1. Introduction
In 2022, the total global supply of major energy sources was broken down by fuel as follows: oil (31.6%), coal (26.7%), natural gas (23.5%), hydropower (6.7%), nuclear energy (4.0%), wind (3.3%), solar (2.1%), biofuels (0.7%), and other renewables (1.4%). The importance of natural gas, which has the third largest share of the total major energy supply, cannot be overstated. Concerns regarding air quality and climate change are increasing. While renewable energy is undergoing a period of rapid growth, its price and convenience remain challenging for wide-scale applications. Natural gas, on the other hand, is the cleanest source of energy and has established itself as the second-largest source of fossil fuels. In addition to being the primary fuel for domestic use, it is also an essential raw material for industry and energy production. Recently, energy giants have taken an interest in natural gas, and futures trading has increased significantly, given the propensity for erratic market oscillations in the natural gas contract trading arena [
1]. Because of its significant environmental benefits and low economic costs, natural gas will continue to play an integral role in the future of global energy. For these reasons, changes in natural gas prices are closely scrutinized by investors, policymakers, and academics. The highly volatile nature of the natural gas market makes it critical to accurately forecast natural gas prices and their movements.
Natural gas prices are a type of time series. A time series is a dynamic sequence of stochastic and interconnected data over time [
2]. Time Series Forecasting (TSF), on the other hand, denotes the use of models or techniques to forecast future values based on observations [
3]. Recently, TSF has been extensively applied across several sectors, such as communication, finance, and energy [
3]. Several methods for forecasting time series have been proposed in recent decades. Classical forecasting methods are mainly based on linear statistical models and their improved models, such as the Autoregressive Integrated Moving Average (ARIMA) model, Conditional Heteroskedasticity Autoregressive Model Autoregressive (ARCH) model [
4], and Generalized Autoregressive Conditional Heteroskedasticity (GARCH) model [
5]. With the increasing research on artificial neural networks, neural network algorithms such as the BP neural network [
6], Radial Basis Function (RBF) neural network [
7], Support Vector Machine (SVM) [
8], Gated Recurrent Unit (GRU) [
9], convolution-enhanced time series mixer [
10], and long short-term memory networks [
11] provide powerful tools for time series forecasting. However, most time series are complex and diverse, and no single model can achieve the desired accuracy [
9]. Therefore, there is a need to develop a composite forecasting framework to improve the accuracy and reliability of forecasting.
To solve the dilemma of forecast instability due to random fluctuations, the latest trend in TSF is to combine machine learning methods with signal decomposition preprocessing methods to further improve forecast accuracy. The preprocessing of energy price series by Empirical Mode Decomposition (EMD) has been revealed as a potent means to improve forecasting accuracy [
12]. Zhan and Tang found that using EEMD to decompose the residual terms after the Variational Mode Decomposition (VMD) can help analysts capture the dynamics of the price data in a more comprehensive way [
13]. In a recent study, Wang et al. proposed a Complete Ensemble Empirical Mode Decomposition with an Adaptive Noise—Sample Entropy (CEEMDAN-SE) to decompose natural gas price series, which is better able to detect the inherent trend of price fluctuations [
14]. These empirical studies have shown that forecasting models incorporating signal decomposition techniques markedly enhance the efficacy of the models and hence demonstrate superior predictive precision over single-category models [
15]. Therefore, in the forecasting model presented in this study, signal processing is performed before introducing the natural gas price series into the predictor.
Time series tend to be nonlinear and unsmooth due to the presence of many uncertainties [
16]. As a type of time series, natural gas price series also have the characteristics of being nonlinear and non-smooth. Therefore, it is more reasonable to use a nonlinear model for prediction. Artificial neural networks have excellent nonlinear adaptation capabilities, which is one of the most important research focuses in the field of nonlinear time series forecasting. The Extreme Learning Machine (ELM) [
17] is a machine learning algorithm for single hidden layer feed-forward neural networks. ELM, an emerging neural network structure, exhibits excellent nonlinear regression capability in time series forecasting by transforming the complex training process into a simple matrix or mathematical computation. In contrast to the conventional BP algorithm, ELM has the benefits of enhanced training efficiency and fewer tuning parameters. Moreover, it overcomes many of the limitations of traditional neural networks, such as local minimum generation, overfitting, and computational complexity [
18]. This leads to improved performance compared with ANN and SVR [
19,
20]. Intensive research on ELM-based time-series forecasting has increasingly demonstrated the advantages of ELM [
21,
22]. Therefore, in this paper, ELM is chosen as the basic predictor for natural gas price forecasting, and the forecasting framework and model are constructed using ELM.
During the fitting process, optimizing the parameters using intelligent algorithms has been proven to be effective in decreasing the prediction error of the time series. The prevalent optimization algorithms employed encompass the Sparrow Search Algorithm (SSA) [
23], Particle Swarm Optimization (PSO) [
24], Genetic Algorithm (GA) [
25], and Whale Optimization Algorithm (WOA) [
26]. Instead of training weights, ELM networks randomly generate their input weights and thresholds, leading to poor and unstable initial predictions. Nevertheless, this weakly learned predictor is well-suited as a basic predictor for integrated prediction frameworks. For example, Sun and Zhang suggested an adaptive WOA built upon multiscale singular value decomposition to predict time series data using an optimized ELM [
26]. Li et al. used optimized VMD and analyzed the IMFs by spatially dependent recursive sample entropy, the complexity of IMFs. Based on the complexity level, they used PSO to forecast intricate IMFs and ELM to forecast the remaining IMFs [
27]. Hao et al. suggested a hybrid model grounded in multi-objective optimization algorithms and feature selection for predicting carbon prices [
28]. In addition to these optimization algorithms, the Grey Wolf Optimizer (GWO) [
29,
30], a recently introduced nature-derived algorithm, shows great promise. The GWO outperforms conventional methods in terms of global convergence [
31] while maintaining computational efficiency in large-scale decision spaces [
32]. Nonetheless, Long et al. noted that the GWO can easily become trapped in local optimization when handling sophisticated multimodal problems [
33]. To mitigate this limitation, researchers have developed a number of improved methods that incorporate evolutionary selection mechanisms to optimize population fitness thresholds [
34], use quadratic formulas instead of linear decay coefficients [
35], and employ Levy flight and greedy selection [
36]. These methods boost the capability of the GWO to run away from local optima to some extent. However, they do not address the problems of the limited diversity of GWO populations and suboptimal search strategies. Different intelligent optimization algorithms use different search strategies. It has been shown that some search strategies can achieve complementary effects, and combining them can improve the comprehensive search capability and convergence of the algorithms. Throughout this research, three strategies, namely, mutation, crossover, and selection, are introduced in GWO, and an intelligent algorithm, Multi-Strategy GWO (MSGWO), with better search capability and faster convergence, is proposed. The MSGWO is used to optimize ELM-based forecasting models.
Natural gas prices can be impacted by a range of elements, such as policy adjustments, economic fluctuations, and changes in energy prices. These factors make it challenging to accurately predict natural gas prices. Single-point forecasts cannot fully describe or reflect volatility and trend changes. To better characterize the uncertainty information that time series may exhibit in the future, some scholars have used prediction methods with uncertainty. Wang et al. represented the original time series as a series of probability density functions to solve the problem of forecasting uncertainty [
37]. Cao et al. proposed a quantized spatio-temporal convolutional network that can accurately describe uncertainty fluctuations in order to accomplish time-series probabilistic forecasting [
38].
The forecasting accuracy of existing point forecasting methods for natural gas prices is still relatively limited, with significant room for improvement. Moreover, existing studies often only provide a single-point forecast or interval forecast model, which makes it difficult to comprehensively describe the fluctuations and changes in natural gas prices from multiple perspectives. To enhance the precision and trustworthiness of forecasting and deliver enhanced assistance to enable enterprises and governments to develop more resilient and adaptable natural gas trading management strategies, this paper adapts and improves the point forecasting framework and develops a composite framework that applies to not only point forecasting but also probability interval and quantile interval forecasting.
In this study, a point-forecasting model named EEMD-ELM-MSGWO was established. In the proposed model, EEMD is responsible for decomposing the natural gas price series, ELM acts as a predictor, and MSGWO is used to improve the parameters of ELM. Different forecasting models are used for comparison, including the model using only the predictor, the model combining different intelligent algorithms, and the model combining different decomposition methods. The results show that EEMD-ELM-MSGWO is highly efficient. Subsequently, the probability interval forecasting model (EEMD-PFELM-MSGWO) and quantile interval forecasting model (EEMD-QRELM-MSGWO) are developed. The comparison results show that the proposed forecasting framework is accurate and stable for point, probability interval, and quantile interval forecasting. In addition, the proposed MSGWO is more effective in optimizing the ELM parameters.
The innovative and futuristic aspects of this research can be summarized as follows:
Firstly, this study suggested an improved algorithm, MSGWO, for optimizing the hidden layer matrices of the ELM and significantly reducing the prediction error. The MSGWO combines GWO with mutation, crossover, and selection strategies, which improves overall performance.
Second, we constructed a novel decomposition and aggregation time-series forecasting framework. The proposed EEMD-ELM-MSGWO framework combines several techniques: EEMD decomposes the natural gas price series into IMFs to analyze the different frequency components separately, ELM predicts each IMF independently, and MSGWO optimizes the ELM. Together, these techniques provide a comprehensive and effective forecasting framework.
Additionally, this study not only proposes a point forecasting model but also suggests the corresponding probability interval forecasting model (EEMD-PFELM-MSGWO) and quantile interval forecasting model (EEMD-QRELM-MSGWO). Among them, EEMD is used for signal processing of natural gas price series, Probability Interval Prediction Extreme Learning Machine (PFELM) and Quartile Interval Prediction Extreme Learning Machine (QRELM) are used as predictors for probability interval forecasting and quartile interval forecasting, respectively, and MSGWO is employed to identify the optimal parameters for the predictors. The three forecasts provide a comprehensive picture of the natural gas price volatility and trends. Finally, the EEMD-ELM-MSGWO, EEMD-PFELM-MSGWO, and EEMD-QRELM-MSGWO models have been successfully applied to point, probability interval, and quantile interval forecasting of natural gas prices. These models have achieved impressive results.
The remainder of this paper is organized as follows:
Section 2 presents the theoretical approach;
Section 3 presents the proposed MSGWO algorithm;
Section 4 presents the proposed forecasting framework;
Section 5,
Section 6 and
Section 7 present the empirical studies of point forecasting, probability interval forecasting, and quantile interval forecasting, respectively; and
Section 8 concludes.
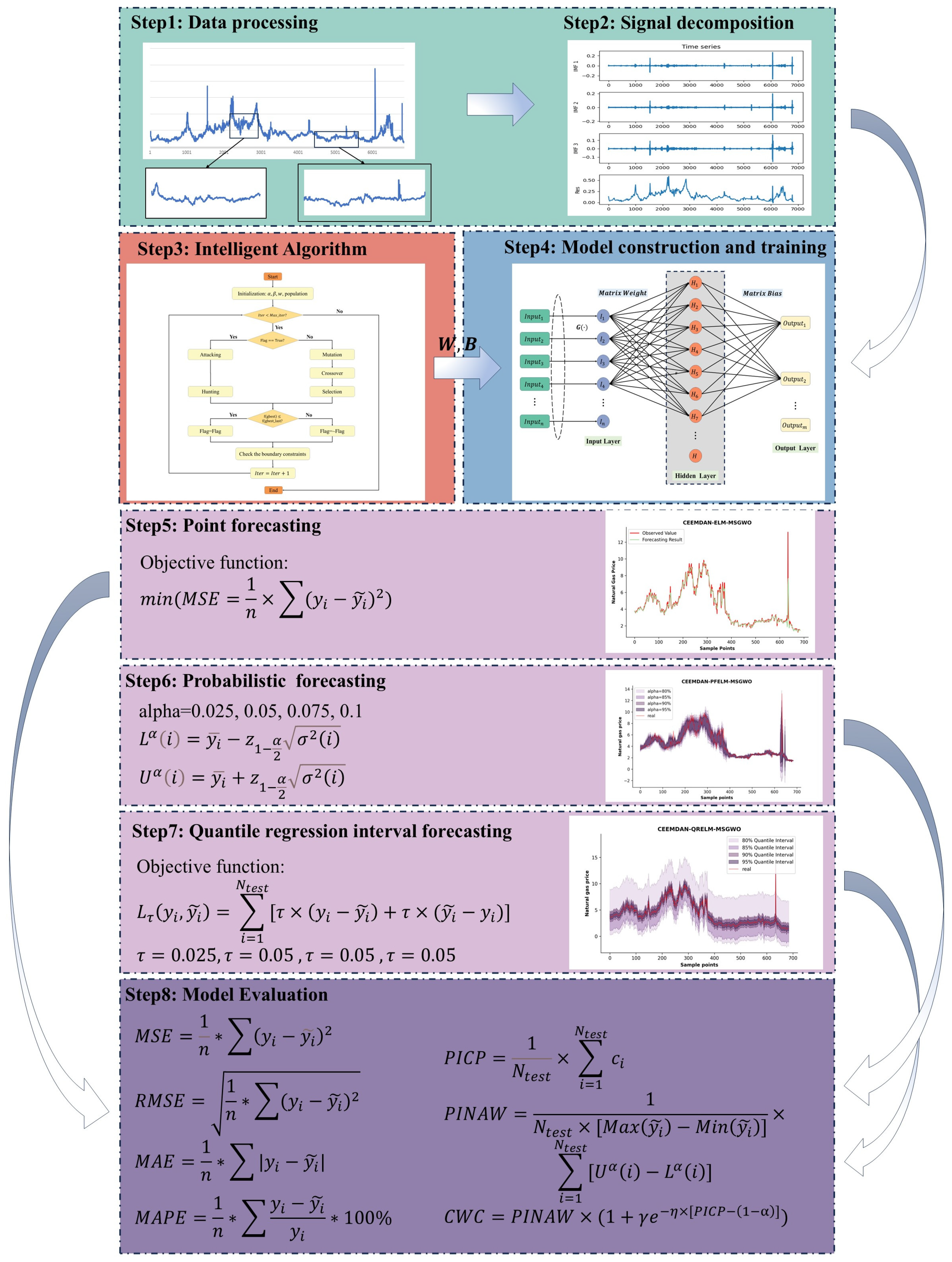
4. Forecasting Framework
As shown in
Figure 3, the proposed forecasting framework comprises eight major components: data preprocessing, signal decomposition, optimization algorithm, predictor, point forecasting, probability interval forecasting, quantile interval forecasting, and model evaluation.
4.1. Data Preprocessing
Natural gas prices are derived from market transaction records; however, these records often contain noise and outliers. These noises and outliers can result from statistical errors, system failures, and other external factors. Therefore, effective preprocessing of the data to remove or smooth out these outliers is critical for improving the predictive model. In addition, missing values may occur in the natural gas price series. Commonly used missing value processing methods include interpolation, nearest neighbor, and regression methods. Additionally, ELM models typically require input variables to have values between 0 and 1 or between −1 and 1. Through normalization, the natural gas price series can be scaled to values between 0 and 1. The benefit of normalization is that the ELM model can be trained correctly, and the optimization algorithm will perform better because the values of the different features remain similar and more consistent with the model’s assumptions. This process allows the model to capture trends in the price series more accurately and improve the forecasting results.
4.2. Decomposition of Natural Gas Price Series
Signal decomposition plays a pivotal role in the field of TSF, and its importance and far-reaching impact should not be underestimated. Through signal decomposition, complex data structures can be effectively separated into simple data patterns, facilitating an in-depth study of the trends. Thus, the prediction model is better able to capture specific patterns in the data. At the same time, signal decomposition techniques improve the robustness and accuracy of the prediction model by removing noise, smoothing the data, and extracting features.
EEMD is a widely used signal-processing technique. It introduces Gaussian white noise into the process, and by averaging the decomposition results several times, it can effectively mitigate the modal aliasing issue because of noise. At the same time, by averaging these IMFs, the EEMD can improve the structural separation and remove the added white noise. Applying EEMD to time series data can enhance the adaptability and accuracy of forecasting models.
4.3. Optimization Algorithm
The proposed MSGWO was used to determine the most suitable ELM hidden layer matrices to improve the prediction model. There are two hidden layer matrices in the ELM, which are known as matrix and matrix . is the weight matrix, which denotes the weights from the input layer to the hidden layer and is used to control the mapping process. The choice of the column number of the matrix , which corresponds to the neuron number, affects the capacity of the model: if the capacity is too small, it may not be able to capture complex relationships from the data, whereas too large a capacity may lead to overfitting. Conversely, the number of rows of the matrix corresponds to the number of features in the input data and controls the fitting process. The matrix represents the bias matrix of the hidden layer, also known as the hidden layer bias term. Matrix introduces a nonlinear transformation so that the output contains nonlinear information. The size of the matrix affects the degree of nonlinearity introduced. Appropriate nonlinear transformations help improve the fit of the model and capture the complex relationships between the data. The greater the number of bias terms, the greater the flexibility; however, it can also lead to overfitting. Correct fitting requires a balance between the model fit and generalizability. When training the model, the main implementation of ELM is to adaptively adjust the size of the and matrices to gradually reduce the difference between the output and the training target in order to achieve a good fit. Matrix and matrix have a significant impact on the adaptability and generality of the model, so the optimization targets are matrix and .
Assuming that the vector
is the decision variable of optimization,
can be expressed by Equation (22):
where
denotes the weight matrix, and
denotes the bias matrix. The search range of matrix
and matrix
is shown in
Table 2:
4.4. Predictor
The learning speed of ELM is extremely fast. Compared with traditional iterative learning methods, ELM usually learns more efficiently because the output layer weights can be computed directly from the parsing solution. In practice, ELM exhibits good generalization performance, especially on large datasets. Therefore, this paper uses ELMs as predictors. Each IMF is divided into two parts: the training and testing parts. The training data were used to tune the model and optimize the hidden layer matrices, whereas the test data were used to measure the performance of the predictive model.
4.5. Point Forecasting
Point forecasting is an important analytical technique in time-series forecasting. The purpose of point forecasting is to analyze historical data to capture patterns to estimate values at a specific point in time in the future. In the case of natural gas price forecasting, the primary objective of point forecasting is to accurately capture future trends in the natural gas market prices. Natural gas produces relatively little carbon dioxide and other air pollutants from combustion as a clean energy source, helping to combat climate change and improve air quality compared to other energy sources. Point-to-point forecasting results not only help companies and governments make real-time decisions but also provide stakeholders in the natural gas market with price trends, thereby facilitating informed decisions on trade and investment in the natural gas industry and promoting sustainable development and the development of a low-carbon economy in the natural gas sector. Forward-looking forecasts provide a more intuitive understanding of future natural gas price trends and provide a scientific basis for achieving carbon reduction targets.
The developed forecasting framework adopts the Mean Squared Error (MSE) metric, defined in Equation (23), to quantify the prediction accuracy and guide parameter optimization.
where
denotes the
th actual observation,
is the
th output, and
is the sample size.
4.6. Probability Interval Forecasting
Probability-interval forecasting can provide more comprehensive information. By introducing probability distributions, the method not only predicts individual sample points but also provides probabilistic estimates of possible future trends in natural gas price volatility. The advantage of the probability interval forecasting method is that it captures the uncertainty of market fluctuations and provides diversified support to decision-makers in the presence of uncertainty.
Assume that the time series , where the sample number is . The data is randomly and putatively sampled times () using the Bootstrap method, and each time, observations () are extracted. The Bootstrap sampling samples are then reordered according to the serial numbers of the extracted observations in the original series to form a dataset containing Bootstrap samples about the time series , so that the nature and distribution of the time series can be further investigated. The specific steps of the probability interval forecasting model of natural gas price based on the Bootstrap method are as follows:
Step 1: Obtain the original sample dataset of natural gas trading prices, where .
Step 2: Resampling. Draw () samples from the natural gas price time series randomly and with a putback, and at the same time construct the first Bootstrap sample by arranging the drawn samples according to their ordinal numbers from smallest to the largest in the original sample Y. Repeat the extraction of () times to get Bootstrap sample set .
Step 3: Construct a point prediction model. Divide each sample in the Bootstrap sample set into training and test sets, and input the training sets to the point forecasting model to obtain point forecasting models.
Step 4: Model Prediction. The prediction model obtained in Step 3 is used to conduct prediction experiments on the test set of Bootstrap samples respectively, and the set of prediction sequences is obtained.
Step 5: Construct probability forecasting intervals. After step 4, a sequence set
can be obtained, which consists of the predicted results of the group of points in group
, where
th predicted sequence set
. In the set of prediction sequences
, for the
th sample point, there are a total of
predicted values, which can form the sequence
. The computation leads to the mean value of the sequence
as
, and variance as
. Assuming that the confidence level is
, the probability forecasting interval
for
can be expressed by Equation (24):
where
denotes the probability forecasting interval when the confidence is
,
and
denote the lower and upper limits of the
th probability forecasting interval, respectively, and
is the ordinal number of the forecasting target. Equation (24) makes the interval coverage
.
and
can be calculated by the following method:
where
and
are the lower and upper boundaries of the
th probability forecasting interval,
denotes the mean of the
point forecasted values obtained by the prediction of the
th observation,
is the variance of the
point predicted values obtained by the prediction of the
th observation, and
denotes the standard Gaussian distribution’s critical value at
confidence level. When the boundary of
exceeds
, it will be adjusted to the lower or upper boundary.
4.7. Quantile Interval Forecasting
In natural gas price forecasting, interquartile range forecasting is an important method for providing more information about uncertainty. By introducing the concept of the interquartile range, this methodology not only focuses on the central tendency but also illustrates the range of natural gas price changes. With interquartile range forecasting, policymakers can gain a more comprehensive understanding of the likelihood of natural gas price volatility and implement adaptive risk governance protocols to enhance strategic responsiveness in exposure control. Interquartile range forecasts are better able to cope with outliers and noise because they do not rely too heavily on a single data point but rather take into account the entire forecast horizon.
4.7.1. Quantile Loss Function
A commonly used objective function for interquartile range forecasting is the quantile loss function, which is intended to model tail risk more completely when forecasting different quantiles. Unlike the objective function for point forecasting models, the quantile loss function does not minimize the total squared errors but rather minimizes the total absolute errors arising from the selected quantile cut points. A commonly used loss function formulation is the pinball loss [
51]. Pinball loss is characterized by directing the focus of the model to the already defined range of quantile values by adjusting the penalty for prediction errors at different quantile values. The mathematical expression for the quantile loss function is as follows:
where
is the quantile forecasting loss in model training,
is the value of the selected quantile,
is the sample size, and
denotes the quantile loss for each prediction target, which can be obtained by using Equation (28).
where
denotes the quantile loss for each prediction target,
is the selected quantile value,
denotes the
th observation, and
denotes the
th quantile forecasting value.
In Equations (27) and (28), is the loss when the forecasted value is smaller than the observation, and denotes the lagers. Through considering different values, this function can be further understood as follows:
- (1)
When , the forecasted value is smaller or larger than the observed value with equal weights. In this situation, the loss function is the same as the Mean Absolute Error (MAE).
- (2)
When , the loss weights are higher when the forecasted value is smaller than the observation. To minimize the loss, the model tends to make the forecasting values relatively large. This contributes to a relative increase in the predicted value, which can be interpreted as obtaining the upper boundary of the quantile forecasting interval.
- (3)
When , the weight of loss is higher when the forecasted result is larger. At this point, the goal of the model is to adjust the forecasted result to be relatively small in order to minimize the loss. This results in a relatively lower predicted value, which can be interpreted as being used to determine the lower limit of the interquartile prediction interval.
4.7.2. Construction of Quantile Forecasting Interval
In practice, quantile interval forecasting often specifies several different quantile values to fully measure the effectiveness of the quantile interval forecasting model. By adjusting the hyperparameter , an error threshold can be chosen that is appropriate for balancing the problems that need to be solved. The output corresponding to each quantile is a complete but biased point prediction result. By using the prediction results of quartile and quartile as the lower and upper boundaries, respectively, a quartile forecasting interval with a confidence level of can be constituted.
4.8. Criterions for Evaluation
4.8.1. Evaluation of Point Forecasting
In this study, four commonly used criteria are set to evaluate the point-forecasting models. First, the MSE is used as a variance measure. The MSE is defined as follows:
where
is the observation,
is the prediction result, and
is the sample size.
Second, the Root Mean Square Error (RMSE) was chosen as a performance criterion, which is defined as follows:
where
is the observation,
is the forecasting result, and
is the sample size.
Third, the MAE is used as the accuracy criterion and is defined as follows:
where
is the observation,
is the prediction result, and
denotes the sample size.
Finally, the Mean Absolute Percentage Error (MAPE) is selected to measure the relative error in natural gas price point forecasting and is represented as follows:
where
is the observation,
is the prediction result, and
denotes the sample size.
4.8.2. Evaluation of Probability and Quantile Interval Forecasting
Given the bands of continuous-value uncertainty generated by interval forecasting, the traditional point prediction evaluation paradigm is inappropriate for evaluating interval-based prediction results. In order to rigorously quantify the reliability and accuracy of these interval forecasting methods, we selected three evaluation criteria, each targeting a different aspect of the interval prediction performance.
The first metric is Prediction Interval Coverage Probability (PICP).
calculates the probability that an actual observation falls within the prediction interval, and it’s calculated as in Equations (33) and (34), as follows:
where
denotes the sample size and
denotes the coefficient of 0 or 1.
can be calculated using Equation (34), as follows:
where
is the
th observation, and
is the interval corresponding to the
th observation at a confidence level of
as calculated by the probability interval forecasting model and the quantile interval forecasting model.
The next indicator is the Prediction Interval Normalized Average Width (PINAW), which is the ratio of the mean value of the width of the forecasting intervals to the standard deviation of the actual observations. The formula for
is Equation (35).
where
and
denote the upper and lower boundaries, respectively,
is the variance of the test data, and
denotes the sample number.
In the realistic forecasting process, the phenomenon of relatively high coverage of intervals but a relatively large average width of intervals often occurs. In this case, we chose the last evaluation metric, the Calibration Width Coverage (CWC). The smaller
means the better effectiveness. Equation (36) defines the calculation method of
.
where
is derived from Equation (35),
is derived from Equation (33),
is used to penalize models that do not meet preset coverage,
is the natural constant, and
is an exponential function that serves to amplify the penalization of models that do not meet the preset coverage, which is usually set to 40,
denotes the confidence level for calculating probability forecasting intervals and the quantile level for calculating quantile forecasting intervals.
can be calculated using Equation (37):
where
is calculated using Equation (33),
denotes the confidence level.
5. Point Forecasting Experiments
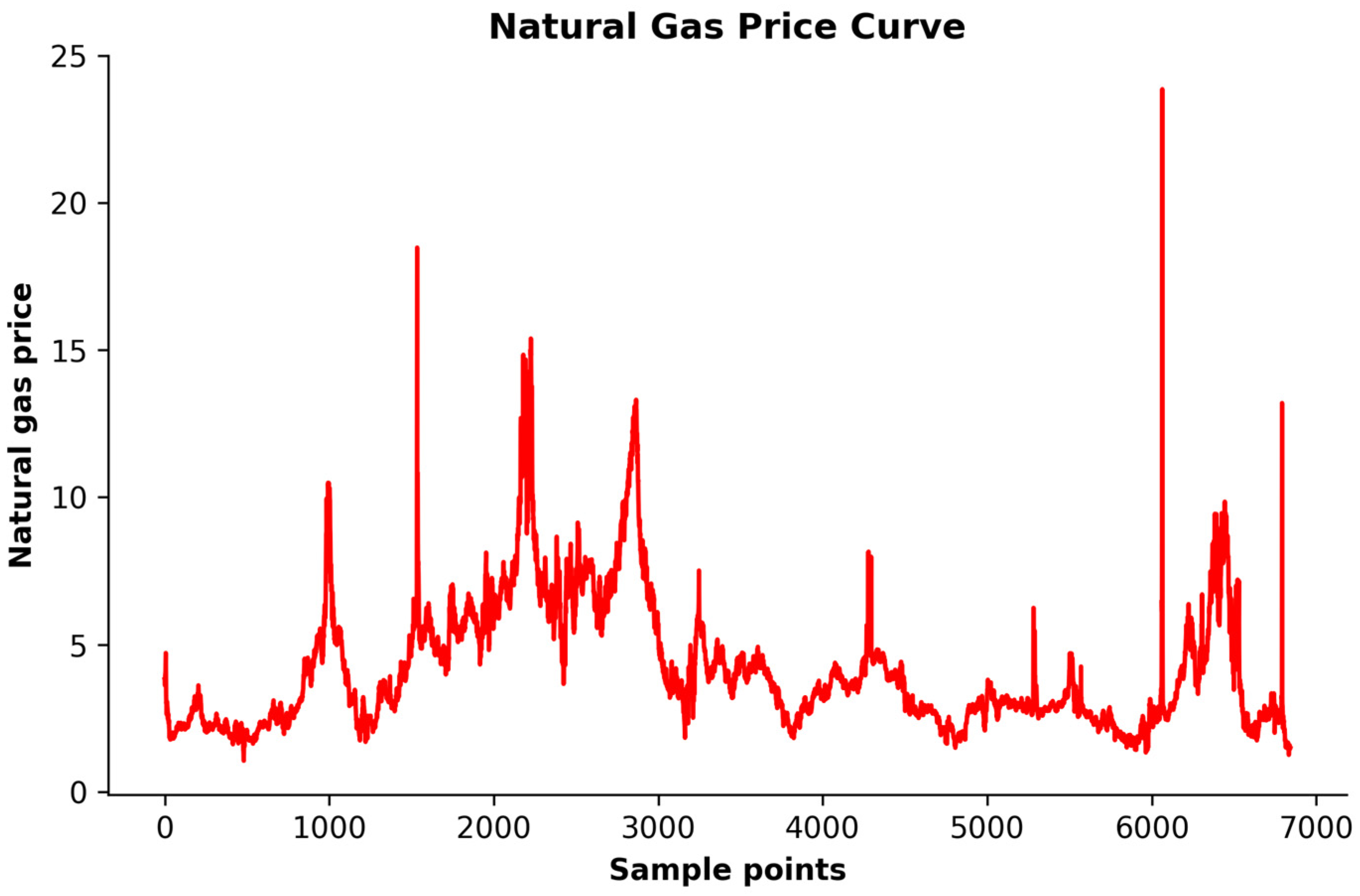
5.1. Research Data and Experimental Setting
This research uses daily natural gas prices from the U.S. Energy Information Administration for this experiment. The experimental data covers natural gas trading prices from 7 January 1997 to 26 March 2024, with a total of 6843 samples. A line graph of the observation data is shown in
Figure 4.
Before the forecasting experiment begins, the natural gas price time series is first preprocessed to correct and fill in outliers and missing values by interpolation. The preprocessed series are then normalized to the range of −1 to 1 to prevent the gradient from disappearing and to meet the input requirements of the ELM. The sequences are split into the training and test sets.
Table 3 shows the series division.
All experiments are conducted under identical conditions using Python 3.9 programming language, a laptop with an Intel Core i7, 3.4 GHz CPU, and 20 GB of RAM, and an operating system of Windows 10.
5.2. ELM with Optimization Algorithms
Although ELM shows great potential for natural gas price forecasting, several challenges persist, particularly in optimizing its hyperparameters. The predictive performance of ELM is highly sensitive to the selection of key parameters, such as synaptic connection weights and bias vectors, which significantly influence the model’s effectiveness.
By employing intelligent optimization algorithms to tune the model’s hyperparameters, the model can be more effectively adapted to varying data characteristics, thereby enhancing its robustness and generalization capability. Optimizing the hyperparameters enables the model to better exploit the intrinsic information contained in the data, ultimately improving its predictive performance for natural gas price forecasting.
In the first part, different optimization algorithms are used to identify the optimal hidden layer matrices for the ELM. Six metaheuristic-driven algorithms—GWO [
29], DE [
52], PSO [
53], Moth-Flame Optimization (MFO) [
54], WOA [
55], and our novel MSGWO are implemented to refine synaptic connection weights and bias vectors through iterative parameter space navigation. Reconstructed ELM variants with evolutionarily optimized neural topologies are subsequently deployed for natural gas price forecasting. The experimental controls incorporate baseline ELM implementations without parametric enhancement. Each configuration undergoes decuple Monte Carlo realizations (
) under identical computational constraints to ensure statistical robustness. Additionally, we selected XGBOOST, Long Short-Term Memory (LSTM), Convolutional Neural Networks (CNN), Temporal Convolutional Networks (TCN), and transformer models for comparison with ELM to validate the rationale behind choosing ELM as the forecasting model. The prognostic performance metrics are aggregated through ensemble averaging, and the comprehensive quantitative evaluation is presented in
Table 4. The forecasting results of the MSGWO-enhanced ELM framework are further visualized in
Figure 5, demonstrating superior market pattern tracking fidelity.
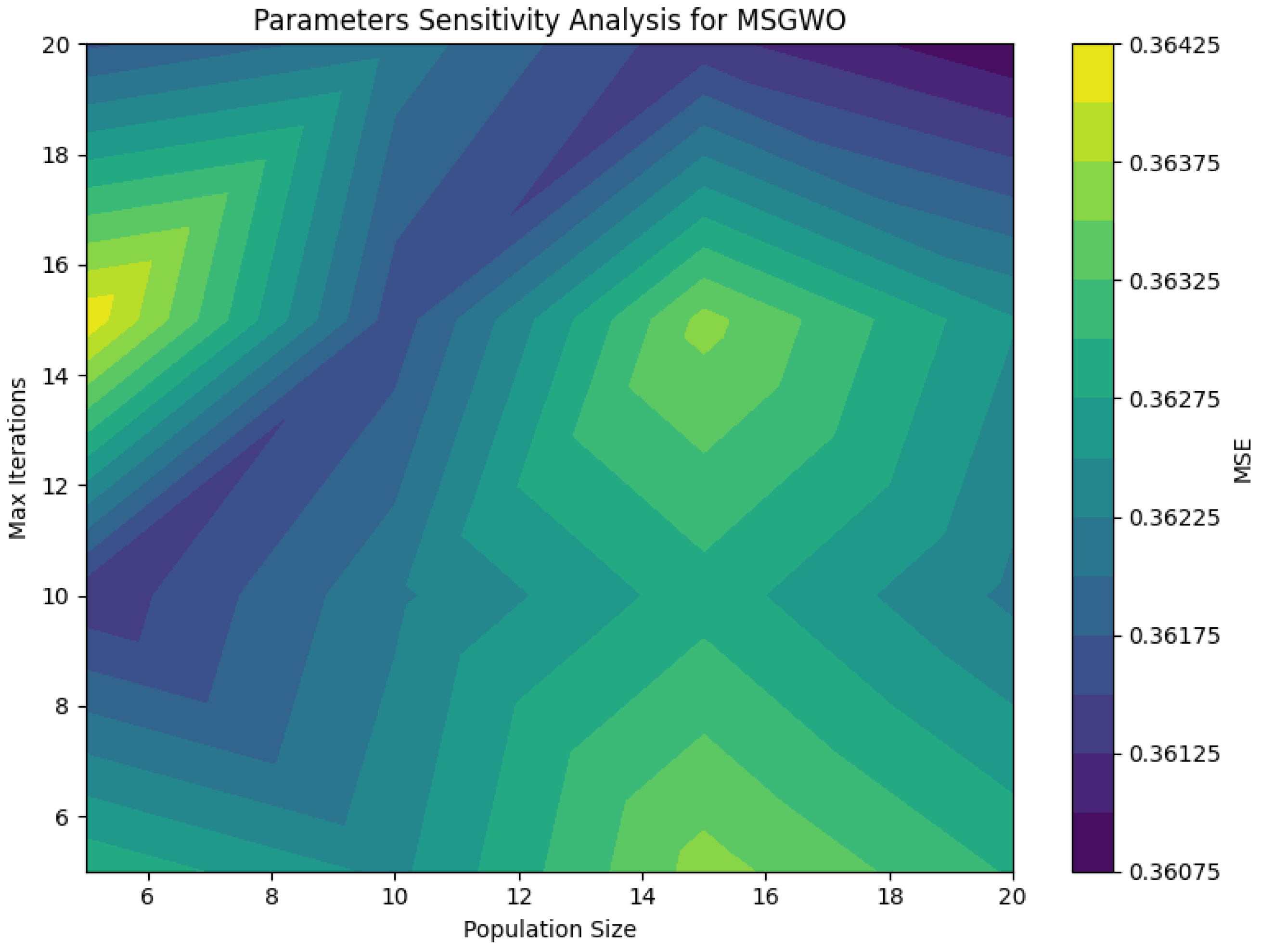
Moreover, to assess the stability of the model, we analyzed the impact of the population size and number of iterations on the prediction accuracy of MSGWO. Both parameters were set to 5, 10, 15, and 20, and the corresponding model performance was evaluated. The results are shown in
Figure 6. The model exhibits stable performance across different parameter configurations, with relatively minor variations in prediction accuracy. Considering the trade-off between predictive performance and computational complexity, both the population size and the number of iterations were set to 10.
By comparing the statistical metrics of the ELM and the models optimized using swarm intelligence mechanisms in
Table 4, the following conclusions can be drawn.
First, the parametric refinement of the hidden layer matrices through metaheuristic-driven optimization frameworks demonstrated measurable improvements in the predictive fidelity of the ELM. The direct forecasting results using the traditional ELM model reached an acceptable level: the MAPE metrics for the forecasting results of the ELM reached 6.6740%, which indicates that ELM has good performance on the accuracy and generalization aspects still have much room for improvement. In particular, when processing non-stationary signals exemplified by natural gas price series, the ELM faces significant bottlenecks in capturing deeper factors. To solve these problems, our methodology integrates evolutionary computation paradigms for the parametric refinement of the synaptic architecture of the ELM. Each evolutionary strategy implements probabilistic search operators, including gradient-free exploration and adaptive mutation heuristics, to systematically calibrate the neural projection matrices. This optimization framework facilitates hierarchical feature abstraction from non-stationary temporal patterns, enabling comprehensive latent variable discovery. Empirical validation demonstrates marked improvements in prognostic capability across all benchmark metrics. The metaheuristic-enhanced ELM variants exhibit superior nonlinear fitting capability, confirming their enhanced capacity for multi-scale pattern recognition in complex energy market dynamics.
Second, the proposed MSGWO exhibits superior overall performance compared with other intelligent optimization algorithms. The MSGWO reached the minimum values in MAE and MAPE and consistently maintained the top performance in MSE and RMSE, ranking second. This not only highlights the excellent performance of the MSGWO in hidden layer parameter finding for ELM but also proves its advantages in helping predictive models capture data features and fit the models. A granular examination of the MSGWO demonstrated that its innovative exploration dynamics and swarm-based metaheuristic framework significantly enhance the parameter optimization capabilities in ELM. The MSGWO emulates social dynamics encompassing wolves, both cooperative pack behavior and individual dominance hierarchies, and simultaneously employs three strategies, namely, mutation, crossover, and selection, to refine the shortcomings of the GWO in navigating high-dimensional search spaces. The mutation strategy greatly improves the group diversity. In contrast, the crossover strategy accelerates the optimization process and facilitates a global search. This selection strategy is conducive to improving the convergence speed and stability. The addition of these three strategies enables the MSGWO to maintain an adaptive equilibrium between exploration-exploitation tradeoffs, which improves the search efficiency, better avoids premature convergence, and achieves remarkable results in the optimization process of ELM’s synaptic connection parameters.
5.3. Decomposition of Natural Gas Price Time Series
In this section, we perform signal decomposition operations on the natural gas price series and conduct a second round of experiments. A methodologically rigorous comparison of temporal decomposition techniques is conducted to quantify their influence on predictive performance by evaluating four principal approaches: EMD [
56], CEEMDAN [
57], Variational Mode Decomposition (VMD) [
58], and EEMD [
46].
It is known from existing studies that the performance of decomposition techniques is more susceptible to two key parameters: the ensemble iteration count
and the Gaussian-distributed perturbation magnitude
[
59]. As formalized in Wu and Huang’s canonical statistical framework in Equation (38), the selection of the above parameters has a large correlation with the standard deviation of the error
[
46]. Theoretical analyses establish that stochastic perturbations exhibit a scaling behavior governed by the mathematical framework in Equation (38). Empirical evaluations across multiple trials have demonstrated an optimal perturbation magnitude of approximately 0.2 times the empirical standard deviation in observational datasets. Complementary investigations by Zhang et al. into the parametric configuration in ensemble decomposition methodologies yielded experimental validation that corroborated the theoretical congruence initially posited in foundational studies [
60].
where
denotes the population standard deviation,
specifies the Gaussian-distributed perturbation magnitude, and
indicates the total iteration cycles in the ensemble process.
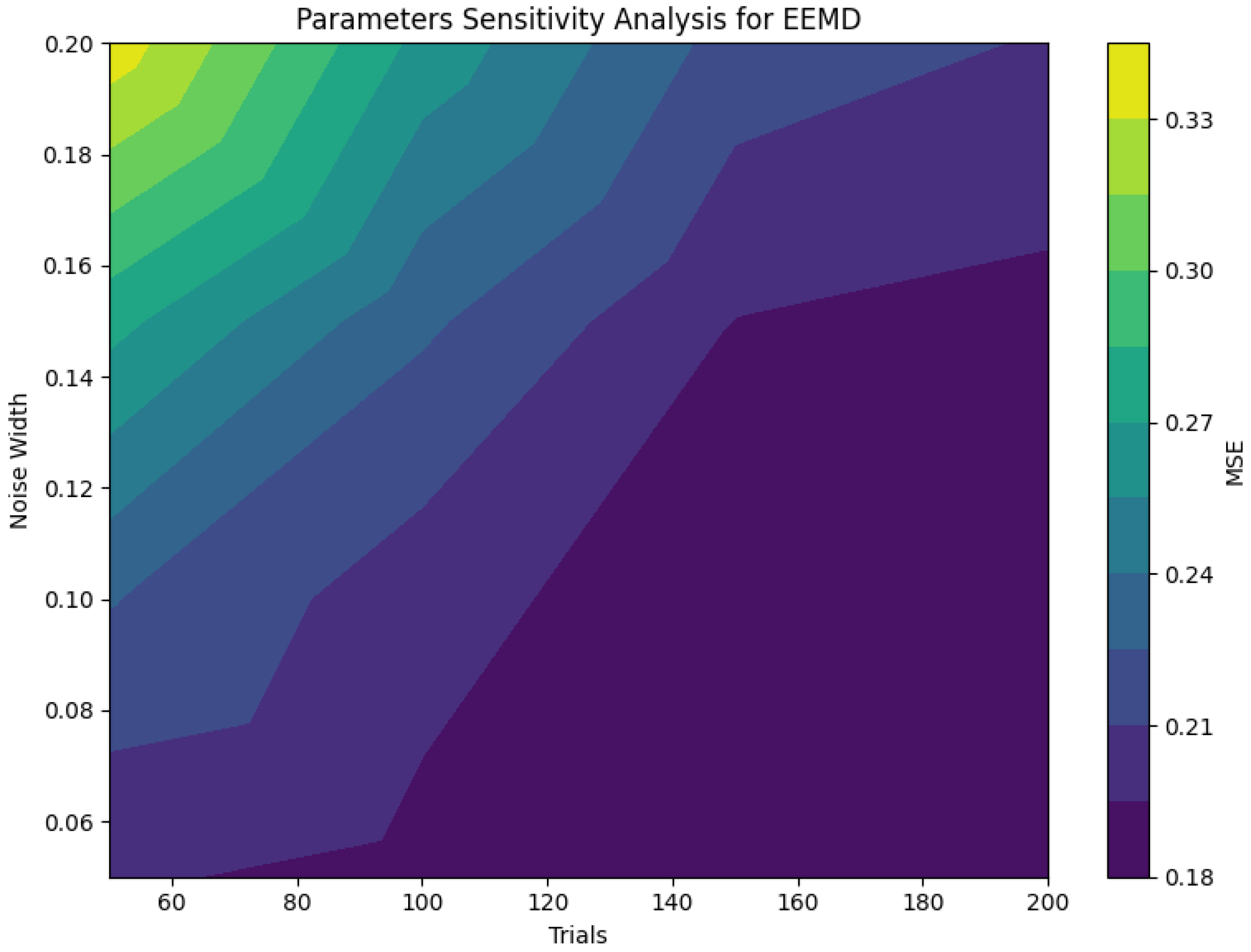
Parametric influence mechanisms are comprehensively addressed in the foundational work of Wu and Huang, to which readers are directed for methodological details. To verify the sensitivity of the EEMD to its parameters, we analyzed two key factors: the noise amplitude and the number of ensemble iterations. Specifically, the noise amplitudes were set to 0.05, 0.1, 0.15, and 0.2, while the number of ensemble iterations was set to 50, 100, 150, and 200. The corresponding variation in the MSE was observed to assess the impact of these settings, and the experimental results are presented in
Figure 7.
It is evident that the prediction accuracy deteriorates as the noise amplitude increases, while it improves with a higher number of ensemble iterations. To ensure the generalization ability of the model and avoid overfitting and underfitting, we refer to the parameter settings recommended in previous studies for guidance. Our implementation employs an ensemble-based modal decomposition methodology configured with 100 iteration cycles and a Gaussian noise component magnitude scaled to 0.05 times the signal’s standard deviation.
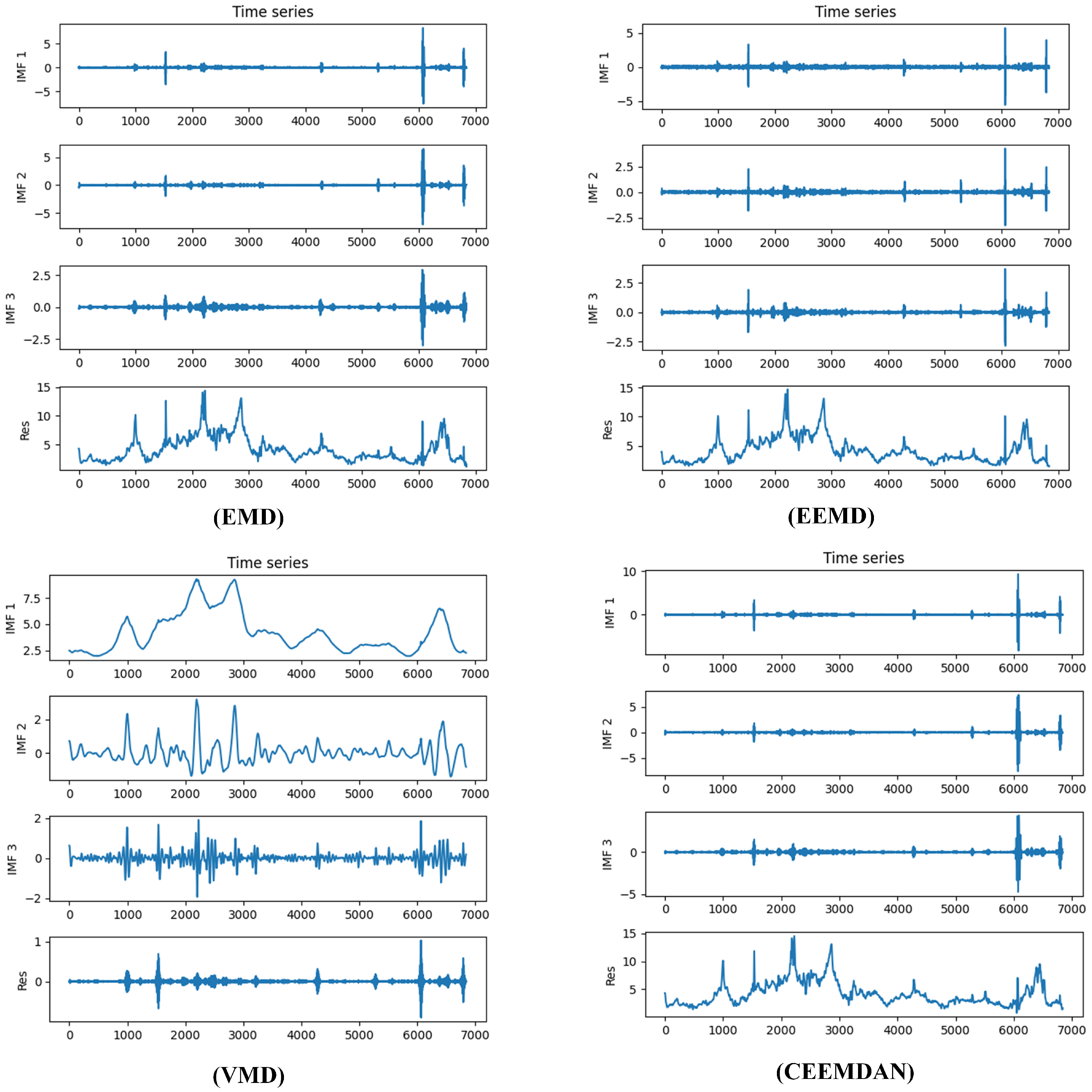
Figure 8 illustrates the application of four distinct decomposition approaches to the natural gas price series, demonstrating the characteristic mode separation capabilities.
5.4. ELM with Decomposition Methods
By analyzing the natural gas price data in both the time and frequency domains, we argue that the IMF components extracted through decomposition effectively capture the key dynamic features of the time series. Specifically, IMF1 reflects high-frequency fluctuations or noise, representing short-term oscillations in natural gas prices. IMF2 captures medium-term cyclical patterns and seasonal variations, while MF3 primarily represents low-frequency components that correspond to long-term trends. These decomposition techniques not only offer a more nuanced understanding of price volatility across different time scales but also provide more structured and informative inputs for subsequent modeling and forecasting tasks.
To assess the effectiveness of various signal decomposition techniques in decomposing the natural gas price time series and their impact on the ELM model, we compare and analyze forecasting models that incorporate these techniques. We first decompose the series using each of the techniques described above, as described in
Section 5.3. In the next step, the obtained IMFs and residuals were split into training and test sets. Using the training sets as input to the ELM model, forecasting models corresponding to different IMFs can be trained, which in turn yields forecasting results corresponding to each IMF and residual. After accumulating the sets of forecast results correspondingly, the point forecasting results can be obtained. In the experiments of the forecasting models with the addition of the signal decomposition techniques, the same 10 experiments were carried out independently for each of these models, and the mean values of the same metrics obtained were calculated. The quantified performance metrics for all experimental configurations are systematically presented in
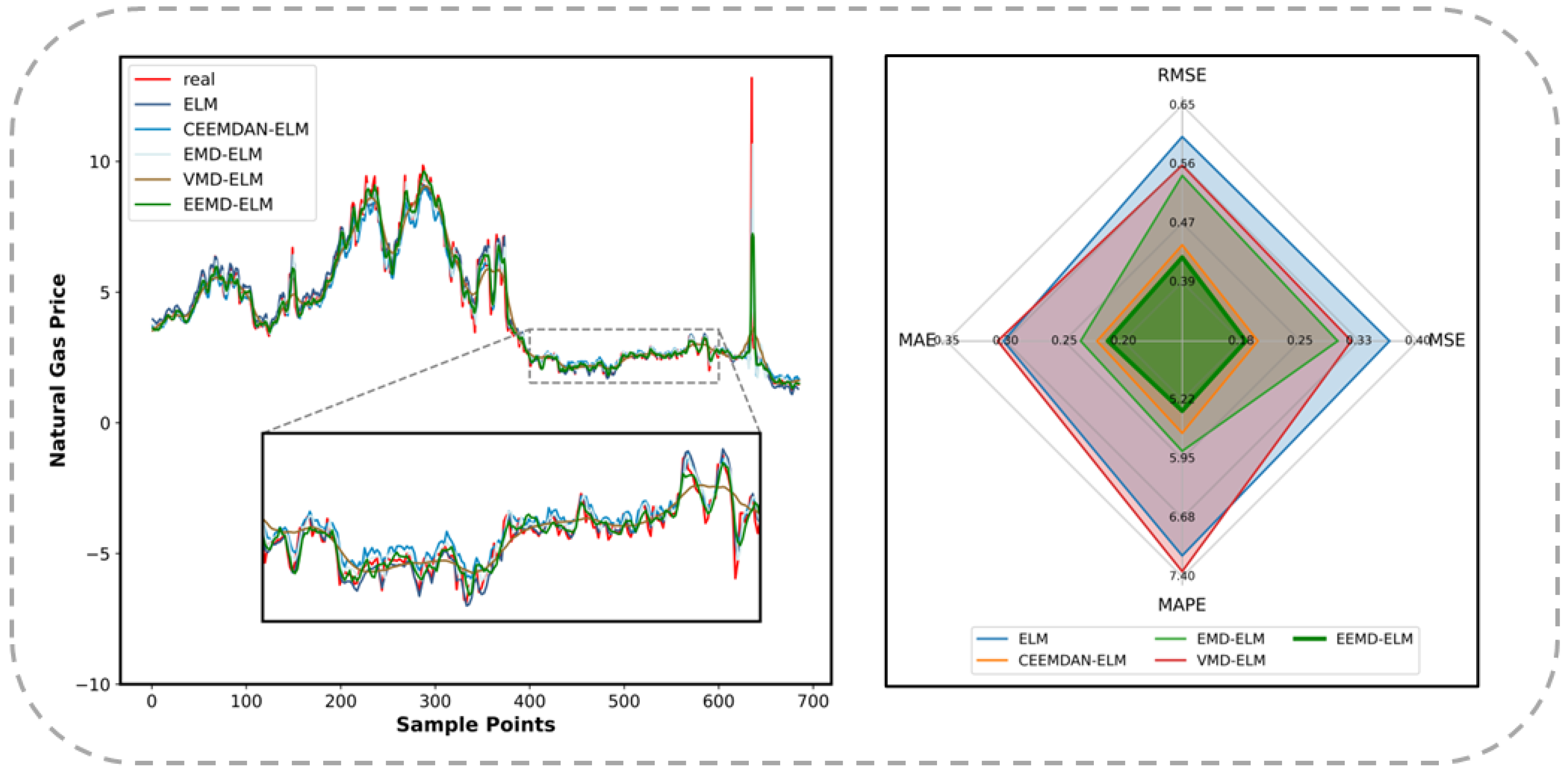
Table 5. Complementary to the tabular data, the prognostic outputs of the EEMD-ELM are visualized through a line graph, as shown in
Figure 9.
As displayed in
Table 5, the ELM forecasting model based on EEMD has the most accurate and highest coincidence results for the natural gas price series, surpassing the predictions by models applying other decomposition methods. Further analysis of the various statistical indicators enables the formulation of the following principal findings:
First, the pre-decomposition of time series has been found to positively contribute to the improvement of the accuracy of the forecasting results. Significant decreases in all four statistical indicators have been shown in the results of the forecasting models that apply the EMD, CEEMDAN, and EEMD methods. The significant reductions in the above indicators indicate that the accuracy of the prediction models has notably improved, representing the positive impact of signal processing techniques on prediction accuracy in time series forecasting. Time series data are typically composed of multiple components with different scales and frequencies, such as secular tendencies, seasonal variations, and high-frequency noise. By decomposing the time series, the components of different scales can be separated, making the characteristics of each component more distinct. In this way, the decomposed sequences, with noise and redundant information removed, become easier to interpret, allowing the true patterns within the data to be more accurately captured by forecasting models. Consequently, the predictive capability of the models is enhanced by the decomposition techniques. The ELM model incorporating the VMD technique showed improvements in MSE and RMSE compared to the original ELM. However, weaker performance was observed in MAE and MAPE, which may be attributed to inaccuracies in feature extraction or information loss, among others. If the signal is overly complex, containing multiple frequency components with mutual interactions, the signal might fail to be accurately decomposed into distinct modes by VMD, which can lead to inaccurate features being extracted and affect the prediction of the ELM model. From this, it can be seen that not all signal decomposition methods are suitable for all the time series. For the natural gas price series, VMD evidently cannot clearly distinguish between important information and noise, resulting in the ELM model being unable to learn sufficiently effective features.
Second, the decomposition effect of the EEMD technique surpasses that of other decomposition methods. Among the original ELM model and the four models incorporating signal decomposition techniques, the EEMD-ELM achieved the most optimal prediction results. For RMSE and MAE, the EEMD-ELM model demonstrated a reduction of more than 20% compared to ELM, the optimization margin in MSE exceeded 45%, and an improvement of nearly 20% was also achieved in MAPE. These optimization margins significantly surpassed those of other decomposition methods, demonstrating the superiority of the EEMD. As a multi-scale signal decomposition method, EEMD can better capture the different scales of features and variations within a time series. Compared to CEEMDAN, EMD, and VMD, EEMD can decompose time series more accurately and extract richer feature information, providing a more robust data foundation for subsequent model training. Furthermore, EEMD involves controlled Gaussian noise injection during the process, which better suppresses the impact of noise and enhances quality and accuracy. This makes the decomposition results closer to the real components of the signal and reduces the interference of noise to the model, thus enhancing accuracy. It is precisely due to these advantages that the EEMD-ELM model achieves the most accurate and stable results in natural gas price prediction experiments.
5.5. ELM with Decomposition Methods and Optimization Algorithms
In this section, comparisons and analyses of different prediction models are conducted from two dimensions: (1) the application of EEMD to decompose the natural gas price series, followed by the use of metaheuristic optimizers to optimize the parameter tensors of the ELM; (2) the adoption of various signal decomposition techniques, with the MSGWO algorithm used to optimize the parameter tensors of the ELM.
Within the methodological framework delineated in
Section 5.3, four distinct temporal decomposition methodologies were applied to the natural gas quotations. The EEMD-generated IMFs of the natural gas price series served as inputs for the ELM, where metaheuristic optimizers conducted neural parameter refinement. IMFs from CEEMDAN, EMD, and VMD are similarly processed through the ELM, with MSGWO executing parameter tensor optimization.
Upon attaining the optimal hidden layer matrices, the forecasting models became operational. The methodological phase transitions to the temporal partitioning of IMFs into calibration and validation subsets. The newly constructed forecasting models were trained using the training sets of IMFs corresponding to each set of hidden layer matrices optima and evaluated using the testing sets. To ensure statistical robustness, each configuration was autonomously executed in ten trials under identical environmental constraints. Subsequent analysis quantifies the metrics across multiple dimensions, as listed in
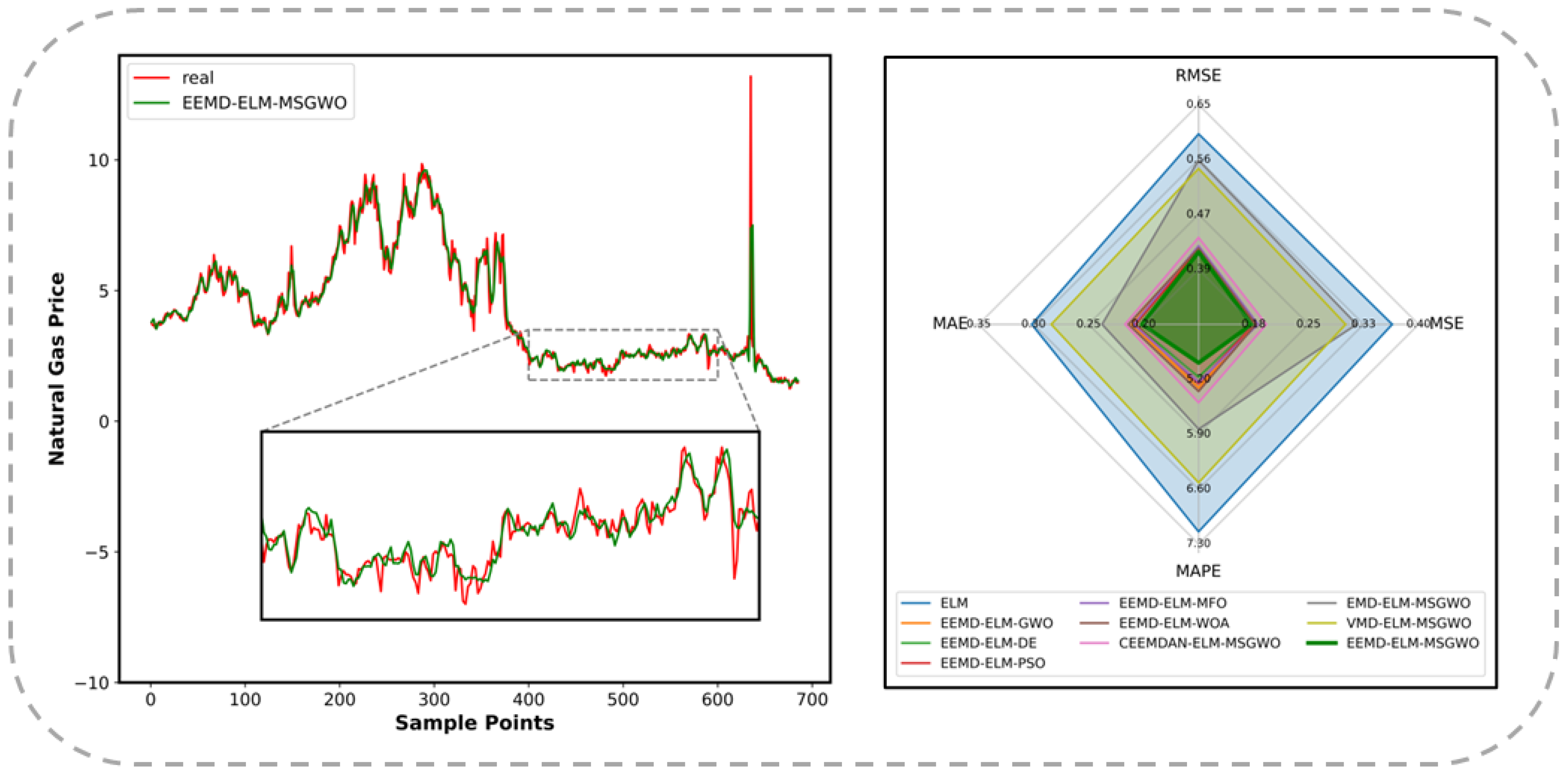
Table 6. The visualizations in
Figure 10 illustrate the alignment fidelity of the EEMD-ELM-MSGWO framework with market observations.
Through rigorous interrogation of the quantitative evidence presented above, three principal findings emerged from the experiment.
First, through the implementation of EEMD-based signal decomposition, MSGWO exhibits superior efficacy in neural parameter optimization compared to conventional metaheuristics. Among the six competing architectures, the EEMD-ELM-MSGWO synthesis achieves minimal prognostic deviation, securing a dominant position across all evaluation criteria. These results indicate that the hidden layer matrices of the ELM that are most suitable for predicting the natural gas price can be effectively determined by the MSGWO. As an enhanced metaheuristic algorithm, the MSGWO innovatively integrates the GWO with three strategies. It utilizes mutation and crossover strategies to enhance population diversity, thereby broadening the scope of the global search. Meanwhile, the powerful local search ability of the GWO is retained. The inclusion of selection strategies allows the wolf pack to explore more promising directions, further improving the convergence speed and optimization capability of the MSGWO. The search characteristics of GWO and the three major strategies can be effectively utilized by MSGWO, enabling comprehensive traversal of hyperdimensional solution spaces and accelerated identification of the globally optimal gray wolf. In MSGWO, the search strategy of GWO and the mechanisms of mutation and crossover for generating new individuals are selected based on the difference between the incumbent optimal candidate and its ancestral best solution from prior iterations. This method effectively prevents the GWO or the mutation and crossover strategies from getting trapped in local optima. The MSGWO achieves balanced exploration-exploitation dynamics, facilitating the convergence of optimal neural parameters for the ELM.
Secondly, by using the EEMD to decompose the natural gas price and employing the MSGWO to establish minimum-error neural configurations, the resulting predictions are the closest to the observed values compared to alternative decomposition modalities. In the experimental simulations involving CEEMDAN-ELM-MSGWO, EMD-ELM-MSGWO, VMD-ELM-MSGWO, and EEMD-ELM-MSGWO, the EEMD-ELM-MSGWO model achieves minimal prognostic deviation. Compared with the original ELM model, the EEMD-ELM-MSGWO model exhibited a reduction of over 25% across all four statistical indicators. Furthermore, EEMD-ELM-MSGWO demonstrates enhanced robustness compared to competing decomposition-prediction hybrids, empirically validating EEMD’s methodological superiority in temporal decomposition fidelity for natural gas price forecasting. EEMD, developed on the EMD, has undergone multiple improvements and optimizations, making it more effective in capturing the characteristics and variations at different scales in natural gas price time series data. By adding white noise signals, the noise interference within the original signal can be suppressed using EEMD. This approach allows the EEMD to better extract the true components of the signal, thereby reducing the effects of noise and improving the decomposition accuracy. Moreover, the EEMD effectively reduces the occurrence of mode mixing, enhancing the clarity and interpretability of the decomposition results. Owing to its ability to better reflect the features and variations within the natural gas price series, the EEMD-ELM-MSGWO model surpasses other ELM-MSGWO models that incorporate different decomposition techniques, achieving the most accurate point-forecasting results.
5.6. Discussion
This section undertakes a deeper interrogation of experimental data to elucidate the multi-dimensional interdependencies among time series decomposition, hidden layer matrix optimization, and the accuracy of natural gas price prediction. Quantitative findings establish that the comprehensive model achieves lower prediction errors than the unimodal approaches, emphasizing only either decomposition or parametric refinement. The integrated model comprises three synergistic phases: (1) decomposition of the natural gas price through EEMD, (2) intelligent optimization of hidden layer matrices via MSGWO, and (3) prognostic execution through enhanced ELM.
Compared to ELM-MSGWO, EEMD-ELM-MSGWO exhibited marked prognostic enhancement, with MSE reduction surpassing 50%, RMSE decrease exceeding 30%, and the decrease in MAE and MAPE exceeding 10%. Similarly, the performance of EEMD-ELM-MSGWO compared with that of the EEMD-ELM model also shows significant progress. These statistical results substantiate the beneficial effects of first decomposing the signal in time-series forecasting and then optimizing neural parameters through the MSGWO algorithm on prediction accuracy. At the same time, these data validate the operational efficacy of the proposed EEMD-ELM-MSGWO.
The pre-decomposition of time series data before prediction and the post-prediction recombination of results play crucial roles in time series forecasting [
46]. Signal decomposition techniques enable the enhanced detection of time-series data, thereby better capturing the overall direction of the time series. Concurrently, these techniques isolate cyclical constituents manifesting recurring oscillations, empowering models to precisely characterize periodic phenomena. Residual components encapsulate irreducible stochastic elements beyond deterministic trends and cycles, predominantly comprising of aleatoric noise. The characteristics and trends of each sub-series can be better captured by decomposing the time series into IMFs and residuals, thereby improving the prediction accuracy. As energy market quotations exhibit non-stationary characteristics, natural gas price trajectories are shaped by multi-factorial influences, including cyclical demand variations, regulatory interventions, and supply−demand dynamics. The accuracy of predictions can be improved to a large extent by processing natural gas price series using a decomposition method before feeding them into a predictor. This finding is consistent with previous studies [
61,
62,
63], which also emphasized the benefits of combining decomposition techniques with machine learning or deep learning models. However, different signal decomposition techniques exhibit slight differences in their ability to decompose natural gas price series. In the comparative analysis, the EEMD established theoretical superiority for natural gas price series processing through its noise-assisted stabilization mechanism. By adding white noise signals to suppress noise interference in the original signals, the EEMD ensures algorithmic robustness against signal distortion, ultimately attaining optimal prognostic fidelity and computational consistency.
Moreover, the nonlinear dynamics and high volatility of natural gas prices present a dual challenge for optimization algorithms: they must effectively explore a complex, multimodal search space while avoiding premature convergence to the local optima. Accurate forecasting in this domain requires not only high predictive accuracy but also robust generalization across varying market conditions. In this regard, the proposed MSGWO algorithm outperformed conventional intelligent approaches, such as PSO, MFO, and WOA, owing to its enhanced spatial diversity preservation mechanism. This feature helps maintain a healthy exploration–exploitation balance, thereby improving the accuracy of the parameter optimization and enhancing the robustness of the forecasting model. Consequently, the MSGWO is better equipped to accommodate the inherent uncertainty and abrupt fluctuations characteristic of natural gas markets. The suggested MSGWO combines GWO with mutation, crossover, and selection strategies. It implements mutation and crossover strategies to maintain swarm heterogeneity, thereby expanding the search area. The selection strategy guides the population in more promising directions. The integration of these three strategies effectively compensates for GWO’s shortcomings in global search. Additionally, MSGWO uses a selection mechanism that compares the current optimal individual with the optimal individual of the previous generation to determine the search direction of the next generation. This mechanism effectively balances global and local searches, enabling the ELM model to converge to optimal neural configuration parameters that maximize prognostic fidelity. This is evident from the comparison between ELM-MSGWO and ELM-GWO, as well as between EEMD-ELM-MSGWO and EEMD-ELM-GWO. Among the decomposition methods, EEMD provides the most reasonable decomposition of the series, while MSGWO demonstrates the strongest global optimization capability. Therefore, by applying EEMD-driven decomposition and leveraging MSGWO’s robust global and local search abilities, the highest prediction accuracy model among all experimental groups can be achieved.
Additionally, the computational complexity of the EEMD-ELM-MSGWO model primarily arises from the EEMD decomposition, ELM training, and MSGWO optimization steps. To verify that the proposed model achieves high prediction accuracy with a reasonable computational cost, we compare its runtime and prediction performance metrics with those of other models. The results are shown in
Table 7.
As shown in
Table 7, the proposed EEMD-ELM-MSGWO model achieved the lowest prediction error among all the comparative models while maintaining a competitive computational efficiency. Given that accurate price forecasting is essential in energy trading, risk management, and policy formulation, the model demonstrates a favorable balance between prediction accuracy and computational cost, making it suitable for real-world applications. The EEMD decomposition can be efficiently accelerated using parallel computing techniques, thereby significantly reducing the runtime. Furthermore, the utilization of modern computing resources—such as GPU acceleration—can further alleviate the computational burden, enhancing the scalability and practical applicability of the model in large-scale data processing scenarios.
7. Quantile Interval Forecasting
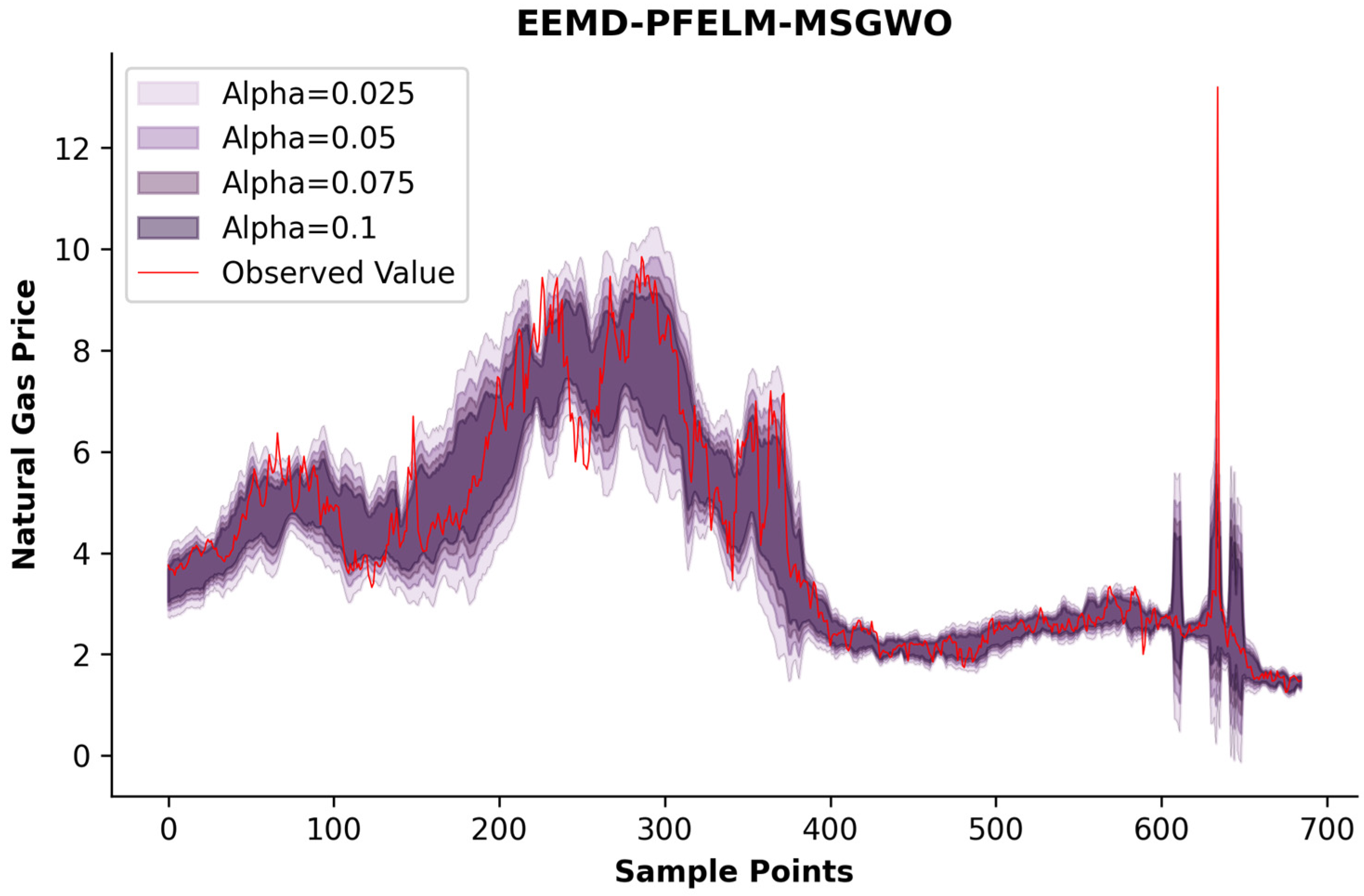
As shown in
Figure 4 and
Table 3, the quantile-based forecasting interval analysis maintains identical temporal data partitioning as employed in previous stages. The model training utilizes a dataset of 6158 observations, with the validation subset containing 685 entries for prognostic verification.
To provide additional confirmation of the operational efficacy of the suggested forecasting framework, this experimental stage compares the models at various quantile levels using distinct temporal decomposition methods and those combining different metaheuristic optimization algorithms. Through a cross-paradigm evaluation of various decomposition approaches and intelligent optimization algorithms, we can acquire knowledge of their potency in the optimization process, directing the choice of the most appropriate algorithm for specific tasks.
The experiments were performed in quadruple experimental iterations to assess the prognostic performance of the QRELM and ensure methodological replicability. Different quantile levels
,
,
, and
correspond to confidence levels of 95%, 90%, 85%, and 80%, respectively, in quantile interval forecasting. All computational trials maintained identical infrastructure specifications and OS kernel parameters, followed by prognostic output post-processing and systematic evaluation of the forecasting results. The quantile forecasting performance metrics are tabulated in
Table 9, and
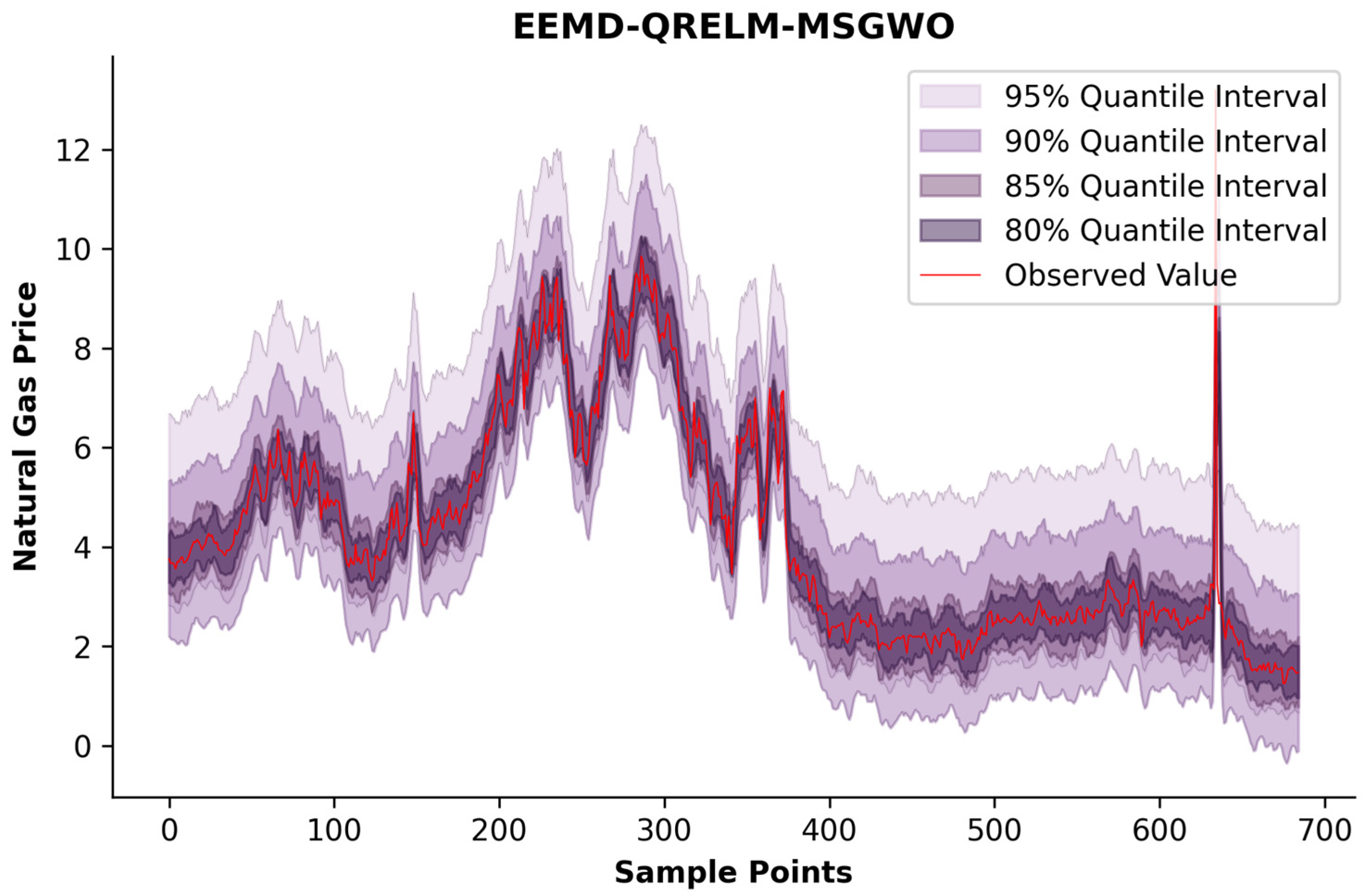
Figure 12 visualizes the EEMD-QRELM-MSGWO synthesis’s trajectory alignment with market dynamics.
As evidenced by the comparative analysis in
Table 9, the proposed MSGWO optimization framework exhibits superior efficacy in identifying neural configuration parameters that minimize the quantile prediction error for QRELM architectures. Through prognostic simulation experiments comparing five distinct probabilistic regression frameworks—designated as GWO-based, DE-driven, PSO-optimized, MFO-enhanced, and MSGWO-integrated EEMD-QRELM variants—the proposed MSGWO consistently ranks first at all quantile levels, showcasing the strongest overall interval prediction capability. This indicates that the EEMD-QRELM-MSGWO model can consistently and accurately perform quantile-interval forecasting tasks and exhibits excellent performance across different levels of uncertainty. These empirical results substantiate the framework’s capacity for precision-calibrated distribution estimation under market conditions, providing actionable intelligence for risk quantification and volatility hedging strategies in the natural gas market.
Compared with the other three signal decomposition techniques, EEMD significantly enhanced the accuracy of the QRELM-MSGWO quantile interval forecasting model. By inheriting the advantages of EMD and addressing its shortcomings, EEMD can handle nonlinear and non-stationary signals more effectively, thereby improving the precision of signal decomposition. Furthermore, the EEMD employs a method of adding white noise, which can dynamically adjust the noise level, thereby effectively suppressing endpoint distortion while maintaining intrinsic oscillatory characteristics. EEMD also demonstrably reduces the occurrence of mode mixing, preventing mutual interference among the signal components and thus enhancing the precision and reliability of the decomposition. The accurate subsequences generated by the EEMD contain more scale information, which helps the QRELM-MSGWO model better grasp the features of the natural gas price series, leading to more precise quantile interval forecasting results.
The effectiveness of MSGWO in optimizing parameters was reaffirmed. The MSGWO excels in parameter optimization for point and probability interval forecasting and significantly reduces the quantile loss for the QRELM model as well. By improving the coverage rate of the quantile forecasting interval while reducing the average width of the forecasting interval, MSGWO enables the QRELM to achieve a quantile-interval-forecasting model that balances precision and robustness. Compared to the original GWO algorithm, MSGWO incorporates a series of innovations that enhance the algorithm’s performance in solving optimal parameter determination problems. The MSGWO leverages GWO’s powerful local search mechanism while using mutation and crossover strategies to increase population diversity, thereby strengthening the exploration of unknown regions. The selection mechanism ensures that the population searches in the correct direction. The fusion of these mechanisms makes the MSGWO’s exploration of the solution space comprehensive and effectively avoids local optima. Consequently, MSGWO stands out among the numerous intelligent algorithms.
8. Conclusions
This paper proposes a composite framework for sequential data forecasting using signal decomposition methods and metaheuristic optimization. The framework utilizes the EEMD to disintegrate the natural gas market quotations into IMFs and employs the proposed MSGWO algorithm to improve the hidden layer weight and bias matrices of the ELM. The enhanced ELM is then trained with the training data and executes prognostic verification trials on the test sample. This established an effective prediction system. The GWO exhibits notable efficacy in neighborhood exploration. The incorporation of mutation and crossover strategies enhances the solution space diversity, thereby boosting the cross-domain search potential. In addition, the algorithm employs a selection strategy to ensure that the population advances in the correct search direction. Through such multi-mechanism fusion, MSGWO achieves balanced exploitation-exploration dynamics, enabling efficient traversal across high-dimensional parameter landscapes and precise identification of optimal neural configuration parameters, ultimately producing superior prognostic performance in energy market forecasting applications.
Forecasting experiments on natural gas price series are divided into three phases: point forecasting, probability interval forecasting, and quantile interval forecasting. In point forecasting, the proposed EEMD-ELM-MSGWO model achieves the smallest prediction error in several evaluation indexes and realizes the most accurate prediction effect. With the acceleration of the global energy transition and increasing involvement of financial markets, natural gas price uncertainty is influenced by a range of market factors, including supply and demand dynamics, pricing of alternative energy sources, and pronounced seasonal sensitivity [
64]. Moreover, climate policies in various countries have dampened investments in fossil energy [
65], while reductions or disruptions in gas supply caused by geopolitical events, such as the Russia–Ukraine conflict [
66], and demand shocks triggered by emergencies, such as the COVID-19 pandemic, have further exacerbated the volatility in overall gas consumption [
67]. Although probabilistic forecasting and quartile interval prediction can effectively capture and quantify such uncertainty, developing appropriate forecasting models is essential to support their implementation. In probability and quantile interval forecasting, the proposed EEMD-PFELM-MSGWO model and EEMD-QRELM-MSGWO model achieve the minimum level of CWC, indicating that the EEMD-PFELM-MSGWO and EEMD-QRELM-MSGWO models in interval coverage forecasting and forecasting under different quantiles can capture the uncertainty in the natural gas price series well. Three experiments confirmed the efficacy of the proposed EEMD-ELM-MSGWO forecasting composite framework.
Point forecasting of natural gas price series helps in understanding and forecasting future market price trends and provides valuable references for decision-makers. Probability interval forecasting quantifies uncertainty and offers decision-makers probability information regarding various potential outcomes. Quantile interval forecasting further delineates the range of price changes, aiding decision-makers in comprehensively assessing the risks and formulating appropriate strategies. These methods provide natural gas market participants with more comprehensive and accurate future price trend information, enabling the formulation of well-informed commercial strategies and regulatory frameworks.
However, it is important to acknowledge the limitations of this study that should be addressed in future research. First, the current model relies solely on historical price data and does not incorporate exogenous variables such as policy changes, exchange rates, or geopolitical events, which may affect the model’s predictive performance during periods of sudden market fluctuations. Future work will aim to examine the drivers of natural gas prices from multiple perspectives and integrate an online learning mechanism to enable the model to dynamically adapt to market uncertainties. Second, the model validation is currently limited to a single natural gas market. Given the diversity in pricing mechanisms across global markets, future research should consider using different data sources to evaluate the model’s applicability and robustness in other countries and regions.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}