Demonstration of Percent Tree Cover Mapping Using Landsat Analysis Ready Data (ARD) and Sensitivity with Respect to Landsat ARD Processing Level

 , ,
, ,  , and
, and
Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Data and Study Area
2.1. Landsat Analysis Ready Data (ARD)
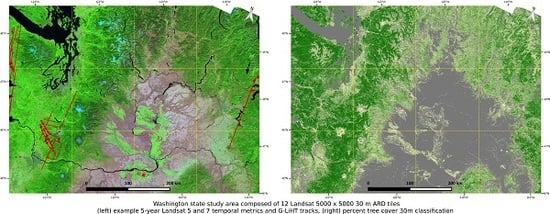
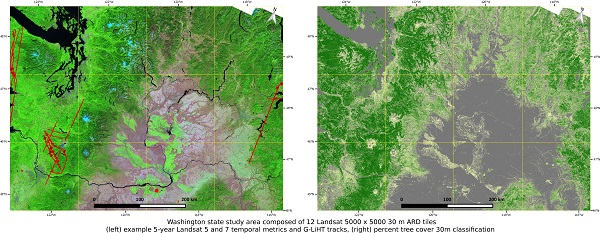
2.2. Study Area
2.3. Percent Tree Cover 30 m Reference Data Derived from Airborne LiDAR
3. Methods
3.1. Additional ARD Processing
3.1.1. Weekly Composite Generation
3.1.2. BRDF Adjustment
3.2. Percent Tree Cover Mapping
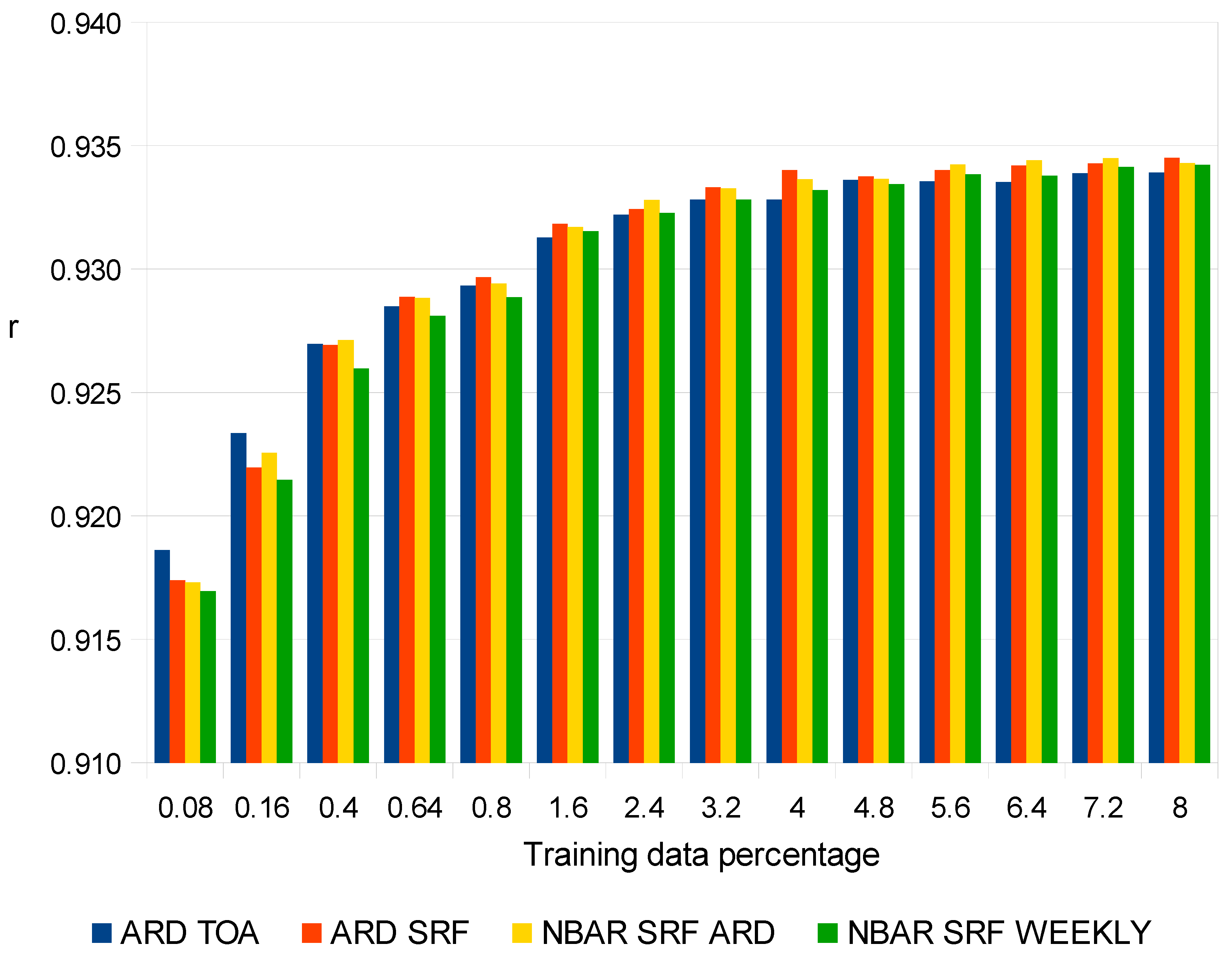
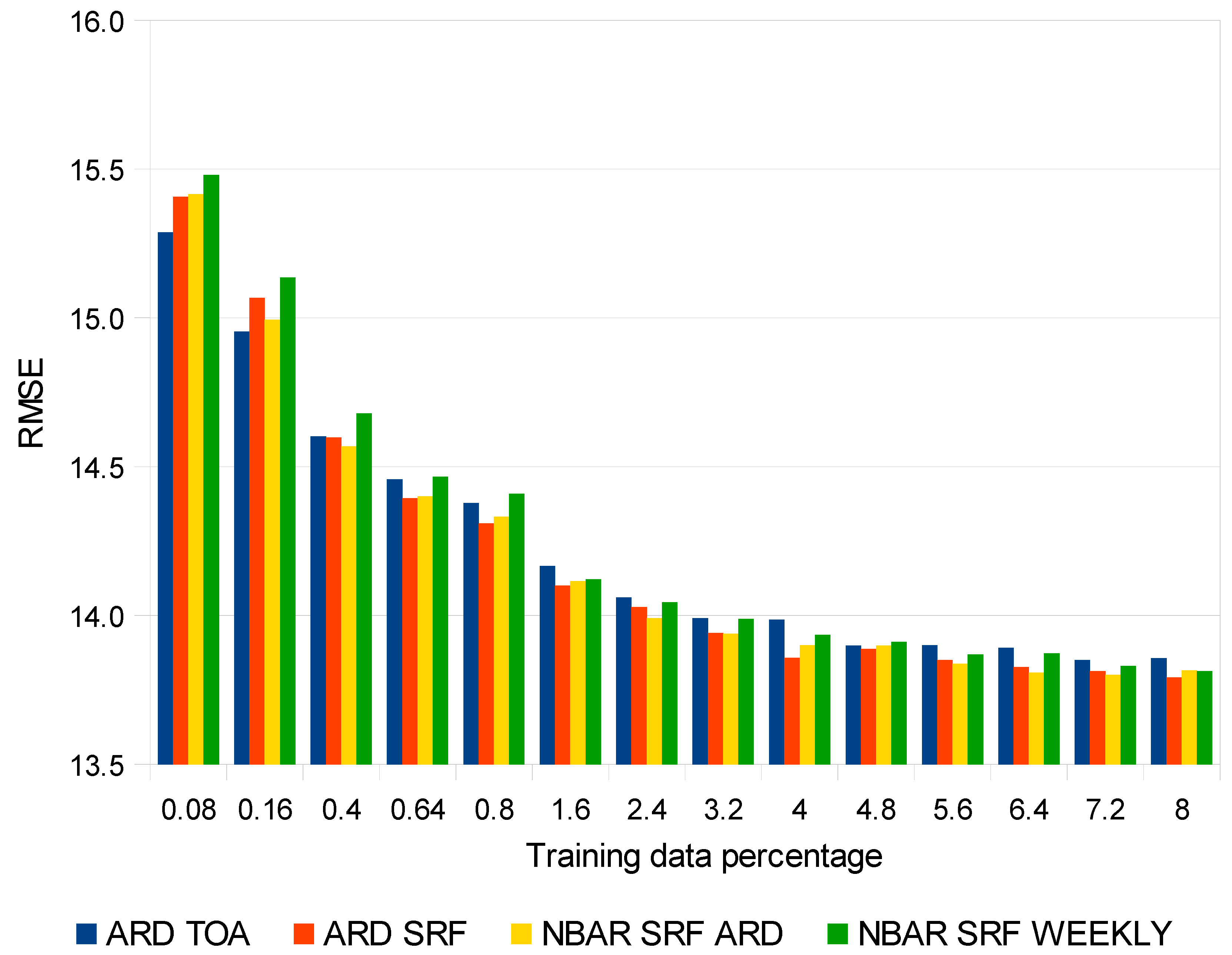
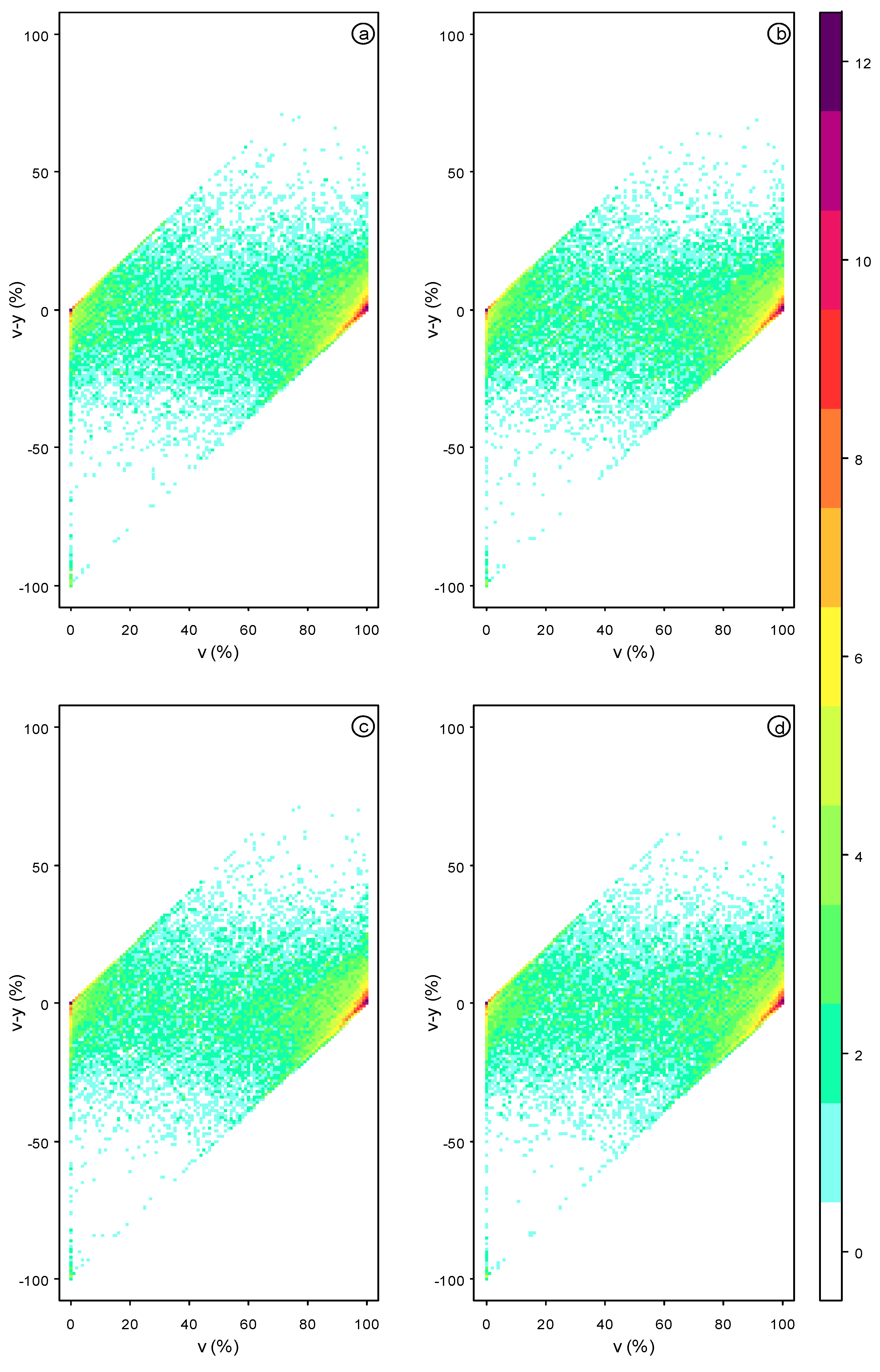
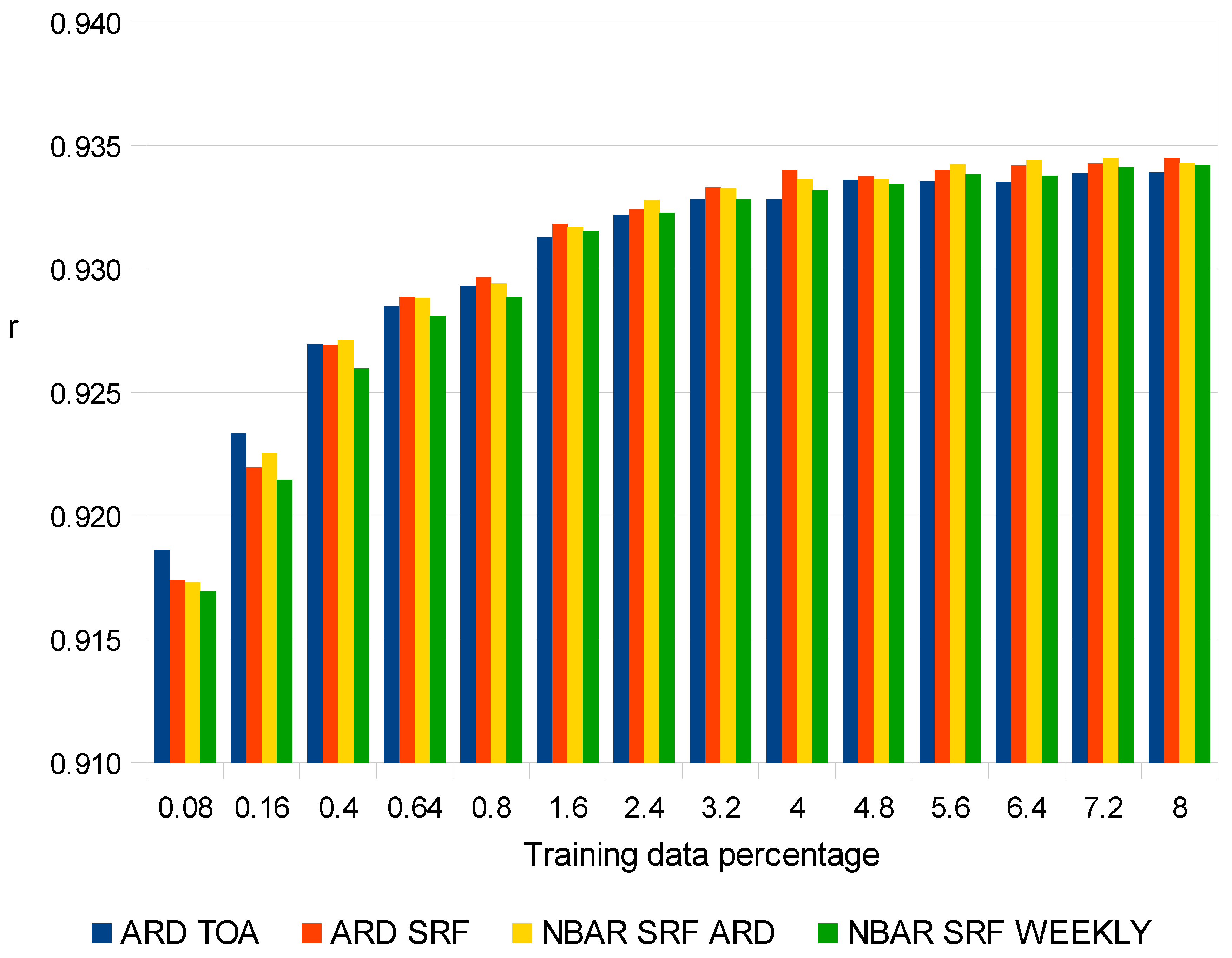
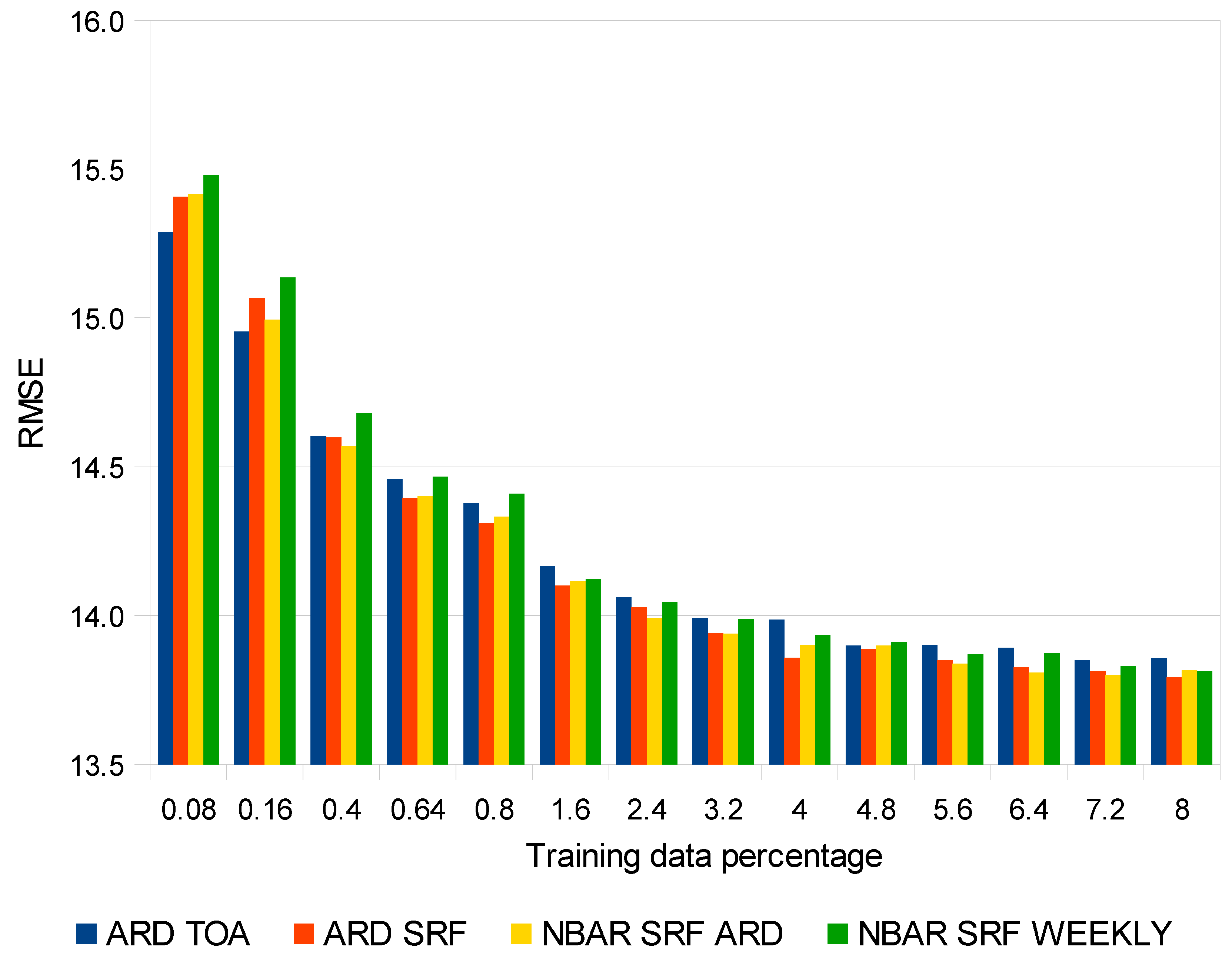
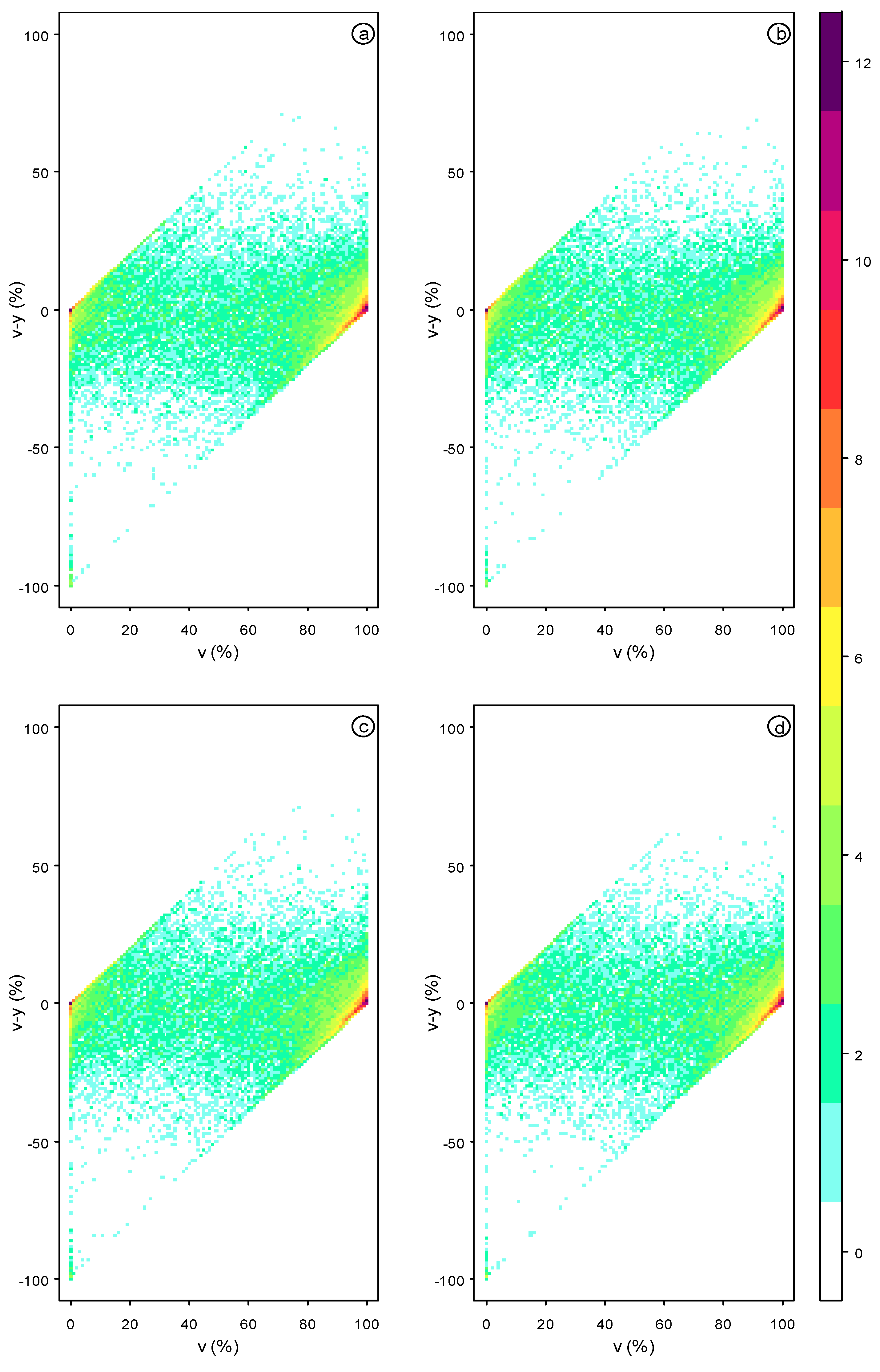
4. Results
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Hansen, M.C.; Loveland, T.R. A review of large area monitoring of land cover change using Landsat data. Remote Sens. Environ. 2012, 122, 66–74. [Google Scholar] [CrossRef]
- Banskota, A.; Kayastha, N.; Falkowski, M.J.; Wulder, M.A.; Froese, R.E.; White, J.C. Forest Monitoring Using Landsat Time Series Data: A Review. Can. J. Remote Sens. 2014, 40, 362–384. [Google Scholar] [CrossRef]
- Song, C.; Woodcock, C.E.; Seto, K.C.; Lenney, M.P.; Macomber, S.A. Classification and change detection using Landsat TM data: When and how to correct atmospheric effects? Remote Sens. Environ. 2001, 75, 230–244. [Google Scholar] [CrossRef]
- Hansen, M.C.; Roy, D.P.; Lindquist, E.; Adusei, B.; Justice, C.O.; Altstaat, A. A method for integrating MODIS and Landsat data for systematic monitoring of forest cover and change and preliminary results for Central Africa. Remote Sens. Environ. 2008, 112, 2495–2513. [Google Scholar] [CrossRef]
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-Resolution Global Maps of 21st-Century Forest Cover Change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef] [PubMed]
- Lindquist, E.; Hansen, M.C.; Roy, D.P.; Justice, C.O. The suitability of decadal image data sets for mapping tropical forest cover change in the Democratic Republic of Congo: Implications for the mid-decadal global land survey. Int. J. Remote Sens. 2008, 29, 7269–7275. [Google Scholar] [CrossRef]
- Potapov, P.V.; Turubanova, S.A.; Tyukavina, A.; Krylov, A.M.; McCarty, J.L.; Radeloff, V.C.; Hansen, M.C. Eastern Europe’s forest cover dynamics from 1985 to 2012 quantified from the full Landsat archive. Remote Sens. Environ. 2015, 159, 28–43. [Google Scholar] [CrossRef]
- White, J.C.; Wulder, M.A.; Hermosilla, T.; Coops, N.C.; Hobart, G.W. A nationwide annual characterization of 25 years of forest disturbance and recovery for Canada using Landsat time series. Remote Sens. Environ. 2017, 194, 303–321. [Google Scholar] [CrossRef]
- Roy, D.P.; Ju, J.; Kline, K.; Scaramuzza, P.L.; Kovalskyy, V.; Hansen, M.C.; Loveland, T.R.; Vermote, E.F.; Zhang, C. Web-enabled Landsat Data (WELD): Landsat ETM+ Composited Mosaics of the Conterminous United States. Remote Sens. Environ. 2010, 114, 35–49. [Google Scholar] [CrossRef]
- Gómez, C.; White, J.C.; Wulder, M.A. Optical remotely sensed time series data for land cover classification: A review. ISPRS J. Photogramm. Remote Sens. 2016, 116, 55–72. [Google Scholar] [CrossRef]
- Zhu, Z. Change detection using Landsat time series: A review of frequencies, preprocessing, algorithms, and applications. ISPRS J. Photogramm. Remote Sens. 2017, 130, 370–384. [Google Scholar] [CrossRef]
- U.S. Landsat Analysis Ready Data (ARD). Available online: https://landsat.usgs.gov/ard (accessed on 21 December 2017).
- Cook, B.D.; Corp, L.W.; Nelson, R.F.; Middleton, E.M.; Morton, D.C.; McCorkel, J.T.; Masek, J.G.; Ranson, K.J.; Ly, V.; Montesano, P.M. NASA Goddard’s Lidar, Hyperspectral and Thermal (G-LiHT) airborne imager. Remote Sens. 2013, 5, 4045–4066. [Google Scholar] [CrossRef]
- Rogan, J.; Franklin, J.; Stow, D.; Miller, J.; Woodcock, C.; Roberts, D. Mapping land-cover modifications over large areas: A comparison of machine learning algorithms. Remote Sens. Environ. 2008, 112, 2272–2283. [Google Scholar] [CrossRef]
- Yan, L.; Roy, D.P. Improved time series land cover classification by missing-observation-adaptive nonlinear dimensionality reduction. Remote Sens. Environ. 2015, 158, 478–491. [Google Scholar] [CrossRef]
- Foody, G.M.; McCulloch, M.B.; Yates, W.B. The effect of training set size and composition on artificial neural network classification. Int. J. Remote Sens. 1995, 16, 1707–1723. [Google Scholar] [CrossRef]
- Egorov, A.V.; Hansen, M.C.; Roy, D.P.; Kommareddy, A.; Potapov, P.V. Image interpretation-guided supervised classification using nested segmentation. Remote Sens. Environ. 2015, 165, 135–147. [Google Scholar] [CrossRef]
- Roy, D.P.; Zhang, H.K.; Ju, J.; Gomez-Dans, J.L.; Lewis, P.E.; Schaaf, C.B.; Sun, Q.; Li, J.; Huang, H.; Kovalskyy, V. A general method to normalize Landsat reflectance data to nadir BRDF adjusted reflectance. Remote Sens. Environ. 2016, 176, 255–271. [Google Scholar]
- Roy, D.P.; Li, J.; Zhang, H.K.; Yan, L.; Huang, H. Examination of Sentinel-2A multi-spectral instrument (MSI) reflectance anisotropy and the suitability of a general method to normalize MSI reflectance to nadir BRDF adjusted reflectance. Remote Sens. Environ. 2017, 199, 25–38. [Google Scholar] [CrossRef]
- Global Web-Enabled Landsat Data. Available online: https://globalweld.cr.usgs.gov/ (accessed on 13 January 2017).
- Loveland, T.R.; Dwyer, J.L. Landsat: Building a strong future. Remote Sens. Environ. 2012, 122, 22–29. [Google Scholar] [CrossRef]
- Landsat Collections. Available online: https://landsat.usgs.gov/landsat-collections (accessed on 21 December 2017).
- Justice, C.; Townshend, J.; Vermote, E.; Masuoka, E.; Wolfe, R.; Saleous, N.; Roy, D.; Morisette, J. An overview of MODIS Land data processing and product status. Remote Sens. Environ. 2002, 83, 3–15. [Google Scholar]
- Storey, J.; Roy, D.P.; Masek, J.; Gascon, F.; Dwyer, J.; Choate, M. A note on the temporary mis-registration of Landsat-8 Operational Land Imager (OLI) and Sentinel-2 Multi Spectral Instrument (MSI) imagery. Remote Sens. Environ. 2016, 186, 121–122. [Google Scholar] [CrossRef]
- Ju, J.; Roy, D.P. The Availability of Cloud-free Landsat ETM+ data over the Conterminous United States and Globally. Remote Sens. Environ. 2008, 112, 1196–1211. [Google Scholar] [CrossRef]
- Kovalskyy, V.; Roy, D.P. A one year Landsat 8 conterminous United States study of cirrus and non-cirrus clouds. Remote Sens. 2015, 7, 564–578. [Google Scholar] [CrossRef]
- Masek, J.G.; Vermote, E.F.; Saleous, N.E.; Wolfe, R.; Hall, F.G.; Huemmrich, K.F.; Gao, F.; Kutler, J.; Lim, T.K. A Landsat surface reflectance dataset for North America, 1990–2000. IEEE Geosci. Remote Sens. Lett. 2006, 3, 68–72. [Google Scholar] [CrossRef]
- Ju, J.; Roy, D.P.; Vermote, E.; Masek, J.; Kovalskyy, V. Continental-scale validation of MODIS-based and LEDAPS Landsat ETM+ atmospheric correction methods. Remote Sens. Environ. 2012, 122, 175–184. [Google Scholar] [CrossRef]
- Roy, D.P.; Qin, Y.; Kovalskyy, V.; Vermote, E.F.; Ju, J.; Egorov, A.; Hansen, M.C.; Kommareddy, I.; Yan, L. Conterminous United States demonstration and characterization of MODIS-based Landsat ETM+ atmospheric correction. Remote Sens. Environ. 2014, 140, 433–449. [Google Scholar] [CrossRef]
- Zhang, H.K.; Roy, D.P. Landsat 5 Thematic Mapper reflectance and NDVI 27-year time series inconsistencies due to satellite orbit change. Remote Sens. Environ. 2016, 186, 217–233. [Google Scholar] [CrossRef]
- Hansen, M.C.; Egorov, A.; Roy, D.P.; Potapov, P.; Ju, J.; Turubanova, S.; Kommareddy, I.; Loveland, T.R. Continuous fields of land cover for the conterminous United States using Landsat data: First results from the Web-Enabled Landsat Data (WELD) project. Remote Sens. Lett. 2011, 2, 279–288. [Google Scholar] [CrossRef]
- Franklin, J.F.; Dyrness, C.T. Natural Vegetation of Oregon and Washington; General Technical Report PNW Holt Library of Science: Series 3; Oregon State University Press: Corvallis, OR, USA, 1988; Volume 8, p. 452. [Google Scholar]
- Whiteman, C.D. Mountain Meteorology: Fundamentals and Applications; Oxford University Press: New York, NY, USA, 2000; p. 355. [Google Scholar]
- Boryan, C.; Yang, Z.; Mueller, R.; Craig, M. Monitoring US agriculture: The US Department of Agriculture, National Agricultural Statistics Service, Cropland Data Layer Program. Geocarto Int. 2011, 26, 341–358. [Google Scholar] [CrossRef]
- G-LiHT: Goddard’s LiDAR, Hyperspectral & Thermal Imager. Available online: http://gliht.gsfc.nasa.gov (accessed on 21 December 2017).
- Hansen, M.C.; DeFries, R.S.; Townshend, J.R.G.; Carroll, M.; Dimiceli, C.; Sohlberg, R.A. Global percent tree cover at a spatial resolution of 500 meters: First results of the MODIS vegetation continuous fields algorithm. Earth Interact. 2003, 7. [Google Scholar] [CrossRef]
- FRA 2000 on Definitions of Forest and Forest Change. Available online: http://www.fao.org/docrep/006/ad665e/ad665e06.htm (accessed on 21 December 2017).
- Holben, B. Characteristics of maximum-value composite images from temporal AVHRR data. Int. J. Remote Sens. 1986, 7, 1417–1434. [Google Scholar] [CrossRef]
- Roy, D.P. Investigation of the maximum normalized difference vegetation index (NDVI) and the maximum surface temperature (Ts) AVHRR compositing procedures for the extraction of NDVI and Ts over forest. Int. J. Remote Sens. 1997, 18, 2383–2401. [Google Scholar] [CrossRef]
- Potapov, P.V.; Turubanova, S.A.; Hansen, M.C.; Adusei, B.; Broich, M.; Altstatt, A.; Mane, L.; Justice, C.O. Quantifying forest cover loss in Democratic Republic of the Congo, 2000–2010, with Landsat ETM + data. Remote Sens. Environ. 2012, 122, 106–116. [Google Scholar] [CrossRef]
- Hermosilla, T.; Wulder, M.A.; White, J.C.; Coops, N.C.; Hobart, G.W. An integrated Landsat time series protocol for change detection and generation of annual gap-free surface reflectance composites. Remote Sens. Environ. 2015, 158, 220–234. [Google Scholar] [CrossRef]
- Claverie, M.; Vermote, E.F.; Franch, B.; Masek, J.G. Evaluation of the Landsat-5 TM and Landsat-7 ETM+ surface reflectance products. Remote Sens. Environ. 2015, 169, 390–403. [Google Scholar] [CrossRef]
- Toivonen, T.; Kalliola, R.; Ruokolainen, K.; Malik, R.N. Across-path DN gradient in Landsat TM imagery of Amazonian forests: A challenge for image interpretation and mosaicking. Remote Sens. Environ. 2006, 100, 550–562. [Google Scholar] [CrossRef]
- Broich, M.; Hansen, M.C.; Potapov, P.; Adusei, B.; Lindquist, E.; Stehman, S.V. Time-series analysis of multi-resolution optical imagery for quantifying forest cover loss in Sumatra and Kalimantan, Indonesia. Int. J. Appl. Earth Obs. Geoinf. 2011, 13, 277–291. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Olshen, R.; Stone, C. Classification and Regression Trees; Wadsworth and Brooks/Cole: Monterey, CA, USA, 1984. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Kovalskyy, V.; Roy, D.P. The global availability of Landsat 5 TM and Landsat 7 ETM+ land surface observations and implications for global 30 m Landsat data product generation. Remote Sens. Environ. 2013, 130, 280–293. [Google Scholar] [CrossRef]
- Wulder, M.A.; White, J.C.; Loveland, T.R.; Woodcock, C.E.; Belward, A.S.; Cohen, W.B.; Fosnight, E.A.; Shaw, J.; Masek, J.G.; Roy, D.P. The global Landsat archive: Status, consolidation, and direction. Remote Sens. Environ. 2016, 185, 271–283. [Google Scholar] [CrossRef]
- Markham, B.L.; Storey, J.C.; Williams, D.L.; Irons, J.R. Landsat sensor performance: History and current status. IEEE Trans. Geosci. Remote Sens. 2004, 42, 2691–2694. [Google Scholar] [CrossRef]
- Zhang, H.K.; Roy, D.P. Using the 500 m MODIS land cover product to derive a consistent continental scale 30 m Landsat land cover classification. Remote Sens. Environ. 2017, 197, 15–34. [Google Scholar] [CrossRef]
- Hansen, M.C.; Egorov, A.; Potapov, P.V.; Stehman, S.V.; Tyukavina, A.; Turubanova, S.A.; Roy, D.P.; Goetz, S.J.; Loveland, T.R.; Ju, J.; et al. Monitoring conterminous United States (CONUS) land cover change with Web-Enabled Landsat Data (WELD). Remote Sens. Environ. 2014, 140, 466–484. [Google Scholar] [CrossRef]
- Foody, G.M.; Mathur, A. Toward intelligent training of supervised image classifications: Directing training data acquisition for SVM classification. Remote Sens. Environ. 2004, 93, 107–117. [Google Scholar] [CrossRef]
- Tanre, D.; Herman, M.; Deschamps, P.Y. Influence of the background contribution upon space measurements of ground reflectance. Appl. Opt. 1981, 20, 3676–3684. [Google Scholar] [CrossRef] [PubMed]
- Vermote, E.F.; Kotchenova, S. Atmospheric correction for the monitoring of land surfaces. J. Geophys. Res. 2008, 113. [Google Scholar] [CrossRef]
- Roy, D.P.; Ju, J.; Lewis, P.; Schaaf, C.; Gao, F.; Hansen, M.; Lindquist, E. Multi-temporal MODIS-Landsat data fusion for relative radiometric normalization, gap filling, and prediction of Landsat data. Remote Sens. Environ. 2008, 112, 3112–3130. [Google Scholar] [CrossRef]
- Li, F.; Jupp, D.L.; Thankappan, M.; Lymburner, L.; Mueller, N.; Lewis, A.; Held, A. A physics based atmospheric and BRDF correction for Landsat data over mountainous terrain. Remote Sens. Environ. 2012, 124, 756–770. [Google Scholar] [CrossRef]
- Houborg, R.; McCabe, M.F. Impacts of dust aerosol and adjacency effects on the accuracy of Landsat 8 and RapidEye surface reflectances. Remote Sens. Environ. 2017, 194, 127–145. [Google Scholar] [CrossRef]
- Franch, B.; Vermote, E.F.; Sobrino, J.A.; Fédèle, E. Analysis of directional effects on atmospheric correction. Remote Sens. Environ. 2013, 128, 276–288. [Google Scholar] [CrossRef]
- Gao, F.; Jin, Y.; Schaaf, C.B.; Strahler, A.H. Bidirectional NDVI and atmospherically resistant BRDF inversion for vegetation canopy. IEEE Trans. Geosci. Remote Sens. 2002, 40, 1269–1278. [Google Scholar]
- Khatami, R.; Mountrakis, G.; Stehman, S.V. Mapping per-pixel predicted accuracy of classified remote sensing images. Remote Sens. Environ. 2017, 191, 156–167. [Google Scholar] [CrossRef]
- Heydari, S.S.; Mountrakis, G. Effect of classifier selection, reference sample size, reference class distribution and scene heterogeneity in per-pixel classification accuracy using 26 Landsat sites. Remote Sens. Environ. 2018, 204, 648–658. [Google Scholar] [CrossRef]
- Hansen, M.C.; DeFries, R.S.; Townshend, J.R.G.; Marufu, L.; Sohlberg, R. Development of a MODIS percent tree cover validation data set for Western Province, Zambia. Remote Sens. Environ. 2002, 83, 320–335. [Google Scholar] [CrossRef]
- Sexton, J.O.; Song, X.P.; Feng, M.; Noojipady, P.; Anand, A.; Huang, C.; Kim, D.H.; Collins, K.M.; Channan, S.; DiMiceli, C.; et al. Global, 30-m resolution continuous fields of tree cover: Landsat-based rescaling of MODIS vegetation continuous fields with lidar-based estimates of error. Int. J. Digit. Earth 2013, 6, 427–448. [Google Scholar] [CrossRef]
- Cliff, A.D.; Ord, J.K. Spatial Processes: Models & Applications; Pion: London, UK, 1981. [Google Scholar]
- Lennon, J.J. Red-Shifts and Red Herrings in Geographical Ecology. Ecography 2000, 23, 101–113. [Google Scholar] [CrossRef]

© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Egorov, A.V.; Roy, D.P.; Zhang, H.K.; Hansen, M.C.; Kommareddy, A. Demonstration of Percent Tree Cover Mapping Using Landsat Analysis Ready Data (ARD) and Sensitivity with Respect to Landsat ARD Processing Level. Remote Sens. 2018, 10, 209. https://doi.org/10.3390/rs10020209
Egorov AV, Roy DP, Zhang HK, Hansen MC, Kommareddy A. Demonstration of Percent Tree Cover Mapping Using Landsat Analysis Ready Data (ARD) and Sensitivity with Respect to Landsat ARD Processing Level. Remote Sensing. 2018; 10(2):209. https://doi.org/10.3390/rs10020209
Chicago/Turabian StyleEgorov, Alexey V., David P. Roy, Hankui K. Zhang, Matthew C. Hansen, and Anil Kommareddy. 2018. "Demonstration of Percent Tree Cover Mapping Using Landsat Analysis Ready Data (ARD) and Sensitivity with Respect to Landsat ARD Processing Level" Remote Sensing 10, no. 2: 209. https://doi.org/10.3390/rs10020209
APA StyleEgorov, A. V., Roy, D. P., Zhang, H. K., Hansen, M. C., & Kommareddy, A. (2018). Demonstration of Percent Tree Cover Mapping Using Landsat Analysis Ready Data (ARD) and Sensitivity with Respect to Landsat ARD Processing Level. Remote Sensing, 10(2), 209. https://doi.org/10.3390/rs10020209