
A Machine Learning and Panel Data Analysis of N2O Emissions in an ESG Framework




Abstract
1. Introduction
2. Literature Review
- H0: At the global level, ESG indicators do not significantly account for variation in N2O emissions.
- H1 (main hypothesis): Environmental, social, and governance (ESG) indicators significantly account for cross-country variation in nitrous oxide (N2O) emissions. Specifically, changes in ESG performance metrics are linked to observable variations in N2O emissions per capita, and their predictive relevance can be confirmed using both econometric estimation and machine learning-based modelling.
3. Data and Methodology
4. Econometric Analysis
4.1. E—Environment Econometric Results
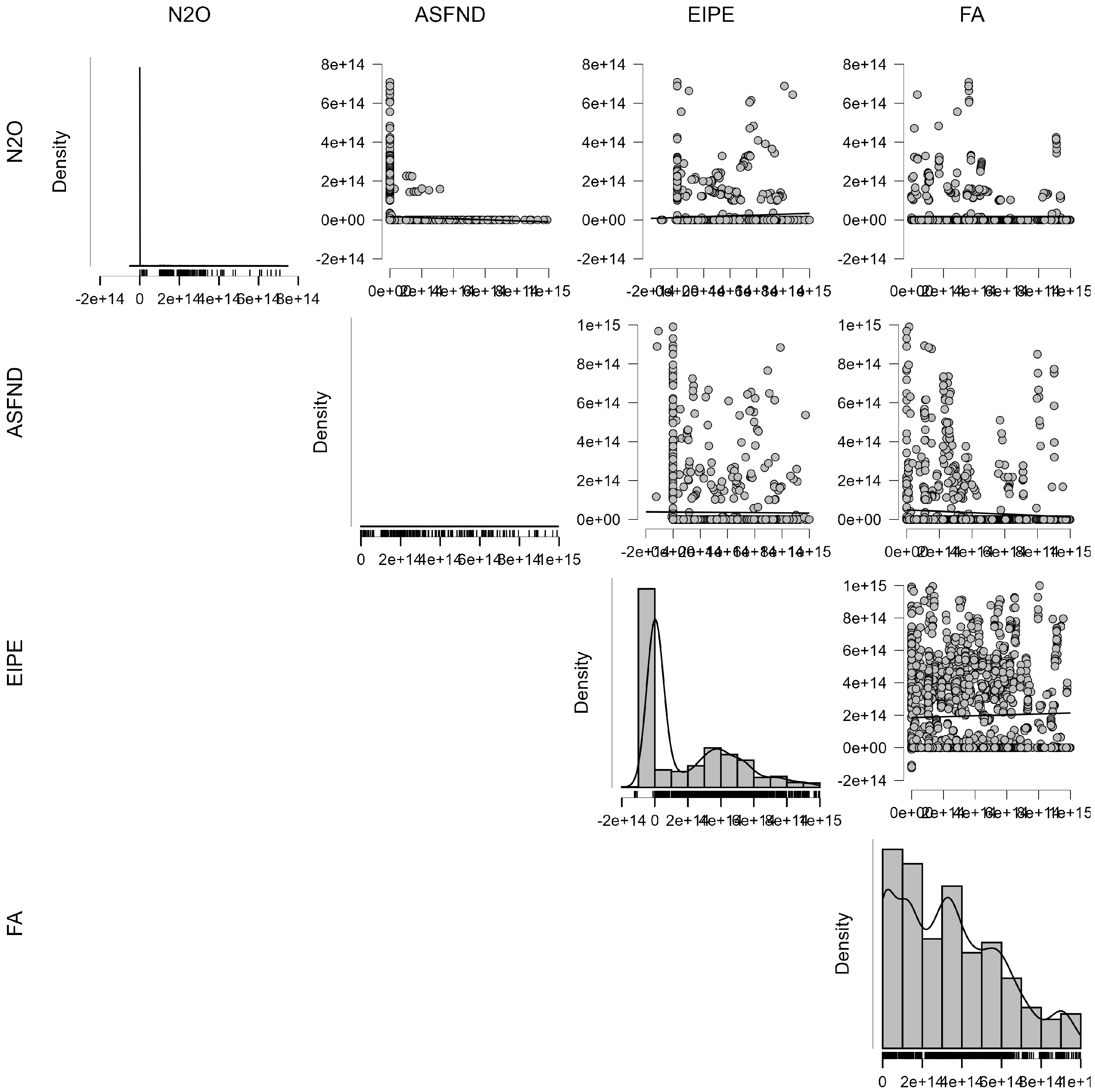
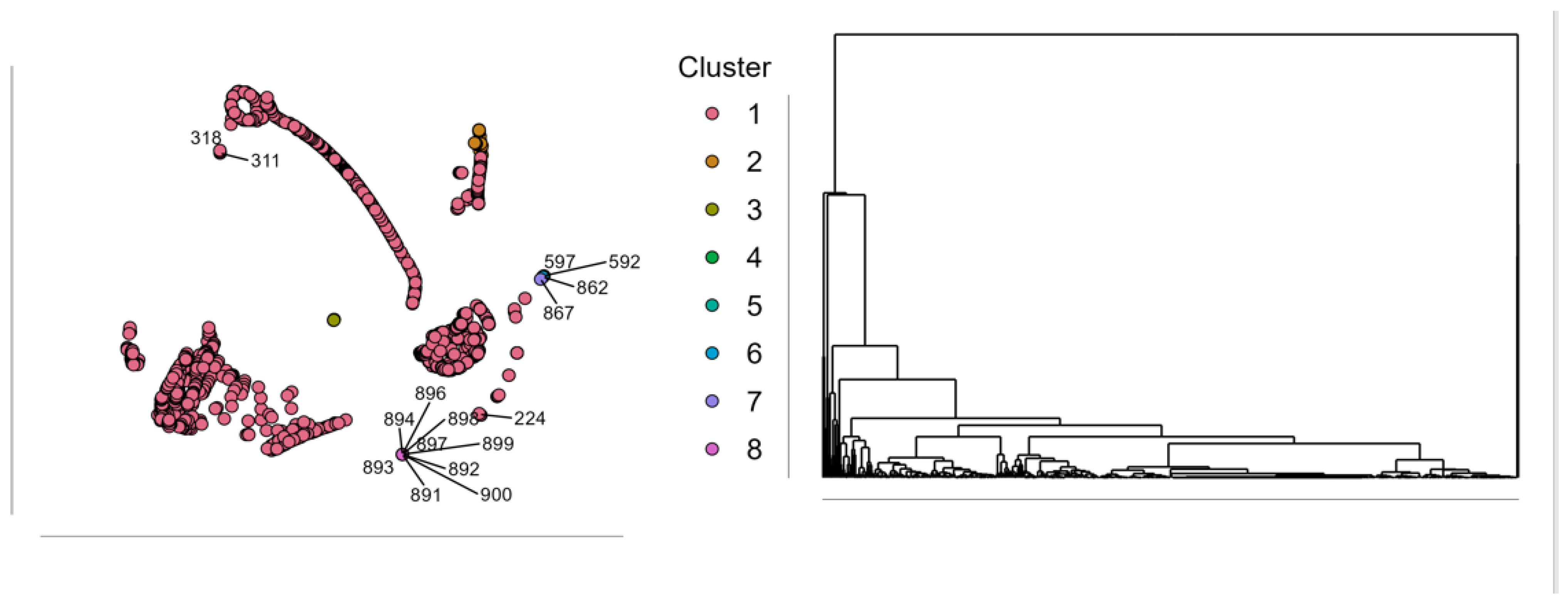
4.1.1. Clusterization Model for the Estimation of the E-Environmental Component Within the ESG Model
4.1.2. ML Regressions for the Estimation of the E-Environmental Component Within the ESG Model
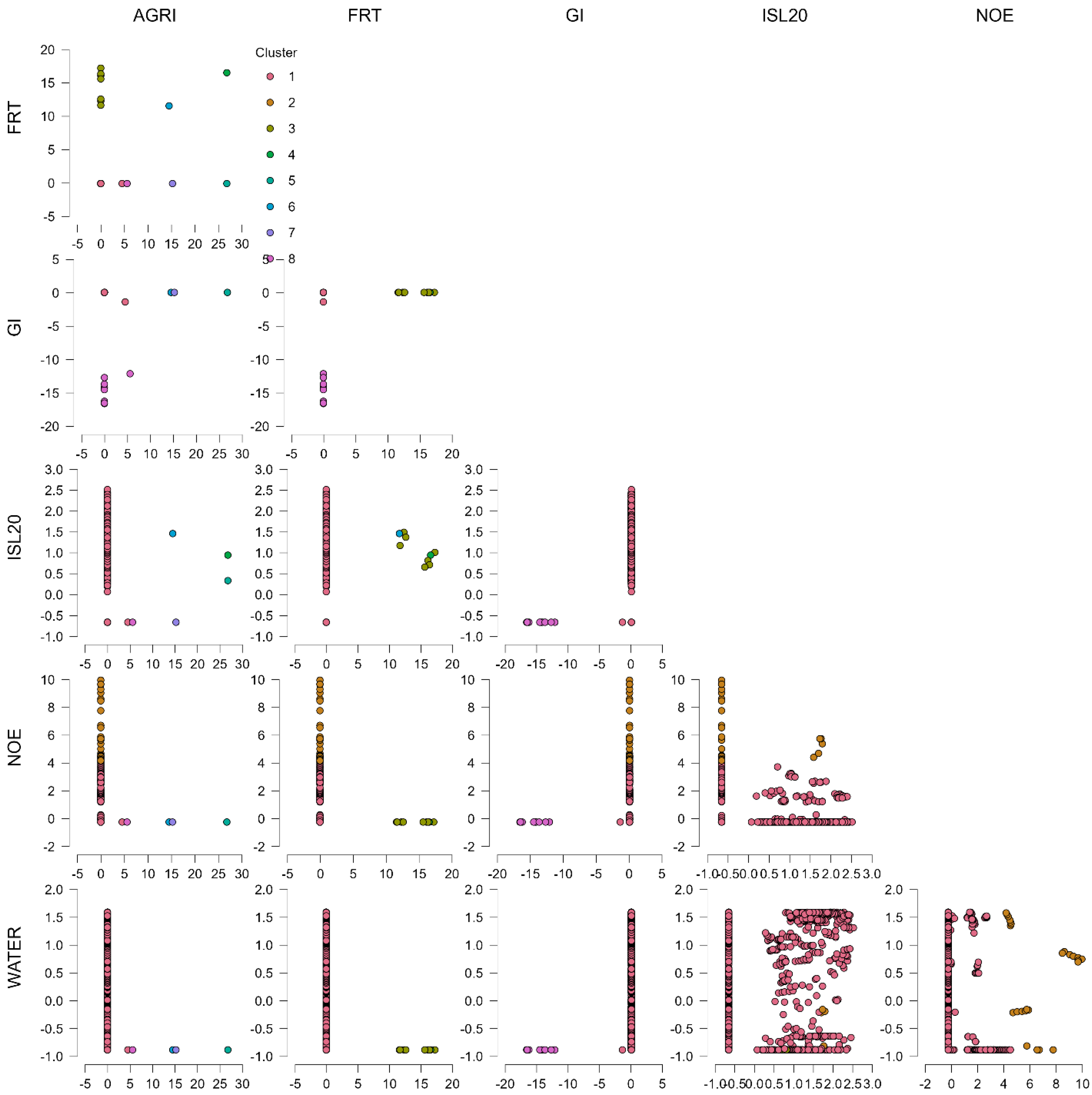
4.2. S—Social Econometric Results
4.2.1. Clusterization Model for the Estimation of the S-Social Component Within the ESG Model
4.2.2. ML Regressions for the Estimation of the S-Social Component Within the ESG Model
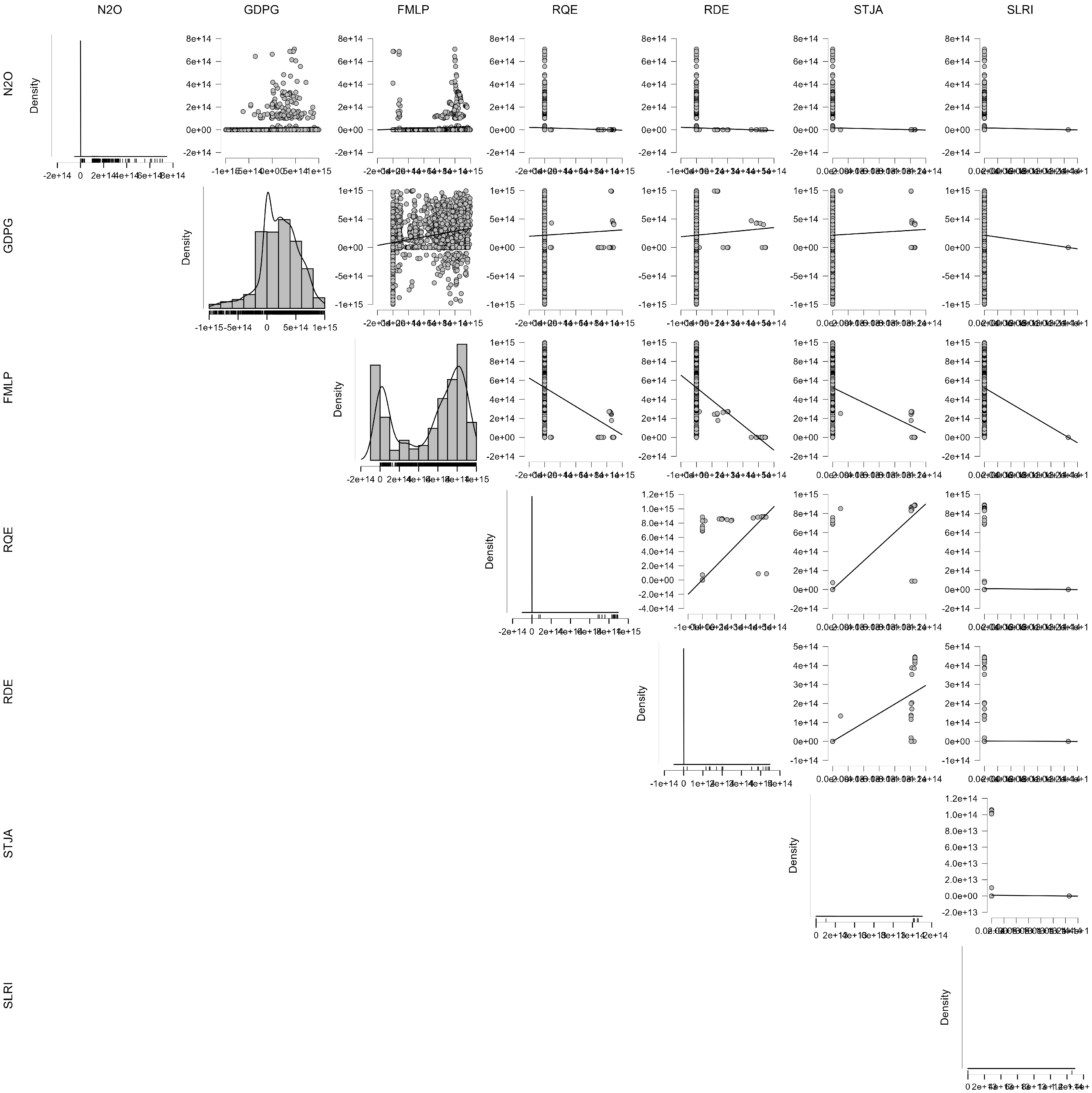
4.3. G—Governance
4.3.1. Clusterization Model for the Estimation of the G-Governance Component Within the ESG Model
4.3.2. ML Regressions for the Estimation of the G-Governance Component Within the ESG Model
5. Discussions of the Results and Innovativeness of the Contribution
6. Limitations and Future Research
7. Policy Recommendations
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Split Preferences | Holdout Test Data | 20 Sample % of All Data |
|---|---|---|
| Training and Validation Test | 20% for Validation Data | |
| Training Parameters | Shrinkage | 0.1 |
| Interaction Depth | 1 | |
| Min Observation in node | 10 | |
| Training data used per tree | 50 | |
| Loss Function | Gaussian | |
| Scale Features | Yes | |
| Optimized max trees | 100 | |
| Data Split | Train | 1235 |
| Validation | 309 | |
| Test | 386 |
| Data Split Preferences | Holdout Test Data | Sample 20% of All Data |
|---|---|---|
| Training and Validation Data | Sample 20% for Validation Data | |
| Training Parameters | Min Observations of Split | 20 |
| Min Observations in terminal | 7 | |
| Max Interaction Depth | 30 | |
| Scale Features | Yes | |
| Optimized | Max complexity penalty 1 | |
| Data Split | Train | 1235 |
| Validation | 309 | |
| Test | 386 |
| Data Split Preferences | Holdout Test Data | Sample 20% of All Data |
|---|---|---|
| Training and Validation Data | Sample 20% for Validation Data | |
| Training Parameters | Weights | Rectangular |
| Distance | Euclidian | |
| Scale Features | 1 | |
| Optimized | Max Nearest Neighbors 10 | |
| Data Split | Train | 1235 |
| Validation | 309 | |
| Test | 386 |
| Data Split Preferences | Holdout Test Data | Sample 20% of All Data |
|---|---|---|
| Training Parameters | Include Intercept | Yes |
| Scale Features | Yes | |
| Data Split | Train | 1544 |
| Test | 386 |
| Data Split Preferences | Holdout Test Data | Sample 20% of All Data |
|---|---|---|
| Training and Validation Data | Sample 20% for Validation Data | |
| Training Parameters | Activation Function | Logistic Sigmoid |
| Algorithm | rprop+ | |
| Stopping criteria loss function | 1 | |
| Max training repetitions | 100,000 | |
| Scale Features | Yes | |
| Population size | 20 | |
| Generation | 10 | |
| Max number of layers | 10 | |
| Max nodes in each layer | 10 | |
| Parent selection | Roulette wheel | |
| Crossover method | Uniform | |
| Mutations | Reset | |
| Probability | 10% | |
| Survival Method | Fitness based | |
| Elitism | 10% | |
| Data Split | Train | 1235 |
| Validation | 309 | |
| Test | 386 |
| Data Split Preferences | Holdout Test Data | Sample 20% of All Data |
|---|---|---|
| Training and Validation Data | Sample 20% for Validation Data | |
| Training Parameters | Training data used per tree | 50% |
| Features per split | Auto | |
| Scale Features | Yes | |
| Max Trees | 100 | |
| Data Split | Train | 1235 |
| Validation | 309 | |
| Test | 386 |
| Data Split Preferences | Holdout Test Data | Sample 20% of All Data |
|---|---|---|
| Training and Validation Data | Sample 20% for Validation Data | |
| Training Parameters | Penalty | Lasso |
| Include Intercept | Yes | |
| Scale Features | Yes | |
| Optimized | Yes | |
| Data Split | Train | 1235 |
| Validation | 309 | |
| Test | 386 |
| Data Split Preferences | Holdout Test Data | Sample 20% of All Data |
|---|---|---|
| Training and Validation Data | Sample 20% for Validation Data | |
| Training Parameters | Weights | Linear |
| Tolerance of termination criterion | 0.001 | |
| Epsilon | 0.01 | |
| Scale Features | Yes | |
| Max violation cost | 5 | |
| Data Split | Train | 1235 |
| Validation | 309 | |
| Test | 386 |
| Training Parameters | |
|---|---|
| Epsilon Neighborhood size | 2 |
| Min. core points | 5 |
| Distance | Normal |
| Scale Features | Yes |
| Training Parameters | |
|---|---|
| Max Iterations | 25 |
| Fuzziness parameter | 2 |
| Scale Features | Yes |
| Optimized according to | BIG |
| Max clusters | 10 |
| Training Parameters | |
|---|---|
| Distance | Euclidean |
| Linkage | Average |
| Scale features | Yes |
| Optimized According to | BIC |
| Max Clusters | 10 |
| Training Parameters | |
|---|---|
| Model | Auto |
| Max Iterations | 25 |
| Scale features | Yes |
| Optimized According to | BIC |
| Max Clusters | 10 |
| Training Parameters | |
|---|---|
| Center type | Means |
| Algorithm | Hartigan-Wong |
| Max Iterations | 25 |
| Random sets | 25 |
| Scale features | Yes |
| Optimized according to | BIC |
| Max clusters | 10 |
| Training Parameters | |
|---|---|
| Trees | 1000 |
| Scale features | Yes |
| Optimized according to | BIC |
| Max Clusters | 10 |
Appendix B
Appendix C. List of Abbreviations
| Acronym | Definition | Acronym | Definition |
|---|---|---|---|
| N2O | Nitrous oxide | WATER | People using safely managed drinking water services (% of population) |
| ESG | Environmental, social, and governance | GDPG | GDP growth (annual %) |
| CO2 | Carbon dioxide | FMLP | Ratio of female to male labor force participation rates (%) (modeled ILO estimate) |
| CH4 | Methane | RQE | Regulatory quality: estimate |
| GWP | Global warming potential | RDE | Research and development expenditure (% of GDP) |
| EU | European Union | STJA | Scientific and technical journal articles |
| E | Environmental | SLRI | Strength of Legal Rights Index (0 = weak to 12 = strong) |
| S | Social | GDP | Gross domestic product |
| G | Governance | PPP | Purchasing power parity |
| NOE | Nitrous oxide emissions (metric tons of CO2 equivalent per capita) | ML | Machine learning |
| ASNFD | Adjusted savings–net forest depletion (% of GNI) | MSE | Mean squared error |
| EIPE | Energy intensity level of primary energy (MJ/USD 2017 PPP GDP) | RMSE | Root mean squared error |
| FA | Forest area (% of land area) | MAE | Mean absolute error |
| AGRI | Annualized average growth rate in per capita real survey mean consumption or income, total population (%) | MAD | Mean absolute deviation |
| FRT | Fertility rate, total (births per woman) | R2 | Coefficient of determination |
| GI | Gini index | R&D | Research and development |
| ISL20 | Income share held by lowest 20% | ILO | International Labour Organization |
Appendix D. Descriptive Statistics
| 95% Confidence Interval Mean | 95% Confidence Interval Variance | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Valid | Missing | Median | Mean | Std. Error of Mean | Upper | Lower | Std. Deviation | Coefficient of Variation | MAD | MAD Robust | IQR | Upper | Lower | |
| AGRI | 1930 | 0 | 0.000 | 1.108 × 1012 | 5.204 × 1011 | 2.129 × 1012 | 8.761 × 1010 | 2.286 × 1013 | 20.630 | 0.000 | 0.000 | 0.000 | 5.574 × 1026 | 4.913 × 1026 |
| FRT | 1930 | 0 | 1.909 | 2.558 × 1012 | 8.606 × 1011 | 4.245 × 1012 | 8.697 × 1011 | 3.781 × 1013 | 14.783 | 1.907 | 2.827 | 3.239 | 1.524 × 1027 | 1.343 × 1027 |
| GI | 1930 | 0 | 0.000 | −7.876 | 2.611 | −2.754 | −12.997 | 114.727 | −14.566 | 0.000 | 0.000 | 30.500 | 1.403 × 1010 | 1.237 × 1010 |
| ISL20 | 1930 | 0 | 0.000 | 2.171 | 0.075 | 2.319 | 2.023 | 3.309 | 1.524 | 0.000 | 0.000 | 5.200 | 11.673 | 10.288 |
| N2O | 1930 | 0 | 0.284 | 1.666 × 1013 | 1.581 × 1012 | 1.976 × 1013 | 1.356 × 1013 | 6.945 × 1013 | 4.170 | 0.200 | 0.296 | 0.420 | 5.143 × 1027 | 4.533 × 1027 |
| WATER | 1930 | 0 | 1.000 × 109 | 3.563 × 109 | 9.203 × 107 | 3.744 × 109 | 3.383 × 109 | 4.043 × 109 | 1.135 | 1.000 × 109 | 1.483 × 109 | 8.041 × 109 | 1.743 × 1019 | 1.536 × 1019 |
| GDPG | 1930 | 0 | 2.215 × 1014 | 2.162 × 1014 | 7.647 × 1012 | 2.312 × 1014 | 2.012 × 1014 | 3.359 × 1014 | 1.554 | 2.215 × 1014 | 3.284 × 1014 | 4.440 × 1014 | 1.203 × 1029 | 1.061 × 1029 |
| FMLP | 1930 | 0 | 6.460 × 1014 | 5.204 × 1014 | 7.873 × 1012 | 5.359 × 1014 | 5.050 × 1014 | 3.459 × 1014 | 0.665 | 2.110 × 1014 | 3.128 × 1014 | 7.300 × 1014 | 1.275 × 1029 | 1.124 × 1029 |
| RQE | 1930 | 0 | −0.178 | 8.771 × 1012 | 1.929 × 1012 | 1.256 × 1013 | 4.987 × 1012 | 8.476 × 1013 | 9.664 | 0.651 | 0.965 | 1.335 | 7.661 × 1027 | 6.752 × 1027 |
| RDE | 1930 | 0 | 0.000 | 2.277 × 1012 | 6.394 × 1011 | 3.531 × 1012 | 1.023 × 1012 | 2.809 × 1013 | 12.336 | 0.000 | 0.000 | 0.349 | 8.412 × 1026 | 7.414 × 1026 |
| STJA | 1930 | 0 | 103.530 | 9.141 × 1011 | 2.196 × 1011 | 1.345 × 1012 | 4.834 × 1011 | 9.648 × 1012 | 10.554 | 103.530 | 153.494 | 1842 | 9.924 × 1025 | 8.747 × 1025 |
| SLRI | 1930 | 0 | 2.000 | 1.959 × 1011 | 1.130 × 1011 | 4.175 × 1011 | −2.580 × 1010 | 4.965 × 1012 | 25.351 | 2.000 | 2.965 | 6.000 | 2.629 × 1025 | 2.317 × 1025 |
| ASFND | 1930 | 0 | 0.000 | 3.729 × 1013 | 2.949 × 1012 | 4.308 × 1013 | 3.151 × 1013 | 1.296 × 1014 | 3.475 | 0.000 | 0.000 | 0.094 | 1.790 × 1028 | 1.578 × 1028 |
| EIPE | 1930 | 0 | 0.000 | 1.946 × 1014 | 5.776 × 1012 | 2.060 × 1014 | 1.833 × 1014 | 2.537 × 1014 | 1.304 | 0.000 | 0.000 | 3.840 × 1014 | 6.865 × 1028 | 6.051 × 1028 |
| FA | 1930 | 0 | 3.110 × 1014 | 3.343 × 1014 | 5.880 × 1012 | 3.459 × 1014 | 3.228 × 1014 | 2.583 × 1014 | 0.773 | 2.010 × 1014 | 2.980 × 1014 | 4.090 × 1014 | 7.114 × 1028 | 6.271 × 1028 |
| Skewness | Kurtosis | Shapiro-Wilk | Range | Minimum | Maximum | 25th percentile | 50th percentile | 75th percentile | 25th percentile | 50th percentile | 75th percentile | Sum | Variance | |
| AGRI | 23.431 | 581.910 | 0.024 | 6.130 × 1014 | −9.230 | 6.130 × 1014 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 2.139 × 1015 | 5.228 × 1026 |
| FRT | 15.039 | 228.666 | 0.040 | 6.540 × 1014 | 0.000 | 6.540 × 1014 | 1.593 | 1.909 | 3.241 | 1.593 | 1.909 | 3.241 | 4.936 × 1015 | 1.429 × 1027 |
| GI | −14.773 | 218.983 | 0.041 | 1.911 × 106 | −1.911 × 106 | 63.000 | 0.000 | 0.000 | 30.500 | 0.000 | 0.000 | 30.500 | −1.520 × 107 | 1.316 × 1010 |
| ISL20 | 1.053 | −0.549 | 0.668 | 10.500 | 0.000 | 10.500 | 0.000 | 0.000 | 5.200 | 0.000 | 0.000 | 5.200 | 4.189 | 10.947 |
| N2O | 5.755 | 40.252 | 0.260 | 7.080 × 1014 | −90.000 | 7.080 × 1014 | 0.046 | 0.284 | 0.466 | 0.046 | 0.284 | 0.466 | 3.215 × 1016 | 4.824 × 1027 |
| WATER | 0.526 | −1.466 | 0.766 | 1.000 × 1010 | 0.000 | 1.000 × 1010 | 0.000 | 1.000 × 109 | 8.041 × 109 | 0.000 | 1.000 × 109 | 8.041 × 109 | 6.877 × 1012 | 1.635 × 1019 |
| GDPG | −0.551 | 0.925 | 0.969 | 1.999 × 1015 | −9.990 × 1014 | 1.000 × 1015 | 0.682 | 2.215 × 1014 | 4.440 × 1014 | 0.682 | 2.215 × 1014 | 4.440 × 1014 | 4.172 × 1017 | 1.129 × 1029 |
| FMLP | −0.479 | −1.389 | 0.845 | 9.980 × 1014 | −2.530 × 106 | 9.980 × 1014 | 8.703 × 1013 | 6.460 × 1014 | 8.170 × 1014 | 8.703 × 1013 | 6.460 × 1014 | 8.170 × 1014 | 1.004 × 1018 | 1.196 × 1029 |
| RQE | 9.733 | 93.385 | 0.076 | 8.910 × 1014 | −2.378 × 106 | 8.910 × 1014 | −0.771 | −0.178 | 0.564 | −0.771 | −0.178 | 0.564 | 1.693 × 1016 | 7.185 × 1027 |
| RDE | 13.597 | 192.082 | 0.054 | 4.450 × 1014 | −1.716 × 106 | 4.450 × 1014 | 0.000 | 0.000 | 0.349 | 0.000 | 0.000 | 0.349 | 4.395 × 1015 | 7.889 × 1026 |
| STJA | 10.520 | 108.898 | 0.066 | 1.060 × 1014 | 0.000 | 1.060 × 1014 | 3.592 | 103.530 | 1.845 | 3.592 | 103.530 | 1.845 | 1.764 × 1015 | 9.308 × 1025 |
| SLRI | 25.325 | 639.995 | 0.017 | 1.260 × 1014 | 0.000 | 1.260 × 1014 | 0.000 | 2.000 | 6.000 | 0.000 | 2.000 | 6.000 | 3.780 × 1014 | 2.465 × 1025 |
| ASFND | 4.211 | 18.872 | 0.326 | 9.900 × 1014 | 0.000 | 9.900 × 1014 | 0.000 | 0.000 | 0.094 | 0.000 | 0.000 | 0.094 | 7.197 × 1016 | 1.679 × 1028 |
| EIPE | 1.034 | −0.014 | 0.776 | 1.122 × 1015 | −1.230 × 1014 | 9.990 × 1014 | 0.000 | 0.000 | 3.840 × 1014 | 0.000 | 0.000 | 3.840 × 1014 | 3.757 × 1017 | 6.438 × 1028 |
| FA | 0.528 | −0.557 | 0.943 | 9.990 × 1014 | 0.000 | 9.990 × 1014 | 1.130 × 1014 | 3.110 × 1014 | 5.220 × 1014 | 1.130 × 1014 | 3.110 × 1014 | 5.220 × 1014 | 6.453 × 1017 | 6.673 × 1028 |
| AGRI | FRT | GI | ISL20 | N2O | Water | GDPG | FMLP | RQE | RDE | STJA | SLRI | ASFND | EIPE | FA | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AGRI | 5.228 × 1026 | 2.725 × 1026 | −9.277 × 1016 | 1.526 × 1012 | −1.847 × 1025 | −3.951 × 1021 | 6.714 × 1025 | −4.862 × 1026 | 3.841 × 1026 | 3.211 × 1026 | 1.007 × 1026 | −2.172 × 1023 | 1.302 × 1026 | −8.129 × 1025 | −3.707 × 1026 |
| FRT | 2.725 × 1026 | 1.429 × 1027 | 2.015 × 1016 | 8.761 × 1012 | −4.262 × 1025 | −9.117 × 1021 | 1.080 × 1027 | −1.115 × 1027 | 1.956 × 1027 | 7.509 × 1026 | 2.403 × 1026 | −5.012 × 1023 | 3.790 × 1026 | 1.824 × 1026 | −8.555 × 1026 |
| GI | −9.277 × 1016 | 2.015 × 1016 | 1.316 × 1010 | 17.182 | 1.315 × 1017 | 2.814 × 1013 | 1.707 × 1018 | 4.109 × 1018 | −2.164 × 1018 | 1.794 × 1016 | 7.203 × 1015 | −3.168 × 1017 | −1.103 × 1018 | −4.159 × 1017 | 2.607 × 1017 |
| ISL20 | 1.526 × 1012 | 8.761 × 1012 | 17.182 | 10.947 | 3.793 × 1012 | 4.972 × 109 | 8.231 × 1013 | 2.883 × 1014 | 5.607 × 1012 | 4.318 × 1012 | 1.060 × 1012 | −4.254 × 1011 | −3.975 × 1013 | 1.315 × 1014 | −4.124 × 1013 |
| N2O | −1.847 × 1025 | −4.262 × 1025 | 1.315 × 1017 | 3.793 × 1012 | 4.824 × 1027 | 5.979 × 1021 | 8.793 × 1026 | 2.887 × 1027 | −1.462 × 1026 | −3.795 × 1025 | −1.523 × 1025 | −3.264 × 1024 | −4.672 × 1026 | 1.364 × 1027 | 1.324 × 1026 |
| WATER | −3.951 × 1021 | −9.117 × 1021 | 2.814 × 1013 | 4.972 × 109 | 5.979 × 1021 | 1.635 × 1019 | −1.070 × 1023 | 1.408 × 1023 | −3.127 × 1022 | −8.117 × 1021 | −3.259 × 1021 | −6.982 × 1020 | −8.215 × 1022 | 2.792 × 1022 | −1.161 × 1022 |
| GDPG | 6.714 × 1025 | 1.080 × 1027 | 1.707 × 1018 | 8.231 × 1013 | 8.793 × 1026 | −1.070 × 1023 | 1.129 × 1029 | 2.992 × 1028 | 6.727 × 1026 | 2.127 × 1026 | 7.909 × 1025 | −4.236 × 1025 | 7.166 × 1027 | 1.258 × 1028 | −9.573 × 1026 |
| FMLP | −4.862 × 1026 | −1.115 × 1027 | 4.109 × 1018 | 2.883 × 1014 | 2.887 × 1027 | 1.408 × 1023 | 2.992 × 1028 | 1.196 × 1029 | −3.576 × 1027 | −1.042 × 1027 | −3.691 × 1026 | −1.020 × 1026 | 4.612 × 1027 | 1.537 × 1028 | 6.531 × 1027 |
| RQE | 3.841 × 1026 | 1.956 × 1027 | −2.164 × 1018 | 5.607 × 1012 | −1.462 × 1026 | −3.127 × 1022 | 6.727 × 1026 | −3.576 × 1027 | 7.185 × 1027 | 1.630 × 1027 | 6.983 × 1026 | −1.719 × 1024 | 2.112 × 1027 | −3.834 × 1026 | −2.213 × 1027 |
| RDE | 3.211 × 1026 | 7.509 × 1026 | 1.794 × 1016 | 4.318 × 1012 | −3.795 × 1025 | −8.117 × 1021 | 2.127 × 1026 | −1.042 × 1027 | 1.630 × 1027 | 7.889 × 1026 | 2.287 × 1026 | −4.462 × 1023 | 2.235 × 1026 | 1.554 × 1025 | −7.617 × 1026 |
| STJA | 1.007 × 1026 | 2.403 × 1026 | 7.203 × 1015 | 1.060 × 1012 | −1.523 × 1025 | −3.259 × 1021 | 7.909 × 1025 | −3.691 × 1026 | 6.983 × 1026 | 2.287 × 1026 | 9.308 × 1025 | −1.791 × 1023 | 1.765 × 1026 | −6.332 × 1025 | −3.058 × 1026 |
| SLRI | −2.172 × 1023 | −5.012 × 1023 | −3.168 × 1017 | −4.254 × 1011 | −3.264 × 1024 | −6.982 × 1020 | −4.236 × 1025 | −1.020 × 1026 | −1.719 × 1024 | −4.462 × 1023 | −1.791 × 1023 | 2.465 × 1025 | 3.541 × 1025 | −3.814 × 1025 | −6.551 × 1025 |
| ASFND | 1.302 × 1026 | 3.790 × 1026 | −1.103 × 1018 | −3.975 × 1013 | −4.672 × 1026 | −8.215 × 1022 | 7.166 × 1027 | 4.612 × 1027 | 2.112 × 1027 | 2.235 × 1026 | 1.765 × 1026 | 3.541 × 1025 | 1.679 × 1028 | −3.448 × 1026 | −2.429 × 1027 |
| EIPE | −8.129 × 1025 | 1.824 × 1026 | −4.159 × 1017 | 1.315 × 1014 | 1.364 × 1027 | 2.792 × 1022 | 1.258 × 1028 | 1.537 × 1028 | −3.834 × 1026 | 1.554 × 1025 | −6.332 × 1025 | −3.814 × 1025 | −3.448 × 1026 | 6.438 × 1028 | 1.918 × 1027 |
| FA | −3.707 × 1026 | −8.555 × 1026 | 2.607 × 1017 | −4.124 × 1013 | 1.324 × 1026 | −1.161 × 1022 | −9.573 × 1026 | 6.531 × 1027 | −2.213 × 1027 | −7.617 × 1026 | −3.058 × 1026 | −6.551 × 1025 | −2.429 × 1027 | 1.918 × 1027 | 6.673 × 1028 |
| AGRI | FRT | GI | ISL20 | N2O | Water | GDPG | FMLP | RQE | RDE | STJA | SLRI | ASFND | EIPE | FA | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AGRI | 1.000 | 0.315 | −0.035 | 0.020 | −0.012 | −0.043 | 0.009 | −0.061 | 0.198 | 0.500 | 0.457 | −0.002 | 0.044 | −0.014 | −0.063 |
| FRT | 0.315 | 1.000 | 0.005 | 0.070 | −0.016 | −0.060 | 0.085 | −0.085 | 0.610 | 0.707 | 0.659 | −0.003 | 0.077 | 0.019 | −0.088 |
| GI | −0.035 | 0.005 | 1.000 | 0.045 | 0.016 | 0.061 | 0.044 | 0.104 | −0.222 | 0.006 | 0.007 | −0.556 | −0.074 | −0.014 | 0.009 |
| ISL20 | 0.020 | 0.070 | 0.045 | 1.000 | 0.017 | 0.372 | 0.074 | 0.252 | 0.020 | 0.046 | 0.033 | −0.026 | −0.093 | 0.157 | −0.048 |
| N2O | −0.012 | −0.016 | 0.016 | 0.017 | 1.000 | 0.021 | 0.038 | 0.120 | −0.025 | −0.019 | −0.023 | −0.009 | −0.052 | 0.077 | 0.007 |
| WATER | −0.043 | −0.060 | 0.061 | 0.372 | 0.021 | 1.000 | −0.079 | 0.101 | −0.091 | −0.071 | −0.084 | −0.035 | −0.157 | 0.027 | −0.011 |
| GDPG | 0.009 | 0.085 | 0.044 | 0.074 | 0.038 | −0.079 | 1.000 | 0.258 | 0.024 | 0.023 | 0.024 | −0.025 | 0.165 | 0.148 | −0.011 |
| FMLP | −0.061 | −0.085 | 0.104 | 0.252 | 0.120 | 0.101 | 0.258 | 1.000 | −0.122 | −0.107 | −0.111 | −0.059 | 0.103 | 0.175 | 0.073 |
| RQE | 0.198 | 0.610 | −0.222 | 0.020 | −0.025 | −0.091 | 0.024 | −0.122 | 1.000 | 0.685 | 0.854 | −0.004 | 0.192 | −0.018 | −0.101 |
| RDE | 0.500 | 0.707 | 0.006 | 0.046 | −0.019 | −0.071 | 0.023 | −0.107 | 0.685 | 1.000 | 0.844 | −0.003 | 0.061 | 0.002 | −0.105 |
| STJA | 0.457 | 0.659 | 0.007 | 0.033 | −0.023 | −0.084 | 0.024 | −0.111 | 0.854 | 0.844 | 1.000 | −0.004 | 0.141 | −0.026 | −0.123 |
| SLRI | −0.002 | −0.003 | −0.556 | −0.026 | −0.009 | −0.035 | −0.025 | −0.059 | −0.004 | −0.003 | −0.004 | 1.000 | 0.055 | −0.030 | −0.051 |
| ASFND | 0.044 | 0.077 | −0.074 | −0.093 | −0.052 | −0.157 | 0.165 | 0.103 | 0.192 | 0.061 | 0.141 | 0.055 | 1.000 | −0.010 | −0.073 |
| EIPE | −0.014 | 0.019 | −0.014 | 0.157 | 0.077 | 0.027 | 0.148 | 0.175 | −0.018 | 0.002 | −0.026 | −0.030 | −0.010 | 1.000 | 0.029 |
| FA | −0.063 | −0.088 | 0.009 | −0.048 | 0.007 | −0.011 | −0.011 | 0.073 | −0.101 | −0.105 | −0.123 | −0.051 | −0.073 | 0.029 | 1.000 |

References
- Kanter, D.R.; Ogle, S.M.; Winiwarter, W. Building on Paris: Integrating nitrous oxide mitigation into future climate policy. Curr. Opin. Environ. Sustain. 2020, 47, 7–12. [Google Scholar] [CrossRef]
- Reay, D. Nitrogen and Climate Change: An Explosive Story; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Kollar, A.J. Bridging the gap between agriculture and climate: Mitigation of nitrous oxide emissions from fertilizers. Environ. Prog. Sustain. Energy 2023, 42, e14069. [Google Scholar] [CrossRef]
- Szeląg, B.; Zaborowska, E.; Mąkinia, J. An algorithm for selecting a machine learning method for predicting nitrous oxide emissions in municipal wastewater treatment plants. J. Water Process. Eng. 2023, 54, 103939. [Google Scholar] [CrossRef]
- Dhaliwal, J.K.; Panday, D.; Robertson, G.P.; Saha, D. Machine learning reveals dynamic controls of soil nitrous oxide emissions from diverse long-term cropping systems. J. Environ. Qual. 2025, 54, 132–146. [Google Scholar] [CrossRef] [PubMed]
- Costantiello, A.; Leogrande, A. The Impact of Research and Development Expenditures on ESG Model in the Global Economy. 2023. Available online: https://hal.science/hal-04064022/ (accessed on 21 March 2025).
- Wang, R.; Bian, Y.; Xiong, X. Impact of ESG preferences on investments and emissions in a DSGE framework. Econ. Model. 2024, 135, 106731. [Google Scholar] [CrossRef]
- Samy, S.; Jaini, K.; Preheim, S. A Novel Machine Learning-Driven Approach for Predicting Nitrous Oxide Flux in Precision Managed Agricultural Systems. World J. Adv. Res. Rev. 2024, 24, 679–685. [Google Scholar] [CrossRef]
- Benghzial, K.; Raki, H.; Bamansour, S.; Elhamdi, M.; Aalaila, Y.; Peluffo-Ordóñez, D.H. GHG global emission prediction of synthetic N fertilizers using expectile regression techniques. Atmosphere 2023, 14, 283. [Google Scholar] [CrossRef]
- Vasilaki, V.; Conca, V.; Frison, N.; Eusebi, A.; Fatone, F.; Katsou, E. A knowledge discovery framework to predict the N2O emissions in the wastewater sector. Water Res. 2020, 178, 115799. [Google Scholar] [CrossRef]
- Castle, J.L.; Hendry, D.F. Climate econometrics: An overview. Found. Trends® Econom. 2020, 10, 145–322. [Google Scholar] [CrossRef]
- Piñeiro-Guerra, J.M.; Lewczuk, N.A.; Della Chiesa, T.; Araujo, P.I.; Acreche, M.; Alvarez, C.R.; Vera, J.C.; Alejandro, C.; José, D.T.; Petrasek, M.; et al. Spatial variability of nitrous oxide emissions from croplands and unmanaged natural ecosystems across a large environmental gradient. J. Environ. Qual. 2025, 54, 483–498. [Google Scholar] [CrossRef]
- Čapla, J.; Zajác, P.; Čurlej, J.; Hanušovský, O. The current state of carbon footprint quantification and tracking in the agri-food industry. Scifood 2025, 19, 110–127. [Google Scholar] [CrossRef]
- Park, D.-G.; Jeong, H.-C.; Jang, E.-B.; Lee, J.-M.; Lee, H.-S.; Park, H.-R.; Lee, S.-I.; Oh, T.-K. Effect of rice hull biochar treatment on net ecosystem carbon budget and greenhouse gas emissions in Chinese cabbage cultivation on infertile soil. Appl. Biol. Chem. 2024, 67, 44. [Google Scholar] [CrossRef]
- Padhi, P.P.; Padhy, S.R.; Swain, S.; Bhattacharyya, P. Greenhouse gas emission mitigation from rice through efficient use of industrial and value-added agricultural wastes: A review. Environ. Dev. Sustain. 2024, 1–39. [Google Scholar] [CrossRef]
- Cui, X.; Shang, Z.; Xia, L.; Xu, R.; Adalibieke, W.; Zhan, X.; Smith, P.; Zhou, F. Deceleration of cropland-N2O emissions in China and future mitigation potentials. Environ. Sci. Technol. 2022, 56, 4665–4675. [Google Scholar] [CrossRef]
- Biswas, M.K.; Azad, A.K.; Datta, A.; Dutta, S.; Roy, S.; Chopra, S.S. Navigating sustainability through greenhouse gas emission inventory: ESG practices and energy shift in Bangladesh’s textile and readymade garment industries. Environ. Pollut. 2024, 345, 123392. [Google Scholar] [CrossRef]
- Lambiasi, L.; Ddiba, D.; Andersson, K.; Parvage, M.; Dickin, S. Greenhouse gas emissions from sanitation and wastewater management systems: A review. J. Water Clim. Chang. 2024, 15, 1797–1819. [Google Scholar] [CrossRef]
- Voicu, Ș.M. Lowering greenhouse gases emissions from the energy and oil companies in the European union: An economic overview. Athens J. Sci. 2023, 10, 131–152. [Google Scholar] [CrossRef]
- Rogalev, N.D.; Rogalev, A.N.; Kindra, V.O.; Zlyvko, O.V.; Bryzgunov, P.A. Carbon Footprint Comparative Analaysis for Existing and Promising Thermal Power Plants. Eurasian Phys. Tech. J. 2022, 19, 34. [Google Scholar] [CrossRef]
- Al-Sinan, M.A.; Bubshait, A.A.; Alamri, F. Saudi Arabia’s journey toward net-zero emissions: Progress and challenges. Energies 2023, 16, 978. [Google Scholar] [CrossRef]
- Drago, C.; Leogrande, A. Beyond Temperature: How the Heat Index 35 Shapes Environmental, Social, and Governance Standards. 2024. Available online: https://www.researchsquare.com/article/rs-5462822/v1 (accessed on 21 March 2025).
- Turjak, S. Greenhouse Gas Emissions and Guidelines for Changes in Environmental Governance of European Union Companies. Ph.D. Thesis, Faculty of Economics in Osijek, Josip Juraj Strossmayer University of Osijek, Osijek, Croatia, 2023. [Google Scholar]
- Schuuring, R.J. The Effect of National ESG Score on Greenhouse Gas Emissions, Moderated by Quality of Government. Bachelor’s Thesis, Erasmus University Rotterdam, Rotterdam, The Netherlands, 2024. [Google Scholar]
- Orsini, A. To What Extent the UK Emissions Disclosure Mandate of 2013 Impacted the Subsequent Emissions Level and ESG Ratings? Master’s Thesis, Norwegian School of Economics, Bergen, Norway, 2022. Available online: https://openaccess.nhh.no/nhh-xmlui/bitstream/handle/11250/3055605/masterthesis.pdf?sequence=1 (accessed on 21 March 2025).
- Blair, M. Evolution of ESG Reporting Within the Canadian Energy Industry; University of Calgary: Calgary, AB, Canada, 2021. [Google Scholar]
- Stinchcombe, A.M. Assessing the State of Scope 3 Greenhouse Gas Emissions Reporting in Norway. Master’s Thesis, Norwegian University of Life Sciences, Ås, Norway, 2023. [Google Scholar]
- Kaplan, R.S.; Ramanna, K. How to Fix ESG Reporting; Harvard Business School: Boston, MA, USA, 2021. [Google Scholar]
- Gu, Y.; Katz, S.; Wang, X.; Vasarhelyi, M.; Dai, J. Government ESG reporting in smart cities. Int. J. Account. Inf. Syst. 2024, 54, 100701. [Google Scholar] [CrossRef]
- Sidestam, A.; Karam, S. Evaluation of Net Zero Alignment Models for Investments. Master’s Thesis, KTH Royal Institute of Technology, Stockholm, Sweden, KTH Digital Archive. 2024. Available online: https://www.diva-portal.org/smash/get/diva2:1898235/FULLTEXT01.pdf (accessed on 21 March 2025).
- Sacco, D.; Emea, C.I.O.; Chowdhury, A. ESG Investment: Understanding System Changes. 2023, Volume 3. Available online: https://www.deutschewealth.com/content/dam/deutschewealth/cio-perspectives/cio-special-assets/esg-system-changes/CIO-Special-ESG-investment-understanding-system-changes.pdf (accessed on 21 March 2025).
- Mamatzakis, E.C.; Tzouvanas, P. Greenhouse gas emissions and quality of financial reporting: Evidence from the EU. J. Appl. Account. Res. 2025. ahead-of-print. [Google Scholar] [CrossRef]
- Rothman, T. Climate Change Risk for Financial Institutions: Predicting Corporate Greenhouse Gas Emissions. Master’s Thesis, University of Twente, Enschede, The Netherlands, 2023. [Google Scholar]
- Yoshino, N.; Yuyama, T. ESG/Green investment and allocation of portfolio assets. Stud. Appl. Econ. 2021, 39. [Google Scholar] [CrossRef]
- Kabir, M.N.; Rahman, S.; Rahman, M.A.; Anwar, M. Carbon emissions and default risk: International evidence from firm-level data. Econ. Model. 2021, 103, 105617. [Google Scholar] [CrossRef]
- Çıtak, F.; Meo, M.S. Quantifying Portfolio Environmental and Social Impact: Assessing Metrics and Tools with a Focus on Green Bonds. In Green Bonds and Sustainable Finance; Routledge: London, UK, 2024; pp. 69–87. [Google Scholar]
- Brühl, V. Green Finance in Europe: Strategy, Regulation and Instruments; CFS Working Paper Series; Goethe University Frankfurt, Center for Financial Studies (CFS): Frankfurt am Main, Germany, 2021. [Google Scholar]
- Boubaker, S.; Choudhury, T.; Hasan, F.; Nguyen, D.K. Firm carbon risk exposure, stock returns, and dividend payment. J. Econ. Behav. Organ. 2024, 221, 248–276. [Google Scholar] [CrossRef]
- Bolton, P.; Halem, Z.; Kacperczyk, M. The financial cost of carbon. J. Appl. Corp. Financ. 2022, 34, 17–29. [Google Scholar] [CrossRef]
- Dennis, B.N.; Işcan, T.B. A New Measure of Climate Transition Risk Based on Distance to a Global Emission Factor Frontier. Financ. Econ. Discuss. Ser. 2024. Available online: https://www.federalreserve.gov/econres/feds/files/2024017pap.pdf (accessed on 21 March 2025). [CrossRef]
- Wang, S.; Li, J.; Yuan, X.; Senadheera, S.S.; Chang, S.X.; Wang, X.; Ok, Y.S. Machine learning predicts biochar aging effects on nitrous oxide emissions from agricultural soils. ACS Agric. Sci. Technol. 2024, 4, 888–898. [Google Scholar] [CrossRef]
- Rafiee, J.; Sarma, P.; Gutierrez, F.; Hilliard, R.; Calad, C.M.; Angulo, O.; Boyer, B. Energy transition meets digital transformation: Design and implementation of a comprehensive carbon emissions estimation and forecasting platform. In Proceedings of the Offshore Technology Conference, OTC, Houston, TX, USA, 2–5 May 2022; p. D031S038R003. [Google Scholar]
- Muller, N.Z. Measuring firm environmental performance to inform ESG investing. Natl. Bur. Econ. Res. 2021. Available online: https://www.nber.org/papers/w29454 (accessed on 21 March 2025).
- Jiang, L.; Gu, Y.; Yu, W.; Dai, J. Blockchain-Based Life Cycle Assessment System for ESG Reporting. SSRN 2022, 4121907. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4121907 (accessed on 21 March 2025). [CrossRef]
- Gruber, W. Long-Term N2O Emission Monitoring in Biological Wastewater Treatment: Methods, Applications and Relevance. Ph.D. Thesis, ETH Zurich, Zurich, Switzerland, 2021. [Google Scholar]
- Zhang, M.; Ghia, K.; Lindeman, A. From Micro to Macro: Estimating Commodity Emissions and Water Exposures from Corporate Data. J. Impact ESG Investig. 2024, 4, 20. [Google Scholar] [CrossRef]
- Ali, I.; Islam, M.; Ceh, B. Assessing the impact of three emission (3E) parameters on environmental quality in Canada: A provincial data analysis using the quantiles via moments approach. Int. J. Green Energy 2025, 22, 551–569. [Google Scholar] [CrossRef]
- Agbo, E.; Uchenna, U.; Achema, F. Greenhouse gas emission and energy consumption disclosure on market competitiveness of listed non financial firms in Nigeria. IGWEBUIKE Afr. J. Arts Humanit. 2024, 10. Available online: https://www.igwebuikeresearchinstitute.org/journal/igwebuike_1730112354.pdf (accessed on 21 March 2025).
- Yulianti, R.; Irfan, A.; Afrila, W.; Yuliasmi, I. The Unfolding of ESG investment as a realization of sustainable development goals. Proc. Int. Conf. Econ. Soc. Sci. 2023, 1, 1–15. [Google Scholar]
- Prieto, B. Environmental, Social and Governance Risks in the Engineering and Construction Sector. 2022. Available online: https://pmworldlibrary.net/wp-content/uploads/2022/05/pmwj118-Jun2022-Prieto-ESG-Risks-in-the-Engineering-and-Construction-Sector.pdf (accessed on 21 March 2025).
- Squillace, M. Accounting for Climate Impacts in Decisionmaking. Environ. Law 2023, 53, 649–705. [Google Scholar]
- Ng, C.K.-C.; Webber, D. Aligning corporate carbon accounting with natural climate solutions in Southeast Asia. Environ. Dev. 2023, 45, 100805. [Google Scholar]
- Long, H.; Feng, G.; Gong, Q.; Chang, C. ESG performance and green innovation: An investigation based on quantile regression. Bus. Strat. Environ. 2023, 32, 5102–5118. [Google Scholar] [CrossRef]
- Harasheh, M.; Harasheh, M. Commodities and the Sustainability Transition. Glob. Commod. Phys. Financ. Sustain. Asp. 2021, 129–154. Available online: https://ideas.repec.org/h/spr/sprchp/978-3-030-64026-2_6.html (accessed on 21 March 2025).
- Micol, L.; Costa, C. Why and How to Scale up Low-Emissions Beef in Brazil, and the Role of Carbon Markets: Insights for Beef Production in Latin America. 2023. Available online: https://cgspace.cgiar.org/server/api/core/bitstreams/0a2ce856-bedb-456e-99cc-2f5039b61430/content (accessed on 21 March 2025).
- Song, H.; Peng, C.; Zhang, K.; Li, T.; Yang, M.; Liu, Q.; Zhu, Q. Quantifying patterns, sources and uncertainty of nitrous oxide emissions from global grazing lands: Nitrogen forms are the determinant factors for estimation and mitigation. Glob. Planet. Chang. 2023, 223, 104080. [Google Scholar] [CrossRef]
- Saha, D.; Basso, B.; Robertson, G.P. Machine learning improves predictions of agricultural nitrous oxide (N2O) emissions from intensively managed cropping systems. Environ. Res. Lett. 2021, 16, 024004. [Google Scholar] [CrossRef]
- Addington, O.; Zeng, Z.C.; Pongetti, T.; Shia, R.L.; Gurney, K.R.; Liang, J.; Roest, G.; He, L.; Yung, Y.L.; Sander, S.P. Addington, Estimating nitrous oxide (N2O) emissions for the Los Angeles Megacity using mountaintop remote sensing observations. Remote Sens. Environ. 2021, 259, 112351. [Google Scholar] [CrossRef]
- Ko, J.; Leung, C.K.; Chen, X.; Palmer, D.A. From emissions to emotions: Exploring the impact of climate change on happiness across 140 countries. Glob. Transit. 2024, 6, 231–240. [Google Scholar] [CrossRef]
- Dradra, Z.; Abdennadher, C. Modeling the contribution of energy consumption to climate change: A panel cointegration analysis for mediterranean countries. J. Knowl. Econ. 2024, 15, 1142–1158. [Google Scholar] [CrossRef]
- Best, R.; Nazifi, F.; Cheng, H. Carbon Pricing Impacts on Four Pollutants: A Cross-Country Analysis. Energies 2024, 17, 2596. [Google Scholar] [CrossRef]
- Dhanoa, M.; Sanderson, R.; Lister, S.; Cardenas, L.; Ellis, J.; López, S.; France, J. Decision tree learning with random forest models using agricultural and ecological field data incorporating multi-factor studies and covariate structure. CAB Rev. 2024, 19, 1. [Google Scholar] [CrossRef]
- Sengupta, A.; Ismail, F.N. Modelling methane emissions from rice paddies using machine learning. In Proceedings of the 2024 39th International Conference on Image and Vision Computing New Zealand (IVCNZ), Christchurch, New Zealand, 4–6 December 2024; pp. 1–6. [Google Scholar]
- Sivakumar, S.; Venkataraman, S. Evaluating Machine Learning Approaches: A Comparative Study of Random Forest and Neural Networks in Grade Classification. Indones. J. Data Sci. 2025, 6, 74–81. [Google Scholar] [CrossRef]
- Bourel, M.; Cugliari, J.; Goude, Y.; Poggi, J.M. Boosting diversity in regression ensembles. Stat. Anal. Data Min. ASA Data Sci. J. 2024, 17, e11654. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, T.; Li, J.; Li, N.; Bai, X.; Liu, X.; Ao, J.; Chang, R. Temporal-scale-dependent mechanisms of forest soil nitrous oxide emissions under nitrogen addition. Commun. Earth Environ. 2024, 5, 512. [Google Scholar] [CrossRef]
- Cen, X.; Müller, C.; Kang, X.; Zhou, X.; Zhang, J.; Yu, G.; He, N. Nitrogen deposition contributed to a global increase in nitrous oxide emissions from forest soils. Commun. Earth Environ. 2024, 5, 532. [Google Scholar] [CrossRef]
- Yu, L.; Zhang, Q.; Tian, Y.; Sun, W.; Scheer, C.; Li, T.; Zhang, W. Global variations and drivers of nitrous oxide emissions from forests and grasslands. Front. Soil Sci. 2022, 2, 1094177. [Google Scholar] [CrossRef]
- Marzadri, A.; Amatulli, G.; Tonina, D.; Bellin, A.; Shen, L.Q.; Allen, G.H.; Raymond, P.A. Global riverine nitrous oxide emissions: The role of small streams and large rivers. Sci. Total Environ. 2021, 776, 145148. [Google Scholar] [CrossRef]
- Liao, J.; Zheng, W.; Liao, Q.; Lu, S. Global latitudinal patterns in forest ecosystem nitrous oxide emissions are related to hydroclimate. Npj Clim. Atmos. Sci. 2024, 7, 187. [Google Scholar] [CrossRef]
- Kalra, S.; Lamba, R.; Sharma, M. Machine learning based analysis for relation between global temperature and concentrations of greenhouse gases. J. Inf. Optim. Sci. 2020, 41, 73–84. [Google Scholar] [CrossRef]
- Fan, S.; Yoh, M. Nitrous oxide emissions in proportion to nitrification in moist temperate forests. Biogeochemistry 2020, 148, 223–236. [Google Scholar] [CrossRef]
- Yuan, Y.; Zhuang, Q.; Zhao, B.; Shurpali, N. Nitrous oxide emissions from pan-Arctic terrestrial ecosystems: A process-based biogeochemistry model analysis from 1969 to 2019. EGUsphere 2023, 2023, 1–37. [Google Scholar]
- Anwar, S.; Yani, M.; Hendrizal, M. Nitrous oxide emission from conservation forest of Kampar Peninsula peatland ecosystem. Jurnal Pengelolaan Sumberdaya Alam dan Lingkungan. J. Nat. Resour. Environ. Manag. 2021, 11, 442–452. [Google Scholar]
- Qamruzzaman, M. Nexus between energy intensity, human capital development, Trade and environmental quality in LIC, LMIC and UMIC: Evidence from GMM. GSC Adv. Res. Rev. 2022, 13, 051–068. [Google Scholar] [CrossRef]
- Baimukhamedova, A. The Role of Energy Intensity and Investment in Reducing Emissions in Türkiye. Eurasian J. Econ. Bus. Stud. 2024, 68, 127–140. [Google Scholar] [CrossRef]
- Calleja-Cervantes, M.E.; Huerfano, X.; Barrena, I.; Estavillo, J.M.; Aparicio-Tejo, P.M.; Gonzalez-Murua, C.; Menéndez, S. Nitrous Oxide (N2O) Emissions from Forests, Grasslands and Agricultural Soils in Northern Spain. In Just Enough Nitrogen: Perspectives on How to Get There for Regions with Too Much and Too LITTLE Nitrogen; Springer: Cham, Switzerland, 2020; pp. 341–349. [Google Scholar]
- Hossen, M.B.; Auwul, M.R. Comparative study of K-means, partitioning around medoids, agglomerative hierarchical, and DIANA clustering algorithms by using cancer datasets. Biomed. Stat. Inform. 2020, 5, 20–25. [Google Scholar] [CrossRef]
- Da Silva, L.E.B.; Melton, N.M.; Wunsch, D.C. Incremental cluster validity indices for online learning of hard partitions: Extensions and comparative study. IEEE Access 2020, 8, 22025–22047. [Google Scholar] [CrossRef]
- Ben Ncir, C.-E.; Hamza, A.; Bouaguel, W. Parallel and scalable Dunn Index for the validation of big data clusters. Parallel Comput. 2021, 102, 102751. [Google Scholar] [CrossRef]
- Shahapure, K.R.; Nicholas, C. Cluster quality analysis using silhouette score. In Proceedings of the 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA), Sydney, Australia, 6–9 October 2020; pp. 747–748. [Google Scholar]
- Pavlopoulos, J.; Vardakas, G.; Likas, A. Revisiting Silhouette Aggregation. In International Conference on Discovery Science; Springer Nature: Cham, Switzerland, 2024; pp. 354–368. [Google Scholar]
- Bombina, P.; Tally, D.; Abrams, Z.B.; Coombes, K.R. SillyPutty: Improved clustering by optimizing the silhouette width. PLoS ONE 2024, 19, e0300358. [Google Scholar] [CrossRef] [PubMed]
- Vărzaru, A.A.; Bocean, C.G. An Empirical Analysis of Relationships between Forest Resources and Economic and Green Performances in the European Union. Forests 2023, 14, 2327. [Google Scholar] [CrossRef]
- Zhang, T. Visual Analysis of Ecological Economic Data Based on Clustering Algorithm. In Proceedings of the 2024 3rd International Conference on Artificial Intelligence and Autonomous Robot Systems (AIARS), Bristol, UK, 29–31 July 2024; pp. 929–933. [Google Scholar]
- Dursun, M.; Alkurt, R.D. Net zero performance evaluation of European Continent Countries considering Paris Agreement climate goals. Kybernetes 2024. ahead-of-print. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]
- Nyasulu, C.; Diattara, A.; Traore, A.; Deme, A.; Ba, C. Towards resilient agriculture to hostile climate change in the Sahel region: A case study of machine learning-based weather prediction in Senegal. Agriculture 2022, 12, 1473. [Google Scholar] [CrossRef]
- Rezazadeh, A. Environmental pollution prediction of nox by process analysis and predictive modelling in natural gas turbine power plants. arXiv 2020, arXiv:2011.08978. [Google Scholar]
- Adjuik, T.A.; Davis, S.C. Machine learning approach to simulate soil CO2 fluxes under cropping systems. Agronomy 2022, 12, 197. [Google Scholar] [CrossRef]
- Pei, E.; Fokoué, E. Improving the Predictive Performances of k Nearest Neighbors Learning by Efficient Variable Selection. arXiv 2022, arXiv:2211.02600. [Google Scholar]
- Zhang, K.; Wu, H.; Li, M.; Yan, Z.; Li, Y.; Wang, J.; Zhang, X.; Yan, L.; Kang, X. Magnitude and edaphic controls of nitrous oxide fluxes in natural forests at different scales. Forests 2020, 11, 251. [Google Scholar] [CrossRef]
- Vestin, P.; Mölder, M.; Kljun, N.; Cai, Z.; Hasan, A.; Holst, J.; Lindroth, A. Impacts of clear-cutting of a boreal forest on carbon dioxide, methane and nitrous oxide fluxes. Forests 2020, 11, 961. [Google Scholar] [CrossRef]
- Haider, A.; Husnain, M.I.U.; Rankaduwa, W.; Shaheen, F. Nexus between nitrous oxide emissions and agricultural land use in agrarian economy: An ardl bounds testing approach. Sustainability 2021, 13, 2808. [Google Scholar] [CrossRef]
- Haider, A.; Bashir, A.; Husnain, M.I.U. Impact of agricultural land use and economic growth on nitrous oxide emissions: Evidence from developed and developing countries. Sci. Total. Environ. 2020, 741, 140421. [Google Scholar] [CrossRef]
- Telly, Y.; Liu, X.; Gbenou, T.R.S. Investigating the Growth effect of carbon-intensive economic activities on economic growth: Evidence from Angola. Energies 2023, 16, 3487. [Google Scholar] [CrossRef]
- Saha, D.; Kaye, J.P.; Bhowmik, A.; Bruns, M.A.; Wallace, J.M.; Kemanian, A.R. Organic fertility inputs synergistically increase denitrification-derived nitrous oxide emissions in agroecosystems. Ecol. Appl. 2021, 31, e02403. [Google Scholar] [CrossRef] [PubMed]
- Anderson, F.C.; Clough, T.J.; Condron, L.M.; Richards, K.G.; Rousset, C. Nitrous oxide responses to long-term phosphorus application on pasture soil. N. Z. J. Agric. Res. 2023, 66, 171–188. [Google Scholar] [CrossRef]
- Takeda, N.; Friedl, J.; Rowlings, D.; De Rosa, D.; Scheer, C.; Grace, P. Exponential response of nitrous oxide (N2O) emissions to increasing nitrogen fertiliser rates in a tropical sugarcane cropping system. Agric. Ecosyst. Environ. 2021, 313, 107376. [Google Scholar] [CrossRef]
- Kang, H. Impacts of income inequality and economic growth on CO2 emissions: Comparing the Gini coefficient and the top income share in OECD countries. Energies 2022, 15, 6954. [Google Scholar] [CrossRef]
- Hailemariam, A.; Dzhumashev, R.; Shahbaz, M. Carbon emissions, income inequality and economic development. Empir. Econ. 2020, 59, 1139–1159. [Google Scholar] [CrossRef]
- Alataş, S.; Akın, T. The impact of income inequality on environmental quality: A sectoral-level analysis. J. Environ. Plan. Manag. 2022, 65, 1949–1974. [Google Scholar] [CrossRef]
- Koloszko-Chomentowska, Z.; Sieczko, L.; Trochimczuk, R. Production profile of farms and methane and nitrous oxide emissions. Energies 2021, 14, 4904. [Google Scholar] [CrossRef]
- Naser, H.; Alaali, F. Mitigation of nitrous oxide emission for green growth: An empirical approach using ARDL. Adv. Sci. Technol. Eng. Syst. J. 2021, 6, 189–195. [Google Scholar] [CrossRef]
- Abbruzzese, M.; Infante, D.; Smirnova, J. European Countries on a Green Path. Connections Between Environmental Quality, Renewable Energy and Economic Growth. 2020. Available online: https://mpra.ub.uni-muenchen.de/106247/ (accessed on 21 March 2025).
- Zhang, Q.; Smith, K.; Zhao, X.; Jin, X.; Wang, S.; Shen, J.; Ren, Z.J. Greenhouse gas emissions associated with urban water infrastructure: What we have learnt from China’s practice. WIREs Water 2021, 8, e1529. [Google Scholar] [CrossRef]
- Sieranen, M.; Hilander, H.; Haimi, H.; Larsson, T.; Kuokkanen, A.; Mikola, A. Seasonality of nitrous oxide emissions at six full-scale wastewater treatment plants. Water Sci. Technol. 2024, 89, 603–612. [Google Scholar] [CrossRef] [PubMed]
- Uri-Carreño, N.; Nielsen, P.H.; Gernaey, K.V.; Domingo-Félez, C.; Flores-Alsina, X. Nitrous oxide emissions from two full-scale membrane-aerated biofilm reactors. Sci. Total. Environ. 2024, 908, 168030. [Google Scholar] [CrossRef]
- Fahrudin, T.; Asror, I.; Wibowo, Y.F.A. Analyzing schools admission performance achievement using hierarchical clustering. Int. J. Electr. Comput. Eng. (IJECE) 2024, 14, 2088–8708. [Google Scholar] [CrossRef]
- Laurenso, J.; Jiustian, D.; Fernando, F.; Suhandi, V.; Rochadiani, T.H. Implementation of K-Means, Hierarchical, and BIRCH Clustering Algorithms to Determine Marketing Targets for Vape Sales in Indonesia. J. Appl. INFORMATICS Comput. 2024, 8, 62–70. [Google Scholar] [CrossRef]
- Saleem, S.N.; Butt, W.H. Assisted Requirements Selection by Clustering using Analytical Hierarchical Process. Comput. Sci. Math. 2023. preprint. [Google Scholar] [CrossRef]
- Marzadri, A.; Amatulli, G.; Tonina, D.; Bellin, A.; Shen, L.Q.; Allen, G.H.; Raymond, P.A. A Scalable Hybrid Model to Predict Riverine Nitrous Oxide Emissions from the Reach to the Global Scale. EGU General Assembly Conference Abstracts. 2021, p. EGU21-9220. Available online: https://ui.adsabs.harvard.edu/abs/2021EGUGA..23.9220M/abstract (accessed on 21 March 2025).
- Das, A.C.; Mozumder, M.S.A.; Hasan, M.A.; Bhuiyan, M.; Islam, M.R.; Hossain, M.N.; Alam, M.I. Machine learning approaches for demand forecasting: The impact of customer satisfaction on prediction accuracy. Am. J. Eng. Technol. 2024, 6, 42–53. [Google Scholar]
- Jiang, C.; Zhang, S.; Wang, J.; Xia, X. Nitrous oxide (N2O) emissions decrease significantly under stronger light irradiance in riverine water columns with suspended particles. Environ. Sci. Technol. 2023, 57, 19749–19759. [Google Scholar] [CrossRef]
- Wang, J.; Wang, G.; Zhang, S.; Xin, Y.; Jiang, C.; Liu, S.; He, X.; McDowell, W.H.; Xia, X. Indirect nitrous oxide emission factors of fluvial networks can be predicted by dissolved organic carbon and nitrate from local to global scales. Glob. Change Biol. 2022, 28, 7270–7285. [Google Scholar] [CrossRef]
- Datta, S.K.; De, T. Linkage between energy use, pollution, and economic growth—A cross-country analysis. In Environmental Sustainability and Economy; Elsevier: Amsterdam, The Netherlands, 2021; pp. 85–110. [Google Scholar]
- Altunbas, Y.; Gambacorta, L.; Reghezza, A.; Velliscig, G. Does gender diversity in the workplace mitigate climate change? J. Corp. Finance 2022, 77, 102303. [Google Scholar] [CrossRef]
- Kim, E. The effect of female personnel on the voluntary disclosure of carbon emissions information. Int. J. Environ. Res. Public Health 2022, 19, 13247. [Google Scholar] [CrossRef] [PubMed]
- Dai, S.; Dai, Y.; Yu, H. The effect of gender gap in labor market participation on carbon emission efficiency: State-level empirical evidence from the US. Energy Environ. 2024, 0958305X241277623. Available online: https://journals.sagepub.com/doi/abs/10.1177/0958305X241277623 (accessed on 21 March 2025). [CrossRef]
- Bueno, E.; Mania, D.; Mesa, S.; Bedmar, E.J.; Frostegård, Å.; Bakken, L.R.; Delgado, M.J. Regulation of the emissions of the greenhouse gas nitrous oxide by the soybean endosymbiont Bradyrhizobium diazoefficiens. Int. J. Mol. Sci. 2022, 23, 1486. [Google Scholar] [CrossRef]
- Usman, M.; Rahman, S.U.; Shafique, M.R.; Sadiq, A.; Idrees, S. Renewable energy, trade and economic growth on nitrous oxide emission in G-7 countries using panel ARDL approach. J. Soc. Sci. Rev. 2023, 3, 131–143. [Google Scholar] [CrossRef]
- Molden, N. Innovative Emissions Measurement and Perspective on Future Tailpipe Regulation: Real-world measurement and role of VOCs and N2O emissions. Johns. Matthey Technol. Rev. 2023, 67, 130–137. [Google Scholar] [CrossRef]
- Gulaliyev, M.; Hasanov, R.; Sultanova, N.; Ibrahimli, L.; Guliyeva, N. R&D Expenditure and its Macroeconomic effects: A comparative study of Israel and South Caucasus countries. Public Munic. Finance 2024, 13, 44–55. [Google Scholar]
- Aleixandre-Tudó, J.L.; Castelló-Cogollos, L.; Aleixandre, J.L.; Aleixandre-Benavent, R. Trends in funding research and international collaboration on greenhouse gas emissions: A bibliometric approach. Environ. Sci. Pollut. Res. 2021, 28, 32330–32346. [Google Scholar] [CrossRef]
- Ding, M.; Chen, G. Assessment of nitrous oxide emissions from agricultural systems in Thailand and low carbon measures. In Proceedings of the Conference on Sustainable Technology and Management (ICSTM 2022), Macao, China, 22–24 July 2022; Volume 12299, pp. 87–94. [Google Scholar]
- Syahputri, Z.; Sutarman, S.; Siregar, M.A.P. Determining the optimal number of k-means clusters using the calinski harabasz index and krzanowski and lai index methods for groupsing flood prone areas in north sumatra. Sinkron 2024, 9, 571–580. [Google Scholar] [CrossRef]
- Vysala, A.; Gomes, J. Evaluating and validating cluster results. arXiv 2020, arXiv:2007.08034. [Google Scholar]
- Sibarani, M.A.J.A.; Diyasa, I.G.S.M.; Sugiarto, S. Penggunaan K-Means Dan Hierarchical Clustering Single Linkage Dalam Pengelompokkan Stok Obat. J. Lebesgue J. Ilm. Pendidik. Mat. Mat. Stat. 2024, 5, 1286–1294. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, H. Global data distribution weighted synthetic oversampling technique for imbalanced learning. IEEE Access 2021, 9, 44770–44783. [Google Scholar] [CrossRef]
- Hamrani, A.; Akbarzadeh, A.; Madramootoo, C.A. Machine learning for predicting greenhouse gas emissions from agricultural soils. Sci. Total. Environ. 2020, 741, 140338. [Google Scholar] [CrossRef] [PubMed]
- Li, K.; Duan, H.; Liu, L.; Qiu, R.; van der Akker, B.; Ni, B.-J.; Chen, T.; Yin, H.; Yuan, Z.; Ye, L. An integrated first principal and deep learning approach for modeling nitrous oxide emissions from wastewater treatment plants. Environ. Sci. Technol. 2022, 56, 2816–2826. [Google Scholar] [CrossRef]
- Wen, H.T.; Lu, J.H.; Jhang, D.S. Features importance analysis of diesel vehicles’ NOx and CO2 emission predictions in real road driving based on gradient boosting regression model. Int. J. Environ. Res. Public Health 2021, 18, 13044. [Google Scholar] [CrossRef]
- Garcia-Ceja, E.; Hugo, A.; Morin, B.; Hansen, P.O.; Martinsen, E.; Lam, A.N.; Haugen, O. A Feature Importance Analysis for Soft-Sensing-Based Predictions in a Chemical Sulphonation Process. In Proceedings of the 2020 IEEE Conference on Industrial Cyberphysical Systems (ICPS), Tampere, Finland, 10–12 June 2020. [Google Scholar]



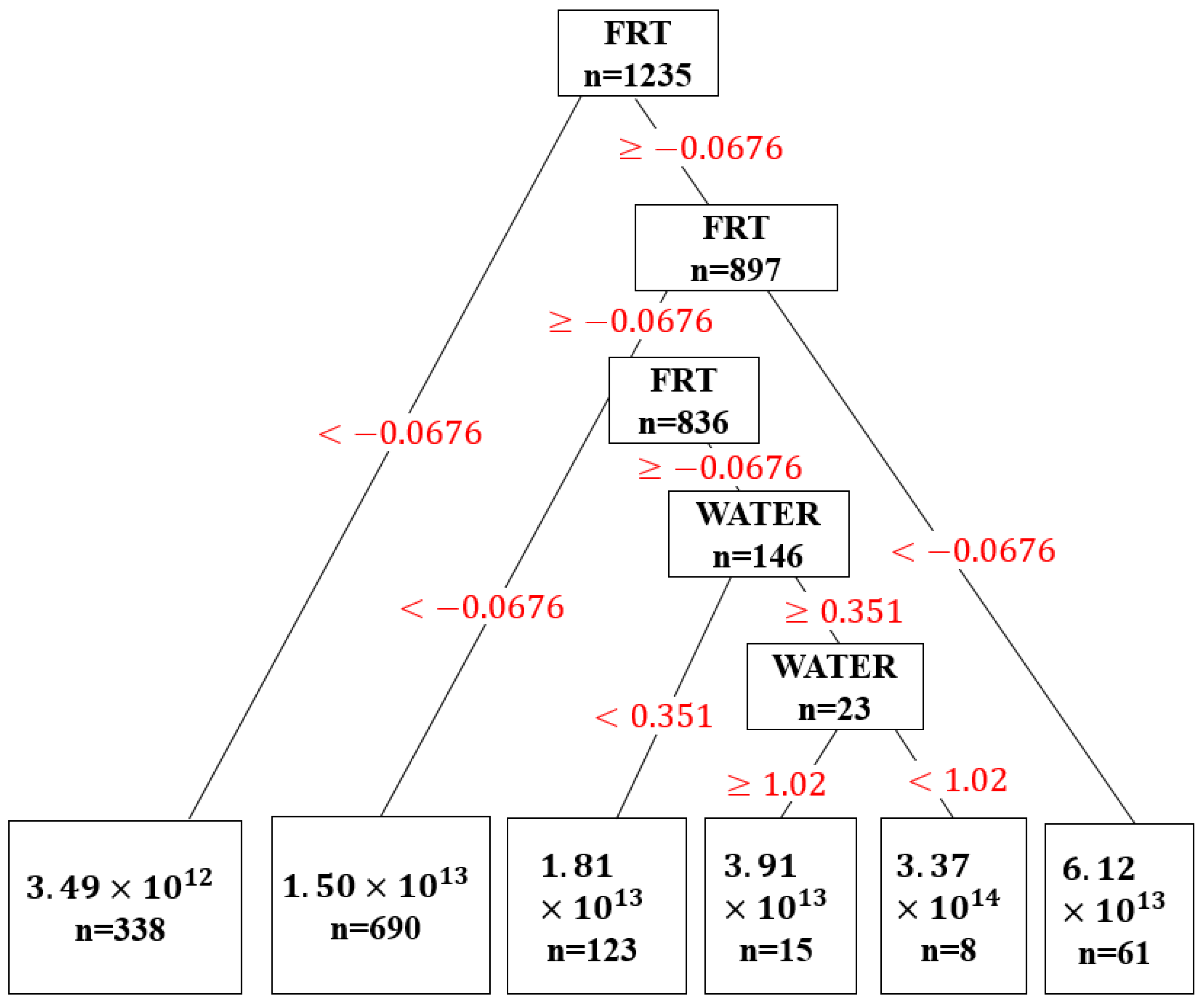
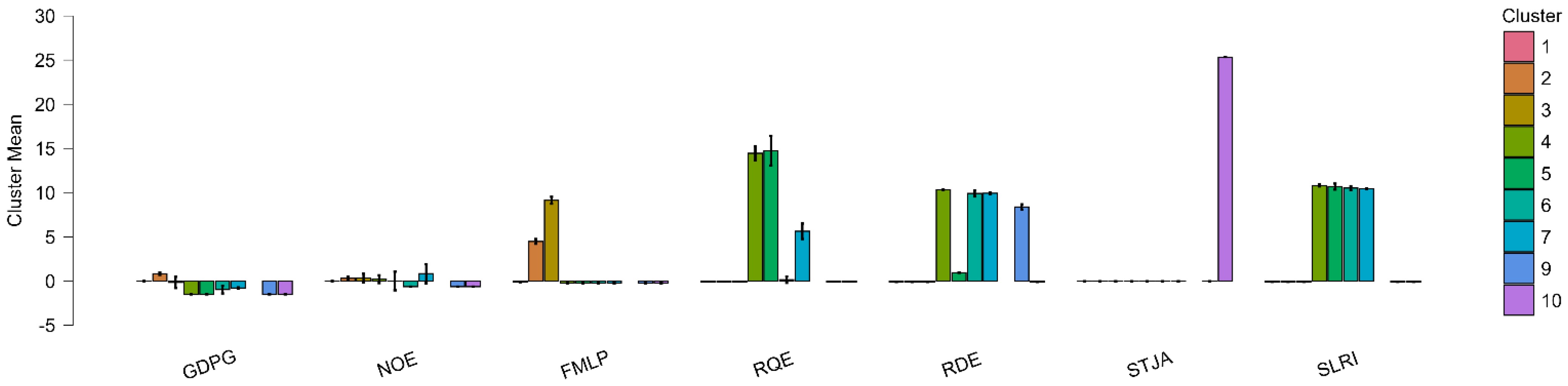

| ESG Pillar | Macro-Theme | Focus on N2O Emissions | Key References |
|---|---|---|---|
| Environmental (E) | Agriculture, Land Use & Industry | N2O emissions from fertilizer, livestock, biochar, wastewater, textile and energy sectors | [13,14,15,16,17,18,19,20,50,54] |
| Monitoring & Environmental Technologies | N2O prediction and tracking using digital tools, ML, blockchain, and urban ESG systems | [29,42,43,44,45] | |
| Social (S) | Social Equity, Accountability & Inclusion | Social factors in emissions management, SDGs, corporate ESG disclosures, and Scope 3 N2O tracking | [27,47,48,49,51] |
| Governance (G) | Policy, Regulation & Institutional Capacity | Effectiveness of ESG-aligned policies, mandatory reporting, governance quality, climate compliance | [21,23,24,25,26,27,29,38,44] |
| Risk Management & ESG Standards | ESG standardization, default risk for polluting firms, and transition readiness | [33,40] | |
| Finance (Cross-cutting) | ESG Investment, Green Finance & Disclosure | Use of green bonds, financial risk metrics, investor preferences, and carbon/N2O footprint accountability | [30,31,32,34,36,37,39,55] |
| Methodological (Cross-cutting) | Predictive Analytics & ESG Benchmarking | ESG index construction, forecasting tools, and integration of N2O into ESG scoring systems | [22] |
| Variable | Acronym | Description |
|---|---|---|
| Nitrous oxide emissions (metric tons of CO2 equivalent per capita) | NOE | This metric quantifies annual nitrous oxide (N2O) emissions from agriculture, energy, waste, and industry, excluding LULUCF. Emissions are converted to carbon dioxide equivalents using Global Warming Potential (GWP) factors from the IPCC’s Fifth Assessment Report (AR5), ensuring consistency in climate impact assessments. |
| Adjusted savings–net forest depletion (% of GNI) | ASNFD | Net forest depletion is determined by multiplying unit resource rents by the amount of roundwood harvested beyond natural forest growth. This metric reflects the economic cost of unsustainable logging, highlighting the depletion of forest resources beyond their regeneration capacity. By assessing the gap between harvest rates and natural growth, it provides insight into forest sustainability and the long-term environmental and economic impacts of excessive resource extraction. |
| Energy intensity level of primary energy | EIPE | The energy intensity level of primary energy measures the ratio of energy supply to GDP at purchasing power parity. It reflects the amount of energy required to produce one unit of economic output. A lower energy intensity indicates greater efficiency, meaning less energy is consumed per unit of output. This metric is crucial for assessing energy efficiency and sustainability in economic growth, guiding policies toward reduced energy consumption and improved resource management. |
| Forest area (% of land area) | FA | Forest area refers to land covered by natural or planted trees reaching at least 5 m in height, regardless of productivity. It excludes tree stands within agricultural systems, such as fruit plantations and agroforestry, as well as trees in urban parks and gardens. This definition helps distinguish forest ecosystems from other tree-covered landscapes, ensuring accurate assessments of forest resources for environmental monitoring, conservation efforts, and sustainable land management. |
| Annualized average growth rate in per capita real survey mean consumption or income, total population (%) | AGRI | The welfare aggregate growth rate measures the annualized average increase in per capita real consumption or income for the total population over approximately five years. Derived from household surveys, this metric reflects overall economic well-being and living standards. By tracking changes in consumption or income, it provides insights into economic growth, poverty reduction, and inequality, helping policymakers assess the effectiveness of development strategies and social programs. |
| Fertility rate, total (births per woman) | FRT | The total fertility rate estimates the number of children a woman would have if she lived through her reproductive years and experienced the age-specific fertility rates of a given year. This measure reflects reproductive behavior and population growth trends, serving as a key demographic indicator. It helps policymakers assess fertility patterns, plan for future population changes, and develop strategies for healthcare, education, and economic development based on projected birth rates. |
| Gini index | GI | The Gini index quantifies income or consumption inequality within an economy, indicating how far distribution deviates from perfect equality. A value of 0 signifies complete equality, where everyone has the same income, while a value of 100 represents total inequality, where one individual holds all the income. This metric is widely used to assess economic disparity, helping policymakers evaluate social equity, design welfare programs, and track progress in reducing income inequality over time. |
| Income share held by lowest 20% | ISL20 | The percentage share of income or consumption represents the portion received by specific population subgroups, categorized by deciles or quintiles. This measure helps analyze income distribution and economic inequality. Due to rounding, the total percentage across quintiles may not always sum to 100. By assessing these shares, policymakers and researchers can evaluate disparities, monitor economic trends, and design policies to promote fairer income distribution and social equity. |
| People using safely managed drinking water services (% of population) | WATER | This metric measures the percentage of people using improved drinking water sources that are accessible on-site, available when needed, and free from fecal or harmful chemical contamination. Improved sources include piped water, boreholes, tubewells, protected wells and springs, as well as packaged or delivered water. Ensuring access to safe drinking water is crucial for public health, reducing waterborne diseases, and supporting sustainable development and well-being in communities worldwide. |
| GDP growth (annual %) | GDPG | The annual GDP growth rate measures the percentage increase in GDP at market prices, based on constant local currency. Aggregates use constant 2010 U.S. dollars. GDP represents the total gross value added by resident producers, including product taxes and excluding subsidies. It does not account for asset depreciation or natural resource depletion. This indicator helps assess economic performance, guiding policymakers in evaluating growth trends and formulating development strategies. |
| Ratio of female to male labor force participation rate (%) (modeled ILO estimate) | FMLP | The labor force participation rate measures the percentage of people aged 15 and older who are economically active, contributing labor to goods and services production. The female-to-male participation ratio is calculated by dividing the female labor force participation rate by the male rate and multiplying by 100. This metric helps assess gender disparities in employment, informing policies on workforce inclusion and economic development. |
| Regulatory Quality: Estimate | RQE | Regulatory quality assesses a government’s ability to develop and enforce effective policies that support private sector growth. It reflects the efficiency, fairness, and stability of regulations impacting businesses and economic activities. Strong regulatory frameworks encourage investment and economic development |
| Research and development expenditure (% of GDP) | RDE | Gross domestic R&D expenditures measure the percentage of GDP spent on research and development, including both capital and current costs. These expenditures span four key sectors: business enterprise, government, higher education, and private non-profit. R&D activities encompass basic research, applied research, and experimental development. This indicator reflects a country’s commitment to innovation, technological progress, and economic growth, guiding policy decisions on science and technology investment. |
| Scientific and technical journal articles | STJA | Scientific and technical journal articles represent the number of published research papers in fields such as physics, biology, chemistry, mathematics, clinical medicine, biomedical research, engineering, technology, and earth and space sciences. This metric reflects a country’s research output, scientific progress, and contributions to global knowledge. Tracking publication trends helps assess innovation, academic productivity, and the impact of research investments on technological and scientific advancements. |
| Strength of Legal Rights Index (0 = weak to 12 = strong) | SLRI | The Strength of Legal Rights Index assesses how well collateral and bankruptcy laws protect borrowers and lenders, promoting secure lending. It ranges from 0 to 12, with higher scores indicating stronger legal frameworks that enhance access to credit. A well-designed legal system fosters financial stability, encouraging investment and economic growth. This index helps policymakers and investors evaluate the effectiveness of credit laws in supporting a robust financial environment. |
| Fixed-Effects, Using 1930 Observations | Random-Effects (GLS), Using 1930 Observations | |||||
|---|---|---|---|---|---|---|
| Coefficient | Std. Error | t-Ratio | Coefficient | Std. Error | z | |
| Constant | −1537.59 * | 875.027 | −1.757 | −356.662 | 261.750 | −1.363 |
| ASFND | 388.620 *** | 111.720 | 3.479 | 226.326 | 63.2516 | 3.578 |
| EIPE | −23.9106 *** | 6.61187 | −3.616 | −16.2174 | 5.23974 | −3.095 |
| FA | 45.1940 * | 26.8273 | 1.685 | 11.7874 | 6.23894 | 1.889 |
| Statistics | Mean dependent var | 123.4940 | Mean dependent var | 123.4940 | ||
| Sum squared resid | Sum squared resid | |||||
| LSDV R-squared | 0.073296 | Log-likelihood | −19,105.89 | |||
| LSDV F(195, 1734) | 0.703319 | Schwarz criterion | 38,242.05 | |||
| Log-likelihood | −19,041.77 | rho | −0.092917 | |||
| Schwarz criterion | 39,566.33 | S.D. dependent var | 4844.417 | |||
| rho | −0.092917 | S.E. of regression | 4823.555 | |||
| S.D. dependent var | 4844.417 | Akaike criterion | 38,219.79 | |||
| S.E. of regression | 4918.738 | Hannan–Quinn | 38,227.98 | |||
| Within R-squared | 0.012731 | Durbin–Watson | 2.166681 | |||
| p-value(F) | 0.999081 | |||||
| Akaike criterion | 38,475.54 | |||||
| Hannan–Quinn | 38,876.78 | |||||
| Durbin–Watson | 2.166681 | |||||
| Tests | Joint test on named regressors - Test statistic: F(3, 1734) = 7.45344 with p-value = P(F(3, 1734) > 7.45344) = | ‘Between’ variance = ‘Within’ variance = theta used for quasi-demeaning = 0.31056 Joint test on named regressors - Asymptotic test statistic: Chi-square(3) = 19.4119 with p-value = 0.000224696 | ||||
| Test for differing group intercepts - Null hypothesis: The groups have a common intercept Test statistic: F(192, 1734) = 0.615528 with p-value = P(F(192, 1734) > 0.615528) = 0.999987 | Breusch–Pagan test - Null hypothesis: Variance of the unit-specific error = 0 Asymptotic test statistic: Chi-square(1) = 16.8159 with p-value = | |||||
| Hausman test - Null hypothesis: GLS estimates are consistent Asymptotic test statistic: Chi-square(3) = 7.93254 with p-value = 0.0474267 | ||||||
| Metrics | Density-Based | Fuzzy C-Means | Hierarchical | Neighborhood-Based |
|---|---|---|---|---|
| Maximum diameter | 9.377 | 8.730 | 4.851 | 6.373 |
| Minimum separation | 0.626 | 0.003 | 0.233 | 0.008 |
| Pearson’s γ | 0.495 | 0.312 | 0.646 | 0.415 |
| Dunn index | 0.067 | 3.104 × 10−4 | 0.048 | 0.001 |
| Entropy | 0.059 | 2.043 | 0.810 | 2.060 |
| Calinski–Harabasz index | 157.775 | 331.266 | 276.568 | 966.206 |
| Cluster | 2 | 9 | 10 | 10 |
| Metrics | Maximum Diameter | Minimum Separation | Pearson’s γ | Dunn Index | Entropy | Calinski–Harabasz |
|---|---|---|---|---|---|---|
| Density-Based | 0.000 | 1.000 | 0.549 | 1.000 | 1.000 | 0.000 |
| Fuzzy C-Means | 0.182 | 0.000 | 0.000 | 0.000 | 0.010 | 0.212 |
| Hierarchical | 1.000 | 0.368 | 1.000 | 0.716 | 0.621 | 0.151 |
| Neighborhood-Based | 0.398 | 0.008 | 0.308 | 0.010 | 0.000 | 1.000 |
| Algorithms | MSE | MSE (Scaled) | RMSE | MAE/MAD | R2 |
|---|---|---|---|---|---|
| Boosting Regression | 1766 | 56,554,677,919,974.9 | 27,495,573,662,284.5 | 0.013 | |
| Decision Tree | 1279 | 27,884,948,108,250.7 | 0.129 | ||
| K-Nearest Neighbors | 1143 | 57,510,088,985,819.6 | 20,214,183,938,440.9 | 0.182 | |
| Linear Regression | 1832 | 65,441,594,103,392.5 | 30,141,169,680,947.5 | 0.007 | |
| Random Forest | 1235 | 62,363,539,135,740.7 | 25,751,902,907,169.1 | 0.145 | |
| Regularized Linear | 1911 | 55,399,392,260,728.8 | 27,330,517,747,988.2 | 0.002 | |
| Support Vector Machine | 1715 | 52,325,517,606,098.3 | 12,483,937,823,834.3 | 0.02 |
| Variables | Mean Dropout Loss |
|---|---|
| FA | |
| EIPE | |
| ASNFD |
| Case | Predicted | Base | ASNFD | EIPE | FA |
|---|---|---|---|---|---|
| 1 | 0.190 | 91.144 | |||
| 2 | |||||
| 3 | |||||
| 4 | 0.251 | 1 | |||
| 5 | 0.251 |
| Fixed-Effects, Using 1930 Observations | Random-Effects (GLS), Using 1930 Observations | |||||
|---|---|---|---|---|---|---|
| Coefficient | Std. Error | t-Ratio | Coefficient | Std. Error | z | |
| Constant | 1454.83 *** | 170.230 | 8.546 | 899.333 *** | 262.237 | 3.429 |
| AGRI | 472.423 *** | 79.2103 | 5.964 | 586.143 *** | 74.9708 | 7.818 |
| FRT | 6.80979 *** | 0.409731 | 16.62 | 6.73673 *** | 0.390629 | 17.25 |
| GI | −56.4683 *** | 18.2848 | −3.088 | −48.0761 *** | 15.3428 | −3.133 |
| ISL20 | 325.574 *** | 101.327 | 3.213 | 285.434 *** | 84.3385 | 3.384 |
| WATER | −31.6670 *** | 1.93732 | −16.35 | −21.4558 *** | 1.52574 | −14.06 |
| Statistics | Mean dependent var | 123.4940 | Mean dependent var | 123.4940 | ||
| Sum squared resid | Sum squared resid | |||||
| LSDV R-squared | 0.270528 | Log-likelihood | −18984.86 | |||
| LSDV F(197, 1732) | 3.260515 | Schwarz criterion | 38,015.10 | |||
| Log-likelihood | −18,810.83 | rho | −0.053556 | |||
| Schwarz criterion | 39,119.58 | S.D. dependent var | 4844.417 | |||
| rho | −0.053556 | S.E. of regression | 4532.691 | |||
| S.D. dependent var | 4844.417 | Akaike criterion | 37,981.71 | |||
| S.E. of regression | 4532.691 | Hannan–Quinn | 37,993.99 | |||
| Within R-squared | 37,981.71 | Durbin–Watson | 2.027854 | |||
| p-value(F) | 37,993.99 | |||||
| Akaike criterion | 2.027854 | |||||
| Hannan–Quinn | 4844.417 | |||||
| Durbin–Watson | 4532.691 | |||||
| Tests | Joint test on named regressors - Test statistic: F(5, 1732) = 99.3334 with p-value = P(F(5, 1732) > 99.3334) = | ‘Between’ variance = ‘Within’ variance = theta used for quasi-demeaning = 0.591392 Joint test on named regressors - Asymptotic test statistic: Chi-square(5) = 461.246 with p-value = | ||||
| Test for differing group intercepts - Null hypothesis: The groups have a common intercept Test statistic: F(192, 1732) = 0.942888 with p-value = P(F(192, 1732) > 0.942888) = 0.696184 | Breusch–Pagan test - Null hypothesis: Variance of the unit-specific error = 0 Asymptotic test statistic: Chi-square(1) = 58.3018 with p-value = | |||||
| Hausman test - Null hypothesis: GLS estimates are consistent Asymptotic test statistic: Chi-square(5) = 94.715 with p-value = | ||||||
| Neighborhood-Based | Density-Based | Fuzzy C-Means | Hierarchical | Random Forest | |
|---|---|---|---|---|---|
| Maximum diameter | 20.291 | 35.700 | 35.700 | 7.167 | 35.700 |
| Minimum separation | 0.008 | 0.268 | 0.014 | 0.855 | 9.159 × 10−16 |
| Pearson’s γ | 0.413 | 0.777 | 0.200 | 0.751 | 0.042 |
| Dunn index | 4.133 × 10−4 | 0.008 | 3.914 × 10−4 | 0.119 | 2.566 × 10−17 |
| Entropy | 1.679 | 0.067 | 1.138 | 0.143 | 2.054 |
| Calinski–Harabasz index | 1.943.052 | 351.756 | 200.783 | 395.441 | 67.591 |
| Cluster | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| Size | 1884 | 26 | 7 | 1 | 1 | 1 | 1 | 9 |
| Explained proportion within-cluster heterogeneity | 0.951 | 0.032 | 0.007 | 0.000 | 0.000 | 0.000 | 0.000 | 0.010 |
| Within sum of squares | 4.509.331 | 152.614 | 31.928 | 0.000 | 0.000 | 0.000 | 0.000 | 49.157 |
| Silhouette score | 0.727 | 0.526 | 0.801 | 0.000 | 0.000 | 0.000 | 0.000 | 0.811 |
| Annualized Average Growth Rate in Per Capita Real Survey Mean Consumption or Income, Total Population (%) | Fertility Rate, Total (Births Per Woman) | Gini Index | Income Share Held by Lowest 20% | Nitrous Oxide Emissions (Metric Tons of CO2 Equivalent Per Capita) | People Using Safely Managed Drinking Water Services (% of Population) | |
|---|---|---|---|---|---|---|
| Cluster 1 | −0.046 | −0.068 | 0.068 | 9.487 × 10−4 | −0.087 | 0.003 |
| Cluster 2 | −0.048 | −0.068 | 0.069 | −0.200 | 6.491 | 0.428 |
| Cluster 3 | −0.048 | 14.549 | 0.069 | 1.035 | −0.240 | −0.881 |
| Cluster 4 | 26.764 | 16.532 | 0.069 | 0.946 | −0.240 | −0.881 |
| Cluster 5 | 26.764 | −0.068 | 0.069 | 0.335 | −0.240 | −0.881 |
| Cluster 6 | 14.484 | 11.568 | 0.069 | 1.463 | −0.240 | −0.881 |
| Cluster 7 | 15.204 | −0.068 | 0.069 | −0.656 | −0.240 | −0.881 |
| Cluster 8 | 0.573 | −0.068 | −14.517 | −0.656 | −0.240 | −0.881 |
| MSE | MSE (Scaled) | RMSE | MAE/MAD | ||
|---|---|---|---|---|---|
| Random Forest | 0.3600117698984846 | 0.4052044609665427 | 0.0 | 0.40304705986553213 | 1.0 |
| Boosting | 0.53508900985729 | 0.8131970260223048 | 0.32368112518096126 | 0.0 | 0.0473186119873817 |
| Decision Tree | 0.0 | 1.0 | 0.054866835868048414 | 0.5070895929367109 | 0.01892744479495268 |
| K-Nearest Neighbors | 0.42180373694276885 | 0.8155204460966542 | 0.12098647345216462 | 0.38438382120220915 | 0.04416403785488959 |
| Linear Regression | 0.0382521700750331 | 0.9223977695167287 | 0.6911298418038796 | 0.8766936557107904 | 0.0 |
| Regularized Linear | 0.9999999999999999 | 0.0 | 1.0 | 0.9999999999999999 | 0.0 |
| Support Vector Machine | 0.902898337501839 | 0.9423791821561338 | 0.8729590916197361 | 0.19592520124232793 | 0.0 |
| Variables | Relative Importance | Mean Dropout Loss |
|---|---|---|
| People using safely managed drinking water services (% of population) | 52.228 | |
| Fertility rate, total (births per woman) | 36.154 | |
| Income share held by lowest 20% | 7.708 | |
| Gini index | 3.854 | |
| Annualized average growth rate in per capita real survey mean consumption or income, total population (%) | 0.057 |
| Case | Predicted | Base | Annualized Average Growth Rate in Per Capita Real Survey Mean Consumption or Income, Total Population (%) | Fertility Rate, Total (Births per Woman) | Gini Index | Income Share Held by Lowest 20% | People Using Safely Managed Drinking Water Services (% of Population) |
|---|---|---|---|---|---|---|---|
| 1 | 0.000 | 0.000 | 0.000 | ||||
| 2 | 0.000 | 0.000 | 0.000 | ||||
| 3 | 0.000 | 0.000 | 0.000 | ||||
| 4 | 0.000 | 0.000 | 0.000 | ||||
| 5 | 0.000 | 0.000 | 0.000 |
| Fixed-Effects, Using 1930 Observations | Random-Effects (GLS), Using 1930 Observations | |||||
|---|---|---|---|---|---|---|
| Coefficient | Std. Error | t-Ratio | Coefficient | Std. Error | z | |
| Constant | 556.472 | 320.867 | 1.734 | 103.524 | 216.422 | 0.4783 |
| GDPG | 164.956 *** | 17.3297 | 9.519 | 145.221 *** | 15.0543 | 9.647 |
| FMLP | −25.5933 *** | 5.50773 | −4.647 | −11.6487 *** | 3.43191 | −3.394 |
| RQE | 71.9341 *** | 31.3453 | 2.295 | 51.2178 *** | 16.4078 | 3.122 |
| RDE | 2127.27 *** | 253.026 | 8.407 | 843.694 *** | 143.536 | 5.878 |
| STJA | −0.018322 ** | 0.00601105 | −3.048 | −0.0070 ** | 0.00277893 | −2.553 |
| SLRI | −7.80164 *** | 1.00910 | −7.731 | −2.39160 *** | 0.594355 | −4.024 |
| Statistics | Mean dependent var | 123.4940 | Mean dependent var | 123.4940 | ||
| Sum squared resid | Sum squared resid | |||||
| LSDV R-squared | 0.150695 | Log-likelihood | −18,990.93 | |||
| LSDV F(198, 1731) | 1.551193 | Schwarz criterion | 38,034.82 | |||
| Log-likelihood | −18,957.61 | rho | −0.228742 | |||
| Schwarz criterion | 39,420.70 | S.D. dependent var | 4844.417 | |||
| rho | −0.228742 | S.E. of regression | 4548.164 | |||
| S.D. dependent var | 4844.417 | Akaike criterion | 37,995.86 | |||
| S.E. of regression | 4712.930 | Hannan–Quinn | 38,010.19 | |||
| Within R-squared | 0.095188 | Durbin–Watson | 2.415716 | |||
| p-value(F) | ||||||
| Akaike criterion | 38,313.21 | |||||
| Hannan–Quinn | 38,720.59 | |||||
| Durbin–Watson | 2.415716 | |||||
| Tests | Joint test on named regressors - Test statistic: F(6, 1731) = 30.3509 with p-value = P(F(6, 1731) > 30.3509) = | Between’ variance = 0 ‘Within’ variance = theta used for quasi-demeaning = 0 Joint test on named regressors - Asymptotic test statistic: Chi-square(6) = 264.345 with p-value = | ||||
| Test for differing group intercepts - Null hypothesis: The groups have a common intercept Test statistic: F(192, 1731) = 0.316789 with p-value = P(F(192, 1731) > 0.316789) = 1 | Breusch–Pagan test - Null hypothesis: Variance of the unit-specific error = 0 Asymptotic test statistic: Chi-square(1) = 75.4695 with p-value = | |||||
| Hausman test - Null hypothesis: GLS estimates are consistent Asymptotic test statistic: Chi-square(6) = 67.1804 with p-value = | ||||||
| Density-Based | Fuzzy C-Means | Hierarchical Clustering | Model Based | Neighborhood Based | Random Forest | |
|---|---|---|---|---|---|---|
| Maximum diameter | 0.06745352911624239 | 0.22273019387353776 | 0.014490492399853205 | 0.04702319565817511 | 0.015907641995282558 | 0.8812466415905428 |
| Minimum separation | 0.0043137529226470964 | 0.0008921959227085836 | ||||
| Pearson’s Î3 | 0.0016216319340663532 | 0.0013952893047397283 | 0.001445972702320808 | 0.0004108959502102246 | 0.0002271315632102517 | 0.0009254283837841031 |
| Dunn index | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Entropy | 0.012457710676359694 | 0.0002944686050318971 | 0.0031294973180489346 | 0.0015837832808435588 | 0.04218162278344975 | |
| Calinski–Harabasz index | 1.0 | 0.9999999999999999 | 0.9999999999999999 | 1.0 | 1.0 | 1.0 |
| Cluster | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Size | 1864 | 32 | 9 | 6 | 2 | 3 | 6 | 1 | 4 | 3 |
| Explained proportion within-cluster heterogeneity | 0.977 | 0.010 | 0.005 | 0.002 | 2.534 × 10−4 | 0.005 | 0.000 | 9.414 × 10−5 | 9.886 × 10−22 | |
| Within sum of squares | 4210.053 | 42.132 | 21.572 | 9.421 | 2.964 | 1.092 | 21.715 | 0.000 | 0.406 | 4.260 × 10−18 |
| Silhouette score | 0.611 | 0.653 | 0.559 | 0.795 | 0.745 | 0.830 | 0.572 | 0.000 | 0.921 | 1.000 |
| Clusters | GDP Growth (Annual %) | Nitrous Oxide Emissions (Metric Tons of CO2 Equivalent Per Capita) | Ratio of Female to Male Labor Force Participation Rate (%) (Modeled ILO Estimate) | Regulatory Quality: Estimate | Research and Development Expenditure (% of GDP) | Scientific and Technical Journal Articles | Strength of Legal Rights Index (0 = Weak to 12 = Strong) |
|---|---|---|---|---|---|---|---|
| Cluster 1 | 0.003 | −0.008 | −0.118 | −0.081 | −0.103 | −0.039 | −0.095 |
| Cluster 2 | 0.822 | 0.300 | 4.471 | −0.081 | −0.103 | −0.039 | −0.095 |
| Cluster 3 | −0.165 | 0.318 | 9.127 | −0.081 | −0.103 | −0.039 | −0.095 |
| Cluster 4 | −1.505 | 0.210 | −0.240 | 14.445 | 10.327 | −0.039 | 10.806 |
| Cluster 5 | −1.505 | −0.004 | −0.240 | 14.747 | 0.936 | −0.039 | 10.685 |
| Cluster 6 | −0.982 | −0.644 | −0.240 | 0.140 | 9.909 | −0.039 | 10.512 |
| Cluster 7 | −0.797 | 0.830 | −0.240 | 5.621 | 9.926 | −0.039 | 10.409 |
| Cluster 8 | −0.776 | 2.309 | −0.240 | 4.690 | 9.960 | −0.039 | 0.963 |
| Cluster 9 | −1.505 | −0.644 | −0.240 | −0.081 | 8.376 | −0.039 | −0.095 |
| Cluster 10 | −1.505 | −0.644 | −0.240 | −0.081 | −0.103 | 25.338 | −0.095 |
| Algorithms | MSE | MSE (Scaled) | RMSE | MAE/MAD | |
|---|---|---|---|---|---|
| Boosting | 0.9728629579375847 | 0.7763313609467455 | 0.8359913803089771 | 0.7568395879174474 | 0.09583333333333335 |
| Decision Tree | 0.7053692576080636 | 0.6248520710059171 | 0.0 | 0.2360953723670376 | 0.2 |
| K-Nearest Neighbors | 0.8914518317503393 | 0.7136094674556213 | 0.5943462348840258 | 0.9127409854532011 | 0.13333333333333333 |
| Linear Regression | 0.9340957549912774 | 0.8520710059171599 | 0.719097048440756 | 0.8641982435387621 | 0.05416666666666666 |
| Random Forest | 0.0 | 0.0 | 1.0 | 0.6100728056507307 | 10.000.000.000.000.000 |
| Regularized Linear | 0.9592944369063772 | 10.000.000.000.000.000 | 0.7917614846829375 | 1.0 | 0.0 |
| Support Vector Machine | 1.0 | 0.9810650887573964 | 0.913767544533286 | 0.0 | 0.004166666666666666 |
| Variables | Mean Decrease in Accuracy | Total Increase in Node Purity |
|---|---|---|
| Regulatory quality: estimate | 2.195 × 1027 | 6.433 × 1029 |
| Ratio of female to male labor force participation rates (%) (modeled ILO estimate) | 2.076 × 1027 | 5.768 × 1029 |
| Scientific and technical journal articles | 2.171 × 1027 | 4.340 × 1029 |
| GDP growth (annual %) | 3.630 × 1026 | 3.111 × 1029 |
| Strength of Legal Rights Index | 1.153 × 1027 | 2.296 × 1029 |
| Research and development expenditure (% of GDP) | 1.385 × 1027 | 1.891 × 1029 |
| Macro | Variables | Panel Data Relationships | Best Clustering Algorithm | Clusters | Best ML Algorithm | Machine Learning Results | |
|---|---|---|---|---|---|---|---|
| E | ASFND | Positive | Density-Based | 2 | K-Nearest Neighbors | Mean Dropout Loss | |
| EIPE | Negative | ||||||
| FA | Positive | ||||||
| S | AGRI | Positive | Hierarchical Clustering | 8 | Random Forest | ||
| FRT | Positive | ||||||
| GI | Negative | ||||||
| ISL20 | Positive | ||||||
| WATER | Negative | ||||||
| G | GDPG | Positive | Hierarchical Clustering | 10 | Random Forest | Mean decrease in accuracy | |
| FMLP | Negative | ||||||
| RQE | Positive | ||||||
| RDE | Positive | ||||||
| STJA | Negative | ||||||
| SLRI | Negative | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Drago, C.; Arnone, M.; Leogrande, A. A Machine Learning and Panel Data Analysis of N2O Emissions in an ESG Framework. Sustainability 2025, 17, 4433. https://doi.org/10.3390/su17104433
Drago C, Arnone M, Leogrande A. A Machine Learning and Panel Data Analysis of N2O Emissions in an ESG Framework. Sustainability. 2025; 17(10):4433. https://doi.org/10.3390/su17104433
Chicago/Turabian StyleDrago, Carlo, Massimo Arnone, and Angelo Leogrande. 2025. "A Machine Learning and Panel Data Analysis of N2O Emissions in an ESG Framework" Sustainability 17, no. 10: 4433. https://doi.org/10.3390/su17104433
APA StyleDrago, C., Arnone, M., & Leogrande, A. (2025). A Machine Learning and Panel Data Analysis of N2O Emissions in an ESG Framework. Sustainability, 17(10), 4433. https://doi.org/10.3390/su17104433