Retrieval of Daily PM2.5 Concentrations Using Nonlinear Methods: A Case Study of the Beijing–Tianjin–Hebei Region, China

 ,
, 

Abstract
1. Introduction
2. Materials and Methods
2.1. Data Description
2.1.1. Ground Measurements
2.1.2. Satellite Data
2.1.3. Meteorological Data
2.2. Data Processing and Integration
2.3. Nonlinear Model Approach
2.3.1. Orthogonal Regression (OR)
2.3.2. Regression Tree (Rpart)
2.3.3. Random Forest (RF) Regression
2.3.4. Support Vector Machine (SVM)
2.3.5. Model Validation
2.4. Model Development
3. Results
3.1. Model Evaluation and Selection
3.2. Time Series of Satellite-Derived and Ground-Based PM2.5 Concentration Estimates
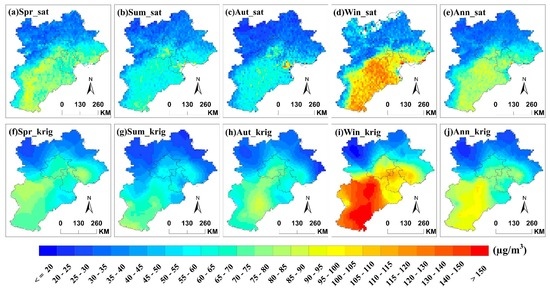
3.3. PM2.5 Concentration Prediction Maps and Descriptive Statistics
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kioumourtzoglou, M.-A.; Schwartz, J.D.; Weisskopf, M.G.; Melly, S.J.; Wang, Y.; Dominici, F.; Zanobetti, A. Long-term PM2.5 Exposure and Neurological Hospital Admissions in the Northeastern United States. Environ. Health Perspect. 2016, 124, 23–29. [Google Scholar] [CrossRef] [PubMed]
- Wellenius, G.A.; Bateson, T.F.; Mittleman, M.A.; Schwartz, J. Particulate air pollution and the rate of hospitalization for congestive heart failure among Medicare beneficiaries in Pittsburgh, Pennsylvania. Am. J. Epidemiol. 2005, 161, 1030–1036. [Google Scholar] [CrossRef] [PubMed]
- Boldo, E.; Linares, C.; Lumbreras, J.; Borge, R.; Narros, A.; Garcia-Perez, J.; Fernandez-Navarro, P.; Perez-Gomez, B.; Aragones, N.; Ramis, R.; et al. Health impact assessment of a reduction in ambient PM2.5 levels in Spain. Environ. Int. 2011, 37, 342–348. [Google Scholar] [CrossRef] [PubMed]
- Ostro, B.; Lipsett, M.; Reynolds, P.; Goldberg, D.; Hertz, A.; Garcia, C.; Henderson, K.D.; Bernstein, L. Long-Term Exposure to Constituents of Fine Particulate Air Pollution and Mortality: Results from the California Teachers Study. Environ. Health Perspect. 2010, 118, 363–369. [Google Scholar] [CrossRef] [PubMed]
- Guo, J.-P.; Zhang, X.-Y.; Che, H.-Z.; Gong, S.-L.; An, X.; Cao, C.-X.; Guang, J.; Zhang, H.; Wang, Y.-Q.; Zhang, X.-C.; et al. Correlation between PM concentrations and aerosol optical depth in eastern China. Atmosp. Environ. 2009, 43, 5876–5886. [Google Scholar] [CrossRef]
- Qi, Y.; Ge, J.; Huang, J. Spatial and temporal distribution of MODIS and MISR aerosol optical depth over northern China and comparison with AERONET. Chin. Sci. Bull. 2013, 58, 2497–2506. [Google Scholar] [CrossRef]
- Sayer, A.M.; Hsu, N.C.; Bettenhausen, C.; Jeong, M.J.; Holben, B.N.; Zhang, J. Global and regional evaluation of over-land spectral aerosol optical depth retrievals from SeaWiFS. Atmosp. Meas. Tech. 2012, 5, 1761–1778. [Google Scholar] [CrossRef]
- Xiao, Q.; Zhang, H.; Choi, M.; Li, S.; Kondragunta, S.; Kim, J.; Holben, B.; Levy, R.C.; Liu, Y. Evaluation of VIIRS, GOCI, and MODIS Collection 6AOD retrievals against ground sunphotometer observations over East Asia. Atmosp. Chem. Phys. 2016, 16, 1255–1269. [Google Scholar] [CrossRef]
- Li, J.; Carlson, B.E.; Lacis, A.A. Application of spectral analysis techniques in the intercomparison of aerosol data: Part III. Using combined PCA to compare spatiotemporal variability of MODIS, MISR, and OMI aerosol optical depth. J. Geophys. Res.-Atmosp. 2014, 119, 4017–4042. [Google Scholar] [CrossRef]
- Paciorek, C.J.; Liu, Y.; Moreno-Macias, H.; Kondragunta, S. Spatiotemporal associations between GOES aerosol optical depth retrievals and ground-level PM(2.5). Environ. Sci. Technol. 2008, 42, 5800–5806. [Google Scholar] [CrossRef]
- Gupta, P.; Christopher, S.A. Particulate matter air quality assessment using integrated surface, satellite, and meteorological products: Multiple regression approach. J. Geophys. Res. 2009, 114. [Google Scholar] [CrossRef]
- Liu, Y.; Park, R.J.; Jacob, D.J.; Li, Q.; Kilaru, V.; Sarnat, J.A. Mapping annual mean ground-level PM2.5 concentrations using Multiangle Imaging Spectroradiometer aerosol optical thickness over the contiguous United States. J. Geophys. Res. Atmosp. 2004, 109. [Google Scholar] [CrossRef]
- Van Donkelaar, A.; Martin, R.V.; Park, R.J. Estimating ground-level PM2.5 using aerosol optical depth determined from satellite Remote Sensing. J. Geophys. Res. 2006, 111. [Google Scholar] [CrossRef]
- Van Donkelaar, A.; Martin, R.V.; Spurr, R.J.D.; Drury, E.; Remer, L.A.; Levy, R.C.; Wang, J. Optimal estimation for global ground-level fine particulate matter concentrations. J. Geophys. Res.-Atmosp. 2013, 118, 5621–5636. [Google Scholar] [CrossRef]
- Chu, D.A.; Tsai, T.-C.; Chen, J.-P.; Chang, S.-C.; Jeng, Y.-J.; Chiang, W.-L.; Lin, N.-H. Interpreting aerosol lidar profiles to better estimate surface PM2.5 for columnar AOD measurements. Atmosp. Environ. 2013, 79, 172–187. [Google Scholar] [CrossRef]
- Lin, C.; Li, Y.; Yuan, Z.; Lau, A.K.H.; Li, C.; Fung, J.C.H. Using satellite Remote Sens. data to estimate the high-resolution distribution of ground-level PM2.5. Remote Sens. Environ. 2015, 156, 117–128. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Z. Remote Sens. of atmospheric fine particulate matter (PM2.5) mass concentration near the ground from satellite observation. Remote Sens. Environ. 2015, 160, 252–262. [Google Scholar] [CrossRef]
- Gardner, M.W.; Dorling, S.R. Artificial neural networks (the multilayer perceptron)—A review of applications in the atmospheric sciences. Atmosp. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- Wang, J. Intercomparison between satellite-derived aerosol optical thickness and PM2.5 mass: Implications for air quality studies. Geophys. Res. Lett. 2003, 30. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, X.; Li, B.; Hou, Y.; Yang, J.; Yi, L. Development of a novel morphological paclitaxel-loaded PLGA microspheres for effective cancer therapy: In vitro and in vivo evaluations. Drug Deliv. 2018, 25, 166–177. [Google Scholar] [CrossRef]
- Liu, Y.; Sarnat, J.A.; Kilaru, V.; Jacob, D.J.; Koutrakis, P. Estimating Ground-Level PM2.5 in the Eastern United States Using Satellite Remote Sensing. Environ. Sci. Technol. 2005, 39, 3269–3278. [Google Scholar] [CrossRef] [PubMed]
- Beckerman, B.S.; Jerrett, M.; Serre, M.; Martin, R.V.; Lee, S.J.; van Donkelaar, A.; Ross, Z.; Su, J.; Burnett, R.T. A hybrid approach to estimating national scale spatiotemporal variability of PM2.5 in the contiguous United States. Environ. Sci. Technol. 2013, 47, 7233–7241. [Google Scholar] [CrossRef] [PubMed]
- Hu, X.; Waller, L.A.; Al-Hamdan, M.Z.; Crosson, W.L.; Estes, M.G., Jr.; Estes, S.M.; Quattrochi, D.A.; Sarnat, J.A.; Liu, Y. Estimating ground-level PM(2.5) concentrations in the southeastern U.S. using geographically weighted regression. Environ. Res. 2013, 121, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Jiang, M.; Sun, W.; Yang, G.; Zhang, D. Modelling Seasonal GWR of Daily PM2.5 with Proper Auxiliary Variables for the Yangtze River Delta. Remote Sens. 2017, 9, 346. [Google Scholar] [CrossRef]
- Ma, Z.; Hu, X.; Huang, L.; Bi, J.; Liu, Y. Estimating ground-level PM2.5 in China using satellite Remote Sensing. Environ. Sci. Technol. 2014, 48, 7436–7444. [Google Scholar] [CrossRef] [PubMed]
- You, W.; Zang, Z.; Zhang, L.; Li, Y.; Pan, X.; Wang, W. National-Scale Estimates of Ground-Level PM2.5 Concentration in China Using Geographically Weighted Regression Based on 3 km Resolution MODIS AOD. Remote Sens. 2016, 8, 184. [Google Scholar] [CrossRef]
- Bai, Y.; Wu, L.; Qin, K.; Zhang, Y.; Shen, Y.; Zhou, Y. A Geographically and Temporally Weighted Regression Model for Ground-Level PM2.5 Estimation from Satellite-Derived 500 m Resolution AOD. Remote Sens. 2016, 8, 262. [Google Scholar] [CrossRef]
- Hu, X.; Waller, L.A.; Lyapustin, A.; Wang, Y.; Liu, Y. 10-year spatial and temporal trends of PM2.5 concentrations in the southeastern US estimated using high-resolution satellite data. Atmos Chem. Phys. 2014, 14, 6301–6314. [Google Scholar] [CrossRef]
- Chuang, Y.-H.; Mazumdar, S.; Park, T.; Tang, G.; Arena, V.C.; Nicolich, M.J. Generalized linear mixed models in time series studies of air pollution. Atmosp. Pollut. Res. 2011, 2, 428–435. [Google Scholar] [CrossRef]
- Liang, F.; Xiao, Q.; Wang, Y.; Lyapustin, A.; Li, G.; Gu, D.; Pan, X.; Liu, Y. MAIAC-based long-term spatiotemporal trends of PM2.5 in Beijing, China. Sci. Total Environ. 2018, 616, 1589–1598. [Google Scholar] [CrossRef]
- Gupta, P.; Christopher, S.A. Particulate matter air quality assessment using integrated surface, satellite, and meteorological products: 2. A neural network approach. J. Geophys. Res. 2009, 114. [Google Scholar] [CrossRef]
- Nguyen, T.N.T.; Ta, V.C.; Le, T.H.; Mantovani, S. Particulate Matter Concentration Estimation from Satellite Aerosol and Meteorological Parameters: Data-Driven Approaches. Knowl. Syst. Eng. 2014, 244, 351–362. [Google Scholar] [CrossRef]
- Sorek-Hamer, M.; Strawa, A.W.; Chatfield, R.B.; Esswein, R.; Cohen, A.; Broday, D.M. Improved retrieval of PM2.5 from satellite data products using non-linear methods. Environ. Pollut. 2013, 182, 417–423. [Google Scholar] [CrossRef] [PubMed]
- Huang, K.; Xiao, Q.; Meng, X.; Geng, G.; Wang, Y.; Lyapustin, A.; Gu, D.; Liu, Y. Predicting monthly high-resolution PM2.5 concentrations with random forest model in the North China Plain. Environ. Pollut. 2018, 242, 675–683. [Google Scholar] [CrossRef] [PubMed]
- Yu, R.; Yang, Y.; Yang, L.; Han, G.; Move, O.A. RAQ-A Random Forest Approach for Predicting Air Quality in Urban Sensing Systems. Sensors 2016, 16, 86. [Google Scholar] [CrossRef] [PubMed]
- Isobe, T.; Feigelson, E.D.; Akritas, M.G.; Babu, G.J. Linear-Regression in Astronomy. I. Astrophys. J. 1990, 364, 104–113. [Google Scholar] [CrossRef]
- Gass, K.; Klein, M.; Chang, H.H.; Flanders, W.D.; Strickland, M.J. Classification and regression trees for epidemiologic research: An air pollution example. Environ. Health 2014, 13. [Google Scholar] [CrossRef] [PubMed]
- Levy, R.C.; Mattoo, S.; Munchak, L.A.; Remer, L.A.; Sayer, A.M.; Patadia, F.; Hsu, N.C. The Collection 6 MODIS aerosol products over land and ocean. Atmosp. Meas. Tech. 2013, 6, 2989–3034. [Google Scholar] [CrossRef]
- Sayer, A.M.; Munchak, L.A.; Hsu, N.C.; Levy, R.C.; Bettenhausen, C.; Jeong, M.J. MODIS Collection 6 aerosol products: Comparison between Aqua’s e-Deep Blue, Dark Target, and “merged” data sets, and usage recommendations. J. Geophys. Res.-Atmosp. 2014, 119, 13965–13989. [Google Scholar] [CrossRef]
- Lee, H.J.; Liu, Y.; Coull, B.A.; Schwartz, J.; Koutrakis, P. A novel calibration approach of MODIS AOD data to predict PM2.5 concentrations. Atmosp. Chem. Phys. Discuss. 2011, 11, 9769–9795. [Google Scholar] [CrossRef]
- Oleson, J.J.; Kumar, N.; Smith, B.J. Spatiotemporal modeling of irregularly spaced Aerosol Optical Depth data. Environ. Ecol. Stat. 2013, 20, 297–314. [Google Scholar] [CrossRef] [PubMed]
- Cantrell, C.A. Technical Note: Review of methods for linear least-squares fitting of data and application to atmospheric chemistry problems. Atmosp. Chem. Phys. 2008, 8, 5477–5487. [Google Scholar] [CrossRef]
- Wu, C.; Yu, J.Z. Evaluation of linear regression techniques for atmospheric applications: The importance of appropriate weighting. Atmosp. Meas. Tech. 2018, 11, 1233–1250. [Google Scholar] [CrossRef]
- De’ath, G.; Fabricius, K.E. Classification and regression trees: A powerful yet simple technique for ecological data analysis. Ecology 2000, 81, 3178–3192. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Campbell, C. Kernel methods: A survey of current techniques. Neurocomputing 2002, 48, 63–84. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. Training nu-support vector regression: Theory and algorithms. Neural Comput. 2002, 14, 1959–1977. [Google Scholar] [CrossRef]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A Library for Support Vector Machines. Acm Trans. Intell. Syst. Technol. 2011, 2. [Google Scholar] [CrossRef]
- Mahmood, Z.; Khan, S. On the Use of K-Fold Cross-Validation to Choose Cutoff Values and Assess the Performance of Predictive Models in Stepwise Regression. Int. J. Biostat. 2009, 5. [Google Scholar] [CrossRef]
- Levy, R.C.; Mattoo, S.; Sawyer, V.; Shi, Y.; Colarco, P.R.; Lyapustin, A.I.; Wang, Y.; Remer, L.A. Exploring systematic offsets between aerosol products from the two MODIS sensors. Atmosp. Meas. Tech. 2018, 11, 4073–4092. [Google Scholar] [CrossRef]
- Kuhn, S.; Egert, B.; Neumann, S.; Steinbeck, C. Building blocks for automated elucidation of metabolites: Machine learning methods for NMR prediction. Bmc Bioinform. 2008, 9. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.J.; Serre, M.L.; van Donkelaar, A.; Martin, R.V.; Burnett, R.T.; Jerrett, M. Comparison of geostatistical interpolation and Remote Sens. techniques for estimating long-term exposure to ambient PM2.5 concentrations across the continental United States. Environ. Health Perspect. 2012, 120, 1727–1732. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Kumar, V.; Ross Quinlan, J.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2007, 14, 1–37. [Google Scholar] [CrossRef]
- Li, X.; Sha, J.; Wang, Z.-L. Application of feature selection and regression models for chlorophyll-a prediction in a shallow lake. Environ. Sci. Pollut. Res. 2018, 25, 19488–19498. [Google Scholar] [CrossRef] [PubMed]
- Markovic, R.; Wolf, S.; Cao, J.; Spinnraker, E.; Wolki, D.; Frisch, J.; van Treeck, C. Comparison of Different Classification Algorithms for the Detection of User’s Interaction with Windows in Office Buildings. In Proceedings of the Cisbat 2017 International Conference Future Buildings & Districts-Energy Efficiency from Nano to Urban Scale, Lausanne, Switzerland, 6–8 September 2017; Volume 122, pp. 337–342. [Google Scholar]
- Zheng, Y.; Zhang, Q.; Liu, Y.; Geng, G.; He, K. Estimating ground-level PM2.5 concentrations over three megalopolises in China using satellite-derived aerosol optical depth measurements. Atmosp. Environ. 2016, 124, 232–242. [Google Scholar] [CrossRef]
- Ma, Q.; Li, Y.; Liu, J.; Chen, J.M. Long Temporal Analysis of 3-km MODIS Aerosol Product Over East China. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2017, 10, 2478–2490. [Google Scholar] [CrossRef]
- Nichol, J.E.; Bilal, M. Validation of MODIS 3 km Resolution Aerosol Optical Depth Retrievals Over Asia. Remote Sens. 2016, 8, 328. [Google Scholar] [CrossRef]
- Remer, L.A.; Mattoo, S.; Levy, R.C.; Munchak, L.A. MODIS 3 km aerosol product: Algorithm and global perspective. Atmosp. Meas. Tech. 2013, 6, 1829–1844. [Google Scholar] [CrossRef]
- Lyapustin, A.; Wang, Y.; Laszlo, I.; Kahn, R.; Korkin, S.; Remer, L.; Levy, R.; Reid, J.S. Multiangle implementation of atmospheric correction (MAIAC): 2. Aerosol algorithm. J. Geophys. Res. 2011, 116. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Dataset | R | RMSE | Bias | |||
|---|---|---|---|---|---|---|---|
| Mean (std) | Range | Mean (std) | Range | Mean (std) | Range | ||
| OR | CV_valid_T | 0.68 (0.03) | 0.64~0.73 | 49.14 (4.18) | 45.22~50.96 | 0.63 (3.85) | −8.54~9.15 |
| CV_valid_A | 0.74 (0.03) | 0.73~0.76 | 40.47 (2.49) | 36.92~42.48 | −0.91 (3.52) | −7.21~6.89 | |
| Rpart | CV_valid_T | 0.65 (0.04) | 0.56~0.73 | 52.63 (3.92) | 43.35~60.44 | 0.02 (3.90) | −9.65~9.45 |
| CV_valid_A | 0.76 (0.04) | 0.68~0.83 | 41.82 (2.38) | 35.42~46.20 | 0.01 (3.52) | −7.03~7.32 | |
| SVM | CV_valid_T | 0.72 (0.03) | 0.65~0.77 | 47.31 (3.66) | 39.29~56.68 | −2.79 (3.94) | −12.59~6.23 |
| CV_valid_A | 0.78 (0.03) | 0.69~0.84 | 39.96 (2.23) | 36.34~44.59 | −3.96 (3.49) | −11.31~3.36 | |
| RF | CV_valid_T | 0.77 (0.02) | 0.70~0.82 | 43.51 (3.81) | 34.07~53.11 | 0.37 (3.96) | −9.32~9.88 |
| CV_valid_A | 0.85 (0.02) | 0.77~0.88 | 33.90 (2.08) | 29.50~38.32 | 0.21 (3.53) | −6.88~7.55 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.; Chen, B.; Zhang, Y.; Zhao, Y.; Xian, Y.; Xu, G.; Zhang, H.; Guo, L. Retrieval of Daily PM2.5 Concentrations Using Nonlinear Methods: A Case Study of the Beijing–Tianjin–Hebei Region, China. Remote Sens. 2018, 10, 2006. https://doi.org/10.3390/rs10122006
Li L, Chen B, Zhang Y, Zhao Y, Xian Y, Xu G, Zhang H, Guo L. Retrieval of Daily PM2.5 Concentrations Using Nonlinear Methods: A Case Study of the Beijing–Tianjin–Hebei Region, China. Remote Sensing. 2018; 10(12):2006. https://doi.org/10.3390/rs10122006
Chicago/Turabian StyleLi, Lijuan, Baozhang Chen, Yanhu Zhang, Youzheng Zhao, Yue Xian, Guang Xu, Huifang Zhang, and Lifeng Guo. 2018. "Retrieval of Daily PM2.5 Concentrations Using Nonlinear Methods: A Case Study of the Beijing–Tianjin–Hebei Region, China" Remote Sensing 10, no. 12: 2006. https://doi.org/10.3390/rs10122006
APA StyleLi, L., Chen, B., Zhang, Y., Zhao, Y., Xian, Y., Xu, G., Zhang, H., & Guo, L. (2018). Retrieval of Daily PM2.5 Concentrations Using Nonlinear Methods: A Case Study of the Beijing–Tianjin–Hebei Region, China. Remote Sensing, 10(12), 2006. https://doi.org/10.3390/rs10122006