1. Introduction
The measurement of intervehicle spacing is a fundamental element of traffic analysis for characterizing traffic conditions, driving behaviors, and road safety, as it directly relates to vehicle density [
1]. This, in turn, affects traffic characteristics and the levels of service on uninterrupted flow facilities, such as multilane highways and freeways [
2,
3].
Thus, understanding proper intervehicle spacing is a key factor for developing traffic models that enhance highway safety, support sustainability initiatives for safer roads, set minimum and recommended distances, and enforce necessary safety standards. According to existing research, a significant number of traffic accident investigations reveal that rear-end collisions are a major type of traffic accident and make up a significant share of all crashes [
4,
5,
6]. These collisions typically occur when the leading vehicle suddenly decelerates or when the following vehicle accelerates more rapidly than expected. The primary causes include driver inattention, unintentional close following due to misjudging deceleration needs, and intentional aggressive tailgating [
7].
In this context, it is essential to analyze and accurately characterize driver behaviors in terms of intervehicle spacing to specify and calibrate rear-end collision models and test mitigation strategies. Recent technological advancements now allow the precise tracking of vehicle positions using video recording and image processing methods that previously relied on aerial photography [
8]. In contrast, inter-arrival times, speeds, and volumes can be easily recorded at transverse highway sections using various sensor-based measurement systems, which have advanced alongside traffic flow research [
9].
Recent studies demonstrate a growing interest in applying machine learning (ML) and deep learning (DL) to traffic flow analysis, particularly for modeling intervehicle spacing and estimating safe following distances. Several notable studies include deep learning approaches for car following behavior classification [
10], LSTM-based vehicle trajectory prediction [
11], hybrid clustering–deep learning models for vehicle acceleration estimation [
12], and computer vision methods for spacing estimation in agricultural contexts [
13]. Additionally, research leveraging ensemble regression [
14], super-deep learning for automated driving [
15], and CNN-LSTM models for lane change behavior prediction [
16] further confirm the relevance of AI technologies in this domain.
To address limitations in detecting vehicle positions and spacing along a lane, indirect methods are often used to estimate vehicle density. These derive from instantaneous vehicle volume and average speed measurements at a transverse section or from temporal headways and point-based speed monitoring [
17]. Sensors positioned at a fixed point collect data on two consecutive vehicles to generate real-time intervehicle spacings. These spacings are essential for analyzing vehicle interactions and platoon formation based on standard research thresholds [
18]. The resulting density values are local to a small highway segment (elementary stretch) at the observation section. Extending these to longer road stretches assumes stationary traffic conditions over a given period. Therefore, only average values can represent spacing, limiting probabilistic insights over entire highway segments [
19]. Alternative methods apply sensors, like GPS, LiDAR, radar, or infrared, over short segments—typically in experimental settings—to estimate intervehicle spacing. These devices measure real-time spacing but are confined to the localized areas where they are installed [
17].
Given these challenges, the direct measurement of intervehicle spacing and density has historically been difficult. However, advancements in image and video analysis technologies now enable the extraction of traffic parameters from camera recordings [
20]. On instrumented highways, such as motorways, the availability of video systems enables the real-time monitoring of larger segments and the direct measurement of spacing and density at specific times. Such data are crucial for traffic management and control [
21] and play a key role in modern Intelligent Transport Systems and Smart Road applications [
22]. Accurately predicting and modeling intervehicle spacings support traffic control strategies, including speed limits and lane management [
23].
Despite this progress, current research highlights that much of the technology is still primarily applicable to well-instrumented highways. Studies such as those by [
24] demonstrate ML and DL models’ performance for parking prediction—an area closely related to intervehicle spacing. Meanwhile, methodologies integrating multiple algorithms (e.g., ensemble regression) for accurate V2V distance prediction [
14] show promising capabilities for implementation beyond traditional infrastructures. These models represent significant progress but also underscore the need for simpler, cost-effective solutions suited for rural or under-equipped roads.
The importance of studying intervehicle spacing, particularly their probabilistic distributions, is clear. This research responds by addressing the under-representation of spacing (as opposed to temporal headways) in traffic modeling. It identifies suitable probabilistic distributions for modeling vehicle distances. While image and sensor systems allow data collection on equipped motorways, this capability does not extend to most two-lane rural roads that make up national traffic networks [
25].
Two-lane roads serve as a critical link between urban and interurban traffic systems, connecting higher-level infrastructures, such as roads, railways, ports, and airports, to local markets and vice versa. Enhancing the functionality [
26] and safety [
27] of these roads is essential for sustainable corridor development. However, their geometric complexity and low funding make sensor installations impractical. In such contexts, analyzing intervehicle spacing distributions using probabilistic models under varying traffic conditions can support practical safety and sustainability improvements.
This study proposes a simulation-based method to evaluate the probability density of intervehicle spacing on a two-lane rural road with no overtaking. Unlike approaches that rely on sensor-rich environments or high-resolution visual data, the model simulates intervehicular spacing over an extended highway segment using macroscopic and microscopic traffic models integrated with probabilistic tools. It operates under varying traffic conditions, including different levels of the initial traffic volume and density. Calibrated on monitored road sections in Italy, this approach distinguishes itself by offering a realistic, innovative, and cost-efficient solution that supplements recent research advancements while addressing the specific safety and sustainability challenges of rural road networks.
This paper is structured as follows:
Section 2 details the methodology for analyzing intervehicle spacing distributions using a simulation model that integrates a macro approach (a Fundamental Diagram analysis) with a micro approach (the car following model) for single-lane traffic without overtaking. It also describes vehicle generation functions based on temporal headways and arrival speeds, varying with the average hourly arrival flow rate. Calibration and validation are performed using data from a two-lane road in Northern Italy, for which the geometric characteristics and axis alignment have already been recognized and identified [
28].
Section 3 provides an analysis of the results, highlighting the variations in the experimental spatial headways distribution due to variations in the simulated arrival flow rate and the resulting average density. It also discusses the findings in relation to the statistical characteristics of spatial headways and explores suitable probabilistic models for their representation, while
Section 4 presents the study’s main conclusions.
2. Materials and Methods
2.1. Spacing Simulation Model for a Single-Lane Traffic Stream
We consider an infinitely long stretch of a two-lane highway, focusing on one direction of travel, where only light vehicles are permitted, and overtaking is completely restricted. This allows for a single vehicle class analysis. The defined segment is represented by the half-line, , oriented in the direction of travel, with the origin, O, marking the initial cross-section of the modeled highway segment.
Figure 1 shows a sequence of increasing random abscissas,
,
, …,
, representing vehicle positions along
. The spacing between consecutive vehicles is given by
=
for
= 1, 2, …,
, indicating mutual distances. The vehicle sequence can be expressed in terms of spacing alone as
;
;
…, without explicitly considering individual positions.
The Spacing Simulation Model analyzes spatial distancing probability distributions within a single-lane traffic stream, examining their variations with different hourly flow rates and average densities. It consists of two main components: the Vehicle Generation Model (VGM) and the Vehicle Interaction Model (VIM).
The VGM defines vehicle entry parameters at the origin point of , representing a single-lane traffic stream of indefinite length. It includes the Temporal Headway Distribution Model (THDM) and the Initial Speed Distribution Model (ISDM):
The VIM governs how vehicles interact after entering the traffic stream. It comprises two sub-models, namely the First Vehicle Speed Pattern (FVSP) and the car following model (CFM):
The FVSP sets the speed behavior of the lead vehicle, influencing the dynamics of all the following vehicles.
The CFM simulates how trailing vehicles adjust their speeds and distances based on the preceding vehicle, incorporating reaction times and safe following distances to prevent collisions.
This structured approach enables a detailed analysis of traffic flow dynamics and spatial dynamics, facilitating the study of how varying traffic densities and flow rates impact overall traffic behavior. The following sections define the simulation model, with a focus on each of the four sub-models.
2.1.1. Temporal Headway Distribution Model (THDM)
In assigning temporal headways to each vehicle at O, the THDM differentiates between conditioned and non-conditioned vehicles [
18]. Specifically, conditioned vehicles are restricted to speeds lower than their desired speed due to the inability to overtake the preceding vehicle, while non-conditioned vehicles have a desired speed equal to or lower than that of the preceding vehicle. By probabilistically identifying the status of each following vehicle (conditioned vs. non-conditioned), a mixed-type headway distribution model is applied. The probability distribution of time headways,
, is expressed as
[
19], where
represents the probability of a conditioned vehicle, with its time headway probability distribution,
; and
represents the probability of a non-conditioned vehicle, with its time headway probability distribution,
). This formulation separates constrained (following) and free (non-following) conditions, enabling a more precise characterization of time headway distributions in the traffic stream. The transition from non-congested to congested conditions, shifting from
to
, can be modeled using established approaches from the literature [
29,
30], such as Buckley’s Semi-Poisson Model [
31], Cowan’s M3 and M4 models [
32], and Branston’s Generalized Queuing Model [
33], among others [
26]. In this simulation, we adopted the TLR-SPM model by [
26], which defines
based on
, which is a function representing the proportion of constrained (non-free) vehicles in the traffic stream as a function of flow rate
.
The
function can be estimated for the specific lane type under consideration using a data-driven approach [
26]. For the
and
functions, the general criteria and references outlined in
Section 2 apply. Consistent with previous definitions, the simulation model assumes, for conditioned vehicles (in platoons), a Pearson type III (three-parameter Gamma) distribution for headways, with a defined
, considering
and
as functions of the hourly flow rate,
(or its equivalent in vehicles per second,
) [
34]. Similarly, for unconditioned vehicles (that are free from interactions), the model considers a shifted exponential headway distribution, with a minimum headway threshold of
. Thus, the probability distribution is as follows:
with
and
, where
. For unconditioned vehicles, since the shifted exponential distribution is a special case of the Pearson type III distribution, the function
can be derived from Equation (1) by setting
,
, and
.
2.1.2. Initial Speed Distribution Model (ISDM)
In assigning the initial speed,
, to each vehicle,
(i.e., its speed in O when it is generated by the simulation), the ISDM considers a normal distribution for both conditioned and non-conditioned vehicles as follows:
with
and
, which can be estimated based on real data for situations of the type under consideration (for example, as we will see in the next section, considering a macroscopic model of a Fundamental Diagram (FD) for the function describing the variation of the mean value and an interval regression model for the function of the standard deviation), to obtain a simplified yet convenient form of a stochastic (namely, Gaussian) Fundamental Diagram [
1,
35,
36].
2.1.3. First Vehicle Speed Pattern (FVSP)
The First Vehicle Speed Pattern (FVSP) defines the speed trajectory of the first vehicle () entering the simulation at t . The model describes speed variations along the lane without distinguishing whether the vehicle is conditioned or not. The speed trend is expressed as a function of , where speed varies with position along . Since the simulation operates with constant time steps ( s), the speed profile can be implemented as a step function, , at one-second intervals. This speed trend can be freely defined to analyze specific effects, such as variations in the desired speed, along the path. The initial speed, , is assigned according to the Initial Speed Distribution Model (ISDM).
2.1.4. Car Following Model (CFM)
Following the sequence of the sub-models, when a vehicle ) is generated, its temporal headway relative to the preceding vehicle is assigned based on the THDM; its entry speed, , is determined by the ISDM; the speed trend of the first vehicle () is set by the FVSP. At this stage, the car following model (CFM) governs interactions between consecutive vehicles and , for .
Car following models are essential in traffic simulation and transportation engineering, providing insights into individual vehicle behavior in response to preceding vehicles [
37]. These models describe the dynamic relationship between vehicles, focusing on variables such as speed, acceleration, and intervehicle distance [
38]. They simulate real-world traffic dynamics using phenomenological assumptions [
39], often structured around the fundamental relationship, Response = Sensitivity · Stimulus, first proposed by [
40,
41], where acceleration is the response, and the speed difference between vehicles acts as the stimulus [
42,
43].
In this study, the car following model (CFM) adopted is the one formulated by [
44,
45], commonly known as the General Motors (GM) model, certainly one of the most well-known stimulus-based models [
46]. In the GM model, the sensitivity, denoted as
, is not constant but varies as a function of the following vehicle’s travel speed and the spacing between vehicles. For a discrete time simulation with an updating time,
, the sensitivity,
, is expressed as
where
is the instantaneous speed of the i-th vehicle at time
t,
is the updating time interval in the discrete simulation,
is the reaction time of the driver,
is the travelling distance of the i-th vehicle from O at time
t,
is the speed exponent,
is the spacing exponent, and
the sensitivity coefficient dependent on
and
. The following equations can be used to describe the mathematical form of the GM model:
where
is the instantaneous acceleration rate of the
-th vehicle at time
, and coefficients
,
, and
allow for calibrating and particularizing the model, considering
between [−1, 4] and
between [−2, 2].
Considering that
s, we can conveniently set the reaction time as
, simplifying the application of Equations (4)–(6) in a discrete time simulation:
It has been shown that by assigning precise values to coefficients
and
, and assuming a steady state hypothesis, many macroscopic traffic laws, also known as Fundamental Diagram (FD) functions, can be directly derived from the non-linear GM car following model [
1]. Thus, for different (
,
pairs, a corresponding macroscopic relationship,
, can be identified, establishing a link between microscopic vehicle interactions and the macroscopic behavior of the entire traffic stream. The values of
and
are selected to align with the function
, which represents the average speed in the ISDM model. From this perspective, the base sensitivity coefficient,
, can be estimated, taking on a specific interpretation based on the selected
,
pair and its associated macroscopic traffic law [
45].
2.2. The Simulation Algorithm
Following the structure of the four models outlined in
Section 2.1, the simulation algorithm computes vehicle spacing under different flow rates,
. The key computational steps are
Flow rate definition: A specific flow rate,
, is selected, ranging from 100 to 1300 veh/h in increments of 100 veh/h. For each flow rate, 100 Monte Carlo (MC) simulations [
47,
48] are performed.
The generation of the first vehicle ( = 0): The first vehicle, , is placed at the origin, O, with an initial speed, . In each simulation, a random number, , is generated using Monte Carlo sampling. The initial speed, , follows a Gaussian distribution with a mean of and a standard deviation of , estimated from real data. The vehicle’s trajectory, , is updated over time using FVSP, with discrete steps, s.
The generation of the following vehicles (i = 1 to 100): Vehicle spacing is assigned based on the THDM: the proportion of the following vehicles is determined using , estimated from real data. A random number, , is generated: if , a non-following vehicle is generated, otherwise a following vehicle is generated. For non-following vehicles, the headway, , is sampled from a shifted exponential distribution with and . For the following vehicles, the headway, , is sampled from a three-parameter Gamma distribution, with , , and .
Position and speed calculation for each vehicle (i = 1 to 100): Position is updated at each discrete time step, s, considering its headway, , relative to the previous vehicle, ; its initial speed , sampled from a Gaussian distribution, with and (the same as in step 2); its speed evolution , based on the GM car following model (CFM), using , [−1,4], [−2,2], and , estimated from real data.
The simulation model evaluates traffic flows ranging from 100 veh/h to 1300 veh/h in increments of 100 veh/h (i.e., 100, 200, 300, …, 1100, 1200, 1300 veh/h). For each hourly flow rate, 100 vehicular sequences were simulated, each consisting of 100 vehicles entering the simulation at the origin O of . Vehicle entry follows temporal headways assigned by the THDM, initial speeds determined by the ISDM, mutual interactions governed by the CFM, and speed trends over time defined by the FVSP. The model assumes a single vehicle class and a no-overtaking rule. The specifications of the four sub-models are based on real traffic data collected at a road section that aligns with the model’s assumptions. In total, the simulation generates 130,000 vehicles, tracking their movement along from O over an indefinite lane length under the defined traffic conditions. For each series of 100 simulated vehicles, the following key data points are extracted:
Temporal headways, (). The time intervals between consecutive vehicles at the origin, O (used for validation against the experimental headway distribution from the reference road section).
Initial speeds, (). The speeds at which vehicles enter the simulation at O (compared with the experimental speed distribution from real-world data).
Vehicle spacing, (), includes the average vehicle length (4.5 m). It is defined as , representing the distance to the preceding vehicle at the time, , when the 100th vehicle is generated at O.
2.3. The Specification, Calibration, and Validation of the Simulation Model on a No-Passing, Rural, Two-Lane Road
The data used for specifying, calibrating, and validating the model were obtained from the same monitoring section described in [
26]. The monitoring section was equipped with 24,165 GHz Doppler radar instruments installed on both sides of the carriageway. The site was a straight, level segment of a two-lane rural road in Northern Italy, characterized by a speed limit of 90 km/h, a no-transit rule for heavy vehicles over 3.5 tons, and a no-overtaking rule for all vehicle categories. The monitoring session lasted 24 h in both travel directions, recording approximately 28,000 vehicles under normal-working-day conditions, with no atmospheric disturbances or accidents affecting the traffic flow.
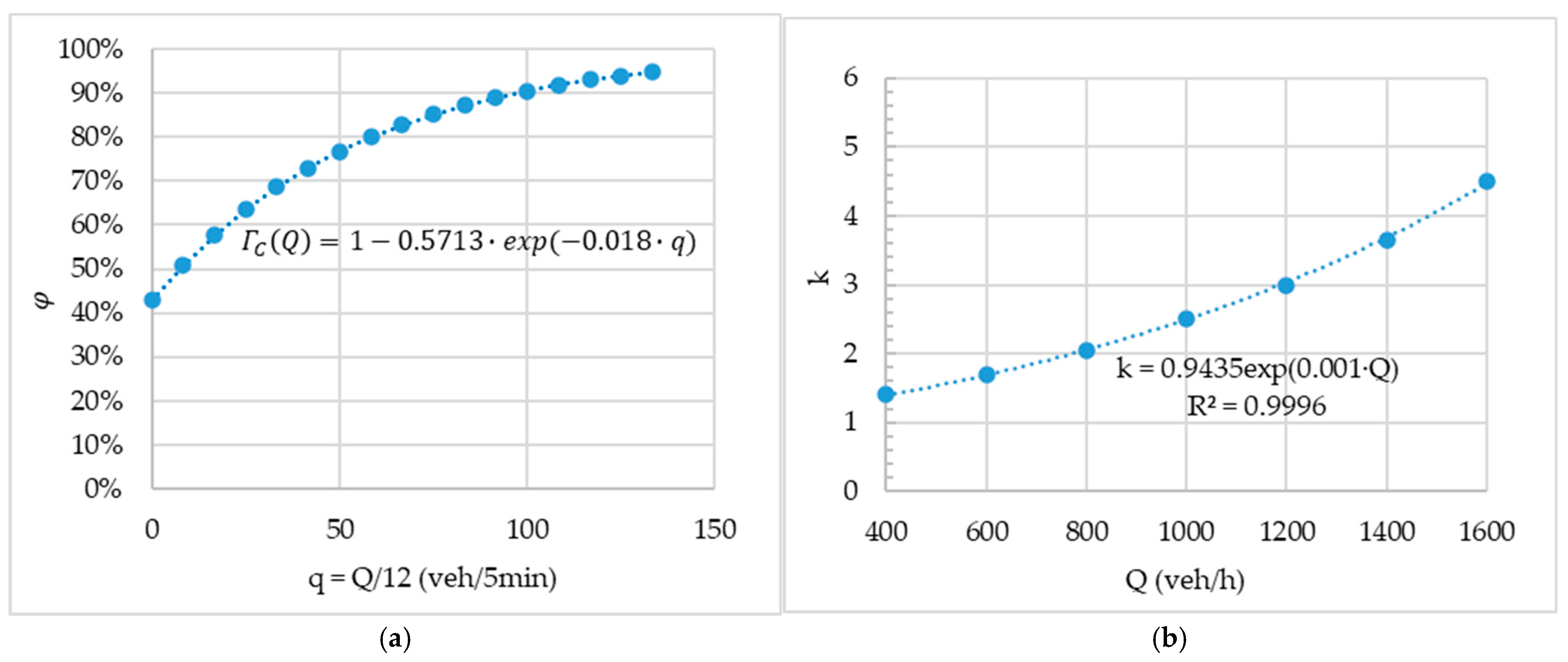
The first step in the modeling chain is defining the vehicle generation process through headway sampling, governed by the Temporal Headway Distribution Model (THDM). This requires both the specification of the function
, which segments hourly traffic into conditioned (following) and unconditioned (free) vehicles, and the probability distributions
and
definition for these two vehicle categories. The function
was calibrated by [
26] for the same monitoring section (
Figure 2a) and determinates the proportion of following vehicles. For non-free vehicles, in line with [
19], a Pearson type III distribution (three-parameter Gamma) was used with
s and
, and the relationship
was defined based on [
19,
49] as
. Similarly, for free vehicles, a shifted exponential distribution was used, with
and
s [
18,
19].
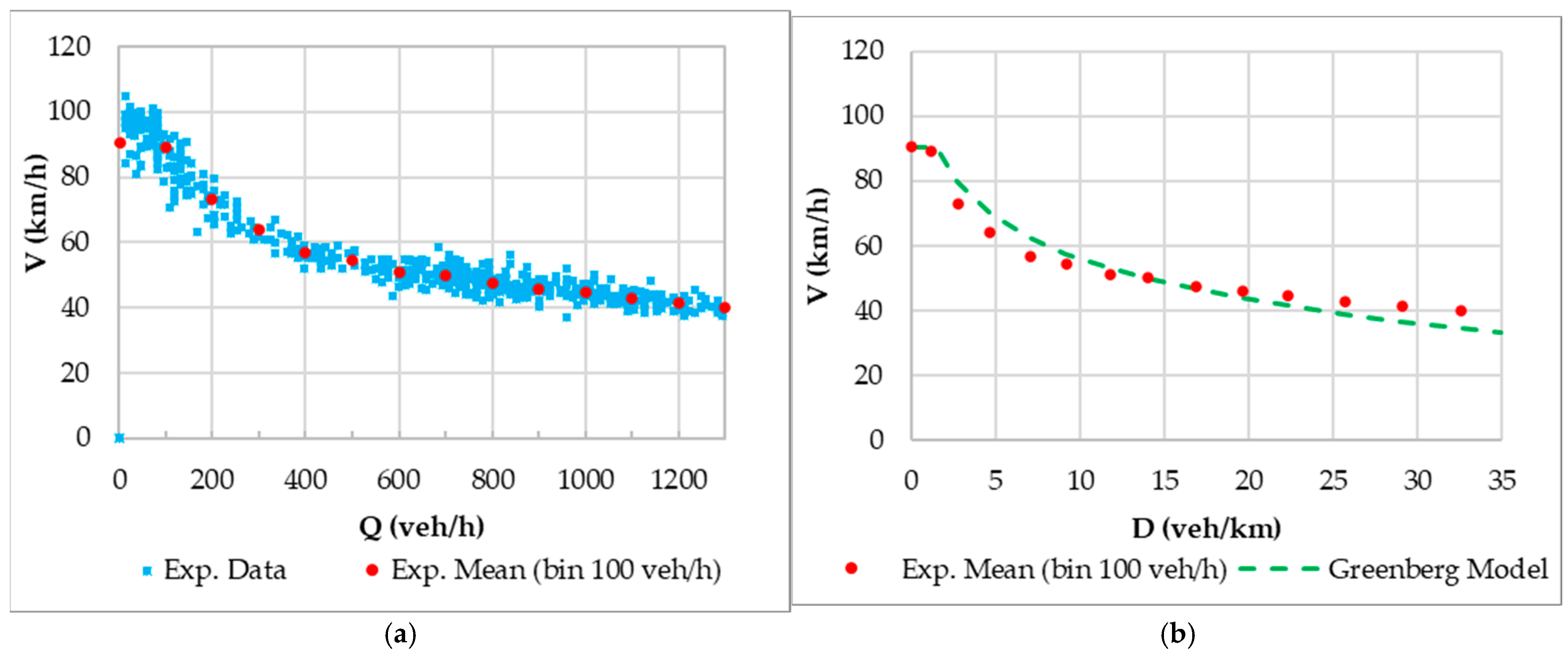
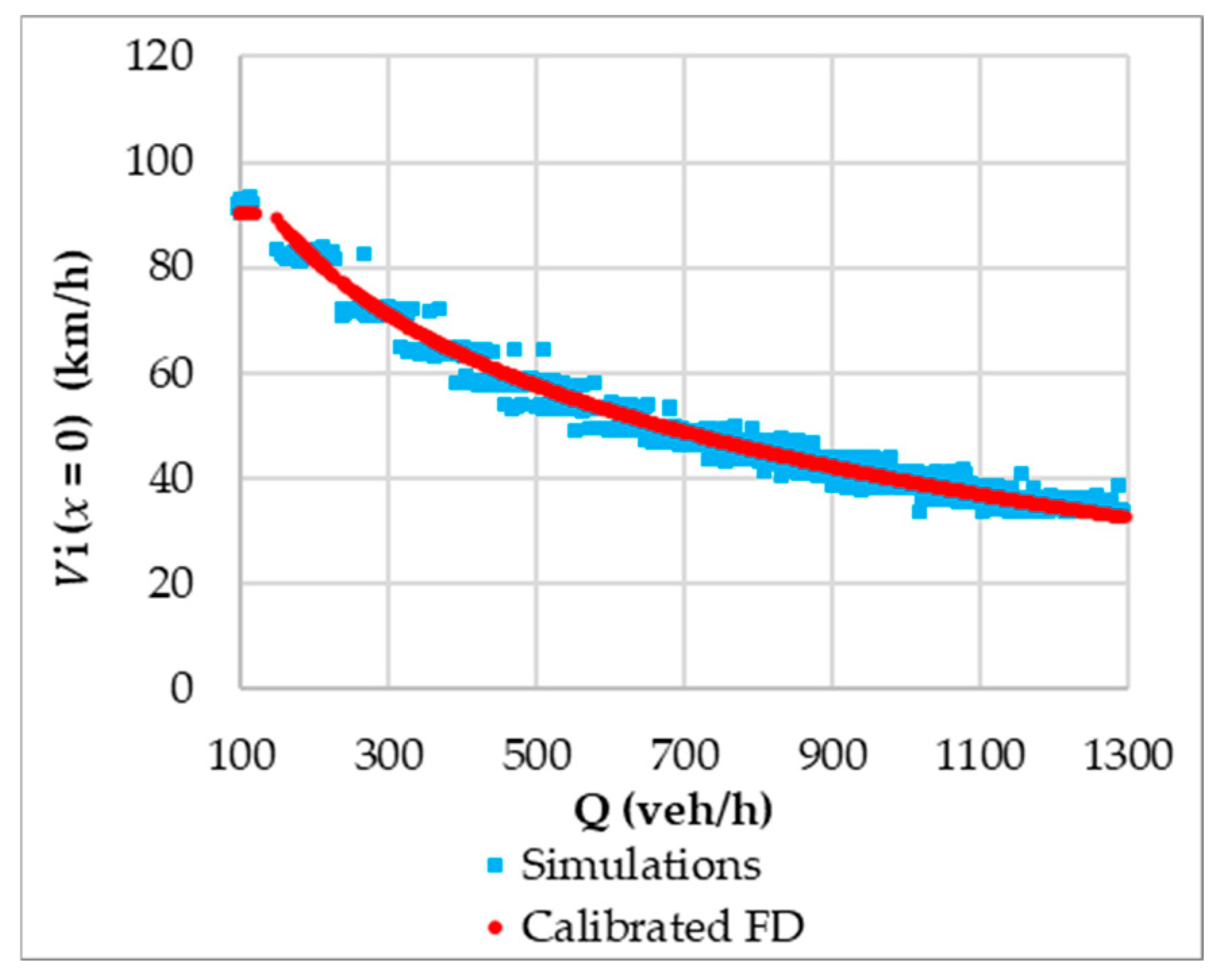
To define the Fundamental Diagram (FD) model for
, the hourly flow data and 5 min average speed data were analyzed, alongside the empirical speed trends for 100 veh/h bins (
Figure 3a). By plotting these values on the speed–density plane (
Figure 3b), a pattern emerges, suggesting a Greenberg-type functional specification [
1,
50]. The estimated Greenberg model is defined as
for
veh/km and
for
veh/km. It produces a calibrated equation with the parameters
= 220 veh/km and
km/h, which approximates the overall trend of the experimental averages, as demonstrated in
Figure 3b.
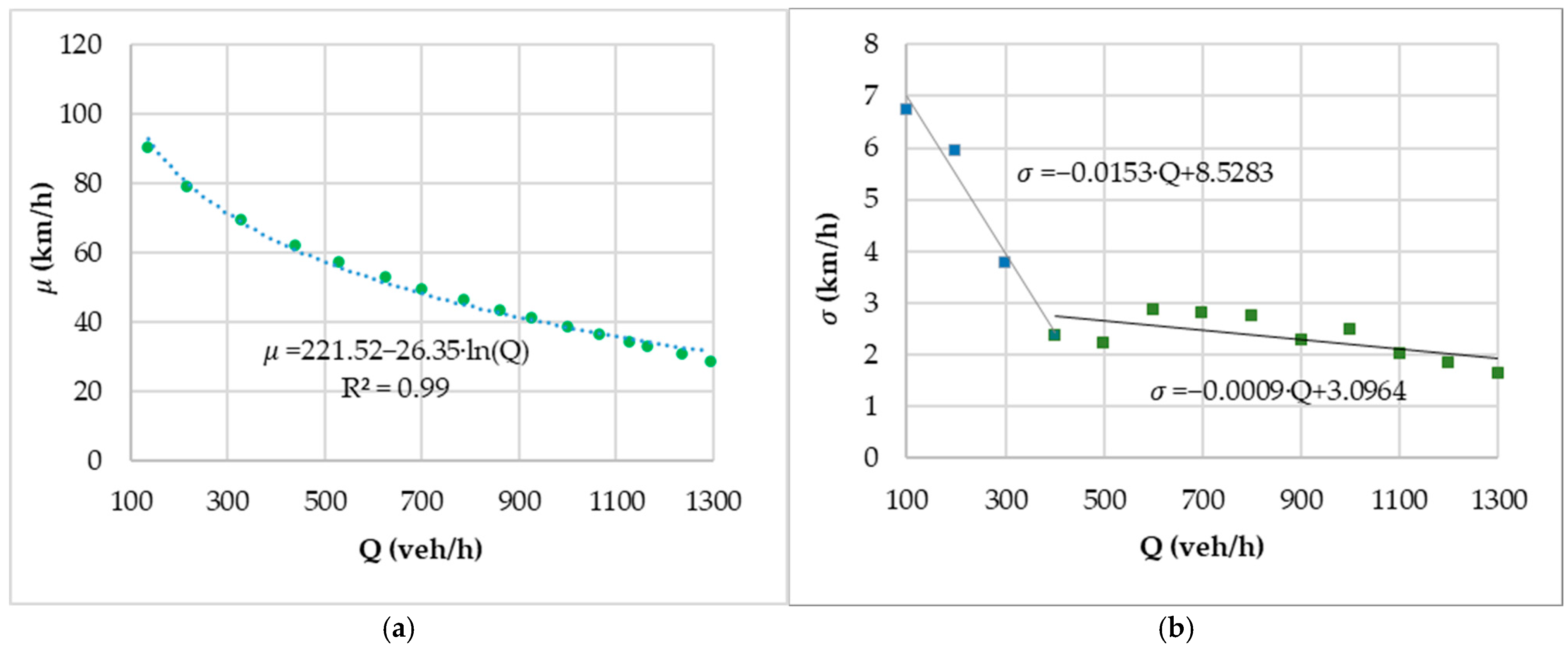
Since
Q =
V⋅
D, the Greenberg model, expressed as
, does not provide a closed-form analytical solution for
due to the implicit logarithmic equation structure. However, this limitation is addressed through numerical solutions for specific Q values. D values are computed numerically for given Q values. These D values are substituted into the Greenberg equation to obtain the corresponding V values. The resulting (
,
) pairs are interpolated to derive an analytical approximation of
. For
veh/h, the equation
provides an excellent approximation of the Greenberg relationship (
Figure 4a). For
veh/h, the speed is assumed to be constant at 90.5 km/h, reflecting free-flow conditions.
To define
, the standard deviation of vehicle speeds was analyzed concerning the flow rate,
, over 5 min periods in the monitoring section. The experimental values are presented in
Figure 4b. A linear regression was performed on two distinct subgroups of data points with similar trends: for
,
, and for
,
. As shown in
Figure 5b, these two linear equations effectively capture the trend of the standard deviation relative to the flow rate.
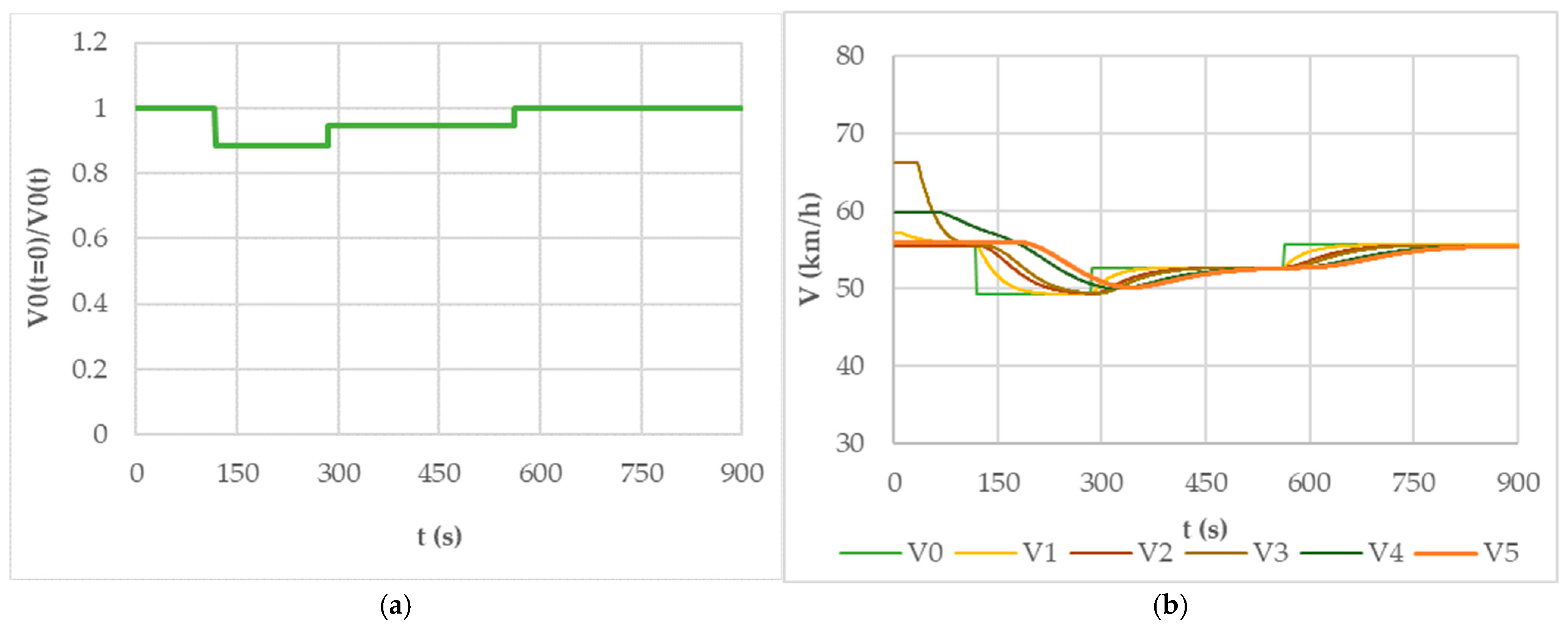
Given the homogeneity of the infrastructure downstream of the monitoring section, speed variations for the first vehicle in the simulated series
were limited. Specifically, a maximum speed reduction of 20% was allowed and over 900 s of simulation, and the average speed deviation did not exceed 5% of the initial value
(
Figure 5a).
To maintain consistency with the Demand Function (DF) model used in the ISDM, the General Motors (GM) model was selected for the CFM. Given the Greenberg specification of the DF model, the CFM’s parameters were defined as
and
, whereas for the sensitivity constant
, the estimated value
km/h was used. This ensures alignment between the CFM and the ISDM, reinforcing the model’s internal consistency.
Figure 5b illustrates the speed evolution of the first 5 vehicles following the lead vehicle (
) in the simulation. The CFM’s dynamics highlight the mutual conditioning between the speeds of leader–follower pairs, demonstrating the influence of the car following model on the simulated traffic stream.
As detailed in
Section 2.2, the simulation model considers hourly traffic flows between 100 veh/h and 1300 veh/h in increments of 100 veh/h. In a complete simulation session, a total of 130,000 vehicles are generated and simulated, moving along
from O over an indefinite lane length. As an example,
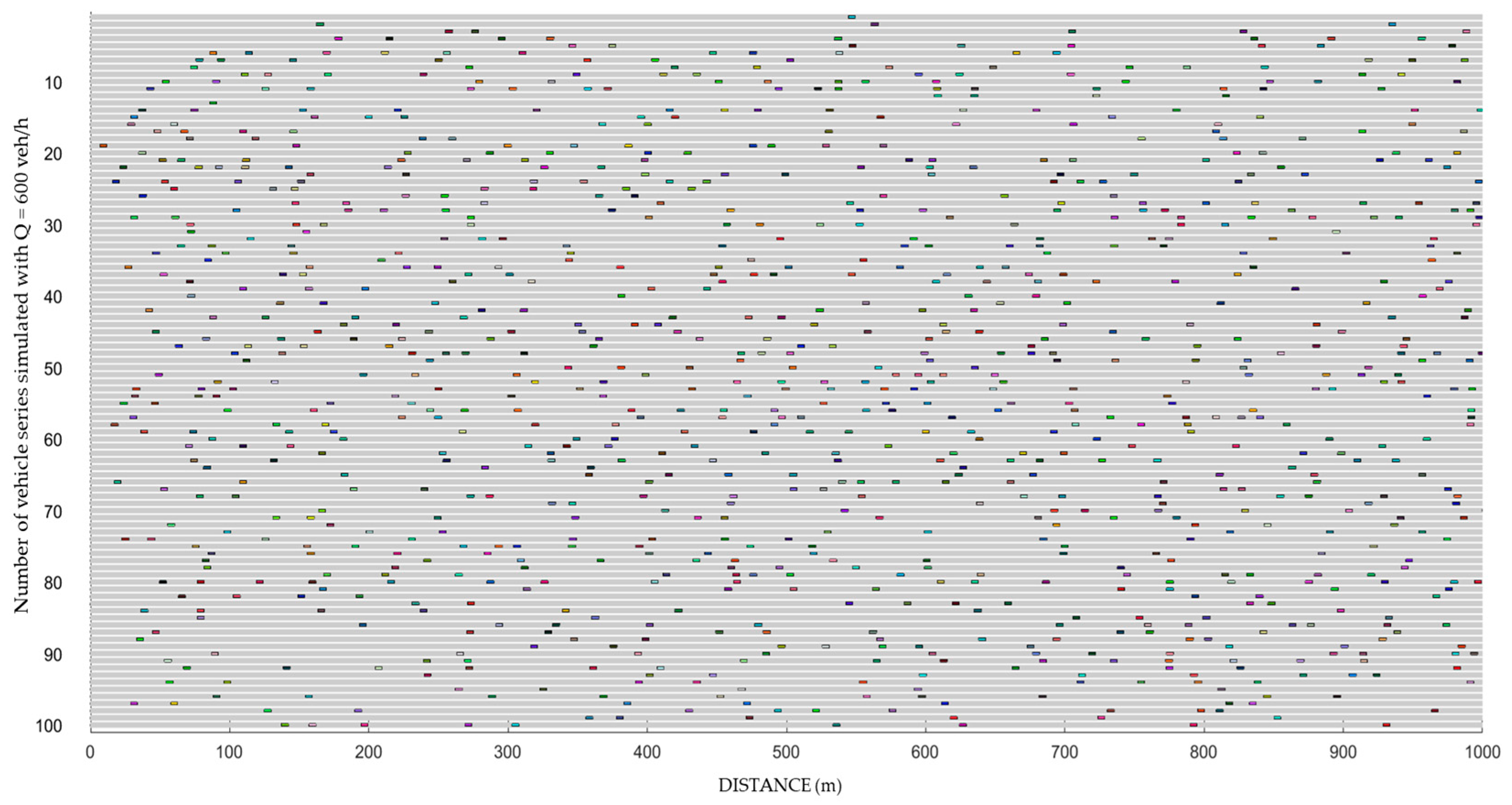
Figure 6 presents a graphical reconstruction of the results at the third simulation point, illustrating the spatial distribution of vehicles over a 1 km segment at the instant the last vehicle in the series is generated, for an average hourly traffic flow of Q = 600 veh/h.
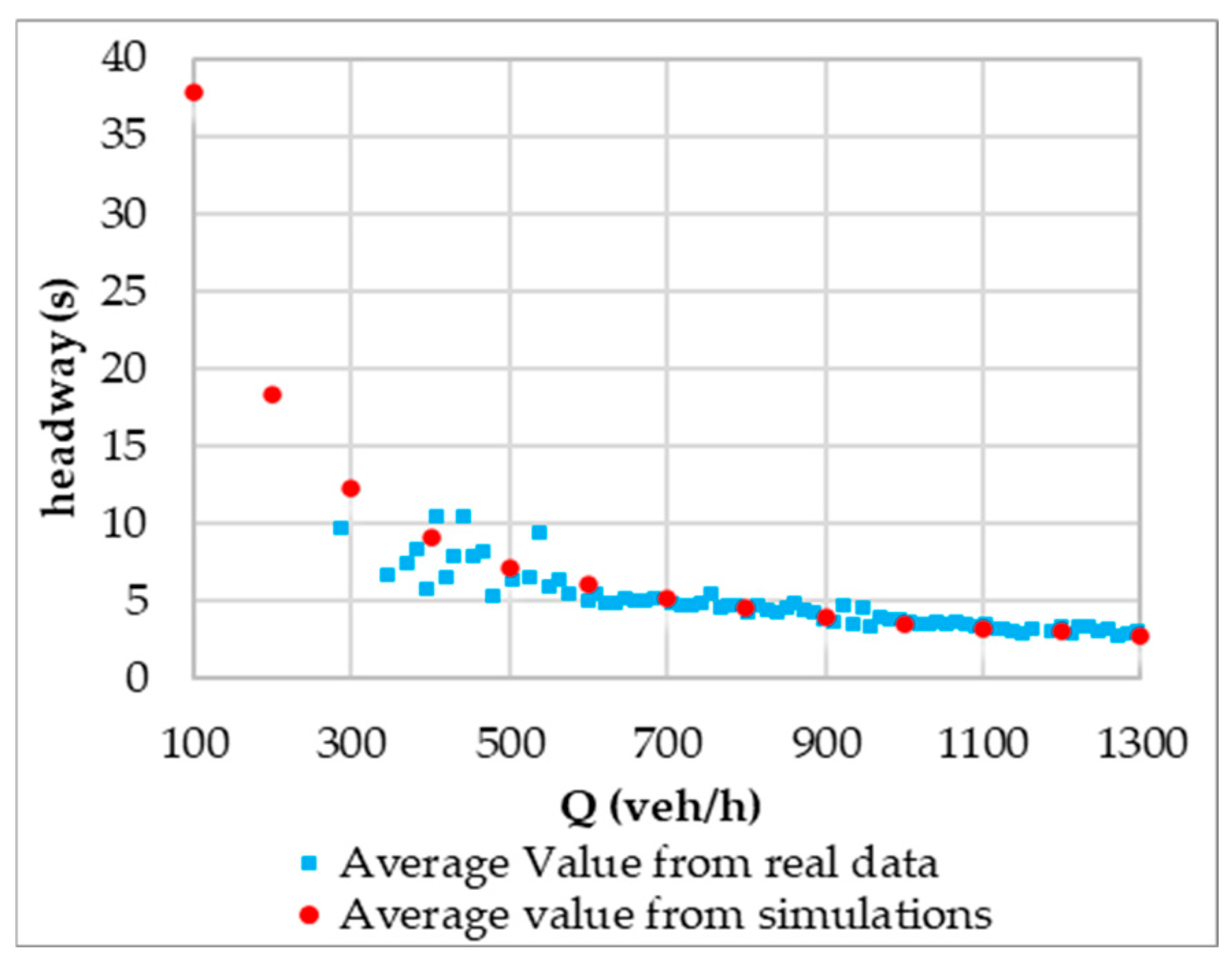
The simulated values for the temporal headways
(
) and the speeds
(
) were validated against real monitoring data. The validation results are presented in
Figure 7 and
Figure 8:
Figure 7 demonstrates a strong agreement between the simulated temporal headway distribution and the empirical headway values observed in the monitoring section;
Figure 8 confirms that the simulated entry speeds align well with the empirical speed distribution derived from the Greenberg model as a function of the hourly flow rate. These results confirm the accuracy and reliability of the simulation model in reproducing real-world traffic dynamics.
3. Results and Discussion
The analyzed results focus on the intervehicle spacing values for at instant , corresponding to the generation of the 100th vehicle at the origin, O. To conduct this analysis, the data were classified according to the traffic flow and density levels. Specifically, the traffic flow was considered in increments of 100 vehicles per hour, ranging from 100 to 1300 veh/h, while the density values were categorized from 1 to 45 vehicles per kilometer, with increments of 1 veh/km. The simulated flow rate was calculated by normalizing the number of vehicles passing the section between and on an hourly scale. The simulated density was obtained by normalizing the total spacing of the 100 vehicles at over a 1 km stretch of roadway.
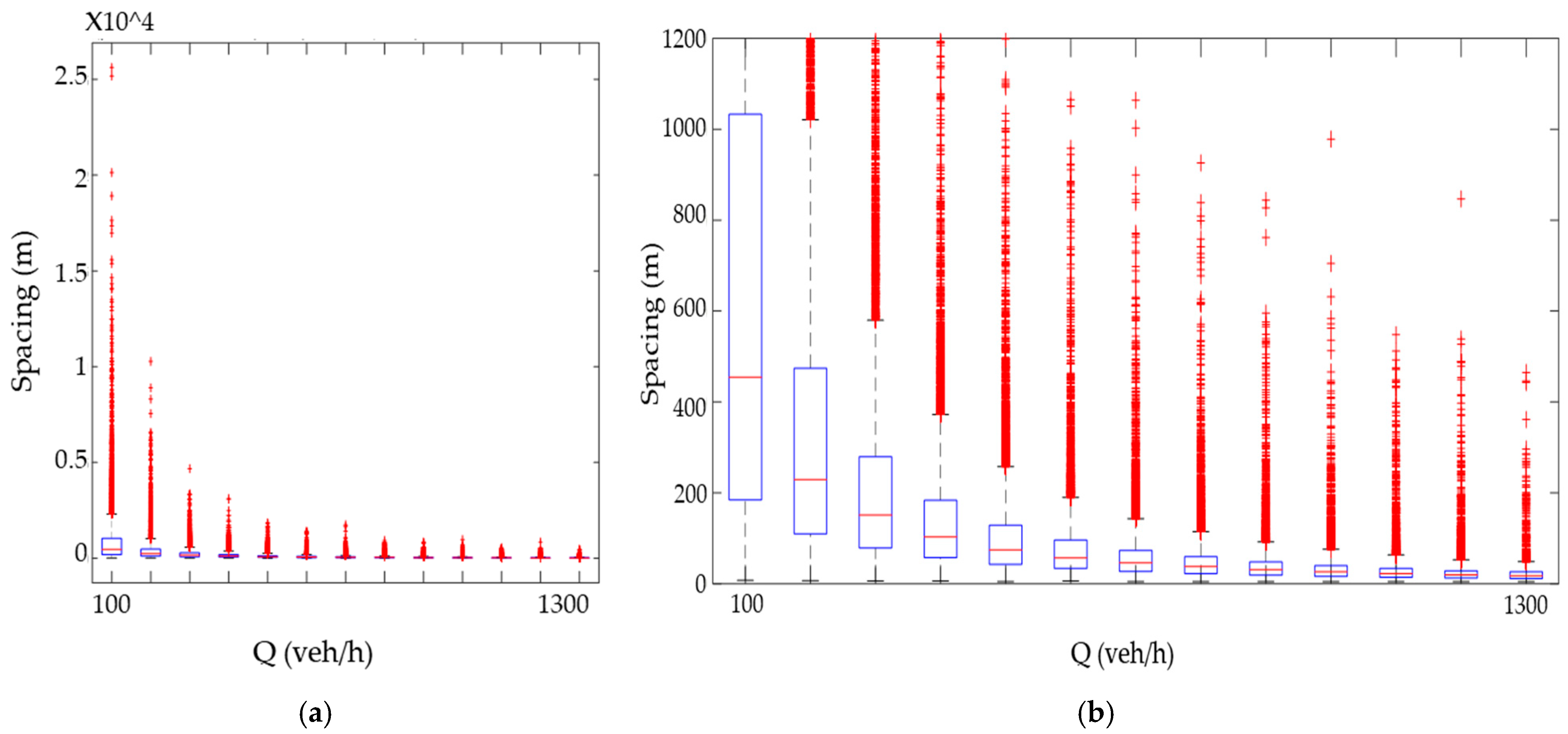
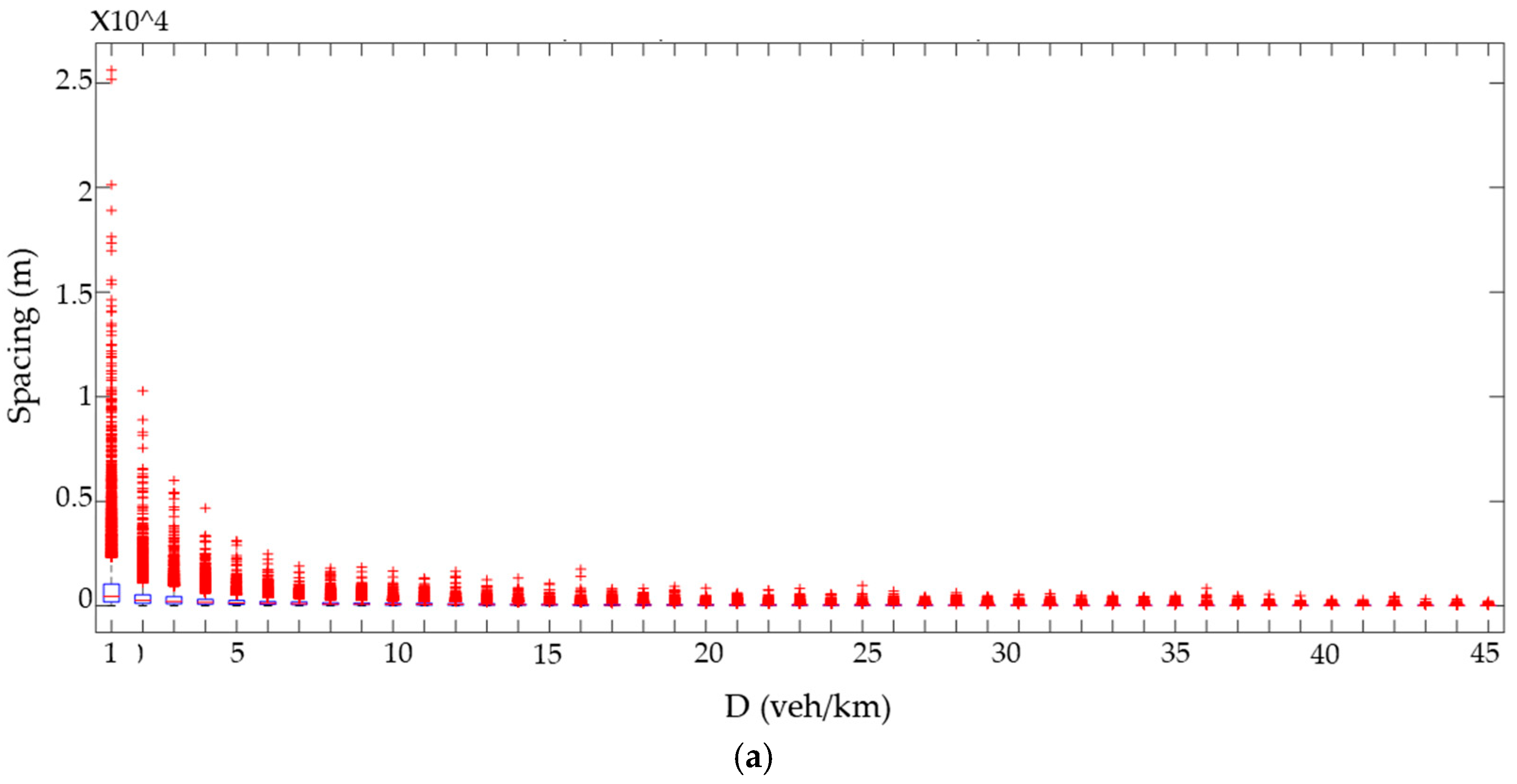
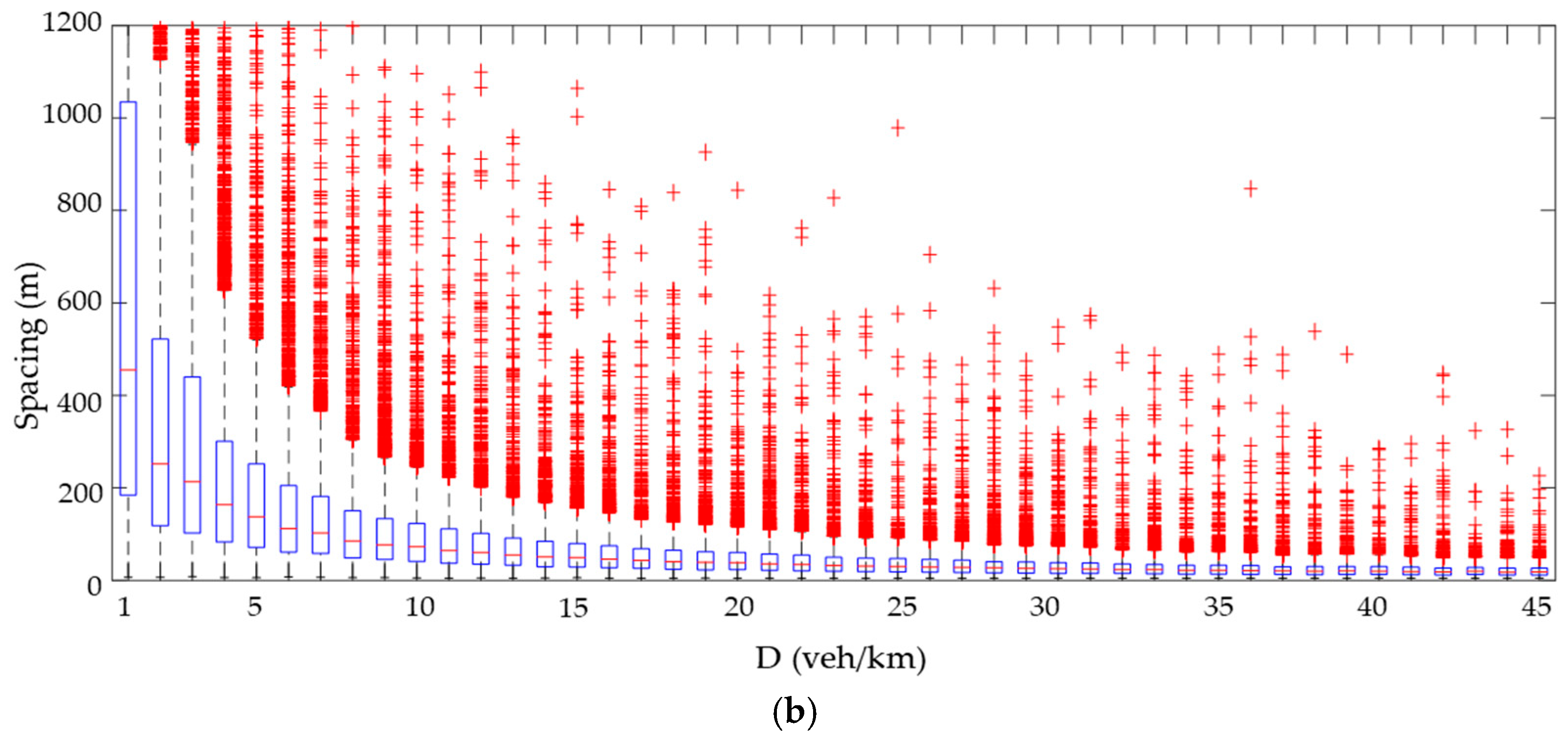
The statistical analysis, based on the central tendency measures and percentiles presented in
Table 1, and further illustrated by the boxplot in
Figure 9, revealed a progressive reduction in intervehicle spacing as the simulated flow rate increased. While the maximum spacing values experienced a significant decline, the minimum values remained relatively stable, although with a slight downward trend. This suggests that shorter vehicle gaps were largely unaffected by traffic density increases, but longer gaps became increasingly rare. Outliers observed in the boxplots are not attributed to simulation errors but are instead reflective of stochastic variability under rare, yet plausible, traffic conditions. These include transitions between free-flow and congested states or erratic spacing patterns at low-density volumes. Such behavior is consistent with natural traffic flow dynamics modeled through Monte Carlo simulation techniques. Examining the distribution of spacing values,
Table 1 shows that the data consistently exhibited positive skewness, indicating a longer tail toward higher spacing values. This asymmetry reflects irregular large gaps between some vehicles. Furthermore, the analysis revealed high kurtosis, signifying a leptokurtic distribution with a sharper peak than a normal distribution. This implies a higher frequency of extreme values, both at the lower and upper ends of the spacing spectrum.
The main findings can be summarized by grouping the results into density intervals and computing the average density for each group. As shown in
Figure 10 and
Table 2, both the central tendency and dispersion measures decreased as the vehicle density increased, consistent with theoretical expectations for traffic flow behavior. The distribution of the simulated data exhibited a positively skewed pattern with leptokurtic characteristics, indicating an asymmetric shape with a pronounced peak.
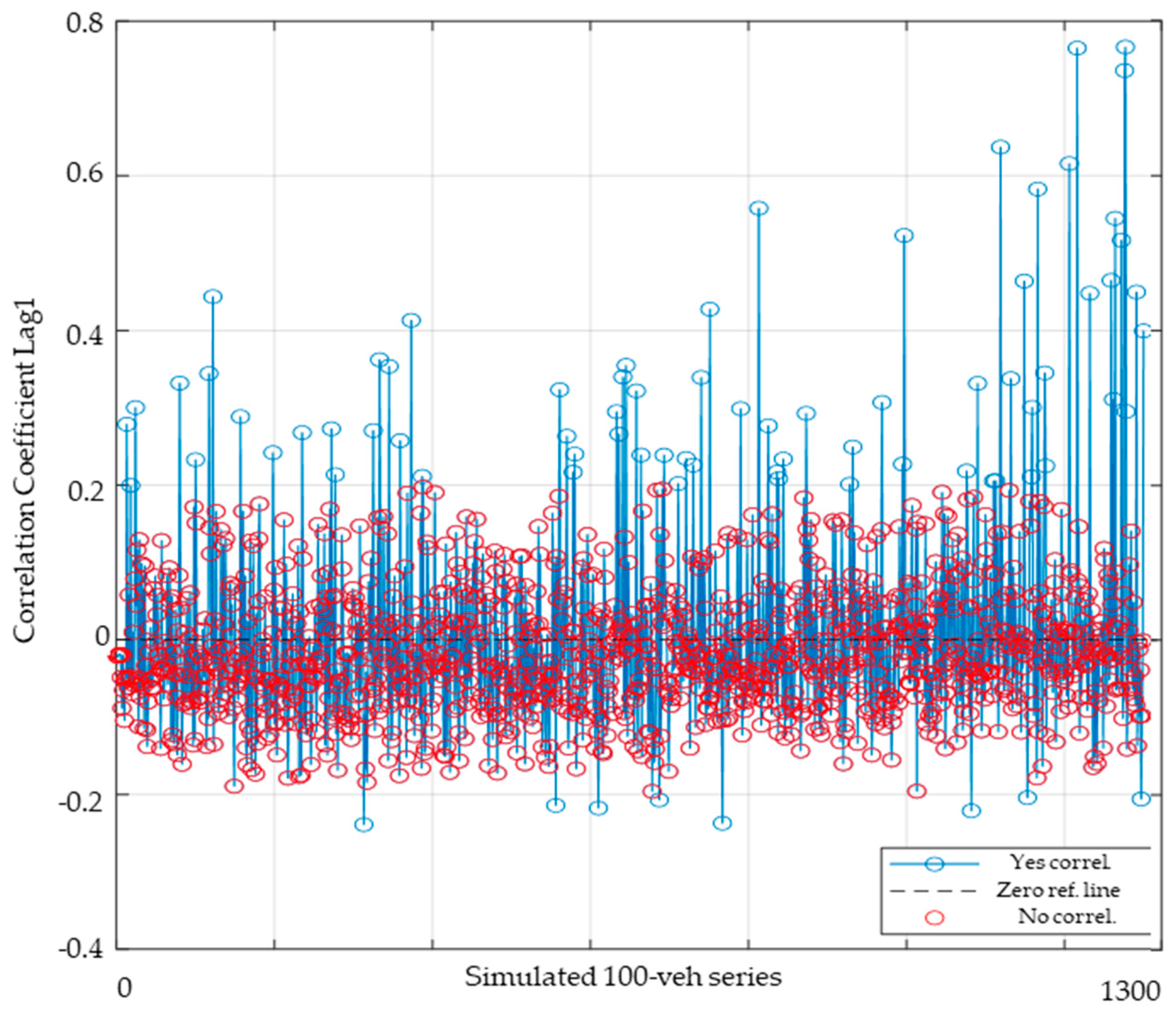
Assessing autocorrelation is essential for understanding the dependency between vehicle distances within each simulated vehicle sequence. In this context, the analysis focuses specifically on autocorrelation at lag1, based on the assumption that no significant correlations at higher lags should exist unless a lag1 correlation (i.e., among three consecutive vehicles) is already present. For each sequence of 100 simulated vehicles, the correlation between consecutive spacings (lag 1) was calculated. These values were extracted from both the correlation matrix and the p-value matrix. The p-value was then used to determine the statistical significance of the correlation, using the commonly accepted threshold of 0.05.
Figure 11 presents the correlation coefficient at lag 1 for each simulated vehicle sequence. Sequences where the correlation was not statistically significant (i.e.,
p-value > 0.05) are highlighted in red, accounting for 94% of the 1300 simulated series. According to [
51], a correlation is considered weak if its absolute value falls between 0.1 and 0.3, moderate if it ranges from 0.3 to 0.5, and strong if it exceeds 0.5. Applying this classification to the 1300 simulated series, the results indicate that 73% exhibited no correlation, 24% showed a weak correlation, and only 3% displayed a moderate or strong correlation. This confirms that significant dependencies between consecutive vehicle spacings are relatively rare under the simulated traffic conditions.
Figure 11 further illustrates how the autocorrelation increases with traffic volume and density. In particular, the correlation values at lag1 are generally higher in sequences simulated under higher traffic conditions. The significant autocorrelation observed in intervehicle spacing at higher traffic densities, illustrated in
Figure 11, indicates the presence of short-range dependencies between consecutive vehicles. This pattern typically arises from platoon formation, where vehicles cluster due to constrained car following behavior. From a practical perspective, this autocorrelation results from drivers continuously adjusting their speed and spacing based on the actions of the vehicle immediately ahead.
In classical car following models, such as the General Motors model, this phenomenon is governed by driver characteristics, including the reaction time and the sensitivity to spacing. At higher densities, shorter distances between vehicles substantially reduce the time available for drivers to perceive and respond to the speed variations of the vehicle in front. Consequently, even minor changes in speed propagate rapidly through the vehicle platoon, magnifying the effects of each driver’s reaction delay [
44,
52]. As a result, small initial disturbances can quickly amplify, leading to traffic instability and pronounced fluctuations in vehicle spacing [
53,
54].
This interaction between delayed driver reactions and their sensitivity to spacing variations leads to the formation of stable vehicle groups—or platoons—characterized by strong temporal correlations. Within these platoons, each vehicle’s motion is directly influenced by the preceding vehicles, creating a persistent autocorrelation in spacing [
55,
56]. To further support the connection between autocorrelation and platooning behavior, future developments of the proposed model should incorporate more comprehensive metrics, such as the average platoon length, the vehicle membership consistency over time, and stability indices. These additional indicators would allow for a deeper understanding of the structure and persistence of vehicle groupings, offering a more detailed assessment of how traffic density and flow conditions influence platoon dynamics and the resulting impacts on road safety and operational efficiency.
Therefore, the observed autocorrelation in intervehicle spacing distributions demonstrates the inherent “memory effect” resulting from drivers’ finite reaction times and limited responsiveness. This effect contradicts the assumptions behind traditional statistical models (such as exponential or Erlang distributions), which rely on the assumption of independent, memoryless events. These findings support the need for spacing models that are not based on memoryless or independent-event assumptions, particularly in congested regimes where the driver behavior introduces dynamic memory effects.
In summary, the data analysis yielded the following key observations:
Positive skewness: The intervehicle spacings exhibit positive skewness, indicating an asymmetric shape with a longer tail towards higher values. Most spacings cluster at lower values, but occasional, large gaps occur.
High kurtosis: The distribution shows high kurtosis, indicating a leptokurtic shape that is more peaked than a normal distribution. This implies a higher frequency of extreme values, both low and high, compared to a normal distribution.
Non-zero minimum value: the minimum values in the distribution are non-zero, reflecting the physical constraint that vehicle spacings cannot fall below a certain threshold.
Autocorrelation: there is some evidence of autocorrelation at a higher traffic volume and density, where consecutive vehicle spacings show a stronger dependency due to platooning effects.
Given these statistical properties, the Pearson type III (PTIII) distribution, previously used to model vehicle headways in the THDM sub model, proved to be a highly adaptable fit for modeling intervehicle spacing. Its flexibility in capturing high asymmetry and kurtosis makes it well-suited for these conditions. The PTIII distribution can be represented by a probability density function (PDF) that depends on three parameters—
,
,
—and is expressed in terms of vehicle spatial distance
as follows:
where
is the Eulerian Gamma function, which is defined as follows:
This Pearson type III (PTIII) distribution is particularly suited for modeling right-skewed data, with its degree of skewness controlled by the shape parameter,
k, which is restricted to positive real values. The location parameter,
∈
, shifts the distribution,
, along the s-axis, while the scale parameter,
, affects the spread of the distribution. In general,
∈
with
. If
, then
∈ (
,
), and if
, then
∈ (
,
). For the vehicle spacing distribution, the Pearson type III distribution is always considered with
, ensuring that spacing values remain positive, as required by physical constraints. In addition, the choice of PTIII is further supported by its theoretical advantages over alternative asymmetric distributions typically employed in traffic and reliability modeling, such as the Weibull and the Log-Normal. Unlike these alternatives, the PTIII distribution offers greater parametric stability—i.e., less sensitivity to sampling variability and outliers—and enhanced statistical interpretability, as its parameters are directly related to key descriptive moments of the data (mean, variance, skewness). Moreover, while other distributions, such as the exponential or Erlang, require assumptions of independence and a memoryless structure, the PTIII does not impose such constraints, making it more suitable for modeling spacing data that may exhibit serial dependence. Thus, it can be adapted to model data with interdependencies, such as those revealed in the lag 1 autocorrelation analysis previously discussed and illustrated in
Figure 11.
4. Conclusions
This study highlights the critical role of intervehicle spacing in traffic analysis on two-lane roads, addressing a gap in the existing literature, where temporal headways have traditionally received more attention. The findings have important implications for the development of traffic models that enhance both safety and sustainability. While modern image processing and traffic monitoring technologies have advanced significantly, their deployment remains largely restricted to sensor-rich infrastructures, such as motorways and toll roads. The high cost of sensor networks renders them impractical for widespread use on two-lane rural roads. Given the strategic importance of two-lane roads in connecting urban and interurban networks to higher-level infrastructures, this study proposed an alternative methodology to analyze spacing behavior. A simulation-based model was developed to estimate the probability density of intervehicle spacing under various traffic conditions. This model integrates macroscopic and microscopic traffic flow theories and was calibrated and validated using data from a monitoring section in Northern Italy. The simulation results generated realistic spacing distributions across a wide range of flow and density levels.
The statistical analysis of the simulated data led to several key observations:
Positive skewness: The spacing distribution is positively skewed, indicating a longer tail toward larger values. While most vehicle spacings are clustered at the lower end, occasionally larger spacings occur.
High kurtosis: The distribution shows high kurtosis, characterizing a leptokurtic shape that is more peaked than a normal distribution. This suggests a higher frequency of extreme values (both low and high) compared to a Gaussian model.
Non-zero minimum value: the minimum observed spacing values remain above zero, reflecting the physical constraint that vehicles cannot be spaced below a certain safety threshold.
Autocorrelation: at higher traffic volumes and densities, there is some evidence of autocorrelation, suggesting that spacing patterns become more structured, likely due to platooning effects.
Based on these findings, the Pearson type III (PTIII) distribution was identified as the most appropriate probability model to represent the simulated spacing data. Its flexibility makes it particularly suitable for accurately describing asymmetric distributions with high kurtosis (leptokurtic distributions). Compared to other asymmetric distributions commonly used, such as Weibull or Log-Normal, the PTIII distribution is less sensitive to sampling variability and outliers, and it offers clearer statistical interpretability. Additionally, unlike distributions commonly adopted in vehicle spacing analyses—such as the exponential or Erlang distributions—the PTIII does not require assumptions of independence or memoryless behavior, making it especially valuable for modeling realistic vehicle spacing under different traffic conditions.
It is important to highlight that this study examines only a simplified scenario, involving one-directional traffic with a low vehicle flow, no overtaking maneuvers, and a single type of vehicle, under normal conditions without severe weather or emergency events. Furthermore, this study does not include experimental spacing data from real traffic, limiting the validation of our simulation results. These simplifications were necessary to create a controlled baseline for analysis. Future work will address these limitations by incorporating empirical data and expanding the model to more realistic and complex traffic scenarios, thereby enhancing its generalizability and practical relevance. In addition to its technical contributions, this research also supports broader sustainable development goals by promoting methods for improving traffic flow efficiency, reducing congestion-related emissions, and enhancing road safety—especially in rural areas underserved by traditional traffic monitoring systems. In practical terms, the simulation model can serve as a valuable decision-supporting tool in traffic management applications, such as the optimization of dynamic speed limit systems, adaptive signal control, or congestion mitigation strategies. Moreover, its modular structure lends itself to future adaptation for mixed traffic scenarios, including those involving different levels of autonomous and connected vehicles. Evaluating its performance under these evolving conditions would be crucial to assess its scalability and relevance in next-generation transportation systems. By enabling the analysis of traffic behavior without reliance on costly infrastructure, the proposed simulation approach offers a practical tool for transportation planning in regions where investments in ITS technologies may be economically or logistically infeasible. More efficient spacing leads to smoother traffic flows, reduced fuel consumption, and fewer stop-and-go conditions—factors that directly contribute to environmental sustainability and public health.
To further develop the findings of this study, future research should focus on
Parameter estimation for Pearson type III: Based on qualitative evidence from simulation results and characteristics of spatial headway data, the Pearson type III distribution has been identified as suitable for representing continuous distributions. Future research will focus on refining the parameters of the Pearson type III distribution to improve the statistical representation of vehicle spacings under varying arrival flow rates and density levels. This process will include formal parametric and non-parametric goodness-of-fit tests and comparative analyses.
Traffic safety assessment: An assessment using the estimated spacing distributions to quantify the collision risk, particularly by analyzing the percentage of vehicles traveling at intervehicle distances below a critical safety threshold. This can be linked to stopping distances under real-time traffic conditions.
Extension to other road types and traffic environments: calibrating and validating, also using experimental spacing data directly collected from real traffic situations, the simulation framework to urban road networks, multilane highways, and various traffic compositions to assess how spacing behaviors change under different conditions.
Effects of Intelligent Transportation System (ITS) technologies: Investigating how the probabilistic model of spatial headways could be affected by ITS components under different traffic scenarios in terms of vehicle volumes and density. The specific technologies considered include Variable Speed Limit (VSL) systems, Vehicle-to-Everything (V2X) communications, and mixed traffic flows consisting of Human-Driven and Connected Autonomous Vehicles with varying levels of market penetration. This approach aims to evaluate the potential impacts of ITS integration on traffic management efficiency, flow stability, and overall road safety.
The methodology presented in this study offers a scalable, cost-effective approach for analyzing intervehicle spacing in environments where traditional sensor networks are unavailable. Its application across varied traffic contexts can significantly contribute to designing safer, more efficient, and more sustainable transportation systems, aligning with global efforts to develop equitable, eco-friendly, and resilient infrastructure.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}