Dialectical GAN for SAR Image Translation: From Sentinel-1 to TerraSAR-X

Abstract
:1. Introduction
2. Data Set
2.1. Image Quantization
2.2. Image Coregistration
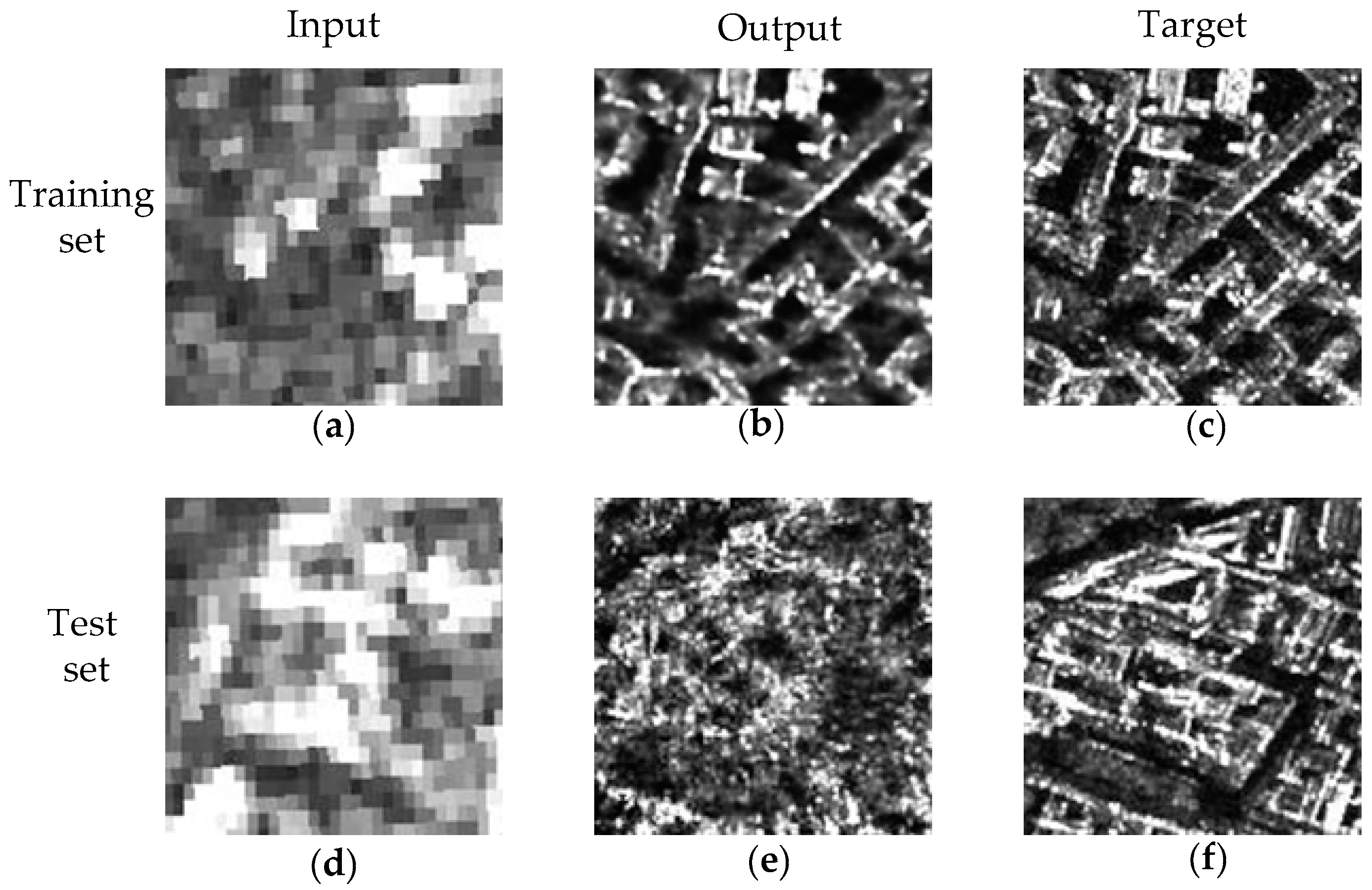
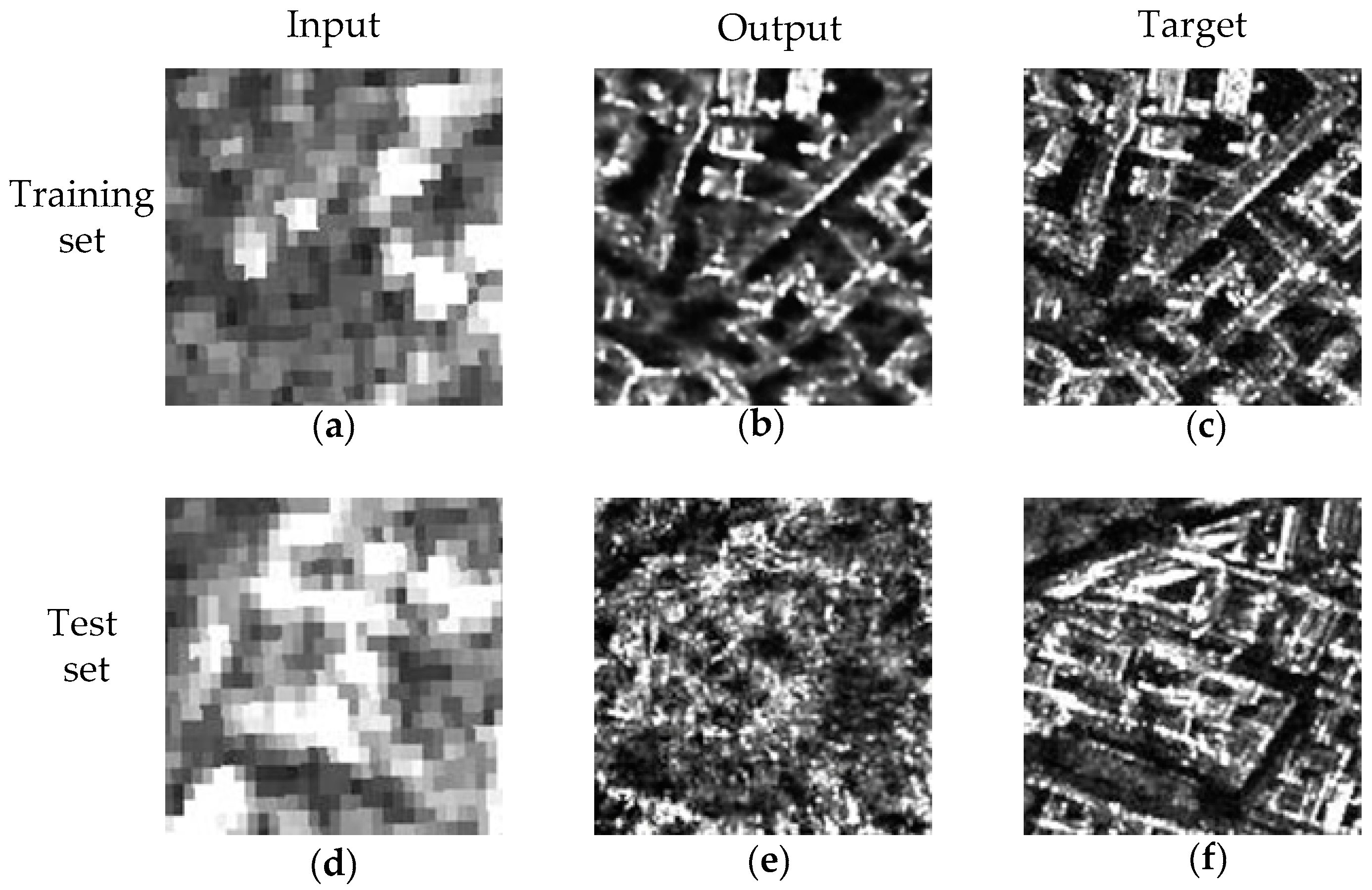
2.3. Training Data and Test Data
3. Related Work
3.1. VGG-19 Network
3.2. Texture Definition—Gram Matrix
3.3. Conditional Generative Adversarial Networks
4. Method
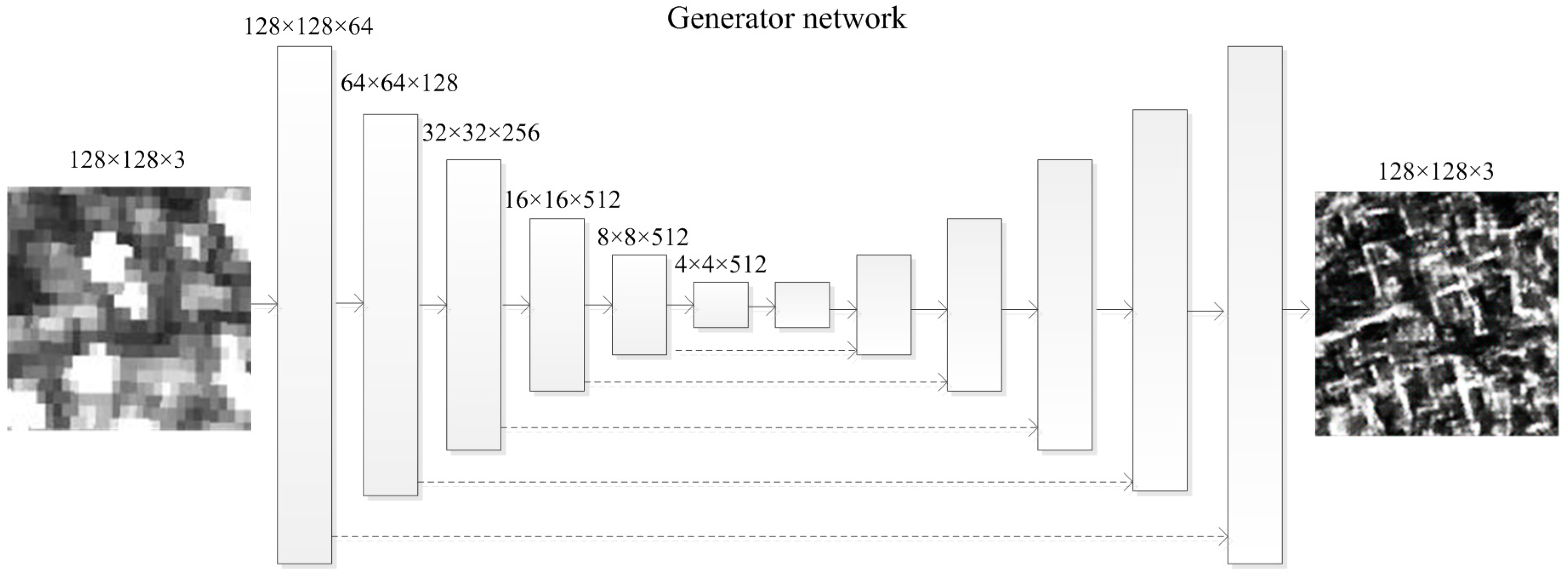
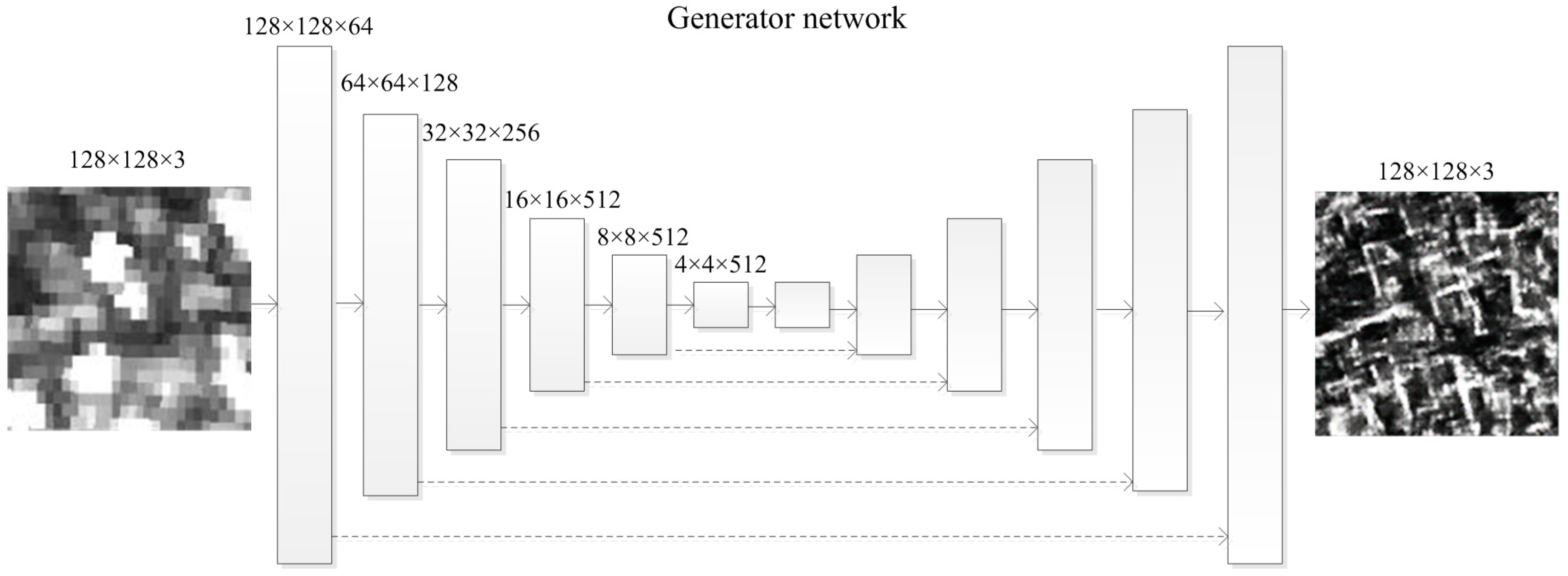
4.1. “Generator” Network—Thesis
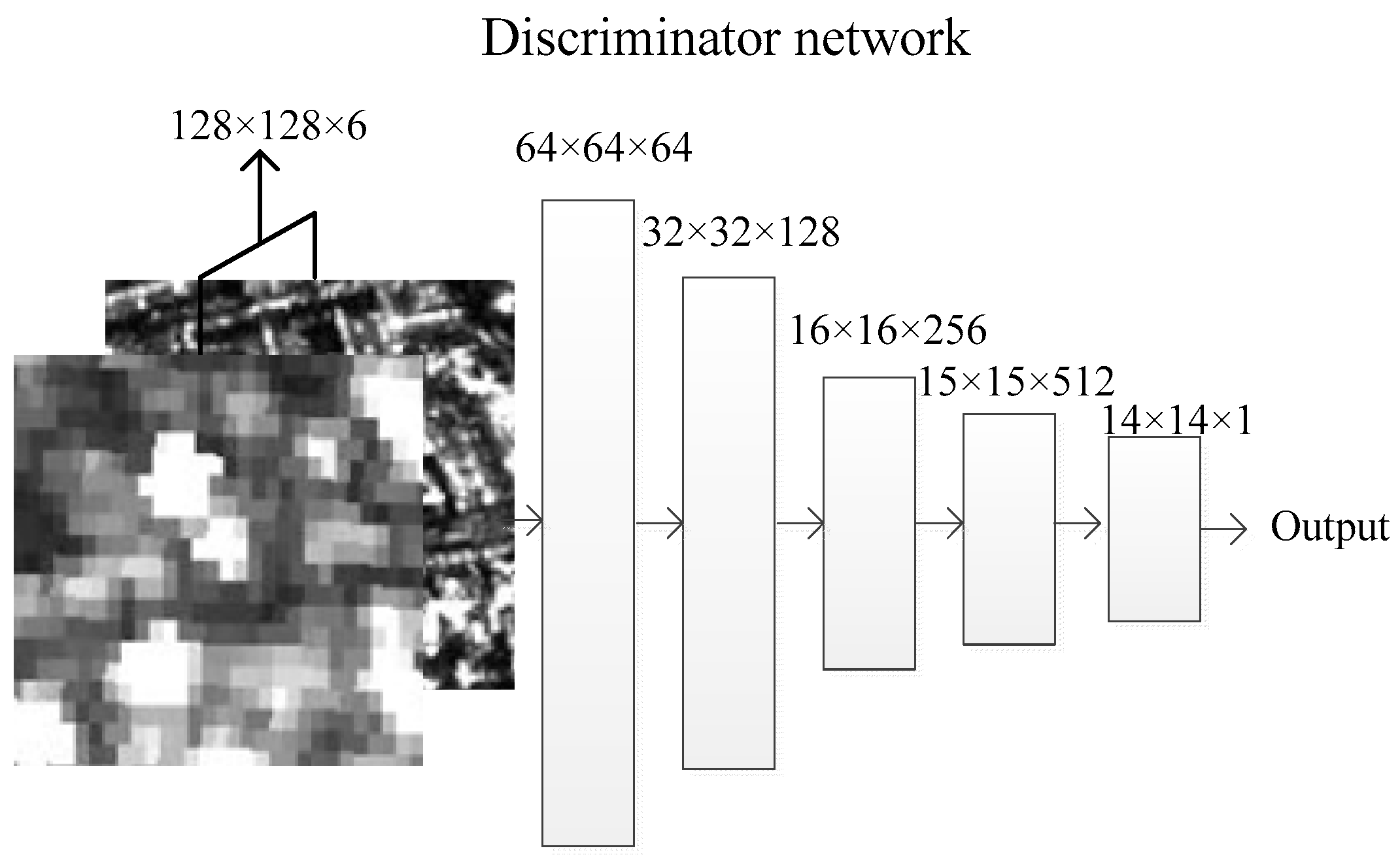
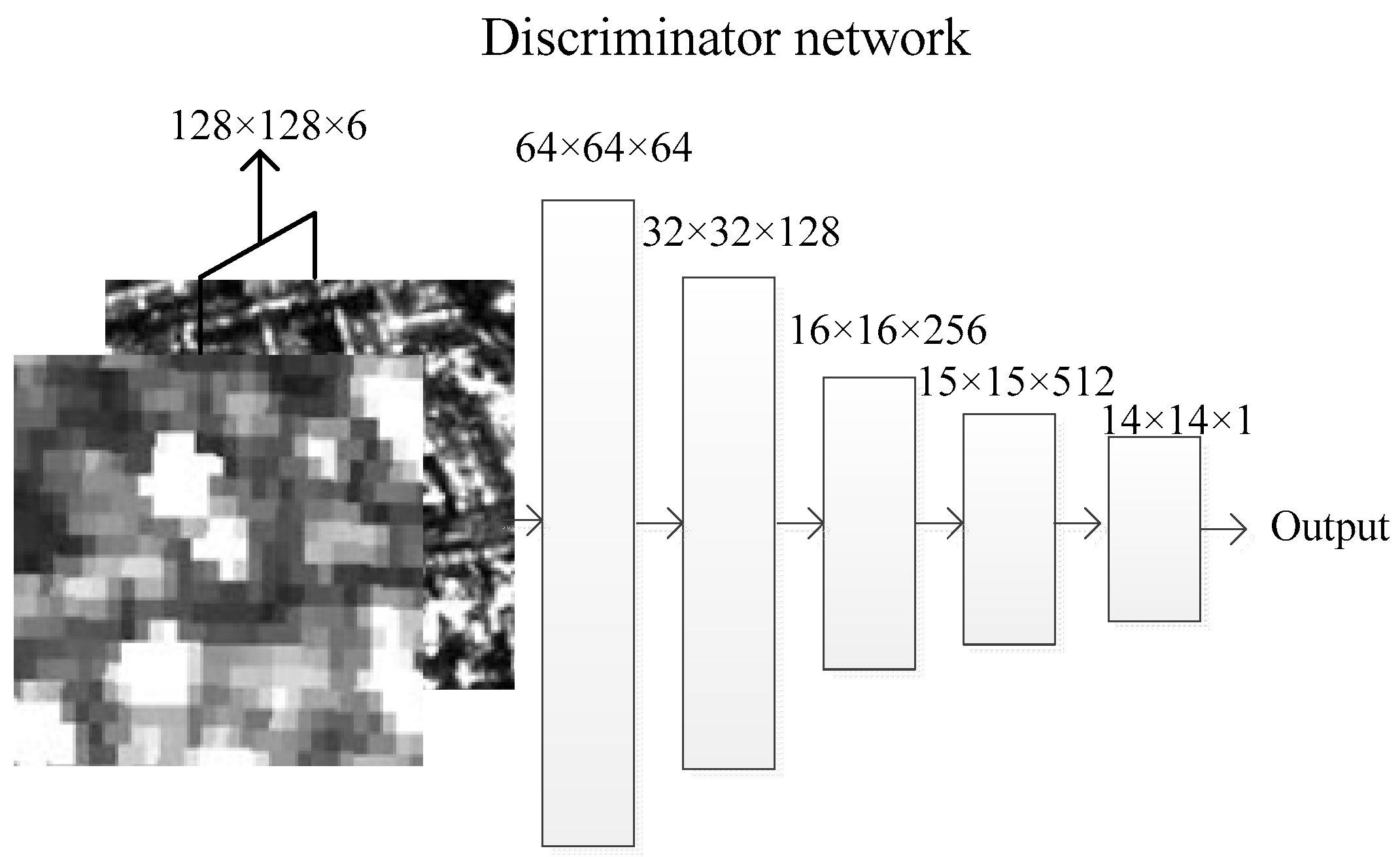
4.2. “Discriminator” Network—Antithesis
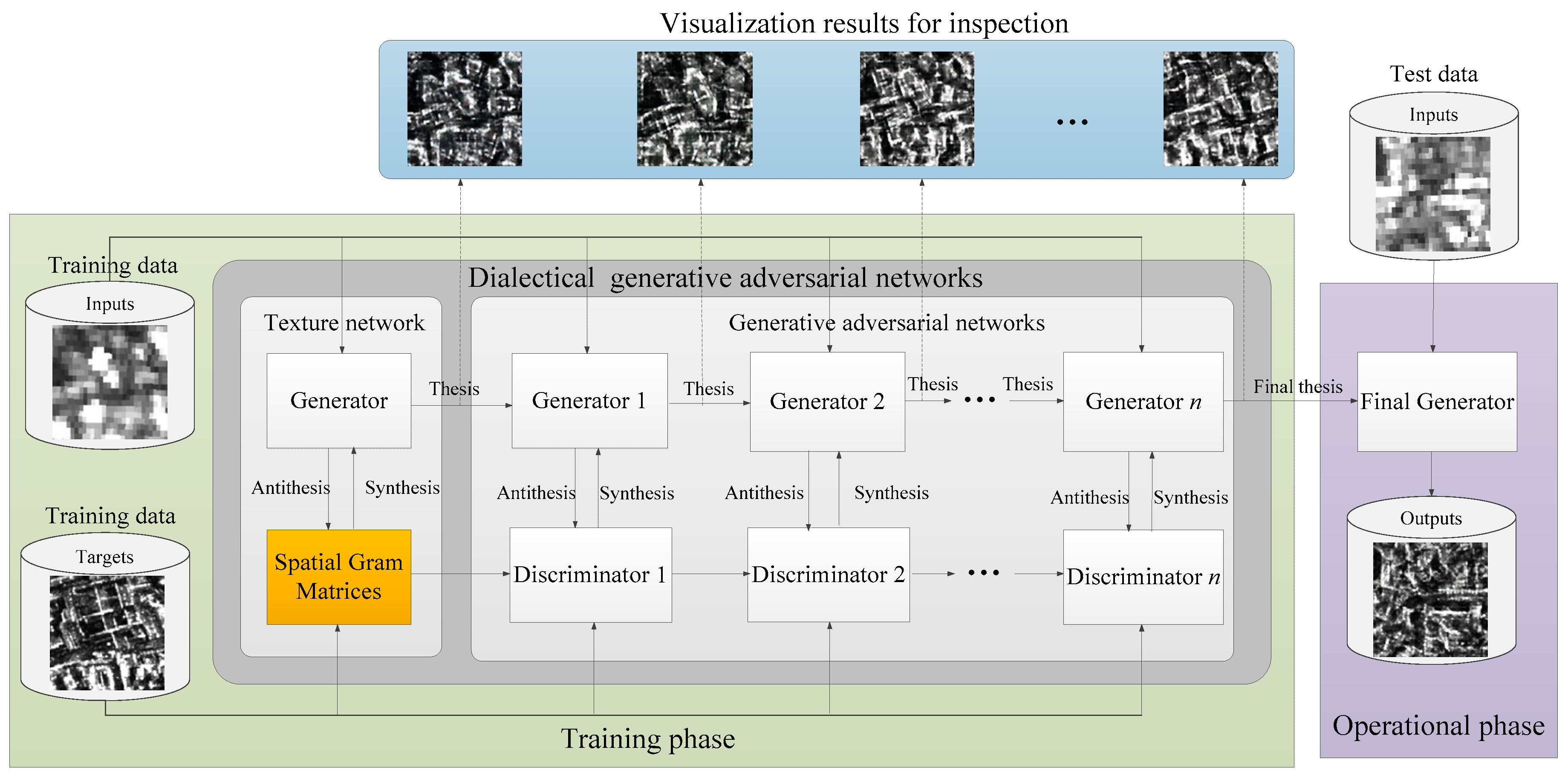
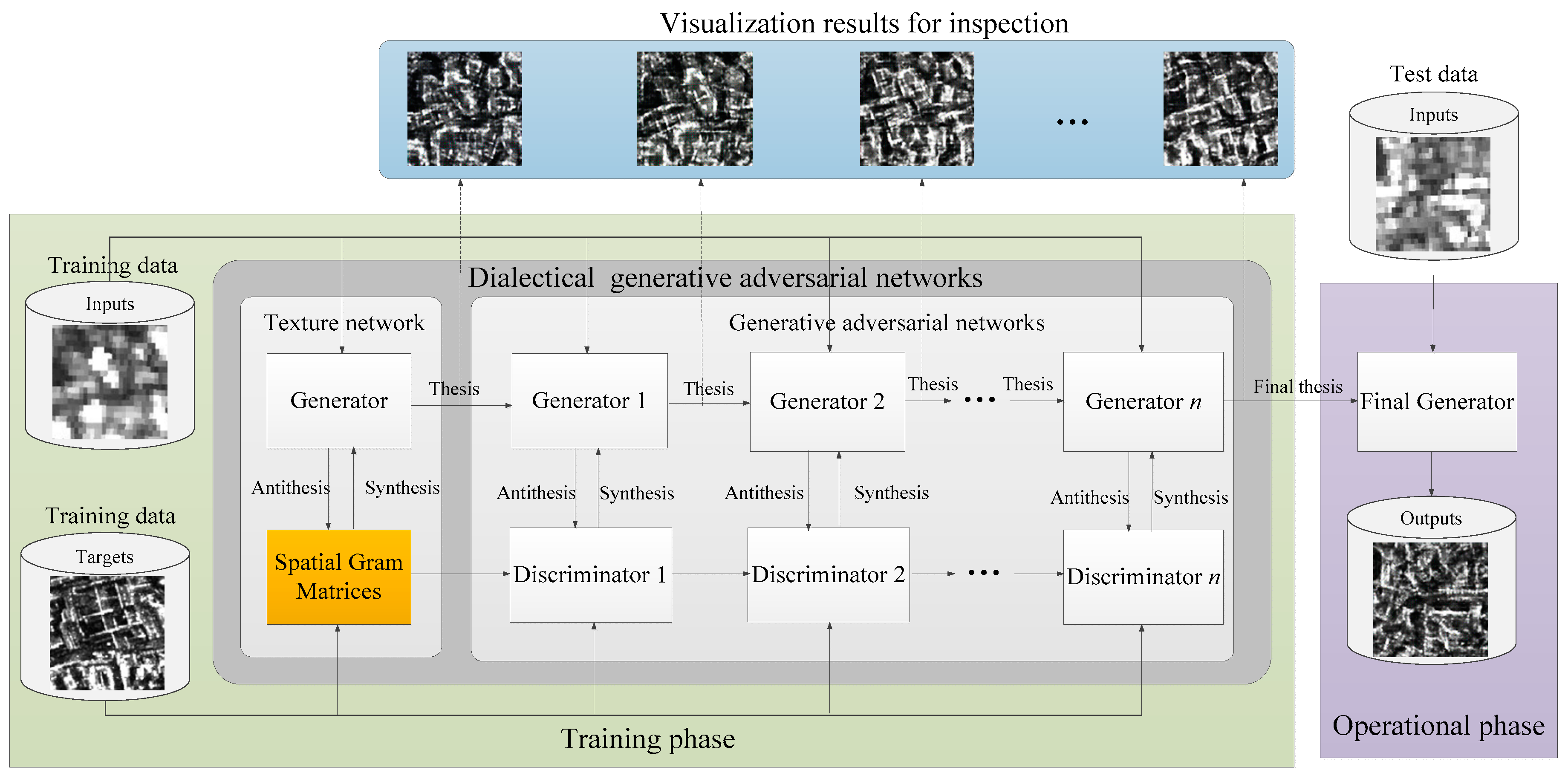
4.3. Dialectical Generative Adversarial Networ—Synthesis
- Step 1, having a Generator and an input image , use them to generate , and then run the Discriminator .
- Step 2, use gradient descent methods to update , following (15).
- Step 3, use gradient descent methods to update , following (16).
- Step 4, repeat Step 1 and Step 3 until the stopping condition is met.
5. Experiments
5.1. SAR Images in VGG-19 Networks
5.2. Gram Martrices vs. Spatial Gram Martrices
5.3. Spatial Gram Matrices vs. Traditional GANs
5.4. The Dialectical GAN vs. Spatial Gram Matrices
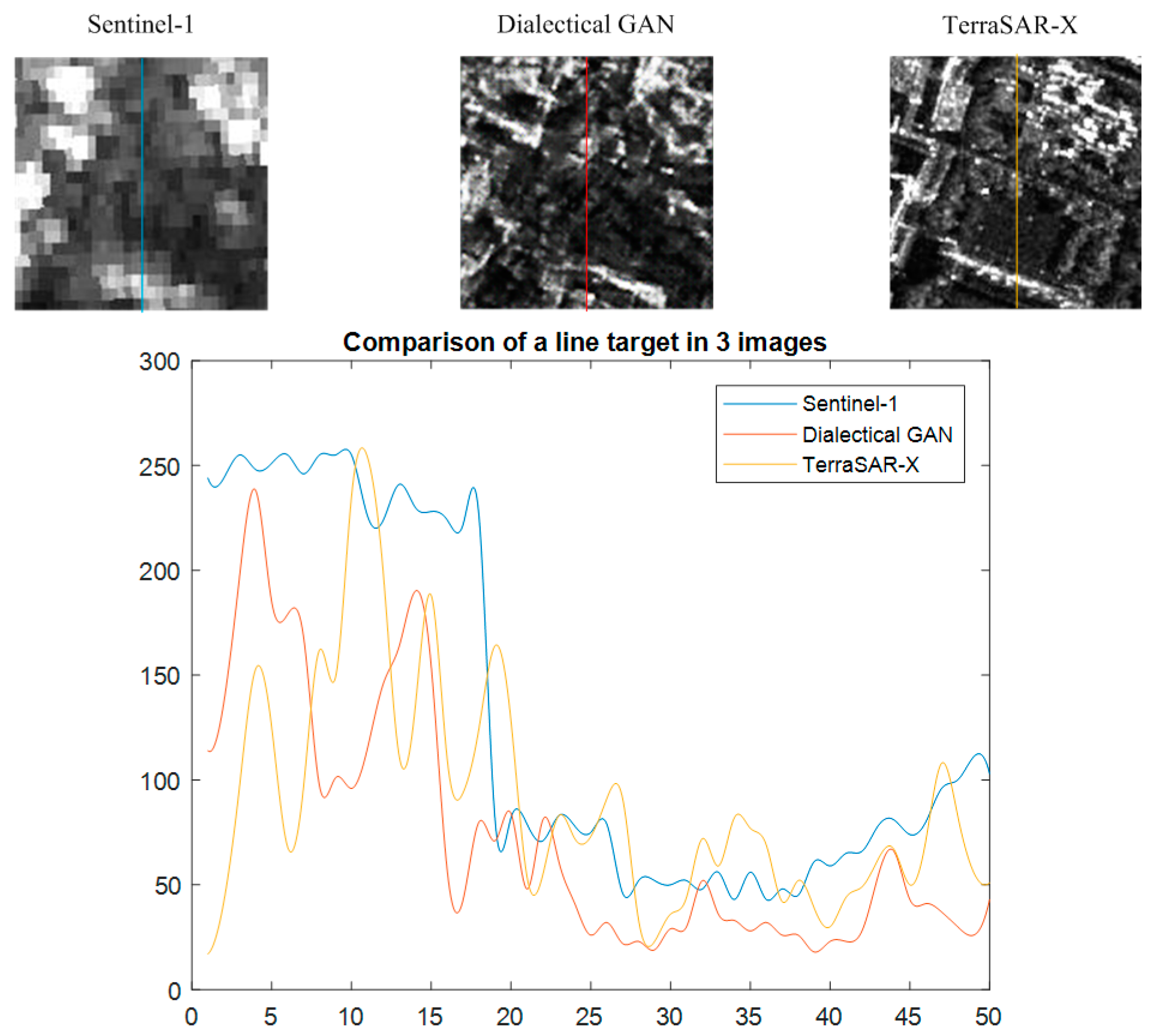
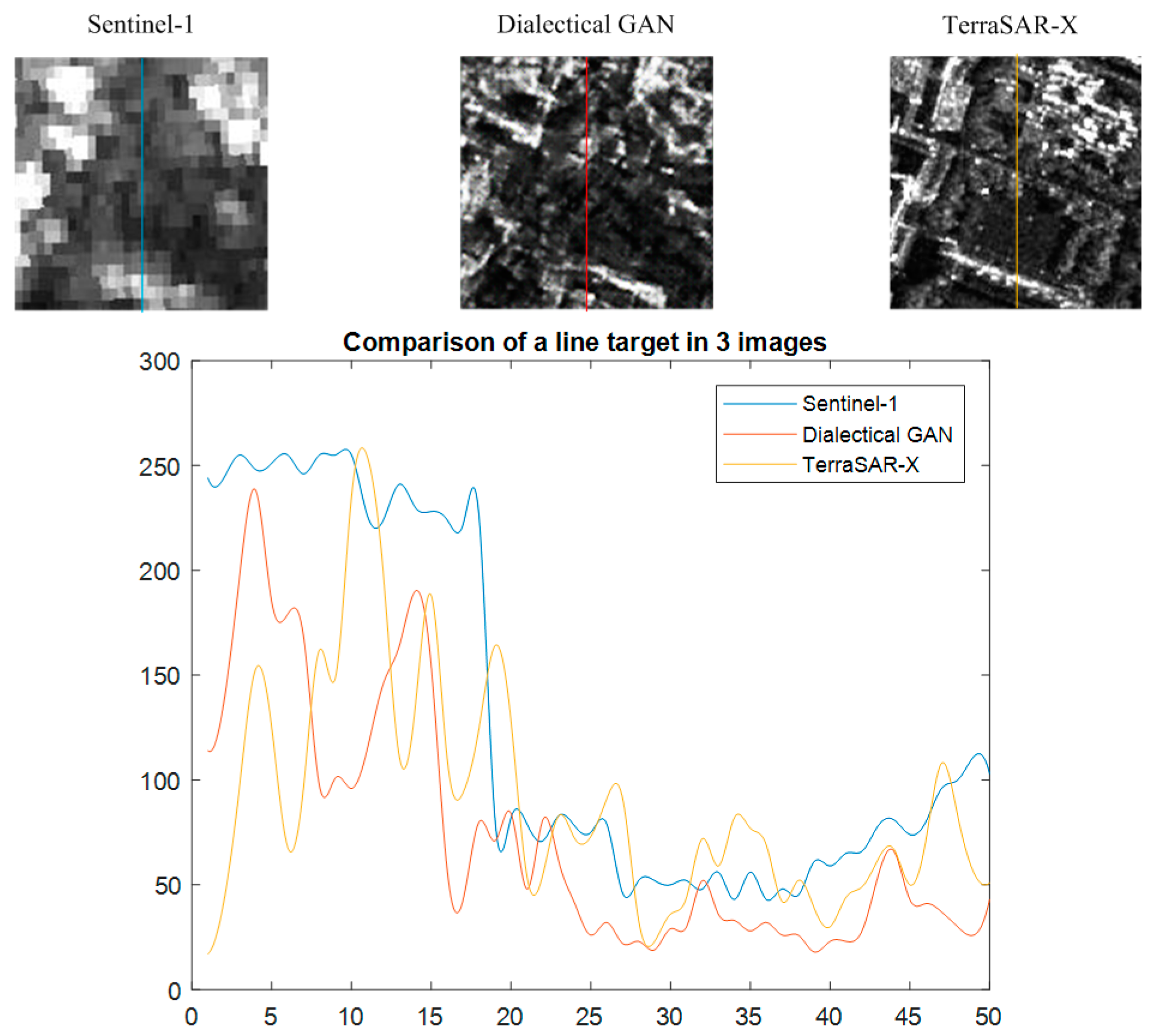
5.5. Overall Visual Perfomance
6. Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Love, A. In memory of Carl A. Wiley. IEEE Antennas Propag. Soc. Newsl. 1985, 27, 17–18. [Google Scholar] [CrossRef]
- TerraSAR-X—Germany’s Radar Eye in Space. Available online: https://www.dlr.de/dlr/en/desktopdefault.aspx/tabid-10377/565_read-436/#/gallery/3501 (accessed on 18 May 2018).
- TanDEM-X—The Earth in Three Dimensions. Available online: https://www.dlr.de/dlr/en/desktopdefault.aspx/tabid-10378/566_read-426/#/gallery/345G (accessed on 18 May 2018).
- RADARSAT. Available online: https://en.wikipedia.org/wiki/RADARSAT (accessed on 18 May 2018).
- COSMO-SkyMed. Available online: http://en.wikipedia.org/wiki/COSMO-SkyMed (accessed on 18 May 2018).
- European Space Agency. Available online: http://en.wikipedia.org/wiki/European_Space_Agency (accessed on 18 May 2018).
- Li, Y.H.; Guarnieri, A.M.; Hu, C.; Rocca, F. Performance and Requirements of GEO SAR Systems in the Presence of Radio Frequency Interferences. Remote Sens. 2018, 10, 82. [Google Scholar] [CrossRef]
- Ao, D.Y.; Li, Y.H.; Hu, C.; Tian, W.M. Accurate Analysis of Target Characteristic in Bistatic SAR Images: A Dihedral Corner Reflectors Case. Sensors 2018, 18, 24. [Google Scholar] [CrossRef] [PubMed]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar]
- Ulyanov, D.; Lebedev, V.; Vedaldi, A.; Lempitsky, V.S. Texture Networks: Feed-forward Synthesis of Textures and Stylized Images. arXiv, 2016; arXiv:1603.03417. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–12 December 2014; pp. 2672–2680. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. arXiv, 2017; arXiv:1611.07004. [Google Scholar]
- Merkle, N.; Auer, S.; Müller, R.; Reinartz, P. Exploring the Potential of Conditional Adversarial Networks for Optical and SAR Image Matching. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1811–1820. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.-S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A review. arXiv, 2017; arXiv:1710.03959. [Google Scholar]
- Garcia-Pineda, O.; Zimmer, B.; Howard, M.; Pichel, W.; Li, X.; MacDonald, I.R. Using SAR Image to Delineate Ocean Oil Slicks with a Texture Classifying Neural Network Algorithm (TCNNA). Can. J. Remote Sens. 2009, 5, 411–421. [Google Scholar] [CrossRef]
- Shi, H.; Chen, L.; Zhuang, Y.; Yang, J.; Yang, Z. A novel method of speckle reduction and enhancement for SAR image. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3128–3131. [Google Scholar]
- Chierchia, G. SAR image despeckling through convolutional neural networks. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017. [Google Scholar]
- Xiang, D.; Tang, T.; Hu, C.; Li, Y.; Su, Y. A kernel clustering algorithm with fuzzy factor: Application to SAR image segmentation. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1290–1294. [Google Scholar] [CrossRef]
- Hu, C.; Li, Y.; Dong, X.; Wang, R.; Cui, C. Optimal 3D deformation measuring in inclined geosynchronous orbit SAR differential interferometry. Sci. China Inf. Sci. 2017, 60, 060303. [Google Scholar] [CrossRef]
- Sentinel-1. Available online: http://en.wikipedia.org/wiki/Sentinel-1 (accessed on 18 May 2018).
- TerraSAR-X. Available online: http://en.wikipedia.org/wiki/ TerraSAR-X (accessed on 18 May 2018).
- Ao, D.; Wang, R.; Hu, C.; Li, Y. A Sparse SAR Imaging Method Based on Multiple Measurement Vectors Model. Remote Sens. 2017, 9, 297. [Google Scholar] [CrossRef]
- Mitas, L.; Mitasova, H. Spatial Interpolation. In Geographical Information Systems: Principles, Techniques, Management and Applications; Longley, P., Goodchild, M.F., Maguire, D.J., Rhind, D.W., Eds.; Wiley: Hoboken, NJ, USA, 1999. [Google Scholar]
- Dumitru, C.O.; Schwarz, G.; Datcu, M. Land cover semantic annotation derived from high-resolution SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2215–2232. [Google Scholar] [CrossRef]
- Jing, Y.; Yang, Y.; Feng, Z.; Ye, J.; Yu, Y.; Song, M. Neural style transfer: A review. arXiv, 2017; arXiv:1705.04058. [Google Scholar]
- Liao, J.; Yao, Y.; Yuan, L.; Hua, G.; Kang, S.B. Visual attribute transfer through deep image analogy. arXiv, 2017; arXiv:1705.01088. [Google Scholar] [CrossRef]
- Berger, G.; Memisevic, R. Incorporating long-range consistency in CNN-based texture generation. arXiv, 2016; arXiv:1606.01286. [Google Scholar]
- The-Gan-Zoo. Available online: http://github.com/hindupuravinash/the-gan-zoo (accessed on 18 May 2018).
- Li, C.; Wand, M. Precomputed real-time texture synthesis with Markovian generative adversarial networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 702–716. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. arXiv, 2016; arXiv:1609.04802. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Amsterdam, The Netherlands, 11–14 October 2016; pp. 2536–2544. [Google Scholar]
- Zhu, J.-Y.; Krähenbühl, P.; Shechtman, E.; Efros, A.A. Generative visual manipulation on the natural image manifold. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 597–613. [Google Scholar]
- Schnitker, S.A.; Emmons, R.A. Hegel’s Thesis-Antithesis-Synthesis Model. In Encyclopedia of Sciences and Religions; Runehov, A.L.C., Oviedo, L., Eds.; Springer: Dordrecht, The Netherlands, 2013. [Google Scholar]
- Liang, S.; Srikant, R. Why deep neural networks for function approximation? arXiv, 2016; arXiv:1610.04161. [Google Scholar]
- Yarotsky, D. Optimal approximation of continuous functions by very deep ReLU networks. arXiv, 2018; arXiv:1802.03620. [Google Scholar]
- Wang, X.; Gupta, A. Generative image modeling using style and structure adversarial networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 318–335. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Metric Space. Available online: https://en.wikipedia.org/wiki/Metric_space (accessed on 18 May 2018).
- Nowozin, S.; Cseke, B.; Tomioka, R. f-gan: Training generative neural samplers using variational divergence minimization. arXiv, 2016; arXiv:1606.00709. [Google Scholar]
- Divergence (Statistics). Available online: https://en.wikipedia.org/wiki/ Divergence_(statistics) (accessed on 18 May 2018).
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Smolley, S.P. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Tampa, FL, USA, 5–8 December 1988; pp. 2813–2821. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein gan. arXiv, 2017; arXiv:1701.07875. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. arXiv, 2017; arXiv:1704.00028. [Google Scholar]
- Pennington, J.; Bahri, Y. Geometry of neural network loss surfaces via random matrix theory. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2798–2806. [Google Scholar]
- Haeffele, B.D.; Vidal, R. Global optimality in neural network training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Tampa, FL, USA, 5–8 December 1988; pp. 7331–7339. [Google Scholar]
- Lucic, M.; Kurach, K.; Michalski, M.; Gelly, S.; Bousquet, O. Are GANs Created Equal? A Large-Scale Study. arXiv, 2017; arXiv:1711.10337. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Zénere, M.P. SAR Image Quality Assessment; Universidad Nacional De Cordoba: Córdoba, Argentina, 2012. [Google Scholar]
- Anfinsen, S.N.; Doulgeris, A.P.; Eltoft, T. Estimation of the equivalent number of looks in polarimetric synthetic aperture radar imagery. IEEE Trans. Geosci. Remote Sens. 2009, 47, 3795–3809. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SAR Instrument | TerraSAR-X | Sentinel-1A |
|---|---|---|
| Carrier frequency band | X-band | C-band |
| Product level | Level 1b | Level 1 |
| Instrument mode | High Resolution Spotlight | Interferometric Wide Swath |
| Polarization | VV | VV |
| Orbit branch | Descending | Ascending |
| Incidence angle | 39° | 30°–46° |
| Product type | Enhanced Ellipsoid Corrected (EEC) (amplitude data) | Ground Range Detected High Resolution (GRDH) (amplitude data) |
| Enhancement | Radiometrically enhanced | Multi-looked |
| Ground range resolution | 2.9 m | 20 m |
| Pixel spacing | 1.25 m | 10 m |
| Equivalent number of looks (range × azimuth) | 3.2 × 2.6 = 8.3 | 5 × 1 = 5 |
| Map projection | WGS-84 | WGS-84 |
| Acquisition date | 29 April 2013 | 13 October 2014 |
| Original full image size (cols × rows) | 9200 × 8000 | 34,255 × 18,893 |
| Used image sizes (cols × rows) | 6370 × 4320 | 1373 × 936 |
| Layers | MSE | SSIM |
|---|---|---|
| ReLU1_1 | 0.1616 | 0.4269 |
| ReLU2_1 | 0.5553 | 0.0566 |
| ReLU3_1 | 0.5786 | 0.2115 |
| ReLU4_1 | 0.3803 | 0.7515 |
| ReLU5_1 | 0.2273 | 0.7637 |
| Image Pairs | Methods | MSE | SSIM | ENL |
|---|---|---|---|---|
| 1 | Gatys et al. Gram | 0.3182 | 0.0925 | 1.8286 |
| Spatial Gram | 0.2762 | 0.1888 | 2.0951 | |
| 2 | Gatys et al. Gram | 0.3795 | 0.0569 | 2.0389 |
| Spatial Gram | 0.3642 | 0.0700 | 1.9055 |
| Image Pairs | Methods | MSE | SSIM | ENL |
|---|---|---|---|---|
| 1 | Texture network | 0.3265 | 0.0614 | 1.3932 |
| WGAN-GP | 0.2464 | 0.1993 | 2.8725 | |
| 2 | Texture network | 0.3396 | 0.0766 | 1.6269 |
| WGAN-GP | 0.2515 | 0.2058 | 3.5205 | |
| Test set | Texture network | 0.3544 | 0.0596 | 1.7005 |
| WGAN-GP | 0.2632 | 0.2117 | 3.3299 |
| Image Pairs | Methods | MSE | SSIM | ENL |
|---|---|---|---|---|
| 1 | Texture network | 0.3264 | 0.0614 | 1.3933 |
| Dialectical GAN | 0.3291 | 0.0884 | 1.5885 | |
| 2 | Texture network | 0.3396 | 0.0766 | 1.6270 |
| Dialectical GAN | 0.3310 | 0.0505 | 1.8147 | |
| Test set | Texture network | 0.3544 | 0.0596 | 1.7005 |
| Dialectical GAN | 0.3383 | 0.0769 | 1.8804 | |
| Original data | Sentinel-1 | 0.3515 | 0.1262 | 5.1991 |
| TerraSAR-X | - | - | 1.6621 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ao, D.; Dumitru, C.O.; Schwarz, G.; Datcu, M. Dialectical GAN for SAR Image Translation: From Sentinel-1 to TerraSAR-X. Remote Sens. 2018, 10, 1597. https://doi.org/10.3390/rs10101597
Ao D, Dumitru CO, Schwarz G, Datcu M. Dialectical GAN for SAR Image Translation: From Sentinel-1 to TerraSAR-X. Remote Sensing. 2018; 10(10):1597. https://doi.org/10.3390/rs10101597
Chicago/Turabian StyleAo, Dongyang, Corneliu Octavian Dumitru, Gottfried Schwarz, and Mihai Datcu. 2018. "Dialectical GAN for SAR Image Translation: From Sentinel-1 to TerraSAR-X" Remote Sensing 10, no. 10: 1597. https://doi.org/10.3390/rs10101597
APA StyleAo, D., Dumitru, C. O., Schwarz, G., & Datcu, M. (2018). Dialectical GAN for SAR Image Translation: From Sentinel-1 to TerraSAR-X. Remote Sensing, 10(10), 1597. https://doi.org/10.3390/rs10101597