
Self-Adaptive Revised Land Use Regression Models for Estimating PM2.5 Concentrations in Beijing, China

Abstract
:1. Introduction
2. Materials and Methods
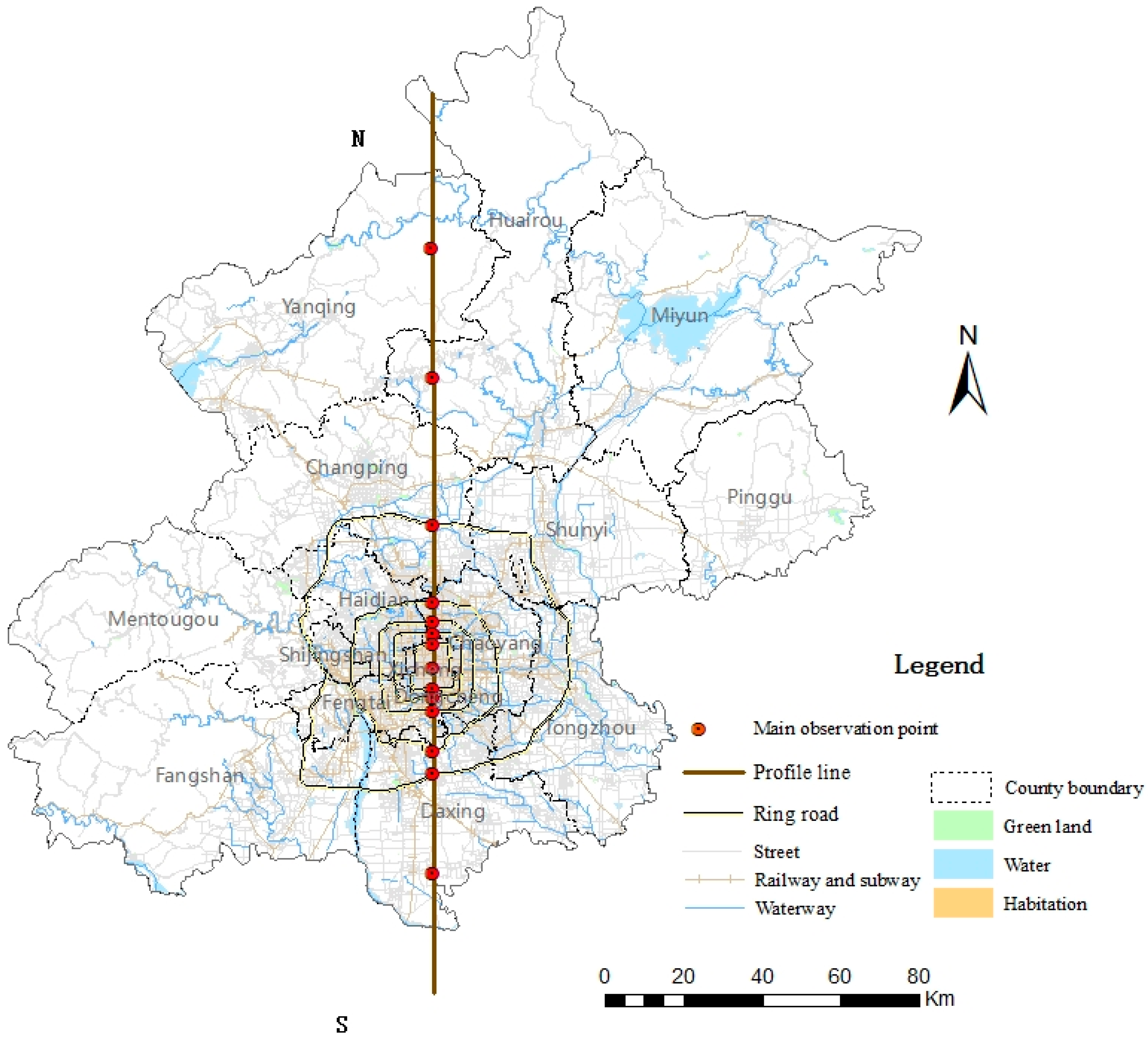
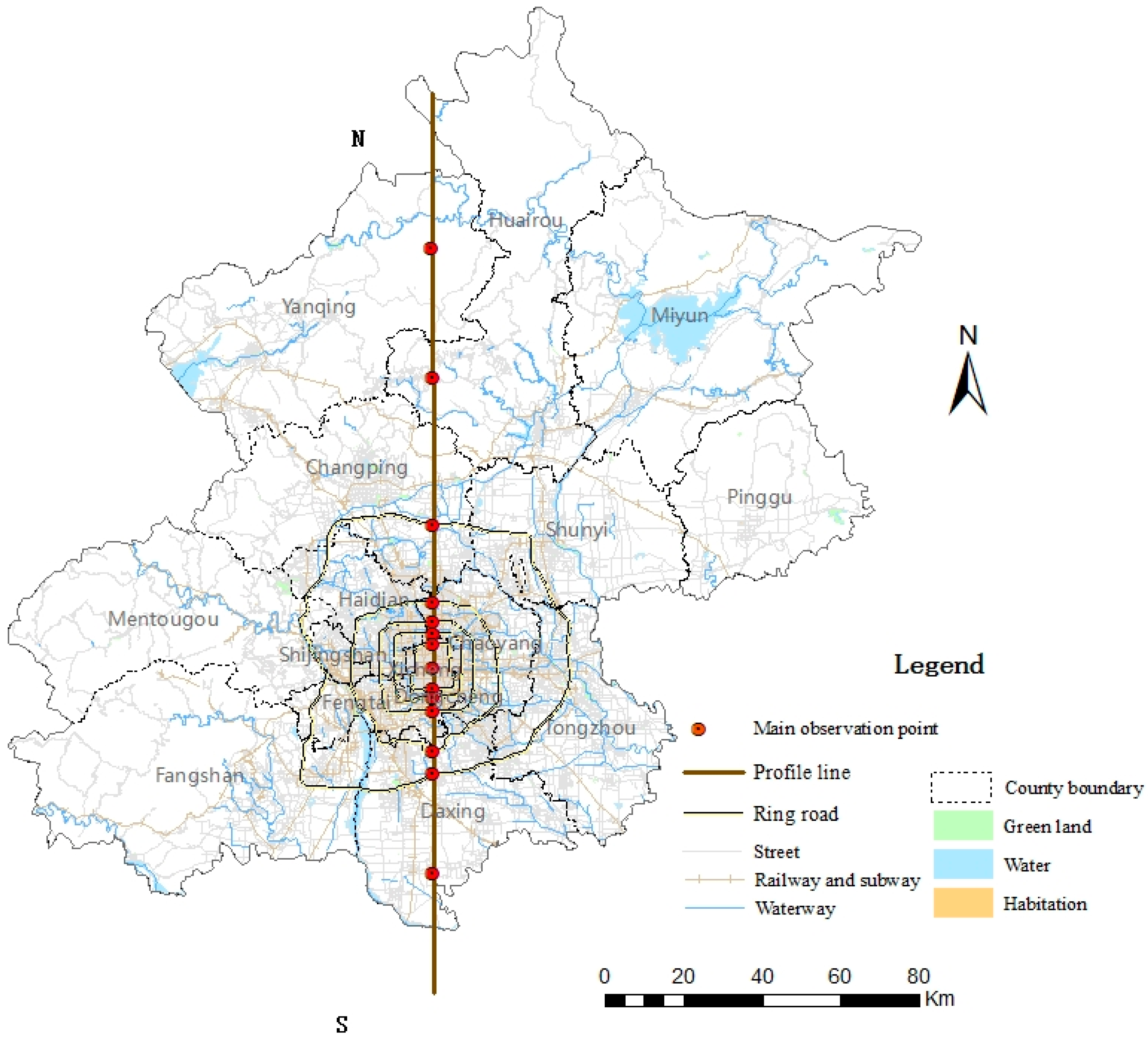
2.1. Study Area
2.2. PM2.5 Data and Predictor Variables
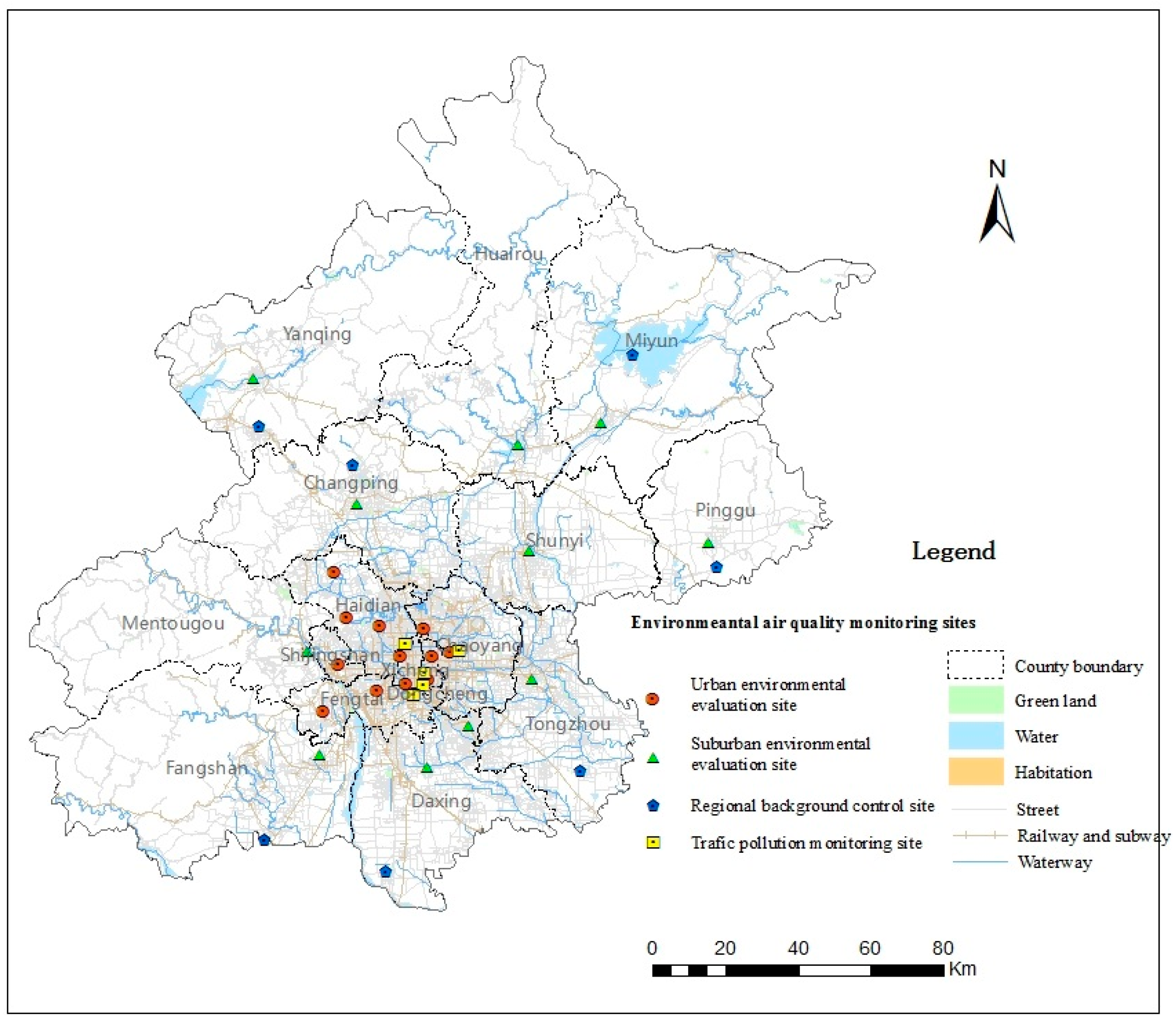
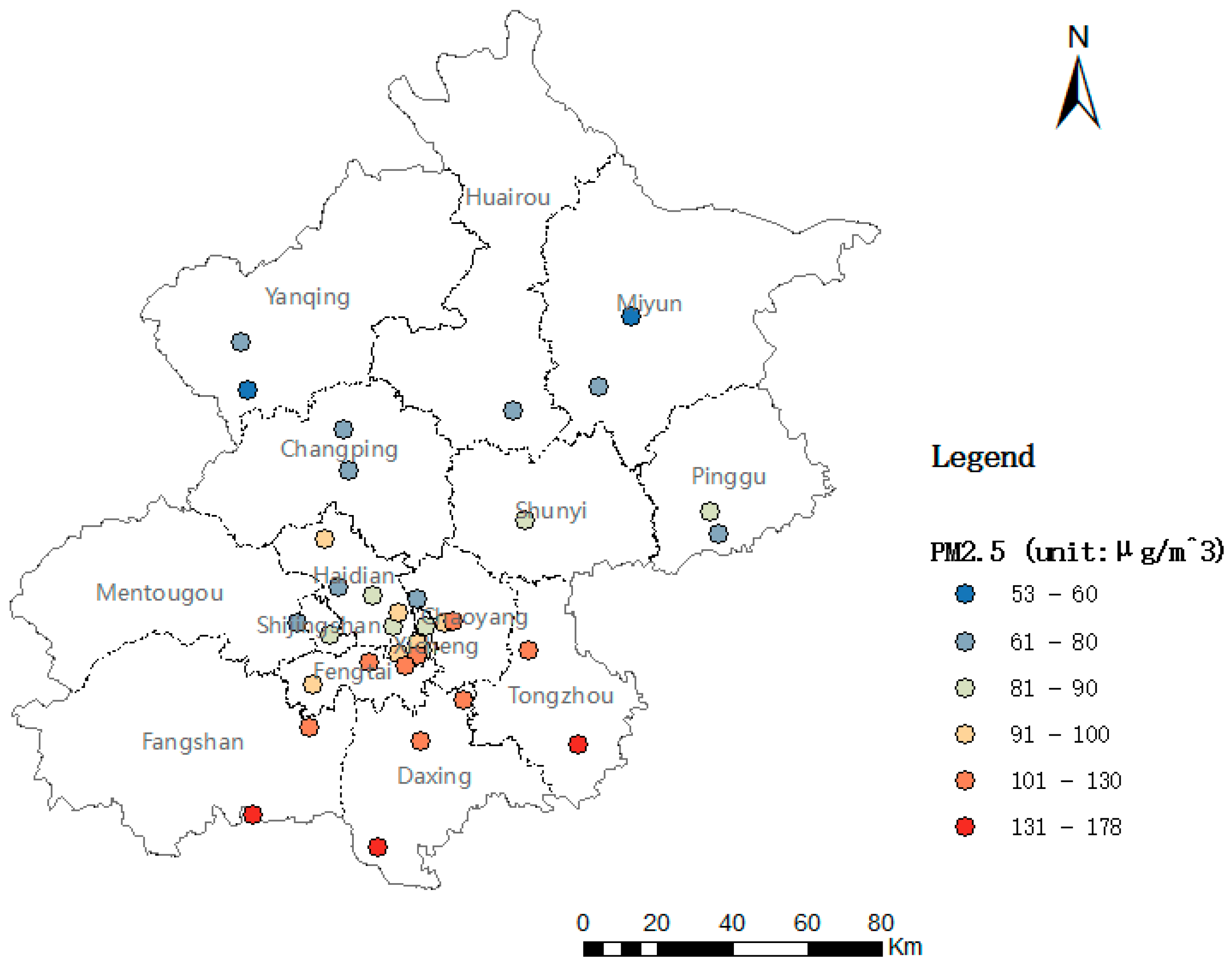
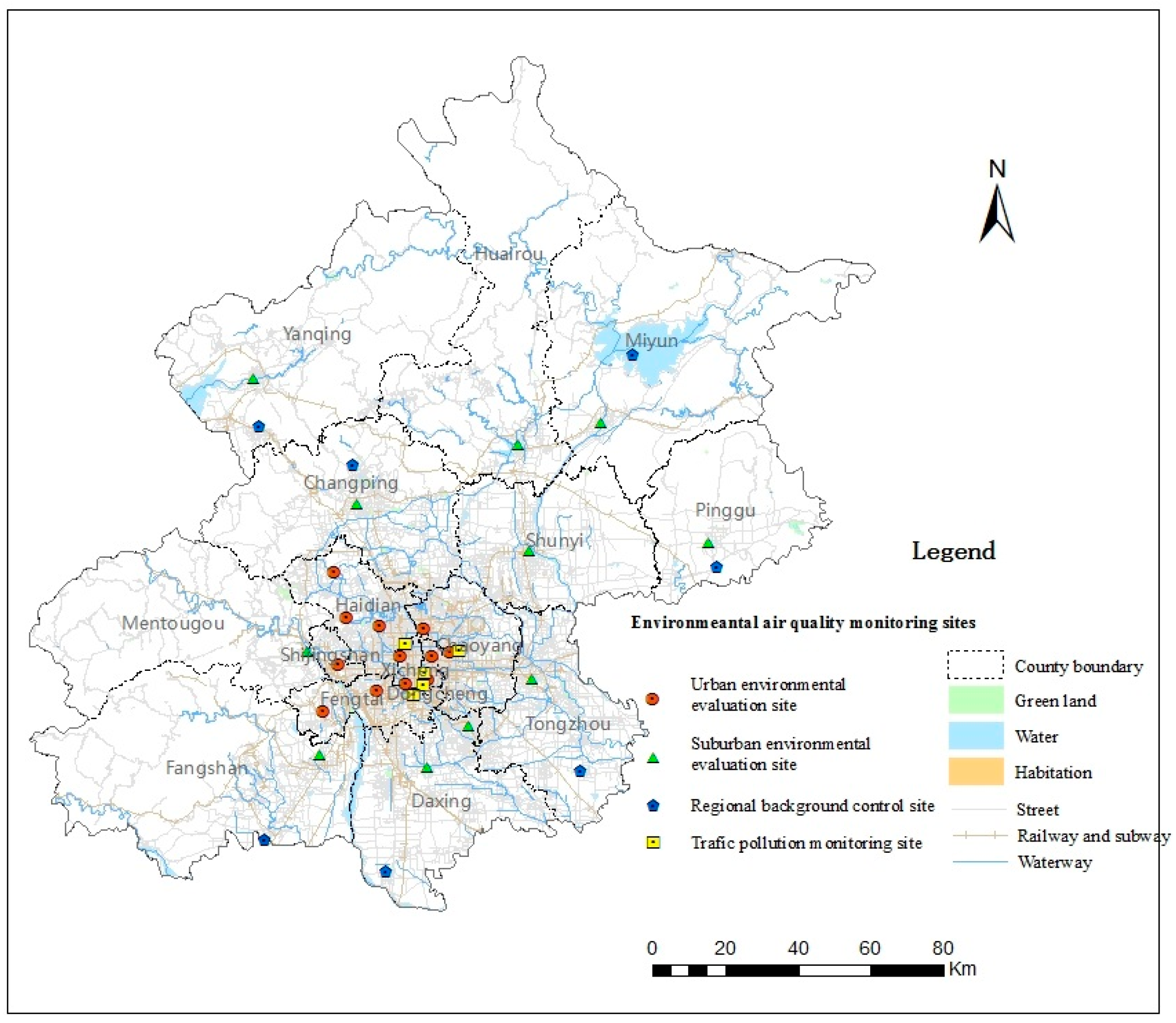
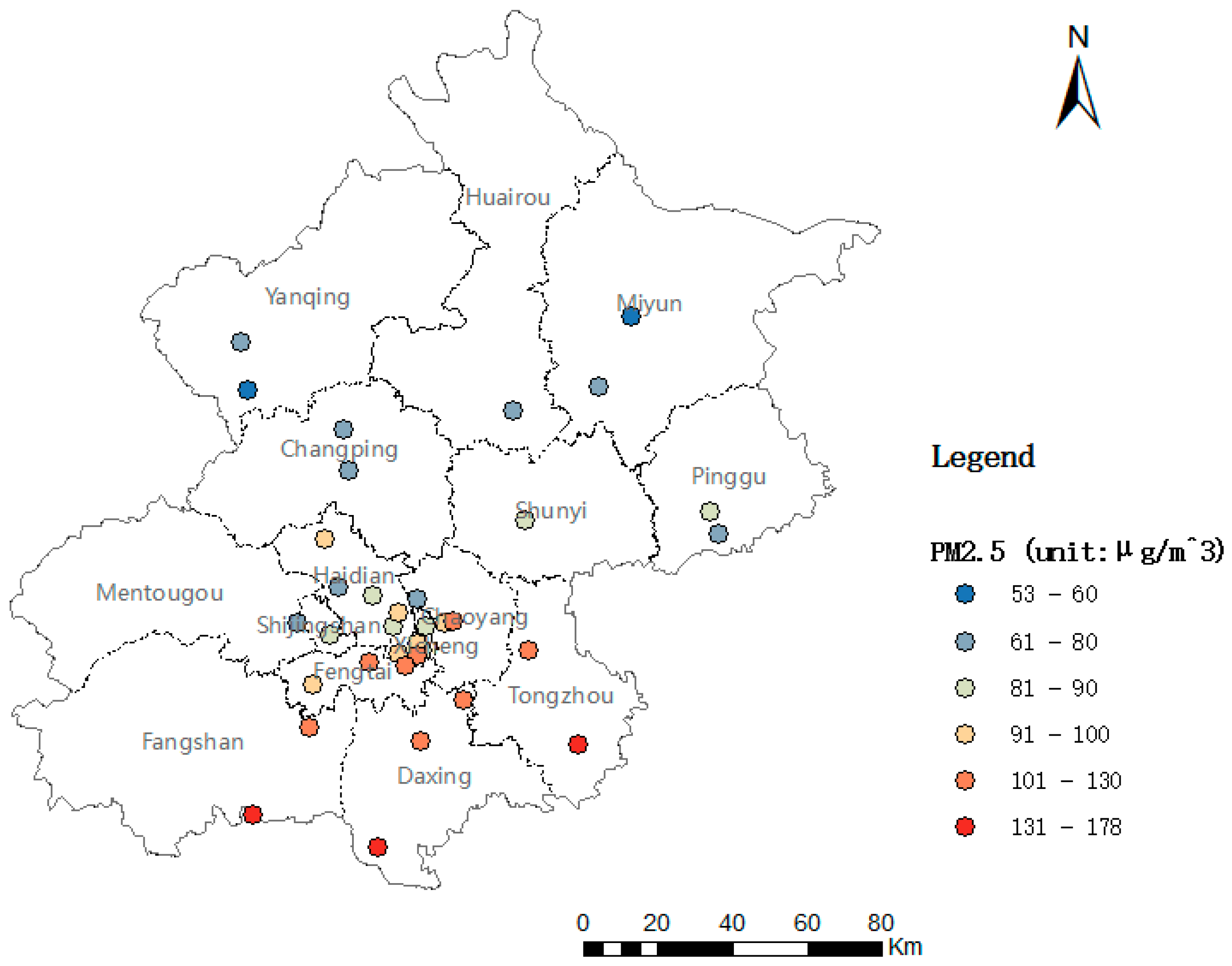
2.2.1. Environmental Pollutant Monitoring Data for PM2.5
2.2.2. Predictor Variables
- (1)
- Land use. Land use data for Beijing were primarily obtained from the latest national census dataset of year 2012 and were classified according to the Chinese National Land Use Classification Standard [46]. After extracting the land use variables for Beijing, it was observed that the main types of land use were farmland, forest land, garden plots, urban land, water, grassland, and roadways. Due to the small roadways and grassland areas, these two types of land use were not considered in this paper. Thus, five predictor variables were used for land class at the area of Beijing: farmland x1, forest land x2, garden plots x3, urban land x4, and water x5.
- (2)
- Terrain. The terrain of Beijing consists of mountains in the northwest and plains in the southeast. Thus, the terrain is more complex in the northwest region of Beijing and less complex in the southeast. Terrain data were obtained from the ASTER GDEM with a resolution of 30 m. For the terrain class, two predictor variables were selected: the average elevation, x6, and the average slope in degrees, x7.
- (3)
- Transportation. The transportation lines in Beijing are more densely located in the center of the city than in the suburbs and include fine street lines x8, railways x9 and water lines x10. Transportation data were obtained from Open Street Map [47], which is an open-source resource.
- (4)
- Population. Demographic data were obtained from the Beijing 2014 statistical yearbook [48]. Based on the different administrative units, the population x11 distribution was used as the main statistic.
- (5)
- Polluting enterprises. Enterprises that release pollutants to the environment are important factors for estimating the environmental pollutant concentrations. Numbers and locations of the polluting enterprises have been obtained from the National Administration for Code Allocation to Organization, and the data were collected in 2012. Based on the national organization code, polluting enterprises can be extracted. The number of polluting enterprises, x12, was selected as the predictor variable for this class.
- (6)
- Points of interest (POIs). As the Open Geospatial Consortium (OGC) defined [49], a “point of interest” (POI) is a location for which information is available. A POI can be as simple as a set of coordinates, a name, and a unique identifier, or more complex. In practice, POIs are usually those places that serve a public function. As such, POIs generally exclude facilities such as private residences, but include many private facilities that seek to attract the general public such as retail businesses, amusement parks, industrial buildings, etc. POI data were primarily obtained from the Open Street Map [49] for the area of Beijing. The number of POIs x13 was selected as the predictor variable for this class.
- (7)
- Distance to the city center. Because most companies and people are distributed in the heart of the city, the distance to the city center x14 from the different monitoring points was selected as a predictor variable.
- (8)
- Buildings. Buildings influence the distribution of people and environmental pollutants. Building data were obtained from Open Street Map [47], and a geometric correction was needed for the source data. The area at the top of building, x15, was used as a predictor variable.
- (9)
- Natural landscape. The natural landscape is different from the land uses discussed above and is defined as the area x16 that has not been affected by human activities. Therefore, area was selected as the predictor variable for this class. Natural landscape information was also collected from Open Street Map [47].
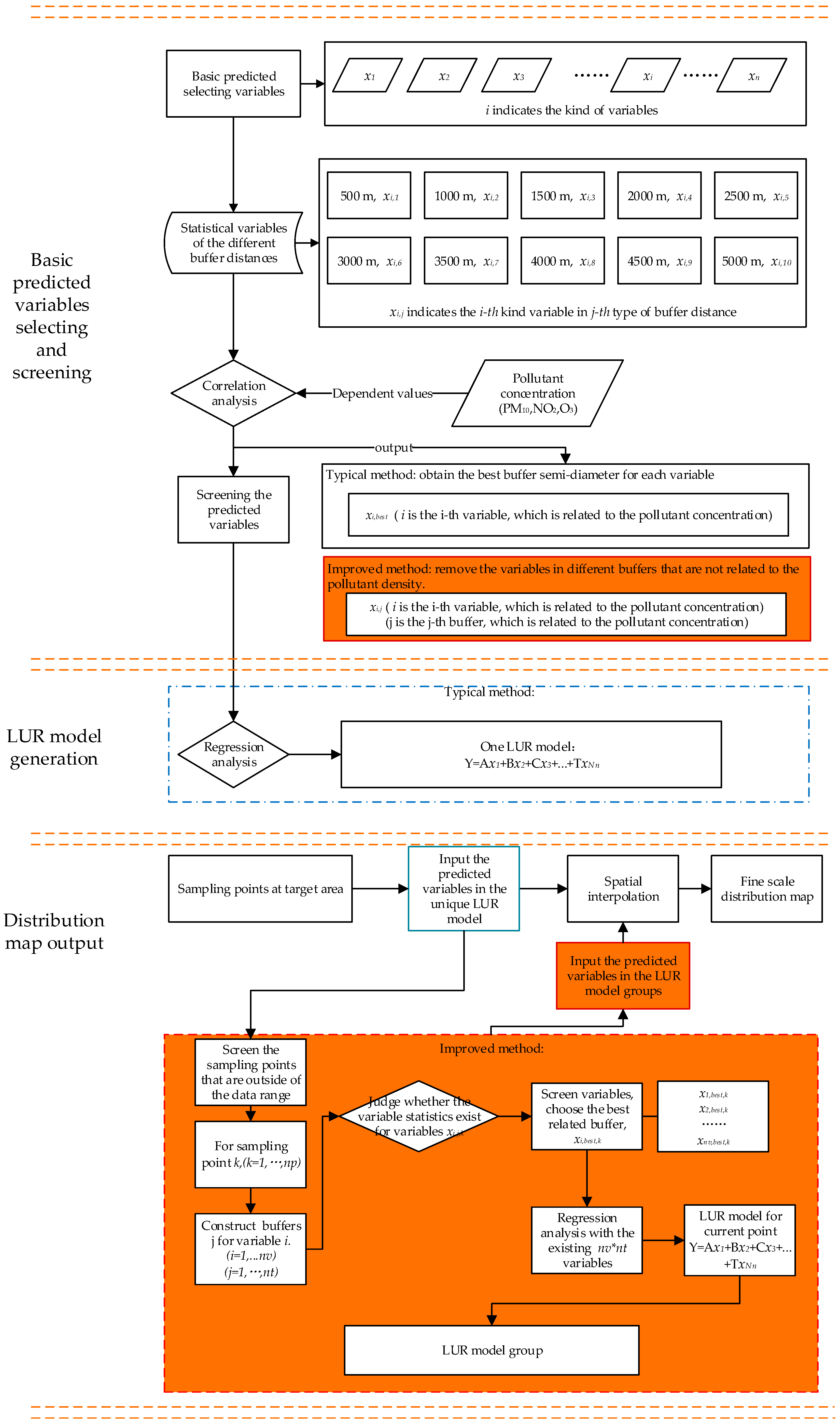
2.3. Self-Adaptive Revised LUR Model
2.3.1. Traditional LUR Model
2.3.2. Self-Adaptive Revised LUR Model
3. Results from the Constructed Self-Adaptive Revised LUR Model for Beijing
3.1. Data Processing and Predictor Variable Screening
3.2. Typical LUR Model Construction and Evaluations of Initial PM2.5 Concentrations
- (1)
- The typical LUR model (which is also called the general LUR model in this paper) was constructed as follows. As shown in Figure 3, after the optimal semi-diameter buffer for each variable has been selected via correlation analysis, the correlation analyses between each two predictor variables should be used to remove the collinear variable based on the rules described in Section 2.2.1. The general LUR model for winter 2014 (the predicted R-squared value is 0.736, the adjusted R-squared value is 0.679 and the p-value of the model is 5.405 × 10−7) is expressed as follows:where x1, x2, … , x16 represent the predictor variable names; the units are shown in Table 3; and Y represents the PM2.5 concentrations in μg/m3.
- (2)
- Initial PM2.5 concentration evaluation
3.3. Self-Adaptive LUR Model Computation
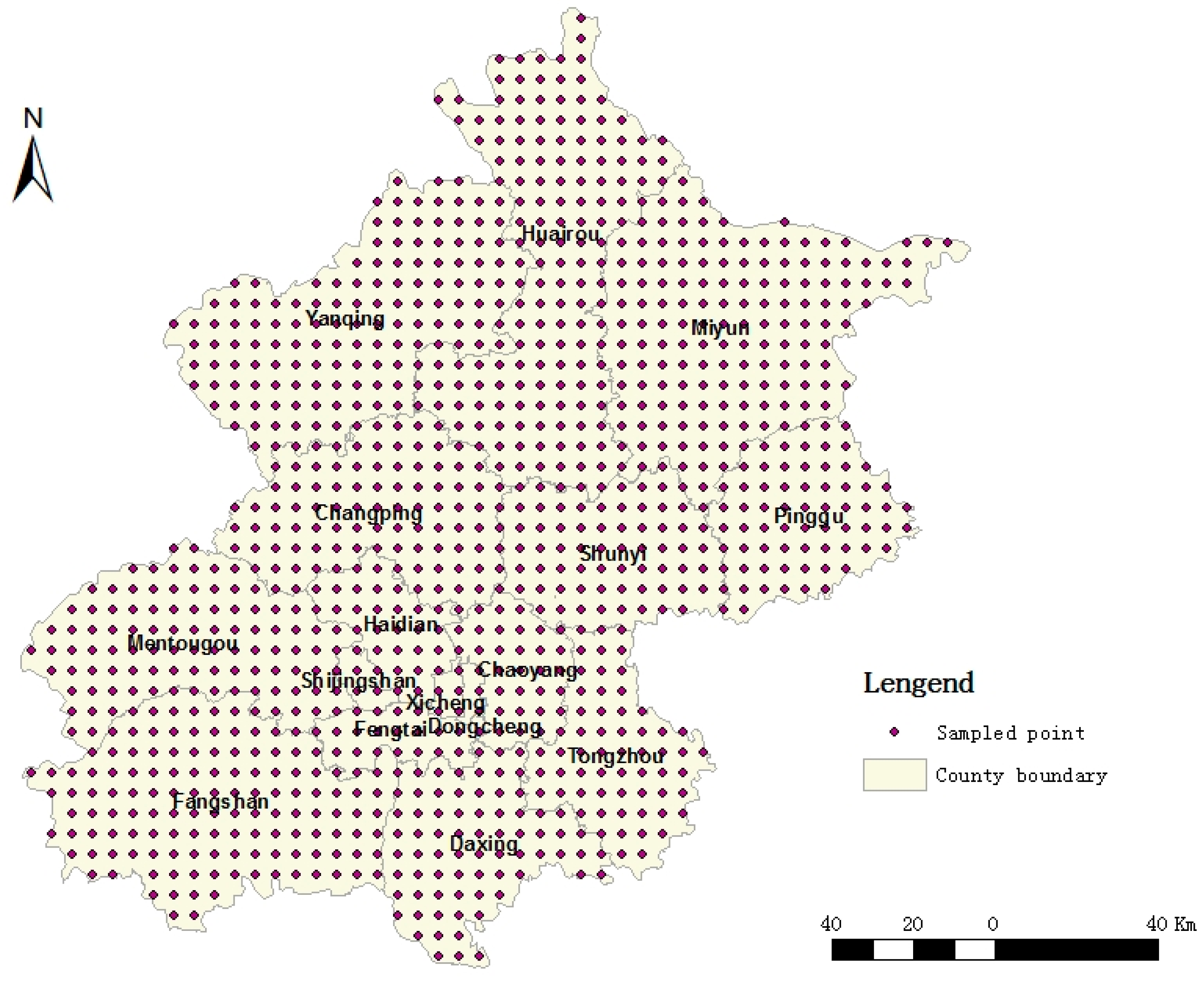
- k represents the sampled points, with a total of 1119 sampled points;
- t represents the monitoring site, with a total of 35 monitoring sites;
- i represents an individual variable (16 variables were considered);
- j represents the buffer, with a total of 10 buffers;
- Sk,i,j represents the value of variable i in buffer j for the sampled point k;
- Xt,i,j represents the value of variable i in buffer j for the monitored site t;
- Xk,i,j represents the value of variable i in buffer j for the out-of-range sampling point k;
- Step 1: define k as the current computation point id, i as the current computation variable id, and j as the current computation buffer id;
- Step 2: define the loop for k with an initial value of 0; if k < 1119, k increases by one;
- Step 3: define the loop for i with an initial value of 0; if i < 16, i increases by one;
- Step 4: define the loop for j with an initial value of 0; if j < 10, j increases by one;
- Step 5: if Sk,i,j equals 0, go step 4; otherwise, go step 6;
- Step 6: find the maximum value of Coi,j as the best related buffer j (i.e., Coi,best); if found, go to step 3 until i = 16; then go to step 7;
- Step 7: compute an array x to store all values of the variables at the 35 monitoring sites using the selected best buffer, i.e., x[i][t] = xt,i,best;
- Step 8: compute the regression coefficients of A,B,C, … T; [Ak,Bk,Ck … Tk] = regress (X[1],X[2], … X[16]), if k = 1119, end; otherwise, go to step 1.
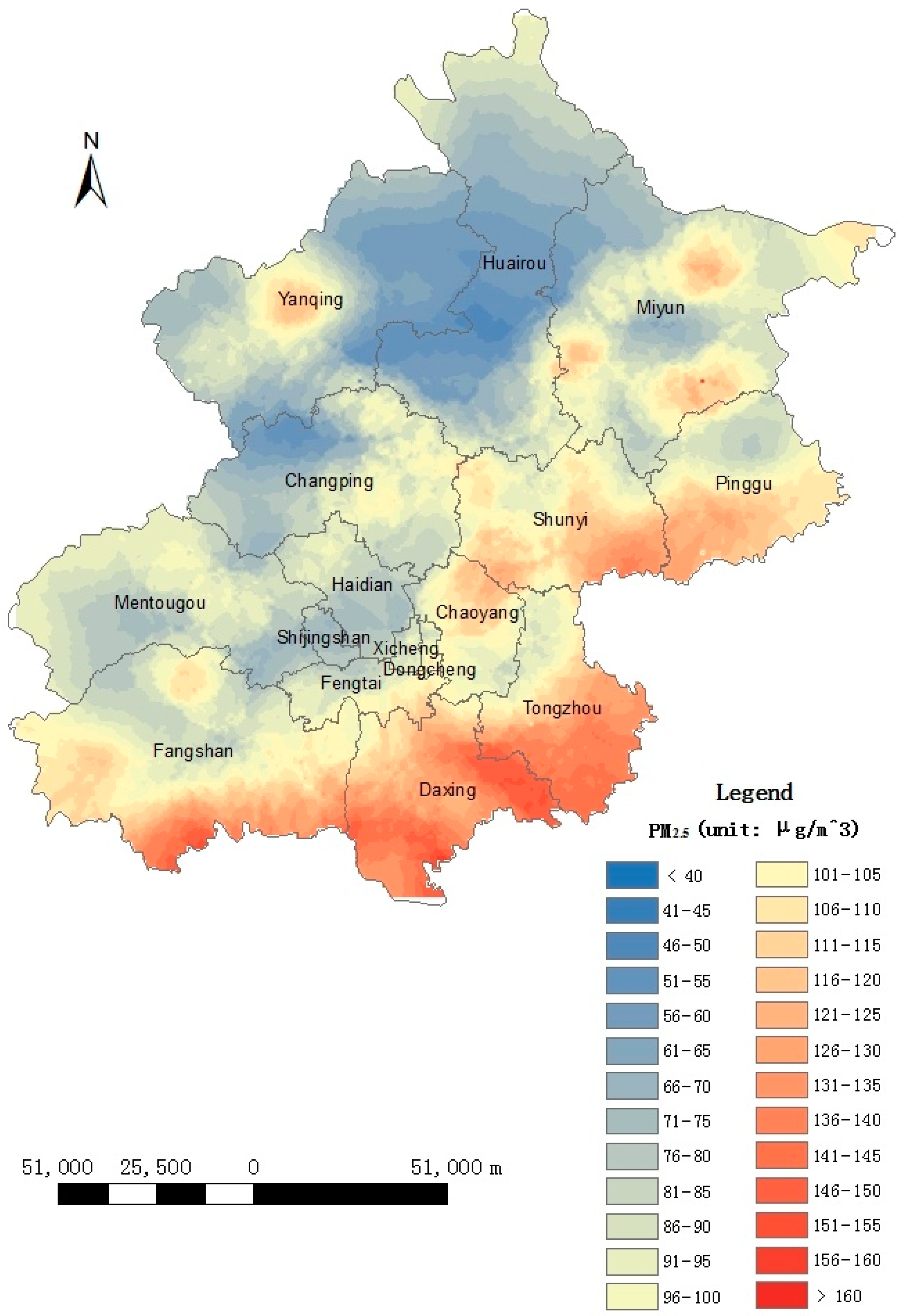
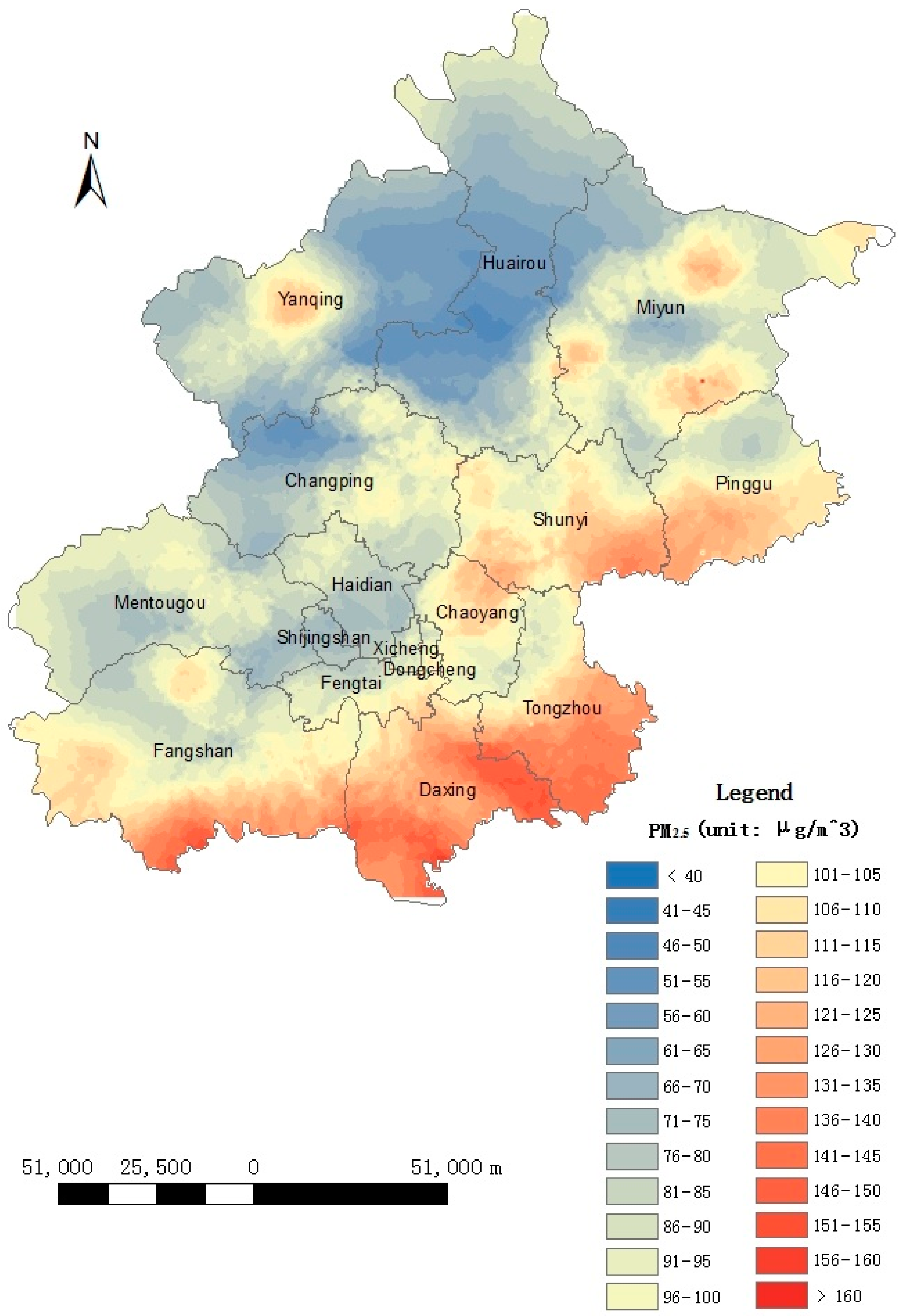
3.4. PM2.5 Map Generation
4. Discussion of the Results
4.1. Accuracy Analysis
4.2. Comparison with the Typical LUR Method
- (1)
- SPER
- (2)
- Accuracy
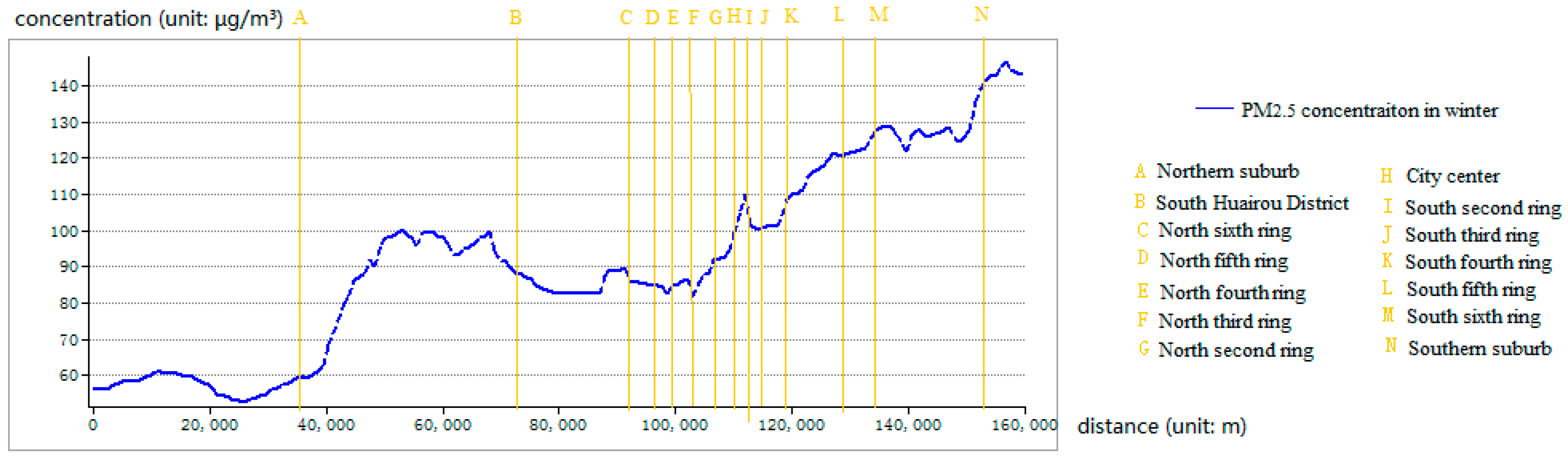
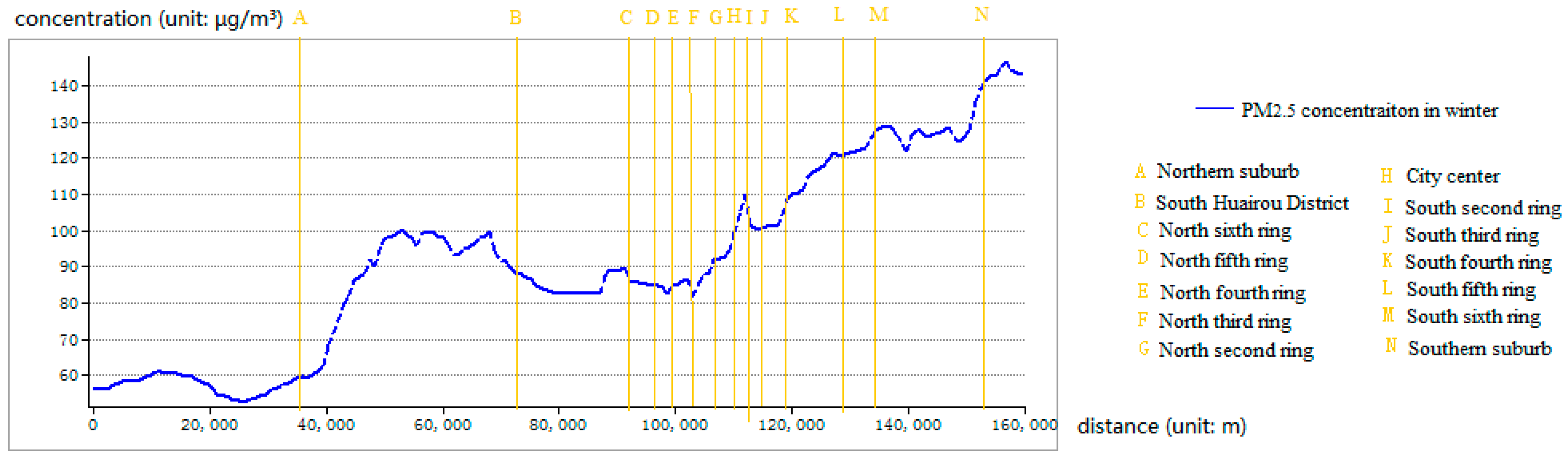
4.3. Spatial Variations of the PM2.5 Concentrations
4.4. Reliability, Superiority, and Limitations of the Revised LUR Model and Future Research
- (1)
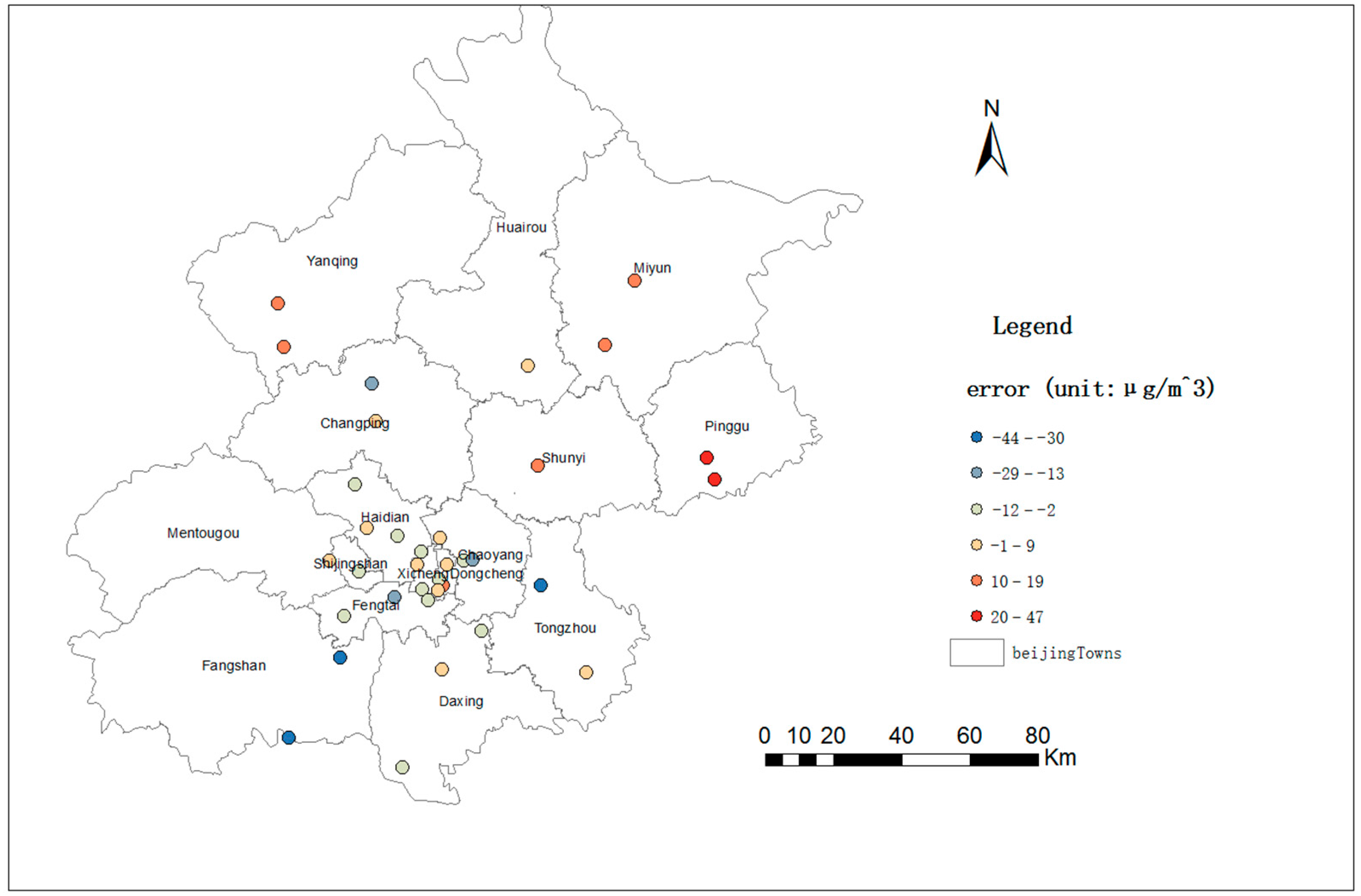
- Reliability of the self-adaptive revised LUR model: The accuracy analysis showed that the overall accuracy is satisfactory, and the analysis of spatial variations in accuracy showed that the accuracy was highest near the city center, which is consistent with the fact that the monitoring sites are concentrated in central Beijing. The spatial variation analysis showed that the PM2.5 concentrations were low to the north, particularly in the northwest region of Beijing, and high in the southern and central regions of Beijing. The spatial variation analysis results were consistent with the fact that the northern region of Beijing is mountainous and contains few people; thus, less transportation is used in this region than in other regions, resulting in reduced pollutant concentrations. In the central region, a high population density and heavy traffic resulted in high pollution levels. Furthermore, the area south and southwest of Beijing, which is adjacent to Hebei province, contains many polluting enterprises. Consequently, high PM2.5 concentrations were found in this region. Therefore, the results are consistent and show the reliability of the self-adaptive revised LUR model. An error distribution map is shown in Figure 8, which is consistent with the results that suburban environmental evaluation sites have low accuracies in Section 4.1. The spatial autocorrelated analysis also showed the errors are not autocorrelated, which increased the reliability of this model.
- (2)
- Superiority of the self-adaptive LUR model: The SPER of the self-adaptive LUR model relative to the typical LUR model increased from 75% to 90%. In addition, the accuracy increased with RMSE from 20.643 μg/m3 to 17.443 μg/m3. Meanwhile, the adjusted R-squared value for the general LUR model was 0.679, and the adjusted R-squared values for the self-adaptive LUR models for the out-of-range sampling points were more than 0.5. Hence, the self-adaptive revised LUR model was superior to the typical LUR model.
- (3)
- Limitations of the self-adaptive LUR model: When the typical LUR model does not result in an SPER of at least 80%, or when negative values are observed in the prediction results, the self-adaptive revised LUR model can be used for improving the SPER and accuracy. If the SPER is at least 90%, the self-adaptive LUR model will not improve the accuracy of the typical LUR model. Thus, if the explanation ability of the model is high and we want to improve the accuracy, the best predictor variables should be chosen because previous studies have indicated that more comprehensive predictor variables result in more accurate final LUR models.
- (4)
- Future work: The effectiveness of the self-adaptive revised LUR model for estimating the PM2.5 concentrations for winter 2014 in Beijing is shown in this study. The presented approach will be effective for estimating the concentrations of other pollutants and other periods (e.g., spring, summer, and autumn of a year) in the future. Furthermore, this method can be used at high spatial scales, such as the national scale, because more sampled points will be outside of the data range, and the self-adaptive revised LUR model will be more effective. However, we used several open-sourced predictor variables. Thus, if possible, more predictor variables (i.e., meteorological data) should be used in future studies.
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Air Quality Expert Group to the Department for Environment. Fine Particulate Matter (PM2.5) in the United Kingdom. Available online: http://UKair.defra.gov.UK/assets/documents/reports/cat11/1212141150_AQEG_Fine_Particulate_Matter_in_the_UK.pdf (accessed on 25 November 2015).
- Martinelli, N.; Olivieri, O.; Girelli, D. Air particulate matter and cardiovascular disease: A narrative review. Eur. J. Intern. Med. 2013, 24, 295–302. [Google Scholar] [CrossRef] [PubMed]
- Fantke, P.; Jolliet, O.; Evans, J.S.; Apte, J.S.; Cohen, A.J.; Hanninen, O.O.; Hurley, F.; Jantunen, M.J.; Jerrett, M.; Levy, J.I.; et al. Health effects of fine particulate matter in life cycle impact assessment: Findings from the Basel Guidance Workshop. Int. J. Life Cycle Assess. 2015, 20, 276–288. [Google Scholar] [CrossRef] [Green Version]
- LUKe, C.; Rea, W.; Smith-Willis, P.; Fenyves, E.; Pan, Y. Adverse health effects of outdoor air pollutants. Environ. Int. 2006, 32, 815–830. [Google Scholar]
- Giorginia, P.; Di Giosia, P.; Grassi, D.; Rubenfire, M.; Brook, R.D.; Ferri, C. Air pollution exposure and blood pressure: An updated review of the literature. Curr. Pharm. Des. 2016, 22, 28–51. [Google Scholar] [CrossRef]
- Wang, M.; Gehring, U.; Hoek, G.; KeUKen, M.; Jonkers, S.; Beelen, R.; Eeftens, M.; Postma, D.S.; Brunekreef, B. Air pollution and lung function in dutch children: A comparison of exposure estimates and associations based on land use regression and dispersion exposure modeling approaches. Environ. Health Perspect. 2015, 123, 847–851. [Google Scholar] [CrossRef] [PubMed]
- Madaniyazi, L.; Nagashima, T.; Guo, Y.M.; Yu, W.W.; Tong, S.L. Projecting fine particulate matter-related mortality in east China. Environ. Sci. Technol. 2015, 49, 11141–11150. [Google Scholar] [CrossRef] [PubMed]
- Dugord, P.A.; Lauf, S.; Schuster, C.; Kleinschmit, B. Land use patterns, temperature distribution, and potential heat stress risk—The case study Berlin, Germany. Comput. Environ. Urban Syst. 2014, 48, 86–98. [Google Scholar] [CrossRef]
- Ito, K.; Kinney, P.L.; Thurston, G.D. Variations in PM10 concentrations within 2 metropolitan-areas and their implications for health-effects analyses. Inhal. Toxicol. 1995, 7, 735–745. [Google Scholar] [CrossRef]
- Hoek, G.; Krishnan, R.M.; Beelen, R.; Peters, A.; Ostro, B.; Brunekreef, B.; Kaufman, J.D. Long-term air pollution exposure and cardio- respiratory mortality: A review. Environ. Health 2013, 12. [Google Scholar] [CrossRef] [PubMed]
- Beelen, R.; Hoek, G.; Raaschou-Nielsen, O.; Stafoggia, M.; Andersen, Z.J.; Weinmayr, G.; Hoffmann, B.; Wolf, K.; Samoli, E.; Fischer, P.H.; et al. Natural-cause mortality and long-term exposure to particle components: An analysis of 19 European cohorts within the multi-center ESCAPE project. Environ. Health Perspect. 2015, 123, 525–533. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beelen, R.; Hoek, G.; Vienneau, D.; Eeftens, M.; Dimakopoulou, K.; Pedeli, X.; Tsai, M.Y.; Kunzli, N.; Schikowski, T.; Marcon, A.; et al. Development of NO2 and NOx land use regression models for estimating air pollution exposure in 36 study areas in Europe—The ESCAPE project. Atmos. Environ. 2013, 72, 10–23. [Google Scholar] [CrossRef]
- Ross, Z.; Ito, K.; Johnson, S.; Yee, M.; Pezeshki, G.; Clougherty, J.E.; Savitz, D.; Matte, T. Spatial and temporal estimation of air pollutants in New York City: Exposure assignment for use in a birth outcomes study. Environ. Health 2013, 12. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Wilhelm, M.; Chung, J.; Ritz, B. Comparing exposure assessment methods for traffic-related air pollution in an adverse pregnancy outcome study. Environ. Res. 2011, 111, 685–692. [Google Scholar] [CrossRef] [PubMed]
- Lakshmanan, A.; Chiu, Y.H.M.; Coull, B.A.; Just, A.C.; Maxwell, S.L.; Schwartz, J.; GryParis, A.; Kloog, I.; Wright, R.J.; Wright, R.O. Associations between prenatal traffic-related air pollution exposure and birth weight: Modification by sex and maternal pre-pregnancy body mass index. Environ. Res. 2015, 137, 268–277. [Google Scholar] [CrossRef] [PubMed]
- Nieuwenhuijsen, M.J.; Basagana, X.; Dadvand, P.; Martinez, D.; Cirach, M.; Beelen, R.; Jacquemin, B. Air pollution and human fertility rates. Environ. Int. 2014, 70, 9–14. [Google Scholar] [CrossRef] [PubMed]
- Krstic, G. A reanalysis of fine particulate matter air pollution versus life expectancy in the United States. J. Air Waste Manag. Assoc. 2013, 63, 133–135. [Google Scholar] [CrossRef] [PubMed]
- Pope, C.A., III; Ezzati, M.; Dockery, D.W. Fine particulate air pollution and life expectancies in the United States: The role of influential observations. J. Air Waste Manag. Assoc. 2013, 63, 129–132. [Google Scholar] [CrossRef] [PubMed]
- Cohen, A.J.; Anderson, H.R.; Ostro, B.; Pandey, K.D.; Krzyzanowski, M.; Kunzli, N.; Gutschmidt, K.; Pope, A.; Romieu, I.; Samet, J.M.; et al. The global burden of disease due to outdoor air pollution. J. Toxicol. Environ. Health A 2005, 68, 1301–1307. [Google Scholar] [CrossRef] [PubMed]
- Mehta, S.; Shin, H.; Burnett, R.; North, T.; Cohen, A.J. Ambient particulate air pollution and acute lower respiratory infections: A systematic review and implications for estimating the global burden of disease. Air Qual. Atmos. Health 2013, 6, 69–83. [Google Scholar] [CrossRef] [PubMed]
- WHO Press (2006) WHO Air Quality Guidelines for Particulate Matter, Ozone, Nitrogen Dioxide and Sulfur Dioxide. World Health Organization. Available online: http://whqlibdoc.who.int/hq/2006/WHO_SDE_PHE_OEH_06.02_eng.pdf (accessed on 25 October 2014).
- Restrictions Announcement of Traffic Management Measures of Beijing Municipal People’s Government on Weekday Peak Areas. Available online: http://zhengwu.Beijing.gov.cn/gzdt/gggs/t1430212.htm (accessed on 5 October 2015).
- Air Quality of Beijing. Available online: http://zx.bjmemc.com.cn/ (accessed on 5 October 2015).
- Beckerman, B.S.; Jerrett, M.; Serre, M.; Martin, R.V.; Lee, S.J.; van Donkelaar, A.; Ross, Z.; Su, J.; Burnett, R.T. A hybrid approach to estimating national scale spatiotemporal variability of PM2.5 in the contiguous United States. Environ. Sci. Technol. 2013, 47, 7233–7241. [Google Scholar] [PubMed]
- Briggs, D.J.; Collins, S.; Elliott, P.; Fischer, P.; Kingham, S.; Lebret, E.; Pryl, K.; Van Reeuwijk, H.; Smallbone, K.; Van Der Veen, A. Mapping urban air pollution using GIS: A regression-based approach. Int. J. Geogr. Inf. Sci. 1997, 11, 699–718. [Google Scholar] [CrossRef]
- Aguilera, I.; Eeftens, M.; Meier, R.; Ducret-Stich, R.E.; Schindler, C.; Ineichen, A.; Phuleria, H.C.; Probst-Hensch, N.; Tsai, M.Y.; Kunzli, N. Land use regression models for crustal and traffic-related PM2.5 constituents in four areas of the SAPALDIA study. Environ. Res. 2015, 140, 377–384. [Google Scholar] [CrossRef] [PubMed]
- Reyes, J.M.; Serre, M.L. An LUR/BME framework to estimate PM2.5 explained by on road mobile and stationary sources. Environ. Sci. Technol. 2014, 48, 1736–1744. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.F.; Lin, H.I.; Ho, C.C.; Yang, T.H.; Chen, C.C.; Chan, C.C. Modeling horizontal and vertical variation in intraurban exposure to PM2.5 concentrations and compositions. Environ. Res. 2014, 133, 96–102. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.C.; Wu, C.F.; Yu, H.L.; Chan, C.C.; Cheng, T.J. Spatiotemporal modeling with temporal-invariant variogram subgroups to estimate fine particulate matter PM2.5 concentrations. Atmos. Environ. 2012, 54, 1–8. [Google Scholar] [CrossRef]
- Hankey, S.; Marshall, J.D. Land use regression models of on-road particulate air pollution (particle number, black carbon, PM2.5, particle size) using mobile monitoring. Environ. Sci. Technol. 2015, 49, 9194–9202. [Google Scholar] [CrossRef] [PubMed]
- Saraswat, A.; Apte, J.S.; Kandlikar, M.; Brauer, M.; Henderson, S.B.; Marshall, J.D. Spatiotemporal land use regression models of fine, ultrafine, and black carbon particulate matter in New Delhi, India. Environ. Sci. Technol. 2013, 47, 12903–12911. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Beelen, R.; Basagana, X.; Becker, T.; Cesaroni, G.; de Hoogh, K.; Dedele, A.; Declercq, C.; Dimakopoulou, K.; Eeftens, M.; et al. Evaluation of land use regression models for NO2 and particulate matter in 20 European study areas: The ESCAPE project. Environ. Sci. Technol. 2013, 47, 4357–4364. [Google Scholar] [CrossRef] [PubMed]
- Vienneau, D.; de Hoogh, K.; Bechle, M.J.; Beelen, R.; van Donkelaar, A.; Martin, R.V.; Millet, D.B.; Hoek, G.; Marshall, J.D. Western European land use regression incorporating satellite- and ground-based measurements of NO2 and PM10. Environ. Sci. Technol. 2013, 47, 13555–13564. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Li, X.D.; Chen, Z.; Zeng, G.M.; Leon, T.; Liang, J.; Huang, G.H.; Gao, Z.H.; Jiao, S.; He, X.X.; et al. Land use regression models coupled with meteorology to model spatial and temporal variability of NO2 and PM10 in Changsha, China. Atmos. Environ. 2015, 116, 272–280. [Google Scholar] [CrossRef]
- Kerckhoffs, J.; Wang, M.; Meliefste, K.; Malmqvist, E.; Fischer, P.; Janssen, N.A.H.; Beelen, R.; Hoek, G. A national fine spatial scale land-use regression model for ozone. Environ. Res. 2015, 140, 440–448. [Google Scholar] [CrossRef] [PubMed]
- Molter, A.; Lindley, S.; de Vocht, F.; Simpson, A.; Agius, R. Modelling air pollution for epidemiologic research—Part i: A novel approach combining land use regression and air dispersion. Sci. Total Environ. 2010, 408, 5862–5869. [Google Scholar] [CrossRef] [PubMed]
- De Hoogh, K.; Korek, M.; Vienneau, D.; Keuken, M.; Kukkonen, J.; Nieuwenhuijsen, M.J.; Badaloni, C.; Beelen, R.; Bolignano, A.; Cesaroni, G.; et al. Comparing land use regression and dispersion modelling to assess residential exposure to ambient air pollution for epidemiological studies. Environ. Int. 2014, 73, 382–392. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.L.; Wang, C.H.; Liu, M.C.; Kuo, Y.M. Estimation of fine particulate matter in Taipei using landuse regression and bayesian maximum entropy methods. Int. J. Environ. Res. Public Health 2011, 8, 2153–2169. [Google Scholar] [CrossRef] [PubMed]
- Fischer, P.H.; Marra, M.; Ameling, C.B.; Hoek, G.; Beelen, R.; de Hoogh, K.; Breugelmans, O.; Kruize, H.; Janssen, N.A.H.; Houthuijs, D. Air pollution and mortality in seven million adults: The dutch environmental longitudinal study (DUELS). Environ. Health Perspect. 2015, 123, 697–704. [Google Scholar] [CrossRef] [PubMed]
- Ryan, P.H.; LeMasters, G.K. A review of land-use regression for characterizing intraurban air models pollution exposure. Inhal. Toxicol. 2007, 19, 127–133. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.S.; Li, J.C.; Peng, J.; Li, W.F.; Xu, G.; Dong, C.C. Applying land use regression model to estimate spatial variation of PM2.5 in Beijing, China. Environ. Sci. Pollut. Res. 2015, 22, 7045–7061. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.H.; Wu, C.F.; Hoek, G.; de Hoogh, K.; Beelen, R.; Brunekreef, B.; Chan, C.C. Lur models for particulate matters in the Taipei metropolis with high densities of roads and strong activities of industry, commerce and construction. Sci. Total Environ. 2015, 514, 178–184. [Google Scholar] [CrossRef] [PubMed]
- Carter, E.M.; Shan, M.; Yang, X.D.; Li, J.R.; Baumgartner, J. Pollutant emissions and energy efficiency of Chinese gasifier cooking stoves and implications for future intervention studies. Environ. Sci. Technol. 2014, 48, 6461–6467. [Google Scholar] [CrossRef] [PubMed]
- National Bureau of Technical Supervision of the People’s Republic of China, GB3095-2012. Ambient Air Quality Standards; Chinese Standard Press: Beijing, China, 2013.
- National Bureau of Technical Supervision of the People’s Republic of China, HJ633-2012. Technical Regulation on Ambient Air Quality Index (on Trial); Chinese Standard Press: Beijing, China, 2013.
- National Bureau of Technical Supervision of the People’s Republic of China, 21010-2007, G.T. Current Land Use Classification Standard; Chinese Standard Press: Beijing, China, 2007.
- Openstreetmap Geofabrik Downloads. Available online: http://download.geofabrik.de/ (accessed on 5 October 2015).
- Beijing statistics Bureau. Beijing Statistical Yearbook of 2014; China Statistic Press: Beijing, China, 2014.
- Points of Interest SWG. Available online: http://www.opengeospatial.org/projects/groups/poiswg (accessed on 15 May 2016).
- Zou, B.; Luo, Y.Q.; Wan, N.; Zheng, Z.; Sternberg, T.; Liao, Y.L. Performance comparison of LUR and OK in PM2.5 concentration mapping: A multidimensional perspective. Sci. Rep. 2015, 5. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Variable Type | Predicted Variable Name | Unit |
|---|---|---|
| Land use | Cropland | Area (unit: m2) |
| Forest land | Area (unit: m2) | |
| Garden plots | Area (unit: m2) | |
| Urban land | Area (unit: m2) | |
| Water | Area (unit: m2) | |
| Terrain | Mean elevation | Height (unit: m) |
| Mean slope degree | Angle (unit: degree) | |
| Transport | Street | Length (unit: m) |
| Railway and subway | Length (unit: m) | |
| Waterway | Length (unit: m) | |
| Population | Population | number |
| Polluting enterprise | Polluting enterprise | number |
| Point of interest | Point of interest | number |
| Distance to city center | Distance to city center | Length (unit: m) |
| Buildings | Buildings | Area (unit: m2) |
| Natural landscape | Natural landscape | Area (unit: m2) |
| Variable Type | Buffer Semi-Diameter | 500 m (j = 1) | 1000 m (j = 2) | 1500 m (j = 3) | 2000 m (j = 4) | 2500 m (j = 5) | 3000 m (j = 6) | 3500 m (j = 7) | 4000 m (j = 8) | 4500 m (j = 9) | 5000 m (j = 10) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Land use | Cropland (i = 1) | 0.632 | 0.641 | 0.592 | 0.531 | 0.486 | 0.446 | 0.418 | 0.389 | 0.373 | 0.348 |
| Forest land (i = 2) | -- | −0.355 | −0.385 | −0.387 | −0.393 | −0.413 | −0.434 | −0.452 | −0.467 | −0.479 | |
| Garden plots (i = 3) | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | |
| Urban land (i = 4) | -- | -- | 0.424 | -- | -- | -- | -- | -- | -- | -- | |
| Water (i = 5) | -- | -- | −0.324 | −0.332 | −0.334 | −0.334 | −0.329 | −0.324 | -- | -- | |
| Terrain | Mean Elevation (i = 6) | −0.326 | −0.341 | −0.348 | −0.352 | −0.358 | −0.364 | −0.368 | −0.373 | −0.379 | −0.383 |
| Mean slope (i = 7) | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | |
| Transport | Street (i = 8) | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- |
| Railway and subway (i = 9) | -- | -- | -- | 0.428 | -- | -- | -- | -- | -- | -- | |
| Waterway (i = 10) | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | |
| Population (i = 11) | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | |
| Polluting enterprise (i = 12) | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | |
| Point of interest (i = 13) | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | |
| Distance to city center (i = 14) | −0.633 | ||||||||||
| Buildings (i = 15) | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | |
| Natural landscape (i = 16) | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | |
| Predictor Variable | Predictor Variable Name (Unit) | Best Buffer Semi-Diameter | Correlation Coefficient | p-Value |
|---|---|---|---|---|
| Land use | Urban land x1 (m2) | -- | -- | -- |
| Cropland x2 (m2) | 1000 | 0.641 | 0.000 | |
| Forest x3 (m2) | 5000 | −0.479 | 0.004 | |
| Garden plots x4 (m2) | -- | -- | -- | |
| Water x5 (m2) | 3000 | −0.334 | 0.049 | |
| Terrain | Elevation x6 (m) | 5000 | −0.383 | 0.023 |
| Slope x7 (degree) | -- | -- | -- | |
| Transport | Street x8 (m) | -- | -- | -- |
| Railway and subway x9 (m) | 2000 | 0.428 | 0.010 | |
| Waterway x10 (m) | -- | -- | -- | |
| Population | Population x11 (people) | -- | -- | -- |
| Polluted enterprises | Polluted enterprises x12 (number) | -- | -- | -- |
| POI | POI x13 (number) | -- | -- | -- |
| Distance to city center | Distance to city center x14 (m) | -- | −0.633 | 0.00 |
| Buildings | Buildings x15 (m2) | -- | -- | -- |
| Natural landscape | Natural landscape x16 (m2) | -- | -- | -- |
| Error | ME (μg/m3) | RMSE (μg/m3) | SD (μg/m3) | MER (%) |
|---|---|---|---|---|
| Self-adaptive LUR models (Final map accuracy) | 1.296 | 17.443 | 17.395 | 14.658 |
| Typical model (Final map accuracy) | 9.982 | 20.643 | 18.069 | 19.488 |
| Typical model (LOO cross validation) | 1.438 | 24.7389 | 24.6971 | 21.365 |
| Monitoring Sites in the Different Regions | ME (μg/m3) | RMSE (μg/m3) | SD (μg/m3) | MER (%) | |
|---|---|---|---|---|---|
| Urban environmental evaluation site | Self-adaptive LUR models | 0.768 | 11.897 | 11.873 | 10.598 |
| Typical model | 13.414 | 17.546 | 11.311 | 17.147 | |
| Suburban environmental evaluation site | Self-adaptive LUR models | 5.070 | 18.748 | 18.050 | 17.475 |
| Typical model | 12.600 | 19.792 | 15.263 | 20.369 | |
| Regional background control site | Self-adaptive LUR models | 1.243 | 25.946 | 25.916 | 23.004 |
| Typical model | −2.112 | 28.639 | 28.561 | 26.371 | |
| Traffic pollution monitoring site | Self-adaptive LUR models | −5.666 | 8.629 | 6.508 | 6.526 |
| Typical model | 12.914 | 15.298 | 8.201 | 13.535 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, L.; Liu, J.; He, Z. Self-Adaptive Revised Land Use Regression Models for Estimating PM2.5 Concentrations in Beijing, China. Sustainability 2016, 8, 786. https://doi.org/10.3390/su8080786
Hu L, Liu J, He Z. Self-Adaptive Revised Land Use Regression Models for Estimating PM2.5 Concentrations in Beijing, China. Sustainability. 2016; 8(8):786. https://doi.org/10.3390/su8080786
Chicago/Turabian StyleHu, Lujin, Jiping Liu, and Zongyi He. 2016. "Self-Adaptive Revised Land Use Regression Models for Estimating PM2.5 Concentrations in Beijing, China" Sustainability 8, no. 8: 786. https://doi.org/10.3390/su8080786