1. Introduction
The growing availability of medium-resolution satellite images for Earth observation (EO) gives an unprecedented opportunity to monitor land cover changes and dynamic processes, up to a hyper-temporal resolution of a few days. Operating satellites such as Landsat, Disaster Monitoring Constellation, and Sentinel-2 may provide data at geometric resolution between 10 m and 30 m in terms of ground sample distance (GSD), while covering a large radiometric spectrum [
1,
2,
3,
4].
Typically, such datasets are delivered after topographic correction to remove relief displacement errors and the effect of Earth curvature [
5]. These pre-processing steps result in the fact that image registration, which is a fundamental pre-requisite for any multi-image analyses, can be accomplished by using 2-D transformations [
6]. The direct use of metadata information for registering image time series is not enough to carry out the precise alignment at pixel and subpixel levels, as required in many applications.
Traditional methods for
image alignment (or
registration) [
7,
8,
9] rely on the use of corresponding features identified between a
reference image (frequently called ‘master’ image) and each
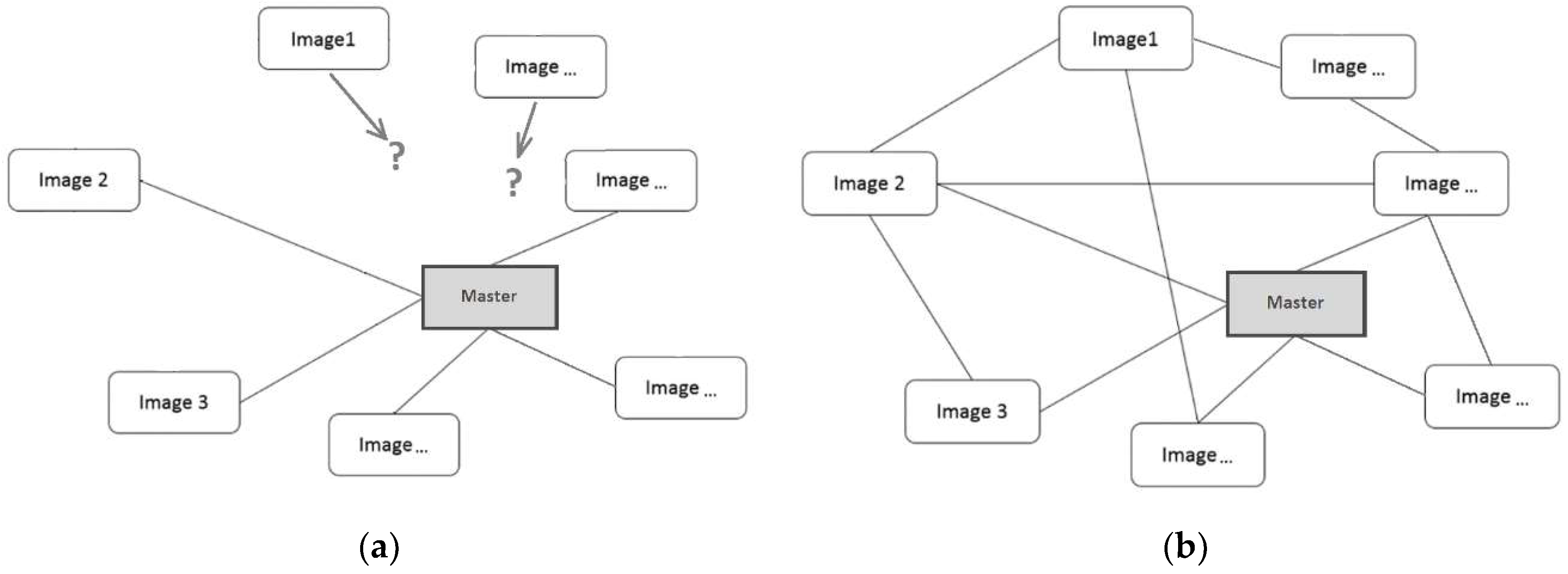
generic image (‘slave’ image) in the time series. This registration method is usually carried out for all the ‘master-to-slave’ combinations, as shown in
Figure 1a. Corresponding features may be measured manually, but several procedures have been developed for their automatic extraction [
10,
11,
12]. Such features are used for estimating a geometric 2D transformation to map the images to each other and to obtain pixel-to-pixel overlap after resampling. The ‘master’ image defines the absolute spatial datum, for example by using metadata information or
ground control points (GCPs), which may come from in situ GNSS measurements or from existing digital maps [
13].
In remote-sensing applications for change detection, the acquisition of data collected over the same geographic area but at different epochs (e.g., time of the day, season, year) may be accomplished in uneven conditions of cloud cover, illumination, viewing geometry, and/or imaging sensors [
14]. Consequently, the radiometric content of a multi-temporal dataset may sharply differ from one image to another [
15], even if the sensed areas overlap. In such a case, the image alignment of long time series may become an involved task. This may also result in the fact that all ‘slave’ images may not share enough corresponding features with the ‘master’ image, resulting in need of concatenating additional ‘master’ images with consequent error propagation.
Starting from Orun and Natarajan [
16], an alternative approach for the registration of satellite images on the basis of
bundle block adjustment (BBA) was introduced. BBA is commonly applied in photogrammetry and computer vision for image orientation [
17]. The basic concept is to use not only corresponding features for estimating the ‘master-to-slave’ registration parameters, but also to introduce corresponding points shared between the ‘slave’ images, see
Figure 1b. The coordinates of these correspondencies, which are usually addressed to as
tie points (TPs), are used to instantiate a system of redundant equations to be solved within a least-squares (LS) framework for the determination of the unknown registration parameters and the coordinates of TPs in a given geodetic
datum. This can be defined by introducing enough GCPs or using some inner constraints [
18]. In such a way, also those ‘slave’ images without corresponding features that are directly shared with the ‘master’ may be registered, limiting error propagation. In addition, since TPs may be observed on more than two images and used to write multiple equations in the BBA formulation, the
inner reliability of the observations increases and the procedure may gain robustness against gross errors. Moreover, some additional images could be added into the data processing workflow to improve the network geometry and to benefit to the alignment.
The application of BBA approach to the registration of satellite data has been already proposed in the technical literature. Toutin [
19] developed a solution for the BBA of Landsat 7 ETM+ based on a 3D analytical geometric model for multi-sensor images, including orbital constraints. Different sets of 3D GCPs integrated to TPs with only known elevations were tested. Results obtained from BBA were similar to the ones from single ‘image-to-GCP’ alignment, but with a significant reduction of GCP number. The same approach was then extended to deal with high-resolution Ikonos data [
20] and to multi-sensor fusion [
21,
22]. At the same time, Grodecki and Dial [
23] investigated a similar technique but based on
rational polynomial coefficients (RPCs). Since this model can deal with a large variety of sensors, it applies to any imaging systems with a narrow field-of-view, a calibrated stable interior orientation, and an accurate a priori exterior orientation. The same research direction was continued in Fraser and Hanley [
24] and Rottensteiner [
25], where a bias-compensated BBA based on RPCs was demonstrated to provide subpixel accuracy notwithstanding the minimum ground control. High-resolution Ikonos, QuickBird, and ALOS data were used in this study. As far as new sensors have been launched, new approaches for BBA of high-resolution satellite images were introduced, as in the case of Chinese ZY3 data [
26].
The studies mentioned above mainly focus on the analytical aspects of BBA and the evaluation of the obtainable accuracy when using the proposed methods. In Barazzetti [
27] the focus was given on the automatic extraction of TPs for the registration of medium-resolution satellite image sequences, instead of using manual interactive measurements. These TPs are obtained on the basis of robust
feature-based matching (FBM) techniques (see
Section 2.1), and then input in the BBA for the simultaneous computation of all image registration parameters. Of course, in the case of poor image texture, the automatic extraction of TPs may easily fail. This case frequently happens, for instance, when a significant portion of the image depicts a water body. On the other hand, this problem does not depend on the method used for the measurement of TPs, since, in the case of poor image texture, the interactive approach may also result in severe problems.
The automatic extraction of TPs is a fundamental step towards the complete automation of the registration process, which represents a task of high relevance when dealing with large datasets. An important objective in automatic procedures is to minimize the influence of possible residual measurement errors. Even though FBM may limit the number of blunders, also a small fraction of them in the set of observations to be processed within the BBA might lead to significant biases in the final image registration parameters. The methods usually adopted to reject outliers in BBA are more efficient when data redundancy is large. This property may be obtained on one side by extracting multiple connections between images. On the other hand, the application of the
inner and
outer reliability concepts, widely popular in geodesy and photogrammetry, also allows evaluating which is the risk to have registration errors larger than prefixed thresholds. Thus, the focus in this paper is given to develop the concept presented in Barazzetti [
27] to be integrated into a full, robust procedure (multi-image robust alignment) for the automatic registration of medium-resolution satellite images, with special emphasis on the reliability analysis (see
Section 2). In
Section 3 an application to a dataset of Landsat-5/TM images is presented. After a discussion on the experimental results in
Section 4,
Section 5 draws some conclusions and addresses future work.
2. Methods
2.1. Overview
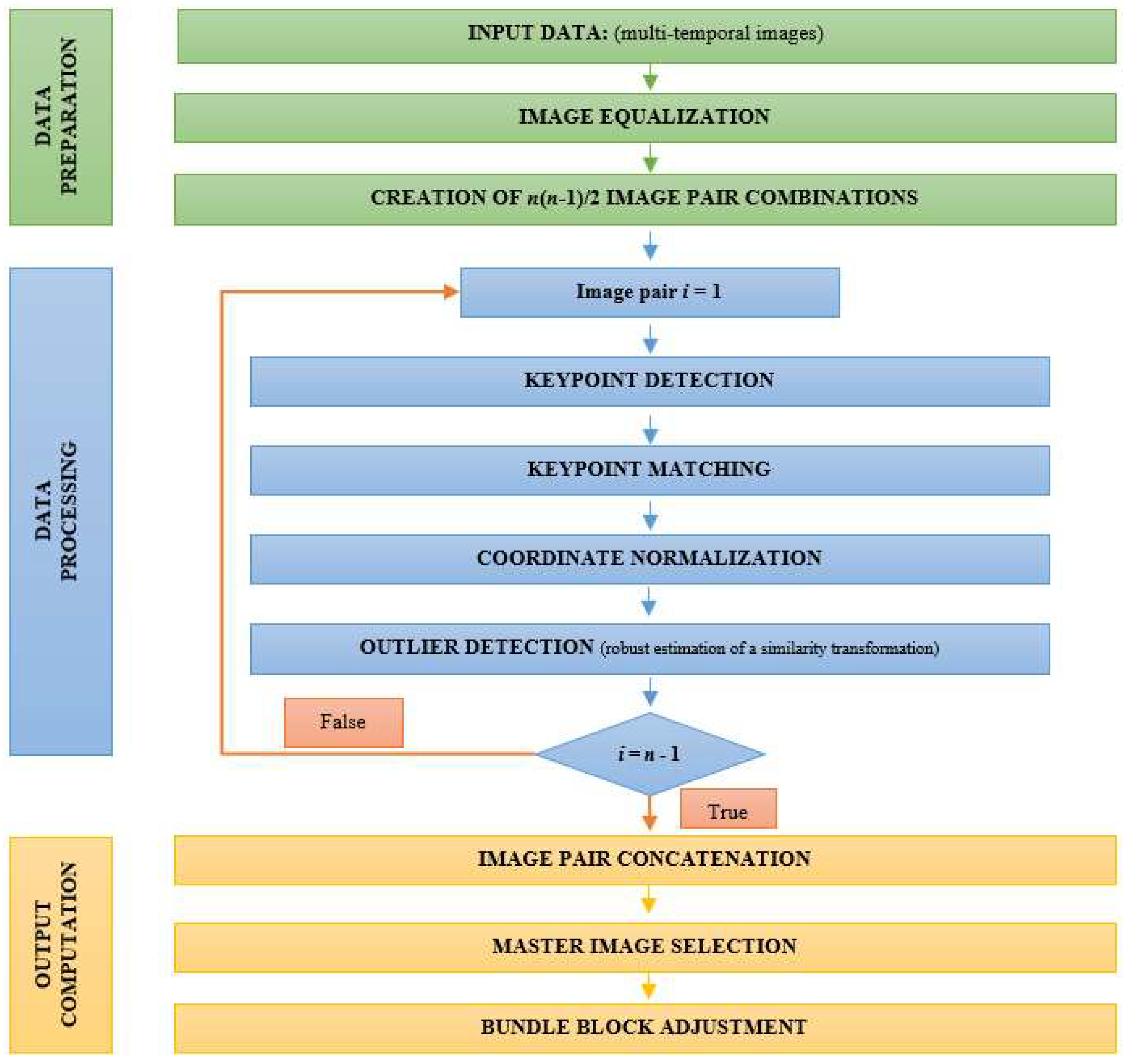
The multi-image robust alignment (MIRA) procedure consists in a multi-step process, as shown in
Figure 2. The core is a preliminary subdivision of the original dataset made up of n images into all n(n − 1)/2 possible image-pair combinations. Image correspondences are looked for independently in each image pair by using FBM, as described in
Section 2.2. In a second stage, all the extracted features are reordered to find multiple TPs (
Section 2.3). A reference ‘master’ image is selected with the only purpose to set up the spatial
datum. This selection is based on the analysis of extracted connections between images (see
Section 2.4). The TP set is used to jointly estimate all transformations’ parameters within a BBA (see
Section 2.5). One crucial aspect of this procedure is the analysis of observations’ inner reliability, which will be the subject of
Section 2.6.
2.2. Analysis of Individual Image Pairs
After the publication of SIFT [
28], a new category of
SIFT-like algorithms has started to be successfully applied in FBM procedures for the registration of images in close-range photogrammetry and computer vision (see Wu [
29]). Thanks to a multi-resolution analysis, SIFT-like algorithms are able to extract distinctive features in the images with a high degree of robustness against shift, scale, and rotation. Each feature is also assigned a
descriptor (for example, a vector of 128 elements that can be characterized using its norm) that may be exploited for matching features in different images. SIFT-like algorithms have replaced
correlation-based techniques that were previously used in FBM. These were based on the similarity between radiometric values and consequently were less robust against geometric and radiometric changes [
11].
Here, the SURF operator has been specifically used [
30]. SURF has a lower computational time than other SIFT-like algorithms [
31,
32] and is prone to extract a large number of
key-points (i.e., points that are candidates to become TPs) that may be observed in more than a single image pair (
manifold features), as proved in Barazzetti [
33]. This capability is very important to obtain a redundant dataset of TPs, which is the primary purpose of MIRA.
Corresponding features are obtained by exhaustively comparing the SURF descriptors (in vectors
Dm and
Dn) of all key-points extracted on the image pair to register. No preliminary information about the spatial location in the images is used for registration. Then the Euclidean distance (d
mn) between descriptors of points in different images is used as metrics for FBM:
The following procedure is applied to find a set of homologous points:
Distances dmn are worked out between all combinations of key-points in the image pair;
Distances dmn are ranked from the shortest d1mn to the largest dpmn;
The couple of key-points corresponding to the smallest distance d1mn are assumed to be matched;
A
ratio test [
34] (first distance d
1mn/second distance d
2mn) is applied to scrutinize distinctive matches;
If the ratio test has passed, both key-points are assigned as corresponding points and are removed from the list of potential matches; otherwise, the points are kept available to be considered at a later stage; and
The analysis moves on to consider the following distance d2mn in the rank up to the completion of the list.
When SURF retrieves a sufficient number of image correspondences, some mismatches may often still be present. To remove such outliers, the procedure makes use of the robust estimation of a 2D similarity transformation between both sets of extracted features in the images. In Barazzetti [
27] more details can be found about the implementation of this step, which is based on the use of the popular high-breakdown point estimator RANSAC [
35].
The similarity transformation may not be the best model to fit real data, depending on the sensor and the ground topography [
13]. On the other hand, at this stage, the aim is to remove large blunders, which may account for tens of pixels. The recourse to a similarity transformation may help cope with this problem, while the rejection of smaller measurement errors is afforded afterward by using more refined models (see
Table 1) that may be selected during the successive multi-image adjustment. For this reason, a relatively large threshold (e.g., 2–3 pixels) is selected for discriminating outliers with RANSAC.
The geometric distribution of corresponding points is analyzed to seek for weak configurations during RANSAC estimation. The covariance matrix
Cxx of the registration parameters is compared against a
criterion matrix H constructed by assuming an optimal point distribution. The analysis is based on the maximum eigenvalue λ
max of matrix
K, which is computed as follows:
Here the approach proposed in Förstner and Wrobel [
36] has been modified to account for the different number of points in the real (
nc) and the ideal case (
nh), see Syrris [
15]. If λ
max ≤ 1 the real configuration is better than the ideal one. In such a case, the solution is accepted, and the RANSAC estimate is terminated. If the condition λ
max ≤ 1 is never verified, the solution corresponding to the minimum eigenvalue, but less than a safety threshold (λ
th = 4) is selected.
After the completion of RANSAC cycle, the set of inliers is rejected if the number of corresponding points is below N
min = 12, otherwise they are used for estimating the four parameters of the similarity transformation on the basis of LS regression [
37]. The threshold N
min corresponds to six times the minimum dataset to compute a similarity transformation (i.e., two points), which is twice the safety value (three) frequently adopted in geodesy to guarantee a sufficient global redundancy in LS regressions. A statistical testing procedure based on
data snooping [
38] is applied to remove the possible remaining tiny fraction of outliers (<5%).
The quality assessment of the solution is based on checking the theoretical accuracy of shift parameters (
and
along columns and rows, respectively) that may be extracted from the estimated covariance matrix
Cxx. These are related to the standard deviation of an observation with unit weight (
) estimated after LS regression, and to the number of extracted inliers (F):
A threshold on
and
is introduced to check weak configurations. In fact, results worse than
pixels for shift parameters are mainly caused by incorrect matches and should be removed from the datasets.
It should be also mentioned that the FBM process is highly prone to be parallelized. On one side the extraction of key-points with the SURF operator may be independently carried out in each image. On the other, the pairwise FBM procedure may be applied to each considered image pair disregarding others.
2.3. Derivation of Multiple Tie Points
As expected from the multiple overlaps, it is likely that some corresponding features are ‘visible’ on more than a single image pair. Indeed, as already addressed in
Section 2.2, an essential characteristic of SURF operator is the capability of finding the same feature in multiple images under different geometric and radiometric conditions. A comparison of the numerical value of the extracted pixel coordinates of corresponding points obtained from the image-to-image matching stage may provide a regular structure of multiple (or
manifold) tie points (TPs), i.e., TPs that may be measured on more than two images. Such points improve the inner reliability of the observations and make the registration process less sensitive to residual measurement errors [
39], as it will be illustrated in
Section 2.6.
2.4. Selection of the ‘Master’ Image
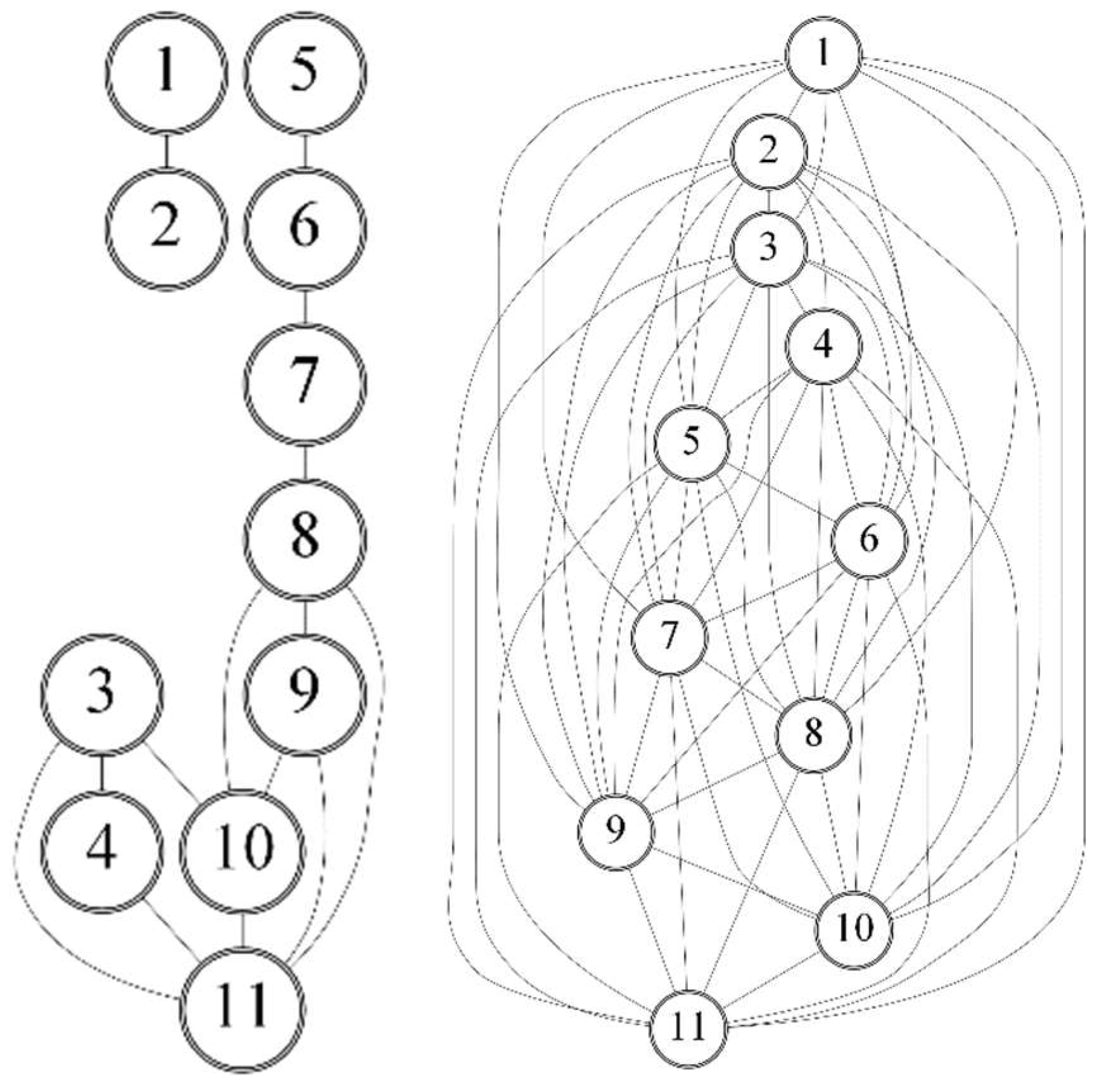
The selection of the ‘master’ image is based on the distribution of corresponding points between the images. A
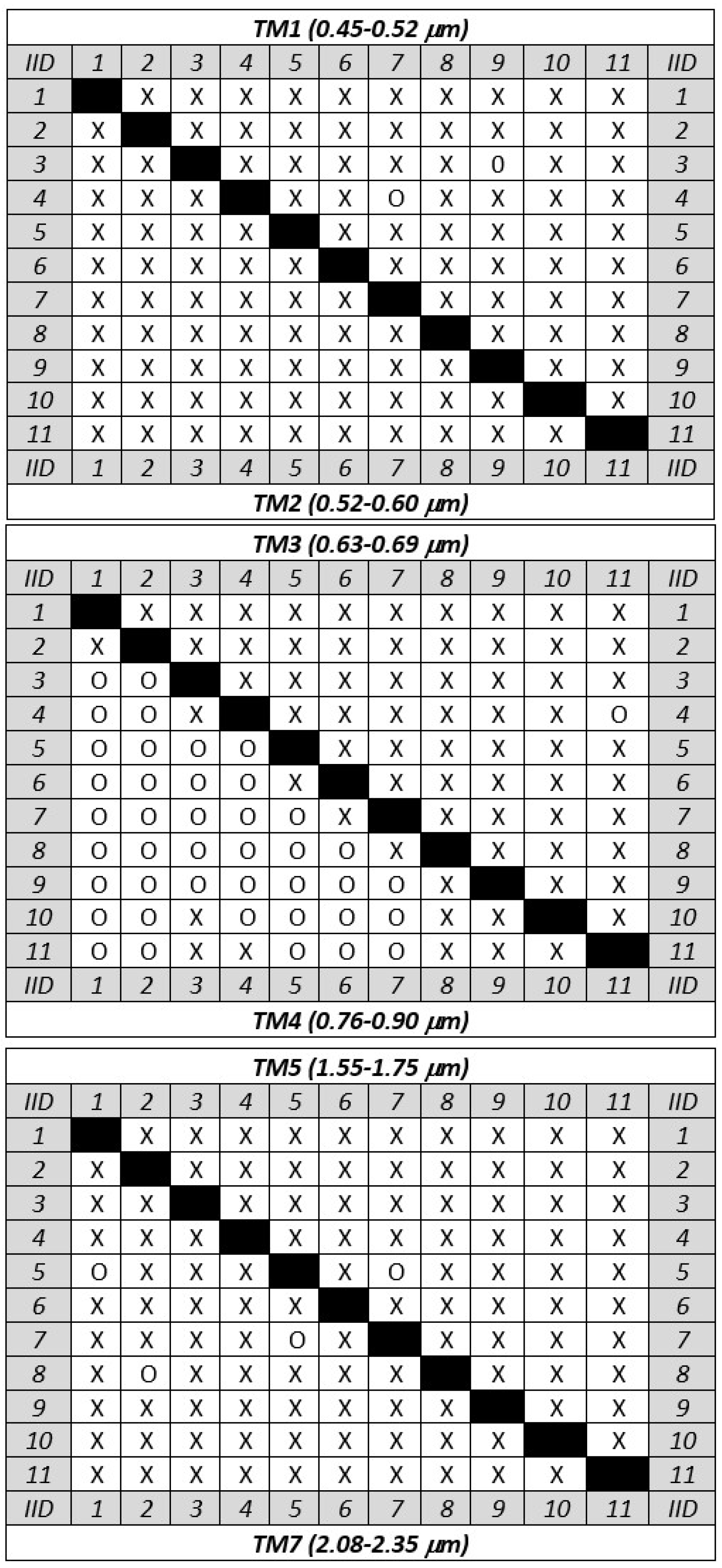
connectivity graph is drawn to show the relationship between the images and to highlight possible weak connections in the network. An example of connectivity graph related to the example presented in
Section 3 is displayed in
Figure 3 using a matrix representation, where a cross indicates the presence of sufficient TPs for co-registering the pair of images corresponding to the intersecting row and column. While a rapid look at the
connectivity matrix is enough to check out its consistency in the case of visual interpretation, a test is implemented to afford this task automatically. Once the consistency of the connectivity graph is assessed, the ‘master’ image is chosen on the basis of the following criteria:
to maximize the number of images that share enough TPs with the ‘master’, i.e., at least Nmin; and
the ‘master’ image should be preferably in a central position in the time series t = 1, 2, 3, …, n. Indeed, a time series covers the same spatial region within a time span and, consequently, the temporal factor is more important than the spatial factor for selecting the ‘master’ image.
The connectivity graph is also useful to work out the approximate values for any parameters to be estimated in the global multi-image BBA, see
Section 2.5. The adopted procedure is similar to the scheme followed in the ‘structure-from-motion’ technique [
40] for image orientation in close-range photogrammetry. By looking at the connectivity graph, all ‘slave’ images that are directly linked to the ‘master’ image may be approximately registered in pairwise, independent manner. In this way, any images in this first group of registered images can be used as new ‘master’ images to register other ‘slaves’ that would share sufficient corresponding points with one of them. By using such approximate registration parameters it is then possible to re-project the coordinates of any points on the space of the main ‘master’ image.
2.5. Analysis of Multiple Images
Since the MIRA method provides corresponding TPs not only for ‘master-to-slave’ combinations but also for ‘slave-to-slave’ pairs, all transformation parameters can be concurrently estimated.
A generic 2D polynomial transformation of degree p between two images is implemented at this stage. Given a feature k, the transformation of its coordinates between images i and j is given by:
The number (n
p) of transformation parameters (
) depends on the selected geometric model (see
Table 1).
The implementation of Equation (4) in the BBA has been revised with respect to the previous version published in Barazzetti [
27] to define a more rigorous stochastic model. All transformations in the global adjustment are written between the 2D image space of the generic ‘slave’ j and the 2D image space of the ‘master’ (M). The
functional model of the observation equations based on Equation (4) then becomes:
where
and
are the image coordinates of tie point k projected in the image space of the ‘master’ image, while
and
are residuals. Underlined parameters in Equation (5) are considered as unknowns, including TP coordinates re-projected on the ‘master’ image. This formulation is stochastically corrected, since the observed quantities (with errors) are bounded on the left side and unknowns are on the right side. Consequently, the observed coordinates (
) of any TPs may be properly weighted if their measurement precision is uneven. Equation (5) is not linear in the parameters and requires linearization around approximate values (see
Section 2.4). Consequently, the unknown parameters in Equation (5) are replaced by corrections
,
,
, and
.
Since it is not possible to predict the accuracy of individual features extracted by SURF, the observations are assigned unit weights. In the case a TP is cast into Equation (5), its coordinates on the ‘master’ image will have to be fixed to the measured value. A set of additional pseudo-observation equations is introduced to keep corresponding corrections constrained to zero. Additional constraint equations may also be included in the functional model to enforce conditions between parameters, for example, when a first-degree polynomial has to be reduced to a similarity transformation.
A TPs found on n
im image (see
Section 2.3) provides 2n
im observation equations. The total number of unknowns depends on the number of images (n), the parameters of the adopted geometric transformation (n
p), the coordinates of ‘slave-to-slave’ matches re-projected onto the ‘master’ image (2n
rep), and the number of 2D points (2u) used as a reference (GCPs) on the ‘master’ image.
The system of observation, pseudo-observation and constrain equations can be rewritten in compact form as follows:
where:
- dx1:
vector of corrections to the transformation parameters between any ‘slaves’ and the ‘master’ image;
- dx2:
vector of corrections to point coordinates on the ‘master’ image;
- A1, A2:
coefficient (or design) matrices of parameter vectors dx1 and dx2;
- y:
vector of measured coordinates of TPs;
- c:
vector of constants in linearized observation equations;
- v, w1, w2:
vectors of residuals; and
- D:
coefficient matrix of additional constraint equations, if any.
After casting all unknown parameters into a single unknown vector
dx = [
dx1 dx2]
T the
design matrix can be redefined as follows:
The system of linearized equations may be solved to estimate the vector of unknowns , where N = ATWA is the normal matrix and b = ATWY, while Y = [c−y 0 0]T is the constant vector and W the weight matrix. The theoretical accuracy of the solution may be derived from the estimate of the covariance matrix , where is the estimated variance of unit weight observations (or sigma naught).
Data snooping is applied again on the residuals after BBA to remove small errors. The effectiveness of this procedure is directly related to the evaluation of reliability that is described in the following section.
2.6. Analysis of the Reliability of Multi-Image BBA
With the term
reliability the chance to identify a gross error in the observations (
inner reliability) and the estimated parameters (
outer reliability) is referred to. While the readers may find the theoretical background about reliability analysis in Förstner [
41] and Kraus [
42], the basic concepts are briefly reviewed in the following of this section.
It is well known that a gross error in the
ith observation may be reflected only to a limited extent into the corresponding residual v
i after BBA. Thus, the largest residual does not necessarily correspond to a gross error. Moreover, outliers and random errors mask one another, so that the localization of gross errors may be difficult. In the case no gross errors are in the observations, the probability distribution of each residual is supposed to be Gaussian as N(0,
). The estimated variance of residual v
i may be derived from the estimated covariance matrix of residuals:
The
data snooping [
38] technique implemented for scrutinizing gross errors is based on the analysis of standardized residuals z
i = v
i/σ
vi, which are expected to be distributed as a standard Gaussian probability density function N(0,1). In the hypothesis that each z
i should follow the distribution N(0,1), an upper threshold k
α on the absolute size of acceptable standardized residuals is then fixed to filter out possible outliers. An observation is accepted only if the corresponding standardized residual |z
i| ≤ k
α, where k
α is directly related to a given
risk probability (α) that |z
i|> k
α (see
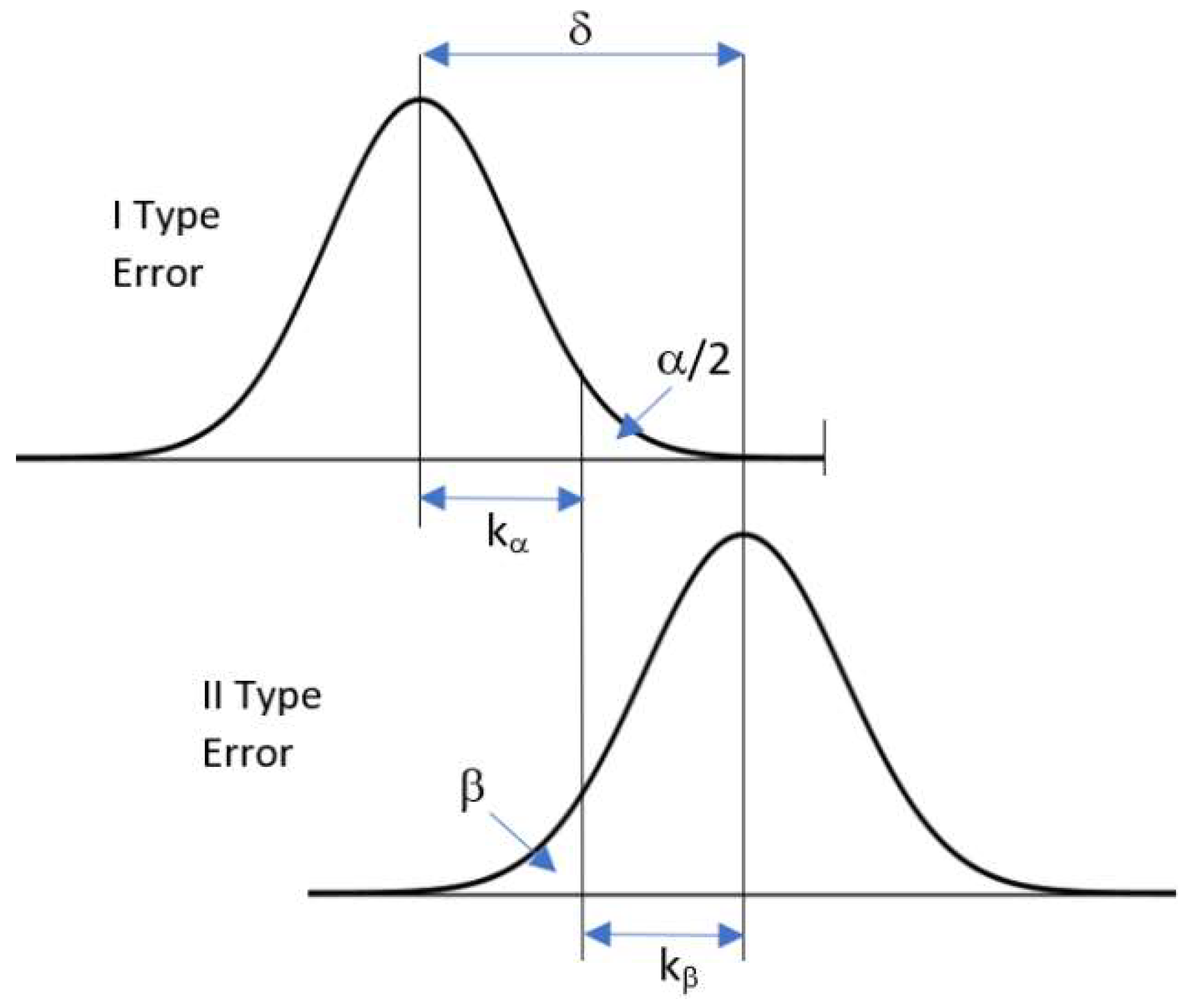
Figure 4). The rejection might occur in two different cases: (1) the residual is supposed not to follow the distribution N(0,1) because the related observation is a gross error; or (2) a rare event belonging to the distribution N(0,1) but with low risk probability α has happened. In such a case, an inlier would be erroneously discarded (type I error).
The test adopted to scrutinize the residuals may also fail in the presence of an outlier that does not follow the standard Gaussian distribution, but has a biased expectation E(z
i) = δ. As shown in
Figure 4, a small outlier may not be detected because it features a corresponding standardized residual z
i that is smaller than the acceptance threshold k
α. The probability of accepting an outlier (type II error) is given by β, which is related either to the risk probability α and to the bias δ. This last parameter is commonly referred to as the
non-centrality parameter (δ) and gives in standardized coordinates the size of the minimum measurement error that may be detected using data snooping. Once the
risk probability (α) and the power of the test (β) have been selected, the
non-centrality parameter (δ) can be worked out. A typical set of parameters that has been also adopted in the experiments reported in this paper is: α = 1%, β = 93%, k
α = 2.56, and δ = 4.
The
inner reliability (E(Δl
a)
rel) of the observation
ith is defined as the size of the minimum detectable error, according to selected parameters α and β. Its corresponding value can be computed using the expression:
where
is the expected precision of the
ith observation and
is its
local redundancy, which may be obtained from the
ith element of the main diagonal of the
redundancy matrix R:
Equation (9) shows that the test on standardized residuals may leave undetected a gross error whose size is times the precision of the observation ith, given prefixed values for α and β. On the other hand, the local redundancy may have a mitigating effect on the inner reliability. Higher values of lead to a smaller size for the detectable errors in corresponding observations. In a BBA, a manifold observation results in a high and consequently in a better inner reliability.
The final step is to evaluate the effect of an undetected gross error on the estimated parameters. This may be computed through the corresponding
outer reliability:
where vector
reports the value of inner reliability
on the line
ith and zero elsewhere.
To demonstrate how the inner and outer reliabilities may be obtained in the case of a BBA adopted to register a satellite time series implementing a 2D similarity transformation model, the following simulated examples are proposed (see also Scaioni [
43]). In
Table 2 the range of inner reliabilities and their average values are shown for three different cases. Additionally, the outer reliability corresponding to the average inner reliability is reported in the same table.
In Case 1, two images have been registered by using 16 corresponding features. It may be seen that the limit for the minimum detectable error corresponds to a bias of 0.27 pixels in the estimated shift in the same direction. In Case 2, a total number of three ‘slave’ images have been included, in addition to the ‘master’. Any ‘slaves’ share 16 TPs with the ‘master’. ‘Slaves’ also share nine TPs among them. As may be seen from
Table 2, the inner reliability of TPs shared with the ‘master’ is only slightly better than the one in Case 1. Looking at TPs between ‘slaves’, the minimum detectable error is larger with respect to the previous group of TPs. However, when looking at the corresponding outer reliability, the maximum detectable errors lead to biases in the estimated parameters that are significantly smaller than in Case 1.
In Case 3, the dataset adopted in Case 2 has been integrated by three additional images, leading to a total number of six ‘slaves.’ New images are not directly connected to the ‘master’, but they share 16 TPs among them.
The result regarding the inner reliability shows a further improvement concerning both Cases 1 and 2. Similarly, TPs have a higher threshold for non-detectable errors when they are shared among ‘slave’ images only. In
Table 2 the inner reliabilities have been separately computed for TPs shared between three (as in Case 2) and six ‘slave’ images, respectively. As expected, values of inner reliability are lower in the case of points visible on six images (Subset ‘SS6’) than in the case of points visible on three images only (Subset ‘SS3’). It is also interesting to observe how the outer reliability has improved in Case 3 concerning the previous cases with less redundant observations. In particular, the effect of maximum non-detectable gross errors in TPs is quite low (less than 1/10 pixels for shifts). In
Section 3, some results related to a real dataset are also presented.
4. Discussion
The quality of image registration obtained from the MIRA method may be evaluated by considering three different aspects: the estimated value of the variance of unit weight observations (), the comparison against results obtained from ‘slave-to-master’ registration based on automatically extracted TPs, and the results obtained using manual measurements of TPs, but within a BBA solution.
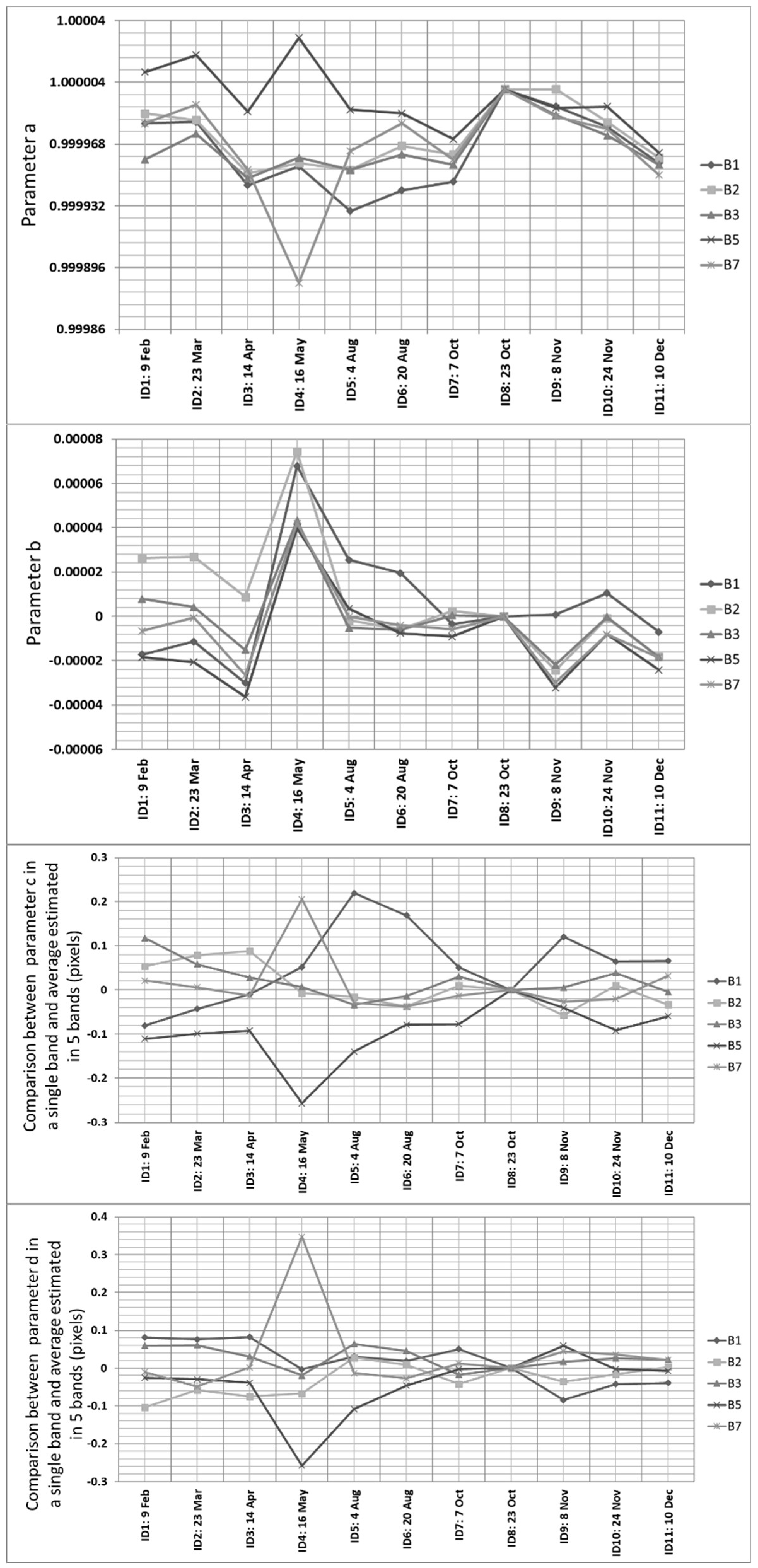
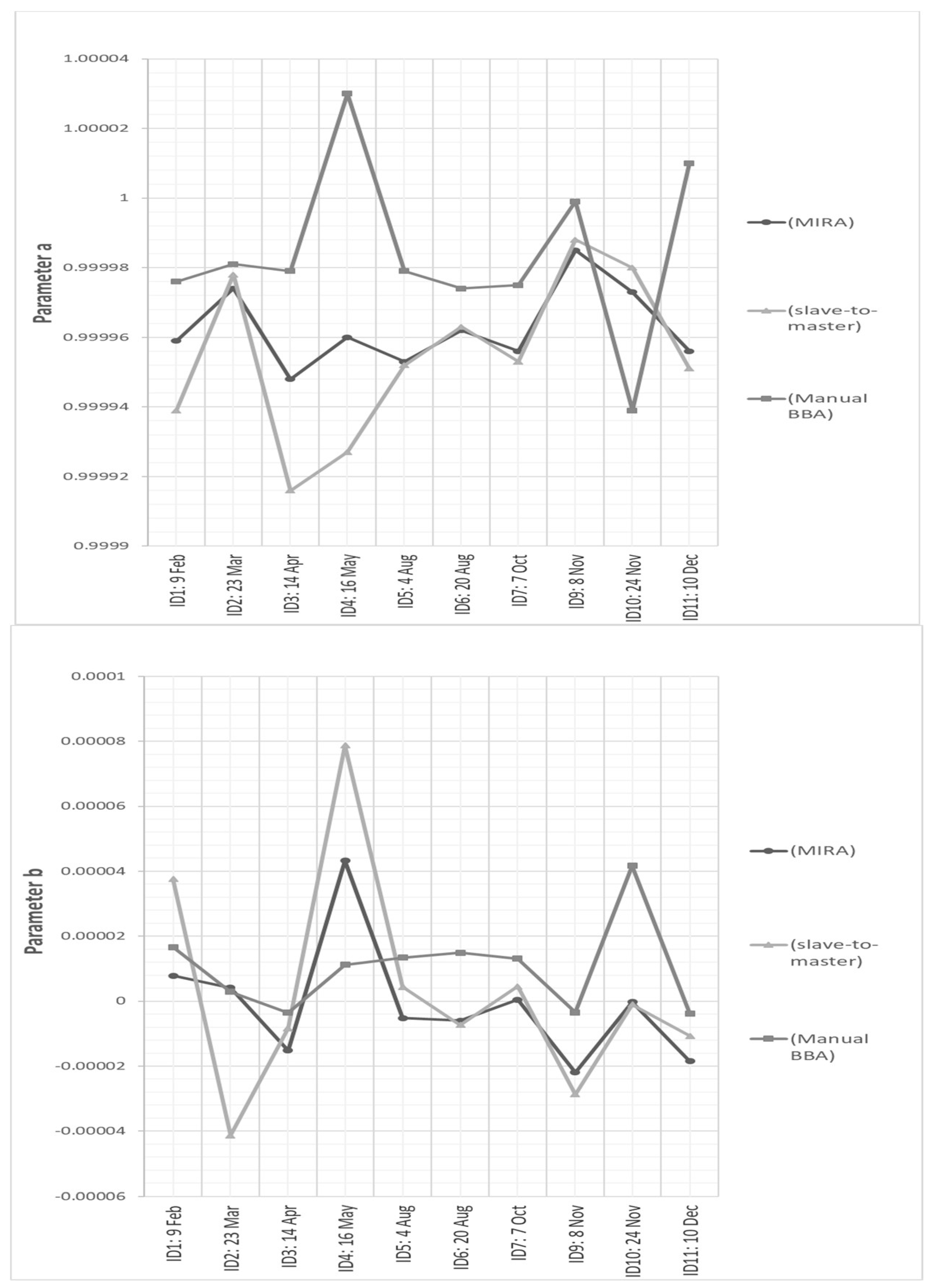
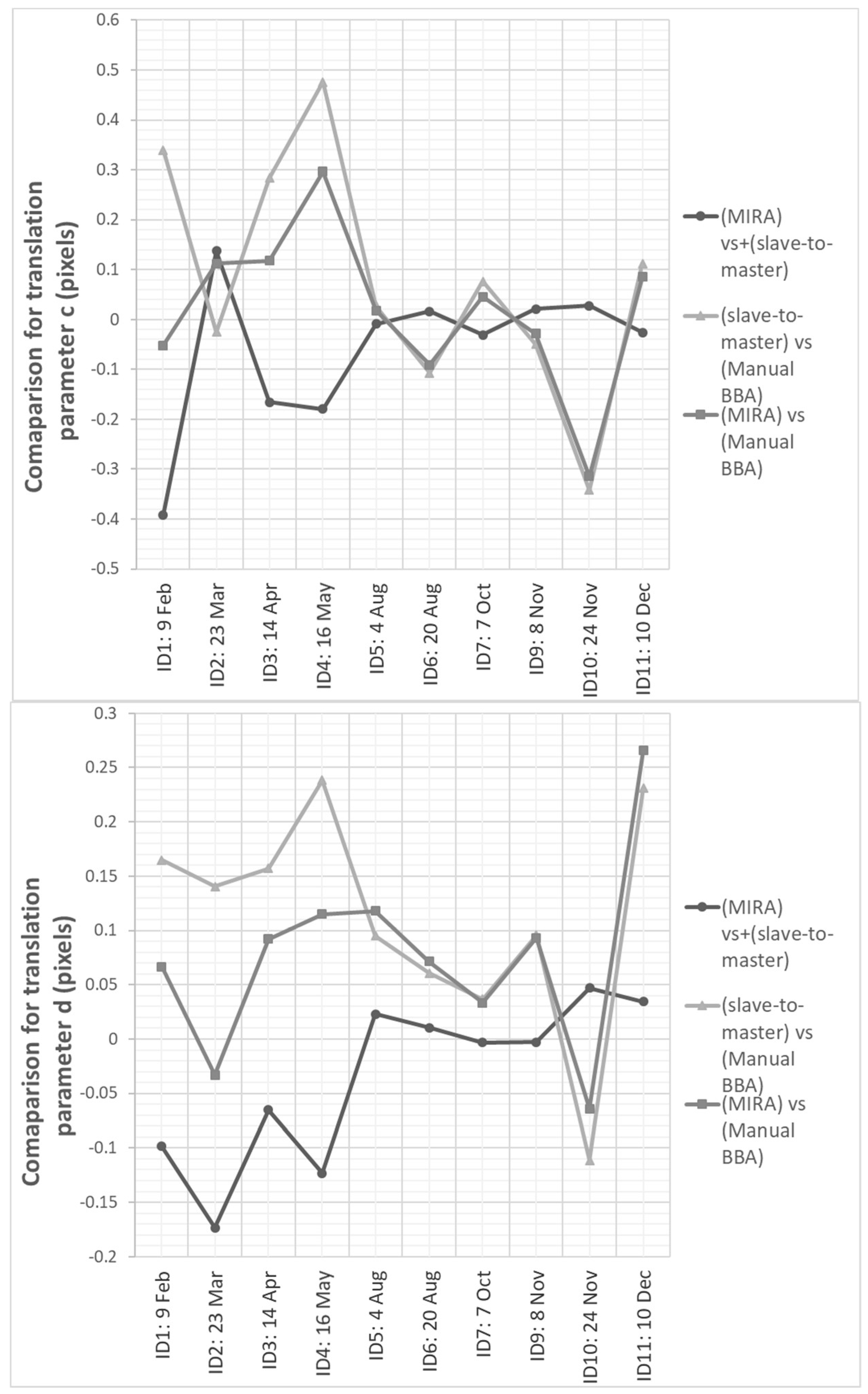
The estimated
after BBA based on observation extracted with MIRA has resulted in the order of approximately half pixel size, with small variations depending on the adopted spectral band (see
Table 5). The achieved subpixel value has confirmed the good fit with the adopted geometric model implemented for image registration (2D similarity) as well as the precision of automatically extracted TPs remained after data snooping. In
Figure 9 and
Figure 10 the results achieved with all three applied registration methods are graphically compared. No significant variations may be noticed about rotations and scales, which can be derived from parameters a
j and b
j. This is due to the imaging scheme of Landsat: fixed nadir-looking. Thus, images of the same site, but collected at different times, will have tiny variations in image scale and very small rotations. However, when processing time series imaged with different viewing angles, image rotations and scale variations could not be neglected. That is the typical case of high-resolution satellite images, but also that of multi-sensor datasets, including the data processing of radar images, which are usually collected with different incidence viewing angles and/or different orbits [
45,
46]. On the other hand, subpixel discrepancies have been found for shifts (parameters c
j and d
j,) in the Landsat time-series. The consistency between all these outputs confirms the correctness of MIRA approach.
Inner and outer reliabilities have been computed for all three processing methods based on MIRA and manual observations. Values are reported in
Table 8, where the results based on automatically extracted TPs have been also recomputed using the same precision of ‘manual’ measurements, which is supposed to be ±1 pixel. This solution has allowed to normalize the results and to make them comparable, since the TP precision had a linear scaling effect. In fact, the theoretical accuracy of MIRA observations has been estimated in the order of 0.5 pixels, which is consistent with the expected precision of FBM [
33]. The analysis of
inner reliability clearly highlights that the minimum size of detectable errors during data snooping significantly decreases when moving from ‘slave-to-master’ to BBA approach. In the former case, the inner reliability of twofold TPs (i.e., the ones visible on two images) is in the order of 6.1 pixels, while it improves up to 4.1 pixels when considering multiple TPs that can be obtained from BBA. As can be seen in
Table 8, the inner reliabilities do not depend only on the multiplicity and the precision of the considered TP, but also on the fact that this is shared with the ‘master’ image or not (see the second column). These discrepancies are in the order of a few tenths pixels and are motivated by the fact that the observation equations implemented in BBA are always referred to the ‘master’. When looking at the
outer reliability, a first comment should concern the evident advantage of using the large number of TPs extracted by the automatic MIRA procedure. Indeed, the negative effect of a maximum undetected error, which is indicated by the inner reliability value, is mitigated by the redundancy of the observations. Consequently, similar values for the inner reliability for manual and automatic measurements (in the range between 4–6 pixels), when they are processed within the BBA, may result in errors on the final shift estimates up to approximately 1.5 pixels in the former case and 0.04 pixels in in the latter case, respectively. The differences of scaling and rotation parameters are less influenced.
These results conclude that the high data redundancy and the improved inner/outer reliability that may be obtained when using MIRA are two fundamental properties supporting the use of such an automatic procedure. The high redundancy allows to mitigate the degrading effect of residual measurement errors. The low values for the inner reliability may support the chance to limit the size of undetected errors. Of course, this second advantage depends on the fact that a small number of residual outliers are input in the BBA observation dataset. This chance is supported by the preliminary application of multiple scrutinizing technique to detect outliers during the FBM stage, which is supposed to leave a small number of outliers.
It should be also recalled that the other important advantage of the MIRA procedure is given by the chance to register possible images that are not directly connected to the ‘master’ because they do not individually share enough TPs with it. If these images may be linked to other images in the block that are connected to the ‘master’, the BBA solution allows to compute the registration of the whole dataset. This alternative solution is not possible using traditional ‘slave-to-master’ registration approach.
5. Conclusions
This paper presented some important developments of an automatic method (multi-image robust alignment—MIRA) for the registration of remotely sensed time series, where multiple images are simultaneously registered in a bundle block adjustment fashion after the extraction of corresponding features using feature-based matching (FBM).
This approach has two main advantages if compared to standard ‘slave-to-master’ registration methods. The first consists in the chance to align also those images without direct connection with the ‘master’, which in the MIRA procedure is only adopted for setting up the spatial datum. The second is the higher reliability of the solution since the redundancy of the observations is fully exploited. While in a previous paper [
27] the basic concept of this approach was presented, here the focus is given to the automation of the whole procedure, which requires a high-degree of robustness against blunders, the availability of objective parameters and criteria to support decisions within the process, a rigorous stochastic formulation for the observation equations in least-squares adjustment, and the presence of intermediate quality checks (e.g., after pairwise FBM).
A set of 2D polynomial transformations is available to better fit different datasets and images from diverse sensors. Consequently, MIRA may be successfully applied to medium-resolution satellite data (GSD between 10 m and 30 m), while its implementation with high- and very high-resolution imagery still needs additional development to integrate more suitable geometric models, e.g., rational polynomial functions or physical sensor models [
47]. Anyway, it should be mentioned that with more involved geometric models that require a larger number of parameters, the reliability analysis that has been proposed here may be less meaningful. On the other hand, 2D polynomial transformations are sufficient for the registration of medium-resolution satellite images, such as the ones derived from NASA Landsat, ESA Sentinel-2 platform, and the British Disaster Monitoring Constellation. These datasets and other similar ones, which may be expected in the future, are highly prone to be exploited for hyper-temporal remote sensing with very short revisit time (a few days between observations). The MIRA procedure may play a vital role in the automatic subpixel alignment of such datasets.
In the perspective of processing huge datasets as well, the large size may create some problems in the inversion of the normal matrix
N, due to the high computational cost of this operation. This would prevent the computation of the covariance matrix of the solution, and then the evaluation of the theoretical accuracy of estimated parameters as well as the redundancy matrix that is necessary for the reliability analysis [
48]. To overcome this shortcoming, an ad hoc procedure for the decimation of the corresponding features based on their image multiplicity will be implemented in future developments.
At the moment, the selection of the spectral band to be used for the image alignment is left to the user. In the considered case study, similar results regarding the achievable precision have been obtained from different wavelengths, with the exception of near and thermal infrared. On the other hand, combining the point correspondences obtained in different bands may also be an opportunity to extend the use of the MIRA procedure, especially when different types of images should be registered together.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}