1. Introduction
Many RS images have been accumulated due to the rapid development of Remote Sensing (RS) sensors and imaging techniques. The interpretation of such huge amount of RS imagery is a challenging task of significant sense for disaster monitoring, urban planning, traffic controlling and so on [
1,
2,
3,
4,
5]. RS scene classification, which aims at automatically classifying extracted sub-regions of the scenes into a set of semantic categories, is an effective method for RS image interpreting [
6,
7]. However, the complex spatial arrangement and the variety of surface objects in RS scenes make the classification quite challenging, especially for scenes in low quality (e.g., various scales and noises), since their within-class differences are more indistinct and between-class similarity are more distinct. How to automatically recognize and represent the RS scene from these different scale and quality RS image data effectively has become a critical task. To deal with such a challenge, this paper proposes a deep salient feature based anti-noise transfer network (DSFATN) approach that effectively enhances and explores the high-layer features for RS scene classification in different scales and noise conditions with great efficiency and robustness.
Many attempts have been made for RS scene classification. Among various previous approach, the bag-of-visual-words (BoVW) based models have drawn much attention for their good performance [
1,
8,
9,
10]. The BoVW based models encode local invariant features of an image and represent the image as a histogram of visual word occurrences. However, the BoVW based models utilize a collection of local features, which may not fully exploit the spatial layouts information thus result in information loss [
11]. To solve the problem, the spatial pyramid matching kernel (SPMK) [
12] introduced the spatial layout to form improved local features. Even though SPMK shows inspiring results, it only considers the absolute spatial arrangement of visual words. Thus, the improved version of SPMK, spatial co-occurrence kernel (SCK) [
1], and its pyramidal version spatial pyramid co-occurrence kernel (SPCK) [
13], were proposed to capture both absolute and relative spatial arrangements. Other alternative models, e.g., latent Dirichlet allocation (LDA) model [
14,
15,
16] and the probabilistic latent semantic analysis (pLSA) model [
17,
18], represent the image scene as a finite random mixture of topics and obtain competitive performance. In general, these approaches have made some achievements in RS scene classification but demand prior knowledge in handcrafted feature extraction, which is still opening challenging task in scene classification.
Recently, deep learning (DL) methods have achieved dramatic improvements and state-of–the-art performance in many fields (e.g., image recognition [
19], object detection [
20,
21], and image synthesis [
22]) due to automatic high-level feature representations from images and powerful ability of abstraction. DL methods also draw much attention in RS image classification [
23,
24]. For example, Lu et al. [
25] proposed a discriminative representation for high spatial resolution remote sensing image by utilizing a shallow weighted deconvolution network and spatial pyramid model (SPM), and classified the representation vector by support vector machine (SVM). Chen et al. [
26] utilized the single-layer restricted Boltzmann machine (RBM) and multilayer deep belief network (DBN) based model to learn the shallow and deep features of hyperspectral data, the learnt features can be used in logistic regression to achieve the hyperspectral data classification. As one of the most popular DL approaches, convolutional neural networks (CNNs) show incomparable superiority on several benchmark datasets such as Imagenet [
27], and have been widely used in the recognition, detection tasks and obtained impressive results [
28,
29,
30]. However, training a powerful CNN is complicated since many labeled training samples and techniques are needed, while the available labeled RS scene datasets are not comparable to any natural scene dataset. For example, compared with the dataset ImageNet containing 15 million labeled images in 22,000 classes, the most famous and widely used UC Merced Land Use (UCM) [
1] RS scene dataset only contains 21 classes and 2100 label images.
To address the data limitation, an effective strategy is data augmentation. It generates more training image samples by adding rotated, flipped versions and random cropped, stretched patches of the training images [
31,
32], or patches sampled by some optimized strategy [
11,
33]. Another effective strategy is transfer learning based on a pre-trained CNN model. Castelluccio et al. [
34] fine-tuned the pre-trained CNNs on the UCM dataset. The best result reached 97.10% when fine-tuning the GoogLeNet [
35] while training a GoogLeNet from scratch just reached 91.2%. Penatti et al. [
36] and Hu et al. [
37] investigated the deep features extracted from different pre-trained CNNs for RS scene representation and classification, and proved the effectiveness and superiority of the features from the 1st full-connected layer of CNNs. The features extracted from pre-trained CNNs also have some invariance to small-scale deformations, larger-scale and so on [
38,
39]. Compared with training a new CNN, transfer learning methods are faster and the classification results are much promising without large amount of training data. It is known that most of the pre-trained CNNs have been trained in dataset with large number of natural images such as ImageNet. In natural image scenes, the objects are almost centrally focused, and the center pixels have more influence on the image semantic labels [
11], while, in RS image scenes, the surface objects are usually distributed randomly, and the central parts may not relate closely with the semantic label. Hence, due to the objects distributions difference between natural scenes and RS scenes, the pre-trained CNNs based on transfer learning method is applicable for a limit amount of training date but lacks robustness to low quality variance (e.g., various scales and noises) in RS scene classification.
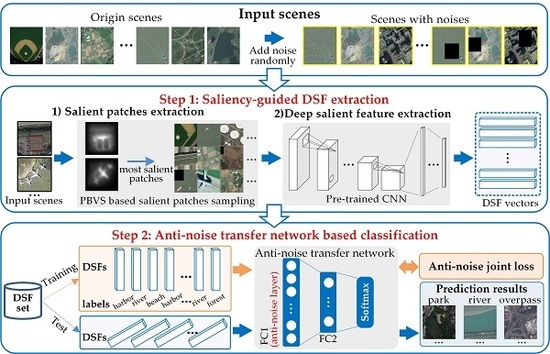
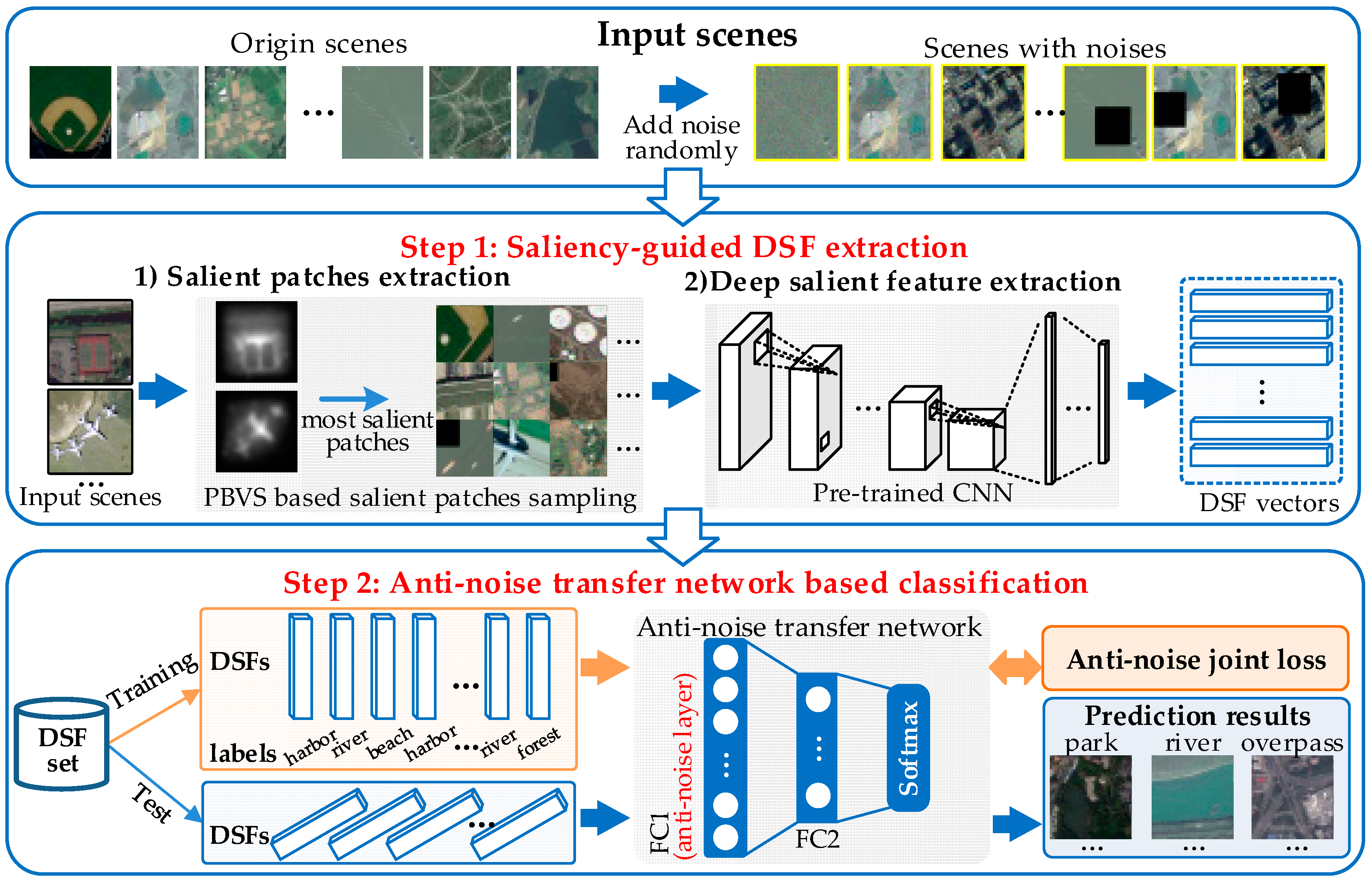
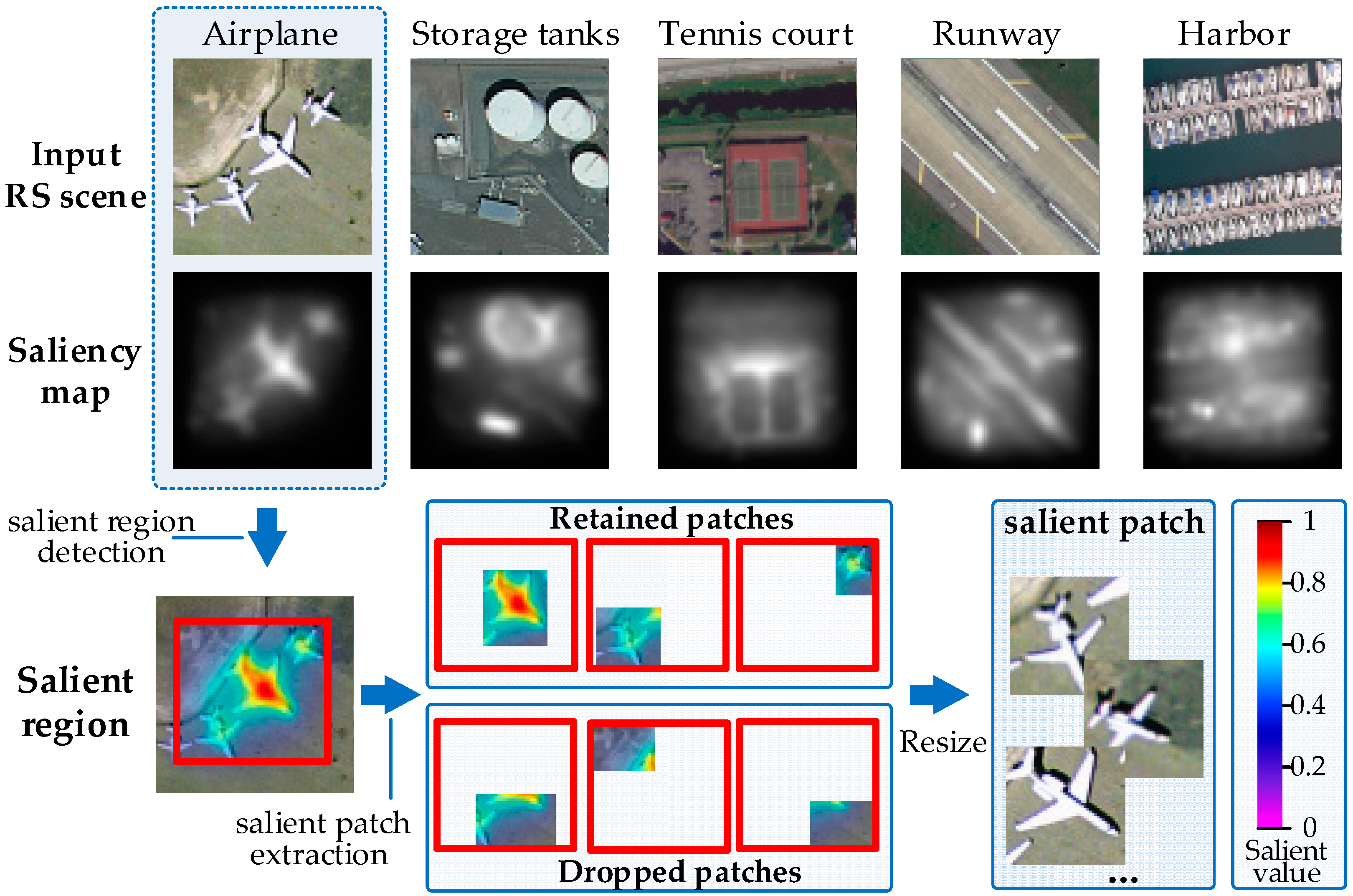
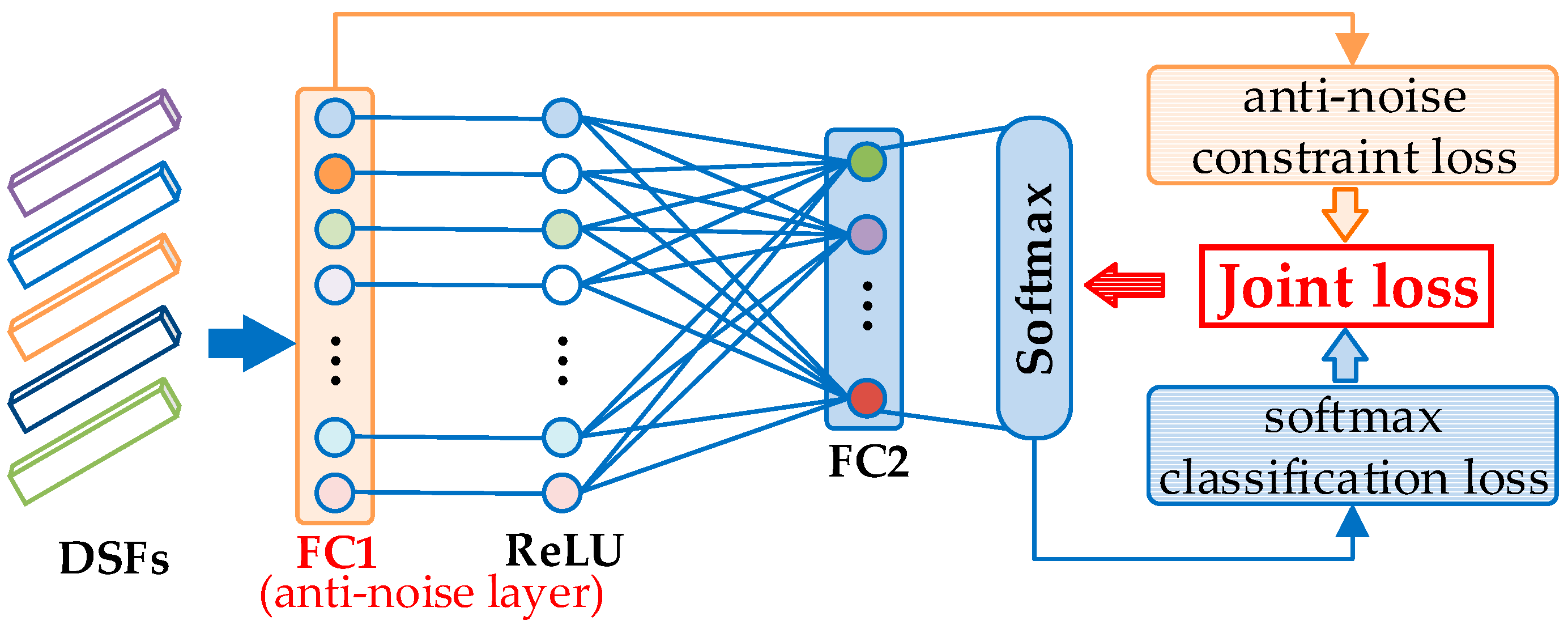
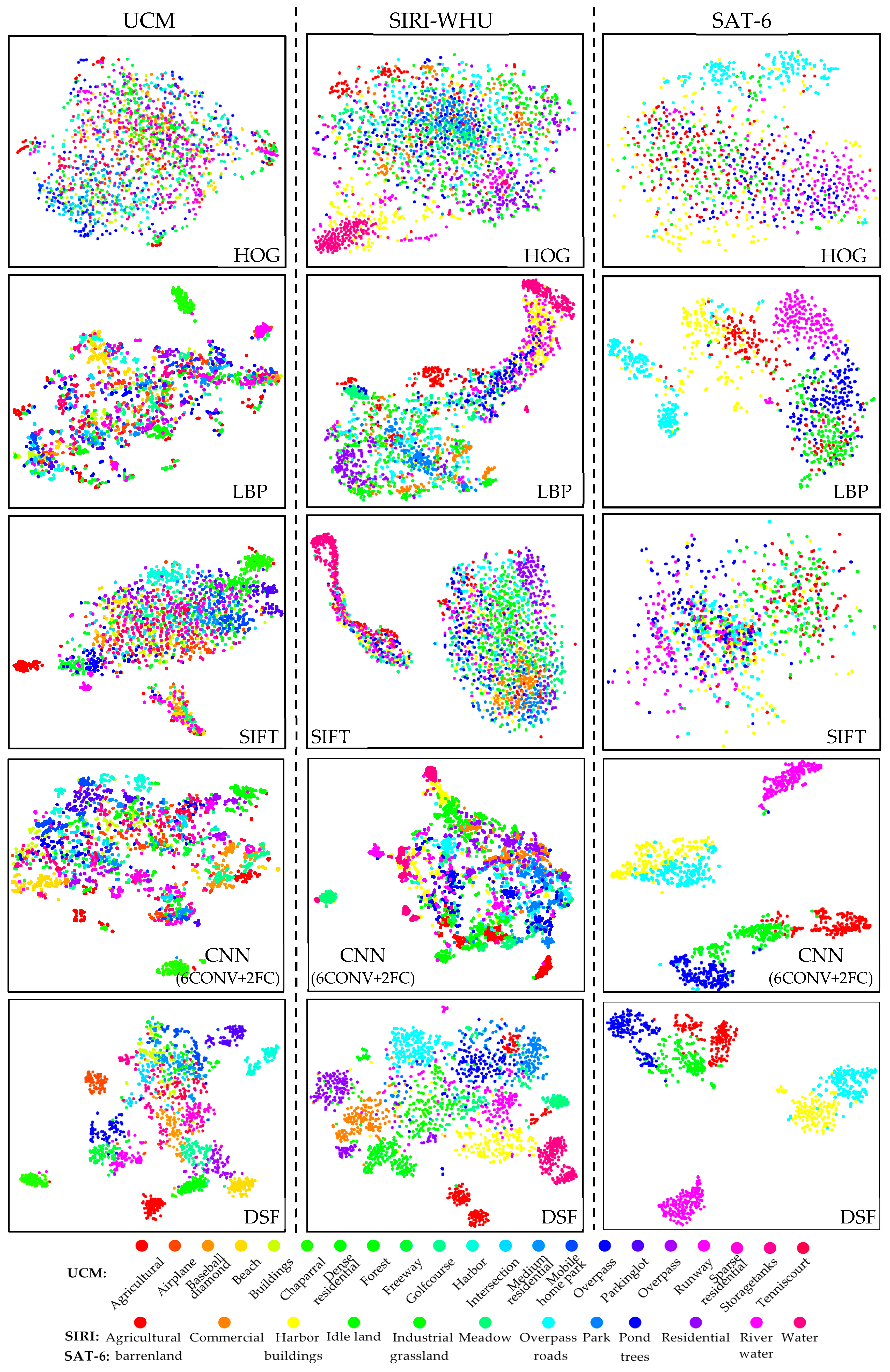
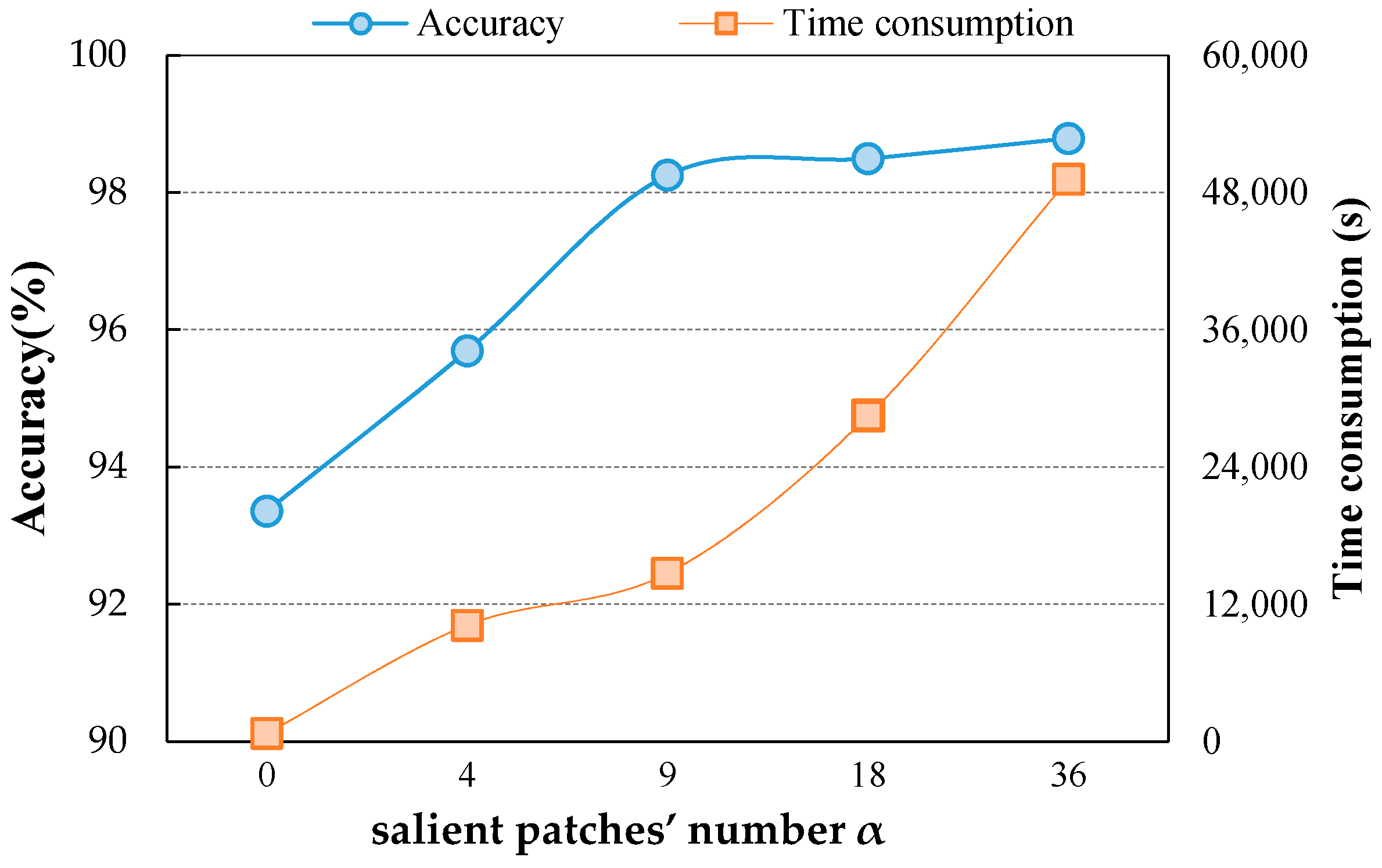
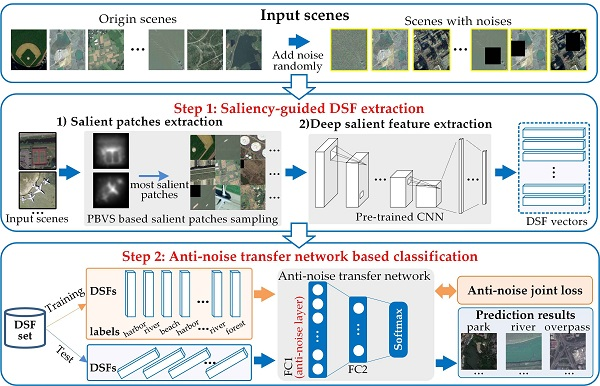
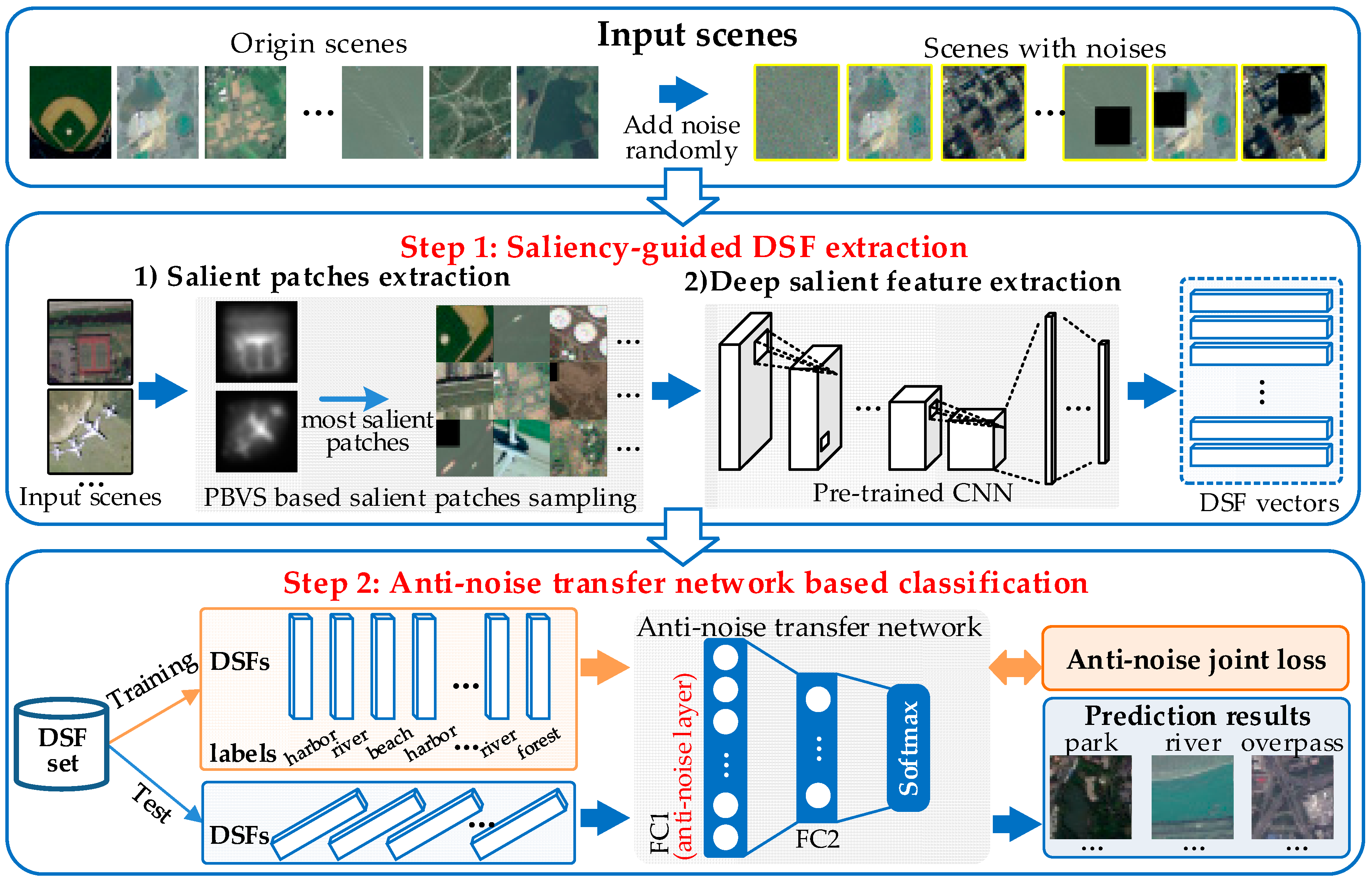
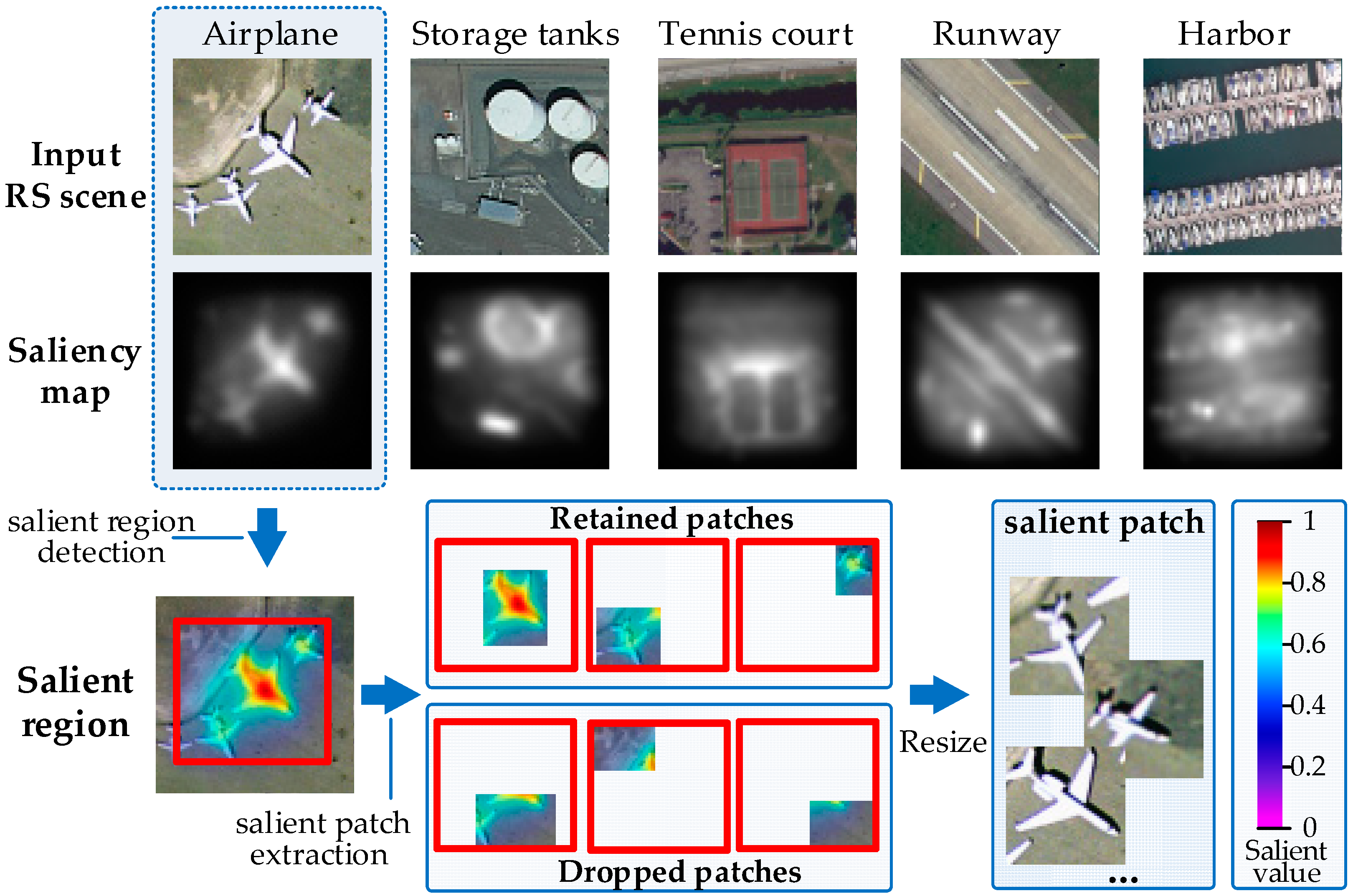
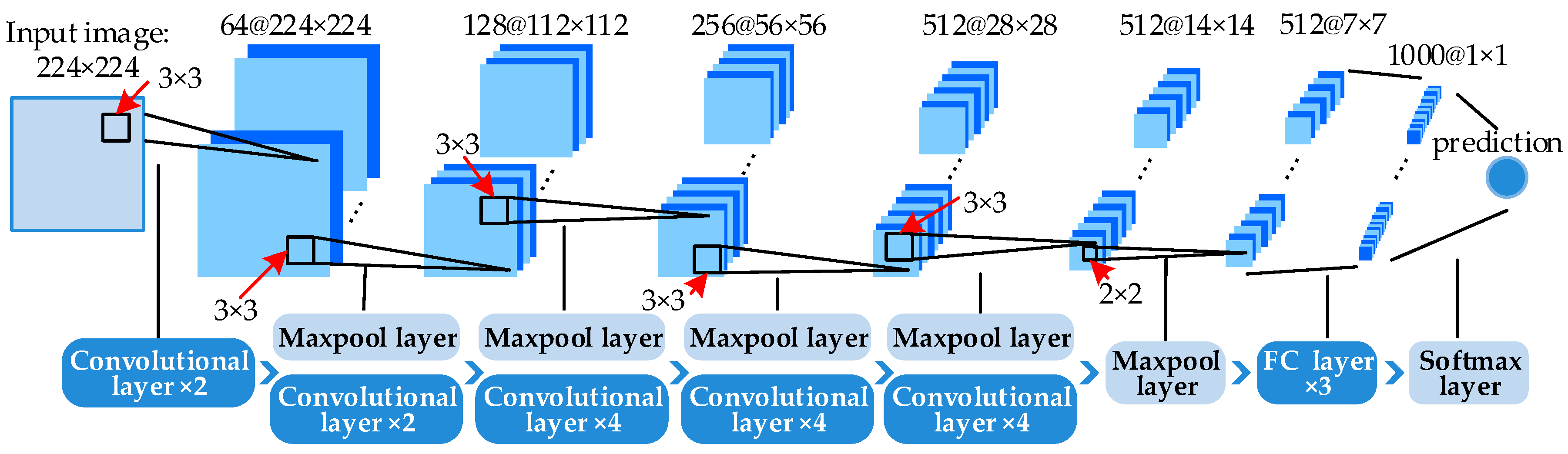
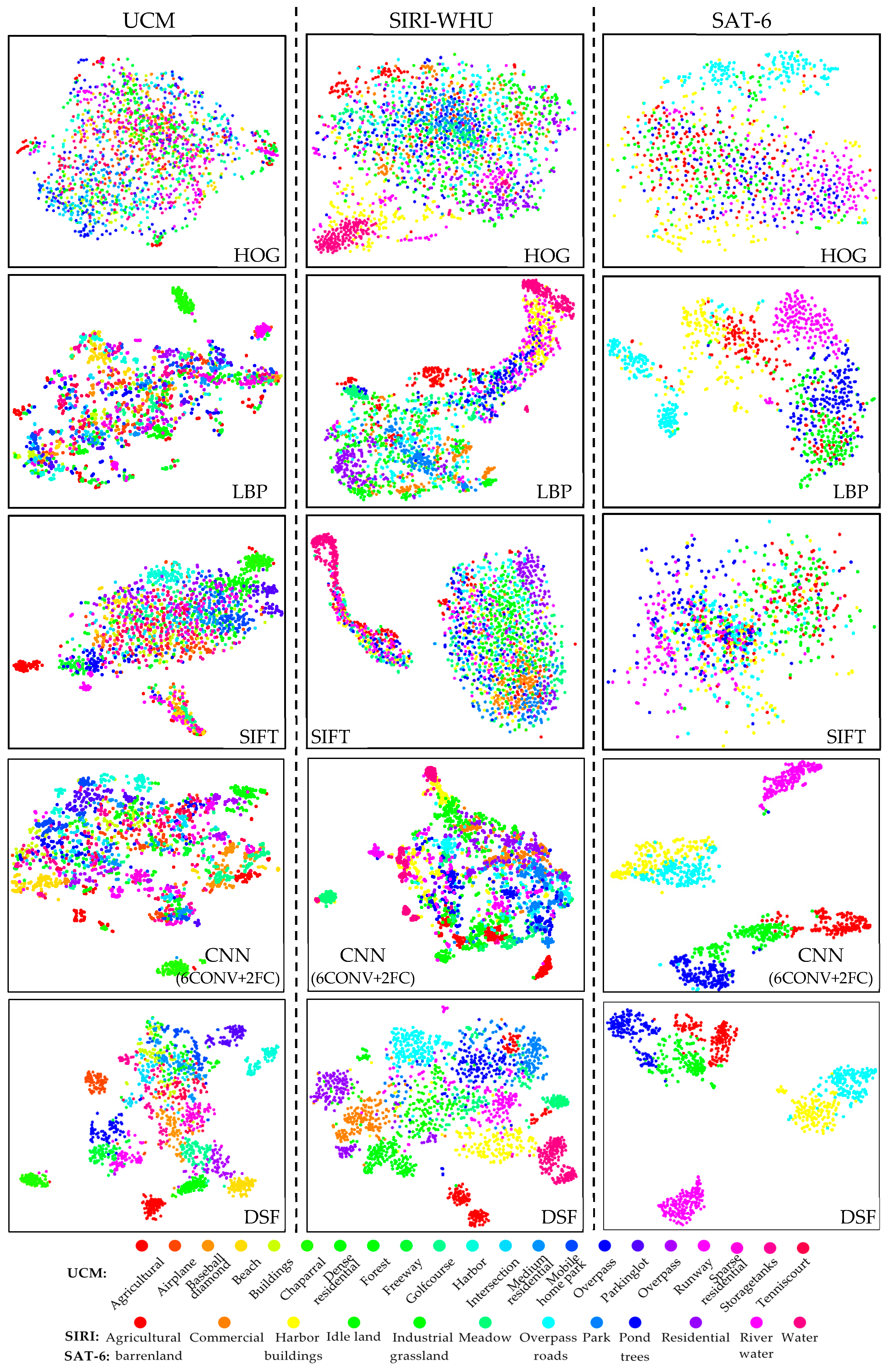
To address the challenging task, we propose a deep salient feature based anti-noise transfer network (DSFATN) for classification of RS scenes with different scales and various noises. Our method aims at improving both feature representation of RS scene and classification accuracy. In DSFATN, a novel deep salient feature (DSF) and an anti-noise transfer network are introduced to suppress the influences of different scales and noise variances. The saliency-guided DSF extraction conducts a patch-based visual saliency (PBVS) algorithm to guide pre-trained CNNs for producing the discriminative high-level DSF. It compensates the affect caused by objects distribution difference between natural scenes and RS scenes, thus makes the DSF extracted exactly from the most relevant, informative and representative patches of the RS scene related to its category. The anti-noise transfer network is trained to learn and enhance the robust and anti-noise structure information of RS scene by minimizing a joint loss. DSFATN performs excellent with RS scenes in different scales and qualities, even with noise.
The major contributions of this paper are as follows:
We propose a novel DSF representation using “visual attention” mechanisms. DSF can achieve discriminative high-level feature representation learnt from pre-trained CNN for the RS scenes.
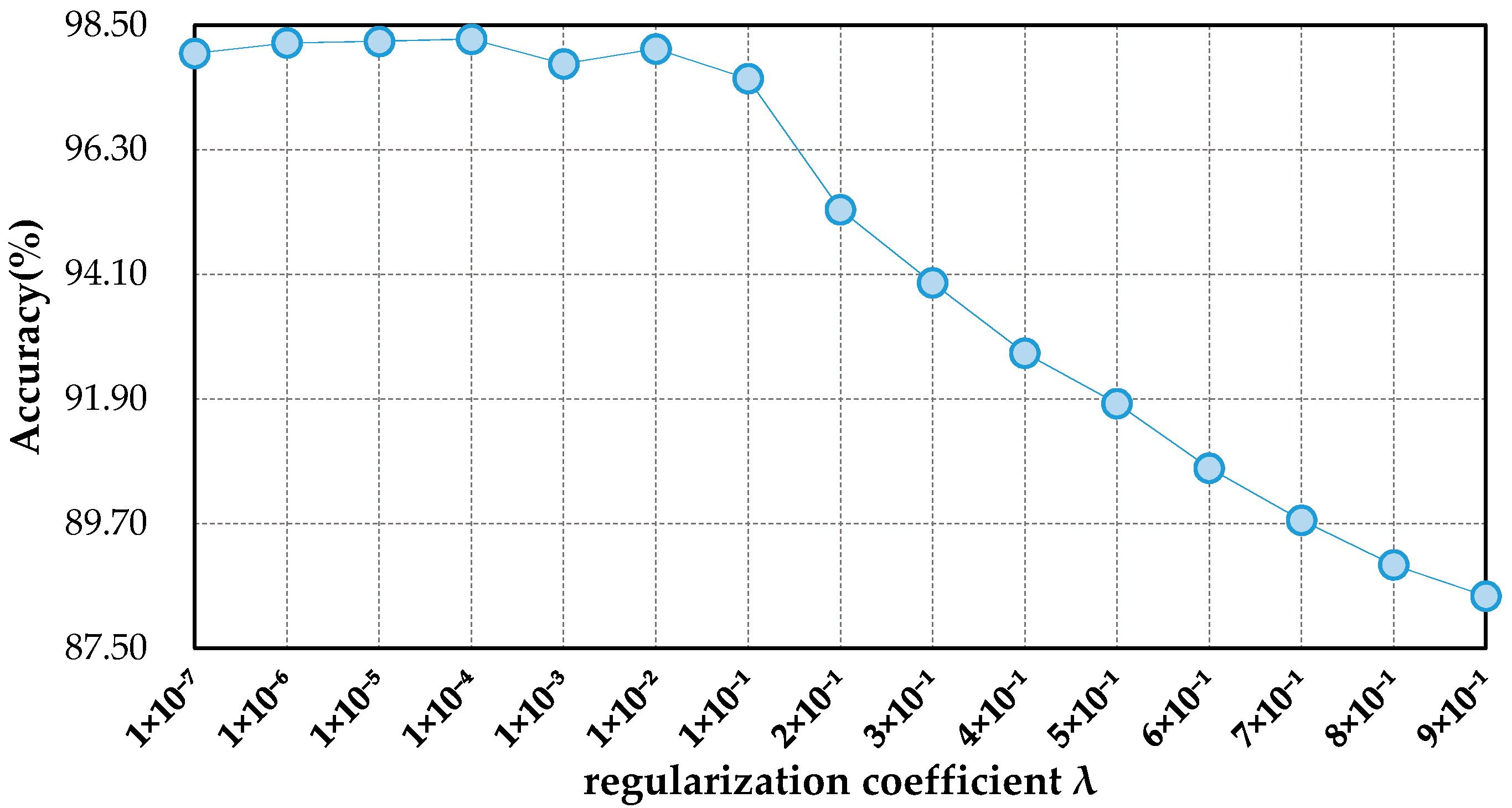
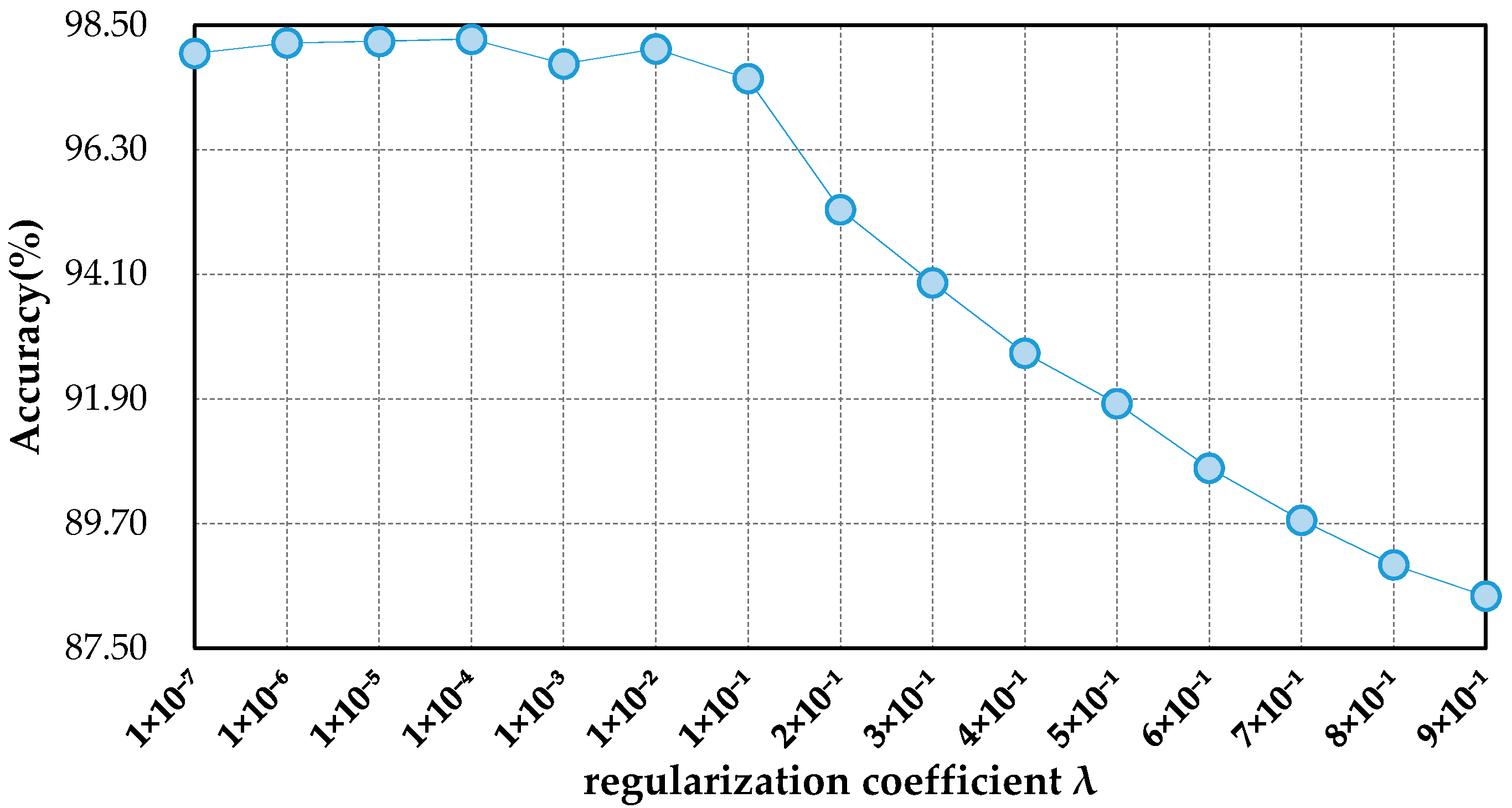
An anti-noise transfer network is improved to learn and enhance the robust and anti-noise structure information of RS scene, where a joint loss is used to minimize the network by considering anti-noise constraint and softmax classification loss. The simple architecture of the anti-noise transfer network makes it easier to be trained with the limited availability of training data.
The proposed DSFATN is evaluated on several public RS scene classification benchmarks. The significant performance demonstrated our method is of great robustness and efficiency in various scales, occlusions, and noise conditions and advanced the state-of-the-arts methods.
This paper is organized as follows. In
Section 2, we illustrate the proposed DSFATN method in detail. In
Section 3, we introduce the experimental data and protocol, provide the performance of the proposed DSFATN and discuss the influence of serval factors.
Section 4 concludes the paper with a summary of our method.
4. Conclusions
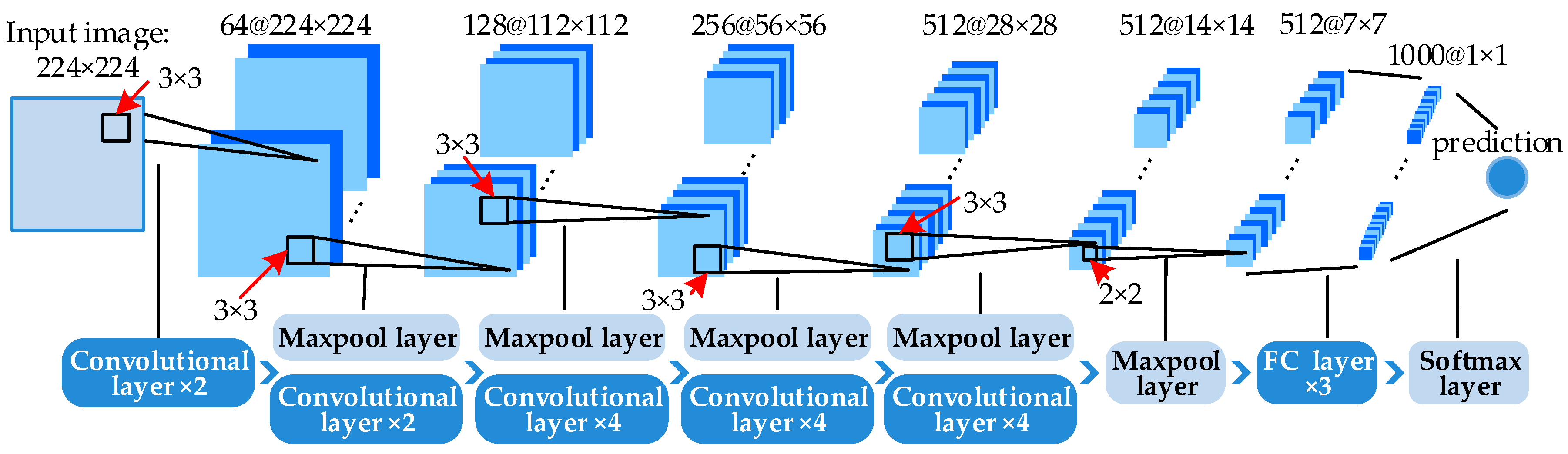
This paper proposes a deep salient feature based anti-noise transfer network (DSFATN) method for RS scene classification with different scales and various noises. In DSFATN, the saliency-guided DSF extraction extracts the discriminative high-level DSF from the most relevant, informative and representative patches of the RS scene sampled by the Patch-Based Visual Saliency (PBVS) method. The VGG-19 is selected as the pre-trained CNN to extract DSF among various candidate CNNs for its better performance. DSF achieves discriminative high-level feature representation learned from pre-trained VGG-19 for the RS scenes. Meanwhile, an anti-noise transfer network is introduced to learn and enhance the robust and anti-noise structure information of RS scene by directly propagating the label information to fully-connected layers. By minimizing the joint loss concerning anti-noise constraint and softmax classification loss simultaneously, the anti-noise transfer network can be trained easily with limited amount of data and without accuracy loss. DSFATN performs excellent with RS scenes in different quality, even with noise.
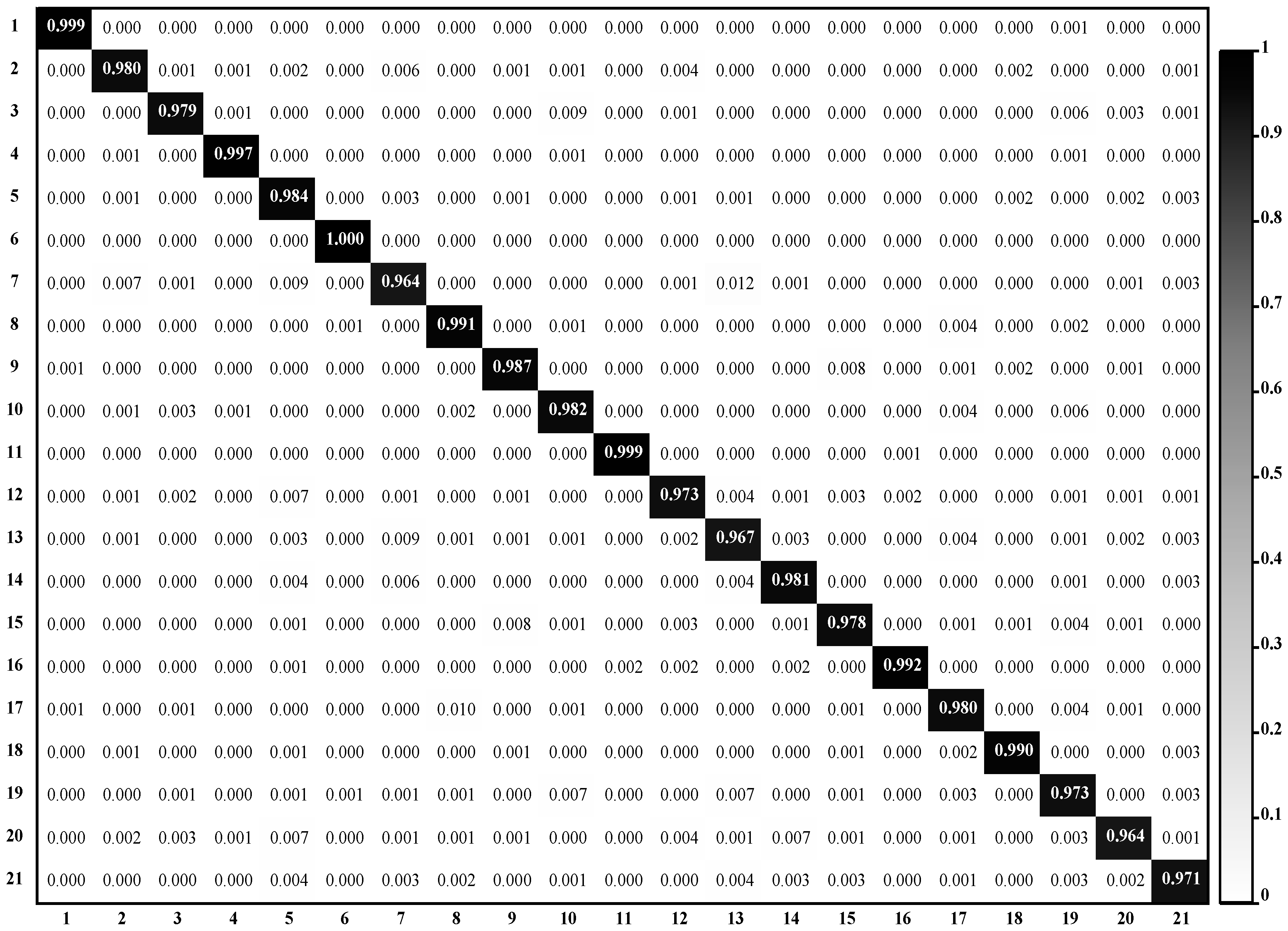
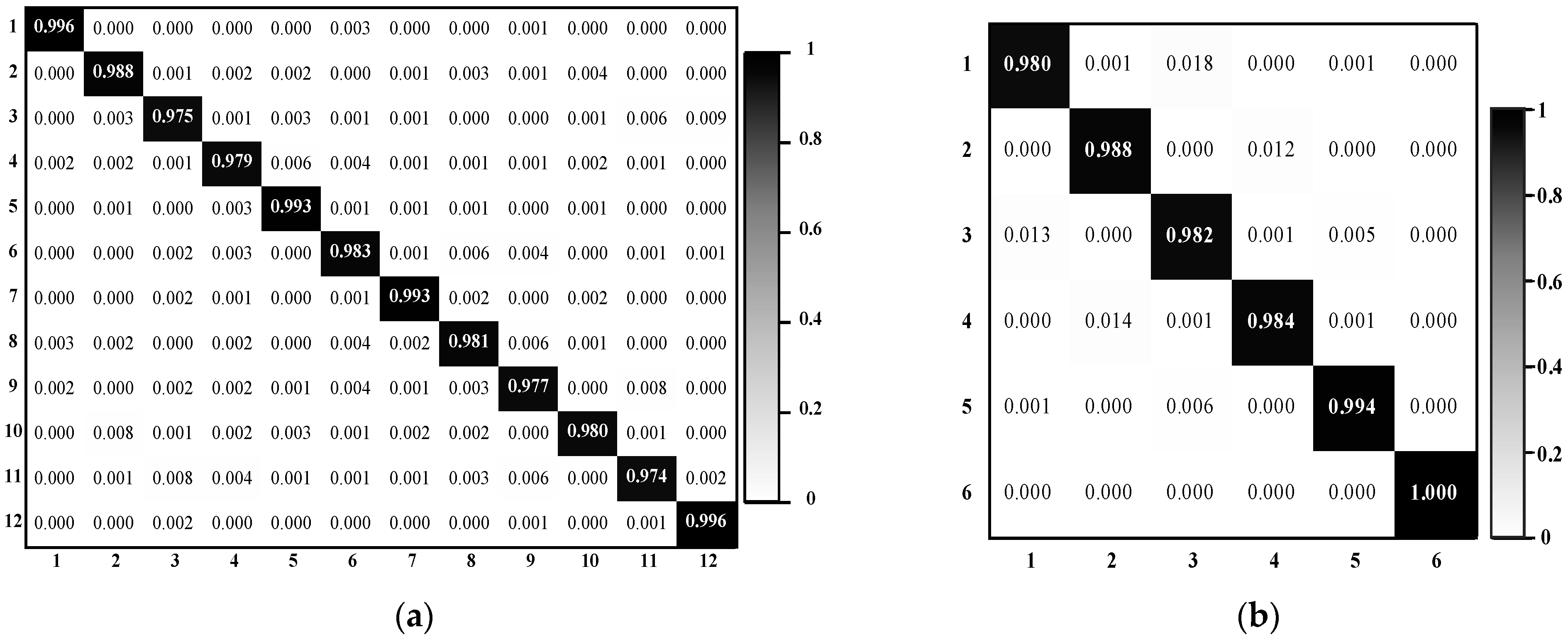
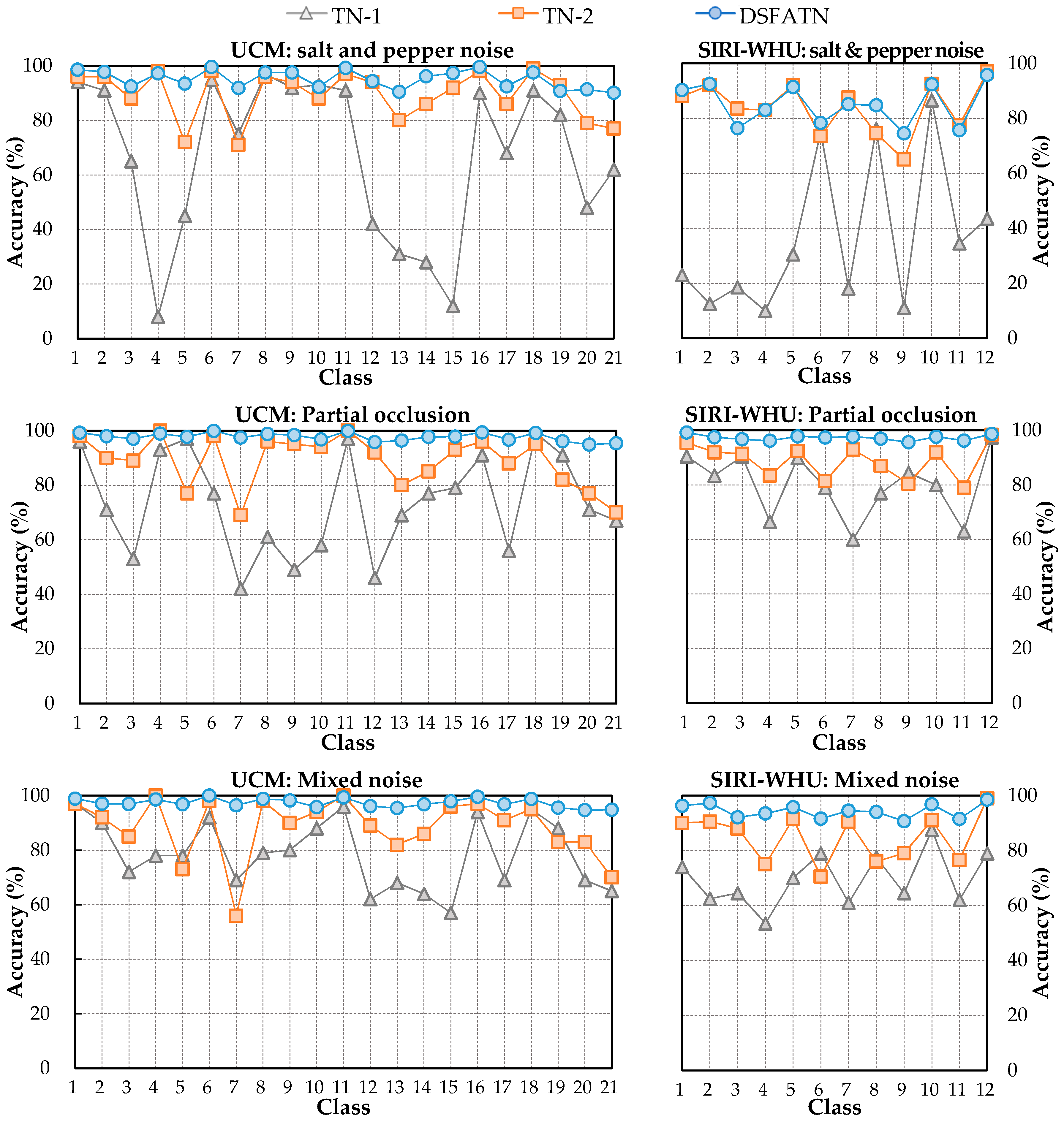
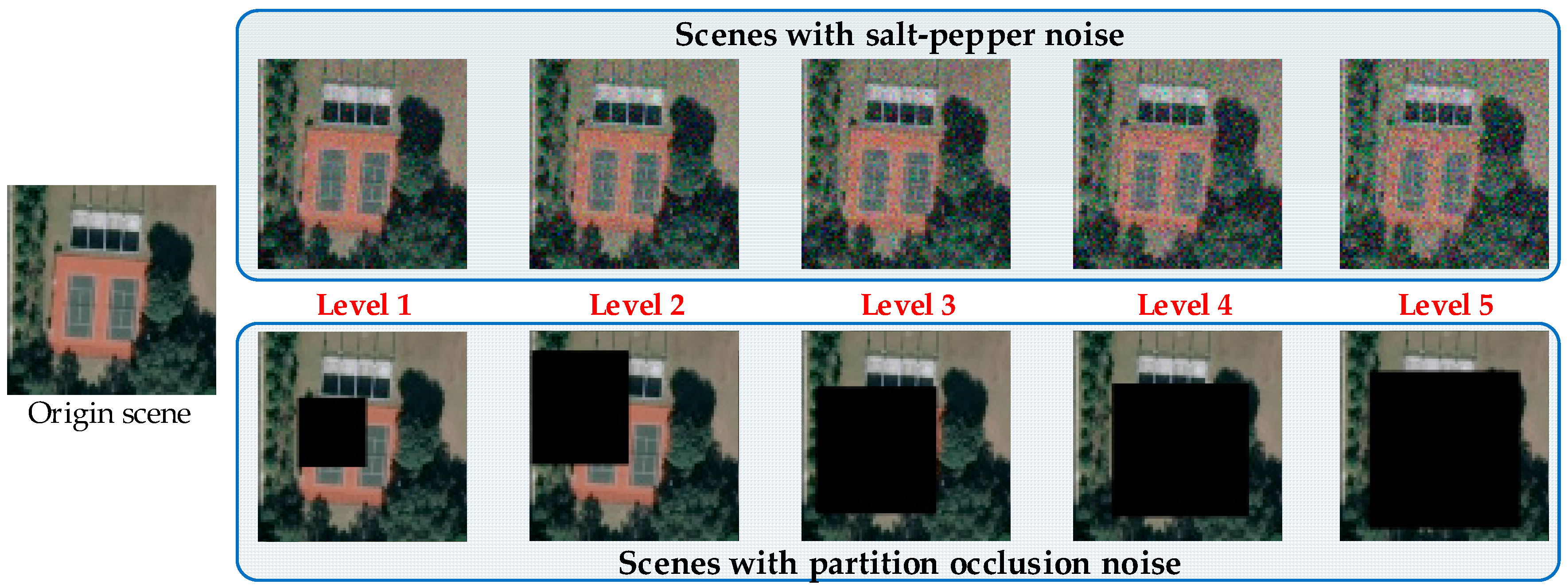
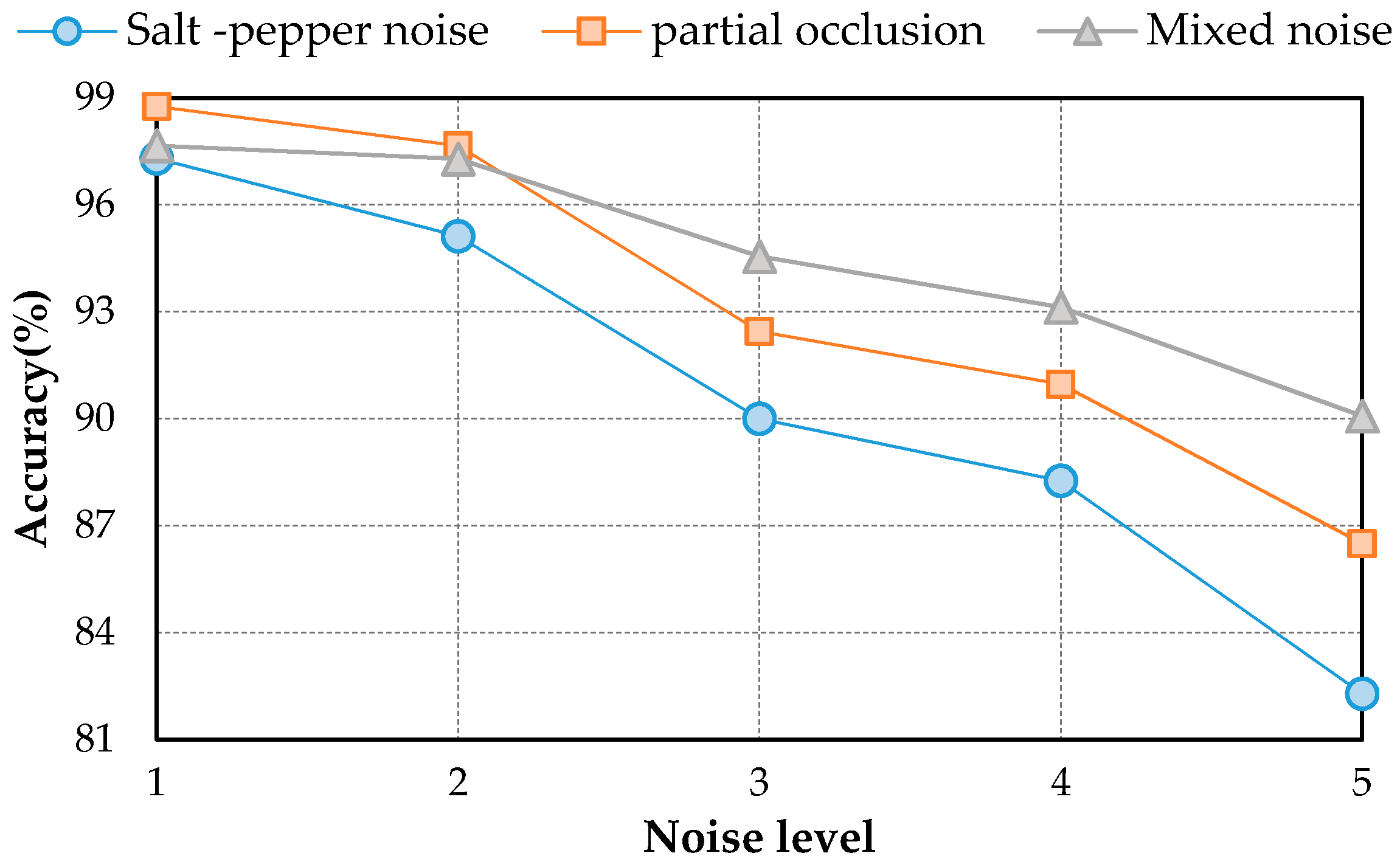
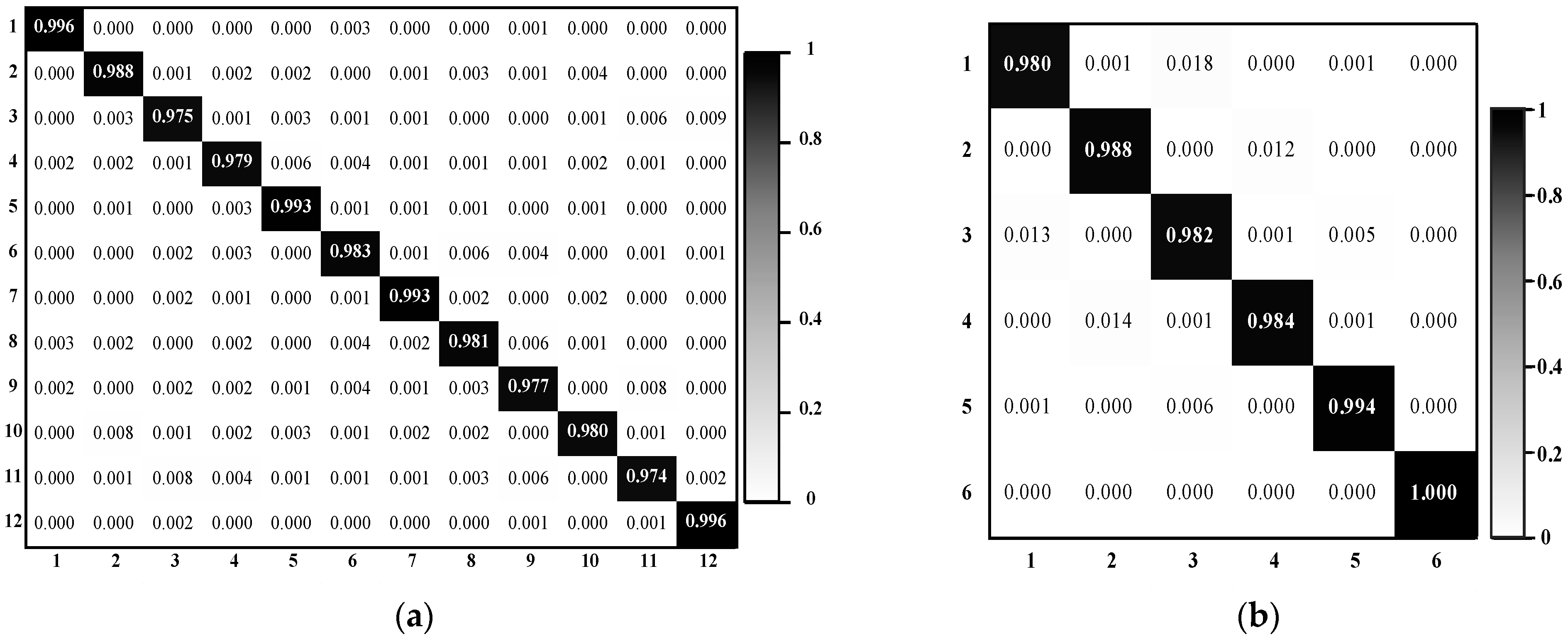
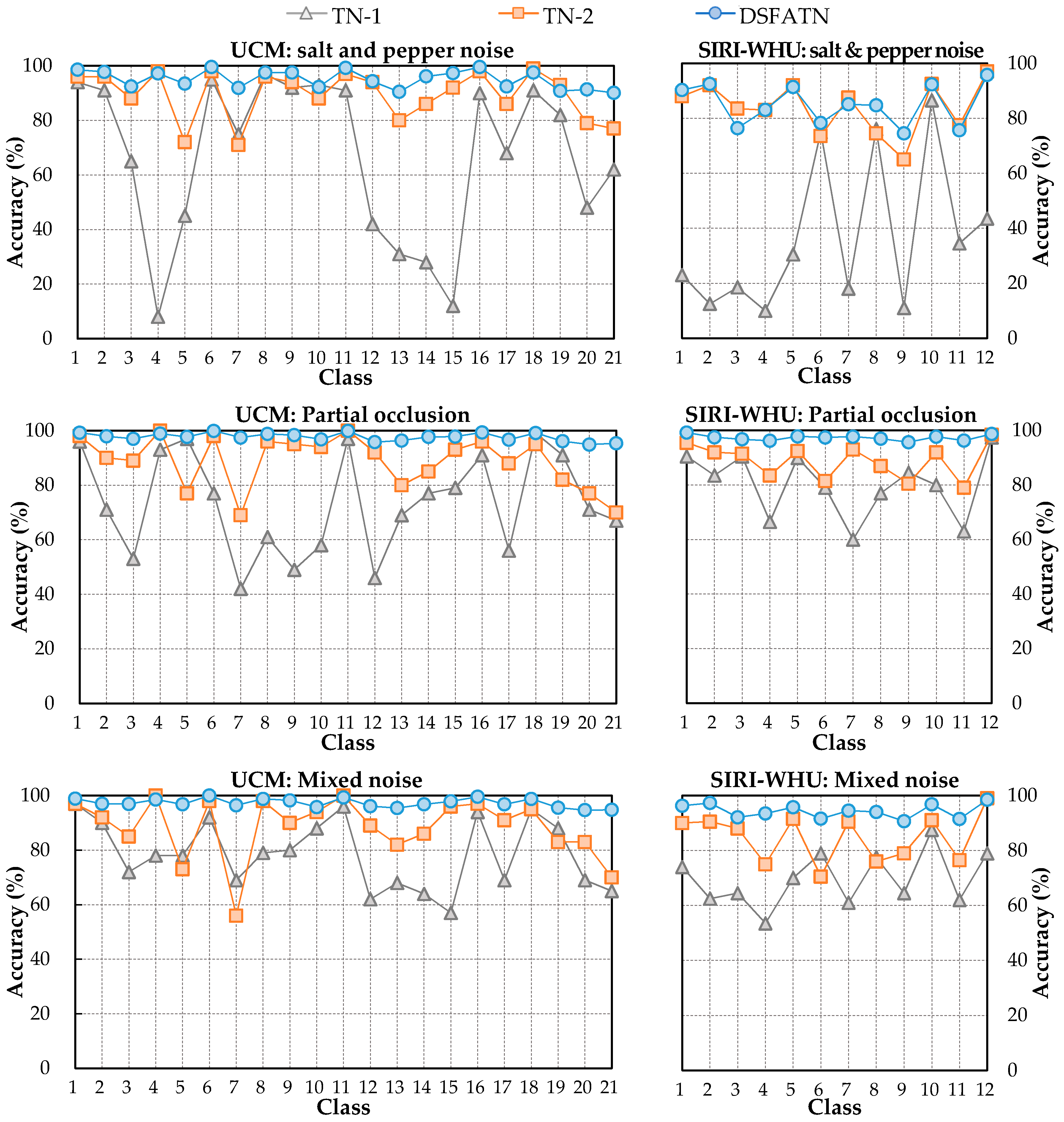
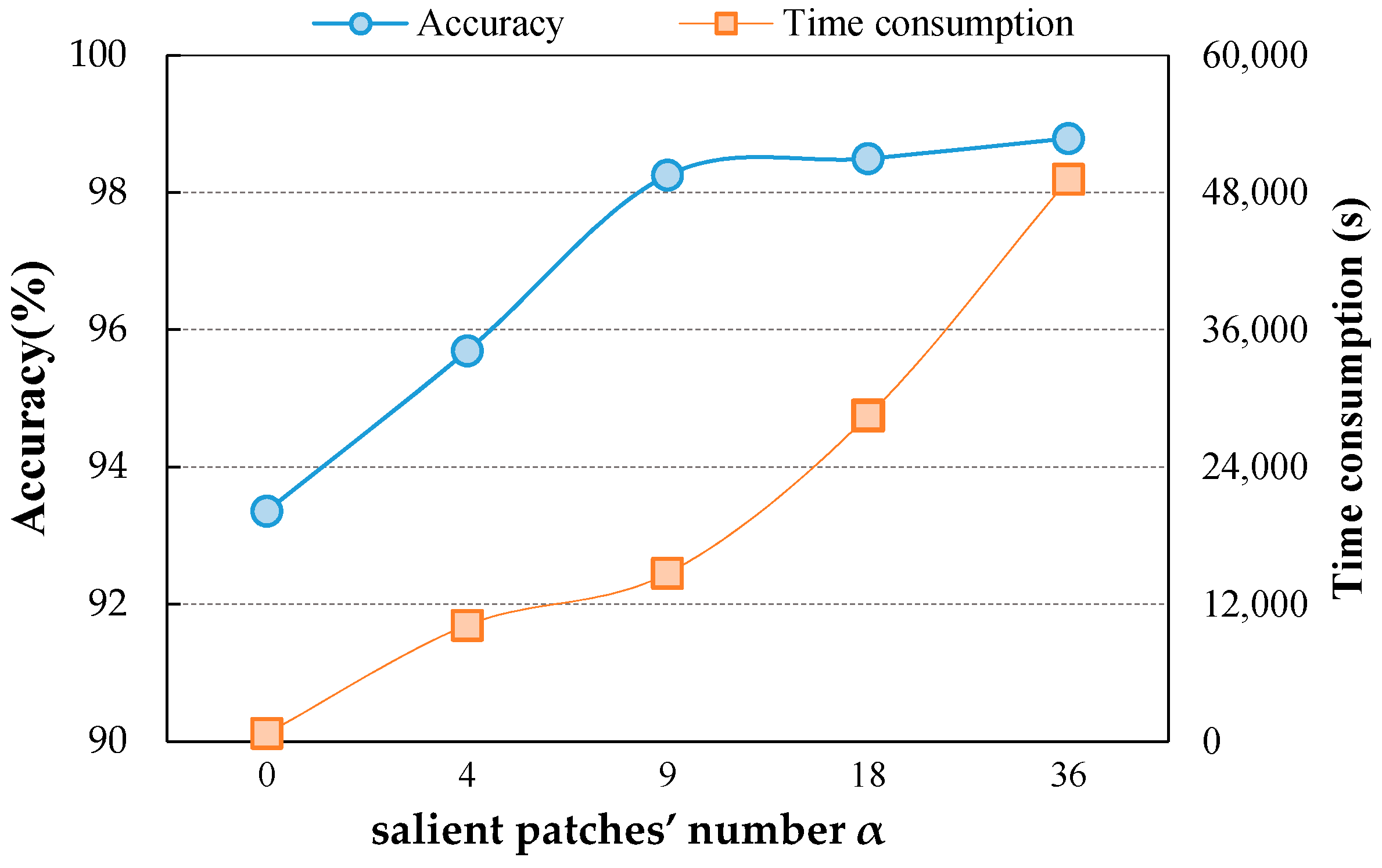
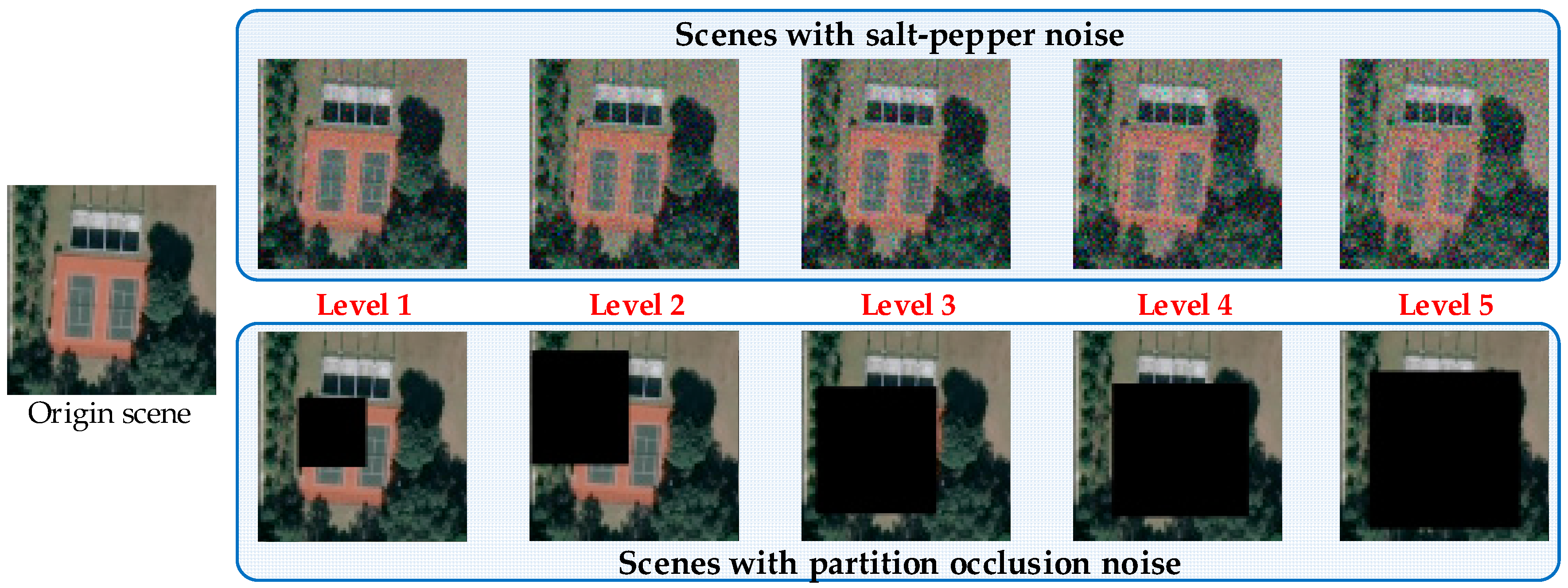
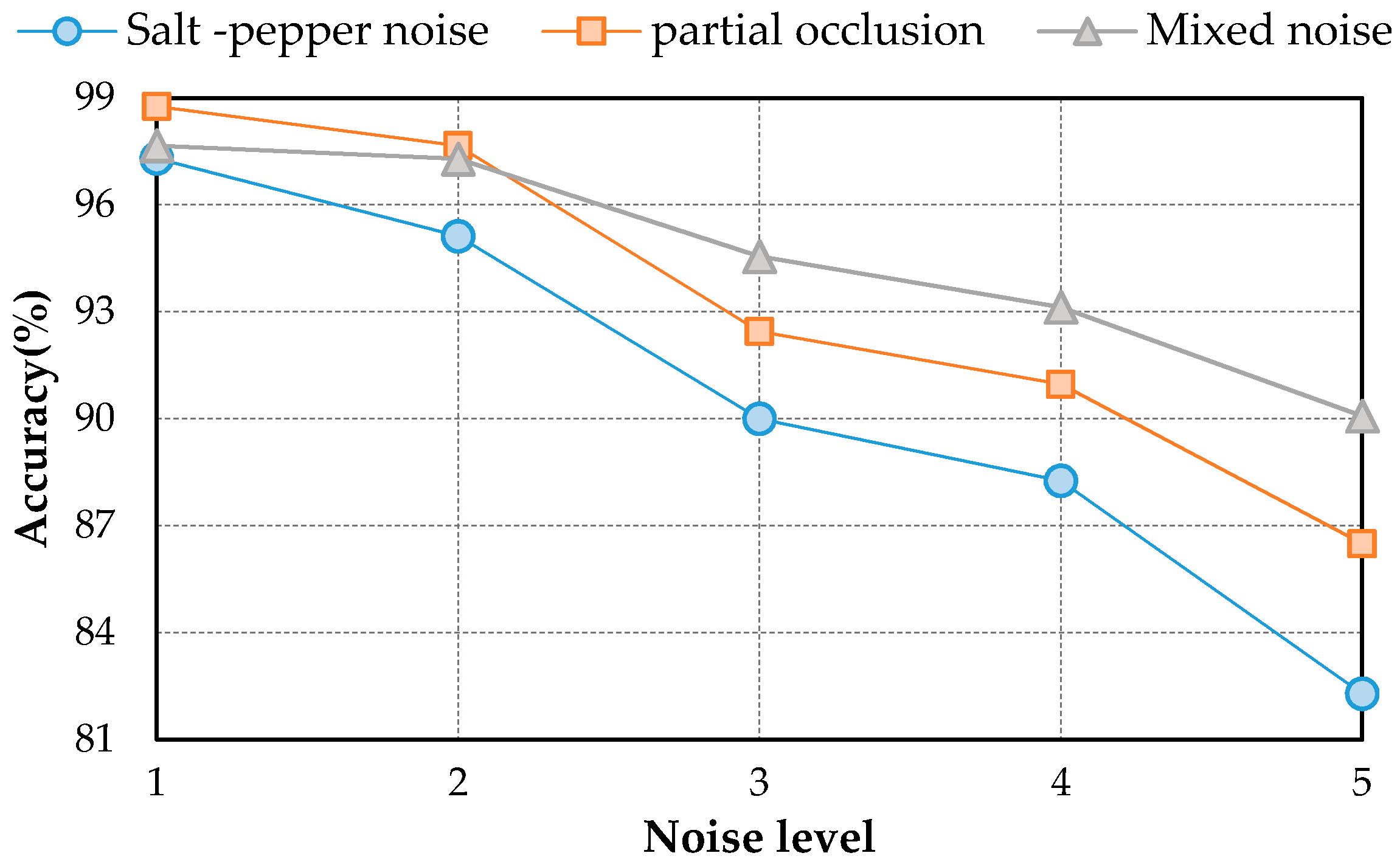
The results on three different scale datasets with limited data are encouraging: the classification results are all above 98%, which outperforms the results of state-of-the-art methods. DSFATN also obtains satisfactory results under various noises. For example, the results on the widespread UCM with noises are higher than 95%, which is even better than the best results of some state-of-the-art methods on UCM without noise. The remarkable results indicate the effectiveness and wide applicability of DSFATN and prove the robustness of DSFATN.
However, the strong anti-noise property of DSFATN is dependent on different datasets; for example, under salt and pepper noise, the accuracy of DSFATN reaches 95.12% on the UCM dataset while it dropped to 84.98% on the SIRI-WHU dataset. In the future, we will conduct an end-to-end multi-scale and multi-channel network to jointly extract more adaptive representation for RS scene with limited availability of training data for complex scene understanding.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}