End-to-End Airplane Detection Using Transfer Learning in Remote Sensing Images

Abstract
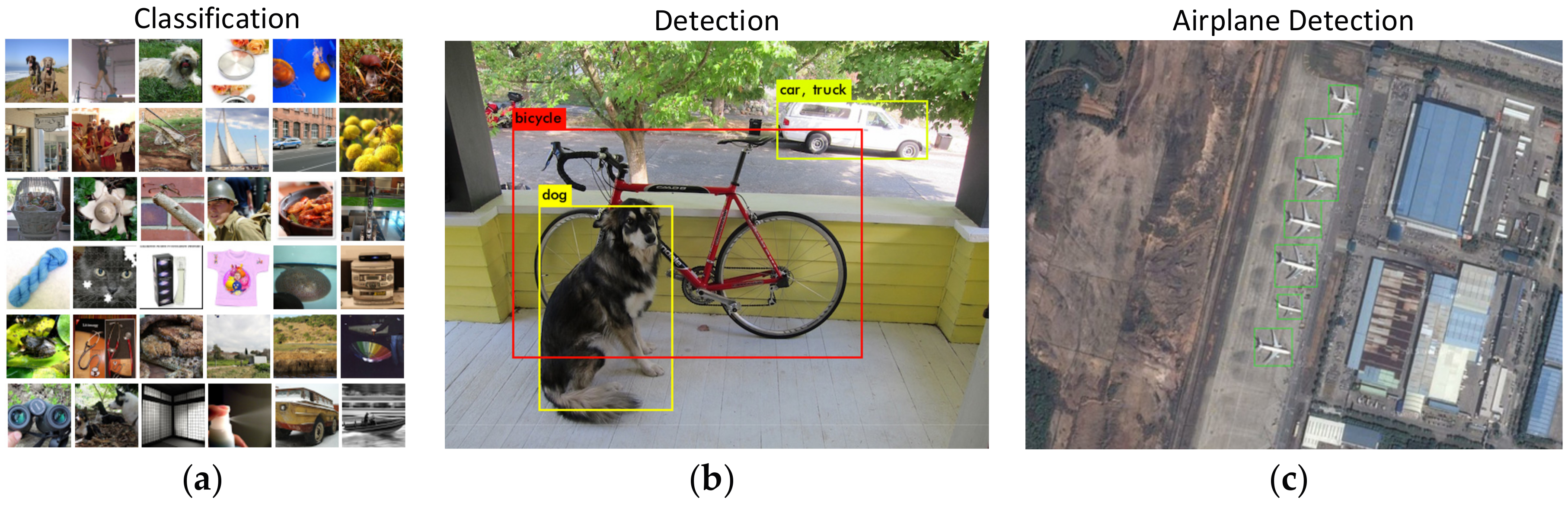
:1. Introduction
- Resolution information often is given by the remote sensing images, so the size of the object in the image can be inferred based on some prior knowledge, which is crucial for the object detection task.
- The observed field of view changes very slightly. Natural images from different perspectives will have a great difference, while all the remote sensing images are obtained from a top-down view, which also makes the visual changes of object usually minimally severe.
- The object in the remote sensing image is, generally, relatively small when compared with the background, but the current small object detection is not well solved in the natural image. Therefore, improvements still need to be made when applying the detection algorithm on natural images to determine object detection in remote sensing images.
- We collected samples of the airplanes from Google Earth and labeled them manually. In addition to the common data augmentation operations in natural images, we also add rotation and other operations.
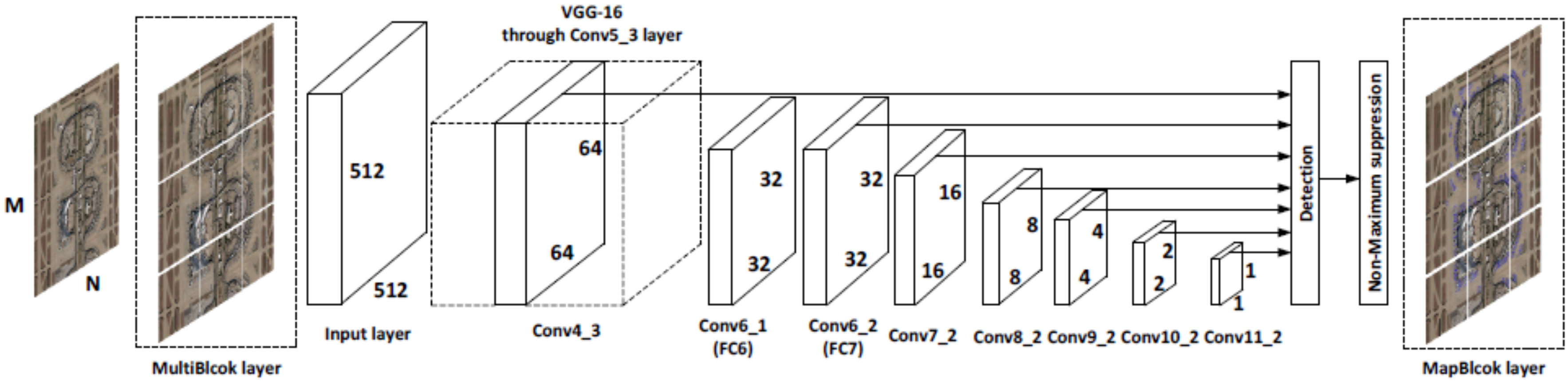
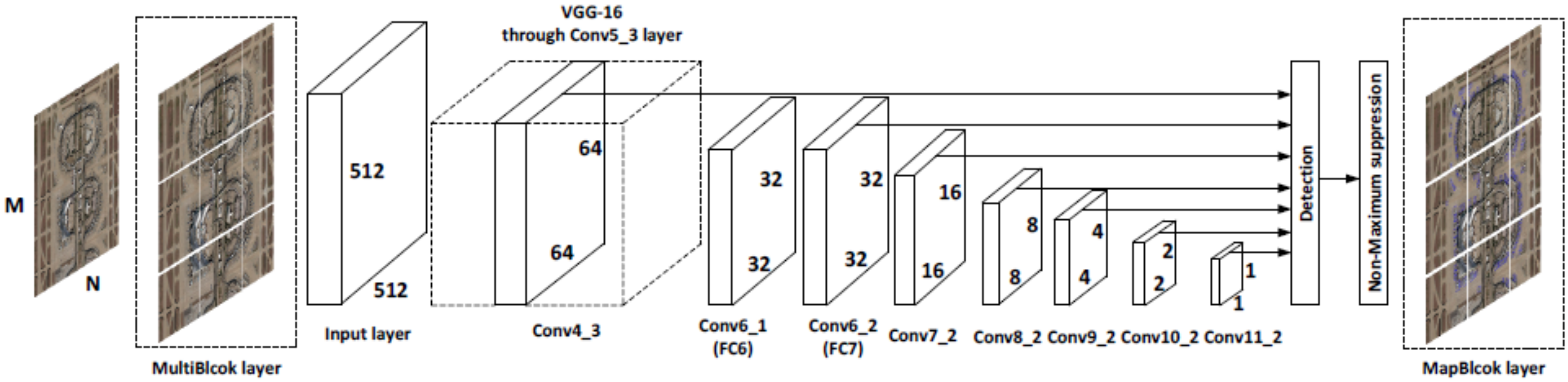
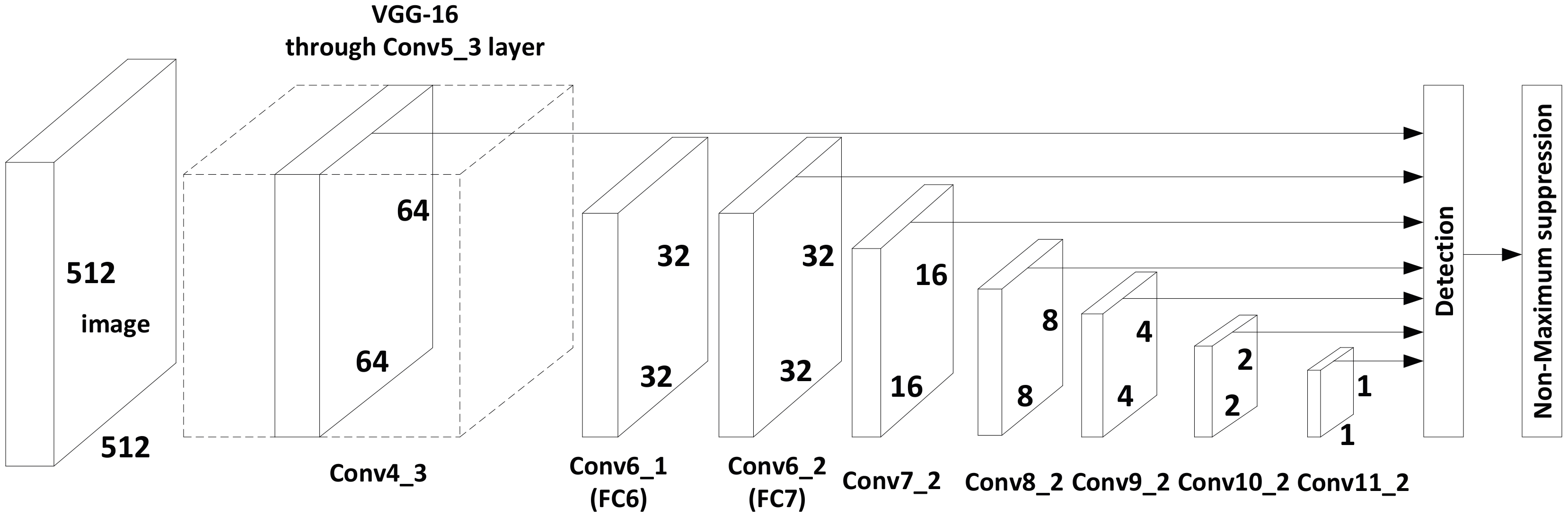
- Using the idea of transfer learning and a limited number of airplane samples for training, an end-to-end airplane detection framework is achieved, as shown in Figure 1.
- A method is proposed to solve the size restrictions of the input images, which first divides the image into blocks and then detects the airplane.
2. Related Work
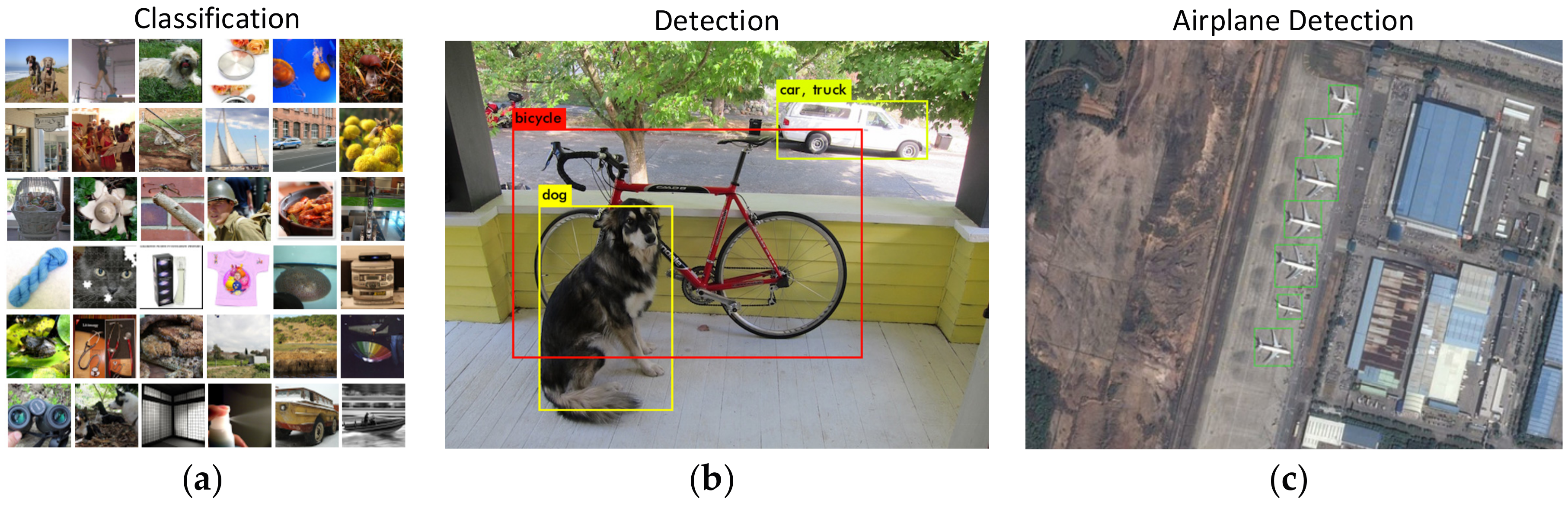
2.1. Object Detection with CNNs
2.2. Airplane Detection Method
2.3. Transfer Learning
3. Methods
3.1. Data
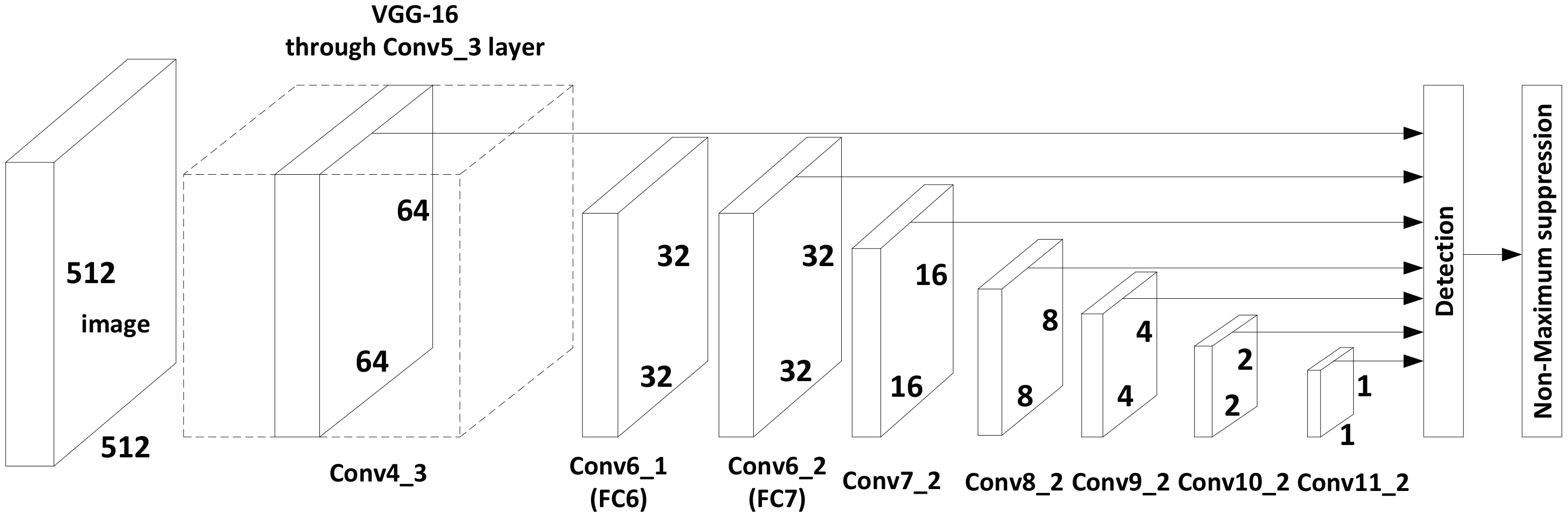
3.2. The Network Framework
3.3. Training
3.3.1. Data Augmentation
3.3.2. The Selection of Positive and Negative Samples
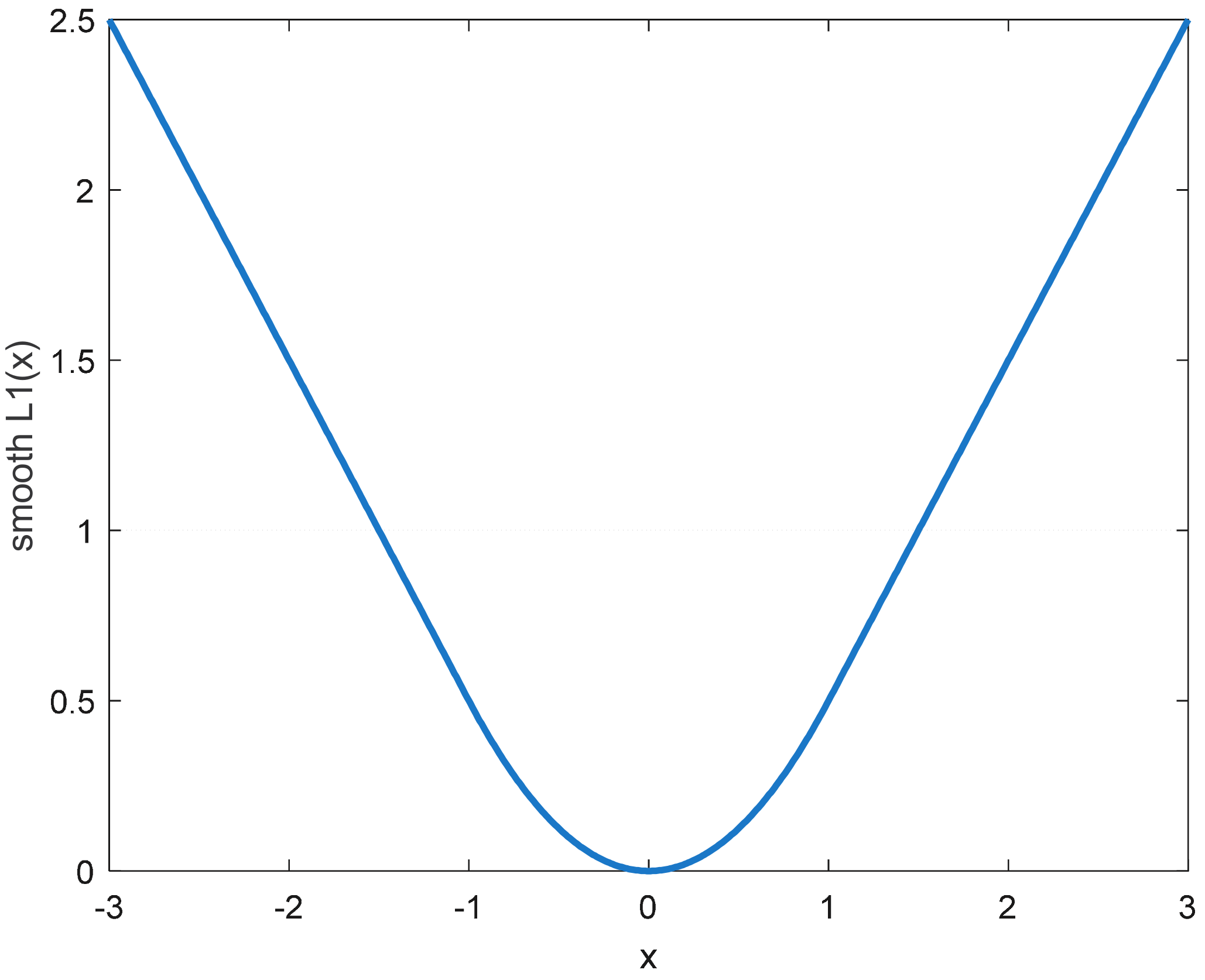
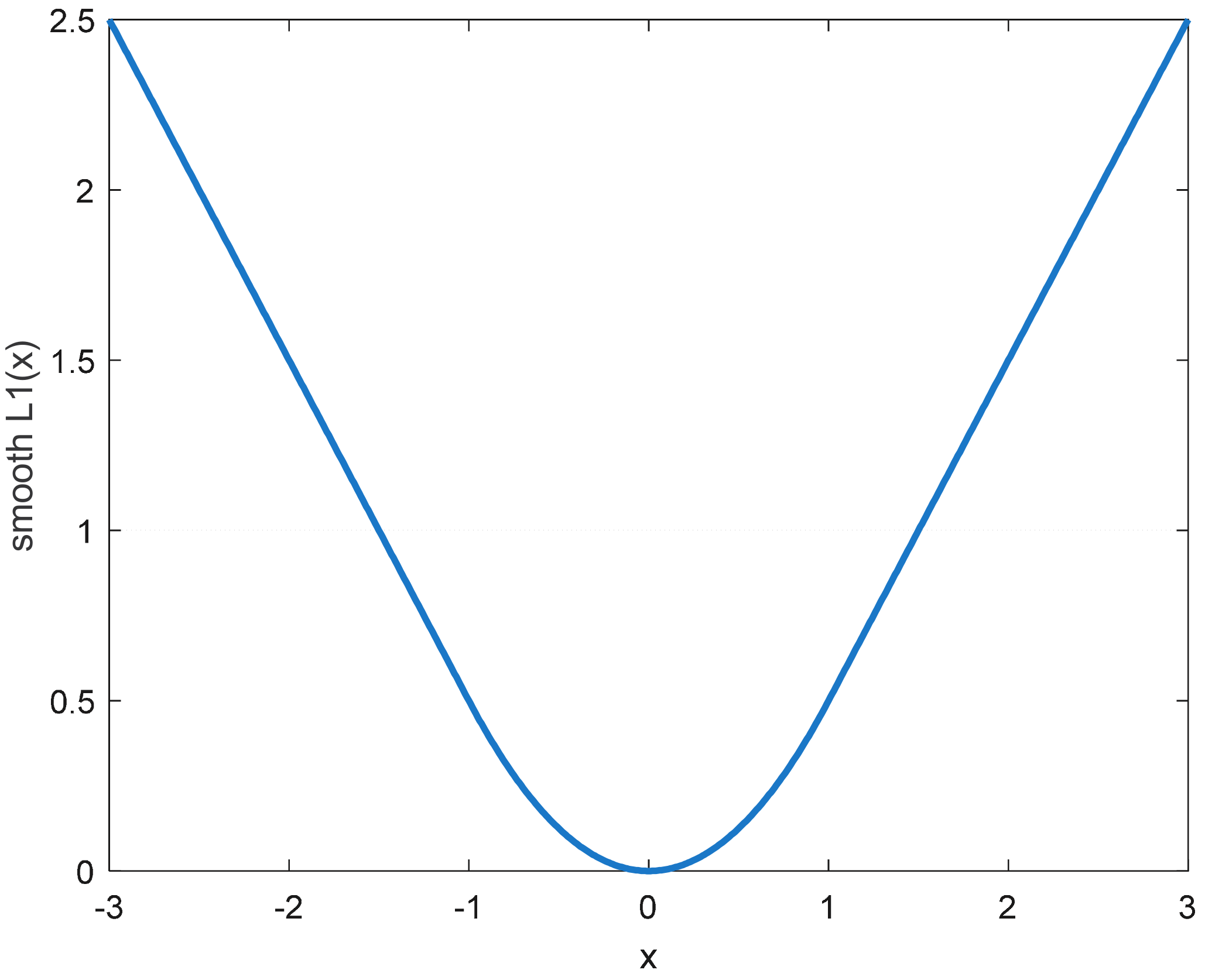
3.3.3. Loss Function
3.4. Test
3.4.1. MultiBlock and MapBlock Layers
3.4.2. Non-Maximum Suppression
3.5. Implementation
4. Results and Discussion
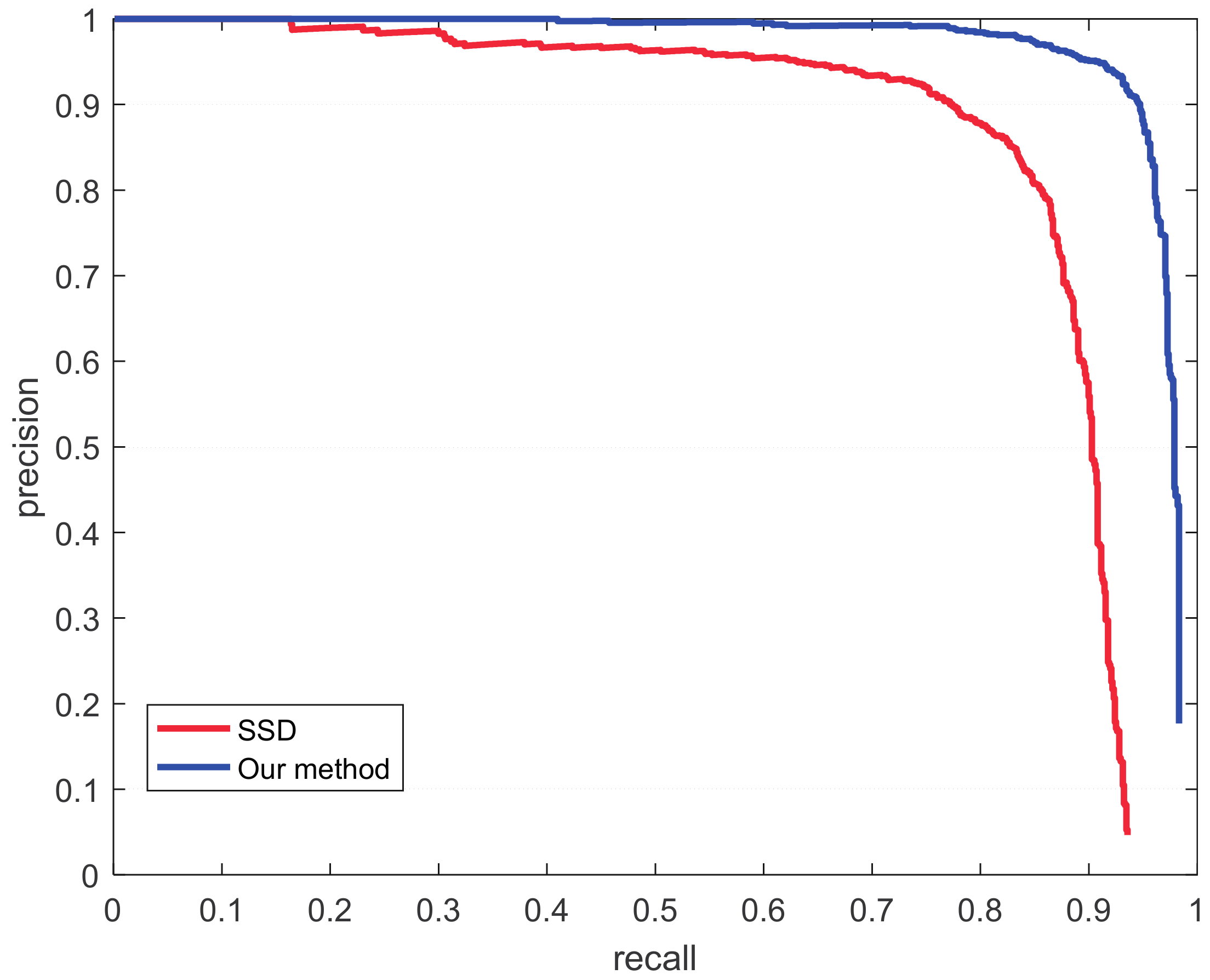
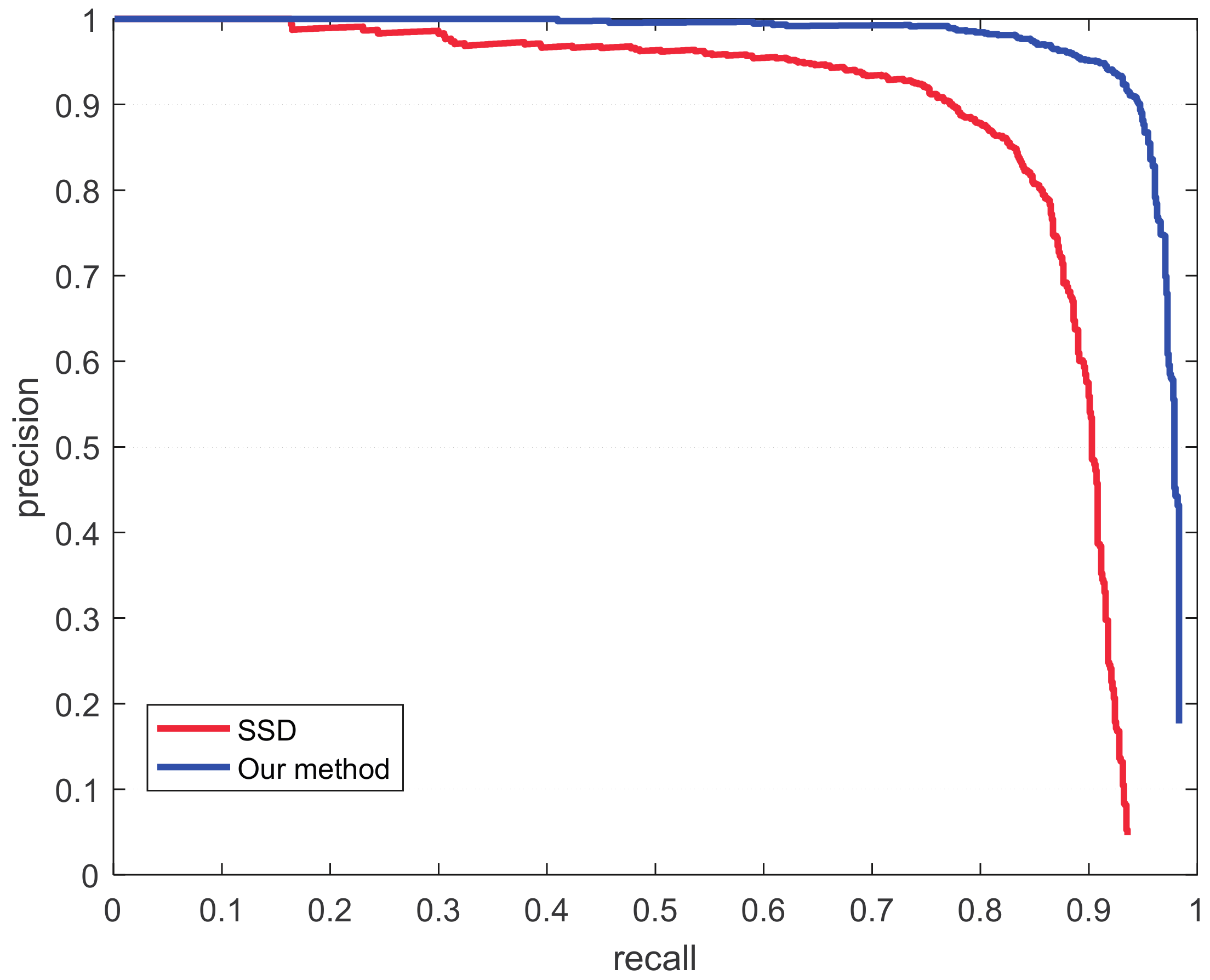
4.1. Results
4.2. Discussion
5. Conclusions
Author Contributions
Conflicts of Interest
References
- Filippidis, A.; Jain, L.C.; Martin, N. Fusion of intelligent agents for the detection of aircraft in SAR images. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 378–384. [Google Scholar] [CrossRef]
- Yao, J.; Zhang, Z. Semi-supervised learning based object detection in aerial imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 1011–1016. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012; Volume 2, pp. 1097–1105. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. IJCV 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- He, K.M.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.M.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the 28th International Conference on Computer Vision, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL visual object classes (VOC) challenge. IJCV 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Hosang, J.; Benenson, R.; Dollár, P.; Schiele, B. What makes for effective detection proposals? IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 814–830. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Zhang, H.; Zhang, J.; Xu, F. Fast aircraft detection in satellite images based on convolutional neural networks. In Proceedings of the IEEE International Conference on Image Processing, Quebec City, QC, Canada, 27–30 September 2015; pp. 4210–4214. [Google Scholar]
- Cheng, M.M.; Zhang, Z.; Lin, W.Y.; Torr, P. BING: Binarized normed gradients for objectness estimation at 300fps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3286–3293. [Google Scholar]
- Zitnick, C.L.; Dollár, P. Edge boxes: Locating object proposals from edges. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 391–405. [Google Scholar]
- Carreira, J.; Sminchisescu, C. Cpmc: Automatic object segmentation using constrained parametric min-cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1312–1328. [Google Scholar] [CrossRef] [PubMed]
- Arbeláez, P.; Pont-Tuset, J.; Barron, J.T.; Marques, F.; Malik, J. Multiscale combinatorial grouping. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 328–335. [Google Scholar]
- Alexe, B.; Deselaers, T.; Ferrari, V. Measuring the objectness of image windows. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2189–2202. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Sun, X.; Fu, K.; Wang, C.; Wang, H. Object detection in high-resolution remote sensing images using rotation invariant parts based model. IEEE Trans. Geosci. Remote Sens. 2014, 11, 74–78. [Google Scholar] [CrossRef]
- Wang, G.; Wang, X.; Fan, B.; Pan, C. Feature Extraction by Rotation-Invariant Matrix Representation for Object Detection in Aerial Image. IEEE Trans. Geosci. Remote Sens. 2017, 14, 851–855. [Google Scholar] [CrossRef]
- Liu, L.; Shi, Z. Airplane detection based on rotation invariant and sparse coding in remote sensing images. Optik-Int. J. Light Electron Opt. 2014, 125, 5327–5333. [Google Scholar] [CrossRef]
- West, J.; Ventura, D.; Warnick, S. Spring Research Presentation: A Theoretical Foundation for Inductive Transfer; Brigham Young University, College of Physical and Mathematical Sciences: Provo, UT, USA, 2007. [Google Scholar]
- Jia, Y.Q.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Samples | Number of Airplanes | |
|---|---|---|
| Training set | 253 | 2578 |
| Validation set | 52 | 383 |
| Test set | 276 | 2344 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Zhang, T.; Ouyang, C. End-to-End Airplane Detection Using Transfer Learning in Remote Sensing Images. Remote Sens. 2018, 10, 139. https://doi.org/10.3390/rs10010139
Chen Z, Zhang T, Ouyang C. End-to-End Airplane Detection Using Transfer Learning in Remote Sensing Images. Remote Sensing. 2018; 10(1):139. https://doi.org/10.3390/rs10010139
Chicago/Turabian StyleChen, Zhong, Ting Zhang, and Chao Ouyang. 2018. "End-to-End Airplane Detection Using Transfer Learning in Remote Sensing Images" Remote Sensing 10, no. 1: 139. https://doi.org/10.3390/rs10010139
APA StyleChen, Z., Zhang, T., & Ouyang, C. (2018). End-to-End Airplane Detection Using Transfer Learning in Remote Sensing Images. Remote Sensing, 10(1), 139. https://doi.org/10.3390/rs10010139