1.1. Motivation and Background
With the global energy crisis and environmental concerns that are making energy sustainability a pressing issue, the efficient and reliable operation of power systems as the core of power conversion and transmission is key to achieving this goal. Distribution transformers play a pivotal role as indispensable equipment in a power system, and their operational status directly affects the sustainable power supply of the entire system [
1].
Transformers are utilized for converting electrical power across different voltage levels. During long-term operation, a multitude of issues and failures may arise, among which, heavy overload is particularly prominent [
2]. Heavy overload may not only lead to equipment damage and affect the normal operation of a power system but may also aggravate energy waste and environmental pollution.
With the acceleration of industrialization and rapid urban development, there is a frequent occurrence of power demand peaks, necessitating transformers to endure loads exceeding their rated capacity. This operating condition, although potentially temporary, poses a serious threat to transformers’ health and equipment lifespan.
The prolonged operation of a transformer under heavy overload conditions imposes additional thermal stress on its internal components, particularly the insulation material, thereby accelerating the aging process [
3]. Specifically, overheating and the accelerated aging of insulation materials can release toxic chemicals such as nitrogen oxides, which can seriously pollute air quality. This pollution not only harms humans but also directly affects the surrounding ecosystem and biodiversity. Moreover, transformers are susceptible to experiencing partial discharge during heavy overload, which can result in insulation breakdown, short circuits, structural damage, or even more severe failures, such as fire incidents, which pose risks to the safety of both equipment and personnel [
4]. Overheating or fire accidents in the surrounding environment can cause oil leakage. This can contaminate soil and water quality, disrupt the ecological balance, and affect biological habitats and food chains [
5].
Therefore, the accurate prediction and assessment of transformer heavy overload conditions are crucial for maintaining power supply and environmental sustainability [
6,
7]. Currently, methods for predicting and assessing electrical equipment are rapidly advancing and can be categorized into three primary categories.
The first category is the widely used predictive analysis method that uses signal and visual sensing systems. This process entails identifying various aspects of a target through the use of multiple devices and algorithms for perceptual processing. For example, Huang et al. detected transmission lines by constructing application sensors to obtain icing data [
8]. A method of collecting the feature factor parameters of the external environment by establishing multiple sets of external sensors was proposed in [
9]. Jalilian et al. proposed a new method for monitoring the galloping of transmission lines using wireless communication and inertial measurement units [
10]. Although the prediction method based on signal and visual sensing systems can intuitively feel the operating state of electrical equipment and has good accuracy, its internal structure is complex, costly, and easily influenced by the external environment. It also requires external accuracy instruments. As the complexity of power systems continues to deepen, the utilization of sense recognition presents drawbacks due to its complex structure and high cost. Therefore, it is not suitable for large-scale deployment and is only viable for prediction and assessment on a limited scale.
The second category is the predictive analysis method based on the physical model. This method entails developing a model based on the thermal and electrical parameters of the equipment, followed by simulating and predicting the operational state and potential fault effects of the electrical equipment. For example, Gorgan et al. proposed a model for hot-spot temperature that explained the impact of solar radiation on the temperature rise of transformer windings [
11]. A model based on the fundamental heat transfer theory used for the thermal behavior prediction of the top oil of indoor distribution transformers was proposed in [
12]. Shadab et al. proposed a methodology for predicting Top Oil Temperature (TOT) and estimating parameters [
13]. The physical model-based prediction method yields high accuracy. However, it requires the accurate modeling of equipment parameters and a large amount of real-world data. Modeling, calibration, complexity, skill quality, and cost requirements are also steep, making it challenging to apply to aging or obsolete equipment.
The third category is predictive analysis based on machine learning. In recent years, due to the ongoing enhancement of intelligent power systems development, intelligent algorithms have found extensive applications in the domain of fault analysis and the predictive assessment of electrical equipment. Behkam et al. proposed a modified method based on Artificial Neural Network (ANN) techniques to predict fault type detection in distribution transformer windings [
14]. Bacha et al. proposed a Support Vector Machine (SVM) method to realize the classification and discrimination of transformer fault diagnosis [
15]. Sun et al. proposed a novel method based on the MobileNets convolutional neural network (MCNN) to identify the partial discharge mode of transformers [
16]. Yang et al. proposed an integrated method for the fault diagnosis of power transformers based on the Bat Algorithm and Probabilistic Neural Network (BA-PNN) models [
17]. Huang et al. proposed a dissolved gas analysis method for power transformers based on fuzzy logic [
18]. Xiao et al. proposed establishing a Bayesian network to determine the causality between various tests and fault factors and using Bayesian causal probability to diagnose transformer faults [
19]. Lakehal et al. proposed a Bayesian model based on Duval’s triangle for transformer fault analysis prediction [
20]. A short-term heavy overload prediction method for public transformers based on the Long Short-term Memory (LSTM-XGBOOST) combined model was proposed in [
21]. The aforementioned approach has significantly advanced the development of machine learning methods. However, the number of factors considered remains relatively limited. When attempting to incorporate a broader array of factors, there is a noticeable increase in computational complexity. This statement is not applicable to modern large and complex power systems.
The method of pattern recognition (PR) is dedicated to directly excavating the latent patterns and connections within vast and complex datasets. This method is particularly well-suited for predictive evaluations in scenarios involving multiple factors, offering a more comprehensive analysis by seamlessly integrating an extensive range of variables. This capability not only enhances the accuracy of predictions but also extends the applicability of machine learning models to more complex, multifactorial contexts.
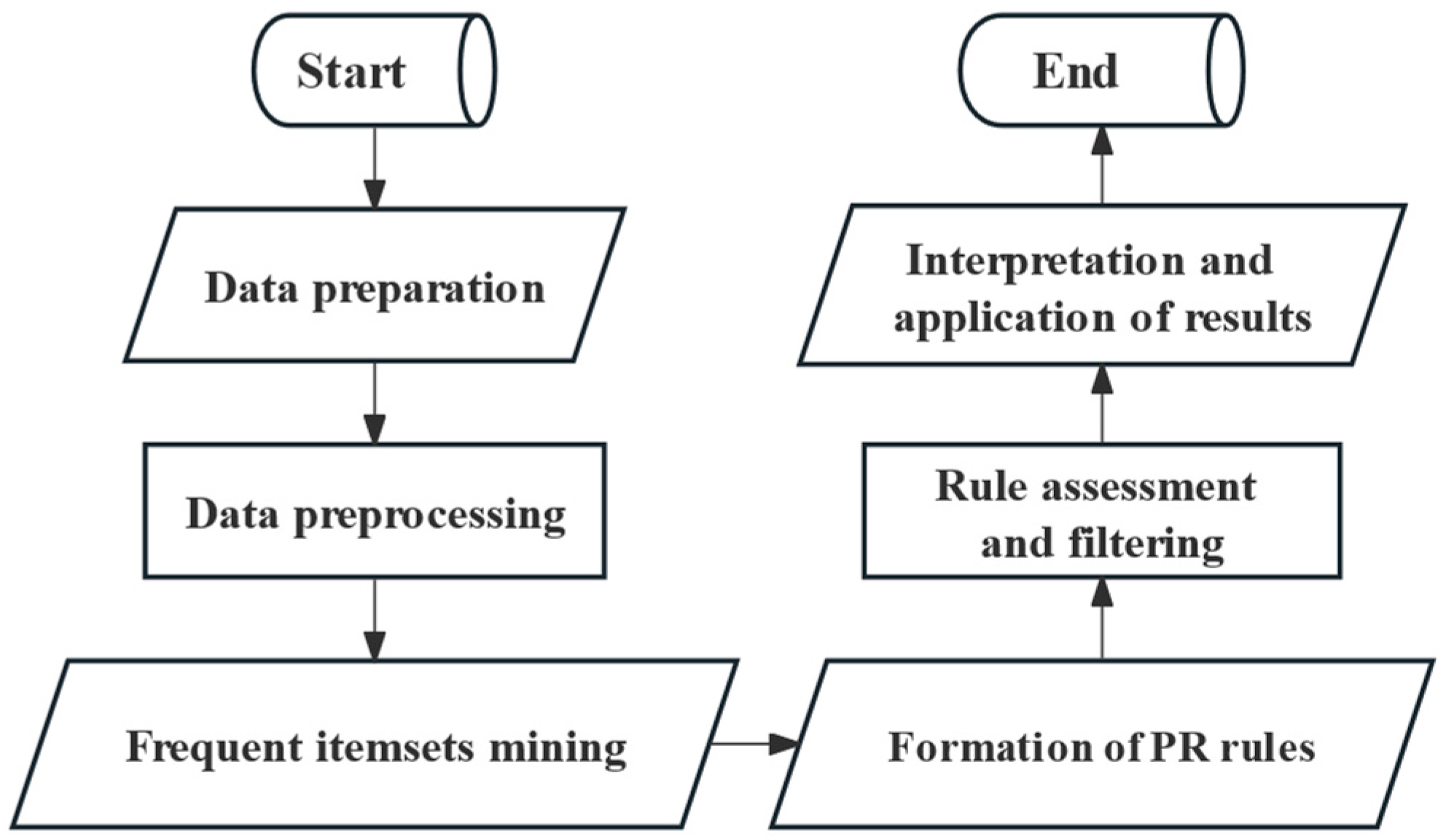
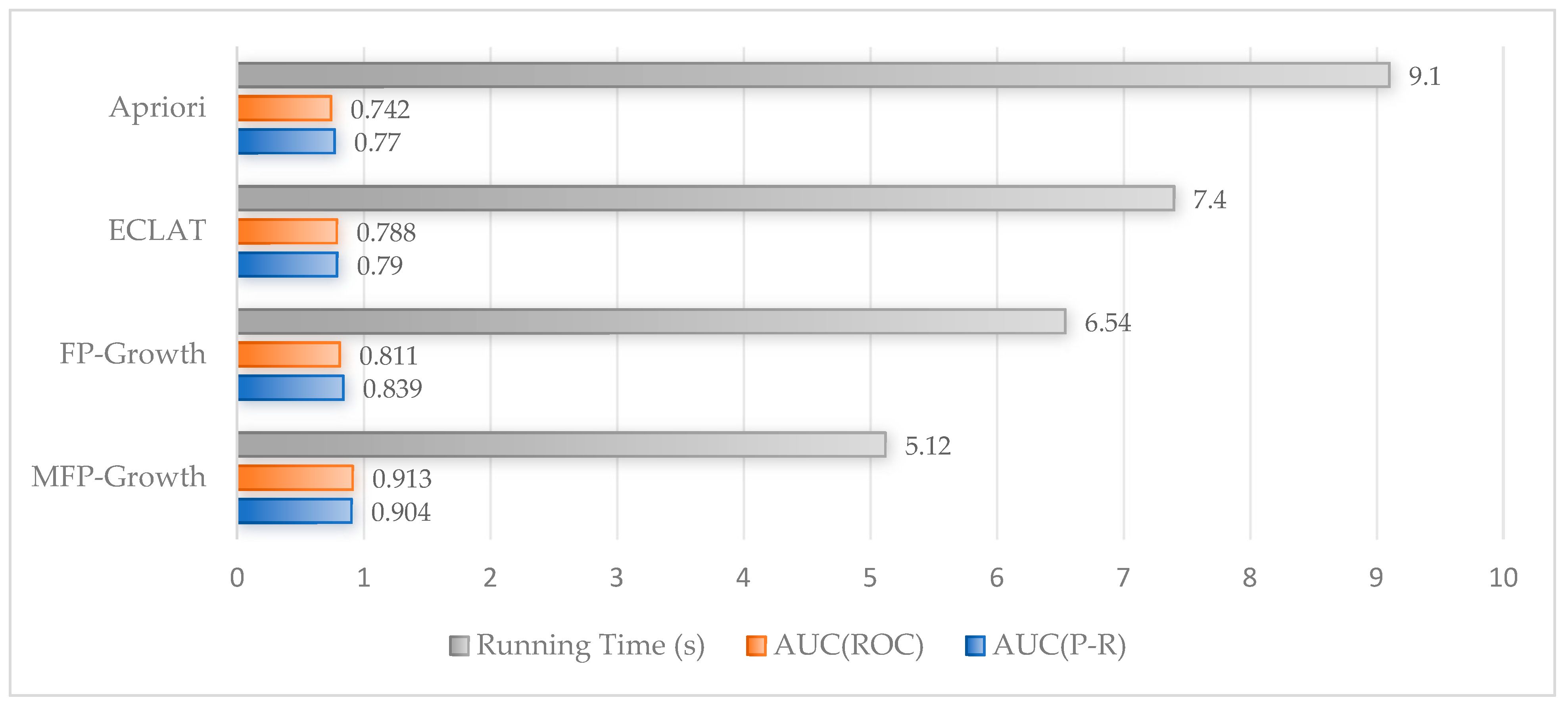
In the field of PR, the Apriori algorithm is one of the most common PR rule algorithms and mainly uses the iterative method of layer-by-layer search to mine the relevance in the item sets and then form PR rules [
22]. Hong et al. proposed using pattern recognition combined with probability images for data mining while constructing a scheme to assess the state of transformers [
23]. Sheng et al. constructed a new multi-state fault prediction model for transformers by combining the Apriori algorithm with the probabilistic image model [
24]. When searching for frequent item sets, the model needs to scan the database several times to generate a large number of redundant candidate item sets. The Eclat algorithm utilizes a vertical data format as the input, which reads the database only once and does not need to read the transaction database several times to determine the support [
25]. Thus, the Eclat algorithm is more efficient than Apriori. But, if the item frequency is very high and the frequent item sets are huge, the intersection operation may consume significant memory, causing mining inefficiency. To overcome the limitations of the Apriori algorithm, the FP-Growth algorithm just scans the database twice and compresses the input data through the FP-tree structure, which greatly optimizes the operation efficiency [
26]. Although these methods effectively combine large amounts of data from multiple sources, they do not provide relevant analyses for the uneven spatio-temporal data of realistic scenarios.
1.2. Problems
While traditional PR has the innate ability to directly integrate massive amounts of data, it is still idealized in data correlation analysis: it typically computes the evaluation PR indexes based on the frequency or ratio of occurrence for feature factors. This means that these algorithms are designed based on the uniform distribution of data in both spatial and temporal dimensions. However, the feature factors contributing to faults often exhibit an imbalance distribution in both temporal and spatial dimensions in real-world scenarios. The traditional method of determining significance by proportionality to the frequency of fault feature factors is unrealistic. Therefore, traditional PR algorithms may overlook or filter out Unusual High-Risk (UHR) factors in calculations. UHR factors have a low frequency of occurrence, but their impact on failure outcomes is significant. It is crucial to handle them promptly to avoid serious consequences. The traditional method does not fully consider these UHR factors under spatiotemporal conditions but, instead, directly adopts fixed thresholds and significance score calculations.
Lightning strike accidents exemplify the imbalance distribution of temporal dimensions, occurring more frequently during summer and less frequently in other seasons. However, conventional methods for assessing this issue still use fixed thresholds for significance diagnostics, i.e., evaluating phenomena with imbalanced data distribution due to seasonal variations using uniform thresholds. Furthermore, general calculations disregard the low frequency of failures during the winter, spring, and autumn seasons. Consequently, the significant scores assigned to corresponding temporal states fall below the thresholds established based on annual failure occurrences, resulting in overlooking these unusual time series straightforwardly. In terms of spatial dimensions, traditional intelligent algorithms use a fixed significance score calculation method, which is inadequate in dealing with the influence of different environmental features on the significance index scores. In regions with temperatures below zero degrees Celsius during winter, the occurrence of ice flash accidents poses a serious threat to the stable operation of power systems due to climatic or topographical factors. In low-latitude flat areas, the probability of ice flash accidents is relatively low due to the warmer climate. However, when confronted with scenarios with the same problem but different environmental features, the use of the traditional method of calculating the severity score may result in the exclusion of ice flash accidents in the low-latitude flat regions that do not meet the minimum thresholds. Differences in environmental features thus have a significant impact on the determination of significance scores, making the traditional definition unable to adapt to the spatial distribution of data in realistic scenarios.
Moreover, the conventional weighting method cannot be applied to real-world scenarios due to the imbalanced nonlinear distribution of data. Most weight calculation methods determine relative impact weights based on the proportion of data. However, this approach cannot effectively measure the high-risk component of unusual factors, and setting weights directly based on frequency of appearance does not align with real-life complex scenarios involving non-linear data. Therefore, additional research is necessary to accurately quantify nonlinear scenarios in real-world data, take into account UHR factors, and design novel weighting models.
1.3. Research and Contributions
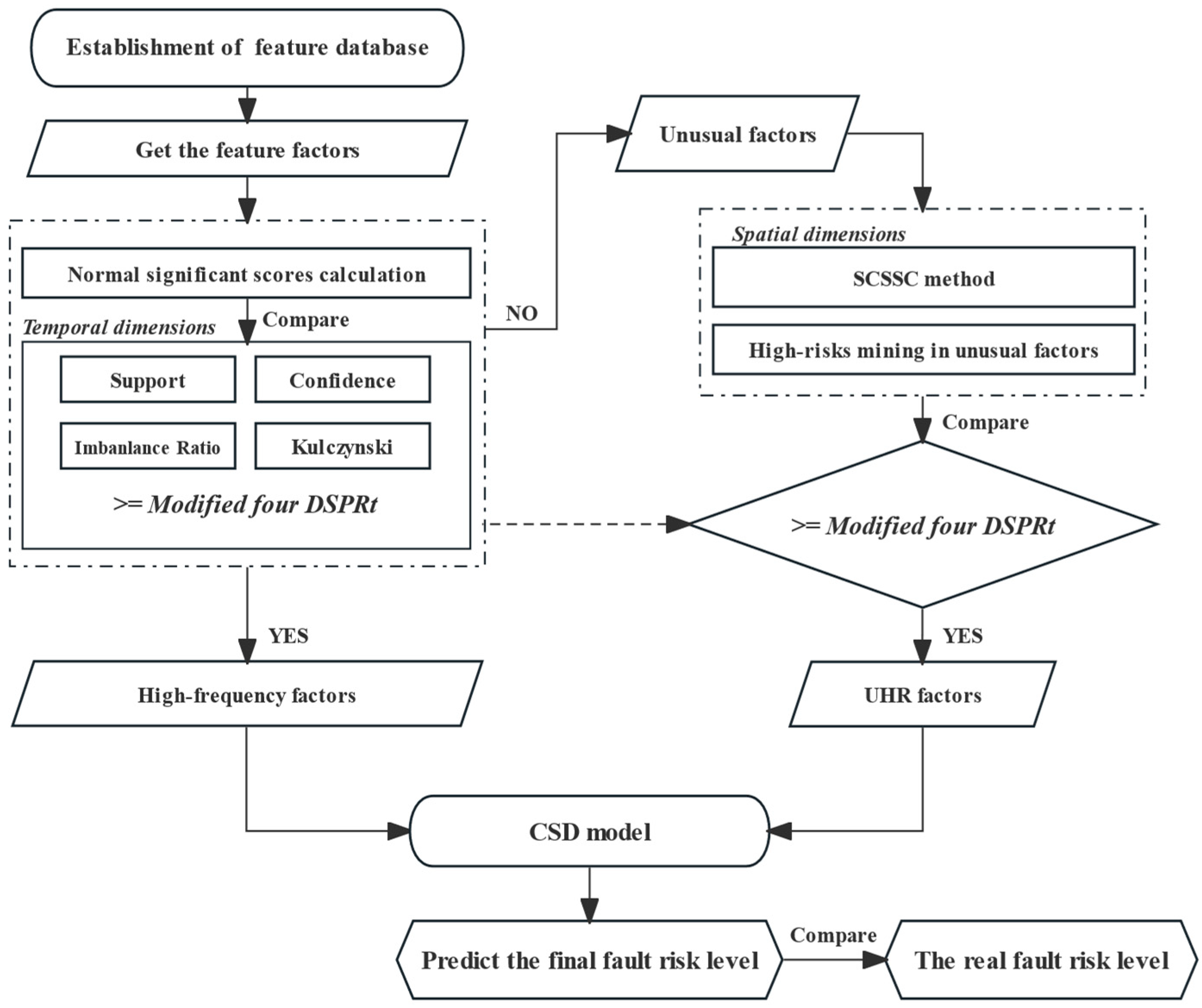
To address those aforementioned limitations, this paper proposes a novel prediction ensemble for transformer heavy overload spatiotemporal distributions. This method can effectively handle the potential imbalance distributions and nonlinear characteristics of feature factors under both spatial and temporal scales by combining the Two-fold Conditional Connection Pattern Recognition (TCCPR) and Component Significance Diagnostic (CSD) models.
Four PR significance indices were reformed to incorporate the risks in different time series. In the temporal dimension, the corresponding four Dynamic Self-adaptive PR thresholds (DSPRt) were updated periodically to ensure that the feature factors under different temporal states were also evaluated differently. This revealed the rules and trends related to transformer heavy overload in time scales. The method of Spatial Conditional Significance Score Calculation (SCSSC) considered the influence of the spatial distribution of diverse environmental condition features and factors. The significance score calculations of the unusual factors were decided via dynamic self-adaptive PR threshold screening. This comprehensively assessed these unusual factors once again to enable the identification of included high-risk components (UHR factors). Hence, the TCCPR model was established by integrating DSPRt and the SCSSC to cover potential UHR factors when various imbalanced time series and spatial factor distributions were probed.
Additionally, the CSD model was built to measure impacting weights for the distinguished risk factors for nonlinear data scenarios. The CSD model captured the potential relevance between environmental feature factors and overload failures. The risk of overall system failure could be determined utilizing the component significance (CS) and risk structure theory. The impacting weights of each risky factor were then figured out by measuring the trend and magnitude of changes by each factor pair on the overall system failure risk. For instance, the appearance of a high-risk factor led to a more significant change in the overall system risk compared to that with lower risks. As a result, the impacting weight could be decided straightforwardly according to the extra risks generated by each factor, rather than merely data proportion or appearance frequency.
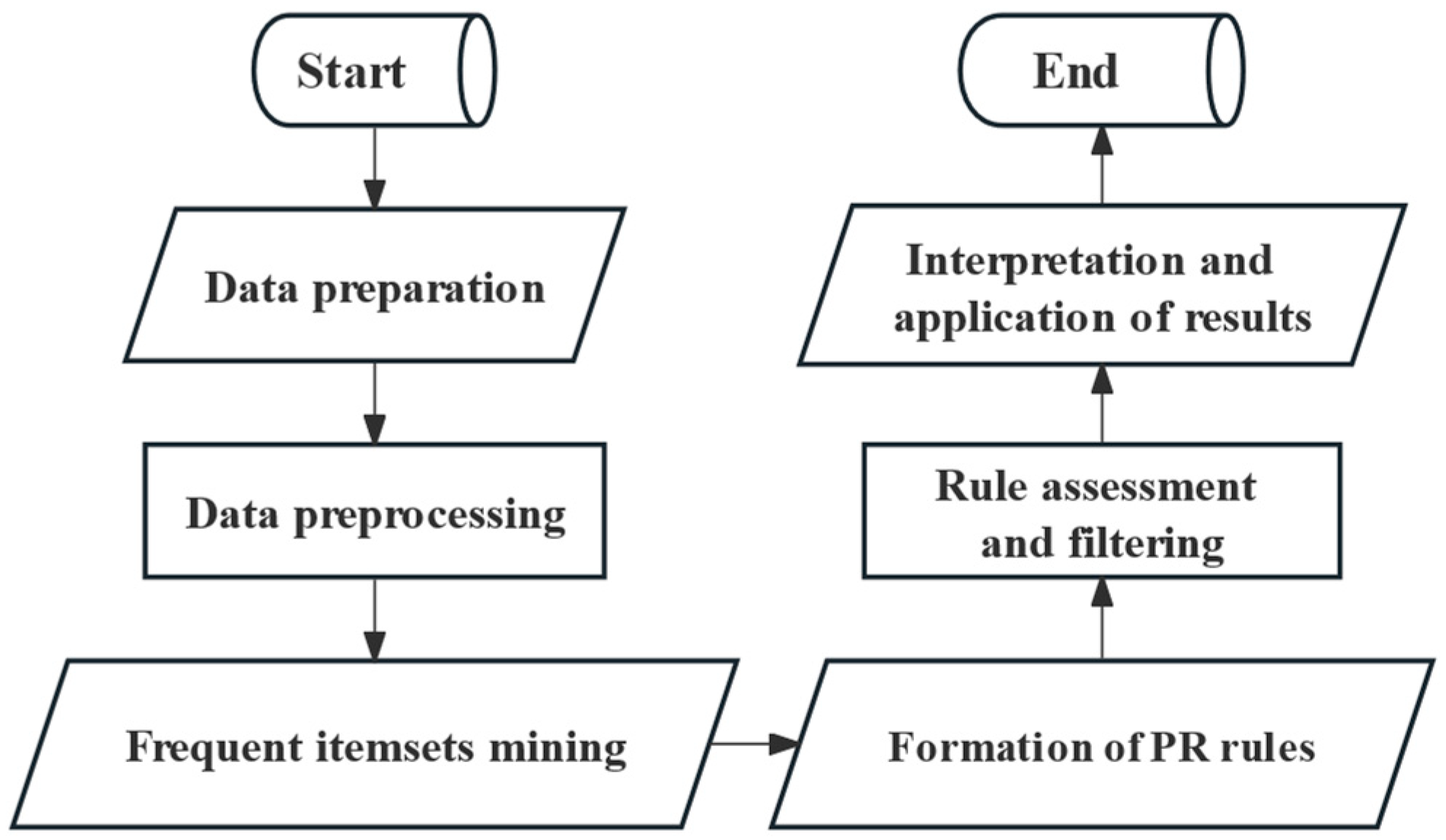
Finally, this ensemble was conducted via the MFP-Growth algorithm, and an empirical case study demonstrated its adaptability in the multi-source imbalanced and nonlinear data environment, enhancing the prediction performance of transformer heavy overload occurrences.
In modern power systems, the amount of data generated by various devices, sensors, and control systems is so large and complex that traditional data processing and analysis methods may struggle to handle it. The proposed method offers significant advantages in terms of comprehensiveness and flexibility, allowing for the direct mining of potential laws and connections in massive and complex datasets. The DSPRt and SCSSC models can self-adapt the threshold and significance according to different power system data spatiotemporal distributions and thus can be widely used in various power system scenarios. This approach can be widely applied in various power system scenarios, regardless of data type or number, and is therefore highly scalable to other predictions in a power system.
The challenges in implementing the TCCPR model should not be underestimated. Precise description of the data is particularly difficult due to the continuous nature of environmental factors, which require discretization. It is important to note that different discretization methods may have varying impacts on the results.
The contributions of this paper include the following:
The proposed method obviates the necessity for the direct extraction of potential relationships between condition components and transformer heavy overloads, thereby enabling heavy overload predictions for distribution transformers under application data scenarios in the real world.
The TCCPR model incorporates DSPRt and SCSSC to effectively consider the distribution of UHR factors across different time series and environmental features. This enables an all-inclusive analysis of multi-source inputs in cases of both imbalanced spatial and temporal data distributions, which results in enhanced prediction performance, especially in imbalanced data scenes.
The CSD model applies a direct measurement of the relative risk impact weights of each factor by analyzing the changing trend and amplitude of the overall system risk that results from their appearance. Compared with the appearance frequency or data proportion, this model provides a more straightforward weight assessment via their impacts on fault results, making it more feasible, especially within nonlinear data scenarios.
The remaining sections of this paper are organized as follows:
Section 2 provides a detailed exposition of the theoretical underpinnings and construction process of the TCCPR-CSD model, including the establishment of an evaluation feature database, the determination method for Dynamic Self-adaptive PR thresholds (DSPRts), and the application of Spatial Condition Significance Scoring Calculation (SCSSC).
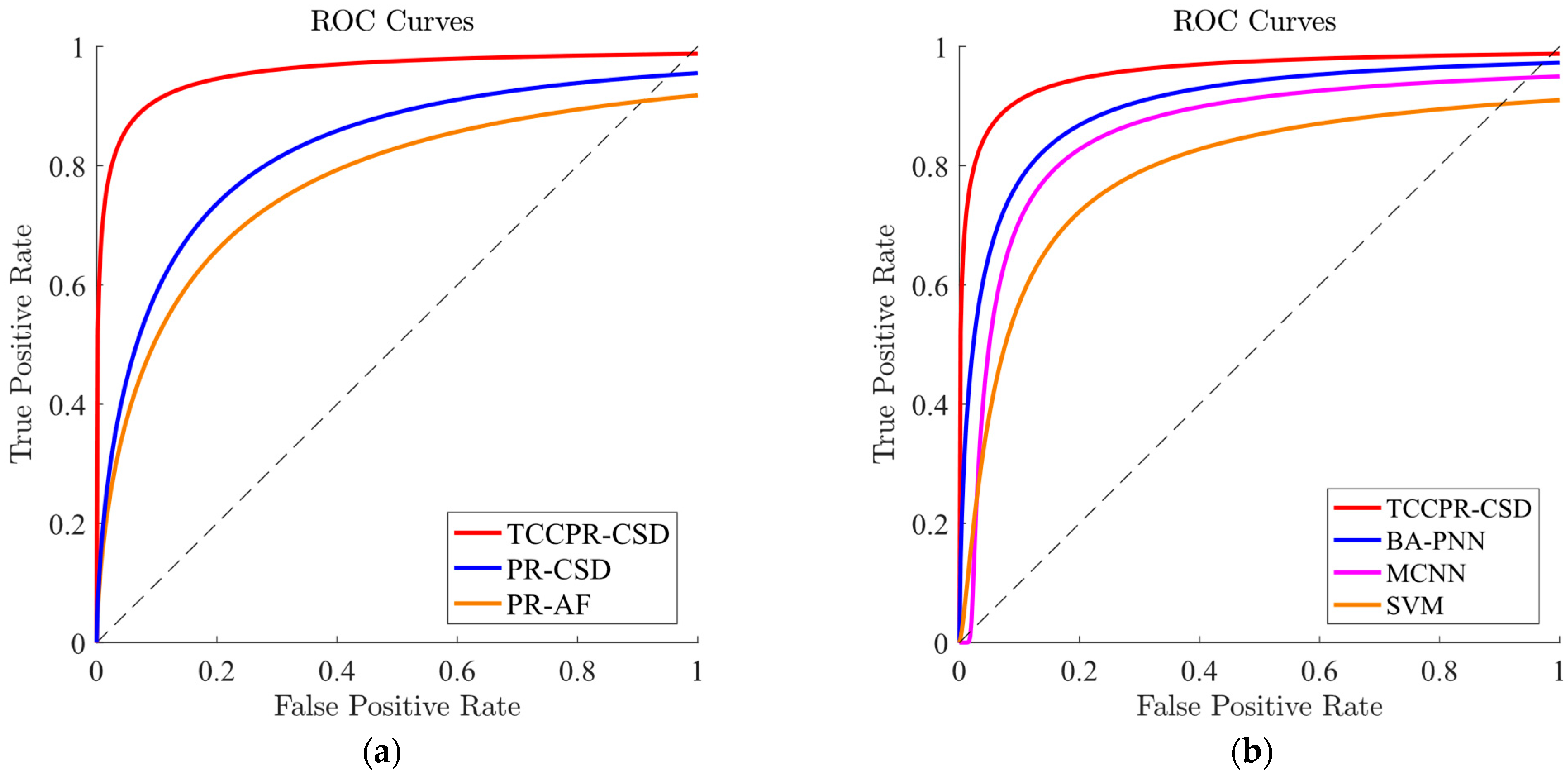
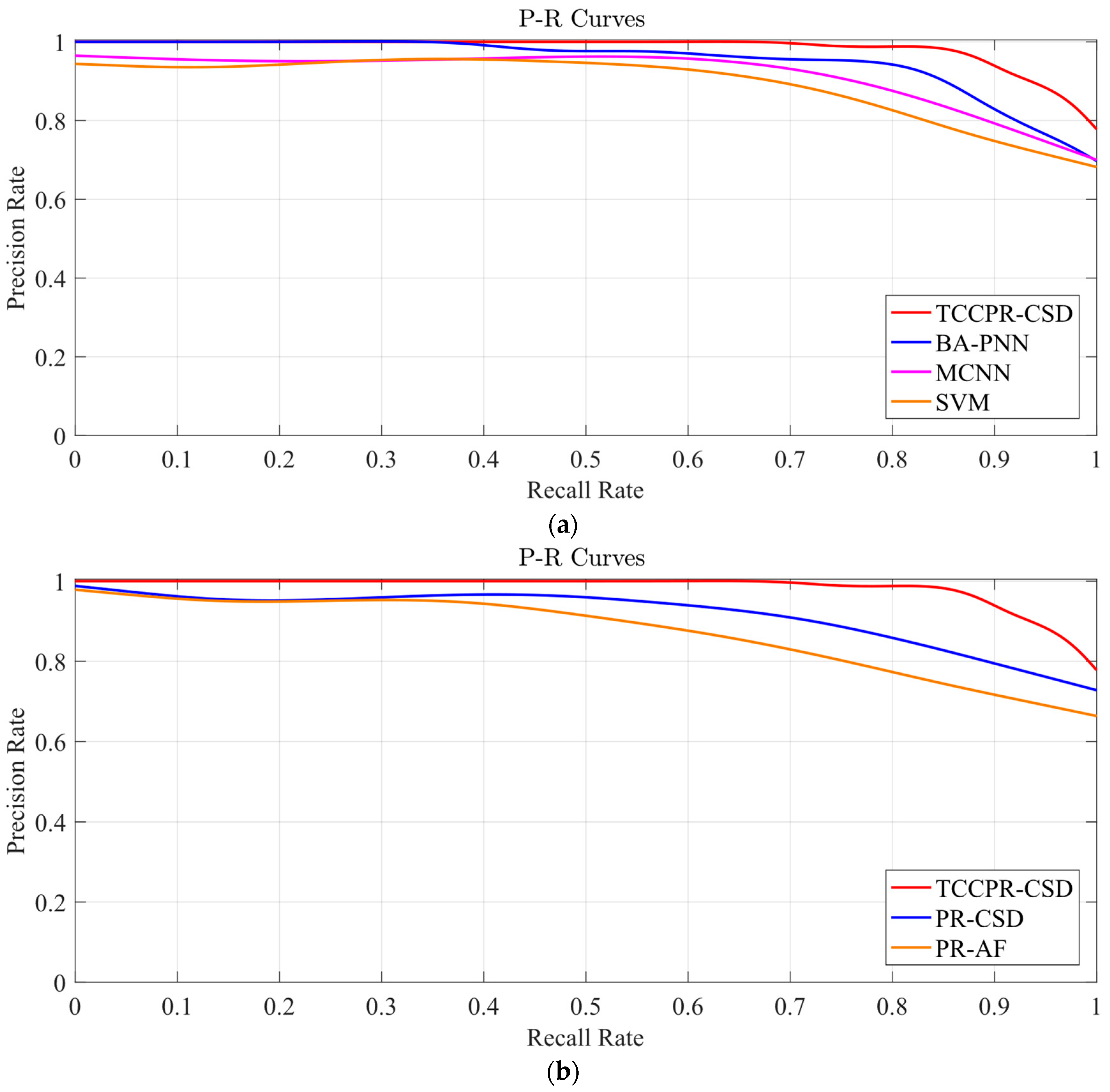
Section 3 demonstrates the application process and results of the model through an empirical case study, validating the model’s effectiveness in predicting heavy overload events in distribution transformers.
Section 4 concludes with the main findings of the research.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}