_Li.png)
The Industrial Application of Artificial Intelligence-Based Optical Character Recognition in Modern Manufacturing Innovations


Abstract
1. Introduction
- 1.
- OCR systems significantly enhance the efficiency of production lines by providing continuous operation, which markedly contrasts with the slower, more error-prone manual inspection processes, particularly in high-volume manufacturing environments.
- 2.
- These systems offer consistent and accurate text-reading capabilities, ensuring precise product identification, a critical requirement often compromised in manual inspections, especially at scale.
- 3.
- The ability of OCR systems to rapidly convert optical character data into digital format is increasingly crucial as manufacturers integrate Internet of Things (IoT) and Big Data analytics into their operations. This integration, facilitated by OCR, enables real-time data management and analysis, a cornerstone of Industry 4.0.
- 1.
- Data Availability: There is a lack of suitable public data for training the OCR system. Additionally, the collection and labeling of on-site data are challenges regarding both time and financial resources.
- 2.
- The on-site data quality is poor as illustrated in Figure 2. It causes difficulty in both training and testing. Specific issues include the following:
- Figure 2a: High background noise.
- Figure 2b: Variable text sizing due to the varying distances between the camera and the target text.
- Figure 2c: Issues with illumination, leading to reflections or shadows.
- Figure 2d: Wear and tear: Text on iron plates erodes due to water stains and material wear in outdoor and factory settings. This degradation is exacerbated when the plates are stacked, leading to further deterioration.
- Figure 2e: The use of varied, uncommon, and non-standard fonts renders public font datasets and pre-trained models unsuitable for direct application in our specific task.
- Figure 2f: Non-frontal shooting angles result in severe perspective transformations of text images.

- 1.
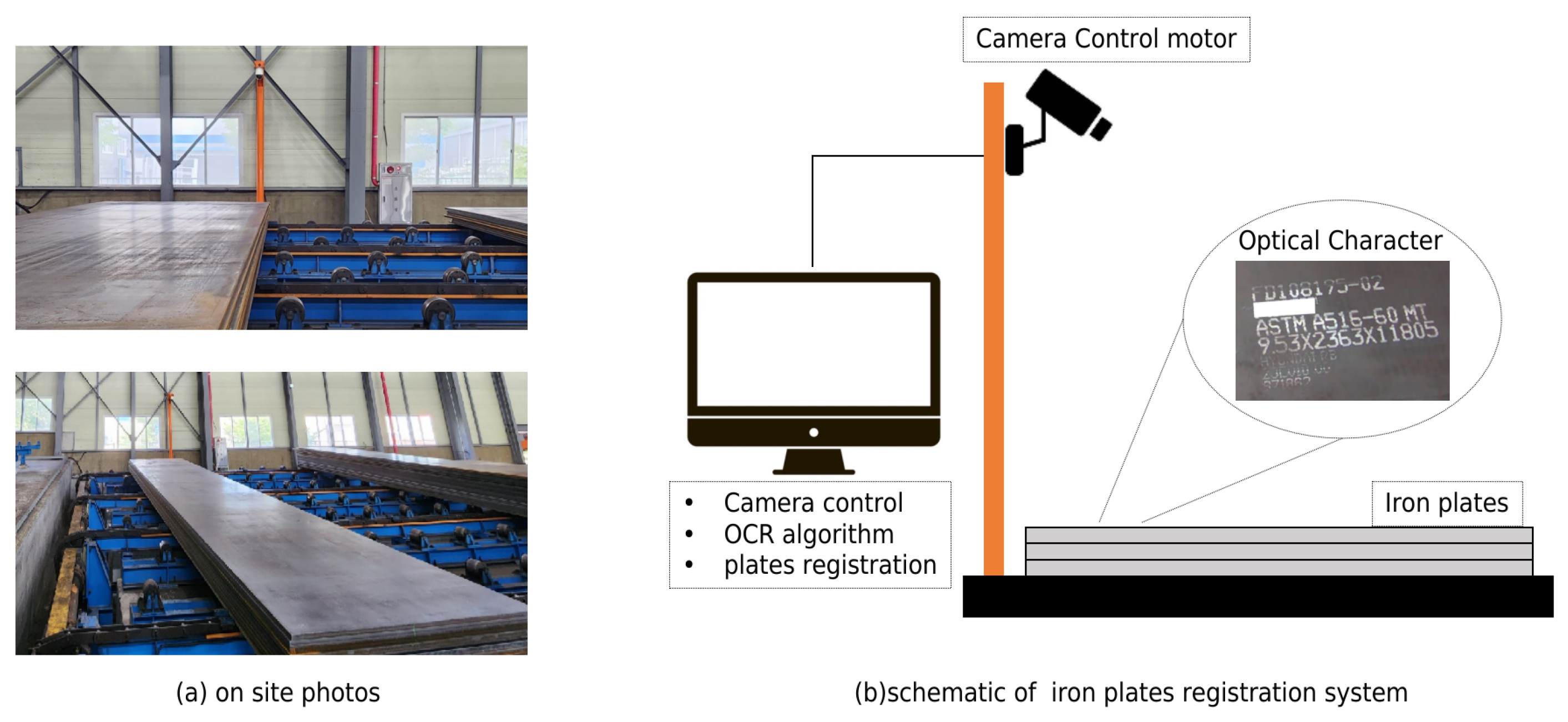
- This study develops a comprehensive on-site industrial OCR system tailored for the autonomous registration of iron plates. This system encompasses processing from the underlying algorithm to the user interface, offering a holistic solution that addresses the unique challenges of the industrial environment.
- 2.
- This study introduces a novel pre-processing methodology that includes the synthetic image generation (SIG) and strong data augmentation (SDA) techniques. These two technologies effectively mitigate the challenges posed by data scarcity in on-site industrial settings, enhancing the robustness and accuracy of the OCR system.
- 3.
- The designed autonomous OCR system significantly improves the efficiency of iron plate registration processes, leading to substantial reductions in both time and labor costs for factories. These outcomes not only showcase the practical benefits of our system but also highlight its potential to transform on-site industrial operations.
2. Literature Review and Hypothesis Development
2.1. Literature Review
2.1.1. General OCR
2.1.2. Industrial OCR
2.2. Hypothesis Development
3. Proposed Industrial AI-Based OCR System
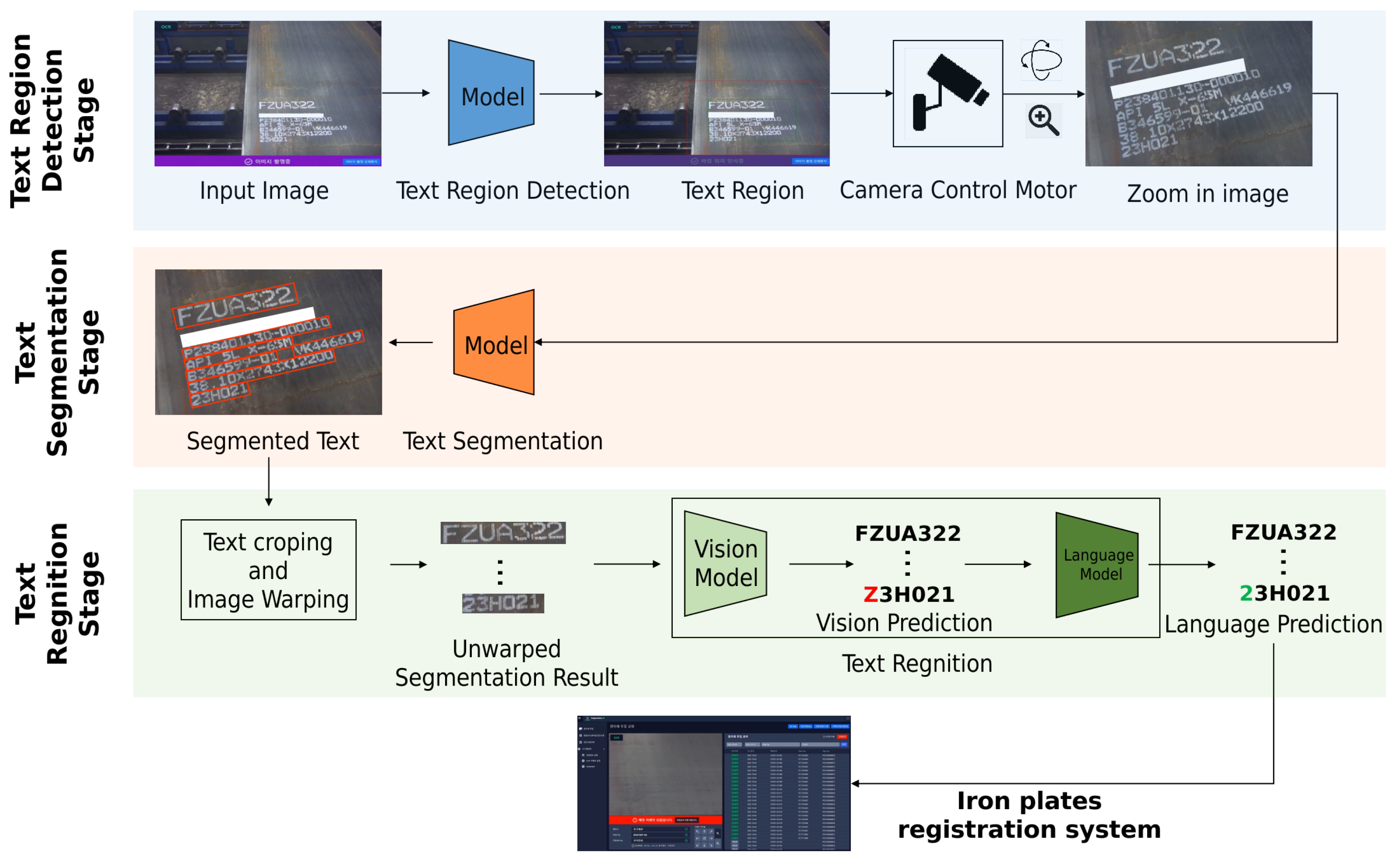
3.1. OCR Image Acquisition
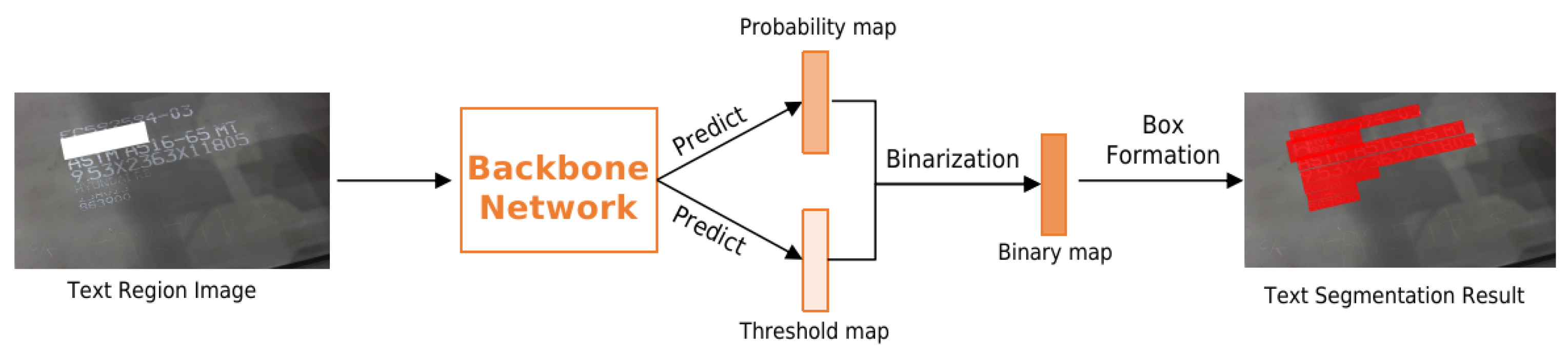
3.2. Text Segmentation
3.3. Segmented Text Image Warping
| Algorithm 1 Text segmentation image warping. |
Require: Z: Zoom in image Require: Text segmentation result : [(, ), (, ), (, ), (, )] Require: , : Width and height of the warped image Ensure: U Step 1: Step 2: transformation matrix Step 3: warped text segmentation result |
3.4. Language-Based Text Recognition Network
- 1.
- Autonomous Strategy: This strategy enables the language model to operate independently of the vision model, allowing for its replacement. In other words, the language model can be trained separately and then serve as a spelling corrector, enhancing the output of the vision model.
- 2.
- Bidirectional Representation: Contrary to models that process character sequences in a unidirectional (left-to-right) manner, ABINet adopts a bidirectional approach, analyzing language features from both left to right, and right to left. This bidirectional representation is crucial for our OCR tasks in industrial products, where the position of characters often conveys specific meanings with patterns. For instance, certain positions might indicate the production date using only numbers, while others could denote the quality level of the material with English letters. The effectiveness of ABINet in these scenarios where character positioning is meaningful highlights its superiority for industrial product OCR tasks. The experimental results presented in Table 2 also support this assertion.
- 3.
- Iterative Correction: ABINet introduces an iterative correction mechanism to address the challenges posed by noisy inputs, such as blurred or occluded text. The language model iteratively refines the vision model’s predictions, making it particularly suitable for our application where text quality is compromised by factors like poor lighting or wear and tear as discussed in Section 1 and illustrated in Figure 2.
4. Proposed Data Pre-Processing Strategy for Industrial OCR System
4.1. Synthetic Image Generation
4.2. Strong Data Augmentation
- Blurring: to mimic variable text resolution that might arise from varying distances between the camera and the target text;
- Random Brightness: implemented to simulate changes in the illumination conditions.
- Random Rain: this technique is used to simulate the appearance of water stains on the images.
- Lightening Specific Regions: this technique mimics the effects of light or sun reflections that can interfere with text visibility.
- Darkening Specific Areas: this is applied to represent shadows or occlusions that can obscure parts of the text.
5. Experiment
5.1. Datasets and Implementation Details
5.2. Comparison Result
5.2.1. Text Segmentation Model
5.2.2. Text Recognition Model
5.3. System Result
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Haseeb, M.; Hussain, H.I.; Ślusarczyk, B.; Jermsittiparsert, K. Industry 4.0: A Solution towards Technology Challenges of Sustainable Business Performance. Soc. Sci. 2019, 8, 154. [Google Scholar] [CrossRef]
- Sanchez, M.; Exposito, E.; Aguilar, J. Industry 4.0: Survey from a system integration perspective. Int. J. Comput. Integr. Manuf. 2020, 33, 1017–1041. [Google Scholar] [CrossRef]
- Oztemel, E.; Gursev, S. Literature review of Industry 4.0 and related technologies. J. Intell. Manuf. 2018, 31, 127–182. [Google Scholar] [CrossRef]
- Woschank, M.; Rauch, E.; Zsifkovits, H. A Review of Further Directions for Artificial Intelligence, Machine Learning, and Deep Learning in Smart Logistics. Sustainability 2020, 12, 3760. [Google Scholar] [CrossRef]
- Devasena, D.; Dharshan, Y.; Vivek, S.; Sharmila, B. AI-Based Quality Inspection of Industrial Products. In Handbook of Research on Thrust Technologies Effect on Image Processing; IGI Global: Hershey, PA, USA, 2023; pp. 116–134. [Google Scholar] [CrossRef]
- Kovvuri, R.R.; Kaushik, A.; Yadav, S. Disruptive technologies for smart farming in developing countries: Tomato leaf disease recognition systems based on machine learning. Electron. J. Inf. Syst. Dev. Ctries. 2023, 89, e12276. [Google Scholar] [CrossRef]
- Li, L.; Lv, M.; Jia, Z.; Ma, H. Sparse Representation-Based Multi-Focus Image Fusion Method via Local Energy in Shearlet Domain. Sensors 2023, 23, 2888. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Li, W.; Gao, C.; Yang, Y.; Chang, K. Hyperspectral pathology image classification using dimension-driven multi-path attention residual network. Expert Syst. Appl. 2023, 230, 120615. [Google Scholar] [CrossRef]
- Jung, H.; Rhee, J. Application of YOLO and ResNet in Heat Staking Process Inspection. Sustainability 2022, 14, 15892. [Google Scholar] [CrossRef]
- Tang, Q.; Jung, H. Reliable Anomaly Detection and Localization System: Implications on Manufacturing Industry. IEEE Access 2023, 11, 114613–114622. [Google Scholar] [CrossRef]
- Wang, X.; Li, Y.; Liu, J.; Zhang, J.; Du, X.; Liu, L.; Liu, Y. Intelligent Micron Optical Character Recognition of DFB Chip Using Deep Convolutional Neural Network. IEEE Trans. Instrum. Meas. 2022, 71, 1–9. [Google Scholar] [CrossRef]
- Caldeira, T.; Ciarelli, P.M.; Neto, G.A. Industrial Optical Character Recognition System in Printing Quality Control of Hot-Rolled Coils Identification. J. Control Autom. Electr. Syst. 2020, 31, 108–118. [Google Scholar] [CrossRef]
- Subedi, B.; Yunusov, J.; Gaybulayev, A.; Kim, T.H. Development of a Low-cost Industrial OCR System with an End-to-end Deep Learning Technology. J. Embed. Syst. Appl. 2020, 15, 51–60. [Google Scholar]
- Cai, B. Deep learning Optical Character Recognition in PCB Dark Silk Recognition. World J. Eng. Technol. 2023, 11, 1–9. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, B.; Chen, Z.; Yan, J.; Liu, F.; Wang, Y.; Zhang, Q. A Machine Vision-Based Character Recognition System for Suspension Insulator Iron Caps. IEEE Trans. Instrum. Meas. 2023, 72, 1–13. [Google Scholar] [CrossRef]
- Kazmi, W.; Nabney, I.; Vogiatzis, G.; Rose, P.; Codd, A. An Efficient Industrial System for Vehicle Tyre (Tire) Detection and Text Recognition Using Deep Learning. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1264–1275. [Google Scholar] [CrossRef]
- Paglinawan, C.C.; Caliolio, M.H.M.; Frias, J.B. Medicine Classification Using YOLOv4 and Tesseract OCR. In Proceedings of the 2023 15th International Conference on Computer and Automation Engineering (ICCAE), Sydney, Australia, 3–5 March 2023; pp. 260–263. [Google Scholar]
- Neumann, L.; Matas, J. Real-time scene text localization and recognition. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3538–3545. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 3rd ed.; Pearson: London, UK, 2007. [Google Scholar]
- Yang, C.; Yang, Y. Improved local binary pattern for real scene optical character recognition. Pattern Recognit. Lett. 2017, 100, 14–21. [Google Scholar] [CrossRef]
- Liao, M.; Zou, Z.; Wan, Z.; Yao, C.; Bai, X. Real-Time Scene Text Detection with Differentiable Binarization and Adaptive Scale Fusion. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 919–931. [Google Scholar] [CrossRef] [PubMed]
- Fang, S.; Mao, Z.; Xie, H.; Wang, Y.; Yan, C.; Zhang, Y. ABINet++: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Spotting. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 7123–7141. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Xie, E.; Li, X.; Hou, W.; Lu, T.; Yu, G.; Shao, S. Shape robust text detection with progressive scale expansion network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9336–9345. [Google Scholar]
- Mudhsh, M.; Almodfer, R. Arabic Handwritten Alphanumeric Character Recognition Using Very Deep Neural Network. IInformation 2017, 8, 105. [Google Scholar] [CrossRef]
- Mathew, A.; Kulkarni, A.; Antony, A.; Bharadwaj, S.; Bhalerao, S. DOCR-CAPTCHA: OCR Classifier based Deep Learning Technique for CAPTCHA Recognition. In Proceedings of the 2021 19th OITS International Conference on Information Technology (OCIT), Bhubaneswar, India, 16–18 December 2021; pp. 347–352. [Google Scholar]
- Alsuhibany, S.A.; Parvez, M.T. Secure Arabic Handwritten CAPTCHA Generation Using OCR Operations. In Proceedings of the 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; pp. 126–131. [Google Scholar]
- Liao, M.; Shi, B.; Bai, X. Textboxes++: A single-shot oriented scene text detector. IEEE Trans. Image Process. 2018, 27, 3676–3690. [Google Scholar] [CrossRef] [PubMed]
- Liao, M.; Shi, B.; Bai, X.; Wang, X.; Liu, W. Textboxes: A fast text detector with a single deep neural network. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- He, P.; Huang, W.; He, T.; Zhu, Q.; Qiao, Y.; Li, X. Single shot text detector with regional attention. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3047–3055. [Google Scholar]
- Zhang, Z.; Zhang, C.; Shen, W.; Yao, C.; Liu, W.; Bai, X. Multioriented text detection with fully convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liao, M.; Lyu, P.; He, M.; Yao, C.; Wu, W.; Bai, X. Mask textspotter: An end-to-end trainable neural network for spotting text with arbitrary shapes. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 532–548. [Google Scholar] [CrossRef] [PubMed]
- Lyu, P.; Liao, M.; Yao, C.; Wu, W.; Bai, X. Mask textspotter: An end-to-end trainable neural network for spotting text with arbitrary shapes. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 67–83. [Google Scholar]
- Xue, C.; Lu, S.; Zhan, F. Accurate Scene Text Detection through Border Semantics Awareness and Bootstrapping. arXiv 2018, arXiv:1807.03547. [Google Scholar]
- Graves, A.; Fernandez, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labeling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully convolutional instance-aware semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2359–2367. [Google Scholar]
- Wan, Z.; He, M.; Chen, H.; Bai, X.; Yao, C. Textscanner: Reading characters in order for robust scene text recognition. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI-20), New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep structured output learning for unconstrained text recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Lee, C.-Y.; Osindero, S. Recursive recurrent nets with attention modeling for ocr in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June–30 June 2016; pp. 2231–2239. [Google Scholar]
- Qiao, Z.; Zhou, Y.; Yang, D.; Zhou, Y.; Wang, W. Seed: Semantics enhanced encoder-decoder framework for scene text recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13528–13537. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhu, Y.; Chen, J.; Liang, L.; Kuang, Z.; Jin, L.; Zhang, W. Fourier Contour Embedding for Arbitrary-Shaped Text Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 3122–3130. [Google Scholar]
- Shi, B.; Yang, M.; Wang, X.; Lyu, P.; Yao, C.; Bai, X. ASTER: An Attentional Scene Text Recognizer with Flexible Rectification. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2035–2048. [Google Scholar] [CrossRef] [PubMed]
- Sheng, F.; Chen, Z.; Xu, B. NRTR: A No-Recurrence Sequence-to-Sequence Model for Scene Text Recognition. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 781–786. [Google Scholar]
- Lee, J.; Park, S.; Baek, J.; Oh, S.J.; Kim, S.; Lee, H. On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 2326–2335. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Tang, Q.; Cao, G.; Jo, K.H. Integrated Feature Pyramid Network with Feature Aggregation for Traffic Sign Detection. IEEE Access 2021, 9, 117784–117794. [Google Scholar] [CrossRef]
- Kuang, Z.; Sun, H.; Li, Z.; Yue, X.; Lin, T.H.; Chen, J.; Wei, H.; Zhu, Y.; Gao, T.; Zhang, W.; et al. MMOCR: A Comprehensive Toolbox for Text Detection, Recognition and Understanding. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Karatzas, D.; Shafait, F.; Uchida, S.; Iwamura, M.; Gomez, L.; Robles, S.; Mas, J.; Fernandez, D.; Almazan, J.; Heras, L.P.d. ICDAR 2013 Robust Reading Competition. In Proceedings of the 12th International Conference of Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1115–1124. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Our Data Pre-Processing Strategy | Recall | Precision | F1 Score | |
|---|---|---|---|---|---|
| SIG | SDA | ||||
| DBNet [21] | ✗ | ✗ | 0.3325 | 0.4961 | 0.3981 |
| ✓ | ✗ | 0.3782 | 0.6257 | 0.4714 | |
| ✓ | ✓ | 0.3818 | 0.6592 | 0.4836 | |
| Mask-RCNN [40] | ✗ | ✗ | 0.4571 | 0.7558 | 0.5668 |
| ✓ | ✗ | 0.4859 | 0.7256 | 0.5820 | |
| ✓ | ✓ | 0.5143 | 0.6828 | 0.5867 | |
| FCENet [41] | ✗ | ✗ | 0.5013 | 0.7539 | 0.6022 |
| ✓ | ✗ | 0.5841 | 0.7234 | 0.6463 | |
| ✓ | ✓ | 0.6130 | 0.6921 | 0.6501 | |
| DBNet++ [21] | ✗ | ✗ | 0.5792 | 0.8577 | 0.6915 |
| ✓ | ✗ | 0.7214 | 0.7532 | 0.7370 | |
| ✓ | ✓ | 0.7481 | 0.8067 | 0.7763 | |
| Model | Our Data Pre-Processing Strategy | Recall | Precision | F1 Score | Accuracy | |
|---|---|---|---|---|---|---|
| SIG | SDA | |||||
| ASTER [42] | ✗ | ✗ | 0.740 | 0.831 | 0.783 | 0.487 |
| ✓ | ✗ | 0.826 | 0.876 | 0.850 | 0.601 | |
| ✓ | ✓ | 0.869 | 0.902 | 0.885 | 0.636 | |
| NTRT [43] | ✗ | ✗ | 0.798 | 0.801 | 0.799 | 0.460 |
| ✓ | ✗ | 0.826 | 0.897 | 0.860 | 0.611 | |
| ✓ | ✓ | 0.834 | 0.910 | 0.870 | 0.623 | |
| SATRN [44] | ✗ | ✗ | 0.795 | 0.711 | 0.751 | 0.443 |
| ✓ | ✗ | 0.843 | 0.879 | 0.860 | 0.625 | |
| ✓ | ✓ | 0.870 | 0.899 | 0.884 | 0.659 | |
| ABINet [22] | ✗ | ✗ | 0.990 | 0.990 | 0.990 | 0.921 |
| ✓ | ✗ | 0.990 | 0.991 | 0.990 | 0.926 | |
| ✓ | ✓ | 0.993 | 0.991 | 0.992 | 0.928 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, Q.; Lee, Y.; Jung, H. The Industrial Application of Artificial Intelligence-Based Optical Character Recognition in Modern Manufacturing Innovations. Sustainability 2024, 16, 2161. https://doi.org/10.3390/su16052161
Tang Q, Lee Y, Jung H. The Industrial Application of Artificial Intelligence-Based Optical Character Recognition in Modern Manufacturing Innovations. Sustainability. 2024; 16(5):2161. https://doi.org/10.3390/su16052161
Chicago/Turabian StyleTang, Qing, YoungSeok Lee, and Hail Jung. 2024. "The Industrial Application of Artificial Intelligence-Based Optical Character Recognition in Modern Manufacturing Innovations" Sustainability 16, no. 5: 2161. https://doi.org/10.3390/su16052161
APA StyleTang, Q., Lee, Y., & Jung, H. (2024). The Industrial Application of Artificial Intelligence-Based Optical Character Recognition in Modern Manufacturing Innovations. Sustainability, 16(5), 2161. https://doi.org/10.3390/su16052161