WSF-NET: Weakly Supervised Feature-Fusion Network for Binary Segmentation in Remote Sensing Image

Abstract
1. Introduction
- Unlike computer vision datasets [35,36], remote sensing datasets [6] contain a small number of all-object images. Using the computer vision’s binary classification strategy [22,23] does not make full use of these images, which can lead to the problem of class imbalance. Specifically, as shown in the first row of Figure 1a, the binary classification strategy treats the images as long as they contain objects as one class, and it does not distinguish the all-object images from them. Moreover, too few non-object images are given another label in this case, thus the strategy leads to the problem of class imbalance.
- Object characteristics are different between remote sensing images and natural images. Two kinds of image localization maps produced by the state-of-the-art Class Activation Mapping (CAM) [33] are shown in Figure 1b. Objects in natural images generally consist of multiple parts, thus only some discriminative parts such as head and hands of a child are highlighted by CAM. Therefore, the latest computer vision approaches [20,21] mainly aim at obtaining integral objects, such as Multi-Dilated Convolution (MDC) [20] in Figure 1b. Nevertheless, the main issue in remote sensing images is that the size of objects or background varies greatly in the same image, thus small objects are difficult to identify and a slender background is often sandwiched between two objects by CAM. In addition, remote sensing objects have another characteristic, i.e., some low-level semantics such as water texture and cloud color are obvious, which would be beneficial for localization if they are applied appropriately.
- A balanced binary classification strategy is proposed to take advantage of all-object images and solve the class imbalance problem caused by binary classification strategy. Our balanced binary classification strategy utilizes this characteristic of remote sensing datasets, as shown in the second row of Figure 1a, thus the class imbalance problem due to the uneven number of object and non-object images can be solved.
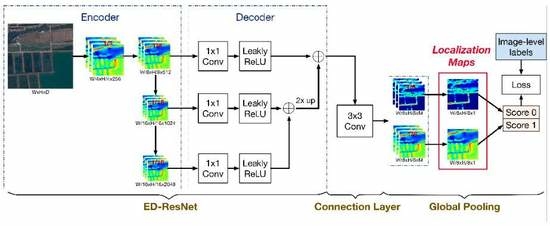
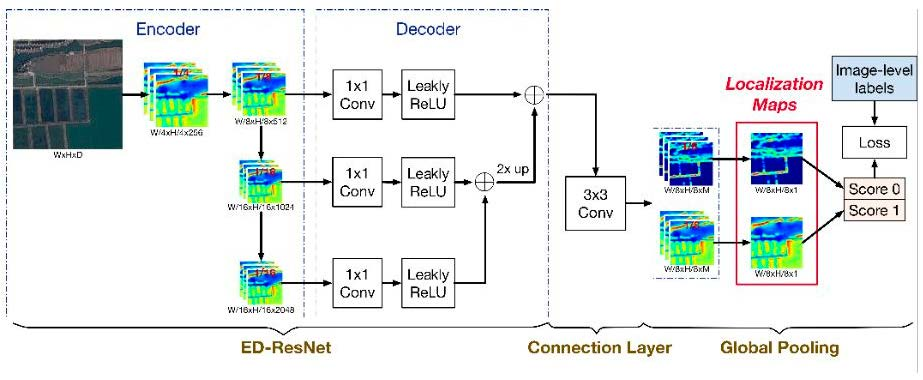
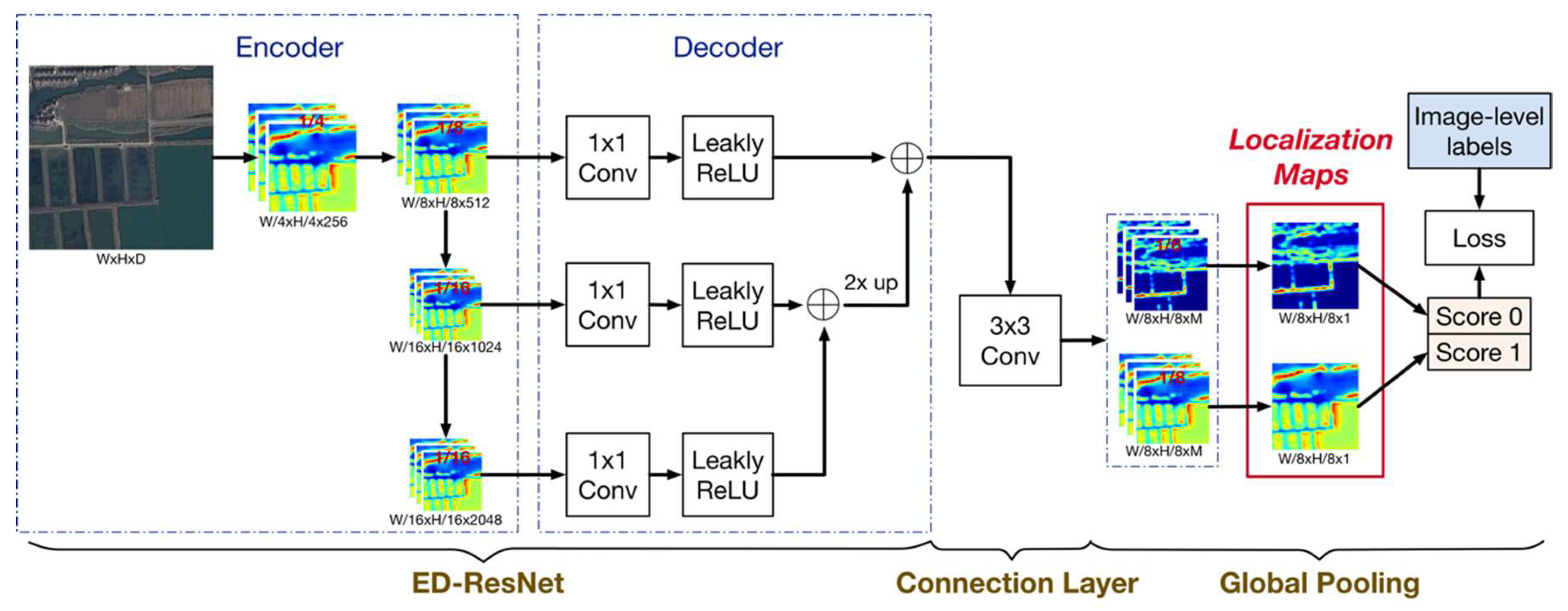
- A WSF-Net that uses a top-down architecture with skip connections is proposed for the unique characteristics of remote sensing objects. In a convolutional network, later layers’ features focus on the category recognition, while early layers’ features can highlight more possible objects due to the high-resolution feature maps and the low-level semantic preference. By combing later layers’ features with early layers’ features, various size objects and background can be observed in the produced localization maps. In Figure 1b, it can be observed that WSF-Net can generate accurate and dense remote sensing object regions for building a good weakly supervised segmentation model.
2. Methods
2.1. Obtain Object Regions via Localization Approach
2.1.1. Brief Review of Localization
2.1.2. Balanced Binary Classification Strategy
2.1.3. Weakly Supervised Feature-Fusion Network (WSF-Net)
2.1.4. Generate Object Regions
2.2. Segmentation Model Training with Object Regions
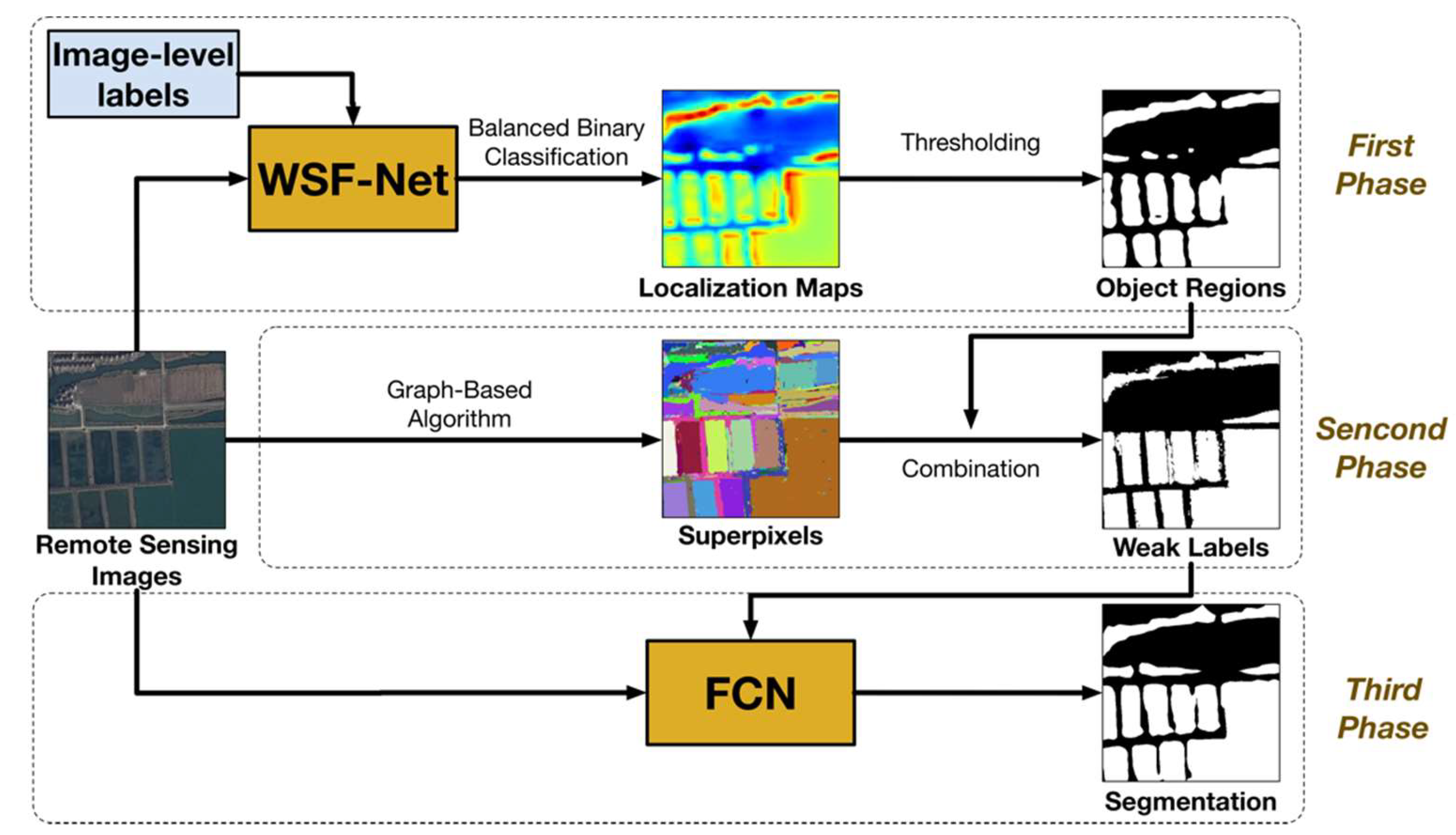
2.2.1. Review of the Three-Phase Method
2.2.2. Object Regions Obtained by Our Localization Approach Used in the First Phase
2.2.3. Modify the Strategy of Generating Weak Labels in the Second Phase
3. Preparation for Experiment
3.1. Datasets
3.1.1. Water Dataset
3.1.2. Cloud Dataset
3.2. Annotation Cost
3.3. Implementation
3.4. Evaluation
4. Experimental Results
4.1. Localization Approach
4.1.1. Model Analysis
4.1.2. Comparison with Other Approaches
4.2. Segmentation Model
4.2.1. Comparison with Models Obtained by Other Methods Using Image-Level Labels
4.2.2. Comparison with Models Obtained by Other Methods Using Pixel-Level Labels
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wang, H.; Wang, Y.; Zhang, Q.; Xiang, S.; Pan, C. Gated convolutional neural network for semantic segmentation in high-resolution images. Remote Sens. 2017, 9, 466. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building Extraction in Very High Resolution Remote Sensing Imagery Using Deep Learning and Guided Filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef]
- Chen, K.; Fu, K.; Yan, M.; Gao, X.; Sun, X.; Wei, X. Semantic Segmentation of Aerial Images with Shuffling Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 173–177. [Google Scholar] [CrossRef]
- Wei, X.; Fu, K.; Gao, X.; Yan, M.; Sun, X.; Chen, K.; Sun, H. Semantic pixel labelling in remote sensing images using a deep convolutional encoder-decoder model. Remote Sens. Lett. 2018, 9, 199–208. [Google Scholar] [CrossRef]
- Zhan, Y.; Fu, K.; Yan, M.; Sun, X.; Wang, H.; Qiu, X. Change Detection Based on Deep Siamese Convolutional Network for Optical Aerial Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1845–1849. [Google Scholar] [CrossRef]
- Miao, Z.; Fu, K.; Sun, H. Automatic Water-Body Segmentation from High-Resolution Satellite Images via Deep Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 602–606. [Google Scholar] [CrossRef]
- Zhuang, Y.; Wang, P.; Yang, Y.; Shi, H.; Chen, H.; Bi, F. Harbor Water Area Extraction from Pan-Sharpened Remotely Sensed Images Based on the Definition Circle Model. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1690–1694. [Google Scholar] [CrossRef]
- Lin, H.; Shi, Z.; Zou, Z. Maritime Semantic Labeling of Optical Remote Sensing Images with Multi-Scale Fully Convolutional Network. Remote Sens. 2017, 9, 480. [Google Scholar] [CrossRef]
- Silveira, M.; Heleno, S. Separation between Water and Land in SAR Images Using Region-Based Level Sets. IEEE Geosci. Remote Sens. Lett. 2009, 6, 471–475. [Google Scholar] [CrossRef]
- Song, Y.; Wu, Y.; Dai, Y. A new active contour remote sensing river image segmentation algorithm inspired from the cross entropy. Dig. Signal Process. 2016, 48, 322–332. [Google Scholar] [CrossRef]
- Ciecholewski, M. River channel segmentation in polarimetric SAR images. Expert Syst. Appl. Int. J. 2017, 82, 196–215. [Google Scholar] [CrossRef]
- Yin, J.; Yang, J. A Modified Level Set Approach for Segmentation of Multiband Polarimetric SAR Images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7222–7232. [Google Scholar]
- Glasbey, C.A. An Analysis of Histogram-Based Thresholding Algorithms; Academic Press, Inc.: Cambridge, MA, USA, 1993. [Google Scholar]
- Chen, J.S.; Huertas, A.; Medioni, G. Fast Convolution with Laplacian-of-Gaussian Masks. IEEE Trans. Pattern Anal. Mach. Intell. 1987, 9, 584–590. [Google Scholar] [CrossRef] [PubMed]
- Kanopoulos, N.; Vasanthavada, N.; Baker, R.L. Design of an image edge detection filter using the Sobel operator. IEEE J. Solid-State Circuits 2002, 23, 358–367. [Google Scholar] [CrossRef]
- Ok, A.O. Automated detection of buildings from single VHR multispectral images using shadow information and graph cuts. ISPRS J. Photogramm. Remote Sens. 2013, 86, 21–40. [Google Scholar] [CrossRef]
- Li, E.; Femiani, J.; Xu, S.; Zhang, X.; Wonka, P. Robust Rooftop Extraction from Visible Band Images Using Higher Order CRF. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4483–4495. [Google Scholar] [CrossRef]
- Li, Z.; Shen, H.; Li, H.; Xia, G.; Gamba, P.; Zhang, L. Multi-feature combined cloud and cloud shadow detection in GaoFen-1 wide field of view imagery. Remote Sens. Environ. 2017, 191, 342–358. [Google Scholar] [CrossRef]
- Luo, W.; Li, H.; Liu, G.; Zeng, L. Semantic Annotation of Satellite Images Using Author–Genre–Topic Model. IEEE Trans. Geosci. Remote Sens. 2013, 52, 1356–1368. [Google Scholar] [CrossRef]
- Wei, Y.; Xiao, H.; Shi, H.; Jie, Z.; Feng, J.; Huang, T.S. Revisiting Dilated Convolution: A Simple Approach for Weakly- and Semi- Supervised Semantic Segmentation. Comput. Vis. Pattern Recognit. 2018, arXiv:1805.04574. [Google Scholar]
- Kolesnikov, A.; Lampert, C.H. Seed, Expand and Constrain: Three Principles for Weakly-Supervised Image Segmentation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 695–711. [Google Scholar]
- Tsutsui, S.; Saito, S.; Kerola, T. Distantly Supervised Road Segmentation. In Proceedings of the IEEE International Conference on Computer Vision Workshop, Istanbul, Turkey, 30–31 January 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 174–181. [Google Scholar]
- Feng, X.; Yang, J.; Laine, A.F.; Angelini, E.D. Discriminative Localization in CNNs for Weakly-Supervised Segmentation of Pulmonary Nodules. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Quebec City, QC, Canada, 11–13 September 2017; Springer: Cham, Switzerland, 2017; pp. 568–576. [Google Scholar]
- Pinheiro, P.O.; Collobert, R. From image-level to pixellevel labeling with convolutional networks. arXiv, 2015; arXiv:1411.6228. [Google Scholar]
- Pathak, D.; Kr¨ahenb¨uhl, P.; Darrell, T. Constrained Convolutional Neural Networks for Weakly Supervised Segmentation. arXiv, 2015; arXiv:1506.03648. [Google Scholar]
- Bearman, A.; Russakovsky, O.; Ferrari, V.; Li, F.-F. What’s the point: Semantic segmentation with point supervision. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 549–565. [Google Scholar]
- Lin, D.; Dai, J.; Jia, J.; He, K.; Sun, J. ScribbleSup: Scribble-Supervised Convolutional Networks for Semantic Segmentation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas Valley, NV, USA, 26 June–1 July 2016; IEEE Computer Society: Washington, DC, USA, 2016. [Google Scholar]
- Tang, M.; Djelouah, A.; Perazzi, F.; Boykov, Y.; Schroers, C. Normalized Cut Loss for Weakly-supervised CNN Segmentation. arXiv, 2018; arXiv:1804.01346. [Google Scholar]
- Dai, J.; He, K.; Sun, J. BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation. arXiv, 2015; arXiv:1503.01640. [Google Scholar]
- Khoreva, A.; Benenson, R.; Hosang, J.; Hein, M.; Schiele, B. Simple Does It: Weakly Supervised Instance and Semantic Segmentation. arXiv, 2016; arXiv:1603.07485. [Google Scholar]
- Andrews, S.; Tsochantaridis, I.; Hofmann, T. Support vector machines for multiple-instance learning. In Proceedings of the Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 8–13 December 2003. [Google Scholar]
- Durand, T.; Mordan, T.; Thome, N.; Cord, M. WILDCAT: Weakly Supervised Learning of Deep ConvNets for Image Classification, Pointwise Localization and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 5957–5966. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. arXiv, 2015; 2921–2929arXiv:1512.04150. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Object Detectors Emerge in Deep Scene CNNs. Comput. Sci. 2014. Available online: https://arxiv.org/abs/1412.6856 (accessed on 5 December 2018).
- Everingham, M.; Gool, L.V.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 3213–3223. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 770–778. [Google Scholar]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient graphbased image segmentation. IJCV 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. 2017. Available online: https://openreview.net/forum?id=BJJsrmfCZ (accessed on 5 December 2018).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv, 2016; arXiv:1603.04467. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Description |
|---|---|
| BC-WILDCAT-Th | Binary classification + WILDCAT + Thresholding |
| BBC-WILDCAT-Th | Balanced binary classification + WILDCAT + Thresholding |
| BBC-WSFN-Th (WSL) | Balanced binary classification + WSF-Net + Thresholding |
| BBC-WSFN-MC | Balanced binary classification + WSF-Net + Max-scored category |
| Method | mIOU | OA | DA | FAR |
|---|---|---|---|---|
| BC-WILDCAT-Th | 78.02 | 90.66 | 82.13 | 6.68 |
| BBC-WILDCAT-Th | 79.26 | 91.11 | 81.27 | 5.57 |
| BBC-WSFN-Th (WSL) | 85.88 | 94.32 | 89.96 | 4.32 |
| BBC-WSFN-MC | 79.87 | 91.60 | 84.68 | 6.29 |
| Method | mIOU | OA | DA | FAR |
|---|---|---|---|---|
| BC-WILDCAT-Th | 77.49 | 89.89 | 85.51 | 8.65 |
| BBC-WILDCAT-Th | 79.99 | 91.07 | 86.46 | 7.32 |
| BBC-WSFN-Th (WSL) | 87.14 | 94.42 | 90.11 | 3.93 |
| BBC-WSFN-MC | 86.32 | 94.20 | 91.73 | 5.91 |
| Method | mIOU | OA | DA | FAR |
|---|---|---|---|---|
| CAM [33] | 76.62 | 89.00 | 71.26 | 2.63 |
| WILDCAT [32] (baseline) | 78.02 | 90.66 | 82.13 | 6.68 |
| WSL | 85.88 | 94.32 | 89.96 | 4.32 |
| Method | mIOU | OA | DA | FAR |
|---|---|---|---|---|
| CAM [33] | 66.69 | 81.71 | 61.72 | 4.66 |
| WILDCAT [32] (baseline) | 77.49 | 89.89 | 85.51 | 8.65 |
| WSL | 87.14 | 94.42 | 90.11 | 3.93 |
| Method | mIOU | OA | DA | FAR |
|---|---|---|---|---|
| SEC [21] | 83.37 | 93.16 | 88.31 | 5.32 |
| Three-phase method [22] (baseline) | 86.41 | 94.68 | 93.84 | 5.08 |
| WSSM | 88.46 | 95.46 | 93.01 | 3.78 |
| Method | mIOU | OA | DA | FAR |
|---|---|---|---|---|
| SEC [21] | 77.76 | 90.23 | 88.73 | 8.29 |
| Three-phase method [22] (baseline) | 68.04 | 82.34 | 61.71 | 1.90 |
| WSSM | 90.28 | 95.89 | 93.77 | 3.32 |
| Method | mIOU | OA | DA | FAR | Annotation Cost (h) |
|---|---|---|---|---|---|
| image-level labels | |||||
| WSSM | 88.46 | 95.46 | 93.01 | 3.78 | 2.61 |
| + part of pixel-level labels | |||||
| WSSM-P (40% pixel-level labels) | 91.22 | 96.59 | 94.25 | 2.55 | 138.18 |
| all pixel-level labels | |||||
| DeeplabV2 [39] (baseline) | 91.22 | 96.58 | 94.19 | 2.54 | 338.91 |
| DC model [7] | - | 93.5 | - | - | 338.91 |
| DeconvNet-RRF [6] | - | 96.9 | - | - | 338.91 |
| Method | mIOU | OA | DA | FAR | Annotation Cost (h) |
|---|---|---|---|---|---|
| image-level label | |||||
| WSSM | 90.28 | 95.89 | 93.77 | 3.32 | 2.42 |
| + part of pixel-level labels | |||||
| WSSM-P (40% pixel-level labels) | 95.42 | 98.11 | 96.99 | 1.38 | 193.23 |
| all pixel-level labels | |||||
| DeeplabV2 [39] (baseline) | 95.31 | 98.06 | 96.74 | 1.43 | 483.08 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, K.; Lu, W.; Diao, W.; Yan, M.; Sun, H.; Zhang, Y.; Sun, X. WSF-NET: Weakly Supervised Feature-Fusion Network for Binary Segmentation in Remote Sensing Image. Remote Sens. 2018, 10, 1970. https://doi.org/10.3390/rs10121970
Fu K, Lu W, Diao W, Yan M, Sun H, Zhang Y, Sun X. WSF-NET: Weakly Supervised Feature-Fusion Network for Binary Segmentation in Remote Sensing Image. Remote Sensing. 2018; 10(12):1970. https://doi.org/10.3390/rs10121970
Chicago/Turabian StyleFu, Kun, Wanxuan Lu, Wenhui Diao, Menglong Yan, Hao Sun, Yi Zhang, and Xian Sun. 2018. "WSF-NET: Weakly Supervised Feature-Fusion Network for Binary Segmentation in Remote Sensing Image" Remote Sensing 10, no. 12: 1970. https://doi.org/10.3390/rs10121970
APA StyleFu, K., Lu, W., Diao, W., Yan, M., Sun, H., Zhang, Y., & Sun, X. (2018). WSF-NET: Weakly Supervised Feature-Fusion Network for Binary Segmentation in Remote Sensing Image. Remote Sensing, 10(12), 1970. https://doi.org/10.3390/rs10121970