Landslide Susceptibility Mapping and Comparison Using Decision Tree Models: A Case Study of Jumunjin Area, Korea





Abstract
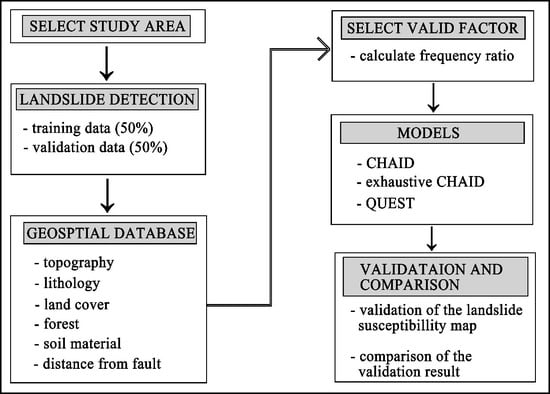
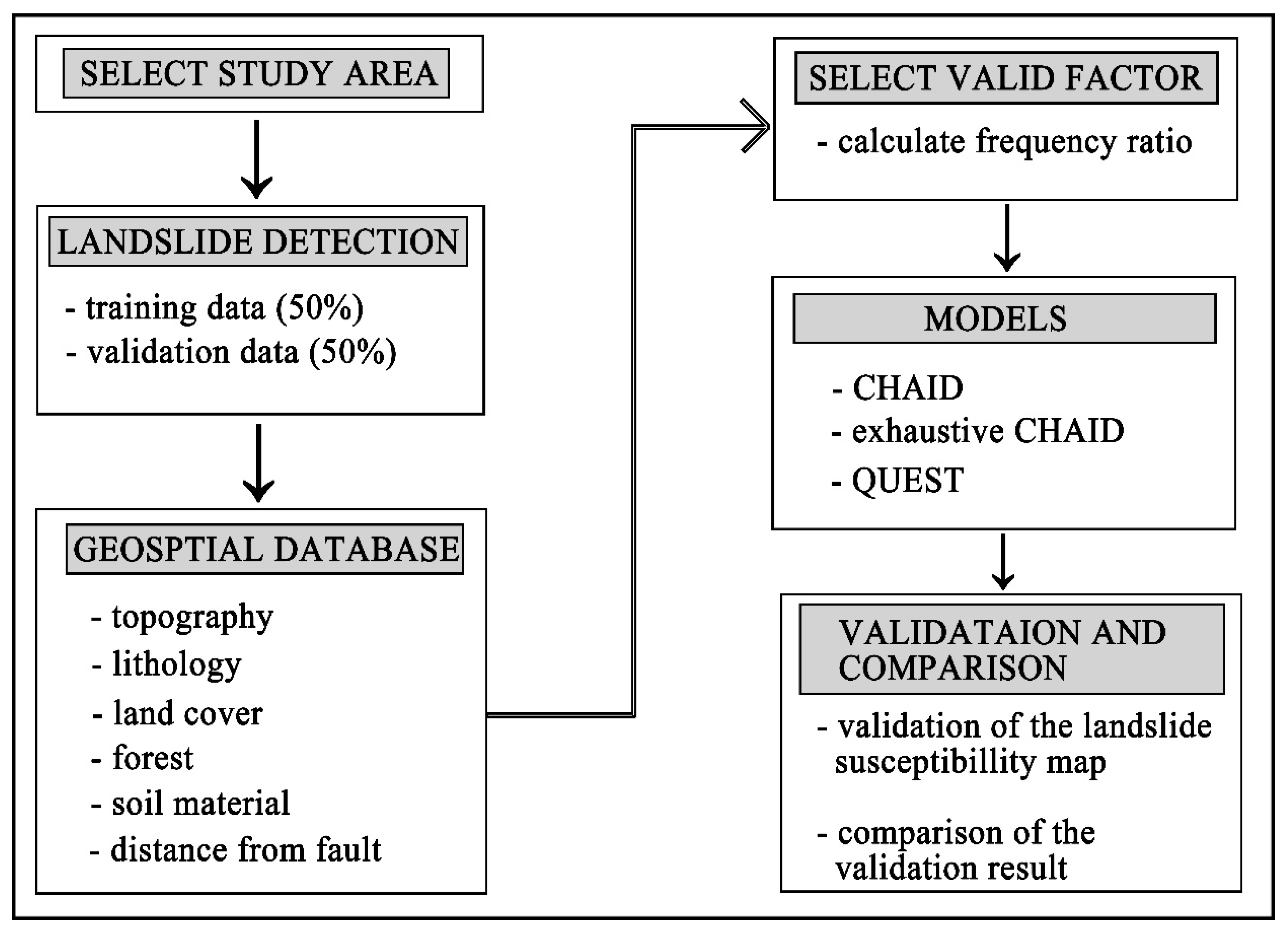
:
1. Introduction
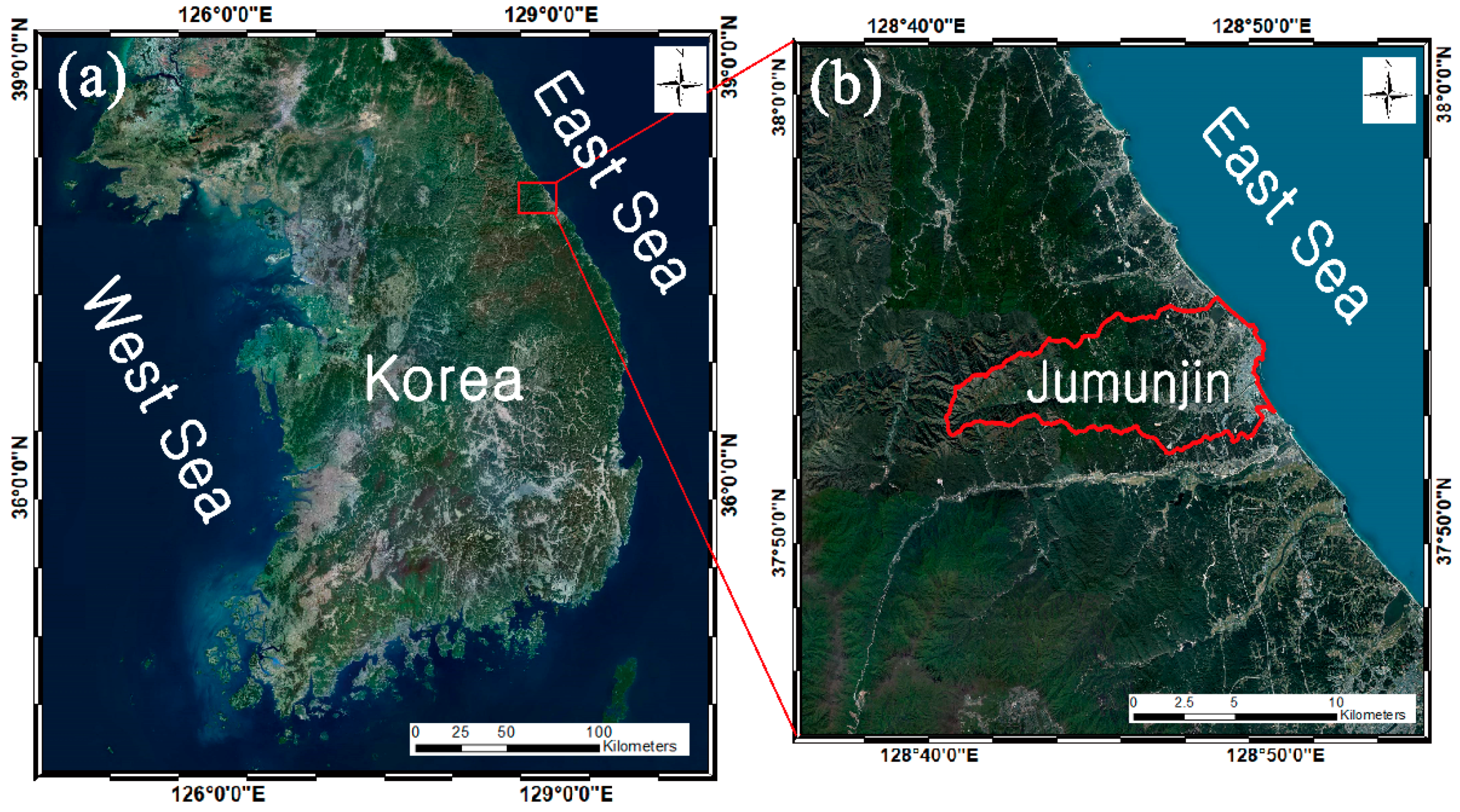
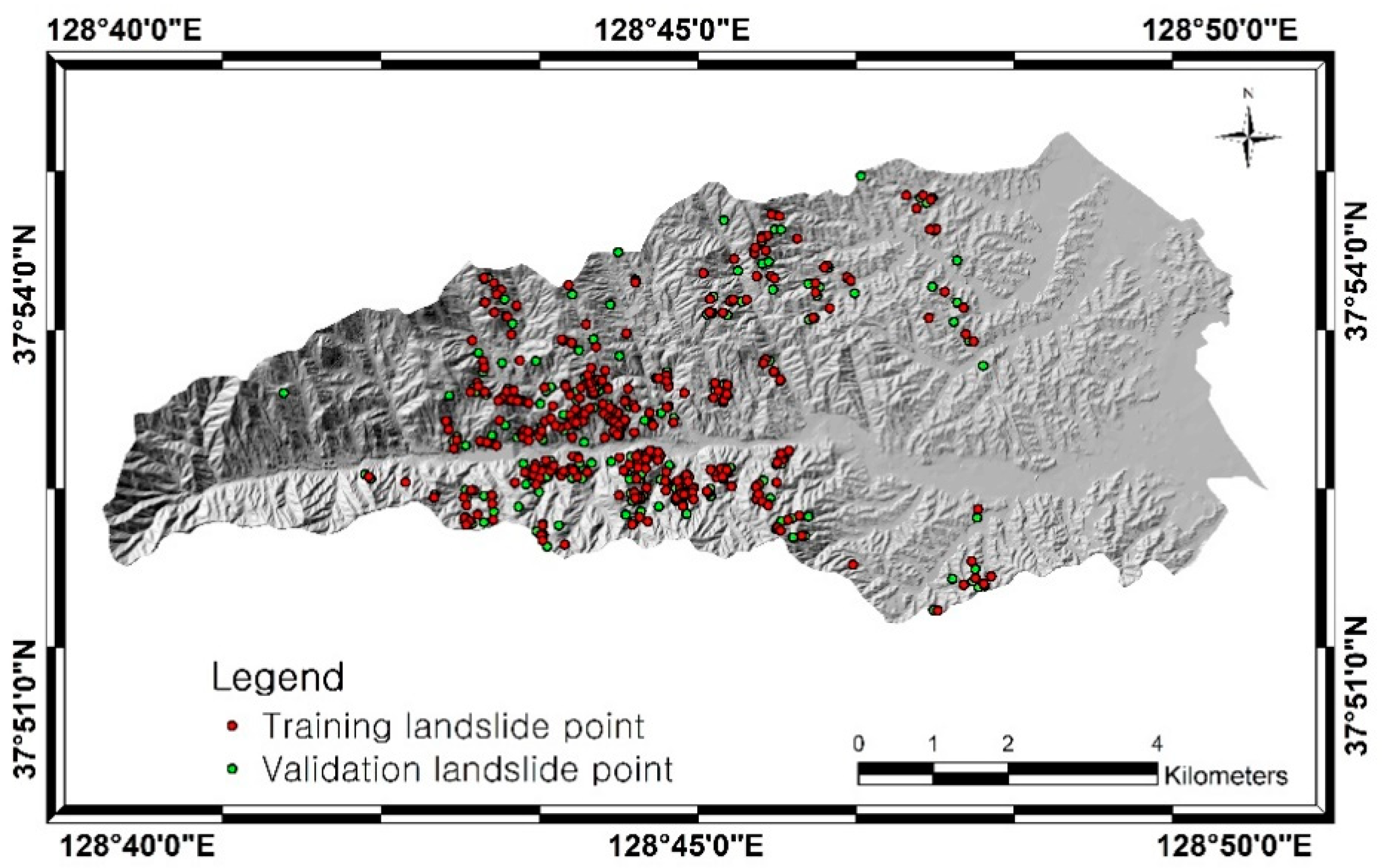
2. Data and Pre-Processing
3. Method
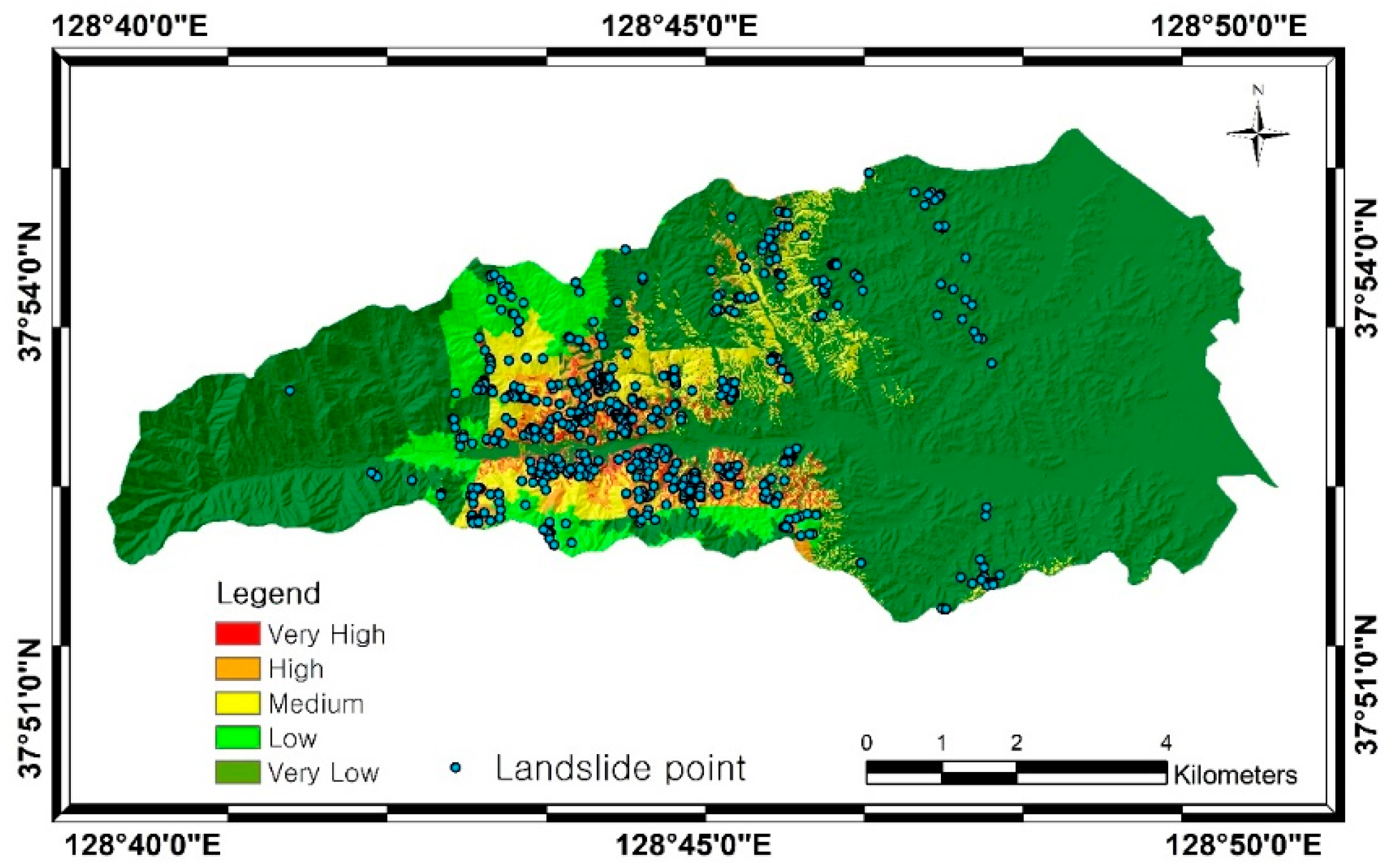
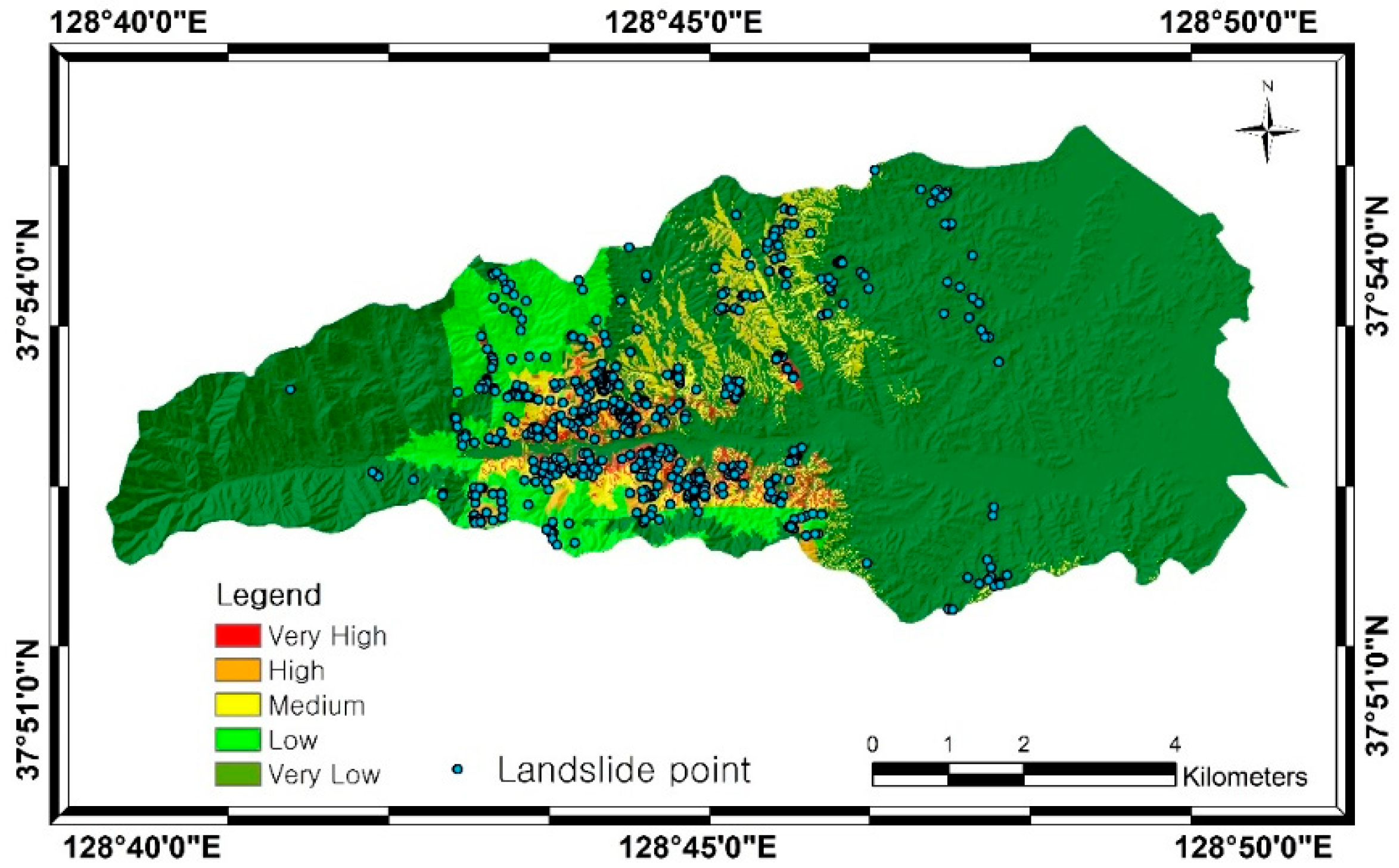
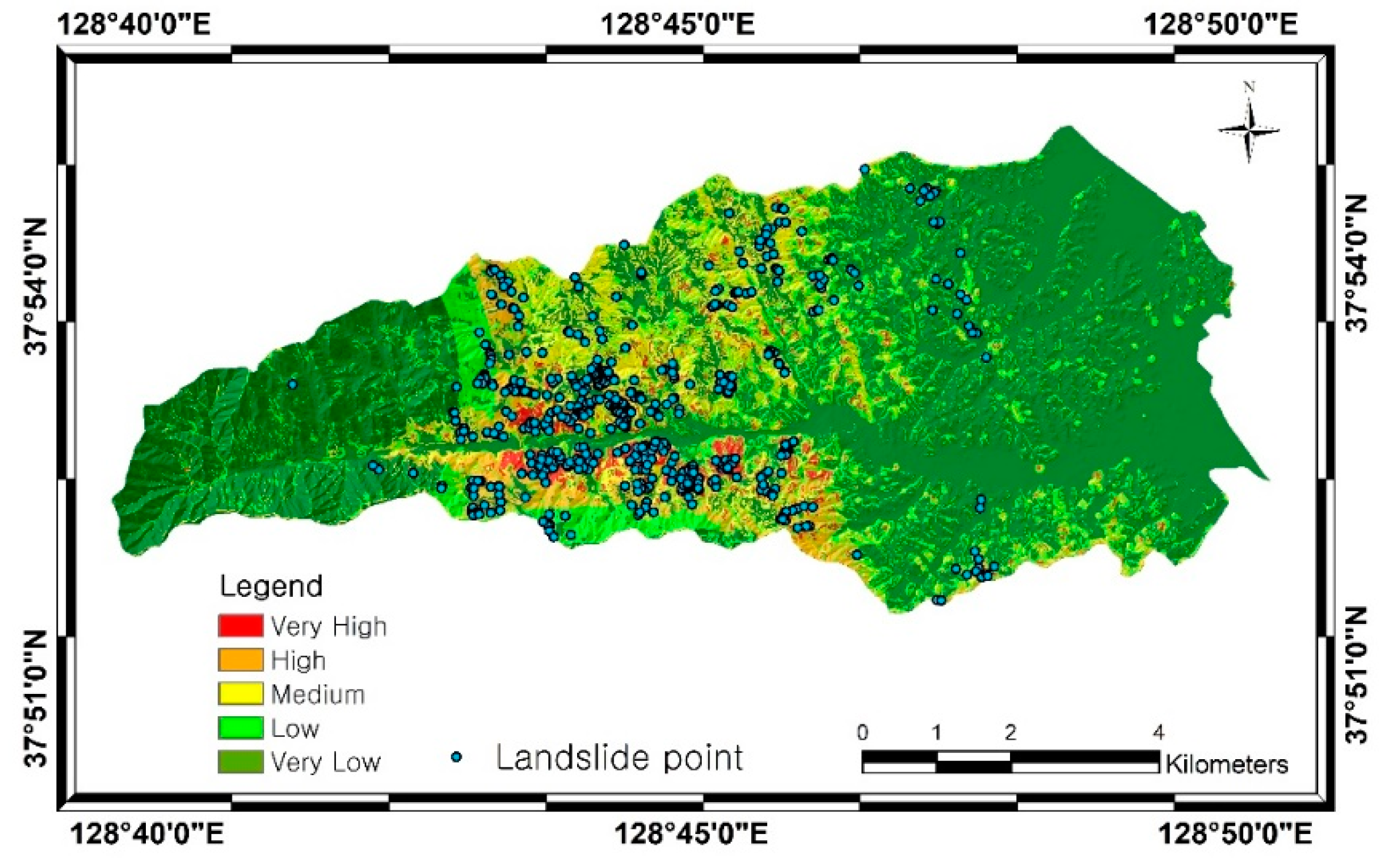
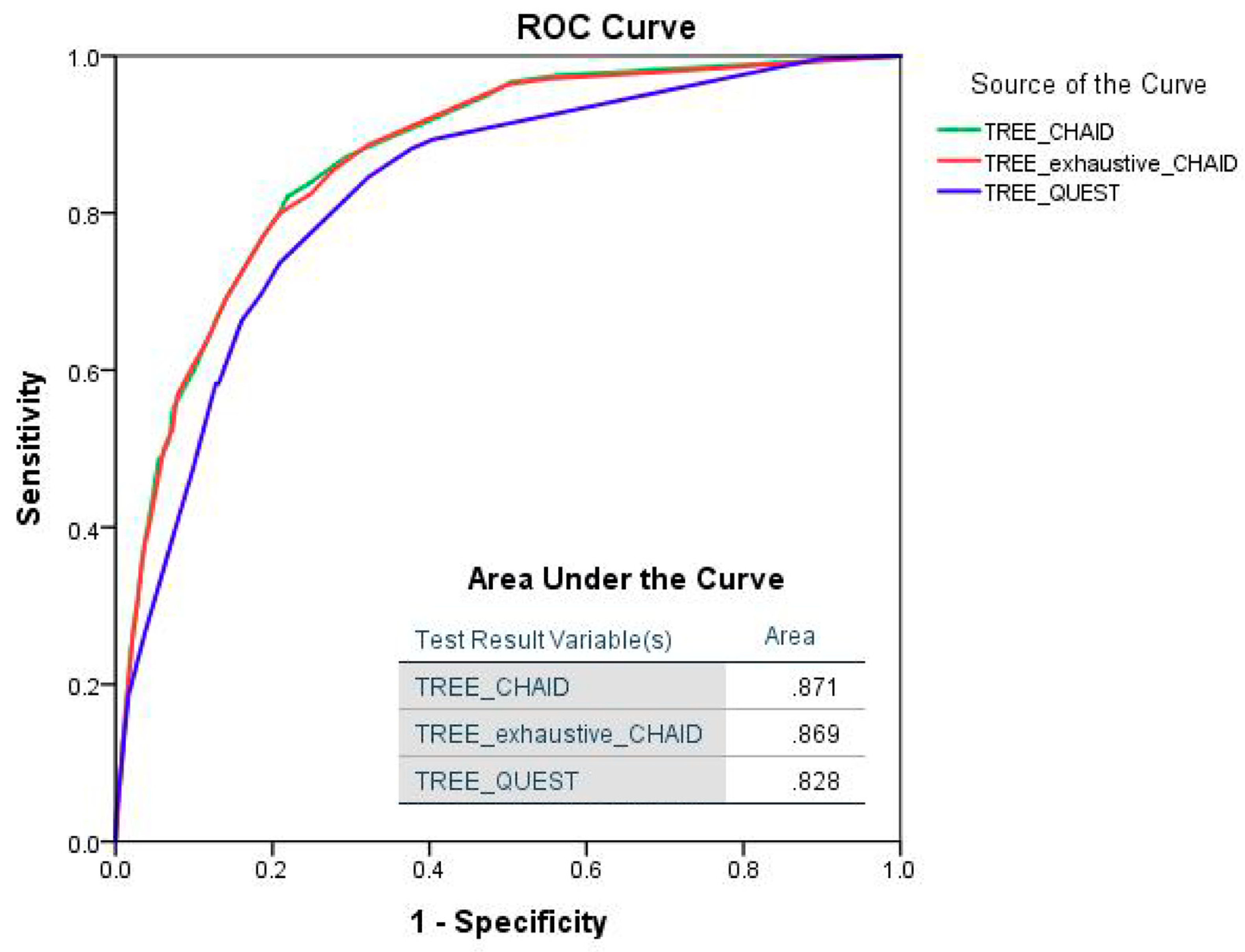
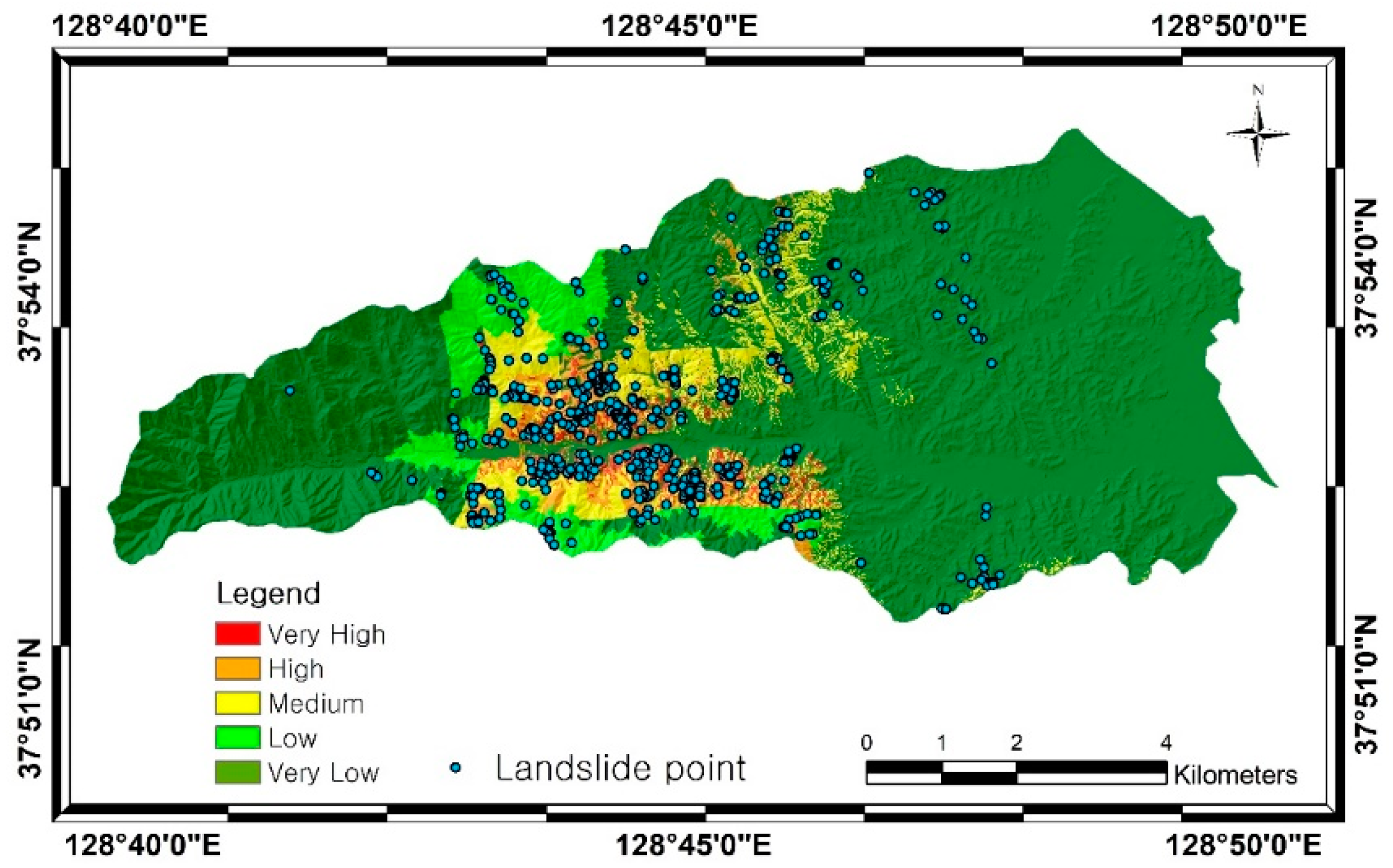
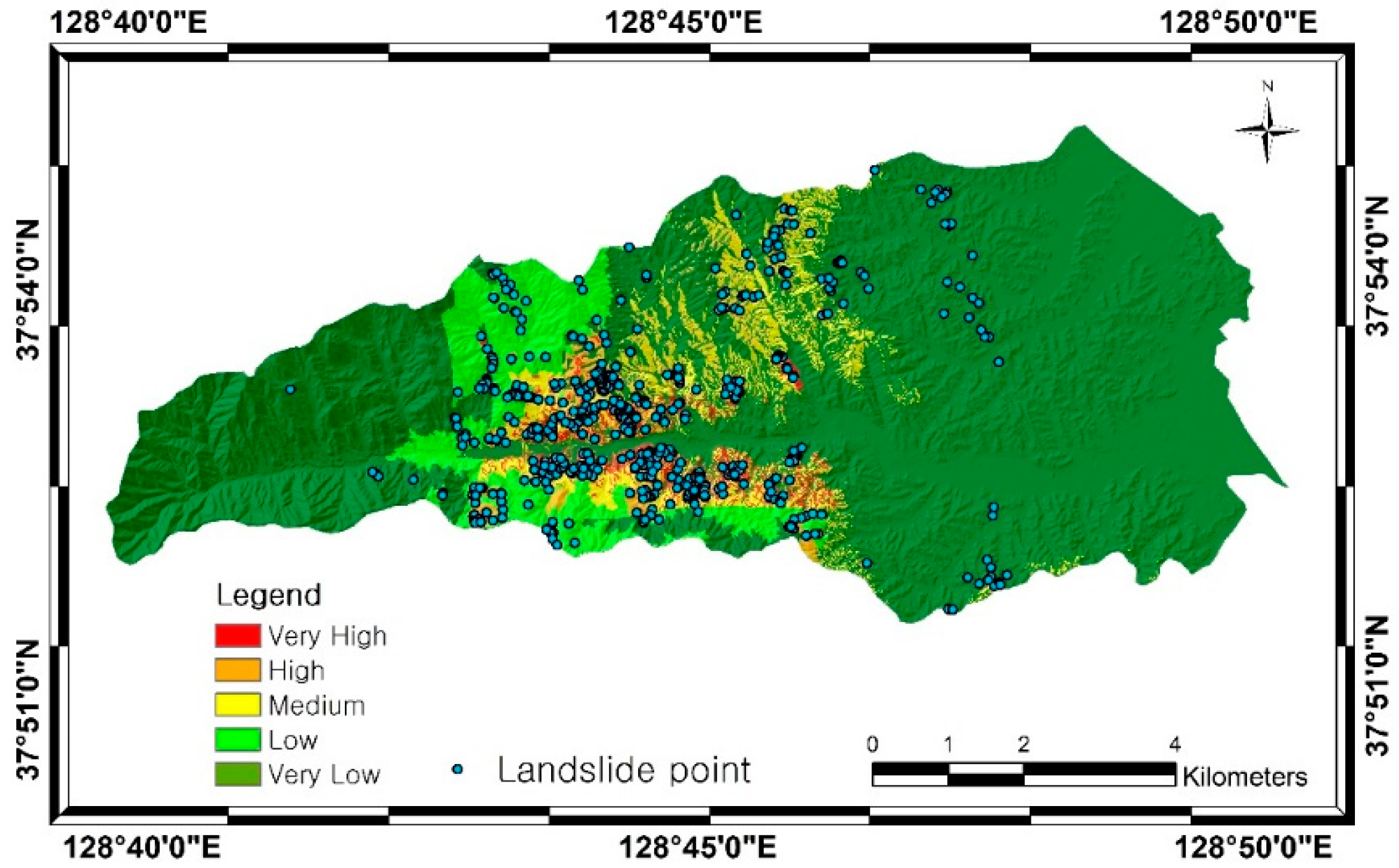
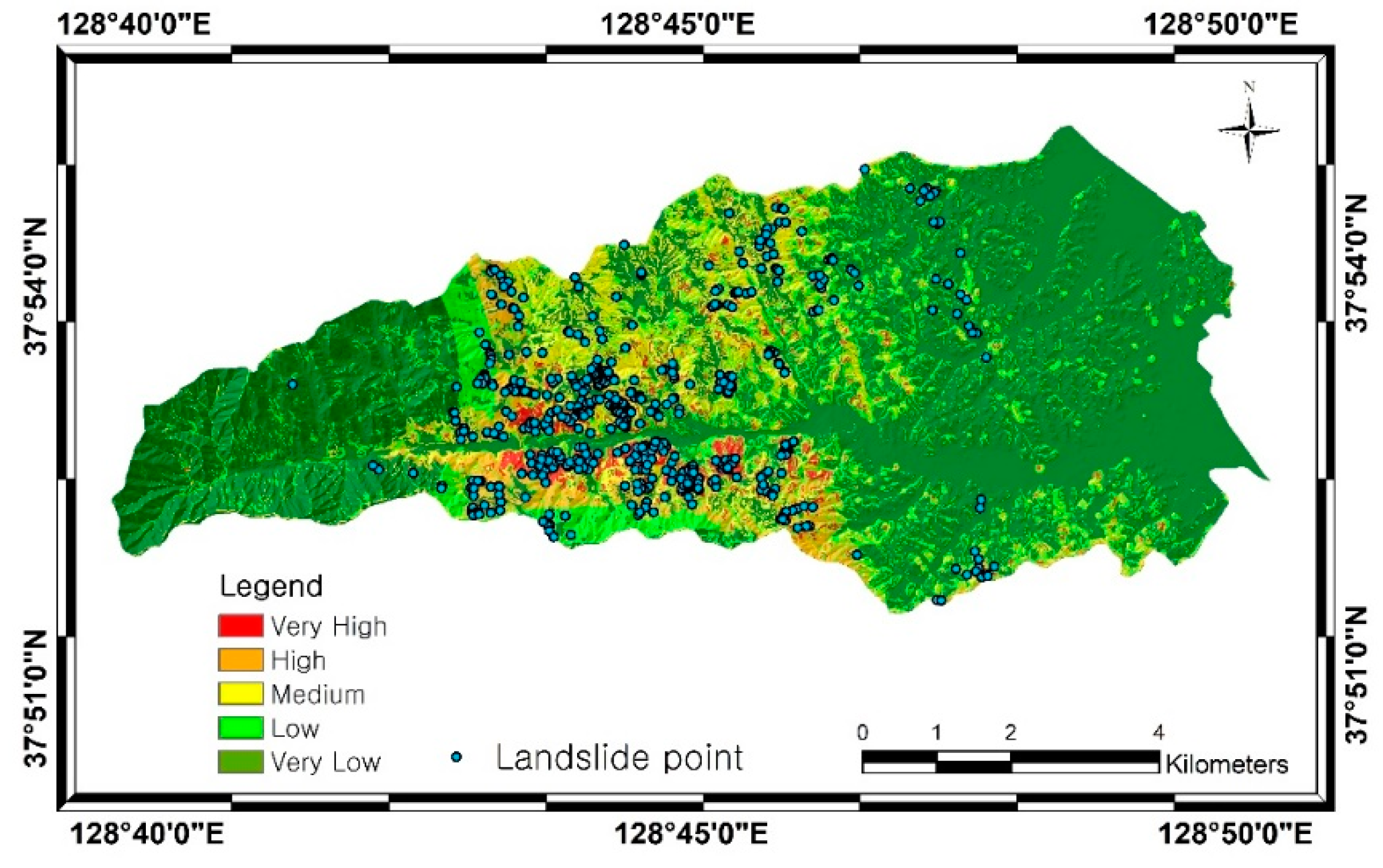
4. Results
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gariano, S.L.; Rianna, G.; Petrucci, O.; Guzzetti, F. Assessing future changes in the occurrence of rainfall-induced landslides at a regional scale. Sci. Total Environ. 2017, 596, 417–426. [Google Scholar] [CrossRef] [PubMed]
- Daum Map. Available online: http://map.daum.net/ (accessed on 20 December 2017).
- Tsangaratos, P.; Ilia, I. Landslide susceptibility mapping using a modified decision tree classifier in the Xanthi Perfection, Greece. Landslides 2016, 13, 305–320. [Google Scholar] [CrossRef]
- Reichenbach, P.; Rossi, M.; Malamud, B.; Mihir, M.; Guzzetti, F. A review of statistically-based landslide susceptibility models. Earth-Sci. Rev. 2018, 180, 60–91. [Google Scholar] [CrossRef]
- Van Westen, C.J.; Van Asch, T.W.J.; Soeters, R. Landslide hazard and risk zonation—Why is it still so difficult? Bull. Eng. Geol. Environ. 2006, 65, 167–184. [Google Scholar] [CrossRef]
- Lee, S.; Choi, J.; Woo, I. The effect of spatial resolution on the accuracy of landslide susceptibility mapping: A case study in Boun, Korea. Geosci. J. 2004, 8, 51–60. [Google Scholar] [CrossRef]
- Hong, H.; Naghibi, S.A.; Pourghasemi, H.R.; Pradhan, B. GIS-based landslide spatial modeling in Ganzhou city, China. Arab. J. Geosci. 2016, 9, 1–26. [Google Scholar] [CrossRef]
- Goetz, J.N.; Brenning, A.; Petschko, H.; Leopold, P. Evaluating machine learning and statistical prediction techniques for landslide susceptibility modeling. Comput. Geosci. 2015, 81, 1–11. [Google Scholar] [CrossRef]
- Lee, M.J.; Park, I.; Won, J.S.; Lee, S. Landslide hazard mapping considering rainfall probability in Inje, Korea. Geomat. Nat. Hazards Risk 2016, 7, 424–446. [Google Scholar] [CrossRef]
- Althuwaynee, O.F.; Pradhan, B.; Lee, S. A novel integrated model for assessing landslide susceptibility mapping using CHAID and AHP pair-wise comparison. Int. J. Remote Sens. 2016, 37, 1190–1209. [Google Scholar] [CrossRef]
- Lee, S.; Pradhan, B. Landslide hazard mapping at Selangor, Malaysia using frequency ratio and logistic regression models. Landslides 2007, 4, 41–47. [Google Scholar] [CrossRef]
- Steger, S.; Brenning, A.; Bell, R.; Petschko, H.; Glade, T. Exploring discrepancies between quantitative validation results and the geomorphic plausibility of statistical landslide susceptibility maps. Geomorphology 2016, 262, 8–23. [Google Scholar] [CrossRef]
- Chen, W.; Xie, X.; Wang, J.; Pradhan, B.; Honh, H.; Tien Bui, D.; Duan, Z.; Ma, J. A comparative study of logistic model tree, random forest, and classification and regression tree models for spatial prediction of landslide susceptibility. Catena 2017, 151, 147–160. [Google Scholar] [CrossRef]
- Feizizadeh, B.; Shadman, R.M.; Jankowski, P.; Blaschke, T. A GIS-based extended fuzzy multi-criteria evaluation for landslide susceptibility mapping. Comput. Geosci. 2014, 73, 208–221. [Google Scholar] [CrossRef] [PubMed]
- Pradhan, B. Manifestation of an advanced fuzzy logic model coupled with geo-information techniques to landslide susceptibility mapping and their comparison with logistic regression modelling. Environ. Ecol. Stat. 2011, 18, 471–493. [Google Scholar] [CrossRef]
- Park, I.; Lee, J.; Lee, S. Ensemble of ground subsidence hazard maps using fuzzy logic. Cent. Eur. J. Geosci. 2014, 6, 207–218. [Google Scholar] [CrossRef] [Green Version]
- Dehnavi, A.; Aghdam, I.N.; Pradhan, B.; Varzandeh, M.H.M. A new hybrid model using step-wise weight assessment ratio analysis (SWAM) technique and adaptive neuro-fuzzy inference system (ANFIS) for regional landslide hazard assessment in Iran. Catena 2015, 135, 122–148. [Google Scholar] [CrossRef]
- Nasiri Aghdam, I.; Varzandeh, M.H.M.; Pradhan, B. Landslide susceptibility mapping using an ensemble statistical index (Wi) and adaptive neuro-fuzzy inference system (ANFIS) model at Alborz Mountains (Iran). Environ. Earth Sci. 2016, 75, 553–572. [Google Scholar] [CrossRef]
- Lee, M.J.; Park, I.; Lee, S. Forecasting and validation of landslide susceptibility using an integration of frequency ratio and neuro-fuzzy models: A case study of Seorak mountain area in Korea. Environ. Earth Sci. 2015, 74, 413–429. [Google Scholar] [CrossRef]
- Conoscenti, C.; Ciaccio, M.; Caraballo-Arias, N.A.; Gomez-Gutierrez, A.; Rotigliano, E.; Agnesi, V. Assessment of susceptibility to earth-flow landslide using logistic regression and multivariate adaptive regression splines: A case of the Bence River basin (western Sicily, Italy). Geomorphology 2015, 242, 49–64. [Google Scholar] [CrossRef]
- Pradhan, B. A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using GIS. Comput. Geosci. 2013, 51, 350–365. [Google Scholar] [CrossRef] [Green Version]
- Pham, B.T.; Tien Bui, D.; Dholakia, M.B.; Prakash, I.; Pham, H.V. A comparative study of least square support vector machines and multiclass alternating decision trees for spatial prediction of rainfall-induced landslides in a tropical cyclones area. Geotech. Geol. Eng. 2016, 34, 1807–1824. [Google Scholar] [CrossRef]
- Pradhan, B. Landslide susceptibility mapping of a catchment area using frequency ratio, fuzzy logic and multivariate logistic regression approaches. J. Indian Soc. Remote Sens. 2010, 38, 301–320. [Google Scholar] [CrossRef]
- Lee, S.; Park, I. Application of decision tree model for the ground subsidence hazard mapping near abandoned underground coal mines. J. Environ. Manag. 2013, 127, 166–176. [Google Scholar] [CrossRef] [PubMed]
- Park, S.; Choi, C.; Kim, B.; Kim, J. Landslide susceptibility mapping using frequency ratio, analytic hierarchy process, logistic regression, and artificial neural network methods at the Inje area, Korea. Environ. Earth Sci. 2013, 68, 1443–1464. [Google Scholar] [CrossRef]
- Pradhan, B.; Lee, S. Landslide susceptibility assessment and factor effect analysis: Backpropagation artificial neural networks and their comparison with frequency ratio and bivariate logistic regression modelling. Environ. Model Softw. 2010, 25, 747–759. [Google Scholar] [CrossRef]
- Conforti, M.; Pascale, S.; Robustelli, G.; Sdao, F. Evaluation of prediction capability of the artificial neural networks for mapping landslide susceptibility in the Turbolo River catchment (northern Calabria, Italy). Catena 2014, 113, 236–250. [Google Scholar] [CrossRef]
- Tsangaratos, P.; Benardos, A. Estimating landslide susceptibility through a artificial neural network classifier. Nat. Hazards 2014, 74, 1489–1516. [Google Scholar] [CrossRef]
- Lee, S.; Hong, S.; Jung, H. A support vector machine for landslide susceptibility mapping in Gangwon province, Korea. Sustainability 2017, 9, 48. [Google Scholar] [CrossRef]
- Tien Bui, D.; Tuan, T.A.; Hoang, N.D.; Thanh, N.Q.; Nguyen, D.B.; Liem, N.V.; Pradhan, B. Spatial prediction of rainfall-induced landslides for the Lao Cai area (Vietnam) using a hybrid intelligent approach of least squares support vector machines inference model and artificial bee colony optimization. Landslides 2017, 14, 447–458. [Google Scholar] [CrossRef]
- Oh, H.J. Landslide detection and landslide susceptibility mapping using aerial photos and artificial neural networks. Korean J. Remote Sens. 2010, 26, 47–57. [Google Scholar]
- Lee, S.; Kim, G.; Lee, C. Preliminary study for tidal flat detection in Yeongjong-do according to tide level using Landsat images. Korean J. Remote Sens. 2016, 32, 639–645. [Google Scholar] [CrossRef]
- Lee, S.K.; Lee, C.W. Predicting the hazard area of the volcanic ash caused by Mt. Ontake Eruption. Korean J. Remote Sens. 2014, 30, 777–786. [Google Scholar] [CrossRef]
- Jang, J.; Eom, J.; Cheong, D.; Lee, C. Monitoring of the Estuary Sand Bar Related with Tidal Inlet in Namdaecheon Stream using Landsat Imagery. Korean J. Remote Sens. 2017, 33, 481–493. [Google Scholar] [CrossRef]
- Eom, J.; Lee, C. Analysis on the area of deltaic Barrier Island and suspended sediments concentration in Nakdong River using satellite images. Korean J. Remote Sens. 2017, 33, 201–211. [Google Scholar] [CrossRef]
- Guisan, A.; Weiss, S.B.; Weiss, A.D. GLM versus CCA spatial modeling of plant species distribution. Plant Ecol. 1999, 143, 107–122. [Google Scholar] [CrossRef]
- Iwahashi, J.; Pike, R.J. Automated classifications of topography from dams by an unsupervised nested-means algorithm and a three-part geometric signature. Geomorphology 2007, 86, 409–440. [Google Scholar] [CrossRef]
- Moore, I.D.; Grayson, R.B.; Ladson, A.R. Digital terrain modelling: A review of hydrological, geomorphological, and biological applications. Hydrol. Process. 1991, 5, 3–30. [Google Scholar] [CrossRef]
- Oh, C.Y.; Kim, K.T.; Choi, C.U. Analysis of landslide characteristics of Inje area using SPOT5 images and GIS analysis. Korean J. Remote Sens. 2009, 25, 445–454. [Google Scholar]
- Schwarz, M.; Preti, F.; Giadrossich, F.; Lehmann, P.; Or, D. Quantifying the role of vegetation in slope stability: A case study in Tuscany (Italy). Ecol. Eng. 2010, 36, 285–291. [Google Scholar] [CrossRef]
- Schmidt, K.M.; Roering, J.J.; Stock, J.D.; Dietrich, W.E.; Montgomery, D.R.; Schaub, T. The variability of root cohesion as an influence on shallow landslide susceptibility in the Oregon Coast Range. Can. Geotech. J. 2001, 38, 995–1024. [Google Scholar] [CrossRef]
- Chi, K.H.; Shin, J.S.; Park, N.W. Quantitative Analysis of GIS-based Landslide Prediction Models Using Prediction Rate Curve. Korean J. Remote Sens. 2001, 17, 199–210. [Google Scholar]
- Loh, W.Y.; Shih, Y.S. Split selection methods for classification trees. Stat. Sin. 1997, 7, 815–840. [Google Scholar]
- Song, Y.S.; Chae, B.G. Development to Prediction Technique of Slope Hazards in Gneiss Area using Decision Tree Model. J. Eng. Geol. 2008, 18, 45–54. [Google Scholar]
- Althuwaynee, O.F.; Pradhan, B.; Park, H.J.; Lee, J.H. A novel ensemble decision tree-based CHi-squared Automatic Interaction Detection (CHAID) and multivariate logistic regression models in landslide susceptibility mapping. Landslides 2014, 11, 1063–1078. [Google Scholar] [CrossRef]
- Yeon, Y.K.; Han, J.G.; Ryu, K.H. Landslide susceptibility mapping in Injae, Korea, using a decision tree. Eng. Geol. 2010, 116, 274–283. [Google Scholar] [CrossRef]
- Peng, L.; Niu, R.Q.; Huang, B.; Wu, X.L.; Zhao, Y.N.; Ye, R.Q. Landslide susceptibility mapping based on rough set theory and support vector machines: A case of the Three Gorges area, China. Geomorphology 2014, 204, 287–301. [Google Scholar] [CrossRef]
- Lee, S.; Song, K.Y.; Oh, H.J.; Choi, J. Detection of landslide using web-based aerial photographs and landslide susceptibility mapping using geospatial analysis. Int. J. Remote Sens. 2012, 33, 4937–4966. [Google Scholar] [CrossRef]
- Xu, M.; Watanachaturaporn, P.; Varshney, P.K.; Arora, M.K. Decision tree regression for soft classification of remote sensing data. Remote Sens. Environ. 2005, 97, 322–336. [Google Scholar] [CrossRef]
- Biggs, D.; Barry, D.V.; Suen, E. A method of choosing multi way partitions for classification and decision trees. J. Appl. Stat. 2006, 18, 49–62. [Google Scholar] [CrossRef]
- Alkhasawneh, M.S.; Ngah, U.K.; Tay, L.T.; Isa, M.; Ashidi, N.; Al-Batah, M.S. Modeling and testing landslide hazard using decision tree. J. Appl. Math. 2014. [Google Scholar] [CrossRef]
- Baker, S.; Cousins, R.D. Clarification of the use of chi-square and likelihood functions in fits to histograms. Nucl. Instrum. Methods Phys. Res. 1984, 221, 437–442. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
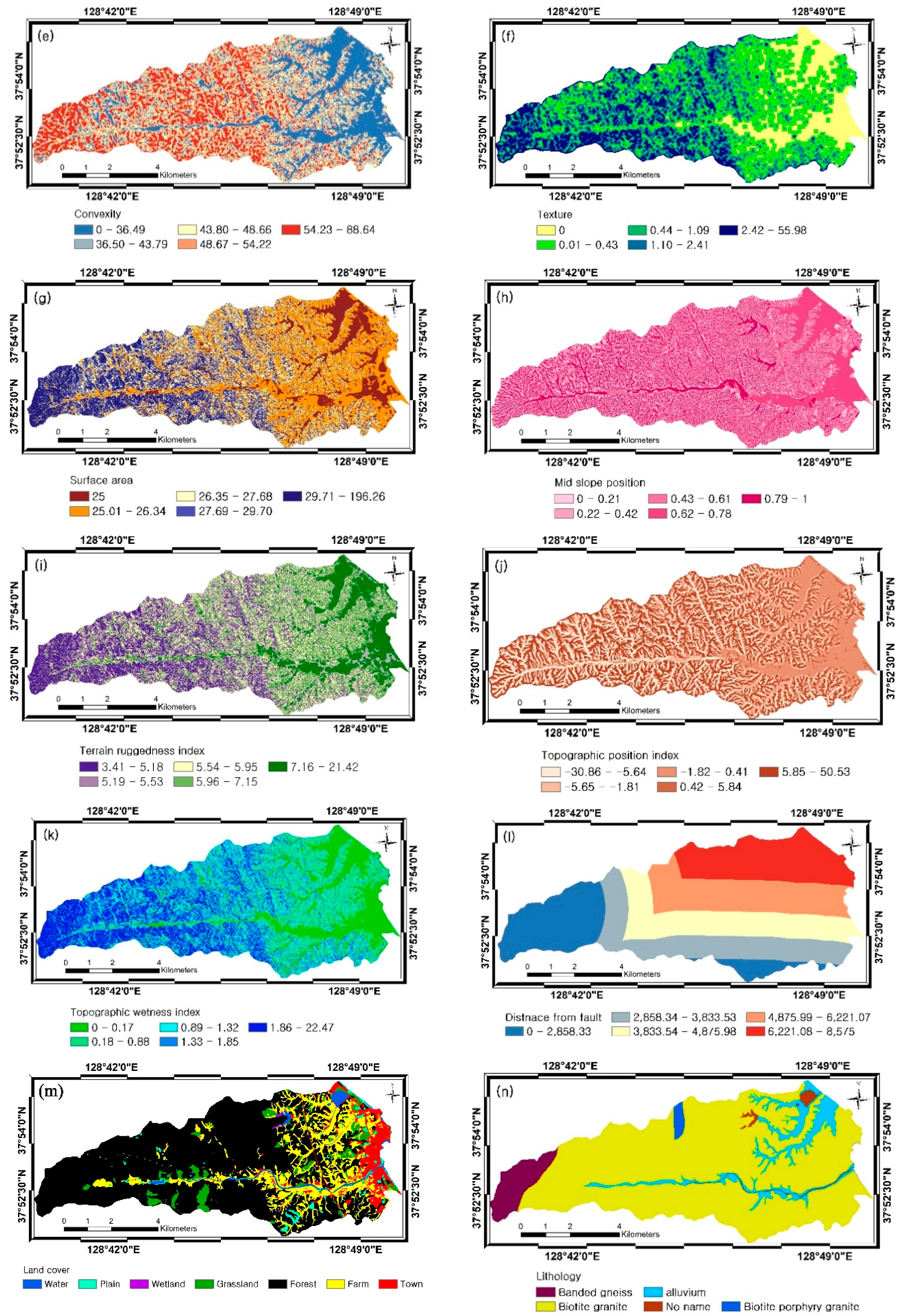
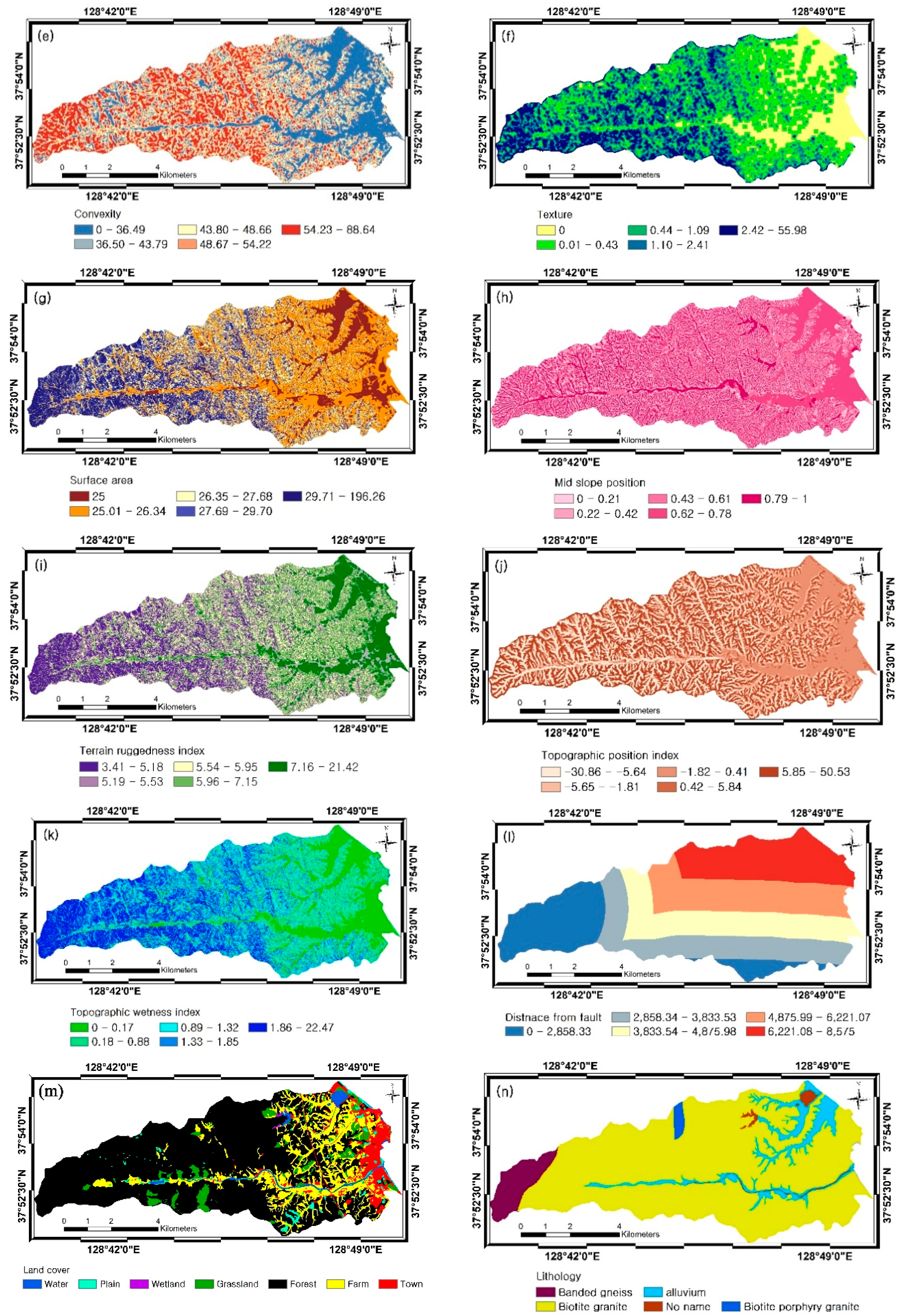
| Category | Factors | Data Type | Scale | Source | |
|---|---|---|---|---|---|
| DEM | Topographic factors | Slope | Grid | 1:5000 | National Geographic Information Institute (NGII) |
| Aspect | |||||
| Maximum curvature | |||||
| Profile curvature | |||||
| Convexity | |||||
| Texture | |||||
| Surface area | |||||
| Mid-slope position (MSP) | |||||
| Terrain ruggedness index (TRI) | |||||
| Topographic position index (TPI) | |||||
| Hydrologic factors | Flow accumulation | ||||
| Topographic wetness index (TWI) | |||||
| Soil map | Land-cover Material | Polygon | 1:5000 | National Academy of Agricultural Science (NAAS) | |
| Forest map | Forest type | Polygon | 1:5000 | Korea Forest Research Institute (KFRI) | |
| Forest age | |||||
| Forest density | |||||
| Forest diameter | |||||
| Geology | Lithology Distance from fault | Polygon | 1:25,000 | Korean Institute of Geoscience and Mineral Resources (KIGAM) | |
| Factor | Class | % Landslide (+) | % Domain (+) | FR Value |
|---|---|---|---|---|
| aspect | Flat | 13.44 | 10.82 | 1.24 |
| North | 15.42 | 10.37 | 1.49 | |
| NorthEast | 15.42 | 12.03 | 1.28 | |
| East | 7.51 | 11.00 | 0.68 | |
| SouthEast | 5.14 | 11.39 | 0.45 | |
| South | 9.09 | 11.23 | 0.81 | |
| SouthWest | 8.30 | 11.04 | 0.75 | |
| West | 12.25 | 10.80 | 1.13 | |
| NorthWest | 13.44 | 11.33 | 1.19 | |
| convexity | 0–36.49 | 0.73 | 19.68 | 0.04 |
| 36.50–43.79 | 10.95 | 19.25 | 0.57 | |
| 43.80–48.66 | 20.44 | 19.72 | 1.04 | |
| 48.67–54.22 | 30.29 | 20.87 | 1.45 | |
| 54.23–88.64 | 37.59 | 20.48 | 1.84 | |
| 0.25–2.07 | 33.58 | 22.86 | 1.47 | |
| 2.08–4.11 | 22.99 | 21.54 | 1.07 | |
| 4.12–10.25 | 13.87 | 18.02 | 0.77 | |
| 10.26–521.90 | 10.22 | 17.44 | 0.59 | |
| mid slope position | 0–0.21 | 29.56 | 19.74 | 1.50 |
| 0.43–0.61 | 20.80 | 19.36 | 1.07 | |
| 0.62–0.78 | 9.85 | 20.75 | 0.47 | |
| 0.79–1 | 14.60 | 20.33 | 0.72 | |
| slope | 0–0.05 | 1.82 | 19.90 | 0.09 |
| 0.06–0.25 | 8.03 | 19.91 | 0.40 | |
| 0.39–0.52 | 28.10 | 19.80 | 1.42 | |
| 0.53–1.44 | 47.45 | 19.91 | 2.38 | |
| surface area | 25 | 0.73 | 12.83 | 0.06 |
| 25.01–26.34 | 16.79 | 37.35 | 0.45 | |
| 26.35–27.68 | 17.52 | 19.50 | 0.90 | |
| 29.71–196.26 | 33.58 | 13.82 | 2.43 | |
| texture | 0 | 0.36 | 13.90 | 0.03 |
| 0.01–0.43 | 9.12 | 34.28 | 0.27 | |
| 0.44–1.09 | 19.71 | 18.62 | 1.06 | |
| 1.10–2.41 | 32.48 | 18.15 | 1.79 | |
| tpi | −30.86–5.64 | 12.41 | 19.12 | 0.65 |
| −5.65–1.81 | 14.96 | 19.14 | 0.78 | |
| −1.82–0.41 | 10.22 | 20.08 | 0.51 | |
| 0.42–5.84 | 30.29 | 20.97 | 1.44 | |
| 5.85–50.53 | 32.12 | 20.69 | 1.55 | |
| 5.19–5.53 | 8.03 | 21.03 | 0.38 | |
| 5.54–5.95 | 14.23 | 20.31 | 0.70 | |
| 5.96–7.15 | 29.93 | 20.05 | 1.49 | |
| 7.16–21.42 | 46.72 | 19.48 | 2.40 | |
| twi | 0–0.17 | 44.89 | 19.04 | 2.36 |
| 0.89–1.32 | 18.98 | 20.94 | 0.91 | |
| 1.33–1.85 | 11.68 | 20.07 | 0.58 | |
| 1.86–22.47 | 0.36 | 18.80 | 0.02 | |
| Lithology | Biotite granite | 100 | 83.91 | 1.19 |
| Soil | Samgag Series | 95.24 | 67.04 | 2.33 |
| Sangye Series | 0.36 | 0.59 | 0.62 | |
| River | 0.36 | 2.08 | 0.18 | |
| Yesan Series | 0.36 | 2.27 | 0.16 | |
| Yecheon Series | 1.09 | 4.84 | 0.22 | |
| Forest type | Pinus Koraiensis | 6.57 | 4.57 | 1.44 |
| No data | 0.73 | 28.50 | 0.03 | |
| Forest age | No data | 0.73 | 30.28 | 0.02 |
| 21–30 yr | 44.89 | 32.40 | 1.39 | |
| 31–40 yr | 20.80 | 18.07 | 1.15 | |
| Forest diameter | less than 6 cm | 1.08 | 30.28 | 0.04 |
| 18–29 cm | 67.80 | 46.91 | 1.45 | |
| over than 30 cm | 21.42 | 18.21 | 1.18 | |
| Forest density | No data | 8.39 | 34.87 | 0.24 |
| Medium | 2.19 | 2.06 | 1.07 | |
| Land cover | Farm | 0.36 | 16.73 | 0.02 |
| Grassland | 16.06 | 5.22 | 3.08 | |
| 6221.08–8575 | 10.58 | 20.31 | 0.52 | |
| flat | 16.06 | 31.28 | 0.51 | |
| convex | 51.82 | 38.08 | 1.36 | |
| SgE3 | 1.82 | 2.70 | 0.68 | |
| Forest type | PK | 6.57 | 4.57 | 1.44 |
| D | 74.45 | 46.72 | 1.59 | |
| PL | 5.47 | 0.74 | 7.36 | |
| 99 | 0.73 | 28.50 | 0.03 | |
| PD | 1.09 | 0.21 | 5.22 | |
| M | 11.68 | 9.81 | 1.19 | |
| Forest age | 0 | 0.73 | 30.28 | 0.02 |
| 1 | 7.66 | 4.59 | 1.67 | |
| 2 | 25.91 | 14.51 | 1.79 | |
| 3 | 44.89 | 32.40 | 1.39 | |
| 4 | 20.80 | 18.07 | 1.15 | |
| Forest diameter | 0 | 1.08 | 30.28 | 0.04 |
| 1 | 9.71 | 4.59 | 2.12 | |
| 2 | 67.80 | 46.91 | 1.45 | |
| 3 | 21.42 | 18.21 | 1.18 | |
| Forest density | 0 | 8.39 | 34.87 | 0.24 |
| C | 89.42 | 61.96 | 1.44 | |
| B | 2.19 | 2.06 | 1.07 | |
| Land cover | 200 | 0.36 | 16.73 | 0.02 |
| 300 | 83.58 | 67.73 | 1.23 | |
| 400 | 16.06 | 5.22 | 3.08 | |
| Distance from Fault | 1 | 3.28 | 19.57 | 0.17 |
| 2 | 30.29 | 19.80 | 1.53 | |
| 3 | 41.61 | 20.15 | 2.07 | |
| 4 | 14.23 | 20.18 | 0.71 | |
| 5 | 10.58 | 20.31 | 0.52 | |
| maximum curvature | concave | 18.61 | 30.25 | 0.62 |
| flat | 32.48 | 37.03 | 0.88 | |
| convex | 48.91 | 32.72 | 1.49 | |
| profile curvature | concave | 32.12 | 30.64 | 1.05 |
| flat | 16.06 | 31.28 | 0.51 | |
| convex | 51.82 | 38.08 | 1.36 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, S.-J.; Lee, C.-W.; Lee, S.; Lee, M.-J. Landslide Susceptibility Mapping and Comparison Using Decision Tree Models: A Case Study of Jumunjin Area, Korea. Remote Sens. 2018, 10, 1545. https://doi.org/10.3390/rs10101545
Park S-J, Lee C-W, Lee S, Lee M-J. Landslide Susceptibility Mapping and Comparison Using Decision Tree Models: A Case Study of Jumunjin Area, Korea. Remote Sensing. 2018; 10(10):1545. https://doi.org/10.3390/rs10101545
Chicago/Turabian StylePark, Sung-Jae, Chang-Wook Lee, Saro Lee, and Moung-Jin Lee. 2018. "Landslide Susceptibility Mapping and Comparison Using Decision Tree Models: A Case Study of Jumunjin Area, Korea" Remote Sensing 10, no. 10: 1545. https://doi.org/10.3390/rs10101545
APA StylePark, S.-J., Lee, C.-W., Lee, S., & Lee, M.-J. (2018). Landslide Susceptibility Mapping and Comparison Using Decision Tree Models: A Case Study of Jumunjin Area, Korea. Remote Sensing, 10(10), 1545. https://doi.org/10.3390/rs10101545