1. Introduction
With the accelerated urbanization in China in the past two decades, traffic congestion has risen [
1]. To address this issue, urban rail transit has become the first choice for cities, both domestically and internationally, with its overwhelming advantages of fast running speed, high capacity, and minimal pollution [
2]. By the end of 2023, a total of 58 cities in mainland China had urban rail transit systems in operation, with a total line length of 11,224.54 km. In comparison, there are about 15 cities with urban rail transit systems in the United States and 30 in Europe. In 2023, China added more than 866 km of urban rail transit mileage, accounting for more than 70% of the world’s new mileage. China invested more than 50 billion USD in urban rail transit, accounting for more than 60% of the global total. At present, China has become the biggest urban rail construction market in the world [
3].
Urban rail transit construction projects have some key features, such as the complicated process of construction, complicated hydro-geological conditions, and frequent safety violations during construction [
4]. This makes safety accidents common in urban rail transit construction projects. From 2003 to 2022, 217 safety accidents occurred in the urban rail transit construction sector of China [
5]. Each of these accidents resulted in significant loss of life and property. For example, in 2008, a foundation pit collapse accident occurred in the Hangzhou subway construction project, resulting in 21 deaths, four injuries, and direct property losses of 6.86 million USD. Additionally, in 2012, during the construction of the Shanghai Rail Transit Line 12, a scaffolding collapsed, resulting in five deaths and 18 injuries, with a property loss of about 1 million USD. To mitigate the effects of these safety accidents, a lot of emergency preparedness documents were established and promoted across the urban rail transit construction sector of China [
6].
Currently, the formulation of emergency preparedness documents in China mainly relies on the general guidelines issued by governmental departments and the subjective experience of experts [
7]. This leads to the lack of pertinence and strong subjectivity of the existing emergency preparedness, making it difficult to meet the specific emergency response requirements of safety accidents. To address this problem, this study proposes a case-based reasoning (CBR) method to build emergency preparedness documents based on historical data. CBR technology is a powerful knowledge management and decision support tool that is able to learn and extract experiences from previous similar events [
8]. By using CBR, the retrieved emergency preparedness can be adjusted according to the real situation, which makes the generated emergency preparedness documents more flexible and adaptable.
CBR has strong application potential as a decision support tool [
9], but its successful implementation requires a detailed case representation scheme and an automatic retrieval mechanism. Case representation refers to representing cases according to a certain data structure into a structural form that is easy to retrieve and use. It can ensure the acquisition of domain knowledge in an accurate and simple way and provide a good basis for case retrieval [
10]. Originating from philosophical concepts, ontology is initially the study of being, or of our relation to reality. Since engineering is a very practical discipline, ontology provides a compelling intellectual basis for the notion of practice-based engineering knowledge [
11]. In the field of informatics, ontology is a clear specification of conceptualization [
12]. It can define the structure of the case and create a semantic model of knowledge in each field, which can avoid repeated domain knowledge analysis. This study combines ontology and knowledge reasoning technology to establish an ontology model of safety accidents in urban rail transit construction projects. At the same time, by collecting relevant safety accident cases and their emergency plans, this study is determined to establish a project safety accident case library and perform case reasoning and matching by calculating comprehensive similarities to find the accident cases with the highest similarity, providing a reference for the quick generation of emergency plans.
2. Literature Review
2.1. Emergency Management in Urban Rail Transit Construction Projects
The understanding of emergency management is diverse. Kepaptsoglou et al. [
13] believe that emergency management refers to the process of designing and executing effective strategies to reduce casualties and losses as much as possible in the event of an accident. In the book “Introduction to Emergency Management”, Bullock et al. [
14] defined emergency management as “a discipline that deals with and avoids risks”. China’s emergency plan framework system was initially formed in the “National Overall Contingency Plan for Public Emergencies” issued by the State Council on 8 January 2006. In China, emergency management includes four aspects: prevention before the incident, response to the incident, handling during the incident, and recovery after the incident. The government emphasizes taking a series of necessary measures to protect public life, health, and property safety.
Until the beginning of the last century, the French engineer Fayol firstly proposed “management and risk”, and it was he who firstly applied the idea of enterprise management to the field of safety accident management, creating the precedent of accident management theory. In the field of construction, risk management is generally defined as “the systematic process of identifying, analyzing and responding to risks”. And in the 1970s, Einstein, H.H. [
15] firstly introduced the theory of risk analysis and management into the field of tunneling construction. Subsequently, scholars in various fields began to pay attention to the technical management of safety risks in the construction phase of urban rail transit and gradually conducted in-depth research in this field and obtained a series of theoretical results.
With the advancement of technology, urban rail transit systems are becoming more and more complex, but the current emergency management of urban rail transit systems is still far behind [
16]. To improve the emergency response capability of urban rail transit systems, a large number of scholars have successively conducted research. Based on different accident types and construction methods, Sousa [
17] constructed a global tunnel construction accident case database covering 204 accident cases. Based on the principle of adapting measures to local conditions, a series of emergency management measures were proposed to avoid similar accidents. Fouladgar et al. [
18] used the TOPSIS method and fuzzy logic method to evaluate the effectiveness of tunnel engineering risk management, with the ultimate goal of reducing the impact of uncertain factors on emergency management. Nezarat et al. [
19] proposed using the fuzzy analytic hierarchy process to rank the causes of safety accidents and applied it to the Golab tunnel for an empirical study. Zhang et al. [
20] examined the relationship between emergency response capabilities and the environmental impacts of urban rail transit systems in China. Finally, it was concluded that the configuration and control of emergency elements are the key to achieving cross-organizational emergency collaboration and forming rapid emergency response capabilities. To investigate the complex causal relationships of accidents at subway construction sites, Irizarry et al. [
21] constructed a double-layer subway construction safety risk network containing 56 causal relationships and 44 accidents. Ultimately, he concluded that managers should not pay equal attention to causal relationships and accidents with unequal roles in the network. Ge et al. [
22] systematically investigated the documents of emergency preparedness implemented in 52 cities on the Chinese mainland, reviewed the current emergency preparedness for urban rail transit construction projects in China, summarized its key elements, identified its strengths and limitations, and put forward corresponding suggestions.
In summary, although researchers worldwide have made certain progress in research on emergency management of urban rail transit systems, there is a lack of research on emergency preparedness for safety accidents occurring in urban rail transit construction projects.
2.2. CBR and Its Application in Emergency Management
Case-based reasoning (CBR) is a technique that finds the historical case most similar to the target problem through retrieval and applies the case to analyze the current problem [
23]. At present, case-based reasoning has achieved great success in various fields as a technique for solving problems related to knowledge reuse [
24]. CBR originates from the role of memory in human reasoning activities in cognitive science. Research on case-based reasoning began in 1977 when Schank and Abelson [
25] proposed the concept of dependency theory and script knowledge representation. In 1982, Roger Schank of Yale University in the United States first proposed the CBR cognitive model in the book “Dynamic Memory” and its framework. Later, Kolodner and her students developed a CBR system called CTRUS based on the cognitive model proposed by Roger Schank. Since then, CBR is no longer just a scientific theory but has been a practical application in the research field of machine learning [
26].
As a knowledge reasoning method based on experience, CBR has been widely used in several research areas. In the field of medical diagnosis and treatment, retrieving and inspecting traces that log medical processes execution can be of great help in exception management, which buys resuscitation time for emergency patients [
27]. In the industrial field, CBR has been successfully applied to the fault diagnosis and maintenance of complex machinery, providing effective solutions for mechanical troubleshooting by analyzing historical fault cases [
28]. In the transportation domain, the CBR technique is combined with the Choquet integral to provide personalized itinerary search for travelers in a multimodal transportation system [
29]. CBR has shown its wide application potential in several domains.
In the field of safety management, CBR technology has become an important method to support the intelligent generation of emergency plans in the emergency response stage [
8]. Alemi-ardakani et al. [
30] used Gaussian transformation to replace the traditional distance similarity calculation method, which increased the accuracy of the comprehensive similarity retrieval of the CBR method. They took the risk contingency plan of a logistics outsourcing enterprise as an example to verify the effectiveness and feasibility of the Gaussian-CBR model. Maalel et al. [
31] used technologies such as data mining and semantic reasoning to expand the case library of CBR and took railway accident management as an example to develop a decision support method called Adast, integrating CBR technology to make the results more objective and accurate. Gadomski et al. [
32] combined Markov decision process and CBR methods for planning crisis management actions. Yu et al. [
33] used the CBR method to analyze the risk response of urban water supply networks. They used a two-step case retrieval method to match disaster scenarios to generate a set of usable cases and finally proposed a practical approach that considers natural disaster situations.
Although CBR technology has shown its advantages in various fields, the traditional CBR system lacks the support of theoretical knowledge and resources and is only a simple case classification management. This leads to some shortcomings in the application of CBR technology. For example, there is a lack of connectivity between theoretical knowledge and examples and resources. Furthermore, a CBR tool can only be used with domain-specific exemplar models. Moreover, example retrieval basically only uses keyword retrieval, which cannot guarantee the recall and precision of the retrieval. A combination of ontology with CBR technology will overcome the shortcomings above.
2.3. Application of Ontology in Construction Management Research
Ontology was originally a concept in philosophy, used to describe objectively existing systems in the world [
34]. Later, it was gradually used in artificial intelligence, knowledge management, information science, and other fields and gained new understanding and application. In 1995, Grube [
35] gave the first widely recognized and used definition of ontology, that is, “ontology is an explicit specification of a conceptualization”. In recent years, many studies in the business and scientific communities have adopted ontologies to share, reuse, and process domain knowledge. Currently, the main application areas of ontology include communication and knowledge sharing, logical reasoning, and knowledge reuse.
Ontology has the advantage of supporting multiple knowledge representation logics. In addition to defining the structure of cases, it can also create semantic models of knowledge in various fields to avoid repeated domain knowledge analysis. At the same time, the ontology supports multiple modeling languages and has corresponding integrated heterogeneity. The ability to structure and distribute data can meet the needs of a variety of modeling environments and practical applications [
36]. Based on the above advantages, the combination of ontology and CBR technology can solve most of the limitations of traditional CBR technology.
Up to now, as an important tool for knowledge representation and semantic modeling, ontology technology has achieved remarkable results in several research areas. In the field of Semantic Web, ontology is used to achieve semantic interoperability of data and knowledge representation so as to provide personalized document retrieval services for users [
37]. In the medical domain, ontology is used to build clinical decision support systems to help doctors make diagnosis and treatment decisions [
38]. In the field of cyber-physical systems, Petnga et al. [
39] developed an ontology-based reasoning framework for CPS decision support. It strengthened the model-driven approach to CPS design by developing CPS models supported by sound semantics.
In recent years, a series of ontology-related works have emerged in the field of construction management. For example, the ontology developed by Bień et al. [
40] focuses on modeling bridge defect concepts relevant to railway bridges. According to the impact of degradation mechanisms on bridge structural defects, a degradation mechanism classification method was proposed to identify the relationship between the degradation process and defects. Wang and Boukamp [
41] proposed a framework that uses ontologies to build knowledge about activities, job steps, and hazards. The framework also includes an ontology reasoning mechanism that utilizes the rich semantic features of the ontology to reason about the context to evaluate its suitability. Chi et al. [
42] developed and used a construction safety domain ontology and applied ontology-based text classification to match safety methods identified in existing resources with unsafe scenarios. It is designed to reduce the level of manpower required for job hazard analysis (JHA) and enrich the solution space by serving as an initial reference. Zhang et al. [
43] proposed a construction safety ontology to formalize safety management knowledge for better organization, storage, and reuse of construction safety knowledge. It consists of three main domain ontology models: construction product model, construction process model, and construction safety model. Lee et al. [
44] developed a construction defect ontology. They extracted work context information from the BIM model, converted the extracted BIM data into RDF format, and implemented SPARQL queries. This approach can reduce data search time and improve the accuracy of search results, thereby reducing defect occurrence and improving current construction defect management practices.
This study aims to construct a knowledge base of urban rail construction safety risk ontology and explicitly express knowledge in the fields of accident types, risk factors, accident consequences, and countermeasures. By using the ontology method, the problem of low security management efficiency caused by textualization in the past can be solved. At the same time, it builds a communication bridge for the semantic sharing of safety risk knowledge and promotes the expression of safety risk knowledge in urban rail construction projects.
3. Ontology for Safety Accidents in Urban Rail Transit Construction
3.1. Defining the Domain and Scope of the Ontology
The specification of a representation vocabulary (i.e., the definition of classes, relationships, functions, and other objects) of a shared discourse domain is called ontology. The development of ontology is extremely critical. Its main purpose is to make the developed ontology cover most of the knowledge in the field, and at the same time, there will be no redundancy and contradiction between the knowledge. At present, the widely accepted principles for the development of ontologies are proposed by Gruber [
12], namely: clarity and objectivity, consistency, scalability, minimum coding deviation, and minimum ontology commitment. In this study, an ontology can be defined as a formal knowledge representation framework for structuring key concepts, attributes, and their interrelationships in urban rail construction. For example, define key concepts such as “tunnel” and “station”, and clarify their properties (e.g., “tunnel diameter”) and relationships (e.g., “tunnel connects station”). By developing ontology, knowledge sharing, integration, and intelligent application can be realized.
The development of ontology is a gradual process. It involves proposing, applying, and refining the concepts and relationships that constitute domain ontology [
45]. At present, there is no unified standard for the development method of ontology. Commonly used ones include the TOVE (Toronto Virtual Enterprise) method [
46], the IDEF5 (Integration Definition for Function Modeling) method [
47], the skeleton method [
48], the METHONTOLOGY method [
49], and the seven-step method. All methods have their own advantages and major limitations. Among the above methods, the seven-step approach developed by Stanford University is one of the most widely used ontology development methods in research around the world [
50]. It is a systematic methodology that covers the whole process from domain definition to instantiation and gradually develops an ontology with clear structure and rigorous logic. Compared with other ontology development methods, the seven-step method is relatively mature and complete. It focuses on the ontology development process, is highly suitable for construction work, and is particularly suitable for domain ontology development [
51]. Therefore, in this study, the seven-step method is used as the development method of the ontology of safety accidents in urban rail transit construction projects. The steps for developing an ontology using the seven-step method are shown in
Figure 1.
3.2. Knowledge Representation of Construction Accidents on Urban Rail Projects
Based on a review of a large body of literature and historical cases, this study collected knowledge related to the construction risks of urban rail transit construction projects. The knowledge is divided into five categories: construction activities, hazard factors, risk types, risk consequences, and solutions. The detailed information contained in these five categories of knowledge is shown in
Figure 2.
3.3. Ontology Modeling of Urban Rail Construction Safety Risk Based on Protégé
Protégé v. 5.5.0 is an open-source ontology editing and knowledge acquisition software developed by the Stanford University School of Medicine based on the Java language. It is also a knowledge-based editor and is mainly used for the construction of ontologies. Protégé shields the specific ontology description language and provides the construction of ontology concept classes, relationships, attributes, and instances. Therefore, users only need to develop the domain ontology model at the conceptual level without mastering the specific ontology representation language, which greatly simplifies the ontology development process and is easy for users to learn and use. This study uses Protégé as the ontology modeling tool for architectural structure design and uses the Protégé-owl editor to develop the ontology. Compared with other modeling software, Protégé has many advantages. It supports the construction of XML and RDF type files and meets all tag functions provided by OWL. It can define knowledge rules, such as value ranges, attribute types, constraints, default values, etc. More importantly, Protégé is Java-based and open source for free. Since it has so many advantages, this study uses Protégé to develop the ontology of safety accidents in urban rail transit construction projects. The Protégé interface includes knowledge expression elements such as classes, inheritance relationships between classes, properties, individuals, etc.
3.3.1. Creation of Classes
Classes are used to represent collections of individuals. Based on the review of a large amount of relevant literature and historical cases, this study summarizes the relevant knowledge. In this study, a top-down method was used to enumerate and define the classes included in the developed ontology of safety accidents in urban rail transit construction projects. The five classes are construction activities, hazard factors, risk types, risk consequences, and solutions, as shown in
Table 1. The five classes are only the most basic concepts and need to be broken down further. In Protégé, the relationships between classes are expressed by building a structure diagram. Due to space constraints, only some of the subclasses are shown in
Figure 3.
3.3.2. Creation of Properties
There are two types of properties defined in the developed ontology, namely object property and data property. Object properties are relationships between two individuals. Datatype properties describe relationships between individuals and data values. Data values can be int, string, or Boolean. Properties, like classes, have a hierarchical relationship, and subproperties inherit the characteristics of their parent properties. Unlike classes, properties have their own definition and value domains. Since Protégé software has defaulted to the “is a” property definition for classes, “is a” is used to represent the subordinate relationship between classes. For example, “is a” links “cover and cut method” and “construction activity”, indicating that “cover and cut method” is a subclass of “construction activities”.
- 1.
Definition of Object Properties
There are various object properties, such as functional, inverse functional, transitive, symmetric, asymmetric, reflexive, and irreflexive properties, that can be checked in the property characteristic edit area or property description tab, according to the situation. The inverse functional property represents a given object (class or individual), to which at most one individual can be connected by this property. In this study, all object-based properties were defined as inverse functional.
In urban rail transit construction projects, semantic relationships can be defined as the formal representations describing the logical relationships between various instances in construction. For example, the “impact” relationship between “geological conditions” and “construction risks”. Semantic relationships support the intelligent management of construction information by clarifying the interactions between instances. In the urban rail construction safety accidents ontology developed in this study, the construction project is connected to the construction activity through “has_activity”; the process of the construction activity generates risk factors, which are connected through “has_factor”; the hazard factors causing different types of risks are connected through “cause_risk”; the risk type causes different risk consequences, which are connected through “has_consequence”; and the risk is controlled by solution measures, which are connected by “controlled by”. The relationships between various properties are shown in
Figure 4. Take “has_factor” as an example to create an object property, as shown in
Figure 5.
- 2.
Definition of Data Properties
Data properties depend on classes for their existence, and data are made meaningful by connecting data properties to classes. Data properties can also be used to describe certain common characteristics of classes. For example, some data properties include shape length and investment size. In this study, a “Construction project” was used as an example to determine the data properties of a class, as shown in
Table 2.
As shown in
Figure 6, the “P_ID” data’s property definition is added in “Data property”, and the function characteristics are defined.
3.3.3. Creation of an Instance
The domain knowledge ontology framework was developed after creating a hierarchy of classes and properties and adding property restrictions. To enrich the knowledge base of a domain, individuals must be added to the classes. Individuals inherit all the properties of the class in which they reside, and by restricting the individuals and assigning values to their properties, it is possible to integrate the safety ontology for urban rail construction with actual risk cases. An individual is created under the individuals tab.
Finally, after completing the urban rail construction ontology for safety accidents, the status of the ontology development is displayed using the OWL Viz tab of the Protégé software, as shown in
Figure 7.
4. Construction Safety Accident Knowledge Reuse Based on CBR
4.1. Ontology-Based Case-Based Reasoning
4.1.1. The Process of CBR
Case-based reasoning (CBR) originated in the field of artificial intelligence. The core idea is to store historical data and past experiences in a database in the form of “cases”. In urban rail transit construction projects, CBR can be defined as an intelligent decision-making method based on historical construction cases, which provides references for planning, designing, and constructing new projects by retrieving, matching, and adapting the experiences of similar construction projects [
52]. The most widely used process model for CBR is the 4R model proposed by Aamodt and Plaza [
53], which is also known as the life-cycle process of CBR. When a new event occurs, it is processed as follows.
- (1)
Retrieve: Retrieve the most similar case to the current incident from the case base.
- (2)
Reuse: The retrieved solution is reused as the proposed solution for the new incident.
- (3)
Revise: The solution is tested, evaluated, and revised to obtain the final solution for the current incident.
- (4)
Retain: The final solution and incident may be saved as a new case in the case base so that the system can acquire self-incremental learning capabilities.
Based on the above principles, this study proposes an ontology-based urban rail construction safety accident case representation and a retrieval study. The reasoning process for the urban rail construction accident case is shown in
Figure 8. We collect and analyze accident cases during the construction phase of urban rail projects in China in order to establish a case base. An ontology tree was established to extract characteristic indicators, such as accident type, risk-causing factors, number of casualties, emergency preparedness taken, and rescue results. When a new construction accident occurs, the accident is defined as the target case, and its characteristics and problem description are extracted to retrieve one or more similar cases from the case base. This process is called case retrieval. Case matching is a process of using the similarity algorithm to retrieve the most similar source case. If the match is successful, the experience of the source case can be used to solve the problem of the target case. If the matched case is not suitable for the target case, in order to solve the problem, it is necessary to modify and adjust the source case according to the actual situation, which is called case revision. Finally, the current case is saved in the case database as a new case for later case retrieval. In this process, the knowledge of the system is continuously optimized and improved, and the problem-solving ability and efficiency of the system are also improved [
54]. Each cycle of CBR is not only a process of solving the problem but also a case learning process and a process of updating the knowledge of the system.
It is worth noting that the selection of cases is also important in the case retention phase. The quality and accuracy of CBR do not depend on the number of cases but rather on the breadth of accidents included in the case base. If there is a large data source in the case base, but too much homogeneous data, the efficiency and speed of reasoning will be affected. When the search fails to find a suitable case, it means that there is a lack of relevant types of cases in the case base. At this time, the case needs to be added to the ontology knowledge base to improve and expand the case base. If the case is successfully retrieved, and there is a historical case that is highly similar to it, it is necessary to consider whether to add it to the case base. Generally speaking, when the case similarity is more than 0.9, it is not appropriate to add it to the case base [
55].
4.1.2. Applicable Conditions of O-CBR
Traditional CBR techniques have some shortcomings, such as most of the basic framework of the CBR system being in static form, which has poor extensibility and remodeling and cannot be applied in other fields. Instance retrieval can only use keyword search or full-text search. The methods used in the similarity calculation rarely consider the semantic connection contained in the case description words, which cannot guarantee the recall rate and accuracy of the retrieval.
Ontology-based case-based reasoning (O-CBR) is a combination of CBR technology and ontology technology. The strict grammar rules adopted by ontology can maintain the consistency of knowledge in the process of expression and application. In different domains, ontology can explain its own knowledge structures and express the connections between concepts at different levels. Moreover, the use of ontology can describe the conceptual model of the information system from the semantic and knowledge level, which can solve the problem of poor extensibility and remodeling of the traditional CBR system [
56]. In terms of case retrieval, the hierarchy and interrelationships in the ontology provide support for similarity calculation of different objects, which is more efficient and accurate than traditional keyword retrieval. In addition, by using ontology to define the case structure, cases can be stored as instances in the ontology, and the cases can also be indexed by using the concepts defined in the ontology, which leads to better organization and management of the cases. O-CBR significantly improves the semantic capability and reasoning efficiency of the CBR system. O-CBR has a wide range of applications, particularly in areas that require complex semantic representation and dynamic inference. Since all the conclusions of O-CBR are derived from experience, it is applicable to experienced domains, especially those where large-scale case bases can be built. The construction of urban rail transit is a high-risk industry, and the experience in this field is relatively rich, which can be used as an applicable target for O-CBR.
4.2. Determination of Indicator Weights
4.2.1. Construction of the Judgement Matrix
The attributes of the urban rail construction safety accidents ontology tree in the previous section were used as indicators in the urban rail construction risk case. In the process of determining the case similarity, since the attributes that represent the cases vary in importance, it is necessary to assign appropriate weights to them. The weights of the indicators were determined using a combination of expert assessment and the analytic hierarchy process [
57]. Firstly, establish an indicator judgment matrix.
The analytic hierarchy process (AHP) simplifies the problem of ranking the importance of each attribute in the decision-making process into pairwise comparisons, determining the relative importance between attributes, and assigning values according to the “1–5” scale method as shown in
Table 3.
The relative importance of the two attributes can be determined by sending a questionnaire to domain experts. We invited 57 experts for this questionnaire. A total of 32 of them are university professors and researchers in civil engineering and engineering management-related industries, with rich theoretical knowledge. And 25 of them are project managers and business executives from urban rail transit construction projects, who have rich experience in practical applications. After having experts compare the relative importance of each attribute pairwise according to the “1–5” scale method and obtaining the average relative value of each attribute, the weights of each attribute are calculated by the following method. For the specific field of urban rail construction safety accidents, the relative importance of each attribute of the case is basically fixed, and it will have universal guiding significance after it is given. Thus, the judgment matrix table shown in matrix (1) is obtained. In this matrix (1),
xij represents the relative value of the indicator importance in the
ith row to that in the
jth column.
The matrix is then normalized by column to obtain a new matrix (2).
Then, the normalized values were summed by row to obtain the Formula (3).
By dividing the sum of the relative importance values Y
i of the indicators in each row by the number of all indicators, we obtain the weight of each attribute.
4.2.2. Calculation of the Largest Eigenvalue
Since AHP is essentially a qualitative method to determine the relative importance of attributes, the judgment matrix itself has a certain error range, so the accuracy of the solution is not very high. In this paper, the arithmetic mean method is used for calculation. Multiplying the weight matrix ω = with the indicator judgment matrix before normalization, we can obtain the following matrix: Aω =, and the largest eigenvalue of the matrix is = .
4.2.3. Consistency Test
Finally, a consistency test is performed. In the general decision-making problem, it is often affected by the complexity of the system and the diversity and one-sidedness of the decision-maker, resulting in the decision-maker’s judgment may not be completely consistent. Consistency test can eliminate unreasonable judgment and improve the scientificity and reliability of decision-making. Firstly, the consistency indicator was first calculated as CI = , where n is the order of the judgment matrix. Then calculate the consistency ratio, which is CR =. RI is the random index, and its value can be obtained by looking up the RI table. If CR < 0.1, the degree of consistency of the judgment matrix is within the allowable range, and this weight vector is feasible. Otherwise, the attributes in the judgment matrix need to be corrected and adjusted.
4.3. Calculation of the Attribute Similarities
4.3.1. Calculation of Concept Semantic Similarity
Case matching focuses on similarity calculation. Some commonly used methods are the nearest neighbor, rough set, and fuzzy methods. In this study, an improved comprehensive semantic similarity algorithm is proposed. The concept of semantic similarity of ontology refers to the similar degree of two concepts at a semantic level. By calculating the semantic similarity to find out the synonyms of the user’s query keywords, forming new queries, and then submitting to search, the recall rate can be improved. Traditional ontology-based semantic similarity computation methods mainly include semantic distance-based methods [
58] and content-based similarity measures; however, both have their own shortcomings, such that they fail to achieve a fine-grained distinction of semantic similarity between concepts, with the former ignoring factors affecting the semantic distance and the latter relying on a comparison of the properties of the concept, which requires a rigorous and costly formalization of the concepts [
59].
Concept semantic similarity is not only related to the semantic distance but is also affected by the hierarchical depth of the concept and the density of the concept in the ontology tree. Therefore, this study introduced node depth and density to improve the semantic similarity algorithm. The comprehensive similarity method synthesizes the influences of the attributes, content, and distance of semantic concepts on the similarity result. This method considers the location information of classes in the ontology tree and the content information contained in the keywords themselves, making it suitable for the current urban rail transit safety accidents ontology constructed at present [
60].
- 1.
Semantic Distance
Assume that any two nodes in the ontology tree are marked
A and
B.
sim1(
A,
B) represents the attribute semantic distance between nodes A and B. In an ontology tree, the semantic distance between two concepts is the length of the shortest path connecting the nodes. Here, we consider the number of directed edges of the shortest paths of nodes
A and
B in the ontology tree as their semantic distances, and the length of the shortest path is denoted as
Dist(
A,
B). If the shortest path did not exist, the semantic similarity was zero. After obtaining the semantic distance, it was transformed into the conceptual semantic similarity, written as follows:
- 2.
Node Depth
Node depth is the number of edges in the shortest path between the node and the root of the ontology tree. In the ontology tree, each layer is a refinement of the concepts in the previous layer. The deeper a node is in the hierarchy, the more specific and concrete the lexical meaning represented is. At equal semantic distances, the greater the depth of the two nodes, the greater the similarity between concepts.
The node depth of node A in the ontology tree is denoted depth(A), and the node depth of node B is denoted depth(B). Note that Dep(A,B) values are greater than 1.
- 3.
Node Density
Suppose that
A and
B are any two nodes in the urban rail construction ontology tree, C is their nearest common ancestor, and the number of direct sub-nodes of node
C is the density of nodes
A and
B. The more direct sub-nodes of
C, the greater the node density, the more specific the refined concepts, and therefore, the greater the semantic similarity between those sub-nodes. The influence factor of concept node density on semantic similarity is as follows:
where degree(
canc) is the degree of the nearest ancestor node of the two conceptual nodes, i.e., the number of direct sub-nodes of the nearest ancestor node, and
degree(
O) is the maximum of the degree of each node in the ontology tree
O.
- 4.
Comprehensive Semantic Similarity Algorithm
Considering three factors affecting semantic similarity, namely semantic distance, node depth, and node density, we propose the following comprehensive semantic similarity algorithm:
where
α,
β, and
γ are adjustable parameters representing the weights of semantic distance, node depth, and node density, respectively, on the influence of concept semantic similarity. Notably,
α +
β +
γ = 1. The higher the similarity of key attributes in the similarity case, the more similar the key attributes are, and the higher the key attribute weights. In the field of construction engineering, the semantic distance has the greatest influence on the conceptual similarity when calculating the conceptual semantic similarity, while the node depth and node density have a small influence. Thus, the weight of
α is relatively large, and the weight of
β and
γ is relatively small. In this study,
α = 0.8,
β = 0.1,
γ = 0.1.
4.3.2. Calculation of Feature Attribute Similarity
Measuring the similarity between two cases using semantic similarity alone. For example, if the risk consequences of both cases are casualties, one with one death and the other with ten deaths, the similarity between the two cases is 1 if only semantic similarity is considered. Obviously, this is not reasonable. Therefore, it is necessary to consider the similarity of feature attributes between the two cases. Feature attributes are divided into symbolic and numerical attributes.
- 1.
Symbolic Attribute
When there is a defined standard statement of construction risk for an urban rail project, similarity has only two choices: yes or no. We call this the symbolic attribute. If a source case in the ontology repository has the same attributes as those corresponding to the target case in the risk knowledge representation of the ontology tree, it is taken as 1; otherwise, it is taken as 0. Similarity is calculated as follows:
- 2.
Determining Value Attributes
Suppose that
A and
B are any two nodes in the urban rail construction ontology tree, and their similarity is calculated in the following manner when
A and
B are definite values:
where
Amax,j and
Amin,j represent the maximum and minimum values of the
jth attribute in the case base.
4.3.3. Calculation of Case Similarity
In this study, we considered conceptual semantic similarity to be as important as feature attribute similarity; therefore, we averaged them to obtain the comprehensive similarity of each attribute, written as follows:
Suppose that there are
n cases in the current urban rail construction safety accidents case base, each with m indicators. We can construct a matrix of the comprehensive similarity of the indicators as follows:
By multiplying the matrix of comprehensive similarity by the matrix of indicator weights, we obtain the comprehensive similarity between the source and target cases:
5. Case Validation
5.1. Overview of Target Cases
Next, an example will be assumed to show the specific calculation process of the comprehensive similarity between cases and how to retrieve and match cases based on the similarity. First of all, based on the above content, the ontology of urban rail construction safety accidents is established. Because there are many concepts in the field of urban construction safety accidents, and these concepts have a certain overlap. In order to simplify the calculation, only some concepts are described in this study, and five attributes of construction activity, hazard factor, risk types, risk consequences, and solutions are taken as important indicators. Solutions are the output content of similar cases retrieved by us.
For example, suppose that an urban rail project is under construction using the cut-and-cover method, due to the illegal operation of the construction personnel, which leads to the collapse of the construction site, resulting in economic losses and casualties. Relevant accident control solutions need to be developed. The indicators of the target case are, in order, “cut and cover method”, “operational failure”, “collapse”, “casualties”, and “design safety measures” for the retrieval solution. We assume there are seven source cases in the case base. As shown in
Table 4.
5.2. Calculation of Indicator Weights
According to the expert grading method, five indicators, namely construction activities, risk factors, risk types, risk consequences, and solutions, were compared two-by-two. After collecting 57 questionnaires, the following index judgment matrix is obtained, as shown in
Table 5.
This matrix is normalized, and the normalized values are summed by rows and normalized again to obtain the weights of each indicator as in
Table 6.
Weight ω = =.
Multiplying the weight matrix ω with the indicator judgment matrix before normalization, we can obtain the following matrix:
= =, where the largest eigenvalue of the matrix is == 5.158.
Next, a consistency test is performed in which the consistency indicator is first calculated as CI ==, where n is the order of the judgment matrix. The selected judgment matrix is of order five. Therefore, RI = 1.12.
The final consistency test is CR === 0.03. When C.R. < 0.1, the degree of consistency of judgment matrix A is within tolerance. Therefore, this weight vector is feasible.
5.3. Calculation of Semantic Similarity of Concepts
The results of the distance-based similarity calculation to the Formula (5) are presented in
Table 7 below.
According to the Formula (6), the influence of node depth on semantic similarity is shown in
Table 8.
According to the Formula (7), the influence of node density on semantic similarity is shown in
Table 9.
The comprehensive semantic similarity was calculated using Formula (8). The results are found in
Table 10 below.
5.4. Calculation of Feature Similarity of Concepts
After the semantic similarities of the indicators were calculated, their feature similarities were determined. Construction activities, risk-causing factors, risk types, and solutions were symbolic attributes, whereas risk consequences were deterministic attributes. The similarities of the feature attributes were calculated using Formulas (9) and (10). The results are presented in
Table 11 below.
5.5. Calculation of Comprehensive Similarity
Finally, by synthesizing the semantic and feature similarities, we obtained the synthesized similarity, as reflected in
Table 12 below. Since the value of
Dep(
c1,
c2) is greater than 1,
sim(
c1,
c2) may be a value greater than 1, but this does not affect the comparison and analysis of the results of the semantic similarity calculations.
5.6. Calculation of Case Similarity
The matrix of integrated similarity is multiplied by the matrix of indicator weights to obtain the comprehensive similarity between the source and target cases of the emergency preparedness, as follows:
The comprehensive similarity between case 2, case 6, and the target case is the highest, which is 0.754 and 0.816. Generally, source cases with similarity more than 0.8 can be selected as references. Therefore, when developing contingency measures for the target case, the contingency measures in case 6 can be referred to.
The target case is a collapse accident caused by improper operation of construction personnel in a project constructed with the cut-and-cover method, which eventually resulted in four casualties. And the retrieved case 6 is a collapse accident caused by faulty installation of machinery in a project constructed with the cut-and-cover method, which resulted in 6 casualties. In terms of attributes, the two cases are relatively similar. In contrast, the construction method and accident type of case 2 are different from the target case, and the solution of case 2 is not necessarily applicable to the target case. In summary, the target cases and case 6 are similar through subjective analysis, and the calculated results meet the similarity threshold set by this study, which can verify the rationality of this retrieval method.
6. Discussion
This study introduces a CBR method based on ontology and similarity retrieval, which provides a more scientific method for managers to implement safety accident identification, reuse, and rapid generation of emergency preparedness. Firstly, this study combs the development process of expert decision-making systems, case-based reasoning theory, and ontology methodology. Analyzing the characteristics, processes, and challenges of urban rail construction emergency preparedness design and proposing the basic content of urban rail construction emergency preparedness auxiliary design. Then, based on a large number of literature reviews and case studies, this study extracted the core concepts of urban rail construction safety accident knowledge and represents this knowledge structurally to develop an urban rail safety accident ontology model. Then, an improved semantic similarity and feature similarity algorithm is proposed, which takes the level, distance, and content into account in the calculation of similarity and builds a CBR model for urban rail construction emergency preparedness. When a new urban rail construction accident occurs, the attributes related to the case will be retrieved, the resource case with the highest similarity will be found, and its emergency preparedness will be referred to. Finally, this study also proves the feasibility of the method through case validation. Among the seven cases, case 6 has the highest comprehensive similarity with the target case, which means that managers can refer to case 6 to formulate emergency preparedness for the target case.
At present, the emergency plan assessment of urban rail projects in China mainly focuses on the operation phase, with relatively little work during the construction phase. This study combines ontology with CBR technology and applies them to the emergency management field of urban rail transit construction, providing new ideas for the generation of emergency preparedness for urban rail construction safety accidents. It can also be extended to CBR systems in other fields. In terms of ontology development, this study uses Protégé as an ontology modeling tool for safety accidents during the construction phase of urban rail transit projects, which greatly simplifies the ontology development process and facilitates learning and use by users. In terms of case retrieval, this study proposes a comprehensive similarity calculation method that combines feature attribute similarity and concept semantic similarity, making up for the shortcomings of traditional semantic similarity methods. This study provides a more scientific method for managers to implement identification safety accidents, resource reuse, and management, and is an innovative supplement of CBR and ontology in the safety management of urban rail transit construction projects.
7. Conclusions
Safety accident preparedness decision-making during the urban rail construction phase is a comprehensive management activity to respond to public emergencies and prevent and resolve public safety risks. Urban rail transportation is developing rapidly. As unstructured safety knowledge and cases are difficult to identify and reuse, it is a difficult problem to quickly respond and systematically formulate appropriate action plans as well as a series of alternatives to face emergencies at the beginning of a safety accident. To solve this problem, this study introduces a combination of ontology and case-based reasoning technologies into the field of safety management during the construction phase of urban rail. Based on the results of this study, in order to respond quickly in urban railway construction accidents, we should establish an ontology-based case base and ensure its dynamic updating mechanism. Increase the breadth and depth of the case base by regularly collecting new accident cases. Strengthen the fusion of multi-source data (e.g., design documents, environmental monitoring data, etc.) in urban rail transit construction projects, and build a comprehensive emergency management database. We should also use a common ontology modeling language (e.g., OWL) for ontology development to ensure the consistency of the structural and semantic aspects of the case database so that the case database data can be shared on different platforms.
At the same time, this study realizes the full and effective use of past design resources and experience by tapping the potential of existing knowledge and information. Thus, it can design decision-making ideas quickly, avoid the waste of money and time, and contribute to reducing the loss of property and life caused by construction accidents. In the future, the development of informatization is one of the important development directions of the construction industry. With the continuous enrichment of cases and the continuous improvement of urban rail transit construction safety accident ontology, the system will be able to deal with a wider range of accidents, making contributions to the safety and stability of the urban rail transit construction system. In addition, the use of Protégé as the modeling tool greatly simplifies the development process of ontology and is easy to learn and extend to other construction safety fields. Therefore, the research has certain practical significance in the field of intelligent application of architectural design.
However, the research conducted in this study has its limitations. In terms of domain ontology construction, since ontology research has not been generally carried out in the field of urban rail construction, there is a lack of ontology models that can be borrowed and reused when constructing an ontology. The five types of abstracted indicators cannot fully cover all aspects of safety accident knowledge in the construction process, and some important features have not been taken into account; thus, the concepts of abstraction classes need to be further supplemented. In terms of the case-retrieval mechanism, when calculating the similarity of case semantics, the length of all directed edges in the ontology tree is regarded as 1, such that the semantic distance between two concepts is equal to the number of directed edges of the shortest paths of their corresponding nodes in the ontology tree. The length of such a semantic distance lacks an objective and rigorous definition in the theory. Finally, the number of cases in the ontology knowledge base for reasoning regarding urban rail construction safety accidents should be higher. When the knowledge in the ontology knowledge base is sufficiently rich, it can better support data acquisition, mining, and application, requiring the accumulation of relevant units over time.
Therefore, the future research work mainly focuses on the following aspects: consulting more related specifications and books, consulting experts in the professional field, and improving ontology in terms of conceptual coverage and logical rationality. Seeking more suitable similarity algorithms, taking the amount of information into the calculation of semantic distance, and trying to use weighting coefficients or information theory based on probability statistics to define semantic distance. At the same time, we will use a method that combines text mining and Word2Vec models to construct an ontology model in the field of urban rail safety accidents and achieve structured storage and case identification by extracting causes and parameterizing cases. In order to collect case resources more conveniently, the automatic integration of the ontology case base should be further studied.
Author Contributions
Conceptualization, M.S.; methodology, M.S. and S.X.; formal analysis, S.X.; investigation, S.X.; writing—original draft preparation, S.X.; writing—review and editing, M.S. and Z.Z.; supervision, M.S. and Z.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Natural Science Foundation of Changsha (grant number: kq2402229), Natural Science Foundation of Hunan Province, China (grant number: 2023JJ40055) and Natural Science Foundation of Hunan Province, China (grant number: 2025JJ50415).
Data Availability Statement
Data are not publicly available, though the data may be made available from the corresponding author upon request.
Acknowledgments
Special appreciation goes to the editors and reviewers whose constructive and invaluable comments and suggestions played a decisive role in significantly improving the quality of this work.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Yu, Q.; Huang, S.; Du, J. Fuzzy Comprehensive Evaluation of Risks in Subway Station Construction. In Proceedings of the ICTE 2015, Dailan, China, 26–27 September 2015; American Society of Civil Engineers: Dailan, China, 2015; pp. 994–1000. [Google Scholar]
- Liu, Z.; Jiao, Y.; Li, A.; Liu, X. Risk Assessment of Urban Rail Transit PPP Project Construction Based on Bayesian Network. Sustainability 2021, 13, 11507. [Google Scholar] [CrossRef]
- China Association of Metros Urban Rail Transit 2023 Annual Statistical and Analytical Report. Available online: https://www.camet.org.cn/xytj/tjxx/14894.shtml (accessed on 8 April 2024).
- Ding, L.Y.; Yu, H.L.; Li, H.; Zhou, C.; Wu, X.G.; Yu, M.H. Safety risk identification system for metro construction on the basis of construction drawings. Autom. Constr. 2012, 27, 120–137. [Google Scholar] [CrossRef]
- Liu, P.; Wu, W.; Xu, J.; Shang, T. Statistical analysis of domestic subway construction accidents based on GRA. J. Eng. Manag. 2023, 37, 53–58. [Google Scholar] [CrossRef]
- Liu, P.; Li, Q.; Bian, J.; Song, L.; Xiahou, X. Using Interpretative Structural Modeling to Identify Critical Success Factors for Safety Management in Subway Construction: A China Study. Int. J. Environ. Res. Public Health 2018, 15, 1359. [Google Scholar] [CrossRef]
- Patel, V.L.; Kaufman, D.R.; Arocha, J.F. Emerging paradigms of cognition in medical decision-making. J. Biomed. Inform. 2002, 35, 52–75. [Google Scholar] [CrossRef]
- Amailef, K.; Lu, J. Ontology-supported case-based reasoning approach for intelligent m-Government emergency response services. Decis. Support Syst. 2013, 55, 79–97. [Google Scholar] [CrossRef]
- Su, Y.; Yang, S.; Liu, K.; Hua, K.; Yao, Q. Developing A Case-Based Reasoning Model for Safety Accident Pre-Control and Decision Making in the Construction Industry. Int. J. Environ. Res. Public Health 2019, 16, 1511. [Google Scholar] [CrossRef]
- Lu, Y.; Li, Q.; Xiao, W. Case-based reasoning for automated safety risk analysis on subway operation: Case representation and retrieval. Saf. Sci. 2013, 57, 75–81. [Google Scholar] [CrossRef]
- Dias, P. Philosophy for Engineering: Practice, Context, Ethics, Models, Failure; Springer: Singapore, 2019. [Google Scholar] [CrossRef]
- Gruber, T.R. A translation approach to portable ontology specifications. Knowl. Acquis. 1993, 5, 199–220. [Google Scholar] [CrossRef]
- Kepaptsoglou, K.; Karlaftis, M.G.; Mintsis, G. Model for Planning Emergency Response Services in Road Safety. J. Urban Plan. Dev. 2012, 138, 18–25. [Google Scholar] [CrossRef]
- Bullock, J.; Haddow, G.; Coppola, D. Introduction to Emergency Management; Butterworth-Heinemann: Oxford, UK, 2017; ISBN 978-0-12-803065-3. [Google Scholar]
- Einstein, H.H. Risk and risk analysis in rock engineering. Tunn. Undergr. Technol. 1996, 11, 141–155. [Google Scholar] [CrossRef]
- Dong, H.-R.; Ning, B.; Qin, G.-Y.; Lv, Y.-S.; Li, L. Urban Rail Emergency Response Using Pedestrian Dynamics. IEEE Intell. Syst. 2012, 27, 52–55. [Google Scholar] [CrossRef]
- Sousa, R.L. Risk Analysis for Tunneling Projects. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2010. [Google Scholar]
- Fouladgar, M.M.; Yazdani-Chamzini, A.; Zavadskas, E.K. Risk evaluation of tunneling projects. Arch. Civ. Mech. Eng. 2012, 12, 1–12. [Google Scholar]
- Nezarat, H.; Sereshki, F.; Ataei, M. Ranking of geological risks in mechanized tunneling by using Fuzzy Analytical Hierarchy Process (FAHP). Tunn. Undergr. Space Technol. Inc. Trenchless Technol. Res. 2015, 50, 358–364. [Google Scholar] [CrossRef]
- Zhang, Y.; Zou, D.; Zheng, J.; Fang, X.; Luo, H. Formation mechanism of quick emergency response capability for urban rail transit: Inter-organizational collaboration perspective. Adv. Mech. Eng. 2016, 8, 1687814016647881. [Google Scholar] [CrossRef]
- Zhou, Z.; Irizarry, J.; Guo, W. A network-based approach to modeling safety accidents and causations within the context of subway construction project management. Saf. Sci. 2021, 139, 105261. [Google Scholar] [CrossRef]
- Ge, S.; Shan, M.; Zhai, Z. Emergency Preparedness in China’s Urban Rail Transit System: A Systematic Review. Sustainability 2025, 17, 524. [Google Scholar] [CrossRef]
- Berkat, A. Using Case-Based Reasoning for detecting computer virus. Int. J. Comput. Sci. Issues 2011, 8, 606–610. [Google Scholar]
- Carrick, C.; Yang, Q.; Abi-Zeid, I.; Lamontagne, L. Activating CBR Systems through Autonomous Information Gathering. In Proceedings of the Case-Based Reasoning Research and Development, Seeon-Seebruck, Germany, 27–30 July 1999; Althoff, K.-D., Bergmann, R., Branting, L.K., Eds.; Springer: Berlin/Heidelberg, Germany, 1999; pp. 74–88. [Google Scholar]
- Abelson, R.P.; Schank, R. Scripts, Plans, Goals and Understanding: An Inquiry into Human Knowledge Structures; Psychology Press: Hillsdale, NY, USA, 1977; Volume 248. [Google Scholar]
- Guo, Y.; Deng, G. Review of case-based reasoning (CBR) research. Comput. Eng. Appl. 2004, 1–5. [Google Scholar]
- Montani, S.; Leonardi, G. Non-exhaustive Trace Retrieval for Managing Stroke Patients. In Successful Case-Based Reasoning Applications-2; Montani, S., Jain, L.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 29–42. ISBN 978-3-642-38736-4. [Google Scholar]
- Boral, S.; Chaturvedi, S.K.; Naikan, V.N.A. A case-based reasoning system for fault detection and isolation: A case study on complex gearboxes. J. Qual. Maint. Eng. 2019, 25, 213–235. [Google Scholar] [CrossRef]
- Bouhana, A.; Fekih, A.; Abed, M.; Chabchoub, H. An integrated case-based reasoning approach for personalized itinerary search in multimodal transportation systems. Transp. Res. Part C Emerg. Technol. 2013, 31, 30–50. [Google Scholar] [CrossRef]
- Alemi-Ardakani, M.; Milani, A.S.; Yannacopoulos, S.; Shokouhi, G. On the effect of subjective, objective and combinative weighting in multiple criteria decision making: A case study on impact optimization of composites. Expert Syst. Appl. 2016, 46, 426–438. [Google Scholar] [CrossRef]
- Maalel, A.; Mejri, L.; Ghézala, H.H.B. Adast: A decision support approach based on an ontology and CBR. Application to railroad accidents. Int. J. Inf. Decis. Sci. 2016, 8, 125–152. [Google Scholar] [CrossRef]
- Gadomski, A.M.; Bologna, S.; Costanzo, G.D.; Perini, A.; Schaerf, M. Towards intelligent decision support systems for emergency managers: The IDA approach. Int. J. Risk Assess. Manag. 2001, 2, 224–242. [Google Scholar] [CrossRef]
- Yu, F.; Li, X.Y.; Han, X.S. Risk response for urban water supply network using case-based reasoning during a natural disaster. Saf. Sci. 2018, 106, 121–139. [Google Scholar] [CrossRef]
- Jiao, H. Ontology-Based Construction Safety Risk Knowledge Base Construction and Application for Subway Construction. Master’s Thesis, Southeast University, Nanjing, China, 2016. [Google Scholar]
- Gruber, T.R. Toward principles for the design of ontologies used for knowledge sharing? Int. J. Hum.-Comput. Stud. 1995, 43, 907–928. [Google Scholar] [CrossRef]
- Xie, J. A Study on the Application of Ontology Technology in Knowledge Management Systems. Master’s Thesis, Nanjing University of Aeronautics and Astronautics, Nanjing, China, 2007. [Google Scholar]
- Xing, J.; Tan, A.H. Learning and inferencing in user ontology for personalized Semantic Web search. Inf. Sci. 2009, 179, 2794–2808. [Google Scholar] [CrossRef]
- Rector, A.; Rogers, J. Ontological and Practical Issues in Using a Description Logic to Represent Medical Concept Systems: Experience from GALEN. In Reasoning Web; Barahona, P., Bry, F., Franconi, E., Henze, N., Sattler, U., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4126, pp. 197–231. ISBN 978-3-540-38409-0. [Google Scholar]
- Petnga, L.; Austin, M. An ontological framework for knowledge modeling and decision support in cyber-physical systems. Adv. Eng. Inform. 2016, 30, 77–94. [Google Scholar] [CrossRef]
- Bień, J.; Jakubowski, K.; Kamiński, T.; Kmita, J.; Kmita, P.; Cruz, P.J.S.; Maksymowicz, M. Railway bridge defects and degradation mechanisms. In Sustainable Bridges: Assessment for Future Traffic Demands and Longer Lives; Dolnośląskie Wydawnictwo Edukacyjne: Wroclaw, Poland, 2007. [Google Scholar]
- Wang, H.-H.; Boukamp, F.; Elghamrawy, T. Ontology-Based Approach to Context Representation and Reasoning for Managing Context-Sensitive Construction Information. J. Comput. Civ. Eng. 2011, 25, 331–346. [Google Scholar] [CrossRef]
- Chi, N.-W.; Lin, K.-Y.; Hsieh, S.-H. Using ontology-based text classification to assist Job Hazard Analysis. Adv. Eng. Inform. 2014, 28, 381–394. [Google Scholar] [CrossRef]
- Zhang, S.; Boukamp, F.; Teizer, J. Ontology-based semantic modeling of construction safety knowledge: Towards automated safety planning for job hazard analysis (JHA). Autom. Constr. 2015, 52, 29–41. [Google Scholar] [CrossRef]
- Lee, D.-Y.; Chi, H.; Wang, J.; Wang, X.; Park, C.-S. A linked data system framework for sharing construction defect information using ontologies and BIM environments. Autom. Constr. 2016, 68, 102–113. [Google Scholar] [CrossRef]
- Noy, N.F.; Mcguinness, D.L. Ontology Development 101: A Guide to Creating Your First Ontology. 2001. Available online: https://protege.stanford.edu/publications/ontology_development/ontology101.pdf (accessed on 10 March 2025).
- Gruninger, M.; Fox, M.S. The Logic of Enterprise Modelling. In Re-Engineering the Enterprise; Browne, J., O’Sullivan, D., Eds.; Springer: Boston, MA, USA, 1995; pp. 83–98. ISBN 978-1-4757-6387-4. [Google Scholar]
- Sarder, B.; Liles, D.H. Design Ontology Modeling Using Idef5. In Proceedings of the 17th Annual Conference of the Production and Operations Management Society, Boston, MA, USA, 28 April–1 May 2006; Available online: https://pomsmeetings.org/ConfProceedings/004/PAPERS/004-0127.pdf (accessed on 10 March 2025).
- Uschold, M.; Gruninger, M. Ontologies: Principles, methods and applications. Knowl. Eng. Rev. 1996, 11, 93–136. [Google Scholar] [CrossRef]
- Fernández-López, M.; Gómez-Pérez, A.; Juristo Juzgado, N. METHONTOLOGY: From Ontological Art Towards Ontological Engineering. In Proceedings of the Ontological Engineering AAAI-97 Spring Symposium Series, Palo Alto, CA, USA, 24–26 March 1997; Facultad de Informática (UPM), Stanford University, EEUU: Stanford, CA, USA, 1997. [Google Scholar]
- Swartout, B.; Patil, R.; Knight, K.; Russ, T. Toward distributed use of large-scale ontologies. In Proceedings of the Tenth Workshop on Knowledge Acquisition for Knowledge-Based Systems, Banff, AB, Canada, 9–14 November 1996; Volume 138, p. 25. [Google Scholar]
- Jiang, X.; Wang, S.; Wang, J.; Lyu, S.; Skitmore, M. A Decision Method for Construction Safety Risk Management Based on Ontology and Improved CBR: Example of a Subway Project. Int. J. Environ. Res. Public Health 2020, 17, 3928. [Google Scholar] [CrossRef]
- Quirion-Blais, O.; Chen, L. A case-based reasoning approach to solve the vehicle routing problem with time windows and drivers’ experience. Omega 2021, 102, 102340. [Google Scholar] [CrossRef]
- Aamodt, A.; Plaza, E. Case-Based Reasoning: Foundational Issues, Methodological Variations, and System Approaches. AI Commun. 1994, 7, 39–59. [Google Scholar] [CrossRef]
- Deng, G.; Gao, J. A review of research on ontology-based case-based reasoning systems. Appl. Res. Comput. 2009, 26, 406–410, 418. [Google Scholar] [CrossRef]
- Su, K. Case-Based Reasoning of Foundation Pit ConstructionAccidents Based on Ontology. Master’s Thesis, Capital University of Economics and Business, Beijing, China, 2023; p. 96. [Google Scholar]
- Clayton, C.R.I. Managing Geotechnical Risk: Improving Productivity in UK Building and Construction; Thomas Telford: Telford, UK, 2001; ISBN 978-0-7277-2967-5. [Google Scholar]
- Saaty, R.W. The analytic hierarchy process—What it is and how it is used. Math. Model. 1987, 9, 161–176. [Google Scholar] [CrossRef]
- Rada, R.; Mili, H.; Bicknell, E.; Blettner, M. Development and application of a metric on semantic nets. IEEE Trans. Syst. Man Cybern. 1989, 19, 17–30. [Google Scholar] [CrossRef]
- Steichen, O.; Bozec, C.D.-L.; Thieu, M.; Zapletal, E.; Jaulent, M.-C. Computation of semantic similarity within an ontology of breast pathology to assist inter-observer consensus. Comput. Biol. Med. 2006, 36, 768–788. [Google Scholar] [CrossRef]
- Liu, J.-F.; Zou, P.; Zhang, P.-Z.; Qi, F. Research on an Improved Algorithm of Concept Semantic Similarity Based on Ontology. Wuhan Ligong Daxue Xuebao J. Wuhan Univ. Technol. 2010, 32, 112–117. [Google Scholar]
Figure 1.
Seven-step method to build an ontology model.
Figure 1.
Seven-step method to build an ontology model.
Figure 2.
Ontology tree of urban rail construction safety incidents.
Figure 2.
Ontology tree of urban rail construction safety incidents.
Figure 3.
Relationship between classes.
Figure 3.
Relationship between classes.
Figure 4.
Semantic relationship diagram of classes and subclasses.
Figure 4.
Semantic relationship diagram of classes and subclasses.
Figure 5.
The setting of object property “has_factor”.
Figure 5.
The setting of object property “has_factor”.
Figure 6.
The setting of data property “P_ID”.
Figure 6.
The setting of data property “P_ID”.
Figure 7.
OWL Viz view of ontology.
Figure 7.
OWL Viz view of ontology.
Figure 8.
Reasoning flowchart for CBR.
Figure 8.
Reasoning flowchart for CBR.
Table 1.
Concept and definition of basic classes.
Table 1.
Concept and definition of basic classes.
| Conception | Acronym | Define |
|---|
| Construction project | P | Project name |
| Construction activity | C | Urban rail transit construction activity |
| Hazard factor | F | Factors that can cause accidents during the
construction process |
| Risk type | R | Types of risk events caused by hazard factors |
| Risk consequences | RC | Losses and casualties from risk events |
| Solution | S | Control measures taken to address risk events
and ensure subsequent construction safety |
Table 2.
Some data properties of “Construction project”.
Table 2.
Some data properties of “Construction project”.
| Serial Number | Datatype | Value Type | Characteristic |
|---|
| 1 | P_ID | Int | Functional |
| 2 | P_name | String | Functional |
| 3 | Description | String | Functional |
| 4 | Lot | String | Functional & Allowed Value |
| 5 | Location | String | Functional |
| 6 | City | String | Functional |
| 7 | Country | String | Functional & Allowed Value |
| 8 | Investment | String | Functional |
| 9 | Projectparticipator | String | Functional |
| 10 | Contract_price | Float | Functional |
| 11 | Contract_award_method | String | Functional & Allowed Value |
| 12 | Contract_award_year | Int | Functional |
| 13 | Owner | String | Functional |
| 14 | Designer | String | Functional |
| 15 | Contractor | String | Functional |
| 16 | Supervisor | String | Functional |
| 17 | Project schedule | String | Functional & Allowed Value |
| 18 | Project status | String | Functional & Allowed Value |
Table 3.
The Importance degrees of “1–5” scale method.
Table 3.
The Importance degrees of “1–5” scale method.
| Scale of Importance | Meaning |
|---|
| 1 | The two attributes are of equal importance. |
| 3 | The former is slightly more important than the latter. |
| 5 | The former is significantly more important than the latter |
| 2, 4 | Represents the median value of the above judgments |
| reciprocal | If the ratio of importance of attribute i to attribute j is xij, then the ratio of importance of attribute j to attribute i is xji = 1/xij |
Table 4.
Risk attribute indicators of the target case and source cases in the case base.
Table 4.
Risk attribute indicators of the target case and source cases in the case base.
| Case | Construction Activity | Hazard Factor | Risk Type | Risk Consequences | Solution |
|---|
| target case | cut-and-cover method | operation fault | collapse | casualties: 4 | design safety measures |
| case 1 | shield | installation failure | collapse | casualties: 6 | construction safety measures |
| case 2 | cut-and-cover method | operation fault | leakage | casualty: 1 | construction safety measures |
| case 3 | shield | installation failure | roof fall | casualties: 4 | design safety measures |
| case 4 | immersed tube method | organizational
planning error | settlement | casualties: 3 | design safety measures |
| case 5 | shield | organizational
planning error | roof fall | casualties: 2 | design safety measures |
| case 6 | cut-and-cover method | installation failure | collapse | casualties: 6 | design safety measures |
| case 7 | immersed tube method | flood | leakage | casualties: 1 | construction safety measures |
Table 5.
Judgment matrix for the five indicators.
Table 5.
Judgment matrix for the five indicators.
| Z | Construction Activity | Hazard Factor | Risk Type | Risk Consequences | Solution |
|---|
| Construction activity | 1.00 | 1.75 | 1.63 | 1.55 | 1.60 |
| Hazard factor | 0.57 | 1.00 | 2.02 | 1.92 | 1.55 |
| Risk type | 0.61 | 0.50 | 1.00 | 1.56 | 1.66 |
| Risk consequences | 0.65 | 0.52 | 0.64 | 1.00 | 1.67 |
| Solution | 0.63 | 0.65 | 0.60 | 0.60 | 1.00 |
Table 6.
Normalization matrix and weights for the five indicators.
Table 6.
Normalization matrix and weights for the five indicators.
| Z | Construction Activity | Hazard Factor | Risk Type | Risk Consequences | Solution | ω |
|---|
| Construction activity | 0.29 | 0.40 | 0.28 | 0.23 | 0.21 | 0.28 |
| Hazard factor | 0.16 | 0.23 | 0.34 | 0.29 | 0.21 | 0.25 |
| Risk type | 0.18 | 0.11 | 0.17 | 0.24 | 0.22 | 0.18 |
| Risk consequences | 0.19 | 0.12 | 0.11 | 0.15 | 0.22 | 0.16 |
| Solution | 0.18 | 0.15 | 0.10 | 0.09 | 0.13 | 0.13 |
Table 7.
Semantic similarity based on distance.
Table 7.
Semantic similarity based on distance.
| Case | Construction Activity | Hazard Factor | Risk Type | Risk Consequences | Solution |
|---|
| case 1 | 1/3 | 1/3 | 1 | 1 | 1/3 |
| case 2 | 1 | 1 | 1/3 | 1 | 1/3 |
| case 3 | 1/3 | 1/3 | 1/3 | 1 | 1 |
| case 4 | 1/3 | 1/5 | 1/3 | 1 | 1 |
| case 5 | 1/3 | 1/5 | 1/3 | 1 | 1 |
| case 6 | 1 | 1/3 | 1 | 1 | 1 |
| case 7 | 1/3 | 1/5 | 1/3 | 1 | 1/3 |
Table 8.
Semantic similarity based on node depth.
Table 8.
Semantic similarity based on node depth.
| Case | Construction Activity | Hazard Factor | Risk Type | Risk Consequences | Solution |
|---|
| case 1 | 4 | 6 | 4 | 4 | 4 |
| case 2 | 4 | 6 | 4 | 4 | 4 |
| case 3 | 4 | 6 | 4 | 4 | 4 |
| case 4 | 4 | 6 | 4 | 4 | 4 |
| case 5 | 4 | 6 | 4 | 4 | 4 |
| case 6 | 4 | 6 | 4 | 4 | 4 |
| case 7 | 4 | 6 | 4 | 4 | 4 |
Table 9.
Semantic similarity based on node density.
Table 9.
Semantic similarity based on node density.
| Case | Construction Activity | Hazard Factor | Risk Type | Risk Consequences | Solution |
|---|
| case 1 | 3/5 | 3/5 | 1 | 4/5 | 2/5 |
| case 2 | 3/5 | 3/5 | 1 | 4/5 | 2/5 |
| case 3 | 3/5 | 3/5 | 1 | 4/5 | 2/5 |
| case 4 | 3/5 | 4/5 | 1 | 4/5 | 2/5 |
| case 5 | 3/5 | 3/5 | 1 | 4/5 | 2/5 |
| case 6 | 3/5 | 3/5 | 1 | 4/5 | 2/5 |
| case 7 | 3/5 | 4/5 | 1 | 4/5 | 2/5 |
Table 10.
The results of comprehensive semantic similarity.
Table 10.
The results of comprehensive semantic similarity.
| Case | Construction Activity | Hazard Factor | Risk Type | Risk Consequences | Solution |
|---|
| case 1 | 0.45 | 0.47 | 1.15 | 1.12 | 0.44 |
| case 2 | 1.09 | 1.14 | 0.48 | 1.12 | 0.44 |
| case 3 | 0.45 | 0.47 | 0.48 | 1.12 | 1.05 |
| case 4 | 0.45 | 0.32 | 0.48 | 1.12 | 1.05 |
| case 5 | 0.45 | 0.31 | 0.48 | 1.12 | 1.05 |
| case 6 | 1.09 | 0.47 | 1.15 | 1.12 | 1.05 |
| case 7 | 0.45 | 0.32 | 0.48 | 1.12 | 0.44 |
Table 11.
The results of feature attribute similarity.
Table 11.
The results of feature attribute similarity.
| Case | Construction Activity | Hazard Factor | Risk Type | Risk Consequences | Solution |
|---|
| case 1 | 0 | 0 | 1 | 3/5 | 0 |
| case 2 | 1 | 1 | 0 | 2/5 | 0 |
| case 3 | 0 | 0 | 0 | 1 | 1 |
| case 4 | 0 | 0 | 0 | 4/5 | 1 |
| case 5 | 0 | 0 | 0 | 3/5 | 1 |
| case 6 | 1 | 0 | 1 | 3/5 | 1 |
| case 7 | 0 | 0 | 0 | 2/5 | 0 |
Table 12.
The results of comprehensive similarity.
Table 12.
The results of comprehensive similarity.
| Case | Construction Activity | Hazard Factor | Risk Type | Risk Consequences | Solution |
|---|
| case 1 | 0.225 | 0.235 | 1.075 | 0.860 | 0.220 |
| case 2 | 1.045 | 1.070 | 0.240 | 0.760 | 0.220 |
| case 3 | 0.225 | 0.235 | 0.240 | 1.060 | 1.025 |
| case 4 | 0.225 | 0.160 | 0.240 | 0.960 | 1.025 |
| case 5 | 0.225 | 0.155 | 0.240 | 0.860 | 1.025 |
| case 6 | 1.045 | 0.235 | 1.075 | 0.860 | 1.025 |
| case 7 | 0.225 | 0.160 | 0.240 | 0.760 | 0.220 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




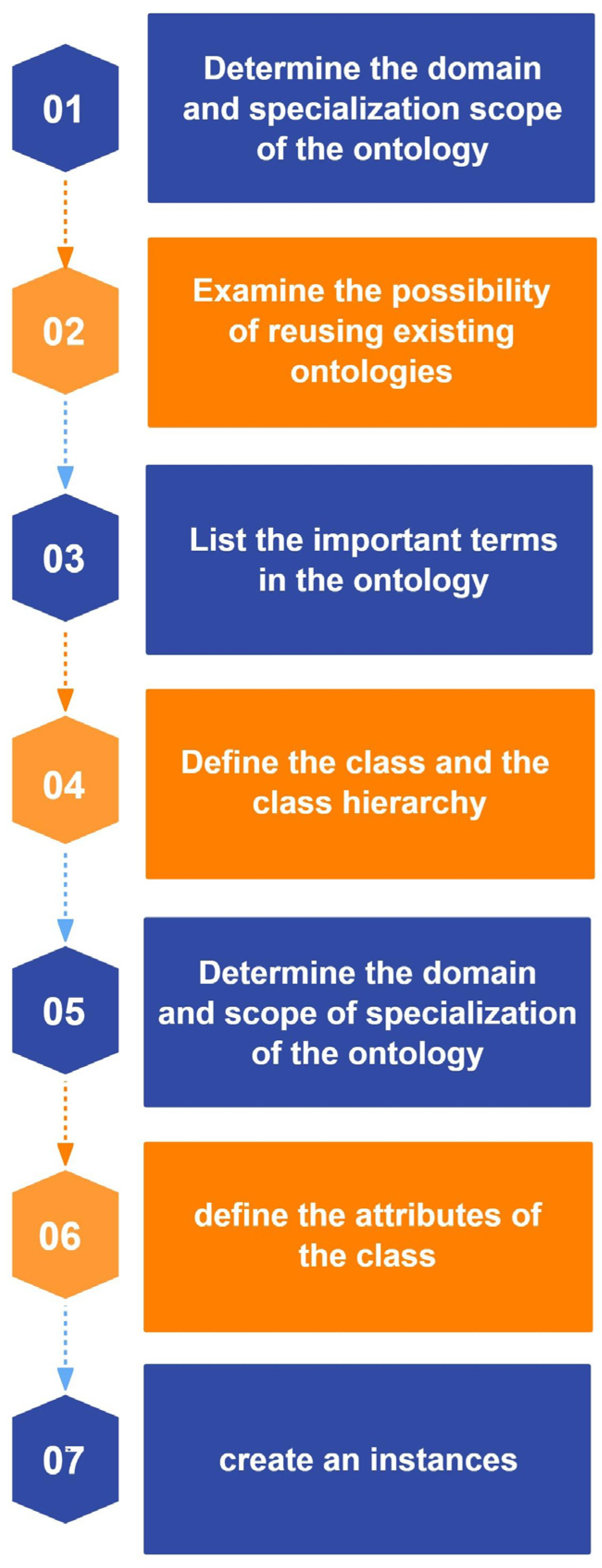
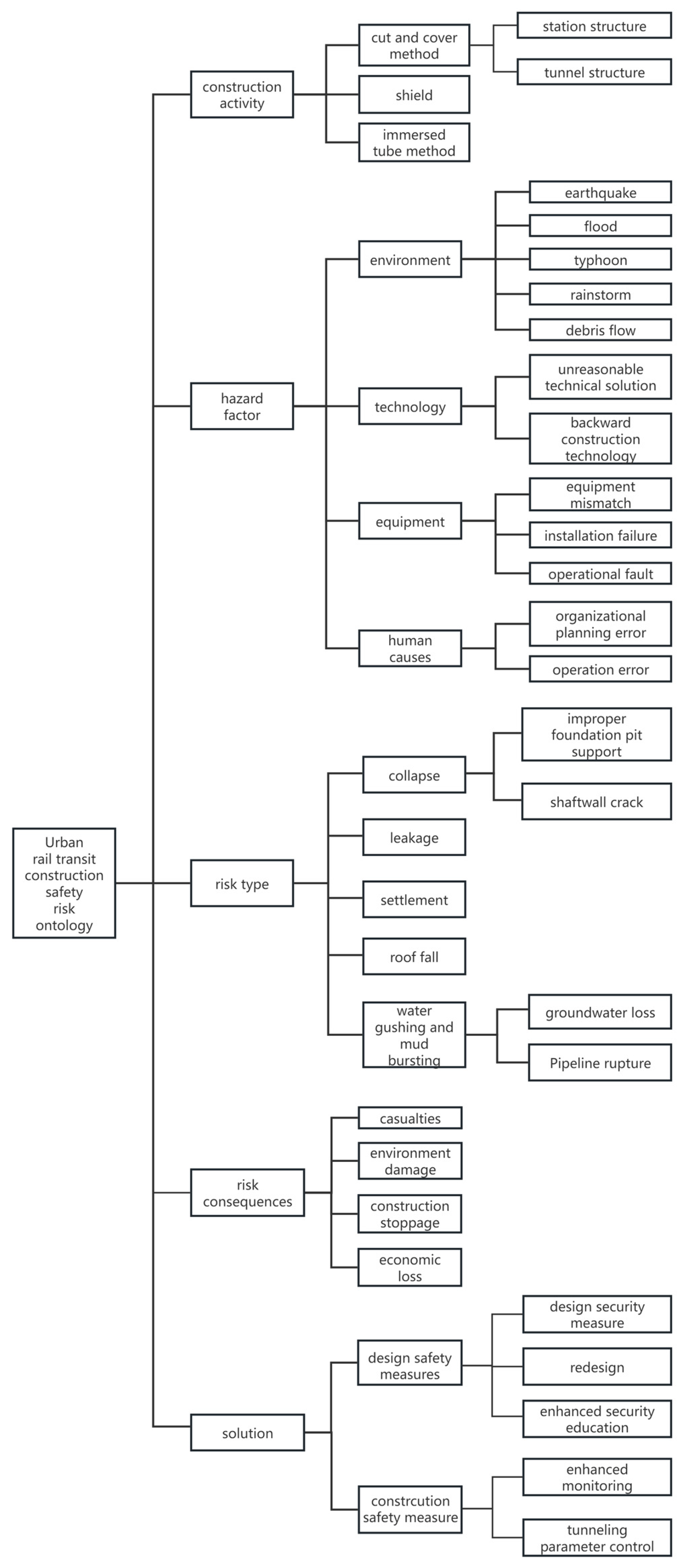

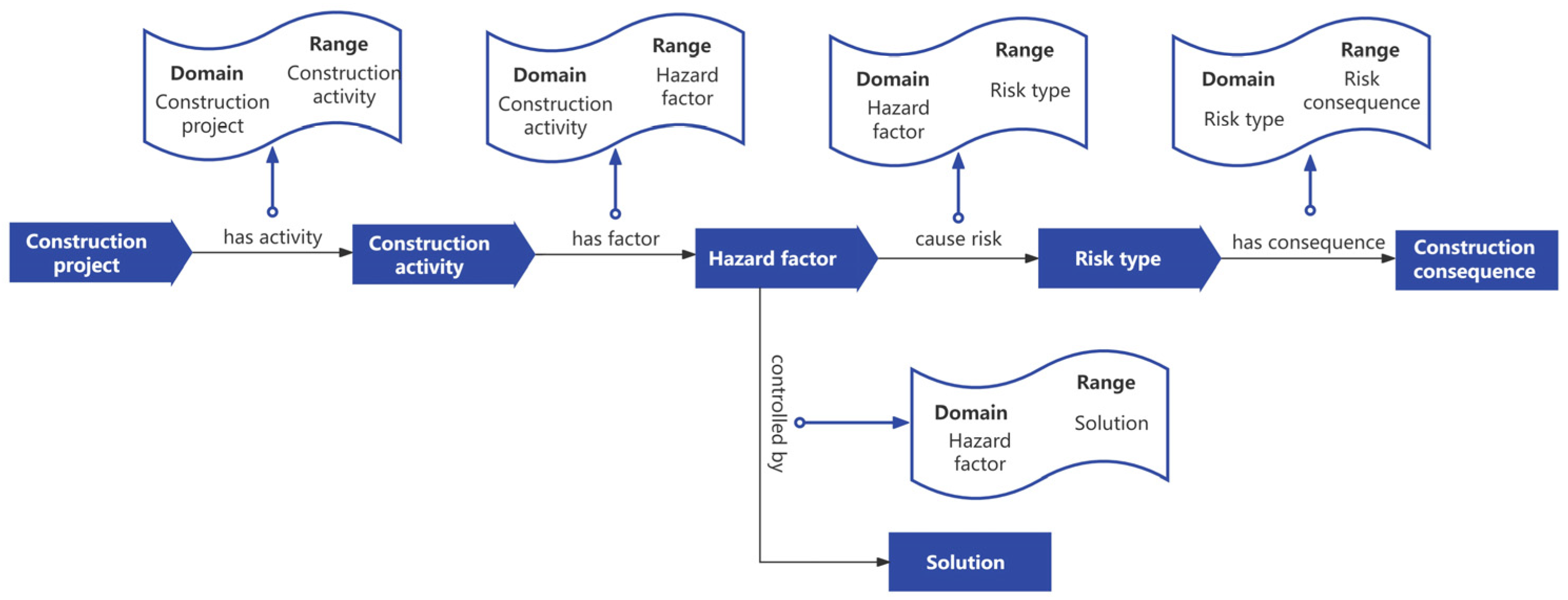
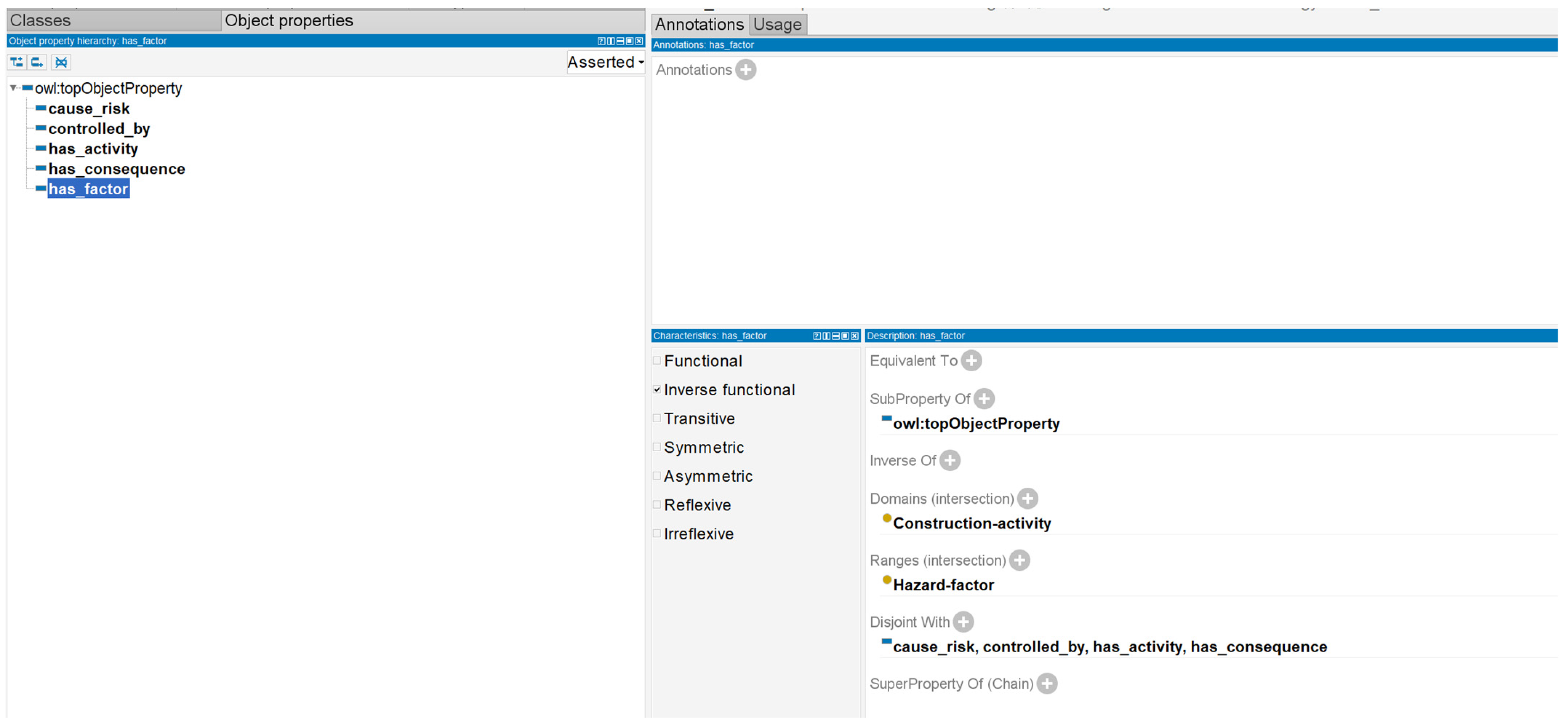
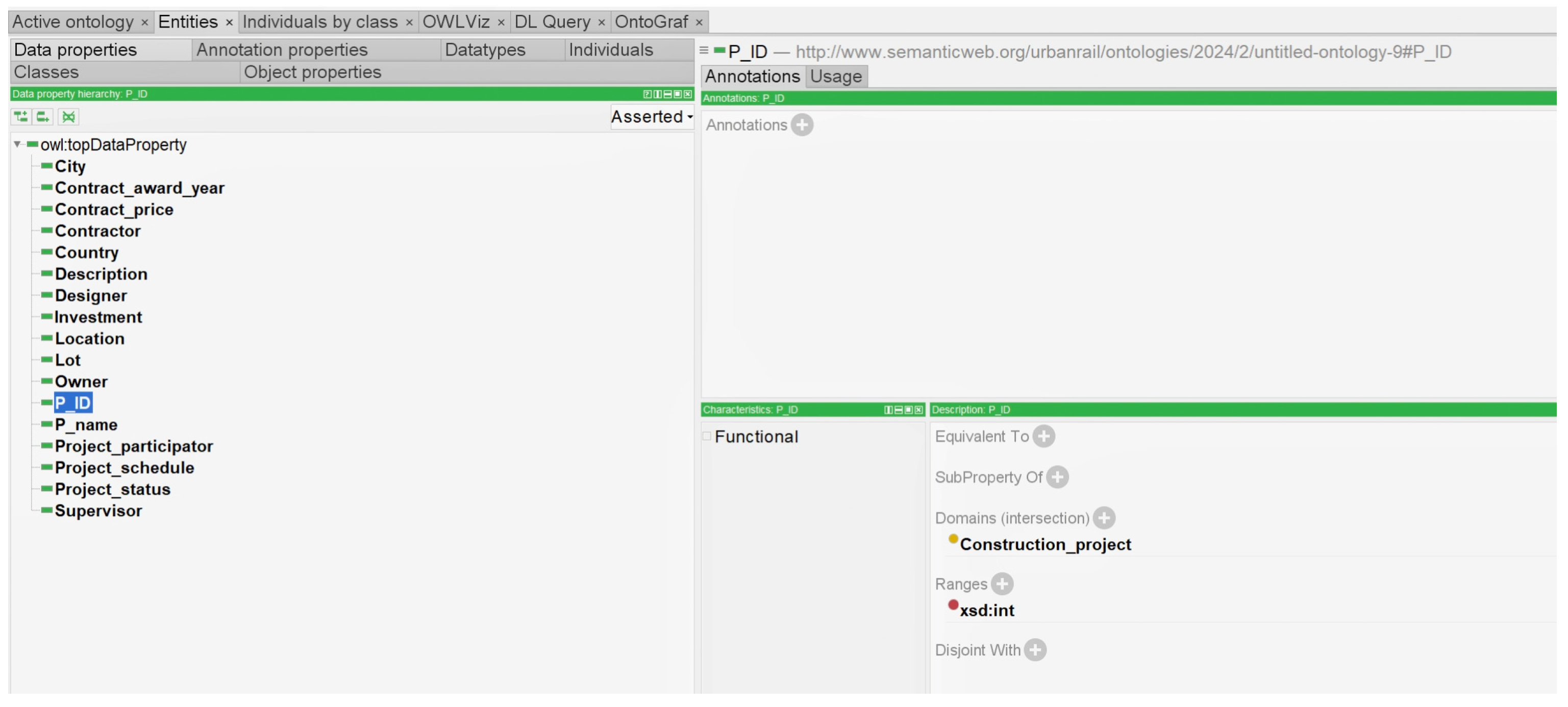
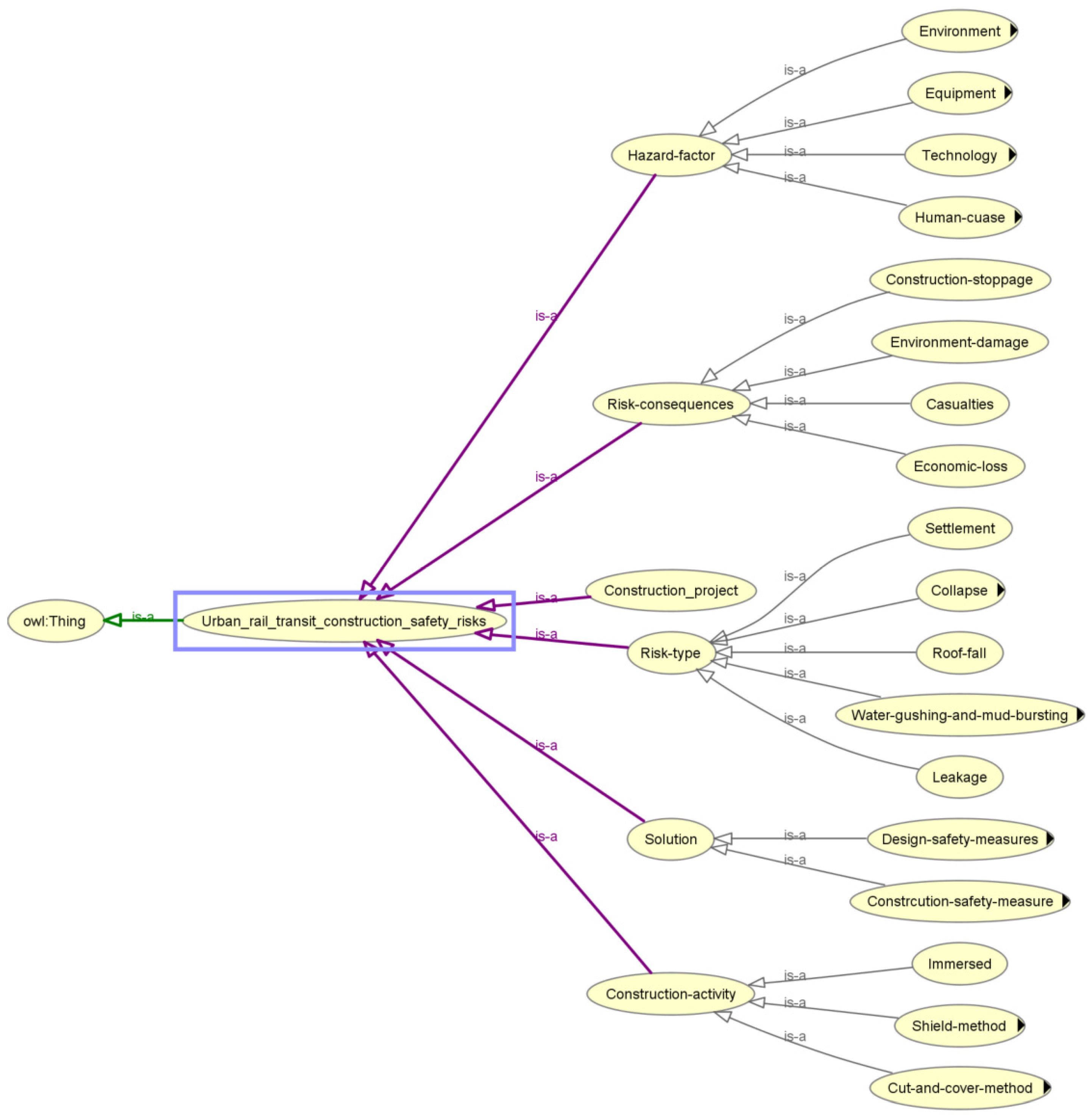
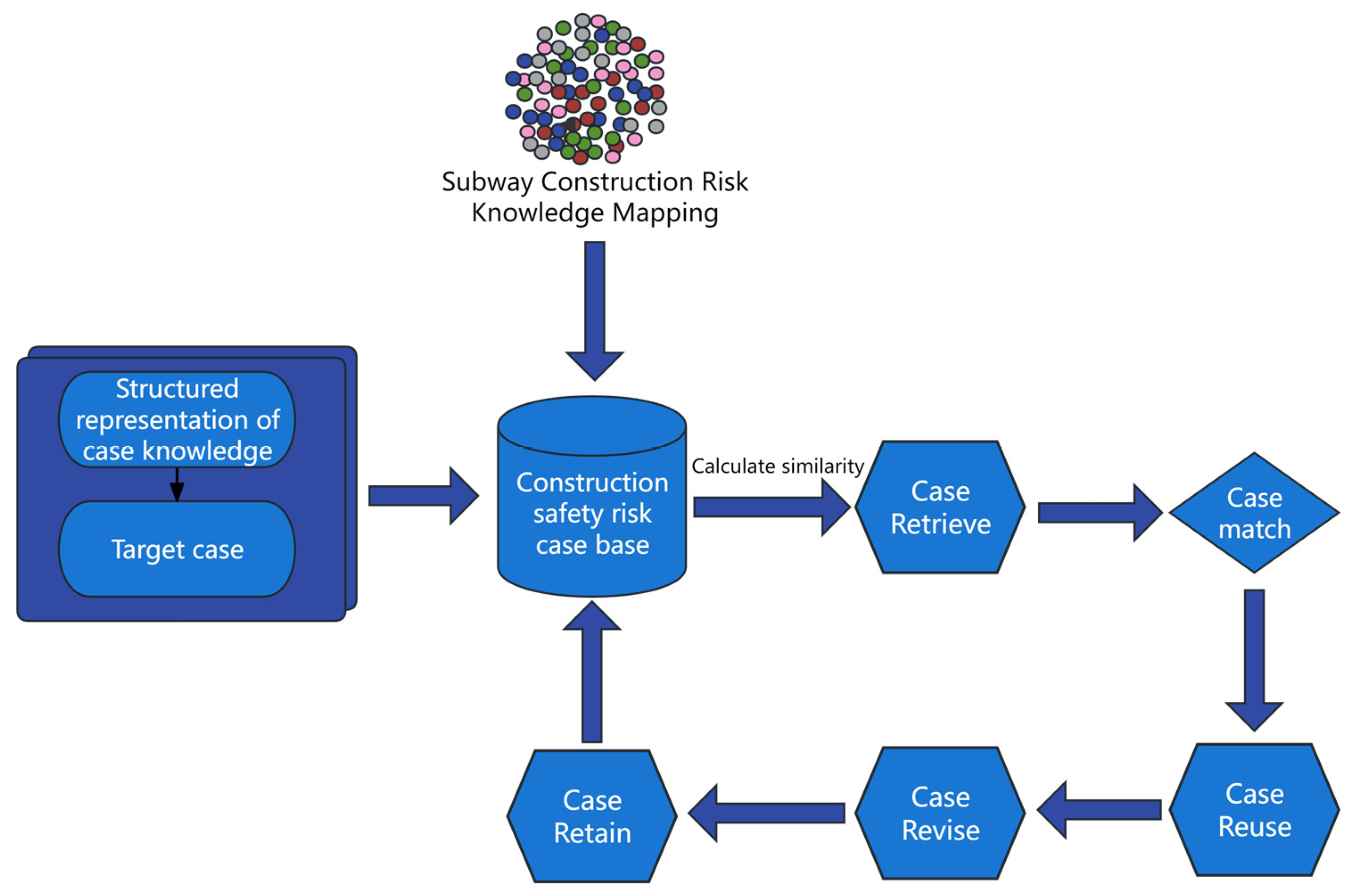

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}