1. Introduction
With technological advancements and the rapid growth of the new energy vehicle industry, graphite, as a key anode material for lithium-ion batteries, has seen continuously increasing demand in critical fields such as high-end manufacturing and energy storage systems. It has become a strategic resource essential for securing the new energy supply chain and enhancing industry competitiveness [
1,
2,
3,
4]. The International Energy Agency (IEA) estimates that achieving net-zero emissions by 2040 will drive graphite demand to grow by 20 to 25 times, thereby requiring global mineral output to rise by over 300% compared to 2020 [
5]. Against this backdrop, the efficient development and green utilization of graphite mineral resources have become focal points for sustainable development worldwide [
6].
Graphite ore is commonly associated with various types of other minerals, especially low-grade minerals characterized by low effectiveness fixed carbon content and high impurity levels. Insufficient pre-screening of large amounts of low-grade ore leads to higher energy and material costs during processing and reduces the end-product graphite quality, ultimately disrupting industrial efficiency and product stability [
7]. Therefore, developing accurate and efficient methods for identifying low-grade minerals is crucial for improving resource utilization, ensuring product quality, and advancing green mining initiatives.
Traditional ore sorting methods primarily rely on complex equipment and manual operations, often supplemented by chemical treatments for mineral separation. These approaches are characterized by intricate processing workflows and high energy consumption, while inevitably causing environmental pollution and ecological burdens due to the use of chemical reagents. Moreover, their strong dependency on manual intervention and low automation levels make them inadequate to meet the demands of modern mining industries for green, intelligent, and efficient sorting. In recent years, with the rapid advancement of deep learning and computer vision technologies, non-contact mineral identification methods based on object detection or image segmentation have emerged as critical research directions in intelligent ore sorting [
8,
9]. These methods enable automatic extraction of texture, color, and structural features from ore images, facilitating precise delineation and recognition of regions with varying grades. Such advancements significantly enhance the intelligence and sustainability of beneficiation systems, optimize mineral sorting processes from the source, reduce wastage of high-quality resources, and effectively support the strategic implementation of green mining and “dual carbon” initiatives. Nevertheless, existing image segmentation models still face significant limitations in terms of parameter scale, computational complexity, and real-time responsiveness, which hinder their practical deployment in mining sites, especially on edge devices [
10,
11].
This study addresses the aforementioned challenges by proposing a lightweight graphite ore image instance segmentation model designed for industrial production lines and deployable on edge devices. The model accurately identifies low-grade regions during the primary ore processing stage, enabling early removal of redundant materials, thereby reducing subsequent ineffective operations and significantly lowering resource consumption and carbon emissions. This approach aims to provide critical technical support and a feasible implementation pathway for building intelligent, green, and sustainable mining systems, demonstrating the broad application potential of data-driven methods in resource development and sustainable utilization.
This study outlines its core contributions and methodology as outlined below:
By employing high-resolution imaging equipment on industrial production lines to capture ore images under varying exposure conditions, followed by extensive manual annotation, a graphite ore dataset was established, comprising three exposure durations and two target grade levels.
By adjusting the network’s depth factor, the global depth was effectively compressed, resulting in a more compact YOLO11t-seg architecture compared to the original model. This modification significantly reduced redundant operations in certain components while preserving core segmentation performance, thereby achieving a substantial reduction in parameter count.
GSConv was introduced into the backbone to replace standard convolutions, effectively maintaining model accuracy while avoiding additional computational overhead. In addition, the Faster Block was integrated into the C3k2 module to construct a novel feature extraction module, termed C3k2-Faster. This design significantly improved global feature extraction efficiency through partial convolution, without incurring noticeable accuracy loss.
The segmentation head was streamlined by removing redundant depthwise separable convolution operations, leading to the development of an efficient segmentation head, termed Segment-Efficient. This optimization significantly reduced model complexity while further enhancing deployment efficiency on resource-constrained devices.
The structure of this paper is arranged as follows.
Section 2 offers a comprehensive overview of existing studies related to the analysis of graphite ore. In
Section 3, a refined segmentation framework tailored for graphite ore is introduced, with emphasis on its architectural improvements.
Section 4 outlines the procedures for dataset compilation, elaborates on the experimental configurations, and explains the performance assessment criteria.
Section 5 delivers a thorough evaluation of the experimental findings, incorporating comparative analysis with baseline models. Lastly,
Section 6 encapsulates the study’s core contributions and proposes future research trajectories.
2. Related Work
Traditional approaches for analyzing the grade of graphite ore predominantly depend on manual visual assessment and physicochemical techniques, typically involving instrumentation such as XRD, SEM-EDS, and OM [
12,
13]. For example, Ye et al. [
14] developed a method to determine fixed carbon using a high-frequency infrared carbon-sulfur analyzer, incorporating HNO
3 pretreatment and flux fusion for accurate detection of low carbon content. Li et al. [
15] proposed a titration-based approach for crystalline graphite using KMnO
4, AlCl
3, and concentrated H
2SO
4 to enhance pretreatment and reduce interference. These methods are limited by destructive sampling, long testing cycles, high costs, and potential chemical pollution. Additionally, traditional manual sorting is labor-intensive, subjective, and inefficient, making it unsuitable for modern requirements of intelligent, efficient, and sustainable mineral processing [
16].
Driven by the swift progress in computer vision technologies, deep learning techniques have become forefront approaches for intelligent mineral identification. These algorithms possess the capability to automatically capture intricate nonlinear correlations between visual characteristics and mineral grades directly from images. This advancement surpasses the constraints of conventional rule-based models, greatly minimizing human bias and subjectivity, and thereby enhancing the precision of mineral classification and recognition tasks [
17]. For instance, Okada et al. [
18] applied NCA in combination with machine learning algorithms to optimize wavelength selection for arsenic mineral detection, achieving over 91.9% accuracy with minimal spectral bands, thus enhancing the efficiency and practicality of multispectral ore sorting. Es-sahly et al. [
19] utilized SWIR spectroscopy combined with machine learning models to pre-concentrate low-grade sedimentary copper ores, achieving up to 90% classification accuracy and a 43% upgrading rate, thereby validating the potential of NIR-based sorting in copper beneficiation. Theerthagiri et al. [
20] developed a deep residual neural network (D-Resnet) for classifying beach sand minerals, achieving 89% accuracy across six mineral types while reducing dependency on high-resolution imagery through effective convolutional feature selection.
However, existing deep learning-based approaches for graphite ore recognition still face several limitations. For example, Krebbers et al. [
21] integrated X-ray and CT with image processing to develop a 3D structure scanning and recognition framework for graphite ore, enabling quantitative characterization of critical mineralogical features. While this approach provides high recognition accuracy and fine-scale structural resolution, it depends on complex sample preparation and laboratory setups, with limited imaging coverage, making it unsuitable for real-time and large-scale industrial deployment. Huang et al. [
22] proposed an image recognition model incorporating pyramid convolutions and spatial attention mechanisms, achieving 92.5% accuracy and significantly advancing the intelligent recognition of graphite grade. Nevertheless, the model was designed for single-piece classification and lacks the capacity for batch-level, rapid sorting in industrial settings. Similarly, Shu et al. [
23] developed a hybrid ResNet-Transformer architecture that enhances both global and local feature modeling through multi-level fusion, attaining 93.4% accuracy on 19 graphite ore classes. Despite its strong performance under laboratory conditions, the model is not readily scalable to high-throughput processing and remains limited to object-level detection, which hinders pixel-wise quality assessment via segmentation.
In addition, most existing models suffer from excessive complexity and large parameter counts. For instance, the improved Inception-ResNet model proposed by Pan et al. [
24] achieves over 90% accuracy but contains tens of millions of parameters, making it impractical for deployment on edge devices or in resource-constrained environments due to limited inference speed and high computational cost. These constraints substantially hinder the applicability of such models in real-world industrial scenarios.
To facilitate smart and sustainable development in graphite ore processing, it is imperative to develop a segmentation model that integrates both accuracy and lightweight architecture. The model should maintain strong segmentation performance while ensuring computational efficiency for deployment on edge devices. Accurate identification and early removal of low-grade ore can reduce unnecessary processing, lower energy and chemical usage, and improve overall resource efficiency and product quality. This provides essential support for building efficient, green, and intelligent mining systems.
3. Methods
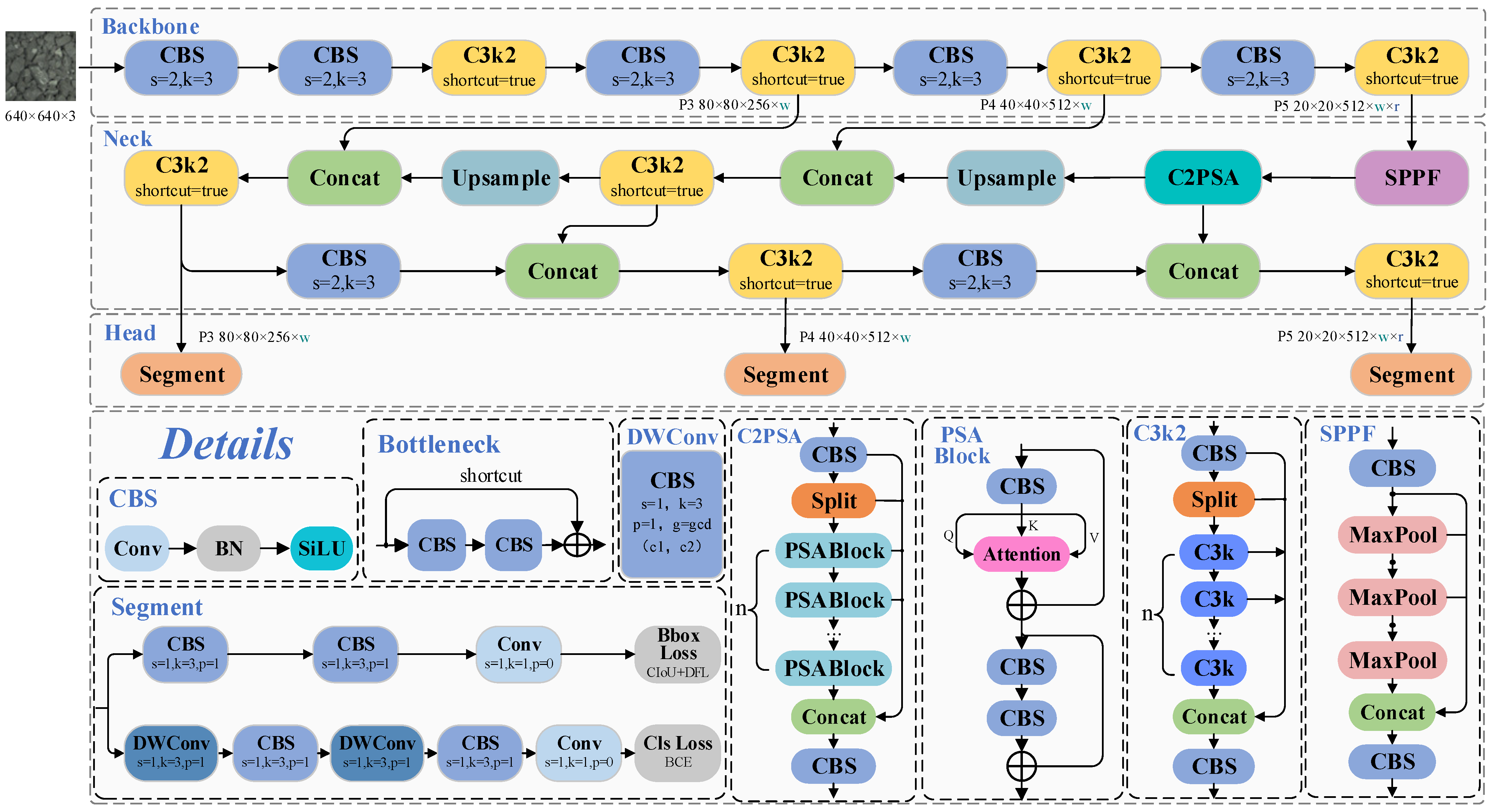
3.1. The Original YOLO11-Seg Network
YOLO11 [
25], as one of the leading object detection algorithms in terms of performance, represents a systematic enhancement and upgrade built upon the PGI framework established in its earlier versions. Its major improvements are summarized as follows: (i) Reconstruction of the feature extraction unit: The original C2f module has been replaced with the newly designed C3k2 module, which integrates the structural advantages of both C2f and C3. This redesign enhances information flow while maintaining feature richness, effectively reducing the number of parameters and improving computational efficiency. (ii) Enhanced multi-scale feature perception: A new C2PSA module is added after the original SPPF module to strengthen the model’s ability to perceive objects at various scales, particularly in cases of occlusion, thereby improving overall detection robustness. (iii) Optimization of the detection head: Depthwise separable convolutions are introduced to replace conventional convolutional layers, partially reducing computational cost and accelerating inference speed. The overall network architecture and its core components are illustrated in
Figure 1.
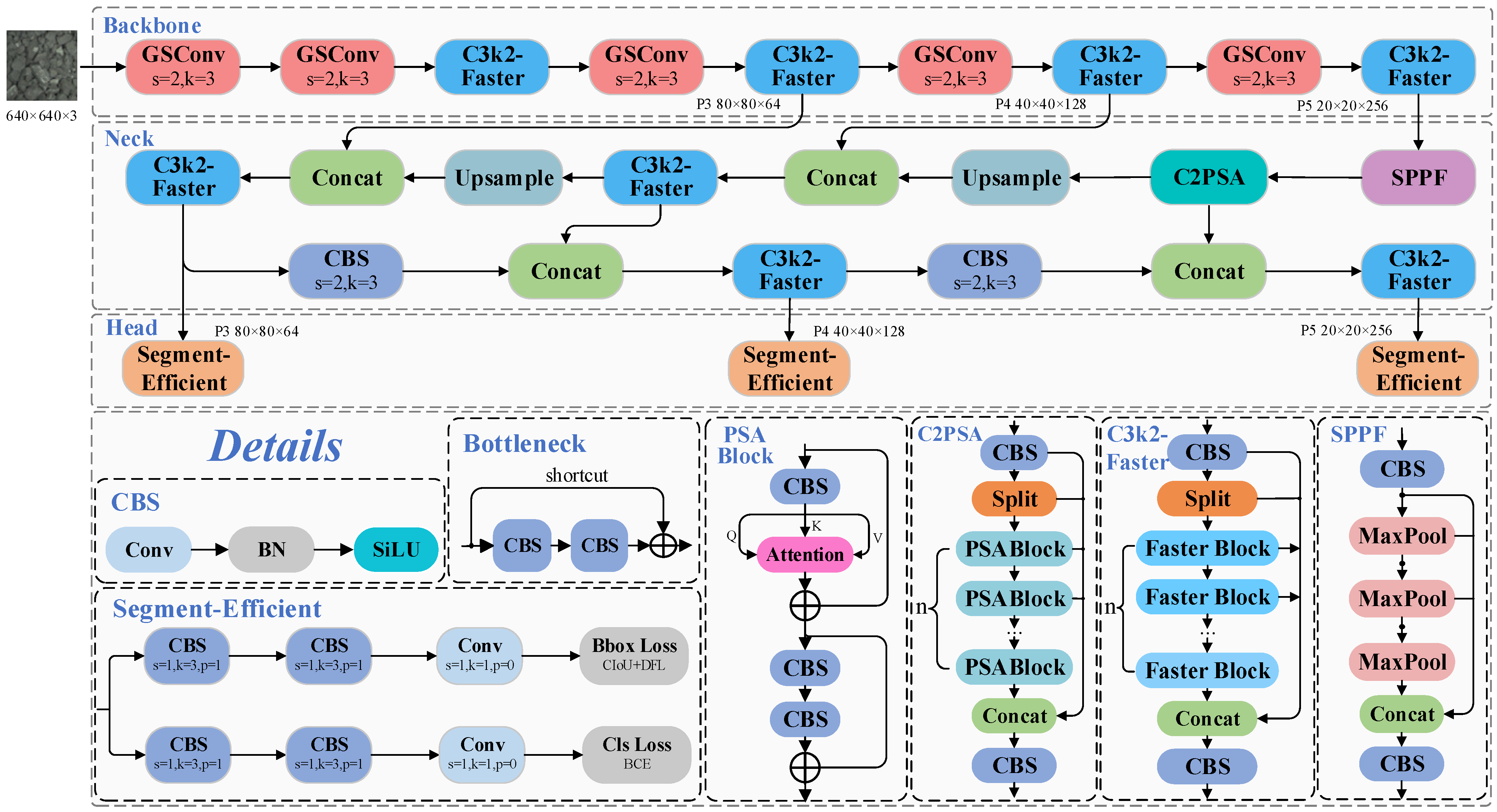
3.2. The Improved GS-YOLO-Seg Network
Given the limited computational resources typically available in practical industrial environments, this study proposes a YOLO11-based segmentation framework tailored for low-grade graphite ore, designed to maintain high accuracy while ensuring lightweight performance. The overall architecture is illustrated in
Figure 2.
The model retains the core structure of YOLO11-seg, comprising the backbone, neck, and head components, while incorporating several key optimizations. First, the global network depth was reduced to half by adjusting the depth factor, significantly decreasing the parameter count and computational burden. Second, GSConv [
26] was introduced into the backbone to replace standard convolutions as a new downsampling module, thereby improving computational efficiency without compromising accuracy. Furthermore, enhancements were made to the traditional C3k2 module through the incorporation of the Faster Block [
27], yielding a streamlined version named C3k2-Faster. This improved design employs partial convolution (PConv), which restricts convolutional operations to a selected subset of channels, thereby decreasing computational burden. Additionally, in light of the focused nature of the application scenario and the limited range of target mineral classes, the segmentation head was simplified by eliminating depthwise separable convolutions. A newly designed structure, named Segment-Efficient, was introduced to maintain essential segmentation capabilities while notably reducing model complexity and improving deployment performance on devices with restricted computational resources.
The upcoming subsections systematically provide an in-depth explanation of each of these optimized components and the underlying technical details.
3.3. YOLO11t-Seg
Scalability in the YOLO11 framework is controlled by adjusting width and depth parameters, which affect channel dimensions and structural repetition. Although larger models improve feature extraction, they incur higher computational costs. Given the limited class set in this industrial application, the YOLO11n-seg model remains overly complex. To improve efficiency, a globally compressed depth strategy was adopted, resulting in a lightweight variant named YOLO11t-seg.
This model maintains the original global width while reducing the depth factor to half of its original value, thereby effectively lowering the repetition of feature extraction modules and avoiding redundant operations. A 50% reduction in the repetition of modules was applied to the Backbone (layers 2, 4, 6, and 8) and Neck (layers 13, 16, 19, and 22) components of YOLO11n-seg to decrease structural redundancy. This adjustment alleviates redundant computations, decreases network depth, and significantly reduces the number of parameters.
Table 1 provides a detailed comparison among YOLO11n-seg, YOLO11s-seg, and the depth-compressed variant YOLO11t-seg in terms of scaling factors, the number of repeats in feature extraction modules (Repeats), and parameter counts (Params).
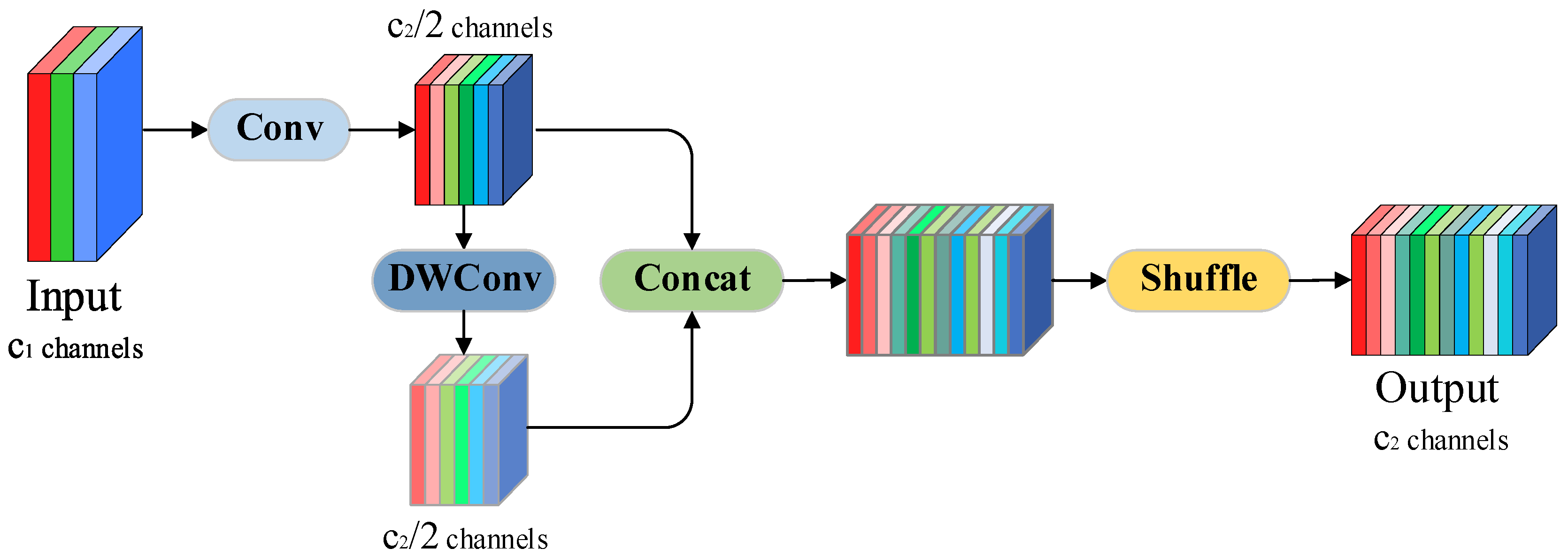
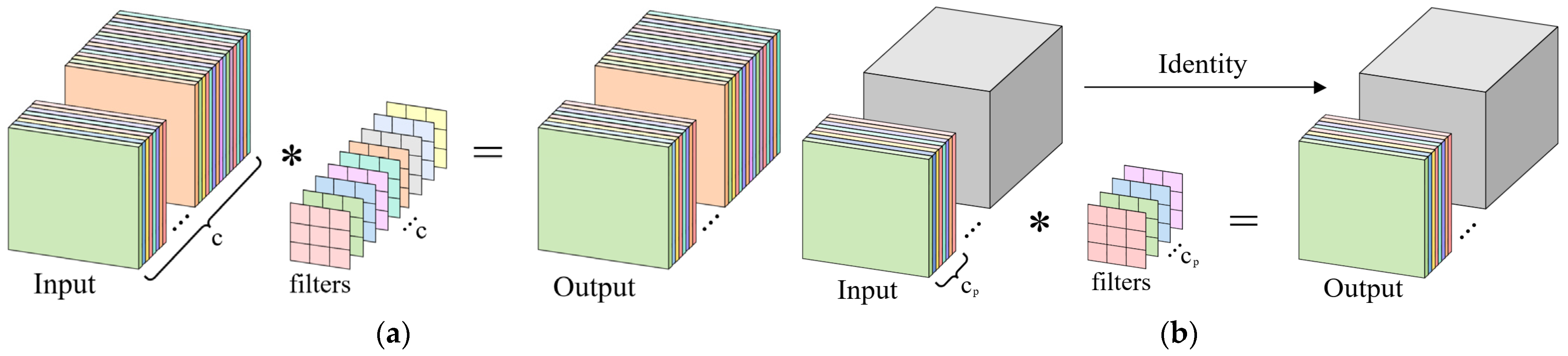
3.4. GSConv
GSConv is a lightweight convolutional structure that combines the advantages of standard convolution and depthwise separable convolution (DWConv) [
28]. Through sophisticated channel partitioning and information mixing fusion strategies, it can significantly reduce the number of parameters and computation while still effectively improving the model’s feature expression ability. A schematic diagram of the convolution process is shown in
Figure 3.
Specifically, for an input tensor
(height
, width
, and input channel number
), the convolution operation in the standard convolution branch can be expressed as:
In this expression, “∗” stands for the convolution operation, while
indicates the count of output channels. The DWConv branch can be similarly represented as follows:
Here, the symbol “⊙” signifies the depthwise separable convolution. Subsequently, the outputs from the two branches are fused through a concatenation (Concat) operation, followed by a channel shuffle mechanism to promote effective interaction and complementarity between features extracted by standard convolution and depthwise separable convolution. This strategy alleviates information isolation across feature channels, facilitating the generation of more uniformly distributed and richly expressed feature maps. The entire process of GSConv can be summarized as follows:
The primary benefit of GSConv is its capacity to merge the advantages of traditional convolution and depthwise separable convolution efficiently by employing a channel shuffle mechanism. This design preserves implicit inter-channel connectivity while significantly reducing computational complexity. As a downsampling strategy, GSConv maintains model prediction accuracy without introducing additional computational overhead, making it particularly suitable for lightweight network architectures.
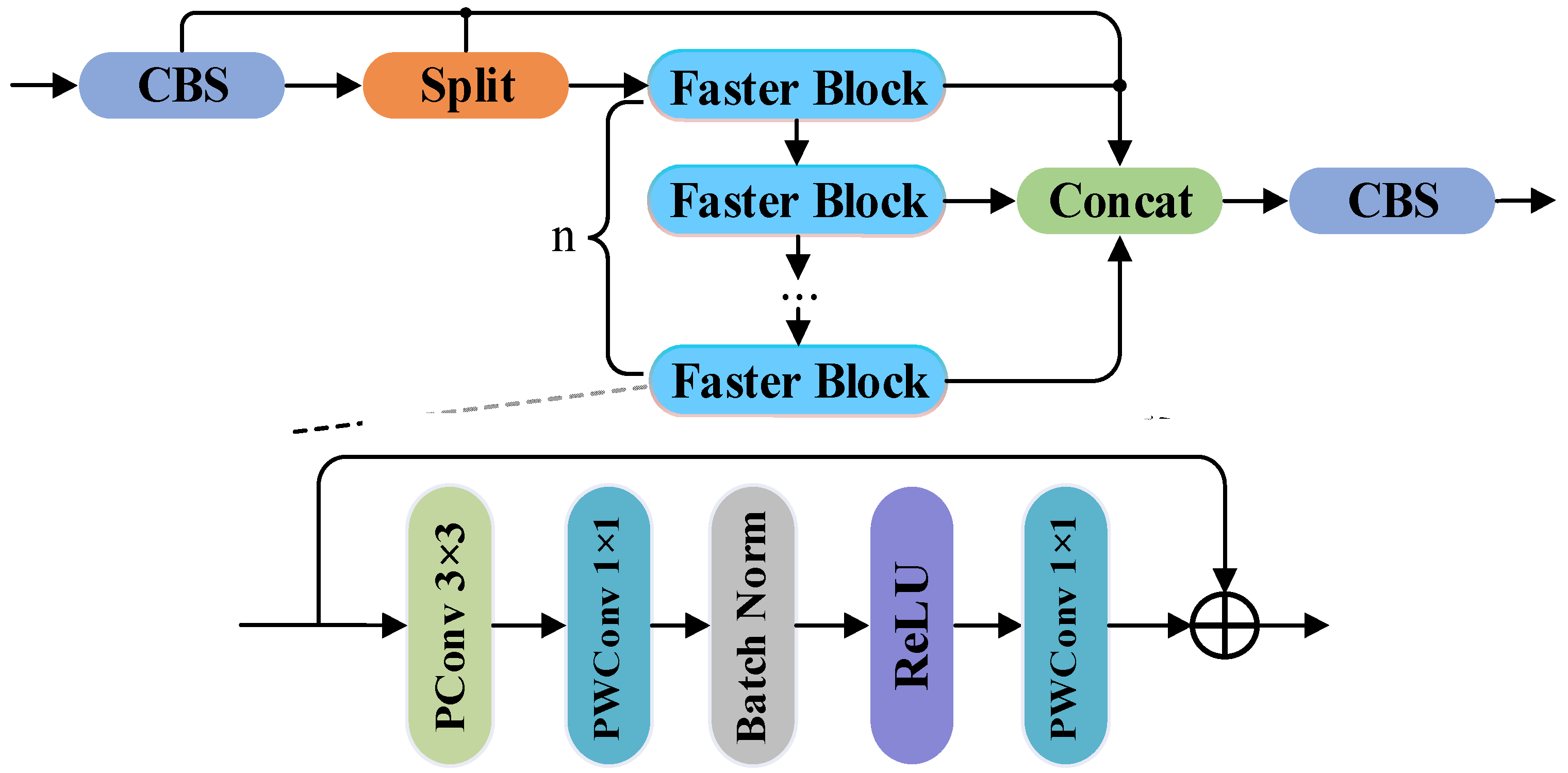
3.5. C3k2-Faster
Although C3k2 enhances both feature representation and semantic fusion through a more dynamic feature flow compared to previous extraction modules, its inference efficiency can be insufficient under specific conditions, falling short of the high-performance demands of industrial edge environments. To address this limitation, this paper introduces an improved version of the original C3k2 module within the YOLO11-seg architecture, termed C3k2-Faster, specifically tailored for rapid sorting of graphite ore. The overall design of the proposed module is illustrated in
Figure 4.
The C3k2-Faster module improves computational efficiency by introducing the Faster Block in the core bottleneck, while retaining a multi-branch structure to enhance feature diversity. Specifically, the input features
are first preprocessed using a standard CBS module (i.e., Conv-BN-SiLU). A Split operation is then applied to divide the features into two branches, denoted as
and
.
is directly reserved for the final concatenation, whereas
is sequentially passed through multiple Faster Block sub-units, denoted as
, to perform deep feature extraction. Subsequently, the features from
and the processed output of the bottleneck path are concatenated along the channel dimension, followed by another CBS module to produce the final output
. The entire process can be formally expressed as:
Within the Faster Block bottleneck, PConv and PWConv are integrated. The main branch input
first undergoes a 3 × 3 PConv to effectively capture local spatial details, then a 1 × 1 PWConv to promote inter-channel communication and modify channel dimensions. The output is then normalized via Batch Normalization and passed through a ReLU activation to boost nonlinear expressiveness. After the main branch is processed through the PBR sequence (PWConv-BN-ReLU), the output features are further passed through an additional 1 × 1 PWConv and then fused with the shortcut branch
via residual connection, denoted as “+”. This fusion with the original input to the bottleneck improves information integration and stabilizes the gradient flow. Mathematically, the full procedure of the Faster Block is described as:
Partial Convolution serves as the core operation enabling faster feature extraction in the C3k2-Faster module. Only a fraction of the input channels undergo convolution, whereas the remaining channels are transmitted straight to the output. This design helps optimize memory access and reduce parameter count. A comparison between the workflows of PConv and standard convolution is illustrated in
Figure 5.
To highlight the significant reduction in parameter count achieved by PConv compared to standard convolution, consider an input tensor of size
, where
and
represent the height and width of the feature map, and
denotes the kernel size. Let
be the number of channels processed by standard convolution in PConv. When the ratio
, the remaining
channels bypass convolution and are directly mapped to the output. For the sake of comparability, we further assume that the output channel count
equals the input channel count
, and the kernel size is fixed at 3. Under these assumptions, the theoretical number of parameters for standard convolution and PConv can be approximated as follows:
Under the assumed conditions, PConv achieves a parameter count that is 1/4 of that of standard convolution, significantly reducing computational complexity. Building on this, the Faster Block and C3k2-Faster structures preserve the core feature extraction capabilities of the original feature extractor, while improving efficiency during both training and inference stages without significant loss in accuracy. This makes them highly suitable for industrial scenarios with limited computational resources or stringent real-time requirements.
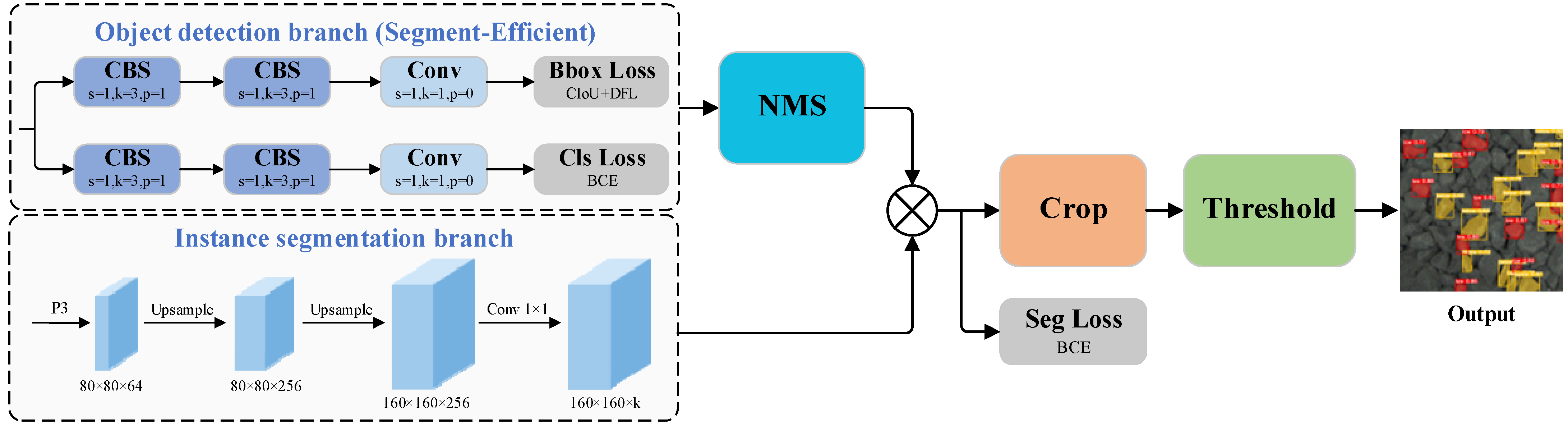
3.6. Segment-Efficient
Given that this study focuses on graphite ore grade segmentation in a single industrial scenario with a limited number of target categories, there is room to further optimize the original segmentation head. In order to better satisfy particular application demands, a streamlined prediction module named Segment-Efficient is introduced, which eliminates redundant processes within the segmentation head. While maintaining the decoupled design between the bounding box regression and classification tasks, the module removes all DWConvs from the classification loss branch, effectively simplifying the head structure. This approach maintains the separation of localization, classification, and segmentation tasks, prevents feature interference, lowers computational demands, boosts inference speed, and facilitates deployment on resource-limited edge devices.
Following the design principles of YOLACT [
29], the model head is structured into two distinct branches: one for object detection and the other for instance segmentation. The detection branch outputs class labels, bounding box coordinates, and mask coefficients, which are used to compute classification and box regression losses. The segmentation branch generates global prototype masks. After non-maximum suppression (NMS), the final instance masks are obtained by combining the predicted mask coefficients with the prototype masks through matrix multiplication, followed by binary cross-entropy (BCE) loss optimization. Final segmentation results are produced via cropping and thresholding operations. The architecture of the head incorporating the Segment-Efficient module is illustrated in
Figure 6.
4. Data and Experimental Preparation
4.1. Dataset Construction
The image data used in this study were collected from China Minmetals Corporation (Heilongjiang) Graphite Industry Co., Ltd. (Hegang City, China), comprising medium-to-coarse graphite ores (2–15 cm) sampled from the conveyor belt post-secondary crushing. These samples exhibit clear textural and compositional features suitable for vision-based recognition. Image acquisition was performed using a Canon EOS 5D Mark II DSLR (Canon Corporation, Kunisaki City, Japan) at an original resolution of 5616 × 3744 pixels. To meet model input requirements and industrial constraints, images were cropped and resized to 3744 × 3744 pixels.
To mitigate the effects of conveyor speed, ore types, and lighting variations on texture visibility in industrial sorting, a multi-exposure imaging strategy was employed to enhance surface detail and dataset diversity. Specifically: (i) Short exposure (400 µs) reduces motion blur during rapid ore movement; (ii) Medium exposure (600 µs) offers balanced brightness for general texture capture; (iii) Long exposure (800 µs) improves texture visibility under low-light or low-reflectivity conditions. This approach enhances model robustness and sorting stability in real-world scenarios. A total of 1978 images were collected: 652 (400 µs), 730 (600 µs), and 596 (800 µs), with examples shown in
Figure 7.
Ore grade is visually correlated with surface features: high-grade primary ore appears darker due to fewer impurities and stronger light absorption, while low-grade ore appears brighter due to light-colored impurities (e.g., quartz, silicate oxides) and higher surface reflectivity. Based on sorting requirements, low-grade ore was further divided into below-average (“below”) and low-grade (“low”) subcategories, annotated using Labelme [
30]. Annotations were saved in JSON and converted to YOLO-compatible TXT format. The final dataset includes two grade categories under three exposure settings, totaling 19,614 low-grade instances, with 11,449 below-average samples (58.39%) and 8,165 low-grade samples (41.61%), resulting in a class ratio of approximately 1.4:1 (Below:Low). The dataset was split into training, validation, and test sets using an 8:1:1 ratio.
Table 2 summarizes the instance distribution across the three subsets, along with their corresponding proportions.
4.2. Experimental Environment
All experiments were carried out on a consistent hardware setup. The system utilized a 12th-generation Intel Core i5-12490F CPU running at 3.00 GHz (Intel Corporation, Ho Chi Minh City, Vietnam) and an NVIDIA GeForce RTX 4060 GPU equipped with 8 GB of VRAM (NVIDIA Corporation, Santa Clara, CA, USA). The operating environment was Windows 11 Professional, with Python 3.8.19 as the primary programming language and PyTorch 1.12 as the deep learning framework, accelerated by CUDA version 11.3.
Training parameters were kept uniform throughout all experimental runs. The network was trained over 150 epochs using a batch size of 8. The optimization algorithm employed was stochastic gradient descent, with a 0.937 momentum factor, an initial learning rate of 0.01, and a weight decay coefficient of 0.0005. To prevent overfitting and unnecessary computation, an early stopping condition with a patience value of 50 epochs was implemented. Moreover, Mosaic data augmentation [
31] was deactivated during the final 10 epochs to enhance convergence behavior.
4.3. Evaluation Criteria
To thoroughly assess both the segmentation effectiveness and lightweight nature of the proposed model under real-world application constraints, eight key evaluation indicators are utilized. Precision (P) and mAP50 (mean Average Precision at an IoU threshold of 0.50) serve as the key indicators of accuracy. Their definitions are mathematically outlined as follows:
In these equations, A refers to the true bounding box annotation, and B represents the corresponding prediction made by the model. TP denotes the count of true positive detections, whereas FP indicates the number of false positives. denotes the interpolated precision corresponding to a recall level for the i-th category, while N signifies the total number of target categories involved.
The accuracy metrics are divided into four parts: and measure the precision of detection and segmentation, while and reflect the average precision for bounding boxes and masks.
The lightweight performance of the model is assessed from four dimensions: FLOPs, FPS, parameter count (Params), and model size (Size). FLOPs and FPS reflect computational load and inference efficiency, while the number of parameters and model size indicate memory usage and deployment feasibility.
5. Experiments and Discussion
5.1. Model Training
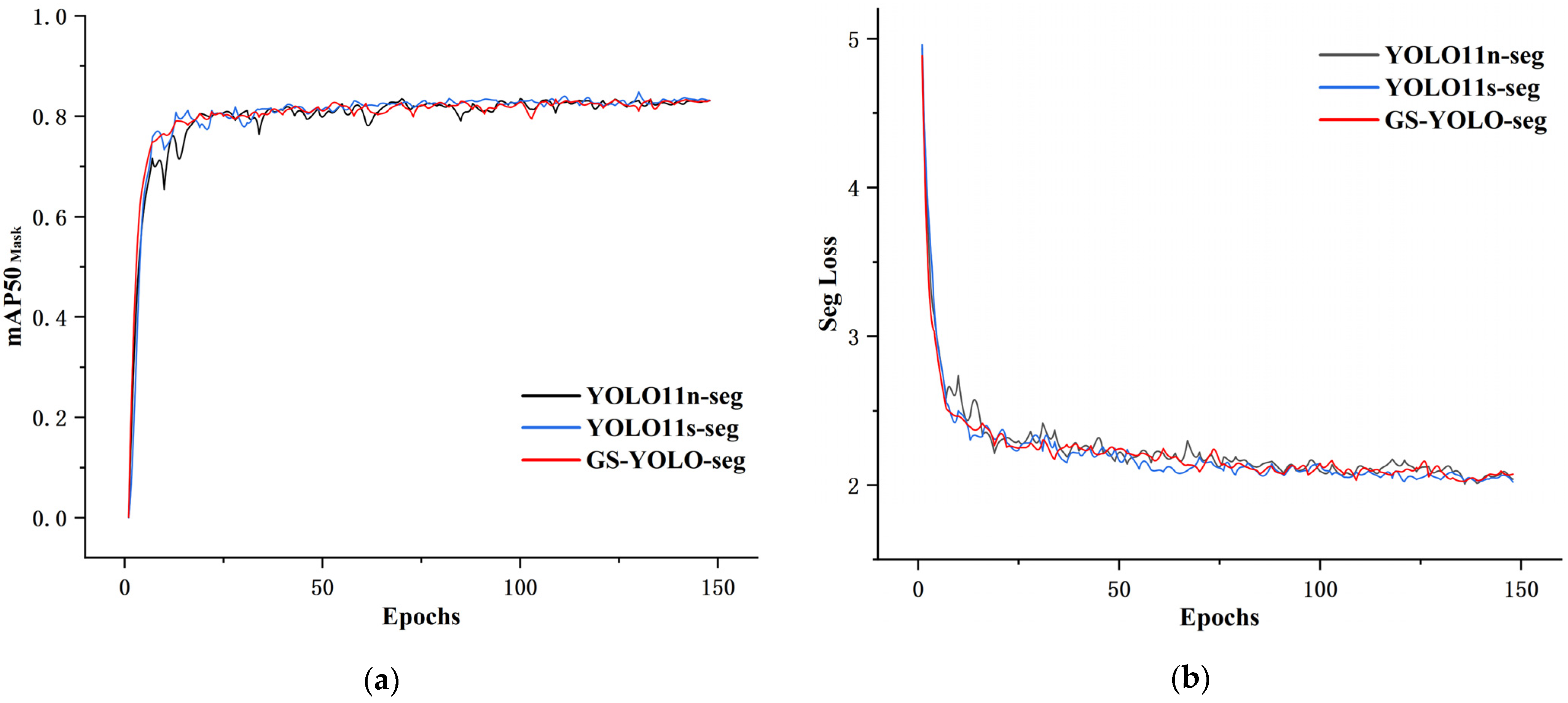
Under the predefined parameter settings, the GS-YOLO-seg model was trained on a custom graphite ore dataset and evaluated alongside the baseline YOLO11n-seg and the larger YOLO11s-seg model from the same series. The training process is illustrated in
Figure 8, showing the changes in the mean Average Precision for segmentation masks and corresponding loss curves. In the early stages of training, all three models quickly adapted to the data characteristics, with a rapid increase in
and a sharp decrease in segmentation loss, indicating good initial convergence. Around the 20th epoch, the GS-YOLO-seg model demonstrated a faster and more stable performance improvement compared to the baseline, while the YOLO11s-seg also exhibited strong performance due to its larger model capacity. As training progressed, the performance of all models gradually stabilized; however, the baseline model still showed noticeable fluctuations in accuracy, whereas GS-YOLO-seg achieved stronger convergence in the later stages, reflecting more stable training dynamics.
5.2. Ablation Study
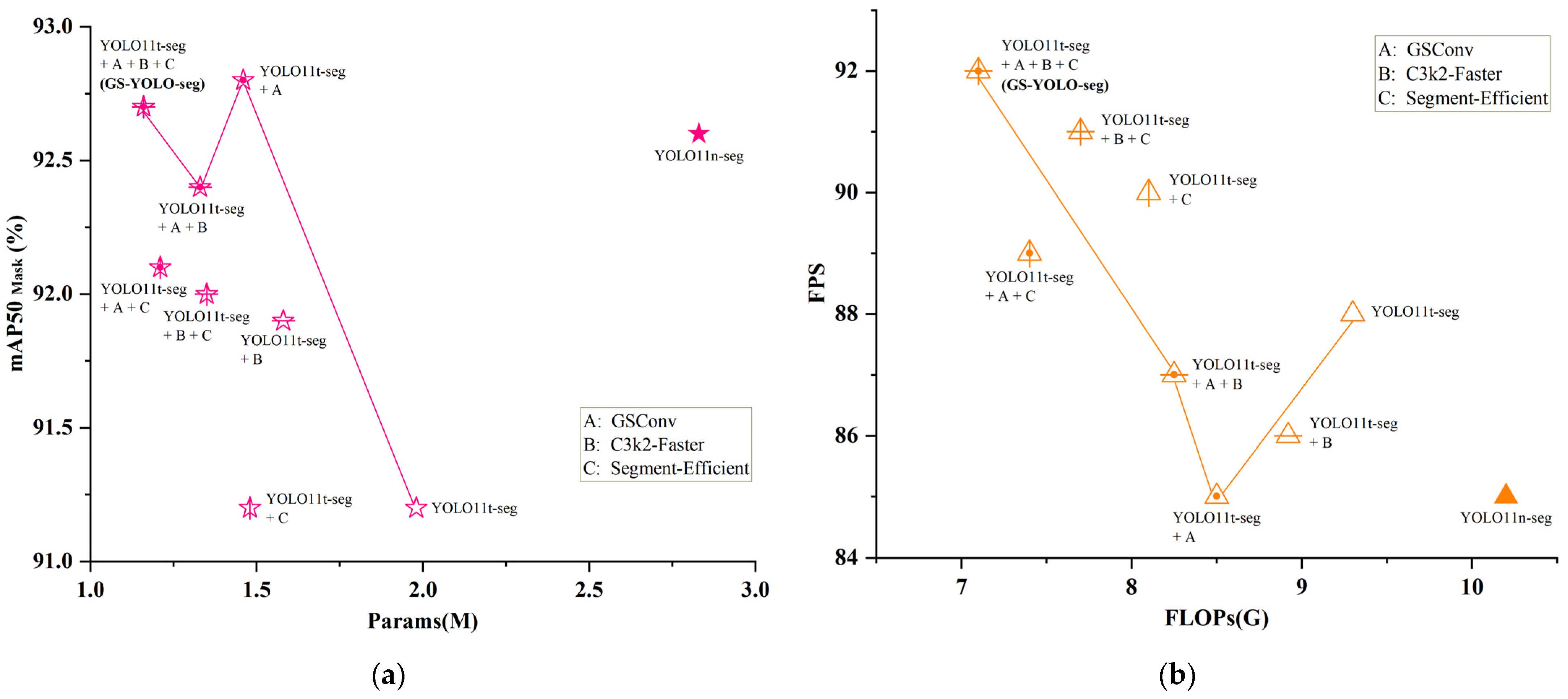
To thoroughly assess the contribution of each proposed module, this work employs the channel-adjusted YOLO11t-seg as the reference architecture. Enhancements were incrementally introduced following a stepwise experimental framework. All tests were performed under uniform hyperparameter settings to maintain fair conditions and ensure that variable control was strictly enforced. A series of ablation trials based on combinatorial configurations were conducted to objectively verify the performance impact of each improvement. The architectural changes are outlined as follows:
A: Utilizing GSConv in place of the conventional downsampling layers within the backbone to improve efficiency and representation;
B: Employing the standard C3k2 module across the network with the accelerated C3k2-Faster structure to reduce computational overhead;
C: Integrating the streamlined Segment-Efficient head to minimize segmentation complexity while preserving performance.
Table 3 presents the outcomes of various module combinations, and
Figure 9 visualizes the performance trends of intermediate models incorporating different configurations. These results distinctly highlight how each individual module influences both the segmentation accuracy and the lightweight characteristics of the network.
As evidenced in
Table 3, the results of the ablation analysis affirm that the introduced modules effectively boost model accuracy while facilitating lightweight optimization. First, the introduction of GSConv led to approximately a 1% improvement in both bounding box precision and segmentation average precision, while significantly reducing the number of model parameters, demonstrating its strong structural optimization capability without compromising performance. Second, the C3k2-Faster and Segment-Efficient modules also contributed to model lightweighting to varying degrees. The Faster Block reduced computational cost by performing convolution only on selected channels, and the Segment-Efficient head minimized unnecessary computation by streamlining the segmentation head. However, introducing the Segment-Efficient module alone resulted in a slightly drop in segmentation average precision, indicating a trade-off between efficiency and detection accuracy.
Building upon the GSConv-only baseline, the staged integration of feature extraction modules (A + B) and segmentation decision modules (A + C) led to further performance improvements while continuing to reduce model complexity. The final model, GS-YOLO-seg, incorporates depth reduction, optimized downsampling, enhanced feature extraction, and an efficient segmentation head. It outperforms the original YOLO11n-seg in three accuracy metrics and achieves significant reductions in FLOPs (30%), parameter count (59%), and model size (56%), along with an 8% increase in FPS. These results clearly demonstrate that the proposed modules can effectively optimize the model structure for lightweight deployment while maintaining high segmentation and detection accuracy.
5.3. Comparison Study
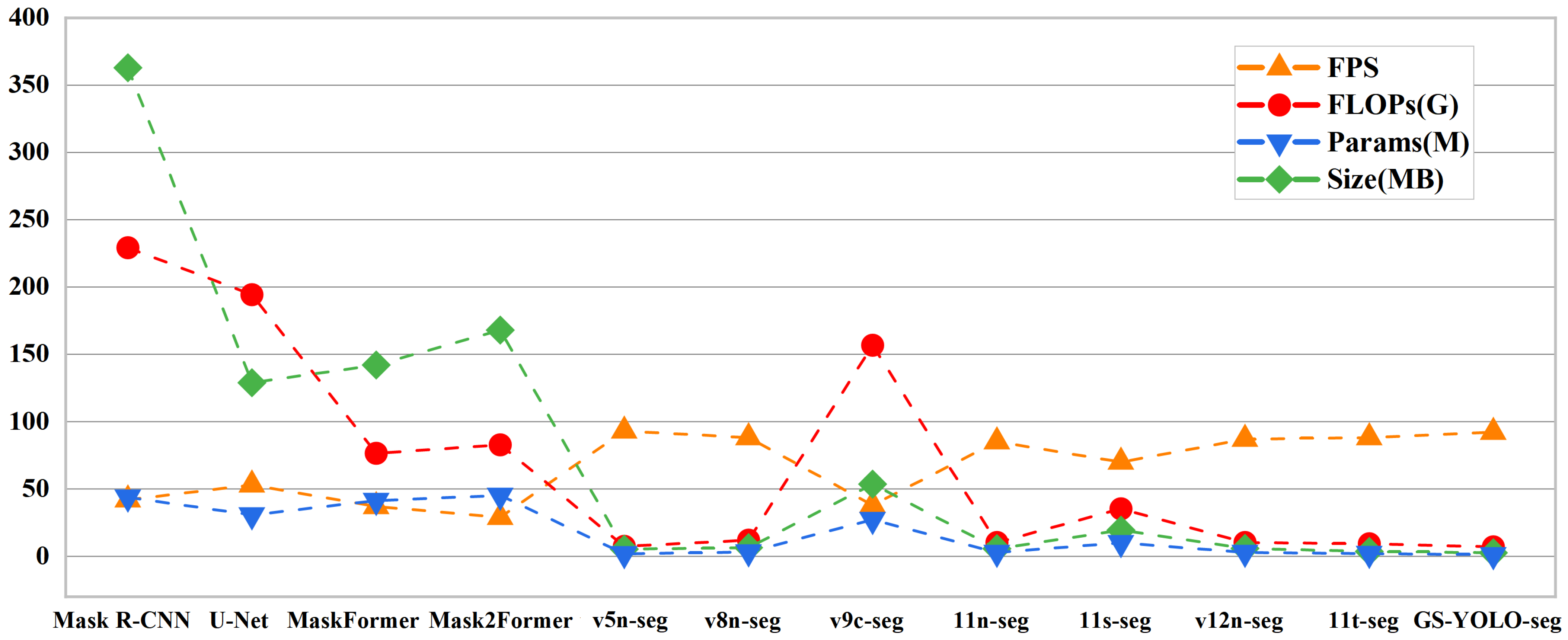
A comprehensive benchmark comparison was performed between GS-YOLO-seg and several representative segmentation models to validate its performance superiority. To maintain experimental fairness, all models were trained without pretrained parameters and relied solely on their standard hyperparameter configurations, without any further adjustment. Comprehensive results for all evaluated models can be found in
Table 4, while
Figure 10 illustrates a comparison of their lightweight performance metrics.
Mainstream segmentation frameworks such as Mask R-CNN, U-Net, and the MaskFormer series, all employing ResNet-50 [
40] as the backbone, demonstrate strong segmentation performance due to their deep architectures. They achieve slightly higher average precision in both object detection and instance segmentation, exceeding the proposed model’s accuracy by less than 2%. However, these models typically require hundreds of GFLOPs and tens of millions of parameters, resulting in large model sizes of several hundred megabytes and low inference speed. These high computational requirements restrict their use on edge devices and in applications requiring real-time processing.
The GS-YOLO-seg shows significant advantages in inference speed compared to other YOLO-series segmentation models of similar scale. Against lightweight models like YOLOv5n-seg and YOLOv8n-seg, GS-YOLO-seg improves mean average precision by 0.4% and 2.7%, respectively, while maintaining a more compact network and faster response. Compared with the more complex YOLO11s-seg model from the same series, GS-YOLO-seg uses the efficient GSConv module, the C3k2-Faster module, and the optimized Segment-Efficient segmentation head to achieve comparable accuracy, with differences in mean average precision for detection and segmentation under 0.5%. Meanwhile, it reduces FLOPs by 80%, parameter count by 88%, and model size by 87%, while increasing FPS by 31%. These results demonstrate that GS-YOLO-seg balances accuracy with substantial model compression and acceleration, making it well suited for resource-limited deployment.
5.4. Visualization Study
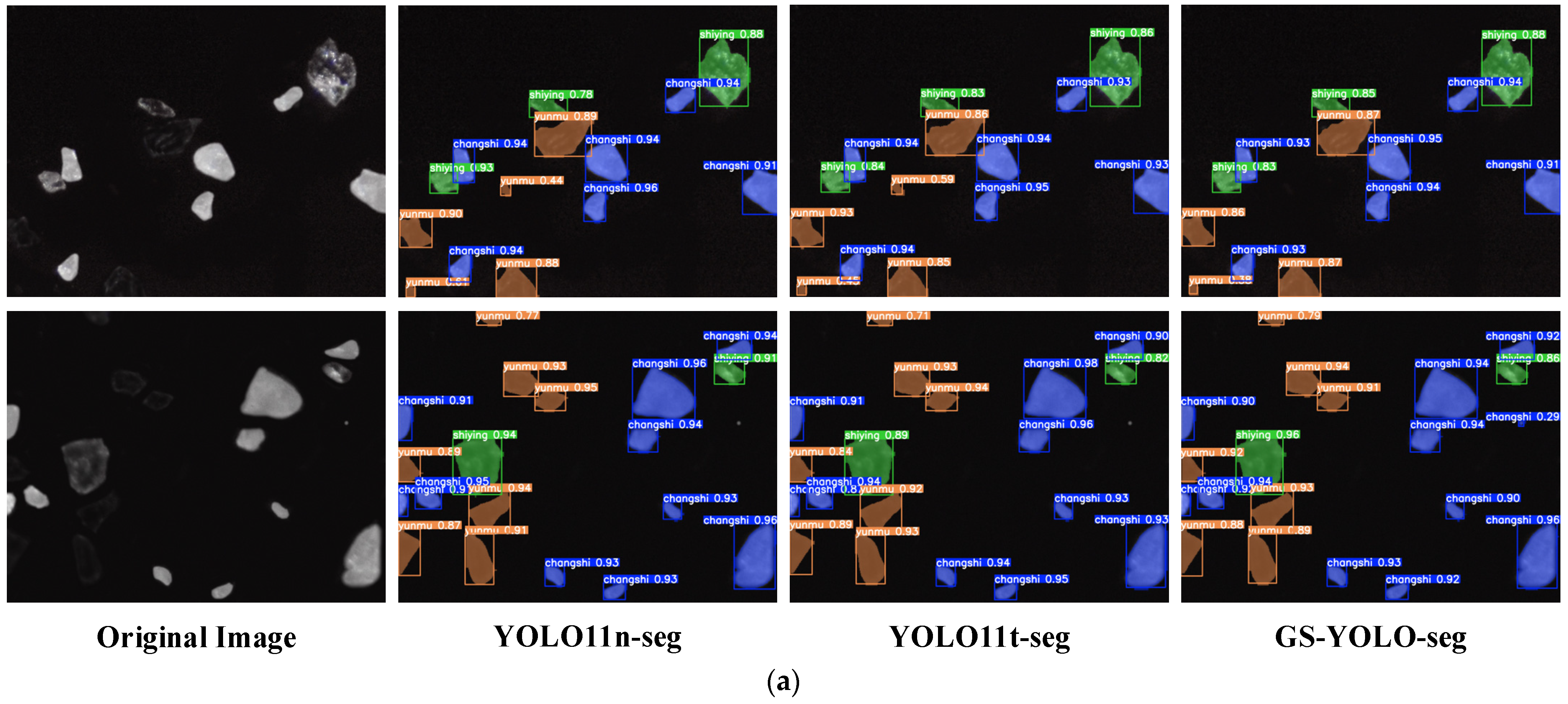
For a straightforward visualization of segmentation effectiveness, four sample test images were used for comparison.
Figure 11 shows the instance segmentation results of the proposed GS-YOLO-seg model alongside baseline models. Two subcategories of low-grade graphite ore are annotated with distinct colors: below-average grade (yellow) and low-grade (red). Confidence scores (0–1) within bounding boxes indicate the model’s estimated accuracy for each detection. Green arrows highlight key regions to emphasize performance differences between models.
The first row shows images at 400 µs exposure, where low-grade ore blocks display distinct visual features. All four models accurately detected and classified the instances with similar confidence scores and precise segmentation. In the second row (600 µs exposure), medium-low grade ores are densely packed. YOLO11s-seg produced overlapping bounding boxes due to duplicate detections in the center, an issue absent in other models. Both YOLO11s-seg and GS-YOLO-seg detected an edge-region ore block missed by the baseline, showing stronger performance in edge and dense target detection. The third row (600 µs exposure) highlights two medium-low grade ores; YOLO11s-seg segmented both correctly, GS-YOLO-seg detected only the larger one, and YOLO11n-seg missed both. The final row (800 µs exposure) features complex lighting with reflection interference. Two high-grade blocks with reflective areas were misclassified by YOLO11n-seg but correctly identified by GS-YOLO-seg and YOLO11s-seg, indicating better robustness under challenging conditions.
Based on the visual analysis of the results, GS-YOLO-seg demonstrates comparable performance to the baseline model in distinguishing low-grade graphite ore under different exposure conditions. This stable performance is mainly attributed to the integration of the GSConv and C3k2-Faster modules, which enhance the model’s ability to extract features across ore grades. In addition, the integration of a global depth scaling technique and a streamlined Segment-Efficient head greatly decreases both parameters and computation, while preserving strong accuracy. With respect to edge deployment needs, GS-YOLO-seg outperforms the baseline by a small margin, reflecting its enhanced competitiveness and real-world value.
5.5. Generalization Study
To assess the generalization capability of the proposed model beyond graphite ore, GS-YOLO-seg was evaluated on two external public datasets: a lithium mineral microscopy dataset [
41] (1013 images, 15,682 annotated instances across feldspar, quartz, and lepidolite) and a petrographic mineral microscopy dataset [
42] (1092 images, 6244 annotated instances across actinolite, garnet, and hornblende). As shown in
Table 5 and
Figure 12, GS-YOLO-seg achieved comparable segmentation performance to YOLO11n-seg while significantly reducing computational complexity. On both datasets, the model reduced FLOPs by over 28%, parameters by up to 61%, and model size by more than 55%, alongside a consistent improvement in inference speed. These results confirm the model’s generalization potential across different mineralogical contexts and its suitability for lightweight deployment in diverse industrial scenarios.
5.6. Limitations and Future Work
Despite the promising results achieved in this study, several limitations remain to be addressed. First, the graphite ore dataset used for model development was collected from a single mining site, which may limit the diversity and representativeness of mineral variations under different geological conditions. Second, the model occasionally exhibits false detections or missed segmentations when dealing with complex scenarios, particularly where ore grade distinctions are subtle or confounded by specular reflections. Third, although GS-YOLO-seg has been optimized for edge deployment, real-time performance and adaptability under varying production environments still require further enhancement before large-scale industrial application.
To overcome these limitations, future research will focus on the following directions: (1) expanding the training dataset to include samples from multiple mining locations and geological backgrounds, thereby enhancing the robustness and generalizability of the model; (2) incorporating multimodal data sources—such as hyperspectral or infrared imaging—in combination with visual data to improve recognition accuracy and grade discrimination; (3) further optimizing the network architecture and hardware acceleration strategy to improve processing speed and adaptability in real-world deployment; (4) extending the framework to support intelligent sorting of other mineral types, promoting broader applicability in industrial ore processing scenarios; and (5) establishing a multi-dimensional evaluation system to quantify the model’s sustainability and green impact, including metrics such as energy efficiency, reduction in manual labor and reagent use, processing throughput, and environmental benefits.
6. Conclusions
Accurate identification and removal of low-grade graphite ore is critical for maintaining product quality, improving resource efficiency, and reducing environmental impact during beneficiation and processing. Traditional sorting methods often rely on complex equipment and manual intervention, resulting in high energy consumption, excessive use of chemical reagents, and significant ecological burden—factors that hinder sustainable production. To address these challenges while enhancing edge deployment efficiency, this study proposes GS-YOLO-seg, a lightweight segmentation model based on an improved YOLO11-seg framework, designed for rapid identification and intelligent classification of low-grade graphite ore in industrial settings. The key contributions of this work include:
A high-quality graphite ore image dataset was independently constructed for real-world industrial scenarios. Images were captured on-site under various exposure conditions using high-resolution imaging equipment, and manually annotated to distinguish between medium-low and low-grade ores. The final dataset comprises diverse samples across three exposure durations and two grade levels.
The YOLO11-seg architecture was comprehensively optimized to improve lightweight characteristics and computational efficiency. First, a global depth factor adjustment was applied to compress the network and construct a lightweight YOLO11t-seg. Second, GSConv was introduced into the backbone as an efficient downsampling operator, reducing computation while enhancing representational capacity. Third, a Faster Block was incorporated into the feature extraction module, forming the C3k2-Faster structure to accelerate processing. Finally, the segmentation head was optimized by eliminating redundant operations and designing the efficient Segment-Efficient module.
Several ablation studies were performed to assess the impact of each proposed module. The GS-YOLO-seg was compared against mainstream segmentation methods and other lightweight variants across several key metrics. Visual comparisons were also carried out to demonstrate the segmentation accuracy and lightweight advantages of the improved model in practical scenarios. Further experiments on additional datasets validated the generalization and robustness of the proposed approach.
Compared with the baseline YOLO11n-seg, GS-YOLO-seg achieves comparable detection and segmentation accuracy while significantly reducing computational and memory overhead. Specifically, FLOPs decreased to 7.1 G, the parameter count dropped to 1.16 M, and model size was reduced to 2.53 MB—corresponding to reductions of approximately 30%, 59%, and 56%, respectively. In addition, inference speed improved by 8% (FPS). These results highlight the model’s well-balanced performance across accuracy, speed, and lightweight deployment, demonstrating its strong potential for industrial application and edge-device integration.
Future work will focus on refining the method for real-world production use, enabling efficient graphite ore sorting. The framework will also be adapted to other minerals to expand its industrial applications. By improving upstream intelligent sorting, the approach aims to reduce low-grade ore processing, minimizing resource waste, energy use, and emissions. These findings provide a foundation for building smart, sustainable mining systems.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}