1. Introduction
With the increasing attention on global warming and climate change, energy-efficient scheduling is becoming an important objective in the process of production [
1]. Since about one-half of energy consumption is industrial [
2], the reduction of the energy consumption in the manufacturing process is a global concern. Two methods are often used to reduce energy consumption: developing power-efficient machines [
3,
4] and designing energy-saving manufacturing system frameworks [
5,
6]. After long-term endeavors, the first method has maintained a good momentum on the single equipment with manufacturing process improvement, material savings, and waste reduction [
7,
8,
9]. As for the second method, energy-saving through optimization the manufacturing system faces great challenges due to changeable market demand, diversified product structure, and flexible processing routes [
10,
11,
12], as well as insufficient accurate data of energy consumption [
13,
14], so researchers still struggle to break down these technical and theoretical barriers.
With respect to the energy-efficient scheduling, the well-known machine turn-on and turn-off scheduling framework has been proposed by Mouzon et al. [
15] and further explored by Mouzon and Yildirim [
16]. Then Dai et al. [
17] applied this framework to the flexible flow shop scheduling problem, and Tang et al. [
18] adopted it to solve an energy-efficient dynamic scheduling. Since some machines and appliances cannot be switched off during the manufacturing process in some workshops [
19], a new method of speed scaling framework has been developed by Fang et al. [
20]. Under this framework, Fang et al. [
20] researched a flow shop scheduling problem with a restriction on peak power consumption, and Liu and Huang [
21] studied a batch-processing machine scheduling problem and a hybrid flow shop problem.
The turning workshop typically involves two processes, i.e., rough turning and fine turning, and each process usually can be completed at any one of parallel lathes, and thus the ordinary turning workshop can be regarded as the flexible flow shop. Salvador [
22] originally has proposed the flexible flow shop scheduling problem (FFSP) in oil industry, and this problem is also known as hybrid flow shop scheduling problem (HFSP) [
23]. For traditional optimization of the flexible flow shop scheduling, Linn and Zhang [
24] pointed out that HFSP is a non-deterministic polynomial (NP) problem after they reviewed computational complexities, scheduling objectives, and solving methods. Aiming at solving the NP problem, Kis and Pesch [
25] put forward a method to determine the lower bounds, and they also developed a new branch and bound method which is faster than the method of Azizoglu et al. [
26]. However, for large-scale scheduling problems, these optimal methods are inefficient due to high demand for computational time and storage space. Therefore, a lot of heuristics and meta-heuristics were put forward, such as the NEH algorithm [
27], Palmer algorithm [
28], CDS algorithm [
29], and genetic algorithm [
30]. More new methods were developed, including artificial immune algorithm [
31], particle swarm optimization algorithm (PSO) [
32], water-flow algorithm [
33], quantum-inspired immune algorithm [
34], iterated greedy algorithm [
35], and intelligent hybrid meta-heuristic [
36].
To our best knowledge, most researchers study process parameters and scheduling schemes in turning processing separately except for the work of Lin et al. [
37], who proposed a two-stage optimization method to successively find out the optimum process parameters and scheduling scheme for the single-machine scheduling in a turning shop. Obviously, more mathematic models and more methods targeting at the synchronous optimization are necessary to be developed. Aiming at this target, this paper approaches the energy-efficient scheduling of the flexible flow shop in the following ways. First, a mixed integer nonlinear programming model of the energy-efficient scheduling is established and this model can be solved with a GAMS/Dicopt solver. Second, a new decoding method is proposed and integrated into the estimation of distribution algorithm (EDA) to solve the problem, which is an effective and promising algorithm based on the statistical learning theory. Thirdly, the model and EDA are verified in a real case.
The paper is organized as follows. In
Section 2, research problem and energy consumption of lathes in the turning process are analyzed in detail. In
Section 3, the mixed integer programming nonlinear model of the research problem is put forward.
Section 4 presents a new decoding method and adopts an estimation of distribution algorithm to solve the energy-efficient scheduling. The verification of the model and algorithm is reported in
Section 5, and conclusions are arrived in
Section 6.
3. Modeling
From the Equation (11), we can find that the energy consumption for completing a turning operation is inversely proportional to the spindle speed. From Equation (2), we can also find that the completion time is an inverse function of the spindle speed, so the weighted method is suitable for dealing with the two objectives of energy consumption and makespan. Considering this multi-objective optimization problem, the complexity of weighted method is lower than that of Pareto non-dominated method. In the scheduling optimization, except for spindle speeds, all processing parameters are known and certain. Therefore, optimization variables are machine allocation, job sequence, and spindle speed. The presented formulation is based on the following assumptions. Firstly, all of the n jobs and m machines are available for processing at the initial time. Secondly, one machine can process only one job at a time and one job can be processed by only one machine at a time. Thirdly, the spindle speed must be selected among several alternative levels.
Indices
| i | Index of jobs, |
| j | Index of stages, |
| k | Index of machines, |
| t | Index of event points, |
| l | Index of spindle speed levels, |
Parameters
| Set of machines in stage j |
| Set of spindle speed levels where job i can be processed on machine k |
| Mv | Positive constant large enough |
| Spindle speed of machine k at level l |
| Total removed volume for Oik |
| Depth of cutting for Oik |
| fik | Feed rate for Oik |
| Semi-product diameter for Oik |
| Coefficients of cutting force for Oik |
| Coefficients of cutting force for Oik |
| Power consumption for starting machine for Oik |
| Power consumption for stopping machine for Oik |
| Power of machine k running without load at speed level l |
| Transport time between machine k and machine k’ |
| Additional load loss coefficient of machine k |
| Weight of energy consumption |
| TCE0 | Normalizing parameter of energy consumption |
| Cmax0 | Normalizing parameter of makespan |
Binary Variables
Positive Variables
| Start time of the event t at machine k |
| Finish time of the event t at machine k |
| Maximum completion time, i.e., makespan |
| Energy consumption |
3.1. Mathematical Model
Equation (12) is the objective function to minimize the normalized total energy consumption and makespan simultaneously, where is the weight of energy consumption obtained by such methods as the analytical hierarchy process (AHP), and fuzzy clustering method after investigating the preference of management. TCE0 and Cmax0, are applied as two normalizing parameters, and they are obtained by a heuristic rule in this paper. Equations (13) and (14) both ensure each job is processed once at any stage. Equation (15) ensures that one of the available spindle speeds is selected when a job is assigned to a machine. Equation (16) controls that, at most, one job is processed in an event point. Equation (17) controls that one machine is available at an event point only after its previous jobs are completed. Equation (18) ensures the completion time of an event point is equal to the sum of the start time and processing time. Equation (19) limits that the starting time of each job in any stage is at least equal to the total time of the completion time in the previous stage and the transport time. Equation (20) controls that the completion time of any event point on a machine is at most equal to the start time of the subsequent event point on the same machine. Equation (21) ensures that TCE is the summation of energy consumption of all turning operations. Equation (22) controls that the Cmax is greater than or equal to the completion times of the last event point on all machines.
3.2. Heuristic Rule for Normalizing Parameters
As pointed out above, normalizing parameters
TCE0 and
Cmax
0 are obtained by the heuristic rule, which can be described as follows.
Step 1: The theoretical linear cutting velocity is calculated with Equation (23), the theoretical spindle speed is obtained with Equation (8), and then the real level of spindle speed noted as l* is determined according to machine operating instructions.
Step 2: The total processing time of one turning operation (
) is calculated by Equation (2), the average processing time (
) of job
i in all stages is calculated with Equation (24), and then the scheduling scheme is obtained by the following three-step circulation.
Step 2.1: Set j = 1 and sequence jobs by the ascending order of , denote the sequence as and set .
Step 2.2: Assign the first free machine noted as to process jobs in stage j, and calculate the completion time of jobs according to Equation (25). Then, calculate the consumed energy for cutting each job in stage j with Equation (11), and calculate the total energy consumption of stage j by .Terminate this circulation when stage j is the last stage or go on to step 2.3.
Step 2.3: Reorder jobs and update in the ascending order of , then set j = j + 1 and return to step 2.2.
Step 3: TEC0 can be obtained by
, and
can be determined by
. Detailed explanations are described with Equations (23)–(25)
In Equation (23), is the theoretical linear cutting speed of job i on the machine k, is the depth of cutting, is the feed rate, is the durability coefficient of cutting tool, T is the durability of cutting tool, and , , are coefficients whose values are set according to the processed materials and conditions. In Equations (24) and (25), is the total processing time of job i processed on machine k at spindle speed level l, S is the number of stages, mj is the number of parallel machines in stage j, and Kj is the set of machines.
The above model of can be solved accurately by the GAMS/Dicopt solver for small-scale problems, but the solver will fail for large-size problems due to limited computer memory and a long running time. Therefore, it is necessary to develop efficient intelligent algorithms to assign parallel machines, select optimal spindle speeds, and sequence jobs simultaneously.
4. EDA Algorithm
The estimation of distribution algorithm (EDA) is a population evolutionary algorithm based on probabilistic model [
44,
45,
46], which guides the population evolution utilizing the probability of the dominant individuals. This algorithm employs the statistical probability to describe the distribution of solutions, and generates new populations by sampling probability. A large number of research groups have paid efforts to improve the performance of EDA algorithm [
47,
48,
49]. The algorithm has been successfully applied to solve flow shop scheduling problems [
50,
51,
52] and flexible flow shop scheduling problems, and it has obtained promising scheduling results. For its advantages, EDA is used to solve the energy-efficient scheduling problems in flexible flow shops in this paper. A novel decoding method is developed to optimize machine allocation, speed selection, and job sequence.
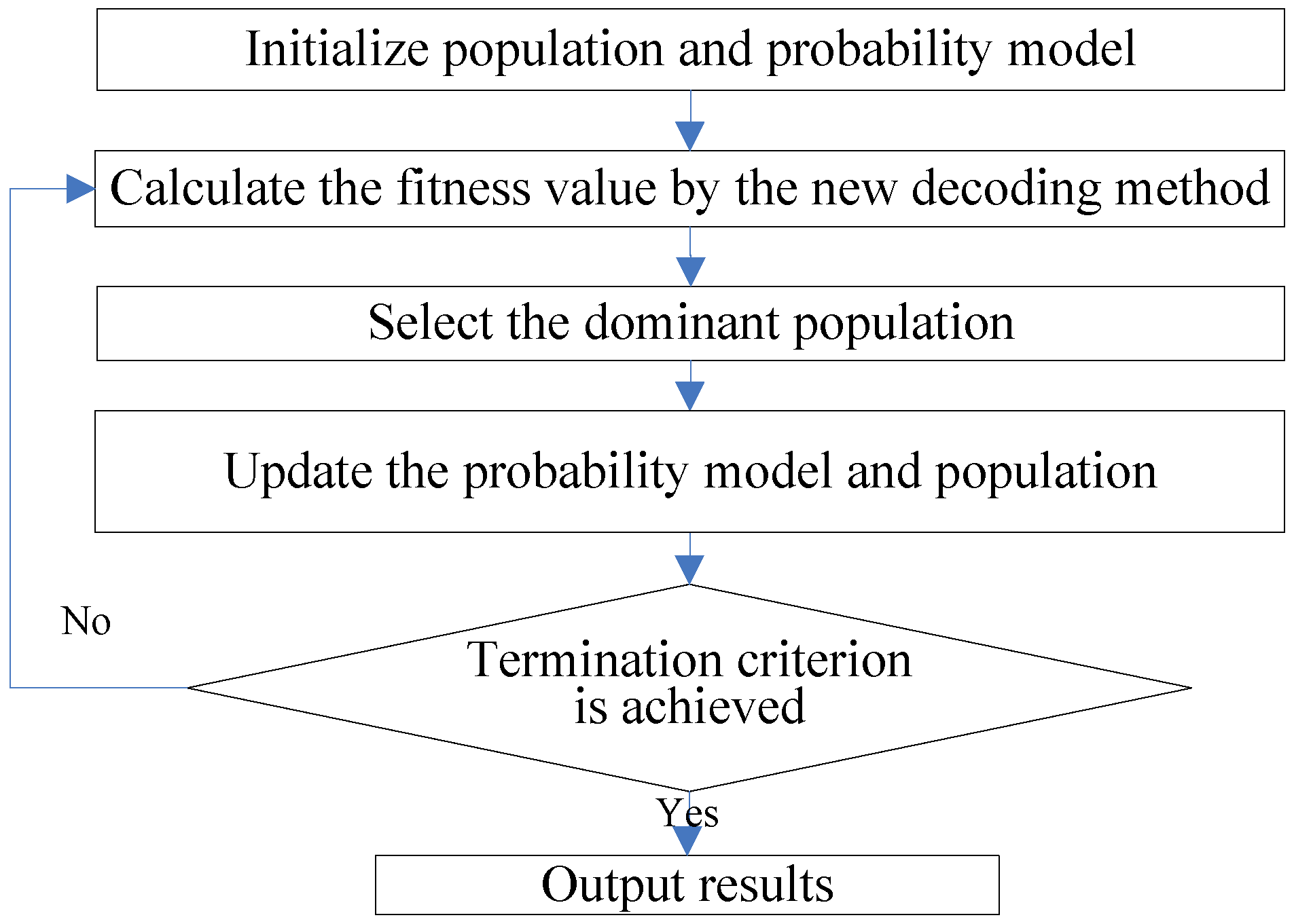
As for the process of EDA, the initialized population is randomly generated first, and the dominant individuals are selected according to their fitness. Then, the probability model is constructed from the dominant individuals to generate new ones. After the new population is generated, the termination criterion works to determine whether to stop this algorithm or not. This process is depicted in
Figure 2.
4.1. Encoding, Decoding, and Dominant Individuals
The frequently utilized encoding method for solving FFSP is the arrangement-based encoding approach, in which only job sequence in the first stage is encoded and the jobs in the next stages are sorted according to dispatching rules like FCFS and SPT. Suppose that there are four jobs with an examplified code of [1 3 4 2], the first job is firstly processed and the third job is processed secondly. This encoding approach is simple to understand and complement, and thus is applied in this paper.
In regard to the population initialization, we adopt the random initialization method to ensure the population diversity. The computational complexity of this initialization method is , where Psize is the population size and n the number of jobs.
On the ground of job sequence of the first stage, machine allocation, spindle speed, and job sequence at other stages are determined by decoding. In order to generate a feasible scheduling scheme, a dispatching rule is embedded in decoding to specify the job with the earliest completion time to be first processed, and any individual in the population can be decoded with Steps 1–3.
Step 1: Choose an individual from the population, obtain its job sequence in the first stage, and set t = 1, , and .
Step 2: Determine the processing machine and the spindle speed of all the jobs in current stage.
Step 2.1: Calculate the processing time () and energy consumption () of the current job () at all alternative speed levels on all available machines by Equations (2) and (11), respectively.
Step 2.2: Calculate the completion time (
) of the job at all alternative speed levels on all available machines by Equation (26). Set
and
.
Step 2.3: Calculate the weighted target value using Equation (12), select the machine and the speed level with the smallest weighted target value for the job, and mark the index of the machine and corresponding speed level with and .
Step 2.4: Set , . If , go to Step 3. Otherwise, set t = t + 1 and return to Step 2.1.
Step 3: If , the decoding process terminates. Otherwise, determine the job sequence in ascending order of the completion times, set j = j + 1, t = 1, , and return to Step 2. Calculate the final weighted target values of this individual using Equation (12).
Next, several dominant individuals are to be selected from the population so that the probability model can be applied. Based on the weighted target values, we sort all individuals in the ascending order of the target values, and then select the top % of individuals.
4.2. Population Updating Based on Probability Model
For the convergence, EDA applies an indicator function to extract the sequence characteristics of dominant individuals, and then constructs a probability model to guide the further population updating. Utilizing indicator functions, the position of a job in a dominant individual is signified and then the probability of this job arranged at all positions is statistically calculated. If the probability is higher, there is more chance for this job to stay at its previous position, and thus the population is updated gradually according to the mechanism of the roulette. The detailed steps of population updating based on probability model are as follows.
Step 1: Set the indicator function to zero, and set all elements in the probability matrix to .
Step 2: At the
gth generation, if job
is on position
of dominant individual
, set
to 1. Repeat this process till all dominant individuals, all jobs and all positions have been iterated. Calculate the total value of job
on position
and then yield the probability
by using Equation (27).
Step 3: Update the population according to by the roulette approach. Terminate the algorithm if termination criterion is met; otherwise, set g = g + 1 and return to Step 2.
5. Verification and Discussion
Computational experiments are conducted to verify the validity of the proposed mathematical model, and the effectiveness of the proposed EDA algorithm. All the experiments are performed on the computer with an Intel Core i5 processor running at 2.8 GHz and a main memory of 4G Bytes. The employed operating system is Windows 7 Professional. Note that the proposed mathematical model is programmed in GAMS/Dicopt and the proposed EDA is encoded in the programming language of MATLAB R2010a (The MathWorks, Inc., Natick, MA, USA).
To compare the performance of the proposed mathematical model and EDA, two smaller size turning cases are designed. Thus, there are three types of problems: a small-scale problem with four rolls, a medium-scale problem with 12 rolls, and a large scale problem with 60 rolls.
Before experiment, the weight of energy consumption was set to 0.8, which derived from Analytic Hierarchy Process (AHP) on the spot. Meanwhile, normalizing parameters of
Cmax
0 and
TEC0 were determined for the three size experiments utilizing the heuristic rule in
Section 3.2. Their values under small-scale, medium-scale, and large-scale circumstances were (3420 s, 29.07 MJ), (18,652 s, 289.17 MJ), and (26,763 s, 1294.1 MJ) respectively.
5.1. Parameter Calibration of EDA
EDA has three main parameters, namely population size noted as
Psize, the ratio of dominant population noted as
which is equal to
, and learning rate noted as
as. In this research, each factor has three levels:
Psize (30, 50, 80),
% (10%, 20%, 30%), and
as (10%, 20%, 30%). We adopt an orthogonal experiment whose size is L9 (3
3) to calibrate these parameters, and the stopping criterion is the elapsed time of 80 s. The numerical results are obtained through the heurisitc rule. Then
TEC0 and
Cmax
0 are used as parameters to calculate weighted goals according to Equation (12), where
. Finally, the AOV of each experiment is obtained as shown in
Table 1, where AOV is the average value of the weighted targets for 30 tests.
Table 1 shows under the third combination of (0, 10%, 0.3), the AOV value is the smallest, and thus the third combination is the best. However, when these parameters are invetsigated independently in
Figure 3, we note that the best population size is 50, the best rate of dominant population 10% and the best learning rate 10% or 30%. The above results are not in accordance with that in the third combination. Considering the incompleteness of the orthogonal experiment, two more tests of the combinations of (50, 10%, 0.1) and (50, 10%, 0.3) are performed, and their AOVs are 0.9229 and 0.9228. Taking these 11 experiments into account, we draw the conclusion that the optimal parameter combination is (50, 10%, 0.3) for the population size, rate of dominant population, and the learning rate.
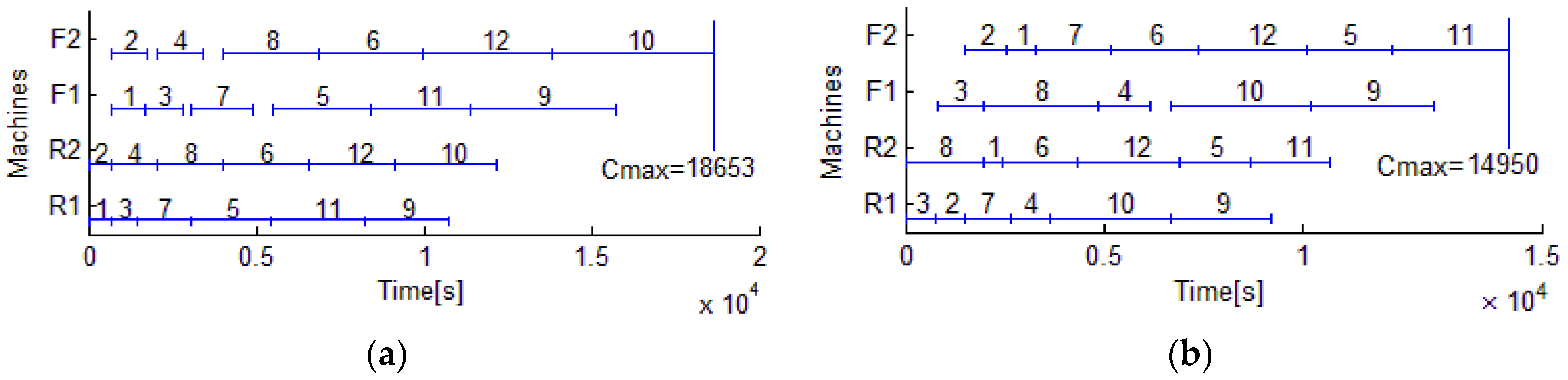
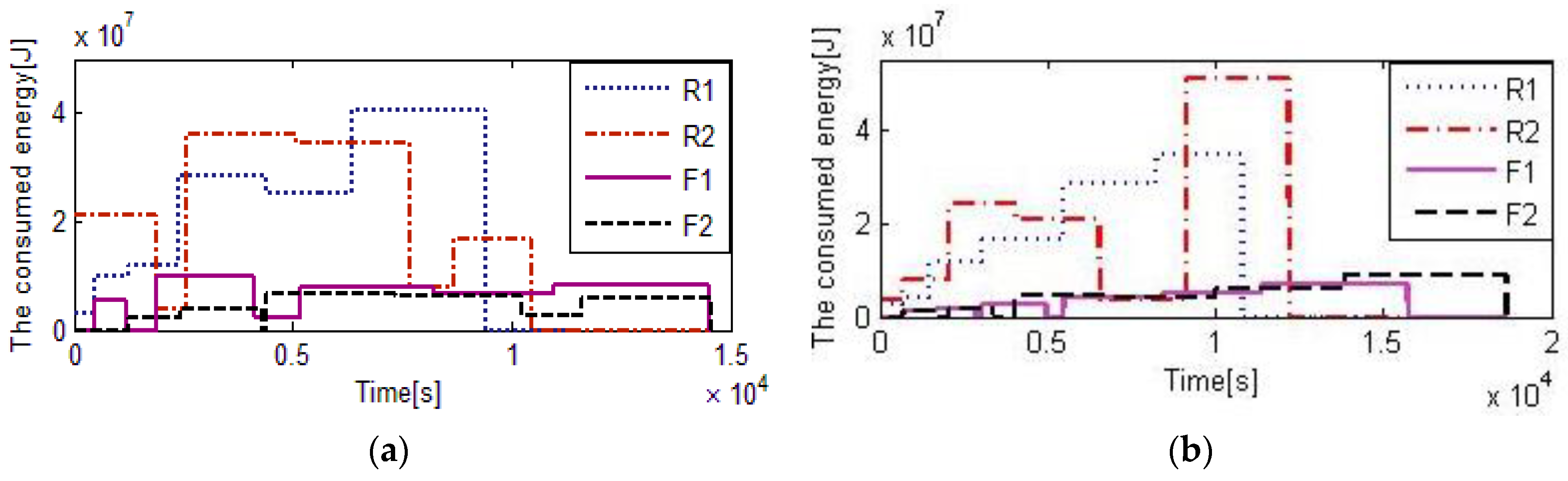
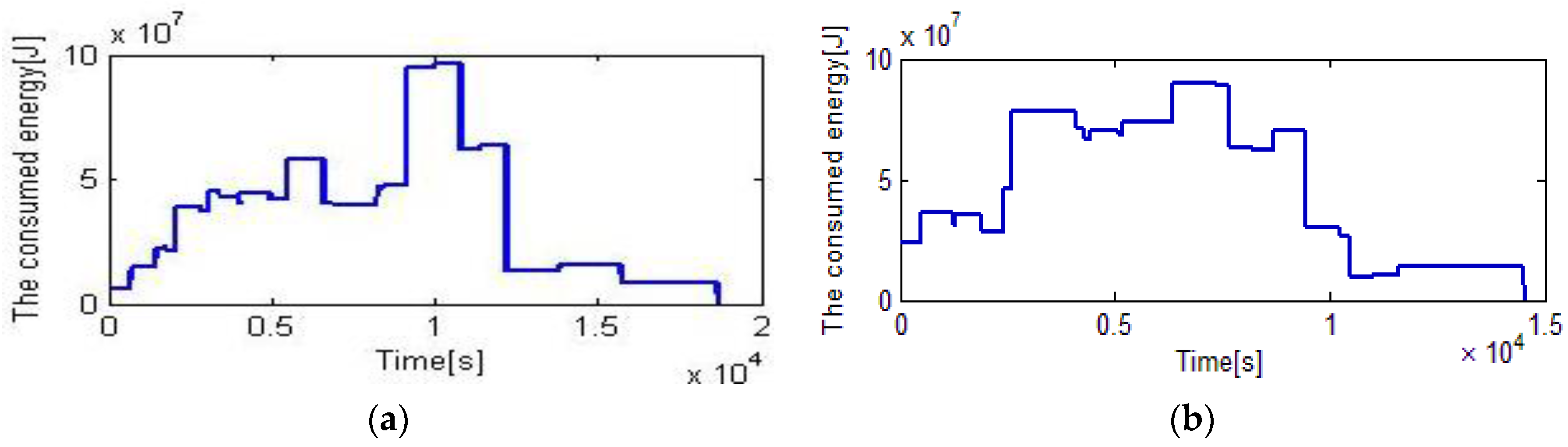
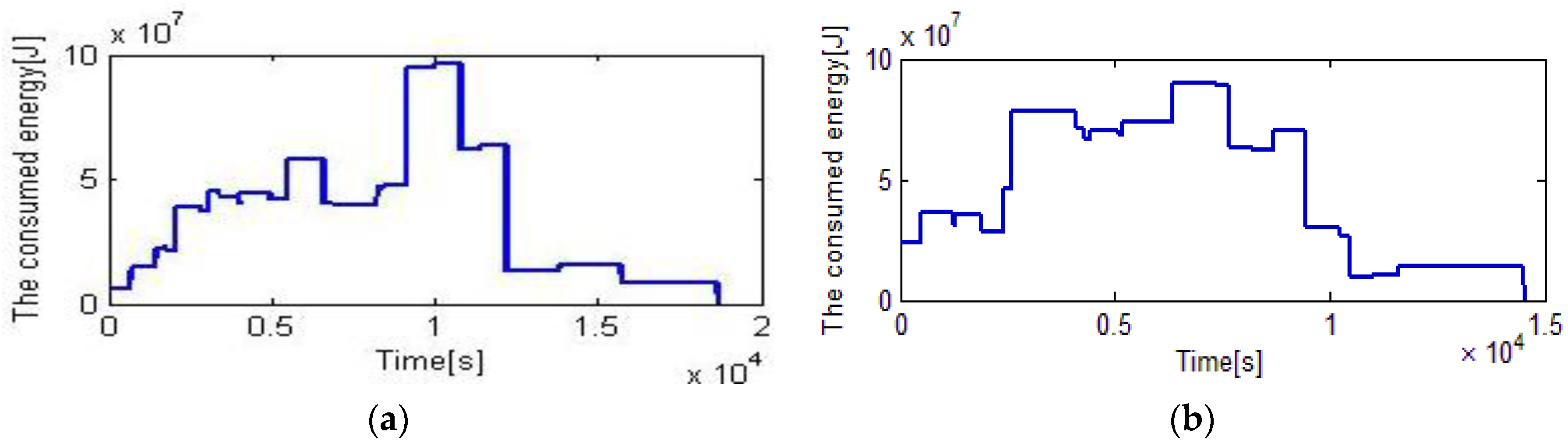
The EDA is applied to schedule 12 rolls, and the termination criterion is that the elapsed time reached 80 s. These jobs are completed in 14,594 s, and 4058 s is saved compared with 18,652 s which is the makespan of the original scheduling by the heuristic rule. The total energy is 280.08 MJ, and 9.09 MJ is saved compared with the original scheduling. The results of the heuristic rule are depicted in
Figure 4a,
Figure 5a and
Figure 6a, and the results of EDA are shown in
Figure 4b,
Figure 5b, and
Figure 6b.
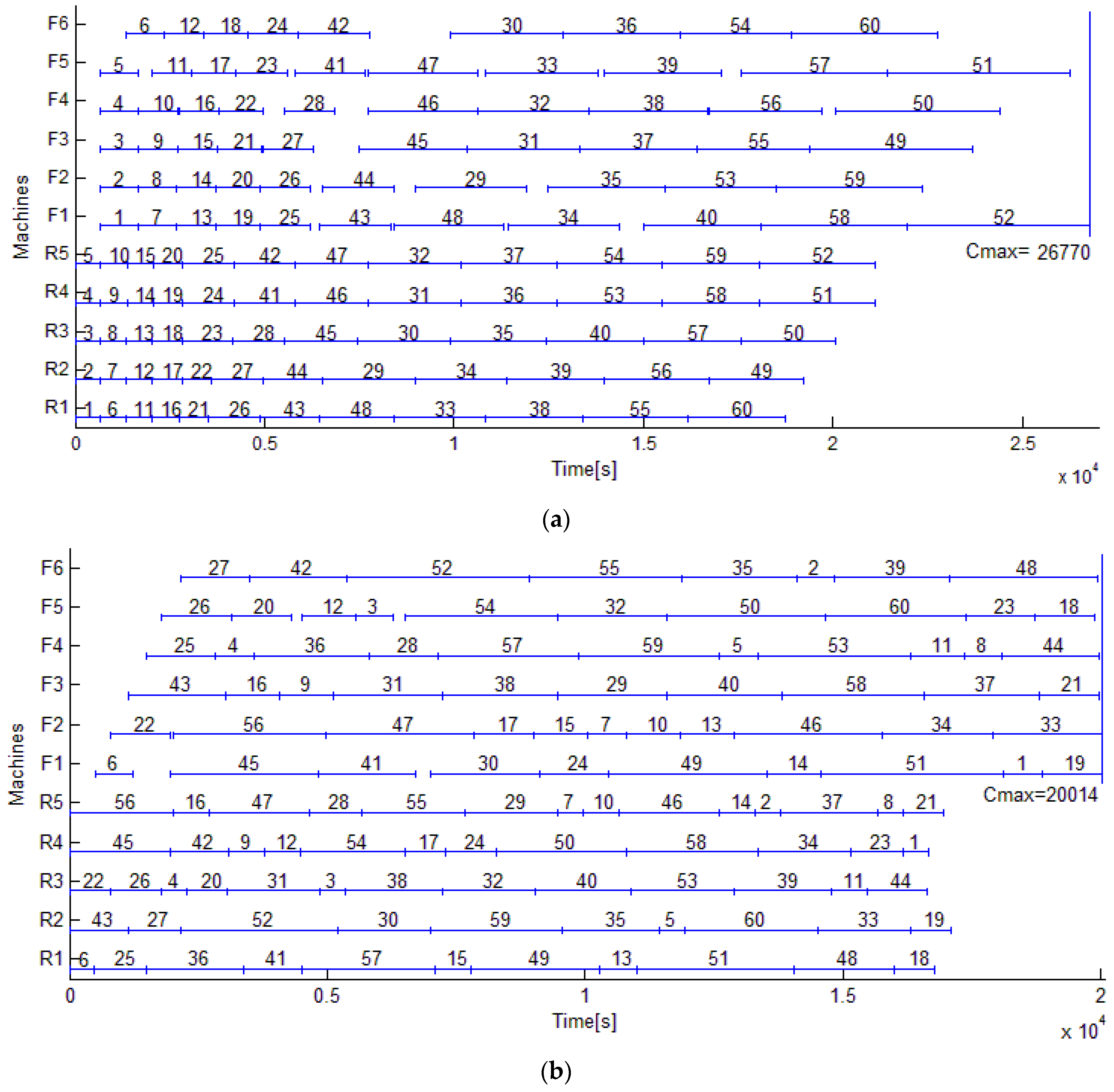
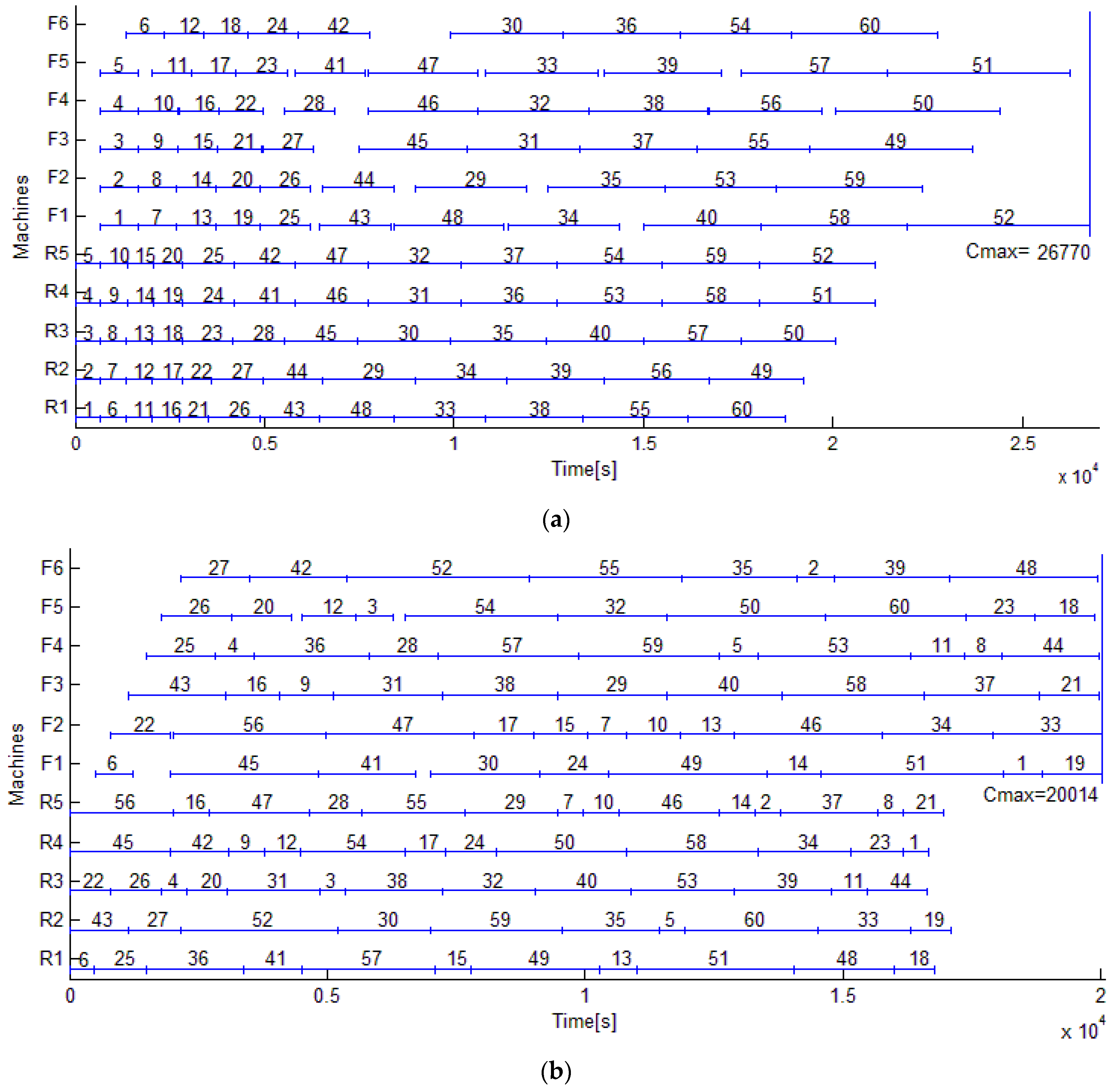
5.2. Experimental Results of the Motivating Example
Figure 7a,b compare the Gantt charts of 60 rolls by heuristic rule and by EDA. Apparently, the derived maximum completion time by EDA is shortened by 6749 s or by 25.22% compared with that by heuristic rule. Only tiny idle times remain in the Gantt chart by EDA.
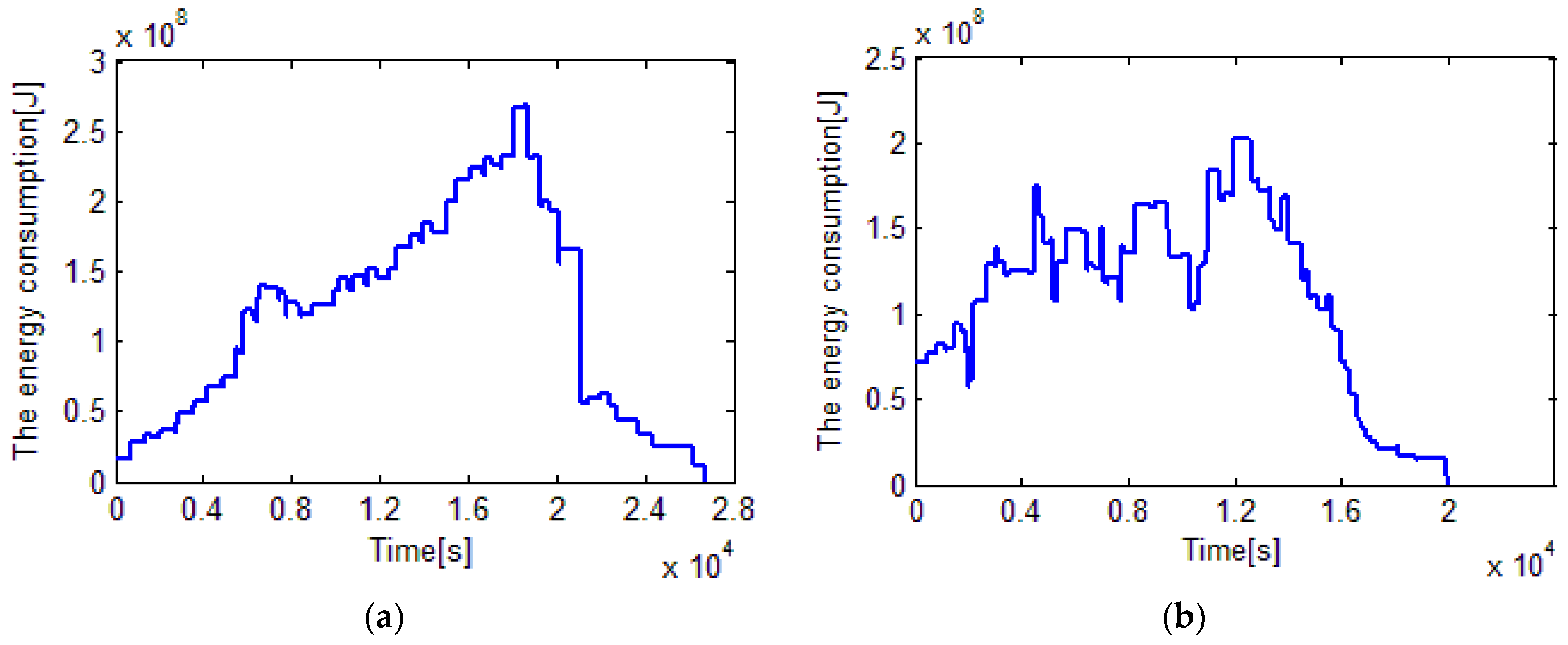
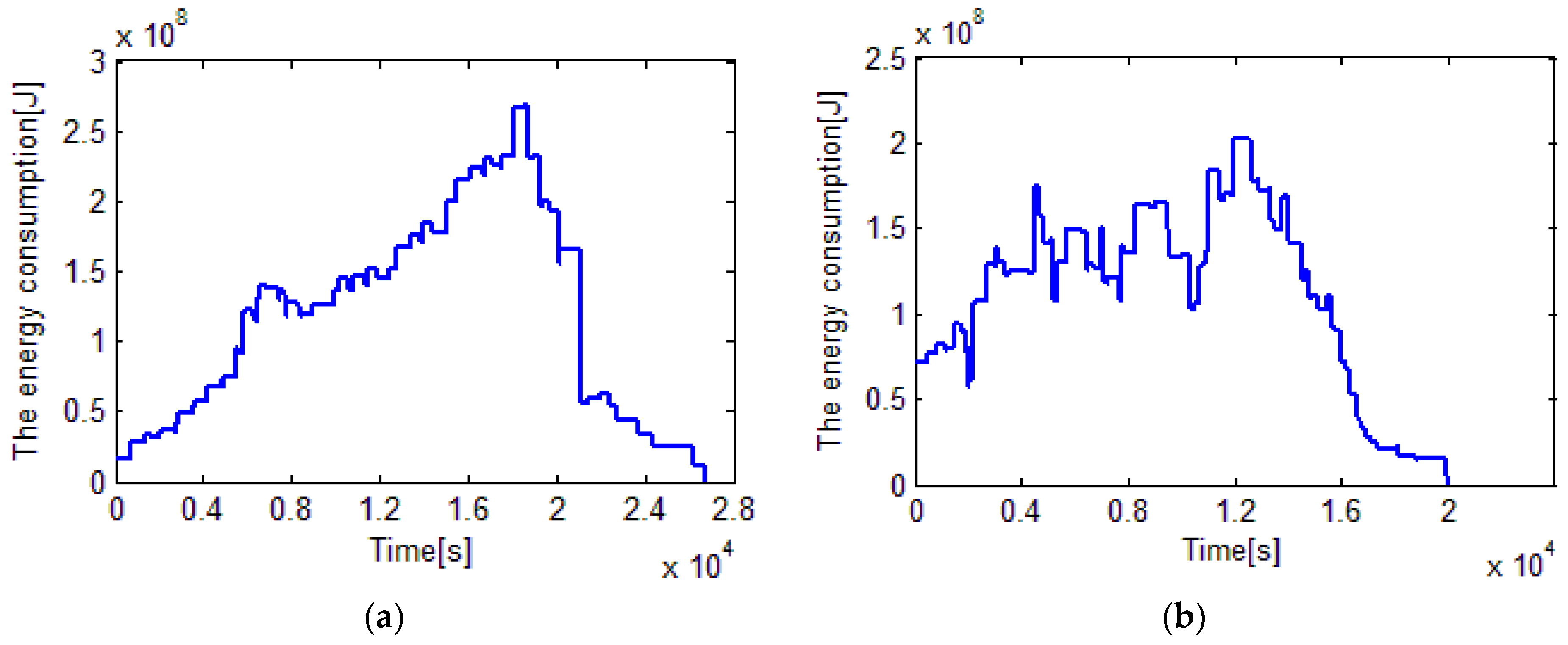
With respect to the consumed energy,
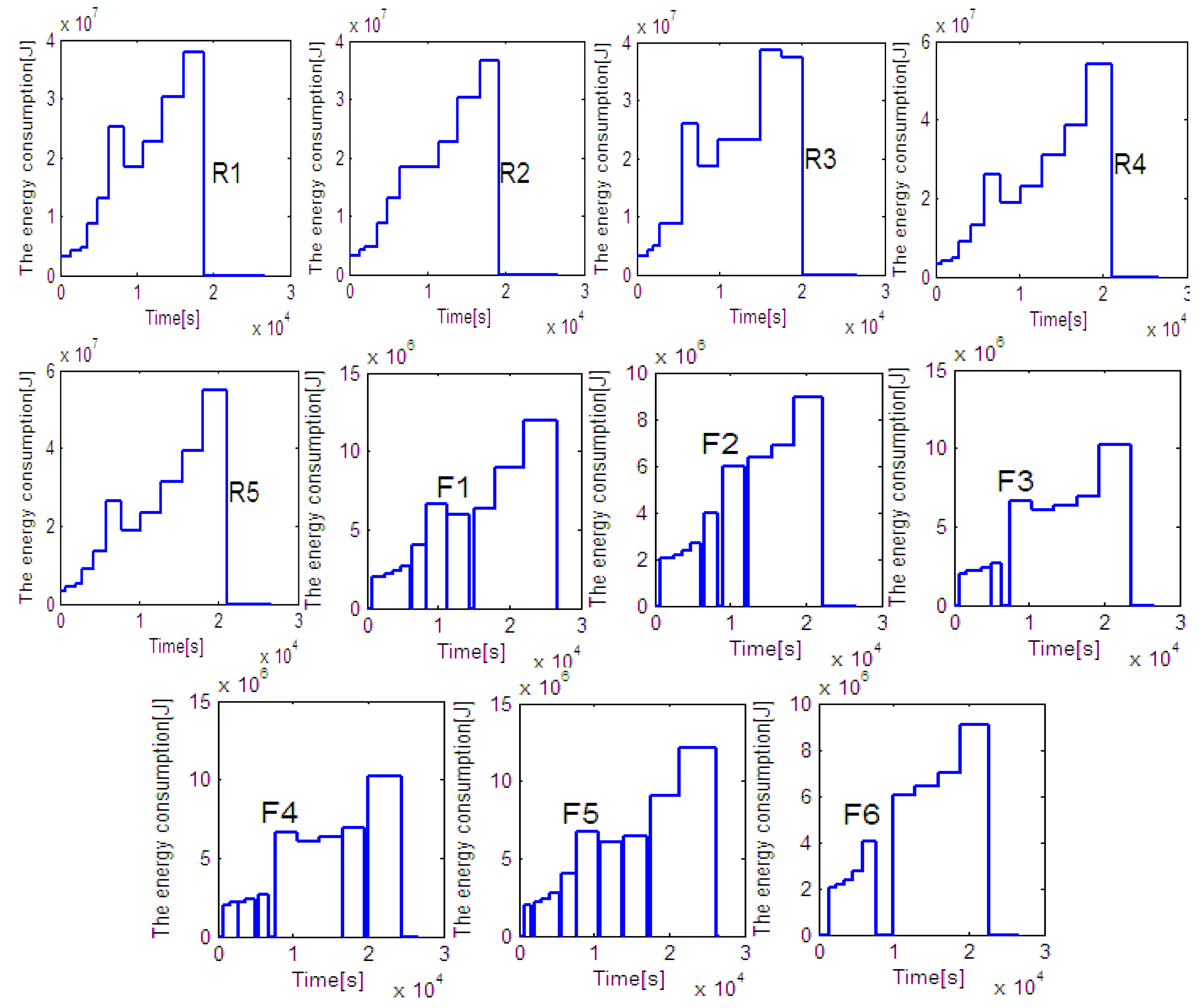
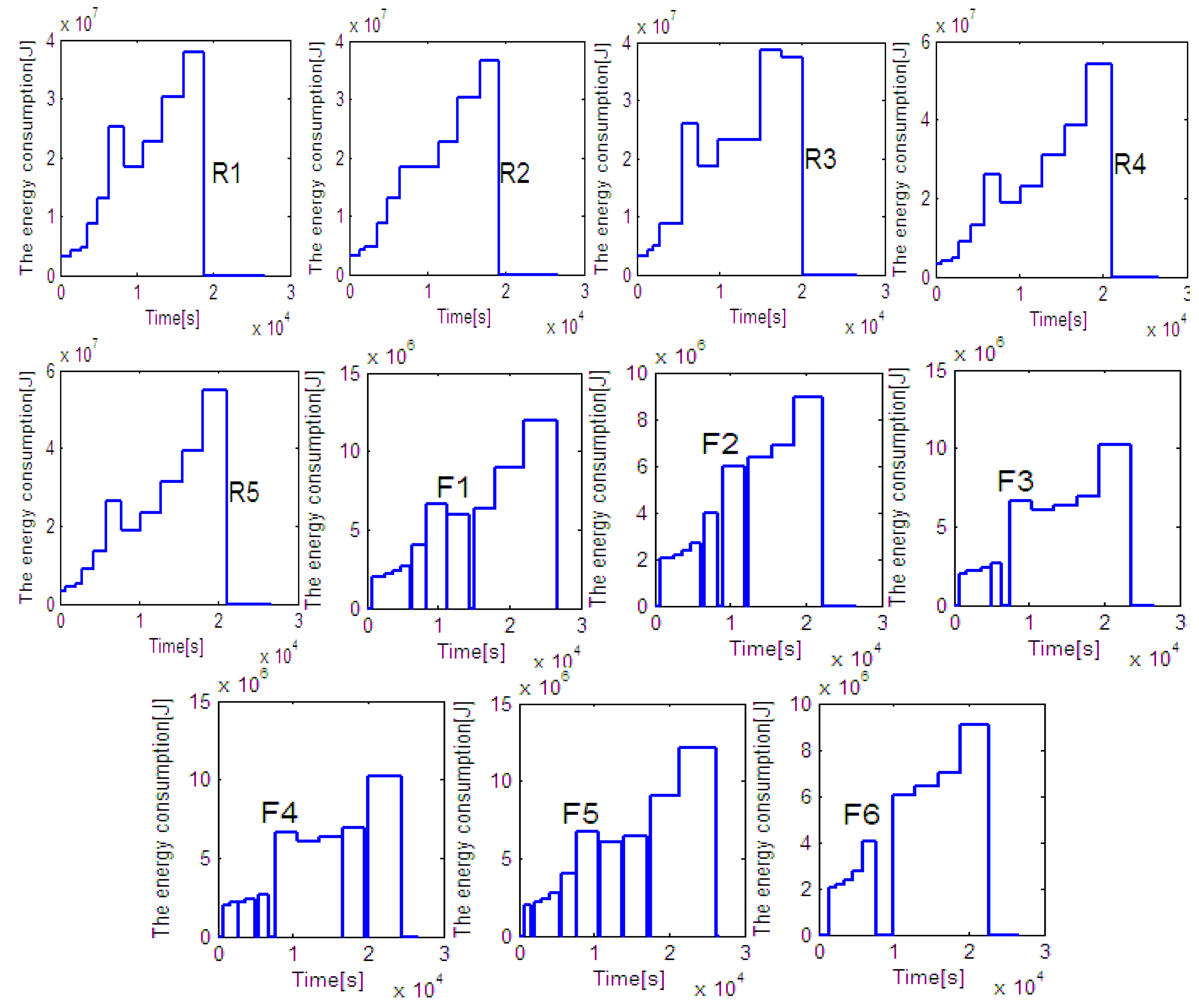
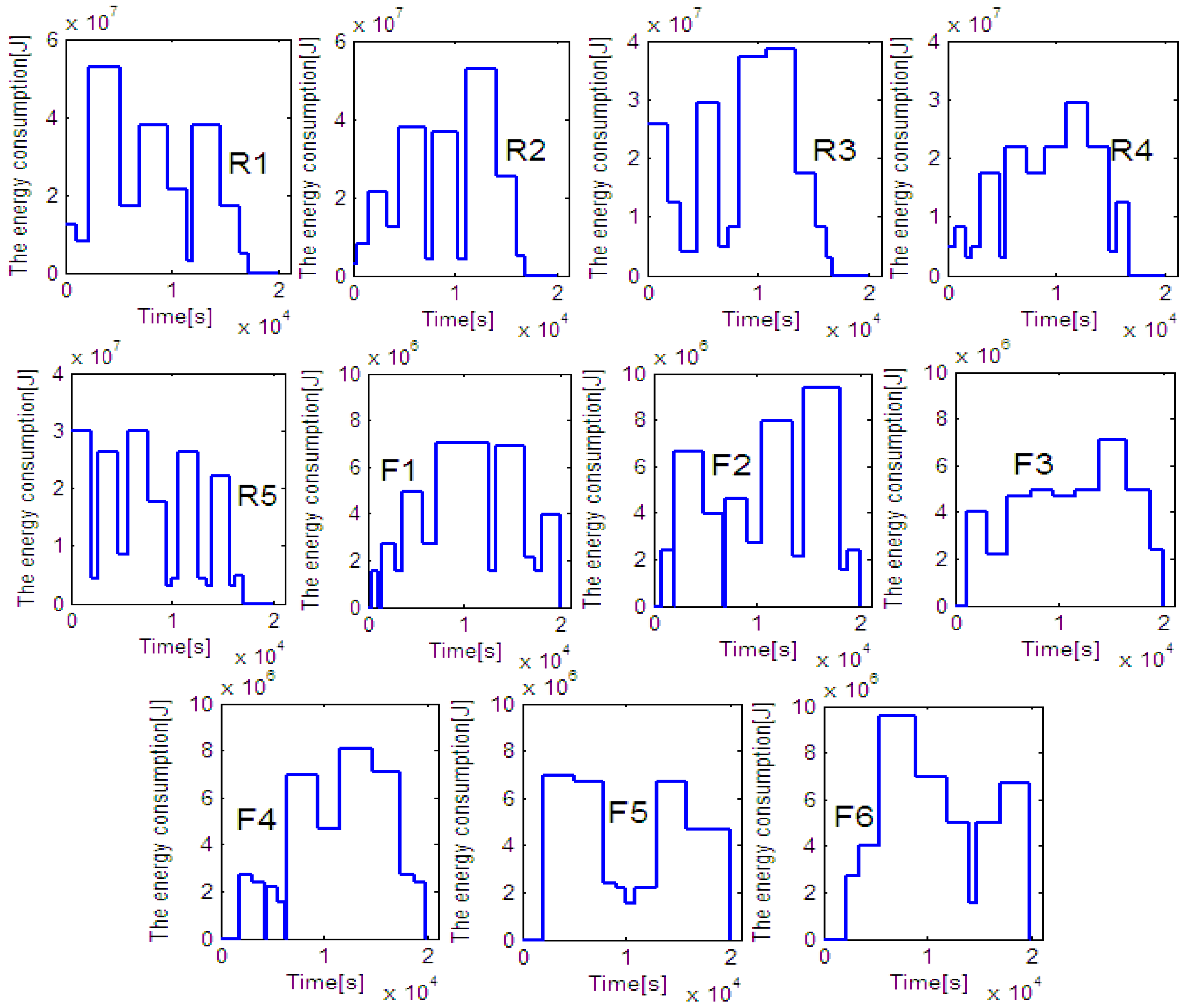
Figure 8b shows that the peak value of energy comsumption of 60 rolls by EDA is less than 250 MJ, while that by heuristic rule is nearly 300 MJ. The total energy consumed by the proposed EDA and the heuristic rule is 1223.2 MJ and 1294.1 MJ. In other words, 70.9 MJ or 5.48% of the total energy is saved by the proposed EDA. Note that, the energy consumptions of all lathes are reported in
Figure A1 and
Figure A2 in
Appendix.
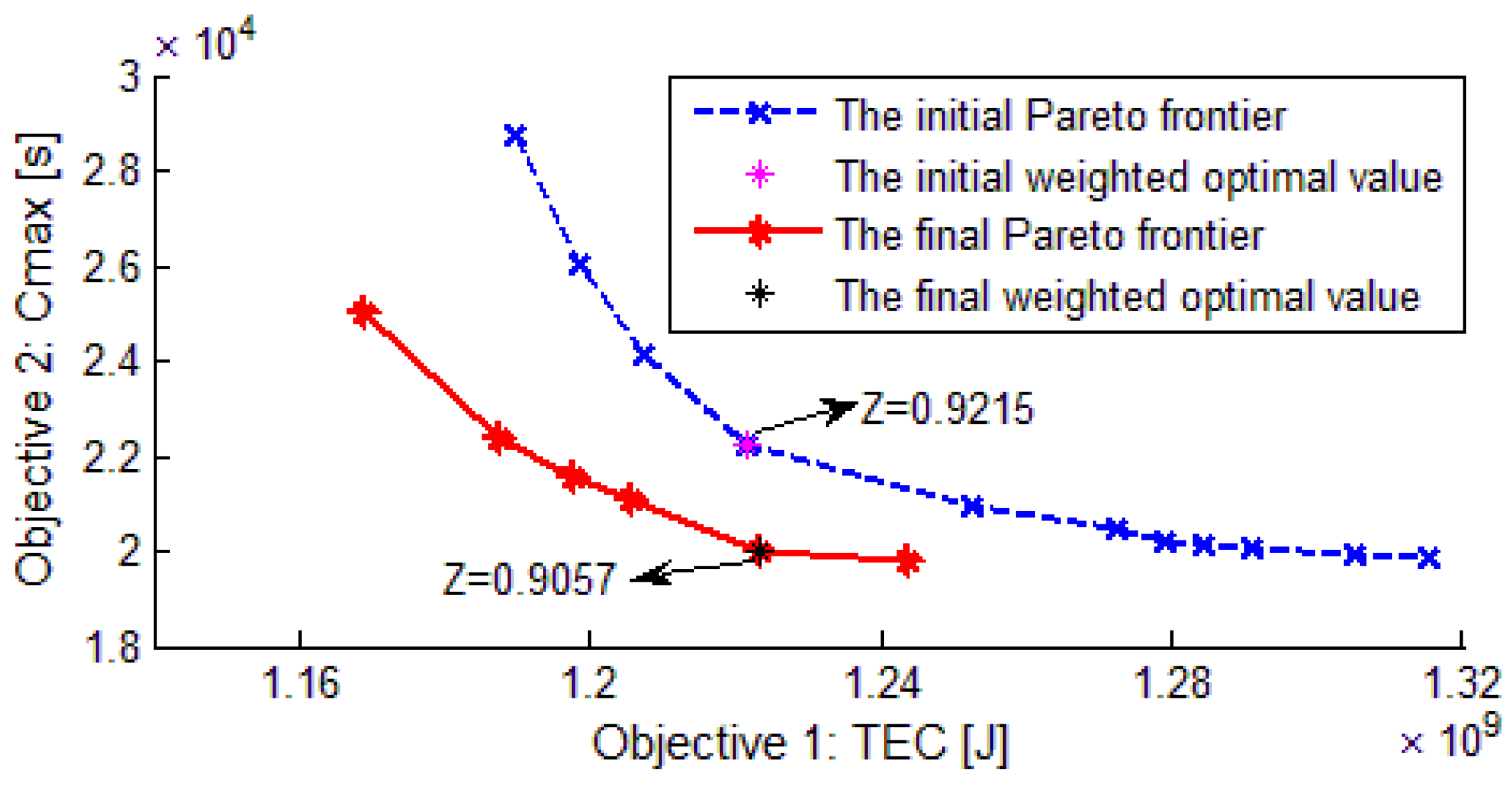
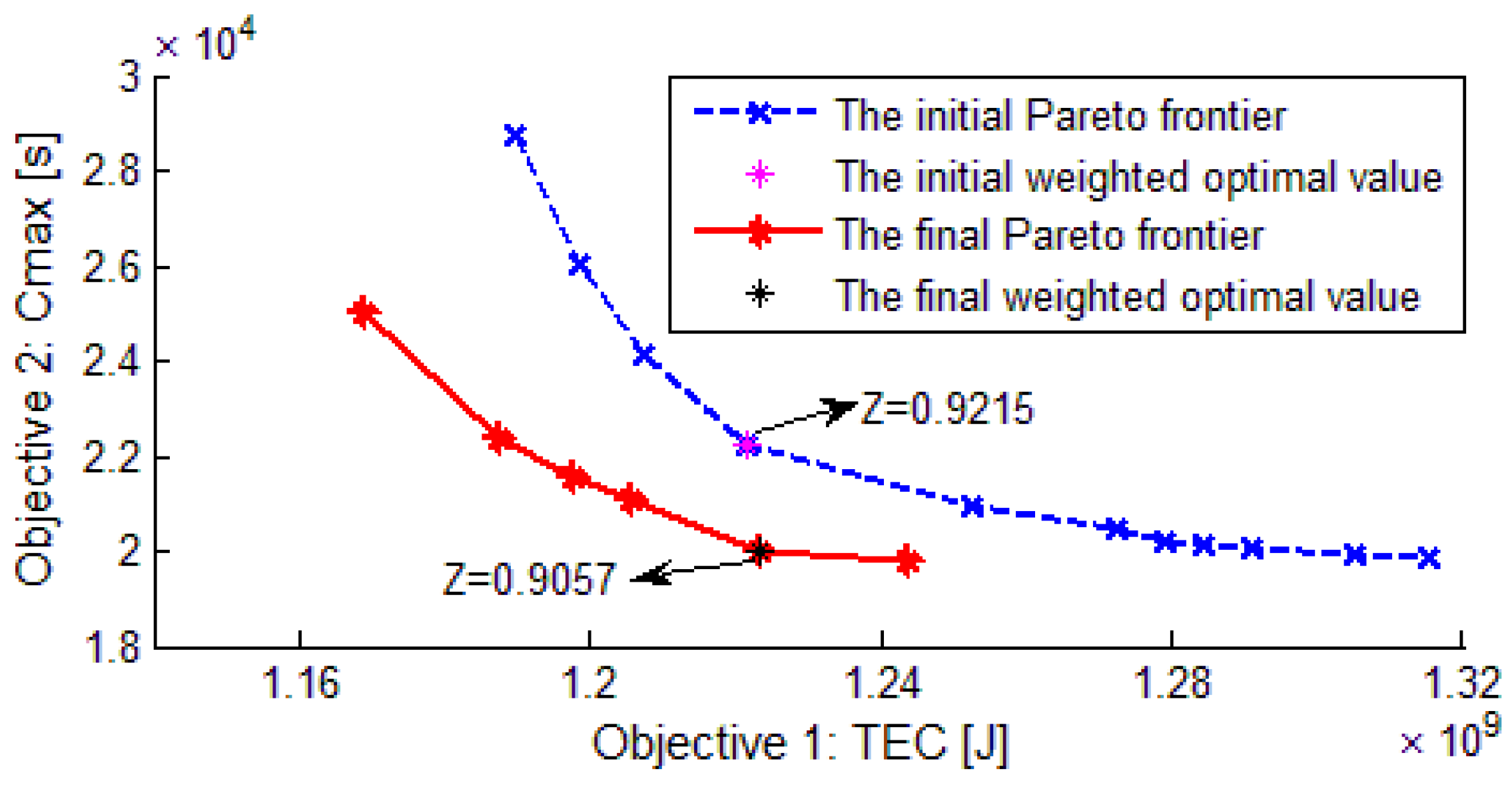
Figure 9 reports the Pareto frontier of the population. We can see the siginificant improvement of the Pareto frontier from the first to the final generation, which clearly demonstrates a bidirectional and synchronous optimization of the two objectives. Obviously, the optimal solution of the proposed mathematical model, in which both the total energy consumption and makespan are weighted, lies on the curve of Pareto frontier.
Table 2 compares the results obtained by the proposed EDA and that solved by GAMS/Dicopt solver for the MINLP model. It shows that, for small-scale problems, Dicopt solver outperforms the proposed EDA in both objectives during the acceptable time. For medium scale cases, the Dicopt solver takes much more time than the proposed EDA, but it produces a tiny improvement in the weighted target. For large-scale cases, the proposed EDA is absolutely superior over the Dicopt solver which cannot provide a feasible solution for the limited memory of the computer.
In summary, using the proposed EDA, energy-efficient scheduling can be achieved effectively. Moreover, makespan and the total energy consumption can be reduced simultaneously, and hence production efficiency improvement and energy saving are realized.
5.3. Discussion
The weight used in this paper is determined by AHP after investigating the preferences of managers in the real case. In order to clarify the weight range, sensitivity analysis experiments are conducted. Experiments show that when the weight is 1, the makespan is 13.41 h and the
TEC is 1218.2. Although this
TEC is slightly better than that under other circumstances, the makespan is particularly worse. Actually, this result originates from the single-objective optimization of the total energy consumption and the ignorance of makespan under this circumstance. Therefore, the weight value of 1 is excluded from the weight range and then the weight range is limited by (0, 0.8).
Table 3 shows the results after this adjustment. It demonstrates that the relative difference of total energy consumption is 2.03%, and that of makespan is 2.76%. Therefore, a conclusion can be reached that the two objectives are not sensitive to the weight when it ranges from 0 to 0.8.
Besides, in order to find out the underlying reasons, three different optimization goals and two optimization methods are analyzed and compared. Three optimization goals are given: (1) the comprehensive goal by weighting the consumed energy and completion time (Obj_C); (2) the single target only considering the consumed energy (Obj_e); and (3) the single target only considering makespan (Obj_t). The two different optimization methods are given as follows: (1) optimizing the scheduling scheme and spindle speed synchronously (Opt_S); and (2) optimizing the scheduling scheme after determining the appropriate spindle speed (Opt_o). The following experiments contain six combinations of the above optimization goals and methods. For testing the robustness of the proposed EDA, it is run 30 times for each combination. The stopping criterion is fixed to a given maximum elapsed CPU time of 180 s. To evaluate the different optimization goals and methods, firstly
Cmax, TCE, and the weighted objective of the best scheduling for each experiment are recorded; secondly the objectives are respectively analyzed by the repeated measures in IBM SPSS 19, in which optimization goals are set as within-subject effects and optimization methods as between-subject effects. The results are shown in
Table 4,
Table 5 and
Table 6.
From
Table 4, we note that in the columns of weighted objective and
Cmax, Obj_C yield the means of 0.9474 and 22,232.57 which are both better than that of Obj_e and Obj_t. In
TEC, the mean of 1,107,939.02 obtained by Obj_C is lower than that of Obj_t. Therefore, adopting the weighted goal to measure energy-efficient scheduling is suitable for optimizing the comprehensive objective and makespan. In
TEC, the means of 1,091,556.00 is the lowest; however, the Obj_e is not often used in real production due to the long makespan, which is 123,687.13 s, more than four times longer than that of Obj_C and Obj_t. The reason is that all the jobs are assigned on the most efficient machine while the other machines are idle. Therefore, among the three optimization goals, the weighted objective is the best measure method for energy-efficient scheduling.
Table 4 also shows that Opt_S yields lower means than Opt_o, no matter which of the three optimization goals is adopted. Therefore, optimizing the scheduling scheme and spindle speed synchronously not only saves the consumed energy but also shortens the makespan. Optimizing the scheduling scheme and turning parameters synchronously has a great effect on environment protection and production efficiency.
Table 5 also shows the multivariate tests of weighted objectives. Since all the differences are significant (0.000 < 0.05), the optimization goals can affect the weighted objective significantly. The interactions between optimization goals and optimization methods also affect the weighted objective significantly. The differences of multivariate tests of
Cmax and
TEC are also significant, so the optimization goals and the interactions can affect
Cmax and
TEC, too. The data of the multivariate tests of
Cmax and
TEC are not reported here since they are similar to
Table 5.
Table 6 shows the tests of between-subjects effects on weighted objectives. Since the difference is significant (0.000 < 0.05), the optimization method can affect the weighted objective significantly. The differences of between-subjects effects on
Cmax and
TEC are significant, so the optimization methods can also affect
Cmax and
TEC significantly.
All in all, we find that different optimization goals and methods affect the Cmax and TEC significantly, so both environmental and production benefits can be enhanced simultaneously by optimizing the spindle speed and scheduling scheme, which is the first realization in this regard.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}