
Research on High Spatiotemporal Resolution of XCO2 in Sichuan Province Based on Stacking Ensemble Learning


Abstract
1. Introduction
2. Data and Methods
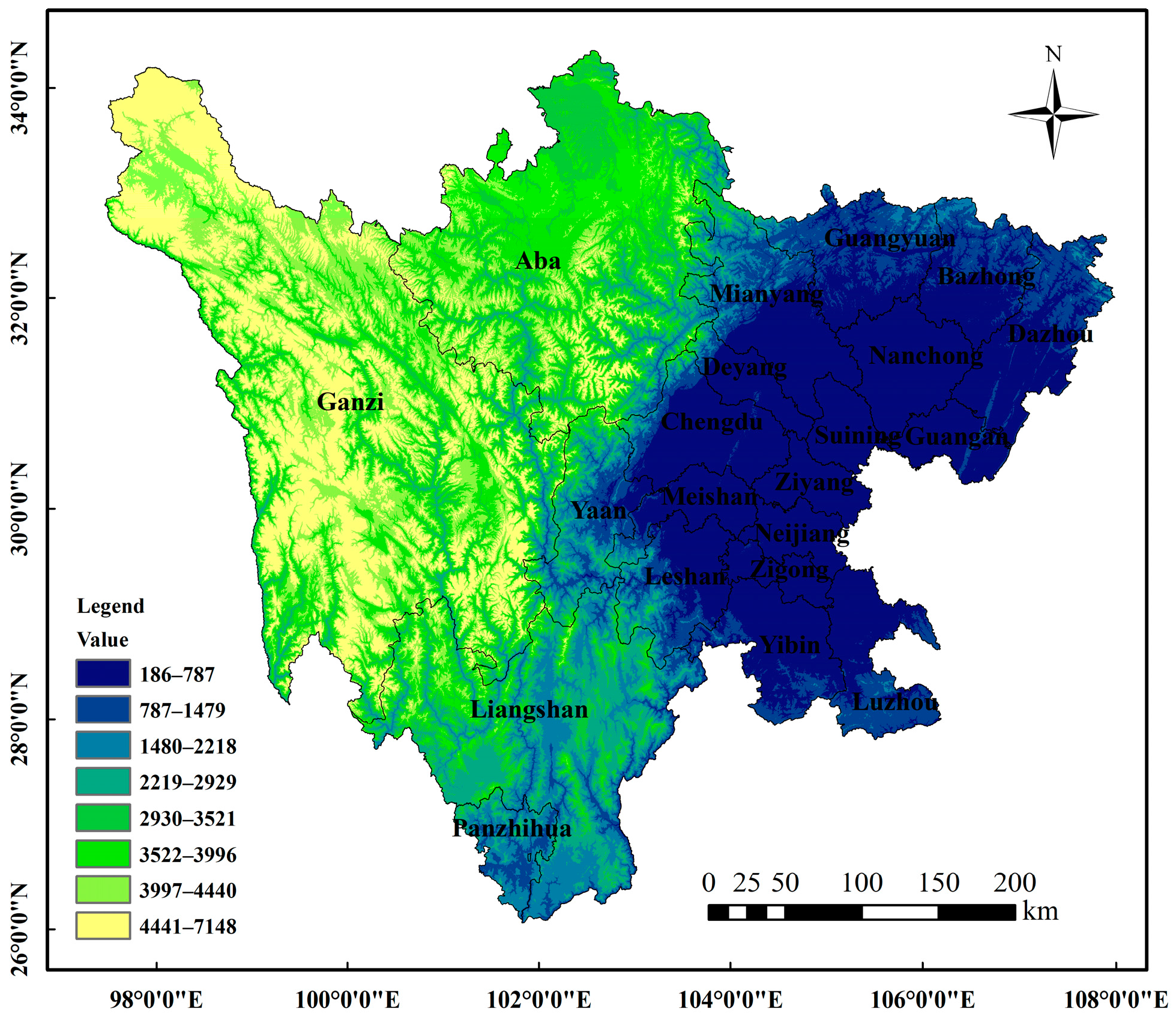
2.1. Overview of the Study Area
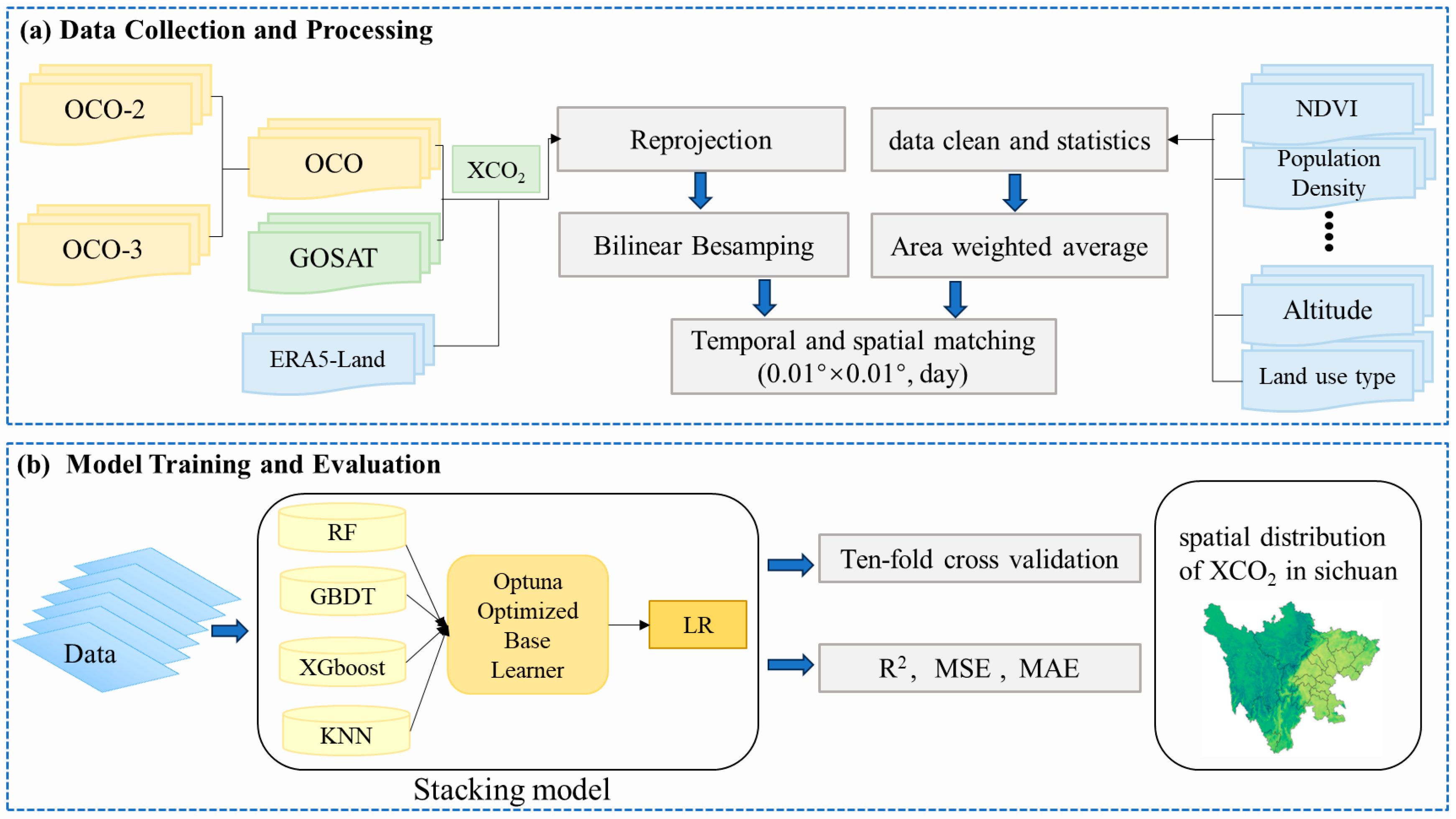
2.2. Data and Processing
2.2.1. XCO2 Concentration Satellite Observation Data
- (1)
- OCO-2 XCO2 data
- (2)
- OCO-3 XCO2 data
- (3)
- GOSAT XCO2 data
- (4)
- TCCON ground station data
2.2.2. Normalized Vegetation Parameters
2.2.3. Meteorological Reanalysis Data
2.2.4. Other Relevant Factor Data
2.2.5. Data Preprocessing
3. Research Methods
3.1. Spearman’s Correlation Analysis
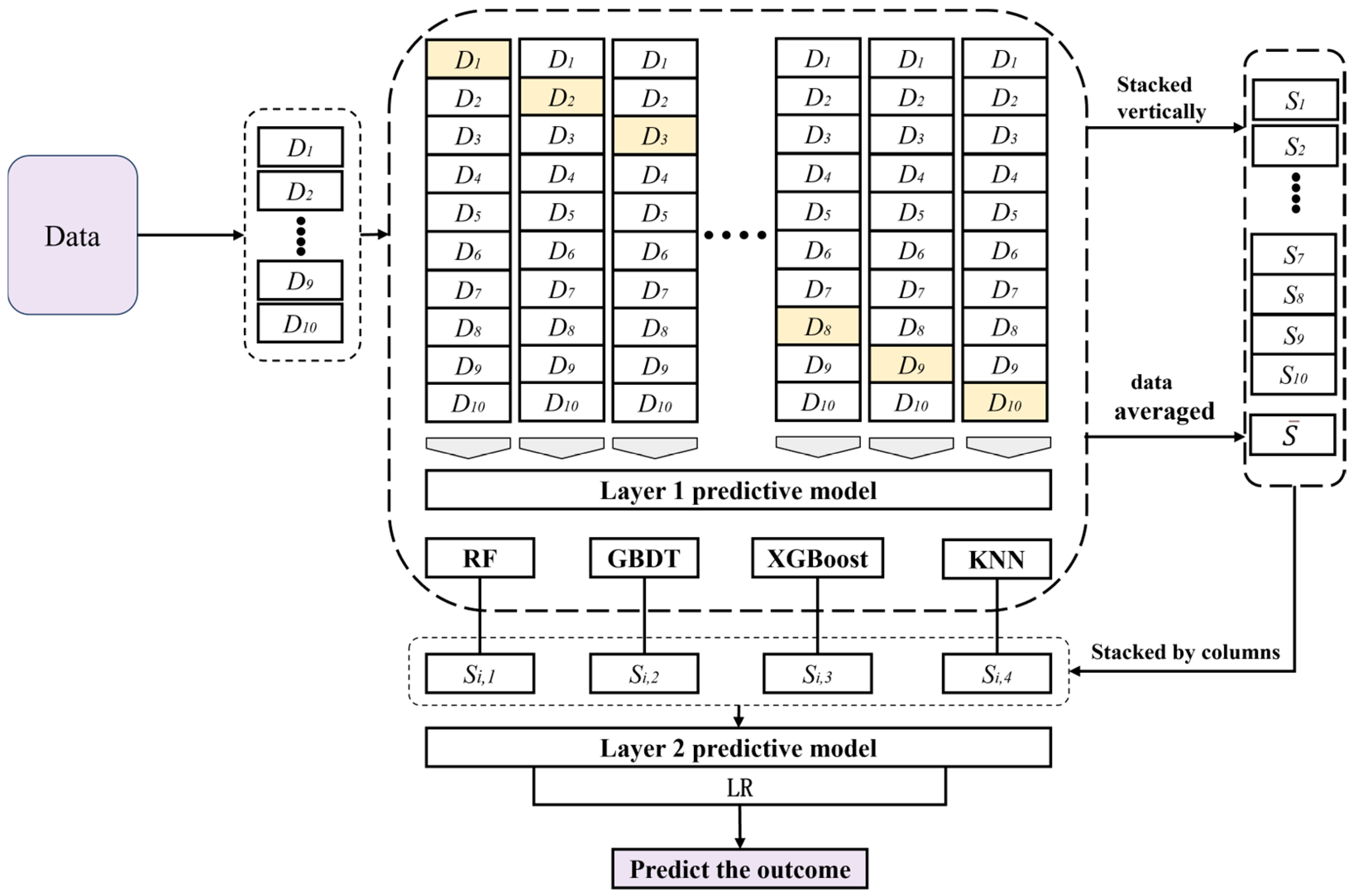
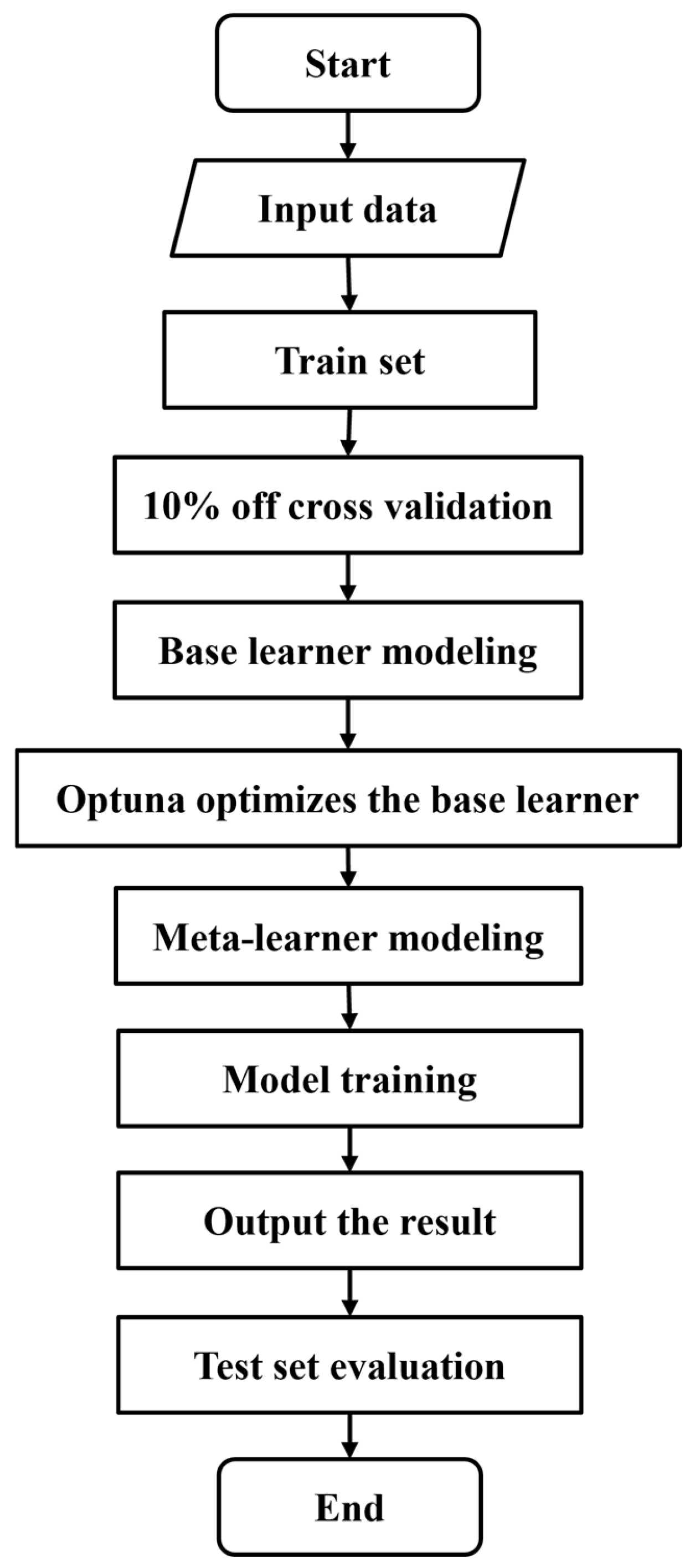
3.2. Stacking Ensemble Learning Model Construction
- (1)
- The data are split into the initial training set D and the initial test set V.
- (2)
- The 10-fold cross-validation method is employed to train each base learner. The original dataset D is divided into 10 mutually exclusive subsets, labeled D1 to D10. For each iteration, the union of 9 subsets is used as the training set, while the remaining subset serves as the test set. This process constructs the training and test sets for the primary learner, ensuring that each primary learner is trained and validated on 10 distinct sets of training and test data.
- (3)
- To construct a new training dataset for the Stacking ensemble model, the process involves leveraging the outputs of the four base learners. Each base learner is trained and tested using the same 10-fold cross-validation datasets. For the nth base learner, after completing the 10-fold cross-validation, 10 prediction results are generated. These results are vertically stacked by row to form the prediction set , representing the sample data predictions under the base learner. Simultaneously, the 10 prediction results are averaged to produce , which serves as the input dataset for the second-layer meta-learner. This approach ensures that the meta-learner receives a comprehensive and refined input, enhancing the overall predictive performance of the Stacking ensemble model.
- (4)
- The meta-learner LR is used for secondary training, the new training set and test set generated by the base learner in the previous stage are inputted into the second-layer meta-learner for secondary training, and the final XCO2 concentration prediction result is obtained.
3.3. Optuna-Stacking Integrated Model
3.4. Model Evaluation Methods
4. Results and Analysis
4.1. Hyperparameter Settings
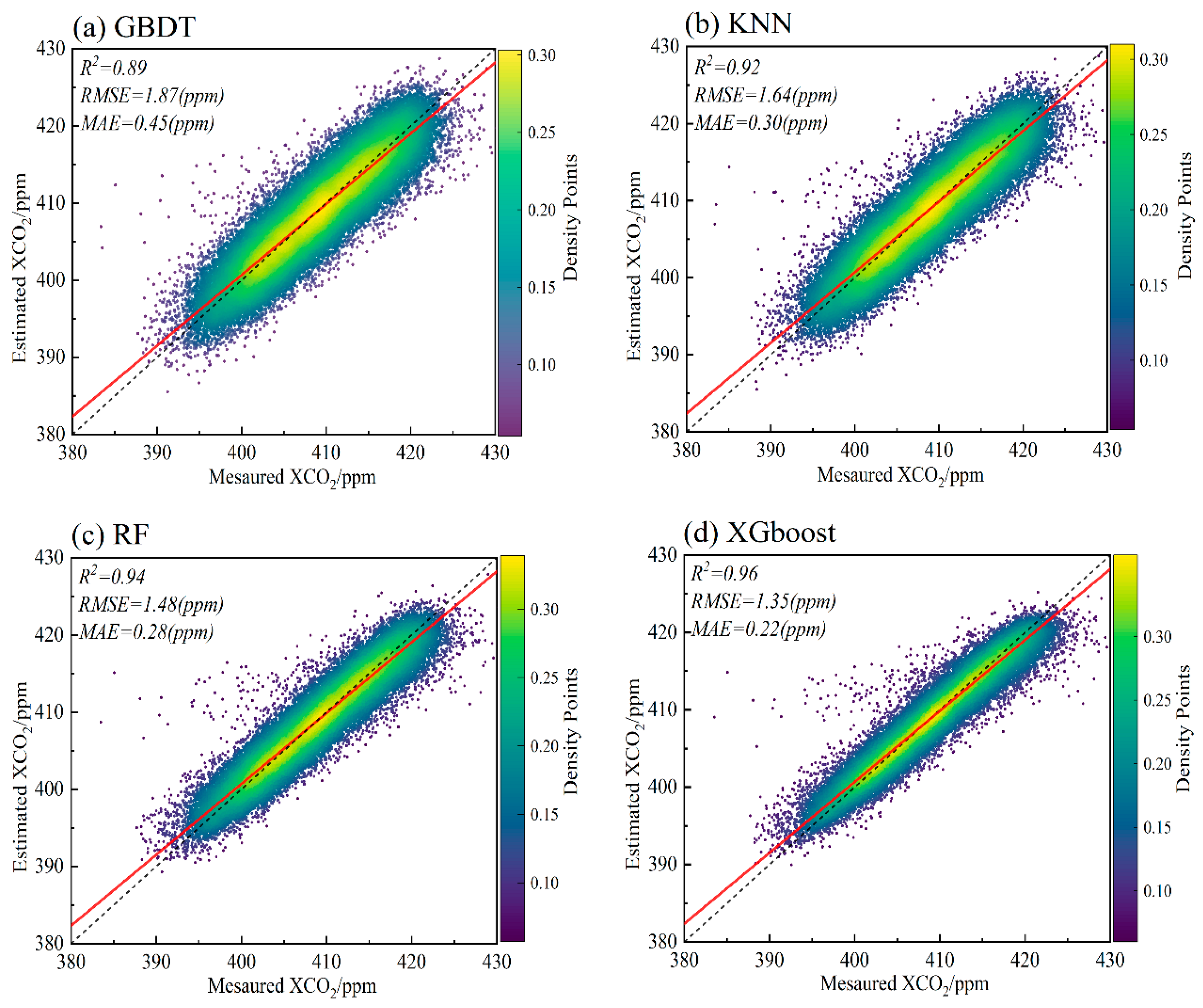
4.2. Model Cross-Validation Results
4.3. Stacking Seasonal Cross-Validation
4.4. Stacking XCO2 Dataset Verification with TCCON Sites
4.5. Temporal and Spatial Changes in Regional Carbon Concentration
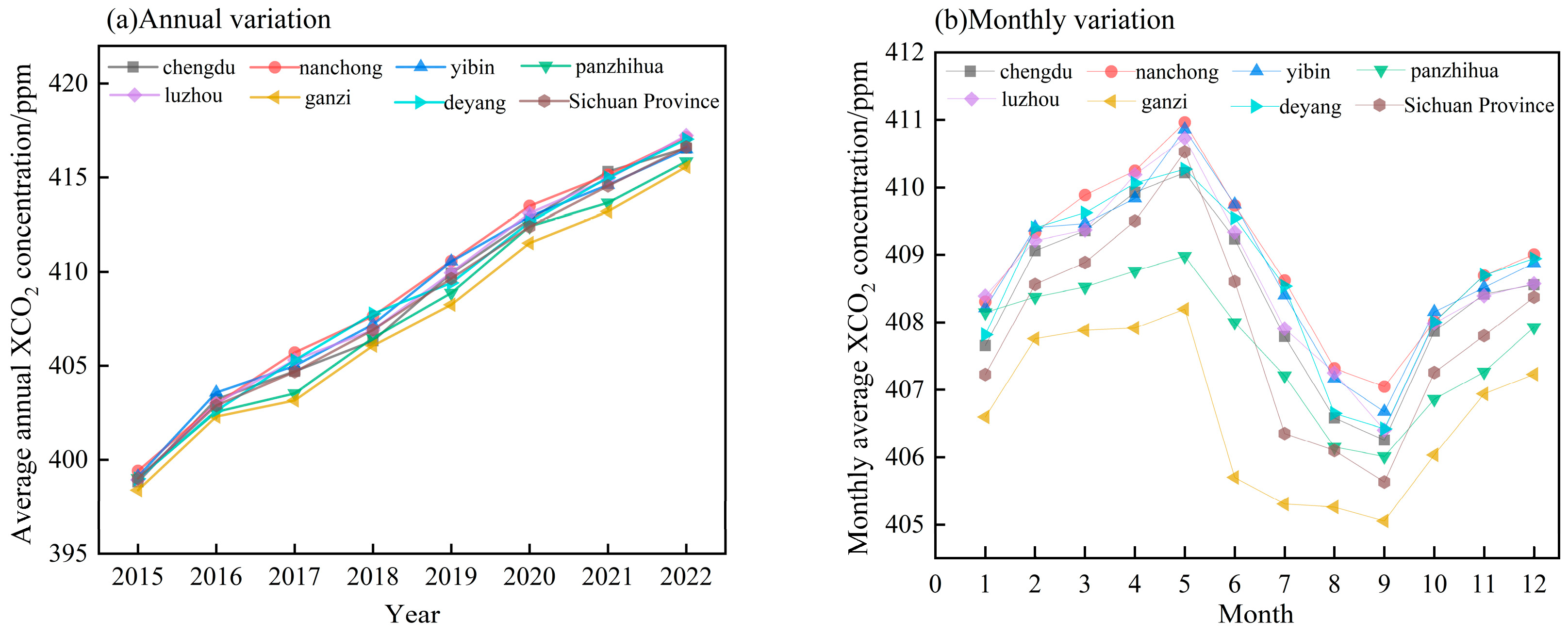
4.5.1. Temporal Characteristics of Atmospheric XCO2 Concentration in Sichuan Province
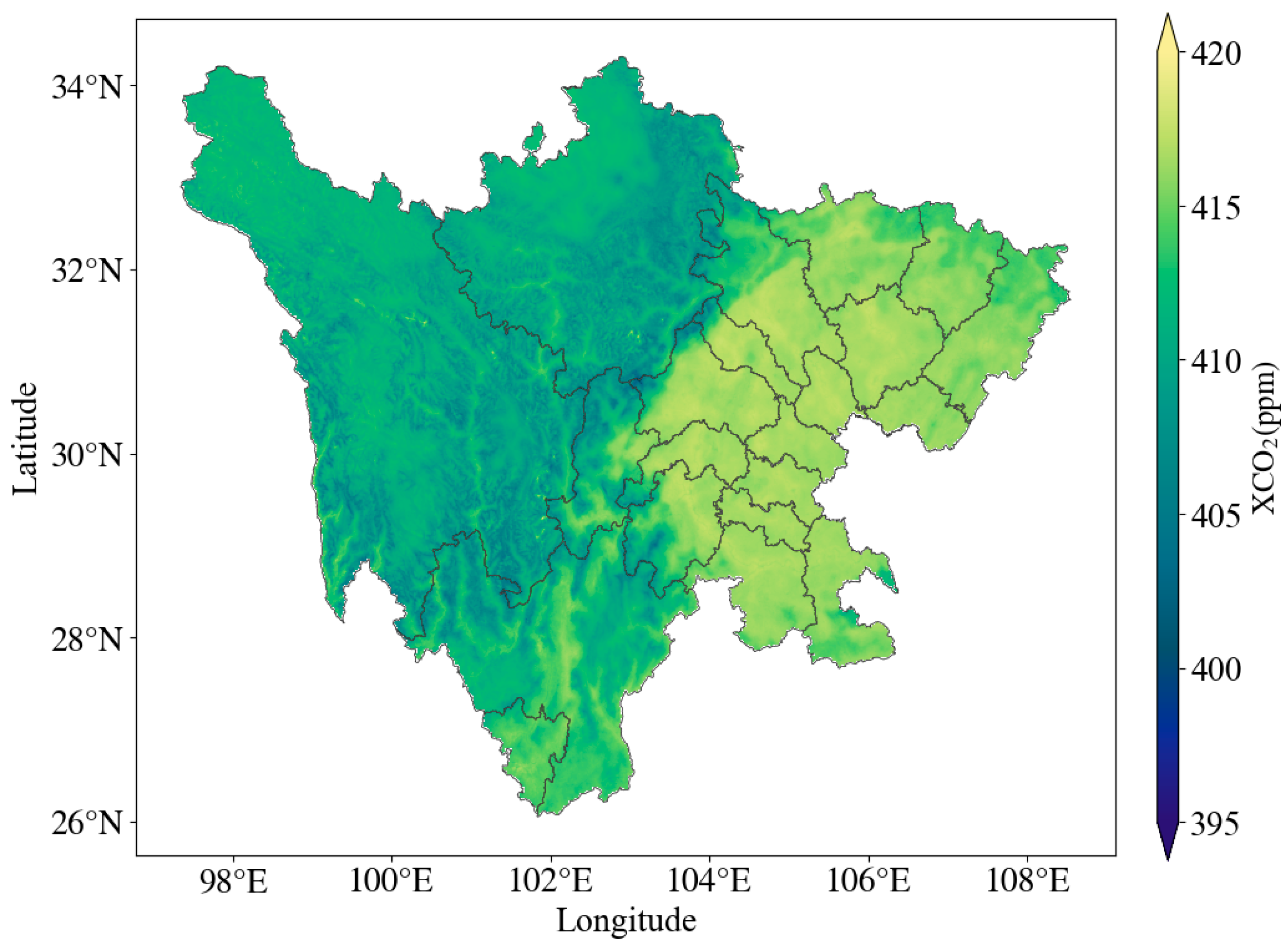
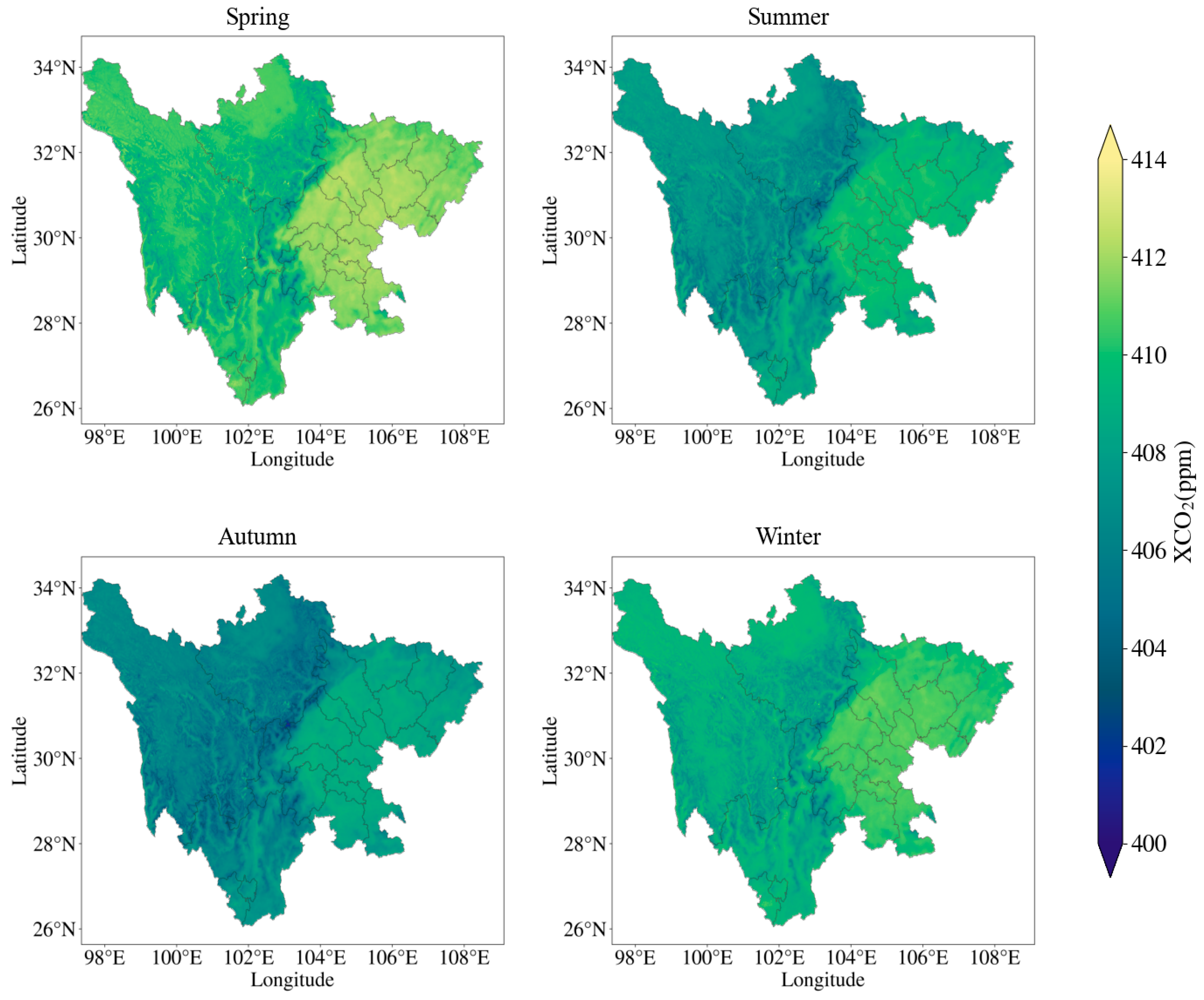
4.5.2. Spatial Distribution of Atmospheric XCO2 Concentration in Sichuan Province
5. Conclusions
- (1)
- In order to solve the problem of low spatial coverage and insufficient temporal resolution in the XCO2 observation data of monitoring satellites, a high-coverage XCO2 concentration inversion model integrating multi-source remote sensing data was proposed, and the accuracy of the Optuna-optimized Stacking ensemble learning model was comprehensively verified and evaluated, with the R2 reaching 0.983, an RMSE of 0.87 ppm, and an MAE of 0.19 ppm. The results show that the Stacking XCO2 dataset is significantly consistent with ground observation data, with the correlation coefficient between the model estimate and the observed value at the XH site being 0.96, and the correlation coefficient at the HF site being as high as 0.98. The model has shown a certain application potential in XCO2 concentration monitoring and effectively reflects the long-term dynamic change characteristics of the atmospheric carbon dioxide concentration in Sichuan Province.
- (2)
- The atmospheric CO2 concentration in Sichuan Province from 2015 to 2022 generally showed a fluctuating upward trend, from 398.9 ppm in 2015 to 416.6 ppm in 2022, but the growth rate has generally shown a downward trend in recent years. At the same time, the variation characteristics of the XCO2 concentration on the annual, seasonal, and monthly scales were analyzed. In each year, the XCO2 concentration showed the characteristics of being high in spring and winter and low in summer and autumn. Therefore, the atmospheric XCO2 concentration in Sichuan Province has significant volatility and periodic characteristics.
- (3)
- The atmospheric CO2 concentration in Sichuan Province shows obvious regional differences in spatial distribution, and the overall distribution pattern is “high in the east and low in the west”. Overall, the spatial distribution of the XCO2 concentration is uneven, and the difference in extreme XCO2 values between the different regions can reach 2.8 ppm, which is related to the local carbon source and carbon sink.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bongaarts, J. IPCC, 2023: Climate Change 2023: Synthesis Report. IPCC, 184 p., doi: https://doi.org/10.59327/IPCC/AR6-9789291691647. Popul. Dev. Rev. 2024, 50, 577–580. [Google Scholar] [CrossRef]
- Vandyck, T.; Keramidas, K.; Saveyn, B.; Kitous, A.; Vrontisi, Z. A global stocktake of the Paris pledges: Implications for energy systems and economy. Glob. Environ. Change 2016, 41, 46–63. [Google Scholar] [CrossRef]
- Deng, S.; Shi, Y.; Jin, Y.; Wang, L. A GIS-based approach for quantifying and mapping carbon sink and stock values of forestecosystem: A case study. Energy Procedia 2011, 5, 1535–1545. [Google Scholar] [CrossRef]
- Li, Z.; Xie, Y.; Shi, Y.; Li, Q.; COHEN, J.; Zhang, Y.; Han, Y.; Xiong, W.; Liu, Y. A review of collaborative remote sensing observation of greenhouse gases and aerosol with atmospheric environment satellites. Natl. Remote Sens. Bull. 2022, 26, 795–816. [Google Scholar] [CrossRef]
- Gurney, K.R.; Liang, J.; O’keeffe, D.; Patarasuk, R.; Hutchins, M.; Huang, J.; Rao, P.; Song, Y. Comparison of global downscaled versus bottom-up fossil fuel CO2 emissions at the urban scale in four US urban areas. J. Geophys. Res. Atmos. 2019, 124, 2823–2840. [Google Scholar] [CrossRef]
- Deng, F.; Jones, D.B.A.; O’Dell, C.W.; Nassar, R.; Parazoo, N.C. Combining GOSAT XCO2 observations over land and ocean to improve regional CO2 flux estimates. J. Geophys. Res. Atmos. 2016, 121, 1896–1913. [Google Scholar] [CrossRef]
- Hu, K.; Liu, Z.; Shao, P.; Ma, K.; Xu, Y.; Wang, S.; Wang, Y.; Wang, H.; Di, L.; Xia, M.; et al. A review of satellite-based CO2 data reconstruction studies: Methodologies, challenges, and advances. Remote Sens. 2024, 16, 3818. [Google Scholar] [CrossRef]
- Crisp, D.; Pollock, R.H.; Rosenberg, R.; Chapsky, L.; Lee, R.A.M.; Oyafuso, F.A.; Frankenberg, C.; O’Dell, C.W.; Bruegge, C.J.; Doran, G.B.; et al. The on-orbit performance of the Orbiting Carbon Observatory-2 (OCO-2) instrument and its radiometrically calibrated products. Atmos. Meas. Technol. 2017, 10, 59–81. [Google Scholar] [CrossRef]
- Han, G.; Xu, H.; Gong, W.; Liu, J.; Du, J.; Ma, X.; Liang, A. Feasibility study on measuring atmospheric CO2 in urban areas using spaceborne CO2-IPDA LIDAR. Remote Sens. 2018, 10, 985. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, J.; Yao, L.; Chen, X.; Cai, Z.; Yang, D.; Yin, Z.; Gu, S.; Tian, L.; Lu, N.; et al. The TanSat mission: Preliminary global observations. Sci. Bull. 2018, 63, 1200–1207. [Google Scholar] [CrossRef]
- Bhattacharjee, S.; Dill, K.; Chen, J. Forecasting Interannual Space-based CO2 Concentration using Geostatistical Mapping Approach. In Proceedings of the 2020 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 2–4 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Wang, W.; He, J.; Feng, H.; Jin, Z. High-Coverage Reconstruction of XCO2 Using Multisource Satellite Remote Sensing Data in Beijing–Tianjin–Hebei Region. Int. J. Environ. Res. Public Health 2022, 19, 10853. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Hu, R.; Chen, L.; Liao, Z.; Che, L.; Li, T. Multi-sensor integrated mapping of global XCO2 from 2015 to 2021 with a local random forest model. ISPRS J. Photogramm. Remote Sens. 2024, 208, 107–120. [Google Scholar] [CrossRef]
- Duan, Z.; Yang, Y.; Wang, L.; Liu, C.; Fan, S.; Chen, C.; Tong, Y.; Lin, X.; Gao, Z. Temporal characteristics of carbon dioxide and ozone over a rural-cropland area in the Yangtze River Delta of eastern China. Sci. Total Environ. 2021, 757, 143750. [Google Scholar] [CrossRef]
- Yang, Z.; Xu, Y.; Lu, X.; Mo, Y.; Ji, M.; Zhu, S. Spatialization of Atmospheric XCO2 in Xinjiang Uygur Autonomous Region based on OCO-2 Remote Sensing Data. Ecol. Environ. 2024, 33, 231. [Google Scholar]
- Tang, Y.; Hu, J.; Tang, D.; Chen, Z. Spatio-temporal distribution of XCO2 concentrations in northeast China based on Downscaling-XGBoost model. In Proceedings of the International Conference on Remote Sensing, Mapping, and Geographic Information Systems (RSMG 2024), Zhengzhou, China, 19–21 July 2024; SPIE: Bellingham, WA, USA, 2024; Volume 13402, pp. 367–372. [Google Scholar]
- Yao, Y.; Li, Z.; Wang, T.; Chen, A.; Wang, X.; Du, M.; Jia, G.; Li, Y.; Li, H.; Luo, W.; et al. A new estimation of China’s net ecosystem productivity based on eddy covariance measurements and a model tree ensemble approach. Agric. For. Meteorol. 2018, 253, 84–93. [Google Scholar] [CrossRef]
- Eldering, A.; O’Dell, C.W.; Wennberg, P.O.; Crisp, D.; Gunson, M.R.; Viatte, C.; Avis, C.; Braverman, A.; Castano, R.; Chang, A.; et al. The Orbiting Carbon Observatory-2: First 18 months of science data products. Atmos. Meas. Technol. 2017, 10, 549–563. [Google Scholar] [CrossRef]
- Eldering, A.; Wennberg, P.O.; Crisp, D.; Schimel, D.S.; Gunson, M.R.; Chatterjee, A.; Liu, J.; Schwandner, F.M.; Sun, Y.; O’dell, C.W.; et al. The Orbiting Carbon Observatory-2 early science investigations of regional carbon dioxide fluxes. Science 2017, 358, eaam5745. [Google Scholar] [CrossRef]
- Yokota, T.; Yoshida, Y.; Eguchi, N.; Ota, Y.; Tanaka, T.; Watanabe, H.; Maksyutov, S. Global Concentrations of CO2 and CH4 Retrieved from GOSAT: First Preliminary Results. Sola 2009, 5, 160–163. [Google Scholar] [CrossRef]
- Vogel, F.R.; Frey, M.; Staufer, J.; Hase, F.; Broquet, G.; Xueref-Remy, I.; Chevallier, F.; Ciais, P.; Sha, M.K.; Chelin, P.; et al. XCO2 in an emission hot-spot region: The COCCON Paris campaign 2015. Atmos. Chem. Phys. 2019, 19, 3271–3285. [Google Scholar] [CrossRef]
- European Centre for Medium-Range Weather Forecasts. ERA5 Reanalysis [Data Set]. Copernicus Climate Change Service. 2018. Available online: https://cds.climate.copernicus.eu (accessed on 1 October 2023).
- Reese, M. NASA Shuttle Radar Topography Mission (SRTM) Version 3.0 Global 1 Arc Second Data. NASA Earth Data, 1 March 2021. [Google Scholar]
- Chen, J.P.; Zhang, C.X. Predicting Citation Counts of Papers. In Proceedings of the 2015 IEEE 14th International Conference on Cognitive Informatics & Cognitive Computing (ICCI*CC), Beijing, China, 6–8 July 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 434–440. [Google Scholar]
- Center for International Earth Science Information Network—CIESIN—Columbia University. Gridded Population of the World, Version 4 (GPWv4): Population Density, Revision 11; NASA Socioeconomic Data and Applications Center (SEDAC): Palisades, NY, USA, 2018.
- Yue, L.Z.; Jian, H.C. Local Dependence Test Between Random Vectors Based on the Robust Conditional Spearman’s ρ and Kendall’s τ. Acta Math. Appl. Sin. Engl. Ser. 2023, 39, 491–510. [Google Scholar]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2623–2631. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Data Source | Temporal Resolution | Spatial Resolution |
|---|---|---|---|
| XCO2 | OCO-2 | 16 d | 1.29 km × 2.25 km |
| OCO-3 | 16 d | 1.29 km × 2.25 km | |
| GOSAT | 3 d | 10 km × 10 km | |
| NDVI | MOD13Q1/MYD13Q1 | Month | 250 m × 250 m |
| Weather | ERA5 | Month | 0.25° × 0.25° |
| Altitude | NASA | - | 30 m × 30 m |
| Land use type | ESA CCI | Year | 30 m × 30 m |
| Population density | Sichuan Statistical Yearbook | - | 30″ × 30″ |
| Site | Latitude | Longitude | Start Date End Date |
|---|---|---|---|
| HF | 31.9° N | 117.17° E | 2 November 2015–31 December 2022 |
| XH | 39.8° N | 116.96° E | 14 June 2018–31 December 2022 |
| Model | Hyperparameters | Numeric |
|---|---|---|
| XGboost | max_depth | 10 |
| learing_date | 0.5 | |
| n_estimators | 116 | |
| colsample_bytree | 0.3 | |
| subsample | 0.5 | |
| KNN | k | 3 |
| RF | n_estimators | 100 |
| max_depth | 12 | |
| GBDT | n_estimators | 178 |
| learning_rate | 0.2 | |
| max_depth | 8 |
| Model | R2 | RMSE | MAE |
|---|---|---|---|
| GBDT | 0.890 | 1.87 | 0.45 |
| KNN | 0.922 | 1.64 | 0.30 |
| RF | 0.943 | 1.48 | 0.28 |
| XGboost | 0.964 | 1.35 | 0.22 |
| Stacking | 0.983 | 0.87 | 0.19 |
| Season | R2 | RMSE | MAE |
|---|---|---|---|
| Spring | 0.959 | 1.20 | 0.36 |
| Summer | 0.967 | 1.35 | 0.41 |
| Autumn | 0.980 | 0.95 | 0.22 |
| Winter | 0.976 | 1.13 | 0.39 |
| Season | Maximum/ppm | Minimum/ppm | Average Value/ppm |
|---|---|---|---|
| Spring | 425.235 | 397.646 | 410.190 |
| Summer | 427.332 | 393.351 | 408.731 |
| Autumn | 420.922 | 394.156 | 406.589 |
| Winter | 423.085 | 397.122 | 409.853 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Zhao, N.; Zhang, H.; Wei, Y.; Chen, Y.; Ma, R. Research on High Spatiotemporal Resolution of XCO2 in Sichuan Province Based on Stacking Ensemble Learning. Sustainability 2025, 17, 3433. https://doi.org/10.3390/su17083433
Li Z, Zhao N, Zhang H, Wei Y, Chen Y, Ma R. Research on High Spatiotemporal Resolution of XCO2 in Sichuan Province Based on Stacking Ensemble Learning. Sustainability. 2025; 17(8):3433. https://doi.org/10.3390/su17083433
Chicago/Turabian StyleLi, Zhaofei, Na Zhao, Han Zhang, Yang Wei, Yumin Chen, and Run Ma. 2025. "Research on High Spatiotemporal Resolution of XCO2 in Sichuan Province Based on Stacking Ensemble Learning" Sustainability 17, no. 8: 3433. https://doi.org/10.3390/su17083433
APA StyleLi, Z., Zhao, N., Zhang, H., Wei, Y., Chen, Y., & Ma, R. (2025). Research on High Spatiotemporal Resolution of XCO2 in Sichuan Province Based on Stacking Ensemble Learning. Sustainability, 17(8), 3433. https://doi.org/10.3390/su17083433