Classification of PolSAR Images Using Multilayer Autoencoders and a Self-Paced Learning Approach



Abstract
:
1. Introduction
2. Related Work
- is monotonically decreasing with respect to the training loss , and it holds that , .
- is monotonically increasing with respect to the pace parameter , and it holds that , .
- Step 1: Initialize the weights of all samples and parameter .
- Step 2: Fix , and update by Equation (2).
- Step 3: Fix , calculate the training loss , and update by Equation (4).
- Step 4: If and have converged, then go to step 5; otherwise, repeat step 2 and step 3.
- Step 5: Update , .
- Step 6: Repeat step 2 to step 5 until the mean of is equal to or approximately 1. Finally, obtain the solution of .
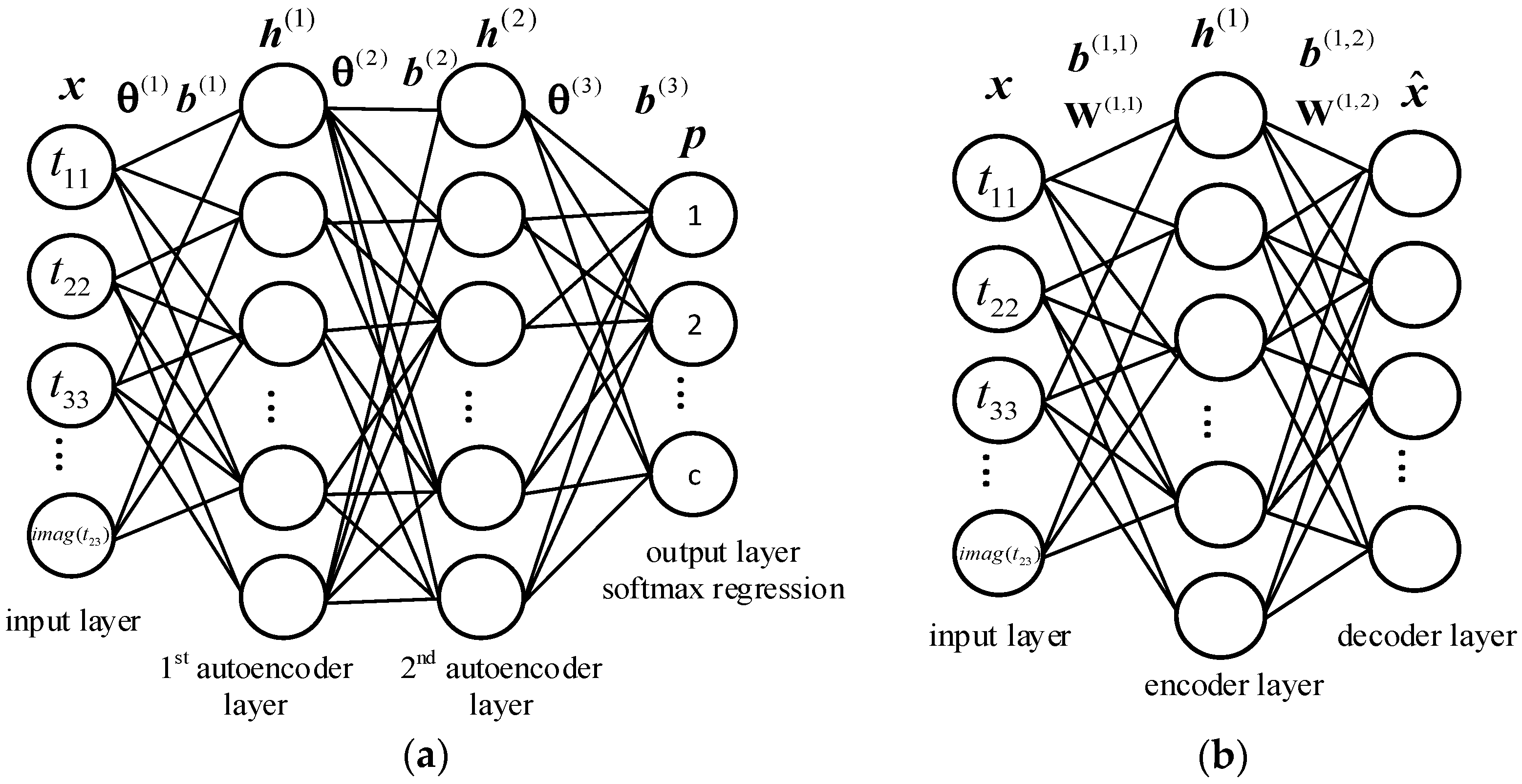
3. Proposed Method
3.1. Multilayer Autoencoders Network
3.2. Optimization of Multilayer Autoencoders Network Based on SPL
3.2.1. Unsupervised Pre-Training the Parameters of Each Autoencoder Layer
- Step 1: initialize the parameters: , , , and .
- Step 2: apply the mini-batch gradient descent algorithm based on SPL to optimize the parameters.
- Step 2.1: select a mini-batch sample to optimize the parameters.
- Step 2.2: calculate the output vector and loss function for each input vector through forward propagation, and then, calculate the weight parameter by Equation (4).
- Step 2.3: fix the weight parameter , and use back propagation to train the parameters , , , .
- Step 2.4: Update , . In general, we need the range of training loss values in advance to determine the initial value of and the step size . In our experiment, the initial value of is set to the first quartile of the sample training losses, and .
- Step 2.5: repeat step 2.2 to step 2.4 until the value of is approximately 1 (all the samples of the current iteration have been completely learned). Here, is defined as .
- Step 2.6: a new mini-batch sample is selected to optimize the parameter until all the samples are learned.
- Step 3: repeat step 2 until the number of epochs achieve a predefined threshold, and then, obtain the parameters and .
3.2.2. Supervised Fine-Tuning Those Parameters with Softmax Regression
4. Experiments
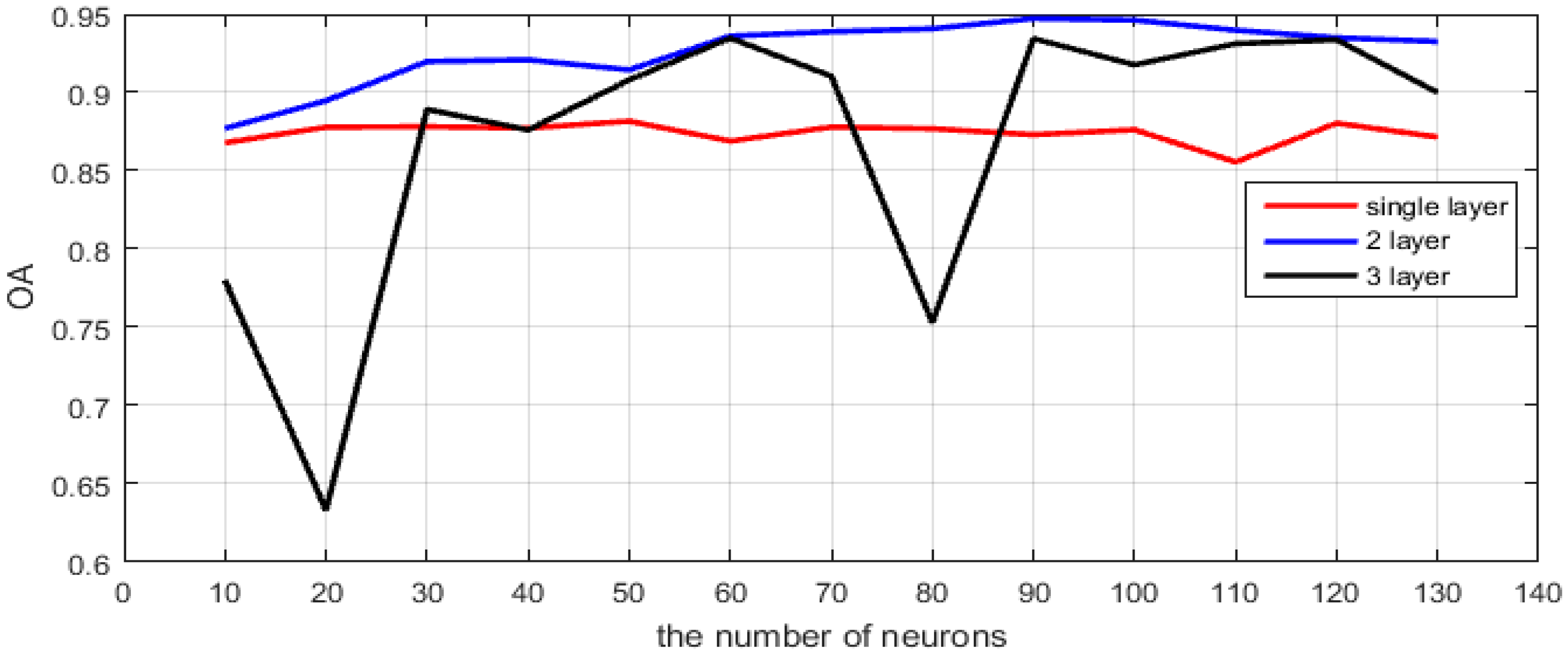
4.1. Network Architecture Analysis
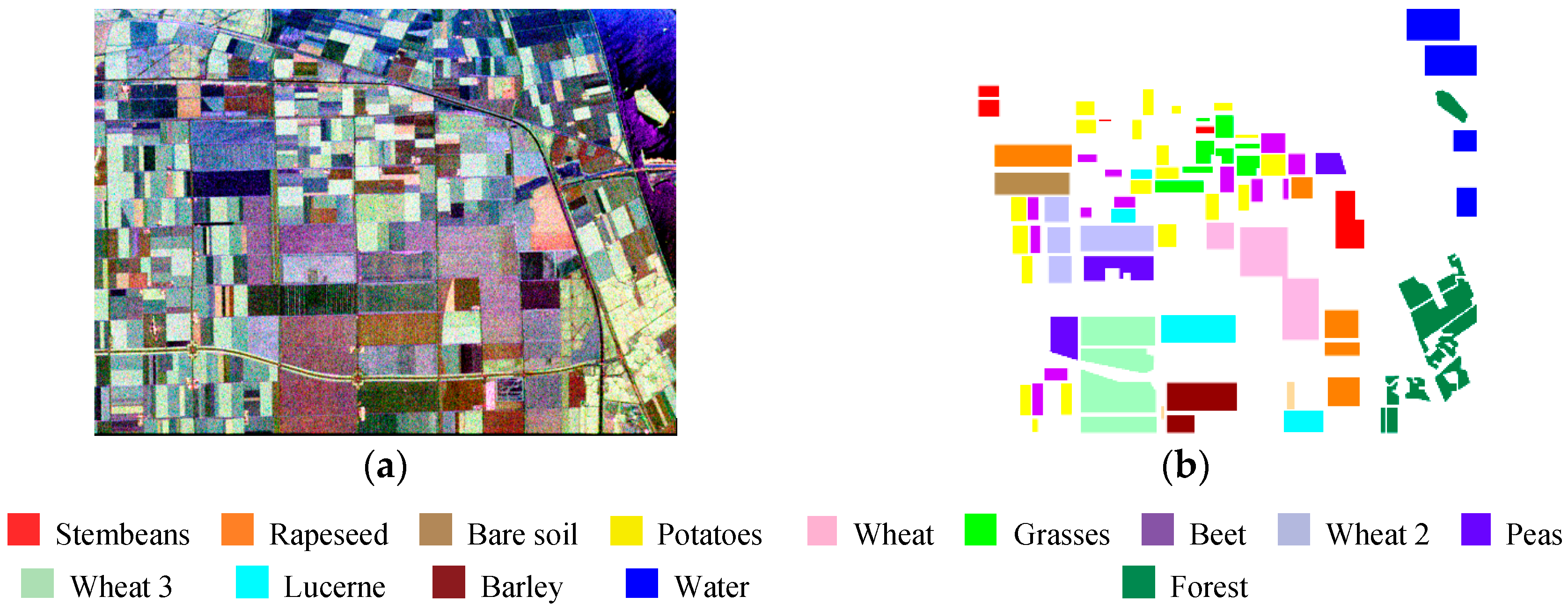
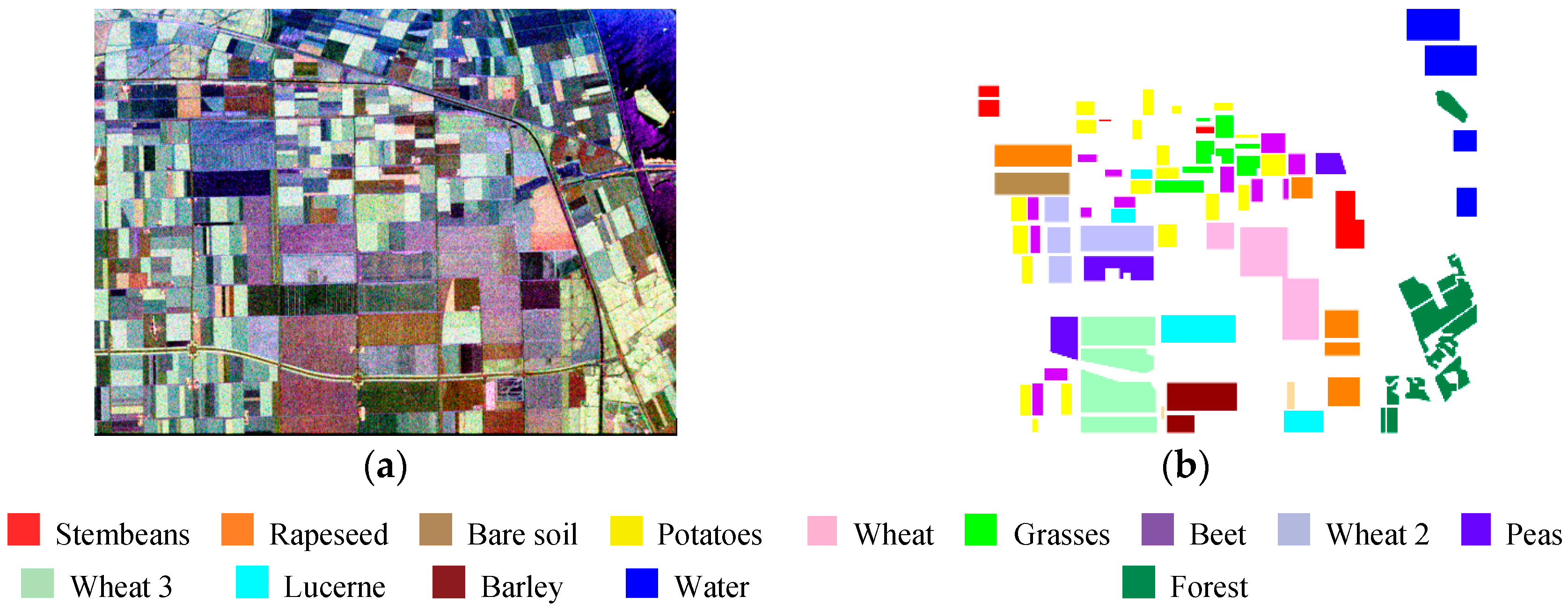
4.2. Flevoland Dataset from AIRSAR
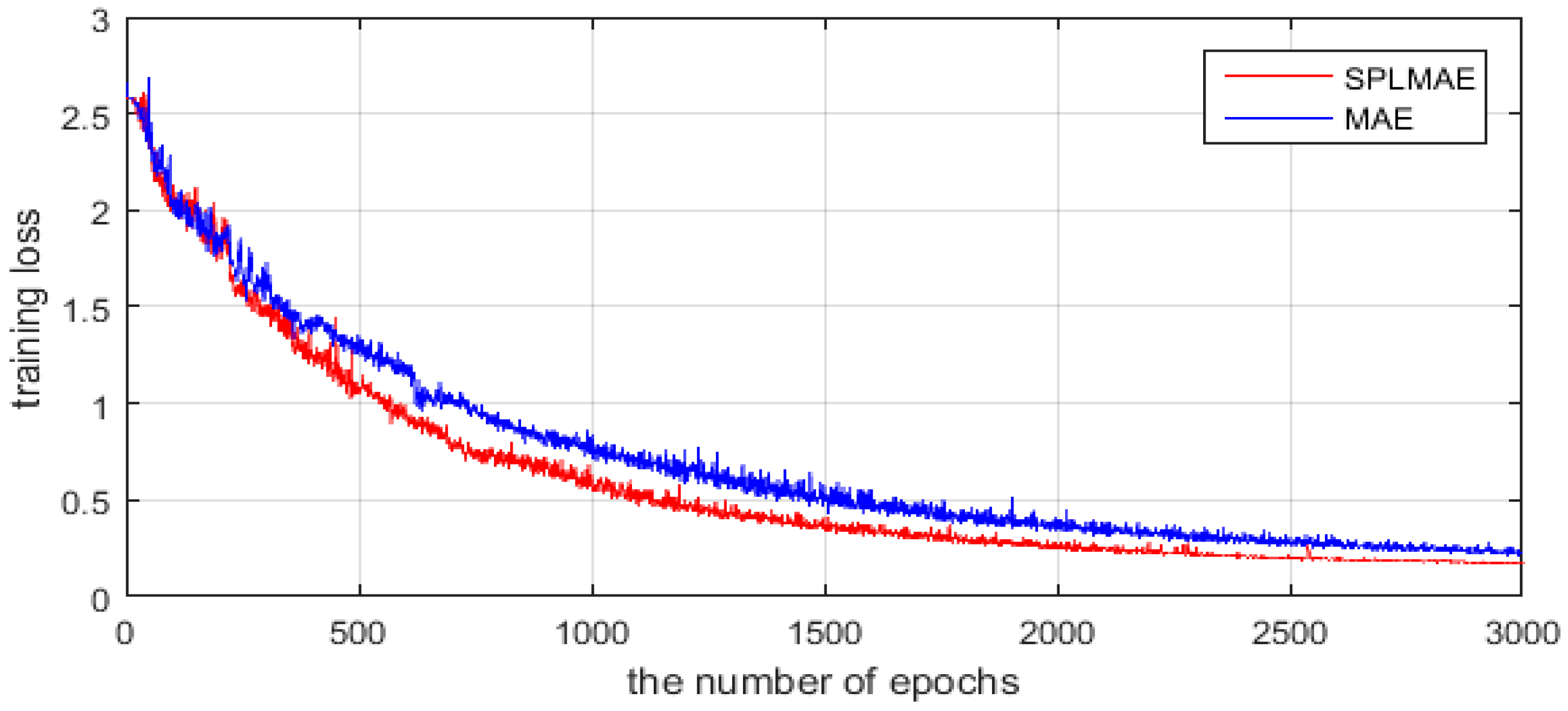
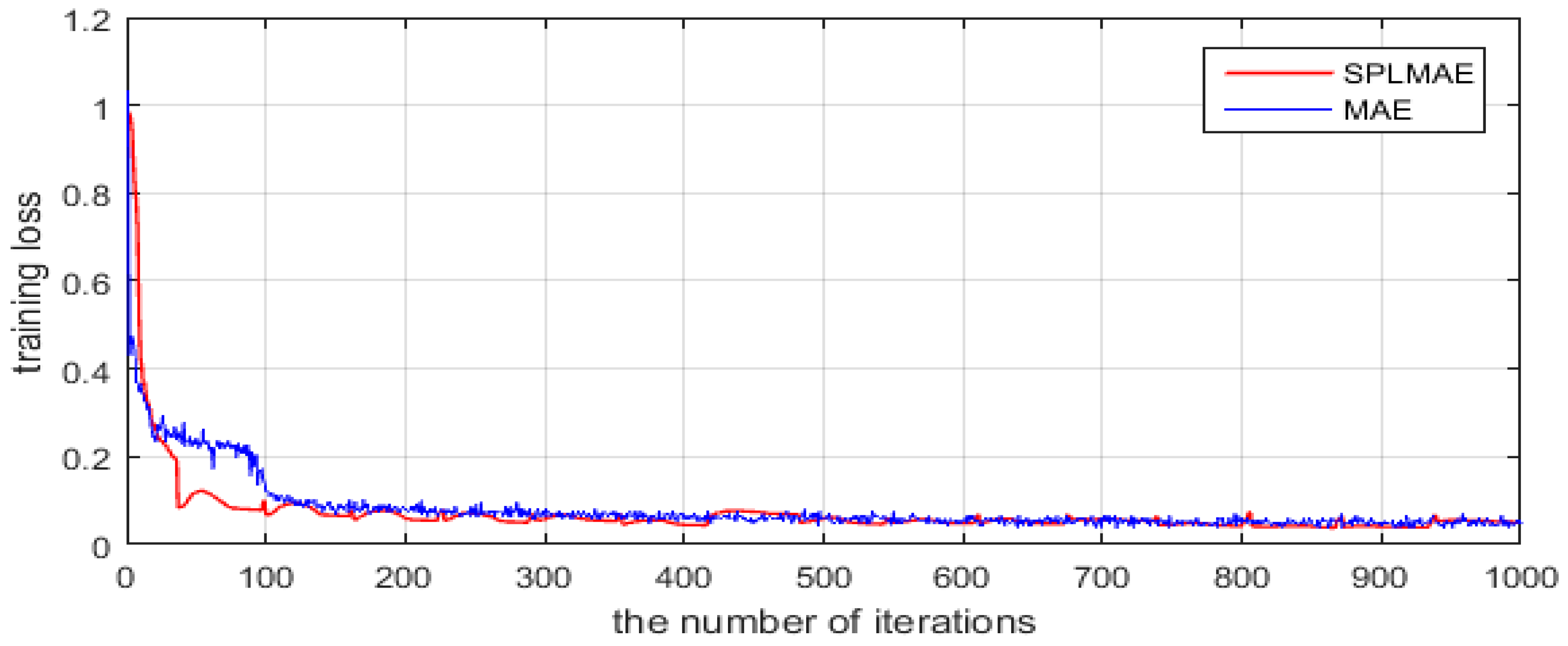
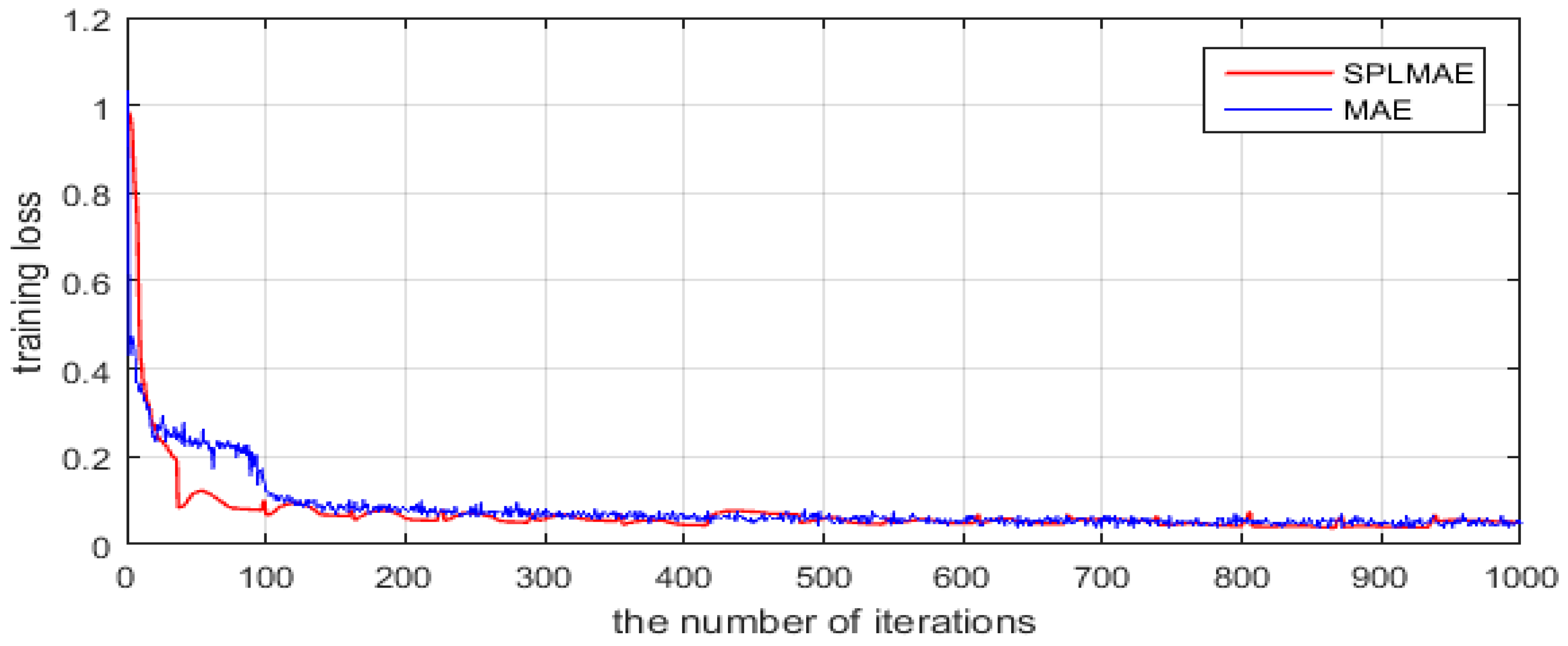
4.2.1. Convergence Analysis of Our Algorithm
4.2.2. Classification Results
4.3. Flevoland Dataset from RADARSAT-2
4.4. Yellow River Delta Dataset from ALOS-2
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Liu, F.; Jiao, L.; Hou, B.; Yang, S. POL-SAR image classification based on Wishart DBN and local spatial information. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3292–3308. [Google Scholar] [CrossRef]
- Nunziata, F.; Migliaccio, M.; Li, X.; Ding, X. Coastline extraction using dual-polarimetric COSMO-SkyMed PingPong mode SAR data. IEEE Geosci. Remote Sens. Lett. 2014, 11, 104–108. [Google Scholar] [CrossRef]
- Ding, X.; Li, X. Shoreline movement monitoring based on SAR images in Shanghai, China. Int. J. Remote Sens. 2014, 35, 3994–4008. [Google Scholar] [CrossRef]
- Ding, X.; Li, X. Monitoring of the water-area variations of Lake Dongting in China with ENVISAT ASAR images. Int. J. Appl. Earth Obs. Geoinform. 2011, 13, 894–901. [Google Scholar] [CrossRef]
- Buono, A.; Nunziata, F.; Migliaccio, M.; Yang, X.; Li, X. Classification of the Yellow River delta area using fully polarimetric SAR measurements. Int. J. Remote Sens. 2017, 38, 6714–6734. [Google Scholar] [CrossRef]
- Xiang, H.; Liu, S.; Zhuang, Z.; Zhang, N. A classification algorithm based on Cloude decomposition model for fully polarimetric SAR image. IOP Conf. Ser. Earth Environ. Sci. 2016, 46. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, L.; Zou, B. Fully polarimetric SAR image classification via sparse representation and polarimetric features. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 7978–7990. [Google Scholar] [CrossRef]
- Du, P.; Samat, A.; Gamba, P.; Xie, X. Polarimetric SAR image classification by boosted multiple-kernel extreme learning machines with polarimetric and spatial features. Int. J. Remote Sens. 2014, 35, 7978–7990. [Google Scholar] [CrossRef]
- Wang, W.; Yang, X.; Li, X. A Fully Polarimetric SAR Imagery Classification Scheme for Mud and Sand Flats in Intertidal Zones. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1734–1742. [Google Scholar] [CrossRef]
- Xie, H.; Wang, S.; Liu, K.; Lin, S.; Hou, B. Multilayer feature learning for polarimetric synthetic radar data classification. In Proceedings of the IEEE Conference on International Geoscience and Remote Sensing Symposium (IGARSS), Quebec City, QC, Canada, 13–18 July 2014; pp. 2818–2821. [Google Scholar]
- Lv, Q.; Dou, Y.; Niu, X. Classification of land cover based on deep belief networks using polarimetric RADARSAT-2 data. In Proceedings of the IEEE Conference on International Geoscience and Remote Sensing Symposium (IGARSS), Quebec City, QC, Canada, 13–18 July 2014; pp. 4679–4682. [Google Scholar]
- Zhou, Y.; Wang, H.; Xu, F. Polarimetric SAR image classification using deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1935–1939. [Google Scholar] [CrossRef]
- Kumar, M.P.; Packer, B.; Koller, D. Self-paced learning for latent variable models. In Proceedings of the Conference on Advances in Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 6–9 December 2010; pp. 1189–1197. [Google Scholar]
- Tang, Y.; Yang, Y.B.; Gao, Y. Self-paced dictionary learning for image classification. In Proceedings of the ACM International Conference on Multimedia, Nara, Japan, 29 October–2 November 2012; pp. 833–836. [Google Scholar]
- Kang, M.; Ji, K.; Leng, X. Synthetic Aperture Radar Target Recognition with Feature Fusion Based on a Stacked Autoencoder. Sensors 2017, 17, 192. [Google Scholar] [CrossRef] [PubMed]
- Ranzato, M.A.; Szummer, M. Semi-supervised learning of compact document representations with deep networks. In Proceedings of the International Conference on Machine Learning (ICML), Helsinki, Finland, 5–9 July 2008; pp. 792–799. [Google Scholar]
- Huang, F.J.; Boureau, Y.L.; LeCun, Y. Unsupervised learning of invariant feature hierarchies with applications to object recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MI, USA, 12–22 June 2007; pp. 1–8. [Google Scholar]
- Hou, B.; Kou, H.D. Classification of polarimetric SAR image using multilayer autoencoders and superpixels. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3072–3081. [Google Scholar] [CrossRef]
- Bengio, Y.; Louradour, J. Curriculum learning. In Proceedings of the International Conference on Machine Learning (ICML), Montreal, QC, Canada, 14–18 June 2009; pp. 41–48. [Google Scholar]
- Meng, D.Y.; Zhao, Q.; Jiang, L. What objective does self-paced learning indeed optimize? arXiv, 2015; arXiv:1511.06049. [Google Scholar]
- Rifai, S.; Mesnil, G.; Vincent, P.; Muller, X.; Bengio, Y.; Dauphin, Y.; Glorot, X. Higher order contractive auto-encoder. In Proceedings of the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD), Athens, Greece, 5–9 September 2011; pp. 645–660. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; pp. 203–218, 277–282. ISBN 9780262337434. [Google Scholar]
- Lardeux, C.; Frison, P.L.; Tison, C. Support vector machine for multifrequency SAR polarimetric data classification. IEEE Trans. Geosci. Remote Sens. 2009, 47, 4143–4152. [Google Scholar] [CrossRef]
- Lee, J.S.; Grunes, M.R.; Ainsworth, T.L. Unsupervised classification using polarimetric decomposition and the complex wishart classifier. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2249–2258. [Google Scholar]
- Feng, J.; Cao, Z.; Pi, Y. Polarimetric contextual classification of PolSAR images using sparse representation and superpixels. Remote Sens. 2014, 6, 7158–7181. [Google Scholar] [CrossRef]
- Cloude, S.R.; Pottier, E. An entropy based classification scheme for land applications of Polarimetric SAR. IEEE Trans. Geosci. Remote Sens. 1997, 35, 68–78. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Proc. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Pati, Y.C.; Rezaiifar, R.; Krishnaprasad, P.S. Orthogonal matching pursuit: Recursive function approximation with applications to wavelet decomposition. In Proceedings of the IEEE Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 1–3 November 1993; pp. 40–44. [Google Scholar]
- Ainsworth, T.; Kelly, J.; Lee, J.S. Classification comparisons between dual-pol, compact polarimetric and quad-pol SAR imagery. ISPRS J. Photogramm. Remote Sens. 2009, 64, 464–471. [Google Scholar] [CrossRef]
- Uhlmann, S.; Kiranyaz, S. Integrating color features in polarimetric SAR image classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2197–2216. [Google Scholar] [CrossRef]
- Buono, A.; Nunziata, F.; Mascoloand, L.; Migliaccio, M. A multi-polarization analysis of coastline extraction using X-band COSMO-SkyMed SAR data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2811–2820. [Google Scholar] [CrossRef]
- Gou, S.P.; Yang, X.F.; Li, X.F. Coastal zone classification with full-polarization SAR imagery. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1616–1620. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | SVM | SRC | WC | MAE | SPLMAE |
|---|---|---|---|---|---|
| Stembeans | 0.9719 | 0.9642 | 0.9508 | 0.9842 | 0.9801 |
| Rapeseed | 0.7351 | 0.6049 | 0.7484 | 0.8487 | 0.9003 |
| Bare soil | 0.9802 | 0.9211 | 0.9920 | 0.9039 | 0.8649 |
| Potatoes | 0.9811 | 0.6631 | 0.8775 | 0.9858 | 0.9815 |
| Beet | 0.9541 | 0.9561 | 0.9513 | 0.9679 | 0.9713 |
| Wheat 2 | 0.7875 | 0.7797 | 0.8272 | 0.8582 | 0.8559 |
| Peas | 0.9258 | 0.9396 | 0.9628 | 0.9664 | 0.9676 |
| Wheat 3 | 0.9288 | 0.8226 | 0.8864 | 0.9732 | 0.9749 |
| Lucerne | 0.9292 | 0.9513 | 0.9293 | 0.9553 | 0.9608 |
| Barley | 0.9365 | 0.9322 | 0.9526 | 0.9738 | 0.9795 |
| Wheat | 0.8128 | 0.7610 | 0.8622 | 0.9656 | 0.9592 |
| Grasses | 0.8373 | 0.6284 | 0.7246 | 0.8203 | 0.8555 |
| Forest | 0.7562 | 0.9797 | 0.8791 | 0.9601 | 0.9707 |
| Water | 0.8213 | 0.8002 | 0.5175 | 0.7981 | 0.9434 |
| AA | 0.8827 | 0.8360 | 0.8616 | 0.9258 | 0.9404 |
| OA | 0.8708 | 0.8231 | 0.8504 | 0.9304 | 0.9473 |
| Train + Test time (s) | 1.3 + 17 | 84 + 155 | 130 | 1539 + 3.4 | 1495 + 3.5 |
| Class | SVM | SRC | WC | MAE | SPLMAE |
|---|---|---|---|---|---|
| Urban | 0.8051 | 0.7579 | 0.6022 | 0.8712 | 0.8921 |
| Water | 0.9693 | 0.9779 | 0.9854 | 0.9878 | 0.9870 |
| Forest | 0.9207 | 0.9195 | 0.8479 | 0.9537 | 0.9468 |
| Cropland | 0.9372 | 0.8759 | 0.8071 | 0.9327 | 0.9408 |
| AA | 0.9080 | 0.8828 | 0.8107 | 0.9363 | 0.9417 |
| OA | 0.9229 | 0.8978 | 0.8382 | 0.9449 | 0.9482 |
| Train + Test time (s) | 1+ 11.7 | 26 + 436 | 87.5 | 51 + 5 | 42 + 4.7 |
| Class | SVM | SRC | WC | MAE | SPLMAE |
|---|---|---|---|---|---|
| Pond | 0.8540 | 0.3680 | -- | 0.9230 | 0.9132 |
| Alkali Soil | 0.8498 | 0.4681 | -- | 0.8350 | 0.8523 |
| Coastal Shoal | 0.7192 | 0.4912 | -- | 0.7798 | 0.7758 |
| Wetland | 0.5544 | 0.2311 | -- | 0.5908 | 0.6678 |
| Plantation | 0.5280 | 0.4377 | -- | 0.7175 | 0.7124 |
| River | 0.1444 | 0.3144 | -- | 0.3215 | 0.4489 |
| AA | 0.6083 | 0.3851 | 0.6 | 0.6946 | 0.7284 |
| OA | 0.7113 | 0.3963 | -- | 0.7627 | 0.7812 |
| Train + Test time (s) | 5 + 305 | 39 + 2871 | -- | 5840 + 52 | 5643 + 53 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, W.; Gou, S.; Wang, X.; Li, X.; Jiao, L. Classification of PolSAR Images Using Multilayer Autoencoders and a Self-Paced Learning Approach. Remote Sens. 2018, 10, 110. https://doi.org/10.3390/rs10010110
Chen W, Gou S, Wang X, Li X, Jiao L. Classification of PolSAR Images Using Multilayer Autoencoders and a Self-Paced Learning Approach. Remote Sensing. 2018; 10(1):110. https://doi.org/10.3390/rs10010110
Chicago/Turabian StyleChen, Wenshuai, Shuiping Gou, Xinlin Wang, Xiaofeng Li, and Licheng Jiao. 2018. "Classification of PolSAR Images Using Multilayer Autoencoders and a Self-Paced Learning Approach" Remote Sensing 10, no. 1: 110. https://doi.org/10.3390/rs10010110
APA StyleChen, W., Gou, S., Wang, X., Li, X., & Jiao, L. (2018). Classification of PolSAR Images Using Multilayer Autoencoders and a Self-Paced Learning Approach. Remote Sensing, 10(1), 110. https://doi.org/10.3390/rs10010110