
Identification and Prediction of Large Pedestrian Flow in Urban Areas Based on a Hybrid Detection Approach

Abstract
:1. Introduction
2. Literature Review
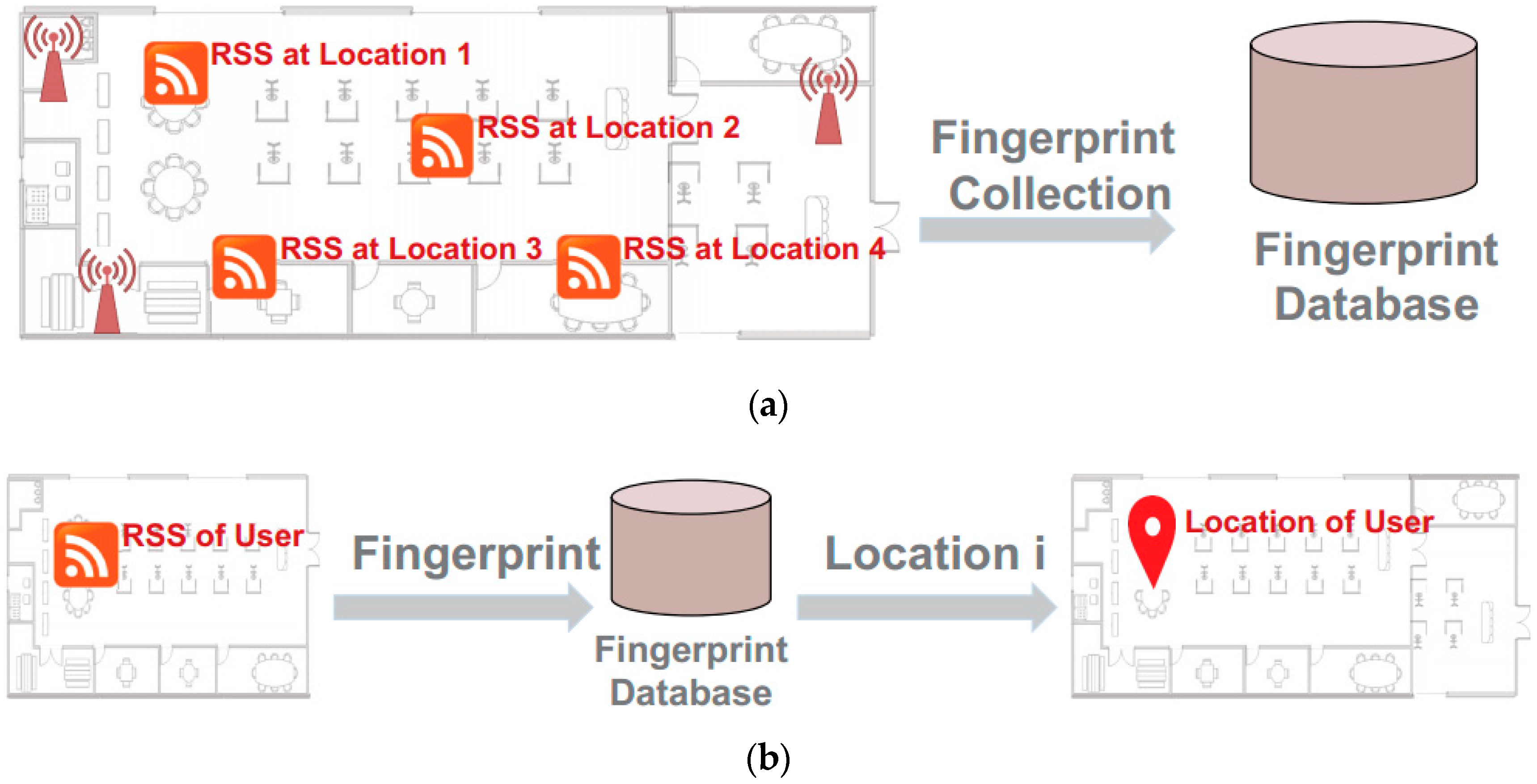
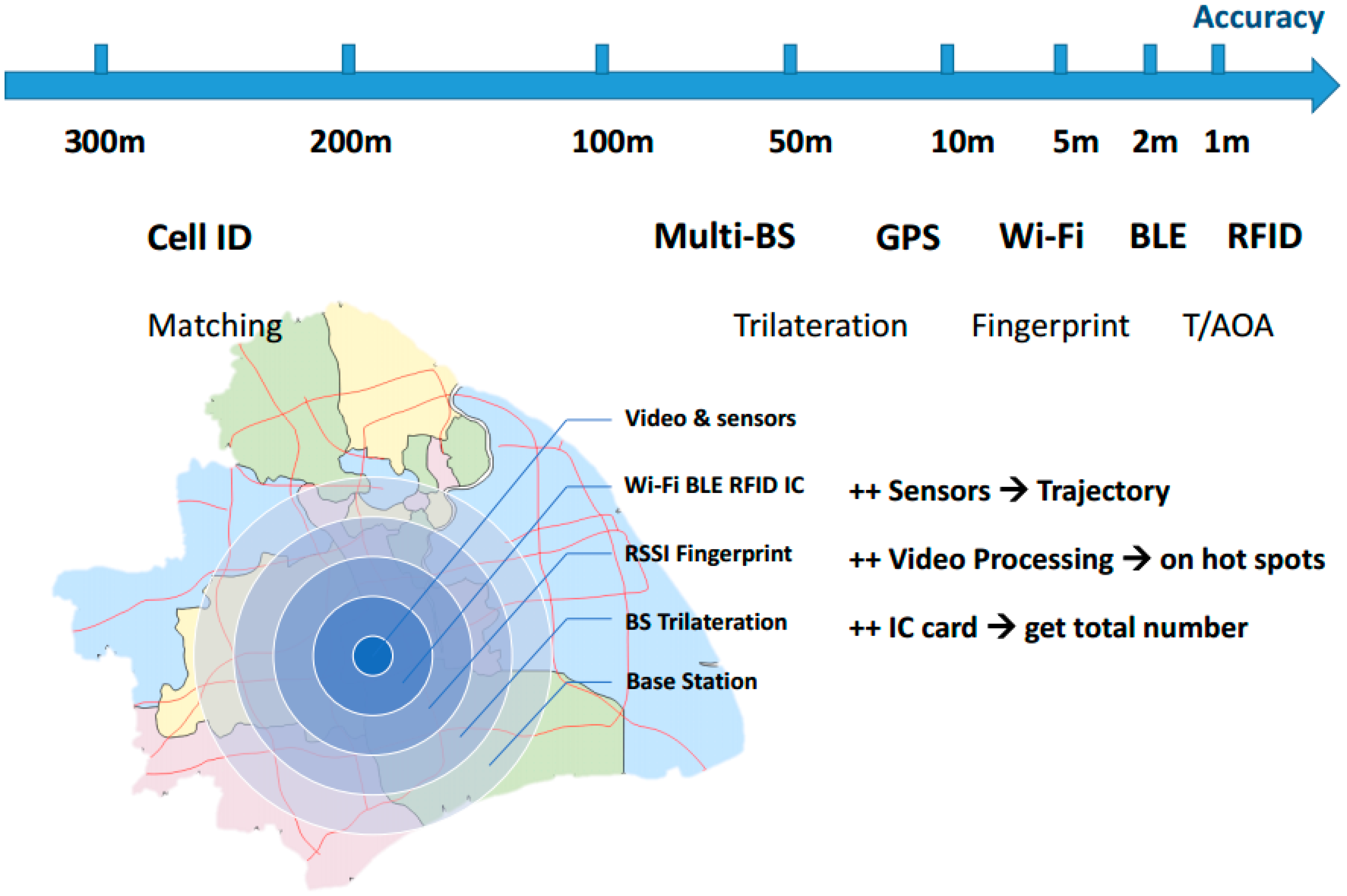
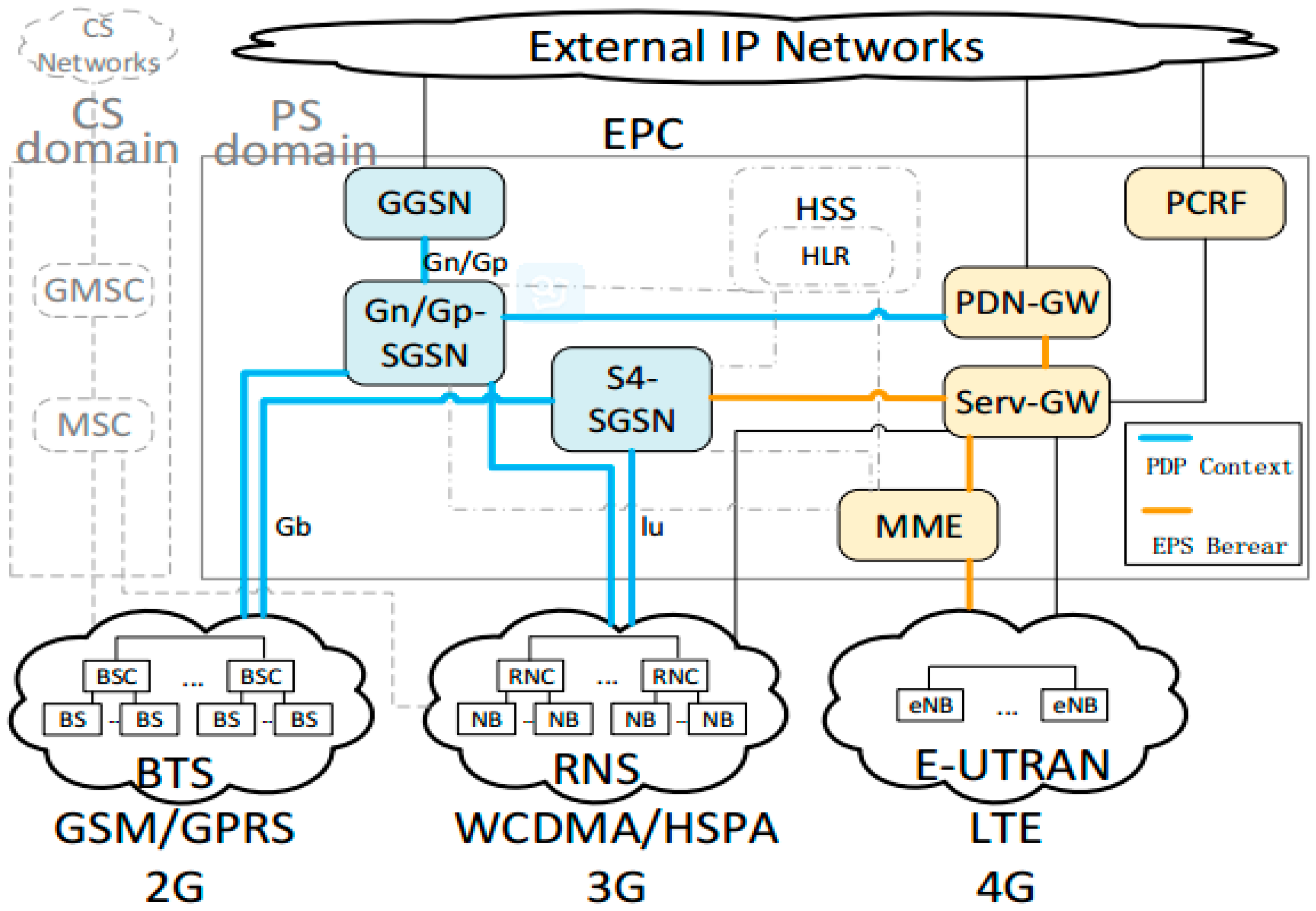
2.1. LAN Mobile Localization
2.2. Temporal Spatial Tracking Prediction
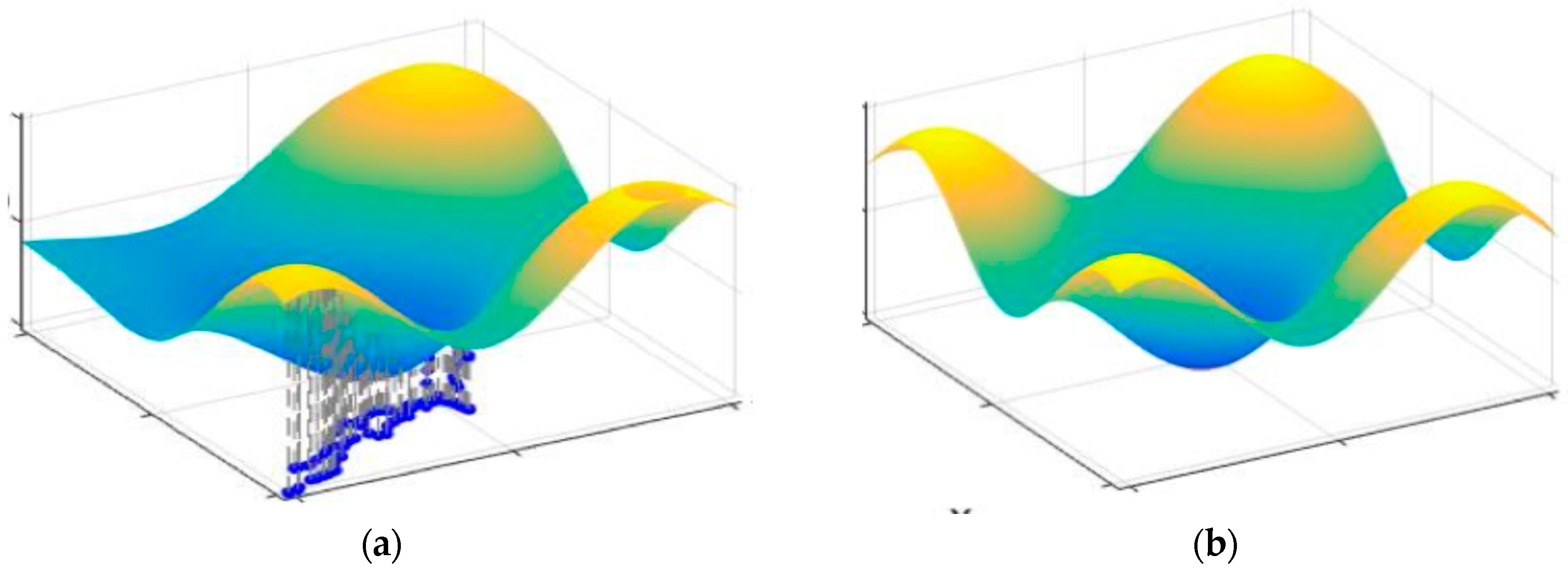
3. HYbrid Pedestrian Flow Model
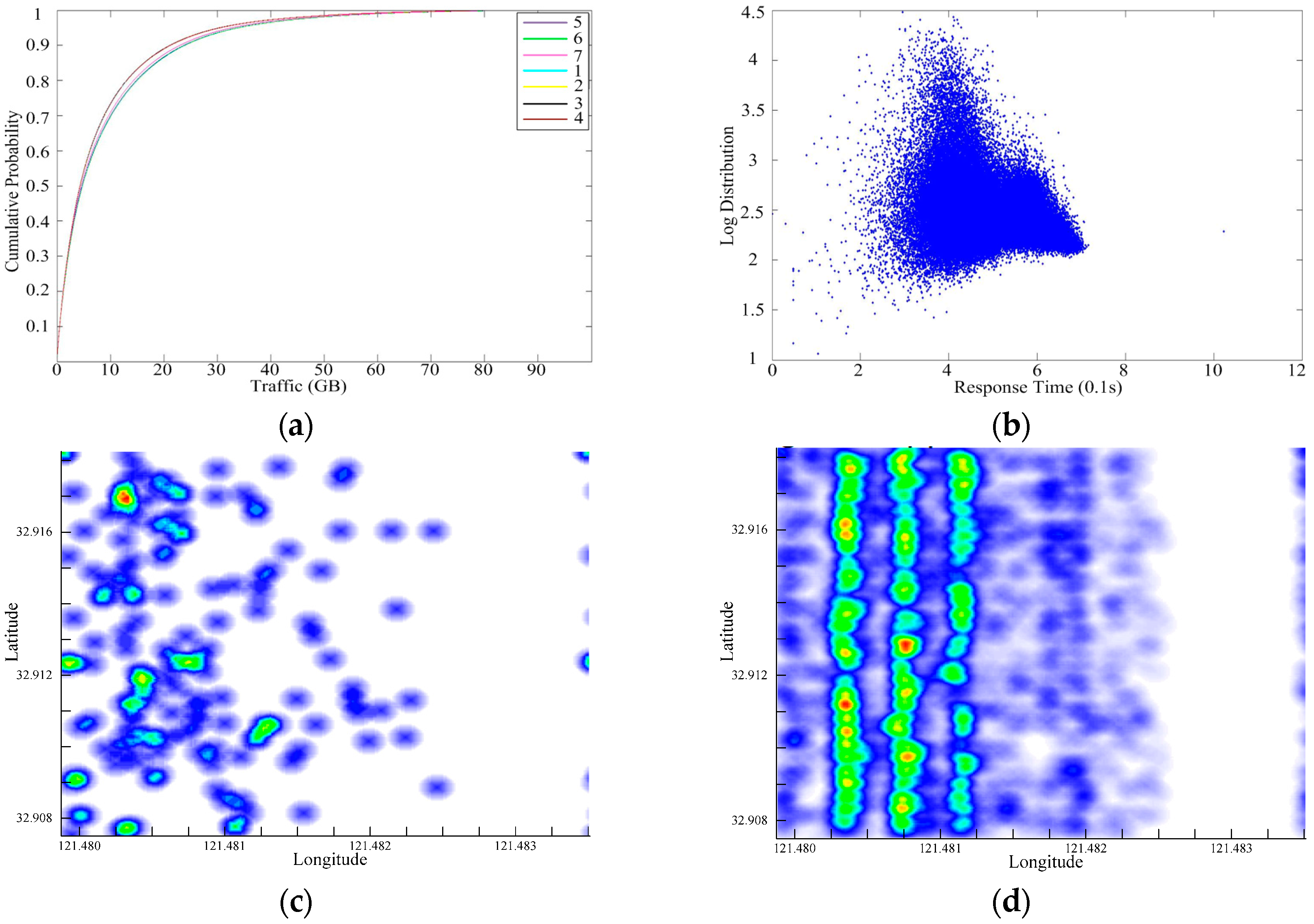
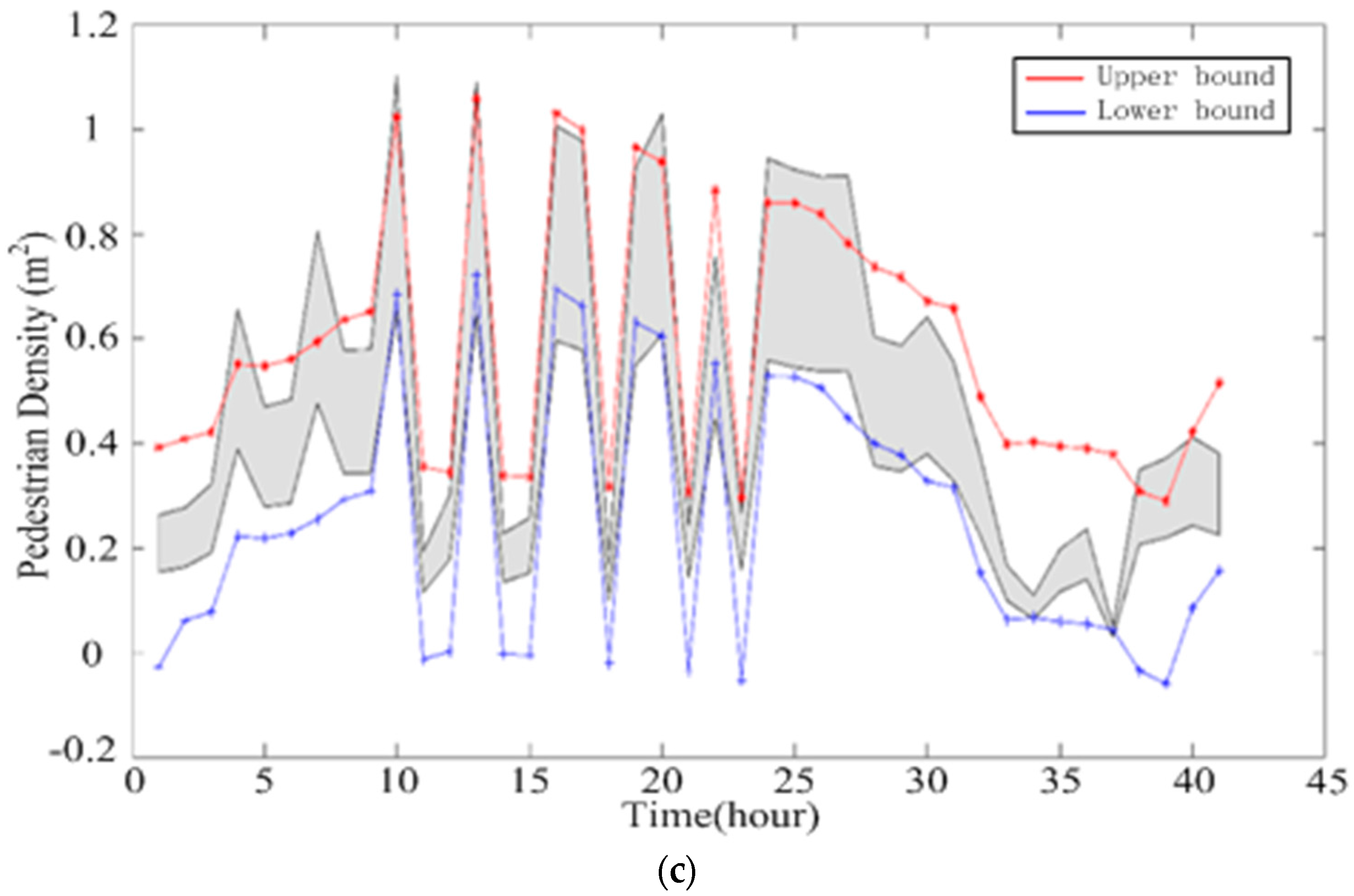
4. Cell Data Process and Analysis
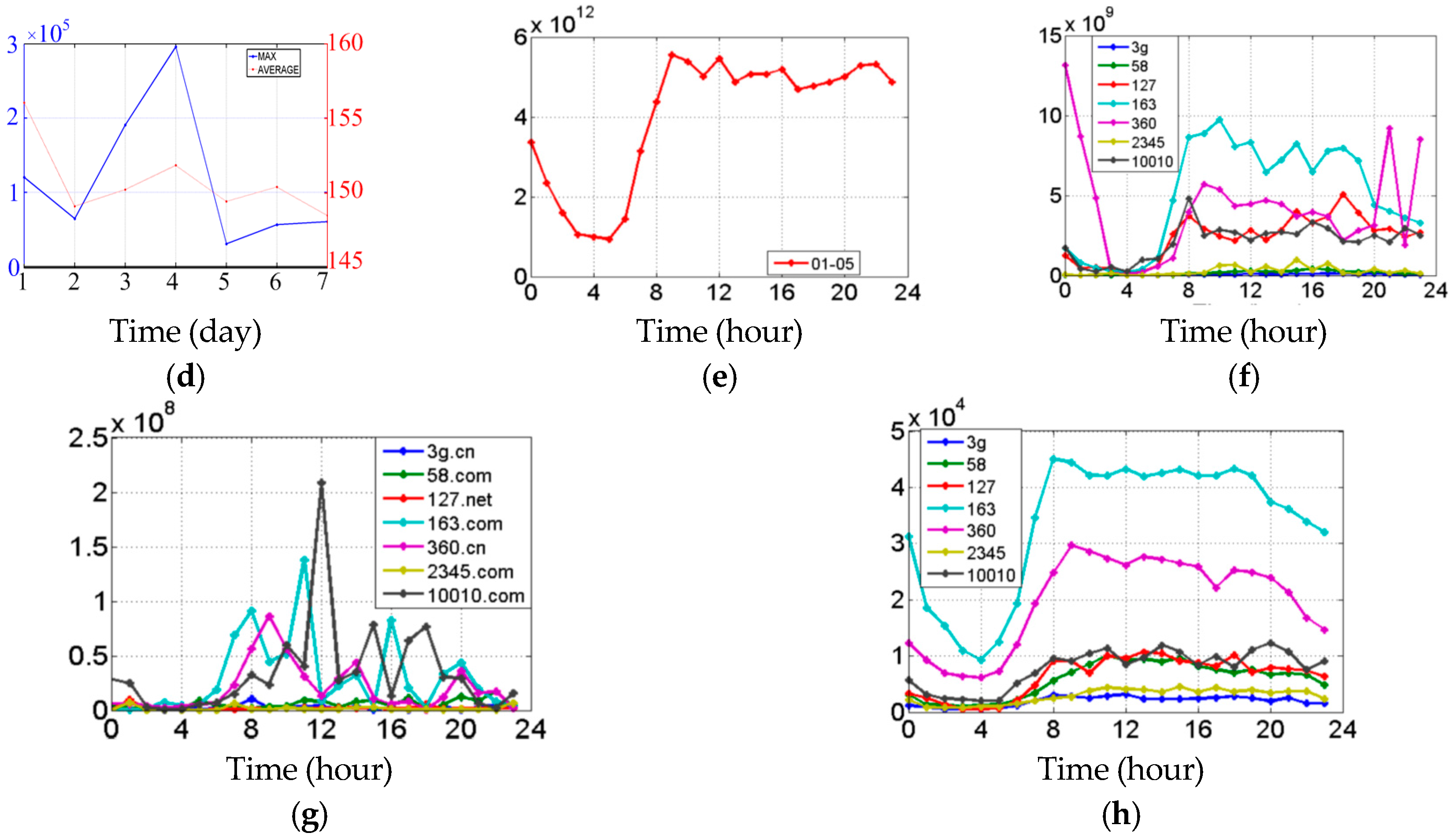
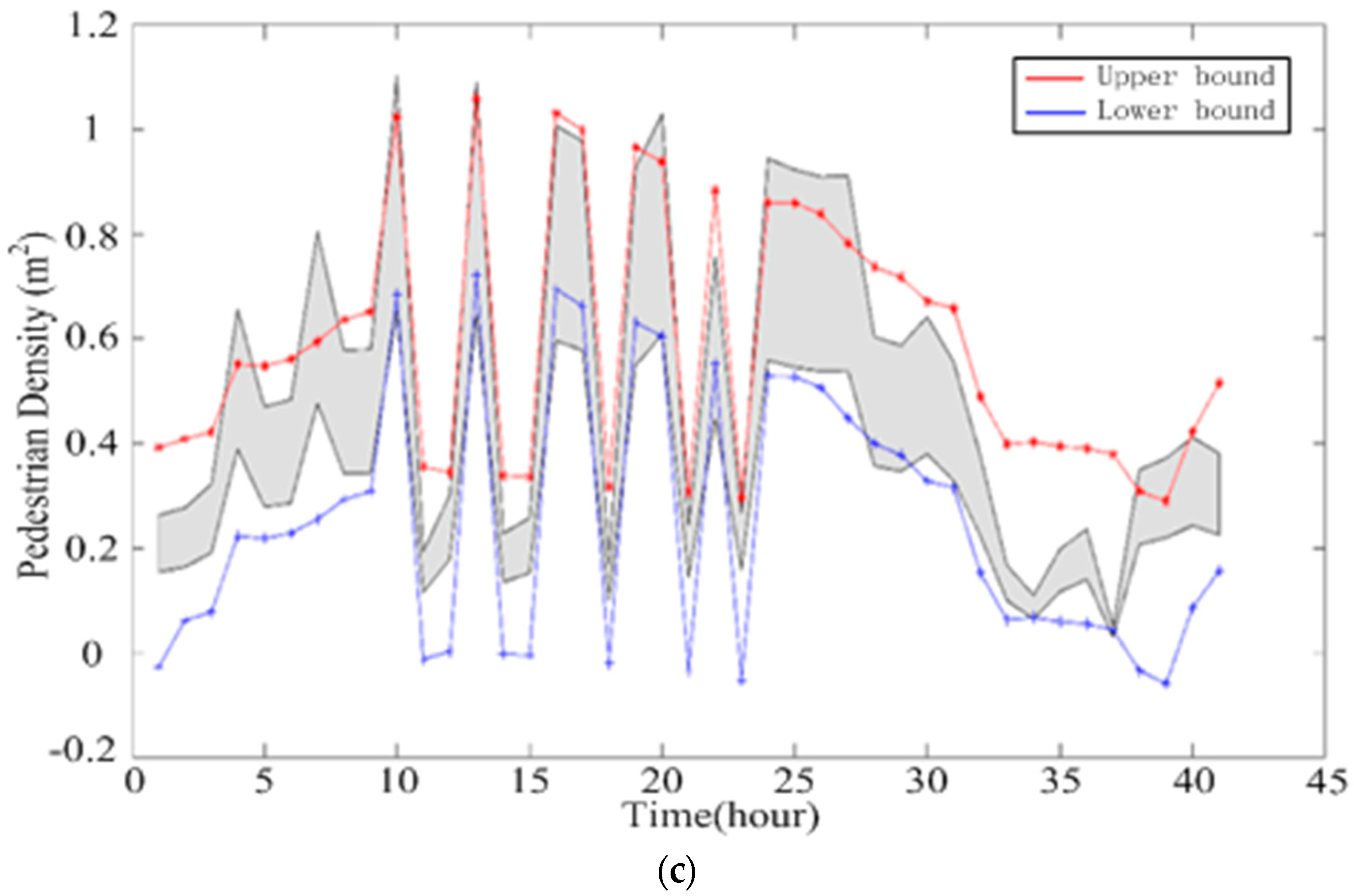
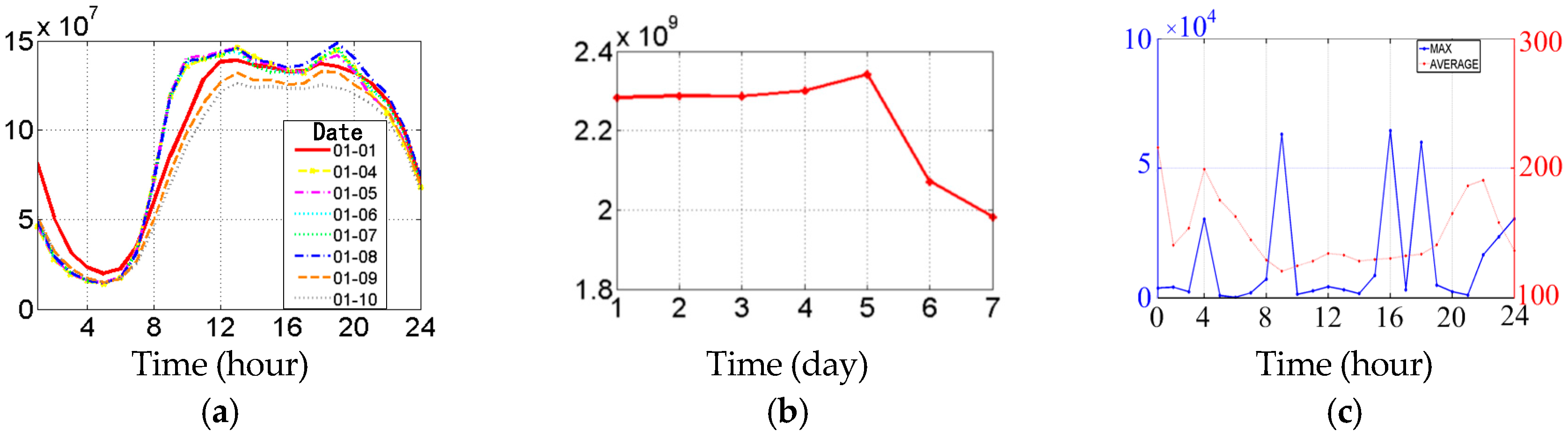
4.1. Pedestrian Temporal Properties
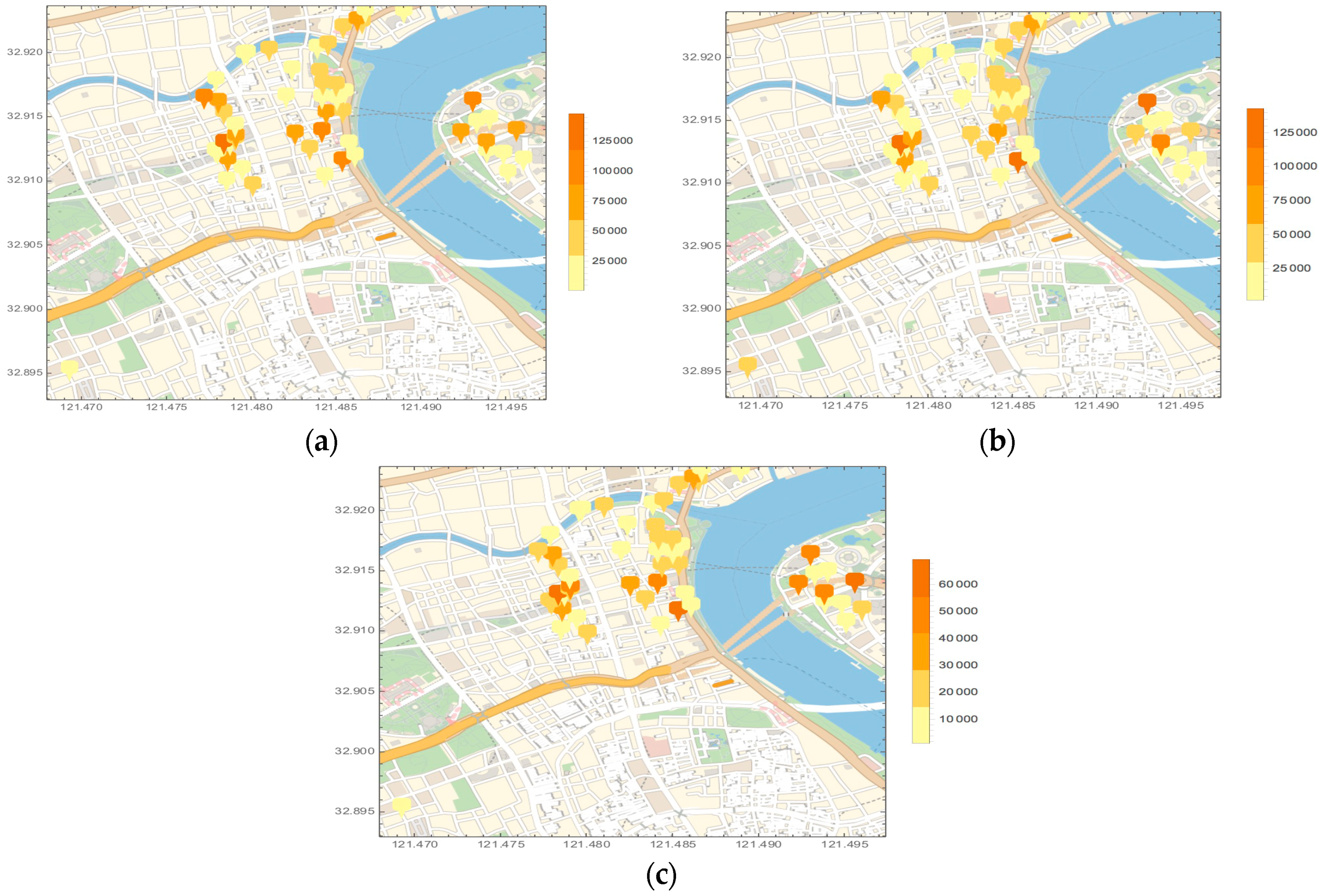
4.2. Spatial Distribution Figures
5. Model Implementation and Case Study
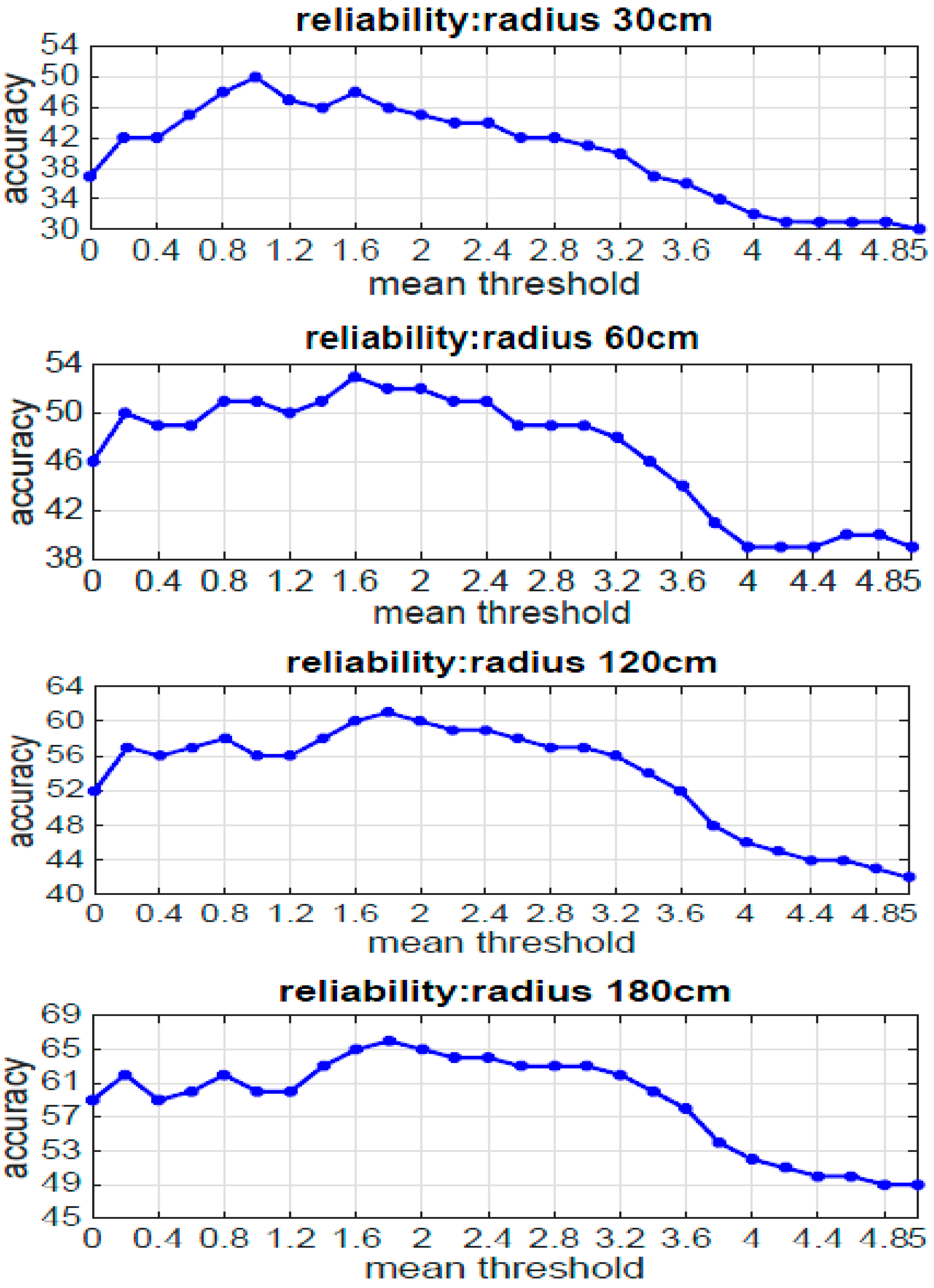
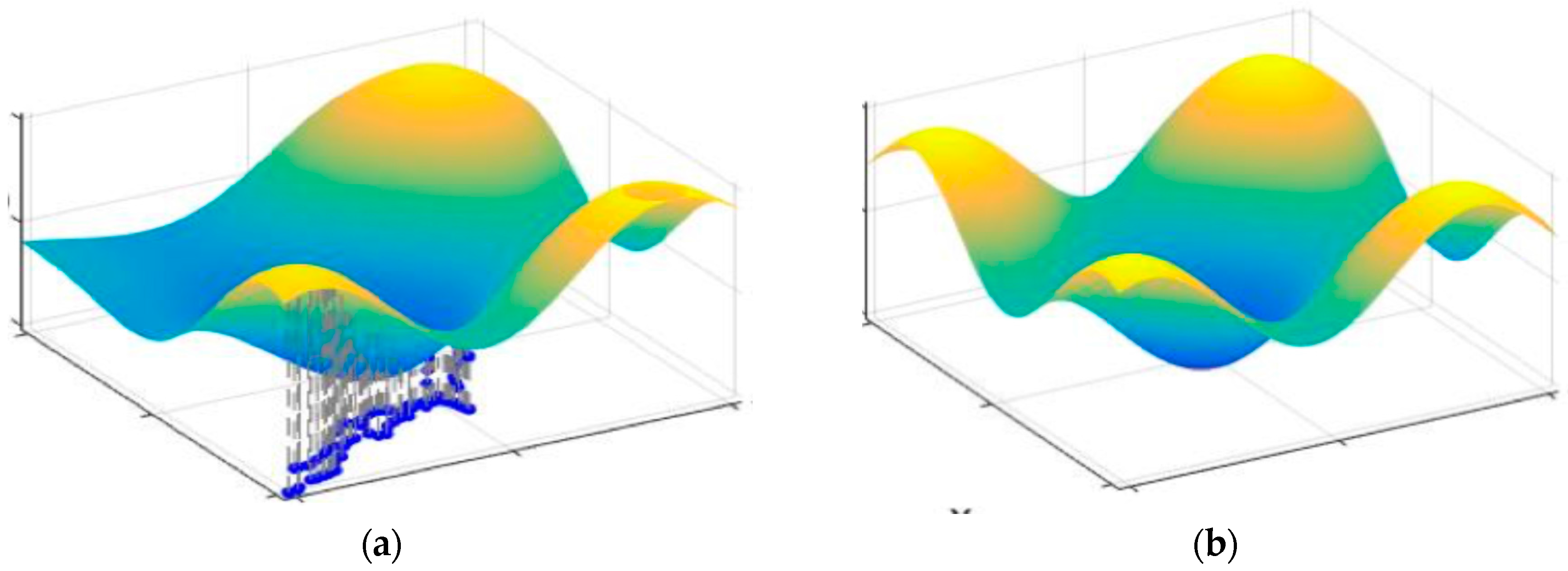
5.1. Pedestrian Tracking Accuracy Improved by RSS Temporal Series
| Algorithm 1: Temporal Correlation for Tracking |
| Input parameters: The training data set for each location , ; The reported RSS sequence from a user; Indoor space is a set of all the identified locations recorded in the database; Threshold Th is the critical value of choice for mean vectors.
|
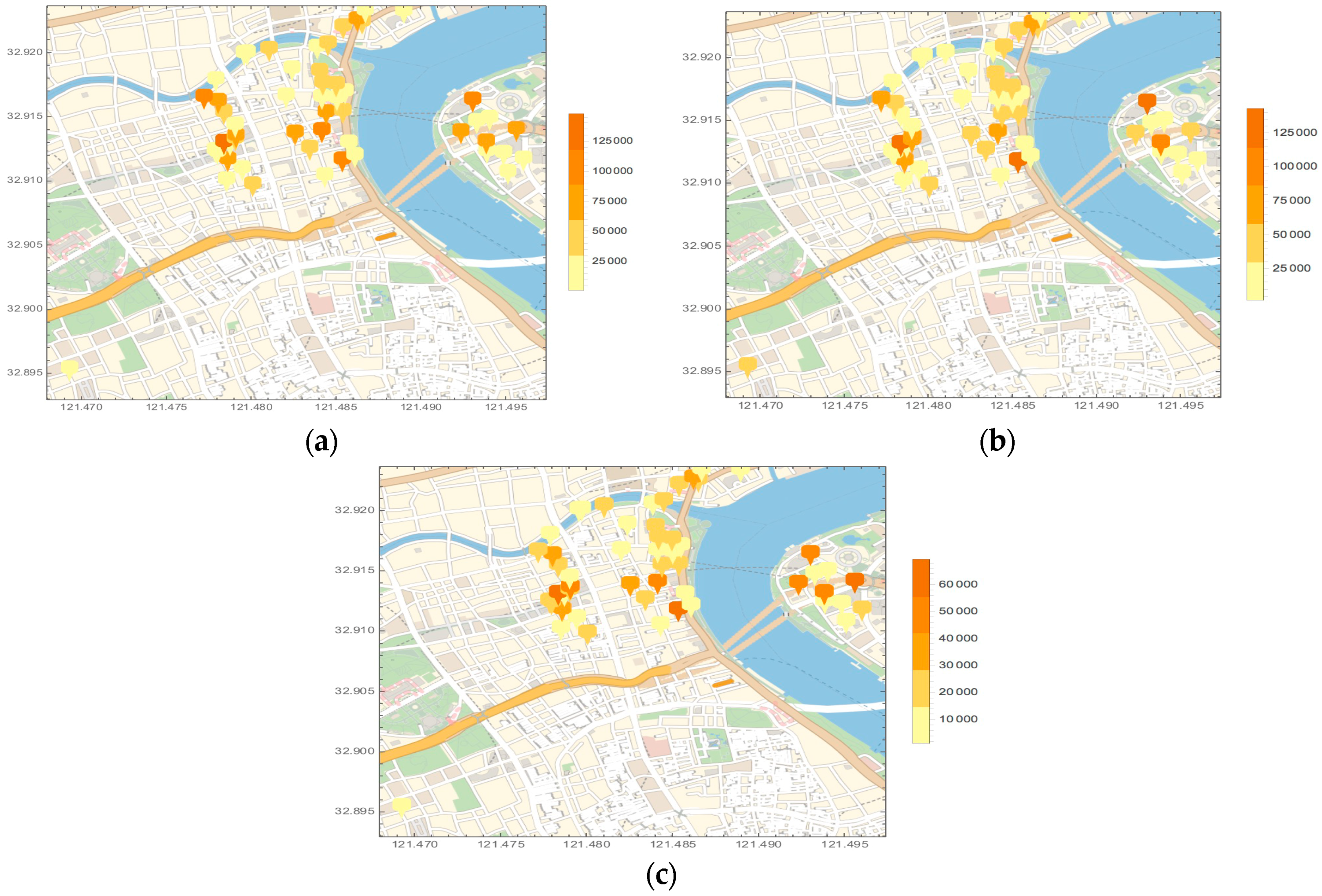
5.2. Pedestrian Prediction and Case Study
6. Conclusion and Future Works
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Mckenna, S.; Jabri, S.; Duric, Z.; Rosenfeld, A.; Wechsler, H. Tracking Groups of People. Comput. Vis. Image Underst. 2000, 90, 42–56. [Google Scholar] [CrossRef]
- Karmann, K.P.; von Brandt, A. Moving Object Recognition Using an Adaptive Background Memory. In Time-Varying Image Processing and Moving Object Recognition; Cappellini, V., Ed.; Elsevier: Amsterdam, The Netherlands, 1990; Volume 2, pp. 289–296. [Google Scholar]
- Kilger, M. A Shadow Handler in a Video-based Real-time Traffic Monitoring System. In Proceedings of the IEEE Workshop on Applications of Computer Vision, Palm Springs, CA, USA, 30 November–2 December 1992; pp. 11–18.
- Stauffer, C.; Grimson, W. Adaptive Background Mixture Models for Real-time Tracking. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Fort Collins, CO, USA, 23–25 June 1999; pp. 2246–2251.
- Lipton, A.J.; Fujiyoshi, H.; Patil, R.S. Moving Target Classification and Tracking from Real-time Video. In Proceedings of the 4th IEEE Workshop on Applications of Computer Vision (WACV’98), Princeton, NJ, USA, 19–21 October 1998; pp. 8–14.
- Wang, L.; Hu, W.; Tan, T. Recent Developments in Human Motion Analysis. Pattern Recognit. 2003, 36, 585–601. [Google Scholar] [CrossRef]
- Friedman, N.; Russell, S. Motion Segmentation from Optical Flow. In Proceedings of the Alvey Vision Conference, Reading, UK, 25–28 September 1989; pp. 209–214.
- Mclachlan, G.; Krishnan, T. The EM Algorithm and Extensions; Morgan Kaufmann: Burlington, MA, USA, 1997; pp. 175–181. [Google Scholar]
- Collins, R.; Lipton, A.; Fujiyoshi, H. Algorithms for Cooperative Multi-sensor Surveillance. IEEE Proc. 2001, 89, 1456–1477. [Google Scholar] [CrossRef]
- Comaniciu, D.; Ramesh, V.; Meer, P. Kernel-based Object Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 564–577. [Google Scholar] [CrossRef]
- Oliver, N.; Rosario, B.; Pentland, A. A Bayesian Computer Vision System for Modeling Human Interactions. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 831–843. [Google Scholar] [CrossRef]
- Yang, Z.; Zhou, Z.; Liu, Y. From RSSI to CSI: Indoor Localization via Channel Response. ACM Comput. Surv. 2013, 46, 1–32. [Google Scholar] [CrossRef]
- Liu, H.; Gan, Y.; Yang, J.; Sidhom, S.; Wang, Y.; Chen, Y.; Ye, F. Push the Limit of WiFi based Localization for Smartphones. In Proceedings of the 18th annual international conference on Mobile computing and networking, Istanbul, Turkey, 22–26 August 2012; pp. 305–316.
- Liu, H.; Yang, J.; Sidhom, S.; Wang, Y.; Chen, Y.; Ye, F. Accurate WiFi Based Localization for Smartphones Using Peer Assistance. IEEE Trans. Mob. Comput. 2013, 13, 2199–2214. [Google Scholar] [CrossRef]
- Rai, A.; Chintalapudi, K.K.; Padmanabhan, V.N.; Sen, R. Zee: Zero-Effort Crowdsourcing for Indoor Localization. In Proceedings of the ACM MobiCom, Istanbul, Turkey, 22–26 August 2012; pp. 293–304.
- Fang, S.; Lu, B.; Hsu, Y. Learning Location from Sequential Signal Strength Based on GSM Experimental Data. IEEE Trans. Veh. Technol. 2012, 61, 726–736. [Google Scholar] [CrossRef]
- Fang, S.; Lin, T. A Dynamic System Approach for Radio Location Fingerprinting in Wireless Local Area Networks. IEEE Trans. Commun. 2010, 58, 1020–1025. [Google Scholar] [CrossRef]
- Kuo, S.; Tseng, Y. A Scrambling Method for Fingerprint Positioning Based on Temporal Diversity and Spatial Dependency. IEEE Trans. Knowl. Data Eng. 2008, 20, 678–684. [Google Scholar]
- Kemppi, P.; Rautiainen, T.; Ranki, V.; Belloni, F.; Pajunen, J. Hybrid Positioning System Combining Angle-based Localization, Pedestrian Dead Reckoning and Map Filtering. In Proceedings of the International Conference on Indoor Positioning and Indoor Navigation (IPIN), Zurich, Switzerland, 15–17 September 2010; pp. 1–7.
- Hodes, T.; Katz, R.; Servan-Schreiber, E.; Rowe, L. Composable Ad-hoc Mobile Services for Universal Interaction. In Proceedings of the 3rd Annual ACM/IEEE International Conference on Mobile Computing and Networking, Budapest, Hungary, 26–30 September 1997; pp. 1–12.
- Bandara, U.; Hasegawa, M.; Inoue, M.; Morikawa, H.; Aoyama, T. Design and Implementation of a Bluetooth Signal Strength based Location Sensing System. In Proceedings of the Radio and Wireless Conference IEEE, Atlanta, GA, USA, 19–22 September 2004; pp. 319–322.
- Want, R.; Hopper, A.; Falcao, V.; Gibbons, J. The Active Badge Location System. Trans. Inf. Syst. (TOIS) 1992, 10, 91–102. [Google Scholar] [CrossRef]
- Peng, R.; Sichitiu, M. Angle of Arrival Localization for Wireless Sensor Networks. Sens. Ad Hoc Commun. Netw. SECON IEEE 2006, 1, 374–382. [Google Scholar]
- Chan, Y.; Tsui, W.; So, H.; Ching, P. Time-of-arrival based Localization under NLOS Conditions. IEEE Trans. Veh. Technol. 2006, 55, 17–24. [Google Scholar] [CrossRef]
- Comsa, C.R.; Luo, J.; Haimovich, A.; Schwartz, S. Wireless Localization Using Time Difference of Arrival in Narrow-band Multipath Systems. In Proceedings of the International Symposium on Signals, Circuits and Systems, ISSCS, Iasi, Romania, 13–14 July 2007; Volume 2, pp. 1–4.
- Patwari, N.; Ash, J.N.; Kyperountas, S.; Hero, A.O.I.; Moses, R.L.; Correal, N.S. Locating the Nodes: Cooperative Localization in Wireless Sensor Networks. IEEE Signal Process. Mag. 2005, 22, 55–69. [Google Scholar] [CrossRef]
- Kaemarungsi, K.; Krishnamurthy, P. Properties of Indoor Received Signal Strength for WLAN Location Fingerprinting. In Proceedings of the First Annual International Conference on Mobile and Ubiquitous Systems: Networking and Services (MobiQuitous’04), Boston, MA, USA, 22–26 August 2004; pp. 14–23.
- Wang, M.; Zhang, Z.; Tian, X.; Wang, X. Temporal Correlation of the RSS Improves Accuracy of Fingerprinting Localization. In Proceedings of the IEEE Conference on Computer Communications, San Francisco, CA, USA, 10–14 April 2016; pp. 1–9.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Begin Time | Response Time | End Time | CELL | Event | Content Length | Pck_Rec | Pck_Send | Byte_Rec | Byte_Send | WAP | TDR | New_Host | Sub_Domain |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2016/01/04 01:01:11 | 2016/01/04 01:01:11 | 2016/01/04 01:01:12 | 10,101 | 64 | 6579 | 9 | 7 | 7294 | 545 | 2 | 8 | apple | push |
| 2016/01/04 01:01:10 | 2016/01/01 01:01:10 | 2016/01/04 01:01:10 | 10,833 | 64 | 213 | 3 | 3 | 475 | 487 | 2 | 8 | izatcloud | xreapath3 |
| 2016/01/04 00:59:17 | 2016/01/04 00:59:17 | 2016/01/04 00:59:17 | 1138 | 96 | 2 | 4 | 6 | 391 | 2548 | 2 | 8 | baidu | map |
| 2016/01/04 01:00:41 | 2016/01/04 01:00:41 | 2016/01/04 01:00:42 | 7355 | 64 | 32,872 | 26 | 18 | 34,988 | 1308 | 2 | 0 | momocdn | img |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, K.; Wang, M.; Wei, B.; Sun, D. Identification and Prediction of Large Pedestrian Flow in Urban Areas Based on a Hybrid Detection Approach. Sustainability 2017, 9, 36. https://doi.org/10.3390/su9010036
Zhang K, Wang M, Wei B, Sun D. Identification and Prediction of Large Pedestrian Flow in Urban Areas Based on a Hybrid Detection Approach. Sustainability. 2017; 9(1):36. https://doi.org/10.3390/su9010036
Chicago/Turabian StyleZhang, Kaisheng, Mei Wang, Bangyang Wei, and Daniel (Jian) Sun. 2017. "Identification and Prediction of Large Pedestrian Flow in Urban Areas Based on a Hybrid Detection Approach" Sustainability 9, no. 1: 36. https://doi.org/10.3390/su9010036
APA StyleZhang, K., Wang, M., Wei, B., & Sun, D. (2017). Identification and Prediction of Large Pedestrian Flow in Urban Areas Based on a Hybrid Detection Approach. Sustainability, 9(1), 36. https://doi.org/10.3390/su9010036