3.2. Method Application
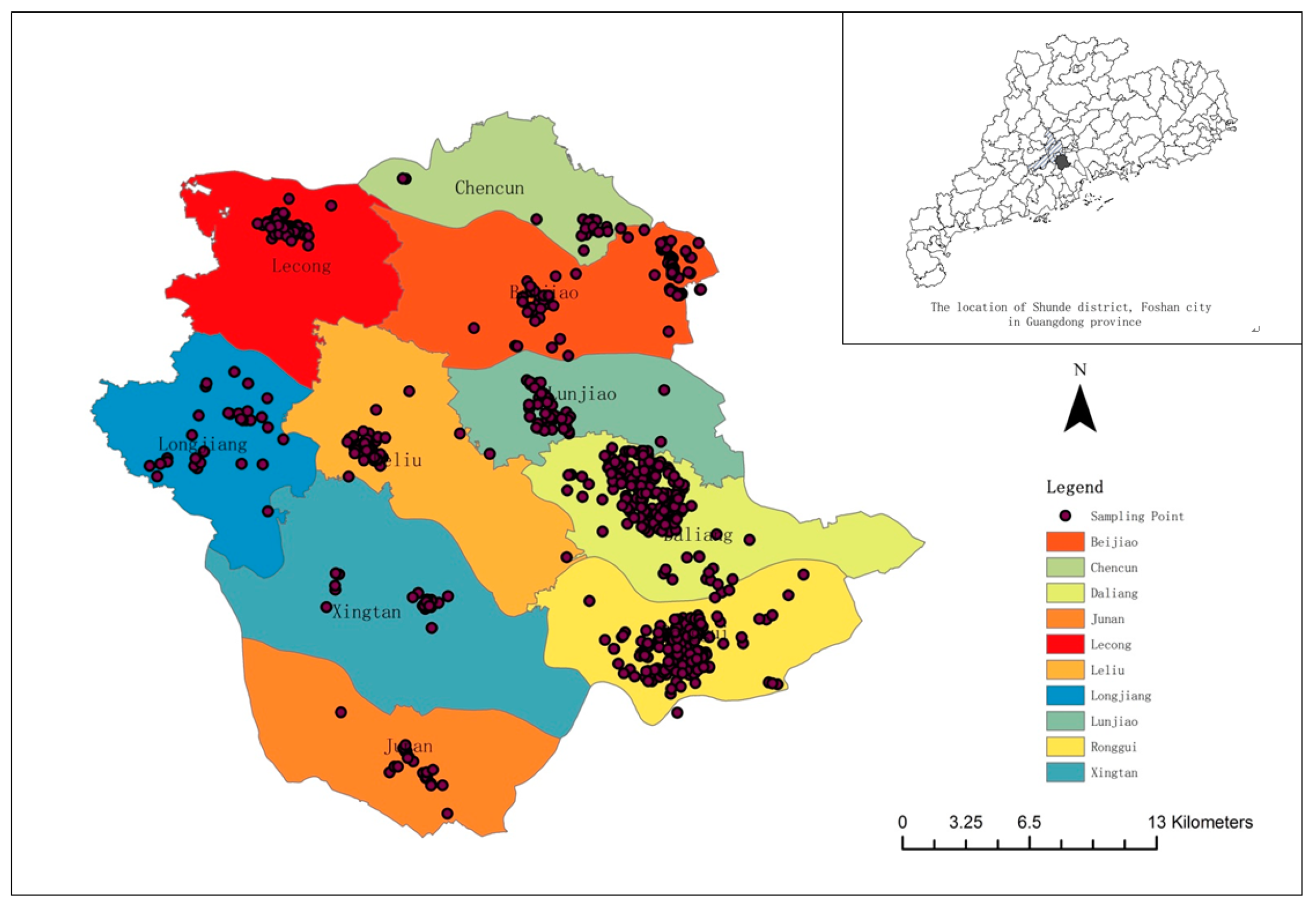
The sample data cover residential and commercial land with a robust market, urban-rural fringe area with a thin market, and some special use areas. The appraisal environment of these estimated points is complex. Twnty sampling points were artificially selected in a thin market. Three of the 20 selected sample points are listed in
Table 2. The price of these selected 20 sampling points was used as the validation data, and the other attributes of the selected sampling points are used as the estimated points. The remaining sampling points act as the training sample and are used to make an appraisal for the estimated price. The proposed method can provide a valuable estimate for these 20 unrepresentative sample data by collecting the extra valuable information from those interested users through the crowdsourcing platform.
The first step is to construct the rubrics model according to the sample data. Each record in the training sample data is regarded as a rubric. With little effect on the model calculation, ID, geographic coordinate (X, Y), architectural structure, date of registration right, date of issue, and address are left out from the 27 attributes in the training sample. The remaining 20 attribute values except for price in the training sample should be numerically graded.
As for a value attribute, it is graded equally. Take the recorded time as an example; the years between 1990–1992 are called level 1, the years between 1993–1995 are called level 2, the years between 1996–1998 are called level 3, the years between 1999–2001 are called level 4, the years between 2002–2004 are called level 5, the years between 2005–2007 are called level 6, and the years between 2008–2010 are called level 7.
As for a non-numeric attribute, it is graded by the attribute classification order, such as the usage of the house, which includes six categories: office, parking, industrial, commercial, residential, and the others. Each classification corresponds to one level of 1–6.
The outliers should be classified together as a level, and the missing value is denoted by 0. Repeat the process above for grading the attribute values of the price estimated points. The attribute grading result is shown in
Table 3.
In the second step, the graded attributes of the rubrics (training sample) and price estimated point should be transformed to the attribute vector, as shown in
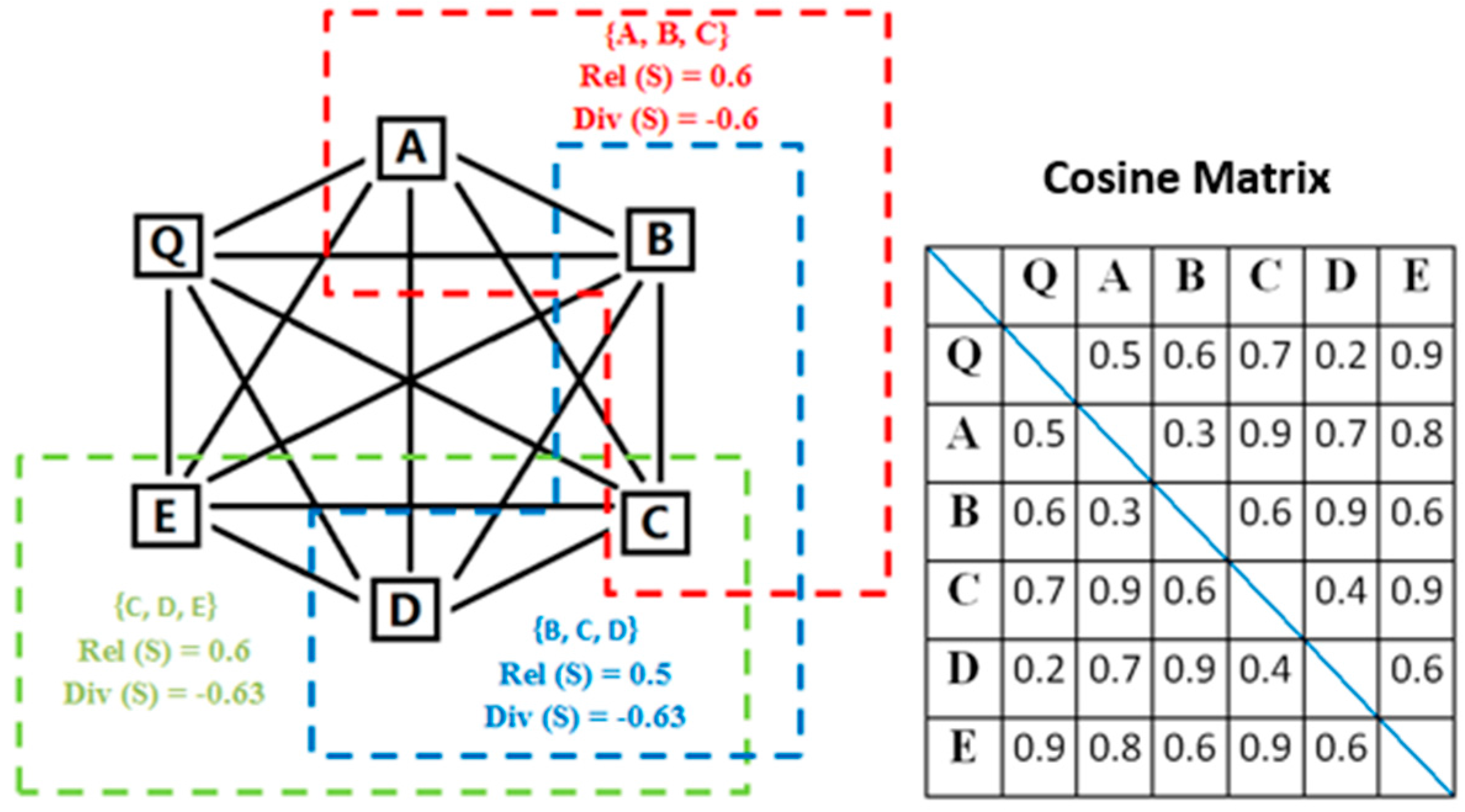
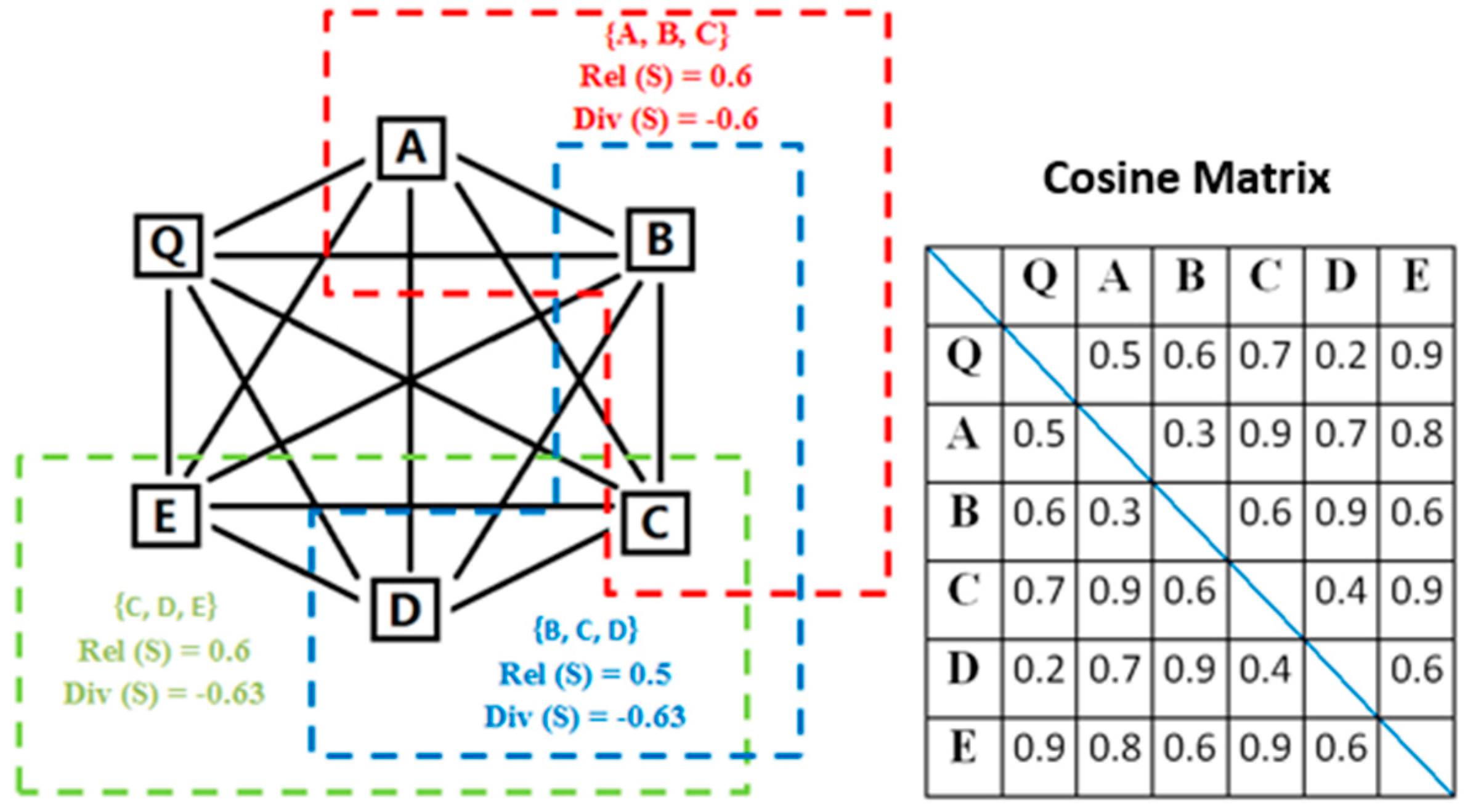
Section 2.3. Cosine similarity
is used to measure the relevance and diversity between price estimated point and each rubric. The linear combination of relevance and diversity can measure the similarity. The results are called the training power, denoted by
TP(S). can be determined by the relative importance of relevance and diversity. If relevance is more important,
should be greater than 0.5.
For instance, because of the large scale computation, sample point 1 is used as an estimated point to illustrate the whole process. The attribute “price” of point 1 is used for validation. The other attributes of point 1 are used as an estimated point, which is denoted by P1. Three other sample points are randomly selected to construct the rubrics for P1, which are denoted by PA, PB, and PC. The original values of these four points are shown in
Table 4.
After being numerically graded, these four points can be expressed by the following attribute vector.
P1 = (4, 1, 1, 1, 4, 2, 1, 2, 0, 1, 1, 2, 2, 1, 1, 1, 1, 1, 1),
PA = (4, 2, 1, 1, 3, 4, 1, 1, 0, 1, 2, 1, 5, 4, 3, 4, 1, 2, 5),
PB = (6, 2, 1, 1, 4, 4, 1, 1, 0, 1, 2, 2, 4, 2, 3, 4, 2, 3, 4),
PC = (7, 3, 1, 2, 4, 4, 2, 2, 1, 1, 2, 1, 5, 4, 3, 4, 3, 1, 5).
The similarity between these four points are calculated as follows,
Assume that the combination number of rubrics is 3, and
. The rubric
S =
{PA, PB, PC} is taken as an example to show the computational process of the training power
TP.
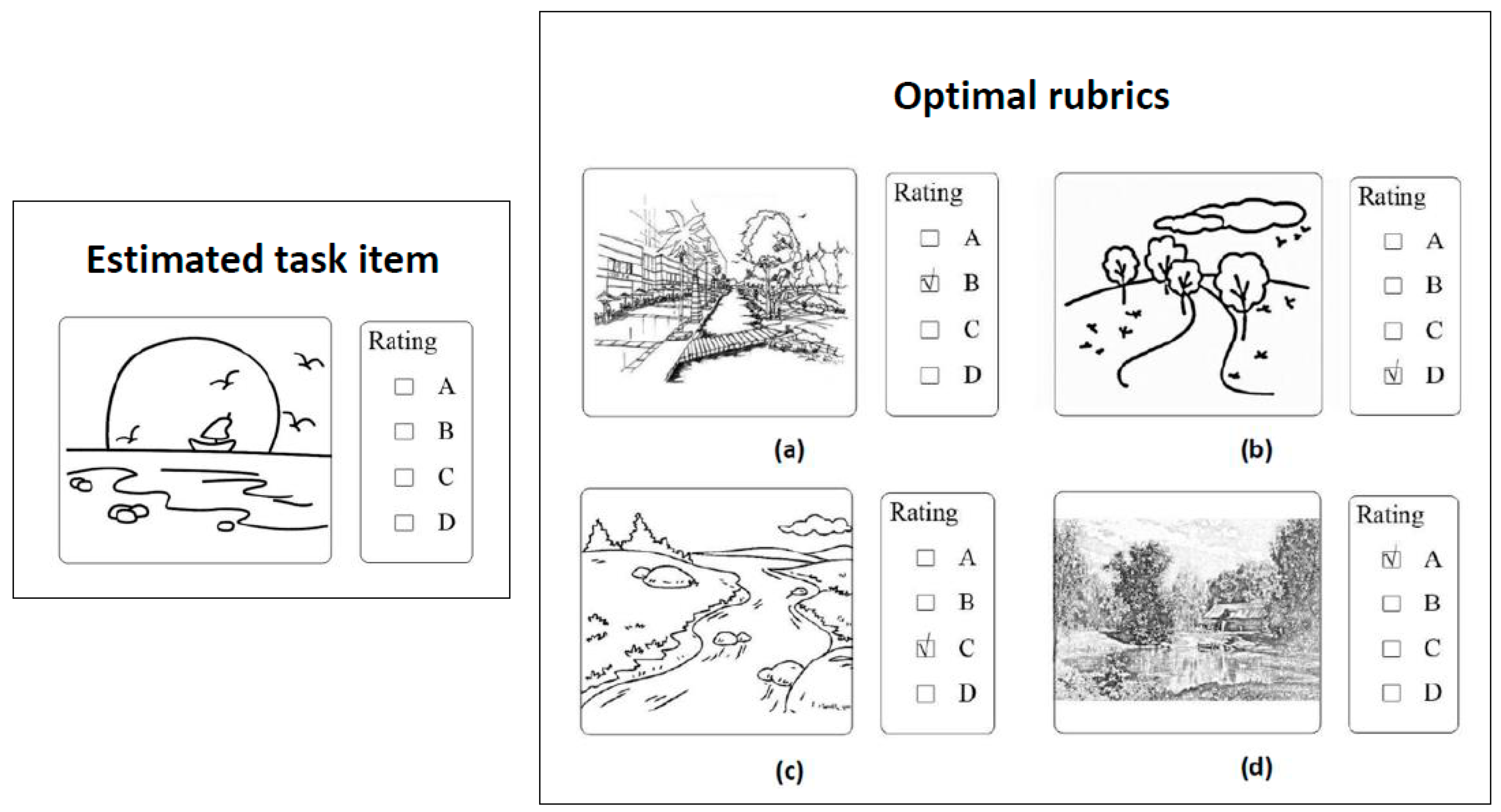
The third step is to find the optimal rubrics that are based on the optimal solution of
TP. In the example above, point 1 is used as an estimated point, assuming that the combination number of the rubrics is 3, and
. After repetitively calculating the TP between point 1 and each rubrics’ combination, the optimal solution of
TP = 0.421 has been found. The corresponding optimal rubrics’ combination is shown in
Table 5.
The fourth is to publish the appraisal task on the crowdsourcing platform and complete the crowdsourcing appraisal. The appraisal task should be an open-ended question. It includes the basic information of the estimated object provided by the estimated users and the optimal rubrics selected by the similarity measurement from the sample data. The crowdsourcing community users are selected from the recommendation of our friends on WeChat, served as a crowdsourcing rater. They are householders living in the neighborhood with the estimated object. They have a basic understanding of the object. After providing the estimate of the object’s market price by comparing the selected optimal rubrics with their own understanding of the object, they can get 50 RMB each time. Any conflict of interest shall be settled through negotiation, and if it still cannot meet their needs, we will leave them out of the account. In order to avoid conflicts of interest, after verifying their identification, we select those who are long-term residents and have no intention of buying a house in the neighborhood.
In the experiment, we published the appraisal task on WeChat as an example, which contains the attributes’ information of the estimated point P1 shown in
Table 4 and the attributes’ information of the three selected optimal rubrics OP1, OP2, and OP3 shown in
Table 5. After verifying the identities, finally, we select 32 users from the recommendation of our friends on WeChat to complete the appraisal. They are householders living nearby the estimated object. They have no intention of buying a house in the neighborhood and have a basic understanding of the estimated object. The feedback results of these 32 users are shown in
Table 6. The average of the crowdsourcing result is used as the average market price of the estimated object, which is denoted by
.
The last step is to compare the validation data and appraisal result of the estimated points to verify the proposed approach. In the example, sample point 1 is used as an estimated point. The attribute “price” of point 1 is used for validation. The others attributes of point 1 are used as an estimated point, which is denoted by P1. The validation data of P1 is denoted by
.
In real estate appraisal, the rules state that the relative error of the estimates should be under 10% [
55]. In the experiment, if the relative error is under 10%, we think the estimates are valid. The relative error of the estimate in the example is denoted by
E.
E is far below 10%, therefore the estimates of the proposed method are valid.
3.3. Validation
The accuracy of the proposed method is calculated by
The accuracy is denoted by A, the number of valid estimated points is denoted by , and the total number of the estimated points is denoted by N.
In an example, assume that the combination number of rubrics is
k = 3 and
. After estimating the 20 estimated points, the relative error of the estimates are shown in
Table 7. Under this situation, the valid number of estimated points (the relative error is under 10%) is 18, the accuracy of the proposed method is calculated by,
Before computation of TP(S),
should be determined by the relative importance of relevance and diversity. The experiment tests three situations, in which
, and
. The optimal rubrics are always a combination of rubrics, not just a single one. So the experiment also tests five combinations of rubrics, when
k = 1,
k = 2,
k = 3,
k = 5, and
k = 10. Under these situations, the accuracy of the proposed method is shown in
Table 8.
The appraisal results in
Table 8 show that the combination of rubrics has a significant impact on appraisal accuracy, but that the effect of the coefficient
is non-significant. When the combination number
k = 3, the accuracy of the appraisal result is highest; the selected rubrics are the best. However, with an increase or decrease from
k = 3, the accuracy of the appraisal results decreases. In general, when someone makes an appraisal, the appraisal will always be restricted by too much or too little reference information. Only appropriate information can help the appraisal. This is consistent with the results in
Table 8. The effect of the coefficient
is non-significant, but it also has some regular patterns. This is because if the volume of data is large, it contains abundant information; at this time, the appraisal result will be unconstrained by the effect of relevance and diversity. With an increase in
, the accuracy of the appraisal result increases slightly. The sample data in this experiment covers a lot of similar sampling points in the same community, so when the coefficient
takes relevance into account, the accuracy increases slightly. The results show that the average accuracy of the proposed approach is 73.7%, and when
k = 3, α = 0.7, the maximum accuracy is 90%. This supports that the proposed method can make an accurate appraisal for the real estate market price, which can provide a market reference for potential buyers and sellers.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}