Abstract
Enterprises engaged in transnational operations are confronted with increasingly complex environmental policies and compliance challenges. A critical hurdle to achieving sustainable development lies in rapidly and accurately extracting environmental protection requirements from vast volumes of policy. To address this, our study introduces an automated framework for knowledge graph construction, termed iteration–extraction–optimization (IEO), driven by a large language model (LLM). Diverging from conventional linear extraction methods, the IEO framework employs an iterative enhancement process to progressively build and refine a policy knowledge network, capturing the intricate relationships among legislation, institutions, and environmental obligations. As a case study, we applied the framework to Niger’s environmental policy, constructing a large-scale knowledge graph with 61,912 entities and 81,389 relations. Preliminary evaluations demonstrate the framework’s high performance in knowledge capture completeness, achieving a recall of 0.93 and an F1-score of 0.84. This research presents a novel paradigm for the intelligent parsing of environmental policy texts, providing a knowledge graph that serves as a vital decision-support tool for corporate environmental risk management and strategic sustainability planning.
1. Introduction
With the deepening of the Belt and Road Initiative (BRI), China’s infrastructure and energy investments in participating countries have steadily increased [1,2]. However, while these transnational projects foster economic growth, they simultaneously face substantial compliance challenges arising from the complex environmental regulations of host nations [2,3]. Consequently, the Chinese government has underscored the importance of a “Green Belt and Road”, prioritizing environmental risk management in overseas investment decisions [4]. In this context, the ability to rapidly and accurately automate the analysis of national environmental policy systems has emerged as a critical imperative for ensuring project success and promoting sustainable development [1,5].
Although individual policy documents are updated at a relatively low frequency, environmental policy systems themselves are both complex and dynamic [6]. They span multiple hierarchical levels—including international conventions, national laws, ministerial regulations, and local ordinances—with intricate relationships of citation, amendment, and repeal that together form a large-scale policy network [7]. Environmental policy also intertwines tightly with domains such as energy, trade, investment, and technology; changes in a single policy can trigger cascading effects [8]. As a result, enterprises must continuously track these interactions and evolutions across documents and levels. In the practice of the Belt and Road Initiative, enterprises urgently require an intelligent tool capable of rapidly, accurately, and comprehensively parsing a host country’s environmental policy system to support investment decision-making, risk assessment, and compliance management.
Knowledge graphs (KGs), as a powerful technology for integrating unstructured information into semantic networks, offer a viable approach for the systematic analysis of policy frameworks [9,10]. In recent years, KGs have demonstrated significant value in the energy and environmental sectors, primarily in applications such as knowledge management, decision support, and risk analysis. For instance, researchers have employed KGs to model complex energy systems in smart cities [11] and combined them with large language models to capture dynamic industrial energy consumption data [12]. In environmental governance, KGs have been similarly utilized to construct “environment–policy–enterprise” relational graph for predicting policy impacts [13] and to extract knowledge from scientific literature to enhance public understanding of climate change [14]. These studies highlight the potential of KGs to integrate, correlate, and present complex environmental information.
Despite its promising applications, constructing a high-quality, domain-specific knowledge graph remains a formidable task. Traditional approaches often rely on labor-intensive manual annotation or brittle rule-based matching [15,16,17,18]. When processing texts characterized by high complexity, dynamism—such as the environmental policies of countries along the Belt and Road—these methods face several challenges: first, the strong domain specificity and terminology density of policy texts demand expert annotation, which is costly and inefficient; second, the diversity of expression means that the same concept may appear in many forms, making rule-based extraction difficult to generalize across paraphrases; third, conventional pipelines typically process documents in isolation and thus fail to capture complex inter-policy relationships, leading to fragmented knowledge. In practical BRI projects, enterprises are encountering increasingly severe environmental compliance challenges. The high cost and poor scalability of traditional methods make them ill-suited for large-scale, dynamic policy analysis [19,20]. This has become a bottleneck hindering the widespread adoption of domain-specific knowledge graphs. Therefore, there is both academic significance and urgent practical need for tools that can automatically and intelligently parse complex environmental policy systems.
Fortunately, the advent of large language models (LLMs) has brought new opportunities for intelligent applications in the environmental, energy, and building sectors. Egbemhenghe [21] explored the application of ChatGPT(GPT 3.5/4) in addressing the global water crisis, emphasizing its benefits in water resource management, predictive maintenance, and ethical considerations while highlighting the necessity of responsible AI governance. In the field of building design, generative AI has been demonstrated to improve building design [22]. Additionally, research comparing the performance of GPT in public building energy management has validated the effectiveness of LLMs in professional domain applications [23]. These studies demonstrate the capability of LLMs in handling complex professional texts, providing theoretical support for automated knowledge graph construction [15,24,25]. With their powerful semantic understanding and few-shot/zero-shot learning capabilities, LLMs present a novel opportunity to overcome the limitations of traditional methods [26,27]. From an environmental informatics perspective, a KG–LLM synergy is emerging: LLMs distill key points from complex policy and technical texts, while knowledge graphs provide structured representation and traceable links, together supporting policy clause parsing, cross-document linkage, and decision-oriented retrieval and analysis. Currently, most research on constructing knowledge graphs with LLM adheres to a paradigm that can be termed “one-pass extraction”. This paradigm typically decomposes the knowledge graph construction task into a linear, single-run pipeline, beginning with named entity recognition followed by relation extraction [26,28]. Many state-of-the-art automated construction frameworks, such as AutoKG [29], Graphusion [30], and EDC [31], although varying in their specific implementations, fundamentally operate within this paradigm.
However, we contend that this “one-pass extraction” paradigm may face two bottlenecks when applied to corpora with high domain specificity and textual complexity, such as environmental policies: First, the lack of contextual dependency leads to knowledge fragmentation; by processing each text chunk independently, this approach fails to effectively leverage global document information, resulting in an inadequate understanding of complex, cross-chunk semantic relationships. Second, error accumulation and propagation are prevalent; any errors generated in the initial extraction stages (e.g., incorrect entity boundary detection or relation misjudgment) become solidified and cascade through subsequent processes, potentially compromising the accuracy of the final knowledge graph. While reinforced prompt learning can improve the quality of a single extraction run, it is typically constrained by fixed context windows and one-shot decisions at the document level, limiting its ability to resolve cross-document dependencies and error propagation.
To explore a potential path to overcome these challenges, we introduce the iteration–extraction–optimization (IEO) framework, a novel, LLM-driven paradigm designed for constructing complex, domain-specific knowledge graphs. The core idea of IEO is to transform the construction of a knowledge graph from a static, “single-pass” process into a dynamic, “iterative and progressive enhancement” process. At the process level, IEO introduces “accumulable context + iterative optimization,” which complements prompt learning and yields benefits in cross-document and long-range dependency scenarios. Through an iterative knowledge augmentation mechanism, the framework feeds previously extracted knowledge back into the current step as contextual background, systematically addressing the problems of missing context and error accumulation. In terms of specific approaches, AutoKG centers on a lightweight “keyword–undirected weighted edge” graphs with hybrid retrieval, emphasizing retrieval/reasoning en-hancement rather than full triplet extraction with cross-iteration memory; Graphusion follows a “seed entities → candidate triplets → global fusion” pipeline that performs one-time integration with a focus on entity merging and conflict resolution; and EDC adopts an “extract–define–normalize” process (with retriever refinement) to achieve post hoc schema alignment and standardization. IEO is complementary to these methods: beyond iteration, it injects accumulable global/local background and density-aware context during extraction, enabling in situ error correction and progressively strengthening cross-document consistency and long-range dependency modeling.
The main contributions of this study are as follows: First, we propose and preliminarily validate the IEO framework, which offers a new approach for the automated construction of high-quality, domain-specific knowledge graphs through iterative processing, a three-phase extraction process, and a two-phase optimization process. Second, we design a density-based context perception (DBCP) mechanism that utilizes a density peak clustering algorithm to build a semantic hierarchical network, selecting highly relevant text chunks as contextual supplements to mitigate knowledge fragmentation in complex texts. Third, through comprehensive experiments on a dataset of environmental policies, we empirically evaluate the effectiveness of the IEO framework, demonstrating its value in the initial construction phase of knowledge graphs in the environmental policy domain. Fourth, we demonstrate the practical application potential of the constructed knowledge graph in policy network analysis, risk path tracing, and intelligent knowledge retrieval. In the remainder of this article, we will detail the IEO framework, present the experimental design and results analysis, and discuss the implications of our research.
2. Methods
This section elaborates on the core methodology we propose: an iterative knowledge graph construction framework driven by LLM. We name it the iteration–extraction–optimization (IEO) framework. Through a synergistic mechanism of iterative processing, three-phase extraction, and two-phase optimization, the framework aims to automatically construct a knowledge graph from vast, complex, and unstructured environmental policy texts.
2.1. IEO Framework: Iterative Knowledge-Augmented Construction
Traditional knowledge graph construction methods, such as one-pass extraction, face challenges with insufficient contextual dependency and error accumulation when processing complex, domain-specific texts. One-pass extraction handles each text chunk independently, failing to leverage information from the entire dataset. This leads to an inadequate resolution of complex semantic relationships and contextual dependencies that span across text chunks. Concurrently, errors generated during the extraction process are directly solidified and propagated into the final knowledge graph, severely compromising its accuracy.
To overcome these limitations, we designed the IEO framework. Its core concept is to shift the knowledge graph construction process from a “one-pass” task to a dynamic, iterative, and progressive enhancement process. The framework preprocesses unstructured text into an ordered sequence of text chunks . For each chunk in the sequence, the IEO framework does not process it in isolation. Instead, the extraction process is doubly enhanced with two sources of background knowledge: semantically related contextual information from text chunks pre-selected by the density-based context perception (DBCP) mechanism (see Section 2.2.1), and contextual information from a subgraph constructed from the previously generated triples . This process can be formally expressed as follows:
where , and represents the cumulative pool of triples after processing the i-th text chunk. We clarify the operators and terms in Equations (1) and (2) as follows:
- : The three-phase extractor runs NER → relation extraction → validation on the current text chunk , with the background generated by Equations (2) injected into the prompts; the output is a set of candidate triples.
- : The two-phase optimizer performs structural cleaning and semantic normalization to produce a set of normalized triples.
- : A dynamic context is generated via density peak clustering, selecting associated text chunks by parent/child/sibling node types and their importance scores , where and are calculated by Equations (3) and (4), respectively.
- : A graph is constructed from historical triples ; the subgraph most relevant to the current entities serves as background.
This iterative process has three key characteristics:
- Dynamic Context Enhancement: When processing each new text chunk, the model can reference a dynamically generated background knowledge base, which facilitates a more comprehensive resolution of complex and long-distance relationships between entities.
- Early Error Correction: By performing immediate validation and optimization on newly generated triples in each iteration, local errors can be effectively identified and corrected. This prevents them from accumulating and amplifying during the construction process, thereby reducing the burden of global fusion for the final graph.
- Progressive Knowledge Discovery: As the background knowledge base grows, the framework can uncover deeper and more implicit entity relationships within the text, contributing to the construction of a more semantically coherent and consistent knowledge graph.
As illustrated in Figure 1, the IEO framework integrates two specially designed core components—a three-phase extractor and a two-phase optimizer—which work synergistically within the iterative process. The specific execution flow of the framework is as follows:
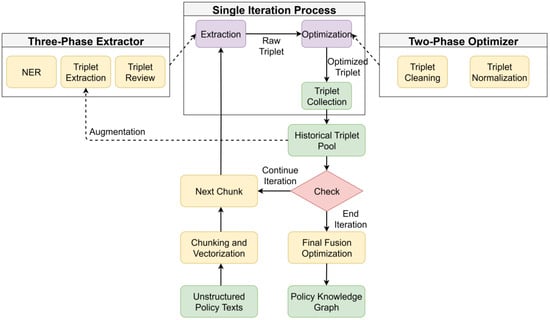
Figure 1.
IEO framework.
Phase 1: Text Serialization and Vectorization: The raw corpus is segmented into an ordered sequence of text chunks and then vectorized.
Phase 2: Iterative Extraction and Optimization: For each text chunk in the sequence, the following operations are performed:
- 1.
- Extraction: A set of candidate triples is generated from using the three-phase extractor, with the subgraph generated from historical triples and the associated text chunks selected by DBCP serving as background knowledge.
- 2.
- Optimization: The newly generated candidate triples are cleaned and normalized using the two-phase optimizer.
- 3.
- Knowledge Augmentation: The optimized triples are merged into the triple pool, updating it to .
Phase 3: Final Global Optimization: After all text chunks have been processed, a final global optimization is performed on the complete set of triples to resolve potential global redundancies and inconsistencies, thereby generating the final knowledge graph.
The IEO main loop processes text chunks in sequence, combining DBCP-selected context with the iterative subgraph for extraction and optimization. The overall time complexity is composed of semantic vector construction , where is the number of chunks and is the embedding cost; DBCP density/neighbor computation in the worst case ; three-phase extraction plus two-phase optimization , where is the number of context chunks per step; and hash-based deduplication approximately , where is the total number of final triples. The space complexity is about , where is the embedding dimension. With bounded and concurrency stable, the overall cost grows near-linearly with ; in the worst case, it degrades to .
2.2. IEO: Extraction Process
High-quality triplet extraction is the core of knowledge graph construction. To address the challenges of semantic complexity and knowledge sparsity in environmental policy texts, we have designed an extraction component consisting of a Density-Based Context Perception mechanism and a three-phase extraction pipeline. The triplet extraction process of the IEO framework is illustrated in Figure 2.
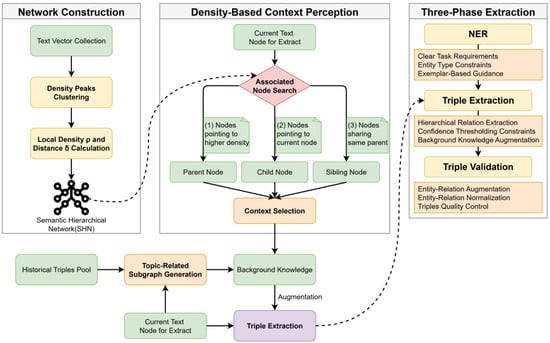
Figure 2.
Triplet extraction process of the IEO framework.
2.2.1. Density-Based Context Perception Mechanism
In LLM-driven knowledge extraction, the quality of the context directly determines the accuracy of the output. Environmental policy texts typically exhibit multi-layered semantic structures and cross-paragraph knowledge dependencies. Traditional fixed-window context construction methods, due to their inherent limitations, often lead to the loss of long-range semantic associations, resulting in knowledge fragmentation and relational rupture.
To address this issue, we propose a density-based context perception (DBCP) mechanism. The core idea of this mechanism is to first locate and construct an optimal, dynamic “set of associated text chunks” for a given text chunk within the semantic space of the entire corpus before processing it. We employ the density peak clustering (DPC) algorithm [32] to achieve this. DPC identifies cluster centers by calculating the local density for each data point (in this case, the vector representation of a text chunk) and its minimum distance to points of higher density. Its advantage lies in its ability to automatically discover non-spherical cluster structures and its robustness to noise, making it highly suitable for revealing complex semantic hierarchies among texts.
The implementation of this mechanism involves the following three steps:
- 1.
- Semantic Hierarchy Network Construction: We map all text chunks into a high-dimensional semantic space using an embedding model. Subsequently, we apply the DPC [32] algorithm to calculate the and for each text chunk and determine its “parent node,” , which is the nearest node with a higher density.
- 2.
- Associated Context Search: For the current text chunk node i to be processed, we define three types of associated nodes to construct context. The selection of these three node types is a direct product of the semantic hierarchy network structure built by the DPC, ensuring the logical relevance and hierarchical nature of the context:
Parent: . In the semantic hierarchy network constructed by DPC, the parent node is the higher-density “conceptual center” to which the current node semantically belongs. It can provide more general background information.
Children: . Child nodes are the set of nodes that are hierarchically subordinate to node . They can offer more detailed and specific supplementary information about node .
Siblings: . Sibling nodes share the same parent as the current node , meaning they are at the same level in the semantic hierarchy. Therefore, they can provide contextual information that is parallel, analogous, or comparable to the content of the current text chunk.
- 3.
- Context Assignment: After searching for associated nodes, we adopt a strategy that combines balanced allocation and importance ranking to select the final context. First, we determine the basic quota for each category based on the preset total number of contexts and the number of non-empty node categories . Within each category, nodes are arranged in descending order of their importance score , prioritizing key nodes in the network. This strategy ensures the diversity and quality of context sources, and a fallback mechanism (such as a cosine similarity supplement) is designed to handle isolated nodes and other special cases.
Through the DBCP mechanism, we provide relevant dynamic background knowledge for each text chunk extraction task, effectively overcoming the shortcomings of traditional methods in dealing with long-distance dependencies
2.2.2. Three-Phase Extraction Mechanism
To enhance the recall and precision of knowledge extracted from the text, we decompose the extraction task into a three-phase pipeline comprising Named Entity Recognition (NER), Triplet Extraction, and Triplet Review. Each phase is executed by a dedicated LLM call and uses the output of the previous phase as its input, achieving a progressive refinement of information. For each phase, we meticulously designed detailed prompts, leveraging Prompt Engineering to guide the LLM’s behavior and ensure it completes the specified tasks accurately and consistently.
- Phase 1: Named Entity Recognition (NER)
This phase aims to comprehensively capture all potential entities from the text. Through prompt engineering, we implement a multi-granularity, semi-open recognition strategy. The prompts not only guide the LLM to identify predefined core entity types (e.g., institution, law, technology) but also encourage it to discover new, domain-specific entity categories. Concurrently, we use rules and few-shot examples to steer the model in handling complex entities (such as the nested entity “Article 5 Environmental Protection Law” and composite entities like the structure “B of A”), thereby enhancing the accuracy of entity boundaries and the completeness of their semantics.
- 2.
- Phase 2: Triplet Extraction
The core task of this phase is to construct relationships between entities based on the entity list from the previous phase. We designed this as a hierarchical extraction process. The prompts guide the LLM to distinguish between three levels of relationships: direct relations (explicitly stated in the text), implicit relations (reasonably inferred from context), and attribute relations (describing the entity’s own characteristics). Notably, we introduced a confidence assessment mechanism, requiring the LLM to assign a confidence score to each extracted triplet. This provides a quantitative basis for subsequent triplet optimization and conflict resolution and may help mitigate model “hallucinations.” Concurrently, the background knowledge, composed of the context selected by the DBCP mechanism and historical triples, is injected at this phase to enhance the model’s ability to resolve complex, cross-textual relationships.
- 3.
- Phase 3: Triplet Review
This is the final quality control step in the extraction process. In this phase, the LLM acts as a “review expert.” The prompt design focuses on quality control, guiding the model to systematically validate and refine the set of candidate triples generated in the previous phase. This process primarily includes: completeness supplementation (checking against the original text to add missing key relationships), expression normalization (unifying the wording of relational terms), redundancy elimination (removing duplicate or semantically equivalent triples), and confidence score calibration. These steps help to improve the overall quality and consistency of the final output triple set.
This three-phase, progressive refinement mechanism decomposes the complex open information extraction task into a series of well-defined, focused subtasks. Through the synergistic action between phases, it aims to systematically enhance the quality of the final knowledge graph. IEO leverages prompt learning to strengthen the three-phase sub-tasks and to alleviate inherent limitations of single-pass prompting in cross-document scenarios, long-range dependencies, and error propagation. Figure 3 summarizes the core tasks and key prompt design points for each phase. The complete prompt templates are detailed in Supplementary Materials Tables S1–S3.
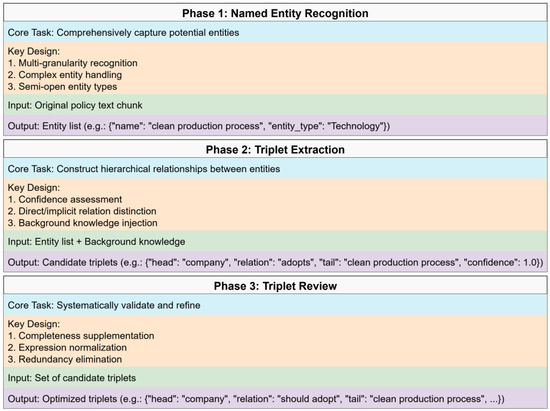
Figure 3.
Prompt design for the three-phase extraction.
2.3. IEO: Optimization Process
Raw triplets automatically extracted from large-scale text corpora inevitably contain noise, redundancy, and inconsistencies. To ensure the quality and usability of the final knowledge graph, we designed a systematic two-phase optimization process aimed at refining the extracted knowledge from the dimensions of both structural integrity and semantic consistency.
2.3.1. Phase 1: Triplet Cleaning
The core objective of this phase is to enhance the foundational structural quality of the knowledge graph by eliminating poorly formatted, uninformative, or structurally erroneous knowledge units through a series of filtering and standardization operations.
- Syntactic and Structural Filtering: This step aims to eliminate the most basic level of noise. We begin by standardizing the text of all triplet components (head, relation, tail), for instance, by removing excess leading/trailing whitespace and meaningless special characters. Subsequently, we identify and remove three types of structurally invalid triplets: null-value triplets (any element is empty), semantically void triplets (elements containing placeholders like “null” or “N/A”), and irrational self-loops (e.g., the head and tail entities are identical in a non-reflexive relationship).
- Confidence-based Filtering: Leveraging the confidence score assigned to each triplet during the extraction phase, we establish a configurable threshold. All triplets with a confidence score below this threshold are filtered out.
- Exact Deduplication: We detect and remove completely identical triplets by concatenating the text of the (head, relation, tail) of each triplet into a unique string identifier. This step is a coarse-grained cleaning process that only considers whether the textual representation of the triplets is identical, without regard to their deeper semantics (such as the specific entity types). When conflicts arise, the version with the highest confidence score is retained.
2.3.2. Phase 2: Triplet Normalization
After ensuring structural validity, this phase focuses on enhancing the semantic consistency and cohesion of the knowledge graph by addressing diverse expression styles and potential logical conflicts, making the knowledge graph more organized and reliable.
- 1.
- Relation Standardization: To resolve issues of synonymous or near-synonymous relationship expressions (e.g., “stipulates,” “requires,” “establishes”), we apply a set of predefined mapping rules to unify these varied expressions into a standardized set of relation predicates. This can enhance semantic coherence and query efficiency.
- 2.
- Conflict Detection and Resolution: We identify potential semantic conflicts by grouping by entity pair. For example, for the same entity pair , mutually exclusive triplets might exist, such as and . In such cases, we adopt a confidence-driven principle, automatically selecting the triplet with the highest confidence score as the final valid relation, thereby resolving internal logical contradictions.
- 3.
- Fine-grained Fusion: This step addresses deep semantic redundancies that “exact deduplication” cannot resolve. It merges semantically equivalent triplets by constructing a more stringent unique identifier that includes entity types (e.g., head name, head type, relation, tail name, tail type). This allows for the precise differentiation of homonymous but different-typed entities (e.g., distinguishing between “Apple” the company and “apple” the fruit), enabling more fine-grained knowledge fusion and ensuring the semantic consistency of the knowledge graph.
Through this hierarchical optimization mechanism, progressing from structure to semantics, we can systematically improve the quality of the initial extraction results, ultimately generating a more accurate, consistent, and reliable knowledge graph.
3. Case
We selected Niger’s environmental policy system as the case study for empirically evaluating the IEO framework based on two considerations. First, Niger combines a heavy dependence on resource extraction with ecological fragility: it is a major global exporter of uranium and oil, yet, located in the Sahel, it faces severe pressures including desertification, water scarcity, and biodiversity loss. This intrinsic tension between development and protection makes Niger an instructive sample for testing IEO; a deep, structured analysis can provide critical risk-management and compliance guidance for investors such as Chinese enterprises and offers lessons for other resource-dependent countries confronting similar challenges. Second, Niger’s policy architecture consists of multi-layered laws, regulations, and international agreements with dense cross-references and implicit inter-document links, furnishing an ideal testbed for assessing IEO’s ability to process complex, unstructured long texts and capture cross-text knowledge associations. Therefore, we used Niger as a proof-of-concept to thoroughly validate IEO’s capabilities; importantly, IEO is not confined to this setting—its iterative process and density-based context perception are only weakly coupled to country and language and, with appropriate LLM adaptation, can be generalized to multi-country and multi-domain policy corpora.
This section will first introduce the construction of the experimental corpus, then describe the comparative experimental design for evaluating the performance of the IEO framework, and finally demonstrate the application potential of the constructed knowledge graph.
3.1. Corpus Construction
To evaluate the performance of the IEO framework in a realistic scenario, we constructed a specialized corpus focused on Niger’s environmental policy, following principles of systematicity and representativeness.
3.1.1. Data Collection
We collected multi-source, heterogeneous texts from official channels, covering various levels from macro-strategies and core regulations to specific guidelines, to ensure the breadth and depth of the corpus. The main data sources include the following:
- Macro-strategic documents: Niger’s Sustainable Development and Inclusive Growth Strategy 2035, which establishes the top-level design for the national environment and development.
- Core laws and regulations: key legal texts in critical areas, including the Mining Law (2022 version), the Petroleum Law (2017/2007 versions), and the Environmental Management Framework Law (1998 version).
- Specific policies and guidelines: including the National Climate Change Adaptation Plan, the National Petroleum Policy, and the Country Guide for Foreign Investment and Cooperation—Niger (2024 Edition), published on China’s Belt and Road Portal.
- News and case: covering policy dynamics and project cases between China and Niger, obtained from China’s Belt and Road Portal.
To ensure consistency in data processing, all documents originally in French were translated and semantically proofread and then integrated with native Chinese documents to form a unified policy text corpus.
3.1.2. Text Preprocessing
The raw text corpus underwent a three-stage preprocessing pipeline to be converted into the standard input format required by the IEO framework—an ordered sequence of text chunk vectors.
- Text Standardization: As a cleaning step, we applied a set of standardization rules aimed at preserving the original semantic structure. This included handling special punctuation, normalizing paragraphs and line breaks, and removing excess whitespace, thereby ensuring format consistency for subsequent processing.
- Semantic-Aware Chunking: To preserve semantic coherence as much as possible while segmenting the text, we used the RecursiveCharacterTextSplitter from the LangChain framework. This method performs hierarchical splitting based on the syntactic structure of Chinese (e.g., periods, semicolons). We set a chunk size of 300 characters and an overlap of 20 characters. Through this step, the entire corpus was divided into 5277 independent text chunks.
- Vector Embedding: Finally, we used ZHIPU AI’s Embedding-3 model to map each text chunk to a high-dimensional semantic vector. This step completed the conversion from discrete text to a continuous semantic space, providing the foundation for the subsequent selection of text chunks based on DBCP.
3.2. Performance Evaluation Scheme
3.2.1. Benchmark and Comparative Methods
To establish a reliable evaluation benchmark, we first constructed a gold-standard dataset. We selected 180 representative text chunks from the complete corpus of 5277 text chunks, ensuring that their content covered different policy areas (e.g., environmental regulation, resource development) and text types (e.g., laws, plans).
We employed a semi-automated annotation process to generate the benchmark triplets. First, we used two advanced large language models (GLM-4-Plus and Qwen-Max) for preliminary knowledge extraction. Subsequently, a team of domain experts meticulously reviewed the models’ outputs. The final benchmark dataset contains 2809 reference triplets.
To comprehensively evaluate the effectiveness of the IEO framework, we selected two representative open-domain knowledge extraction methods as comparative benchmarks: HippoRAG [33] and AIKG [34]. HippoRAG represents a state-of-the-art solution that combines Retrieval-Augmented Generation (RAG) technology with knowledge extraction. AIKG provides a pipeline-based construction paradigm that is macroscopically comparable to IEO. The selection of these two methods allows for a fair and meaningful comparison of IEO with current mainstream knowledge graph construction paradigms.
3.2.2. Evaluation Metrics
Traditional knowledge extraction evaluation metrics rely on exact matching, which is overly strict for evaluating triplets generated by large language models that exhibit rich expressive diversity. Therefore, drawing inspiration from evaluation methods in studies like WEBNLG [31,35], we designed a semantic similarity evaluation method adapted for the Chinese context.
The core of this method is to use BERTScore [36] to calculate the semantic similarity between a candidate triplet and a reference triplet . We calculated the similarity at both the component level (head, relation, tail) and the whole-triplet level and then performed a weighted sum to achieve a comprehensive assessment of the triplet’s content and structure.
First, the component-level average similarity, , was calculated:
Next, the whole-triplet similarity, , was calculated by concatenating all parts of the triplet to evaluate its overall semantics:
The final weighted comprehensive similarity, , is given by the following formula:
where .
We used a greedy matching algorithm, iterating through all triplet pairs sorted from high to low similarity, to find the optimal one-to-one matching between the candidate and reference sets. A matched pair is considered a true positive (TP) only if its final similarity score exceeds a preset threshold.
Based on this matching result, we calculated precision, recall, and F1-score [37]:
where is the total number of candidate triplets, and is the total number of reference triplets. This evaluation scheme provides the standard for the subsequent performance analysis.
3.3. Construction and Application of the Knowledge Graph
We applied the IEO framework to the complete corpus of 5277 text chunks to construct a large-scale knowledge graph of Niger’s environmental policy. The graph contains a total of 61,912 entity nodes and 81,389 relation edges, covering policy knowledge in key areas such as mining, oil development, and climate change. It was ultimately stored in a Neo4j graph database. This section aims to demonstrate how this knowledge graph can be applied to the analysis and decision-making of environmental policy through specific application cases.
3.3.1. Policy Network Analysis
By leveraging the graph structure of the knowledge graph, we can overcome the limitations of simple keyword-based text retrieval and further uncover the complex interactions between policies.
- Multi-dimensional Regulatory Correlation Analysis: For example, as shown in Figure 4a, a multi-hop graph traversal can reveal the deeply embedded relationships of the Petroleum Law within Niger’s legal system. It can not only show its direct regulatory relationship with the Public Tax Law but also trace its legal origins back to the 1999 Constitution. This analysis examines environmental regulations within the broader context of the national fiscal and constitutional framework, revealing the multiple considerations in policymaking.
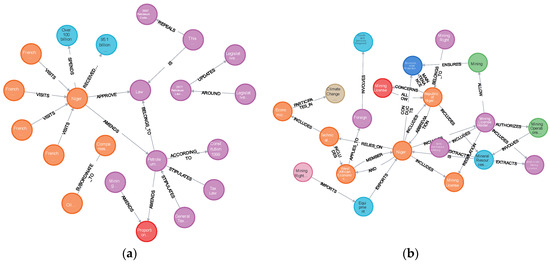 Figure 4. Policy network analysis: (a) petroleum regulation correlation network analysis; (b) tracing environmental risk pathways in the mining industry.
Figure 4. Policy network analysis: (a) petroleum regulation correlation network analysis; (b) tracing environmental risk pathways in the mining industry. - Tracing Hidden Risk Pathways: For example, as shown in Figure 4b, by querying the path from “mining permit holder” to specific environmental impact entities, a key link can be identified. This link connects through regional organizations like the “Economic Community of West African States” to the “Climate Change and Environmental Degradation Risks and Adaptation Project” (CEDRA). This clearly demonstrates how local economic activities are linked to international and regional environmental governance frameworks, helping to trace complex risk transmission pathways. Such multi-layered, implicit relationships are difficult to uncover with traditional text analysis.
3.3.2. Aided Knowledge Retrieval and Analysis
By combining the powerful graph query capabilities of Neo4j with the natural language generation abilities of large language models, the knowledge graph can support complex, analysis-oriented retrieval tasks. The following are four typical application scenarios (detailed query processes and results are provided in SI Tables S4 and S5:
- Multi-dimensional Policy Correlation Identification: Querying all association paths between the Petroleum Law and the Environmental Management Framework Law returns various types of connections, including legislative synergy, legal repeal and updates, and contractual compliance requirements, providing a factual basis for policy coherence analysis.
- Profiling Regulatory Systems in Specific Domains: By querying the theme of “environmental protection in the mining industry”, with the Environmental Management Framework Law as the core, the system aggregates all related international agreements, site remediation regulations, emission standards, etc., to dynamically generate a regulatory network view of the domain.
- Deconstruction of Macro-strategies: Querying the “environmental protection” measures contained in the 2035 Sustainable Development Strategy allows the graph to break them down into a series of specific components, such as associated petroleum policies, multi-departmental coordination plans, and rural development strategies, which helps to reveal the implementation pathways of macro-strategies.
- Identification of Policy Coordination Mechanisms: By analyzing all interaction paths between the two core concept nodes of “environmental protection” and “economic development”, various policy coordination mechanisms can be identified, such as policy formulation, fundraising, high-level coordination, and the application of economic instruments.
The above cases demonstrate that the knowledge graph constructed by the IEO framework is not merely a simple structuring of the original text but a powerful analytical tool. It transforms static, scattered policy information into a dynamic, interconnected knowledge network, thereby enabling deep policy network analysis and intelligent knowledge retrieval that are difficult to achieve with traditional methods.
4. Discussion
This section aims to provide an empirical analysis of the performance of the IEO framework. Table 1 presents a performance comparison of the IEO framework against two benchmark methods across various metrics. All experiments were conducted on two large language models, GLM-4-Plus and Qwen-Max, with the temperature parameter set to 0 to ensure the reproducibility of the results. The scores are the average of the results from the two models.

Table 1.
Triplet extraction performance comparison.
The experimental results show that the IEO framework performs well in terms of the completeness of knowledge capture. Its Micro-Recall (0.930) and Macro-Recall (0.948) are both superior to the comparative methods. This is further corroborated by its lower number of missed triplets, which is 77.4% and 59.9% lower than HippoRAG and AIKG, respectively.
Corresponding to the high recall, the Micro-Precision of the IEO framework is lower than the benchmark methods. To some extent, this reflects a strategic trade-off in our design. Consistent with the views in studies such as [38,39], we believe that redundancy is less harmful than omission, especially when constructing a knowledge graph in specialized domains like environmental policy, where the primary challenge in the initial stage is to overcome the hidden and fragmented nature of knowledge. Therefore, in specific scenarios, maximizing knowledge coverage may be more valuable than pursuing perfect precision. A more comprehensive candidate knowledge base can provide richer raw material for subsequent manual verification or downstream applications. Importantly, the downstream reliability impact of this choice is generally controllable. In common retrieval and reasoning workflows, low-confidence noise can be suppressed via confidence weighting, adjustable thresholds/whitelists, and consistency checks. For decision-support use cases, key findings undergo robustness assessment and sampling-based verification, and only results that are threshold-robust, cross-source consistent, or expert-validated are admitted as decision inputs. The fact that IEO extracts the highest number of matched triplets also reflects the potential of this strategy in discovering more true knowledge.
The core of IEO’s high recall lies in the synergistic effect of its two main mechanisms: (1) The iterative knowledge augmentation mechanism allows the model to use the already constructed subgraph as context to continuously discover new knowledge in subsequent iterations, which helps to mitigate the problem of knowledge omission caused by traditional single-pass processing. (2) The DBCP mechanism ensures that each extraction is performed in a more relevant semantic environment, enabling the model to mine deeper and long-range relationships that might be overlooked by traditional methods. The synergy of these two components aims to achieve a more complete capture of domain knowledge, thereby improving recall.
In terms of the comprehensive Micro-F1, IEO is comparable to the best-performing AIKG. This indicates to some extent that its significant improvement in recall did not come at the cost of excessive precision, demonstrating its feasibility as a novel knowledge discovery framework.
Furthermore, the radar chart in Figure 5 reveals the robustness of the IEO framework across different large language models. The framework shows relatively consistent performance on both models, indicating a certain degree of universality in its architectural design. Taken together, these results demonstrate that the IEO framework provides a promising new paradigm for knowledge graph construction, especially for complex scenarios that require comprehensive capture of domain knowledge.
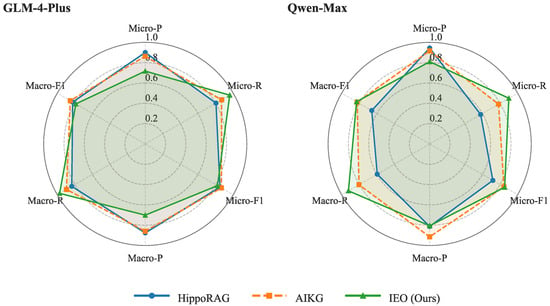
Figure 5.
Performance comparison across different models.
In summary, compared to previous research, the IEO framework provides a new approach for constructing knowledge graphs in complex domains. Traditional single-pass extraction paradigms (such as HippoRAG and AIKG) generally face challenges of missing contextual dependencies and knowledge fragmentation, making it difficult to effectively capture cross-document and long-range semantic relationships, and typically adopt a “high precision, low recall” strategy. Experimental results show that the IEO framework’s recall rate (micro-average 0.930) is significantly superior to HippoRAG (0.692) and AIKG (0.826), with the number of missed triplets (196) reduced by 77.4% and 59.9%, respectively, compared to the two methods, validating the advantage of the iterative approach in knowledge coverage completeness. By introducing iterative knowledge augmentation and density-based context awareness mechanisms, the IEO framework effectively overcomes the limitations of traditional paradigms, achieving an F1-score comparable to baseline methods (0.837 vs. 0.855) while maintaining a high recall rate, providing a feasible path for achieving performance balance while ensuring knowledge coverage completeness.
Notably, this study also has several limitations. First, applying iterative extraction and multi-round context integration to large-scale corpora increases computational and storage overhead; engineering improvements are needed for larger scales and higher update frequencies. Second, biases and hallucinations of LLMs in specialized policy texts may be amplified along the iterative chain; our density-based mechanisms reduce risk, but stronger verification is still required. In addition, transfer across languages and jurisdictions faces challenges such as terminology alignment, legal reasoning differences, and version changes; future work should integrate multilingual alignment, time-aware graphs, and regulatory ontologies to improve extrapolation. Overall, these limitations do not diminish the value of IEO in enhancing knowledge coverage and discovery in complex policy settings; instead, they indicate directions for follow-up work, such as resource-aware efficient scheduling, bias calibration and uncertainty quantification, multilingual alignment, and temporal consistency modeling.
The contributions of this research are reflected at both theoretical and practical levels:
- We propose and validate a new method for constructing knowledge graphs from complex domain-specific texts. The IEO framework surpasses the traditional, static “one-pass extraction” pipeline by introducing the idea of “dynamic iteration and progressive enhancement.” This approach offers a feasible path for using large language models to process specialized, context-dependent corpora.
- Through the case study of Niger’s environmental policy, we demonstrate the potential of transforming large volumes of unstructured policy texts into structured knowledge. The knowledge graph built by IEO is not just a collection of knowledge but also a powerful analytical tool capable of supporting compliance checks, risk pathway tracing, and multi-dimensional policy correlation analysis. This has practical application value for decision support and risk management in transnational projects and investments, such as those under the Belt and Road Initiative.
5. Conclusions
This study proposes and preliminarily validates the iteration–extraction–optimization (IEO) framework, a novel method driven by a large language model aimed at automatically constructing high-quality knowledge graphs from complex domain-specific texts.
Our core conclusions are as follows:
- Through its innovative iterative knowledge augmentation and density-based context perception mechanisms, the IEO framework performs well in the completeness of knowledge extraction. Its recall rate is superior to existing benchmark methods, helping to alleviate problems such as knowledge omission and long-range dependencies in complex texts.
- While achieving a high recall rate, the IEO framework maintains a good F1 comprehensive performance, indicating a good balance between knowledge coverage and accuracy. The framework demonstrates robust performance across different large language models, showcasing the potential universality of its methodology.
- In the case study of Niger’s environmental policy, we preliminarily constructed a structured knowledge graph for in-depth analysis and demonstrated its potential in revealing complex policy networks and supporting intelligent knowledge retrieval.
In summary, the IEO framework provides a feasible approach for transforming unstructured domain knowledge into structured, actionable intelligence. By enabling deeper and more comprehensive automated analysis of environmental policies, the framework offers a technical reference for knowledge-driven environmental governance and the achievement of the Sustainable Development Goals. This study takes a step toward the automated construction of more comprehensive and precise domain knowledge graphs, showing promising application prospects, especially in knowledge domains with high complexity and specialization. In the future, we will explore automated graph construction methods for multilingual scenarios and multimodal data.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/su172210282/s1. Table S1: Named entity recognition prompt template (translated in english), Table S2: Triple extraction prompt template (translated in english), Table S3: Triple review prompt template (translated in english), Table S4: Question answering prompt template (translated in english), Table S5: Questions and results (translated in english).
Author Contributions
Conceptualization, X.L.; Data curation, Y.W.; Formal analysis, X.L.; Funding acquisition, Y.Y.; Investigation, X.T.; Methodology, X.L.; Resources, X.T.; Software, X.L.; Supervision, Y.Y.; Validation, Y.L.; Visualization, Y.W.; Writing—original draft, X.L.; Writing—review and editing, Y.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key R&D Program of China, grant number 2022YFF0607100, and the Central Basic Business Research Funding Project, grant number 552023Y-10371, and the National Key R&D Program of China, grant number 2022YFF0609600.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Dataset available upon request from the authors (the raw data supporting the conclusions of this article will be made available by the authors upon request).
Acknowledgments
The authors have reviewed and edited the output and take full responsibility for the content of this publication.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zhao, L.; Liu, J.; Li, D.; Yang, Y.; Wang, C.; Xue, J. China’s Green Energy Investment Risks in Countries along the Belt and Road. J. Clean. Prod. 2022, 380, 134938. [Google Scholar] [CrossRef]
- Mahadevan, R.; Sun, Y. Effects of Foreign Direct Investment on Carbon Emissions: Evidence from China and Its Belt and Road Countries. J. Environ. Manag. 2020, 276, 111321. [Google Scholar] [CrossRef] [PubMed]
- Cai, X.; Che, X.; Zhu, B.; Zhao, J.; Xie, R. Will Developing Countries Become Pollution Havens for Developed Countries? An Empirical Investigation in the Belt and Road. J. Clean. Prod. 2018, 198, 624–632. [Google Scholar] [CrossRef]
- Cheng, S.; Wang, B. Impact of the Belt and Road Initiative on China’s Overseas Renewable Energy Development Finance: Effects and Features. Renew. Energy 2023, 206, 1036–1048. [Google Scholar] [CrossRef]
- Duan, F.; Ji, Q.; Liu, B.-Y.; Fan, Y. Energy investment risk assessment for nations along China’s belt & road initiative. J. Clean. Prod. 2018, 170, 535–547. [Google Scholar] [CrossRef]
- Macintosh, A.; Wilkinson, D. Complexity Theory and the Constraints on Environmental Policymaking. J. Environ. Law 2016, 28, 65–93. [Google Scholar] [CrossRef]
- Vesterager, J.P.; Frederiksen, P.; Kristensen, S.B.P.; Vadineanu, A.; Gaube, V.; Geamana, N.A.; Pavlis, V.; Terkenli, T.S.; Bucur, M.M.; van der Sluis, T.; et al. Dynamics in national agri-environmental policy implementation under changing EU policy priorities: Does one size fit all? Land Use Policy 2016, 57, 764–776. [Google Scholar] [CrossRef]
- Meckling, J.; Kelsey, N.; Biber, E.; Zysman, J. Winning Coalitions for Climate Policy. Science 2015, 349, 1170–1171. [Google Scholar] [CrossRef]
- Macris, A.M.; Georgakellos, D.A. A New Teaching Tool in Education for Sustainable Development: Ontology-Based Knowledge Networks for Environmental Training. J. Clean. Prod. 2006, 14, 855–867. [Google Scholar] [CrossRef]
- Dong, L.; Ren, M.; Xiang, Z.; Zheng, P.; Cong, J.; Chen, C.-H. A Novel Smart Product-Service System Configuration Method for Mass Personalization Based on Knowledge Graph. J. Clean. Prod. 2023, 382, 135270. [Google Scholar] [CrossRef]
- Hofmeister, M.; Lee, K.F.; Tsai, Y.-K.; Müller, M.; Nagarajan, K.; Mosbach, S.; Akroyd, J.; Kraft, M. Dynamic Control of District Heating Networks with Integrated Emission Modelling: A Dynamic Knowledge Graph Approach. Energy AI 2024, 17, 100376. [Google Scholar] [CrossRef]
- Wu, P.; Tu, H.; Mou, X.; Gong, L. An Intelligent Energy Management Method for the Manufacturing Systems Using the Knowledge Graph and Large Language Model. J. Intell. Manuf. 2025, 1–20. [Google Scholar] [CrossRef]
- Wang, X.; Meng, L.; Wang, X.; Wang, Q. The Construction of Environmental-Policy-Enterprise Knowledge Graph Based on PTA Model and PSA Model. Resour. Conserv. Recycl. Adv. 2021, 12, 200057. [Google Scholar] [CrossRef]
- Islam, M.S.; Proma, A.; Zhou, Y.-S.; Akter, S.N.; Wohn, C.; Hoque, E. KnowUREnvironment: An Automated Knowledge Graph for Climate Change and Environmental Issues. In Proceedings of the AAAI 2022 Fall Symposium: The Role of AI in Responding to Climate Challenges, Arlington, VA, USA, 17–19 November 2022. [Google Scholar]
- Zhong, L.; Wu, J.; Li, Q.; Peng, H.; Wu, X. A Comprehensive Survey on Automatic Knowledge Graph Construction. ACM Comput. Surv. 2024, 56, 1–62. [Google Scholar] [CrossRef]
- Val-Calvo, M.; Egaña Aranguren, M.; Mulero-Hernández, J.; Almagro-Hernández, G.; Deshmukh, P.; Bernabé-Díaz, J.A.; Espinoza-Arias, P.; Sánchez-Fernández, J.L.; Mueller, J.; Fernández-Breis, J.T. OntoGenix: Leveraging Large Language Models for Enhanced Ontology Engineering from Datasets. Inf. Process. Manag. 2025, 62, 104042. [Google Scholar] [CrossRef]
- Guo, L.; Yan, F.; Li, T.; Yang, T.; Lu, Y. An Automatic Method for Constructing Machining Process Knowledge Base from Knowledge Graph. Robot. Comput. Integr. Manuf. 2022, 73, 102222. [Google Scholar] [CrossRef]
- Hu, Y.; Zou, F.; Han, J.; Sun, X.; Wang, Y. LLM-TIKG: Threat Intelligence Knowledge Graph Construction Utilizing Large Language Model. Comput. Secur. 2024, 145, 103999. [Google Scholar] [CrossRef]
- Laver, M.; Benoit, K.; Garry, J. Extracting Policy Positions from Political Texts Using Words as Data. Am. Pol. Sci. Rev. 2003, 97, 311–331. [Google Scholar] [CrossRef]
- Wang, X.; Huang, L.; Daim, T.; Li, X.; Li, Z. Evaluation of China’s New Energy Vehicle Policy Texts with Quantitative and Qualitative Analysis. Technol. Soc. 2021, 67, 101770. [Google Scholar] [CrossRef]
- Egbemhenghe, A.U.; Ojeyemi, T.; Iwuozor, K.O.; Emenike, E.C.; Ogunsanya, T.I.; Anidiobi, S.U.; Adeniyi, A.G. Revolutionizing Water Treatment, Conservation, and Management: Harnessing the Power of AI-Driven ChatGPT Solutions. Environ. Chall. 2023, 13, 100782. [Google Scholar] [CrossRef]
- Liao, W.; Lu, X.; Fei, Y.; Gu, Y.; Huang, Y. Generative AI Design for Building Structures. Autom. Constr. 2024, 157, 105187. [Google Scholar] [CrossRef]
- Jurišević, N.; Kowalik, R.; Gordić, D.; Novaković, A.; Vukasinovic, V.; Rakić, N.; Nikolić, J.; Vukicevic, A. Large Language Models as Tools for Public Building Energy Management: An Assessment of Possibilities and Barriers. Int. J. Qual. Res. 2025, 19, 817–830. [Google Scholar] [CrossRef]
- Zhu, Y.; Wang, X.; Chen, J.; Qiao, S.; Ou, Y.; Yao, Y.; Deng, S.; Chen, H.; Zhang, N. LLMs for Knowledge Graph Construction and Reasoning: Recent Capabilities and Future Opportunities. World Wide Web 2024, 27, 58. [Google Scholar] [CrossRef]
- Carta, S.; Giuliani, A.; Piano, L.; Podda, A.S.; Pompianu, L.; Tiddia, S.G. Iterative Zero-Shot LLM Prompting for Knowledge Graph Construction. arXiv 2023, arXiv:2307.01128. [Google Scholar] [CrossRef]
- Polak, M.P.; Morgan, D. Extracting Accurate Materials Data from Research Papers with Conversational Language Models and Prompt Engineering. Nat. Commun. 2024, 15, 1569. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, H.; Xu, G.; Ren, M. A Novel Large-Language-Model-Driven Framework for Named Entity Recognition. Inf. Process. Manag. 2025, 62, 104054. [Google Scholar] [CrossRef]
- Wei, X.; Cui, X.; Cheng, N.; Wang, X.; Zhang, X.; Huang, S.; Xie, P.; Xu, J.; Chen, Y.; Zhang, M.; et al. ChatIE: Zero-Shot Information Extraction via Chatting with ChatGPT. arXiv 2024, arXiv:2302.10205. [Google Scholar]
- Chen, B.; Bertozzi, A.L. AutoKG: Efficient Automated Knowledge Graph Generation for Language Models. In Proceedings of the 2023 IEEE International Conference on Big Data (BigData), Sorrento, Italy, 15–18 December 2023; pp. 3117–3126. [Google Scholar]
- Yang, R.; Yang, B.; Feng, A.; Ouyang, S.; Blum, M.; She, T.; Jiang, Y.; Lecue, F.; Lu, J.; Li, I. Graphusion: A RAG Framework for Knowledge Graph Construction with a Global Perspective 2024. arXiv 2024, arXiv:2410.17600. [Google Scholar]
- Zhang, B.; Soh, H. Extract, Define, Canonicalize: An LLM-Based Framework for Knowledge Graph Construction 2024. arXiv 2024, arXiv:2404.03868. [Google Scholar]
- Rodriguez, A.; Laio, A. Clustering by Fast Search and Find of Density Peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef]
- Gutiérrez, B.J.; Shu, Y.; Gu, Y.; Yasunaga, M.; Su, Y. HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models. Adv. Neural Inf. Process. Syst. 2024, 37, 59532–59569. [Google Scholar]
- AI Powered Knowledge Graph Generator. Available online: https://github.com/robert-mcdermott/ai-knowledge-graph (accessed on 17 July 2025).
- Castro Ferreira, T.; Gardent, C.; Ilinykh, N.; van der Lee, C.; Mille, S.; Moussallem, D.; Shimorina, A. The 2020 Bilingual, Bi-Directional WebNLG+ Shared Task: Overview and Evaluation Results (WebNLG+ 2020). In Proceedings of the 3rd International Workshop on Natural Language Generation from the Semantic Web (WebNLG+), Virtual, Ireland, 18 December 2020; Castro Ferreira, T., Gardent, C., Ilinykh, N., van der Lee, C., Mille, S., Moussallem, D., Shimorina, A., Eds.; Association for Computational Linguistics: Dublin, Ireland, 2020; pp. 55–76. [Google Scholar]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating Text Generation with BERT. arXiv 2019, arXiv:1904.09675. [Google Scholar]
- Schütze, H.; Manning, C.D.; Raghavan, P. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008; Volume 39. [Google Scholar]
- Zhang, W.; Guo, H.; Yang, J.; Tian, Z.; Zhang, Y.; Chaoran, Y.; Li, Z.; Li, T.; Shi, X.; Zheng, L.; et al. mABC: Multi-Agent Blockchain-Inspired Collaboration for Root Cause Analysis in Micro-Services Architecture. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, FL, USA, 12–16 November 2024; Association for Computational Linguistics: Miami, FL, USA, 2024; pp. 4017–4033. [Google Scholar]
- Pei, C.; Wang, Z.; Liu, F.; Li, Z.; Liu, Y.; He, X.; Kang, R.; Zhang, T.; Chen, J.; Li, J.; et al. Flow-of-Action: SOP Enhanced LLM-Based Multi-Agent System for Root Cause Analysis. In Proceedings of the Companion Proceedings of the ACM on Web Conference 2025, Sydney, Australia, 28 April–2 May 2025; Association for Computing Machinery: New York, NY, USA, 2025; pp. 422–431. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).