1. Introduction
Reliable and accurate subway ridership forecasting is beneficial for passengers and transit authorities. With the predicted passenger demand information, commuters can better arrange their trips by adjusting departure times or changing travel modes to reduce delay caused by crowdedness; subway operators can proactively optimize appropriate timetables, allocate necessary rolling stock and disseminate early warning information to passengers for extreme event (e.g., stampede) prevention. Existing studies mainly lie in long-term transit ridership prediction for public transport planning as the part of traditional four-step travel demand forecasting [
1]. The typical approach is to construct linear or nonlinear regression models between passenger demands and other contributing factors such as demographics, economic features, transit attributes, and geographic information [
2,
3,
4,
5,
6,
7,
8]. As indicated by Dill et al. [
9], most previous studies concentrate on route-level and segment-level ridership forecasting, and neglect the nature of spatial heterogeneity for different stations along the same route [
10,
11]. Moreover, long-term ridership forecasting mainly focuses on transportation planning and policy evaluation through analyzing the elasticity of passenger demand or identifying key influential factors related to transit ridership, but has the inherent disadvantage of not being able to capture the subtle and sudden changes caused by routine passenger flows and disruption in a much finer granularity.
To address the aforementioned issues, short-term ridership prediction approaches have emerged in the recent years with only a scarcity of studies. Tsai et al. utilized multiple temporal units neural network and parallel ensemble neural network to predict short-term railway passenger demands [
12]. Zhao developed a wavelet neural network algorithm for transit passenger flows in Jilin, China [
13]. Sun proposed a wavelet-SVM hybrid model to predict passenger flows in the Beijing subway system [
14]. Chen and Wei proposed to use the Hilbert-Huang transform to capture the time variants of passenger flow from a Bus Rapid Transit (BRT) line in Taipei [
15], and they further improved the short-term metro passenger flow prediction accuracy based on empirical decomposing and neural networks [
16]. Ma et al. proposed an Interactive Multiple Model-based Pattern Hybrid (IMMPH) approach to predict passenger flows using smart card data in Jinan, China [
17]. Later, Xue et al. extended the IMMPH model by incorporating seasonal effects and volatility of time series data [
18]. The majority of the existing short-term ridership forecasting approaches adopted the Computational Intelligence (CI) based algorithms (e.g., support vector machine and neural network) for prediction. These methods present great capability of analyzing highly nonlinear and complex phenomena with less rigorous assumptions and prerequisites than statistical models, and often yield more accurate prediction outcomes [
19]. However, the explanatory power of CI-based approaches is criticized for weak interpretation and inference capabilities [
20,
21].
In the context of subway ridership prediction, the passenger demand is influenced by a wide range of attributes categorized as external and internal factors [
2]. External factors mainly refer to those contributing variables that are outside subway systems, such as employment, land use and population, while the internal factors are determined by transit authorities, such as fares and transit service. The vast majority of previous subway ridership prediction studies either established multivariate regression models with a combination of external and internal factors (for long-term prediction) [
2], or resorted to historical passenger flows for short-term ridership prediction. Very rare literatures take into account the interaction between internal factors and external factors for subway ridership prediction and interpretation. As one of the most representative variables for this interaction, intermodal transfer activities generate a positive impact on subway ridership [
5,
6]. Depending on the various land uses, the increase of subway ridership may be largely attributed to surface public systems since a large number of passengers have to walk access subway services after alighting from buses [
22]. This is especially true in the metropolitan cities, where transfer activities play a significant role in multimodal public transit systems [
23]. How the transfer ridership from feeder buses contributes to the evolution of subway passenger flows remains unclear, and is worth being investigated.
This study aims to bridge this gap by considering the access trips generated from adjacent bus stops in short-term subway ridership forecasting. A Gradient Boosting Decision Trees (GBDT) approach is proposed to capture the subtle and sudden changes of short-term subway ridership based on a series of influential factors. Different from traditional CI-based algorithms and classic statistical methods, GBDT can strategically combine several simple tree models to achieve optimized prediction performance while interpreting model results by identifying the key explanatory variables [
24]. In addition, GBDT poses few restrictions and hypotheses on input data and thus is very flexible to deal with complex nonlinear relationship. These features enable GBDT to be a suitable countermeasure to predict and explain the high variability and randomness of subway passenger flows. In this study, a series of spatial and temporal factors, including historical passenger flows, time of day and transfer ridership generated by feeder buses, are incorporated into the GBDT model for short-time subway ridership. Significant relevant variables and the degree of how these variables impact future subway ridership can be identified and computed. To further demonstrate the transferability and accuracy of the proposed prediction algorithms, three subway stations with different land uses are tested to explain spatial heterogeneity. Such an approach contributes to the current literature on understanding the interaction between transfer connectivity and subway ridership forecasting in a multimodal public transit system.
The remainder of this paper is organized as follows:
Section 2 describes the methodology of GBDT and documents the context of using GBDT for short-term subway ridership prediction.
Section 3 presents the background of Beijing subway system with a detailed explanation of potential influential variables. Model analysis results and discussion are demonstrated in
Section 4, and followed by conclusion and future research directions at the end of this paper.
3. Data Sources and Preparation
The Beijing subway network has been expanding from 4 lines with 114 km in 2006 to 16 lines with 442 km in 2012, leading to a sudden increase of daily ridership from 1.93 million to 6.74 million [
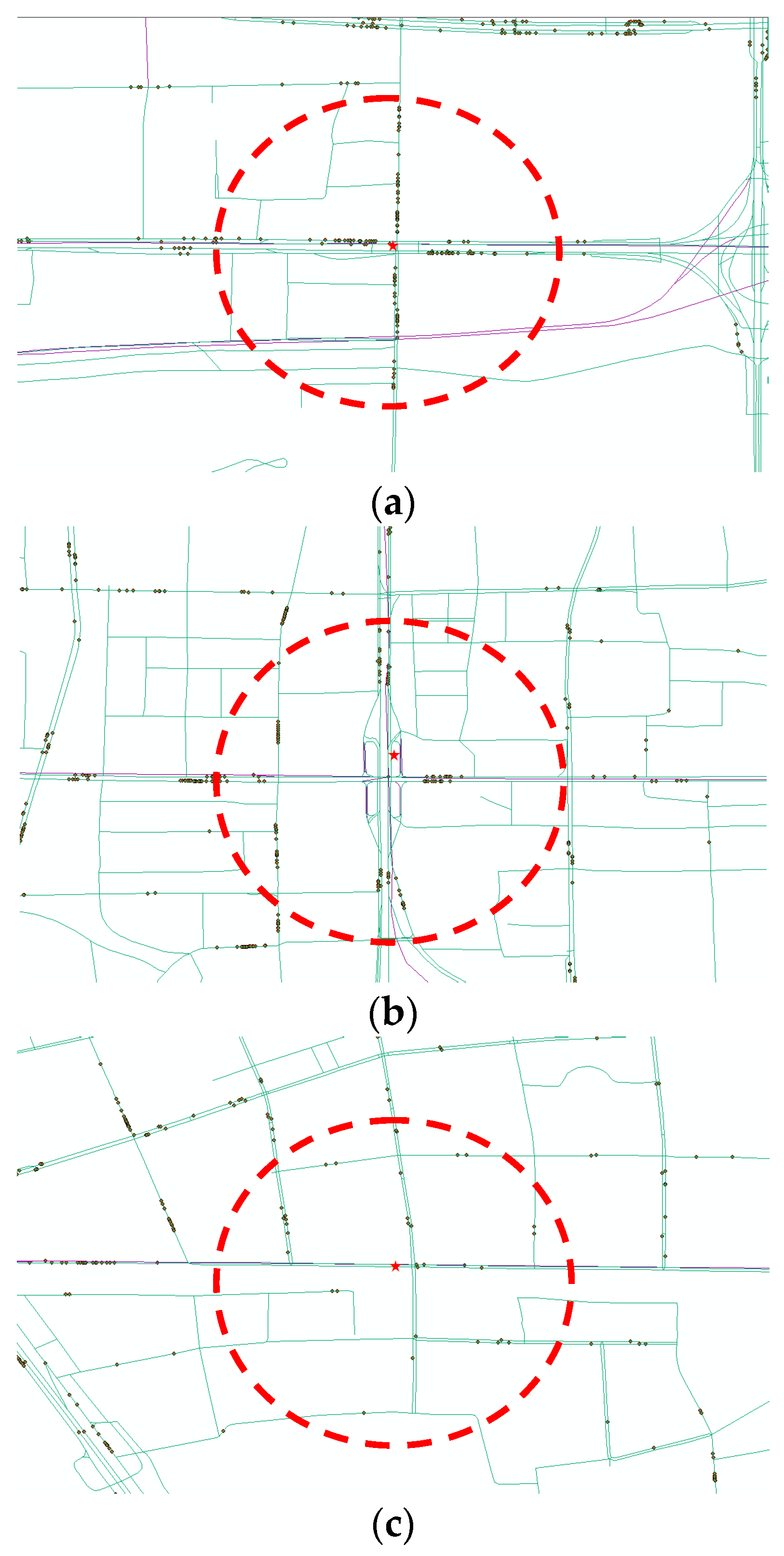
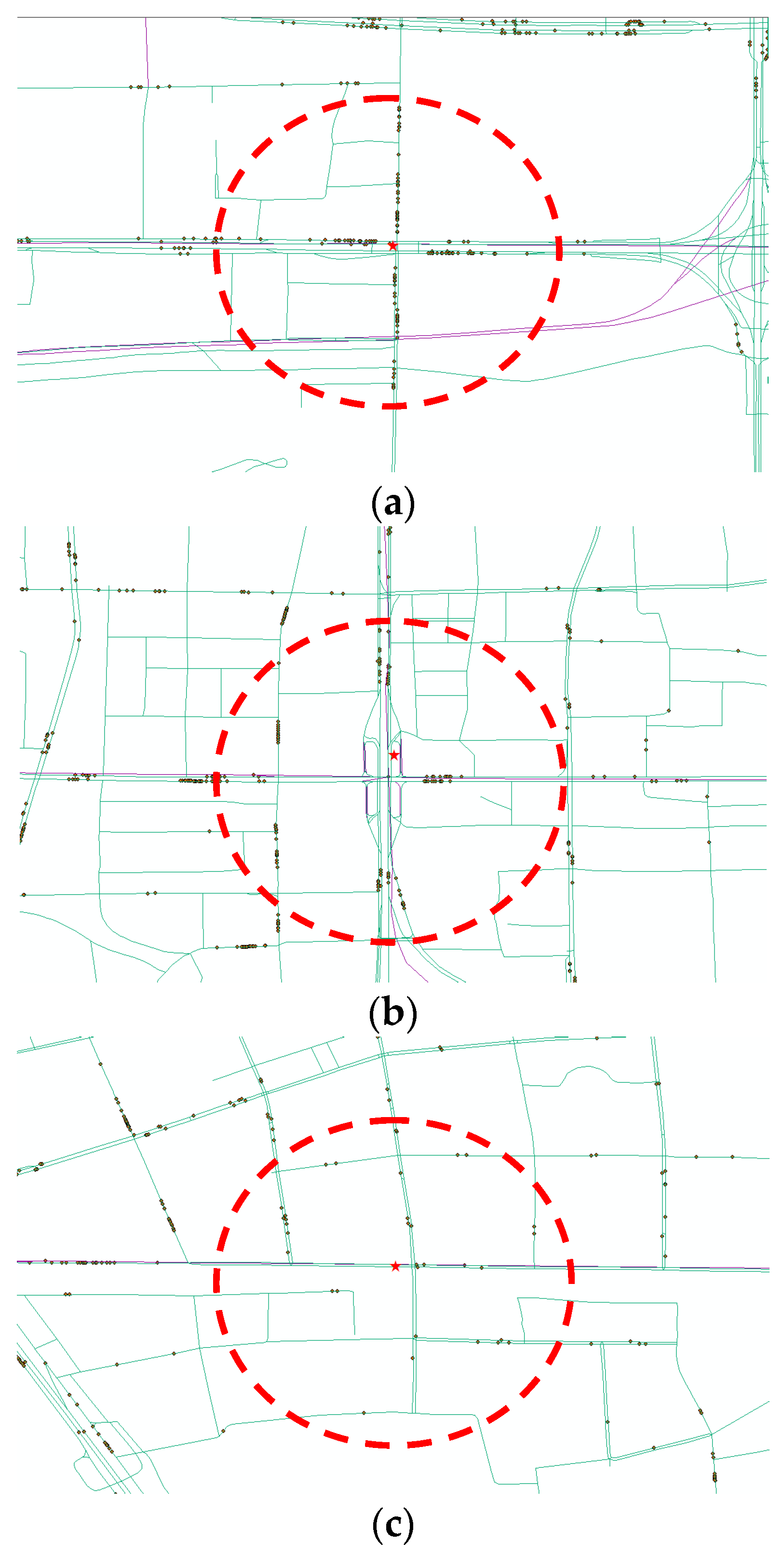
34]. Such a burst of ridership stimulates several critical issues such as crowdedness in trains and insufficient capacity of transferring channels between different lines. To balance the overwhelming passenger demands and limited capacity of subway facilities, 51 subway stations began to restrict passengers’ access during certain time periods (e.g., morning and evening peak hours) in 2015. Among these stations, Da-Wang-Lu (DWL) station, Fu-Xing-Men (FXM) station and Hui-Long-Guan (HLG) station are the three most representative ones with high passenger demands in the Beijing subway system. This is owing to the surrounding land use and built environment attracting a significantly large number of passengers: The DWL station locates in the area of Central Business District (CBD) in Beijing with a wealth of Fortune 500 enterprises and shopping malls, and it also serves as a multimodal transfer hub that embraces multiple bus stops, which connects numerous commuters living in suburban to work in other districts via subway systems. The FXM station sits along the Beijing Financial Street, which is considered as one of the most significant streets in Beijing. A number of foreign and domestic financial companies and government agencies are located around the FXM station. Due to the limited parking space, the majority of commuters take the subway or bus for working in those institutions. Different from the FXM and DWL stations, the HLG station is located in a suburban residential area, where a myriad of residents live and commute to downtown on a daily basis. The layout of the three stations is presented in
Figure 2, where the red pentagram indicates the target subway stations (DWL, FXM and HLG) and black dots represent the adjacent bus stops. In the field of transportation and urban planning, the 500-m circle around the subway station is generally seen as the best transit catchment [
35,
36]. This respectively yields 35, 26 and 15 transfer bus stops that are within passenger walking distances for DWL, FXM and HLG stations.
The acquisition of transit ridership relies on Automatic Fare Collection (AFC) techniques (also known as Smart Card). Transit smart cards have been issued in Beijing bus and subway systems since 2006 with 50% fare reduction for adults and 75% fare reduction for students. Such a substantial fare promotion quickly stimulates the wide usage of smart cards, and more than 90% passengers are smart card holders [
37]. Transit fares on all routes (for bus and subway) have changed to distance-based schedules since December 2014, where passengers have to swipe their cards twice, with both boarding and alighting stops recorded. Prior to 2014, more than half of buses implemented the flat-fare strategy: Passengers are only required to tap the cards on boarding, and thus leave no alighting information for these buses. For other buses and subway systems, distance-based fare collection methods were adopted. The dataset used in this study was collected from the DWL, FXM, HLG subway stations and its adjacent bus stops between July 2012 and November 2012. The alighting stops for those flat-fare based buses can be properly inferred by using the approach proposed by [
23,
24], and the number of passengers transferring from buses to subway can then be estimated by counting the alighting passengers. Similarly, the subway ridership can be calculated based on the smart card transactions entering the station. Both bus ridership and subway ridership is aggregated to the interval of every 15 min. The setting of 15 min is attributed to the common practice of computing peak 15-min rate of passenger flow [
38].
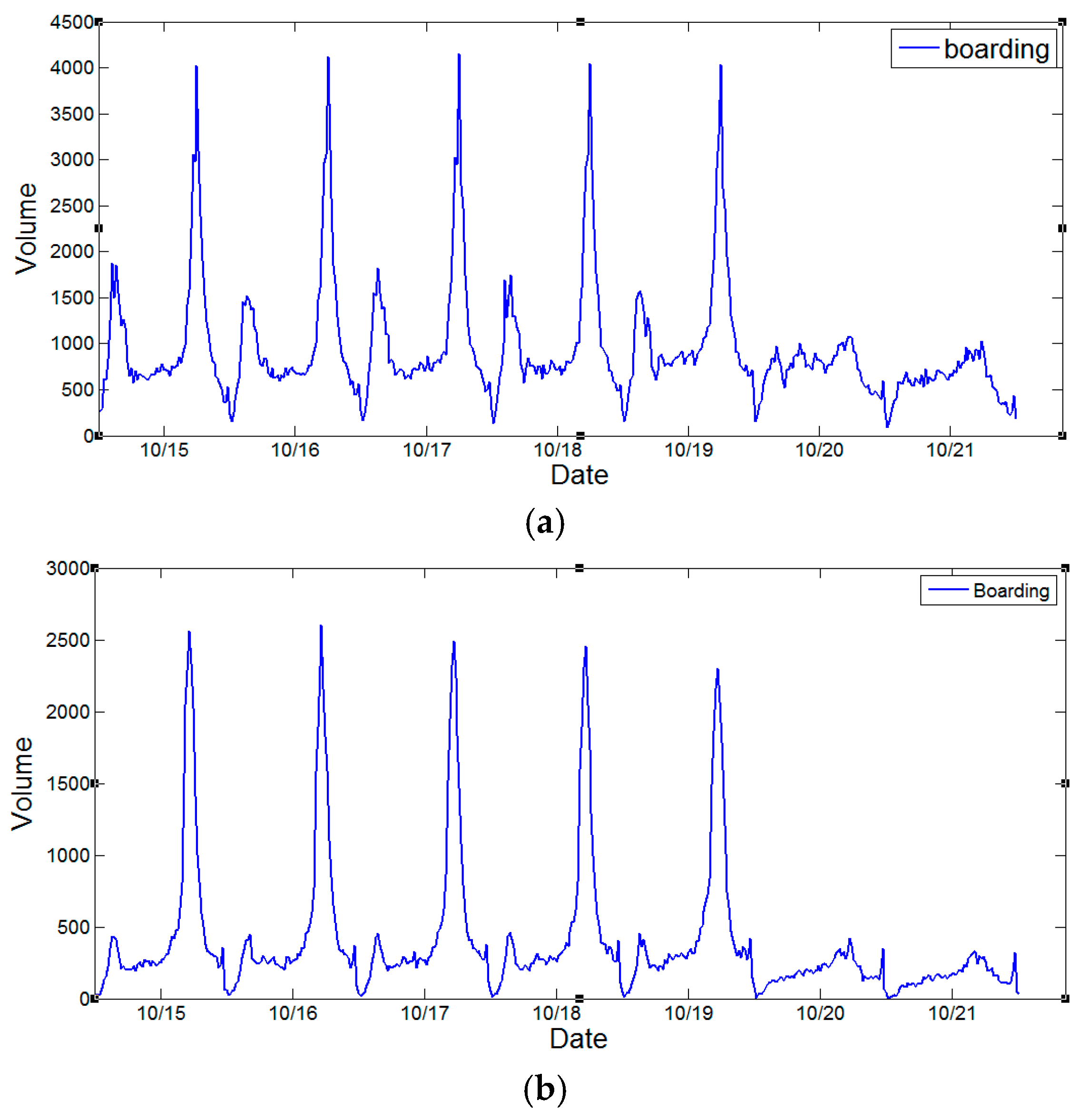
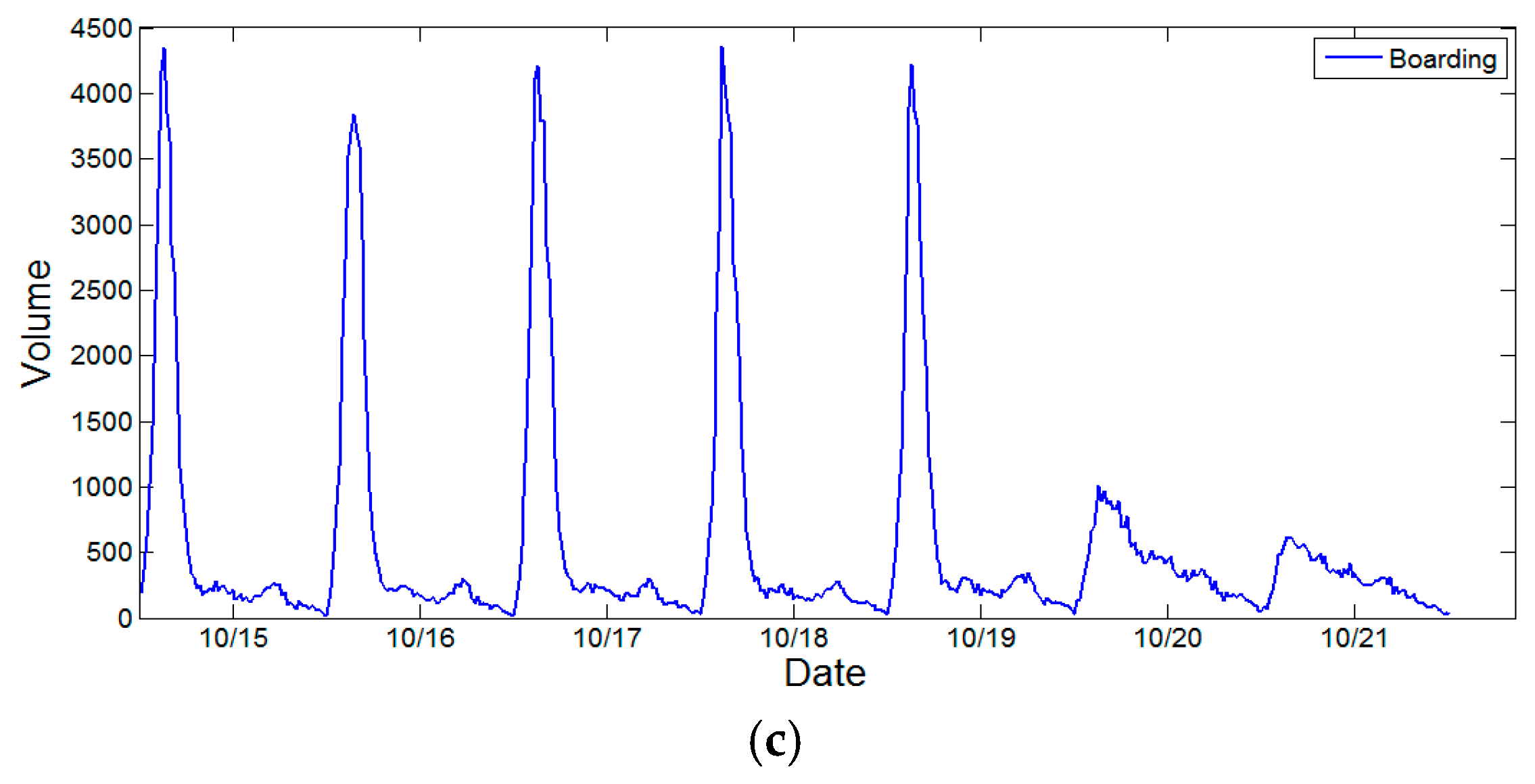
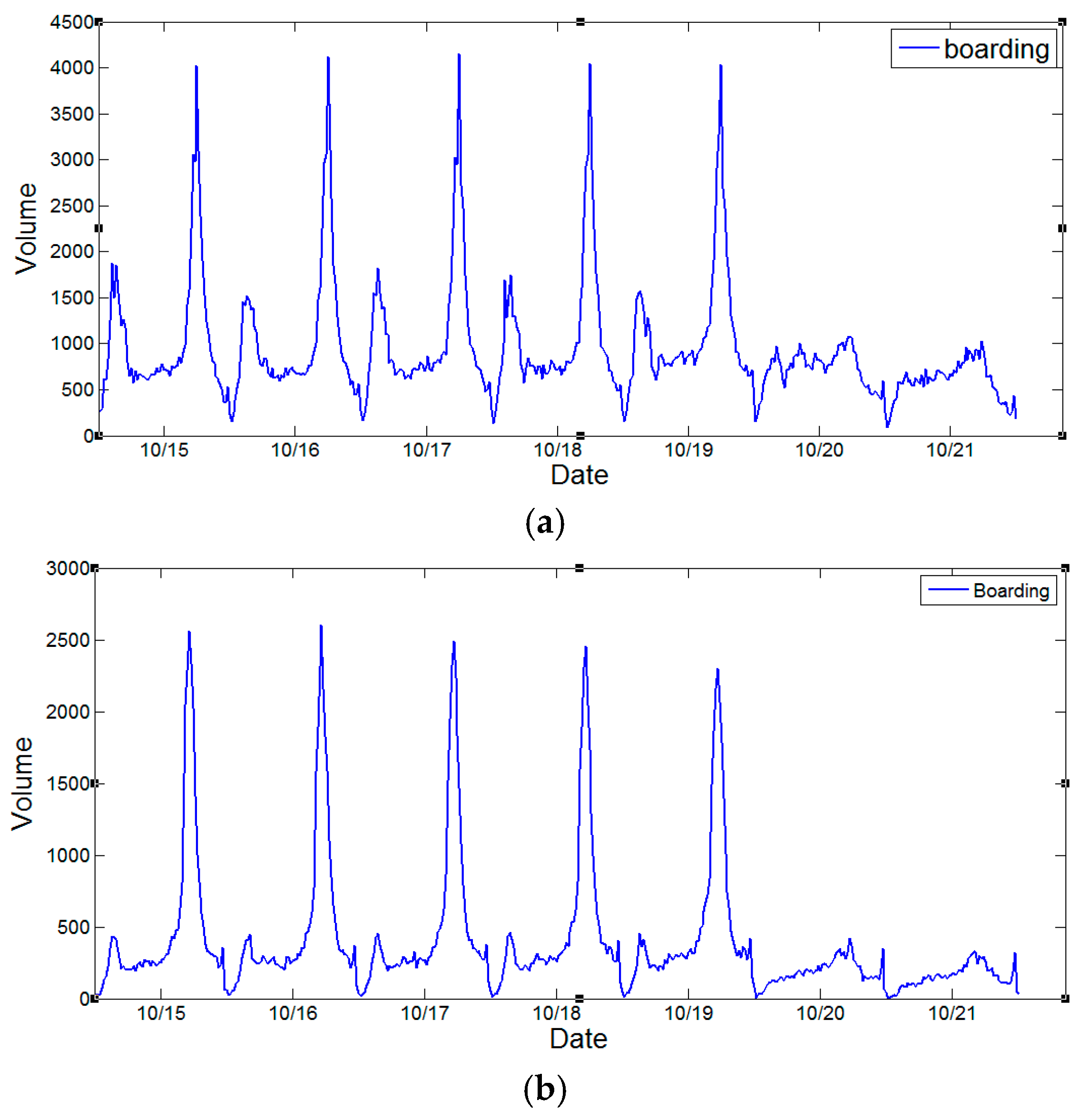
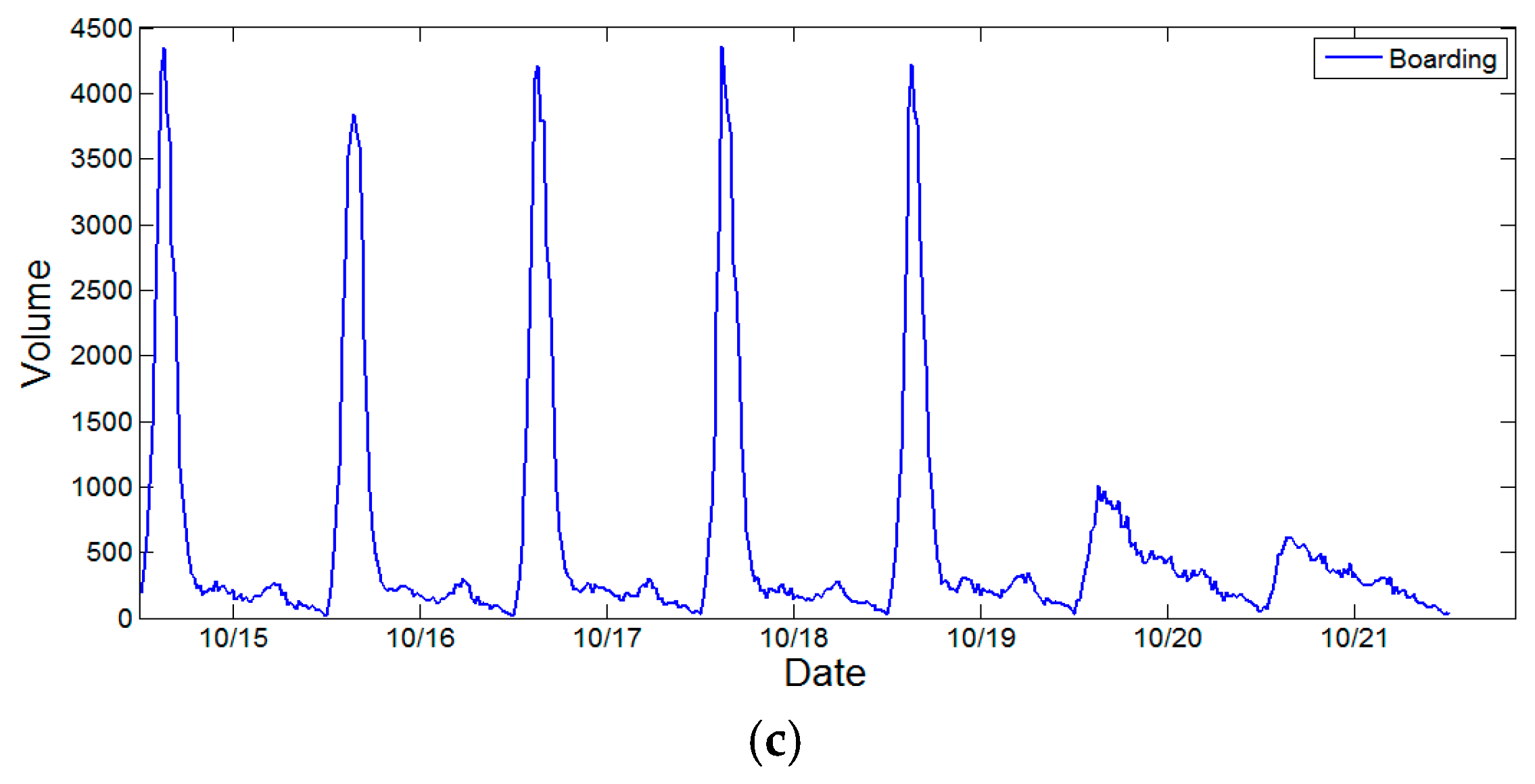
Figure 3 demonstrates the weekly ridership changes at DWL, FXM and HLG stations from 15 October 2012 to 21 October 2012. For each date, the service time of subway system is from 5:00 a.m. to 11:55 p.m. The temporal distributions of subway ridership for different station vary. For DWL station, ridership exhibits a dual-peak effect since most commuters need to transfer in DWL station. For FXM station, most boarding activities occur during evening peak hours rather than morning peak hours. This is because the FXM station is adjacent to a large business and financial center, where people need to take the subway returning home in the evening. The temporal distribution of ridership in HLG station presents a reverse pattern compared with that of FXM station. The surrounding land type is residential, and thus commuters can walk to the subway station for work in the morning. However, these trends become less obvious during weekends since few people need to work on those days.
Based on the aforementioned discussion, the multimodal transfer activities are found to be strongly associated with subway ridership. Therefore, the numbers of alighting passengers at time steps
t,
t − 1,
t − 2,
t − 3 from adjacent bus stops are respectively selected as the primary independent variable with the underlying assumption of at most one-hour transfer time from buses to the subway system. Additionally, the three most relevant subway passenger demands at time steps
t − 1,
t − 2,
t − 3 are used as inputs since the current subway ridership has strong correlations with the past ridership within one hour. Temporal factors such as time of day, day, week and month are also incorporated in the prediction model.
Table 1 provides the overall description of candidate predictor variables for short-term subway ridership in this study.
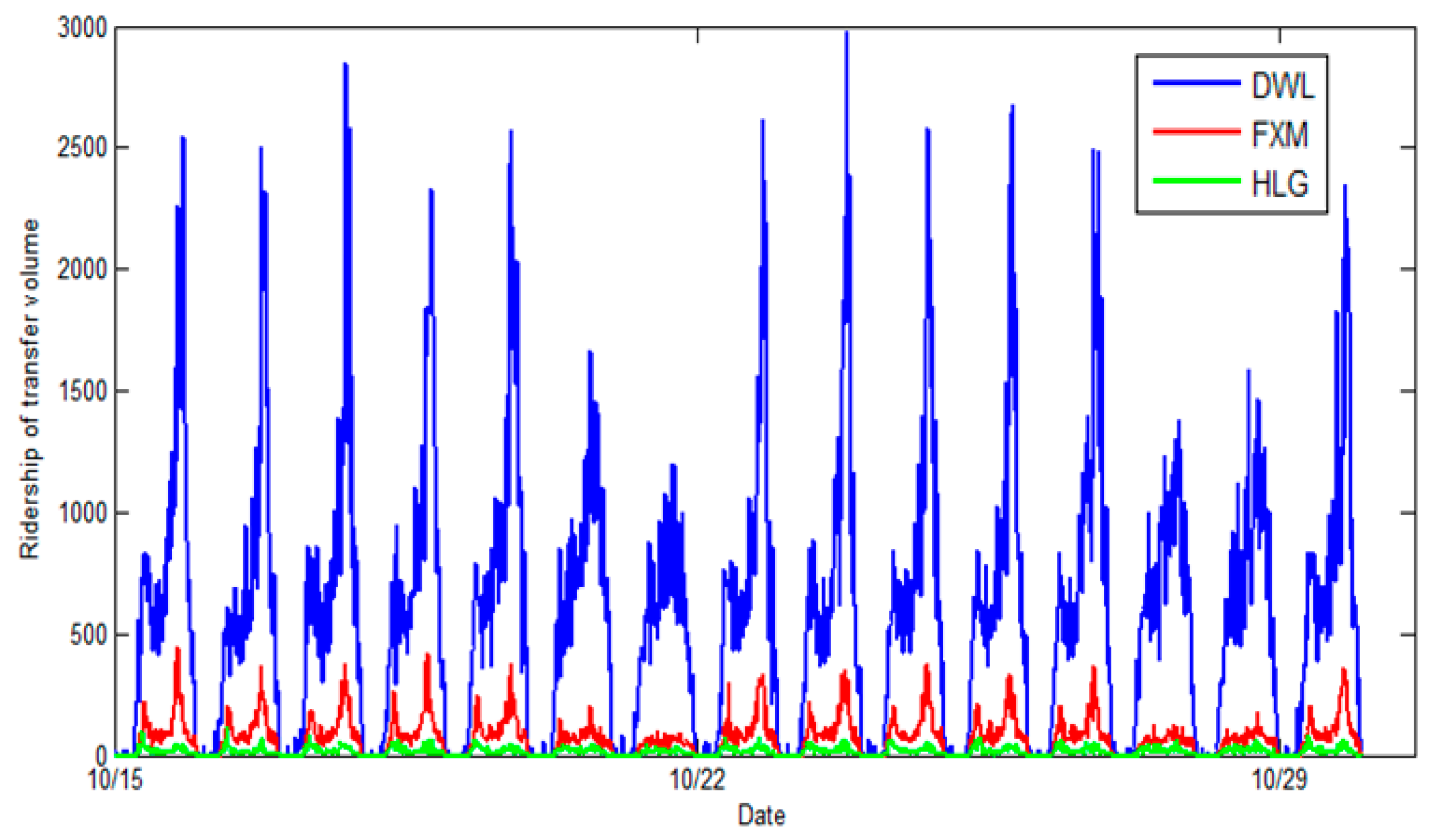
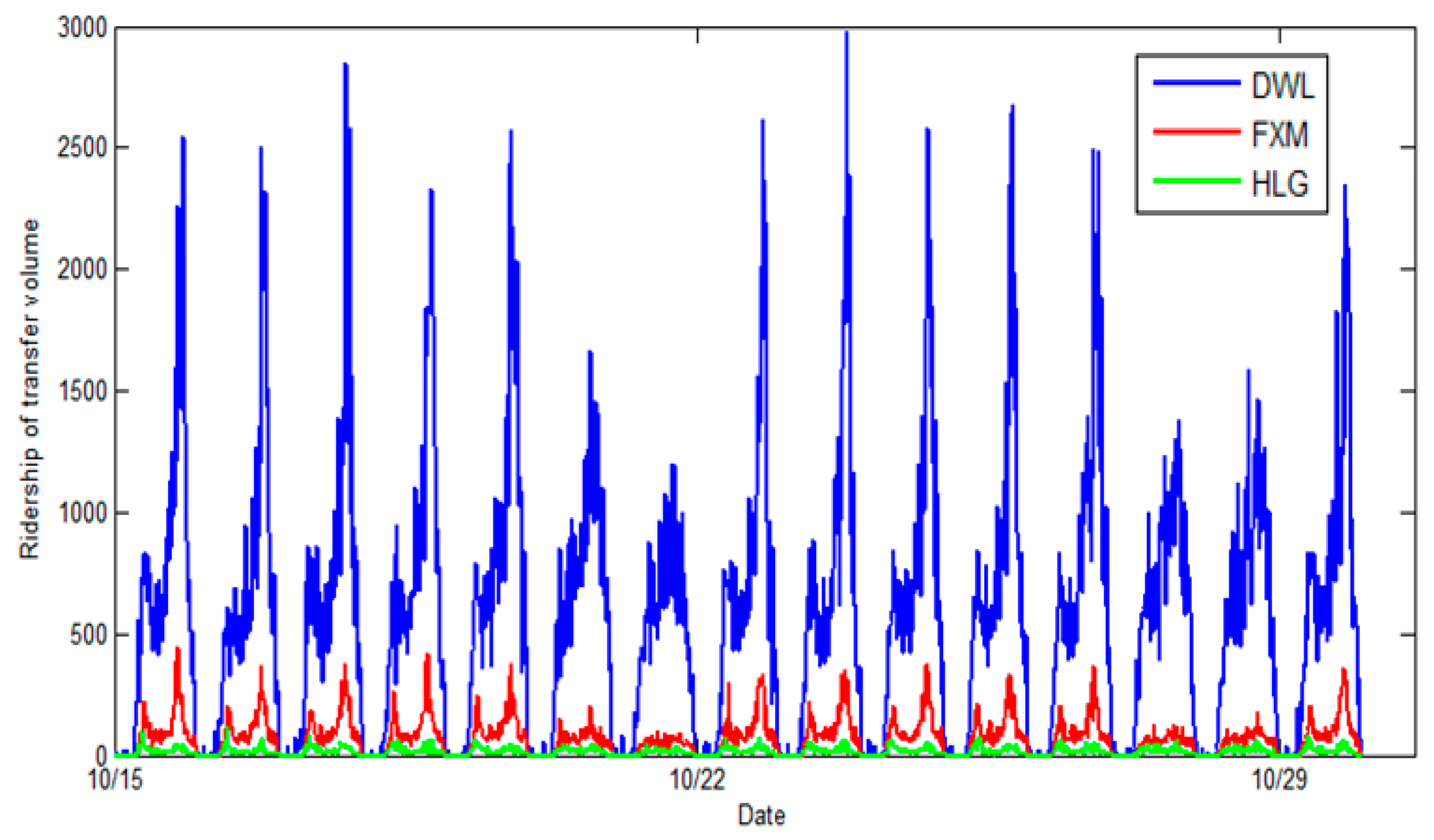
We also investigate the relationship between subway ridership and transfer passenger flows from buses.
Figure 4 demonstrates the weekly ridership changes of the transfer volumes from buses at the three subway stations. The trends are consistent with
Figure 3, indicating that the bus transfer activities are highly coupled with the subway ridership.
Table 2 computes the correlation coefficients between two variables (subway ridership and transfer volumes from buses). The level of correlation decreases as the time step increases.
4. Model Results
4.1. Model Setup
In this study, bagging is the variation used on the boosting algorithm. For the gradient boosting algorithm, only a random fraction of the residuals is selected to build the tree in each iteration. Unselected residuals are not used in that iteration at all [
31]. The randomization is considered to reduce the variation of the final prediction without affecting bias. While not all observations are used in each iteration, all observations are eventually used across all iterations. Bagging with 50% of the data is generally recommended [
29,
30].
For the performance of short-term subway ridership modeling, the pseudo-
R2 is used as the measures in this study. Gradient boosting process determines the number of iterations that maximizes the likelihood or, equivalently, the pseudo-
R2. The pseudo-
R2 is defined as
R2 = 1 −
L1/
L0, where
L1 and
L0 are the log likelihood of the full model and intercept-only model, respectively. In the case of Gaussian (normal) regression, the pseudo-
R2 turns into the familiar
R2 that can be interpreted as “fraction of variance explained by the model” [
31]. For Gaussian regression, it is sometime convenient to compute
R2 as follows:
where
and
refer to the variance and mean squared error, respectively.
T is the number of test samples,
f(
xi) is the model prediction, and
is the mean of the test samples. In this study, the test
R2 is calculated on the test data based on the training model.
The data in this study is divided into three subsets: 50% of the total samples were used for model training, 25% of the total samples were used as validation dataset for model selection, and the remaining 25% were used as test dataset to assess the model performance.
4.2. Model Optimization
To validate the model performance of different combination of regularization parameters, a series of GBDT models are built with various learning rate (ξ = 0.10–0.001), tree complexity (C = 1, 2, 3, 4, 5) by fitting a maximum of M = 30,000 trees. In the gradient boosting process, the maximum number of trees is specified in this study, and the optimal number of trees that maximizes the log likelihood on a validation dataset is automatically found. Therefore, in this study the number of trees is not controlled, since an optimal solution has been achieved. For the three subway stations, the performance of GBDT models based on different combination of regularization parameters are described in the following tables. Meanwhile, given the different combination of shrinkage and tree complexity, the optimal number of trees for each model at which the minimum error is achieved is also found. In this case, if the number of trees continues to increase, then the over-fitting issues will arise.
Using the validation dataset, the influence of the shrinkage parameter on model performance can be seen in
Table 3,
Table 4 and
Table 5. For a given tree complexity, increasing the value of the shrinkage parameter will need fewer trees and less computational time to achieve its minimum error. This is due to the fact that a higher value of shrinkage parameter can increase the contribution of each tree in the model thereby needing fewer trees to be added. Depending on the tree complexity and number of trees, the optimal shrinkage parameter varies. Generally, as shrinkage parameter decreases, the model will obtain a better performance. However, when the value of shrinkage parameter reaches to a certain level, the model performance begins to deteriorate. Taking DWL subway station as an example, the model performance with
C = 1 becomes better as the shrinkage parameter value decreases from
ξ = 0.10 to
ξ = 0.01. However, decreasing the value of shrinkage parameter from
ξ = 0.01 to
ξ = 0.001 leads to a worse result. To gain a better model performance, a reasonable combination of shrinkage parameter and number of trees is preferable. It should be noted that * indicates the optimal number of trees is larger than the given maximum value, and
R2 did not reach its best value in following tables.
The impact of tree complexity on model performance can also be quantified through
Table 3,
Table 4 and
Table 5. For a given shrinkage parameter, increasing the value of tree complexity will generally lead to a more complex model, and thus requires fewer trees for a minimum error. Controlling the value of shrinkage parameter and number of trees, the computational time will increase as the level of tree complexity increases. Therefore, the final computational time depends on the tree complexity and optimal number of trees. Generally, the model will obtain better performance as the tree complexity increases. Taking DWL subway station as an example, the model performance becomes better with
ξ = 0.10 when the tree complexity increase from
C = 2 to
C = 5. This is due to the fact that a higher level of tree complexity can capture more detailed information from the dataset. However, the improvement of model performance is not sensitive after the value of tree complexity reaches a certain level. Therefore, the model performance and computational time should be balanced.
Table 3,
Table 4 and
Table 5 present the model performances for the DWL, FXM and HLG subway stations. By comparing the model results and computational time, the best model performance for the three subway stations can be acquired, which are in bold. For the DWL subway station, the best performance is obtained at the shrinkage parameter of 0.05 and tree complexity of 5 with an optimal ensemble of 604 trees. Similar to the FXM subway station, the best model performance occurs at the shrinkage parameter of 0.01 and tree complexity of 5 with an optimal ensemble of 2912 trees. With regards to the HLG subway station, the model reached its best performance with the shrinkage parameter of 0.10, tree complexity of 3, and optimal ensemble of 217 trees. The final
R2 for the three optimal models are 0.9806, 0.9893 and 0.9916, respectively. This indicates a good prediction accuracy since the GBDT model is able to handle different types of predictor variables, capture interactions among the predictor variables and fit complex nonlinear relationship [
39]. Hence, in this study the GBDT model can handle the nonlinear features of short-term subway ridership and leads to superior prediction accuracy. Similar studies on gradient boosting trees in travel time prediction [
24] and auto insurance loss cost prediction can be also found [
32].
4.3. Model Comparison
To examine the effectiveness of GBDT model used for station-level short-term subway ridership prediction, a comparison was conducted with several conventional techniques including BP-neural network, support vector machine (SVM) and random forest (RF). For BP-neural network, the learning rate is set as 0.1, and the optimal number of hidden layer neurons is calculated as 3 by using the empirical equation in [
40]. For SVM, the Radial Basis Function (RBF) is selected as the kernel function. Through the three-fold cross-validation, the gamma parameter of the RBF is computed as 0.125, 1, and 0.5 for DWL, FXM and HLG stations, respectively, and the soft margin parameter C is calculated as 1. For RF, the number of tress grown is 500, and the number of predictors sampled for splitting at each node is determined as 2.
Table 6 shows the comparison results for the DWL, FXM and HLG subway stations, respectively. In this study, root mean squared error (RMSE) is used additionally with
R2 as the model performance indicators. Lower RMSE value or higher
R2 value means higher accuracy. The RMSE is defined as follows:
where
N is the number of test samples,
is the predicted values, and
is the observed values.
A statistical test is performed to evaluate the statistical significance of the results. By comparing the results of different prediction techniques, we can see that the GBDT model is statistically different to any of other techniques, and receives the best model performance for all the three stations. Overall, the GBDT model outperforms the other three models in station-level short-term subway ridership prediction in terms of both RMSE and R2 measurements. As another ensemble learning method, Random Forest yields the best prediction results among other three approaches excluding GBDT with at most 36% increase of the RMSE value. On the contrary, SVM receives the worst performance for subway ridership prediction at the three stations. This finding further confirms the advantage of GBDT model in modeling complex relations between subway boarding ridership and bus transfer activities.
4.4. Model Interpretation
To explore the different influences of predictor variables on short-term subway ridership among the DWL, FXM and HLG subway stations, the relative contributions of predictor variables for the three subway stations were calculated using the optimal models as shown in
Table 6, respectively. A higher value of relative importance indicates stronger influences of predictor variables in predicting short-term subway ridership.
As shown in
Table 7, each predictor variable has a different impact on short-term subway ridership. For all the three subway stations, the immediate previous subway ridership METRO
t−1 contributes most in predicting short-term subway ridership with a relative importance of 82.03%, 85.06% and 92.28% for the three subway stations, respectively. This finding falls within our expectation that the immediate previous ridership is closely related with the current subway ridership. The current bus alighting passengers BUS
t, with a contribution of 9.41%, 4.42% and 0.08% to the short-term subway ridership prediction, respectively ranks the second, third and eighth most influential predictor variable for the DWL, FXM and HLG subway stations. This result indicates that the bus transfer activities around the DWL subway station have the most potentially significant effects on the subway ridership, and the bus transfer activities around the HLG subway station have little effects on the subway ridership. This is consistent with the fact that the DWL subway station is an important transfer station, and a number of residents live around the HLG subway without needing transfer. For FXM station, bus transfer activities contribute less than 5% of ridership. This is because the station is actually within walking distance of Beijing Finance Street, where office workers can directly take subway for commuting. Meanwhile, 26 bus stops are around FXM station, and these stops still transfer a certain amount of passengers to the subway system.
Another interesting finding relates to the influence of time of day on short-term subway ridership. For the three subway stations, the influence of time of day contributes 3.55%, 7.59% and 6.54% to the short-term subway ridership, respectively. The factor of time of day is associated with the periodic feature of subway ridership: subway ridership is usually high during peak hours and maintains at a moderate level of ridership during non-peak hours. This finding confirmed the important role of time of day in predicting subway ridership. Among other variables, the short-term subway ridership at time step t − 2 METROt−2 and at time step t − 3 METROt−3 have slightly over 1% of contributions in predicting subway ridership for the DWL subway station, while their contributions become less than 1% for the FXM and HLG subway stations.
5. Summary and Discussion
Public Transportation plays an important role in reducing fuel consumption, lowering vehicle emissions and alleviating traffic congestion. As reported in Park and Lee’s study, a strong positive relationship between bus ridership and airborne particulate matter (PM10) can be found [
41]. Therefore, maximizing transit ridership will ultimately improve air quality. This study ranks the potential influential factors on subway ridership, and investigates how varying the built environment impacts on passenger transfer activities to subway systems. The research outcomes provide useful information to design and optimize public transit facilities for attracting more passengers from private cars to the public transport mode, and are expected to enhance the sustainability of the transportation system.
This study contributes to improving short-term subway ridership prediction, accounting for bus transfer activities in a multimodal public transit system. The GBDT model is proposed to handle different types of predictor variables, fit complex nonlinear relationships, and automatically disentangle interaction effects between influential factors. Three subway stations with different land uses are selected to explain the spatial heterogeneity. For each station, the short-term subway ridership and bus alighting passengers are obtained based on the transit smart card data. Moreover, a series of temporal factors are incorporated into the GBDT model for short-time subway ridership. The models were built with various learning rates and tree complexities by fitting a maximum of trees.
In this study, the optimal GBDT model for each station was found by balancing algorithm effectiveness and efficiency. Our study showed that the GBDT model has superior performance in terms of prediction accuracy and model interpretation power. This is different from the traditional computational intelligence algorithms (e.g., SVM, neural networks, and random forest)—“black-box” procedures—and the relative influences of predictor variables on short-term subway ridership predictions can be identified based on the optimal GBDT model. It is greatly helpful to better understand the contribution of bus transfer activities and temporal factors on subway ridership prediction. For all three stations, the immediate previous subway ridership and time of day were found to generate the most important influence on short-term subway ridership prediction. The relative influences of bus transfer activity variables on short-term subway ridership were shown to be different according to various land uses associated with subway stations. For example, the bus transfer activities around the DWL subway station were found to yield more influences on short-term subway ridership than HLG station. These examples show that the GBDT model has the advantage of incorporating different types of predictor variables, capturing complex nonlinear relationship, and providing the relative importance of influential factors. Therefore, the GBDT model can also be applied in the field of travel time prediction, travel flow prediction, etc.
The proposed short-term subway ridership forecasting method can be applied to quantify the impact of subway ridership burst under special events. Large events (e.g., concerts or soccer games) lead to non-habitual passenger demands and may exceed the designed capacity of subway system. If the contribution of buses on subway ridership is identified, more rational and timely management strategies can be then be adopted, such as real-time train timetable adjustment and demand-driven feeder bus allocation. This is especially useful for both operators and travelers to avoid overcrowding. Meanwhile, forecasting subway ridership in the context of bus transfer activities provides insightful evidences for subway system planning. Instead of focusing on the absolute ridership during peak hours, the attractiveness to other transportation modes should be also taken into account for subway station design. One limitation of the GBDT model in this study that should be noted is that the statistical significance for influential factors cannot be captured. Further studies can be made to extend the use of the advanced GBDT model for discrete response variables such as travel model choice.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}