1. Introduction
Recently, remotely sensed data such as aerial images, laser scanning, or satellite images provide more accurate information of forests worldwide than has ever been available before. In the area-based approach (ABA) of forest inventory using remotely sensed data, the forest attributes of interest are predicted over the inventory campaign area at plot or grid cell level. A general goal of operational forest inventory is to predict these attributes accurately and precisely in each plot/grid cell over the whole forested area such that the whole range and statistical behaviour of the real values of the attributes is reproduced in the predictions.
Common prediction methods in model-based or model-assisted forest inventory are e.g., linear models [
1,
2,
3,
4,
5], non-linear models [
6,
7], random forest methods [
8] and
k nearest neighbour (
k-NN) [
2,
9,
10,
11] methods. Part of these methods include also information of the uncertainty in plot level predictions of the attributes. A general problem among all these methods is poor prediction of extreme values, especially for attributes for which the prediction precision is poorest, where the smallest and largest values tend to be systematically over- or underestimated. This can be caused e.g., by poor correlation between extreme values of the attribute and used remotely sensed data based predictors, insufficient number of field measurements of the extreme attribute values in the available training set, or excessive averaging behaviour of the used model. For instance, the above ground biomass (AGB) can generally be predicted using LiDAR or satellite image data with good precision up to some limit, but for AGB values larger than that the models tend to systematically under-estimate the biomass compared to the real values, see e.g., [
3,
7,
12].
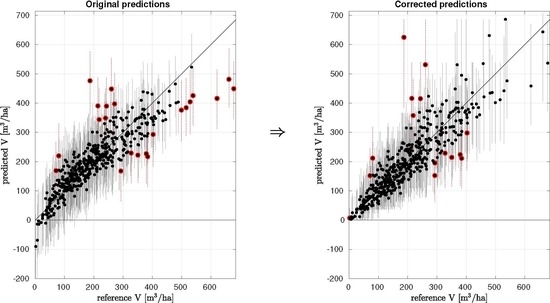
Common statistics used to evaluate the performance of the method may show relatively good behaviour for the predictions: the mean difference (MD) can be close to zero and the root mean square error (RMSE) sufficiently small. However, the overall variance of the predicted attribute values can be smaller than that of the reference set. The lack of model fit generally causes problems especially with the largest and smallest values of the attribute, see
Figure 1 for an example of linear model-based point predictions and their 95% probability intervals of forest attribute total volume (V [m
/ha]) in study site Loppi–Janakkala, which is one of the cases validated later in this study. Here, the prediction errors are most likely a result of lack of correlation between remotely sensed data and the attribute field measurements which can be partly caused by errors in used data.
The large attribute values (>400 ) are systematically under-estimated and also the small attribute values (<50 ) are under-estimated. Here, the smallest, close to zero attribute values are even predicted to be negative, which is an unwanted property of linear models. The same properties of the predictions can be seen also in the accuracy assessment linear fit, also known as the geometric mean functional relationship (GMFR), between attribute reference set (the field measurements) and attribute point predictions. Here, the slope of the red linear fit line is less than one. In an optimal case, the red linear fit line would have slope one (parallel with the 1-1 line), and intercept value equal to the mean value of the attribute reference set.
Figure 1b shows a typical case of linear model-based probability intervals, which in this case follow a normal distribution defined by the model formulation [
13]. In many linear and non-linear models the prediction distributions are assumed to be normally distributed, thus such a case is used as an example here. In this set of predictions, 95% of the reference attribute values were within the estimated 95% probability intervals of corresponding predictions, but the largest attribute values of the reference set tended to be systematically underestimated and also outside the probability interval, see red point predictions and probability intervals in
Figure 1b. In an ideal case the 5% of the attribute reference set values outside the probability interval should be relatively uniformly distributed along the reference set attribute distribution and include both too small and too large predictions.
Excessive averaging and systematic under- or over-estimation—and even more the outright qualitative prediction errors like negative values—have many unwanted consequences. For example, in AGB prediction in incorporating carbon captured into tropical forest in climate financing schemes like UN REDD+ [
14,
15,
16], the plots with LiDAR data-based AGB predictions can be used as surrogate plots in larger area AGB predictions based on satellite data. If the variance of surrogate AGB prediction distribution is under-estimated, the problem is amplified in the final, larger area predictions. Also, if the distribution scatter-grams are rendered flat by saturation for the largest AGB values, then any gains in carbon capture are heavily damped by the statistics used in assessing them. The lack of fit and under-estimation of large values can be accumulated to other levels of prediction also, such as stand level predictions or large plot/grid cell predictions. If the forest is divided into stands according to the homogeneity of the forest, it is likely that plot level attribute values of similar magnitude are located in the same stand and the stand level prediction composed of a (weighted) average of predicted attribute values in plots inside the stand will suffer from the same problems as plot level predictions.
It is a common procedure to use a suitable post-processing or transformation method to overcome this type of problems, see e.g., [
17,
18,
19,
20,
21]. Statistical post-processing methods like histogram matching or quantile–quantile mapping transformation utilize the shape of the underlying attribute training set distribution to correct new attribute predictions. The attribute training set data distribution shapes can be estimated with parametrized, fixed shape distribution functions or arbitrary, non-parametric distribution functions.
Histogram matching algorithms are commonly used to process satellite data [
19,
22], and quantile–quantile mapping transformations are used for bias correction of regional climate models [
18,
23]. It has shown its power also in correction of forest attribute predictions given by
k-NN method, see [
20] for a parametric approach and [
21] for a nonparametric approach. In the forest inventory application, the non-parametric approach which is based on arbitrary shapes of attribute distribution is a natural approach especially if we wish to have a method that generalizes well to any forest attribute of interest in any study site. In regional climate models, a study of [
23] showed that nonparametric transformations had the highest skill in systematically reducing biases in precipitation. Statistical transformations assume that the modelled relation holds also with new data, thus the attribute distribution data used as the training set must be a proper probability sample of the whole population.
The aim of this study is to develop a non-parametric quantile–quantile mapping transformation based on empirical quantiles (QUANT) used e.g., in [
18,
21,
23] for operational, plot level forest inventory for both attribute point predictions and, as a novel approach, uncertainty analysis of the predictions.
As an example case, we validate the performance of the QUANT post-processing method using a linear model with LiDAR data based predictors to generate the raw predictions. The post-processing procedure would be similar for raw predictions estimated with any other method once they are based on a training set, i.e., we have a sample of the real underlying distribution of the forest attribute of interest. In this study we expand our transformation to the natural property of the linear model, the prediction probability interval, as well. The proposed uncertainty analysis can also be adapted to predictions of other models as well, as long as the model generates prediction distributions for the raw predictions.
The performance of the post-processing method is validated both visually and numerically using real forest inventory data with large training set sizes (over 400 field plots) and the robustness of the proposed method is validated also for a reduced number of training set plots. Because of the challenges linked to a small training set size combined with multidimensional, correlated predictors, we use a formulation of the linear model which has shown to be efficient in such situations, the Bayesian Principal Component Regression model (BPCR) introduced in [
13].
This article is organized as follows: In
Section 2, the details of the proposed method, the remotely sensed data, the field data, the validation procedure, and the parameters that are used as indicators of method performance are introduced. In
Section 3, results for different test cases are given. The results are discussed in
Section 4 and then the conclusions about the performance and the pros and cons of the proposed post-processing method are given in
Section 5.
2. Materials and Methods
The forest inventory attribute of interest, given as a vector , is assumed to have real, non-negative values. In the area based approach, the forest attribute is predicted at a plot or grid cell level with a suitable model. A training set of size n (plots) is used to estimate the model parameters. The training set contains field measurements of the forest attribute, , and the remotely sensed data-based predictors, , for each plot in the training set t. The attribute values are predicted in the validation set v that consists of new plots or grid cells using the set of predictors .
Here we use a linear model-based approach that uses singular value decomposition of predictors and automatically emphasizes the use of those singular vectors that best explain the data, BPCR, to estimate the model parameters [
13]. The method is well suited for the cases with highly multicollinear predictors, as if often the case with LiDAR predictors, and small number of field sample plots.
Each new, individual plot/grid cell level prediction given by the used linear model follows the normal distribution with estimated mean value and variance , . In general, the point prediction for the plot is given as the expected value of the normal distribution, , and % prediction probability interval is given as -quantiles of the symmetric normal distribution.
2.1. Non-Parametric Quantile–quantile Mapping Transformation
In the QUANT post-processing method, the training set distribution of the attribute is treated as the true distribution of the forest attribute values in the given area, and compared to the corresponding distribution of the predictions in the training set plots. The distributions are represented by the empirical cumulative distribution functions (ECDFs) where the distribution of a sample (given as an ordered set from smallest to largest value) is represented as a cumulative function
where
is the indicator function which is equal to one if
, and zero otherwise. The values of
vary between zero and one, scaled such that
gets values
. The ECDF values between the measurements are estimated as a piece-wise linear interpolation.
When using linear model-based raw predictions, some values of the raw predictions in new plots may exceed the extreme values found in the training set raw predictions. In such a case, simple extrapolation similar to [
18] is used: outside the range of training set values, the same slope as between the last two extreme points in the data is kept. For instance, the piece-wise linear interpolation curve between the first two ordered points
with corresponding to ECDF values
, holds also for the ECDF range
, and similarly to to the upper tail of the ECDF.
The ECDF values for the training set field measurements of the attribute,
, and for the raw predictions of the training set,
, are constructed separately using Equation (
1), resulting to ECDFs
and
, correspondingly.
Figure 2a illustrates the ECDFs of certain values in training set predictions,
(which in this case correspond to the mean values of the prediction distributions,
), and corresponding training set field measurements,
, of the case shown in
Figure 1.
The quantile–quantile mapping technique QUANT corrects the raw predictions according to their ECDF values among the training set predictions. The cumulative distribution function value
of the prediction
in new plot
i is transformed such that the value,
, that gives the same ECDF value among the training set field measurements
, is found, i.e.,
. The transformation model
to transform
from training set prediction distribution to training set field measurement distribution is given by
In the transformation model, similar extrapolation is applied also to the smallest values which might be smaller than the first quantile of the training set predictions. However, only non-negative values are accepted for the training set field measurement ECDF, as the real attribute values are always non-negative, and thus the ECDF (and probability) of such points is set to zero. See the
Figure 2b for the transformation function corresponding to the distributions in
Figure 2a.
2.2. Uncertainty Analysis for the Transformation
Plot level predictions given by models with possibly imperfect model fit and parameter distributions estimated using a limited number of field measurements, include uncertainty. Linear model-based plot level predictions, for instance, include this information of uncertainty as a normal distribution with estimated variance around the mean value (point prediction), which is used as the “predicted value”. Thus, each new plot level prediction is given as a normal distribution.
In our post-processing procedure, the uncertainty for a new plot
in the validation set can be included by sampling from the attribute prediction distribution of the plot,
,
, and then using the transformation function, Equation (
2), for all the sampled prediction distribution points. However, because of uncertainty in linear model-based predictions, there is also uncertainty among the plot level predictions in the training set, which causes uncertainty also in the transformation function. Thus, also the training set plot level predictions are sampled,
, and the resulting ECDF function (
1),
, is used to generate the new transformation function
for each sample set
l. Thus the transformation of the prediction distribution points is performed by sampling from the training set predictions which are then used to generate the transformation of the sampled prediction distribution points.
In
Figure 3, the transformation procedure is illustrated for one example plot. The normal distribution of the raw prediction for a new plot, represented here as a sample generated from the given plot level prediction distribution, is transformed using the samples of predicted training set plots. The transformed distribution is no longer normal, but has an arbitrary shape. Also, the transformation curve is not symmetric around the mean value transformation curve,
. This is caused by the ECDFs of training set prediction samples, where the spread of predictions is larger than with the mean value predictions, which cause the sampled transformation curves to have a larger spread on x-axis (original, raw predictions).
The asymmetry and arbitrariness of the transformed new plot prediction sample must be taken into account when estimating the probability interval. By definition, for example, the 95% (
) probability interval is estimated by finding
such that
Here, Pr is the probability, which can be estimated using the sample point distribution. That is, 95% of the sample points must be within the given interval, which is obviously not a unique interval. In this paper, the narrowest interval that satisfies the condition (
3) is chosen, similar to [
24], and we require also that the transformed mean value of the validation plot distribution is within the given probability interval.
Although the transformed mean value of the validation plot distribution is no longer at the mean, mode nor the median of the transformed probability distribution, it presents the corrected prediction because it is estimated with the best information we have: the most likely value of the raw predictions (the mean and the mode of the normal distribution), transformed with the most likely training set prediction values (the mean values).
The whole algorithm is given as:
Estimate model parameters and corresponding model with training data .
For each validation set plot :
- (a)
Estimate the prediction probability distribution with the given model. Estimate the point prediction as the mean value .
- (b)
Generate the post-corrected prediction using .
- (c)
Generate the sample of prediction distribution points , (here ).
- (d)
For (here )
- (i)
Generate a new sample of n training set predictions .
- (ii)
Generate ECDF function and the corresponding transformation function .
- (iii)
Transform all prediction distribution points: .
- (e)
Use the transformed prediction distribution points to analyze the probability intervals as described above.
2.3. Study Sites
In this study, forest inventory data from seven separate study sites in different parts of Finland are used to evaluate model performance and to validate the consistency of the results. The sites are located at Matalansalo (Heinävesi), Juuka, Loppi–Janakkala, Pello, Lieksa, Kuhmo, and Karttula. For more detailed information of the datasets used, see [
25]. A total of 472, 511, 441, 553, 483, 470, and 538 field plots were measured in each study site, respectively. These study sites belong to the boreal forest type comprising mostly species like Scots pine (
Pinus sylvestris), Norway spruce (
Picea abies), and different species of hardwoods, mostly birch.
2.3.1. Field Measurements
The sample plots of the study sites were selected with a number of different sampling strategies. Some sites were equipped with a regular sample plot grid, some others were equipped with regularly sampled plot clusters, and still others were equipped with randomly selected plots. Sample plots were always circular plots with a 9-m radius. They were positioned at first with a hand-held global positioning systems (GPS), and the exact position of the plot center was later calculated during measurement and differentially corrected offline.
In this article, we used field measurements of three forest attributes: median tree height (Hgm, [m]), total volume (V, [m
/ha]), and stem number (SN, [number of stems/ha]). They were estimated from the field measurements in a similar manner at each site, using models of Veltheim [
26].
2.3.2. Remotely Sensed Data
The auxiliary data covering the whole study site areas consist of LiDAR measurements and aerial images from each study site, except in Matalansalo where only LiDAR measurements were available.
LiDAR scanning of the different areas was conducted from 2004 until 2008. Three different types of scanners were used, namely Optech ALTM 3600, Leica ALS50, and Leica ALS60. Flying height varied between 700 m and 2000 m, and scanner pulse frequency varied between 58,900 Hz and 125,100 Hz. LiDAR data were clipped to plot extent before LiDAR predictors were extracted. A set of 38 candidate predictors were derived from LiDAR measurements for each sample plot used. This set is similar to the set that has been used in [
27]. It consists of percentile points and cumulative percentile parts of the first and last pulse heights of non-ground hits (height
m), percentile intensities of first and last pulse intensities of non-ground hits, mean of first pulse heights
m, standard deviation of first pulse height, and the number of measurements
m of first and last pulse heights divided by the total number of the same measurements of each plot, depicting vegetation density.
The digital aerial photographs consist of pixel sizes of 0.5 m and three or four channels. Digital ortho-rectified aerial images were used with 0.5 m spatial resolution. The channels used were in most cases blue, green, red and near-infrared. Two candidate predictors, namely percentage of hardwoods and percentage of conifers, were visually interpreted from these images using the approximately 1000 pixels in each plot: The pixels were classified as hardwood trees, conifer trees and hits to the ground, and the resulting candidate predictors were the percentages of hardwood trees (Hwd) and conifer trees (Cnf) in each plot.
As a result, a total of 38 candidate predictors were available for study site Matalansalo and 40 candidate predictors for the other study sites. These predictors were highly correlated with each other with condition numbers between 6400 and 25,350 among different study sites, which means severe multicollinearity.
2.4. Validation Procedure
Leave-One-Plot-Out (LOPO) cross-validation procedure is used to validate the performance of the proposed method. In LOPO, from the total of N plots available, one plot at time is chosen into the validation set, and the rest plots serve as training set plots. The parameters of the linear model used to generate the raw predictions are estimated with the training set data chosen (predictors and measured attribute values of the training set plots), and the attribute prediction distribution of the validation plot is estimated using the resulting model with the validation set predictor values. The post-processing method uses the predicted training set distributions and the training set field measurement values of the attribute to transform the raw validation plot point prediction and its probability distribution. This procedure results in a vector of N point predictions for both raw predictions, , and corrected predictions, , with corresponding probability intervals.
If a reduced number of training set plots is used, the training set plots are selected randomly from the leave-one-out plots. This selection method is assumed to give proper, representative samples. Thus, plots are selected from the plots available in each LOPO repetition.
2.5. Model Performance Estimates
Performance of the QUANT post-processing method is compared to the performance of the BPCR method, i.e., we compare the quality of the post-processed predictions to the quality of the raw predictions.
The first validation parameter is the relative mean difference between the predictions and corresponding reference values,
where
is a vector of the point predictions (either raw predictions or post-corrected predictions),
is the corresponding attribute values in the reference set, and
is the average of the reference set values. The hypothesis of whether the mean difference deviance from zero is significant, is tested by one sample mean t-test and deviances with p-values less than the given significance level
are considered significant.
The second validation parameter is the relative root mean square error,
which describes the standard deviation of the prediction residuals.
A validation parameter describing the linear relationship between the reference values and the point predictions uses a linear model with the intercept and the reference vector as predictors and the vector of predictions as the response. The linear model parameters and for the intercept and the reference values are estimated. For perfect predictions, the intercept parameter is equal to the reference mean and the slope is one. In practice, the difference between and is equal to mean difference, . Thus, only is shown in this study.
We also validate the relative mean absolute error of the differences between the P:th quantiles in the attribute point prediction distribution and the reference distribution, MAE%. Quantiles are used. For perfect point predictions, MAE% is zero.
The probability intervals of each prediction distribution are also estimated. Here, the fraction of reference set values that fall in the 95% percent probability interval of the corresponding prediction distribution are calculated (), and with the 95% probability interval, this fraction should be approximately 95%. Also, the average of the probability interval widths over the whole validation set predictions is calculated ().
4. Discussion
In general, the largest interest in operational forest inventory campaigns in boreal forests in Nordic countries and Canada lies in the largest trees which are most valuable for timber use, or in case of carbon credits in tropical forests, hold the most carbon. As discussed in this article and references given, the commonly used remotely sensed data-based prediction methods tend to under-estimate the height and volume in plots containing such trees. The results given here show that the QUANT post-processing method gives reliable and accurate predictions for plots within forest that contains tall trees and a large timber volume and covers the uncertainty connected to such cases better than the raw predictions. Although the RMSE% values of the post-processed predictions tend to be larger than those of the raw predictions, the difference is relatively small, which supports the results given in [
21]. The gain in the preservation of the attribute distribution characteristics and range combined with the better model fit without under- or over-estimation of values in any range can be considered more important than the small reduction in the average prediction precision. The proposed method is applicaple to different models using different predictor data sources and predicting different attributes as its performance depends only on the quality of the raw attribute predictions compared to the training set attribute measurements. In case of e.g., tropical forest biomass estimation, the precision of the raw predictions based on LiDAR data generally tends to be of similar scale and form as those of the stem number predictions studied here. In our unpublished study, we found that for linear method based predictions of above ground biomass in Nepal (see [
16] for more information about the data) the RMSE% increased 8.6%, the slope error decreased 42.5% and the MAE% decreased 86.4% and the uncertainty estimation gave correct probability intervals with slightly decreased interval widths. These relations held with training set sizes between 50–737 plots, and the results remained close to optimal for training set sizes as small as 100–150. These results align well with the results shown above for other forest types.
The QUANT post-processing method did not introduce any significant, additive deviation from zero in the mean difference of the predictions. This is reasonable as the post-processing fits the transformed attribute prediction distribution to the attribute distribution of the training set. If the training set is a proper, representative probability sample of the whole population, also the predictions fitted to that sample should, having approximately the same mean value, have zero mean difference compared to the truth.
Important property of the prediction methods, the ability to estimate the plot level % probability interval together with the point estimate, is retained in the post-processing procedure. The post-processed probability intervals appear to be more reasonable than those of the of the raw predictions generated by e.g., a linear model, for which the interval shows behaviour of a homoscedastic variance. The probability intervals of the raw attribute predictions tend to be too wide for the near zero values of the attribute, while they can easily be under-estimated for large values of the attribute. The post-processed probability intervals tend to be smaller for small attribute values and larger for the large attribute values.
The proposed post-processing method shows to be robust against reduction in the training set size, i.e., number of used field plots. The performance of the QUANT method depends on the performance of the prediction method used for the raw predictions, and the relation between the raw and post-processed prediction results remains similar for all the training set sizes tested.
The correlation between attributes is not incorporated into the proposed post-processing method. However, as shown in
Figure 10, the post-prosessing of the raw predictions is not violating the correlation structure of the attributes much in our test case, but since this property is not included intrinsically in the proposed method, one must be careful with the impossible or unacceptable correlations among the predictions.
5. Conclusions
The results of this study show that the proposed post-processing method, QUANT, can be used to correct the statistical defects in the predictions generated with some common remotely sensed data-based methods used in forest inventory. Here, the raw predictions were estimated with a linear model, but the method could be applied to other approaches as it uses only the attribute field measurements available and compares them to their predictions. For uncertainty analysis, the uncertainty of the raw predictions must be estimated. The post-processing method produces predictions from the whole range of the true distribution of the attribute values and corrects the skewness in the distribution so that within any range of attribute values, there is no systematic over- or under-estimation. The precision of the post-processed predictions can be slightly worse than the precision of the raw predictions.
The proposed post-processing procedure is based only on the distribution of the attribute values in the selected training set plots. No assumptions on the shape of the attribute distributions are needed since the method is based only on the empirical cumulative distribution function of the available field sample of the attribute. The method is general; it can be used to any shape of distributions and for any attribute of interest, as long as a proper, representative probability sample of the attribute values exists.
In this study only a random training set plot selection procedure was tested in order to validate the effect of reduction of the training set size. The formulation of QUANT method makes it sensitive to defects in the field sample, i.e., training set, selection. If the training set is not a proper, representative probability sample of the true population in the study site, it will probably effect also the post-processing procedure such that the mean difference of predictions can deviate significantly from zero. Thus, when using this method, special care should be given to training set quality and the field plot selection criteria.
Different forest attribute values were predicted as individual, separate outputs in this study. In the real world, there is a correlation among different attributes, even some rules, such as in case of species-specific attributes for which the corresponding total attribute is a sum of the species-specific values. In future research, the post-processing method should be extended to use and preserve also the correlation structures of the attributes of interest.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}