1. Introduction
With the growing demand for sustainable agriculture and real-time decision-making, AIoT has emerged as a transformative solution for precision farming [
1,
2]. Among AI-driven techniques, DL models have demonstrated exceptional capabilities in analyzing complex environmental and climatic data for tasks such as crop recommendation, disease detection, and yield prediction [
3]. However, the practical deployment of such models on edge devices remains a significant challenge due to their computational complexity and memory demands.
While cloud and fog computing paradigms have been explored to offload computation from edge devices [
4,
5], they introduce critical limitations in latency, connectivity, and data privacy. Agricultural fields often suffer from intermittent network access, making real-time inference and decision-making highly unreliable when reliant on remote servers [
6]. Moreover, transmitting large volumes of raw sensory data to the cloud increases bandwidth costs and power consumption, which contradicts the energy-efficiency goals of sustainable AIoT systems [
7].
In light of these constraints, on-device model compression has gained traction as a promising approach to enable efficient deployment of DL models on edge hardware. Researchers have proposed a range of model compression techniques, including pruning, quantization, and knowledge distillation, to reduce the computational and memory footprint of DL models [
8]. However, most of these methods are primarily designed for large-scale convolutional or transformer-based architectures applied to image or multi-dimensional data [
9]. In contrast, compression strategies tailored for lightweight 1D models, particularly for sensor-based agricultural applications, remain relatively underexplored. These systems often rely on 1D sequential data streams such as weather conditions, soil metrics, and sensor readings. Recurrent neural networks (RNNs) [
7], especially GRUs well-suited for such temporal data due to their reduced parameter complexity and efficient training dynamics [
10], have received limited attention in the context of model compression for edge deployment, underscoring the need for a dedicated framework optimized for the unique characteristics of 1D DL in smart agriculture.
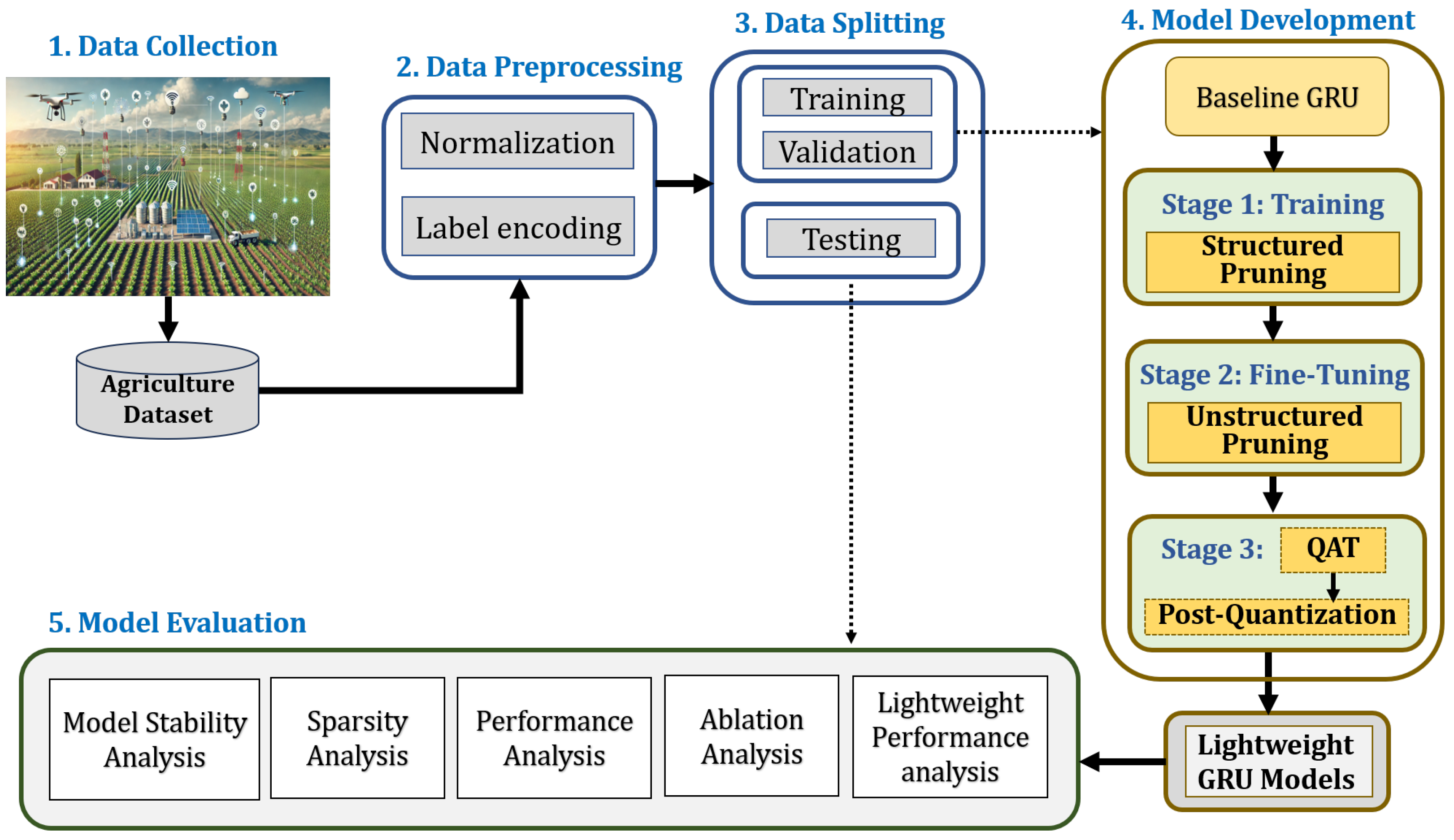
To address the identified gap in the deployment of 1D DL models on edge devices with limited energy, this work introduces SUQ-2, a novel three-stage compression framework designed specifically for AIoT-enabled smart farming. SUQ-3 progressively compresses GRU-based models through (1) structured pruning to impose hardware-friendly block sparsity, (2) unstructured pruning to remove redundant weights at a fine-grained level, and (3) quantization, applied after QAT to support low-precision inference with minimal accuracy loss. This coarse-to-fine pipeline ensures a balance between compression effectiveness and predictive performance. The strategy is evaluated on a GRU model for crop recommendation, leveraging multivariate environmental and climatic datasets relevant to smart agriculture.
2. Related Works
The evolution of crop recommendation systems has progressed from traditional machine learning (ML) methods to advanced DL and edge-computing-enabled models. This section discusses prior efforts across classical ML systems, optimization-enhanced DL approaches, IoT-based smart agriculture solutions, and recent developments in model compression relevant to lightweight edge AI.
Early studies have demonstrated the effectiveness of ML in agriculture, particularly for crop selection using nutrient and climate features. For instance, ref. [
11] evaluated multiple models, including XGBoost, SVM, and random forest, on agri-horticultural data, reporting that XGBoost achieved the highest performance with up to 99% precision, underscoring its suitability for crop recommendation systems. In a complementary approach, ref. [
4] proposed a decision support system integrating GPS data and cloud-based storage, where the stochastic gradient-descent classifier performed best after addressing class imbalance with SMOTE, highlighting the importance of data preprocessing in real-world agricultural applications.
Recognizing the limitations of classical models in capturing temporal dynamics and nonlinear relationships, researchers have increasingly adopted DL techniques to enhance predictive performance. For example, ref. [
12] proposed a long short-term memory (LSTM) network model integrated with an expectation-maximization algorithm, significantly improving prediction robustness. Building on this, ref. [
13] introduced a cascaded GRU-LSTM architecture optimized using the fire hawk metaheuristic for efficient training. Further advancements were demonstrated in [
3], where Harris Hawks optimization (HHO) was applied across multiple DL architectures (e.g., LSTM, BiLSTM, RNN), accelerating convergence while maintaining high accuracy. Similarly, ref. [
14] developed an attention-enhanced GRU-RNN model combined with an improved migration algorithm (IMA), achieving superior performance in processing sequential agricultural data.
The integration of DL with IoT infrastructure is gaining momentum in smart agriculture. In [
15], a weighted LSTM (WLSTM) model was combined with improved distribution-based chicken swarm optimization (IDCSO) for efficient attribute selection, resulting in higher inference speed and predictive accuracy. In contrast, ref. [
6] proposed a cloud-based transformative crop recommendation model (TCRM) that utilizes real-time environmental data to deliver regional recommendations. However, cloud-reliant solutions like TCRM are often hindered by latency, connectivity dependence, and energy inefficiency, making them less viable for remote or resource-constrained agricultural settings.
As the adoption of AIoT in agriculture continues to accelerate, DL models in this domain often prioritize predictive accuracy over computational efficiency, with limited consideration for deployment on lightweight edge devices. In contrast, other fields such as healthcare, human–computer interaction, and natural language processing (NLP) have advanced considerably in designing lightweight, edge-ready architectures. For instance, in computer vision, a self-attention-enhanced multilayer perceptron (MLP) compression strategy has demonstrated substantial reductions in resource usage and improvements in throughput when deployed on FPGA platforms [
16]. In biomedical signal processing, 1D convolutional neural networks (CNNs) for ECG classification have incorporated unstructured pruning and incremental quantization to support real-time inference under stringent power constraints [
17]. Similarly, seizure detection models based on CNN–Transformer hybrids have employed asymmetric pruning alongside adaptive ternary quantization, reducing memory consumption by over 21% without compromising performance [
18]. For gesture recognition tasks, input simplification combined with model compression has produced ultra-compact 1D CNNs with sizes under 10 kB and minimal loss in accuracy [
19]. In embedded NLP, convolutional models compressed via five-bit quantization and structured pruning have achieved memory savings of up to 93% while maintaining classification reliability [
20].
Recently, a few studies have extended lightweight model design to agriculture. For example, ref. [
21] proposed Tiny-LeViT, a transformer-based model for efficient plant disease classification on UAVs, achieving high frame rates on edge devices while maintaining strong accuracy. Similarly, ref. [
22] introduced E-GreenNet, a lightweight MobileNetV3Small-based model that delivers competitive disease classification performance across multiple datasets with improved inference speed. In [
23], a tinyML-based system featuring EvoNet was proposed to detect animal intrusions using edge AI, demonstrating high accuracy with model sizes as low as 1.63 MB through pruning and quantization. In addition to image-based approaches, recent studies have explored lightweight models for time-series data. For instance, ref. [
7] proposed a power-aware RNN-LSTM system for real-time monitoring and energy management in coconut farming, while [
24] presented a TinyML framework using UAV-assisted transfer learning for soil moisture prediction with DNN and LSTM architectures on ultra-low-power edge devices.
While these studies [
21,
22,
23] mark meaningful progress, they are mostly limited to CNN-based image classification or hybrid systems involving vision and sensor data. Few works systematically investigate compression strategies for RNN-based models tailored to time-series forecasting in smart agriculture. Furthermore, existing literature seldom explores hybrid or dynamic compression techniques in this context, nor does it offer comprehensive comparisons across multiple compression strategies in terms of memory footprint and inference latency. To address the identified gap, this work proposes a novel three-stage compression framework, termed SUQ-3, and evaluates its effectiveness using a GRU-based DL model for crop recommendation.
3. Proposed Model Compression Framework (SUQ-3)
To enable the efficient deployment of DL models on lightweight edge devices, this work introduces a compression framework referred to as SUQ-3. The proposed framework progressively reduces the model’s computational and memory footprint while maintaining task-specific performance. It begins with structured pruning, as shown in
Figure 1, which removes redundant neurons at a coarse level. This is followed by unstructured pruning, which imposes fine-grained sparsity by eliminating individual weights based on their importance. In the final stage, quantization is performed after QAT fine-tuning to adapt the pruned model to low-precision arithmetic and preserve the enforced sparsity constraints. The following subsection presents the details of these stages.
3.1. Structured Pruning Stage
The first stage of the SUQ-3 framework applies
structured pruning, which removes entire blocks of weights from the neural network during training. This approach imposes a regular sparsity pattern by eliminating complete rows, columns, or fixed-size submatrices. As a result, it simplifies memory organization and improves computational efficiency. Structured pruning is particularly effective for edge deployment, as it preserves the regular structure of the weight matrix, facilitates dense storage representations, and reduces processing overhead on hardware-constrained platforms such as FPGAs and low-power AI accelerators [
25,
26]. Let
be the trainable weight matrix, where
denotes the weight at row
i and column
j. The pruning process operates on fixed-size, non-overlapping blocks of shape
. Within each block, weights are evaluated based on their absolute magnitudes, and a pruning threshold
is computed as the
M-th smallest absolute value [
27]:
The structured pruning function
is then defined as
where
is a rescaling factor that adjusts the retained weights to maintain their relative importance within the block and is calculated as [
28]
Once the pruned weights are set to zero, only the retained weights remain trainable and are updated during backpropagation. This rescaling operation ensures that the learning dynamics are preserved despite the enforced sparsity. By introducing coarse-grained sparsity early in the training process, structured pruning establishes a computationally efficient foundation for the subsequent compression stages in the SUQ-3 framework.
3.2. Unstructured Pruning Stage
In this stage, unstructured pruning is progressively applied during fine-tuning to further compress the model by removing individual weights deemed unimportant [
29]. This fine-grained pruning complements the structured pruning in Stage 1 by introducing sparsity at the level of individual weights, thereby achieving a higher compression ratio without altering the network’s architecture. Mathematically, the unstructured pruning function
is defined as [
30]
Here,
denotes a general importance scoring function, and
is a time-dependent pruning threshold determined by a sparsity schedule
. The number of weights retained at pruning step
t is given by [
29,
31]
where
N is the number of weights remaining after structured pruning. The top-
weights are selected based on their importance scores
, and all others are pruned.
This formulation ensures that unstructured pruning operates exclusively on weights retained from the structured stage, thereby preserving the architectural constraints established earlier. By supporting arbitrary importance metrics and enabling progressive sparsity scheduling, this stage introduces fine-grained compression with minimal performance degradation. The result is a highly sparse and deployment-efficient model suitable for limited-resource edge environments.
3.3. Quantization Stage
In the final stage of the compression pipeline, we perform QAT to prepare the pruned model for efficient deployment. This stage enables the network to adapt jointly to two key constraints [
32]: low-precision arithmetic introduced by quantization and the sparsity pattern resulting from the preceding structured and unstructured pruning stages.
The input to this stage is the sparse weight matrix
, obtained after unstructured pruning. Quantization is simulated during training using a fake quantization operator that mimics fixed-point behavior while maintaining full-precision weights for gradient updates. The quantized approximation is defined as:
Here, represents the quantization step size derived from the dynamic range of the weights and the target bit precision. The quantized tensor is used during both the forward and backward passes.
To preserve the sparsity pattern, a binary pruning mask
, inherited from Stage 2, is enforced throughout QAT. Only unpruned weights (i.e.,
) are updated, while pruned weights remain fixed at zero. The update rule for each trainable weight becomes [
33]:
This combined training strategy, as detailed in Algorithm 1, enables the model to learn under both quantization-induced numerical constraints and the structural sparsity enforced by pruning. Once fine-tuning is complete, the final model is exported in a fully quantized and sparse format, optimized for efficient inference using low-precision integer arithmetic and sparse matrix operations.
In summary, SUQ-3 provides a lightweight and scalable compression strategy to deploy 1D DL models in constrained edge AI environments. By unifying structured sparsity and quantization within a unified training pipeline, SUQ-3 enables the development of compact models that support low-precision inference while preserving predictive performance. Its deployment-oriented design ensures broad applicability across various edge scenarios, positioning it as a promising framework for high-performance and sustainable AI at the edge.
| Algorithm 1: 3-Stage Coarse-to-Fine Model Compression |
- Input:
Initial full-precision model weights , pruning ratio p, quantization step size , learning rate , training epochs , fine-tuning epochs - Output:
Compressed model with pruning and quantization
|
![Sustainability 17 05230 i001]() |
4. Experimental Setup
4.1. Dataset Preparation
In this study, rigorous data preparation was a critical prerequisite for developing a robust and reliable model tailored to smart farming applications. The preparation pipeline involved systematic dataset selection, comprehensive preprocessing, and stratified partitioning to ensure effective model training and evaluation.
- (a)
Dataset selection: The dataset utilized in this work was obtained from Kaggle, a well-established platform providing access to publicly available datasets across various domains. Specifically curated for agricultural applications, the dataset comprises 2200 instances, each annotated with critical agronomic features, including soil macronutrient concentrations (nitrogen, phosphorus, and potassium), environmental variables (temperature, humidity, pH, and rainfall), and the associated crop label [
34]. These attributes form a comprehensive representation of real-world conditions required for effective crop recommendation.
- (b)
Data preprocessing: To ensure data quality and model readiness, a sequence of preprocessing steps was applied. Missing values were addressed using statistical imputation methods: mean or median substitution, depending on the feature distribution. Continuous input variables such as temperature, humidity, pH, and rainfall were normalized to zero mean and unit variance to ensure numerical stability and accelerate model convergence [
35]. The categorical crop labels were transformed into one-hot encoded vectors to match the expected format of the model’s output layer and support multi-class classification.
- (c)
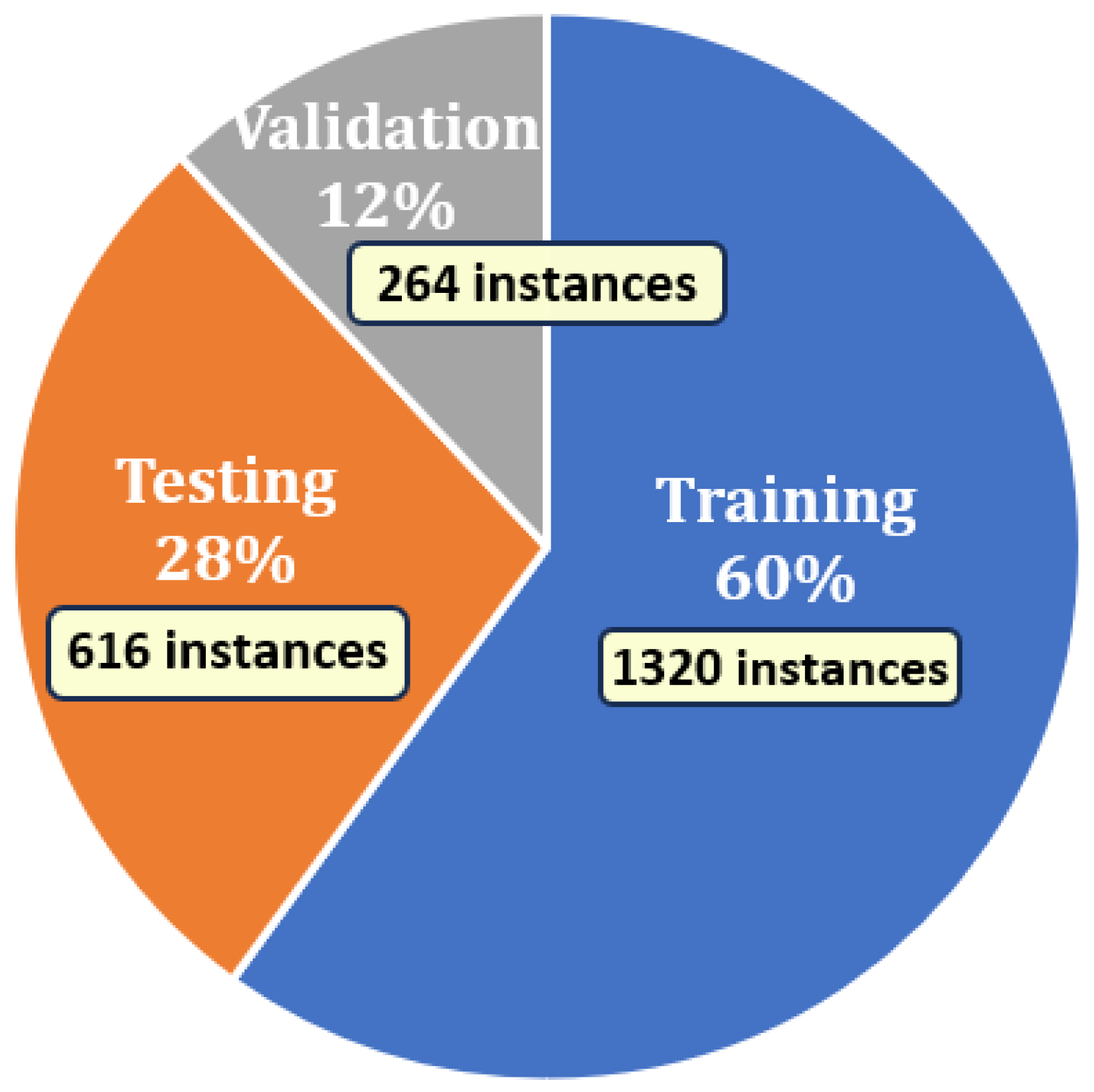
Data splitting: After preprocessing, the dataset was partitioned using stratified sampling to preserve the original class distribution across subsets. The data was divided into training, testing, and validation sets in a 60:28:12 ratio, yielding 1320 samples for training, 616 for testing, and 264 for validation [
5]. This allocation strategy ensures a balanced evaluation pipeline, allowing the model to generalize effectively to unseen data while minimizing overfitting. The distribution of the splits is visually summarized in
Figure 2.
These comprehensive data preparation steps were pivotal in constructing a high-quality, representative dataset that underpins the development of an accurate, efficient, and environmentally sustainable edge AI model for precision agriculture in AIoT-enabled smart farming environments.
4.2. DL Model Selection and Design
In AIoT-enabled smart farming, selecting a computationally efficient DL model is critical due to the limited processing and energy resources of edge devices [
1]. GRUs present a compelling choice for crop recommendation tasks, as they effectively capture temporal dependencies in environmental data while maintaining low computational overhead [
14].
GRUs are a simplified variant of RNNs that use update and reset gates to regulate information flow across time steps, enabling them to retain relevant context and mitigate the vanishing gradient problem [
36]. Compared with LSTMs, GRUs require fewer parameters and less memory [
10], making them well-suited for real-time inference and on-device learning in edge environments. Their compact architecture also aligns well with model compression techniques such as pruning and quantization, further improving their suitability for resource-limited environments.
The GRU-based model developed in this study comprises a reshaping input layer, a GRU layer with 48 hidden units, a dense layer with 24 units, and a softmax output layer for multi-class classification. This lightweight and modular architecture facilitates the application of the SUQ-3 compression framework without structural modification, supporting efficient edge deployment while maintaining competitive predictive performance.
4.3. Hyperparameter Optimization and Sensitivity Analysis
Effective hyperparameter tuning is essential for balancing predictive accuracy with compression efficiency, especially for low-power edge AI applications [
37]. To achieve stable convergence while ensuring high sparsity, both the training and compression stages in this study were empirically optimized.
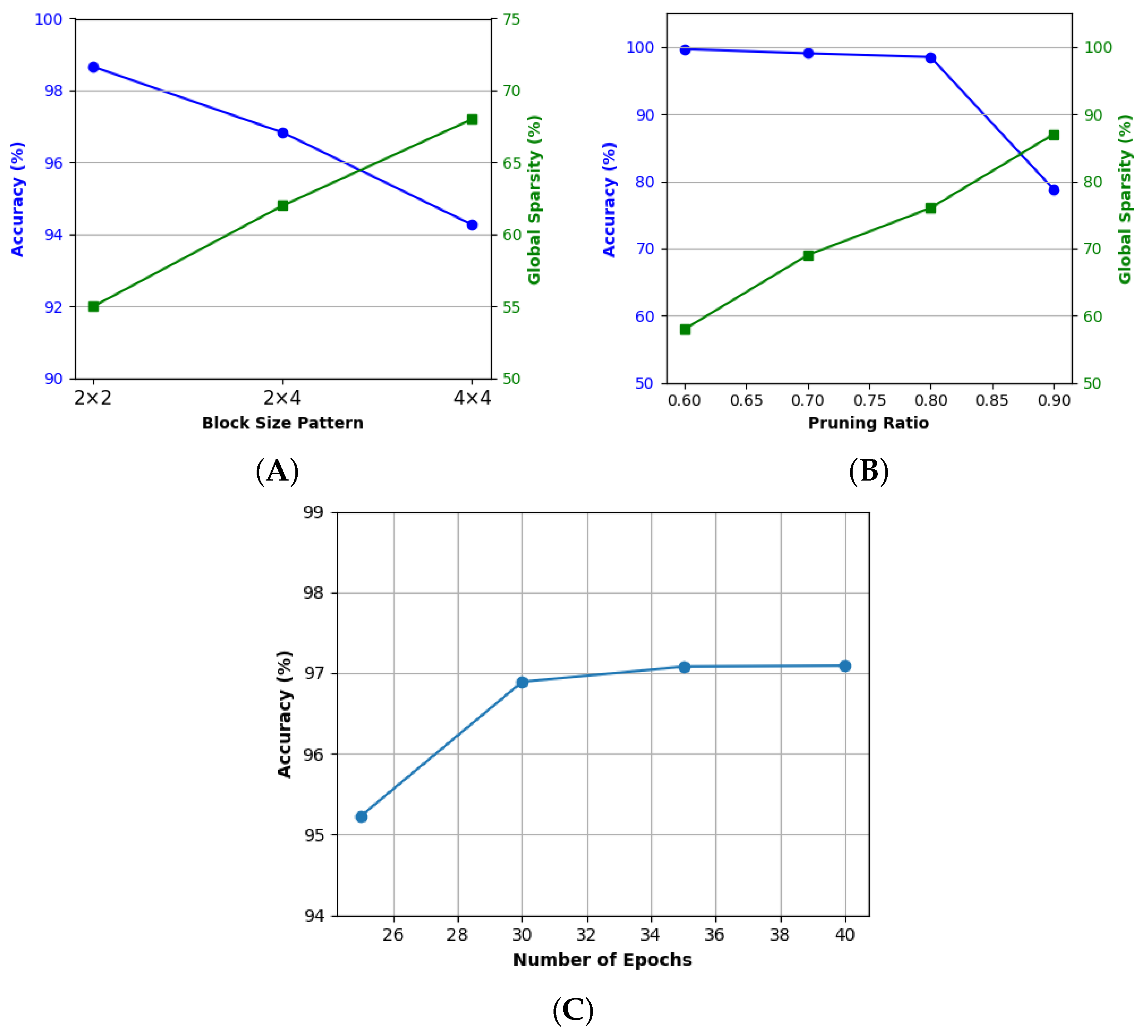
The baseline GRU model was trained using the Adam optimizer with a learning rate of 0.001 and a batch size of 32 for up to 200 epochs, incorporating early stopping based on validation loss. Structured pruning was then applied during training using a coarse-grained
block pattern. This configuration was chosen based on its alignment with tile-based memory access patterns common in edge hardware accelerators (e.g., ARM), enabling efficient matrix loading while retaining acceptable accuracy. As shown in
Figure 3A, the
block pattern achieved a favorable balance between model sparsity and accuracy, yielding 96.83% accuracy at 61% sparsity. In comparison, the
configuration led to higher sparsity (68%) but caused a more significant drop in accuracy (94.27%), indicating over-pruning. On the other hand, the finer
pattern preserved the highest accuracy (98.66%) but resulted in lower sparsity (55%), limiting its effectiveness for aggressive compression goals.
Following structured pruning, unstructured pruning was performed over 35 fine-tuning epochs using a pruning ratio of 0.8 to further introduce fine-grained sparsity. To justify the default pruning ratio selection, we conducted a sensitivity analysis by varying the pruning ratio from 0.6 to 0.9. As shown in
Figure 3B, increasing the pruning ratio led to higher sparsity but also progressively reduced model accuracy, especially beyond 0.8. The 0.8 setting demonstrated the best balance, achieving 96.9% accuracy with 80% sparsity.
The QAT was subsequently applied for 35 epochs to enable eight-bit integer inference. The quantization step size
was calibrated using min–max scaling per layer to capture the dynamics of the activation range. To assess the impact of QAT duration, additional experiments were conducted by varying QAT epochs while keeping pruning settings constant. As shown in
Figure 3C, accuracy improved with more QAT epochs and saturated around epoch 35, indicating that moderate QAT duration is sufficient to adapt the model to quantized operations without overfitting. Since QAT does not influence sparsity, the analysis focused solely on accuracy and latency improvements. A summary of the key hyperparameters and their optimal values is presented in
Table 1.
4.4. Model Implementation
The proposed lightweight GRU-based model was implemented in Python 3.11.12 on the Google Colab platform, leveraging GPU-accelerated cloud resources for efficient experimentation without the need for local hardware. Model development was carried out using TensorFlow 2.11 and the Keras API, which provided a high-level interface for model construction, training, and evaluation [
38]. Data preprocessing, including feature normalization, label encoding, and stratified dataset splitting, was conducted using Scikit-learn [
37].
Structured pruning was applied during training using the TensorFlow Model Optimization Toolkit (TFMOT) [
38], specifically the
prune_low_magnitude API configured with a
block-wise sparsity pattern via the
sparsity_m_by_n parameter. This configuration enabled coarse-grained pruning by eliminating entire weight blocks.
In the subsequent stage, unstructured pruning was also implemented using the same API but with a polynomial decay schedule to progressively enforce sparsity based on weight magnitudes. This fine-grained approach allowed individual weights to be pruned adaptively during fine-tuning.
QAT was then performed using TFMOT by inserting fake quantization nodes into the network to simulate eight-bit integer inference while retaining float32 precision for backpropagation. This strategy enabled the model to adapt to reduced numerical precision during training, thus preserving accuracy under quantized deployment conditions.
5. Experimental Results and Discussion
5.1. Model Stability Analysis
Assessing training stability is essential for evaluating the robustness and generalization capacity of compressed models. In particular, monitoring the evolution of training and validation loss across epochs provides insights into whether compression techniques, such as pruning and quantization, introduce instability or compromise learning dynamics. A stable loss trajectory typically reflects effective optimization, minimal overfitting, and preserved learning under compression constraints.
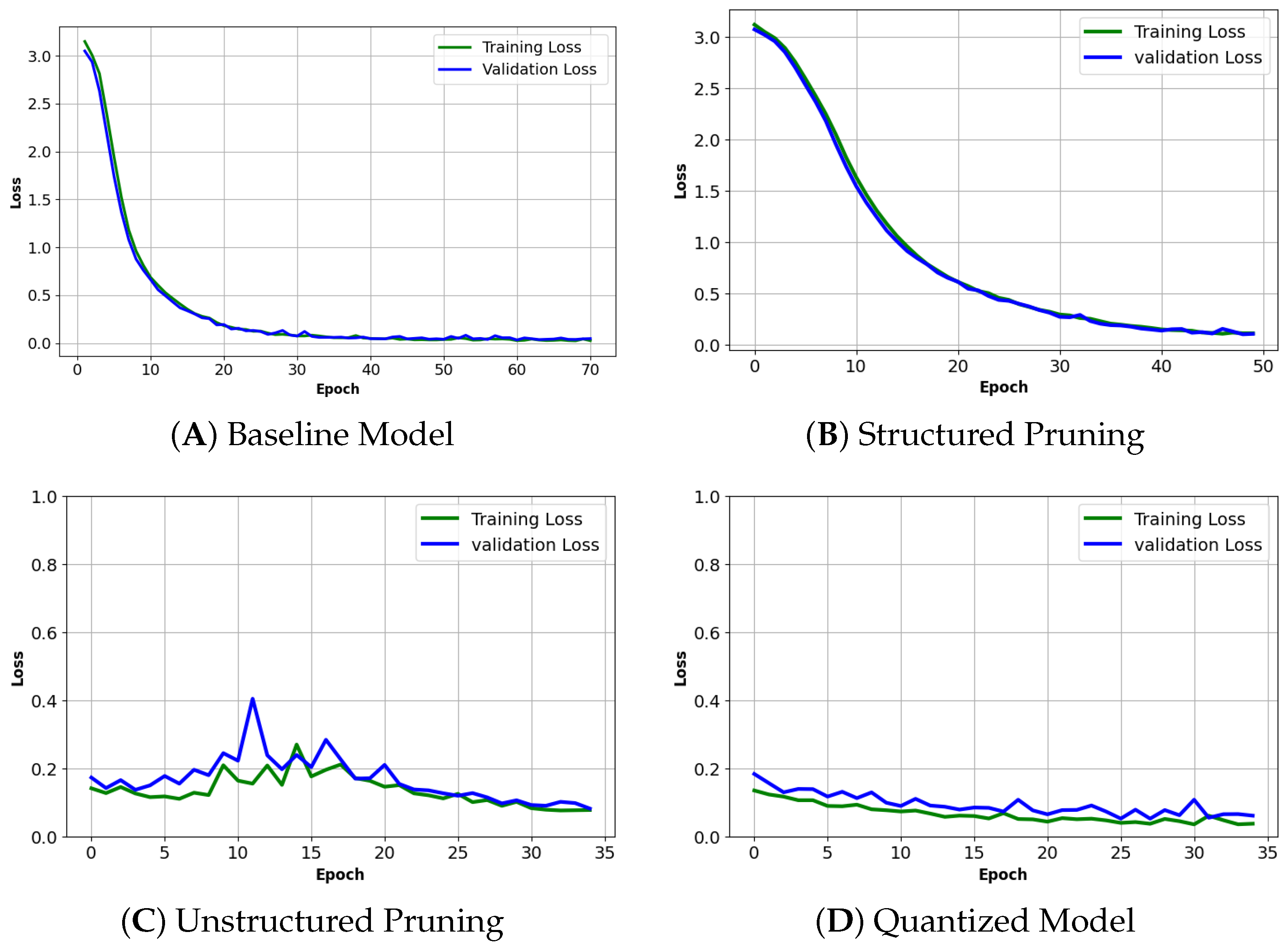
To evaluate the stability of the compressed variants produced by the SUQ-3 framework, we analyze and compare the training and validation loss curves at each compression stage—structured pruning, unstructured pruning, and quantization, against the baseline model. This comparative analysis, shown in
Figure 4, illustrates the impact of each stage on model convergence and generalization.
- (a)
Baseline model: As depicted in
Figure 4A, the baseline model exhibits a smooth and consistent decline in both training and validation losses. The close alignment between the two curves throughout training indicates stable convergence and minimal overfitting, providing a reference point for evaluating subsequent compressed variants.
- (b)
Structured pruned model: In
Figure 4B, the structured-pruned model shows a stable training profile and slightly faster convergence compared with the baseline. The final validation loss is marginally lower, suggesting that structured pruning acts as an implicit regularizer by eliminating redundant weights without disrupting learning. The close tracking of training and validation losses confirms stable generalization.
- (c)
Unstructured pruned model: As shown in
Figure 4C, the unstructured-pruned model introduces moderate variability, particularly in the validation loss, which displays noticeable fluctuations across epochs. This behavior is attributed to the irregular sparsity introduced by weight-level pruning, which can perturb training dynamics. Although the model ultimately converges, the increased variance suggests reduced stability compared with the baseline and structured-pruned models. This effect may also stem from the reuse of fine-tuning hyperparameters initially optimized for the subsequent QAT stage rather than tailored specifically for unstructured pruning.
- (d)
Quantized model: In
Figure 4D, the quantized model exhibits higher loss variance during early training due to the challenges of adapting to low-precision representations. However, both training and validation losses gradually stabilize, and the model converges to a performance level comparable to the baseline. This demonstrates the effectiveness of QAT in enabling the model to adapt to quantization noise while maintaining generalization.
Overall, the analysis confirms that each stage of the SUQ-3 compression pipeline maintains training stability. While some variability is observed in the unstructured and quantized models during early epochs, none of the variants exhibit divergence or severe overfitting. These results underscore the robustness of SUQ-3 and affirm its suitability for lightweight edge AI deployment.
5.2. Sparsity Analysis
Sparsity analysis plays a crucial role in evaluating the effectiveness of model compression, especially for edge AI deployments where memory and compute resources are limited [
39]. The proposed SUQ-3 framework introduces sparsity through two complementary stages: structured pruning using a fixed block pattern and unstructured pruning based on low-magnitude weight elimination. This section analyzes the resulting sparsity across three dimensions: numerical reduction in non-zero weights, visual distribution of sparsity, and its evolution during training.
- (a)
Quantitative weight reduction:
Table 2 summarizes the number of non-zero weights in each layer for the baseline and pruned models. Structured pruning significantly reduces parameter counts in the larger layers. For instance, the GRU layer shrinks from 7344 to 2160 weights. This reduction is further enhanced by unstructured pruning, which brings the count down to 1912. A similar trend is observed in Dense-1, while Dense-2 remains unaffected, as it is exempt from pruning. Overall, the total number of non-zero weights is reduced by over 70% through the combined pruning stages.
- (b)
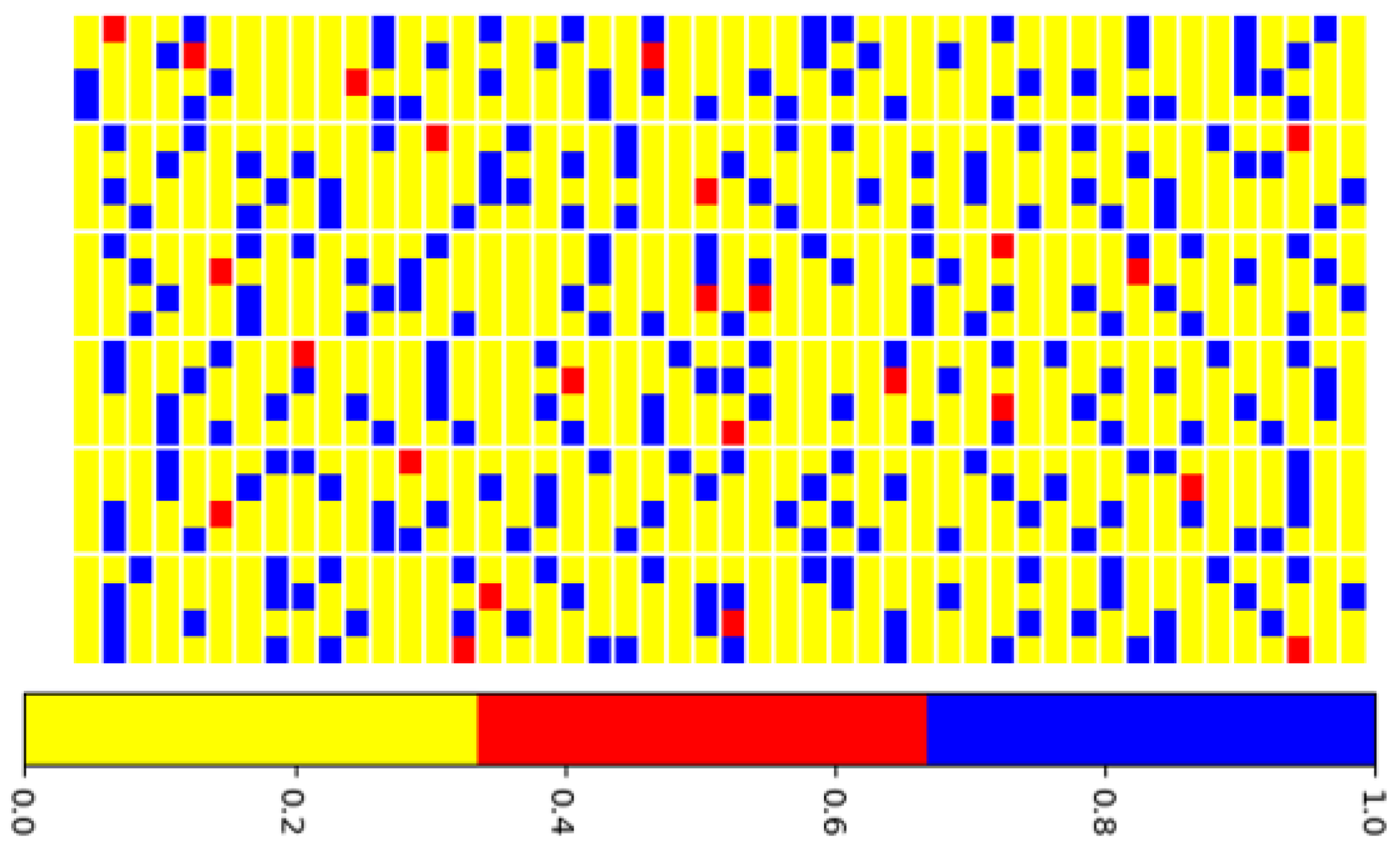
Qualitative visualization of sparsity:
Figure 5 illustrates the spatial distribution of retained and pruned weights in Dense-1. Yellow pixels represent retained weights; blue indicates those removed via structured pruning, and red highlights weights pruned unstructurally. The block-like blue regions reflect the contiguous nature of structured pruning, while the dispersed red elements capture the fine-grained impact of unstructured pruning. This visualization reinforces the complementary role of the two pruning strategies in shaping a structured yet flexible sparsity pattern.
- (c)
Sparsity evolution over training: The progression of global sparsity across epochs is shown in
Figure 6. Structured pruning induces a sharp increase in sparsity, stabilizing around 0.61 by epoch 20, reflecting the early removal of redundant blocks. In contrast, unstructured pruning contributes to a gradual rise in sparsity, reaching approximately 0.76 by the end of training, enabling finer granularity in model refinement. This progressive sparsity profile aligns with the coarse-to-fine philosophy of the SUQ-3 framework.
Together, these analyses demonstrate the efficiency and robustness of SUQ-3’s dual-stage pruning mechanism. Structured pruning effectively addresses coarse-grained redundancy, while unstructured pruning provides fine-tuned compression without compromising model structure. The consistency across quantitative, visual, and temporal metrics highlights SUQ-3’s practicality for deployment in real-world, low-resource edge environments.
5.3. Predictive Performance Analysis
Evaluating predictive performance at each stage of compression is crucial to verify that efficiency gains do not come at the cost of accuracy. This subsection presents a comparative analysis of four model variants corresponding to the progressive stages of the SUQ-3 compression pipeline: the baseline (uncompressed) model, the structured-pruned model, the unstructured-pruned model, and the final quantized model. Key classification metrics, including accuracy (Acc), precision (Pre), recall, and F1 score, are reported in
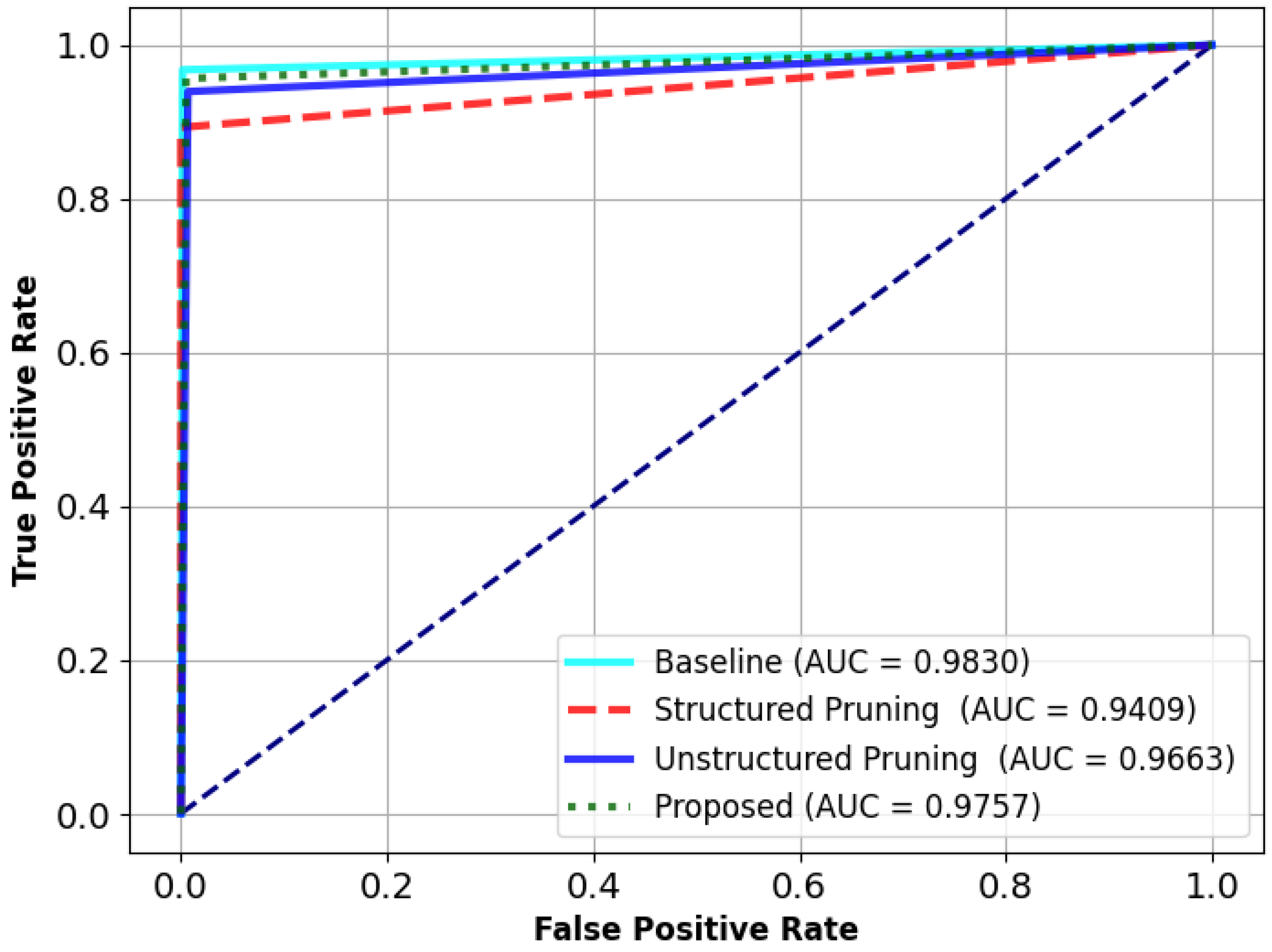
Table 3, while
Figure 7 displays the corresponding ROC curves and AUC values. The results demonstrate that the proposed multi-stage compression approach maintains high predictive performance across all stages, as detailed below:
Baseline model: Serves as the performance benchmark, achieving the highest values across all metrics (Acc: 0.9838, AUC: 0.9830). It provides a reference point for assessing the effect of compression techniques on model quality.
Stage 1: structured pruning: Shows a moderate performance reduction (Acc: 0.9529, AUC: 0.9409) due to the coarse-grained sparsity introduced by block-wise pruning. Nevertheless, the model maintains strong generalization, indicating that structured pruning effectively removes redundant parameters with minimal degradation.
Stage 2: unstructured pruning: Exhibits improved performance over the structured variant (Acc: 0.9692, AUC: 0.9663), as fine-grained pruning selectively removes less important weights. This complements the earlier structured pruning step and helps recover predictive capacity closer to the baseline.
Stage 3: quantization (proposed model): Achieves an optimal trade-off between efficiency and accuracy (Acc: 0.9708, AUC: 0.9757). Through QAT, the model successfully adapts to low-precision inference while preserving high classification performance, highlighting the effectiveness of quantization-aware optimization.
Overall, the analysis confirms that each stage of the SUQ-3 framework contributes to model compactness without significantly compromising predictive accuracy. The final quantized model offers the best balance between efficiency and performance, validating the practicality of the proposed compression strategy for AIoT deployment on constrained edge platforms.
5.4. Ablation Analysis
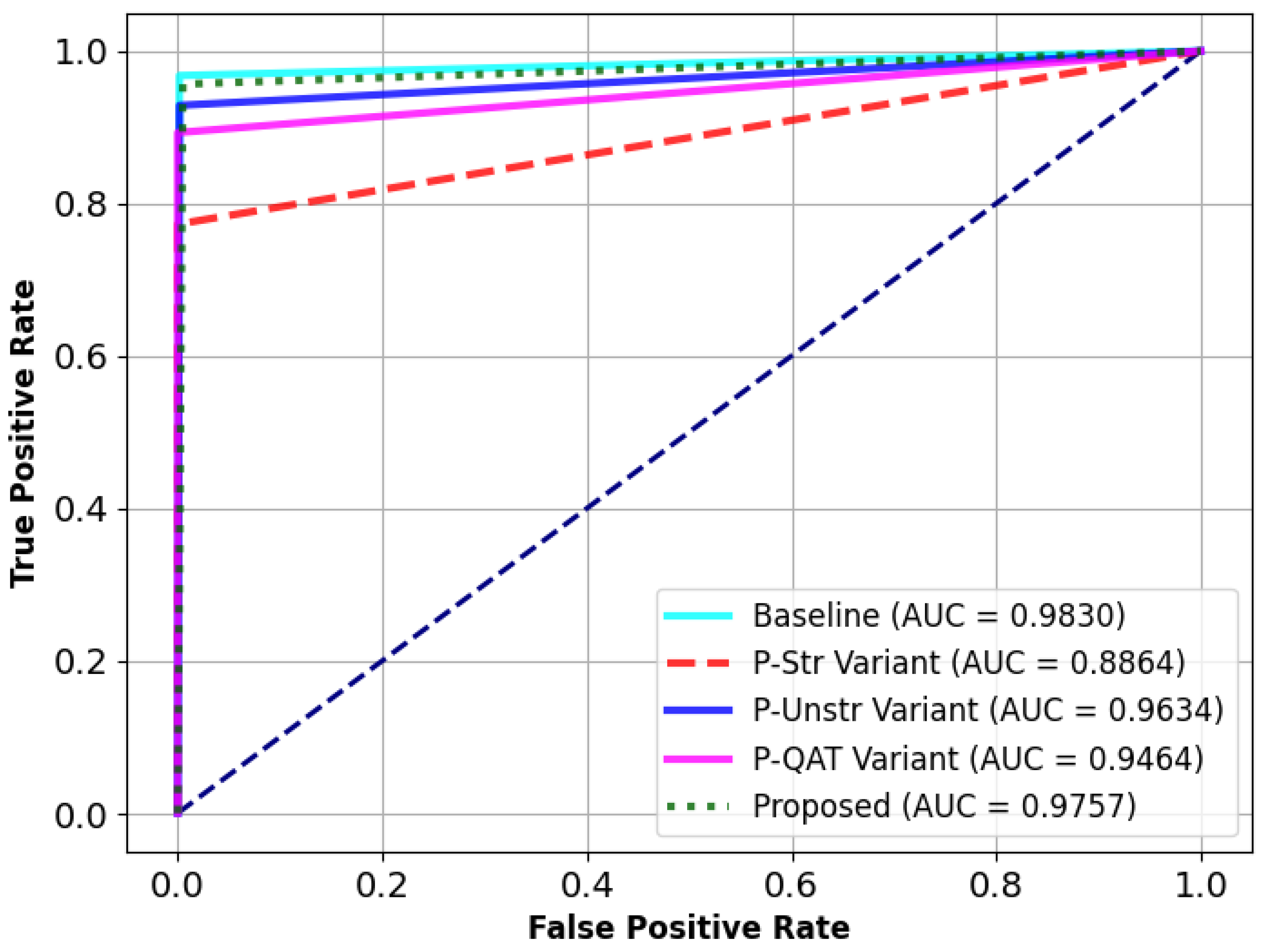
To assess the design decision of the proposed compression framework, an ablation study was conducted across five model variants: the baseline (uncompressed) model, a variant without structured pruning (P-Str), a variant without unstructured pruning (P-Unstr), a variant without QAT (P-QAT), and the full proposed framework. This analysis isolates the impact of each component on predictive performance and model robustness.
Figure 8 presents the ROC curves and corresponding AUC scores, while
Table 4 summarizes the key classification metrics, including Acc, Pre, recall, and F1 score for all variants.
The baseline model achieves the highest overall performance (AUC: 0.9830, Acc: 0.9838, F1: 0.9837), serving as a reference point. The final quantized model from the proposed SUQ-3 framework, incorporating all three compression stages, maintains strong performance (AUC: 0.9757, Acc: 0.9708) with only marginal reductions in other metrics. This confirms that the full pipeline effectively balances compression and accuracy.
The P-Str variant exhibits the most substantial performance degradation (AUC: 0.8864, Acc: 0.8377), highlighting the critical role of structured pruning in eliminating redundant capacity early in training. Its absence notably impacts both model compactness and generalization.
The P-Unstr variant maintains relatively high performance (AUC: 0.9634, Acc: 0.9311, F1: 0.9346), suggesting that while unstructured pruning enhances sparsity and efficiency, it contributes moderately to overall accuracy.
The P-QAT variant shows a decline in performance (AUC: 0.9464, Acc: 0.9016), indicating the importance of QAT for adapting the model to low-precision inference. While functional without QAT, the observed drop underscores its role in preserving accuracy under quantized constraints.
Overall, the ablation results demonstrate that each stage of SUQ-3 contributes meaningfully to model performance and efficiency. Structured pruning emerges as the most impactful component, followed by unstructured pruning and QAT. The consistent superiority of the full SUQ-3 variant across all evaluation metrics validates the effectiveness of the integrated compression strategy for deployment in real-world edge scenarios with limited resources.
5.5. Lightweight Performance Analysis
To evaluate the efficiency and edge-deployment feasibility of the SUQ-3 framework, a staged lightweight performance assessment was conducted across four variants representing successive stages of the compression pipeline: baseline (uncompressed), structured pruned, unstructured pruned, and quantized (proposed) models. This analysis focuses on three critical metrics for resource-constrained deployment scenarios [
40,
41]: model size, training time, and inference time. All metrics are normalized to ensure fair comparison across variants.
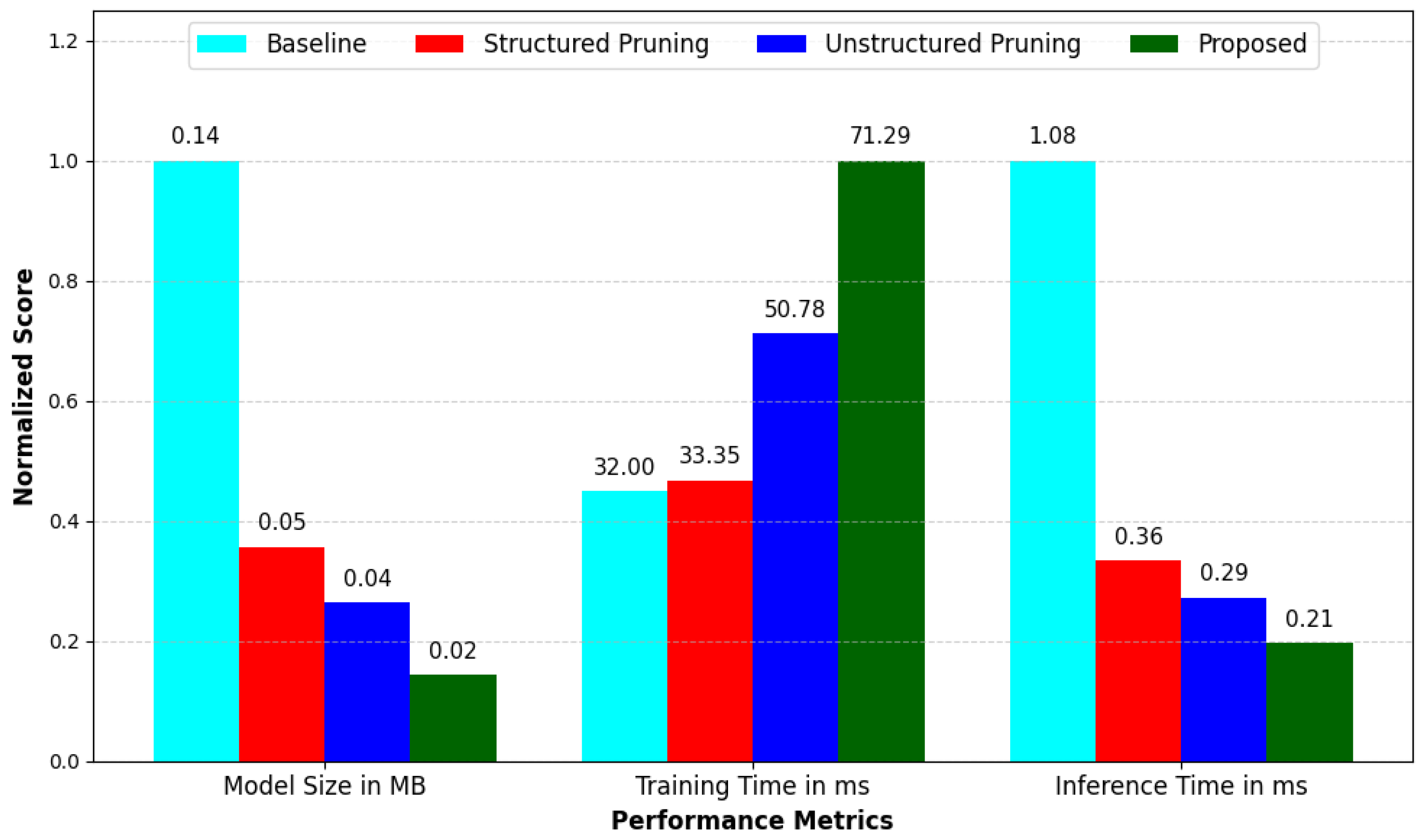
As illustrated in
Figure 9, lightweight performance improves progressively with each stage of the SUQ-3 pipeline. The baseline model used as a reference has a size of 0.14 MB, a training time of 32.00 ms, and an inference time of 1.08 ms.
The application of structured pruning reduces the model size to 0.05 MB and decreases the inference time to 0.36 ms, driven by the removal of redundant weight blocks. The training time slightly increases to 33.35 ms due to the added overhead of pruning-aware optimization, though it remains close to the baseline.
With unstructured pruning, the model size further drops to 0.037 MB, and inference time improves to 0.29 ms. The finer-grained sparsity introduced at this stage enhances compression while maintaining architectural integrity. The training time increases moderately to 50.78 ms, reflecting the additional cost of fine-tuning under irregular sparsity.
The final quantized (proposed), incorporating QAT, achieves the most compact and efficient representation, with a model size of just 0.02 MB and an inference time of 0.21 ms. This corresponds to an 85.7% reduction in size and over 80% improvement in latency compared with the baseline. Although the training time increases to 71.29 ms due to the additional overhead of quantization-aware updates, this is a one-time cost and is justified by the substantial gains in deployment efficiency.
These results demonstrate the effectiveness of the SUQ-3 framework in delivering a lightweight, high-performance DL model. Through its progressive compression stages, SUQ-3 enables substantial reductions in model size and inference latency, making it a practical solution for real-time AIoT applications in agriculture and other environments with limited resources.
5.6. Edge Deployment Analysis
Although the framework was initially developed and evaluated in Google Colab, the proposed SUQ-3 model was exported in .tflite format using the TensorFlow Lite (TFLite) backend. To assess practical deployment feasibility, the model was subsequently deployed and executed on an Android mobile device using the TFLite Interpreter, which is optimized for on-device inference on ARM-based processors. This setup provides a representative approximation of real-world performance in mobile and embedded AI scenarios.
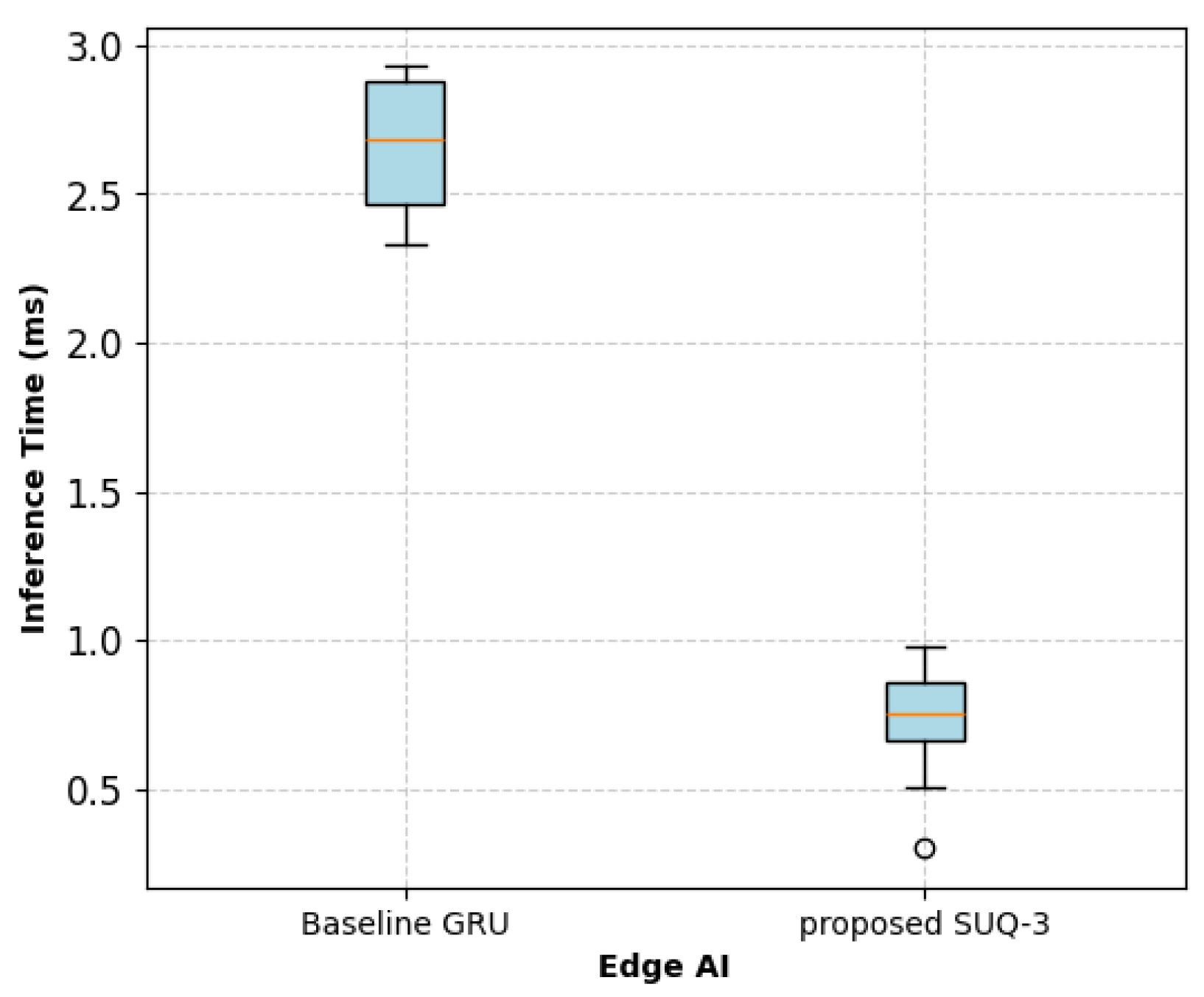
To assess inference performance, both the baseline and proposed SUQ-3 models were evaluated on 25 samples drawn from the validation set. The proposed SUQ-3 model achieved an average inference time of 0.68 ms, with a standard deviation of 0.21 ms. In comparison, the baseline (uncompressed) GRU model recorded a mean inference time of 2.77 ms, with a standard deviation of 0.34 ms, as shown in
Figure 10. For a representative input, the baseline model exhibited an inference latency of 2.803 ms, while the compressed SUQ-3 model demonstrated a substantially reduced latency of 0.5917 ms, as illustrated in
Figure 11B,C, respectively.
Energy efficiency was estimated using the standard relation
, where
P is the average power draw of the mobile processor, and
t is the measured inference time [
42]. For this analysis, a power consumption of
W was assumed to reflect a reasonable and conservative estimate for CPU-bound workloads on mid-range ARM-based mobile processors. Based on this assumption, the proposed model consumes approximately 1.18 μJ per inference (with t = 0.591 ms), whereas the baseline model, with an inference time of t = 2.307 ms, is estimated to consume approximately 4.61 μJ per inference. This represents an approximate 74.4% reduction in energy consumption per inference achieved by the proposed model compared with the baseline.
These findings confirm that the SUQ-3 compression framework substantially reduces both inference latency and energy consumption, thereby supporting its suitability for real-time, energy-efficient deployment on mobile edge hardware with constrained resources.
5.7. Comparison with Related Works
To strengthen the validation of the proposed SUQ-3 model and clearly position its contribution, we present a comparative analysis from two distinct perspectives: (A) lightweight models specifically designed for crop recommendation and (B) compressed 1D DL frameworks developed in other application domains.
5.7.1. Lightweight Models for Crop Recommendation
Several recent studies have proposed lightweight AI models for agriculture by leveraging either metaheuristic optimization, cloud-edge hybridization, or model ensembling. These works have made significant contributions to improving predictive accuracy and energy efficiency. The following are examples:
- (a)
IDCSO-WLSTM [
15]: Combined improved distribution-based chicken swarm optimization with the WLSTM model to optimize feature selection (FS) and improve accuracy to 92.68%. However, it did not apply any neural compression method, such as pruning or quantization.
- (b)
E-CropReco [
43]: Introduced a federated learning (FL)-based framework incorporating dew and edge computing with ML to reduce energy consumption by 70–80% compared with cloud-only inference. While energy-efficient, it relies on external infrastructure and does not involve model compression.
- (c)
EXP-W Ensemble [
44]: Introduced an exponentially weighted voting scheme that combines multiple classifiers, achieving 99.8% accuracy while significantly reducing offline training time up to 87% compared with traditional stacking ensembles. However, despite its efficiency during training, the model introduces increased inference overhead due to the computational complexity of the ensemble structure.
- (d)
iCrop [
45]: Integrated image steganography with edge computing and ML for crop yield prediction and achieved up to 99.9% accuracy, with a 10% energy saving over cloud-only solutions. However, the model remains dependent on cloud resources for core inference.
In contrast, the proposed SUQ-3 framework addresses the lightweight modeling challenge from a model-centric perspective by introducing a three-stage coarse-to-fine compression pipeline. As shown in
Table 5, SUQ-3 achieves competitive accuracy while significantly reducing memory footprint and inference energy, consuming as little as 1.18 μJ per inference on a 2W mobile device. This balance of efficiency and performance makes SUQ-3 particularly well-suited for deployment on resource-limited edge devices in smart agriculture environments.
5.7.2. Lightweight 1D DL Models in Other Domains
To substantiate and contextualize the contribution of SUQ-3 within the broader landscape of lightweight 1D DL, this subsection presents a comparative analysis with established compression frameworks from other domains, including biomedical signal processing, gesture recognition, and embedded NLP. These approaches commonly utilize CNN or MLP-based architectures and apply compression techniques such as unstructured pruning, fixed-point quantization, and low-bit weight encoding to support efficient edge deployment.
While effective in their respective domains, these models are typically optimized for spatial or structured input data and often implement compression stages in isolation. As a result, their adaptability to unstructured, time-series forecasting tasks, particularly in agricultural AIoT contexts, remains limited. Addressing this gap, SUQ-3 introduces a unified, coarse-to-fine compression framework specifically tailored for GRU-based architectures processing sequential temporal data. In contrast to earlier approaches that separate pruning and quantization into distinct phases, SUQ-3 combines structured block pruning (M × N), unstructured fine-grained pruning, and QAT into a single, end-to-end optimization workflow. This integrated design enables the model to simultaneously learn sparse connectivity patterns and reduced-precision representations, resulting in highly compact, low-latency models suitable for real-time inference on lightweight edge platforms.
Table 6 outlines the key distinctions between the proposed SUQ-3 model and representative lightweight models from other domains with respect to model architecture, compression methodology, input modality, and deployment context.
6. Limitations and Future Works
While this study demonstrates significant progress in compressing DL models for edge-based agricultural applications, several limitations must be addressed to further validate and enhance the robustness of the proposed SUQ-3 framework. Firstly, the model was deployed and evaluated on an Android mobile device to approximate real-world edge inference performance. However, energy consumption was estimated analytically using inference time and assumed power values rather than measured through direct hardware-based instrumentation. Although deployment on a real mobile device provides a practical assessment of latency and feasibility, future work should incorporate direct energy profiling using developer-grade edge platforms such as Raspberry Pi and Jetson Nano to more accurately quantify energy consumption under controlled conditions.
Secondly, the dataset used in this study, sourced exclusively from Kaggle with 2200 samples, lacks explicit geographic coverage and seasonal variability information. The absence of these critical attributes may limit the generalizability of the model across diverse agricultural settings, particularly in regions with varying climatic and environmental conditions. To address this limitation, future work should incorporate larger and geographically diverse datasets that explicitly capture seasonal variations and multiple environmental conditions. Validating the proposed model against such datasets would significantly enhance its applicability and reliability in real-world deployments.
In addition, the current study focuses primarily on on-device inference efficiency and does not explicitly assess communication overhead or performance stability under limited or intermittent connectivity, which are challenges commonly faced in remote agricultural settings. Future work should consider testing SUQ-3 under such conditions to evaluate its robustness in fully offline and hybrid edge–cloud scenarios.
Future works should also explore adaptive learning techniques or online fine-tuning to maintain model accuracy under dynamically changing environmental conditions typically encountered in real-world agricultural deployments. This would further ensure that the compressed models remain robust, accurate, and energy-efficient under evolving operational circumstances.
7. Conclusions
This paper presented SUQ-3, a novel three-stage coarse-to-fine compression framework tailored to enhance the deployment efficiency of the 1D GRU model for AIoT-enabled precision agriculture. The framework sequentially integrates structured pruning, unstructured pruning, and quantization applied after QAT, to achieve substantial reductions in model size and inference latency while preserving predictive performance.
The proposed framework was evaluated using a GRU-based crop recommendation model trained on environmental and climatic sensor data. Experimental results demonstrated a model size reduction of approximately 85% and an 80% improvement in inference latency while preserving high predictive accuracy (F1 score: 0.97 vs. baseline: 0.9837). Further detailed analyses, such as sparsity analysis and model stability, validated the robustness and generalization capacity of the compressed model throughout the three stages of the proposed framework. In addition, an ablation study confirmed the additive benefit of each compression stage toward achieving a compact yet accurate model. Notably, when deployed on a mobile edge device, the compressed model achieved an estimated energy consumption of just 1.18 μJ per inference, confirming its suitability for low-power AI applications in real-world agricultural settings.
While the framework was validated in an agricultural setting, the modular and domain-agnostic nature of SUQ-3 makes it applicable for a broader range of use cases, including the compression of larger DL architectures in other edge AI domains where compute, memory, and power constraints are critical.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}