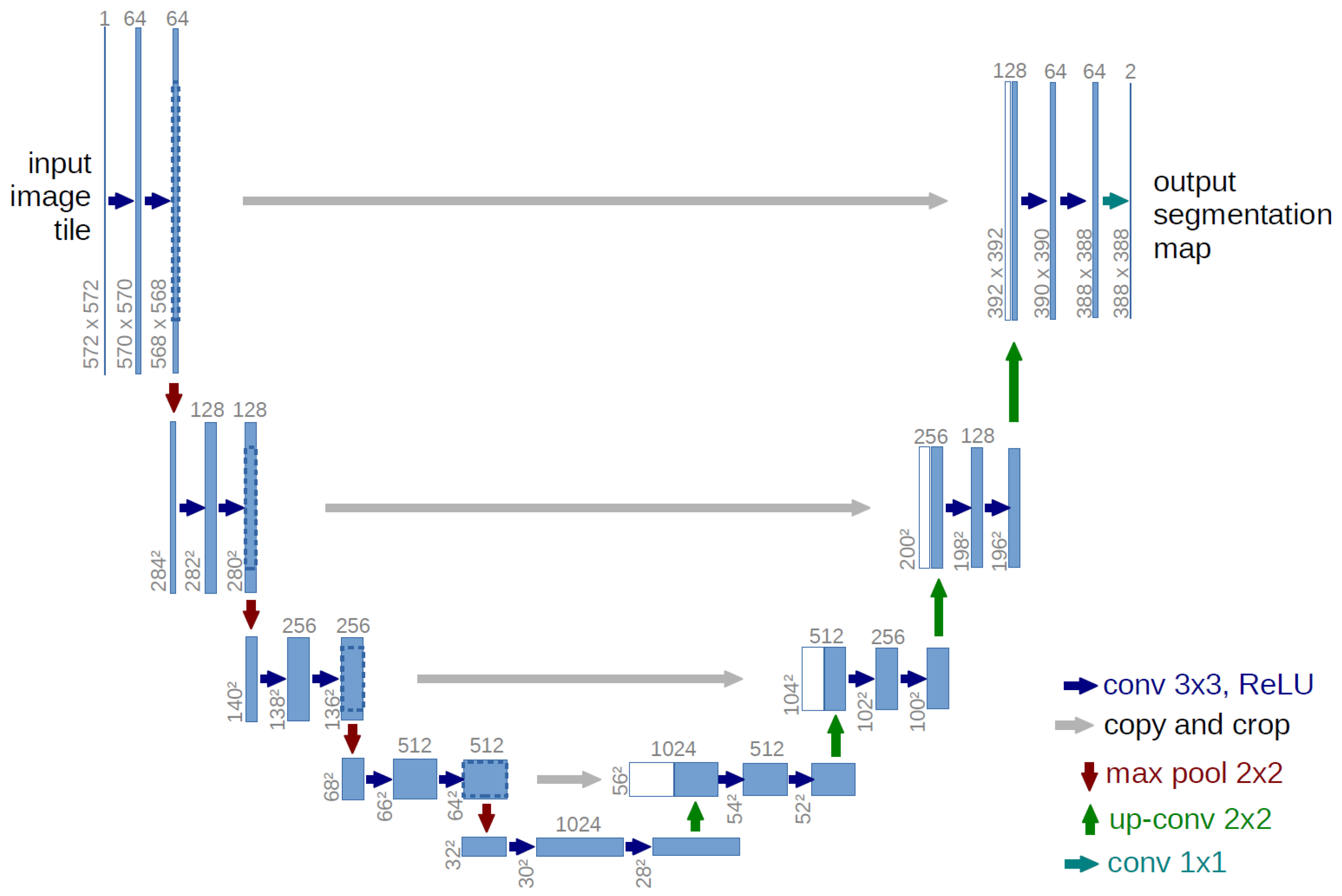
3.1. U-Net Architecture Overview
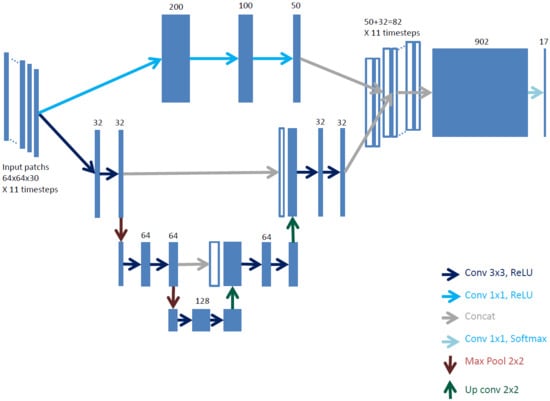
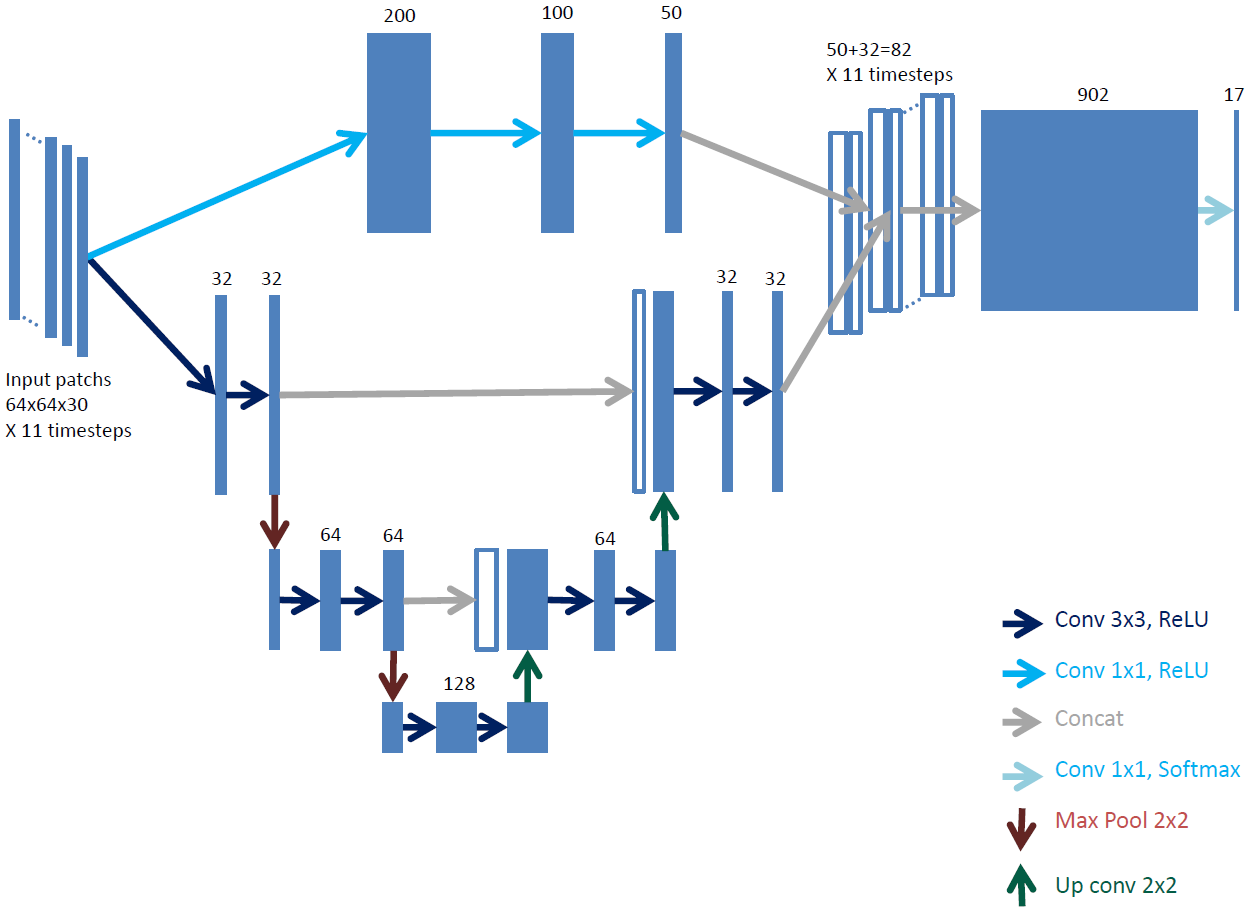
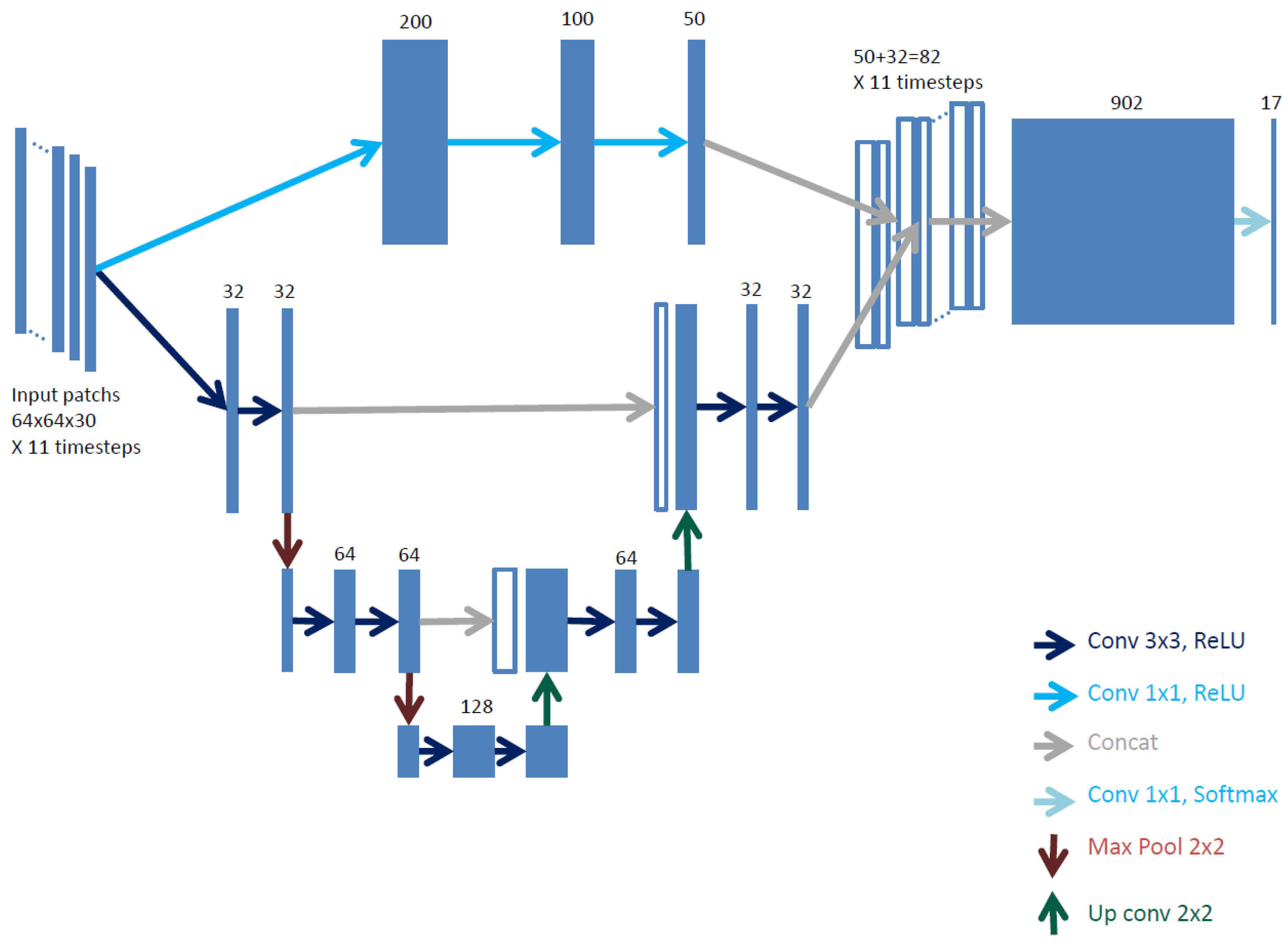
3.2. Fine Grained U-Net Architecture (FG-UNET)
- The receptive field and the number of steps in the network are adapted to our remote sensing data resolution and number of dimensions.
- A pixel-wise fully connected path is added to improve boundary delineation in the produced maps.
- The temporal component of the data is dealt by replication of the network on subsets of the time series.
3.2.1. Receptive Field and Network Size Adaptation
3.2.2. Pixel-Wise 1 × 1 Path
3.2.3. Time Series Handling
3.2.4. Sparse and Imbalanced Annotations Handling
3.2.5. Spectral Indices
- Normalized Difference Vegetation Index (NDVI), computed using Sentinel-2 spectral bands B4 and B8;
- Normalized Difference Water Index (NDWI), computed using Sentinel-2 spectral bands B3 and B8;
- Brightness, as the mean of the ten Sentinel-2 available spectral bands.
3.3. Training Method
3.3.1. Preprocessing
3.3.2. Distributed Patch Generation
3.3.3. Hyperparameters for Distributed Training
3.3.4. Class Imbalance Handling
3.3.5. Data Augmentation
3.3.6. Complete Batch Creation Procedure
- examples of a randomly chosen class are sampled
- B patches containing at least 10% of pixels of the respective class are randomly chosen
- the worker (first node):
- determine which nodes have loaded the tile of each of the B patches
- sets up the patch transfer scheme between nodes: . Say a node must fill patches in the batch. If , must send patches to another node. If , must receive patches for another node. We set as the number of patches node must send or receive to nodes so that in the end it has b patches
- each node :
- receives the transfer scheme
- , if node sends patches to node j. Else, it receives patches from node j
- if spectral indices are enabled, they are computed and additional channels are added to the patches
- data augmentation is applied to the patches.
3.4. Classification Method
4. Experimental Setup
4.1. Experimental Configuration
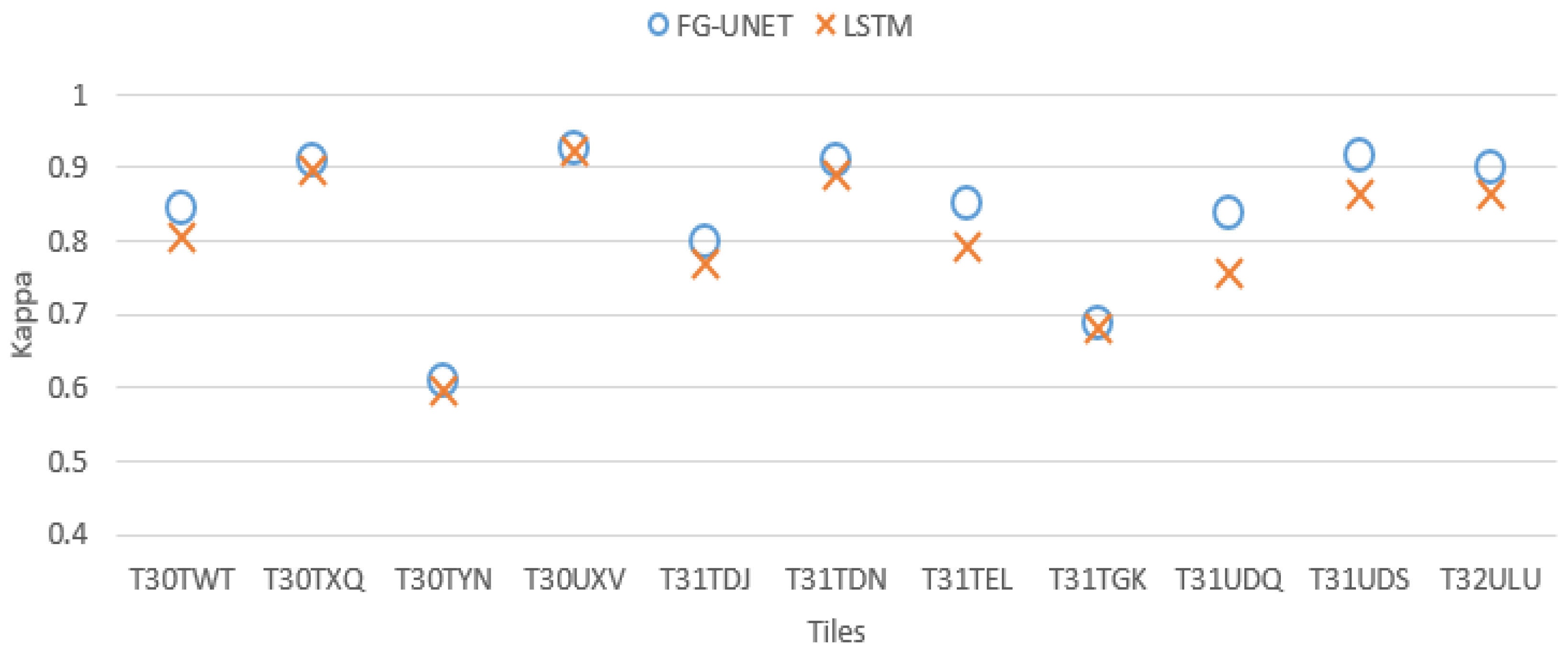
4.2. Baselines
- MLP 3 layers: the 1 × 1 3 layer convolutional path of the FG-UNET model by itself. Time series handling is however done in an early fusion manner, the input layer thus having 330 channels.
- LSTM 3 layers: the 1 × 1 3 layer convolutional path of FG-UNET, using input channel grouping (11 groups of 3 channels) and late fusion through an LSTM layer instead of concatenation followed by linear classification.
- U-Net 3 steps: the U-Net part of FG-UNET by itself, with late fusion through concatenation and linear classification.
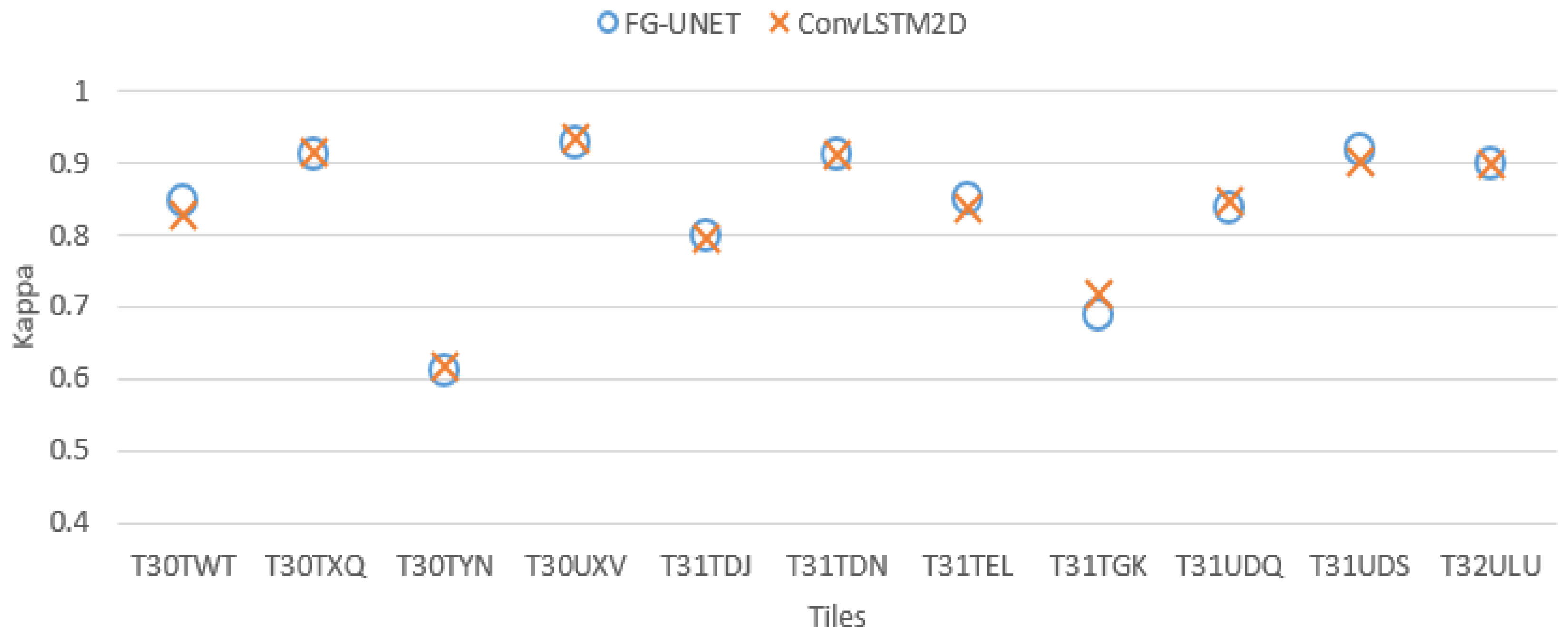
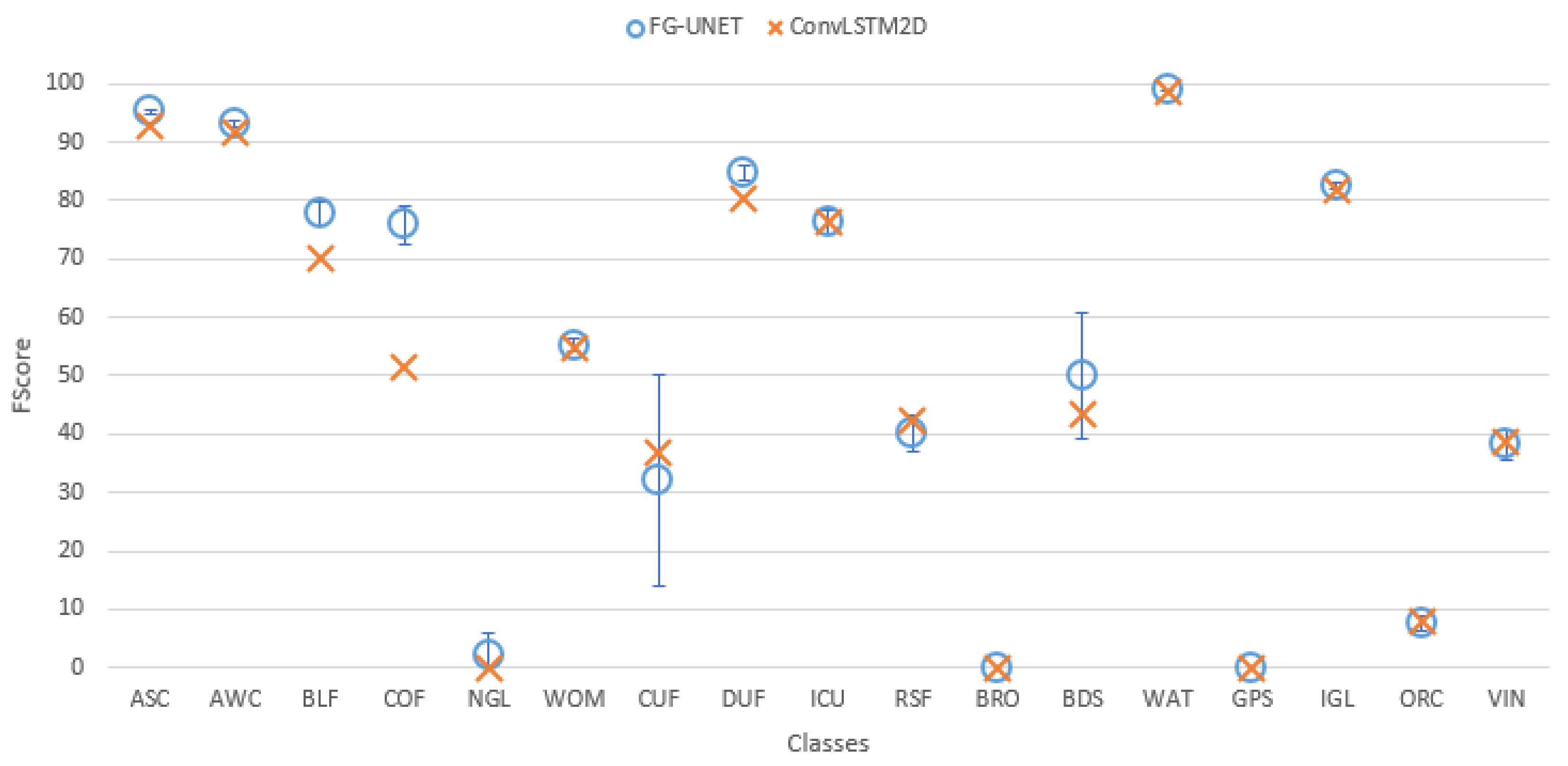
- TSFG-UNET: We replace convolutions by convolutional LSTM layers.
- number of parameters for each convolutional neural network tested. CNN parameter numbers can not be compared with RF, whose parameters are chosen in a discrete set of values.
- learning times for a learning performed on 11 nodes containing 24 CPUs each
- learning time without parallel computing. For CNN methods it corresponds to the previous column multiplied by 11 nodes and 24 CPUs. It can be compared to RF learning which is directly performed on one CPU, because the implementation used does not allow parallelism, but other implementations could be used in order to reduce the time, since each tree in the forest can be trained in parallel.
4.3. Metrics and Their Limitations
5. Results
- statistical comparison on tiles and on individual classes;
- visual comparison on level of detail of the produced maps.
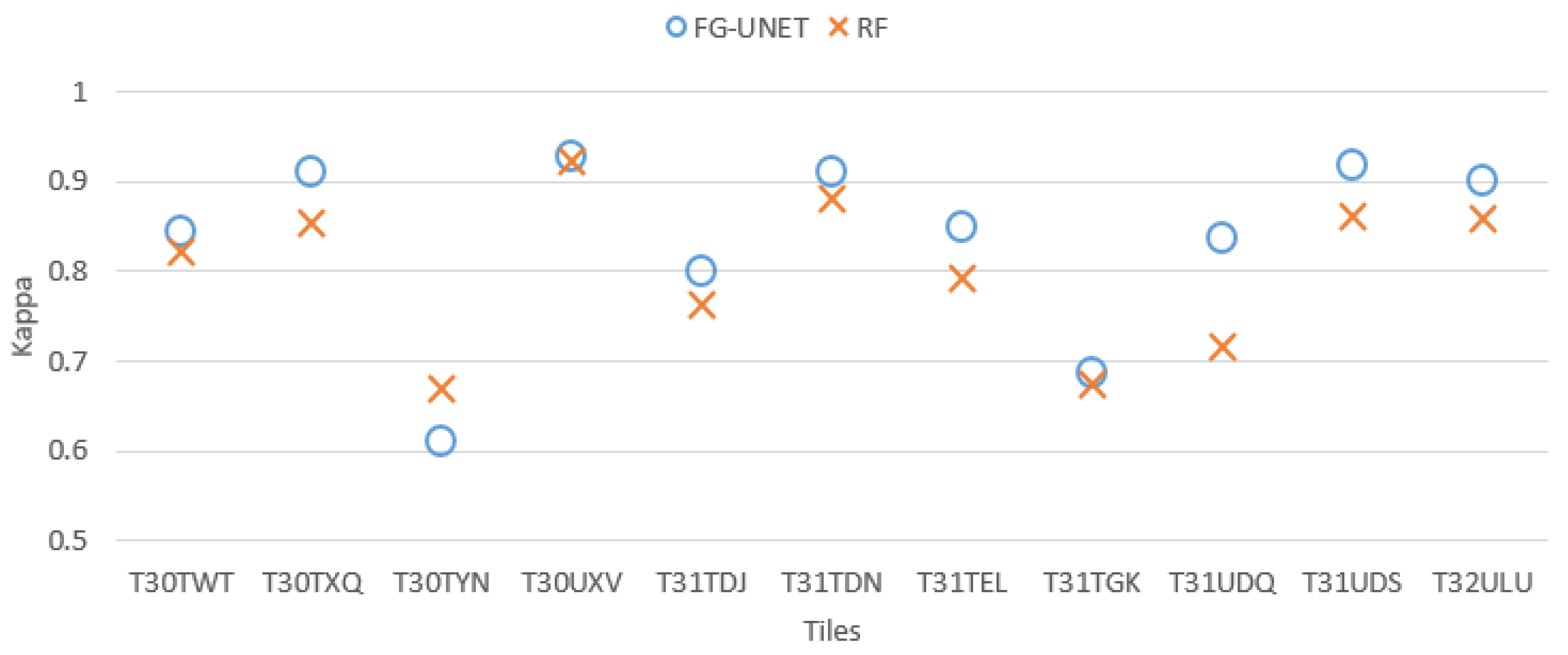
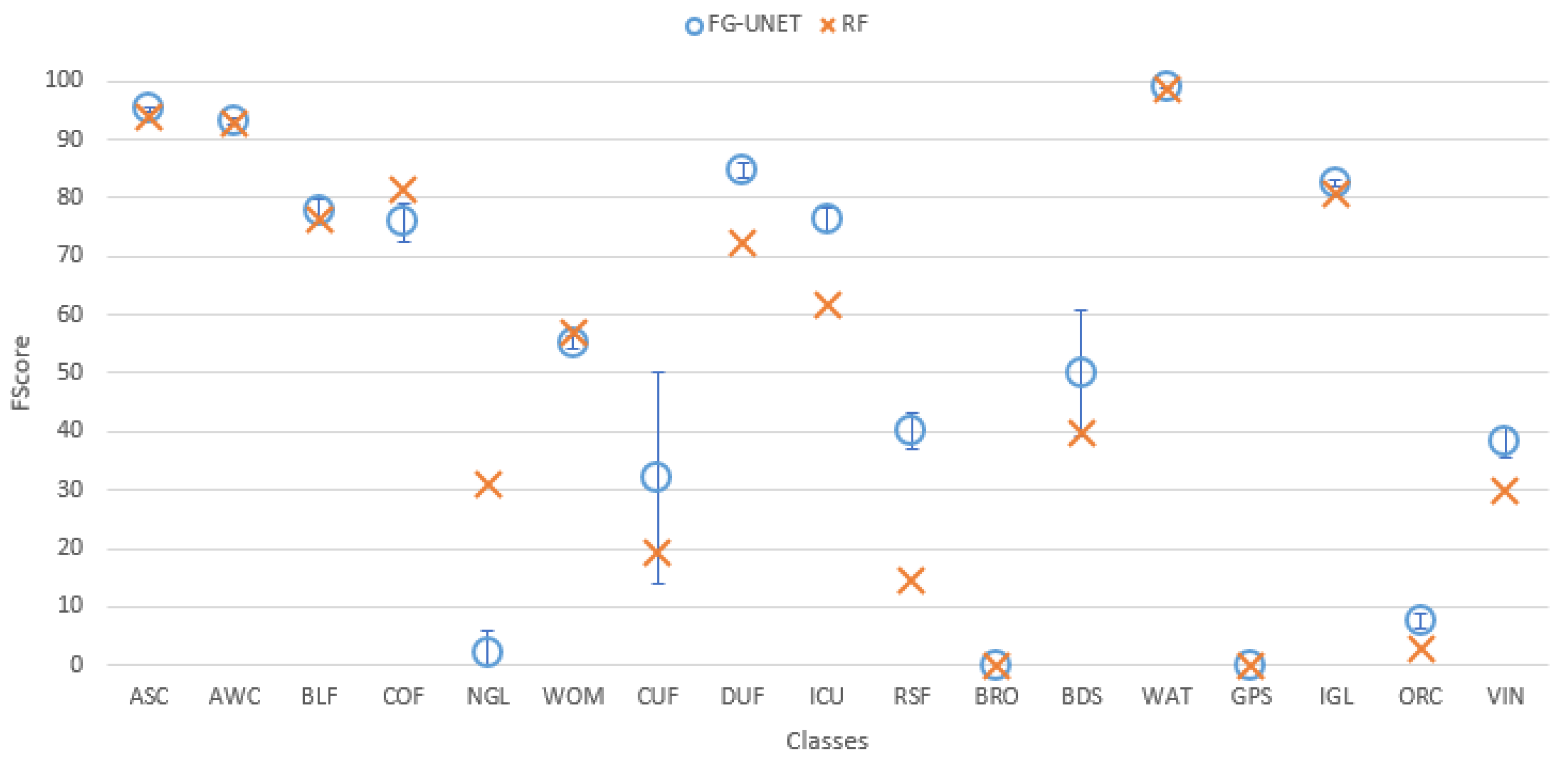
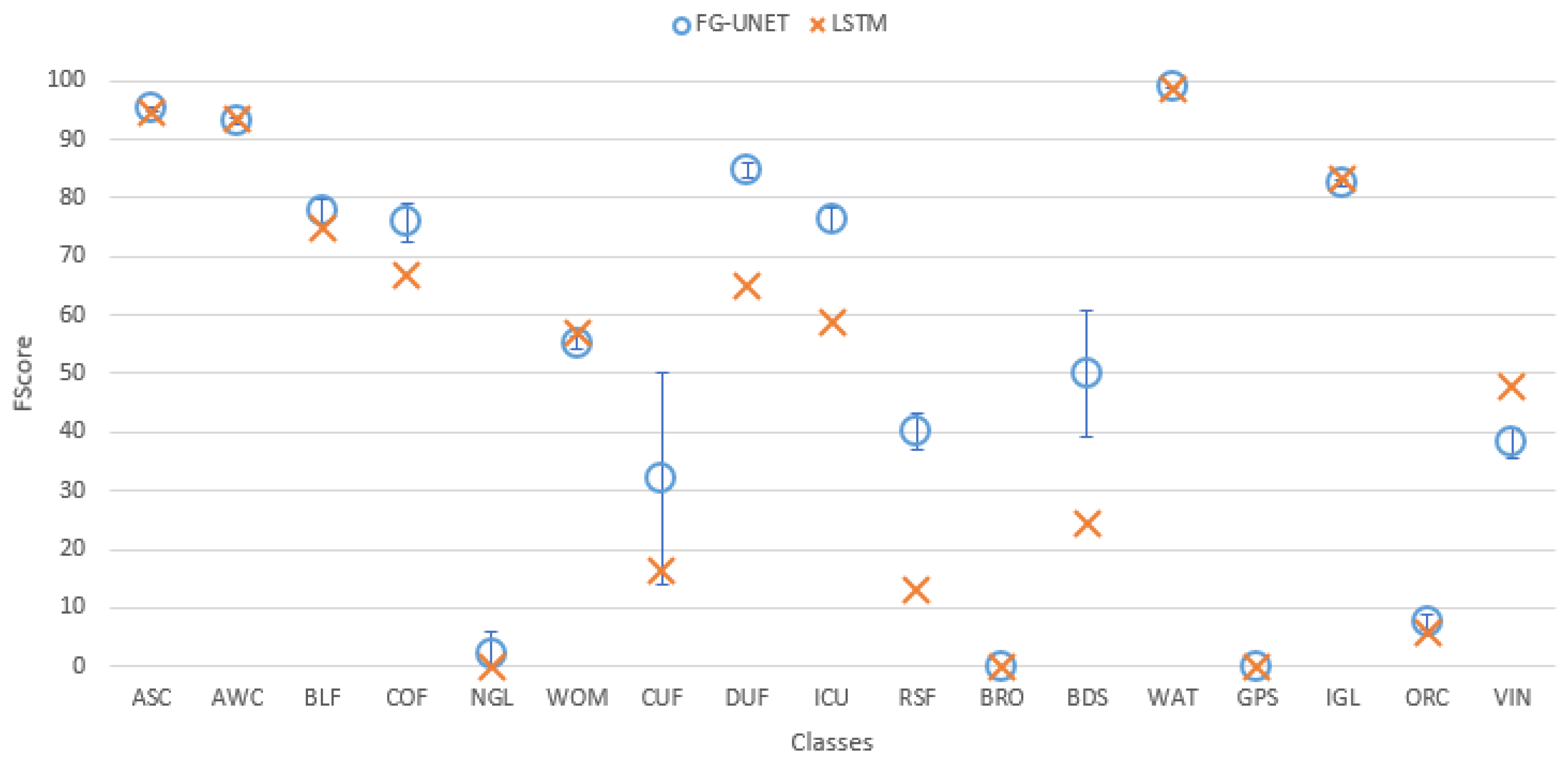
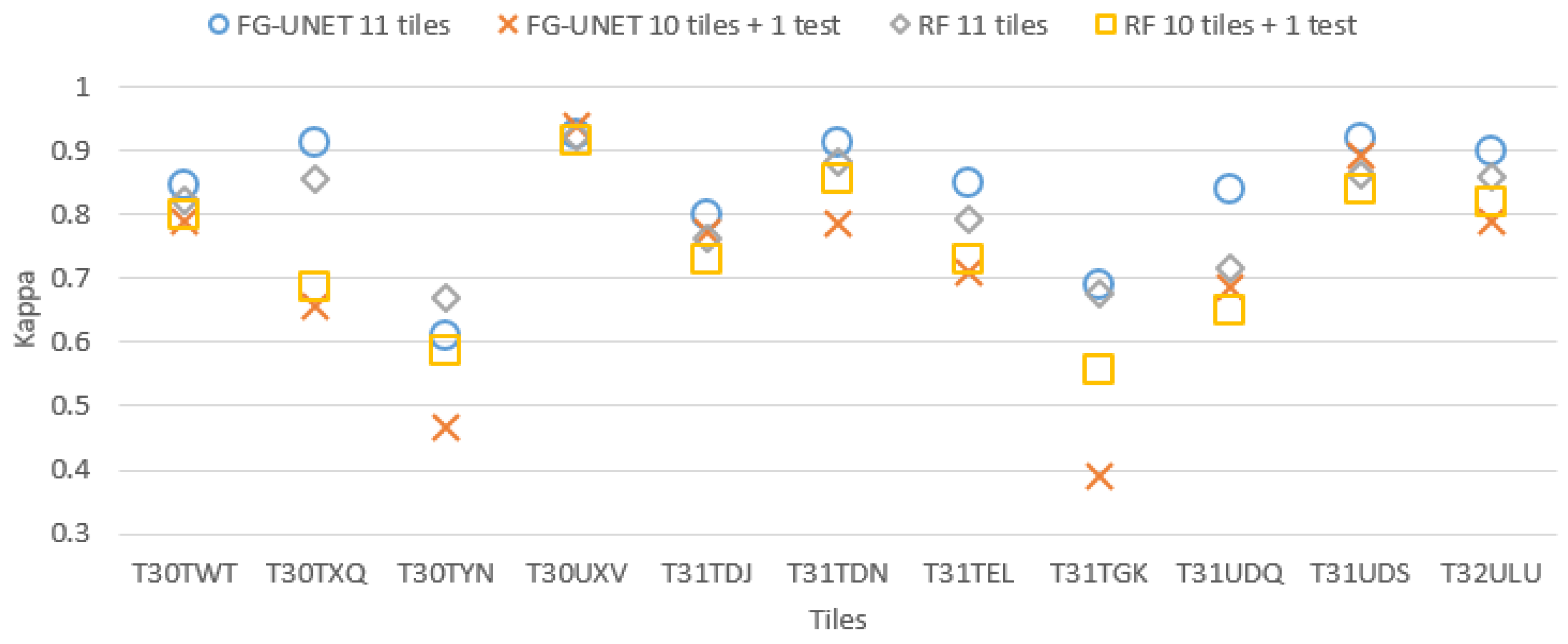
5.1. FG-UNET vs. RF
- FG-UNET is similar or better than RF for all classes, except NGL, a class for which context is less discriminant than spectral and temporal information.
- FG-UNET is significantly better for all urban classes (CUF, DUF, ICU, RSF). FG-UNET takes advantage of the use of the texture. Contrary to pixel-based methods like RF, convolutionnal networks can take into account the context of the pixel to classify, which is crucial in artificial areas.
- Error bars show that the variability of results is higher for FG-UNET than for RF. FG-UNET and RF learning and classification were performed five times, in order to analyze variability of models. The Kappa coefficient remains the same, but for some classes FG-UNET results may vary. This variation is mainly found for minority classes, for which the data augmentation used for training is not sufficient to capture the intra-class variability and therefore, the sensitivity to initialization is important.
- Road recall is better with FG-UNET, but with a lower precision
- Level of detail is similar with FG-UNET and RF in rural regions
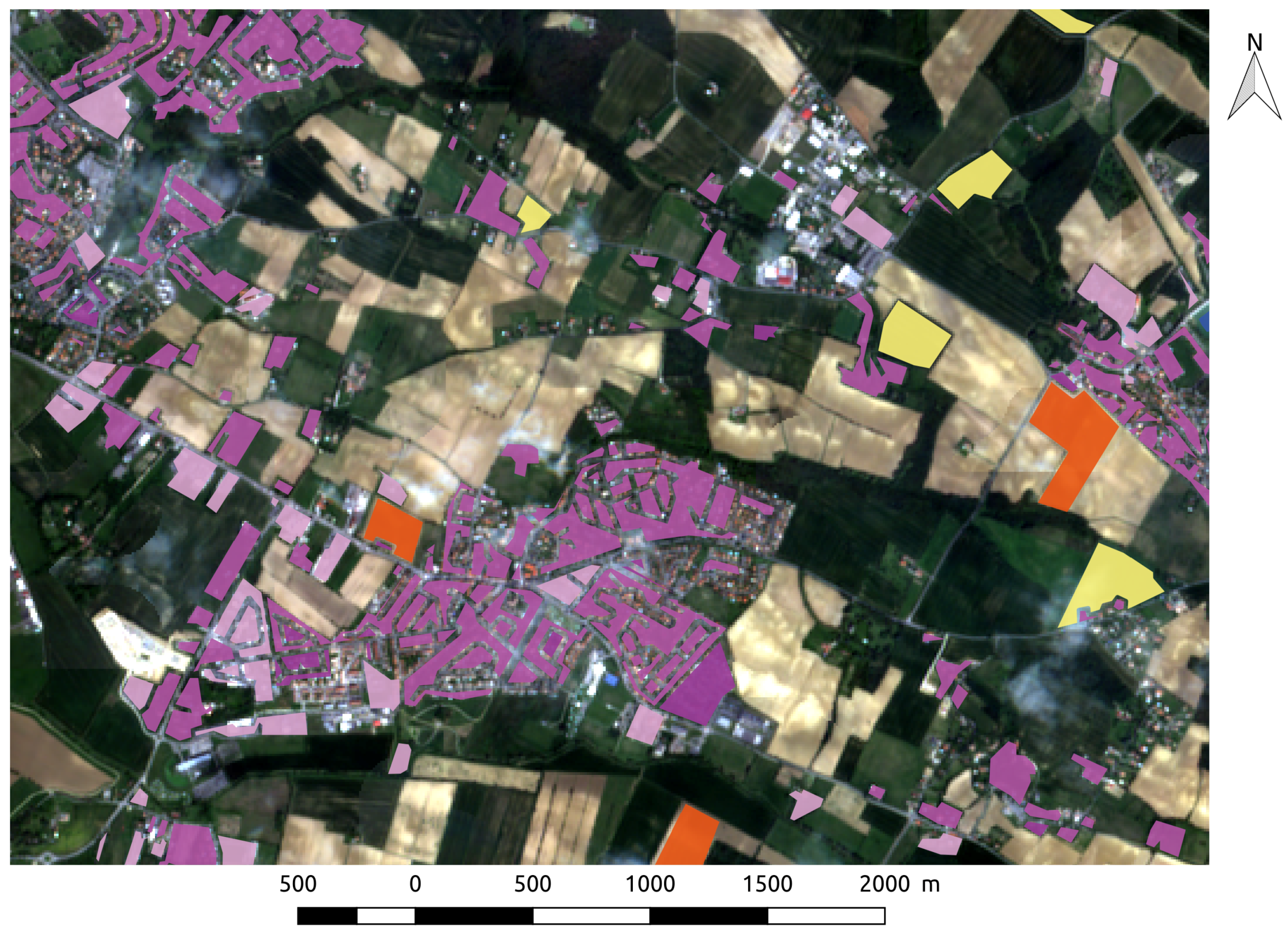
- Comparison of Figure 8a,b highlights that city streets are not classified as roads with FG-UNET, contrary to RF. These streets are not part of the training set, so the expected class is not well defined. However, if some street training samples were part of classes CUF or DUF, FG-UNET with the use of context could be able to classify them correctly, whereas with a pixel-based method like RF, it would be more challenging. On the other hand, these two figures also show that the FG-UNET has more difficulty in preserving sharp details as the harbour area.
5.2. Importance of Individual FG-UNET Features
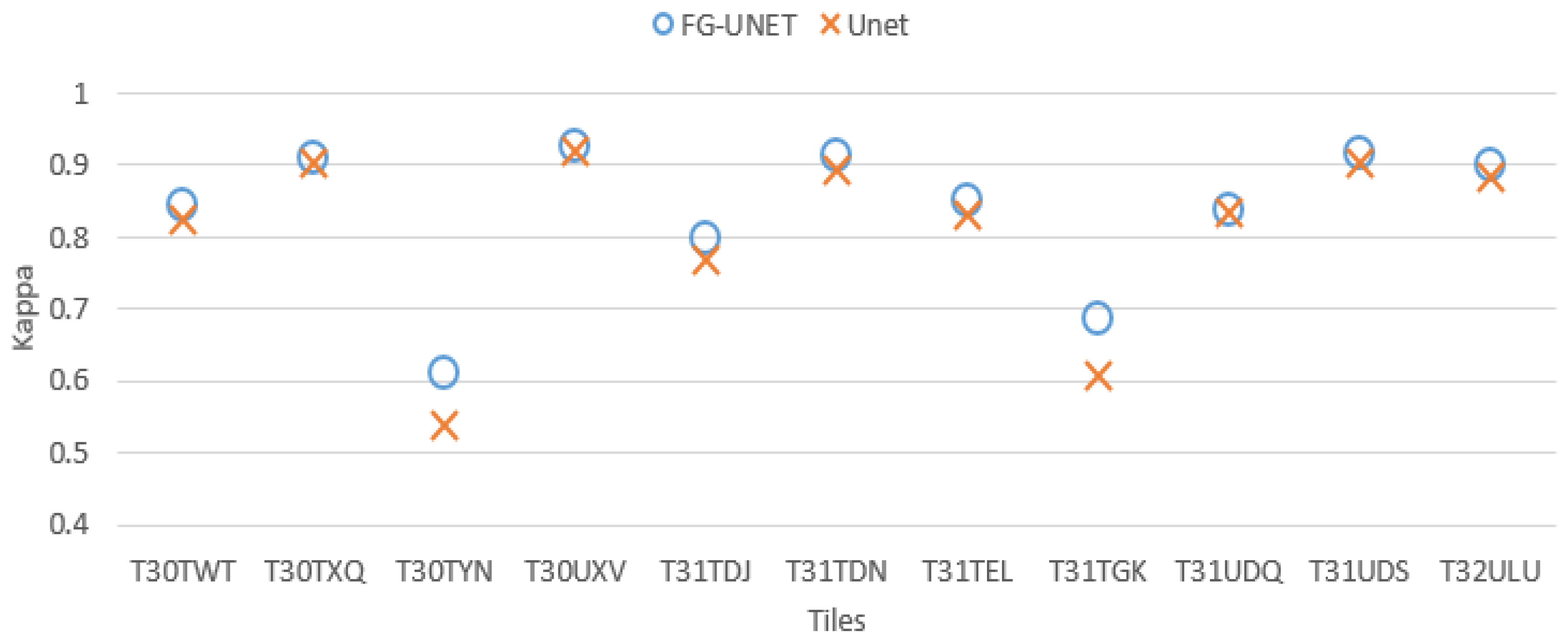
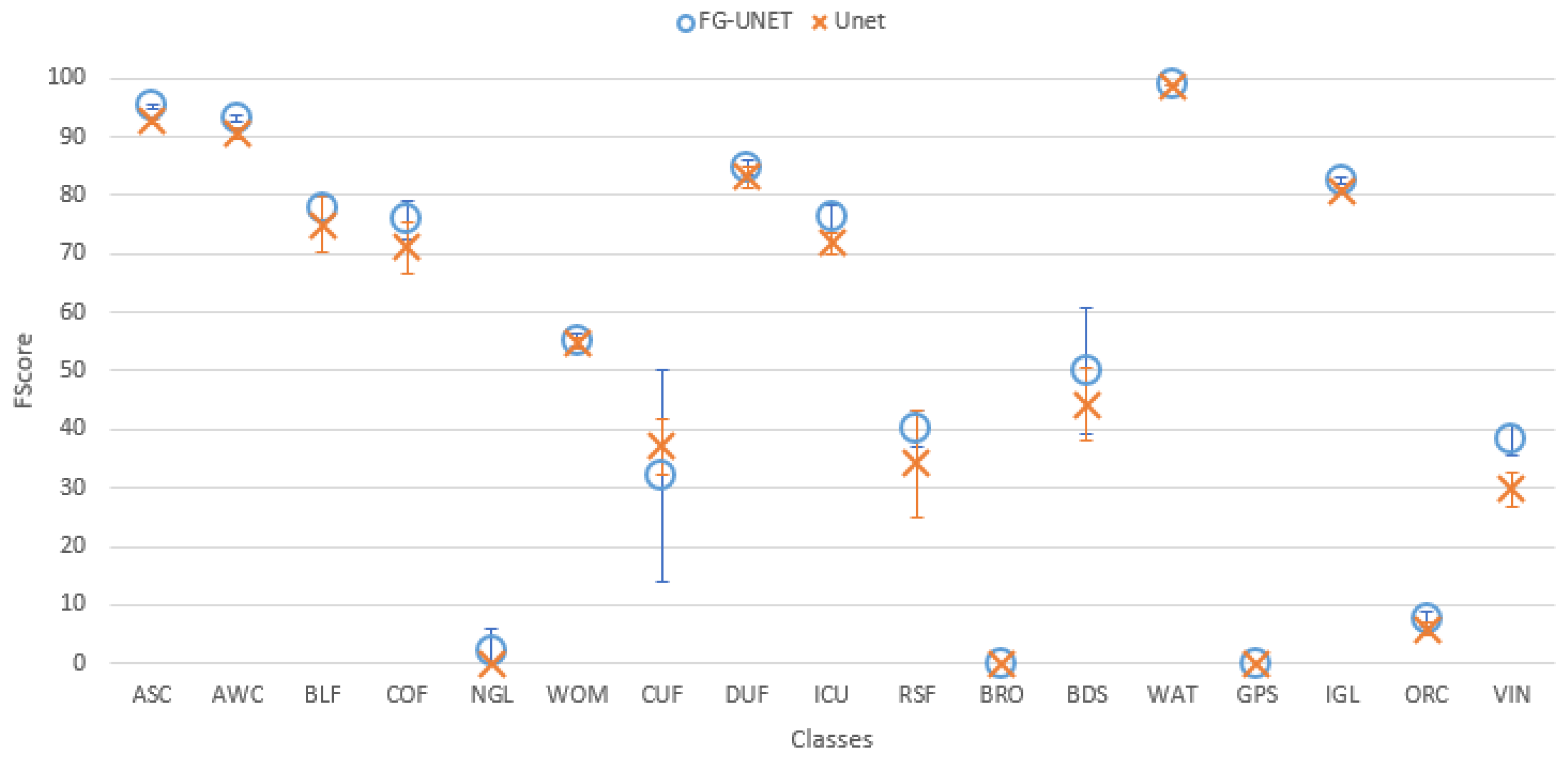
- FG-UNET vs UNET. This test was carried out in order to prove the importance of the pixel-wise 1 × 1 path added to UNET to obtain FG-UNET. Figure 9 shows that FG-UNET gives results slightly above UNET for all tiles. Results are even significantly better for mountain tiles (T30TYN and T31TGK). This is the same phenomenon observed when comparing FG-UNET and RF: pixel-based classification works better for this areas and FG-UNET adds a pixel-based path which complements the contextual classification. The detail by class for T30TWT on Figure 10 shows that FG-UNET is better than UNET (except for CUF). Thus, these statistical results prove the importance of pixel-wise 1 × 1 path contribution. Moreover, visual analysis of produced land cover maps (Figure 11) highlights the increasing in level of detail with FG-UNET. For instance, the jetty of Figure 11c is better rendered in Figure 11a than in Figure 11b.
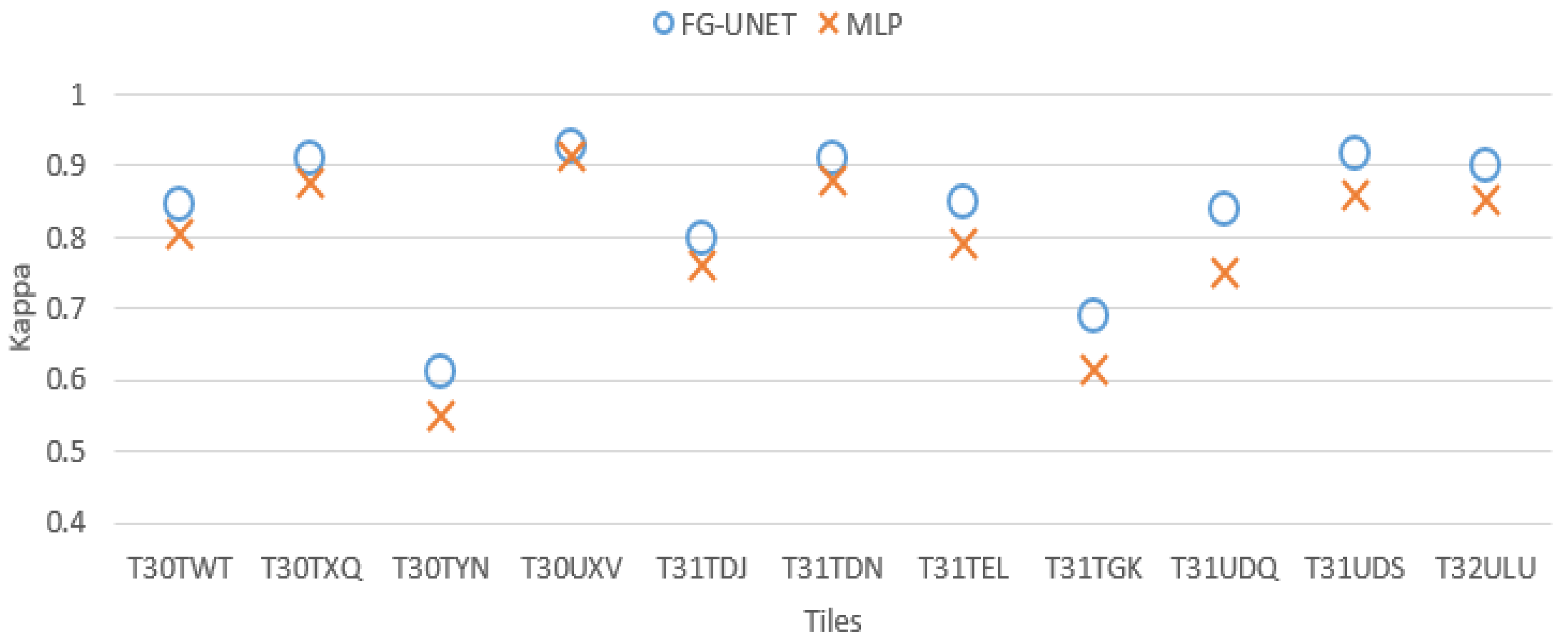
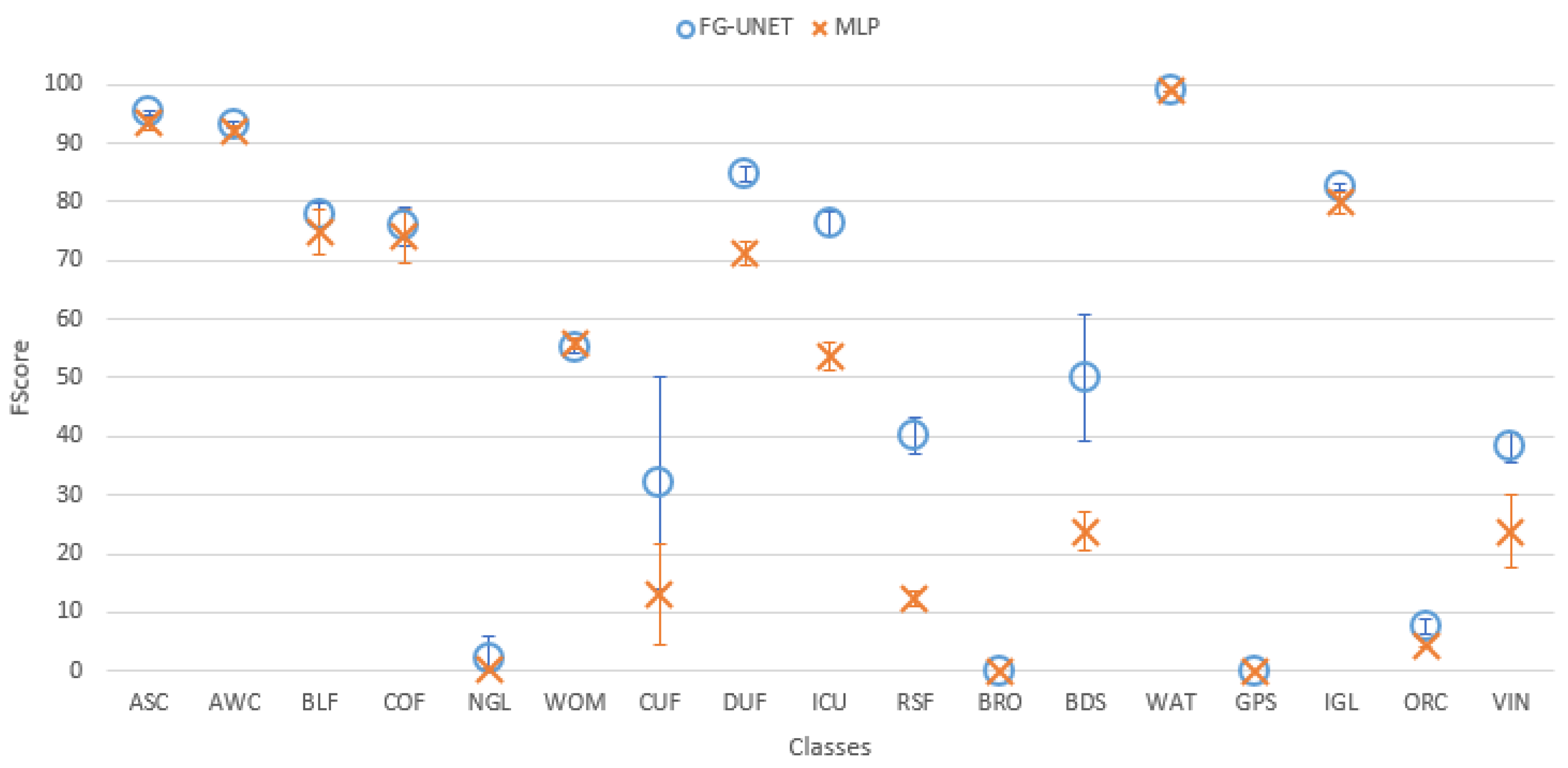
- FG-UNET vs MLP 3 layers. In this test we compare FG-UNET with a network composed of only the pixel-wise 1 × 1 path (MLP). It is a pixel-based method, without use of context, like RF. Results of MLP are below FG-UNET for all tiles, and all classes on T30TWT as represented on Figure 12 and Figure 13. We can also observe that RF provides better results than MLP with 3 layers.
- FG-UNET vs TSFG-UNET. A test was performed replacing all convolutions of FG-UNET by ConvLSTM2D [32], which is a convolutional implementation of LSTM. Figure 16 and Figure 17 show that results of TSFG-UNET are very close to FG-UNET. Yet, as represented in Table 2 the training time is 19 times higher with ConvLSTM2D. Consequently FG-UNET remains more interesting for this application.
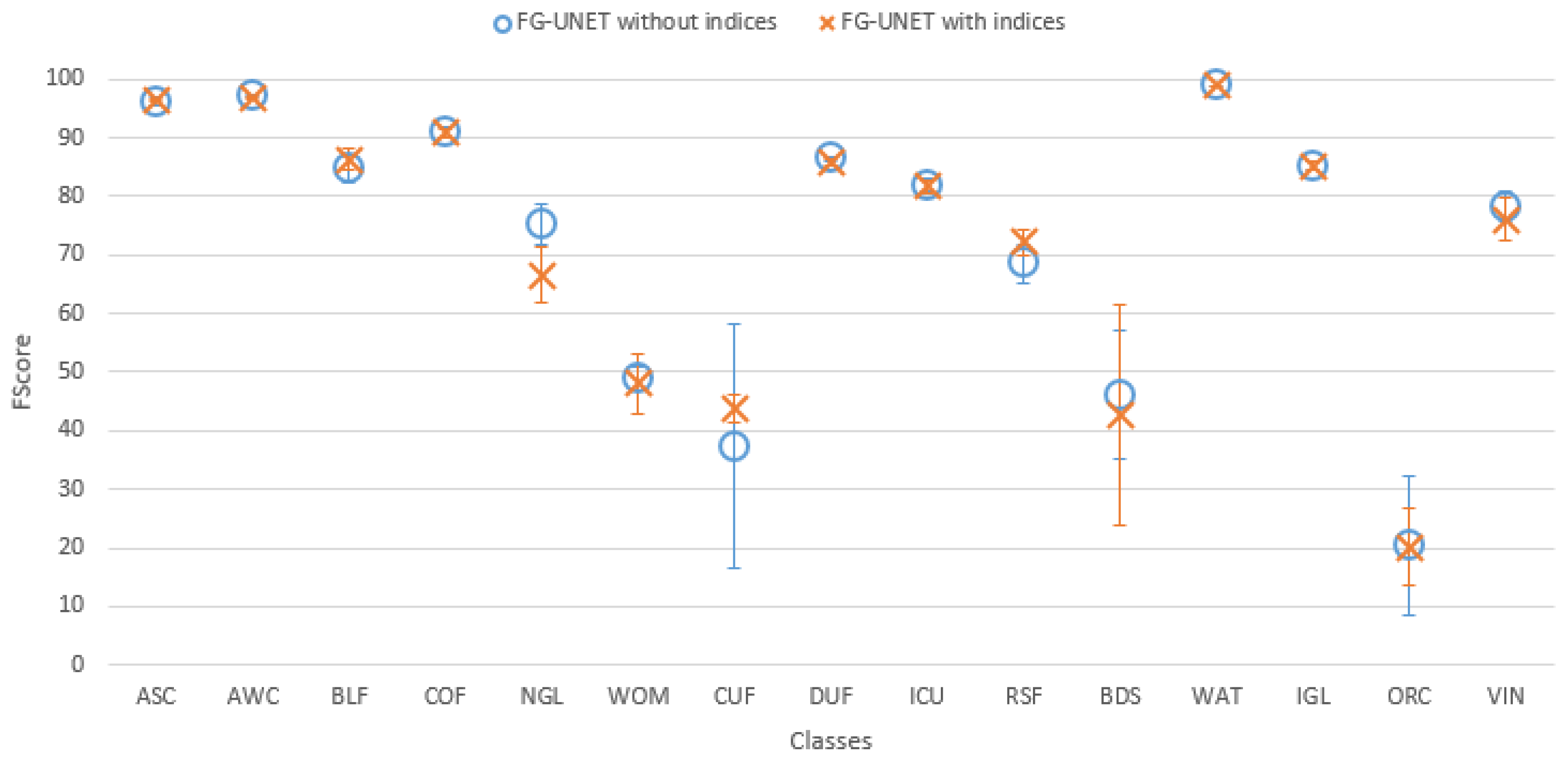
- Spectral indices usefulness. To assess the usefulness of spectral indices NDVI, NDWI and brightness defined in Section 3.2.5, a test was performed on the tile T30TWT. We can see on Figure 18 that results for all classes are very close with and without the use of spectral indices. It confirms that information brought by these features can be learned from the data.
5.3. Cross Domain Transferability
- a drop in performance when a tile is not part of learning. Yet, it highly depends on the tile content. This drop is particularly high for mountain tiles (T30TYN and T31TGK) whose content is different from other tiles, and for T30TXQ which also has very few AWC labels. On the other hand, their is almost no drop for tile T30UXV.
- FG-UNET suffers from a higher decrease than RF. It tends to show that our implementation of FG-UNET cannot generalize as well as RF.
5.4. Geometric Precision
6. Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Heymann, Y. CORINE Land Cover: Technical Guide; Office for Official Publications of the European Communities: Luxembourg, 1994. [Google Scholar]
- Arino, O.; Gross, D.; Ranera, F.; Leroy, M.; Bicheron, P.; Brockman, C.; Defourny, P.; Vancutsem, C.; Achard, F.; Durieux, L.; et al. GlobCover: ESA service for global land cover from MERIS. In Proceedings of the 2007 IEEE International Geoscience and Remote Sensing Symposium, Barcelona, Spain, 23–28 July 2007. [Google Scholar]
- Drusch, M.; Bello, U.D.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s Optical High-Resolution Mission for GMES Operational Services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Whitcraft, A.; Becker-Reshef, I.; Killough, B.; Justice, C. Meeting Earth Observation Requirements for Global Agricultural Monitoring: An Evaluation of the Revisit Capabilities of Current and Planned Moderate Resolution Optical Earth Observing Missions. Remote Sens. 2015, 7, 1482–1503. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global Land Cover Mapping At 30m Resolution: A Pok-Based Operational Approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef]
- Inglada, J.; Vincent, A.; Thierion, V. Theia Oso Land Cover Map 2106. 2017. Available online: https://zenodo.org/record/1048161 (accessed on 22 August 2019).
- Inglada, J.; Vincent, A.; Thierion, V. 2017 Metropolitan France Land Cover Map—CESBIO-OSO. 2018. Available online: https://zenodo.org/record/1993595 (accessed on 22 August 2019).
- Inglada, J.; Vincent, A.; Arias, M.; Tardy, B.; Morin, D.; Rodes, I. Operational High Resolution Land Cover Map Production At the Country Scale Using Satellite Image Time Series. Remote Sens. 2017, 9, 95. [Google Scholar] [CrossRef]
- Defries, R.S.; Townshend, J.R.G. Global Land Cover Characterization From Satellite Data: From Research To Operational Implementation. GCTE/LUCC Research Review. Glob. Ecol. Biogeogr. 1999, 8, 367–379. [Google Scholar] [CrossRef]
- Hansen, M.C.; Loveland, T.R. A Review of Large Area Monitoring of Land Cover Change Using Landsat Data. Remote Sens. Environ. 2012, 122, 66–74. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. CoRR 2015. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Postadjian, T.; Le Bris, A.; Sahbi, H.; Mallet, C. Investigating the potential of deep neural networks for large-scale classification of very high resolution satellite images. ISPRS Ann. Photogramm. Remote. Sens. Spat. Inf. Sci. 2017, IV-1/W1, 183–190. [Google Scholar] [CrossRef]
- Maggiolo, L.; Marcos, D.; Moser, G.; Tuia, D. Improving Maps from Cnns Trained with Sparse, Scribbled Ground Truths Using Fully Connected Crfs. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected Crfs. CoRR 2016. [Google Scholar] [CrossRef]
- Volpi, M.; Tuia, D. Dense Semantic Labeling of Subdecimeter Resolution Images With Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 881–893. [Google Scholar] [CrossRef]
- Lin, D.; Dai, J.; Jia, J.; He, K.; Sun, J. ScribbleSup: Scribble-Supervised Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Marmanis, D.; Schindler, K.; Wegner, J.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an Edge: Improving Semantic Image Segmentation With Boundary Detection. ISPRS J. Photogramm. Remote Sens. 2018, 135, 158–172. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building Extraction in Very High Resolution Remote Sensing Imagery Using Deep Learning and Guided Filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef]
- Fu, T.; Ma, L.; Li, M.; Johnson, B.A. Using Convolutional Neural Network To Identify Irregular Segmentation Objects From Very High-Resolution Remote Sensing Imagery. J. Appl. Remote Sens. 2018, 12. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Ji, S.; Zhang, C.; Xu, A.; Shi, Y.; Duan, Y. 3D Convolutional Neural Networks for Crop Classification with Multi-Temporal Remote Sensing Images. Remote Sens. 2018, 10, 75. [Google Scholar] [CrossRef]
- Mou, L.; Bruzzone, L.; Zhu, X.X. Learning spectral-spatial-temporal features via a recurrent convolutional neural network for change detection in multispectral imagery. arXiv 2018, arXiv:1803.02642. [Google Scholar] [CrossRef]
- Ienco, D.; Gaetano, R.; Dupaquier, C.; Maurel, P. Land Cover Classification Via Multitemporal Spatial Data By Deep Recurrent Neural Networks. IEEE Geosci. Remote. Sens. Lett. 2017. [Google Scholar] [CrossRef]
- Hagolle, O.; Sylvander, S.; Huc, M.; Claverie, M.; Clesse, D.; Dechoz, C.; Lonjou, V.; Poulain, V. SPOT4 (Take5): Simulation of Sentinel-2 Time Series on 45 Large sites. Remote Sens. 2015, 7, 12242–12264. [Google Scholar] [CrossRef]
- Bossard, M.; Feranec, J.; Otahel, J. CORINE Land Cover Technical Guide. Addendum 2000; European Environment Agency: Copenhagen, Denmark, 2000. [Google Scholar]
- Maugeais, E.; Lecordix, F.; Halbecq, X.; Braun, A. Dérivation cartographique multi échelles de la BDTopo de l’IGN France: Mise en œuvre du processus de production de la Nouvelle Carte de Base. In Proceedings of the 25th International Cartographic Conference, Paris, France, 3–8 July 2011; pp. 3–8. [Google Scholar]
- Cantelaube, P.; Carles, M. Le Registre Parcellaire Graphique: Des données géographiques pour décrire la couverture du sol agricole. Le Cahier des Techniques de l’INRA 2014, 58–64. [Google Scholar]
- Pfeffer, W.T.; Arendt, A.A.; Bliss, A.; Bolch, T.; Cogley, J.G.; Gardner, A.S.; Hagen, J.O.; Hock, R.; Kaser, G.; Kienholz, C.; et al. The Randolph Glacier Inventory: A Globally Complete Inventory of Glaciers. J. Glaciol. 2014, 60, 537–552. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.; Wong, W.; Woo, W. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. arXiv 2015, arXiv:1506.04214. [Google Scholar]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Jorge Cardoso, M. Generalised Dice Overlap as a Deep Learning Loss Function for Highly Unbalanced Segmentations. Lect. Notes Comput. Sci. 2017, 240–248. [Google Scholar] [CrossRef]
- Goyal, P.; Dollár, P.; Girshick, R.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, large minibatch SGD: Training imagenet in 1 hour. arXiv 2017, arXiv:1706.02677. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Pontius, R.G.; Millones, M. Death To Kappa: Birth of Quantity Disagreement and Allocation Disagreement for Accuracy Assessment. Int. J. Remote Sens. 2011, 32, 4407–4429. [Google Scholar] [CrossRef]
- Bruzzone, L.; Carlin, L. A multilevel context-based system for classification of very high spatial resolution images. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2587–2600. [Google Scholar] [CrossRef]
- Von Gioi, R.G.; Jakubowicz, J.; Morel, J.M.; Randall, G. LSD: A line segment detector. Image Process. Line 2012, 2, 35–55. [Google Scholar] [CrossRef]
- Tardy, B.; Inglada, J.; Michel, J. Assessment of Optimal Transport for Operational Land-Cover Mapping Using High-Resolution Satellite Images Time Series without Reference Data of the Mapping Period. Remote Sens. 2019, 11, 1047. [Google Scholar] [CrossRef]
- Richmond, D.; Kainmueller, D.; Yang, M.; Myers, E.; Rother, C. Mapping Auto-Context Decision Forests to Deep Convnets for Semantic Segmentation. In Proceedings of the British Machine Vision Conference 2016, York, UK, 19–22 September 2016. [Google Scholar]
- Liu, H.; Simonyan, K.; Yang, Y. Darts: Differentiable architecture search. arXiv 2018, arXiv:1806.09055. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 1195–1204. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tile Name | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T30TWT | T30TXQ | T30TYN | T30UXV | T31TDJ | T31TDN | T31TEL | T31TGK | T31UDQ | T31UDS | T32ULU | Total | |
| ASC | 5650 | 3306 | 2415 | 6738 | 3700 | 4154 | 3849 | 159 | 3327 | 1951 | 6900 | 42,149 (2.43%) |
| AWC | 5204 | 85 | 572 | 10,235 | 7982 | 22,297 | 5617 | 866 | 32,808 | 9125 | 4511 | 99,302 (5.74%) |
| BLF | 2063 | 2659 | 11,636 | 3152 | 9358 | 27,161 | 10,855 | 8144 | 12,829 | 4465 | 17,184 | 109,506 (6.32%) |
| COF | 2546 | 112,152 | 7544 | 803 | 10,961 | 5594 | 47,692 | 57,027 | 2442 | 94 | 52,772 | 299,627 (17.31%) |
| NGL | 272 | 0 | 18,862 | 0 | 7735 | 62 | 1307 | 51,040 | 24 | 201 | 1484 | 80,987 (4.68%) |
| WOM | 3856 | 3952 | 11,312 | 552 | 3788 | 1433 | 3465 | 18,915 | 749 | 466 | 518 | 49,006 (2.83%) |
| CUF | 368 | 1019 | 203 | 863 | 106 | 157 | 1183 | 20 | 8619 | 906 | 941 | 14,385 (0.83%) |
| DUF | 5962 | 11,108 | 1536 | 3059 | 1501 | 1949 | 7019 | 833 | 31,143 | 5045 | 6514 | 75,669 (4.37%) |
| ICU | 5331 | 7951 | 842 | 3116 | 1172 | 2758 | 4689 | 358 | 25,165 | 6525 | 4647 | 62,554 (3.61%) |
| RSF | 108 | 694 | 112 | 138 | 61 | 179 | 584 | 73 | 2031 | 779 | 615 | 5374 (0.31%) |
| BRO | 0 | 0 | 20,990 | 48 | 27 | 0 | 3 | 53,160 | 0 | 0 | 20 | 74,248 (4.29%) |
| BDS | 140 | 4327 | 0 | 374 | 0 | 107 | 0 | 923 | 0 | 348 | 0 | 6219 (0.35%) |
| WAT | 237,383 | 219,169 | 814 | 125,722 | 2204 | 5045 | 1403 | 2293 | 2567 | 113,073 | 3305 | 712,978 (41.21%) |
| GPS | 0 | 0 | 63 | 0 | 0 | 0 | 0 | 2519 | 0 | 0 | 0 | 2582 (0.14%) |
| IGL | 7595 | 648 | 7891 | 18,446 | 5319 | 5493 | 23,270 | 6165 | 4544 | 2479 | 9458 | 91,308 (5.27%) |
| ORC | 48 | 9 | 2 | 120 | 107 | 55 | 5 | 378 | 144 | 19 | 37 | 924 (0.05%) |
| VIN | 139 | 1620 | 6 | 0 | 1002 | 174 | 25 | 3 | 0 | 0 | 190 | 3159 (0.18%) |
| Total | 276,672 | 368,708 | 84,807 | 173,373 | 55,028 | 76,625 | 110,973 | 202,885 | 126,397 | 145,481 | 109,102 | 1,730,051 |
| Method | Parameters | Learning Time | Learning Time on 1 CPU |
|---|---|---|---|
| RF | - | 25 h | 25 h |
| MLP 3 layers | 40,717 | 7 h | 1760 h |
| LSTM 3 layers | 324,024 | 140 h | 36,960 h |
| U-Net 3 steps | 485,297 | 7 h | 1760 h |
| FG-UNET | 525,997 | 13 h | 3300 h |
| TSFG-UNET | 4,137,272 | 237 h | 62,700 h |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stoian, A.; Poulain, V.; Inglada, J.; Poughon, V.; Derksen, D. Land Cover Maps Production with High Resolution Satellite Image Time Series and Convolutional Neural Networks: Adaptations and Limits for Operational Systems. Remote Sens. 2019, 11, 1986. https://doi.org/10.3390/rs11171986
Stoian A, Poulain V, Inglada J, Poughon V, Derksen D. Land Cover Maps Production with High Resolution Satellite Image Time Series and Convolutional Neural Networks: Adaptations and Limits for Operational Systems. Remote Sensing. 2019; 11(17):1986. https://doi.org/10.3390/rs11171986
Chicago/Turabian StyleStoian, Andrei, Vincent Poulain, Jordi Inglada, Victor Poughon, and Dawa Derksen. 2019. "Land Cover Maps Production with High Resolution Satellite Image Time Series and Convolutional Neural Networks: Adaptations and Limits for Operational Systems" Remote Sensing 11, no. 17: 1986. https://doi.org/10.3390/rs11171986
APA StyleStoian, A., Poulain, V., Inglada, J., Poughon, V., & Derksen, D. (2019). Land Cover Maps Production with High Resolution Satellite Image Time Series and Convolutional Neural Networks: Adaptations and Limits for Operational Systems. Remote Sensing, 11(17), 1986. https://doi.org/10.3390/rs11171986