
Method to Select Variables for Estimating the Parameters of Equations That Describe Average Vehicle Travel Speed in Downtown City Areas

 ,
,
Abstract
1. Introduction
- Can static street network features be used as independent variables to describe the average travel speeds in downtown zones?
- Which is the best method to determine the independent variables that might be used to estimate the parameters of the equations that describe the ATS?
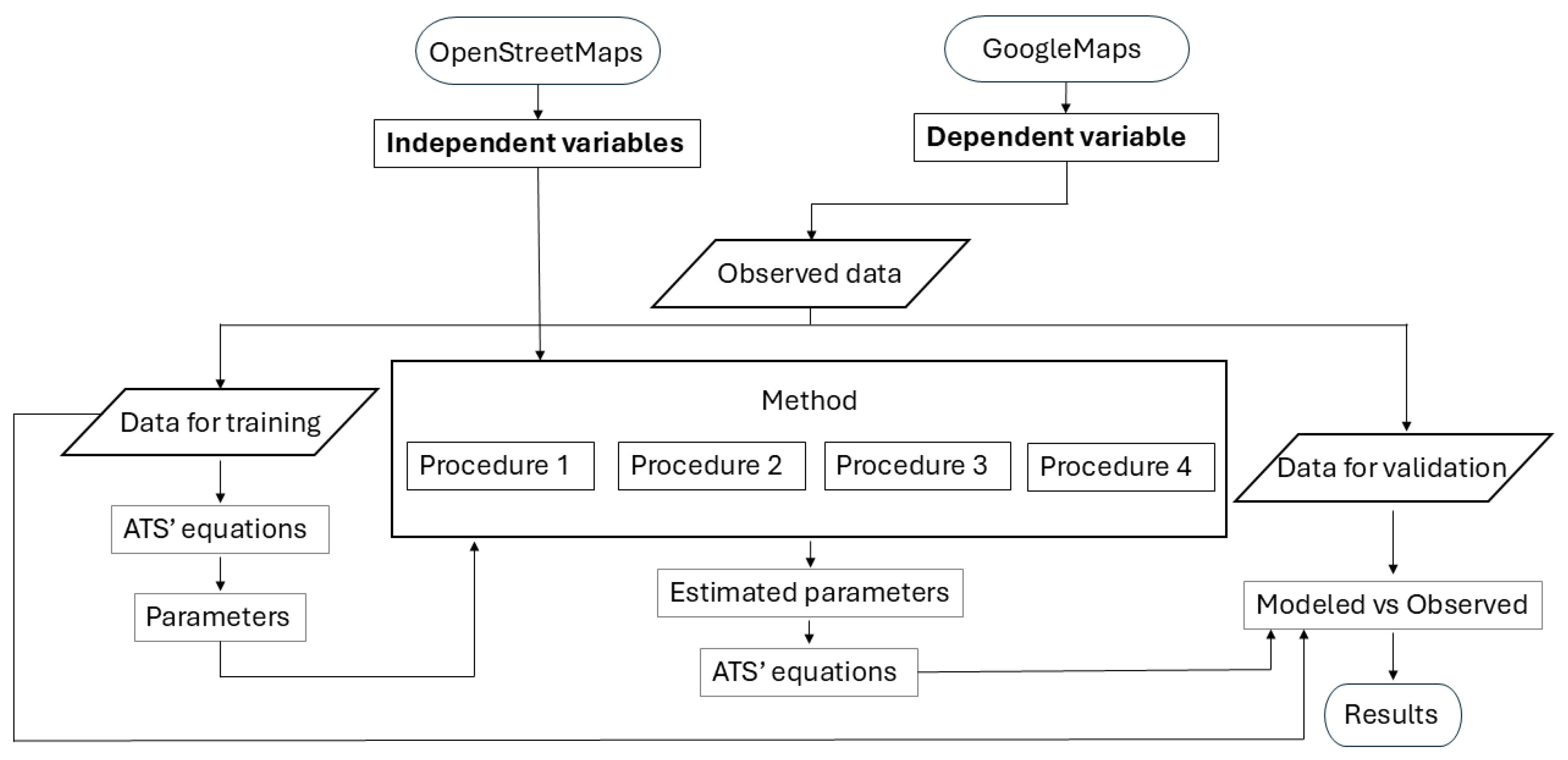
2. Materials and Methods
2.1. Instructions to Extract Street Network Data
2.2. Street Networks of Cities
2.3. Speed Measurements
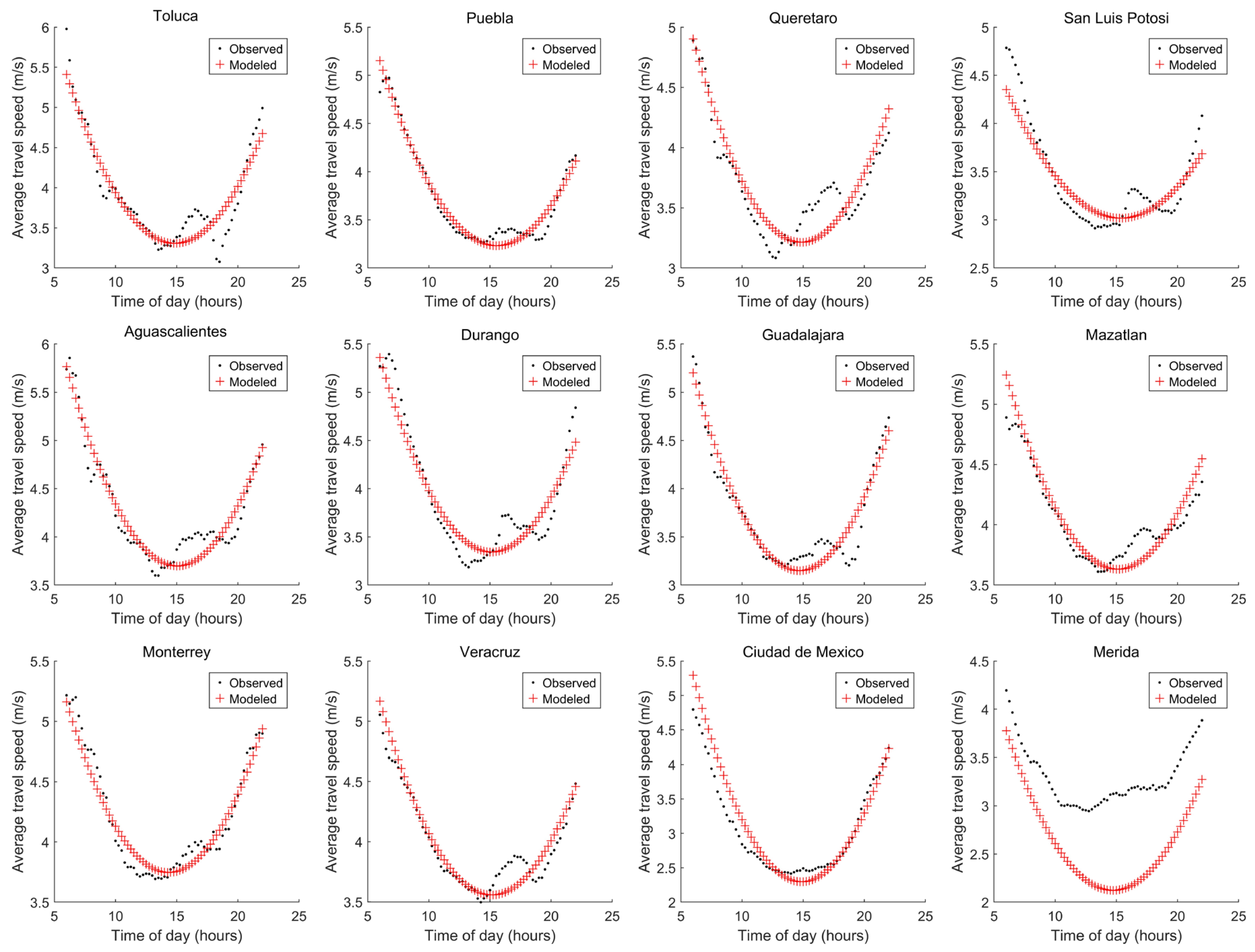
2.4. Model to Describe the Average Travel Speed (ATS)
2.5. Independent Variables
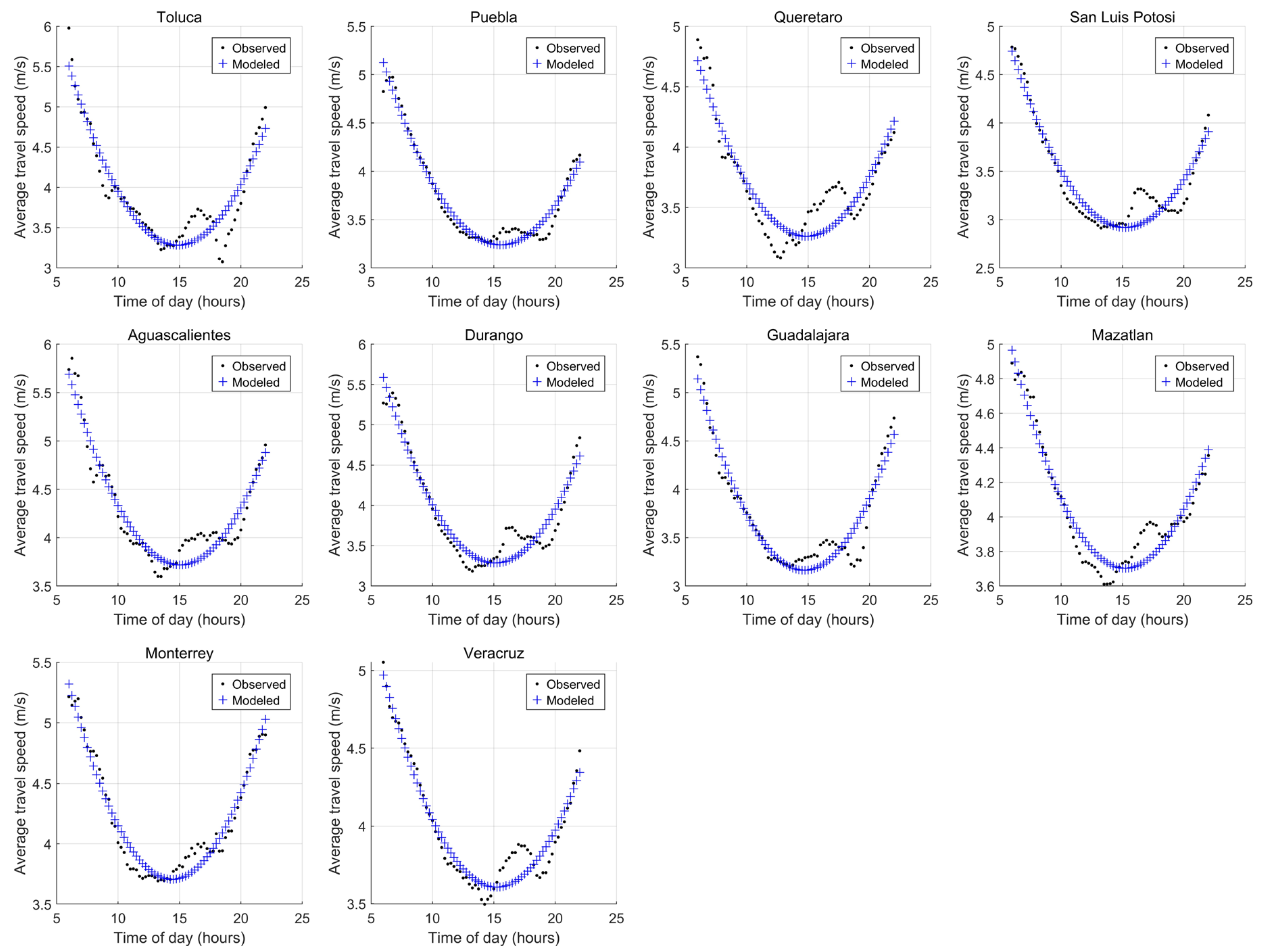
3. Results
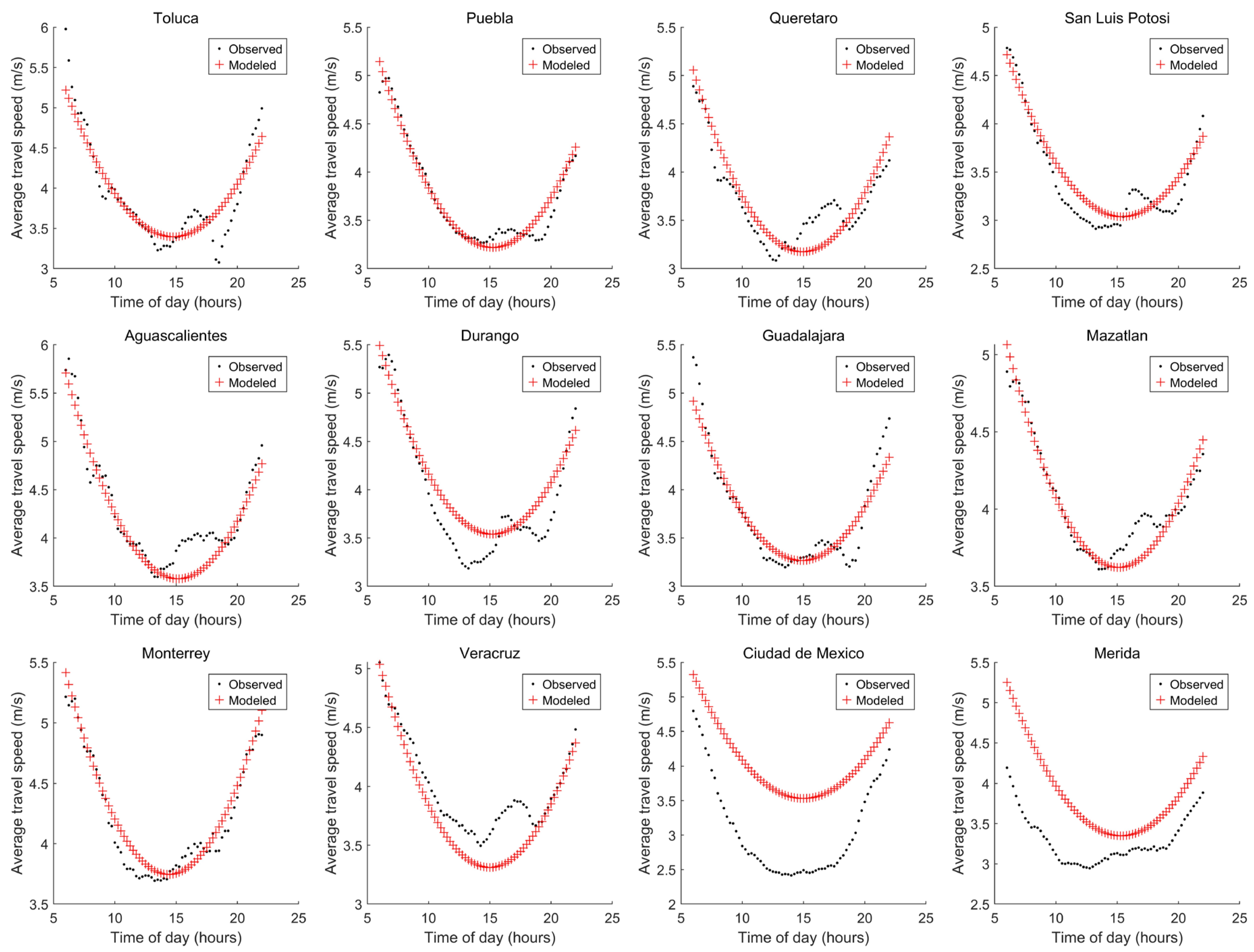
3.1. Procedure 1: Selecting Variables Considering the ATS Error
| Algorithm 1. Generalized steps of Algorithm 1. |
|
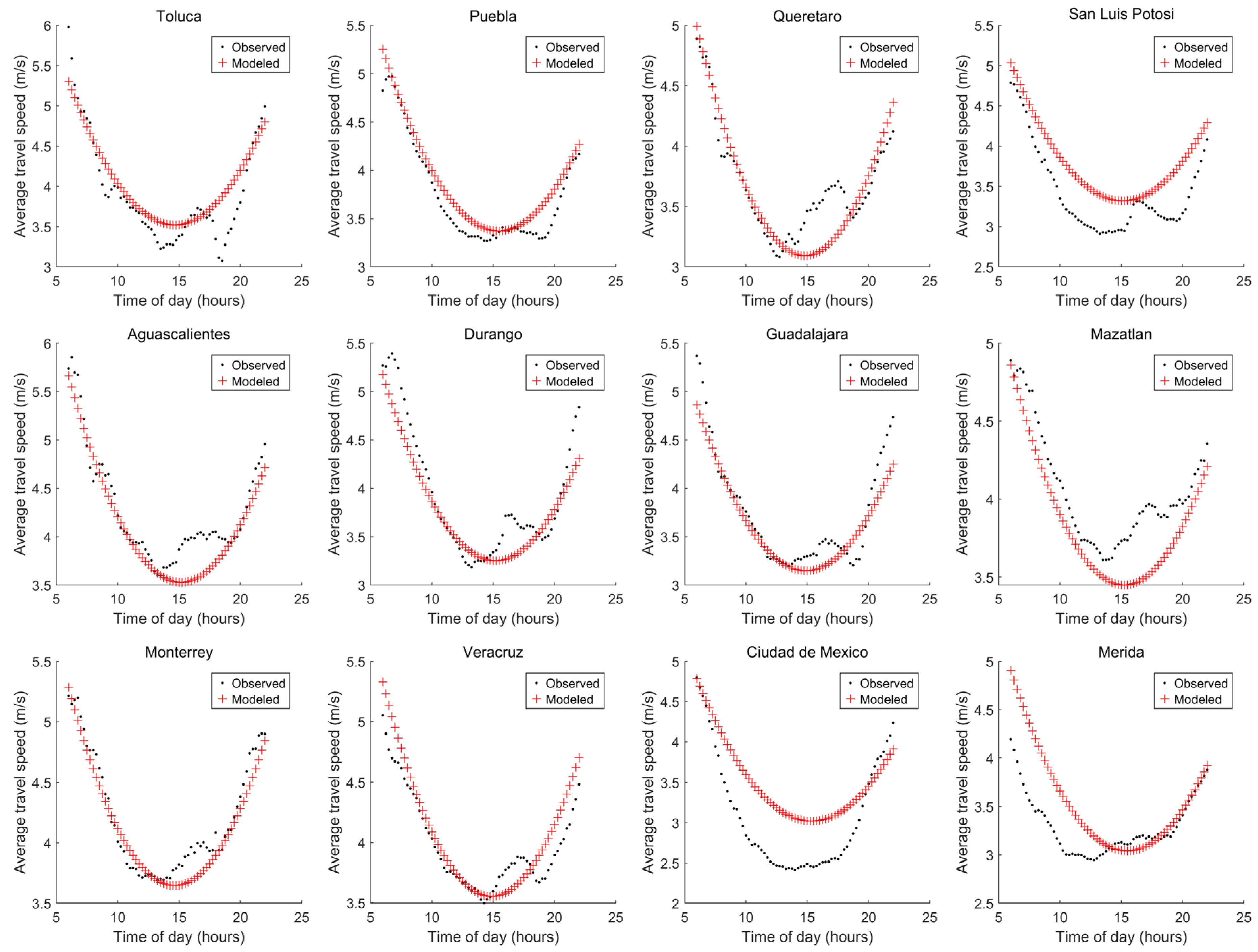
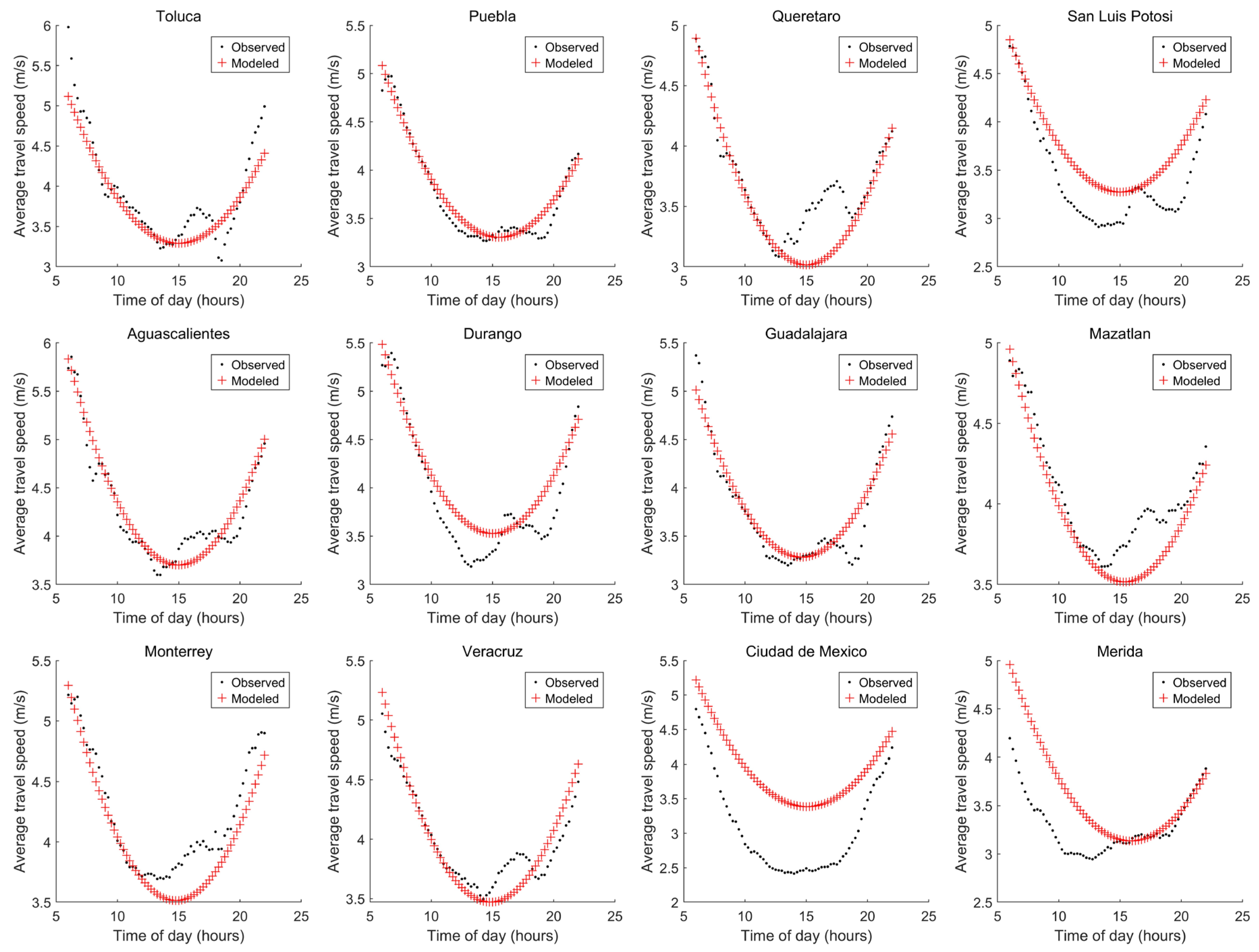
3.2. Procedure 2: Selecting Variables Considering the Spearman Correlation Coefficient
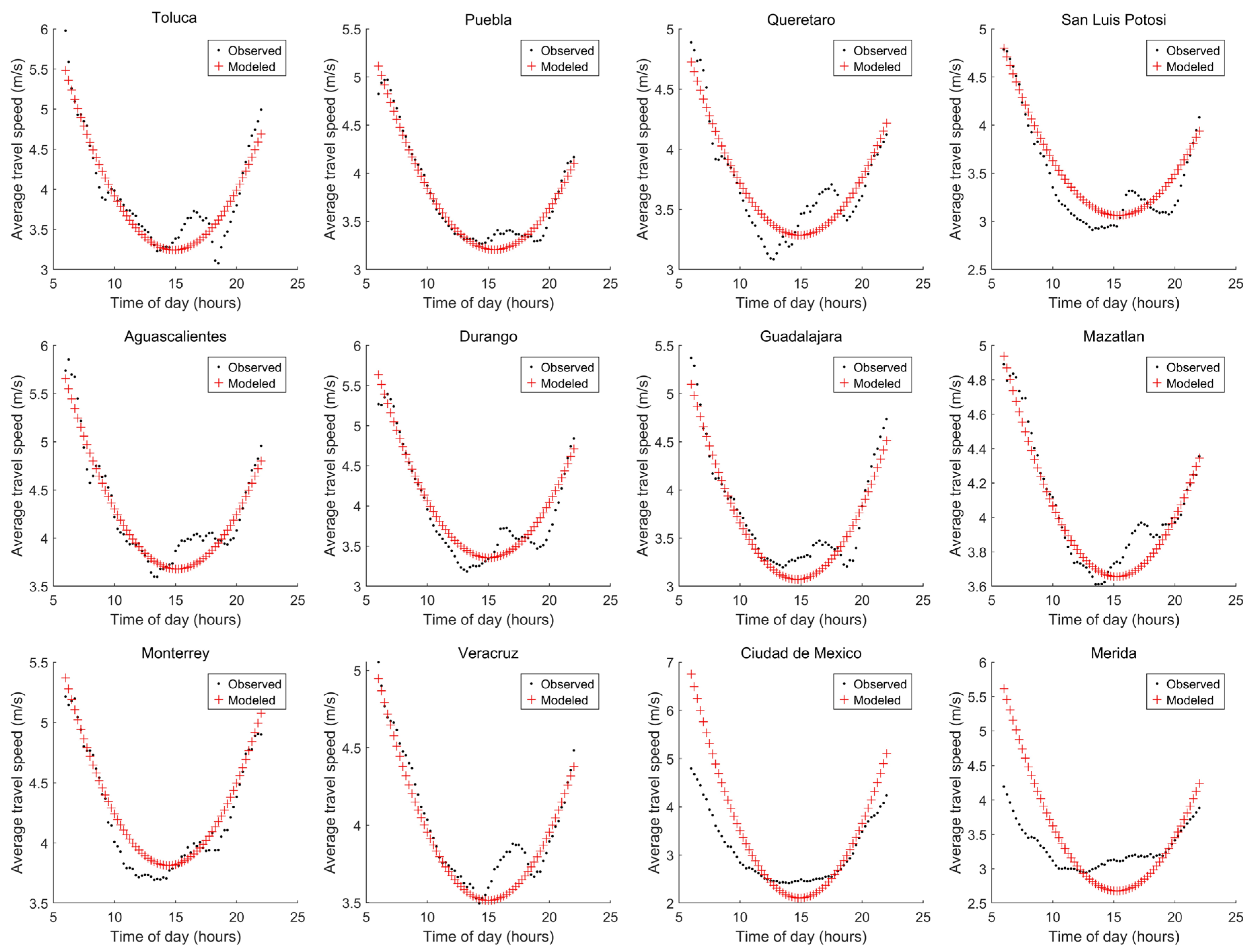
3.3. Procedure 3: Selecting Variables Considering the Kendall Correlation Coefficient
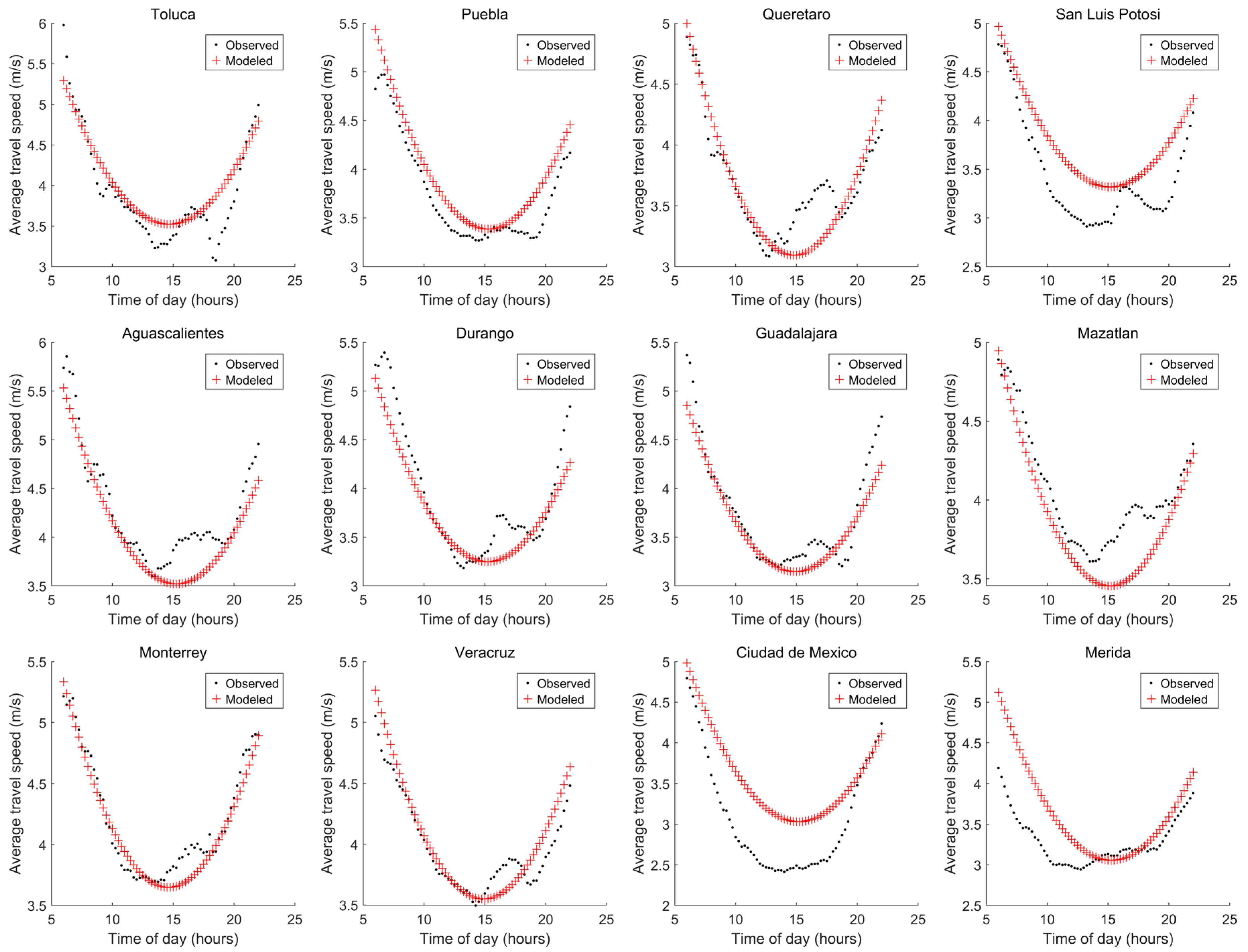
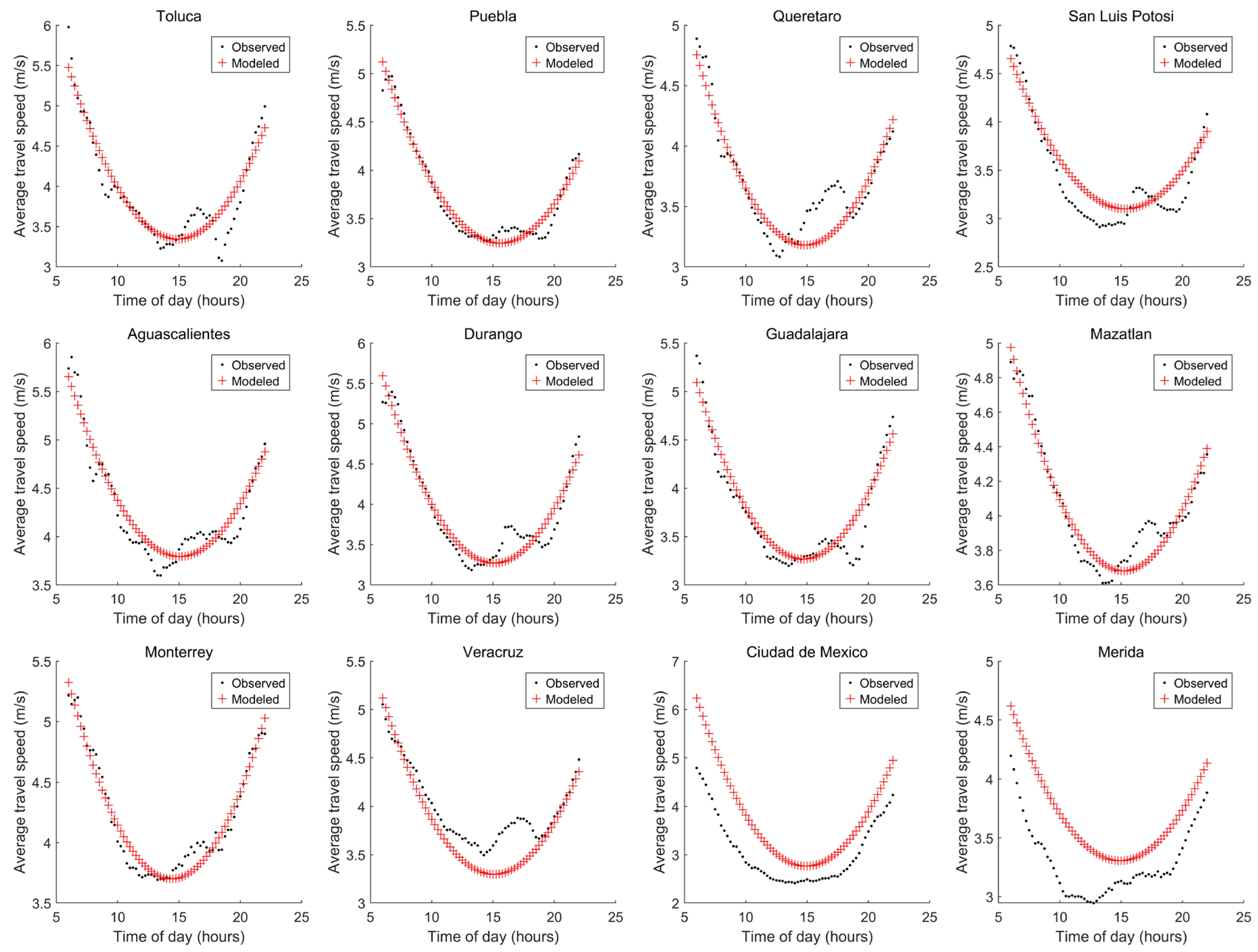
3.4. Procedure 4: Selecting Variables Considering the Pearson Correlation Coefficient
3.5. Algorithm for Procedures 2, 3, and 4
| Algorithm 2. Steps of Algorithm 2. |
|
4. Discussion
Method Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ATS | Average travel speed |
| OSM | OpenStreetMap |
| MAE | Mean Absolut Error |
| MLR | Multiple linear regression |
| SCC | Spearman correlation coefficient |
| KCC | Kendall correlation coefficient |
| PCC | Pearson correlation coefficient |
| SD | Standard deviation |
Appendix A
Appendix A.1
| G = osmnx.graph.graph_from_point(central_point, dist = radio, dist_type = ‘bbox’, network_type = ‘drive’, simplify = False, retain_all = False, truncate_by_edge = False) where central_point is presented in Table 1 and radio = 500 m. Subsequently, in G were eliminated false edges and edges that do not impact on traffic conditions (this is a manual job for each city case). With G1 = osmnx.utils_graph.remove_isolated_nodes(G, warn = False) isolated nodes were removed and G1 was obtained. With G2 = osmnx.simplification.simplify_graph(G1, remove_rings = True, track_merged = False) the nodes that are not intersections or dead ends were removed and G2 was obtained. The street network data is obtained from G2 with network_data = osmnx.stats.basic_stats(G2, area = square, clean_int_tol = None) where square = (radio*2)*(radio*2). |
| The G graph is downloaded and created with G = osmnx.graph.graph_from_point(central_point, dist = radio, dist_type = ‘bbox’, network_type = ‘drive’, simplify = False, retain_all = False, truncate_by_edge = False) G1 was obtained directly from G, G1 = osmnx.simplification.simplify_graph(G, remove_rings = True, track_merged = False) from G1 were removed false edges and edges that do not impact on traffic conditions, then G2 = osmnx.utils_graph.remove_isolated_nodes(G1, warn = False) the network data was obtained from G2 with network_data = osmnx.stats.basic_stats(G2, area = square, clean_int_tol = None) |
Appendix A.2
Appendix A.2.1. Durango
Appendix A.2.2. Toluca
Appendix A.2.3. San Luis Potosi
Appendix A.2.4. Aguascalientes

Appendix A.2.5. Guadalajara
Appendix A.2.6. Puebla

Appendix A.2.7. Ciudad de Mexico
Appendix A.2.8. Monterrey

Appendix A.2.9. Queretaro

Appendix A.2.10. Mazatlan

Appendix A.2.11. Merida

Appendix A.2.12. Veracruz
References
- Crucitti, P.; Latora, V.; Porta, S. Centrality measures in spatial networks of urban streets. Phys. Rev. E 2006, 73, 5. [Google Scholar] [CrossRef] [PubMed]
- Porta, S.; Crucitti, P.; Latora, V. The network analysis of urban streets: A primal approach. Environ. Plan. B-Plan. Des. 2006, 33, 705–725. [Google Scholar] [CrossRef]
- Lin, J.; Ban, Y. Complex Network Topology of Transportation Systems. Transp. Rev. 2013, 33, 658–685. [Google Scholar] [CrossRef]
- Cardillo, A.; Scellato, S.; Latora, V.; Porta, S. Structural properties of planar graphs of urban street patterns. Phys. Rev. E 2006, 73, 8. [Google Scholar] [CrossRef] [PubMed]
- Xie, F.; Levinson, D. Measuring the structure of road networks. Geogr. Anal. 2007, 39, 336–356. [Google Scholar] [CrossRef]
- Zhao, S.; Zhao, P.; Cui, Y. A network centrality measure framework for analyzing urban traffic flow: A case study of Wuhan, China. Phys. A-Stat. Mech. Its Appl. 2017, 478, 143–157. [Google Scholar] [CrossRef]
- Jiang, B.; Liu, C. Street-based topological representations and analyses for predicting traffic flow in GIS. Int. J. Geogr. Inf. Sci. 2009, 23, 1119–1137. [Google Scholar] [CrossRef]
- Jayasinghe, A.; Sano, K.; Nishiuchi, H. Explaining traffic flow patterns using centrality measures. Int. J. Traffic Transp. Eng. 2015, 5, 134–149. [Google Scholar] [CrossRef] [PubMed]
- Pun, L.; Zhao, P.; Liu, X. A Multiple Regression Approach for Traffic Flow Estimation. IEEE Access 2019, 7, 35998–36009. [Google Scholar] [CrossRef]
- Musolino, G.; Polimeni, A.; Rindone, C.; Vitetta, A. Travel time forecasting and dynamic routes design for emergency vehicles. Procedia Soc. Behav. Sci. 2013, 87, 193–202. [Google Scholar] [CrossRef]
- Moses, R.; Mtoi, E. Evaluation of Free Flow Speeds on Interrupted Flow Facilities; Florida Department of Transportation: Tallahassee, FL, USA, 2013. [Google Scholar]
- Dixon, K.K.; Wu, C.-H.; Sarasua, W.; Daniel, J. Estimating free-flow speeds for rural multilane highways. Transp. Res. Rec. 1999, 1678, 73–82. [Google Scholar] [CrossRef]
- Graser, A.; Leodolter, M.; Koller, H.; Brändle, N. Improving vehicle speed estimates using street network centrality. Int. J. Cartogr. 2016, 2, 77–94. [Google Scholar] [CrossRef]
- Leodolter, M.; Koller, H.; Straub, M. Estimating Travel Times from Static Map Attributes. In Proceedings of the 2015 International Conference on Models and Technologies for Intelligent Transportation Systems (Mt-Its), Budapest, Hungary, 3–5 June 2015; pp. 121–126. [Google Scholar]
- Wong, W.; Wong, S.C. Network topological effects on the macroscopic Bureau of Public Roads function. Transp. A-Transp. Sci. 2016, 12, 272–296. [Google Scholar] [CrossRef]
- Wong, W.; Wong, S.C.; Liu, H.X. Network topological effects on the macroscopic fundamental diagram. Transp. B-Transp. Dyn. 2021, 9, 376–398. [Google Scholar] [CrossRef]
- Zhang, K.; Zheng, L.; Liu, Z.; Jia, N. A deep learning based multitask model for network-wide traffic speed prediction. Neurocomputing 2020, 396, 438–450. [Google Scholar] [CrossRef]
- Cao, M.; Li, V.O.; Chan, V.W. A CNN-LSTM model for traffic speed prediction. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Antwerp, Belgium, 25–28 May2020; pp. 1–5. [Google Scholar]
- Dai, F.; Huang, P.; Xu, X.; Qi, L.; Khosravi, M.R. Spatio-temporal deep learning framework for traffic speed forecasting in IoT. IEEE Internet Things Mag. 2021, 3, 66–69. [Google Scholar] [CrossRef]
- Sharma, A.; Sharma, A.; Nikashina, P.; Gavrilenko, V.; Tselykh, A.; Bozhenyuk, A.; Masud, M.; Meshref, H. A Graph Neural Network (GNN)-Based Approach for Real-Time Estimation of Traffic Speed in Sustainable Smart Cities. Sustainability 2023, 15, 1893. [Google Scholar] [CrossRef]
- Shen, Y.; Li, L.; Xie, Q.; Li, X.; Xu, G. A Two-Tower Spatial-Temporal Graph Neural Network for Traffic Speed Prediction. In Proceedings of the Advances in Knowledge Discovery and Data Mining: 26th Pacific-Asia Conference, PAKDD 2022, Chengdu, China, 16–19 May 2022; Proceedings, Part II. pp. 406–418. [Google Scholar]
- Yu, B.; Lee, Y.; Sohn, K. Forecasting road traffic speeds by considering area-wide spatio-temporal dependencies based on a graph convolutional neural network (GCN). Transp. Res. Part C-Emerg. Technol. 2020, 114, 189–204. [Google Scholar] [CrossRef]
- TomTom Traffic Index, Ranking. 2024. Available online: https://www.tomtom.com/traffic-index/ranking/ (accessed on 1 April 2024).
- Boeing, G. OSMnx: New methods for acquiring, constructing, analyzing, and visualizing complex street networks. Comput. Environ. Urban Systems 2017, 65, 126–139. [Google Scholar] [CrossRef]
- Distance Matrix API Request and Response. Available online: https://developers.google.com/maps/documentation/distance-matrix/distance-matrix (accessed on 31 October 2024).
- Key:Highway. Available online: https://wiki.openstreetmap.org/wiki/Key:highway (accessed on 30 October 2024).
- Sakamoto, Y.; Ishiguro, M.; Kitagawa, G. Akaike Information Criterion Statistics; D. Reidel Publishing Company: Dordrecht, The Netherlands, 1986; Volume 81, p. 26853. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| City | Latitude, Longitude (central_point) | Readings’ Date (year/month/day) | id |
|---|---|---|---|
| Toluca | 19.290271, −99.656241 | 2024/4/10 | 1 |
| Puebla | 19.045296, −98.199224 | 2024/5/8 | 2 |
| Queretaro | 20.591938, −100.393755 | 2024/5/22 | 3 |
| San Luis Potosi | 22.152679, −100.977041 | 2024/4/10 | 4 |
| Aguascalientes | 21.883707, −102.295368 | 2024/4/10 | 5 |
| Durango | 24.025159, −104.667530 | 2024/4/3 | 6 |
| Guadalajara | 20.674257, −103.350420 | 2024/4/10 | 7 |
| Mazatlan | 23.202669, −106.420695 | 2024/5/22 | 8 |
| Monterrey | 25.676165, −100.314396 | 2024/5/22 | 9 |
| Veracruz | 19.196422, −96.137607 | 2024/5/29 | 10 |
| Ciudad de Mexico | 19.432574, −99.133204 | 2024/5/8 | 11 |
| Merida | 20.967084, −89.623739 | 2024/5/29 | 12 |
| City | Parameter a | Parameter b | Parameter c | MAE 1 (m/s) |
|---|---|---|---|---|
| Toluca | 0.028396 | −0.843706 | 9.547877 | 0.165484 |
| Puebla | 0.020665 | −0.642999 | 8.239078 | 0.078630 |
| Queretaro | 0.0186069 | −0.552343 | 7.360227 | 0.146007 |
| San Luis Potosi | 0.021510 | −0.654421 | 7.895163 | 0.118764 |
| Aguascalientes | 0.0240903 | −0.725108 | 9.173014 | 0.132317 |
| Durango | 0.0278565 | −0.840950 | 9.630438 | 0.148438 |
| Guadalajara | 0.026250 | −0.770993 | 8.823447 | 0.121535 |
| Mazatlan | 0.014890 | −0.452952 | 7.146595 | 0.076942 |
| Monterrey | 0.022889 | −0.659153 | 8.451607 | 0.087286 |
| Veracruz | 0.016063 | −0.488818 | 7.324627 | 0.079215 |
| Variable | Definition | ID |
|---|---|---|
| n | The number of nodes in the network. | 1 |
| m | The number of edges in the network. | 2 |
| k_avg | Average node degree (in-degree and out-degree). | 3 |
| sum_edges_length | The sum of the edge length in the network (in meters). | 4 |
| avg_edges_length | The average of the edge length (in meters). | 5 |
| circuity_avg | The total edge length divided by the sum of great circle distances between the nodes incident to each edge. | 6 |
| oneway_true | The percentage of one-way edges. | 7 |
| length _75 | The percentage of edges with a length ≤ 75 m. | 8 |
| length _125 | The percentage of edges with a length > 75 m and ≤125 m. | 9 |
| length _ leftover | The percentage of edges with a length > 125 m. | 10 |
| h_residential | The percentage of edges classified as residential. | 11 |
| h_tertiary | The percentage of edges classified as tertiary. | 12 |
| h_ leftover | The sum of the following percentages: % of edges classified as primary + secondary % + living_street % + trunk % + primary_link % + secondary_link % + tertiary_link %. | 13 |
| lanes_1 | The percentage of edges with 1 lane. | 14 |
| lanes_2 | The percentage of edges with 2 lanes. | 15 |
| lanes_ leftover | The sum of: % of edges with 3 lanes + % with 4 lanes + % with 5 lanes + % with 6 lanes. | 16 |
| intercept | The constant term equal to 1. | 17 |
| Variable ID | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| City | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| Toluca | 97 | 159 | 3.27835 | 16,617.4190 | 104.5120 | 1.0097 | 0.6981 | 0.3962 | 0.2830 | 0.3207 | 0.5838 | 0.1118 | 0.3043 | 0.0097 | 0.3106 | 0.6796 |
| Puebla | 68 | 105 | 3.0882 | 16,339.4670 | 155.6139 | 1.0318 | 0.9809 | 0.0285 | 0.4571 | 0.5142 | 0.4363 | 0.1363 | 0.4272 | 0.0740 | 0.9259 | 0 |
| Queretaro | 94 | 130 | 2.7659 | 15,400.8590 | 118.4681 | 1.0175 | 1 | 0.2461 | 0.2538 | 0.5000 | 0.7022 | 0.0534 | 0.2442 | 0.1153 | 0.3269 | 0.5576 |
| San Luis Potosi | 186 | 308 | 3.3118 | 22,967.7810 | 74.5707 | 1.0127 | 0.7987 | 0.5844 | 0.2694 | 0.1461 | 0.7419 | 0.0258 | 0.2322 | 0.2261 | 0.7619 | 0.0119 |
| Aguascalientes | 77 | 110 | 2.8571 | 12,447.2360 | 113.1566 | 1.0256 | 1 | 0.3181 | 0.3181 | 0.3636 | 0.3839 | 0.3571 | 0.2589 | 0.1578 | 0.8157 | 0.0263 |
| Durango | 110 | 181 | 3.2909 | 16,980.1849 | 93.8131 | 1.0147 | 0.9447 | 0.4198 | 0.2762 | 0.3038 | 0.5879 | 0.3021 | 0.1098 | 0 | 0.9636 | 0.0363 |
| Guadalajara | 145 | 247 | 3.4068 | 20,779.2279 | 84.1264 | 1.0087 | 0.9352 | 0.3076 | 0.6234 | 0.0688 | 0.7935 | 0.0121 | 0.1943 | 0.2460 | 0.4047 | 0.3492 |
| Mazatlan | 220 | 391 | 3.5545 | 29,011.3119 | 74.1977 | 1.0132 | 0.8465 | 0.4808 | 0.4936 | 0.0255 | 0.8081 | 0.1867 | 0.0051 | 0 | 1 | 0 |
| Monterrey | 103 | 185 | 3.5922 | 18,577.7809 | 100.4204 | 1.0008 | 0.9027 | 0.0540 | 0.8594 | 0.0864 | 0.5621 | 0.1351 | 0.3027 | 0.0823 | 0.2117 | 0.7058 |
| Veracruz | 140 | 245 | 3.5000 | 20,149.0319 | 82.2409 | 1.0267 | 0.8122 | 0.4897 | 0.3836 | 0.1265 | 0.6491 | 0.0887 | 0.2620 | 0 | 0.6666 | 0.3333 |
| Ciudad de Mexico | 93 | 154 | 3.3118 | 18,876.1639 | 122.5724 | 1.0189 | 0.8311 | 0.0454 | 0.6558 | 0.2987 | 0.6580 | 0.1935 | 0.1483 | 0.1393 | 0.7622 | 0.0983 |
| Merida | 82 | 137 | 3.3414 | 18,445.1519 | 134.6361 | 1.0457 | 0.9562 | 0.1094 | 0.1824 | 0.7080 | 0.6428 | 0.2285 | 0.1285 | 0.4824 | 0.5175 | 0 |
| Variables’ ID | Ecities (m/s) | Emexico (m/s) | Emerida (m/s) | E (m/s) |
|---|---|---|---|---|
| 17 | 2.512963 | 0.817906 | 0.598571 | 3.92944 |
| 12 | 2.034491 | 0.899163 | 0.733928 | 3.667582 |
| 9 | 1.715589 | 1.06559 | 0.590626 | 3.371805 |
| 16 | 1.57167 | 0.989279 | 0.558646 | 3.119595 |
| 4 | 1.480454 | 0.96178 | 0.569536 | 3.01177 |
| 6 | 1.290388 | 0.976852 | 0.826327 | 3.093567 |
| 15 | 1.226494 | 0.991728 | 1.395361 | 3.613583 |
| 7 | 1.18319 | 1.051899 | 1.429597 | 3.664686 |
| 11 | 1.156781 | 1.175445 | 1.439658 | 3.771884 |
| SCC Between Variable and Parameter a | SCC Between Variable and Parameter b | SCC Between Variable and Parameter c | SCC Score | Variable ID |
|---|---|---|---|---|
| −0.35758 | 0.357576 | −0.51515 | 1.230303 | 11 |
| 0.425534 | −0.42553 | 0.32219 | 1.173258 | 16 |
| −0.44242 | 0.442424 | −0.26061 | 1.145455 | 6 |
| −0.28485 | 0.284848 | −0.4303 | 1 | 4 |
| −0.26061 | 0.260606 | −0.41818 | 0.939394 | 2 |
| 0.248485 | −0.24848 | 0.369697 | 0.866667 | 5 |
| −0.22424 | 0.224242 | −0.3697 | 0.818182 | 1 |
| −0.21212 | 0.212121 | −0.29697 | 0.721212 | 3 |
| −0.28485 | 0.284848 | −0.13939 | 0.709091 | 15 |
| 0.239282 | −0.23928 | 0.141115 | 0.619679 | 14 |
| 0.151515 | −0.15152 | 0.272727 | 0.575758 | 10 |
| −0.13939 | 0.139394 | −0.22424 | 0.50303 | 8 |
| 0.066667 | −0.06667 | 0.284848 | 0.418182 | 12 |
| 0.115152 | −0.11515 | 0.139394 | 0.369697 | 13 |
| −0.09091 | 0.090909 | −0.09091 | 0.272727 | 9 |
| −0.05471 | 0.054711 | 0.133739 | 0.243162 | 7 |
| 0 | 0 | 0 | 0 | 17 |
| Considered Variables (Cumulative) | Ecities (m/s) | Emexico (m/s) | Emerida (m/s) | E (m/s) |
|---|---|---|---|---|
| 11, 16, 6, 4, 2 | 1.894663 | 0.46847 | 0.281023 | 2.644156 |
| 5 | 1.80784 | 0.724296 | 0.541257 | 3.073393 |
| 1 | 1.800265 | 0.57598 | 0.497557 | 2.873802 |
| 3 | 1.454441 | 1.041424 | 0.915076 | 3.410941 |
| 15 | 1.268898 | 1.883967 | 2.342394 | 5.495259 |
| 14 | 1.154621 | 1.56436 | 1.926892 | 4.645873 |
| Considered Variables (Cumulative) | Ecities (m/s) | Emexico (m/s) | Emerida (m/s) | E (m/s) |
|---|---|---|---|---|
| 11, 16, 6, 4, 3, 14, 12 | 1.415866 | 0.827168 | 0.887808 | 3.130842 |
| 13 | 1.209601 | 0.929687 | 1.85246 | 3.991748 |
| 9 | 1.183915 | 0.98442 | 1.660821 | 3.829156 |
| 7 | 1.154621 | 1.116746 | 1.584217 | 3.855584 |
| Considered Variables (Cumulative) | Ecities (m/s) | Emexico (m/s) | Emerida (m/s) | E (m/s) |
|---|---|---|---|---|
| 11, 16, 4, 8, 12, 13 | 1.505449 | 0.84545 | 0.627801 | 2.9787 |
| 9 | 1.411389 | 0.862381 | 0.414258 | 2.688028 |
| 7 | 1.308588 | 0.520448 | 0.437807 | 2.266843 |
| KCC Between Variable and Parameter a | KCC Between Variable and Parameter b | KCC Between Variable and Parameter c | KCC Score | Variable ID |
|---|---|---|---|---|
| 0.359573 | −0.35957 | 0.224733 | 0.94388 | 16 |
| −0.24444 | 0.244444 | −0.28889 | 0.777778 | 2 |
| −0.24444 | 0.244444 | −0.28889 | 0.777778 | 4 |
| −0.24444 | 0.244444 | −0.28889 | 0.777778 | 11 |
| −0.28889 | 0.288889 | −0.15556 | 0.733333 | 6 |
| −0.2 | 0.2 | −0.24444 | 0.644444 | 1 |
| 0.2 | −0.2 | 0.244444 | 0.644444 | 5 |
| 0.230022 | −0.23002 | 0.092009 | 0.552052 | 14 |
| −0.15556 | 0.155556 | −0.2 | 0.511111 | 3 |
| −0.2 | 0.2 | −0.06667 | 0.466667 | 15 |
| 0.111111 | −0.11111 | 0.155556 | 0.377778 | 10 |
| −0.06667 | 0.066667 | −0.11111 | 0.244444 | 9 |
| −0.04495 | 0.044947 | 0.089893 | 0.179787 | 7 |
| −0.02222 | 0.022222 | 0.111111 | 0.155556 | 12 |
| 0.022222 | −0.02222 | 0.066667 | 0.111111 | 13 |
| −0.02222 | 0.022222 | 0.022222 | 0.066667 | 8 |
| 0 | 0 | 0 | 0 | 17 |
| Considered Variables (Cumulative) | Ecities (m/s) | Emexico (m/s) | Emerida (m/s) | E (m/s) |
|---|---|---|---|---|
| 16, 2, 4, 11, 6 | 1.894663 | 0.46847 | 0.281023 | 2.644156 |
| 1 | 1.821077 | 0.555933 | 0.444885 | 2.821895 |
| 5 | 1.800265 | 0.57598 | 0.497557 | 2.873802 |
| 14 | 1.794858 | 0.470381 | 0.548603 | 2.813842 |
| 3 | 1.257935 | 1.811006 | 2.210164 | 5.279105 |
| 15 | 1.154621 | 1.56436 | 1.926892 | 4.645873 |
| Considered Variables (Cumulative) | Ecities (m/s) | Emexico (m/s) | Emerida (m/s) | E (m/s) |
|---|---|---|---|---|
| 16, 2, 11, 6 | 1.927766 | 0.502845 | 0.349252 | 2.779863 |
| 5 | 1.854873 | 0.485715 | 0.313103 | 2.653691 |
| 3 | 1.84062 | 0.471167 | 0.37357 | 2.685357 |
| 10 | 1.736947 | 0.535382 | 0.501385 | 2.773714 |
| 9 | 1.662883 | 0.566182 | 0.45813 | 2.687195 |
| 7 | 1.510898 | 0.872757 | 0.869186 | 3.252841 |
| 12 | 1.154621 | 0.843209 | 0.85009 | 2.84792 |
| Considered Variables (Cumulative) | Ecities (m/s) | Emexico (m/s) | Emerida (m/s) | E (m/s) |
|---|---|---|---|---|
| 16, 2, 11, 5, 15, 10, 9, 7 | 1.510042 | 0.444718 | 1.280525 | 3.235285 |
| 12 | 1.297709 | 0.18115 | 0.686969 | 2.165828 |
| 13 | 1.154621 | 0.476005 | 0.820604 | 2.45123 |
| PCC Between Variable and Parameter a | PCC Between Variable and Parameter b | PCC Between Variable and Parameter c | PCC Score | Variable ID |
|---|---|---|---|---|
| −0.4997 | 0.508352 | −0.55008 | 1.558129 | 4 |
| −0.44463 | 0.451677 | −0.50683 | 1.403139 | 1 |
| −0.43684 | 0.447269 | −0.48668 | 1.370791 | 2 |
| −0.30564 | 0.337786 | −0.4857 | 1.129121 | 11 |
| 0.209177 | −0.23868 | 0.451187 | 0.899042 | 12 |
| −0.35202 | 0.277843 | −0.19844 | 0.8283 | 6 |
| 0.168582 | −0.21433 | 0.209689 | 0.592601 | 10 |
| −0.26273 | 0.182782 | −0.09154 | 0.53705 | 15 |
| 0.173218 | −0.184 | 0.157459 | 0.514675 | 13 |
| 0.112082 | −0.14427 | 0.180244 | 0.436591 | 5 |
| 0.201936 | −0.18687 | 0.041965 | 0.430768 | 14 |
| 0.203385 | −0.12669 | 0.079921 | 0.409994 | 16 |
| −0.10661 | 0.137753 | −0.12074 | 0.365103 | 3 |
| −0.11383 | 0.09161 | −0.1309 | 0.336345 | 8 |
| −0.04828 | 0.111084 | −0.07005 | 0.229412 | 9 |
| −0.03663 | 0.030915 | 0.009445 | 0.07699 | 7 |
| 0 | 0 | 0 | 0 | 17 |
| Considered Variables (Cumulative) | Ecities (m/s) | Emexico (m/s) | Emerida (m/s) | E (m/s) |
|---|---|---|---|---|
| 4, 1, 2, 11, 12, 6 | 1.637486 | 0.968751 | 0.960001 | 3.566238 |
| 10 | 1.522002 | 1.126446 | 0.540879 | 3.189327 |
| 15 | 1.366686 | 0.891263 | 0.938676 | 3.196625 |
| 13 | 1.175687 | 1.006183 | 1.359158 | 3.541028 |
| 5 | 1.154621 | 1.201276 | 1.354006 | 3.709903 |
| Considered Variables (Cumulative) | Ecities (m/s) | Emexico (m/s) | Emerida (m/s) | E (m/s) |
|---|---|---|---|---|
| 4, 1, 2, 11, 12, 10, 15, 13 | 1.413888 | 0.881751 | 0.836374 | 3.132013 |
| 5 | 1.263094 | 0.405192 | 1.001969 | 2.670255 |
| 16 | 1.154621 | 0.519341 | 3.894834 | 5.568796 |
| Considered Variables (Cumulative) | Ecities (m/s) | Emexico (m/s) | Emerida (m/s) | E (m/s) |
|---|---|---|---|---|
| 4, 11, 12, 6, 10 | 1.715612 | 0.823187 | 0.326592 | 2.865391 |
| 15 | 1.40208 | 0.813834 | 0.817474 | 3.033388 |
| 13 | 1.237813 | 0.843922 | 1.332179 | 3.413914 |
| 5 | 1.194517 | 0.953743 | 1.25701 | 3.40527 |
| 14 | 1.18102 | 0.946305 | 1.050057 | 3.177382 |
| 3 | 1.154621 | 1.104522 | 12.92633 | 15.185473 |
| Considered Variables (Cumulative) | Ecities (m/s) | Emexico (m/s) | Emerida (m/s) | E (m/s) |
|---|---|---|---|---|
| 4, 11, 12, 10, 15, 13 | 1.44623 | 0.808871 | 0.699084 | 2.954185 |
| 5 | 1.427031 | 0.925099 | 0.625911 | 2.978041 |
| 8 | 1.388221 | 0.934193 | 0.418327 | 2.740741 |
| 7 | 1.329856 | 0.680169 | 0.383759 | 2.393784 |
| Procedure | Selected Variables ID | Number of Variables | Ecities (m/s) | Emexico (m/s) | Emerida (m/s) | E (m/s) | Criteria Condition Satisfied? |
|---|---|---|---|---|---|---|---|
| 3 | 16, 2, 11, 5, 15, 10, 9, 7 and 12 | 9 | 1.2977 | 0.1811 | 0.6869 | 2.1658 | Yes |
| 2 | 11, 16, 4, 8, 12, 13, 9 and 7 | 8 | 1.3085 | 0.5204 | 0.4378 | 2.2668 | Yes |
| 2 or 3 | 11, 16, 6, 4 and 2 | 5 | 1.8946 | 0.4684 | 0.281 | 2.6441 | Yes |
| 3 | 16, 2, 11 and 6 | 4 | 1.9277 | 0.5028 | 0.3492 | 2.7798 | Yes |
| 1 | 17, 12 and 9 | 3 | 1.7155 | 1.0655 | 0.5906 | 3.3718 | No |
| 1 | 17 and 12 | 2 | 2.0344 | 0.8991 | 0.7339 | 3.6675 | No |
| AIC | ||||
|---|---|---|---|---|
| City | Variables 16, 2, 11, 5, 15, 10, 9, 7 and 12 | Variables 11, 16, 4, 8, 12, 13, 9 and 7 | Variables 11, 16, 6, 4 and 2 | Variables 16, 2, 11 and 6 |
| Toluca | 79.8216 | 77.8252 | 72.3146 | 70.3100 |
| Puebla | 78.2486 | 76.3053 | 71.3166 | 69.9867 |
| Queretaro | 79.4806 | 77.3497 | 71.7798 | 69.7849 |
| San Luis Potosi | 79.7076 | 77.5553 | 73.0721 | 70.9668 |
| Aguascalientes | 79.2210 | 77.2679 | 71.8849 | 70.1672 |
| Durango | 79.6188 | 77.5806 | 72.1154 | 70.2339 |
| Guadalajara | 79.2236 | 77.4284 | 71.7783 | 69.8138 |
| Mazatlan | 78.8828 | 76.3096 | 71.9778 | 69.7753 |
| Monterrey | 78.5715 | 76.8614 | 70.8510 | 68.6945 |
| Veracruz | 78.6062 | 76.6270 | 71.4487 | 69.1751 |
| Ciudad de Mexico | 79.9924 | 80.2118 | 73.5662 | 71.7025 |
| Merida | 82.2071 | 79.7871 | 72.9880 | 71.3444 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carrillo-González, J.G.; López-Maldonado, G.; Sánchez-Sánchez, K.L.; Reyes, Y. Method to Select Variables for Estimating the Parameters of Equations That Describe Average Vehicle Travel Speed in Downtown City Areas. Sustainability 2025, 17, 4441. https://doi.org/10.3390/su17104441
Carrillo-González JG, López-Maldonado G, Sánchez-Sánchez KL, Reyes Y. Method to Select Variables for Estimating the Parameters of Equations That Describe Average Vehicle Travel Speed in Downtown City Areas. Sustainability. 2025; 17(10):4441. https://doi.org/10.3390/su17104441
Chicago/Turabian StyleCarrillo-González, José Gerardo, Guillermo López-Maldonado, Karla Lorena Sánchez-Sánchez, and Yuri Reyes. 2025. "Method to Select Variables for Estimating the Parameters of Equations That Describe Average Vehicle Travel Speed in Downtown City Areas" Sustainability 17, no. 10: 4441. https://doi.org/10.3390/su17104441
APA StyleCarrillo-González, J. G., López-Maldonado, G., Sánchez-Sánchez, K. L., & Reyes, Y. (2025). Method to Select Variables for Estimating the Parameters of Equations That Describe Average Vehicle Travel Speed in Downtown City Areas. Sustainability, 17(10), 4441. https://doi.org/10.3390/su17104441