Identification of Critical Factors for Non-Recurrent Congestion Induced by Urban Freeway Crashes and Its Mitigating Strategies


Abstract
:1. Introduction
2. Literature Review
2.1. Overview of Identification of Spatiotemporal Traffic Congestion Impact
2.2. Identification of Spatiotemporal Congestion Impact Induced by Crashes
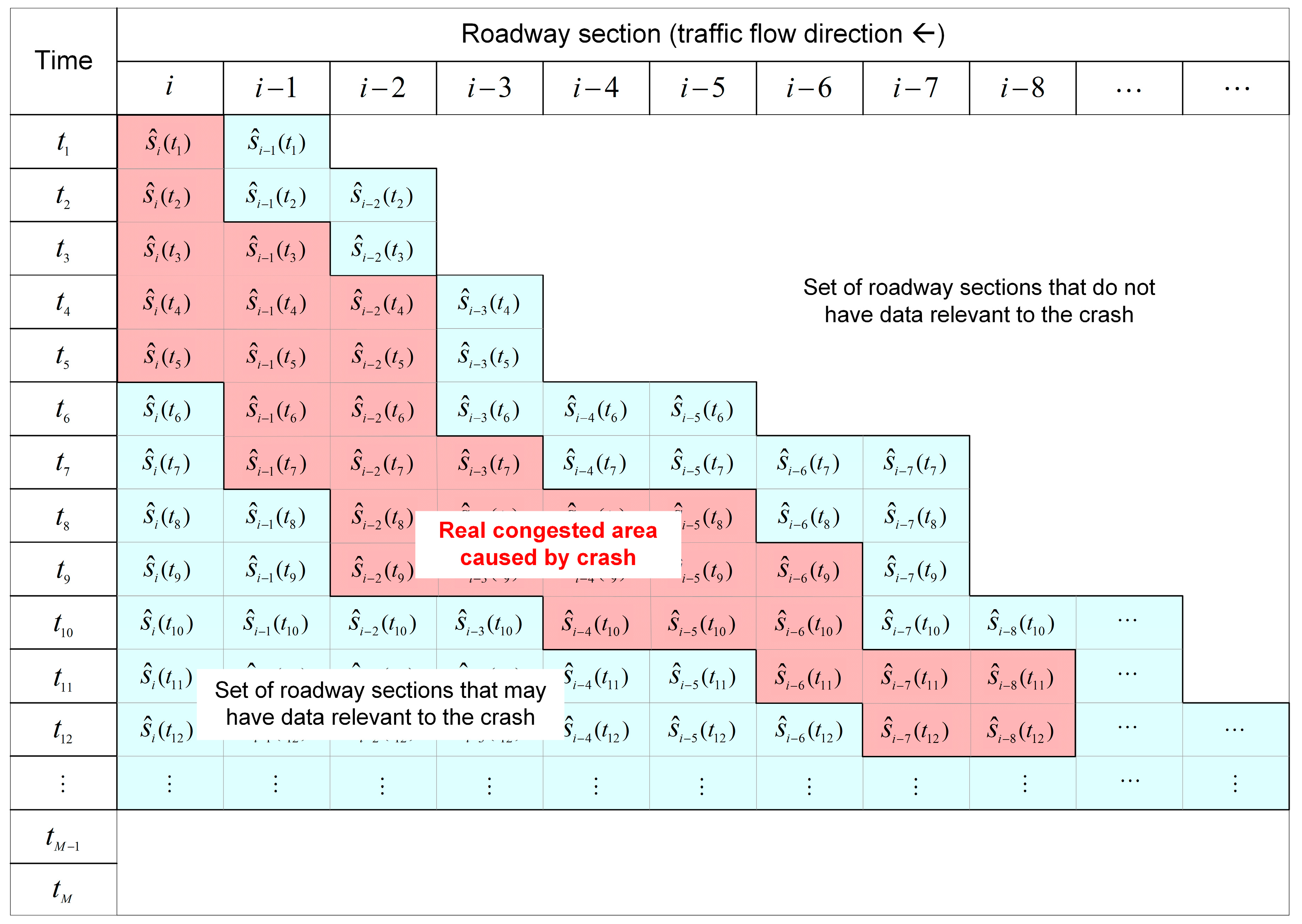
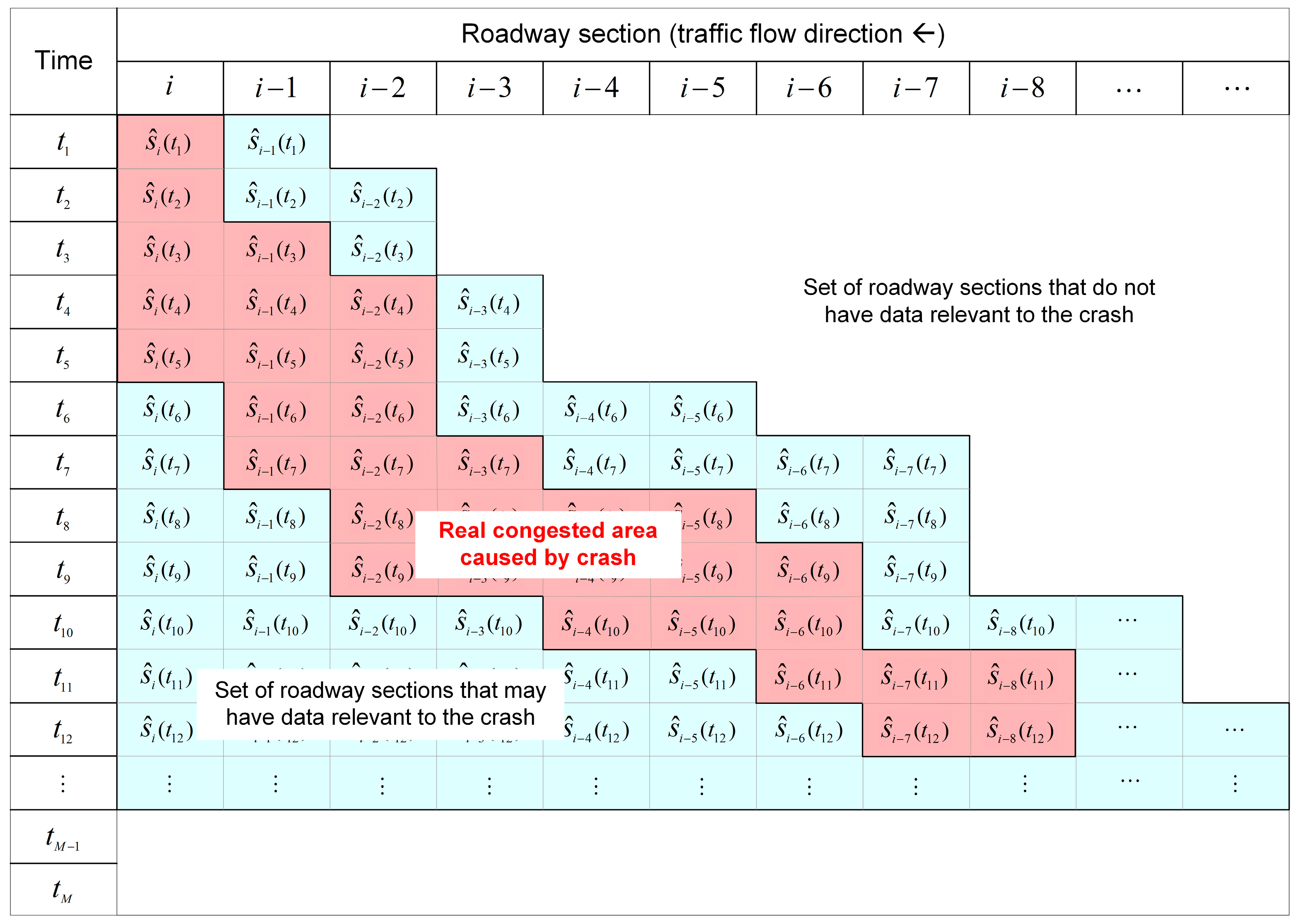
2.2.1. Step 1: Data Arrangement
2.2.2. Step 2: Establishment of Maximum Crash Impact Region
2.2.3. Step 3: Construction of Crash Impact Region
2.3. Multivariate Statistical Analysis
2.3.1. Survival Analysis
2.3.2. Cox Model
3. Case Study
3.1. Data Description
3.2. Calculation of Crash-Induced Traffic Congestion
4. Multivariate Analysis of Non-Recurrent Congestion Causal Factors
4.1. Candidate Variables
4.2. Multivariate Analysis of Non-Recurrent Congestion Causal Factors
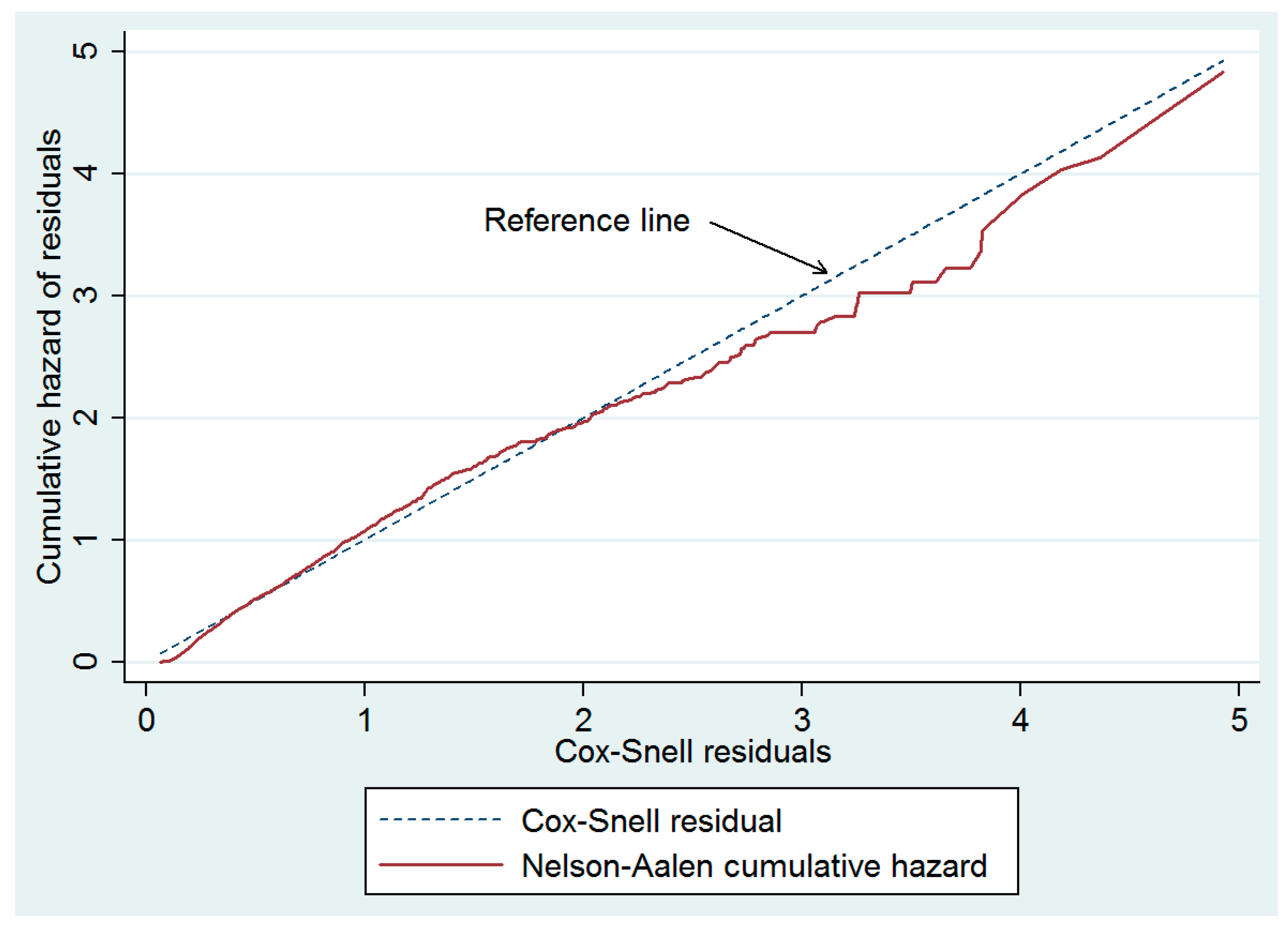
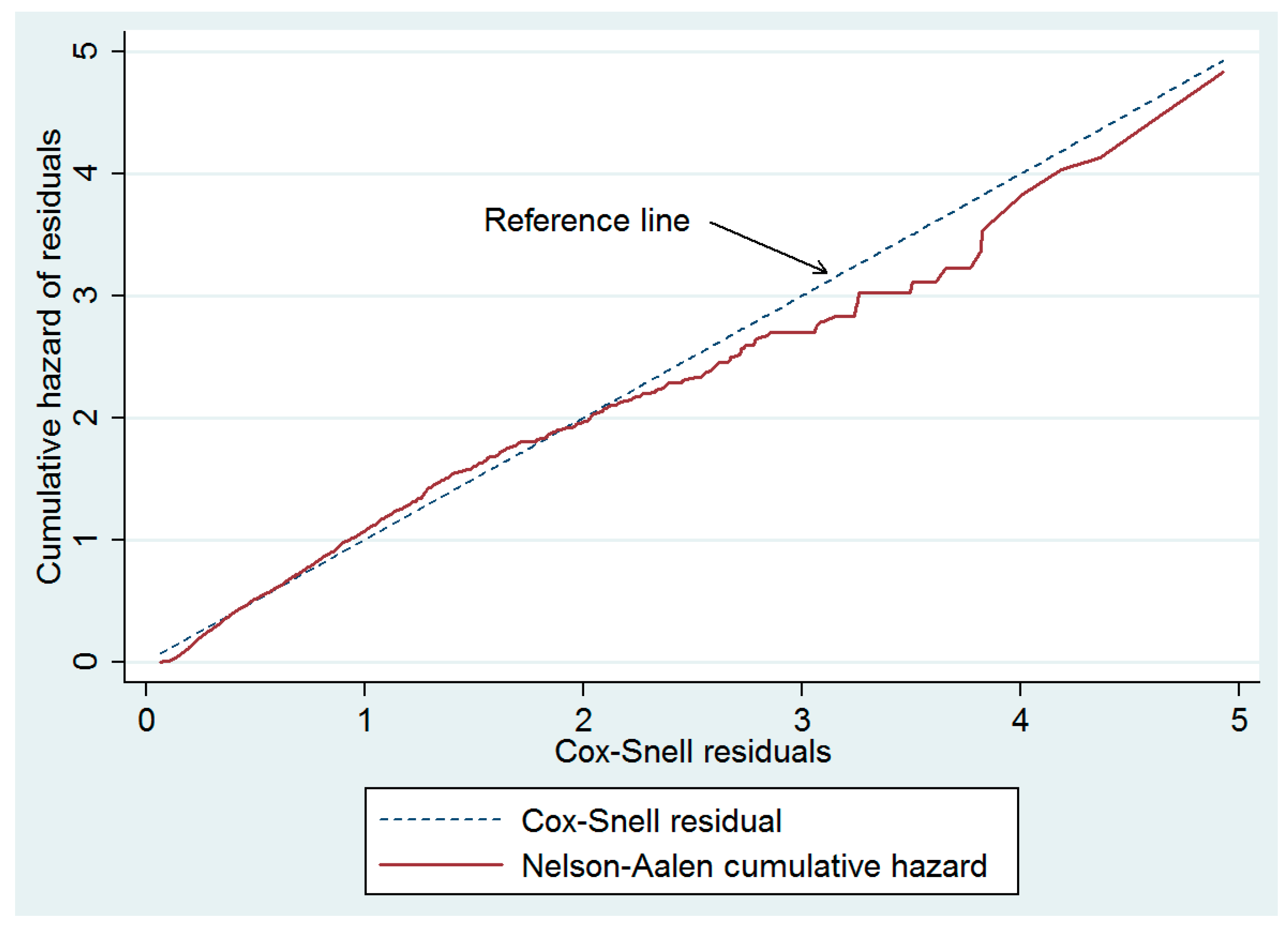
4.3. Interpretation of the Fitted Cox Model
5. Policy Implications
6. Conclusions
Acknowledgments
Conflicts of Interest
References
- Giuliano, G. Incident characteristics, frequency, and duration on a high volume urban freeway. Transp. Res. Part A Gen. 1989, 23, 387–396. [Google Scholar] [CrossRef]
- Organization for Economic Co-operation and Development (OECD). Managing Urban Traffic Congestion; OECD Publishing: Paris, France, 2007. [Google Scholar]
- Chung, Y.; Recker, W.W. A methodological approach for estimating temporal and spatial extent of delays caused by freeway accidents. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1454–1461. [Google Scholar] [CrossRef]
- Fei, W.; Song, G.; Zang, J.; Gao, Y.; Sun, J.; Yu, L. Framework model for time-variant propagation speed and congestion boundary by incident on expressways. IET Intell. Transp. Syst. 2017, 11, 10–17. [Google Scholar] [CrossRef]
- Golob, T.F.; Recker, W.W.; Alvarez, V.M. Safety aspects of freeway weaving sections. Transp. Res. Part A Policy Pract. 2004, 38, 35–51. [Google Scholar] [CrossRef]
- Yang, H.; Ozbay, K.; Xie, K.; Ma, Y. Development of an automated approach for quantifying spatiotemporal impact of traffic incidents. In Proceedings of the Transportation Research Board 95th Annual Meeting, Washington, DC, USA, 10–14 January 2016. [Google Scholar]
- Goolsby, M.E. Influence of incidents on freeway quality of service. Highw. Res. Rec. 1971, 349, 41–46. [Google Scholar]
- Morales, J.M. Analytical procedures for estimating freeway traffic congestion. ITE J. 1987, 57, 45–49. [Google Scholar]
- Lawson, T.W.; Lovell, D.J.; Daganzo, C.F. Using input-output diagram to determine spatial and temporal extents of a queue upstream of a bottleneck. Transp. Res. Rec. J. Transp. Res. Board 1997, 1572, 140–147. [Google Scholar] [CrossRef]
- Erera, A.L.; Lawson, T.W.; Daganzo, C.F. Simple, generalized method for analysis of traffic queue upstream of a bottleneck. Transp. Res. Rec. 1998, 1646, 132–140. [Google Scholar] [CrossRef]
- Skabardonis, A.; Geroliminis, N. Development and application of methodologies to estimate incident impacts. In Proceedings of the 2nd International Congress on Transportation Research, Athens, Greece, 26–27 February 2004. [Google Scholar]
- Sullivan, E.C. New model for predicting freeway incidents and incident delays. J. Transp. Eng. 1997, 123, 267–275. [Google Scholar] [CrossRef]
- Moskowitz, K.; Newman, L. Notes on freeway capacity. Highw. Res. Rec. 1963, 27, 44–68. [Google Scholar]
- Chow, W.-M. A study of traffic performance models under an incident condition. Highw. Res. Rec. 1976, 567, 31–36. [Google Scholar]
- Wirasinghe, S.C. Determination of traffic delays from shock-wave analysis. Transp. Res. 1978, 12, 343–348. [Google Scholar] [CrossRef]
- Heydecker, B. Incidents and Intervention on Freeways; UCB-ITS-PRR-94-5; California PATH: Berkeley, CA, USA, 1994. [Google Scholar]
- Al-Deek, H.; Garib, A.; Radwan, A.E. New method for estimating freeway incident congestion. Transp. Res. Rec. J. Transp. Res. Board 1995, 1494, 30–39. [Google Scholar]
- Wohl, M.; Martin, B.V. Traffic System Analysis for Engineers and Planners; McGraw-Hill: New York, NY, USA, 1967. [Google Scholar]
- Lighthill, M.J.; Whitham, G.B. On kinematic waves. II. A theory of traffic flow on long crowded roads. Proc. R. Soc. Lond. Ser. A Math. Phys. Sci. 1955, 229, 317–345. [Google Scholar] [CrossRef]
- Garib, A.; Radwan, A.E.; Al-Deek, H. Estimating magnitude and duration of incident delays. J. Transp. Eng. 1997, 123, 459–466. [Google Scholar] [CrossRef]
- Skabardonis, A.; Petty, K.; Noeimi, H.; Rydzewski, D.; Varaiya, P.P. I-880 field experiment: Data-base develepment and incident delay estimation procedures. Transp. Res. Rec. J. Transp. Res. Board 1996, 1554, 204–212. [Google Scholar] [CrossRef]
- Skabardonis, A.; Varaiya, P.; Petty, K.F. Measuring recurrent and nonrecurrent traffic congestion. Transp. Res. Rec. J. Transp. Res. Board 2003, 1856, 118–124. [Google Scholar] [CrossRef]
- Chung, Y. Quantification of nonrecurrent congestion delay caused by freeway accidents and analysis of causal factors. Transp. Res. Rec. J. Transp. Res. Board 2011, 2229, 8–18. [Google Scholar] [CrossRef]
- Mannering, F.L. Male/female driver characteristics and accident risk: Some new evidence. Accid. Anal. Prev. 1993, 25, 77–84. [Google Scholar] [CrossRef]
- Jovanis, P.P.; Chang, H.-L. Disaggregate model of highway accident occurrence using survival theory. Accid. Anal. Prev. 1989, 21, 445–458. [Google Scholar] [CrossRef]
- Jones, B.; Janssen, L.; Mannering, F. Analysis of the frequency and duration of freeway accidents in Seattle. Accid. Anal. Prev. 1991, 23, 239–255. [Google Scholar] [CrossRef]
- Nam, D.; Mannering, F. An exploratory hazard-based analysis of highway incident duration. Transp. Res. Part A Policy Pract. 2000, 34, 85–102. [Google Scholar] [CrossRef]
- Stathopoulos, A.; Karlaftis, M.G. Modeling duration of urban traffic congestion. J. Transp. Eng. 2002, 128, 587–590. [Google Scholar] [CrossRef]
- Chung, Y. Development of an accident duration prediction model on the Korean freeway systems. Accid. Anal. Prev. 2010, 42, 282–289. [Google Scholar] [CrossRef] [PubMed]
- Chung, Y.; Yoon, B.-J. Analytical method to estimate accident duration using archived speed profile and its statistical analysis. KSCE J. Civ. Eng. 2012, 16, 1064–1070. [Google Scholar] [CrossRef]
- Gilbert, C.C.S. A duration model of automobile ownership. Transp. Res. Part B Methodol. 1992, 26, 97–114. [Google Scholar] [CrossRef]
- Mannering, F.; Winston, C. Brand Loyalty and the Decline of American Automobile Firms; Brookings Papers on Economic Activity, Microeconomics 1991; Brookings Institution: Washington, DC, USA, 1991; pp. 67–114. [Google Scholar]
- Yamamoto, T.; Kitamura, R. An analysis of household vehicle holding durations considering intended holding durations. Transp. Res. Part A Policy Pract. 2000, 34, 339–351. [Google Scholar] [CrossRef]
- De Jong, G. A disaggregate model system of vehicle holding duration, type choice and use. Transp. Res. Part B Methodol. 1996, 30, 263–276. [Google Scholar] [CrossRef]
- Chung, Y.; Recker, W.W. Spatiotemporal analysis of traffic congestion caused by rubbernecking at freeway accidents. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1416–1422. [Google Scholar] [CrossRef]
- Chung, Y. Assessment of non-recurrent congestion caused by precipitation using archived weather and traffic flow data. Transp. Policy 2012, 19, 167–173. [Google Scholar] [CrossRef]
- Chung, Y. Assessment of non-recurrent traffic congestion caused by freeway work zones and its statistical analysis with unobserved heterogeneity. Transp. Policy 2011, 18, 587–594. [Google Scholar] [CrossRef]
- Chung, Y.; Recker, W.W. Frailty models for the estimation of spatiotemporally maximum congested impact information on freeway accidents. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2104–2112. [Google Scholar] [CrossRef]
- Cox, D.R. Regression models and life-tables. J. R. Stat. Soc. Ser. B (Methodol.) 1972, 34, 187–220. [Google Scholar]
- Bradburn, M.J.; Clark, T.G.; Love, S.B.; Altman, D.G. Survival analysis part II: Multivariate data analysis—An introduction to concepts and methods. Br. J. Cancer 2003, 89, 431–436. [Google Scholar] [CrossRef] [PubMed]
- Therneau, T.M.; Grambsch, P.M. Modeling Survival Data: Extending the Cox Model; Springer: New York, NY, USA, 2000. [Google Scholar]
- Kalbfleisch, J.D.; Prentice, R.L. The Statistical Analysis of Failure Time Data, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2002. [Google Scholar]
- Collett, D. Modelling Survival Data in Medical Research, 2nd ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2003; p. 391. [Google Scholar]
- Cleves, M.A.; Gould, W.W.; Gutierrez, R.G. An Introduction to Survival Analysis Using Stata; Revised Edition; Stata Press: College Station, TX, USA, 2004. [Google Scholar]
- Cox, D.R.; Snell, E.J. A general definition of residuals. J. R. Stat. Soc. Ser. B (Methodol.) 1968, 30, 248–275. [Google Scholar]
- Muhrer, E.; Vollrath, M. The effect of visual and cognitive distraction on driver’s anticipation in a simulated car following scenario. Transp. Res. Part F Traffic Psychol. Behav. 2011, 14, 555–566. [Google Scholar] [CrossRef]
- Neyens, D.M.; Boyle, L.N. The effect of distractions on the crash types of teenage drivers. Accid. Anal. Prev. 2007, 39, 206–212. [Google Scholar] [CrossRef] [PubMed]
- Dingus, T.A.; Klauer, S.G.; Neale, V.L.; Petersen, A.; Lee, S.; Sudweeks, J.; Perez, M.; Hankey, J.; Ramsey, D.; Gupta, S. The 100-Car Naturalistic Driving Study, Phase II—Results of the 100-Car Field Experiment. Available online: http://www.nhtsa.gov/DOT/NHTSA/NRD/Multimedia/PDFs/Crash%20Avoidance/Driver%20Distraction/100CarMain.pdf (accessed on 7 December 2017).

{kind=link}
{kind=link}
| Time | Roadway Section (Traffic Flow Direction ←) | |||
|---|---|---|---|---|
| Freeway | Direction | Length (mi) | Freeway | Direction | Length (mi) |
|---|---|---|---|---|---|
| I-5 | South | 44.27 | SR-55 | South | 17.85 |
| North | 44.45 | North | 17.78 | ||
| I-405 | South | 24.17 | SR-73 | South | 17.23 |
| North | 24.58 | North | 17.17 | ||
| SR-22 | East | 12.47 | SR-91 | East | 22.54 |
| West | 12.52 | West | 22.54 |
| Category | Variable | Frequency | Unit | |
|---|---|---|---|---|
| Crash characteristics | Collision type | 1 veh hit object or overturn | 248 | Dummy |
| 2+ veh hit object or overturn | 100 | |||
| 2 veh sideswipe | 405 | |||
| 3+ veh sideswipe | 116 | |||
| 2 veh rear end | 821 | |||
| 3+ veh rear end | 524 | |||
| Causal factor | Alcohol | 68 | Dummy | |
| Improper turn | 189 | |||
| Speeding | 1386 | |||
| Other violations | 505 | |||
| Other than driver | 63 | |||
| Unknown | 21 | |||
| Truck involvement | Truck involved | 228 | Dummy | |
| Truck not involved | 2004 | |||
| Severity | Property damage only | 1696 | Dummy | |
| Injury and/or fatality | 536 | |||
| Number injured | 0 | 1698 | Dummy | |
| 1 | 352 | |||
| 2+ | 182 | |||
| Number of vehicles involved (1, 2, 3, 4+) | 2232 | Number | ||
| Number killed * | 0 | 2228 | n/a | |
| 1 | 3 | |||
| 2 | 1 | |||
| Collision time | Night (18:01–06:00) | 506 | Dummy | |
| AM peak (06:01–09:00) | 462 | |||
| Midday (09:01–15:30) | 741 | |||
| PM peak (15:31–18:00) | 523 | |||
| Geometric characteristics | Number of lanes | 3 or fewer lanes | 386 | Dummy |
| 4 lanes | 1081 | |||
| 5 lanes | 698 | |||
| 6 lanes | 67 | |||
| Environmental characteristics | Road surface | Wet | 123 | Dummy |
| Dry | 2109 | |||
| Traffic characteristics | AADT (per 100,000 vehicles) | 2232 | Number | |
| Truck AADT (per 1000 vehicles) | 2232 | |||
| Percentage of trucks | 2232 | |||
| 5-min occupancy (%) | 2232 | |||
| Variable | Coefficient | Wald Statistic | p-Value | Hazard Ratio |
|---|---|---|---|---|
| 5-min occupancy (%) | −1.865 | −9.62 | 0.000 | 0.155 |
| Percentage of trucks | −0.068 | −4.09 | 0.000 | 0.934 |
| Collision type: 3+ vehicles sideswipe | −0.304 | −2.67 | 0.008 | 0.738 |
| Collision type: 3+ vehicles rear end | −0.260 | −4.50 | 0.000 | 0.771 |
| Collision time: Night | 0.345 | 5.77 | 0.000 | 1.412 |
| Causal factor: Other than driver | 0.345 | 2.50 | 0.012 | 1.412 |
| Number lanes: 3 lanes or less | −0.150 | −2.27 | 0.023 | 0.861 |
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chung, Y. Identification of Critical Factors for Non-Recurrent Congestion Induced by Urban Freeway Crashes and Its Mitigating Strategies. Sustainability 2017, 9, 2331. https://doi.org/10.3390/su9122331
Chung Y. Identification of Critical Factors for Non-Recurrent Congestion Induced by Urban Freeway Crashes and Its Mitigating Strategies. Sustainability. 2017; 9(12):2331. https://doi.org/10.3390/su9122331
Chicago/Turabian StyleChung, Younshik. 2017. "Identification of Critical Factors for Non-Recurrent Congestion Induced by Urban Freeway Crashes and Its Mitigating Strategies" Sustainability 9, no. 12: 2331. https://doi.org/10.3390/su9122331
APA StyleChung, Y. (2017). Identification of Critical Factors for Non-Recurrent Congestion Induced by Urban Freeway Crashes and Its Mitigating Strategies. Sustainability, 9(12), 2331. https://doi.org/10.3390/su9122331