1. Introduction
Economic and technological globalization have rendered division of labor more pronounced, including more and more companies in supply chain networks, which renders their structures more complex. The consequences arising from unexpected events have direct influences on some (or even all) companies in the network, and may lead to economic losses and unsustainable supplies. The supply chain resilience, which refers to the ability of a system to prepare for unforeseen disruptions and to withstand and recover from them [
1,
2,
3], has drawn attention from researchers in both academia and industry.
The term “resilience“ originates from the Latin word “resiliere”, which means to bounce back [
4]. Many researchers believe that the current interest in the supply chain network resilience was triggered by the events surrounding the 9/11 terrorist attacks. Because not all risks can be avoided, building a resilient supply chain network that can bounce back from disruption easily becomes a new challenge for supply chain managers. Many factors, such as the supply strategy, the network topology, and the recovery strategy, can influence the resilience of a system. For example, the Taiwan earthquake of 1999 disrupted the flow of semiconductors to many computer and laptop manufacturers worldwide. In response to the shortfall, Apple Computer Inc. and Dell reacted quite differently due to their different marketing schemes. During that quarter, Apple’s sales declined, while Dell’s earnings increased 41% over the same period of the previous year [
5]. A fire disrupted the main Philips radio-frequency chip (RFC) plant in the early 2000s. Nokia and Ericsson, two competitors, both depended solely on Philips RFCs, and they responded differently. As a consequence, Nokia met its sales goals, while Ericsson lost $400 million and stopped making cellular phones [
1]. Dell and Nokia showed better resilience to short-term supply disruption than Apple and Ericsson, and resilient supply chain networks with good resilience can improve the economic efficiency of the company.
Although the resilience of supply chain networks is a hot topic among researchers, there is still no unified definition of the term [
6]. According to the systematic review published by Hohenstein et al. [
7], the resilience of a supply chain network as “the ability of the supply chain network to withstand disruptions and return to a normal status quickly”, includes the two most important attributes, response and recovery, and is consistent with the definitions provided in [
8,
9,
10].
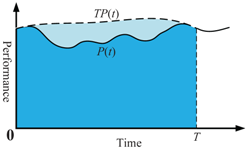
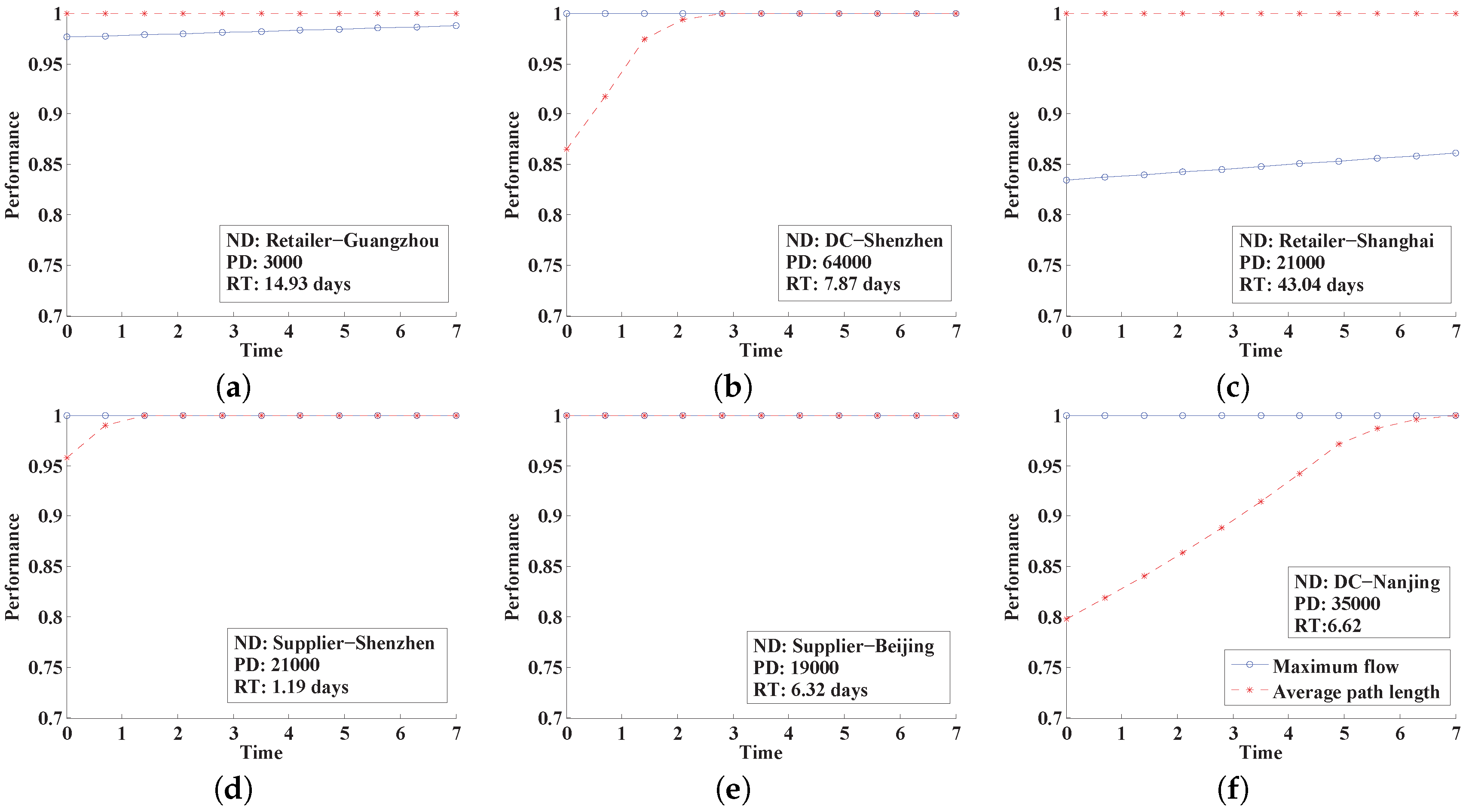
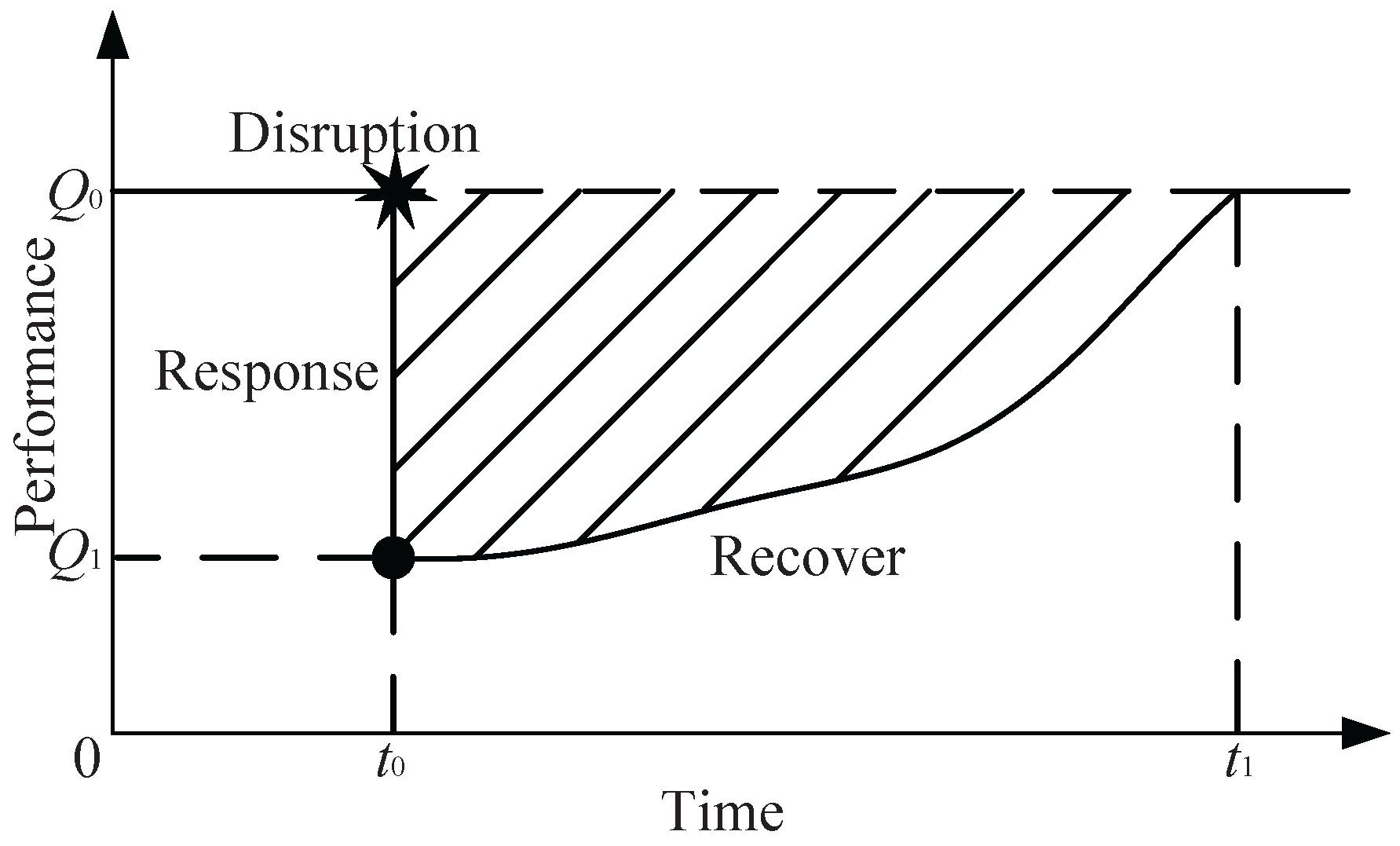
Figure 1 shows the conceptual schematic diagram of the system’s resilience behavior. The figure shows a disruption occurring at time
, and the system performance degrades from
to
. By taking appropriate action, the system finally returns to baseline at time
.
In a systematic review, Hohenstein et al. [
7] summarized that “most research has been qualitative and lacks assessment and measurement of supply chain network resilience”. To measure resilience, the Multidisciplinary Center of Earthquake Engineering to Extreme Events (MCEER) [
11] proposed a measure of addressing “resilience loss”. They defined a normalized system performance curve
, and used the integral of performance loss function from disruption followed by a gradual recovery to describe system resilience loss (i.e., the shadowed area in
Figure 1). This measure considers both the robustness of the system against the disruption and the rapidity of the recovery process. In particular, Mari et al. [
12] applied the expected disruption cost to measure the supply chain resilience, and this metric is an instance of the “resilience loss“ in the supply chain. Based on such work, Cimellaro et al. [
13] provided a further extension to define the resilience as the integral of the area beneath the curve
, which is regarded as a direct measure of resilience itself. Accordingly, the loss of resilience should be minimized, and the resilience itself should be maximized. However, because the recovery time of different systems differs, these two measures cannot be used to compare resilience. To solve this problem, Reed et al. [
14] defined the resilience of a system as the ratio of the area beneath the curve
to the time interval under consideration; Zobel [
15] assumed that all systems will return to their original status before
which serves as a strict upper bound on all possible recovery times, and defined “predicted resilience” as the ratio of the approximate area under the performance curve to
; Ouyang et al. [
16] proposed a resilience measure as the ratio of the area under the real performance curve to that under the targeted performance curve over 0 to
T; Spiegler et al. [
17] applied the integral of time multiplied by the absolute error (ITAE) in the control engineering to measure the resilience of the supply chain network, where the error in the inventory (i.e., the difference between zero and the actual inventory) is calculated by analyzing the inventory levels and shipment rates. These measures allow system resilience to be compared on the same relative scale. However, (1) the
-based scale disregards the fact that not all systems have a strict upper bound on recovery time, and some systems cannot fully recover back; and (2) the lifetime-based one deviates from the original definition of resilience as “bounce back”.
In this paper, a new resilience measure is proposed. It involves using the maximum allowable recovery time as the time interval under consideration and providing a simulation-based estimation method. Our research benefits supply chain managers. When building a new supply chain network or changing the old one, supply chain managers can use our resilience measurement method to evaluate the resilience of the network design alternatives, verify whether the system resilience goal can be satisfied, and choose a resilient alternative that can withstand the disruption and return to the normal state quickly. The remainder of the paper is organized as follows.
Section 2 describes the hierarchical structure of the supply chain network and its delivery mechanism. In
Section 3, the new resilience measure based on the maximum allowable recovery time is proposed, and two specific resilience measures for supply chain networks are provided. This is the resilience based on the amount of product delivered and the resilience based on the average delivery distance.
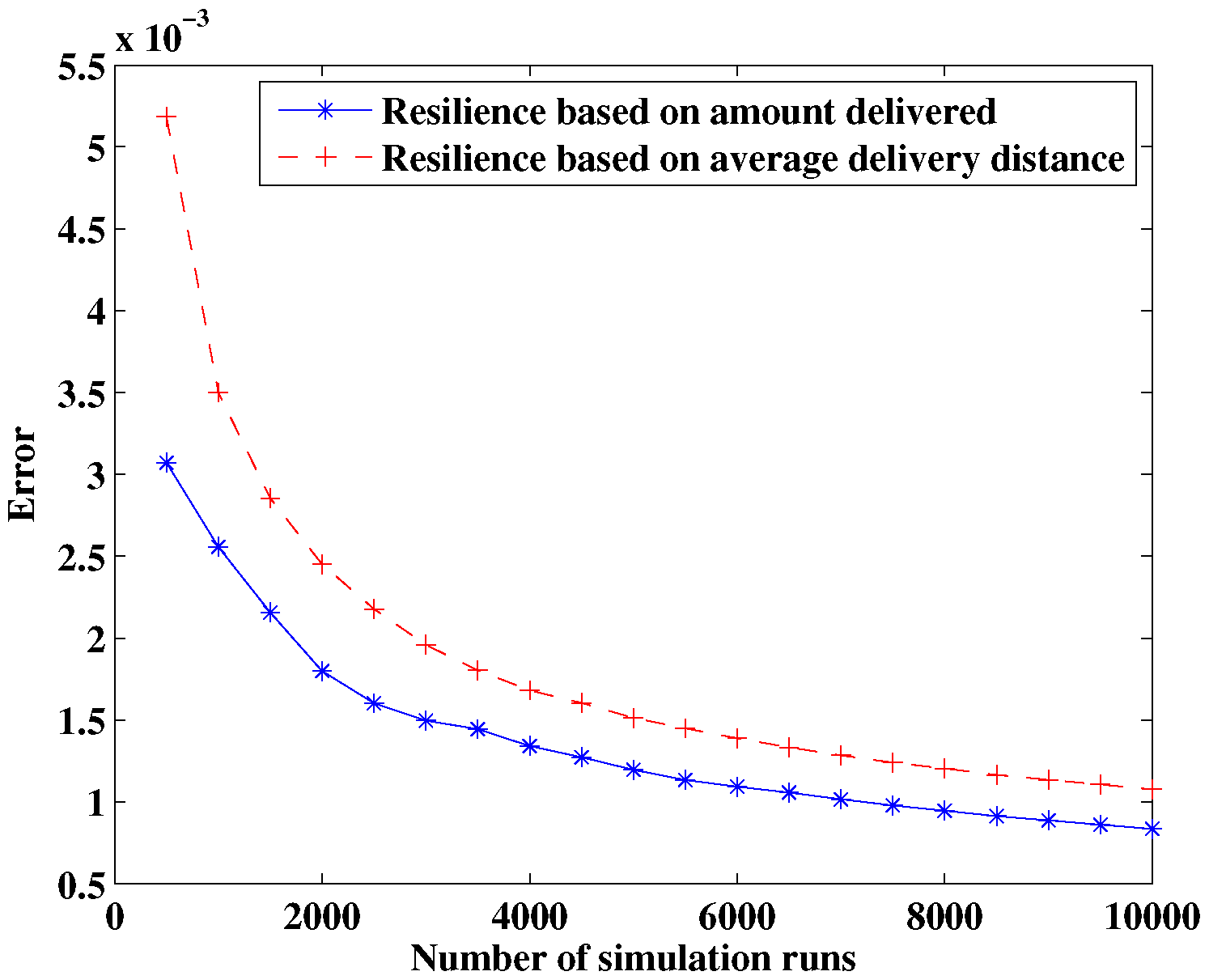
Section 4 describes the development of a resilience simulation method based on the Monte Carlo method, and the simulation models, simulation flow and the error discussion are included. In
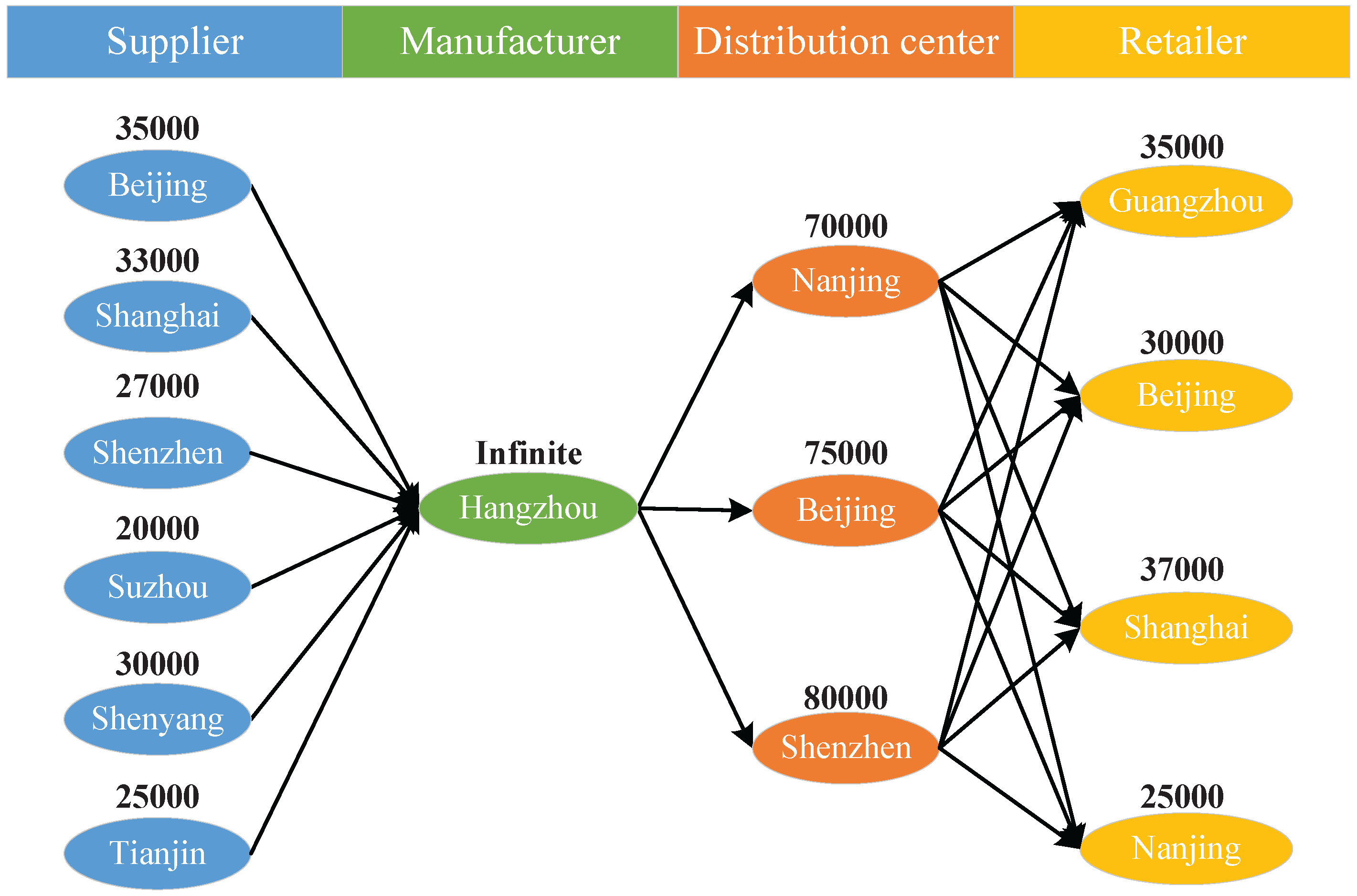
Section 5, a four-layered mobile phone supply chain network is introduced to show the effectiveness of our method, and the manner in which network topology affects the network resilience is discussed. Concluding remarks are provided in
Section 6.
2. Problem
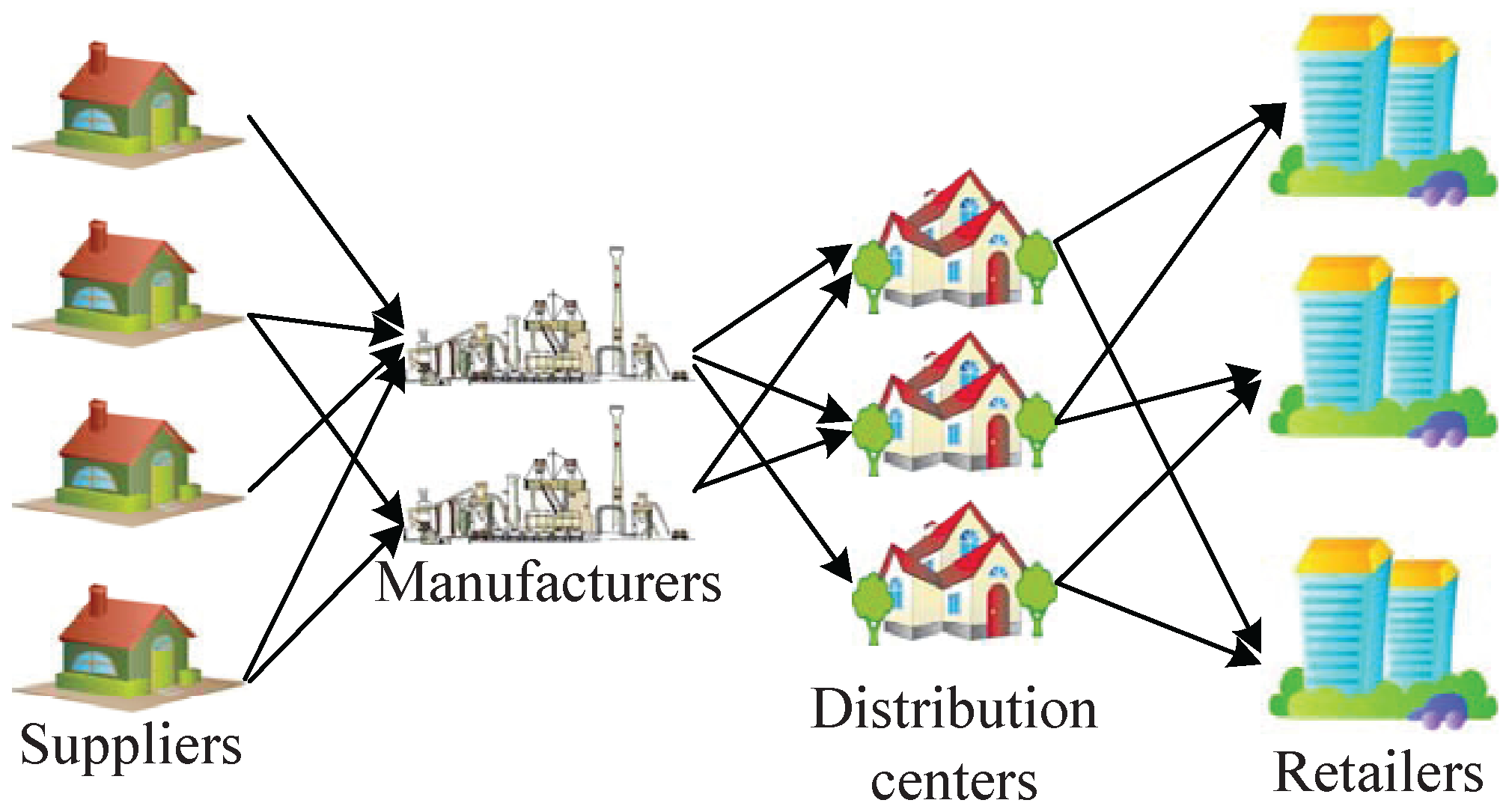
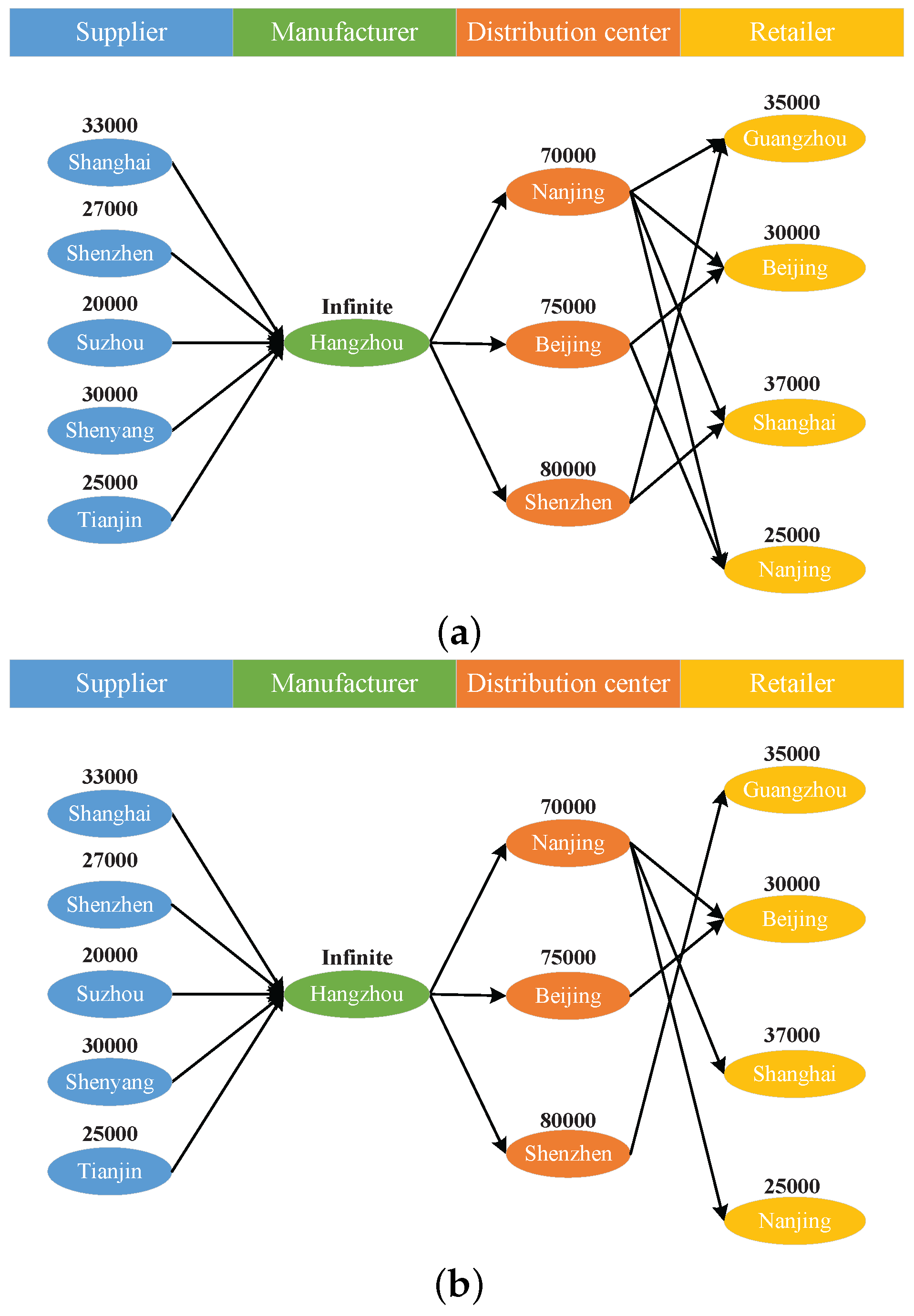
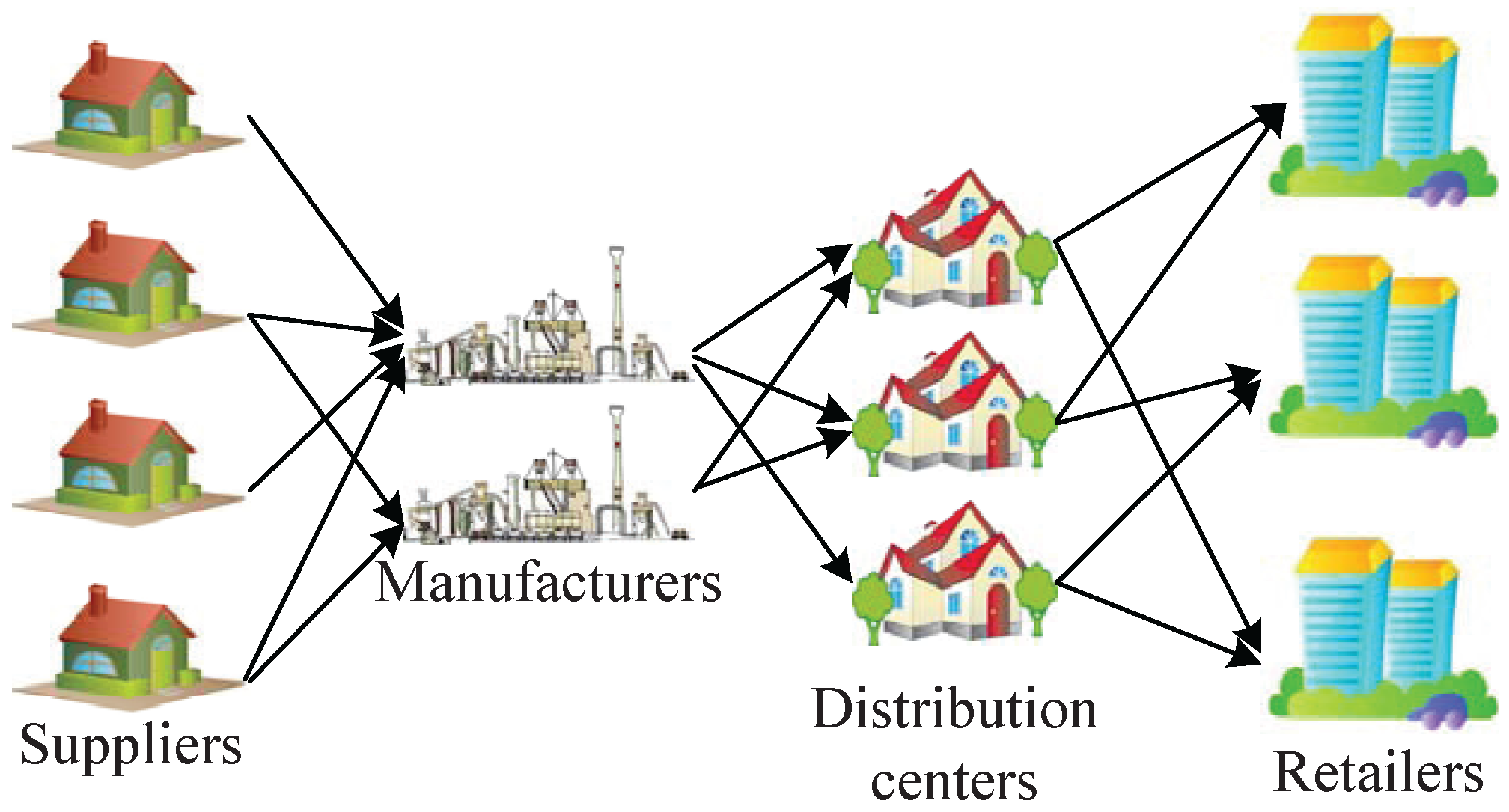
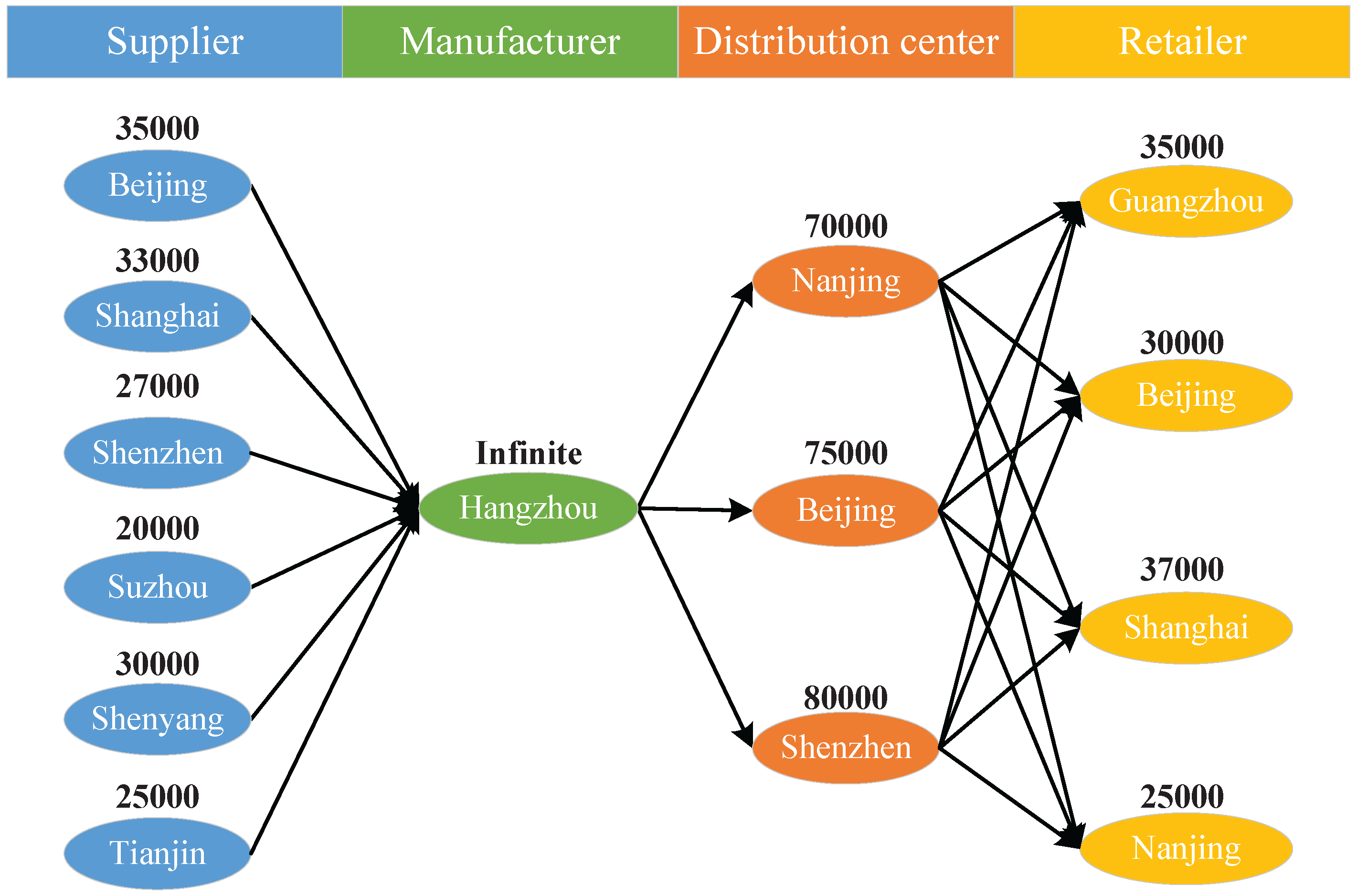
This paper considers hierarchical supply chain networks, as shown in
Figure 2. In the network, all suppliers, manufacturers, distribution centers, retailers, and other involved institutions are considered as nodes, and nodes with the same function are grouped as one layer, e.g., supplier layer, manufacturer layer, distributor layer, retailer layer, etc. There may be a link between any pair of nodes in two adjacent layers for materials or product delivery, and the existence of links depends on the network topology planning. Note that, because nodes in different layers differ in functionality, links only exist between nodes in adjacent layers, i.e., the materials or products can only be transferred between adjacent layers (e.g., from a supplier to a manufacturer, from a manufacturer to a distribution center, and from a distribution center to a retailer) and not within the same layer.
The current paper focuses on measurement of the resilience of supply chain networks, and the following assumptions were made:
- (1)
Only one type of product is produced and delivered per supply chain network.
- (2)
Each node has a certain capacity, which can be used to produce and store productions. The link capacity is unlimited.
- (3)
Both service time and waiting time on nodes are disregarded, and the waiting time on links is also disregarded.
- (4)
Only nodes may suffer from the disruption, and there are no common-cause disruptions.
The first assumption is used to simplify the problem as Shin et al. [
18], in which only one type of product is considered. For networks with multiple types of products, a similar method can be used by computing different resilience measures for different types of products, and then the system’s resilience can be synthetically calculated. Assumption 2 illustrates that the nodes are with finite manufacturing or restoration ability and the links have infinite delivery ability. Assumption 3 indicates that the materials and products are served immediately once they arrive at the node or link, and there is no waiting time. The service time on nodes in the same layer is always the same, so they are disregarded and only the delivery time on links is considered in our problem. The assumption that only nodes may suffer from the disruption is made here to simplify the discussion process, similar to the “perfect edges” assumption in the network reliability analysis [
19,
20,
21], and can be easily extended by regarding links as nodes. The assumption that there would be “no common-cause disruption” means that one disruption can only cause the capacity of one node to degrade, which is similar to the widely used “no common-cause failure“ assumption in reliability research [
22,
23,
24].
Hence, given the network topology, node capacities, node locations, disruptions, node capacity degradations and recovery time, the problem is to estimate the resilience of the supply chain network and verify whether the system resilience goal can be satisfied.
6. Conclusions
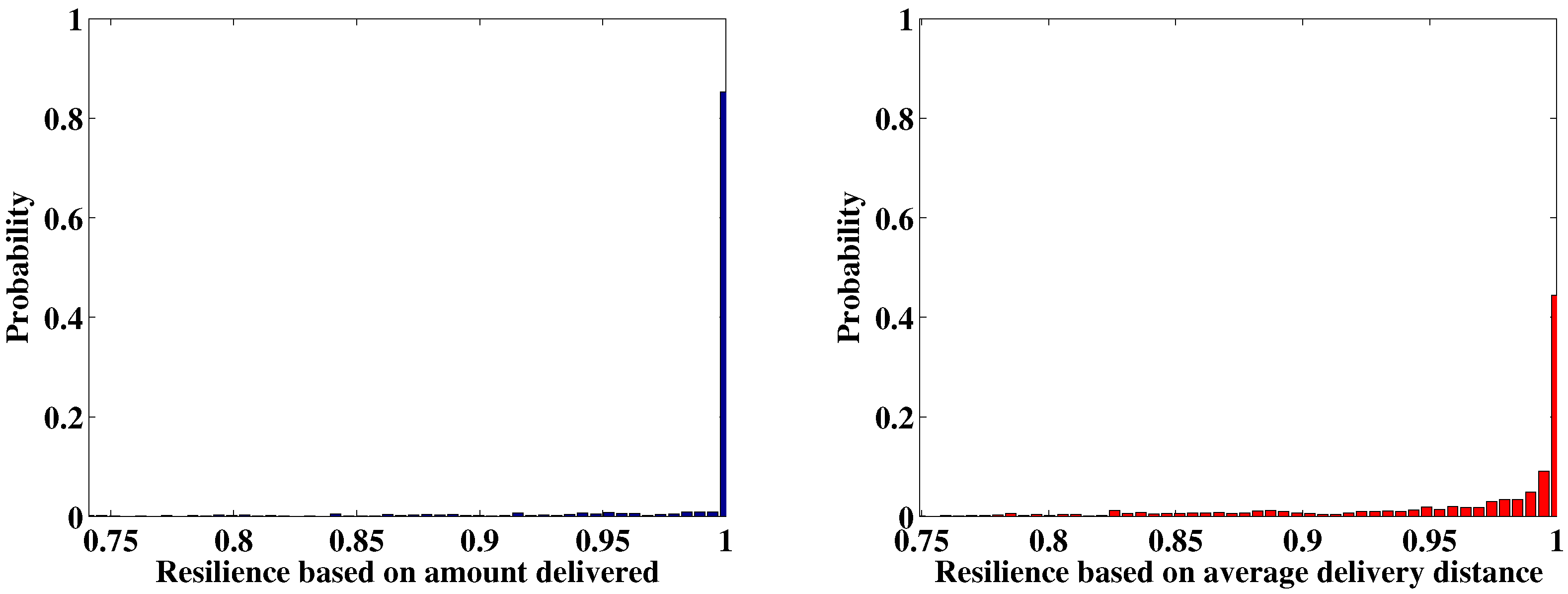
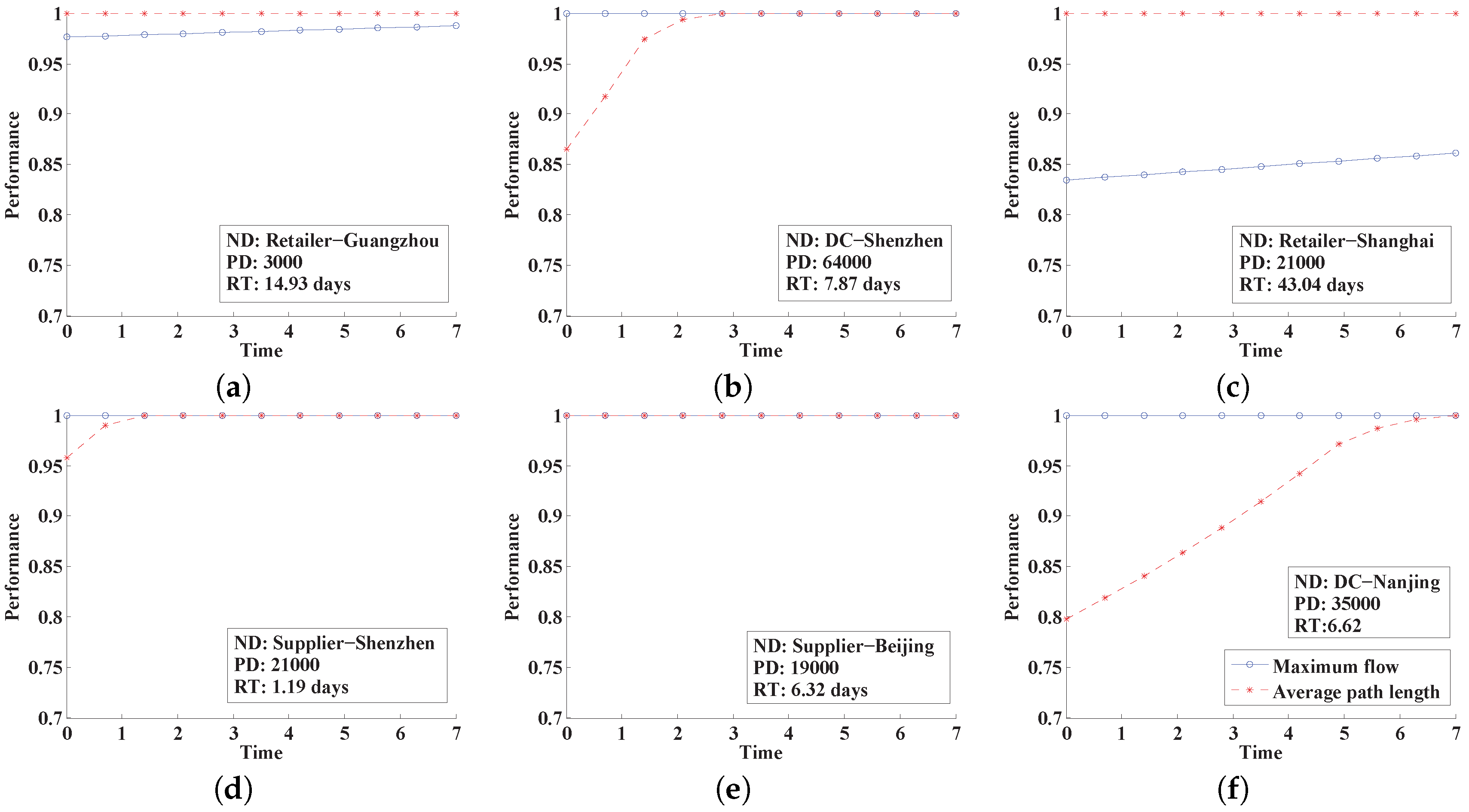
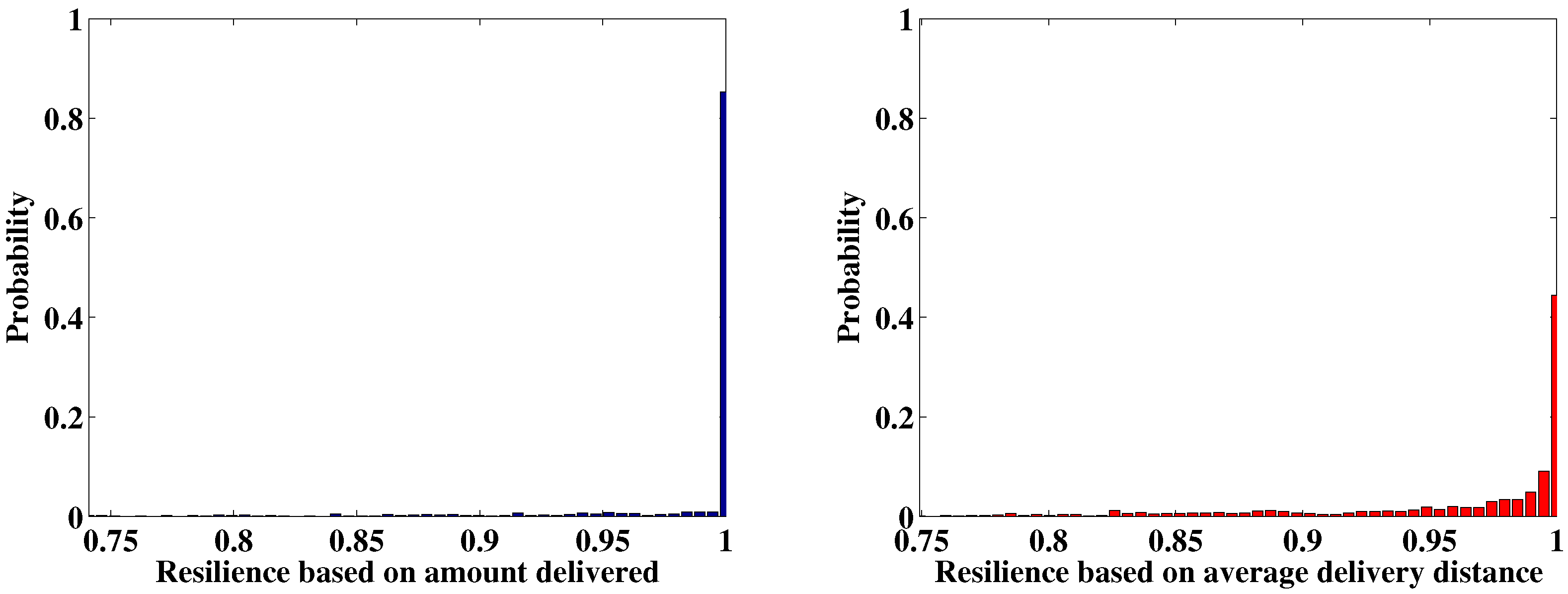
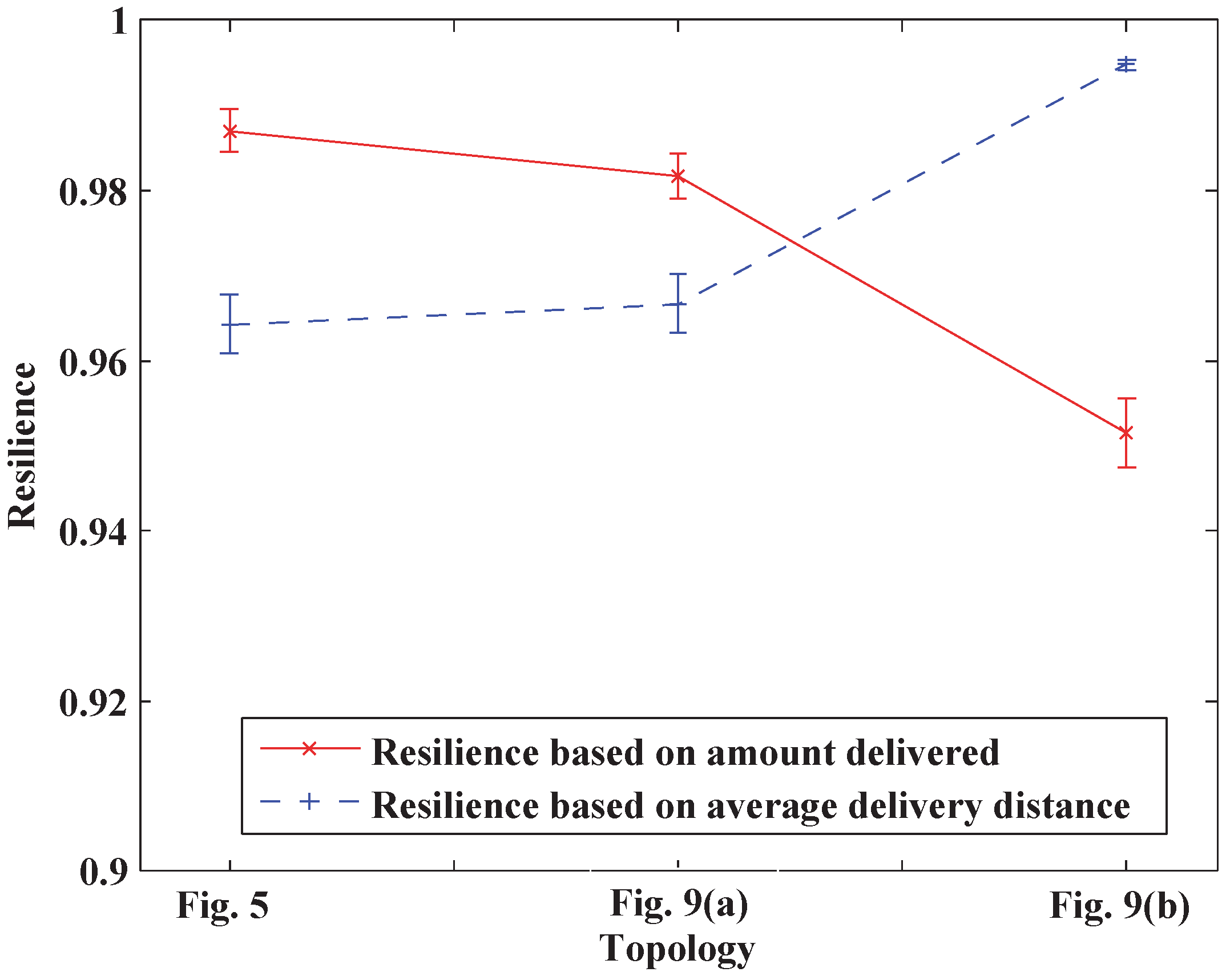
This paper proposes a new resilience measure, in which the maximum allowable recovery time serves as the time interval under consideration, and two specific resilience measures, i.e., the resilience based on the amount of product delivered and the resilience based on average delivery distance, are provided for supply chain networks. A simulation method based on the Monte Carlo is developed to estimate the network resilience. The effectiveness of this method is verified using a mobile phone supply chain network. The contributions of the current paper include the following: (1) a new resilience measure is provided using the maximum allowable recovery time determined by customers as the time scale. It not only allows system resilience to be compared on the same relative scale but also provides a clear physical meaning focusing on the ability of “bounce back“ after disruptions; (2) two resilience measures are proposed for supply chain networks, one based on the amount of product delivered and the other on the average delivery distance, providing quantitative methods for supply chain networks whose resilience is usually qualitatively analyzed (Hohenstein et al. [
7]); and (3) a resilience estimation framework is developed for supply chain networks, in which the Monte Carlo method based simulation and the graph theory are combined. A linear programming model is constructed under the constraint of flow conversations to determine the flow distribution with the minimal delivery distance.
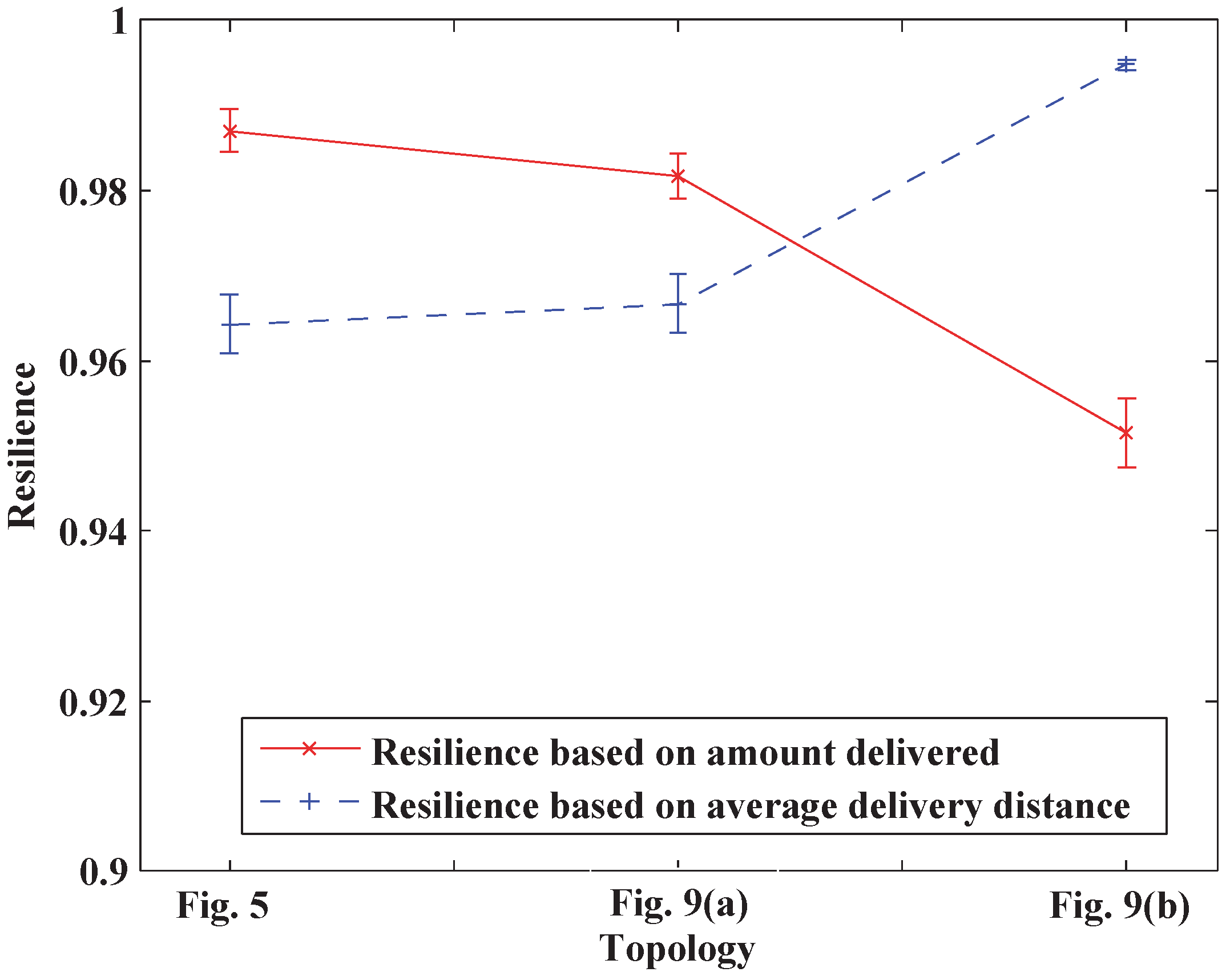
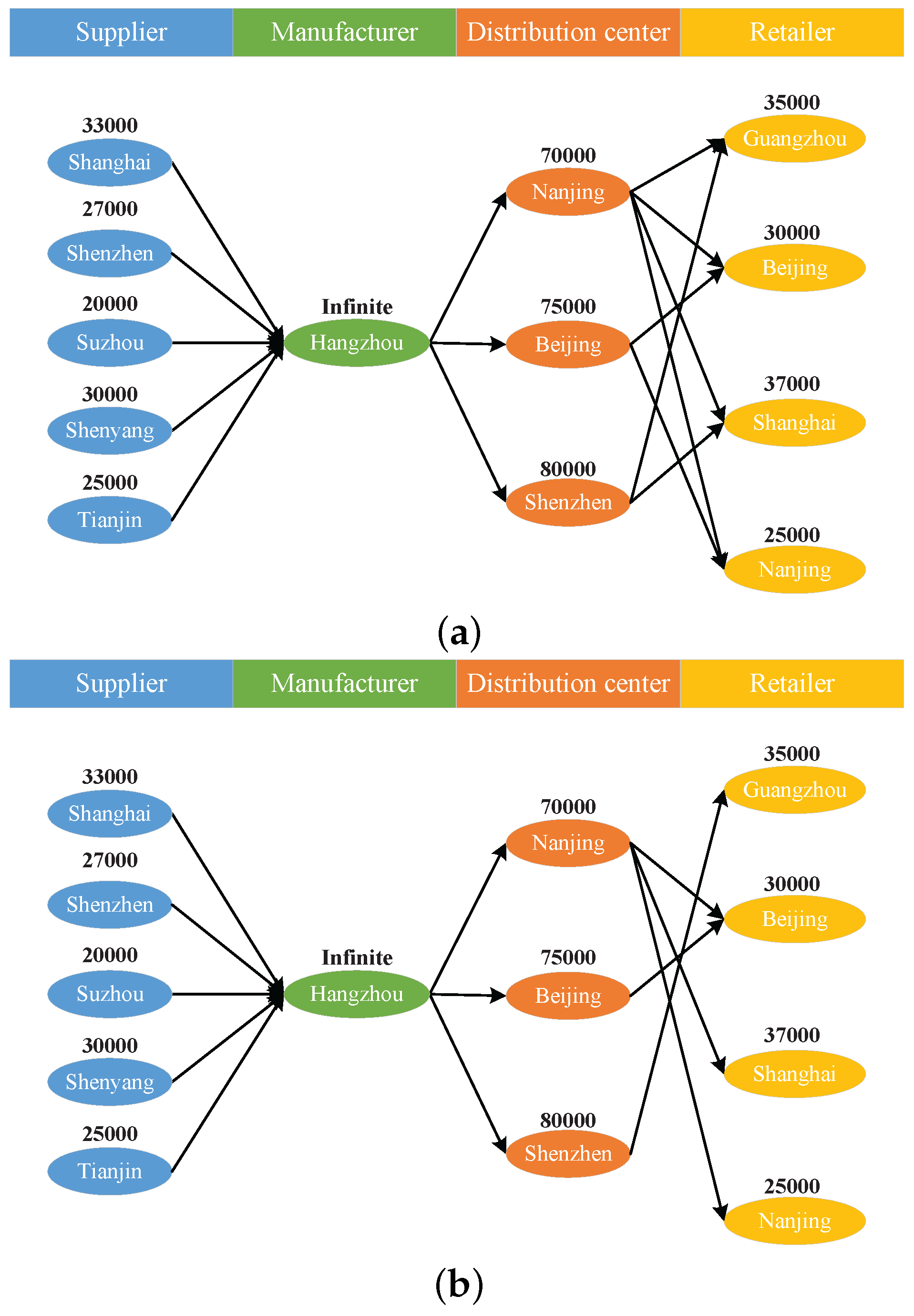
In this paper, the current case study indicates that the topology of the network has a large influence on the system resilience, and the optimization of the network topology using the system resilience as constraints is slated for further study. Moreover, all the institutions (i.e., suppliers, manufacturers, distribution centers and retailers) are supposed to be controlled by the company’s supply chain manager. If not, each institution’s behavior will influence the resilience of the supply chain network. This problem will also be studied together with the Games Theory in our future work.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}