
The Yield Estimation of Apple Trees Based on the Best Combination of Hyperspectral Sensitive Wavelengths Algorithm

 ,
,  and
and
Abstract
1. Introduction
2. Materials and Methods
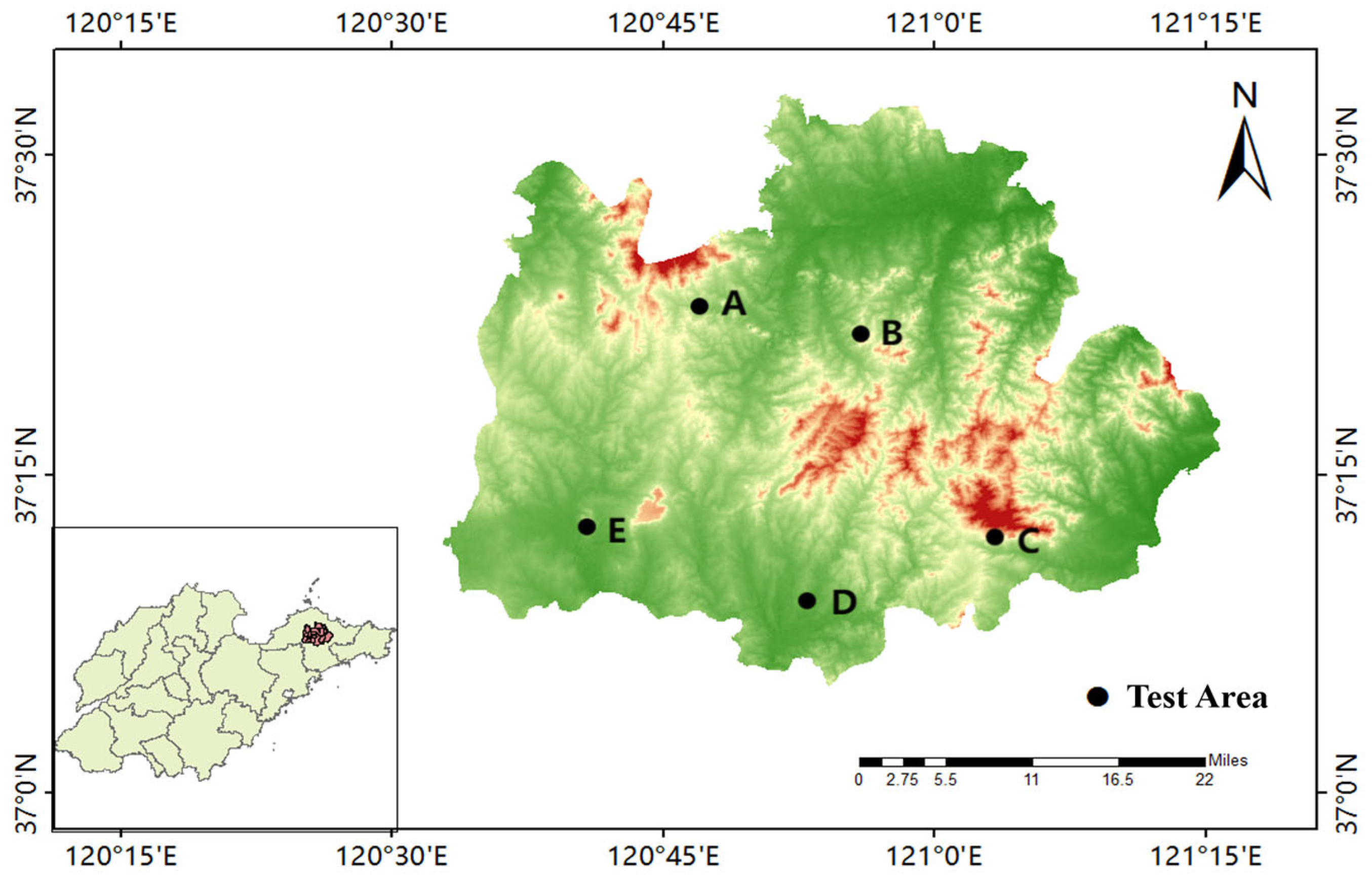
2.1. Study Area
2.2. Data Collection and Preprocessing
2.2.1. Hyperspectral Data Acquisition
2.2.2. Apple Yield Data Acquisition
2.2.3. Preprocessing of Spectral Data
2.3. Sensitive Wavelength Screening Algorithm
2.4. Establishment and Verification of Apple Yield Model
3. Results
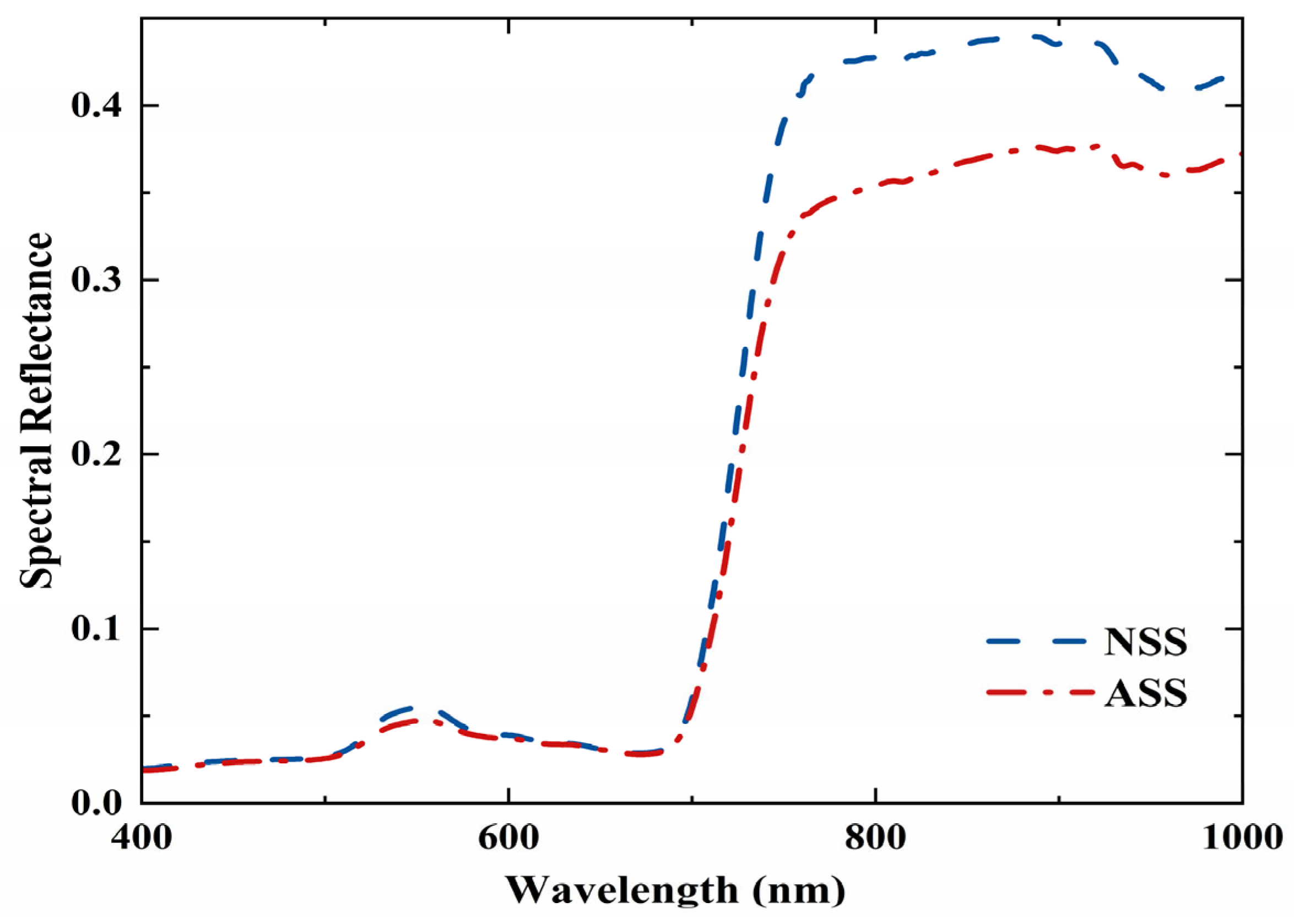
3.1. Analysis of Canopy Spectral Characteristics of Apple Tree During Key Fertility Period
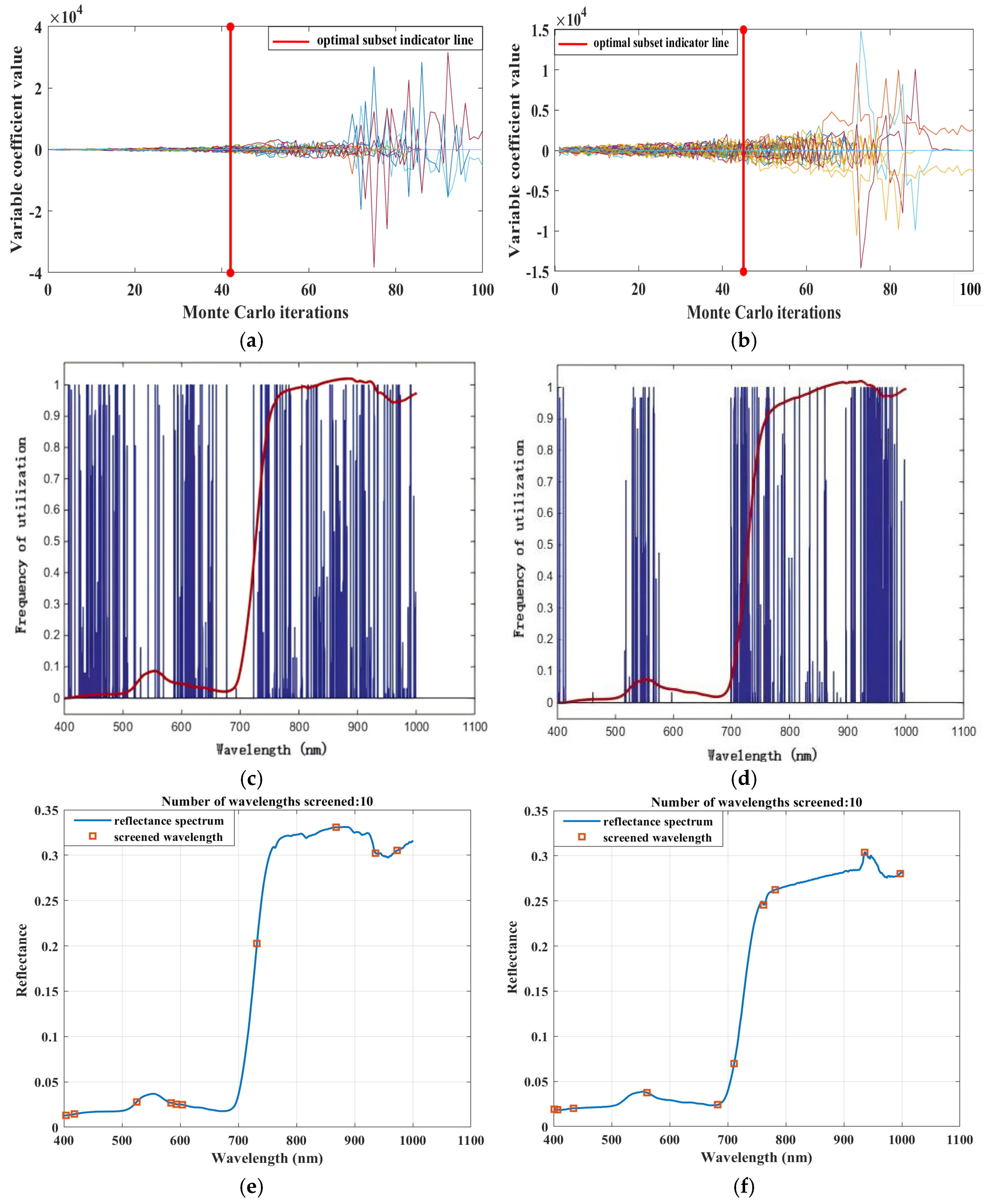
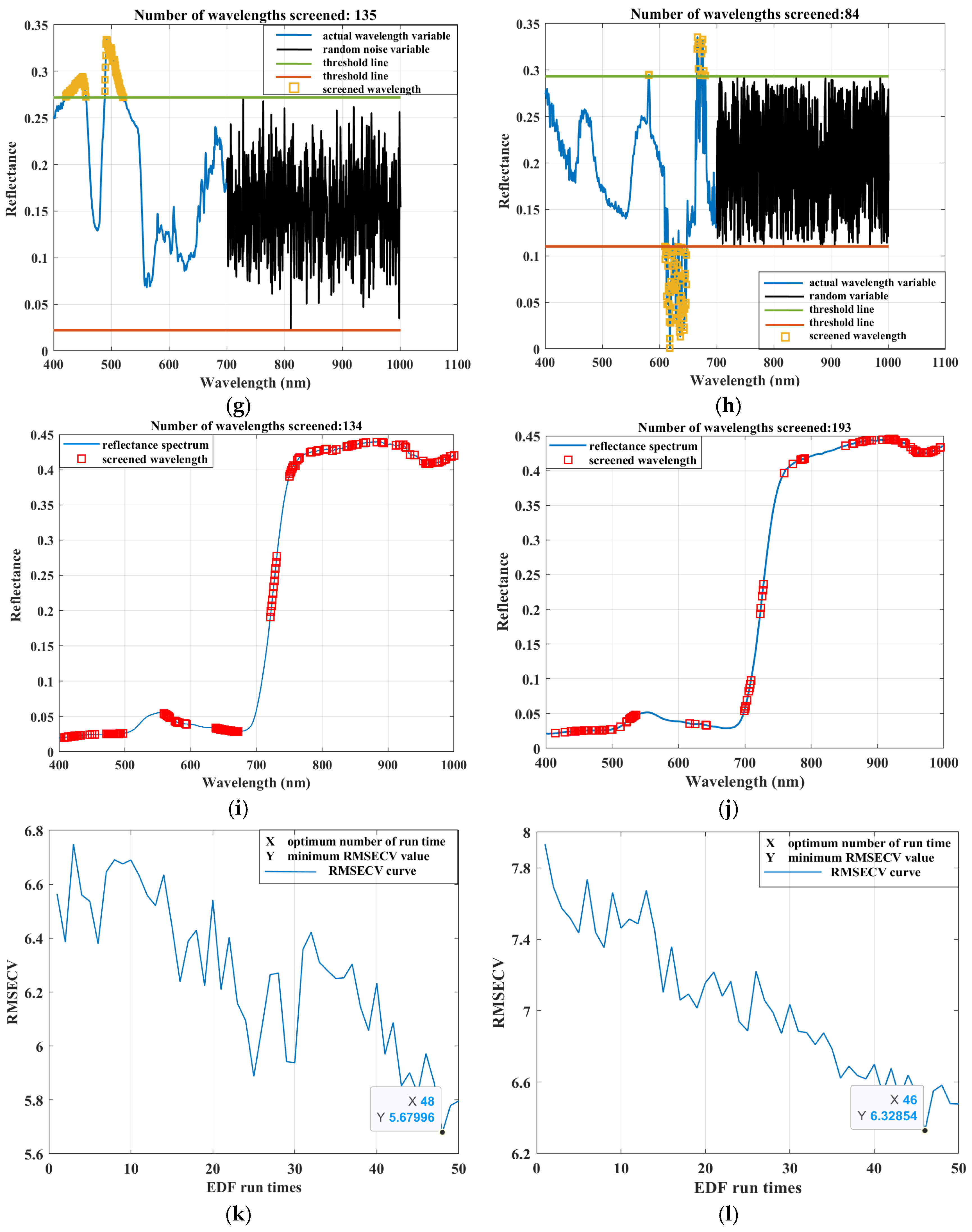
3.2. Analysis of the Results of Different Sensitive Wavelength Screening Algorithms
3.3. Determination of Sensitive Wavelength Screening Algorithm
3.4. Determination of the Optimal Combination of Sensitive Wavelength Screening Algorithms
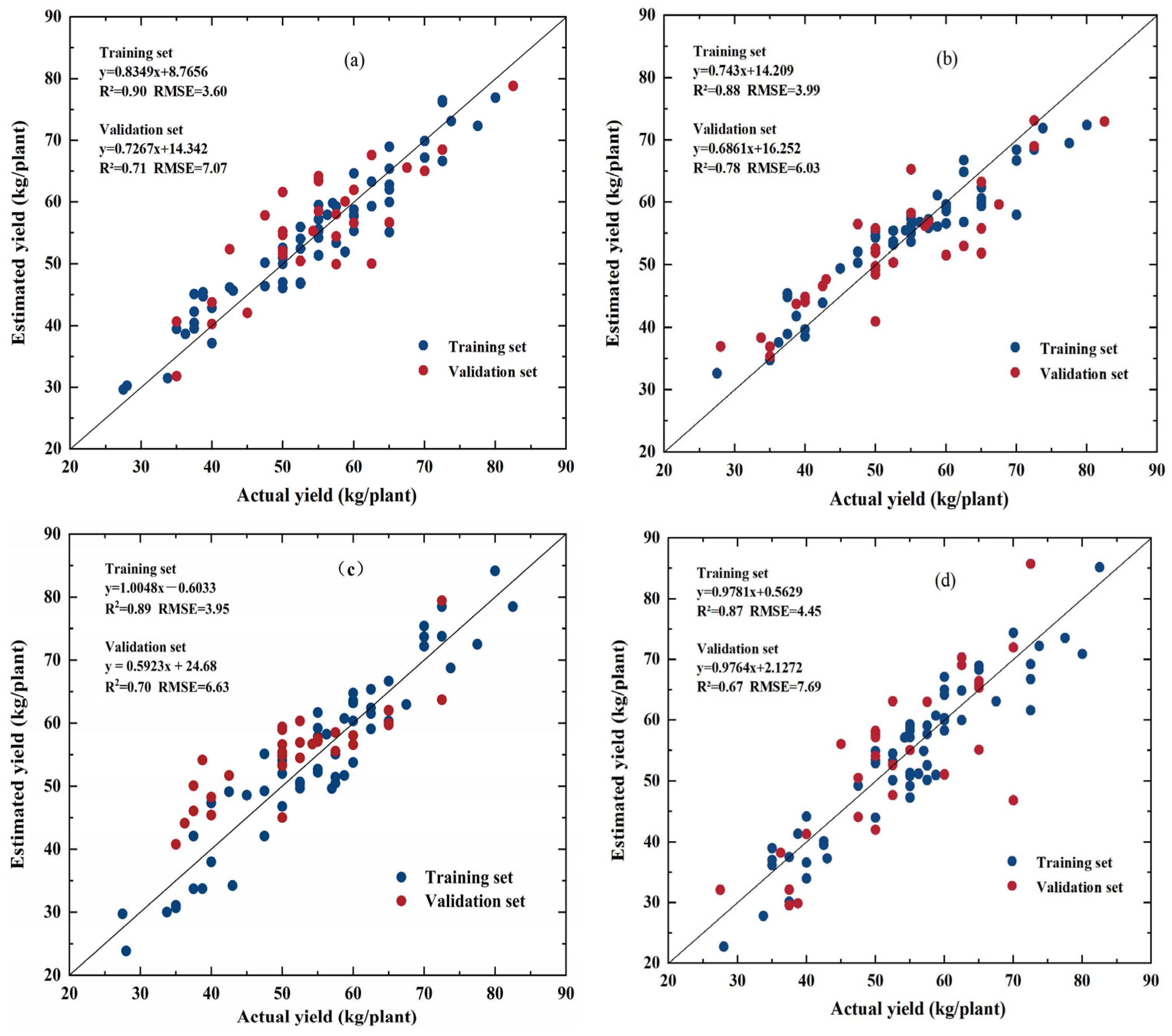
3.5. Construction and Validation of Apple Yield Estimation Models
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, R.W.; Wang, J.; Li, Y.; Bai, R.; Huang, M.X.; Zhang, Z.Z.; Zhao, L.X.; Qu, Z.J.; Liu, L. Higher risk of spring frost under future climate change across China’s apple planting regions. Eur. J. Agron. 2024, 159, 127288. [Google Scholar] [CrossRef]
- Shi, J.; Li, B.Y.; Wang, S.L.; Zhang, W.; Shang, M.Q.; Wang, Y.Z.; Liu, B.Y. Occurrence of Neopestalotiopsis clavispora Causing Apple Leaf Spot in China. Agronomy 2024, 14, 1658. [Google Scholar] [CrossRef]
- Zhang, X.X.; Song, Z.P.; Liang, Q.Y.; Gao, S.M. Yield and maturity estimation of apples in orchards using a 3-step deep learning-based method. Qual. Assur. Saf. Crop. Foods 2022, 14, 101–111. [Google Scholar] [CrossRef]
- Robson, A.; Rahman, M.M.; Muir, J. Using WorldView satellite imagery to map yield in Avocado: A Case Study in Bundaberg, Australia. Remote Sens. 2017, 9, 1223. [Google Scholar] [CrossRef]
- Xia, X.; Chai, X.J.; Zhang, N.; Zhang, Z.; Sun, Q.X.; Sun, T. Culling double counting in sequence images for fruit yield estimation. Agronomy 2022, 12, 440. [Google Scholar] [CrossRef]
- Feng, H.K.; Tao, H.L.; Fan, Y.G.; Liu, Y.; Li, Z.H.; Yang, G.J.; Zhao, C.J. Comparison of winter wheat yield estimation based on near-surface hyperspectral and UAV hyperspectral remote sensing data. Remote Sens. 2022, 14, 4158. [Google Scholar] [CrossRef]
- Lu, J.S.; Chen, S.M.; Huang, W.M. Estimation of aboveground biomass and leaf area index of summer maize using SE-(PLS)-ELM model. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2021, 37, 128–135. [Google Scholar]
- Jing, X.; Zhang, J.; Wang, J.J.; Ming, S.K.; Fu, Y.Q.; Feng, H.K.; Song, X.Y. Comparison of Machine Learning Algorithms for Remote Sensing Monitoring of Rice Yields. Spectrosc. Spectr. Anal. 2022, 42, 1620–1627. [Google Scholar]
- An, L.L.; Liu, Y.; Liu, G.H.; Zhao, R.M.; Tang, W.J.; Liu, M.J.; Li, J.M.; Li, Z.; Sun, H.; Li, M.Z.; et al. Estimation on powdery mildew of wheat canopy based on in-situ hyperspectral responses and characteristic wavelengths optimization. Crop Prot. 2024, 184, 106804. [Google Scholar] [CrossRef]
- Hou, Y.N.; Zhu, W.Z.; Wang, E.L. Hyperspectral mineral target detection based on density peak. Intell. Autom. Soft Comput. 2019, 25, 805–814. [Google Scholar] [CrossRef]
- Guo, F.; Xu, Z.; Ma, H.H.; Liu, X.J.; Yang, Z.; Tang, S.Q. A comparative study of the hyperspectral inversion models based on the PCA for retrieving the Cd content in the soil. Spectrosc. Spectr. Anal. 2021, 41, 1625–1630. [Google Scholar]
- Santos-Rufo, A.; Mesas-Carrascosa, F.J.; García-Ferrer, A.; Meroño-Larriva, J.E. Wavelength Selection Method Based on Partial Least Square from Hyperspectral Unmanned Aerial Vehicle Orthomosaic of Irrigated Olive Orchards. Remote Sens. 2020, 12, 3426. [Google Scholar] [CrossRef]
- Meng, F.J.; Luo, S.; Wu, Y.F.; Sun, H.; Liu, F.; Li, M.Z.; Huang, W.; Li, M. Characteristic extraction method and discriminant model of ear rot of maize seed base on NIR spectra. Spectrosc. Spectr. Anal. 2022, 42, 1716–1720. [Google Scholar]
- Liu, Y.; Zhang, H.; Feng, H.K.; Sun, Q.; Huang, J.; Wang, J.J.; Yang, G.J. Estimation of potato above ground biomass based on hyperspectral images of UAV. Spectrosc. Spectr. Anal. 2021, 41, 2657–2664. [Google Scholar]
- Zhang, D.F.; Zhang, J.; Peng, B. Hyperspectral model based on genetic algorithm and SA-1DCNN for predicting Chinese cabbage chlorophyll content. Sci. Hortic. 2023, 321, 112334. [Google Scholar] [CrossRef]
- Han, J.; Li, Y.Z.; Cao, Z.M.; Liu, Q.; Mou, H.W. Water content prediction for high water-cut crude oil based on SPA-PLS using near infrared spectroscopy. Spectrosc. Spectr. Anal. 2019, 39, 3452–3458. [Google Scholar]
- Zhou, X.; Sun, J.; Tian, Y.; Wu, X.; Dai, C.; Li, B. Spectral classification of lettuce cadmium stress based on information fusion and VISSA-GOA-SVM algorithm. J. Food Process Eng. 2019, 10, 1111. [Google Scholar] [CrossRef]
- Ali Hameed, A.; Jamil, A.; Seyyedabbasi, A. An optimized feature selection approach using sand Cat Swarm optimization for hyperspectral image classification. Infrared Phys. Technol. 2024, 141, 105449. [Google Scholar] [CrossRef]
- Li, X.; Liu, J.P.; Huang, Q.; Hu, P.W. Optimization of prediction model for milk fat content based on improved whale optimization algorithm. Spectrosc. Spectr. Anal. 2023, 43, 2779–2784. [Google Scholar]
- Shen, Y.; Zhan, X.X.; Huang, C.H.; Xie, Y.P.; Guo, C.X.; Huang, F. Rapid determination of chlorella sorokiniana lutein production based on snapshot multispectral feature wavelengths. Spectrosc. Spectr. Anal. 2024, 44, 2216–2223. [Google Scholar]
- Yu, L.; Zhang, T.; Zhu, Y.X.; Zhou, Y.; Xia, T.; Nie, Y. Determination of soybean leaf SPAD value using characteristic wavelength variables preferably selected by IRIV algorithm. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2018, 34, 148–154. [Google Scholar]
- Li, W.; Zhu, X.C.; Yu, X.Y.; Li, M.X.; Tang, X.Y.; Zhang, J.; Xue, Y.L.; Zhang, C.T.; Jiang, Y.M. Inversion of nitrogen concentration in apple canopy based on UAV hyperspectral images. Sensors 2022, 22, 3503. [Google Scholar] [CrossRef] [PubMed]
- Wei, L.F.; Pu, H.C.; Wang, Z.X.; Yuan, Z.R.; Yan, X.R.; Cao, L.Q. Estimation of soil arsenic content with hyperspectral remote sensing. Sensors 2020, 20, 4056. [Google Scholar] [CrossRef]
- Ji, H.; Wang, W.Z.; Chong, D.; Zhang, B.Y. CARS algorithm-based detection of wheat moisture content before harvest. Symmetry 2020, 12, 115. [Google Scholar] [CrossRef]
- Pang, L.; Wang, J.; Men, S.; Yan, L.; Xiao, J. Hyperspectral imaging coupled with multivariate methods for seed vitality estimation and forecast for quercus variabilis. Spectrochim. Acta Part A-Mol. Biomol. Spectrosc. 2020, 245, 118888. [Google Scholar] [CrossRef]
- Xu, L.J.; Zheng, L.N.; Huang, P.; Chen, H.; Kang, Z.L. Detection of kiwifruit dry matter content based on hyperspectral technology using uninformed variable elimination coupled with successive projection algorithm. Dyna 2020, 95, 654–660. [Google Scholar] [CrossRef] [PubMed]
- Tian, Y.; Sun, J.; Zhou, X.; Wu, X.H.; Lu, B.; Dai, C.X. Research on apple origin classification based on variable iterative space shrinkage approach with stepwise regression-support vector machine algorithm and visible-near infrared hyperspectral imaging. J. Food Process Eng. 2020, 43, 8. [Google Scholar] [CrossRef]
- Chen, T.; Guo, H.; Yuan, M.; Tan, F.Y.; Li, Y.Z.; Li, M.L. Recognition of different parts of wild cordyceps sinensis based on infrared spectrum. Spectrosc. Spectr. Anal. 2021, 41, 3727–3732. [Google Scholar]
- Jiang, H.; Lu, J.G. Using an optimal CC-PLSR-RBFNN model and NIR spectroscopy for the starch content determination in corn. Spectrochim. Acta Part A-Mol. Biomol. Spectrosc. 2018, 196, 131–140. [Google Scholar] [CrossRef] [PubMed]
- Liland, K.H.; Stefansson, P.; Indahl, U.G. Much faster cross-validation in PLSR-modelling by avoiding redundant calculations. J. Chemom. 2020, 34, 3. [Google Scholar] [CrossRef]
- Chen, X.; Li, F.; Shi, B.; Chang, Q. Estimation of winter wheat plant nitrogen concentration from UAV hyperspectral remote sensing combined with machine learning methods. Remote Sens. 2023, 15, 2831. [Google Scholar] [CrossRef]
- John, K.; Kebonye, N.M.; Agyeman, P.C.; Ahado, S.K. Comparison of cubist models for soil organic carbon prediction via portable XRF measured data. Environ. Monit. Assess. 2021, 193, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Liu, M.; Zhang, Y.; Mao, D.; Li, F.; Wu, F.; Song, J.; Li, X.; Kou, C.; Li, C. Comparison of Machine Learning Methods for Predicting Soil Total Nitrogen Content UsingLandsat-8, Sentinel-1 and Sentinel-2 Images. Remote Sens. 2023, 15, 2907. [Google Scholar] [CrossRef]
- Zheng, K.Y.; Feng, T.; Zhang, W.; Huang, X.W.; Li, Z.H.; Zhang, D.; Shi, J.Y.; Marunaka, Y.; Zou, X.B. Weighted SPXYE (WSPXYE) and its application to transfer set selection in near infrared spectra. Spectrosc. Spectr. Anal. 2021, 41, 984–989. [Google Scholar]
- Wang, Y.; Li, M.; Ji, R.; Wang, M.; Zheng, L. A deep learning-based method for screening soil total nitrogen characteristic wavelengths. Comput. Electron. Agric. 2021, 10, 1016. [Google Scholar] [CrossRef]
- Rahman, M.M.; Robson, A.; Bristow, M. Exploring the potential of high resolution WorldView-3 imagery for estimating yield of mango. Remote Sens. 2018, 10, 1866. [Google Scholar] [CrossRef]
- Van Beek, J.; Tits, L.; Somers, B.; Deckers, T.; Verjans, W.; Bylemans, D.; Janssens, P.; Coppin, P. Temporal dependency of yield and quality estimation through spectral vegetation indices in pear orchards. Remote Sens. 2015, 7, 9886–9903. [Google Scholar] [CrossRef]
- Bai, T.; Wang, S.; Meng, W.; Zhang, N.; Wang, T.; Chen, Y.; Mercatoris, B. Assimilation of remotely-sensed LAI into WOFOST model with the SUBPLEX algorithm for improving the field-scale jujube yield forecasts. Remote Sens. 2019, 11, 1945. [Google Scholar] [CrossRef]
- Zhao, M.S.; Wang, T.; Lu, Y.; Wang, S.; Wu, Y. Improved multivariate modeling for soil organic matter content estimation using hyperspectral indexes and characteristic bands. PLoS ONE 2023, 10, 1371. [Google Scholar] [CrossRef]
- Chen, X.Y.; Lv, X.; Ma, L.L.; Chen, A.Q.; Zhang, Q.; Zhang, Z. Optimization and Validation of Hyperspectral Estimation Capability of Cotton Leaf Nitrogen Based on SPA and RF. Remote Sens. 2022, 14, 5201. [Google Scholar] [CrossRef]
- Li, Y.; Li, C.L.; Wang, X.; Fan, P.F.; Li, Y.K.; Zhai, C.Y. Identification of cucumber disease and insect pest based on hyperspectral imaging. Spectrosc. Spectr. Anal. 2024, 44, 301–309. [Google Scholar]
- Liu, X.B.; Su, T.; Lei, B.; Zhu, F.; Di, J.N.; Meng, C.; Xu, L.Q.; Wang, R.Y. Inverse model for the photosynthetic pigment content of peanut leaves using coupling algorithm. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2023, 39, 198–207. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Samples | Max (kg/Plant) | Min (kg/Plant) | Avg (kg/Plant) | SD (kg/Plant) | CV (%) |
|---|---|---|---|---|---|---|
| Total | 93 | 82.5 | 27.5 | 54.22 | 11.75 | 21.67 |
| Training Set | 62 | 77.5 | 27.5 | 53.10 | 10.91 | 20.55 |
| Validation Set | 31 | 82.5 | 28.0 | 56.45 | 13.18 | 23.35 |
| Key Fertility Stage | Screening Algorithm | Number of Wavelength Variables | Validation Set | |
|---|---|---|---|---|
| R2 | RMSE | |||
| Spring Shoot Stop-Growing Stage (NSS) | CARS | 42 | 0.54 | 9.88 |
| GA | 111 | 0.37 | 10.72 | |
| SPA | 10 | 0.15 | 13.22 | |
| UVE | 135 | 0.22 | 12.43 | |
| VISSA | 134 | 0.25 | 12.34 | |
| VCPA | 8 | 0.42 | 10.52 | |
| Autumn Shoot Stop-Growing Stage (ASS) | CARS | 45 | 0.66 | 7.97 |
| GA | 150 | 0.65 | 8.19 | |
| SPA | 10 | 0.63 | 8.63 | |
| UVE | 84 | 0.60 | 9.67 | |
| VISSA | 193 | 0.65 | 8.72 | |
| VCPA | 9 | 0.64 | 7.89 | |
| Screening Algorithm | Number of Wavelength Variables | Variable Compression Ratio | Validation Set | |
|---|---|---|---|---|
| R2 | RMSE | |||
| VISSA-GA | 32 | 94.68% | 0.68 | 7.83 |
| VISSA-CARS | 29 | 95.17% | 0.71 | 7.07 |
| GA-CARS | 21 | 96.15% | 0.68 | 7.68 |
| Modeling Methodology | Validation Set | |
|---|---|---|
| R2 | RMSE | |
| PLSR | 0.71 | 7.07 |
| RF | 0.78 | 6.03 |
| Cubist | 0.70 | 6.63 |
| XGboost | 0.67 | 7.69 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, A.; Sun, J.; Zhu, X.; Li, M.; Li, C.; Wang, L.; Yu, X.; Jiang, Y. The Yield Estimation of Apple Trees Based on the Best Combination of Hyperspectral Sensitive Wavelengths Algorithm. Sustainability 2025, 17, 518. https://doi.org/10.3390/su17020518
Qin A, Sun J, Zhu X, Li M, Li C, Wang L, Yu X, Jiang Y. The Yield Estimation of Apple Trees Based on the Best Combination of Hyperspectral Sensitive Wavelengths Algorithm. Sustainability. 2025; 17(2):518. https://doi.org/10.3390/su17020518
Chicago/Turabian StyleQin, Anran, Jiarui Sun, Xicun Zhu, Meixuan Li, Cheng Li, Ling Wang, Xinyang Yu, and Yuanmao Jiang. 2025. "The Yield Estimation of Apple Trees Based on the Best Combination of Hyperspectral Sensitive Wavelengths Algorithm" Sustainability 17, no. 2: 518. https://doi.org/10.3390/su17020518
APA StyleQin, A., Sun, J., Zhu, X., Li, M., Li, C., Wang, L., Yu, X., & Jiang, Y. (2025). The Yield Estimation of Apple Trees Based on the Best Combination of Hyperspectral Sensitive Wavelengths Algorithm. Sustainability, 17(2), 518. https://doi.org/10.3390/su17020518