
DHDRDS: A Deep Reinforcement Learning-Based Ride-Hailing Dispatch System for Integrated Passenger–Parcel Transport


Abstract
1. Introduction
2. Materials and Methods
2.1. Dynamic Heterogeneous Demand-Aware Ride-Hailing Dispatch System
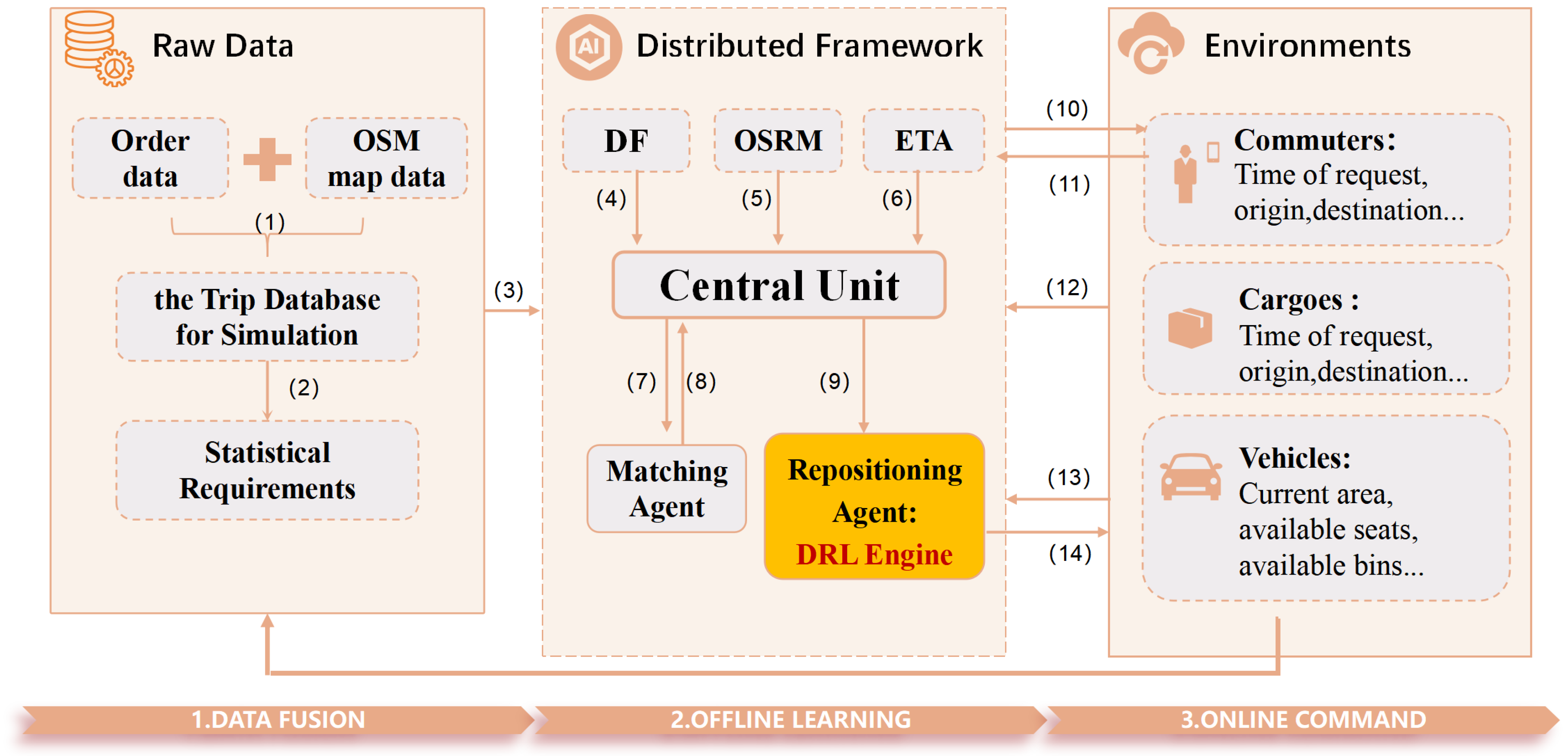
2.1.1. Model Architecture Diagram
2.1.2. Model Parameters and Symbols
- : index of a grid cell.
- n: number of vehicles.
- t: time slot, with a total of time slots.
- : number of deployable vehicles distributed across the geographical partition in zone i at time slot t.
- : time step , where is the initial time, and idle vehicles execute dispatch decisions.
- : number of pickup requests in zone m at time t.
- : current location (grid cell).
- : current capacity.
- : type.
- : maximum capacity.
2.2. Matching and Route Planning
2.2.1. Initial Vehicle–Passenger and Vehicle–Parcel Allocation Stage
2.2.2. Demand-Aware Route Planning Phase
2.2.3. Distributed Pricing and Customer Choice
- Waiting Time Tolerance: The temporal flexibility of service requests is quantified by the maximum acceptable waiting time threshold for each trip i, where passenger trips typically demonstrate stricter time sensitivity compared to parcel orders.
- Ride-sharing Preference: Whether the user is glad to share rides or prefers solo rides, even if it means higher prices. Parcel orders are uniformly set to be willing to share rides (with passenger orders). This is captured by the current capacity of vehicle j.
- Vehicle Type Preference: Whether the customer is willing to pay more under the same condition. The type of vehicle j is denoted by .
2.3. Distributed DQN Repositioning and Dispatch Method
- Discrete Action Optimization: Our dispatch action space comprises 225 discrete grid cells (15 × 15).
- Q-Value Maximization: The DQN’s Q-value maximization directly maps to this setting, whereas actor–critic methods like DDPG require continuous action approximations that introduce instability.
- Training Stability: The DQN’s experience replay buffer and target network mechanism mitigate policy oscillation in multi-agent environments, ensuring convergence in distributed fleet management.
- State Space: State variables reflect the environmental state, influencing the reward feedback for agent actions. We combine all the environmental data explained in Section 2.1.2:
- : tracks vehicle states, including current zone, available seats and trunk capacity, pickup time, and destination zones for each order.
- : predicts the supply of vehicles in each zone over the next T time steps.
- : predicts demand over the next T time steps.
- Action: represents the action taken by vehicle n. Each vehicle can move up to 7 grid cells, allowing it to reach any of the 14 vertical (7 up and 7 down) and 14 horizontal (7 left and 7 right) grid cells. After the DQN determines the target grid cell, the vehicle follows the shortest route to reach the next stop.
- Reward: Equation (5) is a weighted sum of the following components:
- : Number of users served by vehicle n at time t.
- : Time taken by vehicle n to travel to zone m or detour to pick up additional requests at time t. This term prevents the agent from accepting delays for onboard passengers.
- : Total additional time required for vehicle n to serve extra passengers at time t.
- : Profit earned by vehicle n at time t.
- : This term is used to treat the objective of active vehicles at time t to enhance fleet utilization.
| Algorithm 1 Dispatching via DQN. |
|
- Input Layer: dimension equals the concatenated state vector , where includes vehicle location, capacity, and order destinations.
- Hidden Layers: two layers with 256 and 128 nodes, respectively, activated by ReLU.
- Output Layer: 225 nodes (15 × 15 grid action space).
- Experience replay buffer stores 50,000 transitions for mini-batch sampling (batch size = 64).
- Adam optimizer with a learning rate of 0.001 and a discount factor of .
- -greedy exploration: initial decays linearly to 0.1 over 10,000 steps.
3. Results
3.1. Simulator Setup
3.2. DQN Training and Testing
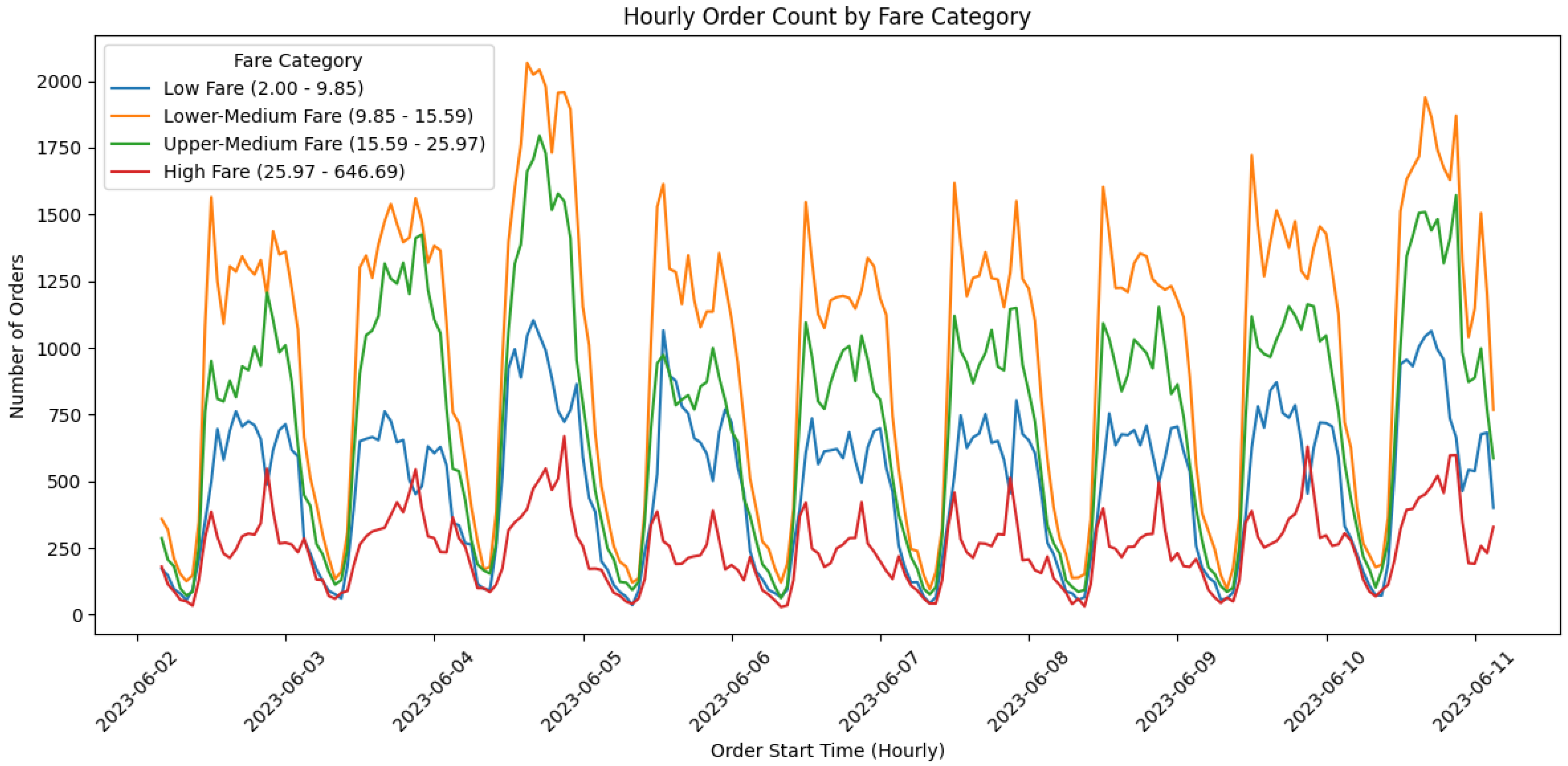
- Passenger orders: 1 million anonymized ride-hailing records obtained from a proprietary industry dataset covering 1–24 June 2023, representing authentic urban travel patterns. Figure 3 depicts the temporal distribution of hourly order counts across four fare categories: Low Fare (≤CNY 9.85), Lower-Medium Fare (CNY 9.85–15.59), Upper-Medium Fare (CNY 15.59–25.97), and High Fare (≥CNY 25.97). To mitigate the overfitting risks from short-distance high-frequency patterns in Low Fare orders (9.2% of total data) and the model bias caused by sparse long-tail distributions in High Fare orders (7.1%), this study employs the K-S test () to select Lower-Medium and Upper-Medium fare orders (collectively 83.7%) as the training set, ensuring distributional stability. The temporal regularity of these two dominant categories encapsulates the principal modes of urban mobility demand, thereby eliminating the influence of outliers on the generalizability of deep reinforcement learning policies.
- Parcel orders: 500,000 synthetically generated delivery requests spatially and temporally aligned with passenger demand distributions, designed to validate multimodal coordination feasibility under data scarcity scenarios.
3.3. Performance Metrics Comparison
3.3.1. Performance Metrics Definition

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
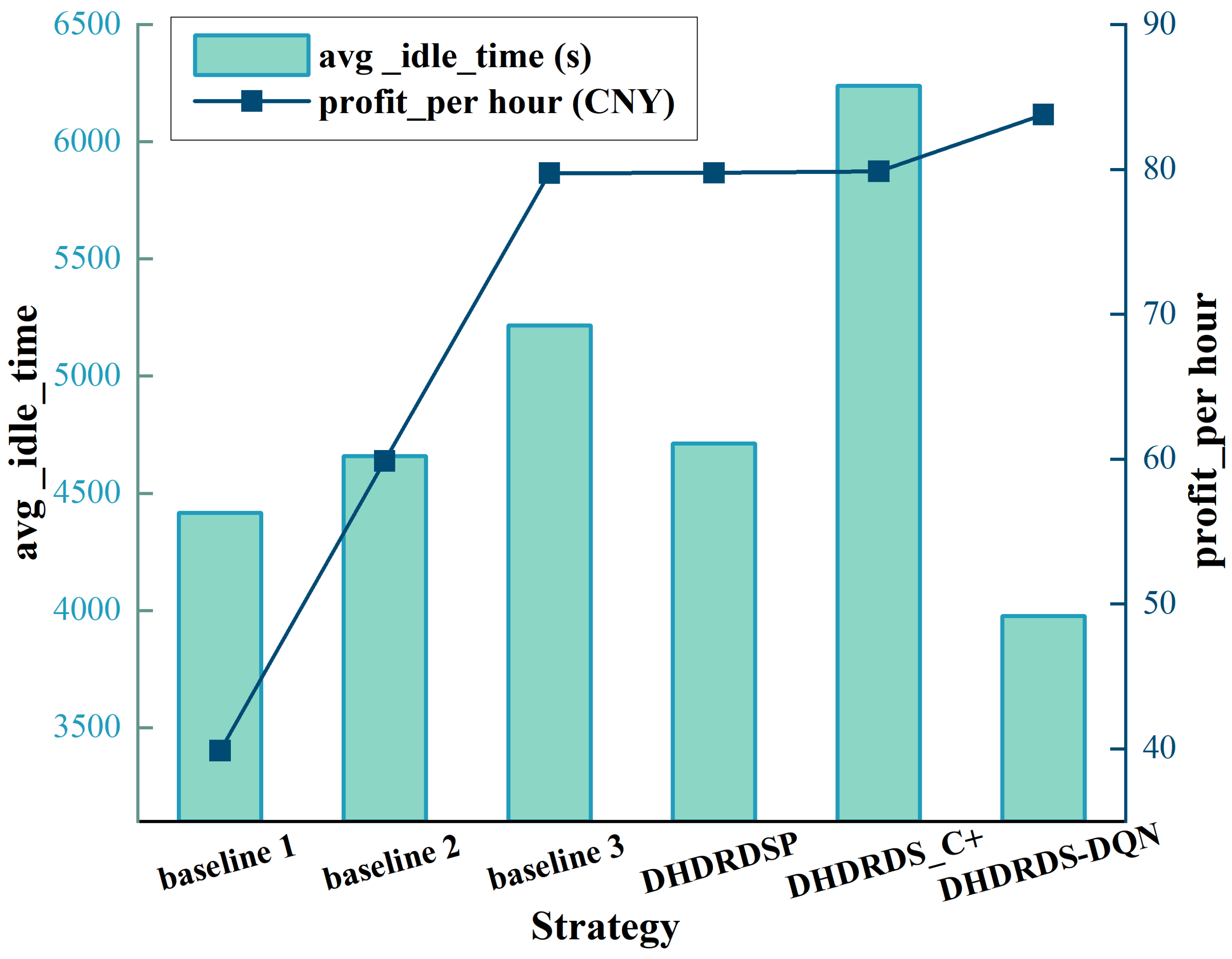
| Strategy | avg_cap | avg_idle_time | per_mileage | profit_per_hour | ||||
|---|---|---|---|---|---|---|---|---|
| Mean | Std | Mean (s) | Std | Mean (km) | Std | Mean ($) | Std | |
| Baseline 1 | 2.09 | 0.449 | 4416.83 | 2971.574 | 4.63 | 1.482 | 39.89 | 1.679 |
| Baseline 2 | 1.79 | 0.437 | 4658.85 | 3174.404 | 3.69 | 5.463 | 59.88 | 19.925 |
| Baseline 3 | 2.23 | 0.460 | 5215.91 | 3239.336 | 2.81 | 0.392 | 79.75 | 1.098 |
| DHDRDS_P | 2.18 | 0.383 | 4713.10 | 3222.404 | 3.86 | 0.349 | 79.77 | 1.173 |
| DHDRDS_C+ | 1.91 | 0.516 | 6239.82 | 3271.285 | 4.55 | 1.497 | 79.87 | 2.207 |
| DHDRDS-DQN | 1.53 | 0.411 | 3976.05 | 1635.533 | 4.74 | 3.437 | 83.80 | 17.855 |
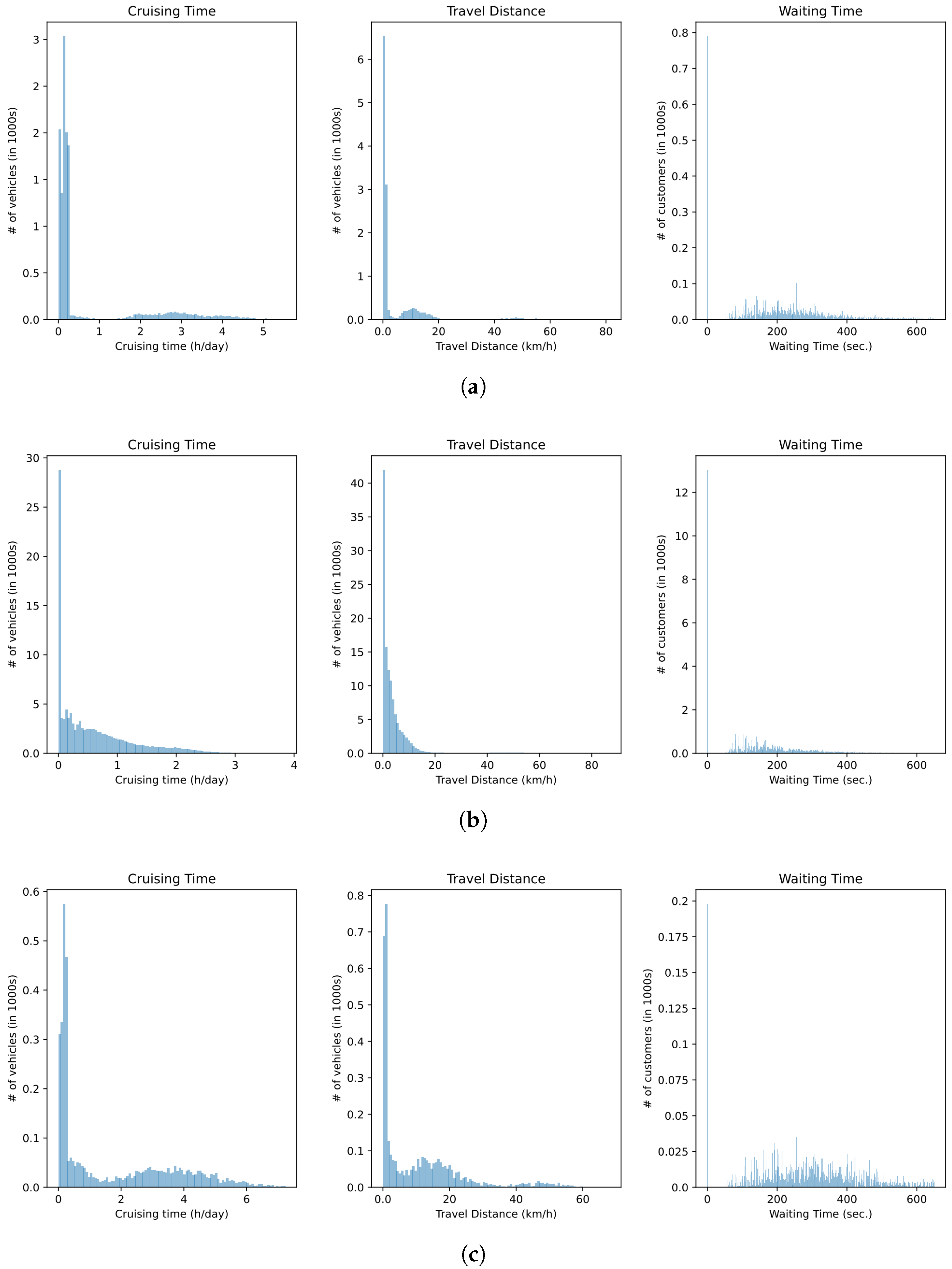
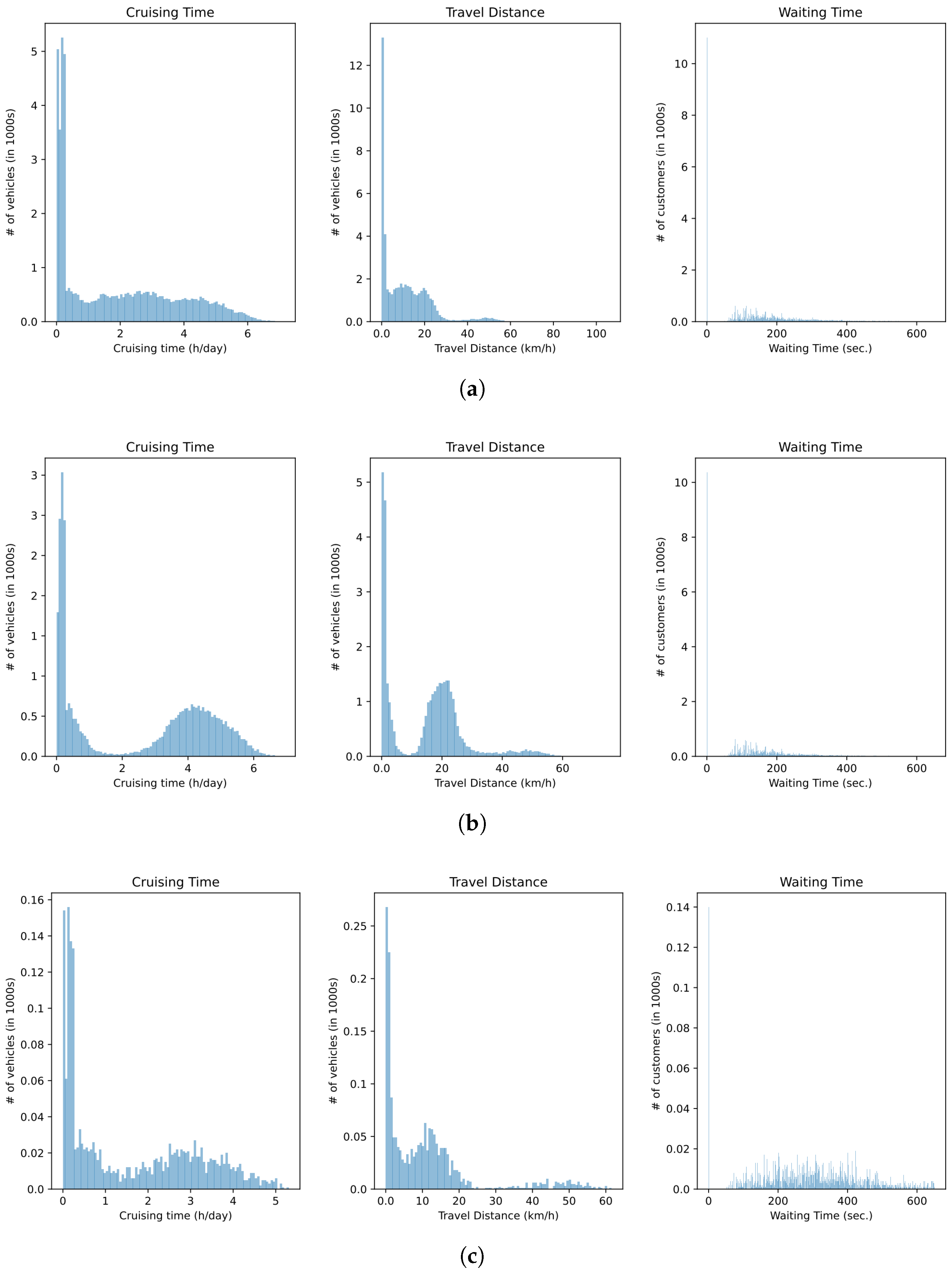
3.3.2. Principle Comparison of DHDRDS with Related Baselines
- Baseline 1 (Greedy Matching without Repositioning or Ride-sharing) employs an immediate greedy matching strategy where each vehicle serves only one order request without repositioning. Matching is based on the shortest pickup distance, ignoring long-term demand prediction and global resource optimization. This approach leads to high idle rates and low profitability.
- Baseline 2 (Greedy Matching with Repositioning [47]) introduces a repositioning strategy where idle vehicles migrate to historically high-demand zones. Demand distribution is updated periodically (every 15 min) to calculate marginal relocation benefits, but ride-sharing is disabled. Despite reducing spatial mismatches, this method lacks real-time adaptability and multi-order optimization capabilities.
- Baseline 3 (Greedy Matching with Repositioning and Passenger Ride-sharing [48]) enhances Baseline 2 by dynamically merging passenger orders through insertion-based route planning, subject to the constraints of maximum waiting time (10 min) and detour distance limits (2 km). While improving vehicle utilization, its static pricing and exclusion of parcel coordination limit adaptability to dynamic market fluctuations.
- DHDRDS_P (passenger-only): focuses on optimizing passenger ride-sharing without parcel coordination.
- DHDRDS_C+ (parcel-enhanced): extends passenger optimization to include parcel transportation with basic routing adjustments.
- DHDRDSDQN (parcel + DRL): incorporates deep reinforcement learning for real-time parcel–passenger demand balancing.
3.3.3. Experimental Data Analysis
4. Discussion
4.1. Advantages and Innovations
4.2. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DRL | Deep Reinforcement Learning |
| DHDRDS | Dynamic Heterogeneous Demand-aware Ride-hailing Dispatch System |
| DQN | Deep Q-Network |
| CNY | Chinese Yuan (Chinese currency) |
| OSRM | Open Source Routing Machine |
| OSM | OpenStreetMap |
| DF | Demand Forecasting |
| ETA | Estimated Time of Arrival |
| MPC | Model Predictive Control |
References
- Padeiro, M.; Santana, P.; Grant, M. Chapter 1—Global aging and health determinants in a changing world. In Aging; Oliveira, P.J., Malva, J.O., Eds.; Academic Press: New York, NY, USA, 2023; pp. 3–30. [Google Scholar] [CrossRef]
- Yan, C.; Zhu, H.; Korolko, N.; Woodard, D.B. Dynamic pricing and matching in ride-hailing platforms. Nav. Res. Logist. NRL 2018, 67, 705–724. [Google Scholar] [CrossRef]
- Chen, J.; Li, W.; Zhang, H.; Cai, Z.; Sui, Y.; Long, Y.; Song, X.; Shibasaki, R. GPS data in urban online ride-hailing: A simulation method to evaluate impact of user scale on emission performance of system. J. Clean. Prod. 2021, 287, 125567. [Google Scholar] [CrossRef]
- He, Z. Portraying ride-hailing mobility using multi-day trip order data: A case study of Beijing, China. Transp. Res. Part A Policy Pract. 2020, 146, 152–169. [Google Scholar] [CrossRef]
- Huang, X.; Song, J.; Wang, C.; Chui, T.F.M.; Chan, P.W. The synergistic effect of urban heat and moisture islands in a compact high-rise city. Build. Environ. 2021, 205, 108274. [Google Scholar] [CrossRef]
- Tafreshian, A.; Masoud, N.; Yin, Y. Frontiers in Service Science: Ride Matching for Peer-to-Peer Ride Sharing: A Review and Future Directions. Serv. Sci. 2020, 12, 44–60. [Google Scholar] [CrossRef]
- Agatz, N.A.H.; Erera, A.L.; Savelsbergh, M.W.P.; Wang, X. Optimization for dynamic ride-sharing: A review. Eur. J. Oper. Res. 2012, 223, 295–303. [Google Scholar] [CrossRef]
- Furuhata, M.; Dessouky, M.M.; Ordóñez, F.; Brunet, M.E.; Wang, X.; Koenig, S. Ridesharing: The state-of-the-art and future directions. Transp. Res. Part B-Methodol. 2013, 57, 28–46. [Google Scholar] [CrossRef]
- Mourad, A.; Puchinger, J.; Chu, C. A survey of models and algorithms for optimizing shared mobility. Transp. Res. Part B Methodol. 2019, 123, 323–346. [Google Scholar] [CrossRef]
- do Carmo Martins, L.; de la Torre, R.; Corlu, C.G.; Juan, A.A.; Masmoudi, M. Optimizing ride-sharing operations in smart sustainable cities: Challenges and the need for agile algorithms. Comput. Ind. Eng. 2021, 153, 107080. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, Y.; Duan, Z.; Tang, L. PROLIFIC: Deep Reinforcement Learning for Efficient EV Fleet Scheduling and Charging. Sustainability 2023, 15, 3553. [Google Scholar] [CrossRef]
- Cao, Y.; Liu, L.; Dong, Y. Convolutional Long Short-Term Memory Two-Dimensional Bidirectional Graph Convolutional Network for Taxi Demand Prediction. Sustainability 2023, 15, 7903. [Google Scholar] [CrossRef]
- Gao, W.; Zhao, C.; Zeng, Y.; Tang, J. Exploring the Spatio-Temporally Heterogeneous Impact of Traffic Network Structure on Ride-Hailing Emissions Using Shenzhen, China, as a Case Study. Sustainability 2024, 16, 4539. [Google Scholar] [CrossRef]
- Jin, K.; Wang, W.; Hua, X.; Zhou, W. Reinforcement Learning for Optimizing Driving Policies on Cruising Taxis Services. Sustainability 2020, 12, 8883. [Google Scholar] [CrossRef]
- Do, M.; Byun, W.; Shin, D.K.; Jin, H. Factors Influencing Matching of Ride-Hailing Service Using Machine Learning Method. Sustainability 2019, 11, 5615. [Google Scholar] [CrossRef]
- Holler, J.; Vuorio, R.; Qin, Z.; Tang, X.; Jiao, Y.; Jin, T.; Singh, S.; Wang, C.; Ye, J. Deep Reinforcement Learning for Multi-driver Vehicle Dispatching and Repositioning Problem. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 1090–1095. [Google Scholar]
- Qin, Z.; Tang, X.; Jiao, Y.; Zhang, F.; Wang, C.; Li, Q. Deep Reinforcement Learning for Ride-sharing Dispatching and Repositioning. In Proceedings of the International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019. [Google Scholar]
- Lin, K.; Zhao, R.; Xu, Z.; Zhou, J. Efficient Large-Scale Fleet Management via Multi-Agent Deep Reinforcement Learning. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD’18, New York, NY, USA, 19–23 August 2018; pp. 1774–1783. [Google Scholar] [CrossRef]
- Tang, X.; Qin, Z.; Zhang, F.; Wang, Z.; Xu, Z.; Ma, Y.; Zhu, H.; Ye, J. A Deep Value-network Based Approach for Multi-Driver Order Dispatching. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Fluri, C.; Ruch, C.; Zilly, J.G.; Hakenberg, J.P.; Frazzoli, E. Learning to Operate a Fleet of Cars. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 2292–2298. [Google Scholar]
- Lloyd, S.P. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–136. [Google Scholar] [CrossRef]
- Deng, Y.; Chen, H.; Shao, S.; Tang, J.; Pi, J.; Gupta, A. Multi-Objective Vehicle Rebalancing for Ridehailing System using a Reinforcement Learning Approach. arXiv 2020, arXiv:2007.06801. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Lu, D.; Hu, D.; Wang, J.; Wei, W.; Zhang, X. A Data-Driven Vehicle Speed Prediction Transfer Learning Method with Improved Adaptability Across Working Conditions for Intelligent Fuel Cell Vehicle. IEEE Trans. Intell. Transp. Syst. 2025, 1–11. [Google Scholar] [CrossRef]
- Shi, D.; Li, X.; Li, M.; Wang, J.; Li, P.; Pan, M. Optimal Transportation Network Company Vehicle Dispatching via Deep Deterministic Policy Gradient. In Proceedings of the Wireless Algorithms, Systems, and Applications, Honolulu, HI, USA, 24–26 June 2019. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.M.O.; Degris, T.; Wierstra, D.; Riedmiller, M.A. Deterministic Policy Gradient Algorithms. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Shou, Z.; Di, X. Reward Design for Driver Repositioning Using Multi-Agent Reinforcement Learning. arXiv 2020, arXiv:2002.06723. [Google Scholar] [CrossRef]
- Huang, X.; Cheng, Y.; Jin, J.; Kou, A. Research on Dynamic Subsidy Based on Deep Reinforcement Learning for Non-Stationary Stochastic Demand in Ride-Hailing. Sustainability 2024, 16, 6289. [Google Scholar] [CrossRef]
- Liu, W.; Liang, J.; Xu, T. Tunnelling-induced ground deformation subjected to the behavior of tail grouting materials. Tunn. Undergr. Space Technol. 2023, 140, 105253. [Google Scholar] [CrossRef]
- Liang, J.; Liu, W.; Yin, X.; Li, W.; Yang, Z.; Yang, J. Experimental study on the performance of shield tunnel tail grout in ground. Undergr. Space 2025, 20, 277–292. [Google Scholar] [CrossRef]
- Hu, D.; Chen, A.; Lu, D.; Wang, J.; Yi, F. A multi-algorithm fusion model for predicting automotive fuel cell system demand power. J. Clean. Prod. 2024, 466, 142848. [Google Scholar] [CrossRef]
- Jin, J.; Zhou, M.; Zhang, W.; Li, M.; Guo, Z.; Qin, Z.; Jiao, Y.; Tang, X.; Wang, C.; Wang, J.; et al. CoRide: Joint Order Dispatching and Fleet Management for Multi-Scale Ride-Hailing Platforms. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019. [Google Scholar]
- Rong, S.; Meng, R.; Guo, J.; Cui, P.; Qiao, Z. Multi-Vehicle Collaborative Planning Technology under Automatic Driving. Sustainability 2024, 16, 4578. [Google Scholar] [CrossRef]
- Agatz, N.; Erera, A.L.; Savelsbergh, M.W.; Wang, X. Dynamic Ride-Sharing: A Simulation Study in Metro Atlanta. Procedia-Soc. Behav. Sci. 2011, 17, 532–550. [Google Scholar] [CrossRef]
- Mao, C.; Liu, Y.; Shen, Z.j.M. Dispatch of autonomous vehicles for taxi services: A deep reinforcement learning approach. Transp. Res. Part C Emerg. Technol. 2020, 115, 102626. [Google Scholar] [CrossRef]
- Mo, D.; Chen, X.M.; Zhang, J. Modeling and Managing Mixed On-Demand Ride Services of Human-Driven Vehicles and Autonomous Vehicles. Transp. Res. Part B Methodol. 2022, 157, 80–119. [Google Scholar] [CrossRef]
- Fan, G.; Jin, H.; Zhao, Y.; Song, Y.; Gan, X.; Ding, J.; Su, L.; Wang, X. Joint Order Dispatch and Charging for Electric Self-Driving Taxi Systems. In Proceedings of the IEEE INFOCOM 2022—IEEE Conference on Computer Communications, London, UK, 2–5 May 2022; pp. 1619–1628. [Google Scholar]
- Wyld, D.C.; Jones, M.A.; Totten, J.W. Where is my suitcase? RFID and airline customer service. Mark. Intell. Plan. 2005, 23, 382–394. [Google Scholar] [CrossRef]
- Bei, X.; Zhang, S. Algorithms for Trip-Vehicle Assignment in Ride-Sharing; AAAI’18/IAAI’18/EAAI’18; AAAI Press: Washington, DC, USA, 2018. [Google Scholar]
- Alonso-Mora, J.; Samaranayake, S.; Wallar, A.; Frazzoli, E.; Rus, D. On-demand high-capacity ride-sharing via dynamic trip-vehicle assignment. Proc. Natl. Acad. Sci. USA 2017, 114, 462–467. [Google Scholar] [CrossRef]
- Tong, Y.; Zeng, Y.; Zhou, Z.; Chen, L.; Ye, J.; Xu, K. A Unified Approach to Route Planning for Shared Mobility. Proc. VLDB Endow. 2018, 11, 1633–1646. [Google Scholar] [CrossRef]
- Ma, S.; Zheng, Y.; Wolfson, O. T-share: A large-scale dynamic taxi ridesharing service. In Proceedings of the 2013 IEEE 29th International Conference on Data Engineering (ICDE), Brisbane, QLD, Australia, 8–12 April 2013; pp. 410–421. [Google Scholar]
- Asghari, M.; Deng, D.; Shahabi, C.; Demiryurek, U.; Li, Y. Price-aware real-time ride-sharing at scale: An auction-based approach. In Proceedings of the 24th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Burlingame, CA, USA, 31 October–3 November 2016. [Google Scholar]
- Xu, Y.; Tong, Y.; Shi, Y.; Tao, Q.; Xu, K.; Li, W. An Efficient Insertion Operator in Dynamic Ridesharing Services. IEEE Trans. Knowl. Data Eng. 2020, 34, 3583–3596. [Google Scholar] [CrossRef]
- Luxen, D.; Vetter, C. Real-time routing with OpenStreetMap data. In Proceedings of the 19th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Hamburg, Germany, 13–16 November 2011. [Google Scholar]
- Haliem, M.; Mani, G.; Aggarwal, V.; Bhargava, B.K. A Distributed Model-Free Ride-Sharing Approach for Joint Matching, Pricing, and Dispatching Using Deep Reinforcement Learning. IEEE Trans. Intell. Transp. Syst. 2020, 22, 7931–7942. [Google Scholar] [CrossRef]
- Oda, T.; Joe-Wong, C. MOVI: A Model-Free Approach to Dynamic Fleet Management. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications, Honolulu, HI, USA, 15–19 April 2018; pp. 2708–2716. [Google Scholar]
- Al-Abbasi, A.O.; Ghosh, A.K.; Aggarwal, V. DeepPool: Distributed Model-Free Algorithm for Ride-Sharing Using Deep Reinforcement Learning. IEEE Trans. Intell. Transp. Syst. 2019, 20, 4714–4727. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ge, H.; Hu, X.; Cheng, M. DHDRDS: A Deep Reinforcement Learning-Based Ride-Hailing Dispatch System for Integrated Passenger–Parcel Transport. Sustainability 2025, 17, 4012. https://doi.org/10.3390/su17094012
Ge H, Hu X, Cheng M. DHDRDS: A Deep Reinforcement Learning-Based Ride-Hailing Dispatch System for Integrated Passenger–Parcel Transport. Sustainability. 2025; 17(9):4012. https://doi.org/10.3390/su17094012
Chicago/Turabian StyleGe, Huanwen, Xiangwang Hu, and Ming Cheng. 2025. "DHDRDS: A Deep Reinforcement Learning-Based Ride-Hailing Dispatch System for Integrated Passenger–Parcel Transport" Sustainability 17, no. 9: 4012. https://doi.org/10.3390/su17094012
APA StyleGe, H., Hu, X., & Cheng, M. (2025). DHDRDS: A Deep Reinforcement Learning-Based Ride-Hailing Dispatch System for Integrated Passenger–Parcel Transport. Sustainability, 17(9), 4012. https://doi.org/10.3390/su17094012