2.1. OLS Model, Moran’s I, and Spatial Weighting Schemes
Our paper aims to model the link between regional economic resilience and its infrastructure. We begin our methodological framework with a simple OLS specification:
where
r is an
n × 1 vector of observations of the resilience variable,
X is an
n ×
k matrix of resilience factors (including infrastructure),
β is a
k × 1 vector of regression coefficients,
e is a normally distributed, independent, and identically distributed error term,
n is the number of NUTS2 regions, and
k is the number of regressors.
The assumption of e~
N(0, σ
2I) is doubtful, and
e is probably a subject of spatial autocorrelation given that a region exists not in isolation but in a complex interrelation with other regions. This is true not just in the case of regions within a particular country but also between countries because, in the EU, countries’ economic borders are irrelevant. Thus, we will compute Moran’s I on the residuals
e of the OLS estimation of Equation (1) using different types of spatial weight matrices
W. This will allow us to identify whether significant spatial autocorrelation remains after estimating OLS regression [
28], and which
W allows us to identify the most suitable spatial structure for Equation (1), since spatial autocorrelation might be evident with one weighting scheme but not another, influencing the choice of spatial model specification. Moran’s I tests across multiple spatial weight matrices increase robustness, ensuring that spatial dependence is not sensitive to arbitrary choices of spatial structures.
As highlighted in the literature [
29,
30,
31], considerable debate persists regarding the importance or relative insignificance of selecting an appropriate spatial weight matrix. Moreover, the wide variety of available types and configurations further complicates the choice of the most suitable matrix. Therefore, we will examine three commonly used types of spatial weight matrices. The first type is contiguity-based weights [
28], identifying regions as neighbours if they share common borders. This is particularly relevant in EU NUTS2 regions, as administrative boundaries are clearly defined. Rook contiguity considers two regions’ neighbours if they share a common edge (border). For example, if two NUTS2 regions share a common administrative boundary (not merely a corner), they are neighbours under the Rook criterion, ignoring corner connections and possibly missing some spatial interactions. Queen contiguity considers two regions as neighbours if they share a common edge or corner (vertex). Thus, accounting for bordering and diagonal (vertex-connected) NUTS2 regions, Queen contiguity becomes more inclusive than Rock, capturing more faint or indirect spatial effects; however, at the same time, it includes potentially weaker connections (only corner-shared), which may not represent genuine spatial spillovers.
The second type is distance-based weights, which define neighbours based on geographic proximity, measured by centroids or actual distances between regions:
where
dij is the distance between the centroids of regions
i and
j, and
d* is a threshold distance. Following recommendations in the literature that suggest spatial spillover effects typically range from 200 to 1000 km and can extend as far as 3000 km [
32], our research defines neighbours based on threshold distances of 200, 500, and 1000 km interregional distance.
This framework explicitly captures spatial decay in interactions and is helpful for large or heterogeneous NUTS2 regions. Still, it is sensitive to the threshold distance choice. It does not expressly account for regional boundaries, potentially linking geographically close but practically disconnected regions (i.e., separated by mountains or water bodies).
The third type is k-nearest neighbours (k-nn) weights [
33], which define a fixed number (
k) of nearest regions as neighbours based on distance ranking:
In this framework, each region, irrespective of its size or location, has the same number of neighbouring regions, ensuring uniformity in connectivity, which is particularly useful when regional densities vary significantly [
33]; however, if the regional density is low, it arbitrarily forces distant regions into neighbour relations, and spatial interaction might be underestimated or overestimated depending on the chosen
k. To address the latter, we calculate Moran’s I for
k ranging from 1 to 24 [
34].
Thus, for 29 types of
W, we calculate Moran’s
I statistics on the obtained OLS residual
e from the non-spatial specification Equation (1):
where
I is a global measure of spatial autocorrelation assessing whether similar (or dissimilar) values are clustered in space;
is a sum of all elements in the spatial weight matrix, which acts as a scaling factor to adjust for the total amount of spatial connectivity;
W is
n ×
n spatial weight matrix where each element
Wij reflects the spatial relationship between region
i and region
j;
is the spatial cross-product of residuals, which measures the degree to which residuals at region
i are systematically related to residuals at region
j across space, weighted by
Wij; and
is the sum of squared residuals, which serves as a normalisation term, ensuring that Moran’s
I is appropriately scaled and comparable across different types of resilience.
I > 0 signals positive spatial autocorrelation, i.e., similar values cluster together (i.e., high-high or low-low resilience regions). I < 0 indicates negative spatial autocorrelation, i.e., dissimilar values are neighbouring (i.e., high-low resilience contrasts). If I ≈ 0, no meaningful spatial autocorrelation is present. A significant Moran’s I would suggest using the spatial model.
2.2. Spatial Models
The simplest spatial model is the Spatial Error Model (SEM), which assumes spatial dependence in the error term rather than in the resilience or its factors [
35]. Spatial dependence might arise from omitted variables or measurement errors that are spatially correlated. To estimate SEM, we will use a general specification (1). Still, with a composite error term, that is e = λ
We + ε, ε~N(0, σ
2I), where
e is the spatially dependent error term, λ is the spatial autoregressive parameter indicating spatial error dependence, and
ε is a normally distributed, independent, and identically distributed error term. Thus, SEM would generally focus in our research on unobserved spatial heterogeneity and omitted variables influencing spatial correlation in errors.
The Spatial Lagged Exogenous Variables Model (SLX) incorporates spatially lagged resilience factors but does not explicitly model spatial dependence in the resilience or the error term [
36]. It allows us to measure how neighbouring regions’ resilience factors affect local resilience. Our specification of SLX is as follows:
where
WX are the spatially lagged resilience factors, and
γ represents the vector of coefficients associated with the spatially lagged resilience factors. Thus, SLX isolates spillover effects from resilience factors, emphasising neighbourhood influences without direct spatial autocorrelation in resilience. It is especially relevant in the context of our research given that infrastructure such as roads, railways, etc., does not stop at a region’s border, and its effect on resilience may strongly depend on what infrastructure is in the surrounding regions since there is no such thing as isolated infrastructure within regional borders that would be useful for the region’s economy.
The Spatial Durbin Error Model (SDEM) combines the SEM and SLX, incorporating spatial dependence in the error term and spatially lagged resilience factors, thus capturing omitted spatially correlated variables and direct neighbourhood effects [
29]. Our specification of SDEM is as follows:
where
e, as previously, is the spatially dependent error term that is decomposed as λ
We + ε, ε~N(0, σ
2I). This way, SDEM captures omitted spatial influences (through errors) and spillover effects from resilience factors.
The Spatial Durbin Model (SDM) explicitly includes spatial dependence in resilience and its factors. This specification distinguishes between direct and indirect (spatial spillover) effects [
29]. Our specification of SDM is as follows:
where
Wr is the spatially lagged resilience, and
ρ represents the spatial autoregressive parameter indicating the strength of dependence in the resilience. This way, SDM allows the estimation of both endogenous spatial spillovers from the resilience and exogenous spatial spillovers from resilience factors.
The model estimations were implemented using custom code written in Python 3.13.2. We used the following libraries: libpysal, spreg, statsmodels, numpy, pandas, and geopandas; we worked in the PyCharm integrated development environment. The shapefiles for the Territorial Units for Statistics (NUTS) were obtained from the Eurostat GISCO database. The configurations used were the NUTS 2016 version, polygon (RG) geometry, 1:20 million scale, and the EPSG:3035 coordinate reference system.
2.3. Measuring Resilience
To measure regional economic resilience r, we will use three perspectives: Resistance (Rsis), Recovery (Rcov), and Reorientation (Rori).
In the context of regional economic resilience,
resistance refers to the ability of a region to withstand or absorb shocks or disruptions without experiencing substantial decline or structural change [
9]. This involves the regional economic systems’ inherent robustness and ecological resilience [
37,
38], which provide them with the capacity for shock absorption and the maintenance of stability and durability in the face of adverse conditions. Resistance emphasises the structural strength and stability that allow a region to continue functioning effectively, avoiding significant negative impacts when confronted with economic disturbances.
In the context of regional economic resilience (also known as engineering resilience),
recovery describes a region’s capability to quickly return to a pre-existing state or level of economic functioning following a disruption [
37,
38]. This capability underscores the region’s potential to bounce back, swiftly rebound, and achieve restoration, effectively ensuring a return to equilibrium [
39]. Recovery thus highlights the speed and effectiveness with which a region can restore its economy to its original condition following a shock [
9], focusing on restoration rather than structural change or adaptation.
In the context of regional economic resilience,
reorientation reflects a region’s capacity to recover, adapt, transform, or even improve its economic structures and processes in response to disruptions or evolving conditions [
8,
40,
41,
42]. Known variously as adaptive or transformative resilience, this concept captures a region’s capacity for adaptation and renewal. It encompasses the ideas of bounce-forward and bounce-beyond, highlighting the region’s potential for reconfiguration, innovation, and evolutionary change. Reorientation stresses the importance of adaptive change, emphasising the region’s ability to utilise disruptions as opportunities for transformation and improvement, actively shaping a new, frequently enhanced economic path rather than merely restoring previous conditions.
We will employ the sensitivity index (SI) to measure resilience in all three cases [
9,
38,
43]. For resistance and recovery, we will use the total employment rate (
TE) and, for reorientation, employment in high-technology sectors (high-technology manufacturing and knowledge-intensive high-technology services) as a percentage of total employment (
HTE). Since we are testing our model targeting the COVID-19 crisis, we will consider 2017–2019 as the pre-crisis period, 2020–2021 as the COVID-19 crisis, and 2022–2024 as the post-COVID-19 period. Following recent developments in the literature, we introduce a slight modification to the classical sensitivity index: rather than comparing NUTS-2 regional levels to national averages, we compare regional performance directly against the broader European context [
44,
45]. We calculate resistance (
Rsis) using the sensitivity index as follows:
where
is the lowest employment rate over the crisis period in region
i and
EU27, and
is the highest employment rate over the pre-crisis period in region
i and
EU27.
We calculate recovery (
Rcov) using the sensitivity index as follows:
where
is the highest employment rate over the post-crisis period in region
i and
EU27.
We calculate reorientation (
Rori) using the sensitivity index as follows:
Table 1 presents the interpretation of all three sensitivity indices. In addition,
Figure A1,
Figure A2 and
Figure A3 in
Appendix A.1 illustrate the results for the resistance, recovery, and reorientation sensitivity indices, respectively.
2.4. Infrastructure and Other Resilience Determinants
The matrix of resilience factors X includes a variety of infrastructure variables that represent different types of infrastructure in the NUTS2 regions. We use the average over 2017–2019 for these variables to proxy pre-crisis regional conditions. Exceptions are made for the population age structure, which uses data from 2021, and the government quality index, which relies on data from 2017.
As it is common to represent transportation infrastructure, we use a motorway (
MD) and a railway (
RD) density measured as kilometres per 1000 sq. kilometres [
46]. Here, we assume that higher densities correlate with better accessibility, as more kilometres of infrastructure per given area implies easier and more convenient access to transportation networks. Good accessibility is crucial for economic activities, influencing trade, investment, and regional development [
47,
48]. Higher-density regions usually have a more comprehensive network coverage, enhancing connectivity. Dense infrastructure networks can reflect effective spatial planning and efficient resource allocation [
49].
To represent tourism infrastructure, we use tourism beds (
TB) [
50], which include beds in hotels, holiday and other short-stay accommodations, camping grounds, recreational vehicle parks, and trailer parks per 100,000 people. Tourism beds indicate a region’s capacity to accommodate tourists [
51]—a fundamental aspect of tourism infrastructure. A higher number indicates a stronger potential for handling tourism flows. Regions with more beds per capita typically have better-developed hospitality sectors, translating into enhanced visitor experiences, more extended tourist stays, and potentially higher tourism expenditure. This metric signals the economic maturity and readiness of a region to benefit economically from tourism, including job creation, local business growth, and overall economic activity generated by visitors. Higher tourism bed densities may also indicate regions specialised in tourism, suggesting greater economic dependency on tourism and potential economic vulnerability, which can shape regional economic resilience.
We use available hospital beds (
HB) per 100,000 people to represent healthcare infrastructure [
5]. The number of hospital beds directly reflects the healthcare system’s capacity to deliver inpatient care [
52], handle emergencies, manage chronic and acute conditions, and respond to public health crises. Higher bed availability indicates a region’s greater preparedness and resilience to healthcare demands and emergencies, such as pandemics or natural disasters. Regions with higher hospital bed densities are typically better equipped to provide timely and adequate medical services, improving accessibility to healthcare services. Sufficient hospital bed numbers often correlate with broader healthcare infrastructure quality, including available specialised medical services, equipment, and qualified medical personnel. Bed density can reflect the efficiency and adequacy of health systems, influencing overall population health outcomes and healthcare accessibility. Adequate hospital bed provision contributes positively to public health outcomes, indirectly influencing productivity, quality of life, economic growth, and regional attractiveness for residents and businesses. Particularly significant during public health emergencies (pandemics like COVID-19), hospital bed availability directly impacts a region’s resilience and capacity to handle surges in healthcare demand.
To represent the information and communication infrastructure, we use the percentage of households with access to the internet at home (
IE). A higher percentage signals the extent to which a reliable and modern communication infrastructure has been deployed and is accessible across a region. Home internet access is critical for participating in the digital economy, including e-commerce, teleworking, online education, e-government services, and telemedicine. Regions with higher household internet access typically show stronger economic development and innovation capacities [
53]. This indicator captures not only the availability but also the social inclusiveness of communication infrastructure, as disparities in access often mirror broader inequalities in income, education, and geographic location [
54]. Internet access at home has become a basic necessity, comparable to utilities such as water and electricity, and is crucial for social participation and information access. A high household internet access rate suggests the widespread adoption of modern technologies, supporting broader communication service expansions such as 5G networks, smart grids, and IoT applications. It indicates a region’s readiness to leverage advanced technological applications, facilitating innovation, research, and smart regional development.
We use the percentage of early leavers from education and training (
EdL) aged 18–24 to represent the education infrastructure. A lower percentage of early leavers suggests that the education system effectively retains students, provides relevant and accessible education, and supports students in completing their studies. High rates of early leaving often indicate systemic weaknesses in the education infrastructure, such as insufficient support services, inadequate school facilities, or limited access to vocational or alternative education pathways. Early leaving rates reflect how accessible and inclusive the education infrastructure is for different social, economic, and geographic groups. Higher early leaving rates may signal barriers such as poor transportation to schools, lack of affordable post-secondary education options, or inadequate technological infrastructure (e.g., lack of digital learning tools). Education infrastructure plays a critical role in developing human capital [
55]. Regions with lower early leaving rates tend to have a better-educated workforce, which supports higher productivity, innovation, and economic growth. Early school leavers face higher risks of unemployment [
56], lower income, and social marginalisation, making this indicator highly relevant for evaluating the broader socio-economic effectiveness of education infrastructure. A low early leaving rate often reflects that schools and training institutions offer high-quality, relevant, and engaging educational programs that meet the needs and expectations of young people. It also suggests that the education system is flexible and can provide diverse pathways, including vocational training, apprenticeships, and higher education alternatives. Variations in early leaving rates between regions reveal disparities in the strength and accessibility of education infrastructure.
In
X, we also include the European Quality of Government Index (QoG) and population density (
POPD) measured as the number of people per sq. kilometre. They are good proxies for the overall quality and quantity of regional infrastructure [
57]. High-quality governments are better at planning, prioritising, and implementing infrastructure projects coherently and in a forward-looking manner. Good governance ensures that public investments in infrastructure are made based on needs assessments, cost-benefit analyses, and long-term regional development goals. Quality government institutions build new infrastructure and maintain and upgrade existing assets, ensuring long-term sustainability [
58]. Lower levels of corruption result in infrastructure investments being used as intended, avoiding issues such as cost overruns, substandard construction, or misallocation. Regions with high government quality are better positioned to attract private investment in infrastructure through public–private partnerships, reducing fiscal pressure and improving efficiency. Trust in government facilitates citizen support for infrastructure projects and minimises resistance to necessary but disruptive investments (e.g., large transport hubs and energy projects).
In densely populated regions, infrastructure can be built and operated more cost-effectively because fixed costs (e.g., roads, water supply, public transport) are spread over a larger population. High-density areas have concentrated demand, justifying investments in complex and high-capacity infrastructure [
59], such as metro systems, high-speed internet, specialised hospitals, and significant education centres. Densely populated regions often require more sophisticated infrastructure systems to efficiently manage congestion, environmental stress, public health, and urban services; however, a very high density can also lead to overburdened systems (i.e., traffic congestion [
60], overloaded sewage systems) if infrastructure investment does not keep pace with population growth. Higher density demands better spatial coordination and integration of infrastructure networks (i.e., linking housing with transport and utilities), increasing the complexity of infrastructure planning.
To capture regional heterogeneity in terms of other factors affecting regional economic resilience and to reduce the likelihood of omitted variable bias, X includes GDP at current market prices PPS per inhabitant (Y) to proxy regional development level, population 0–24 years and population 65 years or over to population 25–64 years (PAS) to proxy regions’ population age structure, and population (POP) to proxy the region’s size.
Per capita GDP is a direct proxy of a region’s economic development [
44], industrial diversification, labour productivity, and market integration. It also might indirectly capture a range of factors strongly associated with economic resilience, such as investment in human capital (education, training), technological adoption and innovation capacity, entrepreneurial activity and business density, and broader financial, labour, and goods market efficiency. Including GDP per capita, we can control for a composite measure of economic health and complexity that underlies many resilience-related characteristics, thereby reducing the risk that unobserved heterogeneity in development levels biases the estimated effects of infrastructure characteristics.
Young and elderly people, relative to the working-age population (dependency ratio), directly capture the demographic burden on productive segments of society. It directly proxies labour market pressure [
44], public service demand (education, healthcare), and future labour force potential. It also might indirectly reflect long-term growth prospects (younger populations imply future labour supply), fiscal sustainability (ageing populations may stress pensions and healthcare systems), innovation potential (younger populations often correlate with higher adaptability and technology adoption), and social cohesion and vulnerability (regions with extreme age structures may be more vulnerable to shocks). By accounting for the age structure, we control for a major source of regional economic heterogeneity that affects resilience [
61], particularly in how regions respond to labour market shocks, adapt to demographic changes, and manage social support systems.
The absolute population size proxies the scale of the region, which has direct and indirect implications for economic resilience. It directly proxies the size of the labour market, local consumer market, economies of agglomeration (benefits from the concentration of people and activities) [
62], and the capacity to achieve scale economies in public infrastructure and services. It indirectly captures urbanisation level, complexity and diversity of economic activities, the potential for network effects (e.g., innovation clusters, knowledge spillovers), and political bargaining power for national investments. Regions of different sizes inherently differ in their capacity to absorb shocks, diversify economic bases, and maintain essential public services. Controlling for population size thus prevents confounding the analysis of resilience with simple side effects.
All in all, X = {ln(MD), ln(RD), ln(TB), ln(HB), IE, EdL, QoG, ln(POPD), ln(Y), PAS, and ln(POP)}.
Table 2 reports the main descriptive statistics of the variables.
As this research focuses on the European context, data sources were selected based on the availability of regionally disaggregated statistics, particularly for infrastructure-related variables. The most comprehensive and reputable source in this context is Eurostat, from which the majority of the data was obtained. An exception is the European Quality of Government Index provided by the QoG Institute, which is widely recognised for its extensive and reliable coverage of government efficiency across European regions. Due to limited data availability at the NUTS2 level in several cases, certain modifications were necessary; a detailed description of these adjustments is provided in
Appendix A.2. Furthermore, the structure of spatial weight matrices combined with the distribution of available data led to the exclusion of some observations in certain models. Specifically, this occurred when regions were isolated (i.e., formed “islands” with no spatial connections to other regions) or when the spatial structure resulted in multiple disconnected components. In such cases, only the largest connected component, along with its associated observations, was retained for analysis to ensure model consistency and proper spatial estimation.
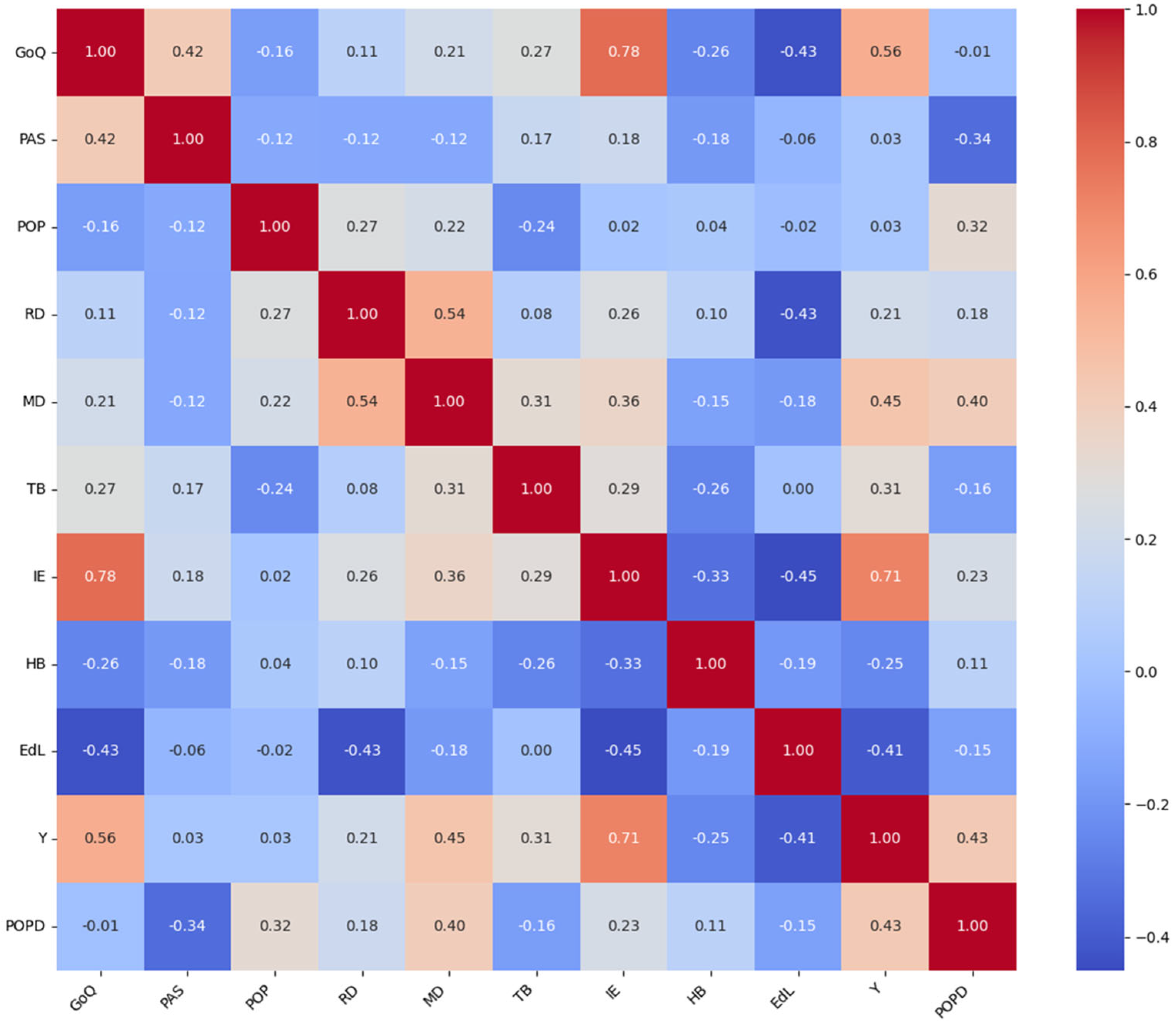
Figure 1 presents the cross-correlation between the independent variables.





{kind=link}
{kind=link}
{kind=link}
{kind=link}