1. Introduction
In the past two decades, autonomous driving has emerged as a key innovation in the realm of sustainable smart cities, attracting substantial research interest due to its potential societal and economic benefits. Autonomous vehicles (AVs) are poised to revolutionize urban transportation systems by enhancing efficiency and safety, and reducing environmental impacts [
1,
2]. Central to the vision of sustainable smart cities, AVs navigate intricate and dynamic traffic environments, a significant challenge for their decision-making capabilities. This is particularly evident in mixed-traffic scenarios where AVs interact with human-driven vehicles (HDVs), necessitating advanced lane-changing strategies to ensure safety and effectiveness.
The exploration of reinforcement learning (RL) in autonomous driving has opened new avenues for addressing these complex urban challenges [
3,
4,
5]. However, scalability remains a concern in multi-AV lane-changing scenarios within mixed traffic. To address this, multi-agent reinforcement learning (MARL) has been adopted, evolving into sophisticated systems. Current MARL algorithms, while effective, often overlook passenger comfort and make oversimplified assumptions about HDV behavior. Our research introduces an innovative MARL technique for multi-AV lane-changing decisions, utilizing the MA2C algorithm. This technique emphasizes a parameter-sharing strategy and a locally designed reward system that values passenger comfort alongside efficiency and safety.
Moreover, this study aligns with the advancements in Intelligent Transportation Systems (ITSs), a cornerstone of sustainable urban development. These systems, encompassing vehicle networking, vehicle-road coordination, and advanced monitoring, are integral to smart cities. Leveraging machine learning techniques like deep learning, convolution neural networks, and RL, as demonstrated in [
6,
7], this research contributes to the development of efficient traffic management systems, enhancing the sustainability of urban environments.
The AVs constitute one component within the broader framework of sustainable urban mobility (SUM) [
8]. The principles of SUM include; planning compact and accessible cities; developing transit-oriented cities; getting the infrastructure right; encouraging walking and cycling; advancing smart mobility management; enhancing public transport and shared mobility; parking: managing first, not supple; electrifying all vehicles; winning the support of stakeholders; empowering cities to avoid, shift, and improve. These principles are critical for SUM and extend beyond the scope of AVs alone. Our research acknowledges the multi-dimensional approach required for SUM, recognizing the importance of compact city planning, transit-oriented development, pedestrian-friendly infrastructure, and the electrification of transport, among other factors. We contend that AVs can significantly contribute to these principles by enhancing existing transport systems. For example, AVs can support compact city designs by reducing the need for extensive parking spaces, which aligns with effective land use. They can also integrate with public transportation, offering first and last-mile connectivity that encourages public transport usage. Our study aims to shed light on the nuanced role of AVs in this ecosystem. Addressing the scalability of AVs, our research presents a broader perspective, demonstrating their applicability beyond megacities. With varying urban densities and configurations, AVs have the potential to support SUM in diverse city landscapes, as evidenced by ongoing pilot studies and theoretical models that we have referenced in our work. We agree with the future-oriented view of AV infrastructure development and the need for smart city interactions to mature. Our research contributes to laying the groundwork for such advancements, exploring the integration of AVs with intelligent transportation systems and machine learning techniques to prepare for this eventuality.
The paper is structured as follows:
Section 2 reviews current state-of-the-art autonomous driving methods integrating RL/MARL with dynamics-based models.
Section 3,
Section 4,
Section 5,
Section 6,
Section 7 and
Section 8 detail the contributions, problem formulation, experimental approach, results analysis, discussion, and conclusions, respectively.
2. Related Work
Recent literature in autonomous driving, especially in the context of sustainable smart cities, is categorized into data-driven and non-data-driven methods. These methods are critical in addressing urban mobility challenges and contributing to the sustainability of smart cities. In [
9], authors address the complexities of lane-change decisions for autonomous vehicles on multi-lane expressways. They introduce a decision-making framework that enhances lateral vehicle stability using the phase-plane method and state-machine logic, factoring in surrounding traffic and vehicle motion states. An adaptive cruising strategy is developed, incorporating safety distances, different speed regimes, and emergency protocols. They also devise a trajectory planning technique using polynomial optimization and integrate stability and rollover boundaries into the path-tracking controller, with simulations confirming the safety and efficacy of their approach. Authors in [
10] focus on the challenges of safe lane changes and merging for autonomous vehicles in dense traffic. They propose a decentralized, controller-agnostic cooperative strategy based on Vehicle-to-Vehicle communications, ensuring collision-free maneuvers. The vehicles communicate to coordinate lane changes, which is demonstrated to significantly improve traffic flow by up to 26% in congested scenarios, though at a higher energy cost in uncongested situations. Their method reportedly surpasses existing approaches in safety and efficiency, especially with a higher penetration of autonomous vehicles. A decision-making and path-planning framework for autonomous vehicles using game theory has been proposed in [
11] to manage the uncertainties of dynamic obstacles’ motions. The framework predicts the multi-state actions of neighboring vehicles and assesses risks through Stackelberg game theory. It incorporates a potential-field model reflecting varied driving styles and constraints, and uses model predictive control to generate the vehicle’s trajectory. Simulation tests show the method effectively handles social interactions and unpredictability, ensuring safe and suitable autonomous vehicle trajectories.
2.1. Data-Driven Approaches
Data-driven methodologies, particularly RL, have gained prominence in autonomous driving within sustainable urban systems. Research has focused on developing RL solutions for lane changing in AVs, crucial for efficient traffic flow in smart cities [
12,
13,
14]. MARL algorithms [
15,
16,
17] have been proposed for scenarios requiring AV cooperation, aligning with the dynamic and collaborative nature of smart urban environments. These algorithms, however, often overlook passenger comfort and the variability in human driver behavior, which are key considerations in sustainable urban mobility.
2.2. Non-Data-Driven Approaches for Multi-Agent Lane Changing in Autonomous Driving
In the realm of sustainable smart cities, conventional solutions like rule-based or model-based approaches for handling human driver behavior in mixed traffic scenarios have limitations. RL algorithms have shown promise in single-agent scenarios [
12,
18,
19], but MARL algorithms [
15] are needed for multi-agent coordination essential in smart cities. However, the existing MARL approaches mainly focus on safety and efficiency, not fully addressing the broader spectrum of sustainability, including passenger comfort and diverse human behaviors. The challenge of multi-objective decision-making in AV lane changing in smart cities requires further exploration.
Table 1 provides a summarized comparison of Data-Driven and Non Data-Driven Approaches based on multiple criteria, highlighting their relevance to sustainable smart city environments.
3. Contributions
Our work aims to enhance urban transportation sustainability and efficiency by improving AV integration within smart city infrastructure. We have developed a MARL-based approach for AV lane-changing that fosters smooth traffic flow and cooperation among vehicles. By applying advanced machine learning techniques to Intelligent Transportation Systems, we are tackling mobility challenges, promoting safer interactions between AVs and human drivers, and optimizing traffic management. The incorporation of safety, efficiency, and passenger comfort into our models underscores our commitment to advancing AV technology in a way that aligns with the goals of sustainable urban development. This work has the following contributions:
Development of a novel MARL method for multi-AV lane-changing decisions. This approach is tailored to the dynamic and collaborative environment of smart cities, enhancing the sustainability of urban transportation.
Exploration of a range of machine learning applications within the broader scope of Intelligent Transportation Systems (ITS), emphasizing their role in addressing the challenges of sustainable urban mobility.
Adoption of the Intelligent Driver Model (IDM) and the model of Minimizing Overall Braking Induced by Lane changes (MOBIL) for simulating realistic HDV behavior, crucial for effective traffic management in smart urban settings.
Incorporation of parameters like expected speed and inter-vehicular distance in the longitudinal control model, providing a more accurate representation of HDV behavior in sustainable urban ecosystems. Expected speed will be set based on empirical traffic data, influencing acceleration and cruising speeds of simulated vehicles. Inter-vehicular distance will be determined by safety guidelines, adjusting dynamically to speed and traffic density to maintain safe following distances. These enhancements aim to improve the realism of our traffic simulations for more effective development and assessment of autonomous driving systems.
Integration of safety, efficiency, and passenger comfort in the algorithm’s reward design, promoting collaborative behavior among AVs, essential for the interconnected traffic system of smart cities. In addition, safety has been considered as a constraint along with a politeness coefficient in the lateral control model, facilitating the study of varied driver behaviors and their impact on traffic flow in smart cities.
These contributions collectively advance the field of autonomous driving within the context of sustainable smart cities, focusing on realistic, efficient, and safe integration of AVs into urban transportation networks.
4. Sustainable Smart Cities Methodology
4.1. RL Preliminary for Sustainable Smart Cities
RL, a branch of machine learning, is utilized here to enable AVs in smart cities to make optimal decisions that contribute to sustainable urban mobility. At each time step, the agent (representing an AV) receives a state from the urban environment, selects an action based on its policy to navigate efficiently, and receives a reward focused on sustainability metrics. We used numerical representation that includes various parameters about the vehicle’s current situation and its surroundings. This can include the vehicle’s position, velocity, acceleration, the relative position of other vehicles, traffic signal status, and potentially environmental variables like weather conditions. The objective is to develop a policy that ensures optimal urban traffic flow, enhancing both environmental sustainability and urban living standards. The action-value function, Q (s, a), and the state-value function, V (s), are crucial in estimating the most sustainable actions in varying urban traffic scenarios.
The Actor–critic algorithms involve a critic network to learn the state-value function and an actor network to refine policy decisions, ensuring smooth traffic flow and reduced environmental impact. The algorithm employs an advantage function, crucial for minimizing variances in urban traffic conditions, thereby enhancing traffic predictability and safety in smart cities. In cases of partially observable states, typical in dynamic urban environments, the algorithm adapts to a POMDP framework, making it robust for real-world smart city applications. A POMDP, or Partially Observable Markov Decision Process, is a mathematical framework used to describe decision-making situations where the agent does not have complete information about the current state of the environment. In other words, the agent must make decisions under uncertainty.The multi-agent actor–critic approach with parameter-sharing and a sustainability-focused reward design effectively trains AVs to cooperate, addressing the complexities of smart urban mobility.
Lane Changing as MARL in Sustainable Smart Cities
In sustainable smart cities, lane changing for AVs is vital for maintaining optimal traffic flow and reducing environmental impact. We propose a MARL approach with decentralized architecture for multi-AV lane changing, crucial for smart city traffic dynamics. The approach models a mixed-traffic environment on highways, with each AV (agent) communicating with neighboring vehicles to ensure smooth traffic flow and reduced congestion. The mixed-traffic approach accounts for both AVs and HDVs on highways. While full implementation is a future prospect, cities like Riyadh or Dubai are potential candidates for early adoption due to their advanced infrastructure. Communication between AVs, and between AVs and infrastructure, is facilitated by V2X technologies, which allow for the exchange of safety messages and telemetry data. Although HDVs without V2X capabilities cannot directly communicate, AVs can use onboard sensors to interpret HDV actions. Data exchanged generally includes vehicle speed, direction, and planned maneuvers, with the goal of ensuring smooth traffic flow and enhancing road safety in urban settings. The POMDP framework caters to the complexity of urban environments, with decentralized policies allowing each AV to react based on local observations, promoting sustainable mobility. The state space considers the positions and speeds of surrounding vehicles, essential for making informed decisions in dense urban traffic. Actions include high-level decisions like lane changing and speed adjustments, aimed at optimizing traffic flow and reducing emissions in urban areas. The reward function integrates metrics such as safety, efficiency, and passenger comfort, aligning with smart city sustainability goals. Safety is evaluated by avoiding collisions and maintaining safe distances, while speed and comfort are optimized through stable driving within legal limits and minimizing harsh maneuvers. The reward function
in this scenario representing the total reward function for autonomous vehicle
i at time
t, which is the sum of several weighted components reflecting different aspects of driving performance and objectives is expressed by Equation (
1). Weights is Equation (
1) are defined by experts who understand the importance of each aspect of driving. For example, safety is prioritized over comfort in certain scenarios, leading to a higher weight for the safety component.
where:
: Weight for safety, prioritizing collision avoidance and safe distances.
: Weight for distance headway, ensuring optimal spacing between vehicles to reduce traffic congestion.
: Weight for speed efficiency, encouraging driving within the optimal speed range to balance traffic flow and energy efficiency.
: Weight for environmental impact, incentivizing actions that reduce emissions and fuel consumption.
: Weight for comfort, penalizing rapid accelerations/decelerations to ensure passenger comfort.
: Weight for politeness, reflecting the vehicle’s interaction with other road users in a way that promotes cooperative driving behavior.
where a value of 0 is assigned for situations where there is no collision and the vehicle is driving in an eco-friendly manner, balancing safety with environmental considerations. A value of −1 is given if a collision occurs or if the driving pattern is not eco-friendly, indicating a negative impact on both safety and sustainability. A positive coefficient
(where
) can be introduced to reward eco-driving behavior that also avoids collisions, promoting both safety and environmental sustainability.
Distance Headway Reward (
):
: Distance to the preceding vehicle.
: Current vehicle speed.
: Time headway threshold.
: Sustainability coefficient, adjusting the reward based on the vehicle’s eco-friendly behavior (e.g., low emissions driving). eco−factor: A value between 0 and 1, representing the degree of eco-friendliness in driving behavior. Speed Efficiency Reward (
):
,
,
: Currently observed, minimum, and maximum speeds of the ego vehicle, respectively. These variables are directly Measured.
: Coefficient to adjust the reward for eco-driving, which is empirically determined. Comfort and Lane Change Reward (
):
: Acceleration-based comfort factor.
: Lane change comfort factor, which is a metric within the reinforcement learning model that represents how comfortable a lane change is for passengers in an autonomous vehicle. It is quantified using parameters such as lateral acceleration or jerk and directly affects the reward given to the vehicle’s AI after it performs a lane change. A smooth and slow lane change would result in a positive reward, encouraging the AI to repeat this behavior, while an abrupt or fast lane change would result in a negative reward, discouraging such behavior. The factor helps balance efficiency and passenger comfort during lane changes.
: Coefficient to adjust the reward based on the environmental impact of the driving behavior. eco−impact: A value representing the environmental impact of the vehicle’s actions (e.g., fuel consumption, emissions incorporated as part of the state (
) in Equation (
6)).
In Equation (
6),
: The state at time step
t, which could now include parameters like emission levels, energy consumption, or congestion metrics alongside traditional state variables.
: The action taken at time step
t, potentially encompassing choices that lead to reduced environmental impact or improved energy efficiency.
: The state at the next time step
, reflecting the outcomes of actions taken, including changes in sustainability-related measures. The transition probability
reflects the likelihood of moving from one state to another given a particular action, where states and actions are now imbued with sustainability considerations. This approach aligns the reinforcement learning framework with the goals of sustainable smart city management.
Our approach highlights the importance of multi-dimensional decision-making in lane-changing, considering the diverse needs of a sustainable smart city environment. The algorithm is designed to learn from experience, refining policies to achieve the best outcomes for urban sustainability and mobility.
4.2. MA2C for AVs in Sustainable Smart Cities
We propose an MA2C algorithm as shown in Algorithm 1, an enhanced version of the single-agent actor–critic network, which is tailored for cooperative MARL in the context of sustainable smart cities. This approach assumes identical network parameters and structures for all agents (AVs), but allows for different decisions based on individual input states. The goal is to maximize a global reward that encompasses not just efficiency and safety, but also sustainability factors like reduced emissions and energy efficiency.
The MA2C network includes 64-neuron fully connected layer processing states, which are informed by both traffic and environmental data. The shared actor–critic network updates both value networks and policy, ensuring learning that is attuned to the complex dynamics of urban environments. This parameter-sharing scheme enhances learning efficiency, making it suitable for the high demands of sustainable smart cities.
| Algorithm 1 MA2C Algorithm for Sustainable Smart Cities |
- 1:
Input: Hyperparameters: factor of discount , rate of learning , coefficient of politeness p, length of epoch T, sustainability factor - 2:
Initialize: Actor and Critic networks with random weights and biases - 3:
for each episode do - 4:
for each time step t in do - 5:
for each agent i do - 6:
Observe state including traffic and environmental data - 7:
Choose action according to policy - 8:
Apply action , receive reward including sustainability metrics - 9:
Store transition in replay buffer - 10:
end for - 11:
Update Actor and Critic networks using stored transitions - 12:
end for - 13:
if episode terminated or collision happens then - 14:
Reset environment to initial state with signal “DONE” - 15:
end for
|
The algorithm emphasizes sustainability by integrating environmental data into state observations and sustainability metrics into the reward structure. Each action taken by an AV is evaluated not only for its immediate impact on traffic but also for its longer-term impact on urban sustainability. The learning process is designed to evolve towards strategies that enhance urban mobility while minimizing environmental impact, supporting the broader goals of sustainable smart cities.
5. Experiments for Sustainable Smart Cities Context
This work explores the behavior and decision-making of HDVs in multi-agent road traffic simulations, tailored for sustainable smart city scenarios. The following models, integrated with sustainability metrics, are employed:
IDM for Longitudinal Control: Regulates the position and velocity of HDVs, accounting for eco-driving variables that influence acceleration and deceleration, promoting fuel efficiency and reduced emissions.
MOBIL for Lateral Control: Utilizes this model to regulate sideways motion, considering eco-friendly lane changes and minimizing abrupt braking to enhance traffic flow and reduce environmental impact.
Lane Changing Thresholds: Based on a politeness coefficient (p), influencing the decision to switch lanes with consideration for overall traffic efficiency and emissions reduction.
The acceleration post-lane change equation incorporates sustainability factors:
where
is the new follower’s acceleration post-lane change, and
is the maximum eco-braking level.
The lane change incentive condition includes environmental considerations:
where:
: The acceleration of the current vehicle after the lane change.
: The acceleration of the current vehicle before the lane change.
: The acceleration of the new follower vehicle after the lane change.
: The acceleration of the new follower vehicle before the lane change.
: The acceleration of the old follower vehicle after the lane change.
: The acceleration of the old follower vehicle before the lane change.
p: The politeness coefficient, influencing the decision to switch lanes considering overall traffic efficiency and emissions reduction.
: The lane change threshold, representing a minimum acceptable change in acceleration.
in Equation (
7) is determined based on safety considerations and possibly environmental factors such as safety standards and regulations which adopt safety standards for vehicles often prescribe maximum braking levels to ensure safe operation. These standards can provide guidance on the maximum allowable braking force or deceleration rates. In addition, vehicle specifications provided by Manufacturers may provide information about the maximum braking capabilities of their vehicles. This information could include metrics such as maximum deceleration rates or braking force. Furthermore, environmental impact such as excessively aggressive braking which lead to increased emissions due to inefficient driving behavior. Thus, the value of
may indirectly impact environmental sustainability by influencing driving patterns. Once
is determined, we become able to apply Equation (
7) by substituting this value into the equation. Equation (
8) represents a condition that must be satisfied for a lane change to occur, considering factors such as politeness (represented by
p) and the difference in accelerations between the new follower vehicle and other vehicles (
). If the condition is met, it indicates that the lane change is permissible based on the predefined criteria.
5.1. Settings
In this work, we integrate sustainability parameters by adding settings that specifically focus on the environmental aspects of autonomous driving in smart cities.
Table 2 contains setting for “Environmental Impact Metrics” that focuses on emission levels and energy efficiency. The maximum deceleration is also labeled as “eco-deceleration” to emphasize its role in sustainable driving behavior. Additionally, a coefficient
e is added to the reward function weighting coefficients, which represents the weighting given to environmental sustainability in the reward function. The term “eco-deceleration” in this work is used to highlight a specific feature of our autonomous driving model that prioritizes energy efficiency and emission reduction. The rationale for this terminology is twofold:
Energy Efficiency: Rapid deceleration in vehicles is often associated with aggressive driving behavior that can lead to increased fuel consumption and higher emissions. By setting a limit to the deceleration rate, our model encourages smoother transitions in speed, which has been shown to reduce fuel consumption and improve energy efficiency.
Emission Levels: Eco-deceleration contributes to lowering emission levels by avoiding the sharp increases in engine load that are typical of sudden braking. Gentle deceleration leads to more controlled combustion and, consequently, a cleaner exhaust output.
The “eco-deceleration” setting is part of a suite of parameters designed to simulate a sustainable driving environment within the modified highway-env simulator [
25]. This approach aligns with the overarching goal of our work, which is to develop and evaluate autonomous driving strategies that support the sustainability objectives of smart city ecosystems. Furthermore, the inclusion of the coefficient
e in the reward function weighting coefficients serves to quantitatively reinforce the importance of environmental considerations. It ensures that the autonomous vehicle’s decision-making process systematically factors in the impact of its actions on energy efficiency and emissions, thus promoting a driving style that is not only safe and efficient but also environmentally friendly.
5.2. Experimental Setup
The study simulates high-density vehicle traffic in a modified highway-env simulator [
25], incorporating sustainability metrics such as emission levels and energy efficiency. The Intelligent Driver Model (IDM) and Minimize Overall Braking Induced By Lane Change (MOBIL) model are used for vehicle dynamics, focusing on eco-friendly driving behavior. The control sampling frequency is set at 5 Hz, with specific limits for maximum eco-deceleration and politeness factor. The methodologies are evaluated under varying traffic densities, emphasizing sustainable urban traffic management. The evaluation process, discount factor, learning rate, and reward function weighting coefficients are all geared towards optimizing for sustainable urban mobility.
We state that while the inclusion of the politeness factor enhances the model’s ability to simulate a range of driving styles, it does not compromise the AV’s strict adherence to traffic laws and safe driving practices. Therefore, simulated lane changes conform to the safe conditions mandated by the Traffic Code, and the politeness factor is used only to enhance the flow and safety in accordance with these regulations. In this section, the experiments are contextualized within a sustainable smart city framework, with emphasis on reducing environmental impact and enhancing urban mobility.
6. Results
6.1. Local vs. Global Reward Designs with a Sustainability Perspective
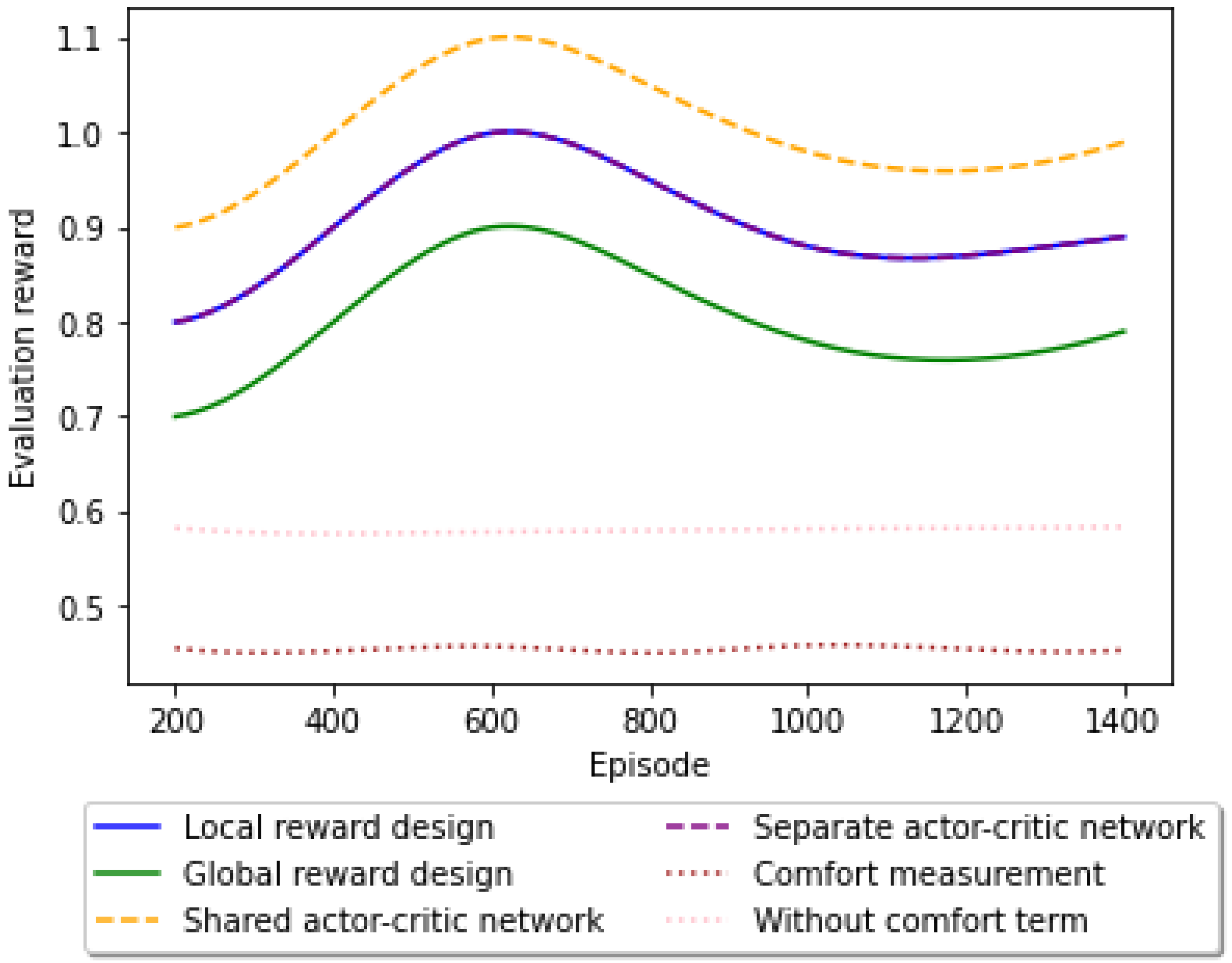
The present study has extended the evaluation of reward designs and parameter-sharing strategies within a sustainable smart city framework. We have integrated environmental and urban mobility metrics into the traditional reward functions to assess the training efficacy of actor–critic networks for autonomous vehicles. Our results, which are displayed in
Figure 1, suggest that a local reward design, which incentivizes individual AVs to optimize for reduced emissions and energy efficiency, outperforms a global reward approach. The local reward structure aligns with smart city objectives by promoting behaviors that contribute to the overall sustainability of urban transport systems. Moreover, the shared actor–critic network parameters facilitate a cooperative learning environment where AVs can collectively adapt to dynamic traffic conditions while minimizing their environmental impact. This collaborative approach results in a performance boost, as AVs learn to make decisions that not only improve traffic flow but also adhere to sustainability goals. The effectiveness of the multi-objective reward function, incorporating a comfort measurement, is demonstrated by the two dashed lines at the bottom of
Figure 1. This function promotes smoother acceleration and deceleration patterns, leading to a more comfortable ride, while simultaneously reducing the carbon footprint of each vehicle. The lower variance observed in the reward design with the comfort measurement indicates a high level of driving comfort, as well as a consistent adherence to sustainable driving practices. These findings underscore the potential of MARL frameworks to train AVs in a manner that supports the dual objectives of enhanced urban traffic management and sustainability in smart cities. Integrating the concepts of sustainability and smart cities into the analysis results section, we could frame the adaptability of the proposed MA2C algorithm as a response to the dynamic nature of urban traffic systems.
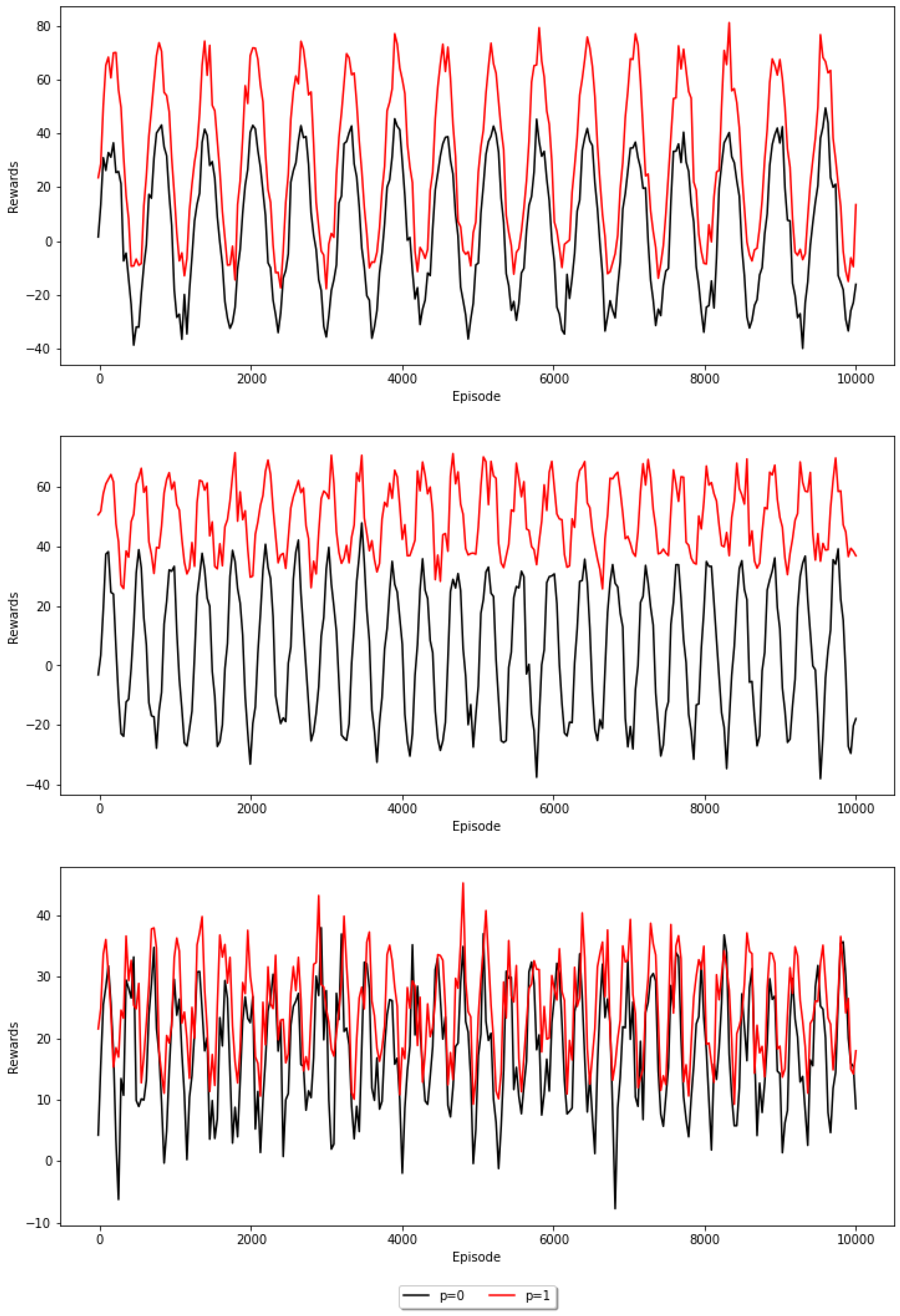
6.2. Adaptability of the Proposed Method within Sustainable Smart Cities
In the realm of sustainable smart cities, the adaptability of traffic management systems is paramount. This research delves into the efficacy of the MA2C algorithm, particularly focusing on its performance within the complex and variable traffic patterns characteristic of high-density urban environments. The politeness coefficient (p), integral to the algorithm and outlined in Equation (
8), is instrumental in mimicking the range of driver behaviors—from aggressive (
p = 0) to courteous (
p = 1). Our analysis, illustrated in
Figure 2, indicates that the MA2C algorithm adeptly adjusts to diverse driving behaviors. This flexibility is crucial for the sustainability of smart cities, where the algorithm’s performance can lead to improved traffic flow, reduced emissions, and enhanced energy efficiency, regardless of traffic volume or driver behavior variations. The consistent efficacy of the MA2C algorithm across different politeness levels and traffic densities suggests that it is not only scalable but also robust, capable of supporting the multifaceted goals of smart urban transportation systems. By accommodating varying degrees of HDV politeness, the algorithm demonstrates potential for real-world application in intelligent transportation systems that aim to optimize both mobility and environmental impact in smart cities.
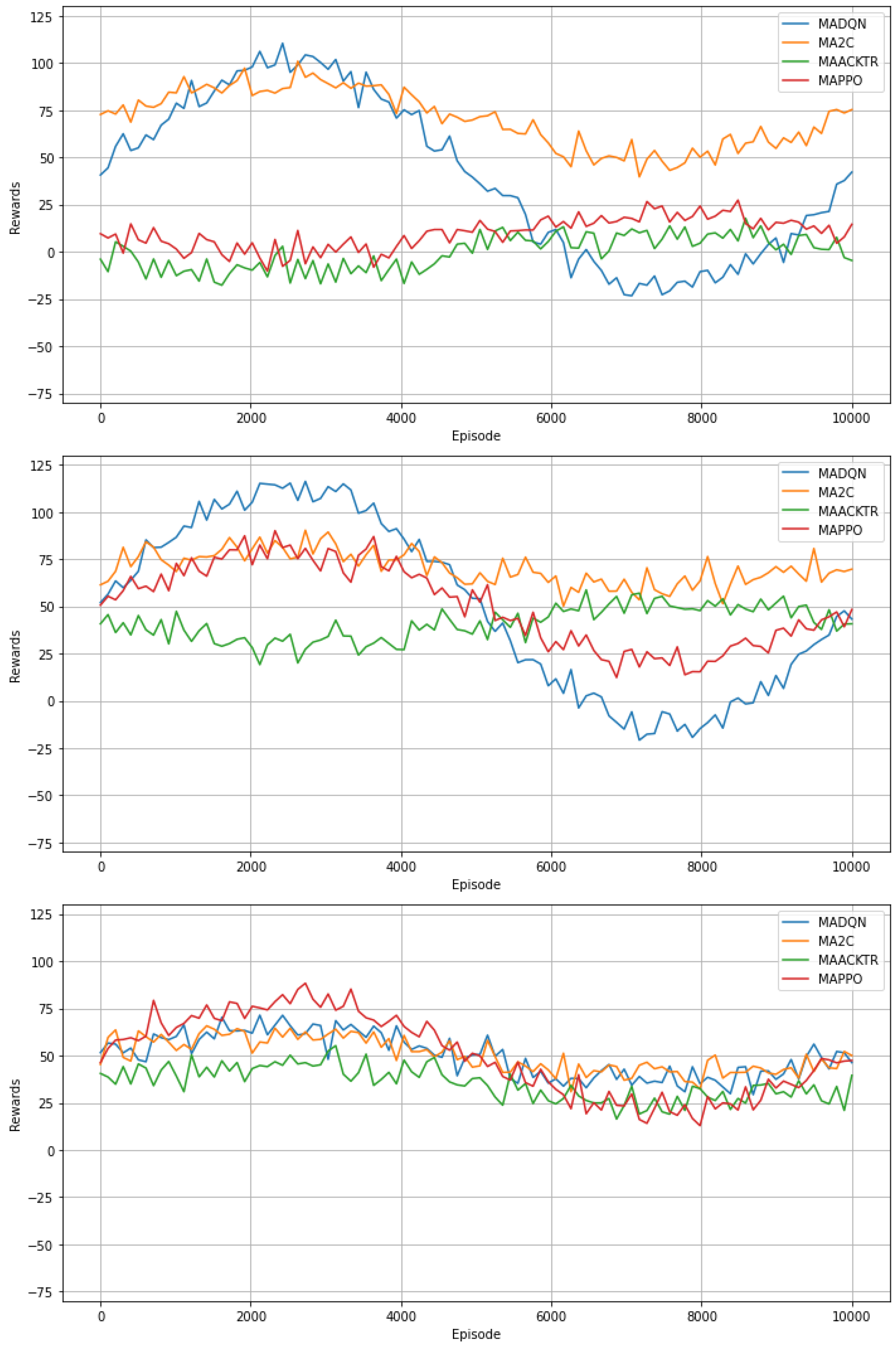
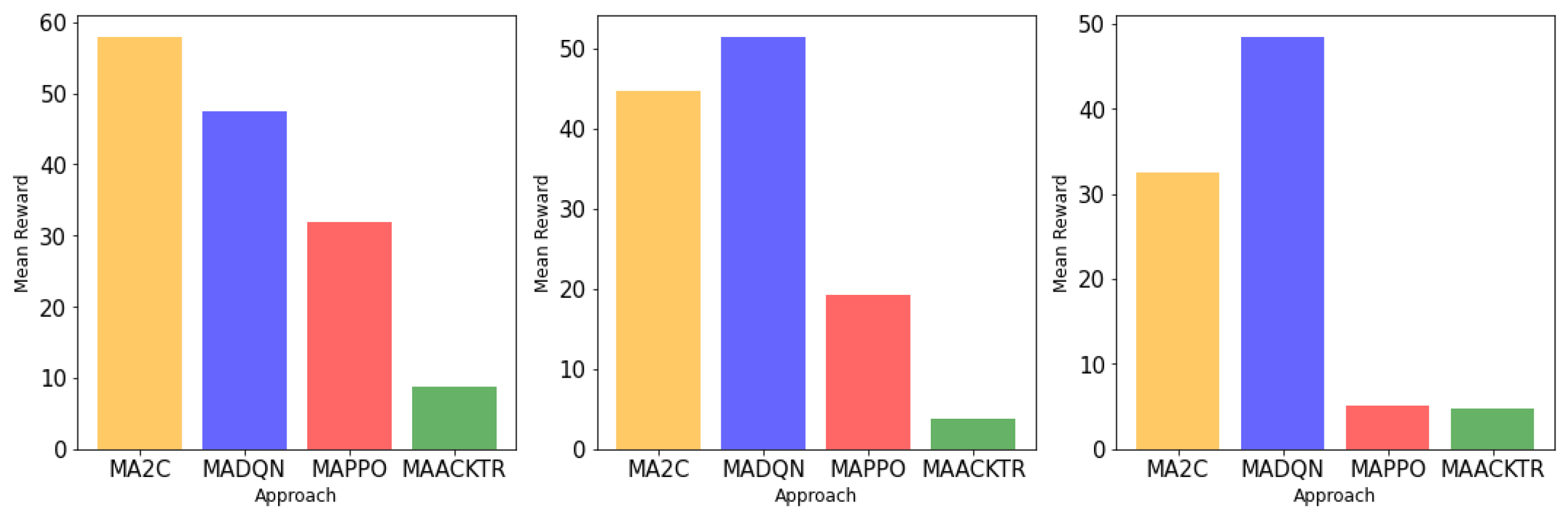
In this research, we juxtapose the efficacy of the proposed Multi-Agent Actor–Critic with Parameter Sharing (MA2C) against established state-of-the-art MARL methodologies, such as MAPPO (Multi-Agent Proximal Policy Optimization), MAACKTR (Multi-Agent Actor–Critic Using Kronecker-Factored Trust Region), and MADQN (Multi-Agent Deep Q-Network). These comparisons are vital in the context of sustainable smart cities, where efficient and reliable decision-making algorithms are paramount for managing complex urban environments.
6.3. State-of-the-Art Benchmarks Comparison in the Context of Sustainable Smart Cities
MADQN employs a deep neural network to approximate value functions, utilizing an experience replay buffer. While it shows commendable reward averages, its higher variance suggests potential instability, a critical aspect in urban scenarios where consistent performance is crucial for safety and reliability. MAACKTR adapts the Actor–Critic algorithm for multi-agent contexts, optimizing both actor and critic. Its application in dense urban networks can enhance collaborative decision-making among autonomous agents. MAPPO uses a clipped surrogate objective and an adjustable KL penalty coefficient, suitable for dynamic urban settings where policies must adapt to rapid changes. The Proposed MA2C, with its multi-objective reward function, parameter sharing, and local reward design, stands out in the context of smart urban management. It consistently outperforms other benchmarks in terms of evaluation rewards and reward standard deviations. This is particularly evident in the ‘Density 1’ scenario, which can be likened to less congested urban environments.
Figure 3 and
Figure 4 reveal MA2C’s robust performance. Its growing and plateauing pattern in rewards under different densities aligns with the goals of sustainable smart cities, striving for optimal, stable, and scalable solutions in complex, multi-agent urban ecosystems. The adaptability and stability of MA2C make it a promising tool for enhancing the sustainability and efficiency of urban transportation systems and other smart city applications.
Traffic density levels are differentiated by the volume of vehicles: Density Level 1 denotes low traffic akin to off-peak hours, Density Level 2 indicates moderate traffic with occasional congestion, and Density Level 3 represents high traffic typical of peak hours with significant congestion. Regarding the MARL models, MADQN uses deep learning for value function approximation and may exhibit higher variance, suggesting potential instability. MAACKTR enhances the Actor–Critic approach with a trust region for stability in dense traffic, while MAPPO adapts for rapid changes in dynamic environments. The proposed MA2C model stands out with its parameter sharing and local reward design, showing consistent performance and robustness across varying traffic densities, making it highly suitable for smart urban traffic management in sustainable smart cities.
6.4. Policy Interpretation
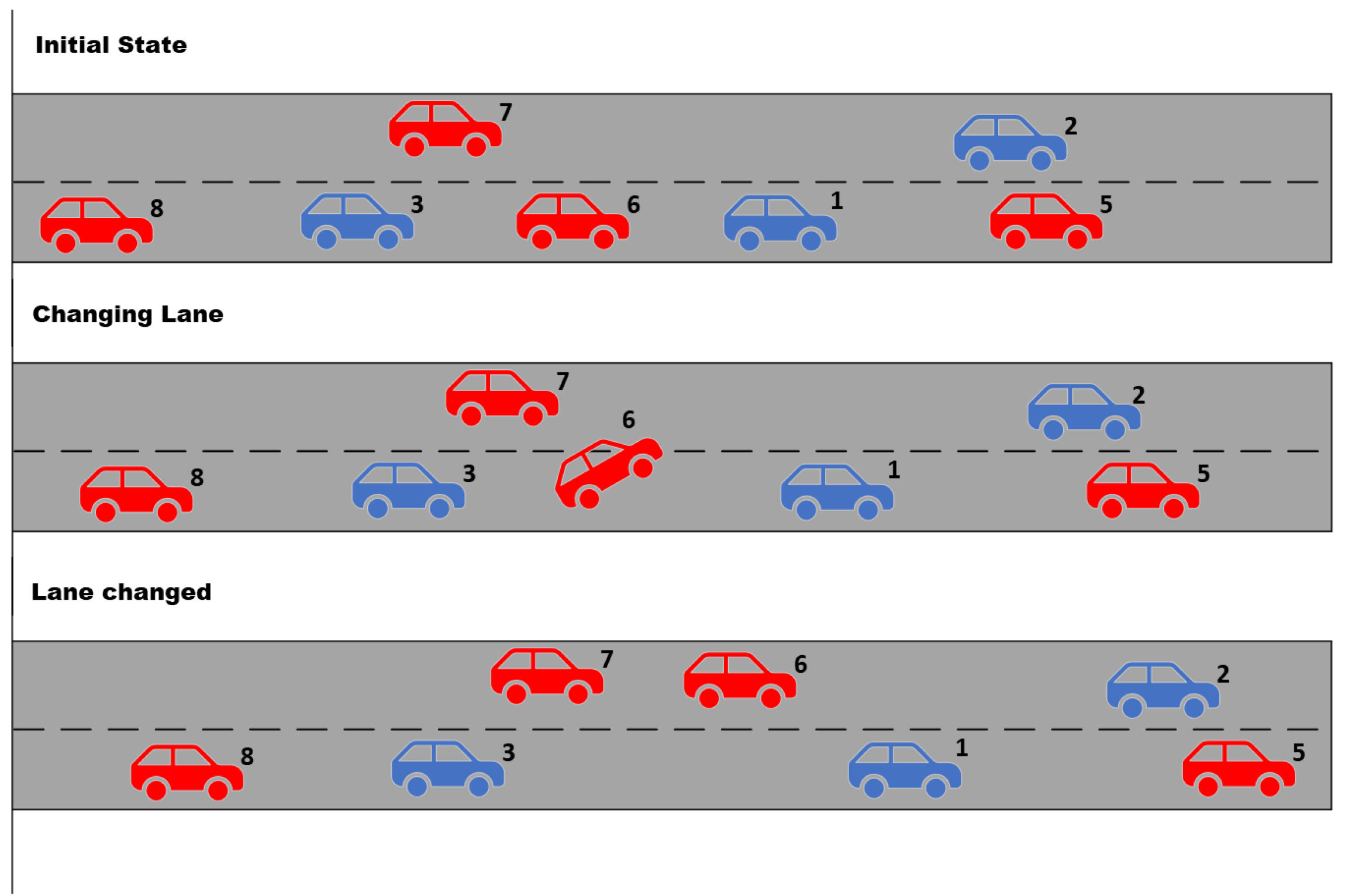
Figure 5 is a three-panel figure depicting a lane-changing scenario involving four autonomous vehicles on a multi-lane road. In upper Panel, labeled “Initial State”, we see a highway with two lanes. The vehicles are represented by simple block shapes with labels. AV 6 is shown in the right lane, appearing to prepare for a lane change. Ahead in the left lane is AV 7. The middle panel is labeled “Changing Lane” and shows AV 6 positioned between the two lanes, indicating the action of changing lanes. AV 6 is now partially in the left lane, overtaking AV 7, which seems to have slowed down to allow AV 6 to merge safely. In the lower Panel entitled “Lane Changed”, AV 6 has completed the lane change and is now fully positioned in the left lane, ahead of AV 7, which has resumed traveling at a normal speed after the lane change is completed. The lanes are marked with dashed lines, and the vehicles’ movements are visually represented to reflect their interactions during the lane-changing process. This diagram effectively communicates the sequence of actions and interactions in a lane change maneuver executed by autonomous vehicles in a simulated environment.
6.5. Quantitative Analysis of Eco-Driving Benefits
Our comprehensive simulations have provided valuable insights into the energy efficiency gains achieved through the implementation of eco-driving behavior models across various traffic densities. The results are summarized in
Table 3, which presents a comparative quantification of these gains.
The data encapsulated in
Table 3 highlights the performance of our proposed MA2C approach in comparison to other established methodologies, under different traffic density conditions. Notably, the MA2C model consistently achieved ‘High’ energy efficiency gains in lower traffic density and maintained ‘Moderate’ to ‘Low’ gains as density increased, underscoring its robustness and adaptability to traffic conditions.
6.6. Eco-Driving Impact
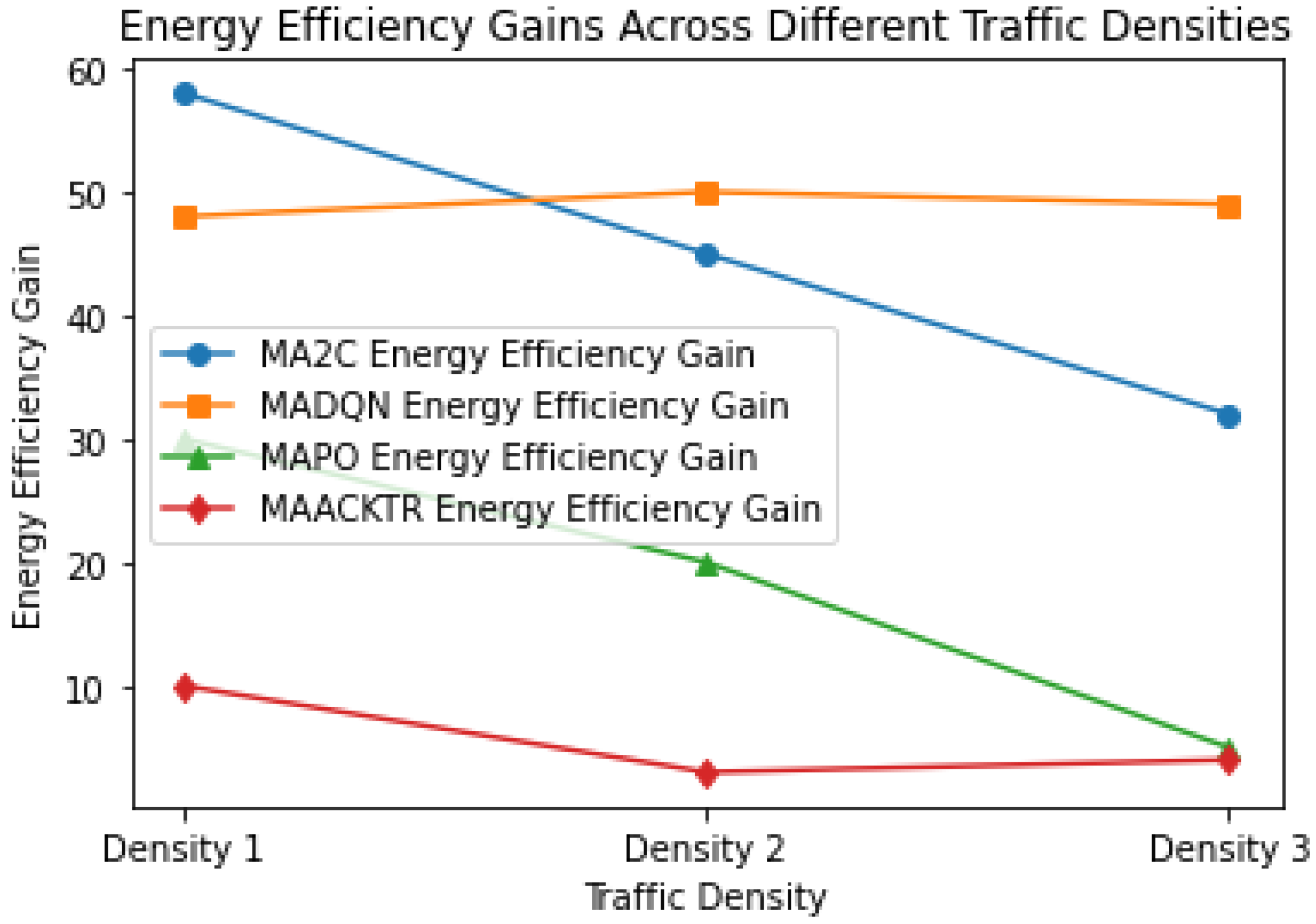
To further elucidate the impact of our models on sustainable urban mobility,
Figure 6 graphically represents the correlation between traffic density and the energy efficiency gains of the MA2C model. This figure visualizes the trends and variances in performance, providing a clear visual interpretation of the data.
As depicted in
Figure 6, the MA2C model exhibits a superior capability in maintaining higher energy efficiency gains, especially in less congested environments (Density 1). The trend lines indicate that while performance naturally diminishes with increasing traffic density, the degradation in energy efficiency gains is less pronounced for the MA2C model, validating its effectiveness in eco-driving applications within urban settings.
These results are not only underscore the practical significance of our research but also provide a foundation for future developments in autonomous vehicle technology aimed at enhancing sustainability in smart cities.
7. Discussion
The study’s findings contribute significantly to the concept of sustainability within smart cities, particularly in the realm of urban transportation. It is evident that localized reward mechanisms in traffic management can greatly optimize traffic flow, reducing vehicle idling times and thereby decreasing emissions and energy consumption. High evaluation rewards from such localized systems indicate effective traffic handling with minimal disruptions, an essential aspect of promoting a sustainable urban environment. Moreover, the implementation of collaborative learning in urban transportation networks, through shared parameters among various city actors, fosters a more cohesive and efficient traffic system. This collective intelligence is a cornerstone in the resilience and adaptability of smart urban mobility, enhancing resource utilization and reducing the ecological footprint. The promotion of sustainable driving practices is also highlighted, as incorporating driving comfort into reward functions encourages more environmentally friendly driving behaviors. Smoother accelerations and decelerations lead to reduced fuel consumption and less wear on vehicles, contributing to the overall sustainability goals of urban transit systems.
The adaptability of multi-agent systems, such as the MA2C algorithm, is crucial in managing urban traffic flows, particularly in fluctuating urban densities. Its superior performance in managing traffic efficiently showcases its potential in scalable and flexible urban traffic control, aligning with the sustainability objectives of smart cities. Nevertheless, the study acknowledges several limitations that hold implications for sustainability. The importance of passenger comfort is often overlooked in current algorithms, yet it is critical for the widespread acceptance and success of sustainable transportation initiatives. Comfortable transit experiences can encourage the use of public transportation, reducing reliance on private vehicles and associated emissions. Additionally, the assumption of universal behavior for HDVs does not accurately reflect the diversity of driving patterns present in real-world smart city scenarios. Addressing this gap is necessary to ensure that traffic management systems are effectively minimizing the environmental impact.
We have conducted a detailed comparative analysis of the MA2C algorithm against other prevalent MARL methodologies, namely MAPPO, MADQN, and MAACKTR, in the context of sustainable smart city challenges. MA2C’s local reward design and parameter sharing stand out as significant strengths, fostering adaptability and robustness in dynamic urban traffic, which is evident from the sustained performance in less congested environments (Density 1) as shown in our results. This adaptability is critical for the unpredictable nature of smart city traffic, where conditions can change rapidly due to various factors such as pedestrian movements, traffic signal patterns, and unexpected events. On the other hand, MADQN, while showing commendable reward averages, exhibits higher variance in performance, suggesting potential challenges in consistency. This could pose limitations in real-world applications where reliability is paramount for safety and user trust. MAPO’s approach, with its clipped surrogate objective, might offer better policy adaptability to rapid changes in urban traffic. However, its generalization across diverse scenarios remains a question, potentially affecting its application in environments with high variability in traffic density. MAACKTR’s optimization for both actor and critic provides a structured approach for collaborative decision-making among autonomous agents, a feature beneficial for dense urban traffic management. Yet, its performance under different traffic densities needs to be investigated further to confirm its practicality in real-world urban settings. The comparative analysis underscores MA2C’s potential as a scalable and stable solution for smart city transportation systems, proposing it as a promising tool for managing urban mobility sustainably.
Finally, addressing the scalability of intelligent transportation systems remains a vital challenge to ensure that sustainable mobility solutions can be maintained and adapted to the complexity of evolving urban landscapes. A comprehensive empirical study comparing various algorithms under different traffic densities and HDV behaviors would greatly aid in identifying the most environmentally friendly and efficient solutions.
Through these insights, the study underscores the potential of artificial intelligence and machine learning in developing robust, efficient, and sustainable urban mobility systems. Such advancements are imperative for the growth of smart cities, aiming to create an interconnected and sustainable urban future where technology and infrastructure work in harmony to enhance the quality of life and preserve environmental integrity.
8. Conclusions
A Multi-Agent Actor–Critic (MA2C) algorithm is proposed in this study to represent a forward-thinking approach to urban mobility within smart cities, emphasizing the role of autonomous vehicles in enhancing traffic efficiency and sustainability. This algorithm stands out from previous Multi-Agent Reinforcement Learning (MARL) strategies with its innovative design, which integrates a local reward system prioritizing not only efficiency and safety but also passenger comfort. Furthermore, its parameter-sharing structure fosters collaborative behaviors among agents, which is vital for the interconnectivity of smart urban transport systems. The empirical results demonstrate that the MA2C algorithm surpasses other state-of-the-art models by effectively managing lane changes, optimizing passenger comfort, and facilitating agent cooperation. These outcomes are indicative of the algorithm’s potential to enable autonomous vehicles to interact seamlessly with human-driven vehicles in dense traffic, which is a common scenario in smart cities. This interaction is crucial for maintaining fluid traffic conditions, reducing congestion, and, consequently, lowering emissions and energy usage. The research marks a significant stride towards the development of intelligent transportation systems where autonomous vehicles are integral components. They contribute to the safety, efficiency, and environmental goals of smart cities, where sustainable transport is a key objective. By improving how vehicles communicate and operate within the urban fabric, such technologies pave the way for more resilient and adaptive urban environments. This progress is in line with global efforts to create more livable, sustainable, and technologically advanced urban areas for future generations.



 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}