
Knowledge Graph- and Bayesian Network-Based Intelligent Diagnosis of Highway Diseases: A Case Study on Maintenance in Xinjiang

Abstract
1. Introduction
2. Literature Review
3. Methodology
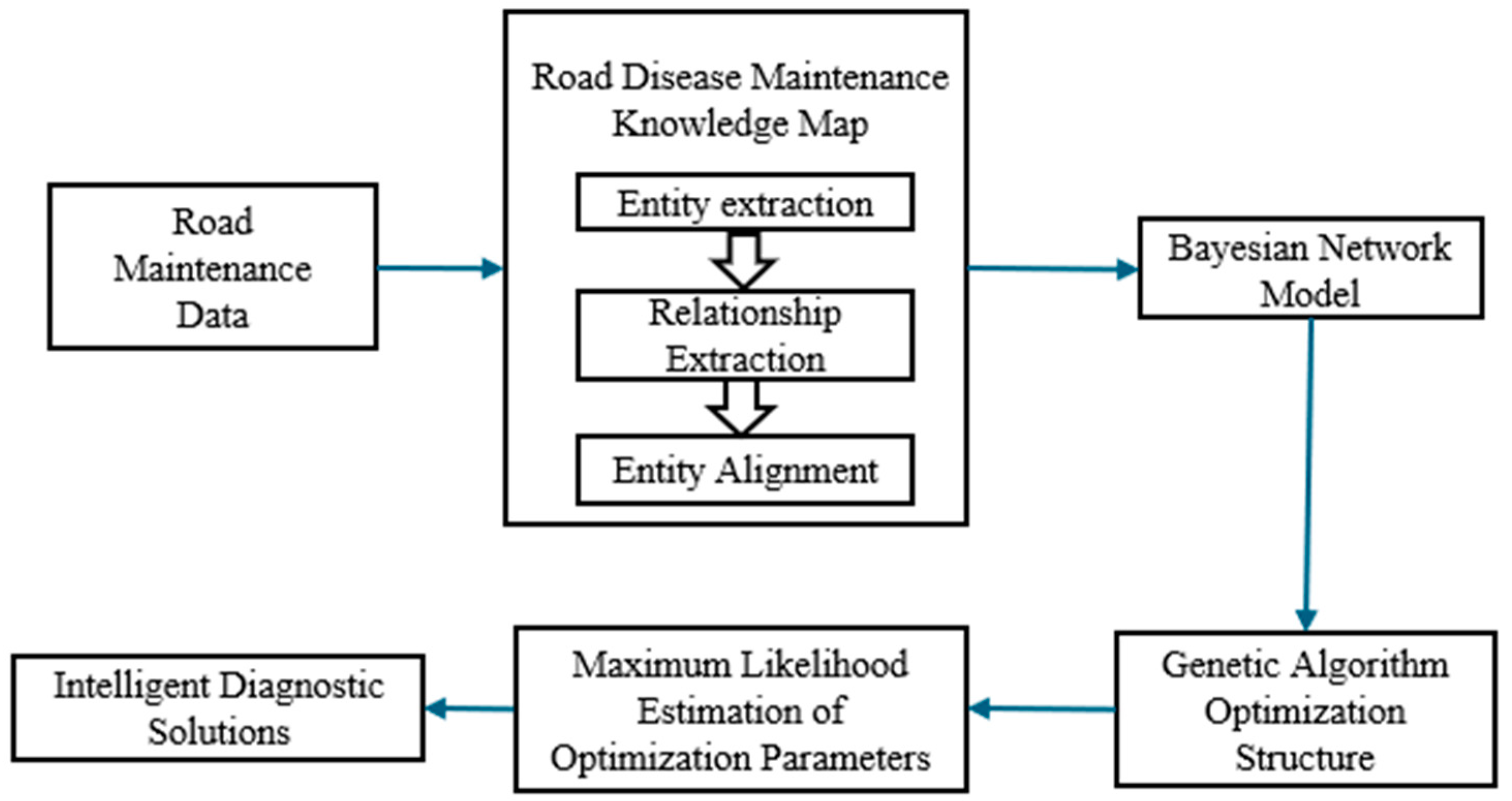
3.1. Highway Disease Diagnosis Method Based on Knowledge Graph and Bayesian Network
3.2. Construction of Knowledge Graph for Highway Disease Maintenance
- (1)
- Road Types: road categories such as highways, secondary roads, and local roads.
- (2)
- Highway Diseases: types of diseases affecting roads, including cracks, rutting, and potholes.
- (3)
- Geographical Locations: specific regions or cities, such as Urumqi or Karamay, where highway diseases have been observed.
- (4)
- Maintenance Methods: types of maintenance activities, such as resurfacing, crack sealing, and patching.
- (5)
- Time: the time frame during which diseases were identified or maintenance occurred.
- (1)
- Road Types: attributes like “Material”, “Design Life”, and “Construction Year”.
- (2)
- Highway Diseases: attributes like “Severity”, “Cause”, and “Affected Area”.
- (3)
- Maintenance Methods: attributes such as “Cost”, “Effectiveness”, and “Duration”.
3.3. Intelligent Diagnosis of Highway Diseases Based on Knowledge Graph
- (1)
- Intelligent diagnosis method
- (2)
- Model initialization guided by diagnostic knowledge
- (3)
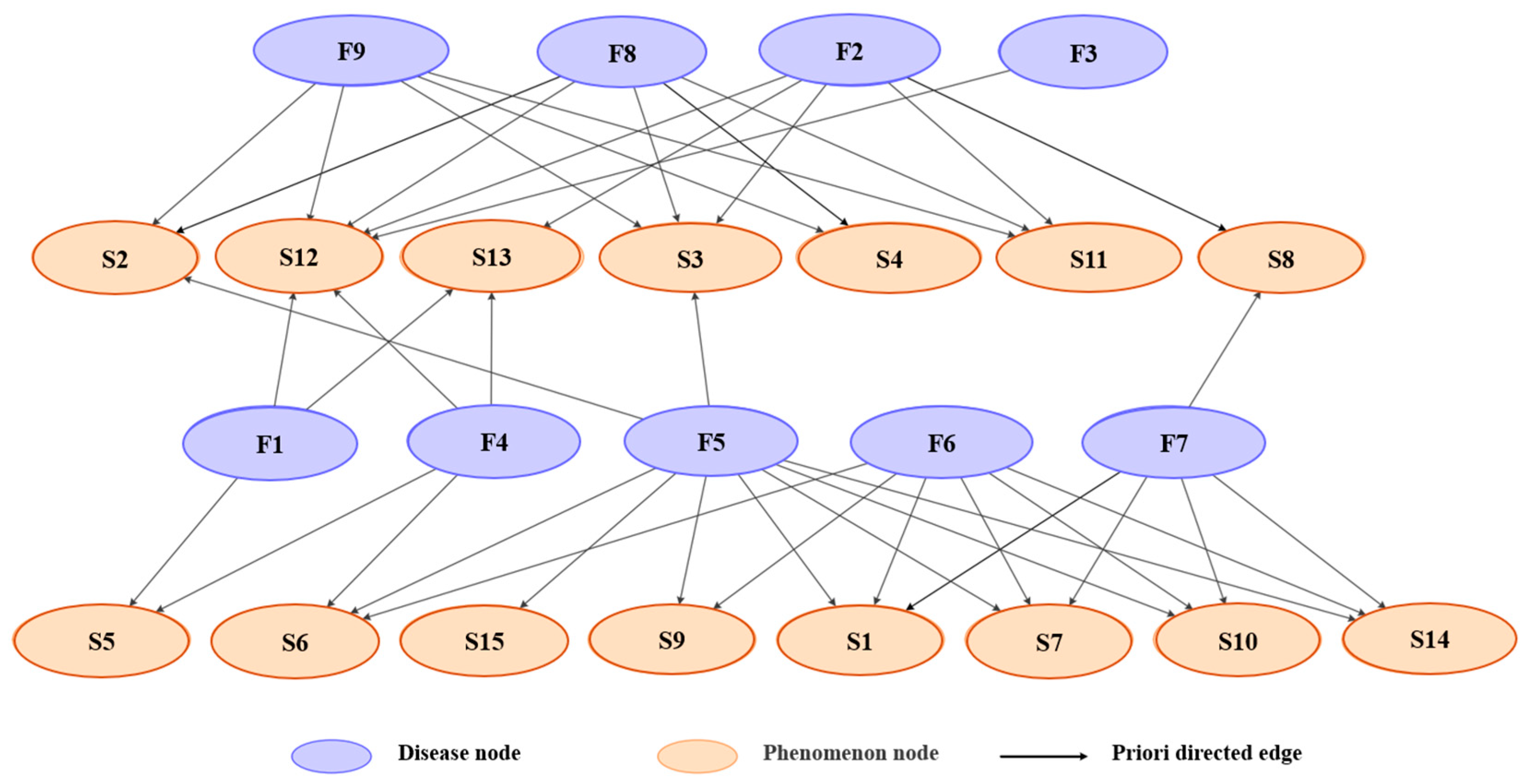
- Bayesian network expression based on expert experience
- (4)
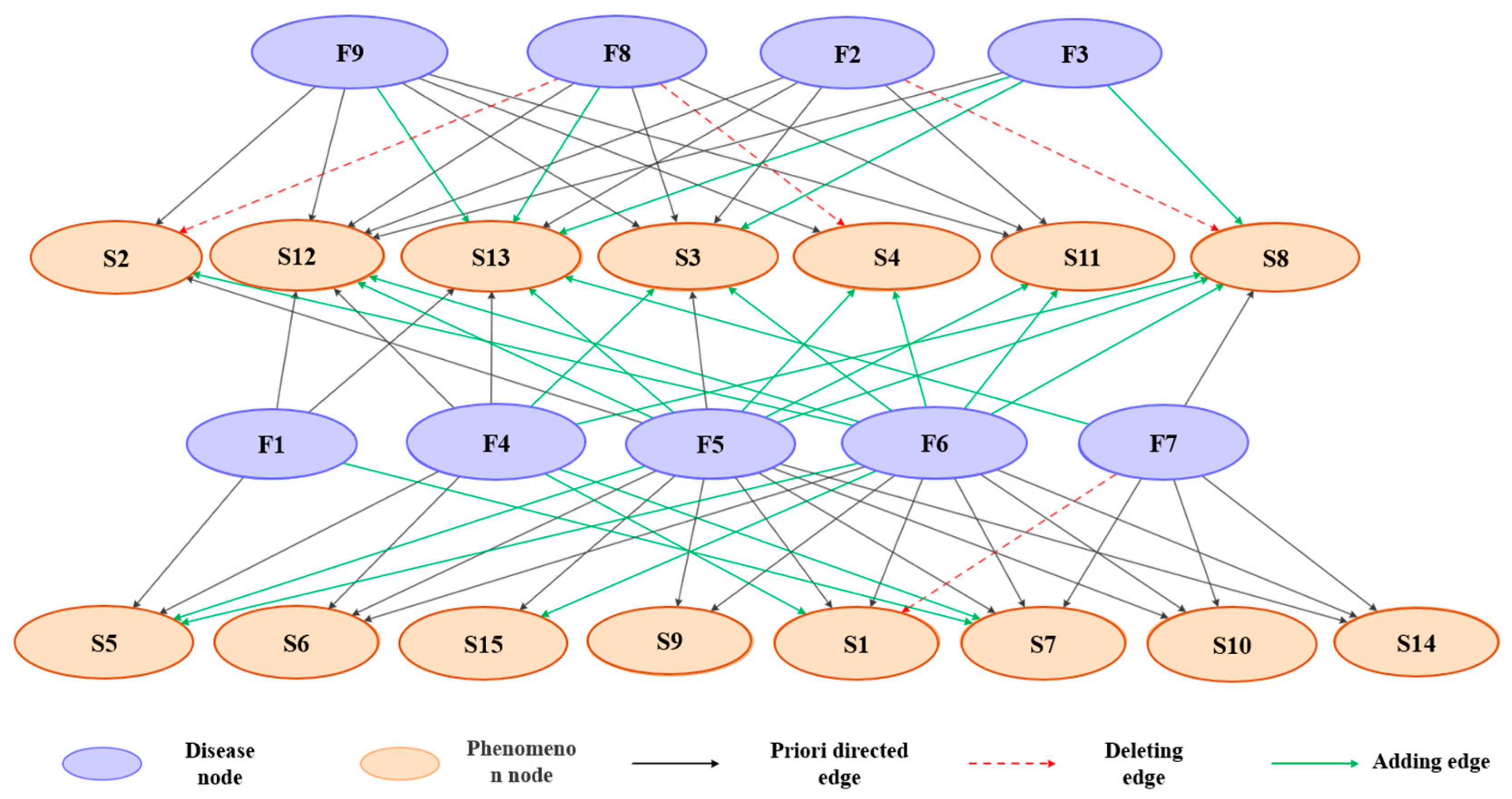
- Knowledge-guided and heuristic network structure optimization
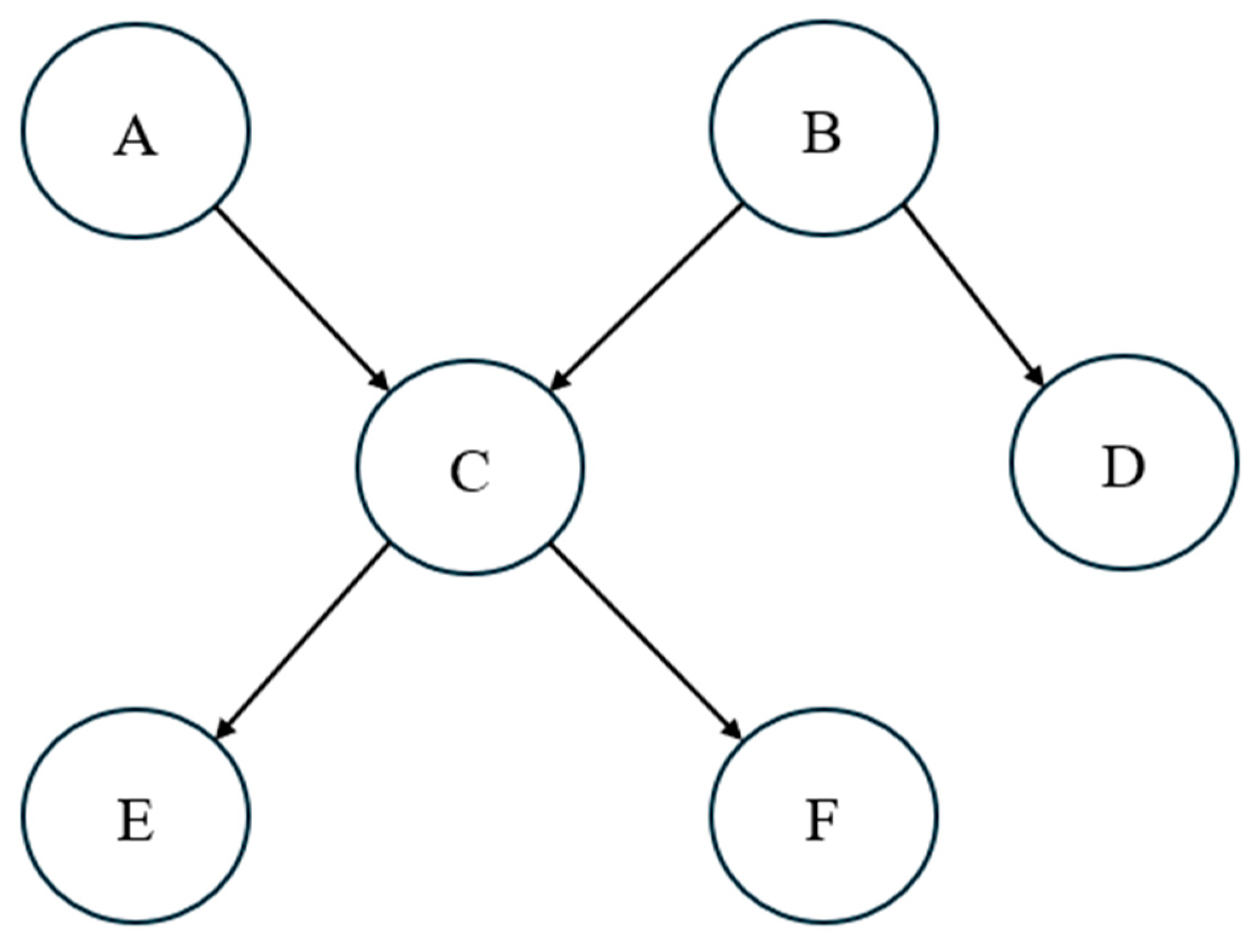
- Uncertain Relationship: if experts cannot clearly determine whether there is a causal relationship between two nodes and (i.e., ), then . In this case, the second term in the scoring function became 0, indicating that the result was entirely derived from data-driven statistics.
- Consistent Relationship: if the expert judgment aligns with the causal relationship between and (i.e., and or and ), then . In this case, the second term in the scoring function was positive. The closer and were to alignment, the larger the value of , resulting in a higher hybrid score.
- Inconsistent Relationship: if the expert judgment contradicts the causal relationship between and (i.e., and or and , then . In this scenario, the second term in the scoring function was negative. The greater the discrepancy between and was, the smaller the value of , resulting in a lower hybrid score.
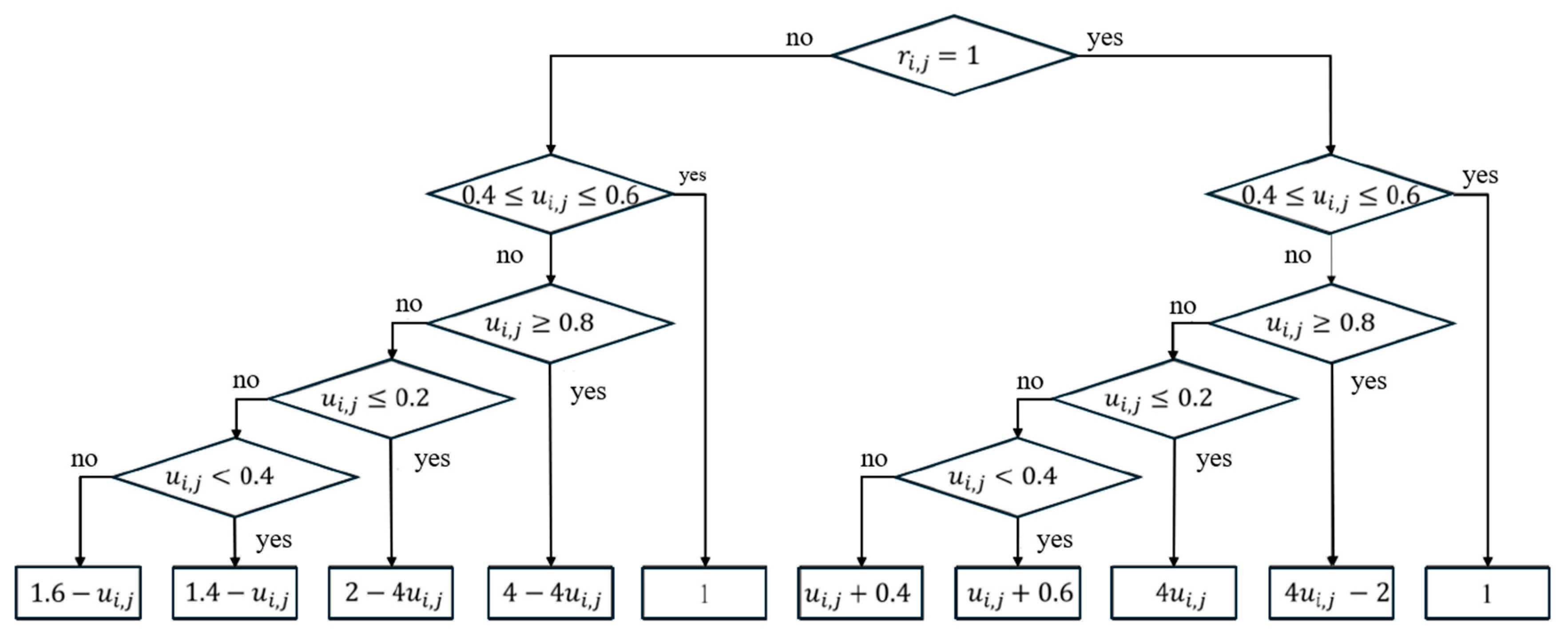
- Uncertain Expert Opinion: when experts cannot determine a connection between and (i.e., ), the mutation probability increases to generate a more diverse population for random selection.
- Expert Agreement: when experts agree on the connection between and (i.e., or ), the mutation probability decreases , enabling the local random search mechanism to accelerate convergence and find the optimal solution more efficiently. Particularly, as or , .where represents the base mutation probability.
- (5)
- Network parameter learning
- (6)
- Highway disease diagnosis, treatment plan, and interpretation
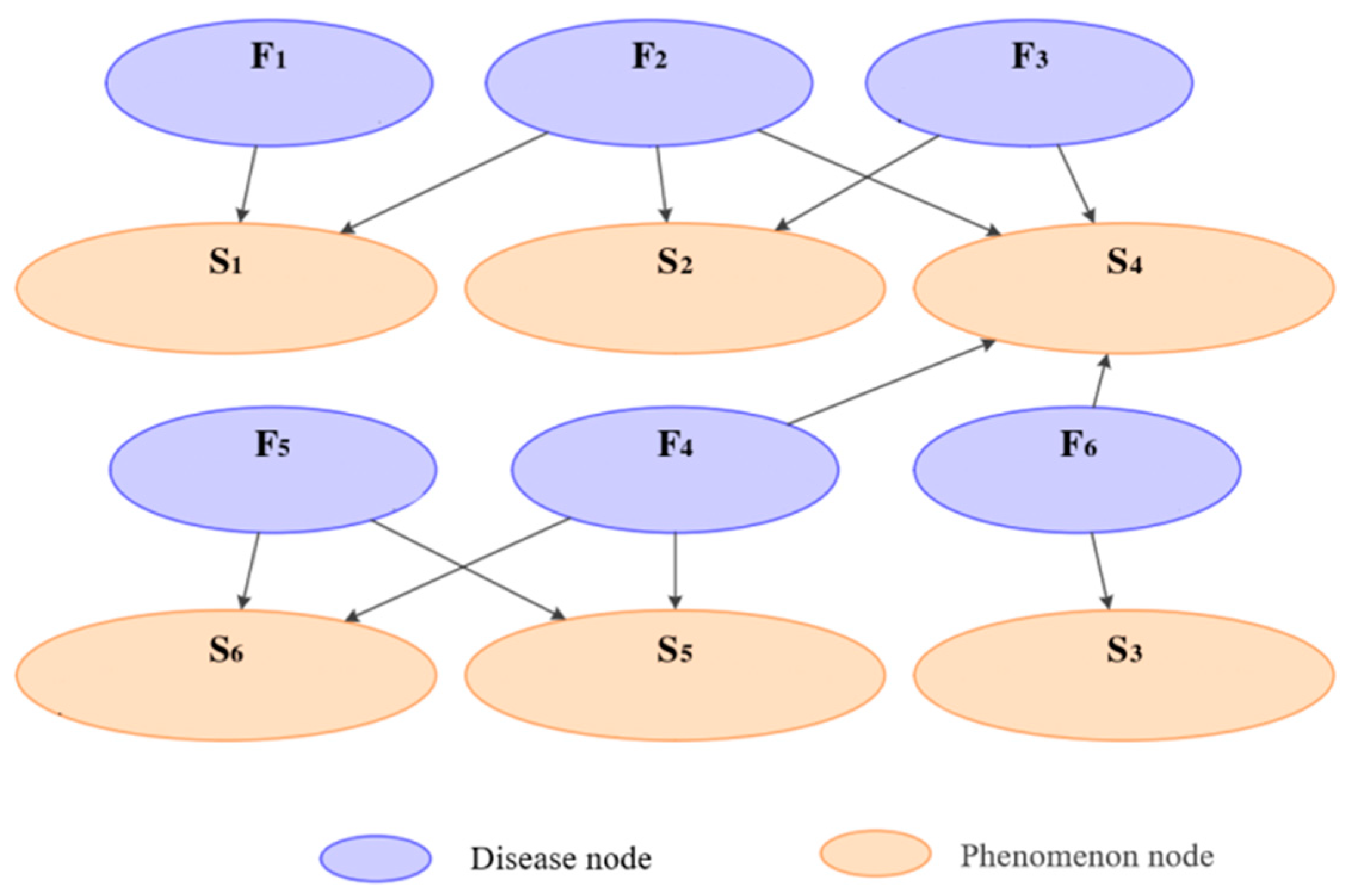
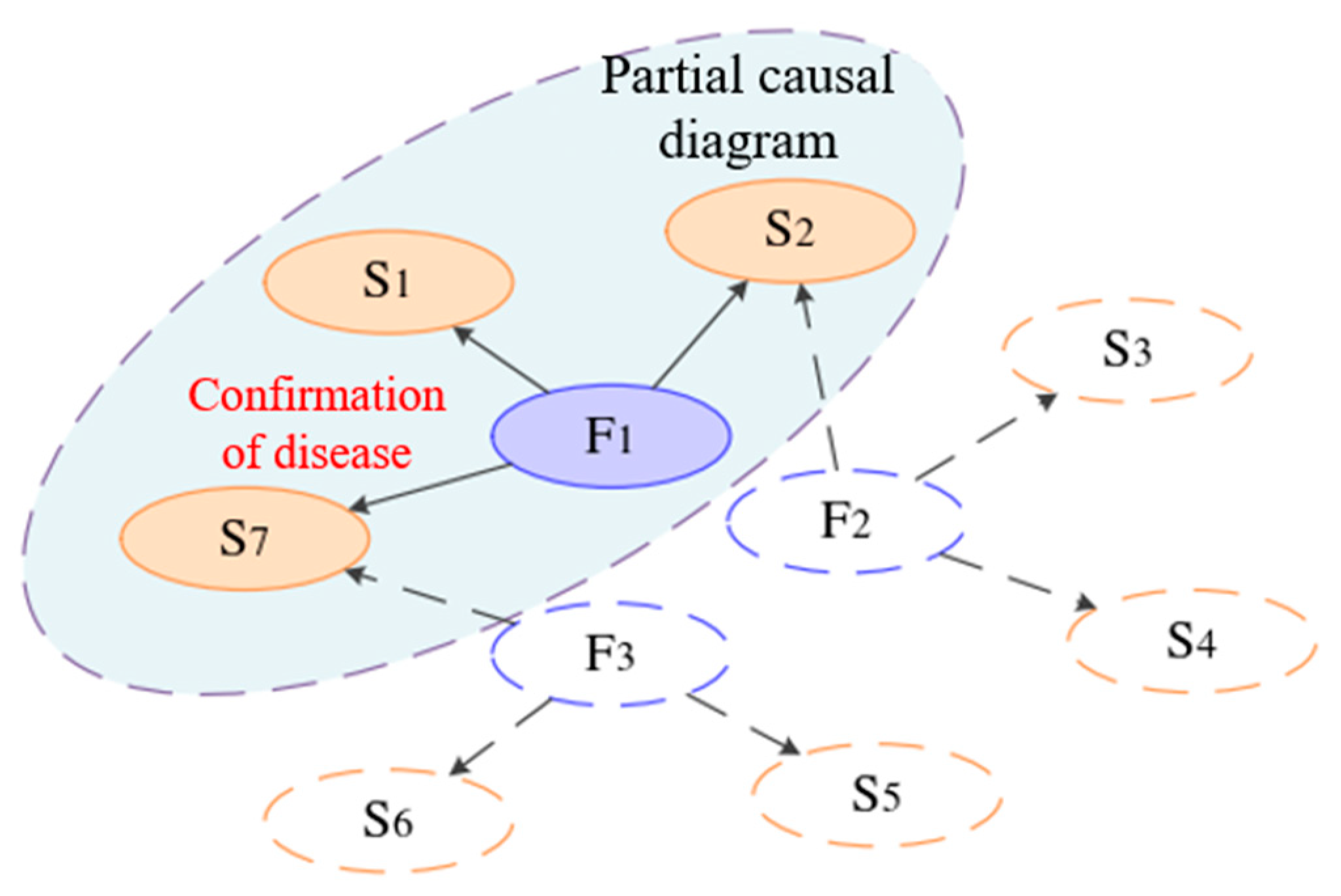
- Model Validation and Revision: Experts can analyze the reasoning path of causal relationships within the graph to determine whether the diagnosis is reasonable. Based on this analysis, they can make necessary adjustments to the model, as illustrated in Figure 6.
- Complex Disease Analysis: For highway diseases that are intricate and challenging to diagnose, the previously generated local causal graph can act as supplementary evidence. This graph aids experts in their research and judgment, offering insights into potential causes and solutions, as demonstrated in Figure 7.
4. Results
4.1. Experimental Setup
- Roadbed: G3012 line K1548+609-K1575+000 section to carry out cleaning debris, trimming shoulder slope weed operation, cleaning the central divider of debris and weeds, clearing the side ditch of silt, debris, and so on.
- Pavement: The road section of G3012 line K1548+609-K1575+000 adopted slotting irrigation sealing to deal with 23,728.54 m of cracks on the road surface (outsourcing), 237 square meters of cracks on the road surface (self-packing) by anti-cracking paste (self-maintained), and comprehensive treatment of pavement and other impacts on traffic safety of the diseases, according to the maintenance plan for the road surface cleaning operations.
- Facilities along roads: The guardrail end, round head reflective film renewal and replacement, and timely repair of damage, deformation, and rub along the facilities. Supplement the missing guardrail bolts every month. Clean the guardrail plate once a month. Keep the implementation along the demonstration road intact and flush the traffic signboards twice a year.
- Bridge and culvert: Two fixed inspection reports about root shaking pinch, focusing on the disease of superstructure in one large bridge and two medium bridges. Culvert dredging of 106.5 cubic meters, to ensure the technically good condition of bridges and culverts.
4.2. Experimental Results
4.3. Example Analysis of Results
- 1.
- Disease Detection Rule: if the posterior probability of a node representing a disease being in a “no disease” state is less than or equal to 30%, it is detected that a disease has occurred at this node, even though the specific disease type may remain undetermined.
- 2.
- Disease Diagnosis Rule: if the posterior probability of a node representing a disease being in a particular disease state is greater than or equal to 70%, the disease at this node is confirmed and its type is identified through probabilistic reasoning.To quantitatively evaluate the effectiveness of highway disease diagnosis, three indicators were introduced:
- 3.
- Detection Rate (DET): indicates the ability to detect the type of disease.
- 4.
- Diagnosis Rate (DIA): measures the ability to detect the severity or state of the disease.
- 5.
- False Alarm Rate (ERR): represents cases where a disease is falsely detected at a node.
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ding, J. The Development Situation and Suggestions of Comprehensive Transportation in China in the New Era. J. Chongqing Jiaotong Univ. Soc. Sci. Ed. 2024, 24, 55–62+112. (In Chinese) [Google Scholar]
- Lakusic, S. Increasing life expectancy of road pavements. J. Croat. Assoc. Civ. Eng. 2020, 72, 515–522. (In Chinese) [Google Scholar] [CrossRef]
- Tuzhang Ming, X.Y.; Hu, G.; Wang, H. Research on the Mechanism of Pavement Diseases and Treatment Measures of Nanjing Airport Expressway. J. China Foreign Highw. 2007, 27, 59–61. (In Chinese) [Google Scholar]
- Ye, Q. Research on the Treatment Technology of Tunnel Pavement Diseases of Operating Expressway. Eng. Technol. Res. 2018, 16, 54–55+63. [Google Scholar]
- Zhang, J.; Liu, L.; Yang, H. An overview of intelligent construction and maintenance technology for highway subgrade engineering. Intell. Transp. Infrastruct. 2023, 2, liad019. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, Y. Evaluation Method of Traffic Safety Maintenance of High-Grade Highway. Appl. Math. Nonlinear Sci. 2021, 6, 65–80. [Google Scholar] [CrossRef]
- Fallah-Fini, S.; Rahmandad, H.; Triantis, K.; de la Garza, J.M. Optimizing highway maintenance operations: Dynamic considerations. Syst. Dyn. Rev. 2010, 26, 216–238. [Google Scholar] [CrossRef]
- Yang, Z. Analysis on the Causes and Prevention Technologies of Typical Pavement Diseases of Expressway. West. China Commun. Sci. Technol. 2018, 7, 71–73+86. (In Chinese) [Google Scholar]
- Yang, P. Evaluation of Highway Maintenance Machinery Configuration Based on Fuzzy Comprehensive Evaluation Method. In Proceedings of the 2nd International Conference on Mechatronics and Intelligent Materials (MIM 2012), Guilin, China, 18–19 May 2012; pp. 319–324. [Google Scholar]
- Neves, L.C.; Frangopol, D.M. Condition, safety and cost profiles for deteriorating structures with emphasis on bridges. Reliab. Eng. Syst. Saf. 2005, 89, 185–198. [Google Scholar] [CrossRef]
- Hudson, W.R.; Haas, R. Future directions and need for innovation in pavement management. In Proceedings of the Third International Conference on Managing Pavements, San Antonio, TX, USA, 22–26 May 1994; National Academy Press: Washington, DC, USA; pp. 122–130. [Google Scholar]
- Söderlund, J. On the broadening scope of the research on projects: A review and a model for analysis. Int. J. Proj. Manag. 2004, 22, 655–667. [Google Scholar] [CrossRef]
- Finn, F.; Peterson, D.; Kulkarni, R. National Cooperative Highway Research Program Final Report. In AASHTO Guidelines for Pavement Management Systems; American Association of State Highway and Transportation Officials: Washington, DC, USA, 1990; pp. 20–27. [Google Scholar]
- Hall, K.T.; Lee, Y.H.; Darter, M.I.; Lippert, D.L. Forecasting pavement rehabilitation needs for Illinois interstate highway system. In Transportation Research Record 1455; National Academy Press: Washington, DC, USA, 1994; pp. 116–122. [Google Scholar]
- Wu, T. Application of Comprehensive Geophysical Prospecting Technology in the Detection of Highway Subgrade Diseases. Commun. Sci. Technol. Heilongjiang 2018, 7, 4–5. (In Chinese) [Google Scholar]
- Aimin Sha, R.C.; Gao, J.; Zheng, T.; Li, S. Highway Subgrade Disease Recognition Based on Cascade Convolutional Neural Network. J. Chang. Univ. Nat. Sci. Ed. 2019, 39, 1–9. (In Chinese) [Google Scholar]
- Xiao, G.J.W.; Wang, D. Research on the Accurate Diagnosis Technology of Expressway Diseases in Coastal Areas. Tianjin Constr. Sci. Technol. 2015, 25, 62–64. (In Chinese) [Google Scholar]
- Yihui, H.L.X.; Banghua, X. Application Research on Highway Maintenance Construction Safety Intelligent Supervision System Based on Internet of Things. Highway 2019, 64, 282–285. (In Chinese) [Google Scholar]
- Ran, X. Research and Analysis on Preventive Maintenance of Expressway Asphalt Pavement. Hous. Real Estate 2018, 34, 240. (In Chinese) [Google Scholar]
- Su, H.D.R.; Han, D.; Wang, X.; Yu, J. Research on the Collection, Classification and Storage of Road Maintenance Big Data. J. Highw. Transp. Res. Dev. Appl. Technol. Ed. 2019, 15, 256–259. (In Chinese) [Google Scholar]
- Pearl, J. Fusion, Propagation and Structuring in Belief Networks. Artif. Intell. 1986, 29, 241–288. [Google Scholar] [CrossRef]
- Herroelen, W.; Leus, R. Project scheduling under uncertainty: Survey and research potentials. Eur. J. Oper. Res. 2005, 165, 289–306. [Google Scholar] [CrossRef]
- Katipamula, S.; Brambley, M.R. Methods for fault detection, diagnostics, and prognostics for building systems—A review, part I. HVAC&R Res. 2005, 11, 3–25. [Google Scholar]
- Lou, C.; Li, X.; Atoui, M.A. Bayesian network based on an adaptive threshold scheme for fault detection and classification. Ind. Eng. Chem. Res. 2020, 59, 15155–15164. [Google Scholar] [CrossRef]
- Madsen, A.L.; Søndberg-Jeppesen, N.; Sayed, M.S.; Peschl, M.; Lohse, N. Applying object-oriented bayesian networks for smart diagnosis and health monitoring at both component and factory level. In Advances in Artificial Intelligence: From Theory to Practice: 30th International Conference on Industrial Engineering and Other Applications of Applied Intelligent Systems, IEA/AIE 2017, Arras, France, 27–30 June 2017, Proceedings, Part II; Springer: Cham, Switzerland, 2017; pp. 132–141. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Highway Diseases |
|---|---|
| Entity Quantity | 739 |
| Quantity of Relationships | 51 |
| Quantity of Attribute Types | 28 |
| Serial Number | Highway Disease Name | Degree of Highway Disease |
|---|---|---|
| F1 | Collapse | Slight, Medium, Severe |
| F2 | Landslide | Small, Medium, Large |
| F3 | Subsidence | Deep, Shallow |
| F4 | Rutting | Deep, Shallow |
| F5 | Pushing up | Small Height Difference, Large Height Difference |
| F6 | Frost boiling | None, Not Obvious, Relatively Obvious, Obvious |
| F7 | Pothole | Deep, Shallow |
| F8 | Block cracking | Large Block Size, Small Block Size |
| F9 | Edge failure | Large Width, Small Width |
| Serial Number | Highway Disease Phenomenon Name | State of Highway Disease Phenomenon |
|---|---|---|
| S1 | Lithology | Extremely Soft, Soft, Sub-Hard, Hard |
| S2 | Gradient of Slope | <15°, 15–20°, 20–45°, >45° |
| S3 | Height of Slope | <10 m, 10–30 m, 30–60 m, >60 m |
| S4 | Occurrence of Structural Plane | Along Slope Direction, Oblique Intersection, Transverse Intersection, Against Slope Direction |
| S5 | Connectivity of Structural Plane | Good, Relatively Good, Fair, Poor |
| S6 | Filling Characteristics | Good, Relatively Poor, Poor |
| S7 | Weak Bottom Layer | None, Poor Water Content in Interlayer, Half Water Content in Interlayer, Rich Water Content in Interlayer |
| S8 | Ground Crack | None, Not Obvious, Relatively Obvious, Very Obvious |
| S9 | Rear Edge Fissure | Underdeveloped, Closed, Relatively Developed, Obvious |
| S10 | Boundary Condition | None, Not Obvious, Slight, Clear |
| S11 | Groundwater Level | Lower Than Subgrade Toe, Lower than One-Third of Subgrade Height, Lower than Subgrade Top Surface, Higher than Subgrade Top Surface |
| S12 | Soil Property | Sandy Gravel Soil, Cohesive Soil, Silty Soil, Soft Soil |
| S13 | Filling Height | <2 m, 2–5 m, 5–10 m, >10 m |
| S14 | Subsidence Depth | <30 mm, 30–50 mm, 50–100 mm, >100 mm |
| S15 | Subsidence Length | <5 m, 5–10 m, 10–20 m, >20 m |
| Method | DET | DIA | ERR |
|---|---|---|---|
| Traditional Bayesian Network | 92.69% | 92.53% | 0.75% |
| Knowledge-Guided and Heuristic Bayesian Network | 95.17% | 95.53% | 0.72% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wubuli, A.; Li, F.; Zhou, C.; Zhang, L.; Jiang, J. Knowledge Graph- and Bayesian Network-Based Intelligent Diagnosis of Highway Diseases: A Case Study on Maintenance in Xinjiang. Sustainability 2025, 17, 1450. https://doi.org/10.3390/su17041450
Wubuli A, Li F, Zhou C, Zhang L, Jiang J. Knowledge Graph- and Bayesian Network-Based Intelligent Diagnosis of Highway Diseases: A Case Study on Maintenance in Xinjiang. Sustainability. 2025; 17(4):1450. https://doi.org/10.3390/su17041450
Chicago/Turabian StyleWubuli, Abulimiti, Fangfang Li, Chenxi Zhou, Lingling Zhang, and Jiaru Jiang. 2025. "Knowledge Graph- and Bayesian Network-Based Intelligent Diagnosis of Highway Diseases: A Case Study on Maintenance in Xinjiang" Sustainability 17, no. 4: 1450. https://doi.org/10.3390/su17041450
APA StyleWubuli, A., Li, F., Zhou, C., Zhang, L., & Jiang, J. (2025). Knowledge Graph- and Bayesian Network-Based Intelligent Diagnosis of Highway Diseases: A Case Study on Maintenance in Xinjiang. Sustainability, 17(4), 1450. https://doi.org/10.3390/su17041450