
Convolutional Neural Network-Based Bidirectional Gated Recurrent Unit–Additive Attention Mechanism Hybrid Deep Neural Networks for Short-Term Traffic Flow Prediction

 ,
,
Abstract
1. Introduction
- (1)
- Adopting the concept of encoding–decoding, using CNN and BiGRU for encoding, and employing the additive attention mechanism as the decoder. Through regularization of the recurrent weights, the model becomes more robust, and, combined with the use of the isolation forest anomaly detection algorithm, can handle data missingness, anomalies, and noise, thus improving the applicability and reliability of the model.
- (2)
- Taking into account the complex spatial and temporal relationships between weather and traffic flow data, using a CNN to determine the spatial attributes of weather and traffic flow in the input sequence, and utilizing BiGRU to encapsulate the temporal dynamics of the input sequence. By applying the additive attention mechanism to endow the model with the capability to dynamically prioritize different components, and concatenating the above models along the feature dimension’s last axis, the accuracy of traffic flow prediction is enhanced.
- (3)
- By using the idea of decomposition–prediction–integration, the model’s efficacy in addressing practical traffic prediction problems is demonstrated through experiments and evaluation.
2. Methodological Overview
2.1. Convolutional Neural Networks
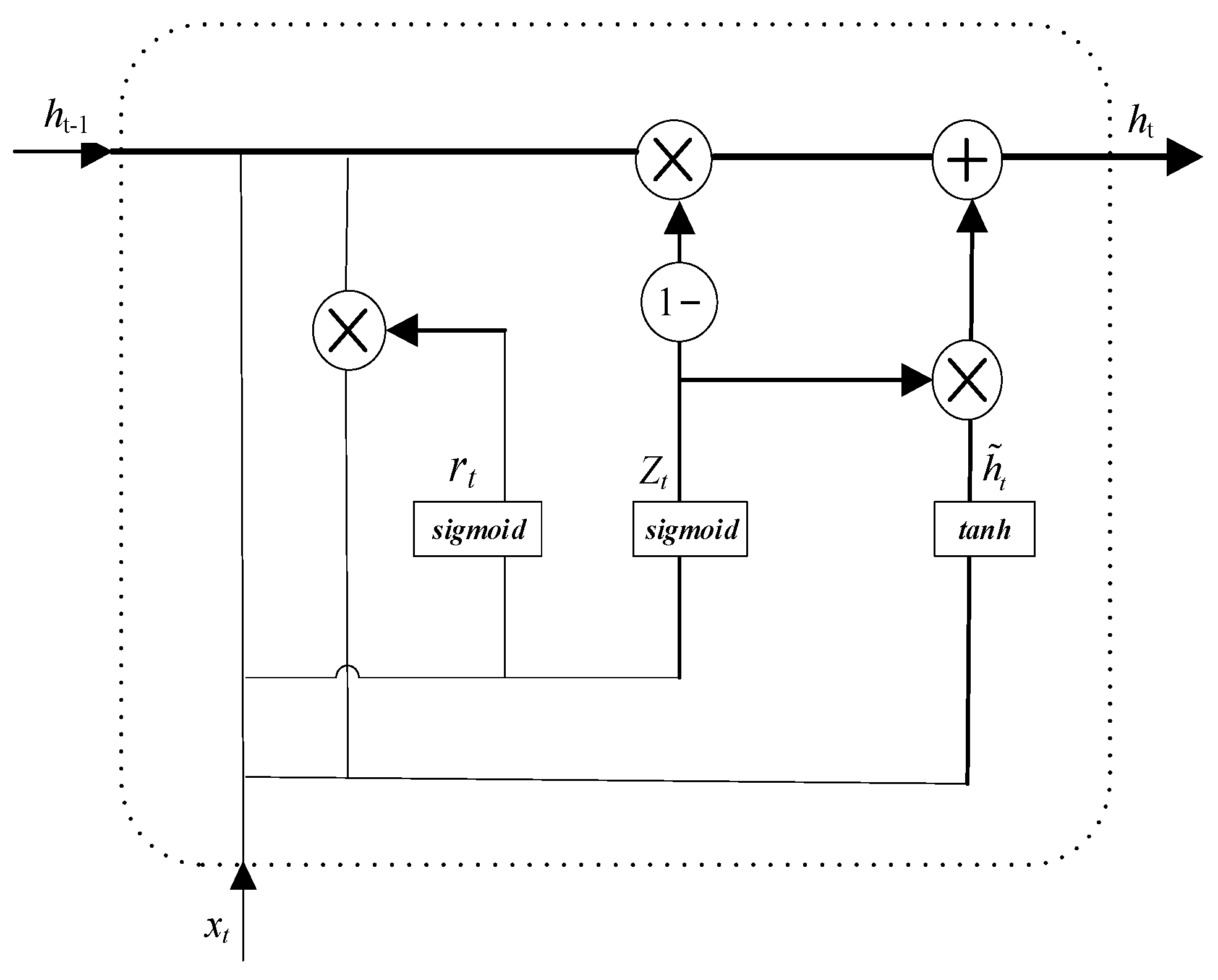
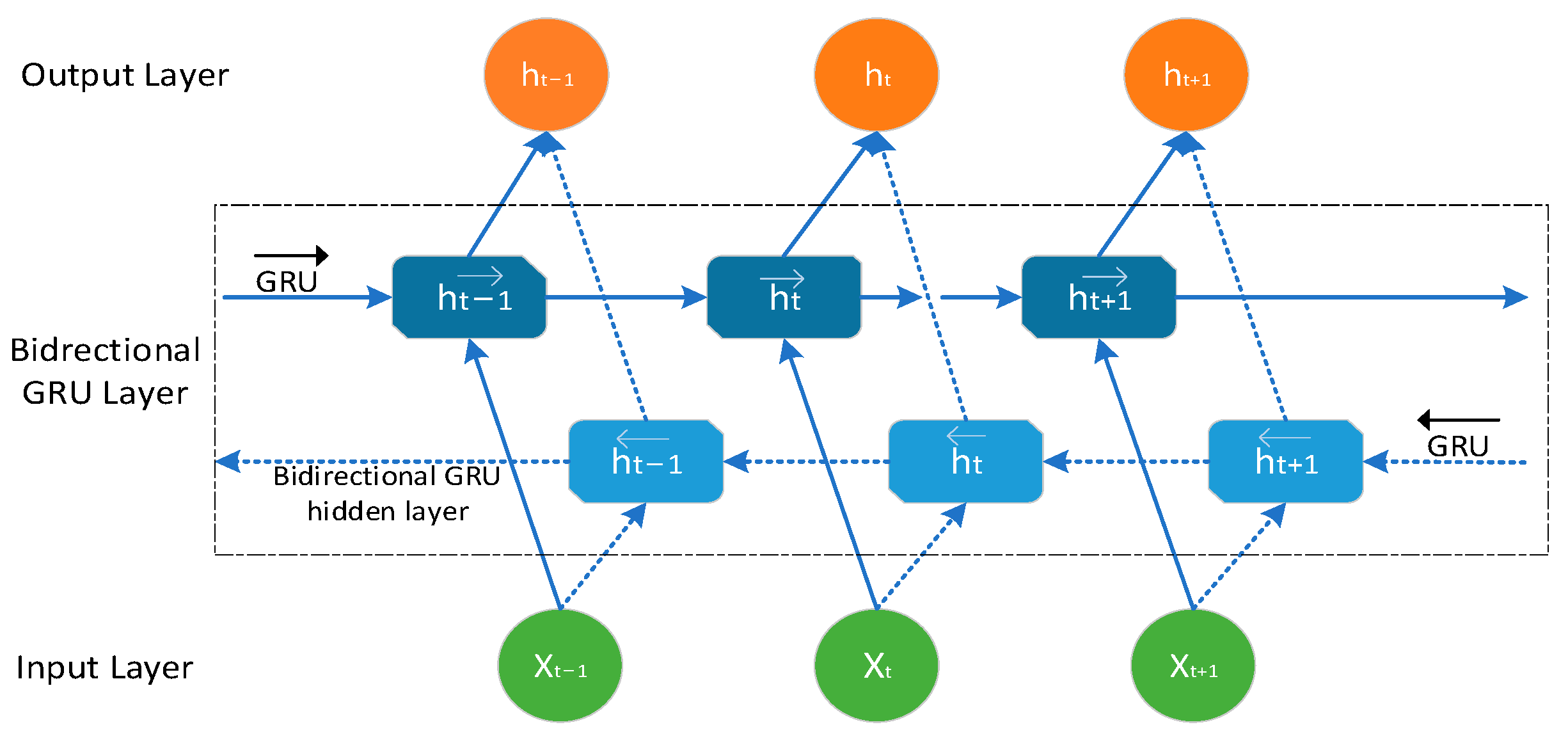
2.2. Bidirectional Gated Recurrent Unit Neural Network
2.3. Additive Attention Mechanism
3. Prediction Method Based on CNN-BiGRU-AAM Model
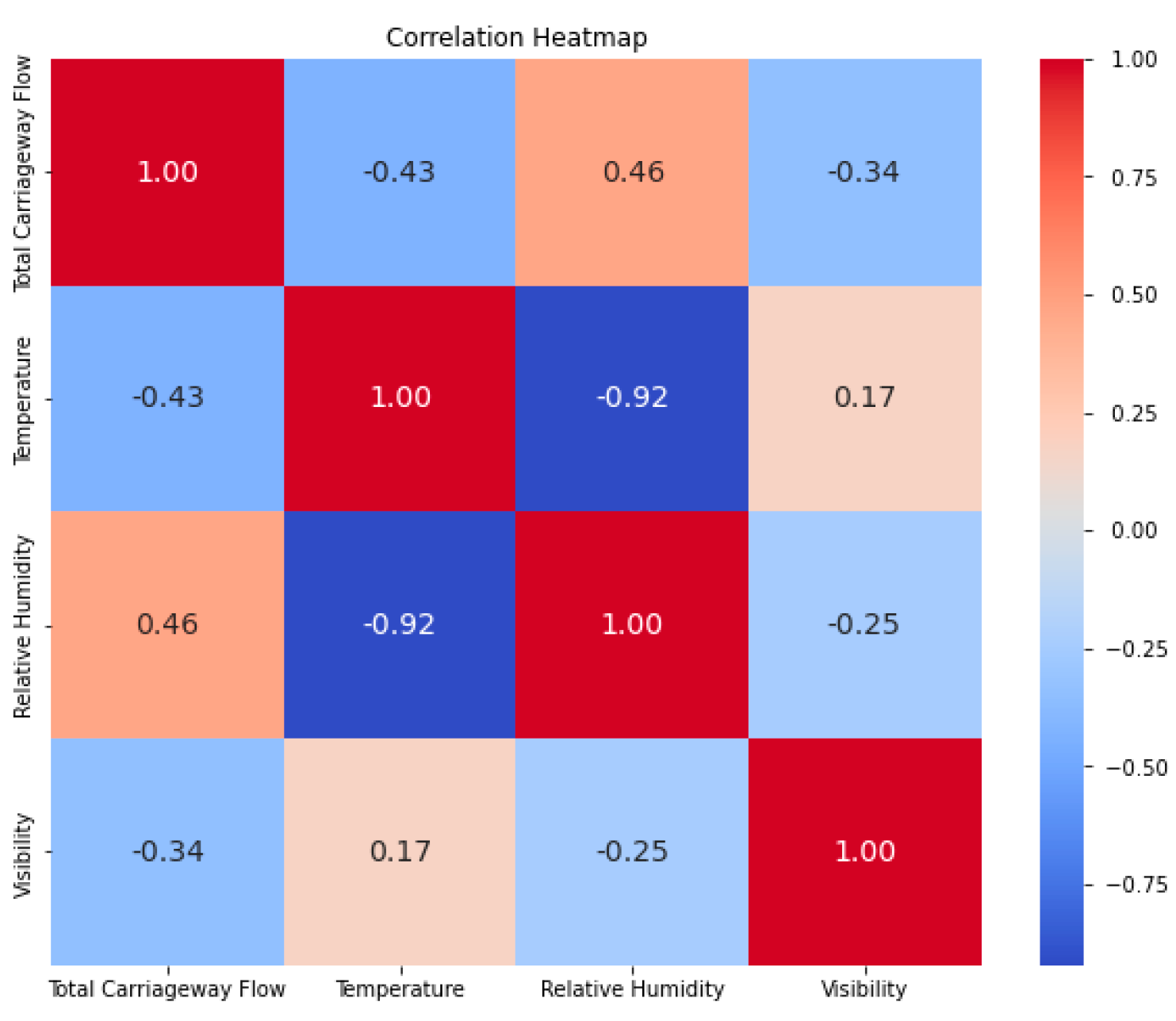
4. Empirical Analysis
5. Conclusions
- (1)
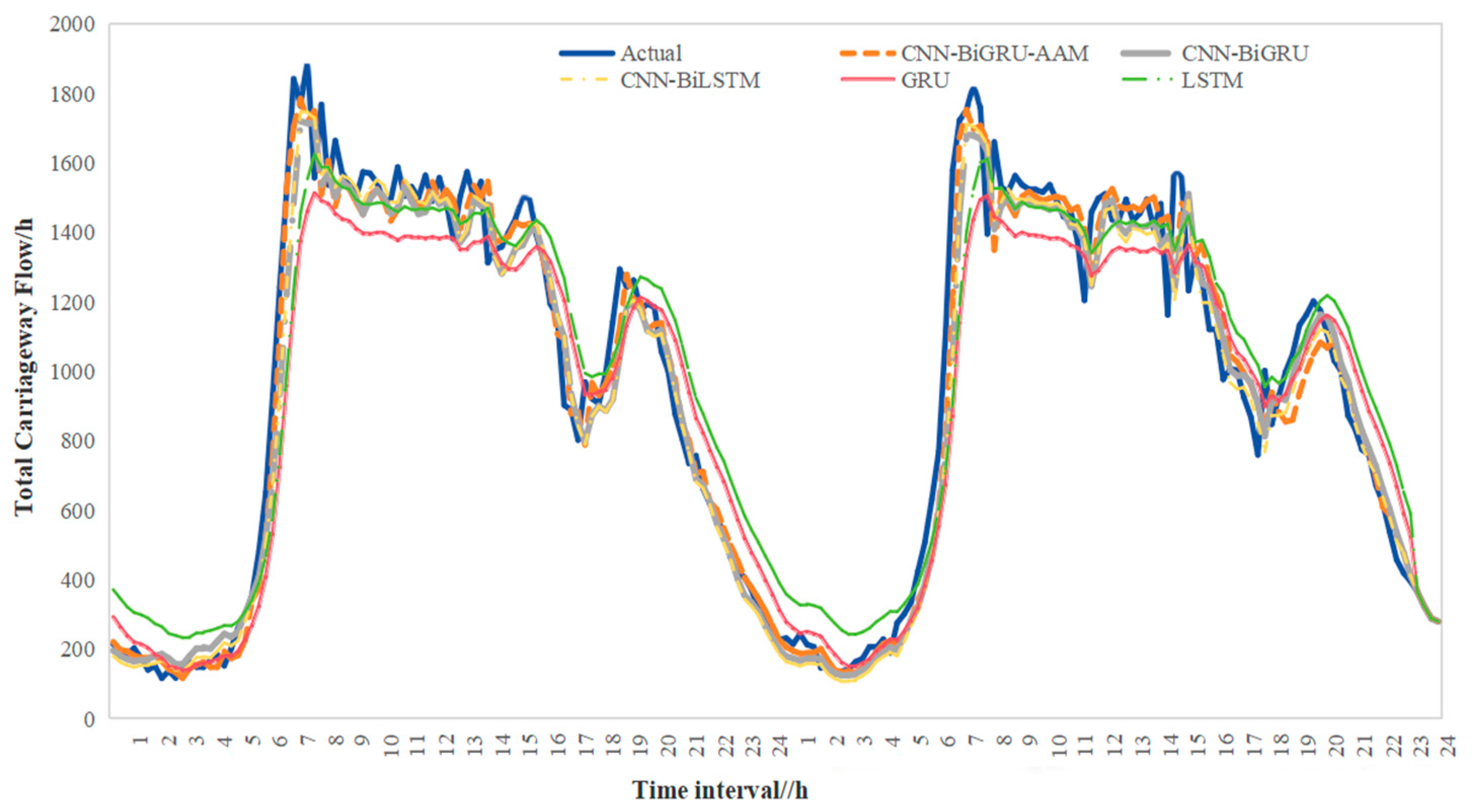
- First, by integrating the driving conditions of vehicles on highways, the CNN-BiGRU-AAM model was validated for traffic flow prediction performance under different weather conditions and air quality levels. The results demonstrate that this model effectively captures the periodic nature of traffic flow and the characteristics of morning and evening peaks. Although the model’s predictive performance may be slightly affected in extreme weather conditions, its overall performance remains good, making it suitable for various scenarios in short-term traffic flow prediction.
- (2)
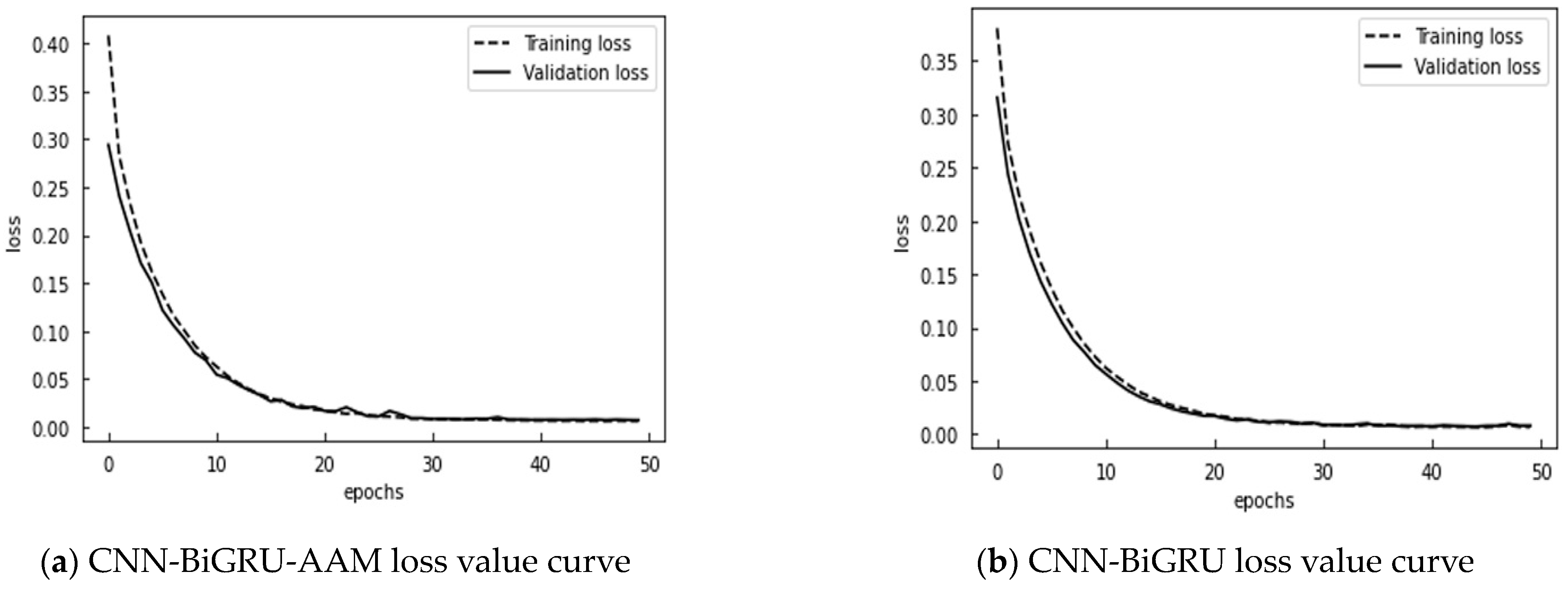
- Additionally, regarding the spatiotemporal characteristics of traffic flow, the model was integrated and optimized; by concatenating the CNN and BiGRU into a multi-layer feature extraction model, it is possible to better analyze complex data. The CNN captures spatial features, while the BiGRU, by incorporating historical and future information, captures the long-term dependencies in time series data. Moreover, by utilizing isolation forests before data standardization, the model can effectively handle data missingness and anomalies, thereby improving its robustness.
- (3)
- Furthermore, the adoption of an additive attention mechanism enables the model to selectively prioritize important time steps and salient features through learnable linear mappings. Compared to traditional attention mechanisms, this dynamic mechanism enhances overall performance, resulting in improved predictive accuracy of the CNN-BiGRU-AAM model over benchmark models.
- (4)
- Finally, while integrating multiple models and techniques increases model complexity, requiring more computational resources and time for training and finetuning, future research will continue to optimize these aspects and explore additional factors that may affect traffic flow prediction performance. This will additionally boost the precision and versatility of the model, fulfilling the requirements for real-world traffic prediction.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Williams, B.M.; Durvasula, P.K. Urban freeway traffic flow prediction: Application of seasonal autoregressive integrated moving average and exponential smoothing models. Trans Res. Rec. 1998, 1644, 132–141. [Google Scholar] [CrossRef]
- Rojas, I.; Valenzuela, O.; Rojas, F.; Guillén, A.; Herrera, L.J.; Pomares, H. Soft-computing techniques and ARMA model for time series prediction. Neurocomputing 2008, 71, 519–537. [Google Scholar] [CrossRef]
- Kumar, S.V.; Vanajakshi, L. Short-term traffic flow prediction using seasonal ARIMA model with limited input data. Eur. Transp. Res. Rev. 2015, 7, 21. [Google Scholar] [CrossRef]
- Zhou, T.; Jiang, D.; Lin, Z.; Han, G.; Xu, X.; Qin, J. Hybrid dual Kalman filtering model for short-term traffic flow forecasting. IET Intell. Transp. Syst. 2019, 13, 1023–1032. [Google Scholar] [CrossRef]
- Kim, J.; Hwang, M.; Jeong, D.H.; Jung, H. Technology trends analysis and forecasting application based on decision tree and statistical feature analysis. Expert. Syst. Appl. 2012, 39, 12618–12625. [Google Scholar] [CrossRef]
- Aljahdali, S.; Hussain, S.N. Comparative prediction performance with support vector machine and random forest classification techniques. Int. J. Comput. Appl. 2013, 69, 12–16. [Google Scholar] [CrossRef]
- John, F.; Kolen; Stefan, C.; Kremer. Gradient Flow in Recurrent Nets: The Difficulty of Learning Long-Term Dependencies. In A Field Guide to Dynamical Recurrent Networks; IEEE: Piscataway, NJ, USA, 2001; pp. 237–243. [Google Scholar] [CrossRef]
- Zhang, W.B.; Yu, Y.H.; Qi, Y.; Shu, F.; Wang, Y.H. Short-term traffic flow prediction based on spatio-temporal analysis and CNN deep learning. Transp. A 2019, 15, 1688–1711. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar] [CrossRef]
- Hussain, B.; Afzal, M.K.; Ahmad, S.; Mostafa, A.M. Intelligent traffic flow prediction using optimized GRU model. IEEE Access 2021, 9, 100736–100746. [Google Scholar] [CrossRef]
- Dai, G.; Ma, C.; Xu, X. Short-term traffic flow prediction method for urban road sections based on space–time analysis and GRU. IEEE Access 2019, 7, 143025–143035. [Google Scholar] [CrossRef]
- Liu, S.; Peng, Y.; Shao, Y.M.; Song, Q.K. Highway Travel Time Prediction Based on Gated Recurrent Unit Neural Networks. Appl. Math. Mech. 2019, 40, 1289–1298. [Google Scholar] [CrossRef]
- Zhao, J.; Gao, Y.; Qu, Y.; Yin, H.; Liu, Y.; Sun, H. Travel time prediction: Based on gated recurrent unit method and data fusion. IEEE Access 2018, 6, 70463–70472. [Google Scholar] [CrossRef]
- Jeong, M.H.; Lee, T.Y.; Jeon, S.-B.; Youm, M. Highway Speed Prediction Using Gated Recurrent Unit Neural Networks. Appl. Sci. 2021, 11, 3059. [Google Scholar] [CrossRef]
- Reza, S.; Ferreira, M.C.; Machado, J.J.M.; Tavares, J.M.R.S. Traffic State Prediction Using One-Dimensional Convolution Neural Networks and Long Short-Term Memory. Appl. Sci. 2022, 12, 5149. [Google Scholar] [CrossRef]
- Lee, G.; Choo, S.; Choi, S.; Lee, H. Does the Inclusion of Spatio-Temporal Features Improve Bus Travel Time Predictions? A Deep Learning-Based Modelling Approach. Sustainability 2022, 14, 7431. [Google Scholar] [CrossRef]
- Narmadha, S.; Vijayakumar, V. Spatio-Temporal vehicle traffic flow prediction using multivariate CNN and LSTM model. Mater. Today Proc. 2023, 81, 826–833. [Google Scholar] [CrossRef]
- Ren, C.; Chai, C.; Yin, C.; Ji, H.; Cheng, X.; Gao, G.; Zhang, H. Short-Term Traffic Flow Prediction: A Method of Combined Deep Learnings. J. Adv. Transp. 2021, 2021, .1–15. [Google Scholar] [CrossRef]
- Yang, Y.Q.; Lin, J.; Zheng, Y.B. Short-Time Traffic Forecasting in Tourist Service Areas Based on a CNN and GRU Neural Network. Appl. Sci. 2022, 12, 9114. [Google Scholar] [CrossRef]
- Yuan, L.; Zeng, Y.; Chen, H.; Jin, J. Terminal Traffic Situation Prediction Model under the Influence of Weather Based on Deep Learning Approaches. Aerospace 2022, 9, 580. [Google Scholar] [CrossRef]
- Wang, B.W.; Wang, J.S.; Wang, T.Y.; Xia, T.Y.; Zhao, D.T. Multivariable traffic flow prediction model based on convolutional neural network and gate recurrent unit. JCQU 2023, 46, 132–140. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Zhao, S.; Zhao, Q.; Bai, Y.; Li, S. A Traffic Flow Prediction Method Based on Road Crossing Vector Coding and a Bidirectional Recursive Neural Network. Electronics 2019, 8, 1006. [Google Scholar] [CrossRef]
- Zhuang, W.; Cao, Y. Short-Term Traffic Flow Prediction Based on CNN-BILSTM with Multicomponent Information. Appl. Sci. 2022, 12, 8714. [Google Scholar] [CrossRef]
- Wang, S.; Shao, C.; Zhang, J.; Zhen, Y.; Meng, M. Traffic flow prediction using bi-directional gated recurrent unit method. Urban Inform. 2022, 1, 16. [Google Scholar] [CrossRef]
- Ma, C.; Zhao, Y.; Dai, G.; Xu, X.; Wong, S.C. A novel STFSA-CNN-GRU hybrid model for short-term traffic speed prediction. IEEE Trans. Intell. Transp. Syst. 2022, 24, 3728–3737. [Google Scholar] [CrossRef]
- Qu, D.; Wang, S.; Liu, H.; Meng, Y. A Car-Following Model Based on Trajectory Data for Connected and Automated Vehicles to Predict Trajectory of Human-Driven Vehicles. Sustainability 2022, 14, 7045. [Google Scholar] [CrossRef]
- Zhou, G.Z.; Guo, Z.; Sun, S.; Jin, Q.S. A CNN-BiGRU-AM neural network for AI applications in shale oil production prediction. Appl. Energy 2023, 344, 121249. [Google Scholar] [CrossRef]
- Zhang, X.J.; Zhang, G.N.; Zhang, H.; Zhang, X.L. Short-term traffic flow prediction based on ACBiGRU model. Huazhong Keji Daxue Xuebao 2023, 51, 88–93. [Google Scholar] [CrossRef]
- Chughtai, J.-u.-R.; Haq, I.u.; Islam, S.u.; Gani, A. A Heterogeneous Ensemble Approach for Travel Time Prediction Using Hybridized Feature Spaces and Support Vector Regression. Sensors 2022, 22, 9735. [Google Scholar] [CrossRef]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Wei, Q.J.; Wang, W.B. Research on image retrieval using deep convolutional neural network combining L1 regularization and PRelu activation function. IOP Sci. 2017, 69, 012156. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar] [CrossRef]
- Shen, T.; Zhou, T.; Long, G.; Jiang, J.; Pan, S.; Zhang, C. DiSAN: Directional Self-Attention Network for RNN/CNN-Free Language Understanding. arXiv 2017, arXiv:1709.04696. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]

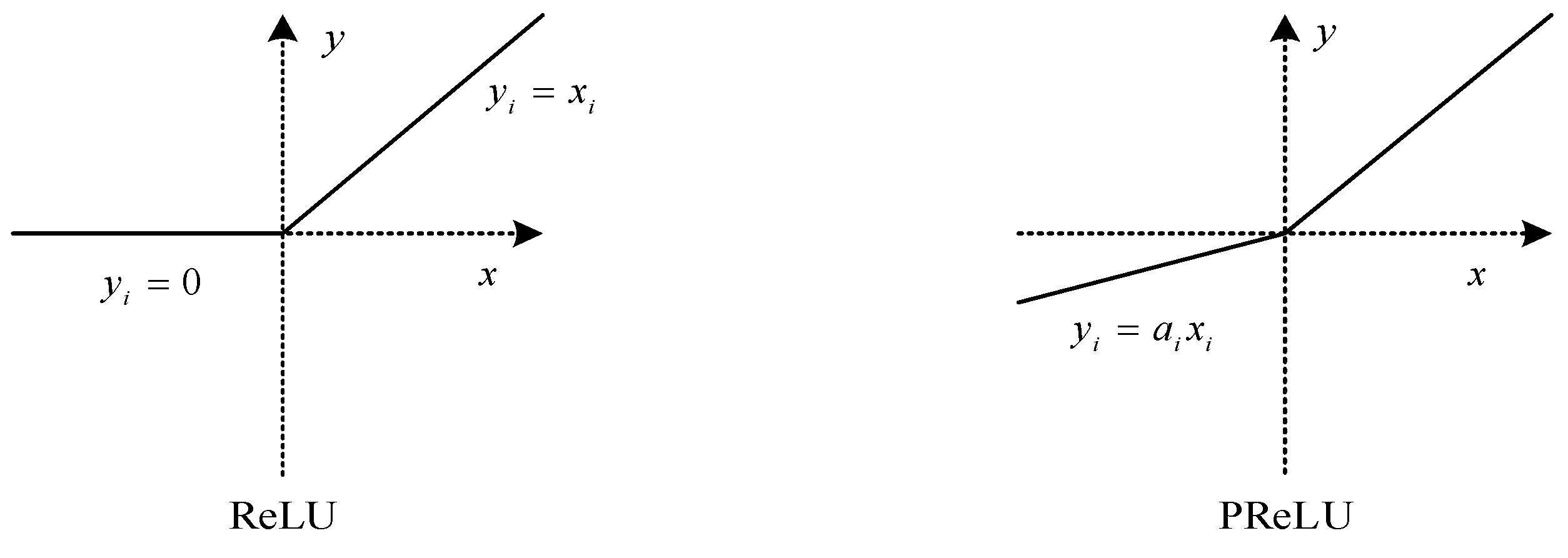


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Attribution | Parameter | Value |
|---|---|---|---|
| 1 | CNN | Conv1D-1 neurons | 128 |
| Conv1D-2 neurons | 64 | ||
| 2 | Bi-GRU | neurons | 16 |
| Dropout | 0.2 | ||
| recurrent_regularizer | 0.01 | ||
| 3 | Dense | neuron | 1 |
| Predictive Model | Performance Indicators | |||
|---|---|---|---|---|
| Training RMSE | Training MAE | Training MAPE | ||
| CNN-BiGRU-AAM | 97.01 | 69.01 | 9.85% | 0.96 |
| CNN-BiGRU | 121.21 | 82.43 | 11.68% | 0.94 |
| CNN-BiLSTM | 123.36 | 84.15 | 11.54% | 0.93 |
| GRU | 154.48 | 107.94 | 14.99% | 0.90 |
| LSTM | 153.48 | 115.31 | 19.09% | 0.90 |
| Predictive Model | Performance Indicators | |||
|---|---|---|---|---|
| Test RMSE | Test MAE | Test MAPE | ||
| CNN-BiGRU-AAM | 96.46 | 67.14 | 8.77% | 0.97 |
| CNN-BiGRU | 109.81 | 74.90 | 9.93% | 0.96 |
| CNN-BiLSTM | 108.89 | 74.07 | 9.99% | 0.96 |
| GRU | 143.95 | 97.86 | 14.04% | 0.92 |
| LSTM | 145.69 | 110.10 | 19.51% | 0.92 |
| ANOVA a | |||||
|---|---|---|---|---|---|
| Model | Sum of Squares | Degrees of Freedom | Mean Square | F | Significance |
| Regression | 195,900,654.935 | 1 | 195,900,654.935 | 21,849.620 | <0.001 b |
| Residual | 7,728,572.159 | 862 | 8965.861 | ||
| Total | 203,629,227.094 | 863 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Lin, W.; Wang, Y.; Yu, D.Z.; Peng, Y.; Ma, X. Convolutional Neural Network-Based Bidirectional Gated Recurrent Unit–Additive Attention Mechanism Hybrid Deep Neural Networks for Short-Term Traffic Flow Prediction. Sustainability 2024, 16, 1986. https://doi.org/10.3390/su16051986
Liu S, Lin W, Wang Y, Yu DZ, Peng Y, Ma X. Convolutional Neural Network-Based Bidirectional Gated Recurrent Unit–Additive Attention Mechanism Hybrid Deep Neural Networks for Short-Term Traffic Flow Prediction. Sustainability. 2024; 16(5):1986. https://doi.org/10.3390/su16051986
Chicago/Turabian StyleLiu, Song, Wenting Lin, Yue Wang, Dennis Z. Yu, Yong Peng, and Xianting Ma. 2024. "Convolutional Neural Network-Based Bidirectional Gated Recurrent Unit–Additive Attention Mechanism Hybrid Deep Neural Networks for Short-Term Traffic Flow Prediction" Sustainability 16, no. 5: 1986. https://doi.org/10.3390/su16051986
APA StyleLiu, S., Lin, W., Wang, Y., Yu, D. Z., Peng, Y., & Ma, X. (2024). Convolutional Neural Network-Based Bidirectional Gated Recurrent Unit–Additive Attention Mechanism Hybrid Deep Neural Networks for Short-Term Traffic Flow Prediction. Sustainability, 16(5), 1986. https://doi.org/10.3390/su16051986