
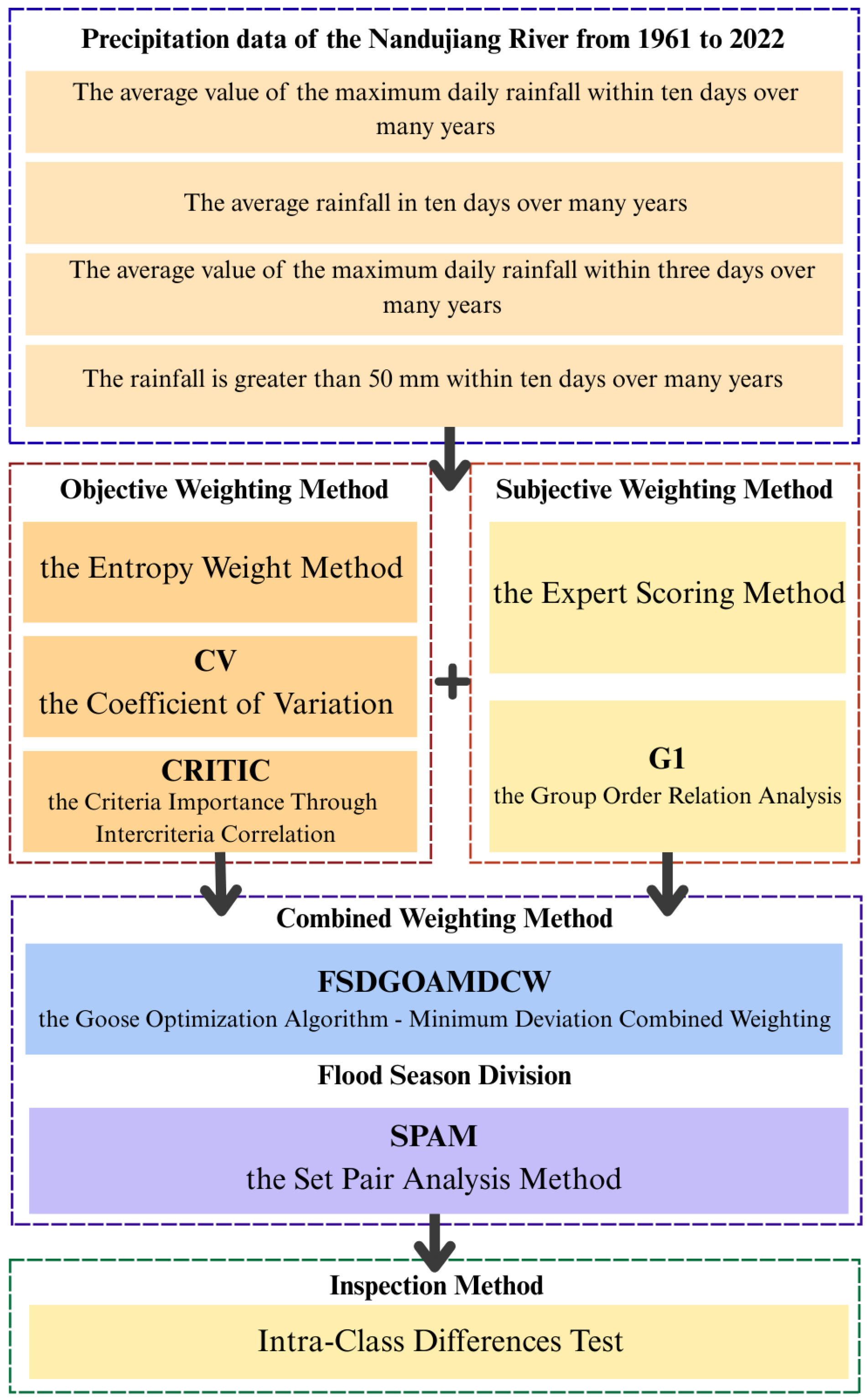
Flood Season Division Model Based on Goose Optimization Algorithm–Minimum Deviation Combination Weighting

Abstract
1. Introduction
2. Methodology
2.1. Objective and Subjective Weighting Methods for Determining Indicator Weights
2.1.1. Calculation of Indicator Weights Using the Entropy Weight Method
- Step 1
- Calculate the indicator weight matrix.
- Step 2
- Compute the information entropy.
- Step 3
- Compute the indicator weights.
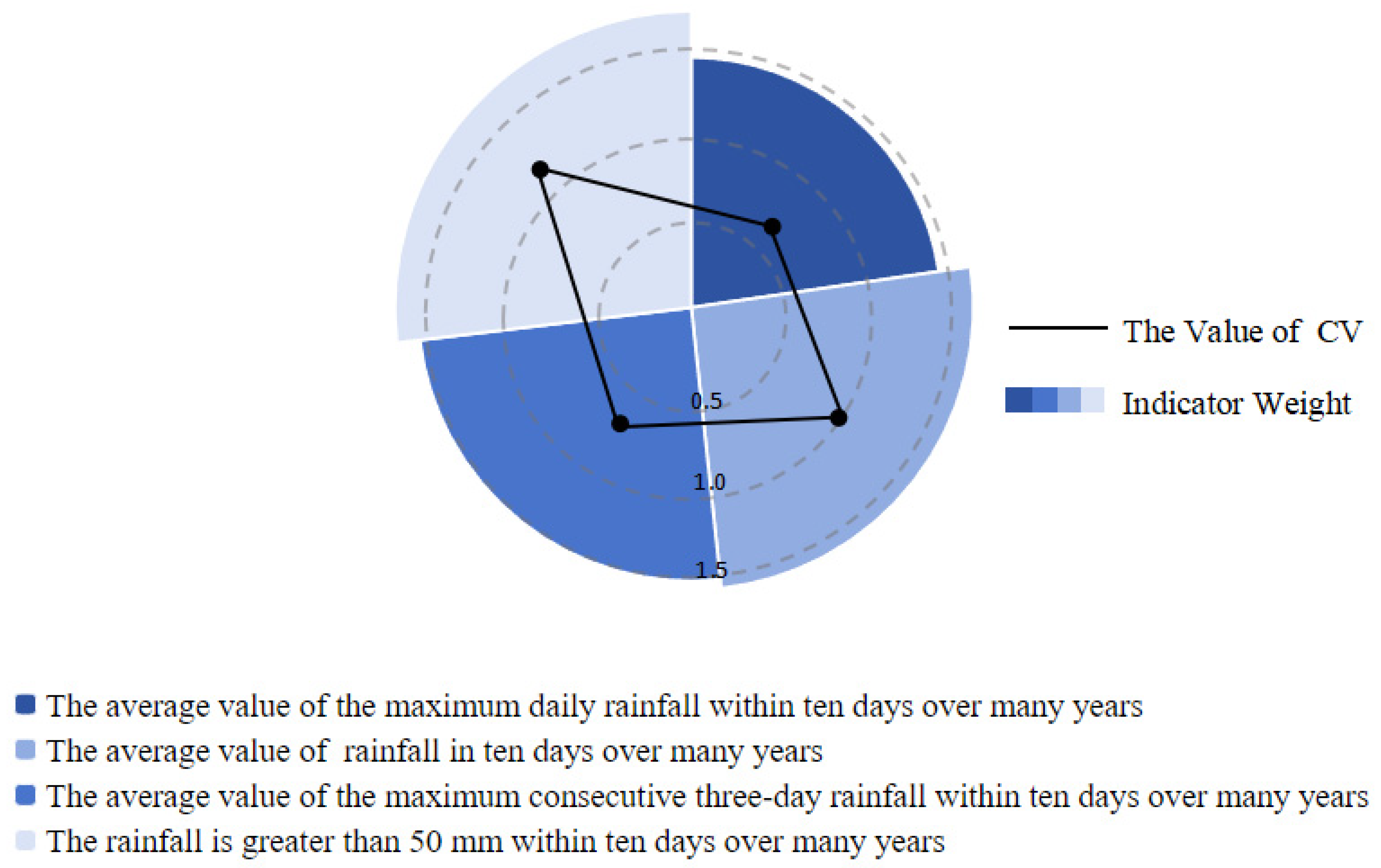
2.1.2. Calculation of Indicator Weights Using the Coefficient of Variation Method
- Step 1
- Calculate the mean.
- Step 2
- Calculate the standard deviation.
- Step 3
- Calculate the CV.
- Step 4
- Calculate the weights.
2.1.3. Calculation of Indicator Weights Using the CRITIC (Criteria Importance Through Intercriteria Correlation) Method
- Step 1
- Calculate correlations between indicators.
- Step 2
- Calculate the amount of information.
- Step 3
- Calculate indicator weights.
2.2. Subjective Weighting Methods for Determining Indicator Weights
2.2.1. Determining Indicator Weights Using the Expert Scoring Method
- Step 1
- Expert Selection: Pick experts with flood season division experience; explain weight definitions, rules, and recording;
- Step 2
- List Compilation: List all indicators with weight ranges, quantified via the scoring scale;
- Step 3
- Scoring: Distribute the list to experts for repeated evaluation (steps 4–9) until scores stabilize;
- Step 4
- Individual Scoring: Experts score indicators by perceived importance;
- Step 5
- Discussion and Revision: Experts discuss scores; revisit inconsistencies, rescore to reach consensus;
- Step 6
- Total Score Calculation: Sum scores per expert across indicators;
- Step 7
- Individual Weight Calculation: Compute indicator weight as (its score/expert’s total score);
- Step 8
- Group Average Weight Calculation: Average weights across experts to obtain “group average weight”;
- Step 9
- Comparative Display: Compare averages with step 7 individual weights to check discrepancies/rationality;
- Step 10
- Finalization: Repeat scoring loop (steps 4–9) if discrepancies exist. Finalize group average weights once wj agreed for decision–making.
2.2.2. Determining Indicator Weights Using the G1 Method (Group Order Relation Analysis)
- Step 1
- Establish the Order Relation.
- Step 2
- Assess Relative Importance Between Adjacent Indicators.
- Step 3
- Calculate Weight Coefficients.
2.3. Optimal Combination Weights via the Goose Optimization Algorithm (GOA)
- Step 1
- Initialize the Goose Population.
- Step 2
- Define the Fitness Function.
- Step 3
- Update Goose Positions.
- Step 4
- Update Individual and Global Bests.
- Step 5
- Termination Criteria.
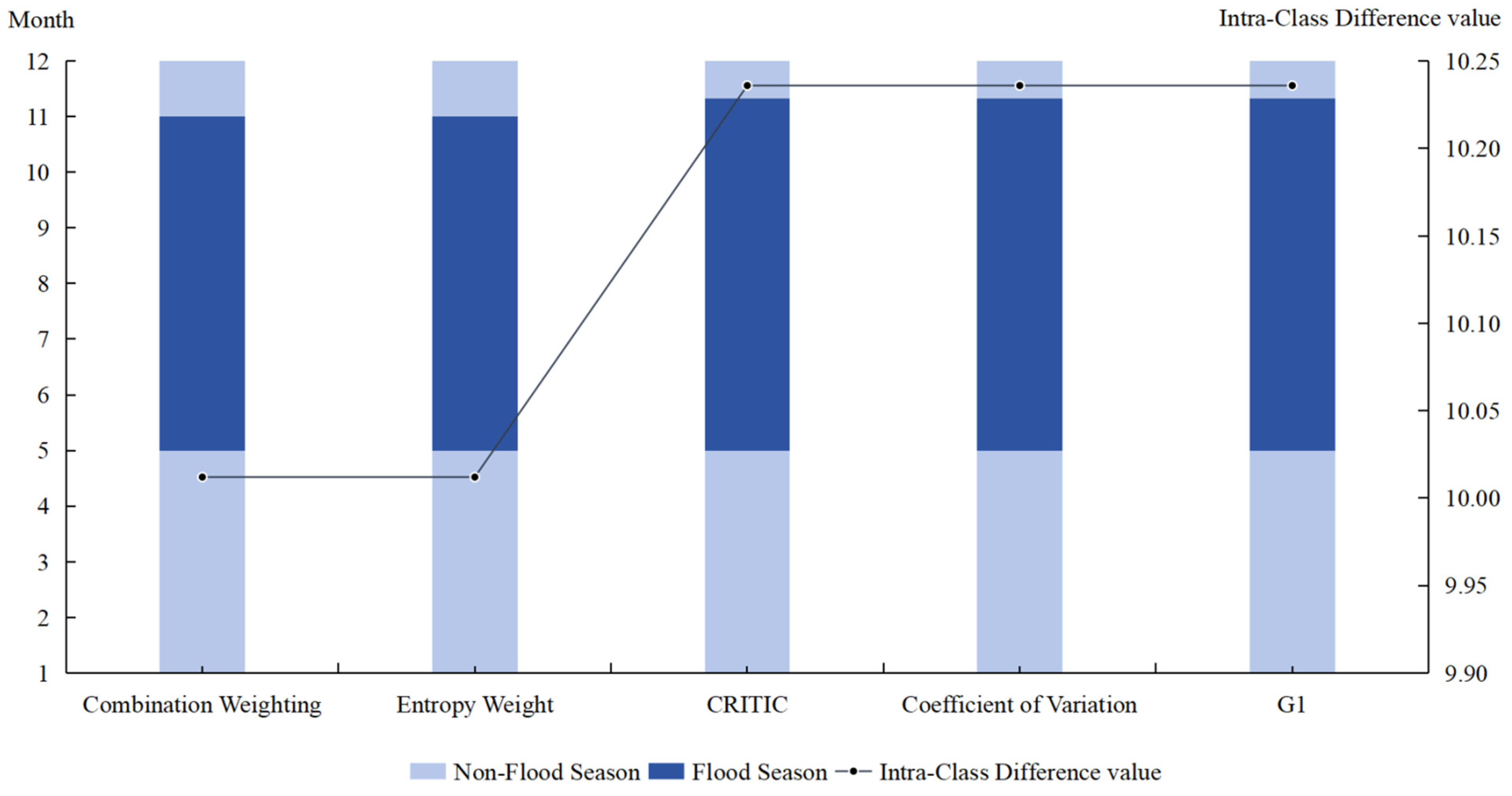
2.4. Validation of Division Methods Under Different Weighting Schemes Using Intra-Class Differences
- Step 1
- Compute Class Mean.
- Step 2
- Compute Intra-Class Differences.
- Step 3
- Compute Overall Intra-Class Differences.
2.5. Set Pair Analysis for the Division of Flood and Non-Flood Periods
- Step 1
- Determine the threshold for indicators.
- Step 2
- Data Symbolization.
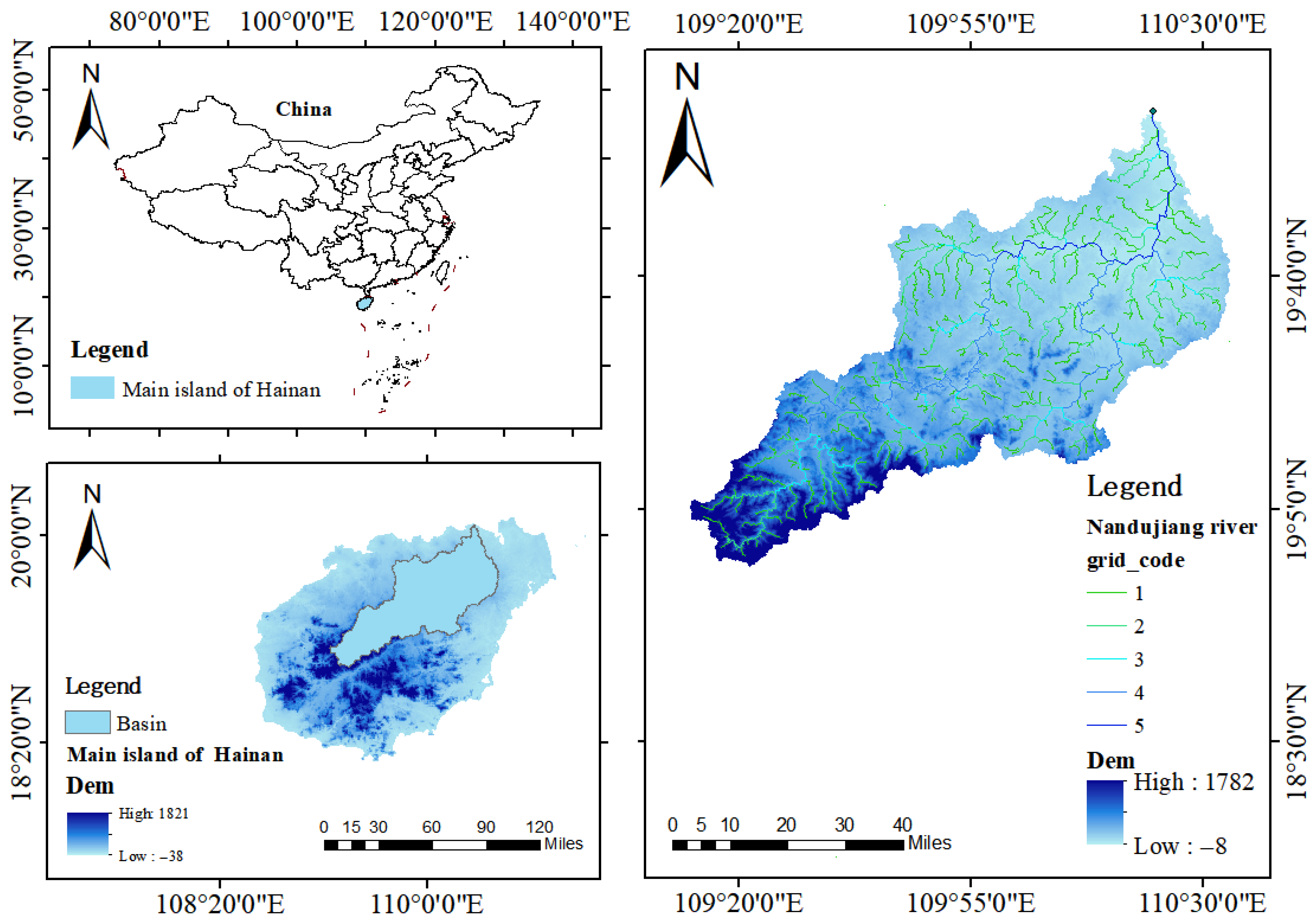
3. Case Study
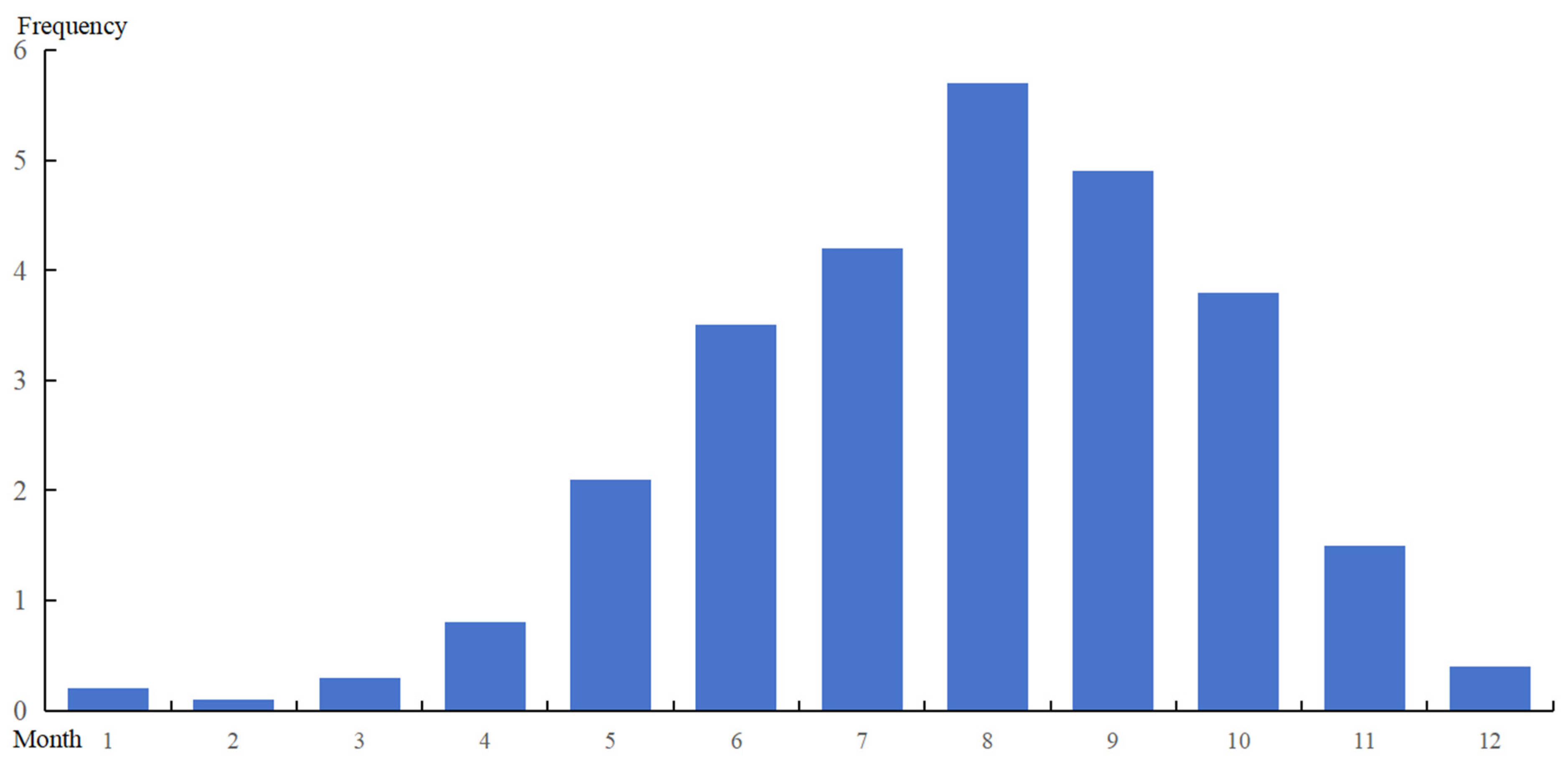
4. Data Preprocessing and Results
4.1. Data Preprocessing for Flood Season Division
4.2. Combination Weight Calculation and Indicator Symbolization
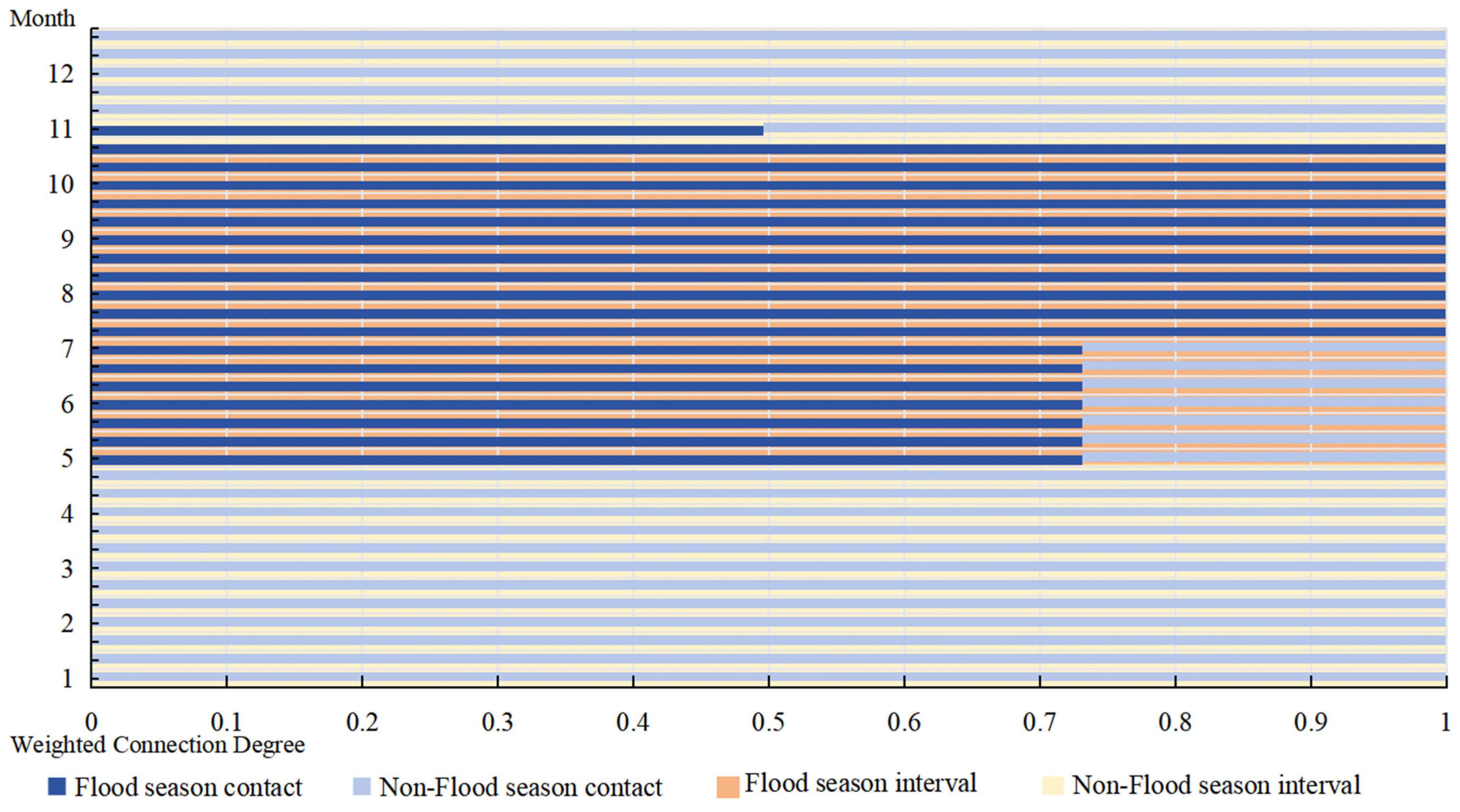
4.3. Flood Season Division Using Set Pair Analysis
5. Discussion
5.1. Comparative Analysis of the Combined Weighting Method and the Single Weighting Method
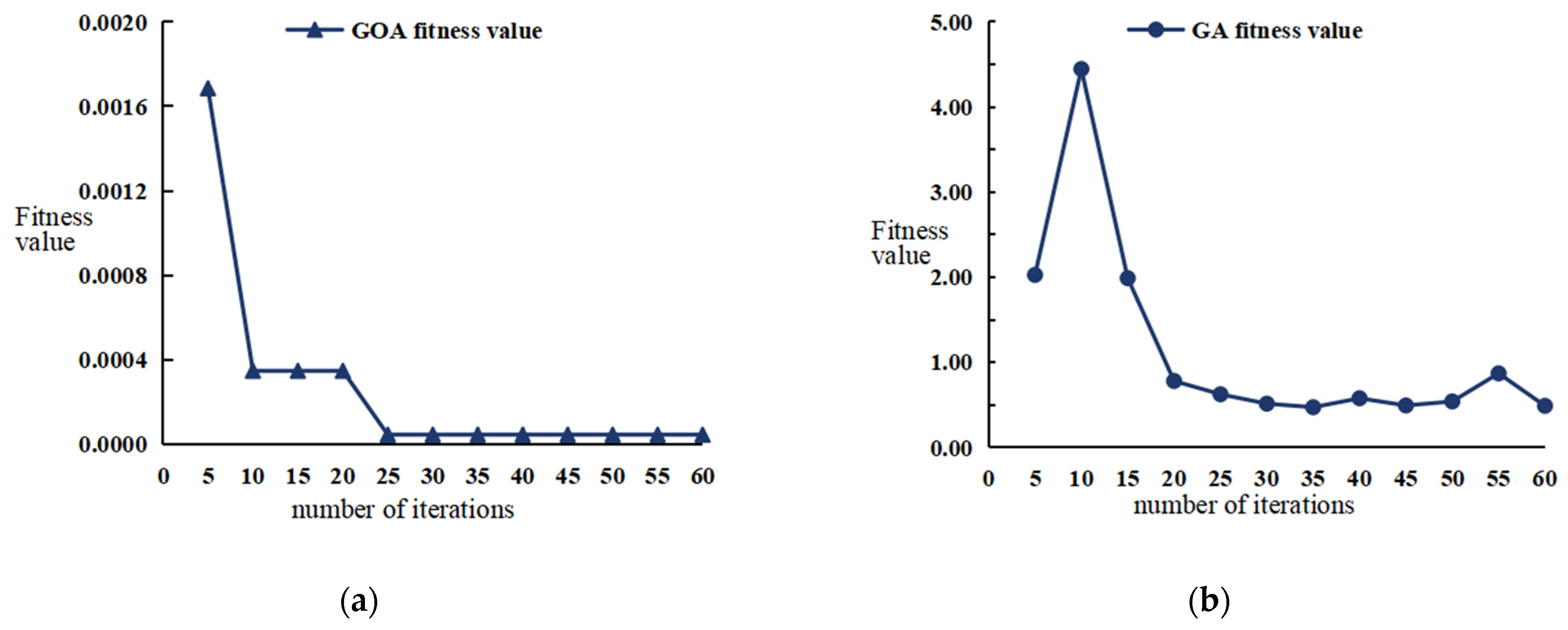
5.2. Comparison of Optimization Algorithm Performance
6. Conclusions
- ①
- GOA converges faster than the Genetic Algorithm, stabilizing at T = 5 and achieving full convergence at T = 24;
- ②
- Based on the calculation results of the model in this paper, the flood season time domain of the Nandujiang River Basin is from 1 May to 30 October. This result can provide a certain reference basis for reservoir operation;
- ③
- In the evaluation process based on Intra-Class Differences, the Intra-Class Differences of the model in this paper is the smallest, which is 10.01. The smallest Intra-Class Differences indicates that the division results based on the model in this paper have good Intra-Class similarity. Compared with the comparison models established based on subjective or objective weighting methods, the model in this paper has better consistency in flood season division in tropical island regions.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| FSDGOAMDCW | Goose Optimization Algorithm–Minimum Deviation Combined Weighting |
| CV | Coefficient of Variation |
| G1 | Group Order Relation Analysis |
| CRITIC | Criteria Importance Through Intercriteria Correlation |
| GOA | Goose Optimization Algorithm |
| SPAM | Set Pair Analysis Method |
| AHP | Analytic Hierarchy Process |
References
- Li, Y.; Li, Y.; Feng, K.; Sun, K.; Cheng, Z. The Influence of Time Domain on Flood Season Segmentation by the Fisher Optimal Partition Method. Water 2024, 16, 580. [Google Scholar] [CrossRef]
- Fang, C.; Guo, S.; Duan, Y.; Duong, D. Two new approaches to dividing flood sub-seasons in flood season using the fractal theory. Chin. Sci. Bull. 2010, 55, 105–110. [Google Scholar] [CrossRef]
- Xu, Z.; Mo, L.; Zhou, J.; Zhang, X. Optimal dispatching rules of hydropower reservoir in flood season considering flood resources utilization: A case study of Three Gorges Reservoir in China. J. Clean. Prod. 2023, 388, 135975. [Google Scholar] [CrossRef]
- Jiang, H.; Wang, Z.; Ye, A.; Liu, K.; Wang, X.; Wang, L. Hydrological characteristic-based methodology for dividing flood seasons: An empirical analysis from china. Environ. Geol. 2019, 78, 399.1–399.9. [Google Scholar] [CrossRef]
- Ghosh, A.; Kar, S.K. Application of analytical hierarchy process (AHP) for flood risk assessment: A case study in Malda district of West Bengal, India. Nat. Hazards 2018, 94, 349–368. [Google Scholar] [CrossRef]
- Kwong, C.K.; Ip, W.H.; Chan, J.W.K. Combining scoring method and fuzzy expert systems approach to supplier assessment: A case study. Integr. Manuf. Syst. 2002, 13, 512–519. [Google Scholar] [CrossRef]
- Li, M.; Zhou, R.R.; Wang, Y.T.; Liu, D. Variable Fuzzy Sets Method for Flood Seasonality of Catchments. In Proceedings of the World Environmental and Water Resources Congress 2015, Austin, TX, USA, 17–21 May 2015; pp. 643–651. [Google Scholar]
- Chen, L.; Singh, V.P.; Guo, S.; Zhou, J.; Zhang, J.; Liu, P. An objective method for partitioning the entire flood season into multiple sub-seasons. J. Hydrol. 2015, 528, 621–630. [Google Scholar] [CrossRef]
- Malekinezhad, H.; Sepehri, M.; Pham, Q.B.; Hosseini, S.Z.; Meshram, S.G.; Vojtek, M.; Vojteková, J. Application of entropy weighting method for urban flood hazard mapping. Acta Geophys. 2021, 69, 841–854. [Google Scholar] [CrossRef]
- Thangjai, W.; Niwitpong, S.A.; Niwitpong, S. Confidence intervals for the common coefficient of variation of rainfall in Thailand. PeerJ 2020, 8, e10004. [Google Scholar] [CrossRef]
- Mu, Z.; Ai, X.; Ding, J.; Huang, K.; Chen, S.; Guo, J.; Dong, Z. Risk analysis of dynamic water level setting of reservoir in flood season based on multi-index. Water Resour. Manag. 2022, 36, 3067–3086. [Google Scholar] [CrossRef]
- Wang, S.; Yang, X. Flood season division based on correlation coefficient and optimum partition method of fisher. J. China Hydrol. 2011, 32, 1–5. [Google Scholar]
- Karunarathne, A.W.S.P.; Piyatilake, I.T.S. Determining Flood Risk Vulnerability Using Factor Analysis Approach. In 2021 6th International Conference on Information Technology Research (ICITR), Moratuwa, Sri Lanka, 1–3 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Mo, C.; Deng, J.; Lei, X.; Ruan, Y.; Lai, S.; Sun, G.; Xing, Z. Flood season staging and adjustment of limited water level for a multi-purpose reservoir. Water 2022, 14, 775. [Google Scholar] [CrossRef]
- Zhao, J.; Jin, J.; Zhu, J.; Xu, J.; Hang, Q.; Chen, Y.; Han, D. Water resources risk assessment model based on the subjective and objective combination weighting methods. Water Resour. Manag. 2016, 30, 3027–3042. [Google Scholar] [CrossRef]
- Ponhan, K.; Sureeyatanapas, P. A comparison between subjective and objective weighting approaches for multi-criteria decision making: A case of industrial location selection. Eng. Appl. Sci. Res. 2022, 49, 763–771. [Google Scholar]
- Ran, L.; Tan, X.; Xu, Y.; Zhang, K.; Chen, X.; Zhang, Y.; Li, M.; Zhang, Y. The application of subjective and objective method in the evaluation of healthy cities: A case study in Central China. Sustain. Cities Soc. 2021, 65, 102581. [Google Scholar] [CrossRef]
- Yao, H.; Dong, Z.; Jia, W.; Ni, X.; Chen, M.; Zhu, C.; Li, D. Competitive relationship between flood control and power generation with flood season division: A case study in downstream Jinsha River Cascade Reservoirs. Water 2019, 11, 2401. [Google Scholar] [CrossRef]
- Ma, P.; Han, L.; Liu, H.; Zhang, H. Fuzzy multi-objective optimization of EMT based on the minimum average weighted deviation algorithm. Energy Procedia 2017, 105, 2409–2414. [Google Scholar] [CrossRef]
- Li, J. A flood season division model considering uncertainty and new information priority. Water Resour. Manag. 2024, 38, 3755–3784. [Google Scholar] [CrossRef]
- Jhong, Y.D.; Chen, C.S.; Jhong, B.C.; Tsai, C.H.; Yang, S.Y. Optimization of LSTM parameters for flash flood forecasting using genetic algorithm. Water Resour. Manag. 2024, 38, 1141–1164. [Google Scholar] [CrossRef]
- Jiang, L.; Tajima, Y.; Wu, L. Application of Particle Swarm Optimization for Auto-Tuning of the Urban Flood Model. Water 2022, 14, 2819. [Google Scholar] [CrossRef]
- Zhai, L.; Feng, S. A novel evacuation path planning method based on improved genetic algorithm. J. Intell. Fuzzy Syst. 2022, 42, 1813–1823. [Google Scholar] [CrossRef]
- Pawan, Y.N.; Prakash, K.B.; Chowdhury, S.; Hu, Y.C. Particle swarm optimization performance improvement using deep learning techniques. Multimed. Tools Appl. 2022, 81, 27949–27968. [Google Scholar] [CrossRef]
- Hamad, R.K.; Rashid, T.A. GOOSE algorithm: A powerful optimization tool for real-world engineering challenges and beyond. Evol. Syst. 2024, 15, 1249–1274. [Google Scholar] [CrossRef]
- Zhang, J.; Xu, L.; Xia, L.; Yang, Q.; Chen, Z.; Dong, W. Comprehensive Evaluation Technology of Photovoltaic Power Station Power Generation Performance Based on Minimum Deviation Combined Weighting Method. In Proceedings of the 2022 IEEE 6th Conference on Energy Internet and Energy System Integration (EI2), Chengdu, China, 11–13 November 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 880–885. [Google Scholar]
- Li, X.; Zhang, W.; Wang, X.; Wang, Z.; Pang, C. Evaluation on the risk of water inrush due to roof bed separation based on improved set pair analysis–variable fuzzy sets. Acs Omega 2022, 7, 9430–9442. [Google Scholar] [CrossRef]
- Jin, D.T.; Zhou, T.; Yang, X.H.; Lu, Y.; Wang, K.W. Assessment of regional water resource carrying capacity by the connection number of set pair analysis. Therm. Sci. 2024, 28, 2287–2294. [Google Scholar] [CrossRef]
- Wang, L.; Liu, Y.; Li, Z.; Yi, H.; Wang, Z.; Liu, H.; Wu, D.; Li, Y.; Liu, M. Distribution characteristics of terrestrial PGEs and its trend into the sea around Hainan Island, China. Sci. Total Environ. 2025, 963, 178372. [Google Scholar] [CrossRef]
- Zhu, Y.; Tian, D.; Yan, F. Effectiveness of entropy weight method in decision-making. Math. Probl. Eng. 2020, 2020, 3564835. [Google Scholar] [CrossRef]
- Sun, Y.; Liang, X.; Xiao, C. Assessing the influence of land use on groundwater pollution based on coefficient of variation weight method: A case study of Shuangliao City. Environ. Sci. Pollut. Res. 2019, 26, 34964–34976. [Google Scholar] [CrossRef]
- Žižović, M.; Miljković, B.; Marinković, D. Objective methods for determining criteria weight coefficients: A modification of the CRITIC method. Decis. Mak. Appl. Manag. Eng. 2020, 3, 149–161. [Google Scholar] [CrossRef]
- Gao, Z.; McCalley, J.; Meeker, W. A transformer health assessment ranking method: Use of model based scoring expert system. In Proceedings of the 41st North American Power Symposium, Starkville, MS, USA, 4–6 October 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1–6. [Google Scholar]
- Xie, X.J. Research on material selection with multi-attribute decision method and G1 method. Adv. Mater. Res. 2014, 952, 20–24. [Google Scholar] [CrossRef]
- Liu, D.H.; Yu, Q.; Ma, X.N.; Yin, D.; Zhang, W.G. Emergency response capability evaluation model based on minimum deviation combined weights. J. China Manag. Sci. 2014, 22, 79–86. [Google Scholar]
- Kotsia, I.; Pitas, I.; Zafeiriou, S. Novel multiclass classifiers based on the minimization of the within-class variance. IEEE Trans. Neural Netw. 2008, 20, 14–34. [Google Scholar] [CrossRef]
- Lu, X.D.; Qi, S.; Chen, J.D.; Guo, J.C.; Zhang, L.; Zhou, P. Spatiotemporal Distribution and Variation Trend of Rainfall Erosivity in the Nandu River Basin. J. Ecol. Rural. Environ. 2023, 39, 1464–1473. [Google Scholar]
- Tang, L.; Zhang, Y. Considering abrupt change in rainfall for flood season division: A case study of the Zhangjia Zhuang reservoir, based on a new model. Water 2018, 10, 1152. [Google Scholar] [CrossRef]
- Song, Y.; Wang, H. Study on stage method of reservoir flood season. Energy Rep. 2022, 8, 138–146. [Google Scholar] [CrossRef]
- Zhe, W.; Xigang, X.; Feng, Y. An abnormal phenomenon in entropy weight method in the dynamic evaluation of water quality index. Ecol. Indic. 2021, 131, 108137. [Google Scholar] [CrossRef]
- Chen, R.; Jin, L.; Li, Z.; Zhang, J. A progressive approach for the detection of the coefficient of variation. Qual. Reliab. Eng. Int. 2021, 37, 2587–2602. [Google Scholar] [CrossRef]
- Kahraman, C.; Onar, S.C.; Öztayşi, B. A novel spherical fuzzy CRITIC method and its application to prioritization of supplier selection criteria. J. Intell. Fuzzy Syst. 2021, 42, 29–36. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Month | Ten Days | Indicator One | Indicator Two | Indicator Three | Indicator Four |
|---|---|---|---|---|---|
| 1 | 1 | × | × | × | × |
| 2 | × | × | × | × | |
| 3 | × | × | × | × | |
| 2 | 1 | × | × | × | × |
| 2 | × | × | × | × | |
| 3 | × | × | × | × | |
| 3 | 1 | × | × | × | × |
| 2 | × | × | × | × | |
| 3 | × | × | × | × | |
| 4 | 1 | × | × | × | × |
| 2 | × | × | × | × | |
| 3 | × | × | × | × | |
| 5 | 1 | √ | √ | √ | × |
| 2 | √ | √ | √ | × | |
| 3 | √ | √ | √ | × | |
| 6 | 1 | √ | √ | √ | × |
| 2 | √ | √ | √ | × | |
| 3 | √ | √ | √ | × | |
| 7 | 1 | √ | √ | √ | × |
| 2 | √ | √ | √ | √ | |
| 3 | √ | √ | √ | √ | |
| 8 | 1 | √ | √ | √ | √ |
| 2 | √ | √ | √ | √ | |
| 3 | √ | √ | √ | √ | |
| 9 | 1 | √ | √ | √ | √ |
| 2 | √ | √ | √ | √ | |
| 3 | √ | √ | √ | √ | |
| 10 | 1 | √ | √ | √ | √ |
| 2 | √ | √ | √ | √ | |
| 3 | √ | √ | √ | √ | |
| 11 | 1 | √ | × | × | √ |
| 2 | × | × | × | × | |
| 3 | × | × | × | × | |
| 12 | 1 | × | × | × | × |
| 2 | × | × | × | × | |
| 3 | × | × | × | × |
| Method | Flood Season/Membership | Non-Flood Season/Membership |
|---|---|---|
| Expert Scoring method | 0.500 | 0.500 |
| Combined Weighting method | 0.495 | 0.505 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Li, J.; Fu, J. Flood Season Division Model Based on Goose Optimization Algorithm–Minimum Deviation Combination Weighting. Sustainability 2025, 17, 6968. https://doi.org/10.3390/su17156968
Wang Y, Li J, Fu J. Flood Season Division Model Based on Goose Optimization Algorithm–Minimum Deviation Combination Weighting. Sustainability. 2025; 17(15):6968. https://doi.org/10.3390/su17156968
Chicago/Turabian StyleWang, Yukai, Jun Li, and Jing Fu. 2025. "Flood Season Division Model Based on Goose Optimization Algorithm–Minimum Deviation Combination Weighting" Sustainability 17, no. 15: 6968. https://doi.org/10.3390/su17156968
APA StyleWang, Y., Li, J., & Fu, J. (2025). Flood Season Division Model Based on Goose Optimization Algorithm–Minimum Deviation Combination Weighting. Sustainability, 17(15), 6968. https://doi.org/10.3390/su17156968