Improving the Accuracy of Land Use and Land Cover Classification of Landsat Data Using Post-Classification Enhancement

Abstract
:
1. Introduction
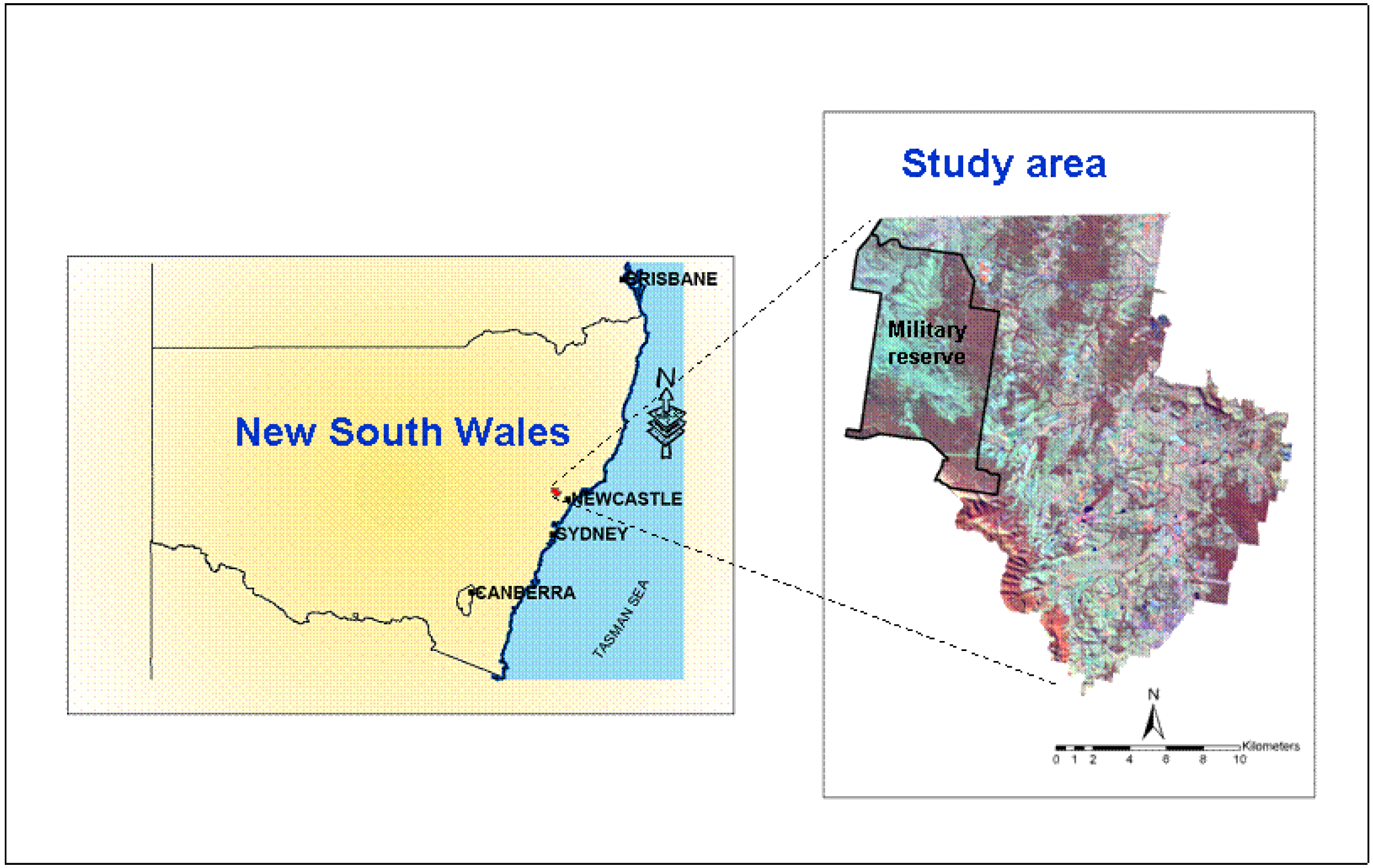
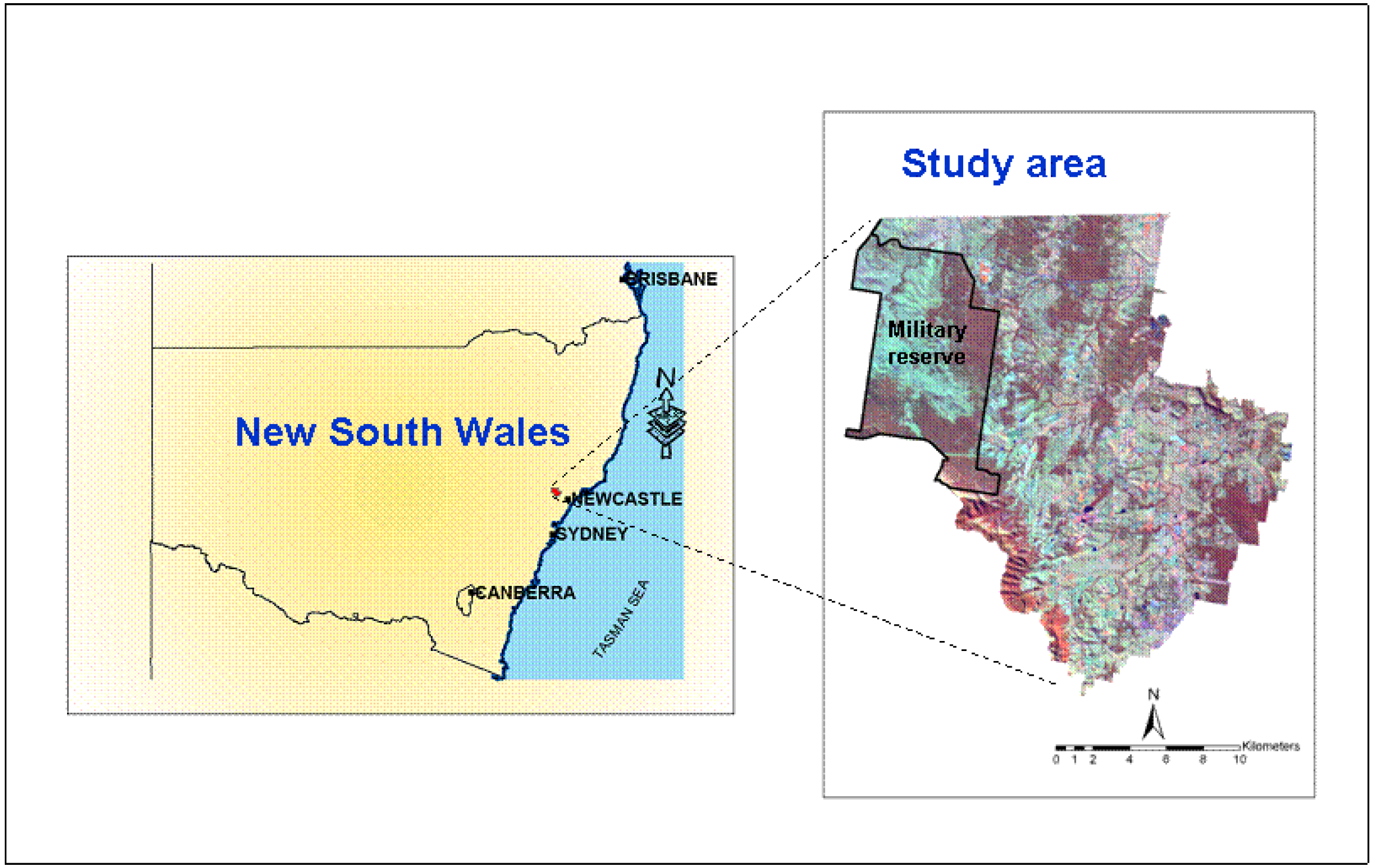
2. Study Area
3. Methods
3.1. Landsat, Ancillary and Reference Data

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LULC category | Description |
|---|---|
| Woodland | Forest covers including tree cover along the creeks |
| Pasture/scrubland | Natural and cultivated pastures, and scrubs with partial grassland |
| Vineyard | Irrigated and non irrigated vineyards |
| Built-up | Commercial, and residential areas, and other areas with man-made structure; roads, railway lines |
| Water-body | Farm dams, sewage ponds |
| Mine/quarry | Mining areas |
| Olive | Olive plantations (for 2005 only) |
3.2. LULC Classification Based on Maximum Likelihood Classifier
3.3. Post-Classification Refinement Using Ancillary Data and Logic Rule
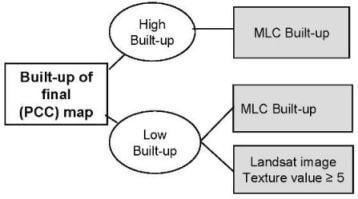
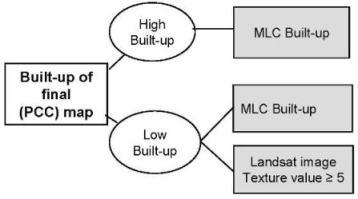
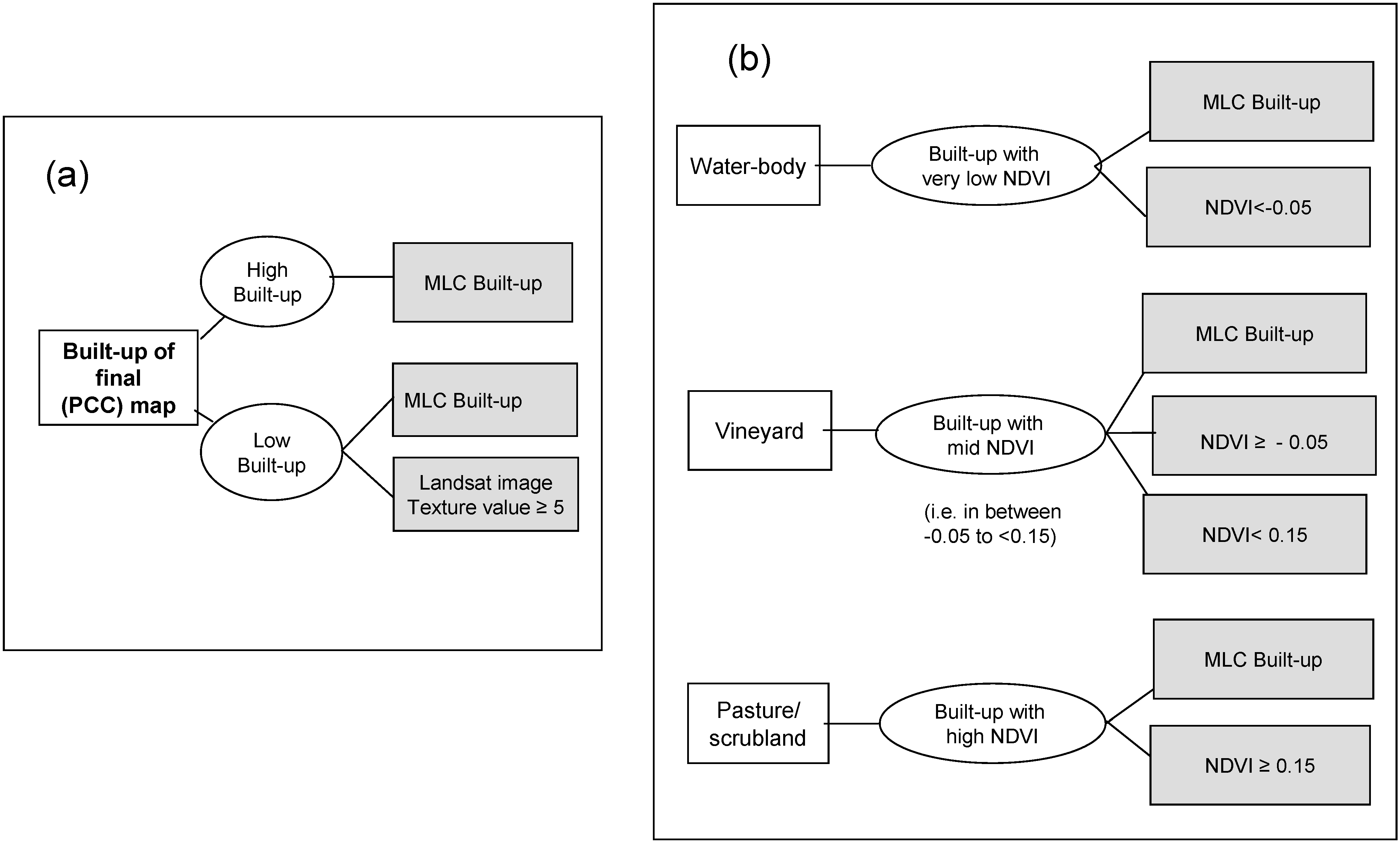
3.3.1. Built-up post-classification correction
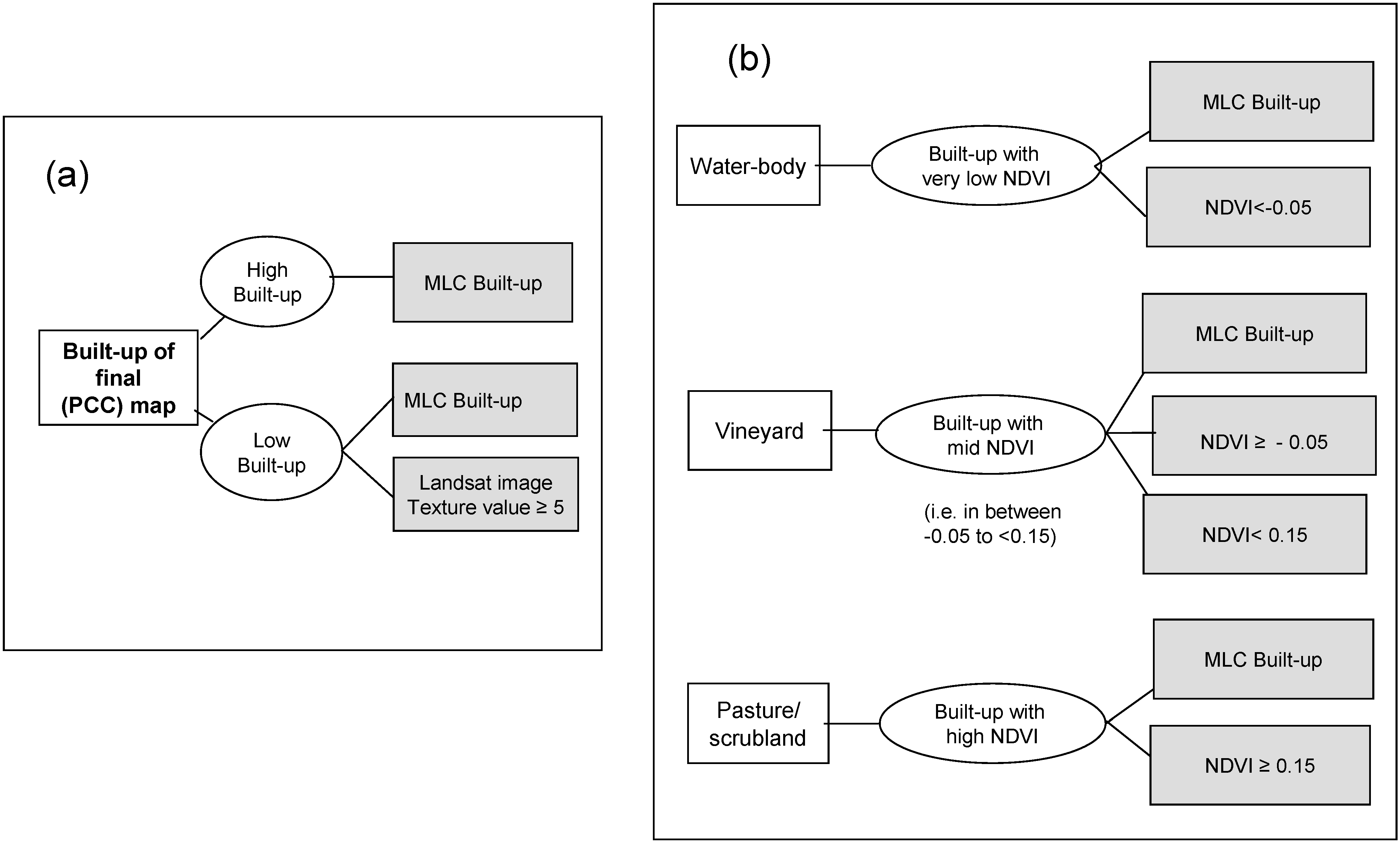
3.3.2. Vineyard post-classification correction
3.3.3. Other minor post-classification corrections
3.4. Accuracy Assessment
3.5. Comparing Classifier Performance
4. Results and Discussion
4.1. Classification Accuracy Assessment Using Error Matrices
| LULC category | Band 1 | Band 2 | Band 3 | Band 4 | Band 5 | Band 7 |
|---|---|---|---|---|---|---|
| Woodland | 36.4 (1.3) | 13.4 (1.1) | 11.2 (1.6) | 34.2 (7.4) | 25.4 (6.9) | 8.5 (2.5) |
| Pasture/scrubland | 43.8 (1.5) | 19.2 (0.9) | 22.1 (1.8) | 32.2 (4.4) | 58.0 (5.0) | 24.4 (3.5) |
| Vineyard | 43.1 (2.7) | 18.8 (2.2) | 21.4 (3.9) | 27.1 (7.3) | 54.4 (8.9) | 27.6 (5.9) |
| Built-up | 47.9 (4.5) | 20.7 (2.4) | 21.6 (3.7) | 30.6 (4.3) | 39.2 (6.6) | 20.5 (4.6) |
| Water-body | 38.3 (1.6) | 14.6 (1.7) | 11.9 (2.2) | 7.2 (2.0) | 7.0 (2.2) | 3.8 (1.3) |
| Mine/quarry | 43.1 (1.2) | 16.7 (0.9) | 16.3 (1.1) | 13.8 (2.3) | 20.1 (3.2) | 11.5 (1.0) |
| Olive | 39.4 (0.8) | 15.9 (0.6) | 16.0 (0.6) | 37.3 (1.2) | 38.3 (1.0) | 13.5 (0.6) |
| LULC category | 1985 Accuracy | 1995 Accuracy | 2005 Accuracy | |||
|---|---|---|---|---|---|---|
| Producer’s | User’s | Producer’s | User’s | Producer’s | User’s | |
| MLC maps | ||||||
| Woodland | 85.1 | 93.4 | 90.7 | 96.3 | 83.2 | 91.8 |
| Pasture/scrubland | 47.9 | 90.0 | 55.4 | 96.7 | 65.0 | 90.3 |
| Vineyard | 81.5 | 44.0 | 89.3 | 52.6 | 87.7 | 62.5 |
| Built-up | 93.2 | 55.6 | 96.0 | 51.1 | 95.7 | 56.3 |
| Water-body | 98.0 | 100.0 | 83.3 | 100.0 | 88.9 | 96.0 |
| Overall accuracy | 71.8 | 76.3 | 79.3 | |||
| Kappa statistics | 0.64 | 0.70 | 0.74 | |||
| PCC maps | ||||||
| Woodland | 98.5 | 100.0 | 94.2 | 91.0 | 88.8 | 89.6 |
| Pasture/scrubland | 81.7 | 98.6 | 88.5 | 90.9 | 81.1 | 88.6 |
| Vineyard | 98.2 | 71.6 | 92.9 | 77.6 | 87.7 | 73.5 |
| Built-up | 98.3 | 82.9 | 80.0 | 88.9 | 91.5 | 82.7 |
| Water-body | 98.0 | 100 | 90.0 | 98.2 | 90.7 | 96.1 |
| Overall accuracy | 91.3 | 89.5 | 86.6 | |||
| Kappa statistics | 0.88 | 0.86 | 0.83 | |||
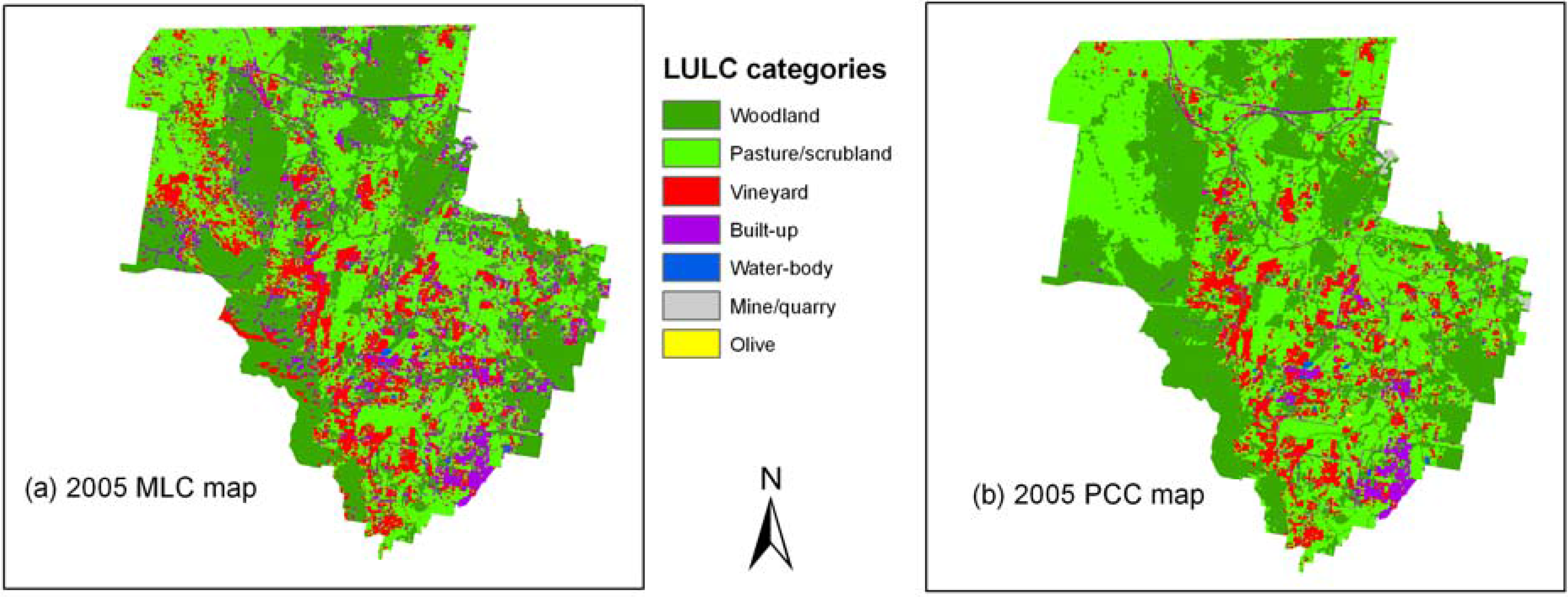
4.2. Classifier Performance
| Year | f11 | f12 | f21 | f22 | Total | Chi-square (χ2) | P value |
|---|---|---|---|---|---|---|---|
| 1985 maps | 34 | 79 | 1 | 286 | 400 | 76.1 | <0.001 |
| 1995 maps | 32 | 65 | 11 | 302 | 410 | 38.4 | <0.001 |
| 2005 maps | 46 | 39 | 9 | 316 | 410 | 18.8 | <0.001 |
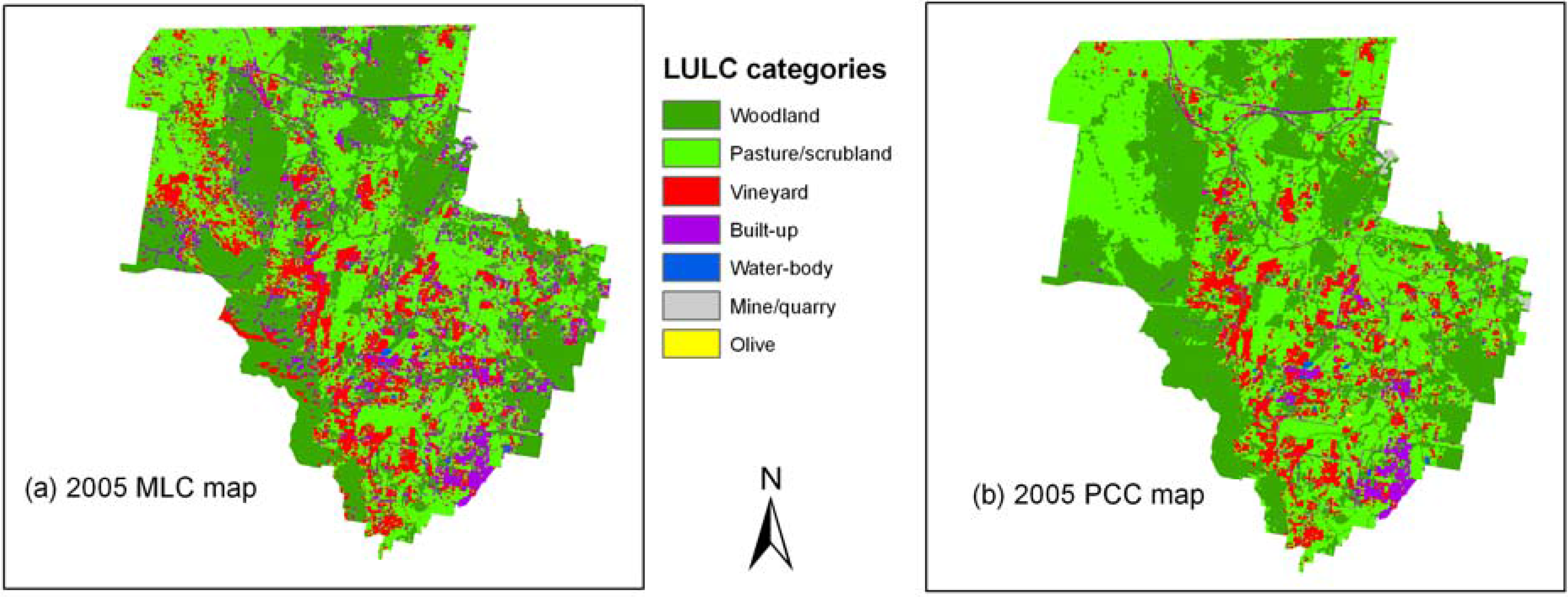
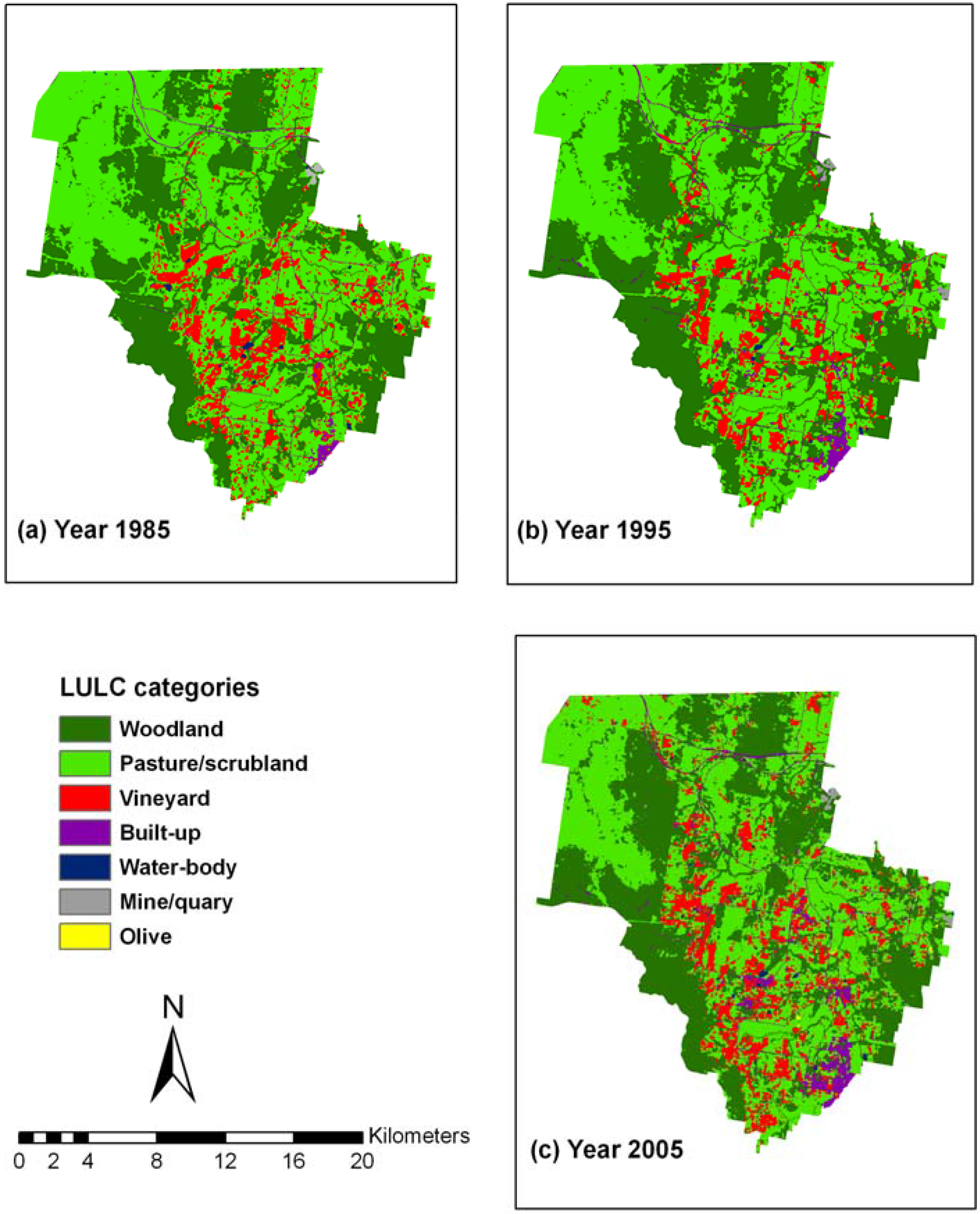
4.3. Maps and Area Statistics of PCC Classifications
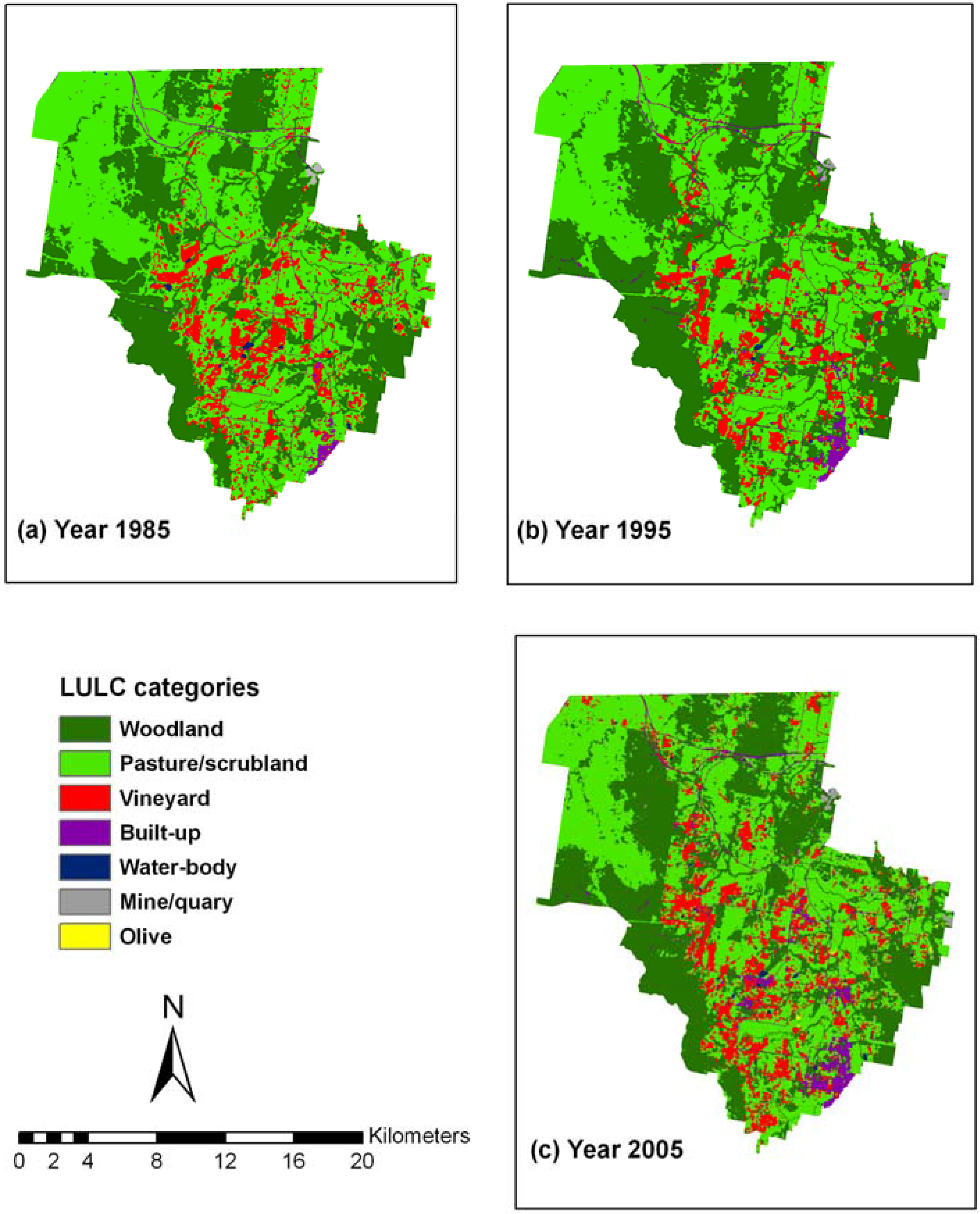
| LULC category | 1985 | 1995 | 2005 | Relative change 1985-2005 (%) | |||
|---|---|---|---|---|---|---|---|
| Area (ha) | % oftotal land | Area (ha) | % of total land | Area (ha) | % of total land | ||
| Woodland | 13,156.1 | 34.7 | 15,190.9 | 40.1 | 14,412.6 | 38.0 | 9.6 |
| Pasture/scrubland | 20,078.8 | 53.0 | 18,526.6 | 48.9 | 17,526.9 | 46.2 | -12.7 |
| Vineyard | 3,766.1 | 9.9 | 2,983.1 | 7.9 | 4,147.1 | 10.9 | 10.1 |
| Built-up | 757.0 | 2.0 | 1,050.7 | 2.8 | 1,580.3 | 4.2 | 108.8 |
| Water-body | 95.3 | 0.3 | 77.1 | 0.2 | 118.2 | 0.3 | 24.1 |
| Mine/quarry | 60.7 | 0.2 | 85.6 | 0.2 | 82.3 | 0.2 | 35.6 |
| Olive | 46.5 | 0.1 | new LULC | ||||
| Total | 37,913.9 | 100 | 37,913.9 | 100 | 37,913.9 | 100 | 12.4 |
5. Conclusions
Acknowledgements
References and Notes
- Lambin, E.F.; Turner, B.L.; Geist, H.J.; Agbola, S.B.; Angelsen, A.; Bruce, J.W.; Coomes, O.T.; Dirzo, R.; Fischer, G.; Folke, C.; George, P.S.; Homewood, K.; Imbernon, J.; Leemans, R.; Li, X.; Moran, E.F.; Mortimore, M.; Ramakrishnan, P.S.; Richards, J.F.; Skanes, H.; Steffen, W.; Stone, G.D.; Svedin, U.; Veldkamp, T.A.; Vogel, C.; Xu, J. The causes of land use and land cover change: Moving beyond the myths. Glob. Environ. Change 2001, 11, 261–269. [Google Scholar] [CrossRef]
- Goldewijk, K. K.; Ramankutty, N. Land cover change over the last three centuries due to human activities: the availability of new global data sets. Geo. J. 2004, 61, 335–344. [Google Scholar] [CrossRef]
- Steele, B.M.; Winne, J.C.; Redmond, R.L. Estimation and mapping of misclassification probabilities for thematic land cover maps. Remote Sens. Environ. 1998, 66, 192–202. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Stow, D.A.; Collins, D.; McKinsey, D. Land use change detection based on multi date imagery from different satellite sensor systems. Geocart. Int. 1990, 5, 3–12. [Google Scholar] [CrossRef]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Wilkinson, G.G. Results of implications of a study of fifteen years of satellite classification experiments. IEEE Trans. Geosci. Remote Sens. 2005, 43, 433–440. [Google Scholar] [CrossRef]
- Jensen, J.R. Thematic information extraction: pattern recognition. In Introductory Digital Image Processing – A Remote Sensing Perspective, 3rd ed.; Keith, C.C., Ed.; Prentice Hall Series in Geographic Information Science: Saddle River, NJ, USA, 2005b; pp. 337–406. [Google Scholar]
- Stefanov, W.L.; Ramsey, M.S.; Christensen, P.R. Monitoring urban land cover change: An expert system approach to land cover classification of semiarid to arid urban centers. Remote Sens. Environ. 2001, 77, 173–185. [Google Scholar] [CrossRef]
- Xiuwan, C. Using remote sensing and GIS to analyse land cover change and its impacts on regional sustainable development. Int. J. Remote Sens. 2002, 23, 107–124. [Google Scholar] [CrossRef]
- Currit, N. Development of remotely sensed, historical land cover change database for rural Chihuahua, Mexico. Int. J. Appl. Earth Obs. Geoinf. 2005, 7, 232–247. [Google Scholar] [CrossRef]
- Yuan, F.; Sawaya, K.E.; Loeffelholz, B.C.; Bauer, M. E. Land cover classification and change analysis of the Twin Cities (Minnesota) Metropolitan Area by multitemporal Landsat Remote Sensing. Remote Sens. Environ. 2005, 98, 317–328. [Google Scholar] [CrossRef]
- Qian, Y.; Zhang, K.; Qiu, F. Spatial contextual noise removal for post classification smoothing of remotely sensed images. ACM Symp. Appl. Comput. 2005, 524–528. [Google Scholar]
- Judex, M.; Thamm, M.J.; Menz, G. Improving land cover classification with a knowledge based approach and ancillary data. In Proceeding of the workshop of the EARSeL sig on Land Use and Land Cover 2006, Bonn, Germany, September 28–30, 2006; pp. 184–191.
- Yang, X.; Lo, C.P. Using a time series of satellite imagery to detect land use and land cover changes in the Atlanta, Georgia Metropolitan Area. Int. J. Remote Sens. 2002, 23, 1775–1798. [Google Scholar] [CrossRef]
- Lower Hunter Regional Strategy; Department of Planning State of New South Wales: Parramatta, New South Wales, Australia, 2006.
- Holmes, J.; Hartig, K. Metropolitan colonization and the reinvention of place: class polarization along the Cessnock- Pokolbin Fault Line. Geograph. Res. 2007, 45, 54–70. [Google Scholar] [CrossRef]
- Bailly, J.S.; Arnaud, M.; Puech, C. Boosting: a classification method for remote sensing. Int. J. Remote Sens. 2007, 28, 1687–1710. [Google Scholar] [CrossRef]
- Liu, X.H.; Skidmore, A.K.; Oosten, H.V. Integration of classification methods for improvement of land cover map accuracy. ISPRS J. Photogramm. Remote Sens. 2002, 56, 257–268. [Google Scholar] [CrossRef]
- Weng, Q. Land use change analysis in the Zhujiang Delta of China using satellite remote sensing, GIS and stochastic modeling. J. Environ. Manage. 2002, 64, 273–284. [Google Scholar] [CrossRef] [PubMed]
- ERDAS Field guide; Leica Geosystems Geospatial Imaging, LLC: Norcross, Georgia, USA, 2005.
- Smits, P.C.; Dellepaine, S.G.; Schowengerdt, R.A. Quality assessment of image classification algorithms for land cover mapping: a review and a proposal for a cost based approach. Int. J. Remote Sens. 1999, 20, 1461–1486. [Google Scholar] [CrossRef]
- Plourde, L.; Congalton, R.G. Sampling method and sample placement: How do they affect the accuracy of remotely sensed maps? Photogramm. Eng. Remote Sens. 2003, 69, 289–297. [Google Scholar] [CrossRef]
- Anderson, J.R.; Hardy, E.E.; Roach, J.T.; Witmer, R.E. A Land Use and Land Cover Classification System for Use with Remote Sensor Data; Government Printing Office: Washington, DC, USA, 1976.
- Congalton, R.G. A review of assessing the accuracy of classification of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Jensen, J.R. Thematic map accuracy assessment. In Introductory Digital Image Processing–A Remote Sensing Perspective, 3rd ed.; Keith, C.C., Ed.; Prentice Hall Series in Geographic Information Science: Saddle River, NJ, USA, 2005; Sect. C; pp. 495–515. [Google Scholar]
- Liu, C.; Frazier, P.; Kumar, L. Comparative assessment of the measures of thematic classification accuracy. Remote Sens. Environ. 2007, 107, 606–616. [Google Scholar] [CrossRef]
- Lunetta, R.S.; Congalton, R.G.; Fenstermaker, L.K.; Jensen, J.R.; Tinney, L.R. Remote sensing and geographic information system data integration: error sources and research issues. Photogramm. Eng. Remote Sens. 1991, 57, 677–687. [Google Scholar]
- Foody, G.M. Thematic map comparison: evaluating the statistical significance of differences in classification accuracy. Photogramm. Eng. Remote Sens. 2004, 70, 627–633. [Google Scholar] [CrossRef]
- De Leeuw, J.; Jia, H.; Yang, L.; Liu, X.; Schmidt, K.; Skidmore, A.K. Comparing accuracy assessments to infer superiority of image classification methods. Int. J. Remote Sens. 2006, 27, 223–232. [Google Scholar] [CrossRef]
- Foody, G.M. Map comparison in GIS. Progr.Phys. Geog. 2007, 31, 439–445. [Google Scholar] [CrossRef]
- Lu, D.; Moran, E.; Batistella, M. Linear mixture model applied to Amazonian vegetation classification. Remote Sens. Environ. 2003, 87, 456–469. [Google Scholar] [CrossRef]
- Jensen, J.R. Information extraction using artificial intelligence. In Introductory Digital Image Processing – A Remote Sensing Perspective, 3rd ed.; Keith, C.C., Ed.; Prentice Hall Series in Geographic Information Science: Saddle River, NJ, USA, 2005; Sect. D; pp. 407–429. [Google Scholar]
- Stuckens, J.; Coppin, P.R.; Bauer, M.E. Integrating contextual information with per-pixel classification for improved land cover classification. Remote Sens. Environ. 2000, 71, 282–296. [Google Scholar] [CrossRef]
© 2009 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Manandhar, R.; Odeh, I.O.A.; Ancev, T. Improving the Accuracy of Land Use and Land Cover Classification of Landsat Data Using Post-Classification Enhancement. Remote Sens. 2009, 1, 330-344. https://doi.org/10.3390/rs1030330
Manandhar R, Odeh IOA, Ancev T. Improving the Accuracy of Land Use and Land Cover Classification of Landsat Data Using Post-Classification Enhancement. Remote Sensing. 2009; 1(3):330-344. https://doi.org/10.3390/rs1030330
Chicago/Turabian StyleManandhar, Ramita, Inakwu O. A. Odeh, and Tiho Ancev. 2009. "Improving the Accuracy of Land Use and Land Cover Classification of Landsat Data Using Post-Classification Enhancement" Remote Sensing 1, no. 3: 330-344. https://doi.org/10.3390/rs1030330
APA StyleManandhar, R., Odeh, I. O. A., & Ancev, T. (2009). Improving the Accuracy of Land Use and Land Cover Classification of Landsat Data Using Post-Classification Enhancement. Remote Sensing, 1(3), 330-344. https://doi.org/10.3390/rs1030330