The Short-Term Power Load Forecasting Based on Sperm Whale Algorithm and Wavelet Least Square Support Vector Machine with DWT-IR for Feature Selection

Abstract
:1. Introduction
2. Wavelet Least Square Support Vector Machine
- (a)
- Wavelet kernel function has an advantage in stepwise data-description and is superior to Gaussian kernel function when applied in LSSVM to simulate arbitrary functions accurately.
- (b)
- Compared with Gaussian kernel function, wavelet kernel function is orthogonal or nearly orthogonal rather than relevant or even redundant.
- (c)
- Particularly because of multi-resolution analysis and processing of the wavelet signal, wavelet kernel function has strong capability in nonlinear processing, which immensely promotes LSSVM’s generalization ability and robustness.
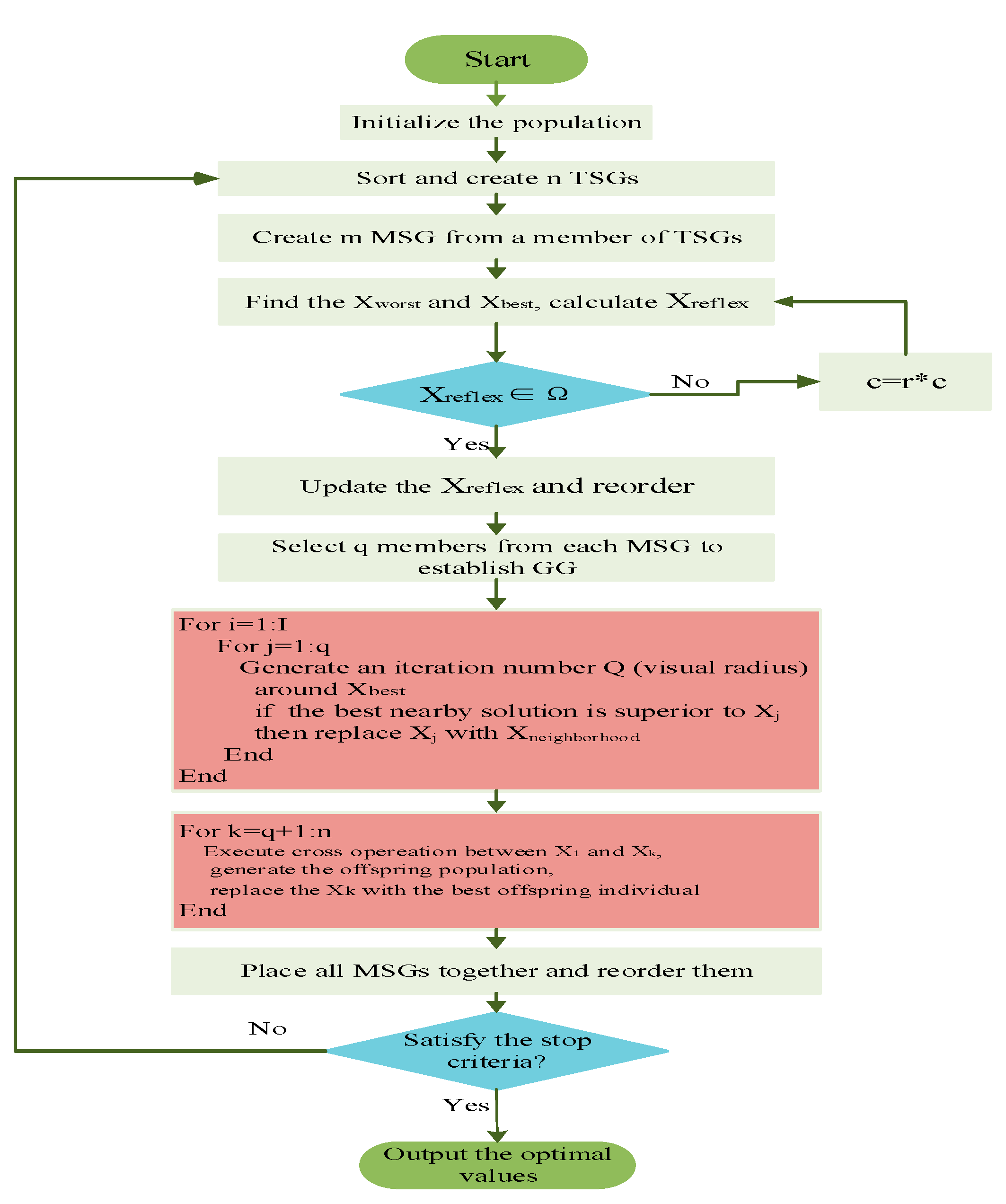
3. Sperm Whale Algorithm
- (1)
- Each sperm whale undergoes two locations in breathing–feeding cycle (it breathes on the sea but takes food undersea), so that the objective function will be calculated by both two positions (current position and relative position). Nevertheless, the best answer of the relative position does not make contributions to seeking the global optimal answer and even increases the computing time, which is the reason for only reflecting the worst answer. In light of these, taking the information exchange between whales into account, location of the worst answer can be transferred into desired space by the reflection to the center of the search space. Thus, as illustrated in Figure 2, the worst and best answers are on the spatial line connecting worst answer and its reflection. Assume that the worst and best whales are named as and , respectively, so:where is conceived as the reflection center and refers to center factor. Besides, is the result obtained from to .
- (2)
- In view of sperm whales’ limited vision, a local search is carried out around the members of the Good Gang (GG) which consists of whales selected from each MSG. The search method is: members of GG can be constantly changed by iterations within the realm of definable vision Q (radius), and once a better answer is gained, the original one in GG will be replaced.
- (3)
- Considering the mating behavior of sperm whales (the strongest male whale mates with several female whales), there will be crossovers between the best answer in GG and other answers in MSG. Afterwards, a descendant answer randomly selected will take place of the mother answer. Finally, all answers in subgroup have a mutual substitute relationship and are reordered when the specified times of iteration are reached. It is not until the best answer is found that repetitions of the procedure above are stopped. Figure 3 displays the optimization flowchart of SWA.
4. Feature Selection with DWT-IR
4.1. Discrete Wavelet Transform (DWT)
4.2. Data Inconsistency Rate (IR)
4.3. The Feature Selection Based on DWT-IR
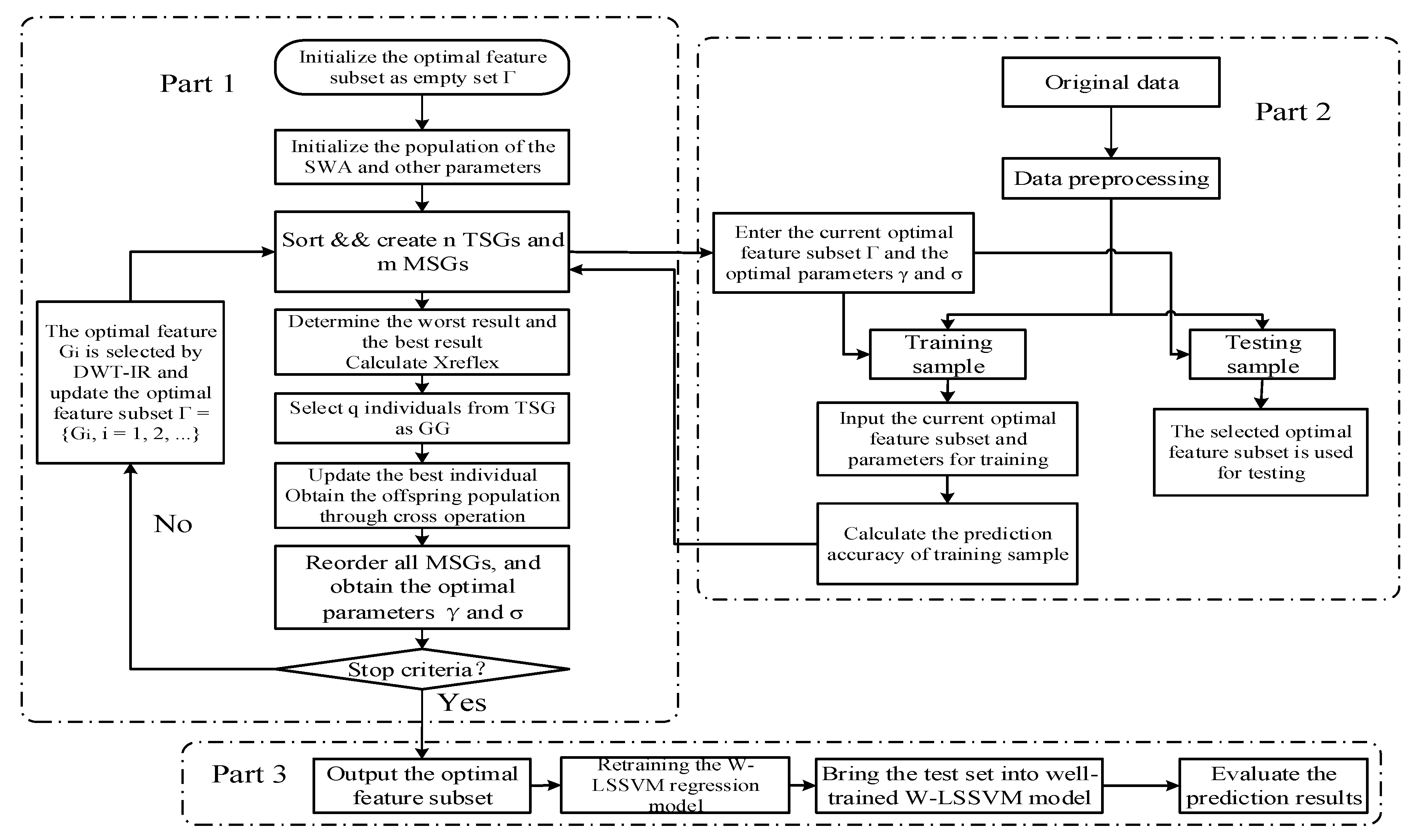
5. Experiment and Results Analysis
5.1. Forecasting System with W-LSSVM-SWA and DWT-IR
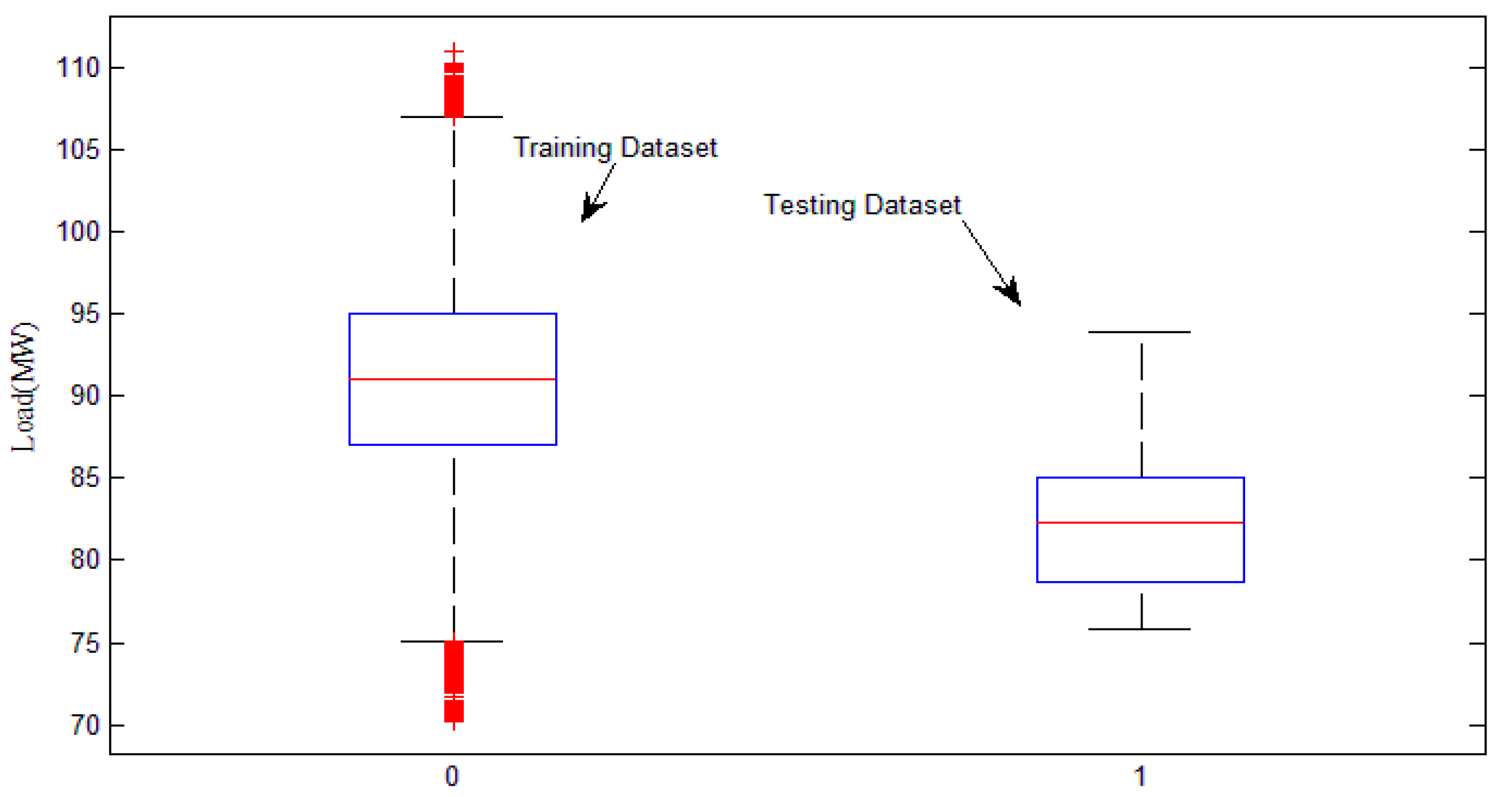
5.2. Data Selection and Pretreatment
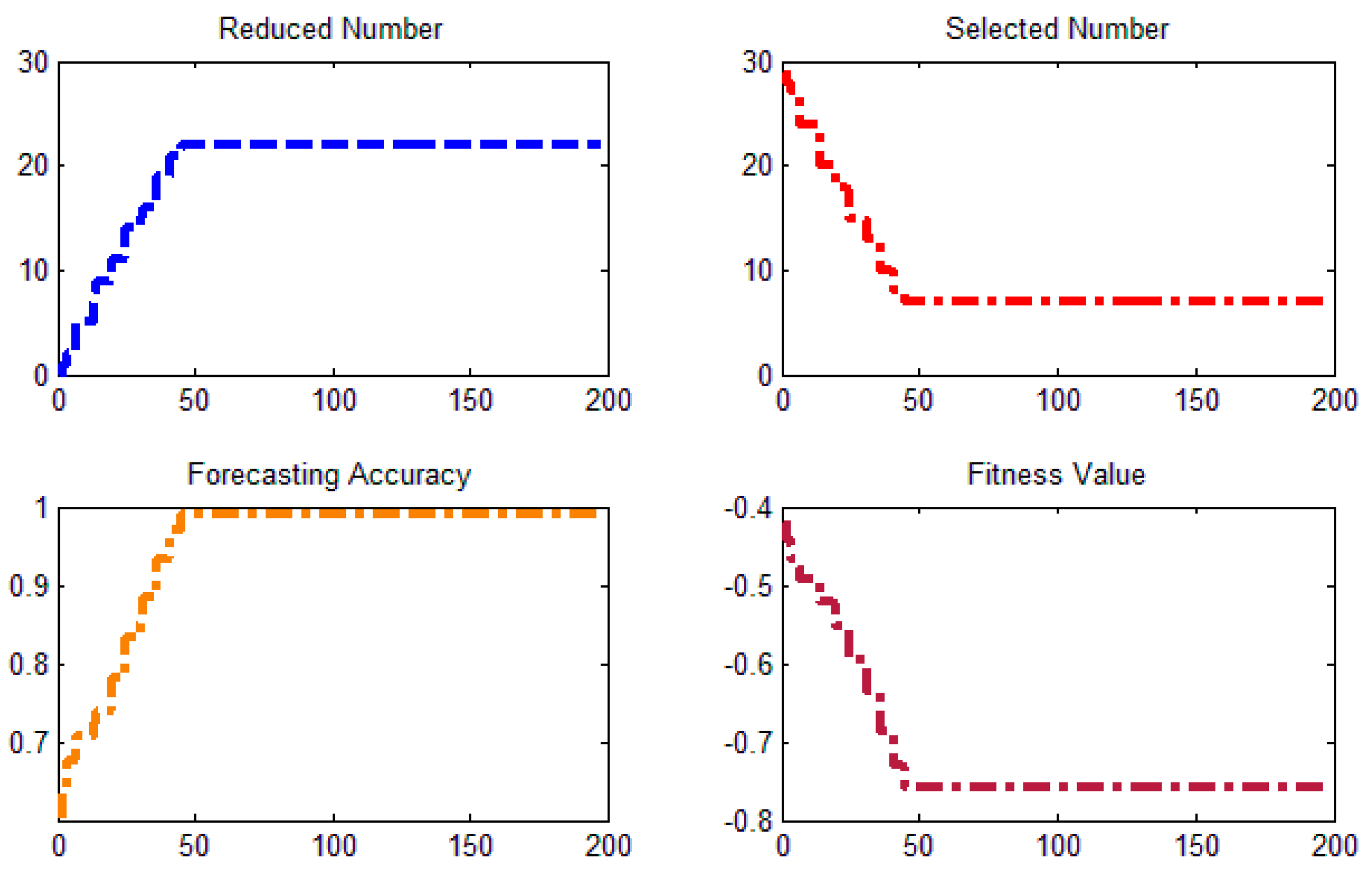
5.3. DWT-IR for Feature Selection
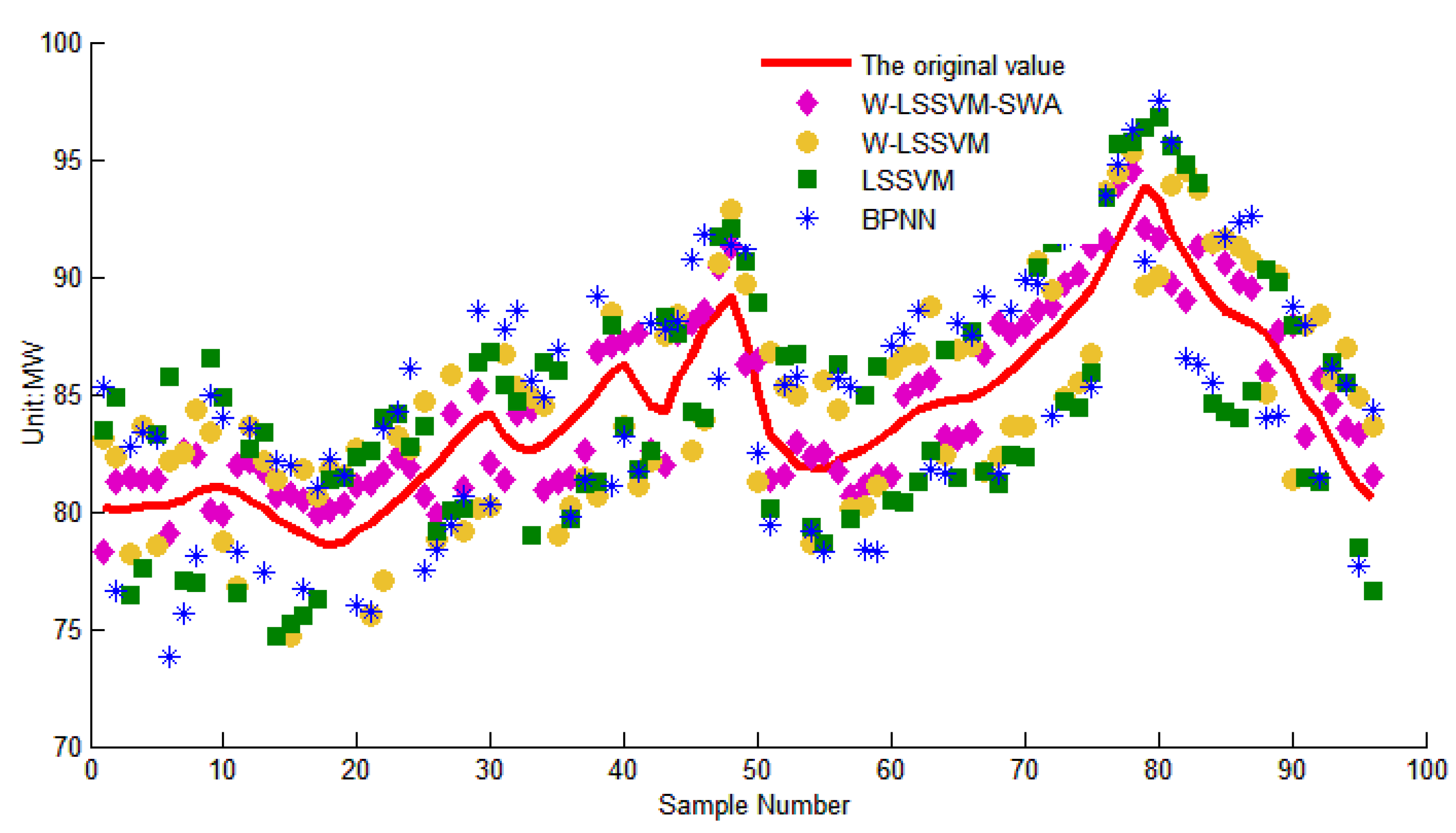
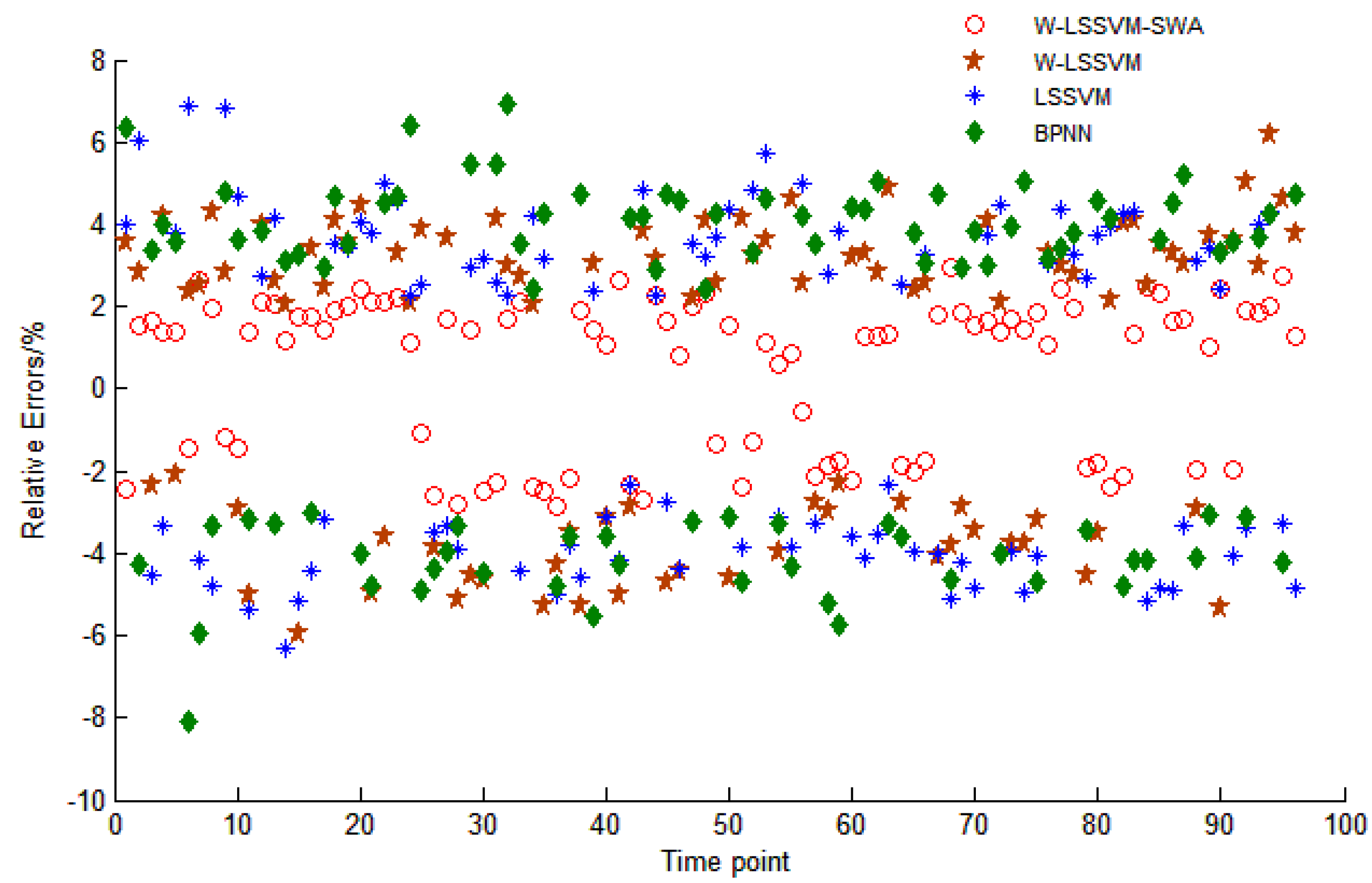
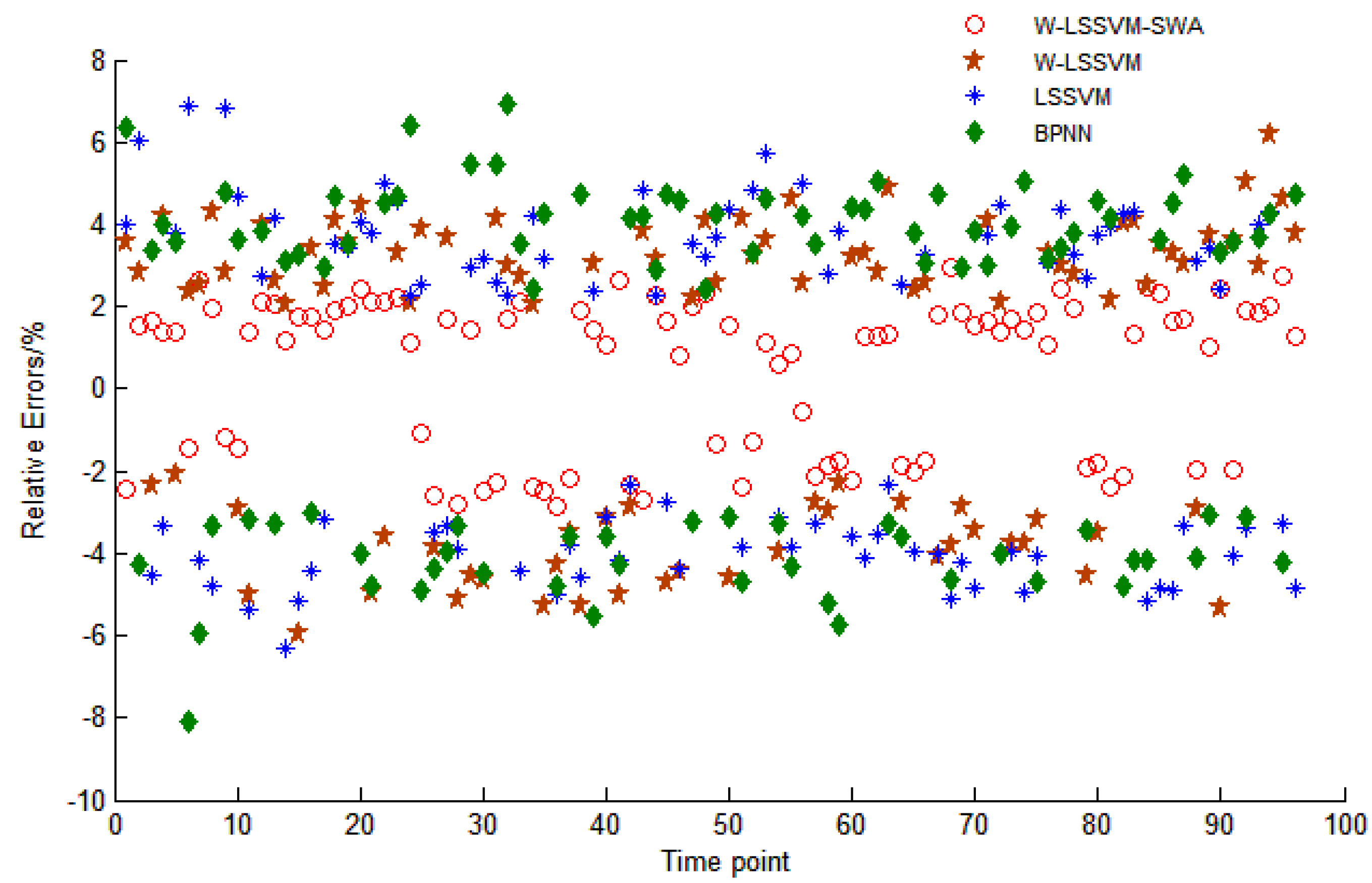
5.4. W-LSSVM for Load Forecasting
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Okabe, T.H.; Kuzmina, O.; Slattery, J.M.; Jiang, C.; Sudmeier, T.; Yu, L.; Wang, H.; Xiao, W.; Xu, L.; Yue, X.; et al. Benefits to energy efficiency and environmental impact: General discussion. Faraday Discuss. 2016, 190, 161–204. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Wang, D.; Jia, H.; Chen, Z.; Guo, B.; Zhou, H.; Fan, M. Review of steady-state analysis of typical regional integrated energy system under the background of energy internet. Proc. CSEE 2016, 36, 3292–3306. [Google Scholar]
- Wu, J. Drivers and state-of-the-art of integrated energy systems in Europe. Autom. Electr. Power Syst. 2016, 40, 1–7. [Google Scholar]
- Clements, A.E.; Hurn, A.S.; Li, Z. Forecasting day-ahead electricity load using a multiple equation time series approach. Eur. J. Oper. Res. 2014, 251, 522–530. [Google Scholar] [CrossRef]
- Cui, H.; Peng, X.; Mu, Y. Electric load forecast using combined models with HP Filter-SARIMA and ARMAX optimized by regression analysis algorithm. Math. Probl. Eng. 2015, 2015, 326925. [Google Scholar]
- Zhao, H.; Guo, S. An optimized grey model for annual power load forecasting. Energy 2016, 107, 272–286. [Google Scholar] [CrossRef]
- Coelho, V.N.; Coelho, I.M.; Coelho, B.N.; Reis, A.J.R.; Enayatifar, R.; Souza, M.J.F.; Guimarães, F.G. A self-adaptive evolutionary fuzzy model for load forecasting problems on smart grid environment. Appl. Energy 2016, 169, 567–584. [Google Scholar] [CrossRef]
- Hernandez, L.; Baladrón, C.; Aguiar, J.M.; Carro, B.; Sanchez-Esguevillas, A.J.; Lloret, J. Short-term load forecasting for microgrids based on artificial neural networks. Energies 2013, 6, 1385–1408. [Google Scholar] [CrossRef]
- Dudek, G. Neural networks for pattern-based short-term load forecasting: A comparative study. Neurocomputing 2016, 205, 64–74. [Google Scholar] [CrossRef]
- Rana, M.; Koprinska, I. Forecasting electricity load with advanced wavelet neural networks. Neurocomputing 2016, 182, 118–132. [Google Scholar] [CrossRef]
- Hu, R.; Wen, S.; Zeng, Z.; Huang, T. A short-term power load forecasting model based on the generalized regression neural network with decreasing step fruit fly optimization algorithm. Neurocomputing 2016, 221, 24–31. [Google Scholar] [CrossRef]
- Pan, X.; Lee, B. A comparison of support vector machines and artificial neural networks for mid-term load forecasting. In Proceedings of the IEEE International Conference on Industrial Technology, Athens, Greece, 19–21 March 2012; pp. 95–101. [Google Scholar]
- Ceperic, E.; Ceperic, V.; Baric, A. A strategy for short-term load forecasting by support vector regression machines. IEEE Trans. Power Syst. 2013, 28, 4356–4364. [Google Scholar] [CrossRef]
- Pai, P.F.; Hong, W.C. Forecasting regional electricity load based on recurrent support vector machines with genetic algorithms. Electr. Power Syst. Res. 2005, 74, 417–425. [Google Scholar] [CrossRef]
- Ren, G.; Wen, S.; Yan, Z.; Hu, R.; Zeng, Z.; Cao, Y. Power load forecasting based on support vector machine and particle swarm optimization. In Proceedings of the 2016 12th World Congress on Intelligent Control and Automation, Guilin, China, 12–15 June 2016; pp. 2003–2008. [Google Scholar]
- Zhang, X.; Wang, J.; Zhang, K. Short-term electric load forecasting based on singular spectrum analysis and support vector machine optimized by Cuckoo search algorithm. Electr. Power Syst. Res. 2017, 146, 270–285. [Google Scholar] [CrossRef]
- Li, H.; Guo, S.; Zhao, H.; Su, C.; Wang, B. Annual electric load forecasting by a least squares support vector machine with a fruit fly optimization algorithm. Energies 2012, 5, 4430–4445. [Google Scholar] [CrossRef]
- Niu, D.; Ma, T.; Liu, B. Power load forecasting by wavelet least squares support vector machine with improved fruit fly optimization algorithm. J. Comb. Optim. 2016, 33, 1122–1143. [Google Scholar]
- Sun, W.; Liang, Y. Least-squares support vector machine based on improved imperialist competitive algorithm in a short-term load forecasting model. J. Energy Eng. 2014. [Google Scholar] [CrossRef]
- Liang, Y.; Niu, D.; Ye, M.; Hong, W.C. Short-term load forecasting based on wavelet transform and least squares support vector machine optimized by improved cuckoo search. Energies 2016, 9, 827. [Google Scholar] [CrossRef]
- Du, J.; Liu, Y.; Yu, Y.; Yan, W. A prediction of precipitation data based on support vector machine and particle swarm optimization (PSO-SVM) algorithms. Algorithms 2017, 10, 57. [Google Scholar] [CrossRef]
- Cai, G.; Wang, W.; Lu, J. A novel hybrid short term load forecasting model considering the error of numerical weather prediction. Energies 2016, 9, 994. [Google Scholar] [CrossRef]
- Ye, F.; Lou, X.Y.; Sun, L.F. An improved chaotic fruit fly optimization based on a mutation strategy for simultaneous feature selection and parameter optimization for SVM and its applications. PLoS ONE 2017, 12, e0173516. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.L.; Chen, X.F.; He, Z.J. An ACO-based algorithm for parameter optimization of support vector machines. Expert Syst. Appl. 2010, 37, 6618–6628. [Google Scholar] [CrossRef]
- Ebrahimi, A.; Khamehchi, E. Sperm whale algorithm: An effective metaheuristic algorithm for production optimization problems. J. Nat. Gas Sci. Eng. 2016, 29, 211–222. [Google Scholar] [CrossRef]
- Gorjaei, R.G.; Songolzadeh, R.; Torkaman, M.; Safari, M.; Zargar, G. A novel PSO-LSSVM model for predicting liquid rate of two phase flow through wellhead chokes. J. Nat. Gas Sci. Eng. 2015, 24, 228–237. [Google Scholar] [CrossRef]
- Ahmadi, M.A.; Bahadori, A. A LSSVM approach for determining well placement and conning phenomena in horizontal wells. Fuel 2015, 153, 276–283. [Google Scholar] [CrossRef]
- Nieto, P.G.; García-Gonzalo, E.; Fernández, J.A.; Muñiz, C.D. A hybrid wavelet kernel SVM-based method using artificial bee colony algorithm for predicting the cyanotoxin content from experimental cyanobacteria concentrations in the Trasona reservoir (Northern Spain). J. Comput. Appl. Math. 2016, 309, 587–602. [Google Scholar] [CrossRef]
- Makbol, N.M.; Khoo, B.E. Robust blind image watermarking scheme based on Redundant Discrete Wavelet Transform and Singular Value Decomposition. AEU—Int. J. Electron. Commun. 2013, 67, 102–112. [Google Scholar] [CrossRef]
- Giri, D.; Acharya, U.R.; Martis, R.J.; Sree, S.V.; Lim, T.C.; Ahamed, T.; Suri, J.S. Automated diagnosis of Coronary Artery Disease affected patients using LDA, PCA, ICA and Discrete Wavelet Transform. Knowl.-Based Syst. 2013, 37, 274–282. [Google Scholar] [CrossRef]
- Salas-Boni, R.; Bai, Y.; Harris, P.R.E.; Drew, B.J.; Hu, X. False ventricular tachycardia alarm suppression in the ICU based on the discrete wavelet transform in the ECG signal. J. Electrocardiol. 2014, 47, 775–780. [Google Scholar] [CrossRef] [PubMed]
- Chhabra, L.; Flynn, A.W. Inconsistency of hemodynamic data in severe aortic stenosis: Yet unexplored reasoning! Int. J. Cardiol. 2016, 67, 2446–2447. [Google Scholar] [CrossRef] [PubMed]
- Pfeifer, M. Different outcomes of meta-analyses and data inconsistency. Osteoporos. Int. 2015, 26, 1–2. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | ||||
|---|---|---|---|---|
| 1 | 2 | |||
| represents the th day’s maximum temperature | |
| represents the th day’s average temperature | |
| represents the th day’s minimum temperature | |
| represents the th day’s precipitation | |
| represents the wind speed on day | |
| represents the humidity on day | |
| represents the cloud situation on day | |
| represents the month in which day is located | |
| represents the season in which day is located | |
| represent whether day is holiday, 0 is holiday, 1 is not holiday. | |
| represent whether day is weekend, 0 is weekend, 1 is not weekend. |
| Time Point | Actual | W-LSSVM-SWA | W-LSSVM | LSSVM | BPNN | ||||
|---|---|---|---|---|---|---|---|---|---|
| Forecast | Error | Forecast | Error | Forecast | Error | Forecast | Error | ||
| T00_00 | 80.23 | 78.28 | −2.43% | 83.12 | 3.60% | 83.45 | 4.01% | 85.32 | 6.34% |
| T01_00 | 80.23 | 81.33 | 1.37% | 78.56 | −2.09% | 83.26 | 3.77% | 83.10 | 3.58% |
| T02_00 | 81.04 | 80.07 | 1.20% | 83.34 | 2.84% | 86.56 | 6.81% | 84.92 | 4.79% |
| T03_00 | 80.09 | 81.74 | 2.06% | 82.19 | 2.62% | 83.4 | 4.13% | 77.45 | −3.29% |
| T04_00 | 78.73 | 79.86 | 1.43% | 80.68 | 2.47% | 76.23 | −3.18% | 81.05 | 2.94% |
| T05_00 | 79.56 | 81.22 | 2.09% | 75.6 | −4.98% | 82.58 | 3.80% | 75.75 | −4.79% |
| T06_00 | 81.52 | 80.63 | −1.09% | 84.7 | 3.90% | 83.6 | 2.55% | 77.53 | −4.89% |
| T07_00 | 83.93 | 85.13 | 1.43% | 80.14 | −4.51% | 86.4 | 2.94% | 88.51 | 5.46% |
| T08_00 | 82.63 | 84.36 | 2.10% | 84.88 | 2.73% | 78.95 | −4.45% | 85.53 | 3.51% |
| T09_00 | 84.43 | 82.58 | −2.19% | 81.49 | −3.48% | 81.22 | −3.80% | 81.39 | −3.59% |
| T10_00 | 85.32 | 87.56 | 2.62% | 81.07 | −4.98% | 81.78 | −4.15% | 81.70 | −4.25% |
| T11_00 | 86.65 | 88.06 | 1.63% | 82.6 | −4.67% | 84.26 | −2.76% | 90.76 | 4.74% |
| T12_00 | 87.42 | 86.23 | −1.36% | 89.66 | 2.56% | 90.65 | 3.69% | 91.15 | 4.27% |
| T13_00 | 81.99 | 82.9 | 1.11% | 84.98 | 3.65% | 86.7 | 5.75% | 85.76 | 4.60% |
| T14_00 | 82.37 | 80.62 | −2.13% | 80.1 | −2.76% | 79.69 | −3.26% | 85.27 | 3.52% |
| T15_00 | 83.87 | 84.96 | 1.30% | 86.65 | 3.32% | 80.42 | −4.11% | 87.55 | 4.39% |
| T16_00 | 84.81 | 83.09 | −2.02% | 86.85 | 2.41% | 81.47 | −3.93% | 88.00 | 3.76% |
| T17_00 | 86.05 | 87.63 | 1.83% | 83.6 | −2.85% | 82.44 | −4.20% | 88.59 | 2.95% |
| T18_00 | 88.19 | 89.7 | 1.71% | 84.9 | −3.73% | 84.7 | −3.96% | 91.66 | 3.93% |
| T19_00 | 91.66 | 93.86 | 2.41% | 94.4 | 2.99% | 95.65 | 4.36% | 94.80 | 3.43% |
| T20_00 | 91.91 | 89.72 | −2.38% | 93.9 | 2.16% | 95.55 | 3.96% | 95.72 | 4.15% |
| T21_00 | 88.53 | 90.6 | 2.34% | 91.66 | 3.53% | 84.25 | −4.84% | 91.74 | 3.63% |
| T22_00 | 86.78 | 87.64 | 0.99% | 90.01 | 3.72% | 89.74 | 3.41% | 84.12 | −3.06% |
| T23_00 | 83.06 | 84.6 | 1.86% | 85.56 | 3.01% | 86.36 | 3.98% | 86.09 | 3.66% |
| MAPE | 1.83% | 3.57% | 3.93% | 4.15% | |||||
| RMSE | 0.0190 | 0.0369 | 0.0404 | 0.0426 | |||||
| Algorithm | Optimal Fitness Value | Accuracy | Running Time/s | ||
|---|---|---|---|---|---|
| SWA | −0.764 | 98.98% | 36.5236 | 12.1445 | 187 |
| PSO | −0.733 | 97.5% | 21.3857 | 9.6840 | 235 |
| GA | −0.728 | 96.9% | 24.5852 | 17.9034 | 244 |
| ACO | −0.736 | 97.2% | 10.1245 | 8.8789 | 212 |
| Time | Actual | W-LSSVM-SWA | PSO-LSSVM | GA-LSSVM | ACO-LSSVM |
|---|---|---|---|---|---|
| T12_00 | 87.42 | 86.23 | 88.72 | 85.14 | 84.78 |
| T13_00 | 81.99 | 82.9 | 83.35 | 83.66 | 83.55 |
| T14_00 | 82.37 | 80.62 | 83.67 | 80.25 | 80.69 |
| T15_00 | 83.87 | 84.96 | 85.39 | 85.63 | 85.85 |
| T16_00 | 84.81 | 83.09 | 85.79 | 86.35 | 84.89 |
| T17_00 | 86.05 | 87.63 | 87.81 | 84.07 | 87.56 |
| T18_00 | 88.19 | 89.7 | 89.82 | 87.24 | 90.65 |
| T19_00 | 91.66 | 93.86 | 94.23 | 94.07 | 93.96 |
| T20_00 | 91.91 | 89.72 | 93.67 | 92.86 | 90.43 |
| T21_00 | 88.53 | 90.6 | 90.85 | 91.5 | 91.23 |
| T22_00 | 86.78 | 87.64 | 88.23 | 88.54 | 88.79 |
| T23_00 | 83.06 | 84.6 | 85.05 | 84.84 | 84.51 |
| MAPE | 1.83% | 1.95% | 2.16% | 2.11% | |
| RMSE | 0.0190 | 0.0201 | 0.2281 | 0.2232 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.-p.; Li, C.-l. The Short-Term Power Load Forecasting Based on Sperm Whale Algorithm and Wavelet Least Square Support Vector Machine with DWT-IR for Feature Selection. Sustainability 2017, 9, 1188. https://doi.org/10.3390/su9071188
Liu J-p, Li C-l. The Short-Term Power Load Forecasting Based on Sperm Whale Algorithm and Wavelet Least Square Support Vector Machine with DWT-IR for Feature Selection. Sustainability. 2017; 9(7):1188. https://doi.org/10.3390/su9071188
Chicago/Turabian StyleLiu, Jin-peng, and Chang-ling Li. 2017. "The Short-Term Power Load Forecasting Based on Sperm Whale Algorithm and Wavelet Least Square Support Vector Machine with DWT-IR for Feature Selection" Sustainability 9, no. 7: 1188. https://doi.org/10.3390/su9071188
APA StyleLiu, J.-p., & Li, C.-l. (2017). The Short-Term Power Load Forecasting Based on Sperm Whale Algorithm and Wavelet Least Square Support Vector Machine with DWT-IR for Feature Selection. Sustainability, 9(7), 1188. https://doi.org/10.3390/su9071188