Statistics for Categorical Surveys—A New Strategy for Multivariate Classification and Determining Variable Importance

Abstract
:1. Introduction
2. Methods
Statistical Methods
- Clustering HH: (i) Use a proximity metric appropriate for mixed data types and (ii) create clusters using a method that prevents HH groupings with large size differences
- Apply a decision tree analysis for allocation of new HH into clusters
- Extract most important variables from the HH clusters for visual inspection using an extended random forest approach
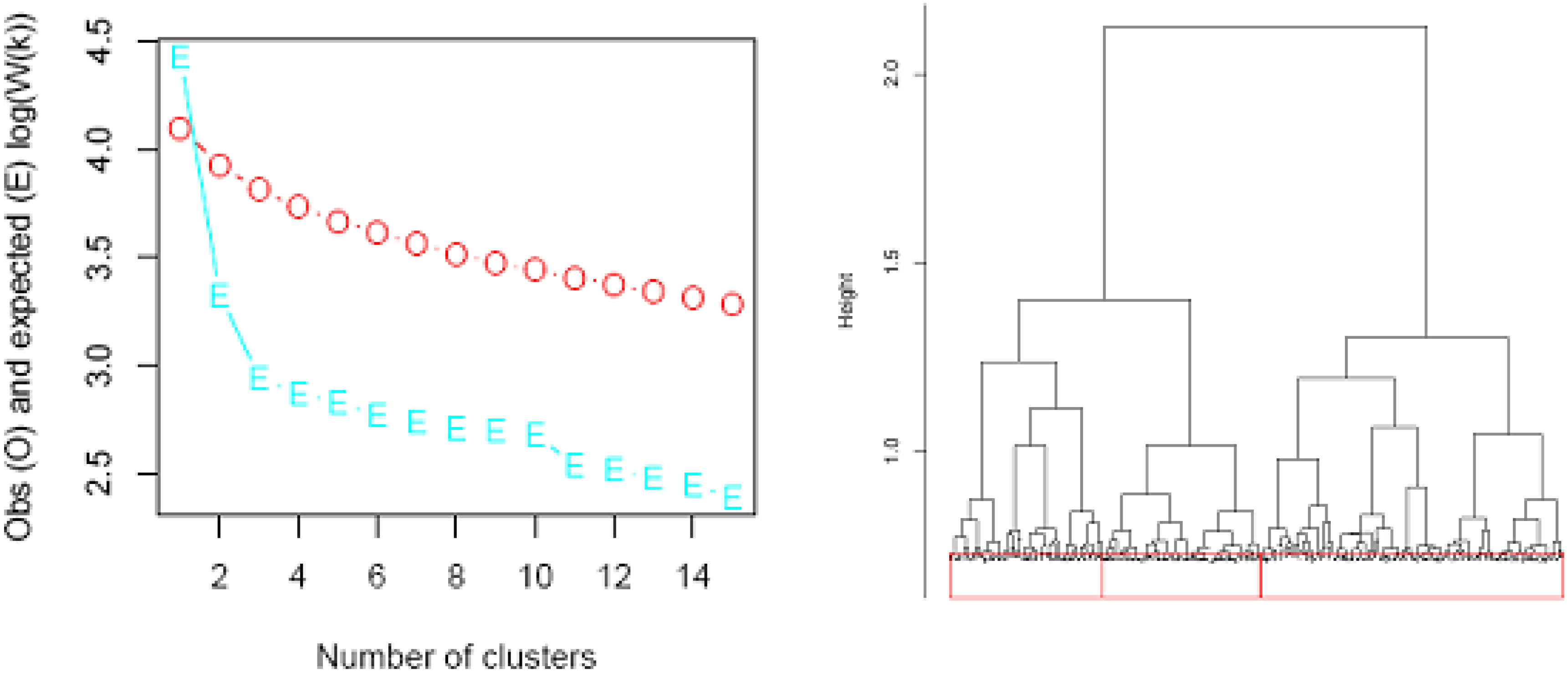
Clustering households

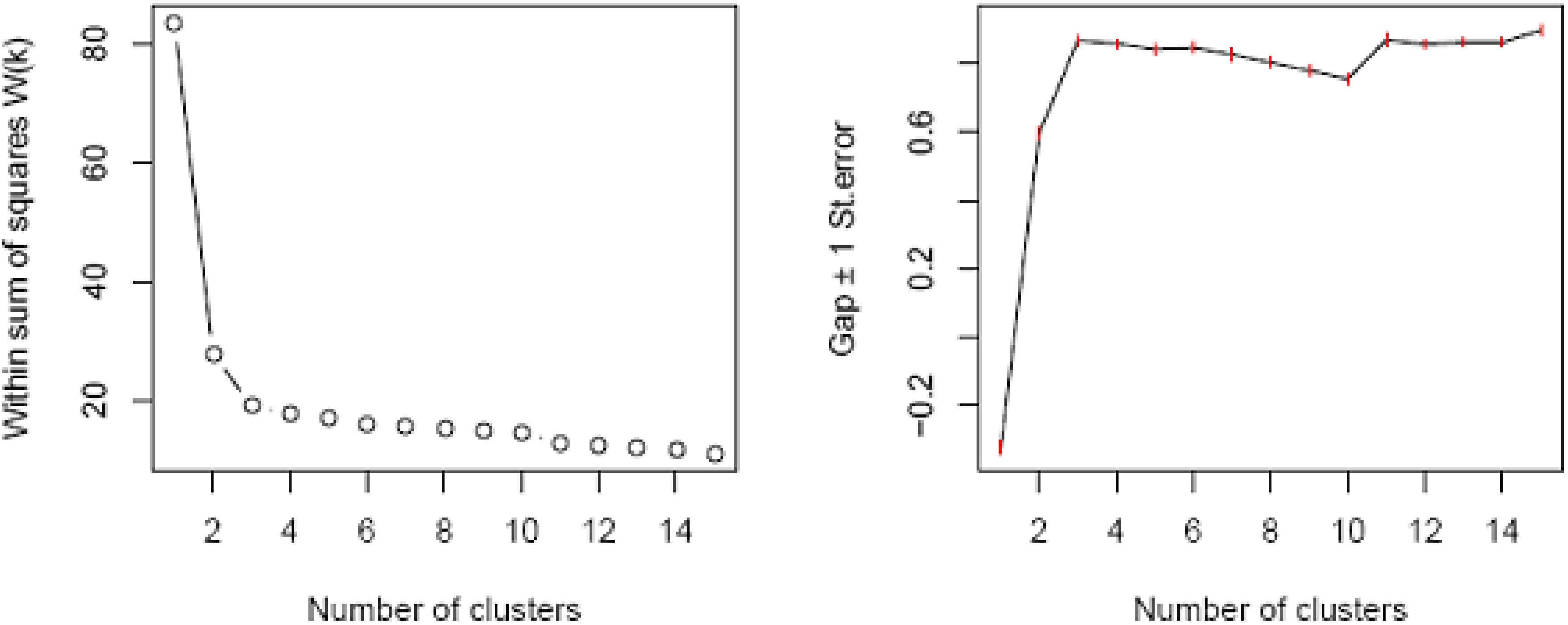{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of variables | Cophenetic Correlation Coefficient | Variables added |
|---|---|---|
| 1 | Initial variable | Other.assets |
| 2 | 0.99 | Recreation.income |
| 3 | 0.98 | Daily.wage.rate |
| 4 | 0.96 | People.in.HH |
| 5 | 0.94 | Car.truck |
| 6 | 0.92 | Kerosene.stove |
| 7 | 0.89 | Children.7.16.years |
| 8 | 0.86 | Honey.income |
| 9 | 0.83 | Income.per.wage.earner |
| 10 | 0.81 | Woodfuel.stove |
| 11 | 0.78 | total.monthly.workdays |
| 12 | 0.76 | Air.conditioner |
| 13 | 0.73 | Wild.pig.income |
| 14 | 0.71 | Total.years.education |
| 15 | 0.70 | Born.in.East.Kalimantan_new |
| 16 | 0.82 | Born.in.Kalimantan |
| 17 | 0.84 | Born.in.district_new |
| 18 | 0.85 | Refrigerator.freezer |
| 19 | 0.84 | Fishing.boat |
| 20 | 0.83 | Rattan.income |
| 21 | 0.82 | Motorbike |
| 22 | 0.82 | Children.under.7 |
| 23 | 0.81 | Ethnic.group |
| 24 | 0.80 | Days.worked.past.month |
| 25 | 0.79 | Months.of.work |
| 26 | 0.78 | Total.monthly.wage.income |
| 27 | 0.78 | House |
| 28 | 0.77 | Boat.engine. |
| 29 | 0.76 | .Wage.earners |
| 30 | 0.75 | Social.networks.income |
| 31 | 0.74 | maxdisttravelled |
| 32 | 0.73 | Small.TV |
| 33 | 0.73 | Fruit.tree.income |
| 34 | 0.72 | Handphone |
| 35 | 0.71 | Fish.income |
| 36 | 0.70 | HHincome.per.person |
| 37 | 0.69 | Timber.income |
| 38 | 0.69 | Kijan.income |
| 39 | 0.68 | Washing.machine |
| 40 | 0.67 | Total.monthly.HH.income |
| 41 | 0.66 | Education.income |
| 42 | 0.65 | Roads.income |
| 43 | 0.65 | Rubber.income |
| 44 | 0.64 | Water.pump |
| 45 | 0.63 | Large.TV. |
| 46 | 0.62 | typeofwork |
| 47 | 0.61 | Computer |
| 48 | 0.59 | Generator |
| 49 | 0.58 | Education.level |
| 50 | 0.56 | Gas.or.electric.stove |
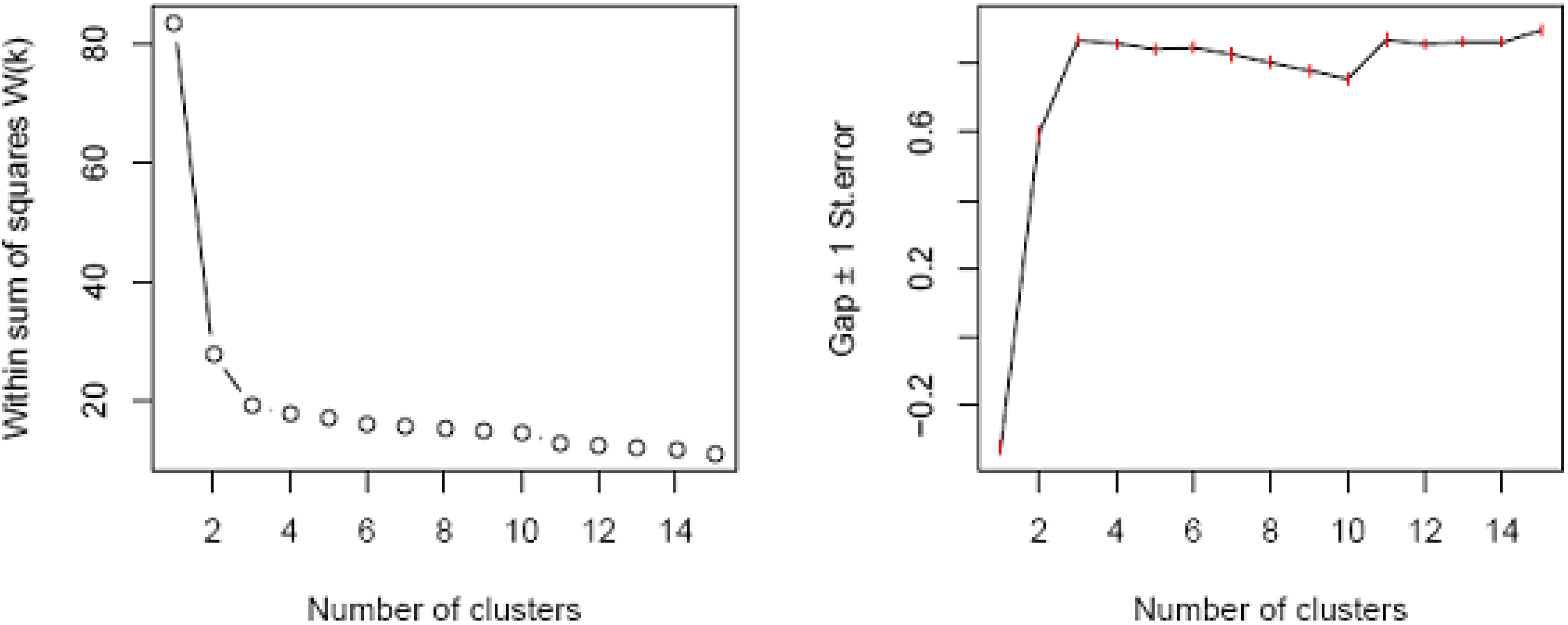
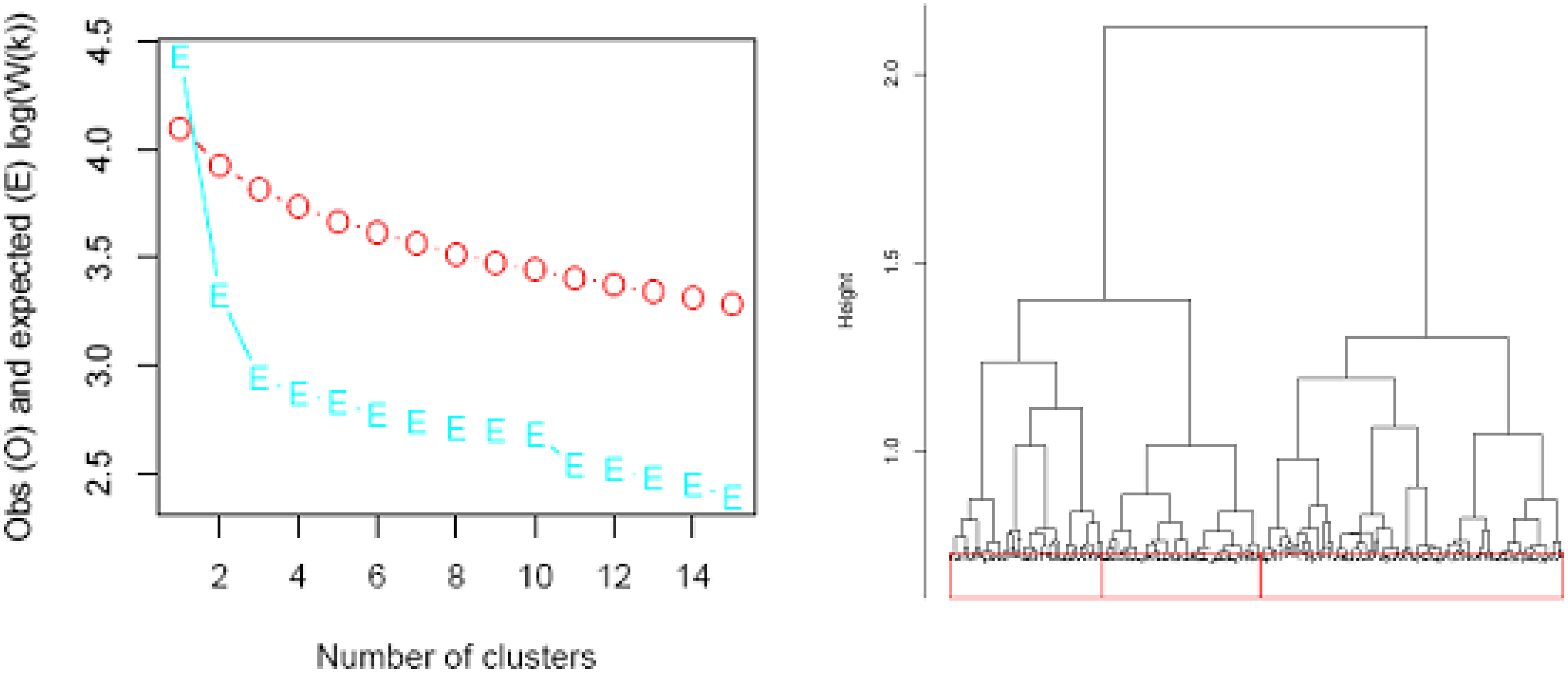
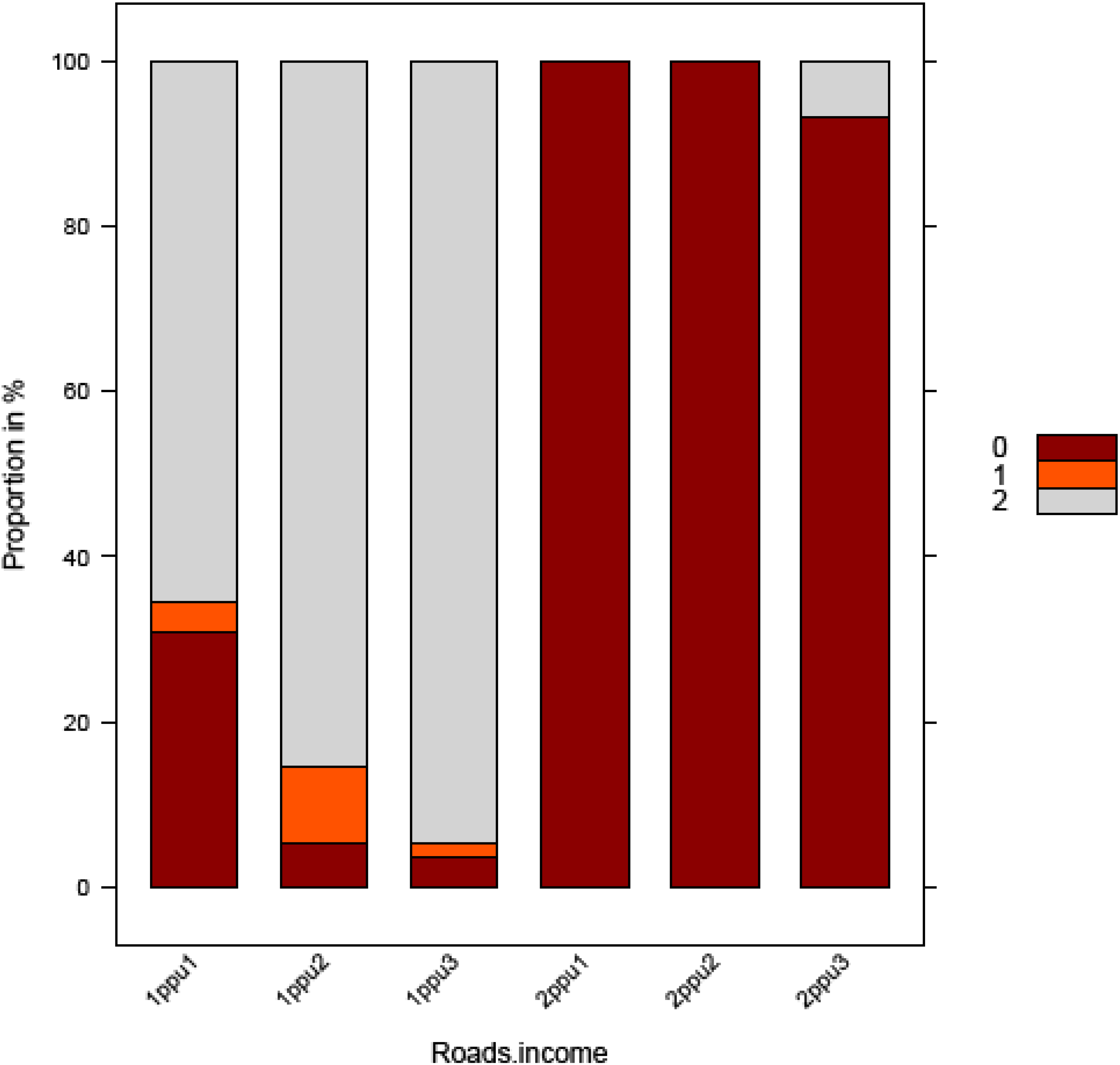
Decision tree analysis for allocating new households
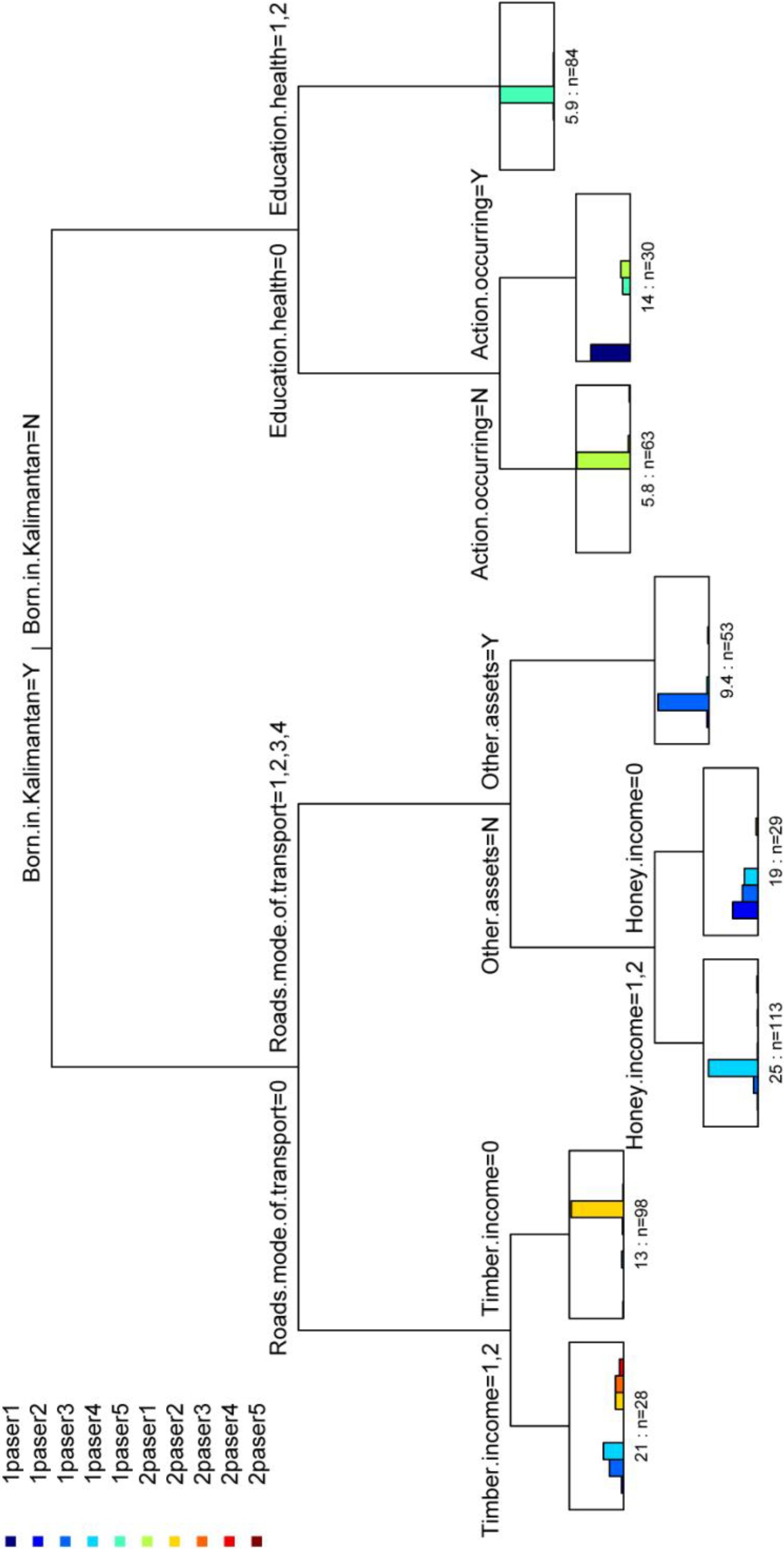
Extract important variables underlying clusters
3. Results
3.1. HH Classes from Clustering
| Site | HH type | HH per HH type (n) |
|---|---|---|
| Balikpapan | 1balikpapan1 | 239 |
| 1balikpapan2 | 24 | |
| 1balikpapan3 | 10 | |
| 2balikpapan1 | 121 | |
| 2balikpapan2 | 2 | |
| 2balikpapan3 | 1 | |
| Balikpapan Total | 397 | |
| Kubar | 1kubar1 | 9 |
| 1kubar2 | 68 | |
| 1kubar3 | 51 | |
| 1kubar4 | 7 | |
| 1kubar5 | 5 | |
| 2kubar1 | 45 | |
| 2kubar2 | 229 | |
| 2kubar3 | 92 | |
| 2kubar4 | 4 | |
| 2kubar5 | 11 | |
| 2kubar6 | 1 | |
| Kubar Total | 522 | |
| Kukar | 1kukar1 | 62 |
| 1kukar2 | 26 | |
| 1kukar3 | 8 | |
| 1kukar4 | 2 | |
| 2kukar1 | 91 | |
| 2kukar2 | 102 | |
| 2kukar3 | 70 | |
| 2kukar4 | 51 | |
| 2kukar5 | 28 | |
| Kukar Total | 440 | |
| Paser | 1paser1 | 25 |
| 1paser2 | 31 | |
| 1paser3 | 132 | |
| 1paser4 | 84 | |
| 1paser5 | 47 | |
| 2paser1 | 67 | |
| 2paser2 | 94 | |
| 2paser3 | 7 | |
| 2paser4 | 2 | |
| 2paser5 | 9 | |
| Paser Total | 498 | |
| PPU | 1ppu1 | 179 |
| 1ppu2 | 14 | |
| 1ppu3 | 76 | |
| 2ppu1 | 4 | |
| 2ppu2 | 132 | |
| 2ppu3 | 79 | |
| PPU Total | 484 | |
| Samarinda | 1samarinda1 | 19 |
| 1samarinda3 | 15 | |
| 2samarinda1 | 402 | |
| 2samarinda2 | 8 | |
| 2samarinda3 | 14 | |
| 2samarinda4 | 20 | |
| Samarinda Total | 478 | |
| Grand Total | 2819 |
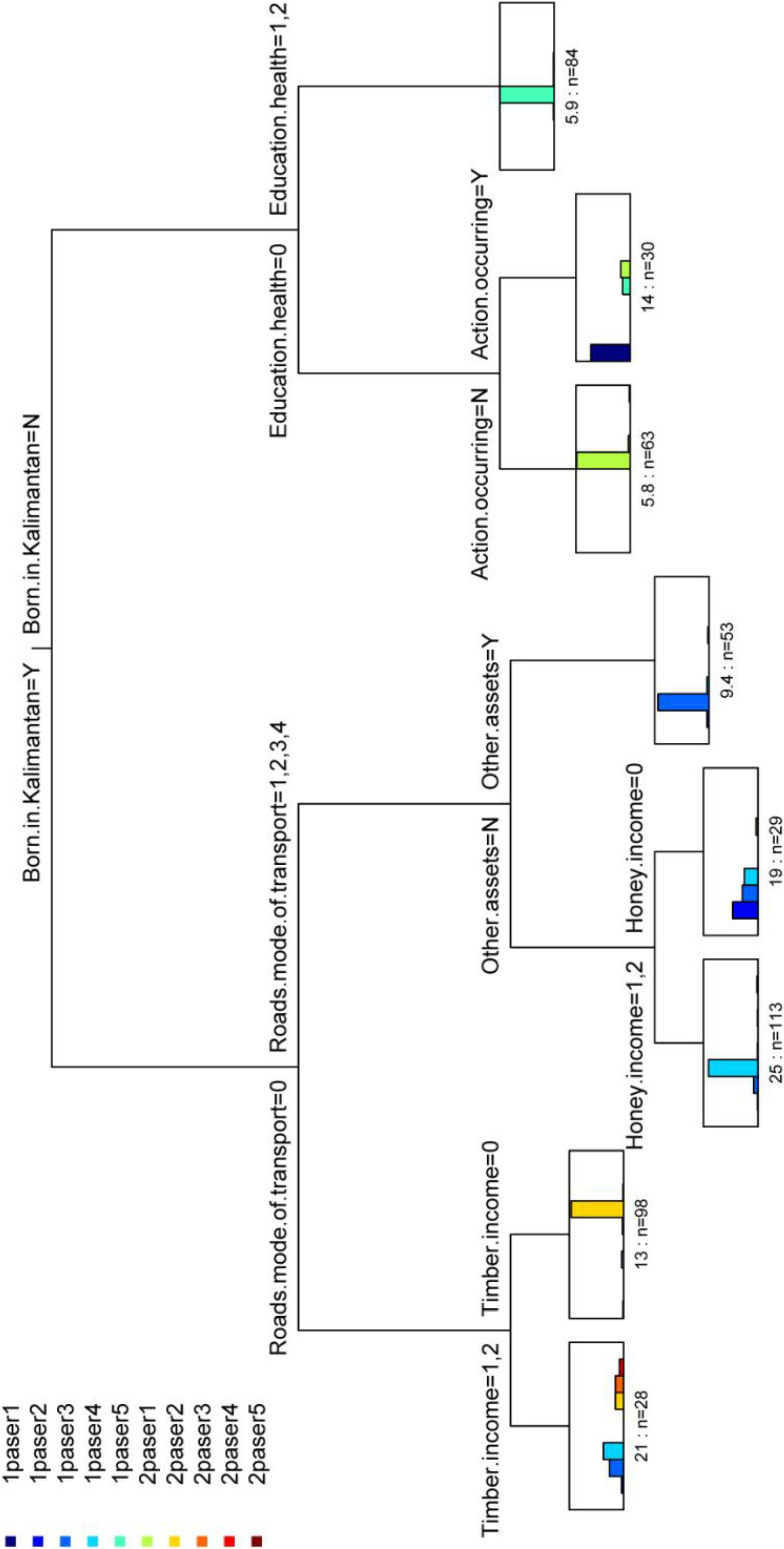
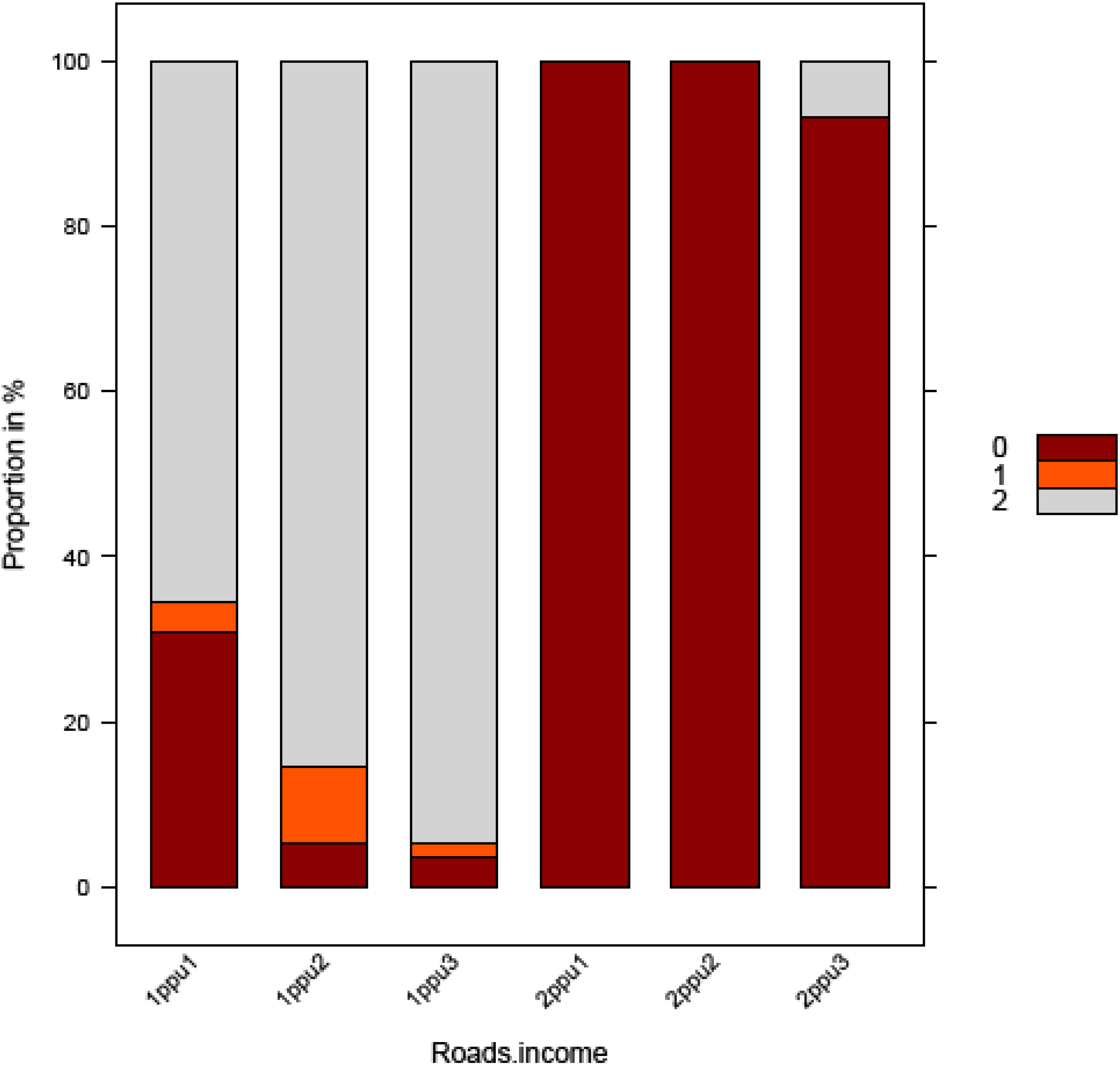
3.2. Extraction of Most Important Variables
| Site | Variable | Variable importance |
|---|---|---|
| Balikpapan | Born.in.East.Kalimantan | 0.0118 |
| Born.in.district_new | 0.0091 | |
| Born.in.Kalimantan | 0.0080 | |
| Roads.income | 0.0016 | |
| Small.TV | 0.0008 | |
| Kubar | Ethnic.group | 0.0176 |
| Rubber.income | 0.0167 | |
| Other.assets | 0.0142 | |
| Born.in.Kalimantan | 0.0129 | |
| Born.in.district_new | 0.0081 | |
| Born.in.East.Kalimantan | 0.0079 | |
| typeofwork | 0.0033 | |
| Months.of.work | 0.0024 | |
| Roads.income | 0.0017 | |
| Boat.engine. | 0.0015 | |
| Education.level | 0.0012 | |
| Fishing.boat | 0.0009 | |
| Hornbill.income | 0.0008 | |
| Fish.income | 0.0004 | |
| Kukar | Born.in.Kalimantan | 0.0154 |
| Born.in.East.Kalimantan_new | 0.0134 | |
| Born.in.district_new | 0.0115 | |
| Fish.income | 0.0081 | |
| Ethnic.group | 0.0061 | |
| Boat.engine. | 0.0047 | |
| Fishing.boat | 0.0037 | |
| Months.of.work | 0.0006 | |
| typeofwork | 0.0001 | |
| Paser | Born.in.Kalimantan | 0.0258 |
| Roads.income | 0.0215 | |
| Timber.income | 0.0197 | |
| Born.in.East.Kalimantan | 0.0186 | |
| Honey.income | 0.0154 | |
| Born.in.district_new | 0.0142 | |
| Generator | 0.0081 | |
| Other.assets | 0.0061 | |
| Fruit.tree.income | 0.0054 | |
| Education.income | 0.0050 | |
| Fishing.boat | 0.0040 | |
| Ethnic.group | 0.0034 | |
| Boat.engine. | 0.0032 | |
| typeofwork | 0.0015 | |
| Water.pump | 0.0014 | |
| Air.conditioner | 0.0003 | |
| Rubber.income | 0.0003 | |
| Washing.machine | 0.0001 | |
| PPU | Roads.income | 0.0298 |
| Born.in.East.Kalimantan | 0.0207 | |
| Born.in.Kalimantan | 0.0174 | |
| Born.in.district_new | 0.0082 | |
| Ethnic.group | 0.0054 | |
| Education.income | 0.0015 | |
| Social.networks.income | 0.0013 | |
| Samarinda | Born.in.Kalimantan | 0.0277 |
| Born.in.East.Kalimantan | 0.0229 | |
| Roads.income | 0.0214 | |
| Ethnic.group | 0.0076 | |
| Born.in.district_new | 0.0068 | |
| Education.income | 0.0063 | |
| Social.networks.income | 0.0041 | |
| typeofwork | 0.0007 |
4. Discussion and Conclusion
Acknowledgements
References and Notes
- Janssen, M.A.; Carpenter, S.A. Managing resilience of lakes: A multi-agent modeling approach. Conserv. Ecol. 1999, 3, 15. [Google Scholar]
- Carpenter, S.A.; Brock, W.A. Spatial complexity, resilience and policy diversity: Fishing on lake-rich landscapes. Ecol. Soc. 2004, 9, 8. [Google Scholar]
- Bousquet, F.; Le Page, C. Multi-agent simulations and ecosystem management: A review. Ecol. Model. 2004, 176, 332. [Google Scholar] [CrossRef]
- Bohensky, E.; Smajgl, A.; Herr, A. Calibrating behavioural variables in Agent-Based Models: Insights from a case study in East Kalimantan, Indonesia. In Modsim 2007; Oxley, L., Kulasiri, D., Eds.; Modelling and Simulation Society of Australia and New Zealand: Canberra, Australia, 2007. [Google Scholar]
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S; Springer: New York, NY, USA, 2002. [Google Scholar]
- Borgatti, S.P. Anthropac 4 Methods Guide; Analytic Technologies: Natick, MA, USA, 1996. [Google Scholar]
- Santos, L.; Marings, I.; Brito, P. Measuring subjective quality of life: A survey of Portos’ residents. Appl. Res. Qual. Life 2007, 2, 51–64. [Google Scholar] [CrossRef]
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2008. [Google Scholar]
- Ferrier, S.; Guisan, A. Spatial modelling of biodiversity at the community level. J. Appl. Ecol. 2006, 43, 393–404. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; Wiley: New York, NY, USA, 1990. [Google Scholar]
- Struyf, A.; Hubert, M.; Rousseeuw, P.J. Clustering in an object-orientated environment. J. Stat. Softw. 1997, 1, 1–30. [Google Scholar]
- Chessel, D.; Dufour, A. B.; Thioulouse, J. The ade4 package-I-One-table methods. R News 2004, 4, 5–10. [Google Scholar]
- Schinka, A.J.; Velicer, W.I.; Weiner, I.B. Handbook of Psychology: Research Methodologies in Psychology; John Wiley and Sons: Somerset, NJ, USA, 2003. [Google Scholar]
- Steinley, D.; Brusco, M.J. Selection of variables in cluster analysis: An empirical comparison of eight procedures. Psychometrika 2008, 73, 125–144. [Google Scholar] [CrossRef]
- Sokal, R.R.; Rohlf, F.J. The comparison of dendrograms by objective methods. Taxon 1962, 11, 33–40. [Google Scholar] [CrossRef]
- Tan, P.N.; Steinbach, M.; Kumar, V. Cluster analysis basic concepts and algorithms. In Introduction to Data Mining; Addison-Wesley: London, UK, 2006. [Google Scholar]
- Milligan, G.W.; Cooper, M.C. Methodology review: Clustering methods. App. Psych. Meas. 1987, 11, 329–354. [Google Scholar] [CrossRef]
- Gordon, A. Null models in cluster evaluation. In From Data to Knowledge; Gaul, W., Pfeiffer, D., Eds.; Springer: New York, NY, USA, 1996; pp. 32–44. [Google Scholar]
- Tibshirani, R.; Walther, G.; Hastie, T. Estimating the number of clusters in a data set via the gap statistic. J. Roy. Statist. Soc. B. 2001, 63, 411–423. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, R.A.; Olshen, R.; Stone, C.J. Classification and Regression Trees; Wadsworth International Group: Belmont, CA, USA, 1984. [Google Scholar]
- De’ath, G. Multivariate regression trees: A new technique for modeling species-environment relationships. Ecology 2002, 83, 1105–1117. [Google Scholar]
- Van der Laan, M. Statistical inference for variable importance. Int. J. Biostat. 2006, 2, 1–31. [Google Scholar]
- Strobl, C.; Boulesteix, A.; Zeileis, A.; Hothorn, T. Bias in random forest variable importance measure: Illustrations, sources and a solution. BMC Bioinformatics 2007, 8, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Hothorn, T.; Hornik, K.; Zeileis, A. Unbiased recursive partitioning: A conditional inference framework. J. Comput. Graph. Stat. 2006, 15, 651–674. [Google Scholar] [CrossRef]
- Harrell, F.E.J. Regression Modelling Strategies: With Applications to Linear Models, Logistic Regressions and Survival Analysis; Springer: New York, NY, USA, 2001. [Google Scholar]
- Bellman, R.E. Adaptive Control Processes; Princeton University Press: Princeton, NJ, USA, 1961. [Google Scholar]
- George, E.I. The variable selection problem. J. Am. Stat. Assoc. 2000, 95, 1304–1308. [Google Scholar] [CrossRef]
- Pino-Mejías, R.; Carrasco-Mairena, M.; Pascual-Acosta, A.; Cubiles-de-la-Vega, M.D.; Muñoz-García, J. A comparison of classification models to identify the fragile X Syndrome. J. Appl. Statists. 2008, 35, 233–244. [Google Scholar] [CrossRef]
© 2010 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Herr, A. Statistics for Categorical Surveys—A New Strategy for Multivariate Classification and Determining Variable Importance. Sustainability 2010, 2, 533-550. https://doi.org/10.3390/su2020533
Herr A. Statistics for Categorical Surveys—A New Strategy for Multivariate Classification and Determining Variable Importance. Sustainability. 2010; 2(2):533-550. https://doi.org/10.3390/su2020533
Chicago/Turabian StyleHerr, Alexander. 2010. "Statistics for Categorical Surveys—A New Strategy for Multivariate Classification and Determining Variable Importance" Sustainability 2, no. 2: 533-550. https://doi.org/10.3390/su2020533
APA StyleHerr, A. (2010). Statistics for Categorical Surveys—A New Strategy for Multivariate Classification and Determining Variable Importance. Sustainability, 2(2), 533-550. https://doi.org/10.3390/su2020533