Large-Area, High Spatial Resolution Land Cover Mapping Using Random Forests, GEOBIA, and NAIP Orthophotography: Findings and Recommendations

 , , ,
, , ,
Abstract

1. Introduction
- How is classification accuracy of RF impacted by training data sample size and feature selection over a large spatial extent?
- Does incorporating GEOBIA super-object information improve classification accuracy?
- Does the addition of geometric measures, first-order textural measures, or second-order textural measures improve classification accuracy? If so, what variables are most important?
- Does the incorporation of ancillary data improve classification accuracy? If so, what variables are most important?
- What practical techniques are useful for processing this large data volume?
1.1. Machine Learning and Training Data
1.2. GEOBIA and Feature Space
1.3. NAIP Orthophotography
2. Materials and Methods
2.1. Study Area
2.2. Data and Pre-Processing
2.3. Image Segmentation
2.4. Variables and Feature Space
2.5. Training Data and Validation Data
2.6. Classification
2.7. Variable Importance and Accuracy Assessment
3. Results
3.1. Classificaton Results
3.2. Feature Space Comparison
3.3. Training Sample Size
3.4. Feature Selection
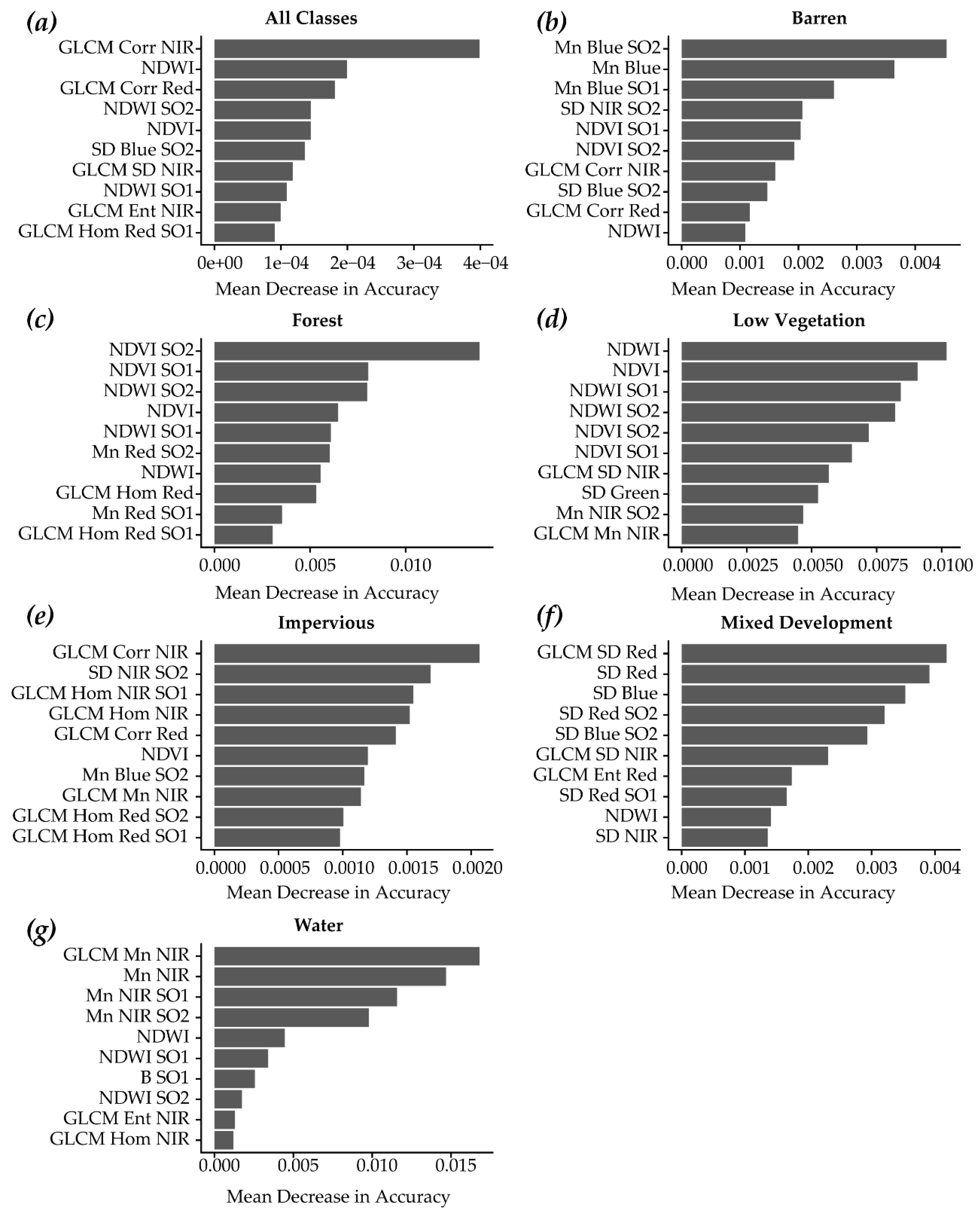
3.5. Variable Importance
4. Discussion
4.1. Sample Size and Feature Selection
4.2. Value of Super-Object Variables
4.3. Value of Measures of Texture and Object Geometry
4.4. Value of Ancillary Data
4.5. Practical Recommendations for Mapping Large Areas
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Basu, S.; Ganguly, S.; Nemani, R.R.; Mukhopadhyay, S.; Zhang, G.; Milesi, C.; Michaelis, A.; Votava, P.; Dubayah, R.; Duncanson, L.; et al. A semiautomated probabilistic framework for tree-cover delineation from 1-m NAIP imagery using a high-performance computing architecture. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5690–5708. [Google Scholar] [CrossRef]
- Li, X.; Shao, G. Object-based land-cover mapping with high resolution aerial photography at a county scale in midwestern USA. Remote Sens. 2014, 6, 11372–11390. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef]
- O’Neil-Dunne, J.; MacFaden, S.; Royar, A. A versatile, production-oriented approach to high-resolution tree-canopy mapping in urban and suburban landscapes using GEOBIA and data fusion. Remote Sens. 2014, 6, 12837–12865. [Google Scholar] [CrossRef]
- Pelletier, C.; Valero, S.; Inglada, J.; Champion, N.; Dedieu, G. Assessing the robustness of Random Forests to map land cover with high resolution satellite image time series over large areas. Remote Sens. Env. 2016, 187, 156–168. [Google Scholar] [CrossRef]
- Ramezan, C.A.; Warner, T.A.; Maxwell, A.E. Evaluation of sampling and cross-validation tuning strategies for regional-scale machine learning classification. Remote Sens. 2019, 11, 185. [Google Scholar] [CrossRef]
- Yang, L.; Jin, S.; Danielson, P.; Homer, C.; Gass, L.; Bender, S.M.; Case, A.; Costello, C.; Dewitz, J.; Fry, J.; et al. A new generation of the United States National Land Cover Database: Requirements, research priorities, design, and implementation strategies. ISPRS J. Photogramm. Remote Sens. 2018, 146, 108–123. [Google Scholar] [CrossRef]
- Feranec, J.; Jaffrain, G.; Soukup, T.; Hazeu, G. Determining changes and flows in European landscapes 1990–2000 using CORINE land cover data. Appl. Geogr. 2010, 30, 19–35. [Google Scholar] [CrossRef]
- Vitousek, P.M. Beyond Global Warming: Ecology and Global Change. Ecology 1994, 75, 1861–1876. [Google Scholar] [CrossRef]
- Haines-Young, R. Land use and biodiversity relationships. Land Use Futur. 2009, 26, S178–S186. [Google Scholar] [CrossRef]
- Hansen, M.C.; Loveland, T.R. A review of large area monitoring of land cover change using Landsat data. Landsat Leg. Spec. Issue 2012, 122, 66–74. [Google Scholar] [CrossRef]
- Feddema, J.J. The importance of land-cover change in simulating future climates. Science 2005, 310, 1674–1678. [Google Scholar] [CrossRef] [PubMed]
- Land Cover Data Project. Available online: https://chesapeakeconservancy.org/conservation-innovation-center/high-resolution-data/land-cover-data-project-2/ (accessed on 12 March 2019).
- Pixel-Level Land Cover Classification Using the Geo AI Data Science Virtual Machine and Batch AI. Available online: https://blogs.technet.microsoft.com/machinelearning/2018/03/12/pixel-level-land-cover-classification-using-the-geo-ai-data-science-virtual-machine-and-batch-ai/ (accessed on 12 March 2019).
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random Forests for land cover classification. Pattern Recognit. Remote Sens. PRRS 2004 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Pal, M. Random Forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Pal, M.; Mather, P.M. Decision tree based classification of remotely sensed data. In Proceedings of the 22nd Asian Conference on Remote Sensing, Singapore, 5–9 November 2001; p. 9. [Google Scholar]
- Guo, L.; Chehata, N.; Mallet, C.; Boukir, S. Relevance of airborne lidar and multispectral image data for urban scene classification using Random Forests. ISPRS J. Photogramm. Remote Sens. 2011, 66, 56–66. [Google Scholar] [CrossRef]
- Ruiz Hernandez, I.E.; Shi, W. A Random Forests classification method for urban land-use mapping integrating spatial metrics and texture analysis. Int. J. Remote Sens. 2018, 39, 1175–1198. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Strager, M.P.; Pal, M. Combining RapidEye satellite imagery and Lidar for mapping of mining and mine reclamation. Photogramm. Eng. Remote Sens. 2014, 80, 179–189. [Google Scholar] [CrossRef]
- Hayes, M.M.; Miller, S.N.; Murphy, M.A. High-resolution landcover classification using Random Forest. Remote Sens. Lett. 2014, 5, 112–121. [Google Scholar] [CrossRef]
- Lawrence, R.L.; Moran, C.J. The AmericaView classification methods accuracy comparison project: A rigorous approach for model selection. Remote Sens. Env. 2015, 170, 115–120. [Google Scholar] [CrossRef]
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A review of supervised object-based land-cover image classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Khoshgoftaar, T.M.; Golawala, M.; Hulse, J.V. An empirical study of learning from imbalanced data using random forest. In Proceedings of the 19th IEEE International Conference on Tools with Artificial Intelligence (ICTAI 2007), Patras, Greece, 29–31 October 2007; IEEE: Piscataway, NJ, USA; pp. 310–317. [Google Scholar]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Shi, D.; Yang, X. An assessment of algorithmic parameters affecting image classification accuracy by Random Forests. Photogramm. Eng. Remote Sens. 2016, 82, 407–417. [Google Scholar]
- Huang, C.; Davis, L.S.; Townshend, J.R.G. An assessment of support vector machines for land cover classification. Int. J. Remote Sens. 2002, 23, 725–749. [Google Scholar] [CrossRef]
- Ghimire, B.; Rogan, J.; Galiano, V.R.; Panday, P.; Neeti, N. An evaluation of bagging, boosting, and Random Forests for land-cover classification in Cape Cod, Massachusetts, USA. GIScience Remote Sens. 2012, 49, 623–643. [Google Scholar] [CrossRef]
- Blagus, R.; Lusa, L. Class prediction for high-dimensional class-imbalanced data. BMC Bioinform. 2010, 11. [Google Scholar] [CrossRef] [PubMed]
- Haibo, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Stumpf, A.; Kerle, N. Object-oriented mapping of landslides using Random Forests. Remote Sens. Env. 2011, 115, 2564–2577. [Google Scholar] [CrossRef]
- Waske, B.; Benediktsson, J.A.; Sveinsson, J.R. Classifying remote sensing data with support vector machines and imbalanced training data. In Multiple Classifier Systems, Proceedings of the 8th International Workshop, MCS 2009, Reykjavik, Iceland, 10–12 June 2009; Benediktsson, J.A., Kittler, J., Roli, F., Eds.; Springer: Berlin/Heidelberg, Germany; pp. 375–384.
- Baker, B.A.; Warner, T.A.; Conley, J.F.; McNeil, B.E. Does spatial resolution matter? A multi-scale comparison of object-based and pixel-based methods for detecting change associated with gas well drilling operations. Int. J. Remote Sens. 2013, 34, 1633–1651. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Queiroz Feitosa, R.; van der Meer, F.; van der Werff, H.; van Coillie, F.; et al. Geographic object-based image analysis—Towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef] [PubMed]
- Chubey, M.S.; Franklin, S.E.; Wulder, M.A. Object-based analysis of Ikonos-2 imagery for extraction of forest inventory parameters. Photogramm. Eng. Remote Sens. 2006, 72, 383–394. [Google Scholar] [CrossRef]
- Drăguţ, L.; Blaschke, T. Automated classification of landform elements using object-based image analysis. Geomorphology 2006, 81, 330–344. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Strager, M.P.; Conley, J.F.; Sharp, A.L. Assessing machine-learning algorithms and image- and lidar-derived variables for GEOBIA classification of mining and mine reclamation. Int. J. Remote Sens. 2015, 36, 954–978. [Google Scholar] [CrossRef]
- Meneguzzo, D.M.; Liknes, G.C.; Nelson, M.D. Mapping trees outside forests using high-resolution aerial imagery: A comparison of pixel- and object-based classification approaches. Env. Monit. Assess. 2013, 185, 6261–6275. [Google Scholar] [CrossRef] [PubMed]
- Walter, V. Object-based classification of remote sensing data for change detection. ISPRS J. Photogramm. Remote Sens. 2004, 58, 225–238. [Google Scholar] [CrossRef]
- Guo, Q.; Kelly, M.; Gong, P.; Liu, D. An object-based classification approach in mapping tree mortality using high spatial resolution imagery. GIScience Remote Sens. 2007, 44, 24–47. [Google Scholar] [CrossRef]
- Kim, M.; Madden, M.; Warner, T.A. Forest type mapping using object-specific texture measures from multispectral ikonos imagery. Photogramm. Eng. Remote Sens. 2009, 75, 819–829. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.S. Combined spectral and spatial processing of ERTS imagery data. Remote Sens. Env. 1974, 3, 3–13. [Google Scholar] [CrossRef]
- Hall-Beyer, M. Practical guidelines for choosing GLCM textures to use in landscape classification tasks over a range of moderate spatial scales. Int. J. Remote Sens. 2017, 38, 1312–1338. [Google Scholar] [CrossRef]
- Warner, T. Kernel-based texture in remote sensing image classification. Geogr. Compass 2011, 5, 781–798. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A. Differentiating mine-reclaimed grasslands from spectrally similar land cover using terrain variables and object-based machine learning classification. Int. J. Remote Sens. 2015, 36, 4384–4410. [Google Scholar] [CrossRef]
- Bishop, B.; Dietterick, B.; White, R.; Mastin, T. Classification of plot-level fire-caused tree mortality in a redwood forest using digital orthophotography and LiDAR. Remote Sens. 2014, 6, 1954–1972. [Google Scholar] [CrossRef]
- Guan, H.; Li, J.; Chapman, M.; Deng, F.; Ji, Z.; Yang, X. Integration of orthoimagery and lidar data for object-based urban thematic mapping using Random Forests. Int. J. Remote Sens. 2013, 34, 5166–5186. [Google Scholar] [CrossRef]
- Zhou, W.; Troy, A.; Grove, M. Object-based land cover classification and change analysis in the Baltimore metropolitan area using multitemporal high resolution remote sensing data. Sensors 2008, 8, 1613–1636. [Google Scholar] [CrossRef] [PubMed]
- Johnson, B.A. High-resolution urban land-cover classification using a competitive multi-scale object-based approach. Remote Sens. Lett. 2013, 4, 131–140. [Google Scholar] [CrossRef]
- Johnson, B.; Xie, Z. Classifying a high resolution image of an urban area using super-object information. ISPRS J. Photogramm. Remote Sens. 2013, 83, 40–49. [Google Scholar] [CrossRef]
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 2006, 14, 55–63. [Google Scholar] [CrossRef]
- Pal, M.; Mather, P.M. An assessment of the effectiveness of decision tree methods for land cover classification. Remote Sens. Env. 2003, 86, 554–565. [Google Scholar] [CrossRef]
- Chan, J.C.-W.; Paelinckx, D. Evaluation of Random Forest and Adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sens. Env. 2008, 112, 2999–3011. [Google Scholar] [CrossRef]
- Lawrence, R.L.; Wood, S.D.; Sheley, R.L. Mapping invasive plants using hyperspectral imagery and Breiman Cutler classifications (randomForest). Remote Sens. Env. 2006, 100, 356–362. [Google Scholar] [CrossRef]
- Duro, D.C.; Franklin, S.E.; Dubé, M.G. Multi-scale object-based image analysis and feature selection of multi-sensor earth observation imagery using random forests. Int. J. Remote Sens. 2012, 33, 4502–4526. [Google Scholar] [CrossRef]
- Genuer, R.; Poggi, J.-M.; Tuleau-Malot, C. Variable selection using Random Forests. Pattern Recognit. Lett. 2010, 31, 2225–2236. [Google Scholar] [CrossRef]
- Strobl, C.; Boulesteix, A.-L.; Kneib, T.; Augustin, T.; Zeileis, A. Conditional variable importance for random forests. BMC Bioinform. 2008, 9, 307. [Google Scholar] [CrossRef] [PubMed]
- Maxwell, A.E.; Warner, T.A.; Vanderbilt, B.C.; Ramezan, C.A. Land cover classification and feature extraction from national agriculture imagery program (NAIP) Orthoimagery: A Review. Photogramm. Eng. Remote Sens. 2017, 83, 737–747. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, Y.Q. An Assessment of impervious surface areas in Rhode Island. Northeast. Nat. 2007, 14, 643–650. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Strager, M.P.; Warner, T.A.; Zégre, N.P.; Yuill, C.B. Comparison of NAIP orthophotography and RapidEye satellite imagery for mapping of mining and mine reclamation. GIScience Remote Sens. 2014, 51, 301–320. [Google Scholar] [CrossRef]
- Gong, P.; Howarth, P.J. Land-use classification of SPOT HRV data using a cover-frequency method. Int. J. Remote Sens. 1992, 13, 1459–1471. [Google Scholar] [CrossRef]
- Strahler, A.H.; Woodcock, C.E.; Smith, J.A. On the nature of models in remote sensing. Remote Sens. Env. 1986, 20, 121–139. [Google Scholar] [CrossRef]
- Yu, Q.; Gong, P.; Clinton, N.; Biging, G.; Kelly, M.; Schirokauer, D. Object-based Detailed Vegetation Classification with Airborne High Spatial Resolution Remote Sensing Imagery. Available online: https://www.ingentaconnect.com/content/asprs/pers/2006/00000072/00000007/art00004# (accessed on 14 March 2019).
- Davies, K.W.; Petersen, S.L.; Johnson, D.D.; Bracken Davis, D.; Madsen, M.D.; Zvirzdin, D.L.; Bates, J.D. Estimating juniper cover from National Agriculture Imagery Program (NAIP) imagery and evaluating relationships between potential cover and environmental variables. Rangel. Ecol. Manag. 2010, 63, 630–637. [Google Scholar] [CrossRef]
- Gartner, M.H.; Veblen, T.T.; Leyk, S.; Wessman, C.A. Detection of mountain pine beetle-killed ponderosa pine in a heterogeneous landscape using high-resolution aerial imagery. Int. J. Remote Sens. 2015, 36, 5353–5372. [Google Scholar] [CrossRef]
- Yuan, F. Land-cover change and environmental impact analysis in the Greater Mankato area of Minnesota using remote sensing and GIS modelling. Int. J. Remote Sens. 2008, 29, 1169–1184. [Google Scholar] [CrossRef]
- Crimmins, S.M.; Mynsberge, A.R.; Warner, T.A. Estimating woody browse abundance from aerial imagery. Int. J. Remote Sens. 2009, 30, 3283–3289. [Google Scholar] [CrossRef]
- Nagel, P.; Yuan, F. High-resolution land cover and impervious surface classifications in the twin cities metropolitan area with NAIP imagery. Photogramm. Eng. Remote Sens. 2016, 82, 63–71. [Google Scholar] [CrossRef]
- Pierce, K. Accuracy Optimization for high resolution object-based change detection: An example mapping regional urbanization with 1-m aerial imagery. Remote Sens. 2015, 7, 12654–12679. [Google Scholar] [CrossRef]
- Strausbaugh, P.D. Flora of West Virginia; Seneca Books: Grantsville, WV, USA, 1978; ISBN 978-0-89092-010-7. [Google Scholar]
- Erdas Imagine 2018; Hexagon Geospatial: Madison, AL, USA, 2018.
- ArcGIS Pro 2.2; ESRI: Redlands, CA, USA, 2018.
- Computer Generated Building Footprints for the United States: Microsoft/USBuildingFootprints; Microsoft: Redmond, WA, USA, 2019.
- eCognition Developer 9; Trimble: Sunnyvale, CA, USA, 2019.
- Baatz, M.; Schäpe, A. Multiresolution segmentation: An optimization approach for high quality multi-scale image segmentation. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2000, 12–23. [Google Scholar]
- Liu, D.; Xia, F. Assessing object-based classification: Advantages and limitations. Remote Sens. Lett. 2010, 1, 187–194. [Google Scholar] [CrossRef]
- Myint, S.W.; Gober, P.; Brazel, A.; Grossman-Clarke, S.; Weng, Q. Per-pixel vs. object-based classification of urban land cover extraction using high spatial resolution imagery. Remote Sens. Env. 2011, 115, 1145–1161. [Google Scholar] [CrossRef]
- Drăguţ, L.; Csillik, O.; Eisank, C.; Tiede, D. Automated parameterisation for multi-scale image segmentation on multiple layers. ISPRS J. Photogramm. Remote Sens. 2014, 88, 119–127. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.S.; Dinstein, I. Textural features for image classification. IEEE Trans Syst. Man Cybern. 1973, 3, 610–621. [Google Scholar] [CrossRef]
- McFEETERS, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Foody, G.M. Thematic map comparison: Evaluating the statistical significance of differences in classification accuracy. Photogramm. Eng. Remote Sens. 2004, 70, 627–633. [Google Scholar] [CrossRef]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Env. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Stehman, S.V. Statistical rigor and practical utility in thematic map accuracy assessment. Photogramm. Eng. Remote Sens. 2001, 67, 727–734. [Google Scholar]
- Stehman, S.V.; Czaplewski, R.L. Design and analysis for thematic map accuracy assessment: Fundamental principles. Remote Sens. Environ. 1998, 64, 331–344. [Google Scholar] [CrossRef]
- Stehman, S.V. Selecting and interpreting measures of thematic classification accuracy. Remote Sens. Env. 1997, 62, 77–89. [Google Scholar] [CrossRef]
- Stehman, S.V. Basic probability sampling designs for thematic map accuracy assessment. Int. J. Remote Sens. 1999, 20, 2423–2441. [Google Scholar] [CrossRef]
- Stehman, S.V. A critical evaluation of the normalized error matrix in map accuracy assessment. Photogramm. Eng. Remote Sens. 2004, 70, 743–751. [Google Scholar] [CrossRef]
- Stehman, S.V. Sampling designs for accuracy assessment of land cover. Int. J. Remote Sens. 2009, 30, 5243–5272. [Google Scholar] [CrossRef]
- Stehman, S.V. Estimating area and map accuracy for stratified random sampling when the strata are different from the map classes. Int. J. Remote Sens. 2014, 35, 4923–4939. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M.C. Classification and regression by randomForest. R News 2007, 2/3, 18–22. [Google Scholar]
- Kuhn, M.; Wing, J.; Weston, S.; Williams, A.; Keefer, C.; Engelhardt, A.; Cooper, T.; Mayer, Z.; Kenkel, B.; Benesty, M.; et al. Caret: Classification and Regression Training. R package version 6.0-73. Available online: https://cran.r-project.org/web/packages/caret/index.html (accessed on 12 March 2019).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Evans, J.S.; Cushman, S.A. Gradient modeling of conifer species using random forests. Landsc. Ecol. 2009, 24, 673–683. [Google Scholar] [CrossRef]
- Strobl, C.; Boulesteix, A.-L.; Zeileis, A.; Hothorn, T. Bias in random forest variable importance measures: Illustrations, sources and a solution. BMC Bioinform. 2007, 8, 25. [Google Scholar] [CrossRef] [PubMed]
- Maxwell, A.E.; Warner, T.A.; Strager, M.P. Predicting palustrine wetland probability using random forest machine learning and digital elevation data-derived terrain variables. Photogramm. Eng. Remote Sens. 2016, 82, 437–447. [Google Scholar] [CrossRef]
- Pontius, R.G.; Millones, M. Death to Kappa: Birth of quantity disagreement and allocation disagreement for accuracy assessment. Int. J. Remote Sens. 2011, 32, 4407–4429. [Google Scholar] [CrossRef]
- Pontius, R.G. Quantification error versus location error in comparison of categorical maps. Photogramm. Eng. Remote Sens. 2000, 66, 1011–1016. [Google Scholar]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- MacLean, M.G.; Congalton, D.R.G. Map accuracy assessment issues when using an object-oriented approach. In Proceedings of the American Society for Photogrammetry and Remote Sensing 2012 Annual Conference, Sacramento, CA, USA, 19–23 March 2012; p. 5. [Google Scholar]
- Dietterich, T.G. Approximate statistical tests for comparing supervised classification learning algorithms. Neural Comput. 1998, 10, 1895–1923. [Google Scholar] [CrossRef] [PubMed]
- Radoux, J.; Bogaert, P.; Fasbender, D.; Defourny, P. Thematic accuracy assessment of geographic object-based image classification. Int. J. Geogr. Inf. Sci. 2011, 25, 895–911. [Google Scholar] [CrossRef]
- Radoux, J.; Bogaert, P. Accounting for the area of polygon sampling units for the prediction of primary accuracy assessment indices. Remote Sens. Env. 2014, 142, 9–19. [Google Scholar] [CrossRef]
- Radoux, J.; Bogaert, P. Good practices for object-based accuracy assessment. Remote Sens. 2017, 9, 646. [Google Scholar] [CrossRef]
- Stehman, S.V.; Wickham, J.D. Pixels, blocks of pixels, and polygons: Choosing a spatial unit for thematic accuracy assessment. Remote Sens. Env. 2011, 115, 3044–3055. [Google Scholar] [CrossRef]
- Ye, S.; Pontius, R.G.; Rakshit, R. A review of accuracy assessment for object-based image analysis: From per-pixel to per-polygon approaches. ISPRS J. Photogramm. Remote Sens. 2018, 141, 137–147. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | Variable Name | Abbreviation | Band Used? | Calculated at Object Scale? | |||||
|---|---|---|---|---|---|---|---|---|---|
| Blue | Green | Red | NIR | Objects | SO1 | SO2 | |||
| Spectral | Brightness | B | NA | NA | NA | NA | ✓ | ✓ | ✓ |
| Mean | Mn | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| NDVI | NDVI | NA | NA | NA | NA | ✓ | ✓ | ✓ | |
| NDWI | NDWI | NA | NA | NA | NA | ✓ | ✓ | ✓ | |
| First-Order Texture | Standard Deviation | SD | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Second-Order Texture (GLCM) | Mean | GLCM Mn | X | X | ✓ | ✓ | ✓ | X | X |
| Standard Deviation | GLCM SD | X | X | ✓ | ✓ | ✓ | X | X | |
| Correlation | GLCM Corr | X | X | ✓ | ✓ | ✓ | X | X | |
| Homogeneity | GLCM Hom | X | X | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Entropy | GLCM Ent | X | X | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Geometry (Geom) | Border Index | BI | NA | NA | NA | NA | ✓ | X | X |
| Compactness | Comp | NA | NA | NA | NA | ✓ | X | X | |
| Roundness | RndI | NA | NA | NA | NA | ✓ | X | X | |
| Shape Index | SI | NA | NA | NA | NA | ✓ | X | X | |
| Ancillary | Mean topographic Slope | Slp | NA | NA | NA | NA | ✓ | X | X |
| Mean Census Block Density | Blk | NA | NA | NA | NA | ✓ | X | X | |
| Mean Census Block House Density | H | NA | NA | NA | NA | ✓ | X | X | |
| Mean Census Block population Density | P | NA | NA | NA | NA | ✓ | X | X | |
| Mean Road Density | Rd | NA | NA | NA | NA | ✓ | X | X | |
| Mean structure Density (Microsoft) | Str | NA | NA | NA | NA | ✓ | X | X | |
| Class | Description | Number of Training Objects | Number of Validation Objects |
|---|---|---|---|
| Forest | Areas dominated by tall, woody vegetation and mature forests. This class includes forest and woodlands. | 13,347 | 20,561 |
| Low Vegetation | Low vegetation such as grasslands, pastureland, agricultural fields, and croplands. | 13,353 | 3146 |
| Barren | Non-vegetated areas not associated with impervious surface. This class includes bare soil, quarries, and surface mine features. | 1056 | 162 |
| Water | All standing water, including rivers, streams, ponds, lakes, and impoundments. | 1098 | 188 |
| Impervious | All areas dominated by impervious surface, such as road surfaces, parking lots, airport runways, and buildings. | 1205 | 424 |
| Mixed Developed | Areas dominated by mixed development and mixed land cover, such as residential areas, yards, and development. | 1022 | 517 |
| Total | 31,081 | 24,998 |
| Reference | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Barren | Forest | Low Vegetation | Impervious | Mixed Developed | Water | Row Total | User’s Accuracy | ||
| Classification | Barren | 0.198 | 0.007 | 0.163 | 0.151 | 0.002 | 0.007 | 0.527 | 37.6% |
| Forest | 0.014 | 82.283 | 1.442 | 0.055 | 0.194 | 0.015 | 84.003 | 98.0% | |
| Low Vegetation | 0.201 | 0.339 | 11.005 | 0.023 | 0.141 | 0.000 | 11.710 | 94.0% | |
| Impervious | 0.024 | 0.005 | 0.050 | 0.456 | 0.020 | 0.023 | 0.578 | 78.9% | |
| Mixed Developed | 0.001 | 0.089 | 0.149 | 0.113 | 0.568 | 0.001 | 0.920 | 61.7% | |
| Water | 0.001 | 0.063 | 0.011 | 0.004 | 0.001 | 2.181 | 2.262 | 96.4% | |
| Column Total | 0.439 | 82.786 | 12.820 | 0.803 | 0.925 | 2.227 | Overall Accuracy: 96.7% | ||
| Producer’s Accuracy | 45.1% | 99.4% | 85.8% | 56.8% | 61.4% | 97.9% | Kappa: 0.886 | ||
| No Super-Object Variables | With Super-Object Variables | With Ancillary | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Measure | B + Mn | B + Mn + NDVI + NDWI | B + Mn + Geom | B + Mn + SD | B + Mn + GLCM | All Image- Derived | B + Mn | B + Mn + NDVI + NDWI | B + Mn + SD | B + Mn + GLCM | All Image- Derived | All |
| OA (%) | 93.8 | 93.8 | 93.0 | 94.8 | 94.7 | 95.5 | 93.4 | 93.7 | 95.3 | 95.7 | 95.7 | 96.7 |
| Kappa | 0.801 | 0.802 | 0.778 | 0.825 | 0.825 | 0.848 | 0.788 | 0.798 | 0.843 | 0.854 | 0.854 | 0.886 |
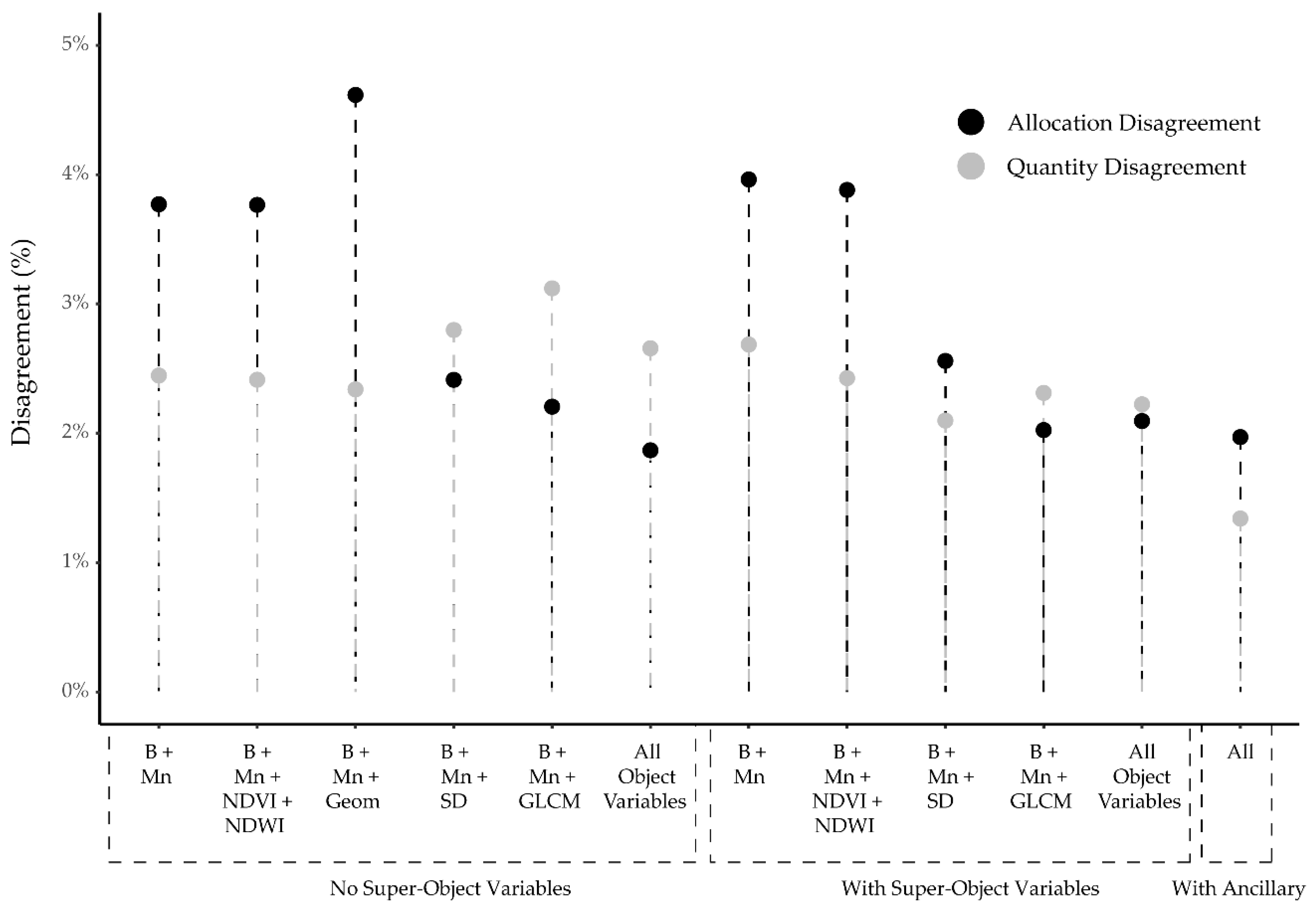
| AD (%) | 3.77 | 3.77 | 4.62 | 2.41 | 2.20 | 1.87 | 3.96 | 3.88 | 2.56 | 2.02 | 2.09 | 1.97 |
| QD (%) | 2.44 | 2.41 | 2.34 | 2.80 | 3.12 | 2.66 | 2.68 | 2.43 | 2.10 | 2.31 | 2.22 | 1.34 |
| UA B (%) | 26.1 | 26.6 | 27.6 | 30.6 | 45.1 | 41.3 | 29.0 | 27.6 | 37.3 | 45.3 | 36.2 | 45.1 |
| UA F (%) | 96.3 | 96.4 | 96.0 | 98.4 | 98.0 | 98.9 | 95.8 | 96.2 | 98.5 | 98.8 | 98.9 | 99.4 |
| UA LV (%) | 86.7 | 86.5 | 80.7 | 78.6 | 78.5 | 78.9 | 86.3 | 86.5 | 82.0 | 81.8 | 81.7 | 85.8 |
| UA I (%) | 33.6 | 33.5 | 48.2 | 31.6 | 34.7 | 44.1 | 32.3 | 33.9 | 38.8 | 33.4 | 37.6 | 56.8 |
| UA MD (%) | 44.0 | 44.8 | 53.4 | 73.1 | 85.8 | 82.4 | 43.2 | 42.0 | 68.2 | 80.1 | 79.1 | 61.3 |
| UA W (%) | 97.3 | 97.2 | 98.3 | 98.4 | 98.3 | 98.3 | 97.4 | 97.7 | 97.8 | 97.4 | 97.7 | 97.9 |
| PA B (%) | 21.3 | 22.6 | 25.2 | 25.0 | 28.9 | 33.2 | 22.8 | 23.8 | 28.2 | 29.7 | 29.4 | 37.6 |
| PA F (%) | 98.6 | 98.7 | 98.4 | 98.0 | 98.5 | 98.4 | 98.5 | 98.6 | 97.9 | 98.4 | 98.3 | 98.0 |
| PA LV (%) | 79.6 | 80.1 | 79.4 | 96.2 | 95.1 | 95.9 | 76.0 | 77.6 | 94.8 | 95.6 | 95.1 | 94.0 |
| PA I (%) | 82.7 | 80.4 | 86.0 | 70.3 | 80.0 | 84.6 | 74.9 | 70.3 | 71.3 | 78.5 | 76.5 | 79.0 |
| PA MD (%) | 21.2 | 19.6 | 17.5 | 21.6 | 21.5 | 26.1 | 24.3 | 23.3 | 27.6 | 28.5 | 29.2 | 61.7 |
| PA W (%) | 89.0 | 92.0 | 91.0 | 92.7 | 93.9 | 93.9 | 92.5 | 91.6 | 93.1 | 95.6 | 94.3 | 96.4 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maxwell, A.E.; Strager, M.P.; Warner, T.A.; Ramezan, C.A.; Morgan, A.N.; Pauley, C.E. Large-Area, High Spatial Resolution Land Cover Mapping Using Random Forests, GEOBIA, and NAIP Orthophotography: Findings and Recommendations. Remote Sens. 2019, 11, 1409. https://doi.org/10.3390/rs11121409
Maxwell AE, Strager MP, Warner TA, Ramezan CA, Morgan AN, Pauley CE. Large-Area, High Spatial Resolution Land Cover Mapping Using Random Forests, GEOBIA, and NAIP Orthophotography: Findings and Recommendations. Remote Sensing. 2019; 11(12):1409. https://doi.org/10.3390/rs11121409
Chicago/Turabian StyleMaxwell, Aaron E., Michael P. Strager, Timothy A. Warner, Christopher A. Ramezan, Alice N. Morgan, and Cameron E. Pauley. 2019. "Large-Area, High Spatial Resolution Land Cover Mapping Using Random Forests, GEOBIA, and NAIP Orthophotography: Findings and Recommendations" Remote Sensing 11, no. 12: 1409. https://doi.org/10.3390/rs11121409
APA StyleMaxwell, A. E., Strager, M. P., Warner, T. A., Ramezan, C. A., Morgan, A. N., & Pauley, C. E. (2019). Large-Area, High Spatial Resolution Land Cover Mapping Using Random Forests, GEOBIA, and NAIP Orthophotography: Findings and Recommendations. Remote Sensing, 11(12), 1409. https://doi.org/10.3390/rs11121409