
A Patent Analysis for Sustainable Technology Management


Abstract
:1. Introduction
2. Sustainable Technology
3. Management of Sustainable Technology using Statistical Patent Analysis
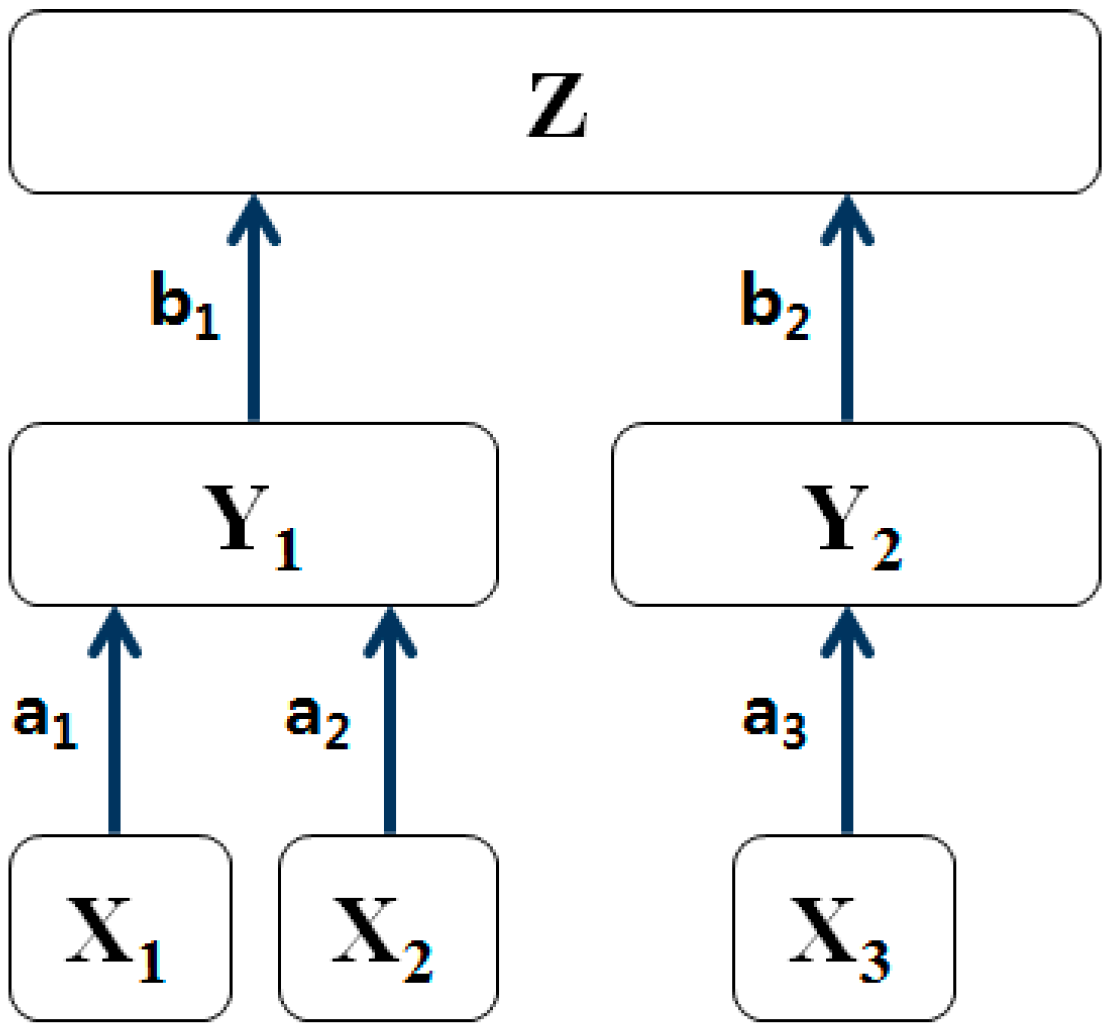
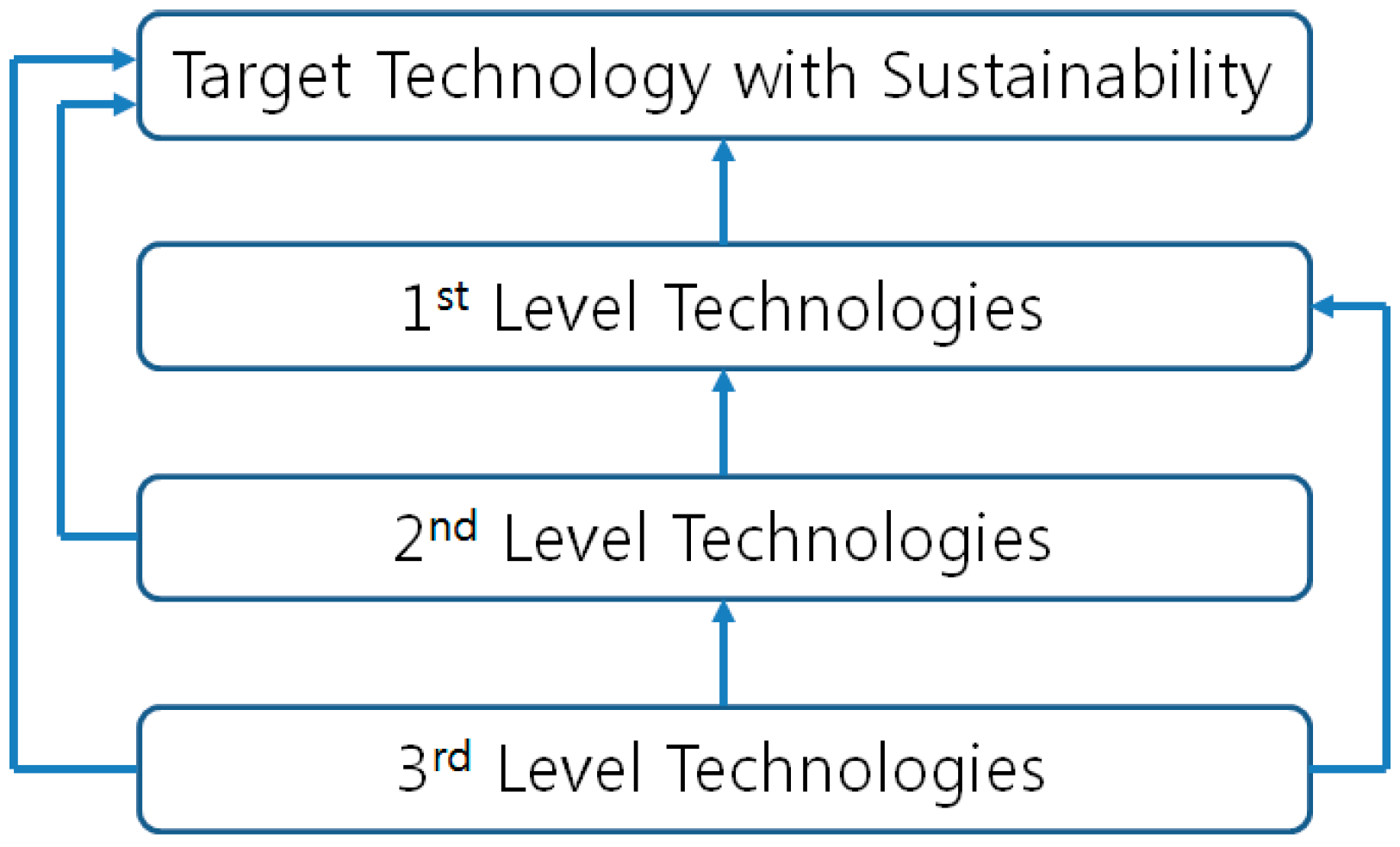
3.1. Statistical Path Analysis for Hierarchical Diagram of Technology
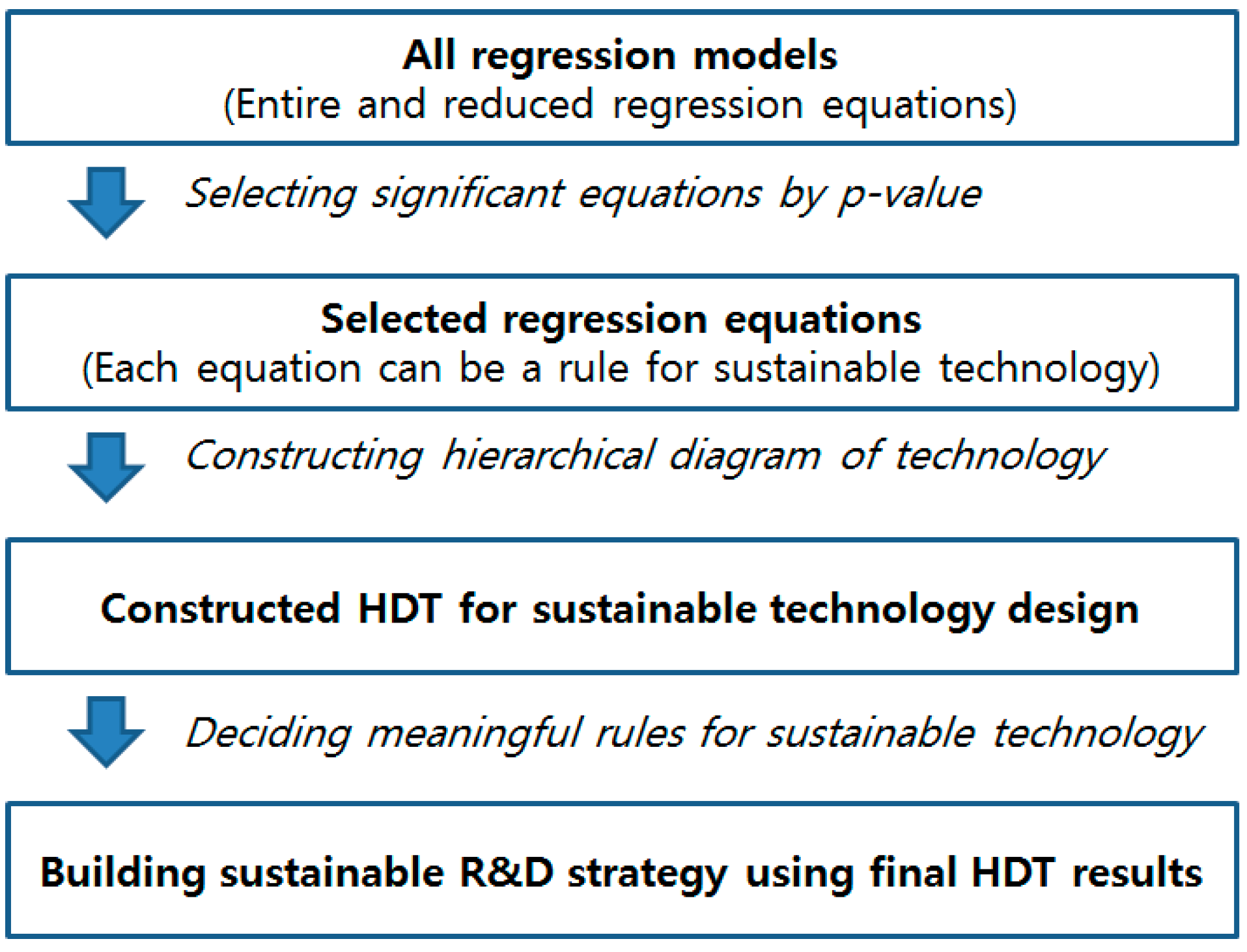
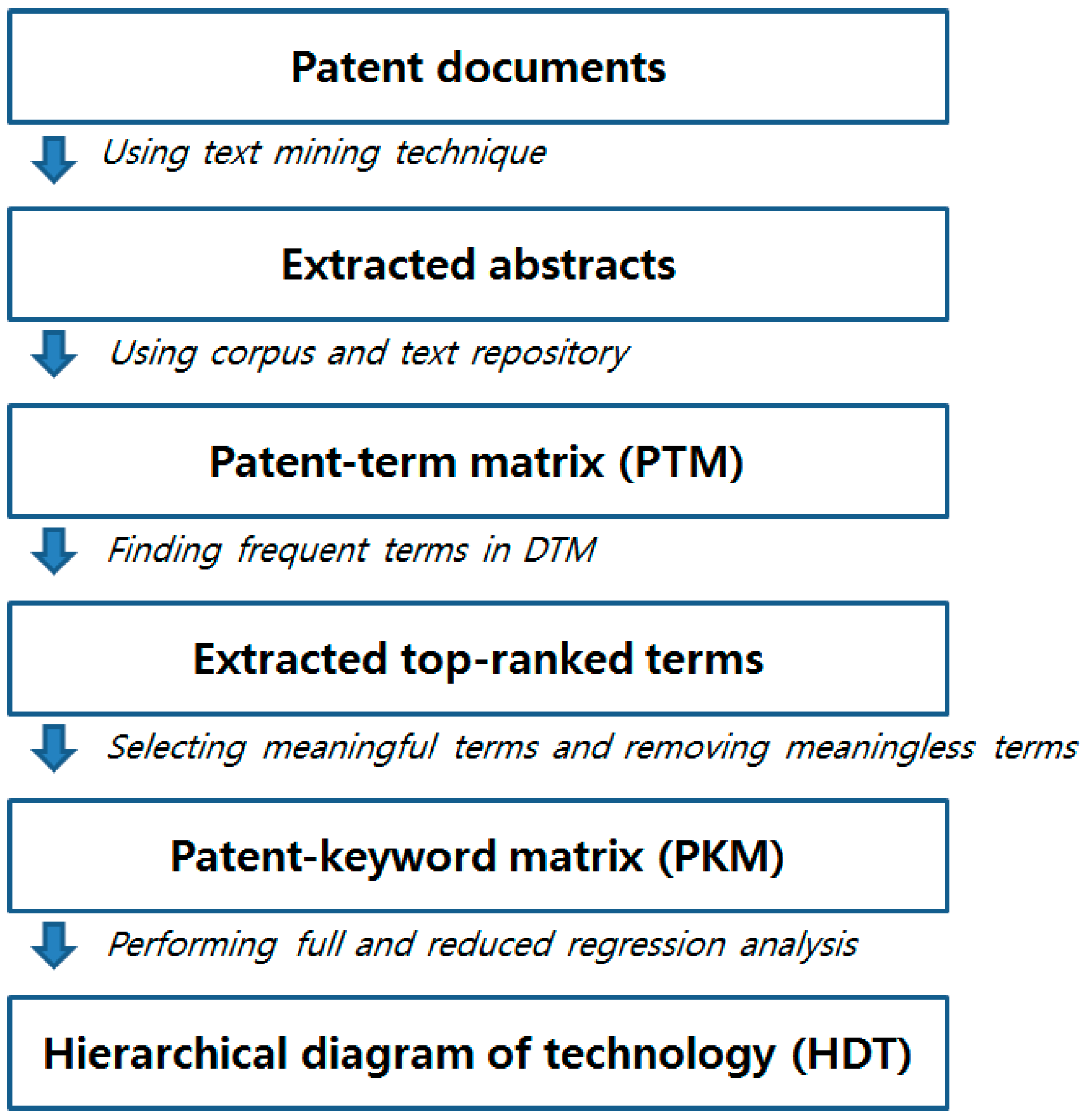
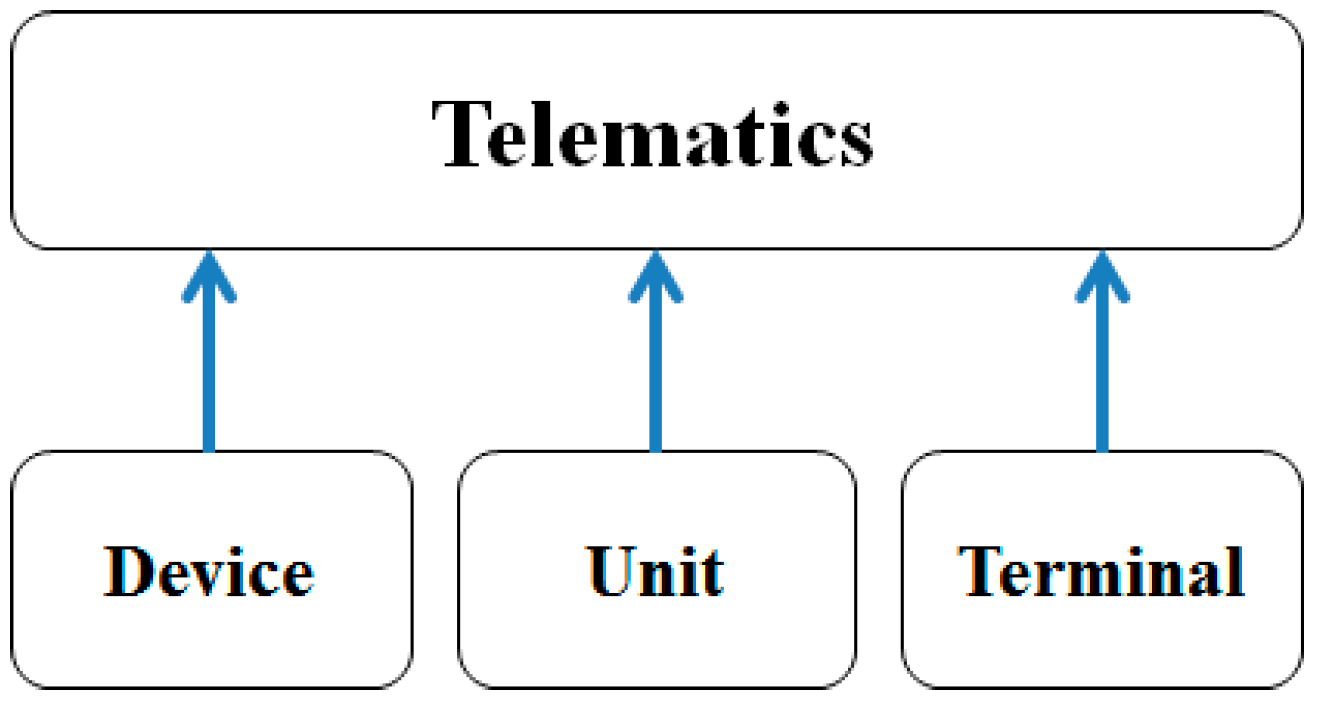
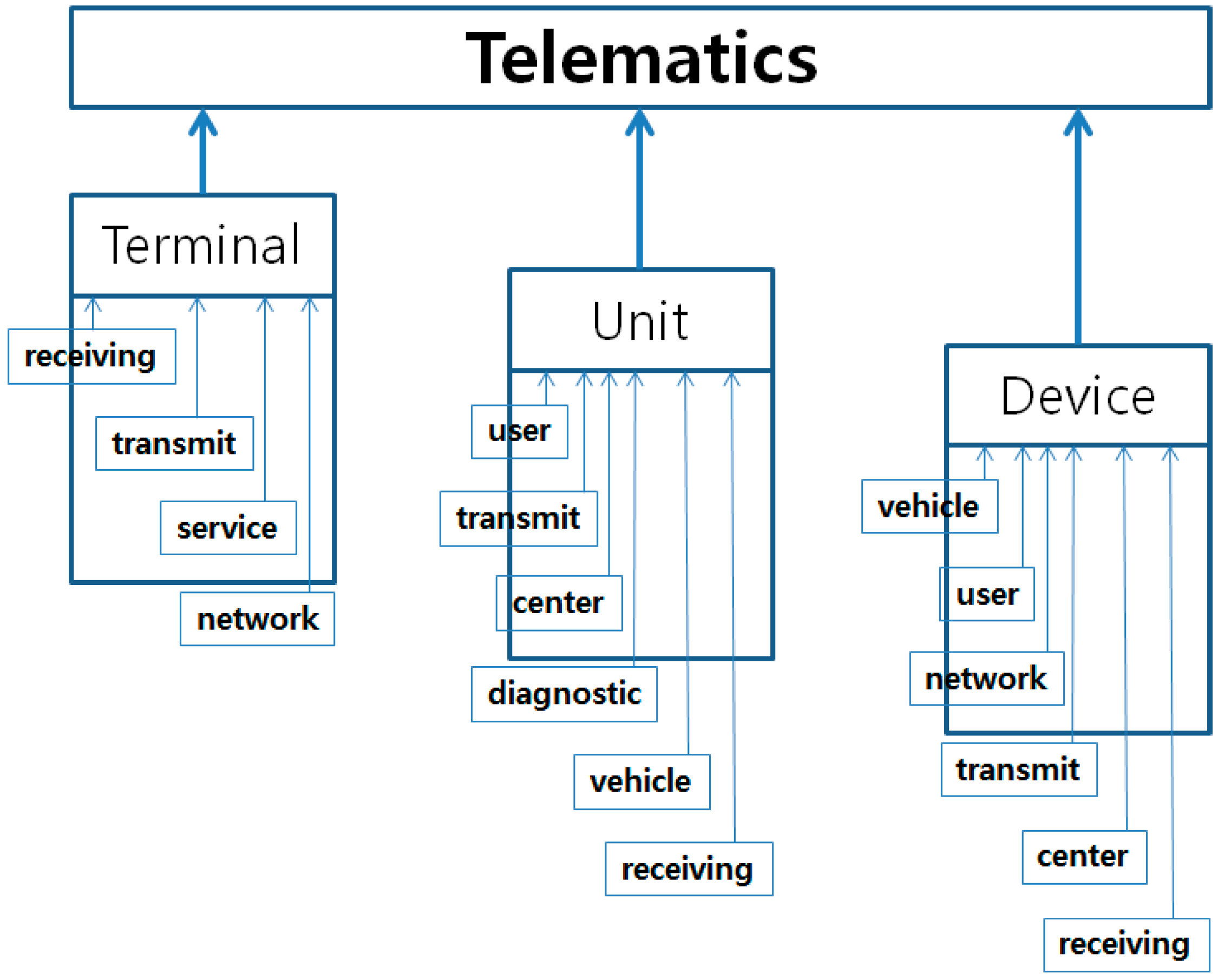
3.2. Hierarchical Diagram of Technology for Sustainable Technology Management
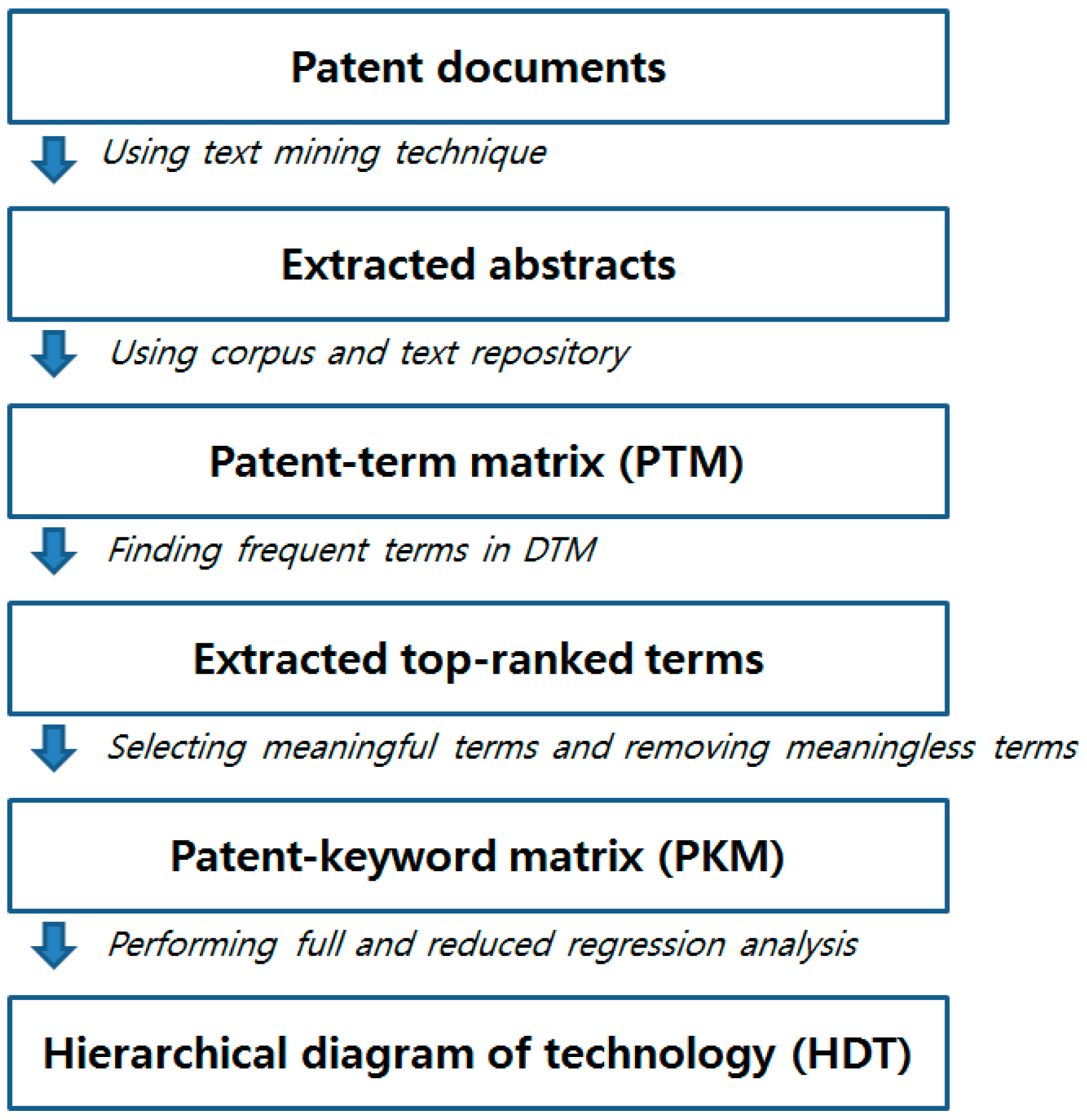
- Step 1.
- Retrieve patent documents for the given technology area
- Step 2.
- Construct a patent-term matrix (PTM) from the abstracts of the patent data
- Step 3.
- Reconstruct a patent-keyword matrix (PKM) from the PTM
- (1)
- Search top-ranked terms in the PTM
- (2)
- Remove meaningless terms
- (3)
- Determine the keywords using the remaining terms
- (4)
- Build a PKM
- Step 4.
- Perform hierarchical regression analysis
- (1)
- Perform a full regression model using all of the keywords
- (2)
- Perform a reduced regression model using selected keywords
- (3)
- Construct the complete HDT
- Step 5.
- Interpret the constructed HDT model for sustainable technology management
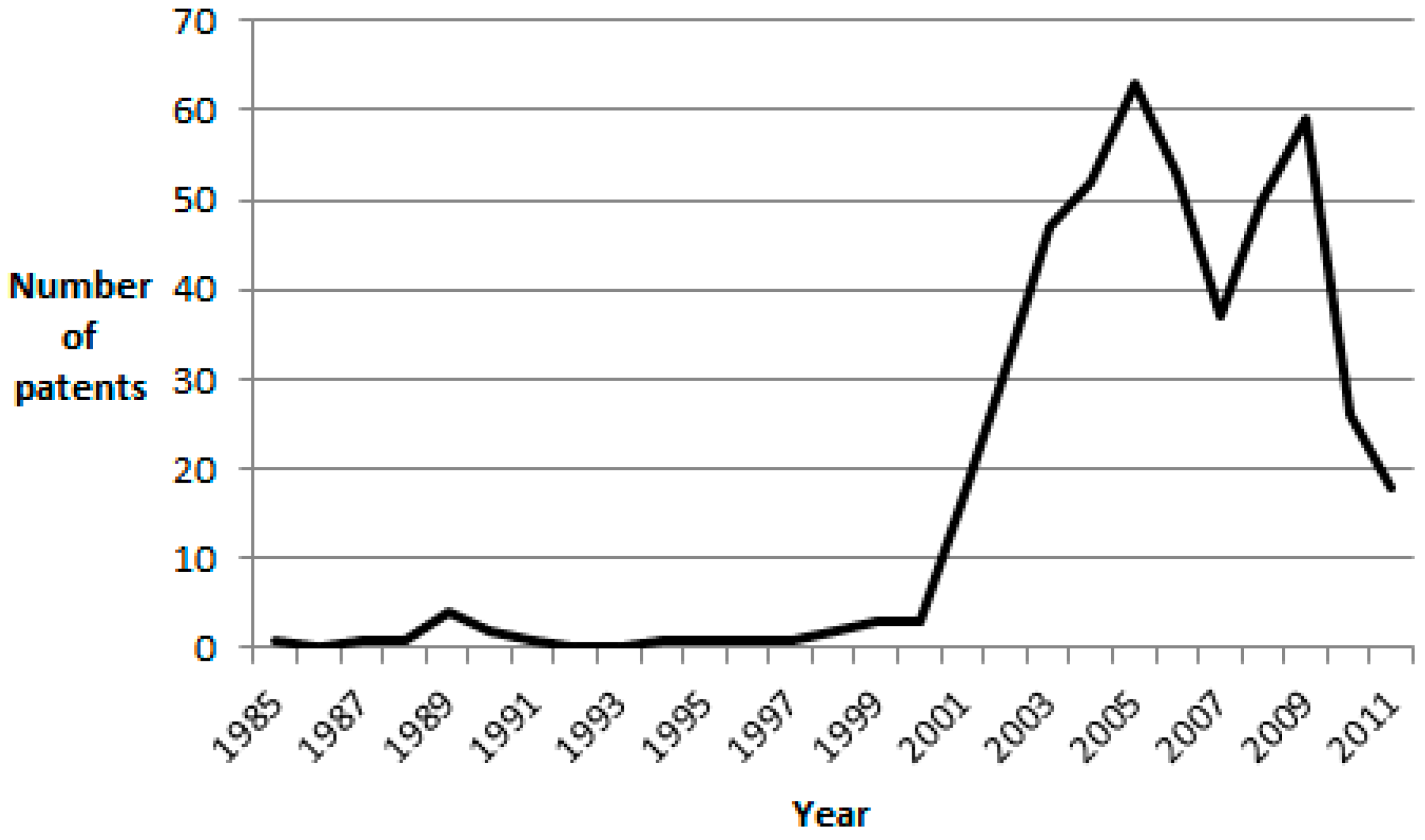
4. Experimental Results
5. Conclusions
Author Contributions
Conflicts of Interest
References
- Choi, J.; Jang, D.; Jun, S.; Park, S. A Predictive Model of Technology Transfer using Patent Analysis. Sustainability 2015, 7, 16175–16195. [Google Scholar] [CrossRef]
- Jun, S.; Park, S.; Jang, D. Technology Forecasting using Matrix Map and Patent Clustering. Ind. Manag. Data Syst. 2012, 112, 786–897. [Google Scholar] [CrossRef]
- Lin, G.T.R.; Lee, Y.C. Scientific Innovation of Bioremediation Technologies. J. Sci. Ind. Res. 2015, 74, 197–201. [Google Scholar]
- Saraf, C.U. Elements of managing transfer of technology from laboratory to industry: Technology Transfer Management (TTM). J. Sci. Ind. Res. 2014, 73, 704–710. [Google Scholar]
- Roper, A.T.; Cunningham, S.W.; Porter, A.L.; Mason, T.W.; Rossini, F.A.; Banks, J. Forecasting and Management of Technology; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Firat, A.K.; Woon, W.L.; Madnick, S. Technological Forecasting—A Review; Composite Information Systems Laboratory (CISL), Massachusetts Institute of Technology: Cambridge, MA, USA, 2008. [Google Scholar]
- Jun, S.; Lee, S. Emerging Technology Forecasting Using New Patent Information Analysis. Int. J. Softw. Eng. Its Appl. 2012, 6, 107–115. [Google Scholar]
- Yoon, B.; Park, Y. Development of New Technology Forecasting Algorithm: Hybrid Approach for Morphology Analysis and Conjoint Analysis of Patent Information. IEEE Trans. Eng. Manag. 2009, 54, 588–599. [Google Scholar] [CrossRef]
- Choi, C.; Park, Y. Monitoring the Organic Structure of Technology Based on the Patent Development Paths. Technol. Forecast. Soc. Chang. 2009, 76, 754–768. [Google Scholar] [CrossRef]
- Wang, M.; Chang, D.; Kao, C. Identifying technology trends for R&D planning using TRIZ and text mining. R&D Manag. 2010, 40, 491–509. [Google Scholar]
- Choi, S.; Kim, H.; Yoon, J.; Kim, K.; Lee, J.Y. An SAO-based text-mining approach for technology roadmapping using patent information. R&D Manag. 2013, 43, 52–74. [Google Scholar]
- Han, E.J.; Sohn, S.Y. Patent valuation based on text mining and survival analysis. J. Technol. Transf. 2015, 40, 821–839. [Google Scholar] [CrossRef]
- Hunt, D.; Nguyen, L.; Rodgers, M. Patent Searching Tools & Techniques; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- Lee, H.J.; Lee, S.; Yoon, B. Technology Clustering Based on Evolutionary Patterns: The Case of Information and Communications Technologies. Technol. Forecast. Soc. Chang. 2011, 78, 953–967. [Google Scholar] [CrossRef]
- Park, Y.; Lee, S.; Lee, S. Patent analysis for promoting technology transfer in multi-technology industries: The Korean aerospace industry case. J. Technol. Transf. 2012, 37, 355–374. [Google Scholar] [CrossRef]
- Kim, Y. From catch-up to overtaking: Competition and innovation in the semiconductor industries of Korea and Japan. Asian J. Technol. Innov. 2012, 19, 297–311. [Google Scholar] [CrossRef]
- Guo, B.; Chen, X. How does FDI influence industry-level knowledge production efficiency in China? Asian J. Technol. Innov. 2012, 19, 263–277. [Google Scholar] [CrossRef]
- Yoon, B.; Phaal, R.; Probert, D. Morphology analysis for technology roadmapping: Application of text mining. R&D Manag. 2008, 38, 51–68. [Google Scholar]
- Banerjee, G. Assessing Visibility of Research Organizations: A Fuzzy Analytic Network Process Approach. J. Sci. Ind. Res. 2014, 73, 283–289. [Google Scholar]
- Grönqvist, C. The private value of patents by patent characteristics: Evidence from Finland. J. Technol. Transf. 2009, 34, 159–168. [Google Scholar] [CrossRef]
- Hall, B.H. Exploring the Patent Explosion. J. Technol. Transf. 2004, 30, 35–48. [Google Scholar] [CrossRef]
- Kim, G.J.; Park, S.S.; Jang, D.S. Technology Forecasting using Topic-Based Patent Analysis. J. Sci. Ind. Res. 2015, 74, 265–270. [Google Scholar]
- Lee, S.; Lee, S.; Seol, H.; Park, Y. Using patent information for designing new product and technology: Keyword based technology roadmapping. R&D Manag. 2008, 38, 169–188. [Google Scholar]
- Lee, S.; Yoon, B.; Lee, C.; Park, J. Business planning based on technological capabilities: Patent analysis for technology-driven roadmapping. Technol. Forecast. Soc. Chang. 2009, 76, 769–786. [Google Scholar] [CrossRef]
- OuYang, K.; Weng, C.S. A new comprehensive patent analysis approach for new product design in mechanical engineering. Technol. Forecast. Soc. Chang. 2011, 78, 1183–1199. [Google Scholar] [CrossRef]
- Grimaldi, M.; Cricelli, L.; Di Giovanni, M.; Rogo, F. The patent portfolio value analysis: A new framework to leverage patent information for strategic technology planning. Technol. Forecast. Soc. Chang. 2015, 94, 286–302. [Google Scholar] [CrossRef]
- Park, S.; Lee, S.; Jun, S. A Network Analysis Model for Selecting Sustainable Technology. Sustainability 2015, 7, 13126–13141. [Google Scholar] [CrossRef]
- Kim, S.; Jang, D.; Jun, S.; Park, S. A Novel Forecasting Methodology for Sustainable Management of Defense Technology. Sustainability 2015, 7, 16720–16736. [Google Scholar] [CrossRef]
- Korea Intellectual Property Rights Information Service (KIPRIS), 2015. Available online: http://www.kipris.or.kr (accessed on 1 September 2015).
- The United States Patent and Trademark Office (USPTO), 2015. Available online: http://www.uspto.gov (accessed on 1 September 2015).
- Wipson Company Ltd. (WIPSON), 2015. Available online: http://www.wipson.com (accessed on 1 September 2015).
- Berthold, M.; Hand, D.J. Intelligent Data Analysis—An Introduction; Springer: Berlin, Germany, 1999. [Google Scholar]
- Robinson, D.K.R.; Propp, T. Multi-path Mapping for Alignment Strategies in Emerging Science and Technologies. Technol. Forecast. Soc. Chang. 2011, 75, 517–538. [Google Scholar] [CrossRef]
- Ng, B.; Chandran, V.G.R.; Kanagasundram, T. Technological knowledge, learning and linkages in the wooden furniture industry in Malaysia: A spatial innovation perspective. Asian J. Technol. Innov. 2012, 20, 187–200. [Google Scholar] [CrossRef]
- Rasiah, R.; Mohamad, M.R.B.; Sanjivee, P. Production linkages, technological intensities and economic performance: Small and medium enterprises in Malaysian manufacturing. Asian J. Technol. Innov. 2011, 19, 279–296. [Google Scholar] [CrossRef]
- Feinerer, I.; Hornik, K.; Meyer, D. Text Mining Infrastructure in R. J. Stat. Softw. 2008, 25, 1–54. [Google Scholar] [CrossRef]
- Feinerer, I. Package tm—Text Mining; CRAN R-Project: Vienna, Austria, 2015. [Google Scholar]
- R Development Core Team. A Language and Environment for Statistical Computing. Vienna, Austria, 2015. Available online: http://www.R-project.org (accessed on 15 July 2016).
- Tseng, Y.H.; Lin, C.J.; Lin, Y.I. Text Mining Techniques for Patent Analysis. Inf. Proc. Manag. 2007, 43, 1216–1247. [Google Scholar] [CrossRef]
- Kim, J.; Jun, S. Graphical Causal Inference and Copula Regression Model for Apple Keywords by Text Mining. Adv. Eng. Inf. 2015, 29, 918–929. [Google Scholar] [CrossRef]
- Ross, S.M. Probability and Statistics for Engineers and Scientists, 4th ed.; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Independent Variable | Beta | p-Value |
|---|---|---|
| center | 0.126 | 0.001 |
| communication | −0.004 | 0.857 |
| connection | −0.009 | 0.642 |
| control | 0.037 | 0.072 |
| device | 0.286 | 0.001 |
| diagnostic | −0.044 | 0.024 |
| information | 0.022 | 0.346 |
| message | 0.024 | 0.236 |
| mobile | 0.003 | 0.893 |
| network | 0.060 | 0.003 |
| receiving | 0.086 | 0.001 |
| request | 0.063 | 0.004 |
| service | 0.169 | 0.001 |
| signal | 0.019 | 0.440 |
| terminal | 0.219 | 0.001 |
| transmit | −0.154 | 0.001 |
| unit | 0.321 | 0.001 |
| user | 0.067 | 0.001 |
| vehicle | 0.152 | 0.001 |
| Independent Variable | Beta | p-Value |
|---|---|---|
| center | 0.124 | 0.001 |
| device | 0.285 | 0.001 |
| diagnostic | −0.045 | 0.001 |
| network | 0.061 | 0.019 |
| receiving | 0.101 | 0.002 |
| request | 0.063 | 0.001 |
| service | 0.171 | 0.003 |
| terminal | 0.220 | 0.001 |
| transmit | −0.134 | 0.001 |
| unit | 0.325 | 0.001 |
| user | 0.069 | 0.001 |
| vehicle | 0.165 | 0.001 |
| Independent Variable | Dependent Variable | |||||
|---|---|---|---|---|---|---|
| Device | Unit | Terminal | ||||
| Beta | p-Value | Beta | p-Value | Beta | p-Value | |
| center | −0.093 | 0.001 | 0.093 | 0.001 | 0.001 | 0.962 |
| diagnostic | 0.040 | 0.140 | −0.093 | 0.001 | 0.015 | 0.579 |
| network | 0.123 | 0.001 | 0.019 | 0.464 | 0.068 | 0.011 |
| receiving | 0.060 | 0.048 | 0.070 | 0.020 | 0.131 | 0.001 |
| request | −0.020 | 0.484 | 0.025 | 0.391 | 0.055 | 0.062 |
| service | 0.033 | 0.253 | 0.044 | 0.125 | 0.100 | 0.001 |
| transmit | 0.096 | 0.001 | 0.096 | 0.001 | 0.124 | 0.001 |
| user | 0.048 | 0.001 | 0.182 | 0.001 | 0.024 | 0.388 |
| vehicle | 0.016 | 0.001 | 0.079 | 0.005 | −0.053 | 0.066 |
| Dependent Variable | Selected Independent Variable |
|---|---|
| device | center, network, receiving, transmit, user, vehicle |
| unit | center, diagnostic, receiving, transmit, user, vehicle |
| terminal | network, receiving, service, transmit |
| Telematics | ||
|---|---|---|
| First | Second | Third |
| Terminal (0.422) | Unit (0.352) | Device (0.282) |
| First: user (0.195) | First: vehicle (0.147) | |
| First: receiving (0.133) | Second: transmit (0.106) | Second: user (0.138) |
| Second: transmit (0.130) | Third: center (0.103) | Third: network (0.125) |
| Third: service (0.113) | Fourth: diagnostic (−0.094) | Fourth: transmit (0.097) |
| Fourth: network (0.067) | Fifth: vehicle (0.087) | Fifth: center (−0.091) |
| Sixth: receiving (0.079) | Sixth: receiving (0.063) | |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, J.; Jun, S.; Park, S. A Patent Analysis for Sustainable Technology Management. Sustainability 2016, 8, 688. https://doi.org/10.3390/su8070688
Choi J, Jun S, Park S. A Patent Analysis for Sustainable Technology Management. Sustainability. 2016; 8(7):688. https://doi.org/10.3390/su8070688
Chicago/Turabian StyleChoi, Junhyeog, Sunghae Jun, and Sangsung Park. 2016. "A Patent Analysis for Sustainable Technology Management" Sustainability 8, no. 7: 688. https://doi.org/10.3390/su8070688
APA StyleChoi, J., Jun, S., & Park, S. (2016). A Patent Analysis for Sustainable Technology Management. Sustainability, 8(7), 688. https://doi.org/10.3390/su8070688