Deriving High Spatiotemporal Remote Sensing Images Using Deep Convolutional Network


Abstract
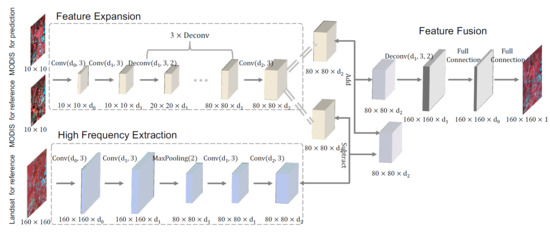
1. Introduction
2. Materials and Methods
2.1. CNN Model
2.2. DCSTFN Architecture
3. Experiment and Evaluation
3.1. Data Preparation
3.2. Experiment
3.3. Comparison
4. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| MODIS | MODerate Resolution Imaging Spectroradiometer |
| OIL | Operational Land Imager |
| HTLS | high temporal but low spatial resolution |
| LTHS | low temporal but high spatial resolution |
| STARFM | spatial and temporal adaptive reflectance fusion model |
| STAARCH | spatial and temporal adaptive algorithm for mapping reflectance change |
| ESTARFM | enhanced spatial and temporal adaptive reflectance fusion model |
| UBDF | unmixed-based data fusion |
| FSDAF | flexible spatiotemporal data fusion |
| SAM | spatial attraction model |
| SPSTFM | sparse-representation-based spatiotemporal reflectance fusion model |
| CNN | convolutional neural network |
| DCSTFN | deep convolutional spatiotemporal fusion network |
| LiDAR | light detection and ranging |
| ReLU | rectified linear unit |
| UTM | Universal Transverse Mercator |
| SGD | stochastic gradient descent |
| NIR | near-infrared |
| RMSE | root-mean-square error |
| KGE | Kling–Gupta efficiency |
| SSIM | structural similarity index |
| NDVI | Normalized Difference Vegetation Index |
References
- Toth, C.; Jóźków, G. Remote sensing platforms and sensors: A survey. ISPRS J. Photogramm. Remote Sens. 2016, 115, 22–36. [Google Scholar] [CrossRef]
- Di, L.; Moe, K.; van Zyl, T.L. Earth Observation Sensor Web: An Overview. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2010, 3, 415–417. [Google Scholar] [CrossRef]
- Di, L. Geospatial sensor web and self-adaptive Earth predictive systems (SEPS). In Proceedings of the Earth Science Technology Office (ESTO)/Advanced Information System Technology (AIST) Sensor Web Principal Investigator (PI) Meeting, San Diego, CA, USA, 13–14 February 2007; pp. 1–4. [Google Scholar]
- Alavipanah, S.; Matinfar, H.; Rafiei Emam, A.; Khodaei, K.; Hadji Bagheri, R.; Yazdan Panah, A. Criteria of selecting satellite data for studying land resources. Desert 2010, 15, 83–102. [Google Scholar]
- Zhu, X.; Chen, J.; Gao, F.; Chen, X.; Masek, J.G. An enhanced spatial and temporal adaptive reflectance fusion model for complex heterogeneous regions. Remote Sens. Environ. 2010, 114, 2610–2623. [Google Scholar] [CrossRef]
- Patanè, G.; Spagnuolo, M. Heterogeneous Spatial Data: Fusion, Modeling, and Analysis for GIS Applications. Synth. Lect. Vis. Comput. Comput. Gr. Anim. Comput. Photogr. Imag. 2016, 8, 1–155. [Google Scholar]
- Roy, D.P.; Wulder, M.A.; Loveland, T.R.; Woodcock, C.E.; Allen, R.G.; Anderson, M.C.; Helder, D.; Irons, J.R.; Johnson, D.M.; Kennedy, R.; et al. Landsat-8: Science and product vision for terrestrial global change research. Remote Sens. Environ. 2014, 145, 154–172. [Google Scholar] [CrossRef]
- Justice, C.O.; Vermote, E.; Townshend, J.R.G.; Defries, R.; Roy, D.P.; Hall, D.K.; Salomonson, V.V.; Privette, J.L.; Riggs, G.; Strahler, A.; et al. The Moderate Resolution Imaging Spectroradiometer (MODIS): Land remote sensing for global change research. IEEE Trans. Geosci. Remote Sens. 1998, 36, 1228–1249. [Google Scholar] [CrossRef]
- Deng, M.; Di, L.; Han, W.; Yagci, A.L.; Peng, C.; Heo, G. Web-service-based Monitoring and Analysis of Global Agricultural Drought. Photogramm. Eng. Remote Sens. 2013, 79, 929–943. [Google Scholar] [CrossRef]
- Yang, Z.; Di, L.; Yu, G.; Chen, Z. Vegetation condition indices for crop vegetation condition monitoring. In Proceedings of the 2011 IEEE International Geoscience and Remote Sensing Symposium, Vancouver, BC, Canada, 24–29 July 2011; pp. 3534–3537. [Google Scholar]
- Nair, H.C.; Padmalal, D.; Joseph, A.; Vinod, P.G. Delineation of Groundwater Potential Zones in River Basins Using Geospatial Tools—An Example from Southern Western Ghats, Kerala, India. J. Geovisualiz. Spat. Anal. 2017, 1, 5. [Google Scholar] [CrossRef]
- Gao, F.; Masek, J.; Schwaller, M.; Hall, F. On the blending of the Landsat and MODIS surface reflectance: predicting daily Landsat surface reflectance. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2207–2218. [Google Scholar] [CrossRef]
- Hilker, T.; Wulder, M.A.; Coops, N.C.; Seitz, N.; White, J.C.; Gao, F.; Masek, J.G.; Stenhouse, G. Generation of dense time series synthetic Landsat data through data blending with MODIS using a spatial and temporal adaptive reflectance fusion model. Remote Sens. Environ. 2009, 113, 1988–1999. [Google Scholar] [CrossRef]
- Emelyanova, I.V.; McVicar, T.R.; Niel, T.G.V.; Li, L.T.; van Dijk, A.I. Assessing the accuracy of blending Landsat–MODIS surface reflectances in two landscapes with contrasting spatial and temporal dynamics: A framework for algorithm selection. Remote Sens. Environ. 2013, 133, 193–209. [Google Scholar] [CrossRef]
- Li, X.; Ling, F.; Foody, G.M.; Ge, Y.; Zhang, Y.; Du, Y. Generating a series of fine spatial and temporal resolution land cover maps by fusing coarse spatial resolution remotely sensed images and fine spatial resolution land cover maps. Remote Sens. Environ. 2017, 196, 293–311. [Google Scholar] [CrossRef]
- Chen, B.; Huang, B.; Xu, B. Comparison of Spatiotemporal Fusion Models: A Review. Remote Sens. 2015, 7, 1798–1835. [Google Scholar] [CrossRef]
- Acerbi-Junior, F.; Clevers, J.; Schaepman, M. The assessment of multi-sensor image fusion using wavelet transforms for mapping the Brazilian Savanna. Int. J. Appl. Earth Obs. Geoinf. 2006, 8, 278–288. [Google Scholar] [CrossRef]
- Hilker, T.; Wulder, M.A.; Coops, N.C.; Linke, J.; McDermid, G.; Masek, J.G.; Gao, F.; White, J.C. A new data fusion model for high spatial- and temporal-resolution mapping of forest disturbance based on Landsat and MODIS. Remote Sens. Environ. 2009, 113, 1613–1627. [Google Scholar] [CrossRef]
- Shen, H.; Wu, P.; Liu, Y.; Ai, T.; Wang, Y.; Liu, X. A spatial and temporal reflectance fusion model considering sensor observation differences. Int. J. Remote Sens. 2013, 34, 4367–4383. [Google Scholar] [CrossRef]
- Zurita-Milla, R.; Clevers, J.G.P.W.; Schaepman, M.E. Unmixing-Based Landsat TM and MERIS FR Data Fusion. IEEE Geosci. Remote Sens. Lett. 2008, 5, 453–457. [Google Scholar] [CrossRef]
- Zhu, X.; Helmer, E.H.; Gao, F.; Liu, D.; Chen, J.; Lefsky, M.A. A flexible spatiotemporal method for fusing satellite images with different resolutions. Remote Sens. Environ. 2016, 172, 165–177. [Google Scholar] [CrossRef]
- Lu, L.; Huang, Y.; Di, L.; Hang, D. A New Spatial Attraction Model for Improving Subpixel Land Cover Classification. Remote Sens. 2017, 9, 360. [Google Scholar] [CrossRef]
- Huang, B.; Song, H. Spatiotemporal Reflectance Fusion via Sparse Representation. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3707–3716. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Peng, H.; Wang, Z. Multi-focus image fusion with a deep convolutional neural network. Inf. Fusion 2017, 36, 191–207. [Google Scholar] [CrossRef]
- Blum, R.S.; Liu, Z. Multi-Sensor Image Fusion and Its Applications; CRC Press: Boca Raton, FL, USA, 2005. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv, 2014; arXiv:1408.5882. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: New York, NY, USA, 2012; Volume 25, pp. 1097–1105. [Google Scholar]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- Zeiler, M.D.; Taylor, G.W.; Fergus, R. Adaptive deconvolutional networks for mid and high level feature learning. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2018–2025. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv, 2015; arXiv:1511.06434. [Google Scholar]
- Dumoulin, V.; Visin, F. A guide to convolution arithmetic for deep learning. arXiv, 2016; arXiv:1603.07285. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Masi, G.; Cozzolino, D.; Verdoliva, L.; Scarpa, G. Pansharpening by Convolutional Neural Networks. Remote Sens. 2016, 8, 594. [Google Scholar] [CrossRef]
- Wei, Y.; Yuan, Q.; Shen, H.; Zhang, L. Boosting the Accuracy of Multispectral Image Pansharpening by Learning a Deep Residual Network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1795–1799. [Google Scholar] [CrossRef]
- Chen, Y.; Li, C.; Ghamisi, P.; Jia, X.; Gu, Y. Deep Fusion of Remote Sensing Data for Accurate Classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1253–1257. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning (ICML’10), Madison, WI, USA, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Chollet, F. Keras. 2015. Available online: https://github.com/keras-team/keras (accessed on 29 June 2018).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. OSDI 2016, 16, 265–283. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Gupta, H.V.; Kling, H.; Yilmaz, K.K.; Martinez, G.F. Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modelling. J. Hydrol. 2009, 377, 80–91. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv, 2015; arXiv:1502.03167. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Green | Red | NIR | |||||||
|---|---|---|---|---|---|---|---|---|---|
| DCSTFN | STARFM | FSDAF | DCSTFN | STARFM | FSDAF | DCSTFN | STARFM | FSDAF | |
| RMSE | 65.470 | 70.350 | 70.632 | 58.348 | 65.158 | 65.899 | 58.064 | 46.020 | 45.502 |
| 0.919 | 0.906 | 0.906 | 0.956 | 0.945 | 0.944 | 0.994 | 0.997 | 0.997 | |
| KGE | 0.879 | −0.950 | 0.667 | 0.901 | −0.551 | 0.745 | 0.884 | 0.706 | 0.846 |
| SSIM | 0.964 | 0.940 | 0.936 | 0.957 | 0.745 | 0.925 | 0.920 | 0.846 | 0.890 |
| Green | Red | NIR | |||||||
|---|---|---|---|---|---|---|---|---|---|
| DCSTFN | STARFM | FSDAF | DCSTFN | STARFM | FSDAF | DCSTFN | STARFM | FSDAF | |
| RMSE | 66.112 | 62.630 | 61.109 | 60.435 | 60.402 | 60.172 | 44.885 | 46.350 | 45.912 |
| 0.971 | 0.974 | 0.975 | 0.984 | 0.984 | 0.984 | 0.998 | 0.998 | 0.998 | |
| KGE | 0.886 | 0.500 | 0.721 | 0.866 | 0.138 | 0.780 | 0.828 | 0.431 | 0.847 |
| SSIM | 0.909 | 0.872 | 0.867 | 0.880 | 0.822 | 0.829 | 0.809 | 0.783 | 0.801 |
| Green | Red | NIR | |||||||
|---|---|---|---|---|---|---|---|---|---|
| DCSTFN | STARFM | FSDAF | DCSTFN | STARFM | FSDAF | DCSTFN | STARFM | FSDAF | |
| RMSE | 60.159 | 66.696 | 64.183 | 61.737 | 66.488 | 65.135 | 49.796 | 44.160 | 43.952 |
| 0.926 | 0.909 | 0.915 | 0.950 | 0.942 | 0.945 | 0.991 | 0.993 | 0.993 | |
| KGE | 0.870 | 0.368 | 0.751 | 0.858 | −0.296 | 0.749 | 0.740 | −0.182 | 0.682 |
| SSIM | 0.948 | 0.913 | 0.907 | 0.914 | 0.865 | 0.866 | 0.762 | 0.694 | 0.718 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, Z.; Yue, P.; Di, L.; Tang, J. Deriving High Spatiotemporal Remote Sensing Images Using Deep Convolutional Network. Remote Sens. 2018, 10, 1066. https://doi.org/10.3390/rs10071066
Tan Z, Yue P, Di L, Tang J. Deriving High Spatiotemporal Remote Sensing Images Using Deep Convolutional Network. Remote Sensing. 2018; 10(7):1066. https://doi.org/10.3390/rs10071066
Chicago/Turabian StyleTan, Zhenyu, Peng Yue, Liping Di, and Junmei Tang. 2018. "Deriving High Spatiotemporal Remote Sensing Images Using Deep Convolutional Network" Remote Sensing 10, no. 7: 1066. https://doi.org/10.3390/rs10071066
APA StyleTan, Z., Yue, P., Di, L., & Tang, J. (2018). Deriving High Spatiotemporal Remote Sensing Images Using Deep Convolutional Network. Remote Sensing, 10(7), 1066. https://doi.org/10.3390/rs10071066