1. Introduction
Thanks to its superior characteristics, including all-weather day-and-night observation, high-resolution imaging capability, and so forth, synthetic aperture radar (SAR) imaging plays an indispensable role in both military and civil applications. Essentially, SAR is an active microwave detection device for remote sensing, which is diversely utilized in geographical surveying, environment and Earth system monitoring, climate change research [
1,
2], and more. The combination of the electromagnetic scattering mechanism and a coherent imaging system enables SAR images to contain rich features, which provides important information for target recognition [
3]. However, such features are contaminated by coherent speckle noise and geometric distortions in the images, accounting for the lower quality of SAR images. This tendency has a negative impact on target detection and recognition [
4]. Furthermore, SAR images are highly sensitive to observation depression and aspect angle variations, as well as inevitable imaging deformation, including the perspective scale-variant, shadow, and layover. Even with a limited observation azimuth gap, the shapes of targets in SAR images are almost distinct from each other. All these factors pose severe difficulties in SAR image interpretation and target recognition. In order to overcome these obstacles, the research of SAR image automatic interpretation algorithms has attracted increasing attention; notably, the automatic target recognition (ATR) has been extensively researched.
ATR is used to locate and classify the target in SAR images. The SAR ATR procedure is typically composed of three steps: preprocessing, feature extraction, and classification. The preprocessing provides a region of interest (ROI) cropped from a specific SAR image using a constant false alarm rate (CFAR) detector. The output of this CFAR detector contains not only the ROI target, but also false alarm clutter, like trees, building, and cars. In addition, data augmentation operations, including rotation, flipping, and random cropping, are also deployed in this step. The second step is to extract the effective features from the output with reduced dimensions and eliminate the false clutters in the meantime. In terms of typical feature extraction, the available SAR image features, mainly consisting of scattering features, polarization features, and ROI features, are mostly extracted from single and independent SAR images [
5,
6,
7]. Finally, a classifier is then applied to specify the category of the target. As the most important step, adopted classification methods in the ATR procedure can be approximately divided into three genres: template-based approaches, model-based approaches, and machine learning approaches [
8,
9,
10]. The template-based methods rely on template-matching, and therefore, are dependent on the template library. But, once some SAR attributes change, the classification rate will drop sharply. To achieve better robustness, the model-based methods introduce a high-fidelity model with both an offline model construction component and online prediction and recognition component. These methods are adaptive and online adjustable but increase the computation overhead significantly. With the advent of machine learning, classification approaches based on deep learning or a support vector machine (SVM) are proven to be feasible and promising [
10]. Accordingly, increasing research efforts have been devoted in the field of SAR image recognition with a deep learning structure, which has thus far reported extraordinary recognition rates [
11,
12,
13].
Although ATR in SAR has been extensively studied in recent years, it remains an unsolved problem. Its significant challenges arise from a severe lack of raw SAR image data and great variations of SAR images, due to their aspect-sensitive characteristics. Firstly, collecting SAR images can be very burdensome, resulting in the awkward fact that there are not enough training and testing samples to train a deep model with almost perfect performance in the usual manner. Naturally, it is vital to design a network structure that is capable of making full use of the limited available data (such as the Moving and Stationary Target Acquisition and Recognition (MSTAR) dataset). Recent studies regarding ATR began to adopt convolutional neural networks (CNNs); this approach provides a powerful tool for ATR in SAR, with significant progress in the past years [
14,
15,
16]. However, CNNs remains unable to overcome the aforementioned challenges, partly because of their high dependency on large data for training an excellent model. In addition, many proposed methods attempted to increase the number of training samples by data augmentation for better recognition performance [
12]. Indeed, the data augmentation approach shows some benefits, but the inherent connection between these raw SAR images in the MSTAR dataset has not been well explored.
Moreover, owing to the SAR imaging mechanism and SAR parameter settings, the SAR images are highly sensitive to the aspect and depression angle changes. In other words, SAR images with different aspects and depression angles contain largely distinct information about the same ground target. In general, SAR images of different aspect angles of the same target can be obtained by either multiple airborne uninhabited aerial vehicle (UAV) SAR joint observations, or single SAR observations along a circular orbit. Therefore, these images may contain space-varying scattering features, and contain much more information than a single image. SAR ATR algorithms can perhaps consider more in terms of multi-view images of the same target as the network input, in order to build more comprehensive representations [
17,
18]. This idea may make full use of the inherent connections of a limited raw MSTAR dataset, possibly enhancing the recognition accuracy, which, however, has not yet been explored.
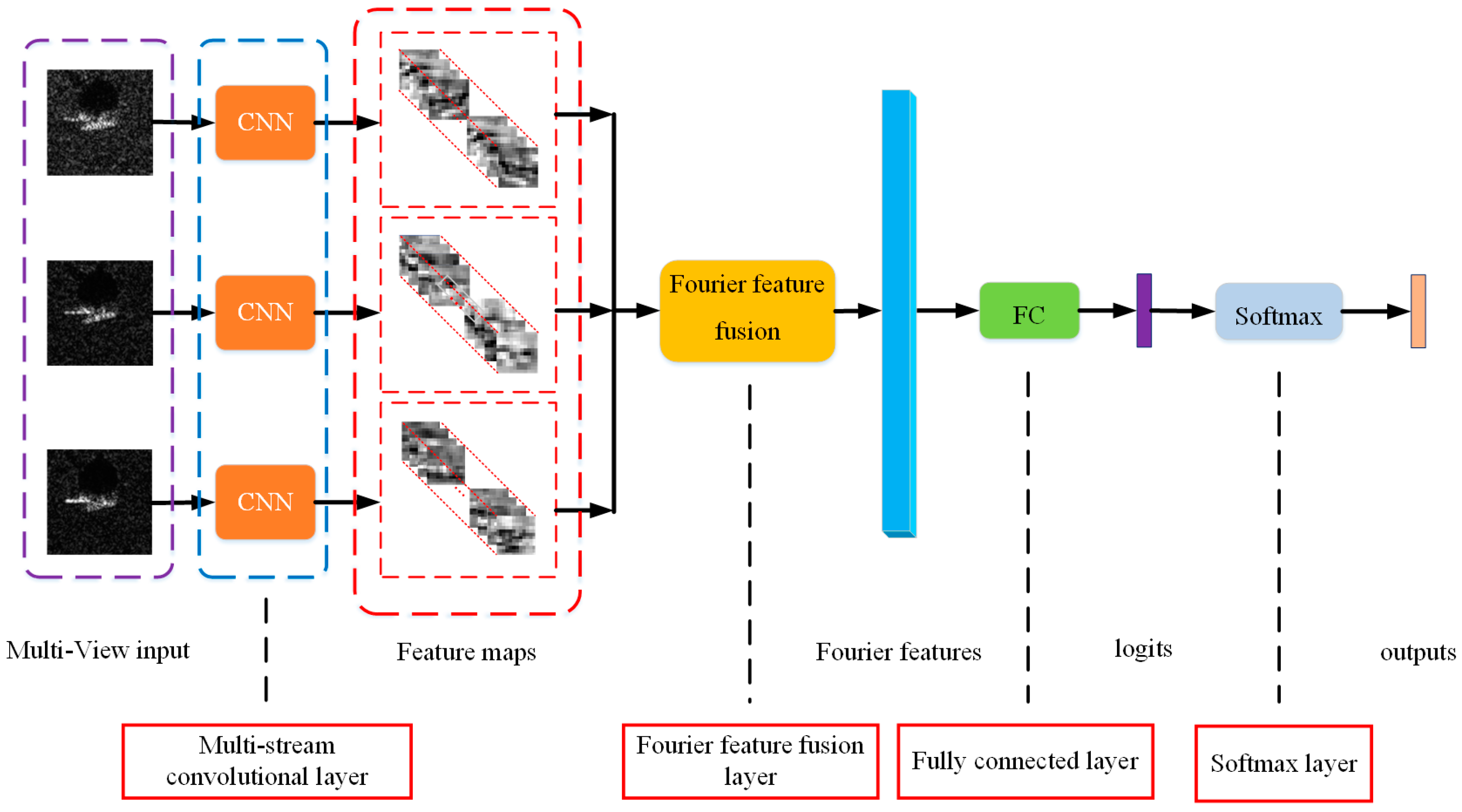
In this paper, we propose a novel deep convolutional learning architecture, called a Multi-Stream CNN (MS-CNN), by using SAR images from multiple views of the same targets to effectively recognize the target classes. MS-CNN handles the aforementioned challenges by disentangling the relationships between images and classes in the learning architecture which is composed of four parts: a multi-stream convolutional layer, a Fourier feature fusion layer, a fully connected layer, and a softmax layer as shown in
Figure 1.
In order to extract not only typical features but also space-varying features induced by multiple views, MS-CNN incorporates a multi-stream convolutional layer, which is more efficient but with fewer parameters. This multiple-input architecture can effectively and efficiently extract features from multiple views of the same targets. Therefore, it can make full use of limited SAR images to improve recognition performance compared to regular CNN, which probably suffers a problem that it can hardly extract effective and interconnected features.
In conjunction with the multi-stream convolutional layer, we introduce a Fourier feature fusion layer into the learning architecture. This part is able to fuse the features of multiple views from upper outputs, and then build strong holistic representations. The Fourier feature fusion is derived from kernel approximation based on random Fourier features, which takes advantage of strength of kernel methods for nonlinear feature extraction and fusion, and it helps unravel the highly nonlinear relationship between images and classes. Furthermore, the Fourier feature fusion turns out to be a nonlinear layer with a cosine activation function, which can make the back-propagation learning process ready to use.
In terms of practical value, our proposed MS-CNN can be easily and quickly operated in real SAR ATR scenarios. This superiority stems from our unique training and testing samples construction approach, which only needs multiple continuous aspect information of multi-view SAR images, rather than requiring the aspects with a fixed interval or larger changeable range mentioned in other methods; these aspects can be calculated by the real-time GPS information of airborne SAR within a tiny time slot.
Our main contributions can be summarized as follows:
We propose a novel convolutional learning architecture, called the multi-stream convolutional neural network (MS-CNN), for ATR in SAR. Our MS-CNN makes full use of discriminating space-varying features, and can largely improve the recognition rates.
We introduce a novel feature extraction structure, the Fourier feature fusion layer, to effectively extract and fuse the features of multi-view SAR images to achieve a strong representation, which in turn establishes the highly nonlinear relationship between SAR images and their associated classes.
We conceive a specific construction approach for corresponding multi-view training and testing samples in our proposed MS-CNN. Its practical value in real SAR ATR scenarios is obvious, simply because it only needs multiple continuous aspect information within a small time slot to construct its testing samples.
The remainder of this paper is organized as follows: The MS-CNN structure and the descriptions of each part are introduced in
Section 2. Experimental results and analyses on the MSTAR dataset are given in
Section 3. In
Section 4, we present some discussions regarding the feasibility and reasonability of the MS-CNN, and future work. Finally,
Section 5 concludes this paper.
2. Multi-Stream Convolutional Neural Network
In this part, we first introduce our proposed multi-stream convolutional neural network (MS-CNN), beginning with problem formulation. Next, we will describe each key part of MS-CNN, including the multi-stream convolutional layer and the Fourier feature fusion layer. Then, the learning process of MS-CNN, such as learning rate setting, convolutional kernel updating and so forth, will be given. Finally, we propose an easily accessible approach for training and testing samples construction in real SAR ATR scenarios.
2.1. Preliminaries
SAR ATR is a classification task with the purpose of establishing the mapping between SAR image input and the corresponding classes the targets belong to. The proposed MS-CNN explores and leverages the space-varying information, which means that different views of the same target contain some different features, from multi-view SAR images to enhance the recognition rates, alleviating the problem of the lack of raw SAR images. Specifically, the multi-stream convolutional layer and the Fourier feature fusion layer can effectively and efficiently extract the nonlinear features—both image-based features and space-varying features—which can be used to identify the relationship between images and target categories, and make it possible to improve recognition rates. Therefore, MS-CNN has got a great generalization ability.
2.2. Multi-Stream Convolutional Layer
Image representation is essential for SAR ATR, and CNNs has been identified as an efficient and powerful tool to extract feature in diverse tasks. However, limited by a lack of raw SAR images for training data, traditional CNNs is unable to deeply explore the inherent correlation of limited SAR images, and in turn, cannot adequately dig out effective features in the training process of ATR tasks.
Instead of using regular CNNs, we introduce a multi-stream convolutional layer, which is inspired by inherent connections of the multiple views of the same targets, to make full use of limited raw SAR data, and then extract complementary features from multi-view SAR images for more informative SAR image representations. Moreover, this method can not only adequately extract multi-view features, but also largely reduce the number of parameters and boost the training efficiency, while improving the recognition performance, which fits the SAR ATR tasks well.
As shown in
Figure 1, we simply provide multi-view SAR images of the same targets as inputs for the multi-stream convolutional layer. The design of the multi-stream convolutional layer combined with Fourier feature fusion layer enables it to sieve more interacted features from multi-view SAR images, and then help identify their corresponding classes. In addition, it removes the flattening operation by setting rational parameters such as the size of the convolutional kernel and pooling, largely reducing the number of parameters, while making possible further accelerating the training process.
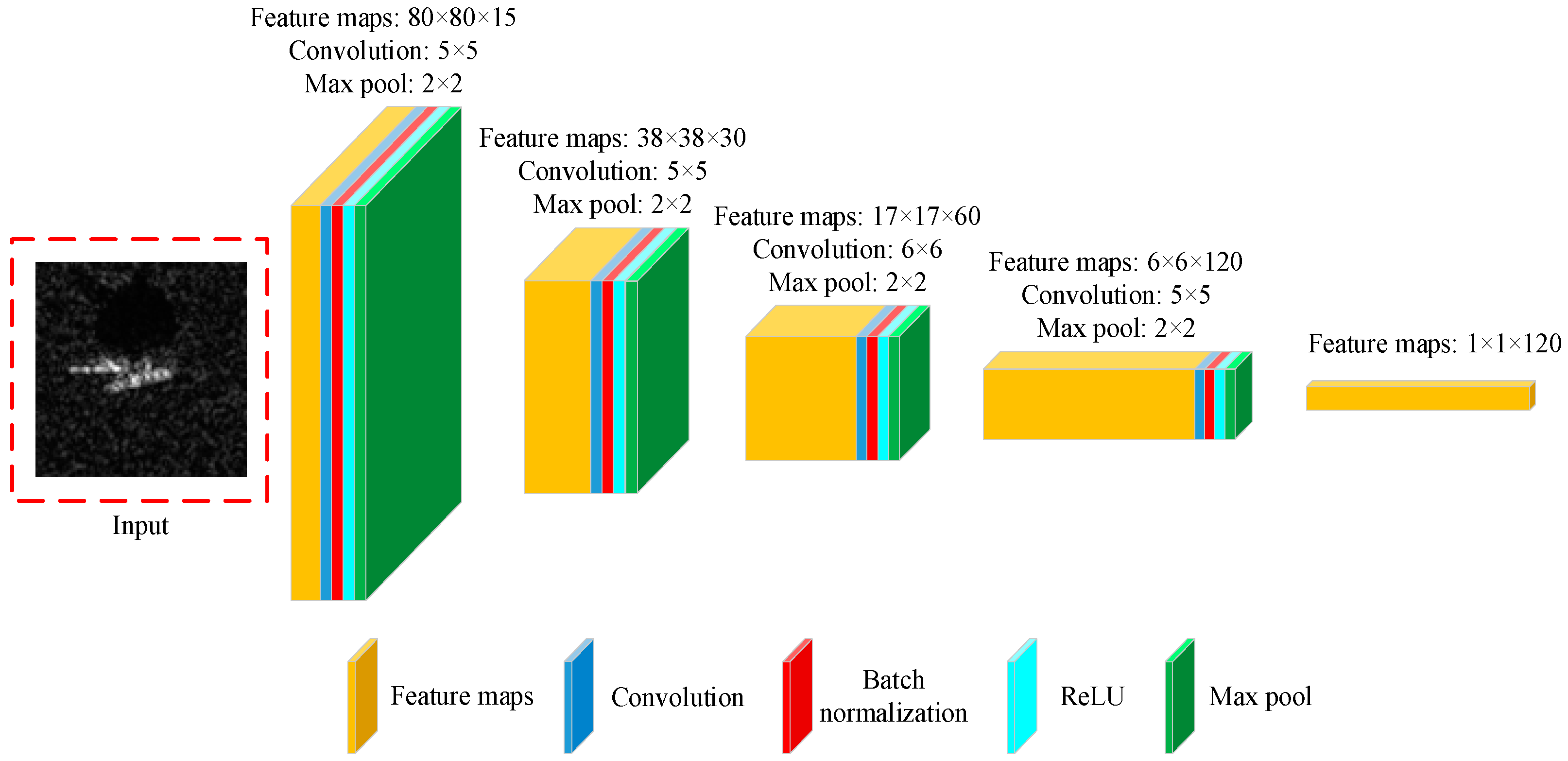
Figure 2 shows the details of one stream of the multi-stream convolutional layer, which consists of four convolutional layers and four pooling layers alternately. The details of each layer and operation will be explained below.
2.2.1. Convolutional Operation
The convolutional layer in each stream of the MS-CNN serves to extract one-view features from the multi-view input images, and all streams work parallelly to additionally extract multi-view complementary feature. Compared to standard CNNs, the number of parameters is relatively smaller because of shared convolutional kernels and biases among multiple streams. Generally, the hyperparameters in the convolutional process consist of the number of feature maps, convolutional kernel size, stride and padding. For instance, if the size of previous feature maps is , is the convolutional kernel size, and the stride and padding are S and P correspondingly. Then, the size of the feature map’s output of each branch is . Typically, we remove the flattening operation by rationally setting the size of the convolutional kernel, further reducing the number of parameters and computations.
2.2.2. Batch Normalization
Batch normalization is also required for our multi-stream convolutional layer. Specifically, a batch normalization operation is utilized after the convolutional operation [
19]. It is essential to do so, because batch normalization of each stream can solve the instability problem of gradient descent in the process of backpropagation, and ultimately speed up the convergence of the whole network.
Batch normalization can change the distribution of the original data, and render most data to be pulled into the linear part of the activation function. However, in our MS-CNN, we choose the ReLU activation function following batch normalization. This is actually a nonlinear function, so the nonlinear transformation is rendered unnecessary.
2.2.3. Nonlinearization
The role of the nonlinear activation function is to increase the nonlinear relationship between layers of the neural network. In this paper, we choose Rectified Linear Units (ReLUs) as the activation function for all streams of multi-stream CNN [
20]. ReLU can largely decrease the training time, and achieve a better performance on labeled SAR data without any unsupervised pre-training.
2.2.4. Pooling Operation
There are two types of pooling functions: max pooling and average pooling. In this paper, the max pooling operator is utilized [
21], and the relevant operation only reserves the maximum value within the pooling-size region extracted from a certain filter, so this operation is processed in each feature map separately.
2.3. Fourier Feaature Fusion Layer
After the multi-stream CNN process, we have extracted multiple feature vectors correspondingly from multi-view images. Next, we need to generate a high-level and holistic representation by fusing these multiple feature vectors in a proper approach. It would not be optimal to simply sum or put all the vectors together, because there are semantic gaps between those separate outputs. Therefore, we propose a Fourier feature fusion layer to integrate these feature vectors by means of kernel methods, so as to leverage its great strength to fill the semantic gaps [
22,
23]. In contrast to regular Fourier features, ours are learned from data in an end-to-end way. This enables us to obtain more compact but discriminant features for more accurate recognition. In addition, feature fusion in the kernel level can also acquire nonlinear feature extraction if nonlinear kernels are utilized. The proposed Fourier feature fusion layer is derived from the approximation of shift-invariant kernels, which is supported by the Bochner’s theorem.
Theorem 1. (
Bochner [
24])
A continuous shift-invariant kernel function on is positive definite if and only if is the Fourier transform of a non-negative measure on .
If the kernel
is properly scaled, then its Fourier transform
will also be a proper probability distribution. Defining
, for any
, we have:
where * is the conjugate and
is an unbiased estimate of
when is
w drawn from
.
Actually, we focus only on the real part, so the integrand can be simplified as . We assume that satisfies .
We can approximate the kernel
by randomly choosing
D random samples and calculating the sum of their inner products:
where
w is drawn from
and
b obey to the uniform distribution over [0,2π].
Therefore, the corresponding feature maps
can be simplified as:
where
is called the random Fourier feature, and
is the cosine function on the element-wise level.
Kernel approximation remains largely underdeveloped. Specifically, the chosen samples are drawn independently from the distributions, and in order to achieve a satisfactory recognition performance, high-dimensional feature maps are always essential for the class prediction. However, on the basis of an approximation operation, it perhaps induces extra computational cost because of the approximate feature maps with high redundancy and low generalization ability. Another problem in sampling is how to select the most suitable kernel configuration parameters. Therefore, approximating the kernel with the random sampling operation probably cannot enhance the recognition performance as expected.
Instead of randomly sampling
w from the distribution
and
b from [0,2π], we learn these two parameters in a supervised way. Thus, we get a nonlinear layer with the cosine activation function:
where
is the weight matrix and
is the bias vector.
The Fourier feature fusion seamlessly aggregates feature maps from the upper multi-stream convolutional layer and achieves a nonlinear activation in the meantime. Fourier feature fusion can concatenate these features by changing them into the same semantic level, and those space-varying potential features can be identified and utilized in this process to strengthen the discrimination of feature maps. To sum up, the induced Fourier feature fusion can be integrated with the multi-stream CNN to achieve a novel and efficient learning structure, which can be trained through back-propagation readily.
In the end, after a fully connected layer, we utilize the softmax layer as the output layer for classification. It will generate the posterior probability distribution for the inputting feature vector. The final output of the network is a k-dimension probability vector, and each element in this vector represents the probability of identifying as the corresponding class.
2.4. Learning Process of the MS-CNN
2.4.1. Learning Rate
The learning rate indicates the speed at which the parameters reach the optimal value. In the beginning, the initial learning rate should be set as a relatively large value to help the trainable network parameters approach a convergence value faster. However, if it is always trained with a large learning rate through the training process, the parameters may finally fluctuate randomly around the optimal value, instead of reaching the optimum. Therefore, we need to adjust the learning rate according to loss and validation accuracy during the training process. For instance, the learning rate can be decreased by multiplying a factor
τ (0 <
τ < 1) when we either find the validation accuracy stops improving for a long time, or just change it in fixed epochs
d. In this paper, we utilized the second updating approach, and its initial value is set to
α, where
where
i (
I ≥ 1) is denoted as the training epochs,
α takes 0.001,
d takes 1, and
τ takes 0.96.
2.4.2. Cost Function with L2 Regularization and Backpropagation
The original cost function in this paper uses the cross-entropy cost function, so the formula of the cost function can be written as:
After the operation of
L2 regularization, the cost function
can be rewritten as:
where
is the Euclid norm, and
λ is the weight decay value and is set to 0.00001.
The aim of backpropagation is to train and update the trainable network parameters to achieve minimum loss, and the parameters
w and
b are updated through the formula below:
where the value of
α is the learning rate. It is obvious that the
L2 regularization operation only influences the update of convolutional kernel
w without any impacts on bias
b.
In the backpropagation algorithm, these two partial derivatives,
and
, can be calculated by resorting to the error term
of each layer. Thus, the formulas of
and
can be written as:
where the error term of each layer
can be calculated by
and the error term of the output layer is
.
2.5. Training and Testing Sample Construction
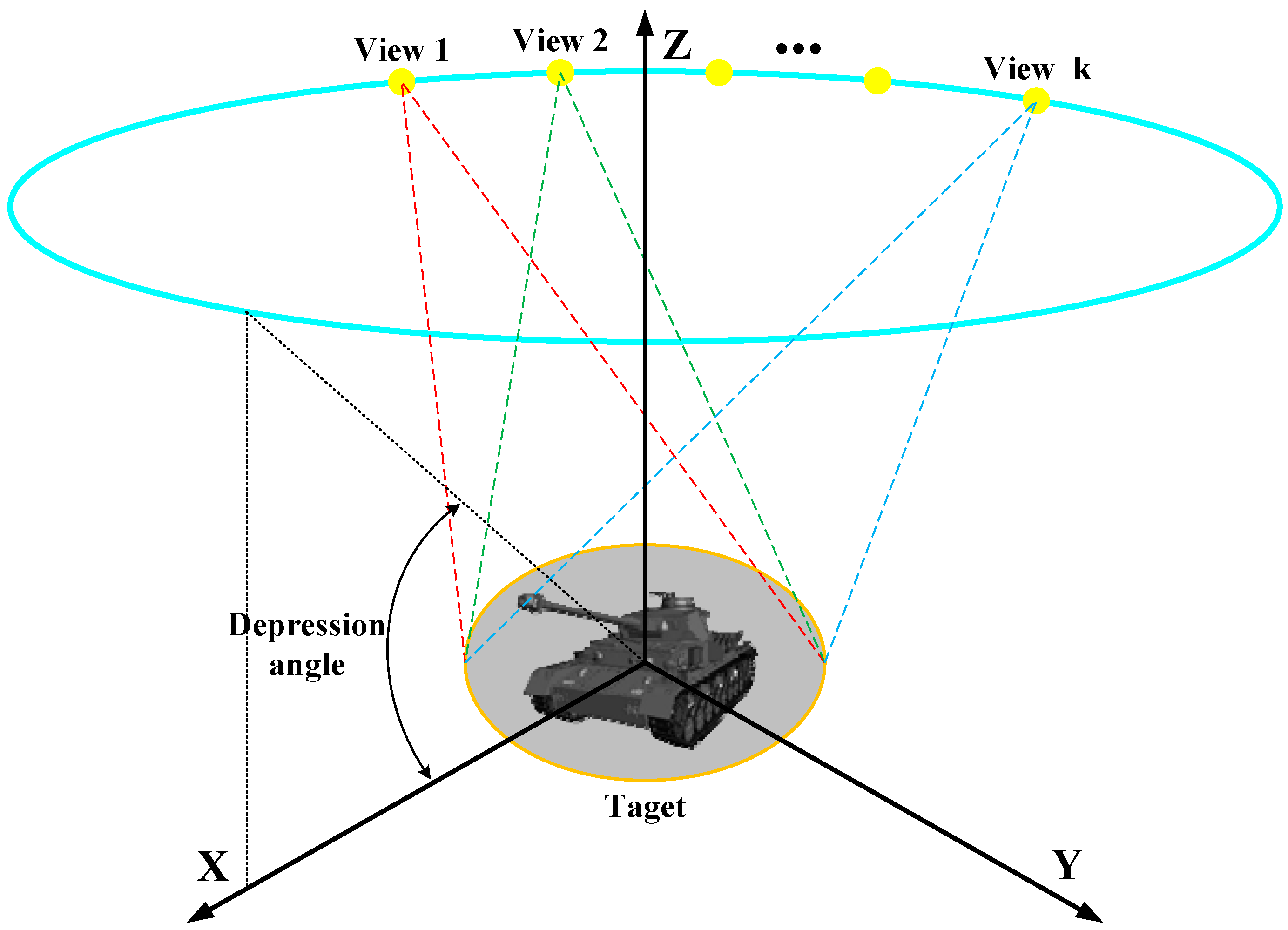
Generally, multi-view SAR images can be acquired by either multiple airborne/UAV SAR joint observations from same depression angle and different aspect angles, or single airborne SAR observations along a circular orbit. We assume that the depression angle is known in advance, so only varying aspect angles are demanded here. As shown in
Figure 3, the airborne SAR sensors within the plane, moving along a circular orbit for a given target, can produce continuous SAR images with different aspects. On the basis of this, we can make our own multi-view SAR image samples for training and testing.
We assume that the raw SAR image sequence for a specific experiment is defined as
, where
is the image set for a specific class
, and their relevant aspect angles are
. The set
indicates the class labels, and
C is the sequence number of classes. For a given view number
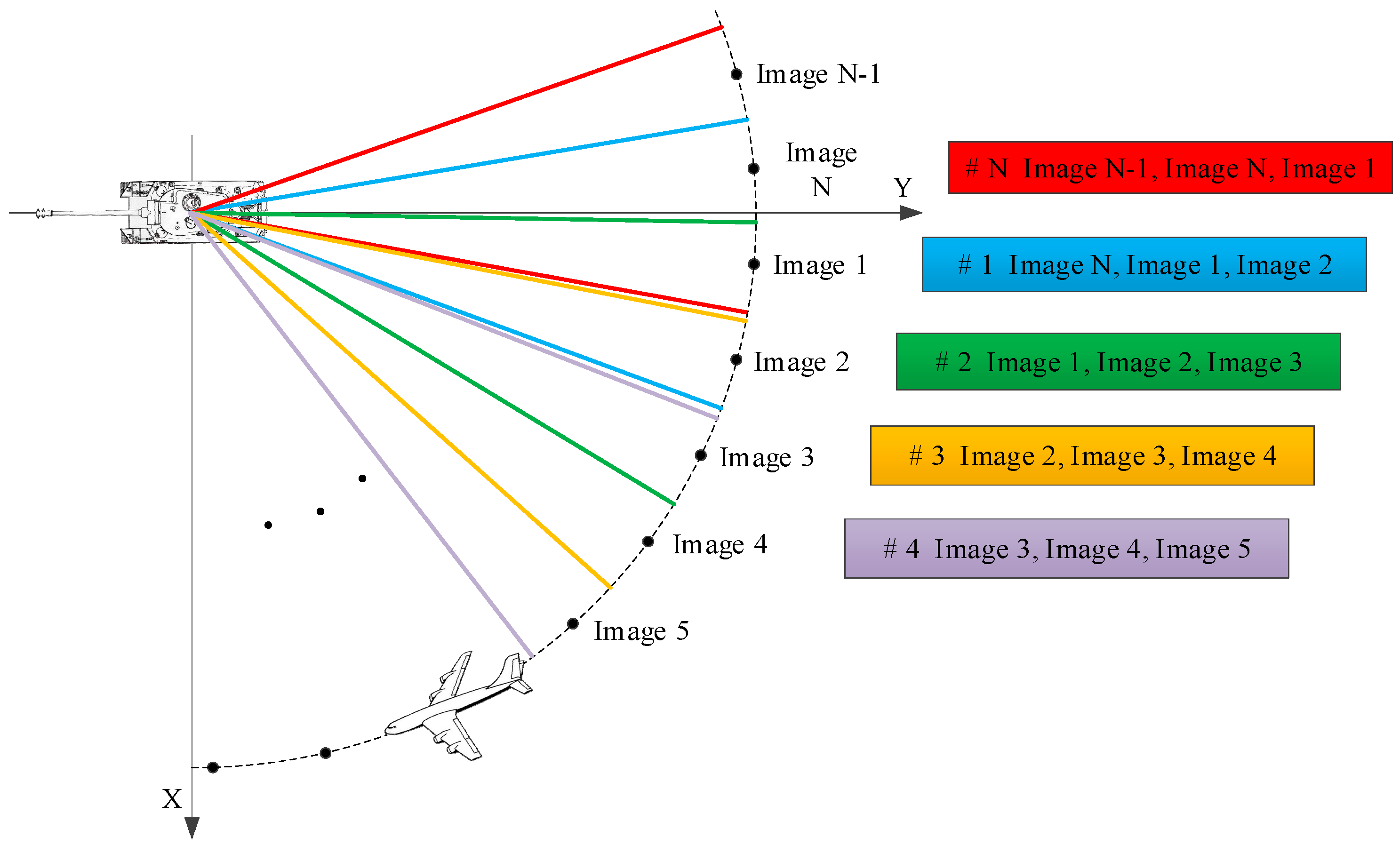
k, the k-view SAR image combinations for each class can be gained by regrouping the current SAR images. Specifically, we first sort these SAR images by azimuth angles in ascending order for each class of each target type. In other words, each image set
is put in order according to their aspect angles, such as
. Then, as shown in
Figure 4, we combine these sorted images according to the view number
k to generate multi-view training and testing samples whose size equals the original, such as
,
,…,
.
For a typical class , let be the set of sizes of sorted k-view images, where and is one k-view SAR image combination. Thus, the sorted k-view SAR image dataset is .
As we mentioned before, the SAR images are very sensitive to the aspect angles. Therefore, before we start the training process, some pre-processing concerning the aspect angles is required. As such, in the second step, the rotation operation will be carried out for all training and testing data to make them stay with the same orientation. For each specific aspect angle of each SAR image, the MSTAR dataset provides us with its precise value for every aspect while we can calculate these aspects by the real-time GPS information of airborne SAR in real ATR scenarios.
Suppose that the multi-view value
k is 3, reflecting three SAR images in the sorted 3-view SAR image dataset
. These three SAR images are
with the relevant aspect angles
, respectively. After the rotation operation for these three images, they can be depicted as follows:
where
represents that the image
X is rotated by
φ degrees counterclockwise.
Actually, we are not likely to obtain the specific orientation of the target in advance in the real scene, and thus, we cannot directly attain accurate information of the ground target, such as the three aspect angles . However, the airborne SAR is capable of acquiring the angle difference between the two adjacent observation angles in the process of SAR images acquisition with the help of GPS information, which means that the value of the angle difference, like , can be obtained. Therefore, the flight platform only needs to acquire the diverse SAR images of the ground target at multiple continuous azimuth angles to meet the requirements of the inputs of MS-CNN designed in this paper. Our proposed MS-CNN outperforms other state-of-the-art methods due to its easy and quick maneuverability in this regard. More specifically, this method only needs multiple continuous aspect information, which can be obtained from the real-time GPS information within a small time slot, to create testing samples for ATR recognition tasks.
3. Results
3.1. Implementation Details
In the experiments, we deploy three network instances with two, three, and four-view inputs to comprehensively assess the recognition performance of MS-CNN. As mentioned before, the MS-CNN is composed of one multi-stream convolutional layer, one Fourier feature fusion layer, and one softmax layer. To tell the details of these three instances, the size of multi-view SAR image inputs is 80 × 80, the kernel sizes of four convolutional layers are 5 × 5, 5 × 5, 6 × 6, and 5 × 5, respectively, the strides of convolutional layers and pooling layers are 1 × 1 and 2 × 2, respectively, and the dropout ratio is set as 0.5. As shown in
Figure 2, the multi-stream convolutional layer removes the flattening operation by setting aforementioned parameters, largely reducing the number of parameters. Of course, the setting of hyperparameters depends on the specific experimental methods.
For our proposed MS-CNN, the framework Tensorflow 1.2 is applied to implement our design. As for hardware supports, a server with four Nvidia TITAN XP GPU is employed for training and testing our proposed network. The parameter for weight decay is 0.00001, and we choose the stochastic optimization algorithm Adam with the cross-entropy loss function to learn the parameters of MS-CNN. The learning rate begins with 0.001 and with 0.96 exponential decay every epoch, and the mini-batch size is set to 24. The epochs of training process vary from 20 to 30 with a constant interval of 5 epochs.
3.2. Dataset
We use the MSTAR dataset provided by Sandia National Laboratory, and in this dataset, all images have a resolution of 0.3 m × 0.3 m, and each target covers each azimuth from 0° to 360°, covering military targets of different categories, different models, different azimuth angles, and different depression angles. However, only a small proportion are publicly available. The publicly released datasets consist of ten different categories of ground targets (BMP-2, BRDM-2, BTR-60, BTR-70, T-62, T-72, 2S1, ZSU-23/4, ZIL-131, and D7), and this available MSTAR benchmark dataset is widely used to evaluate and verify the recognition performance of SAR ATR methods.
On the basis of public SAR data, we have undertaken extensive experiments on this dataset under both the Standard Operating Condition (SOC) and Extended Operating Condition (EOC). Specifically, SOC assumes that the training and testing sets hold the same serial number and target configurations while there are some variations under EOC between training and testing sets, including depression angle variants, target configuration and version variants. Finally, we conduct a comprehensive performance comparison with other state-of-the-art methods mainly from the recognition rates and the number of network parameters. Moreover, our proposed MS-CNN consistently gains high recognition rates and outperforms other previous methods.
3.3. Experiments under SOC
The experiment under SOC is the classic experiment of 10 class ground target recognition; the SAR image dataset consists of T62, T72, BMP2, BRDM2, BTR60, BTR70, D7, ZIL131, ZSU23/4, and 2S1. The optical images and relevant SAR images of the same orientation are shown in
Figure 5. It can be seen that the optical images of different targets vary greatly, and their corresponding SAR images also have discernable differences observable by human eyes.
Table 1 shows the class types and the number of training samples and test samples used in the experiment. Among them, SAR images acquired at a 17° depression angle were used for training, and SAR images acquired at a 15° depression angle were used for testing.
Table 2,
Table 3 and
Table 4 show the recognition accuracy confusion matrix of a two, three, and four-view MS-CNN, respectively. The confusion matrix is widely used for performance illustration; each row in the confusion matrix represents the real category to which the target belongs, and each column represents the prediction result of the network. We found that the recognition rates increase with the change of the number of views under SOC in
Table 2,
Table 3 and
Table 4, reaching 99.84%, 99.88%, and 99.92%, respectively. From this increase among these three instances, we can conclude that our proposed MS-CNN is able to identify and extract more features from multiple views to improve the recognition performance along with the increasing views, while the recognition rates of the four-view instance are nearly all correct. In
Table 3 and
Table 4, we can see that the testing targets of nine classes have been completely identified (except for BTR60 partly because these types of tanks look similar in terms of the appearance and seem hard to classify in certain aspects), and the overall recognition rate reaches 99.88% and 99.92%, which reaffirms that the proposed MS-CNN in this paper can effectively identify the SAR targets.
Table 5 shows the comparison of our MS-CNN with other methods from the perspective of FLOPs, number of parameters, and recognition accuracy. It can be seen that the recognition rate is loosely related to the number of parameters of the network. In other words, the recognition rates increase along with the quantity of parameters, indicating that too few parameters are not sufficient to extract enough effective features from different categories of targets, and result in lower recognition rates. In order to achieve high recognition rates, Furukawa’s ResNet-18 mentioned in [
25] uses millions of parameters and the FLOPs inevitably attains the order of magnitude of ten billion, which demands heavy computing resources and more computation time when training and testing the network, causing the low efficiency. Among these three multi-view methods, our MS-CNN obtains the highest recognition rates with the least number of parameters and FLOPs, benefiting from both parameters sharing of multi-stream convolutional layer and rational parameters setting of MS-CNN. Compared with our proposed MS-CNN, Pei et al.’s network mentioned in [
26] contains more parameters, which resulted from the strategy of fusing multiple layers progressively, leading into low training efficiency. Moreover, the lack of further feature representations, like Fourier random features and Gabor features, accounts for lower recognition rates. However, the MA-BLSTM [
27] encodes the Gabor features with TPLBP operator, achieving relatively high recognition rates. All in all, the comparison results of recognition rates and the quantity of parameters clearly validate the superiority of our proposed MS-CNN in the SOC scenario.
Figure 6 shows the comparison of recognition degree of feature maps to verify the robustness of MS-CNN, mainly including two feature maps for both single-view inputs and three-view inputs, respectively. As mentioned before, the initial SAR image input is 80 × 80, the outputs of the first convolutional layer are 76 × 76 × 15 feature maps, and then it outputs 34 × 34 × 30 feature maps after the second convolutional layer.
Figure 6a,c show 15 feature maps acquired at the first convolutional layer. Apparently, the coherent speckle noise in the raw SAR image has a strong impact on the feature maps in
Figure 6a, so the targets and shadows are not obvious at all, and therefore, hard to distinguish, because the ambient noise around the target is amplified. However, the targets in the feature maps of
Figure 6c are clearly visible, including both the outline of the target and the shadow, without much influence on recognition by speckle noise. Therefore, we can conclude that the three-view SAR image input, containing more information of the targets, is more robust, and can alleviate the effect of speckle noise.
Figure 6b,d are feature maps acquired from the second convolutional layer, from which we can see that the features in
Figure 6b becomes turbulent, but the feature map in
Figure 6d is still very clear—the features extracted in
Figure 6d are much better than those in
Figure 6b, which means higher recognition rates.
3.4. Experiments under EOC
According to the EOC experiment settings of A-ConvNets [
11], we first evaluated the EOC performance with respect to a large depression angle (30°). This big change in depression angle from the 15° of SOC to 30° seems to damage the testing performance in most of the current existing methods, because of the sensitivity characteristic of SAR ATR for depression and aspect angle variance. The MSTAR dataset only contains four types of target samples for testing (2S1, BRDM-2, T72, and ZSU-23/4), which are observed at a depression angle of 30°, while the four corresponding training samples are at the depression angle of 17°. As shown in
Figure 7, the optical images of the four different types of tanks used in this experiment correspond the following SAR images with the same direction. Therefore, we validate the EOC performance of a large depression angle change, called EOC-1, on these four samples, as listed in
Table 6. The corresponding recognition confusion matrix is shown in
Table 7.
Table 7 shows that the proposed MS-CNN with two, three, and four views achieves great recognition performance in this EOC experiment, reaching 96.96%, 97.48%, and 98.61%, respectively. Specifically, in the four-view MS-CNN experiment, the recognition rates of 2S1, BRDM2, and ZSU23/4 are more than 98%, while for type T72 they are still 96.88%. This lower performance of T72 is caused by the difference in both the depression angle and serial number variation of training and testing samples, since other tank types change only in depression angle. We can draw the conclusion that the proposed MS-CNN is robust and resilient to the sensitive depression angle variation.
As for the target configuration variants and version variants, another two EOC experiments were carried out to evaluate the performance of the MS-CNN with respect to EOC. Configuration variants are different from version variants. According to their definition, version variants are built to different blueprints, while configuration variants are built to the same blueprints but have had different post-production equipment added. Specifically, the MSTAR data includes version variants of the T-72 and the BTR-70. Version variants occur when the chassis of the original version has been adapted for an alternate function, such as Personnel Carrier, Ambulance, Command Post, Reconnaissance, and so forth. On the other hand, configuration variants involve the addition or removal of objects, not due to damage. Examples of how configurations may vary include fuel drums on the back of a T72, crewmembers on the vehicle, and mine excavation equipment on the front of vehicle. Moreover, configuration variants also involve the rotation or repositioning of objects, including turret rotations, opening of doors and hatches, and repositioning of tow cables. In these two EOC experiments, we selected four categories of targets (BMP-2, BRDM-2, BTR-70, and T-72) as training samples with 17° depression angles from
Table 1, while the testing samples—acquired at both 17° and 15° depression angles—consisted of two-version variants of BMP-2 and ten-version variants of T-72, as listed in
Table 8 and
Table 9. These two relevant recognition confusion matrixes are shown in
Table 10 and
Table 11.
Table 10 reveals the MS-CNN performance under EOC-2 (version variants) in three types of situations. It shows that there were only nine images which are incorrectly classified into other types of tanks in the two-view instance, and its relevant recognition rate reaches 99.67%. Remarkably, the recognition accuracy of the three-view and four-view instances are all 100%, showing that the proposed MS-CNN is superior in discerning the targets with version variations.
Table 11, which represents the recognition performance of EOC-2 (configuration variants), shows excellent recognition ability in discriminating the BMP2 and T72 targets with configuration differences in training samples. We can see that these three instances reach the recognition accuracy of 98.71%, 99.08%, and 99.58%, respectively. It is obvious that the recognition rate rises with the increasing number of multiple views.
To sum up, our proposed MS-CNN shows high performance under EOC, including with a large depression angle (EOC-1), configuration variants (EOC-2), and version variants (EOC-2), which demonstrate the significate value of MS-CNN in SAR ATR tasks.
3.5. Recognition Performance Comparison
In this section, we undertake a performance comparison between our proposed MS-CNN and ten other SAR ATR methods, including the extended maximum average correlation height filter (EMACH) [
28], support vector machine (SVM) [
28], adaptive boosting (AdaBoost) [
28], iterative graph thickening (IGT) [
28], sparse representation-based representation of Monogenic Signal (MSRC) [
29], monogenic scale-space (MSS) [
30], modified polar mapping classifier (M-PMC) [
31], all-convolutional networks (A-ConvNets) [
11], combined discrimination trees (CDT) [
32], multi-aspect-aware bidirectional LSTM recurrent neural networks (MA-BLSTM) [
27], and multi-view DCNNs (MVDCNNs) [
26]. All these aforementioned ATR methods hold state-of-the-art performance, and therefore, we choose them for comparisons.
Although all these aforementioned SAR ATR methods are based on the MSTAR dataset, they might utilize different training dataset and implement distinct principles. In addition, the quantity of SAR images inputs varies from single-view methods to multi-view. All those factors lead to the difficulty of recognition performance comparison. We can simply compare all these methods by recognition rates and the number of training samples inputs, and assume that an ATR method with higher recognition rates but fewer inputs holds a better recognition performance. On the basis of this assumption, we select the recognition rates under both SOC and EOC and the number of network inputs as criterions to compare the recognition performance.
Table 12 shows comparison with other state-of-the-art methods, including EMACH, SVM, A-ConvNets, MA-BLSTM, and so forth. All these ATR methods are based on the MSTAR dataset, so the results cited from corresponding papers for the recognition rate comparison are reliable. As listed in
Table 12, it is obvious that the deep learning approaches outperform the methods of conventional machine learning, like SVM, AdaBoost, and so forth, in the field of SAR ATR in both SOC and EOC scenarios. Moreover, the performance of the multi-view methods, MVDCNNs, MA-BLSTM, and MS-CNN, is better than that of the other deep learning methods that use single-view input, partly because the extra space-varying information extracted from interconnected multi-view images can improve the recognition performance.
Due to the similar mechanisms by which MVDCNNs [
26] and our proposed MS-CNN are based on the multi-view concept and CNNs, it is necessary to conduct a more detailed comparison to show the superiority of MS-CNN.
Training and testing sample construction. Our proposed training and testing samples construction approach makes full use of MSTAR dataset to produce equivalent amounts of multi-view SAR images, while the multi-view SAR data formation approach mentioned in [
26] merely leverages part of raw images of MSTAR dataset to multiply its training and testing samples by many times. In other words, MS-CNN can be better trained simply because it has more raw images from the training samples to learn, compared with the MVDCNNs. In addition, as shown in
Table 12, due to multiplying the training samples, the quantity of MVDNNs inputs is slightly larger than MS-CNN. Therefore, we can conduct a conclusion that our proposed multi-view training samples construction method is more effective.
Network architecture. Since we incorporate the Fourier feature fusion layer into MS-CNN to achieve high-level and holistic representation, MVDCNNs only rely on the great strength of CNNs, so naturally, some limitations to further improving the recognition rates exist.
Time complexity. In MS-CNN, we remove the flattening operation by setting rational parameters such as the size of the convolutional kernel and pooling, largely reducing the number of parameters, and then decreasing time complexity. Moreover, we parallelly conceive a multi-stream convolutional layer to extract features of multi-view SAR images, instead of fusing feature maps from inputs to last layer progressively in the network topology described in MVDCNNs. This design makes possible to share parameters among multi-view inputs, further reducing the quantity of parameters and accelerating the training process.
All these experiments carried out in this paper reveal that the proposed MS-CNN has a better generalization and recognition ability than other state-of-the-art methods, and naturally achieves a superior recognition performance.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}