1. Introduction
Renewable energy sources, mainly wind or solar, are currently considered essential for sustainable access to humanity’s basic resources, i.e., water, food, and energy [
1], and for climate change mitigation, which is critical to protect humans, wildlife, and ecosystems [
2]. Solar energy serves as a cornerstone for policymakers, engineers, and researchers [
3] and is also discussed in educational projects for sustainability [
4]. Thus, reliable data on solar resources are therefore needed to support the sustainable growth and impact of solar installations [
5,
6].
Solar resource assessment requires relatively expensive direct measurement equipment operating at qualified meteorological stations and providing long data sets to facilitate the validation of solar radiation models. Since radiometric stations are relatively scarce, especially in less developed countries [
7,
8], it is interesting to develop models that allow indirect estimation of global solar radiation (GSR) from abundantly recorded meteorological variables such as temperature.
Numerous GSR models have been developed over decades [
9,
10,
11]. The accuracy of the estimates depends not only on the methodology and the number and type of influential variables considered in the model but also on the quality and the spatial and temporal distribution of the used data [
12,
13]. Models have even been proposed that use non-meteorological input variables, such as declination [
14] or latitude [
15], penalizing accuracy at the expense of simplicity. In general, it can be said that most GSR models are acceptable for the localities or regions where they were validated but less accurate when extended to other areas [
16].
There is a trade-off between the accuracy of a model, its complexity, and its generality, i.e., its adaptability to large regions. Accuracy at the local scale can be increased using a higher number of variables, but a simple model may have advantages for predictions over large regions due to its higher number of degrees of freedom [
17]. In addition, generality can be facilitated using dimensionless variables and complete functional relationships, i.e., dimensionally homogeneous equations. Otherwise, the parameters or coefficients of the functional relationships necessarily depend on variables that are not explicit in the model [
11]. This observation has been little emphasized so far and is applicable to both regression-based and artificial intelligence-based models.
The most widely used models for estimating GSR consist of expressions of the clearness index as a function of the relative sunshine duration, so they are dimensionally homogeneous equations with various mathematical forms. Most equations use site-dependent parameters, but some of them are intended to be valid worldwide. Around 90% of the variability in data recorded at 59 European stations has been explained using relative sunshine hours, elevation, and the monthly index as input variables [
18], but data on sunshine duration are not generally available. Looking for a temperature-based approach and as an evolution of the classical model of Hargreaves and Samani [
19], a model of the monthly average of the atmospheric clearness index has been previously introduced [
20], using the square root of
as the only meteorological variable, where
is the difference between the monthly average of daily maximum temperature,
(in K), and the monthly average of daily minimum temperature,
(in K), and assuming that the proportionality coefficient depends on the ratio
between the elevation
(in m) and the distance to the sea
(in km). This simple and dimensionally homogeneous model has been evaluated with acceptable results in localities of the northern Spanish coast [
11,
12,
13,
17,
20] and two large areas of central and southern Spain, with very different climatology and latitude. The comparison with other temperature-based models in each of the three zones showed both the advantages of this model for obtaining general equations applicable in each zone and the influence of latitude on the geographical variability of the model coefficients [
12].
To analyze the influence of latitude, mathematical methodology, and possible seasonal effects, a model based on a simple ANN was recently developed to estimate the monthly clearness index for the set of 105 stations located in the three areas of peninsular Spain previously studied. Using
,
, the latitude and a monthly index as input variables. This approach allowed the improvement of the accuracy of previous models for both statistical indicators averaged for the set of stations and local deviations [
13].
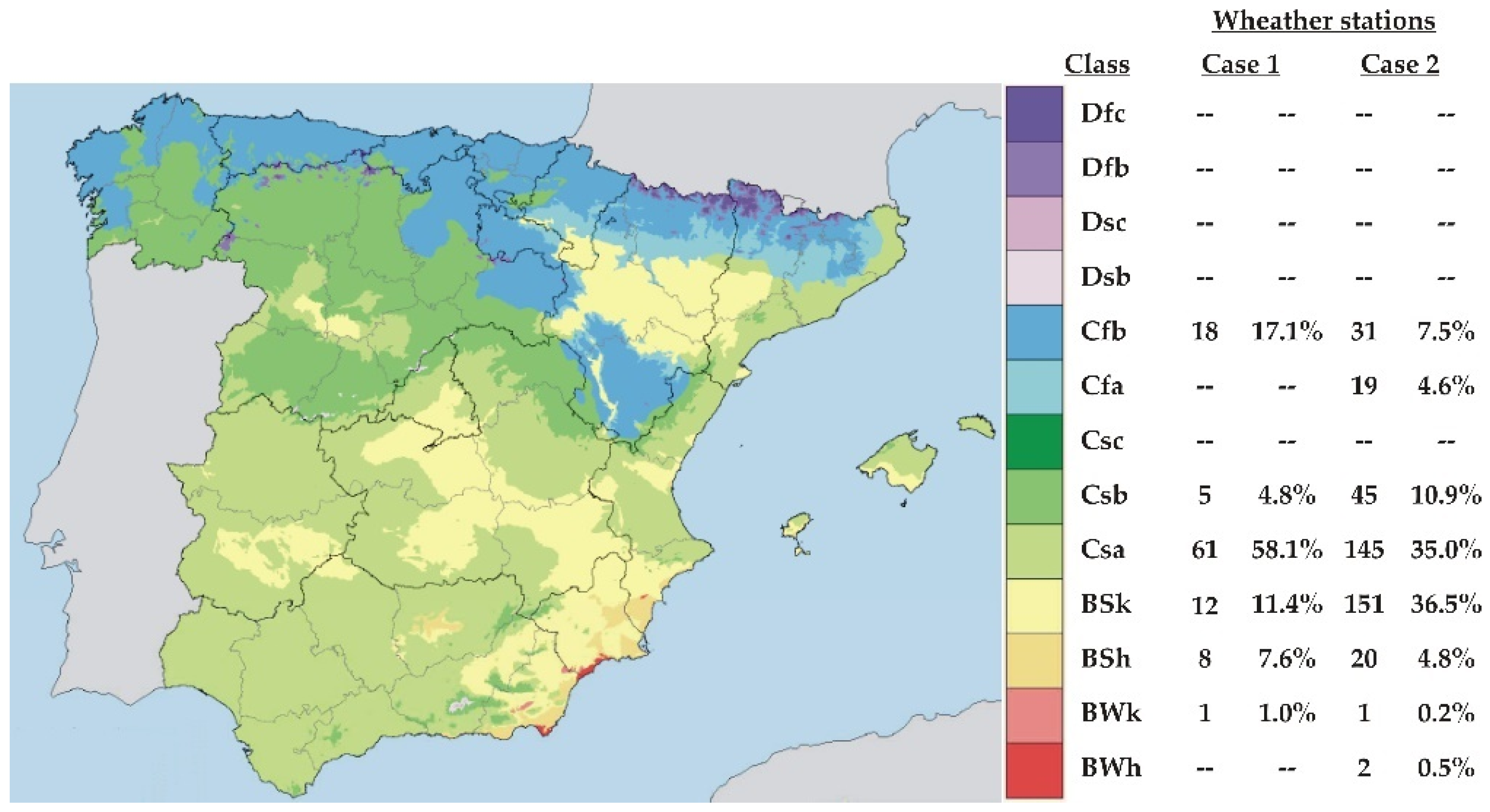
The varied geography and orography of Spain have been considered in many studies to characterize the solar resource, using different methods and data from a smaller number of on-ground stations than in the present article [
21,
22,
23]. Access to the network of the Spanish Ministry of Agriculture, Fisheries and Food’s Agroclimatic Information System for Irrigation (SIAR) has facilitated for this paper the evaluation of the model using data from a total of 414 on-ground stations.
The main objective of the paper is to answer the following three research questions:
- (a)
Is the robustness of the model, based on a simple ANN using the most commonly available input variables, acceptable when the percentage of data collected for network testing is significantly increased while maintaining the clustering algorithms?
- (b)
What would the result be if a similar percentage of data were used for training and testing?
- (c)
Does the procedure allow the detection of any climatic characteristics to improve the estimates without adding input variables?
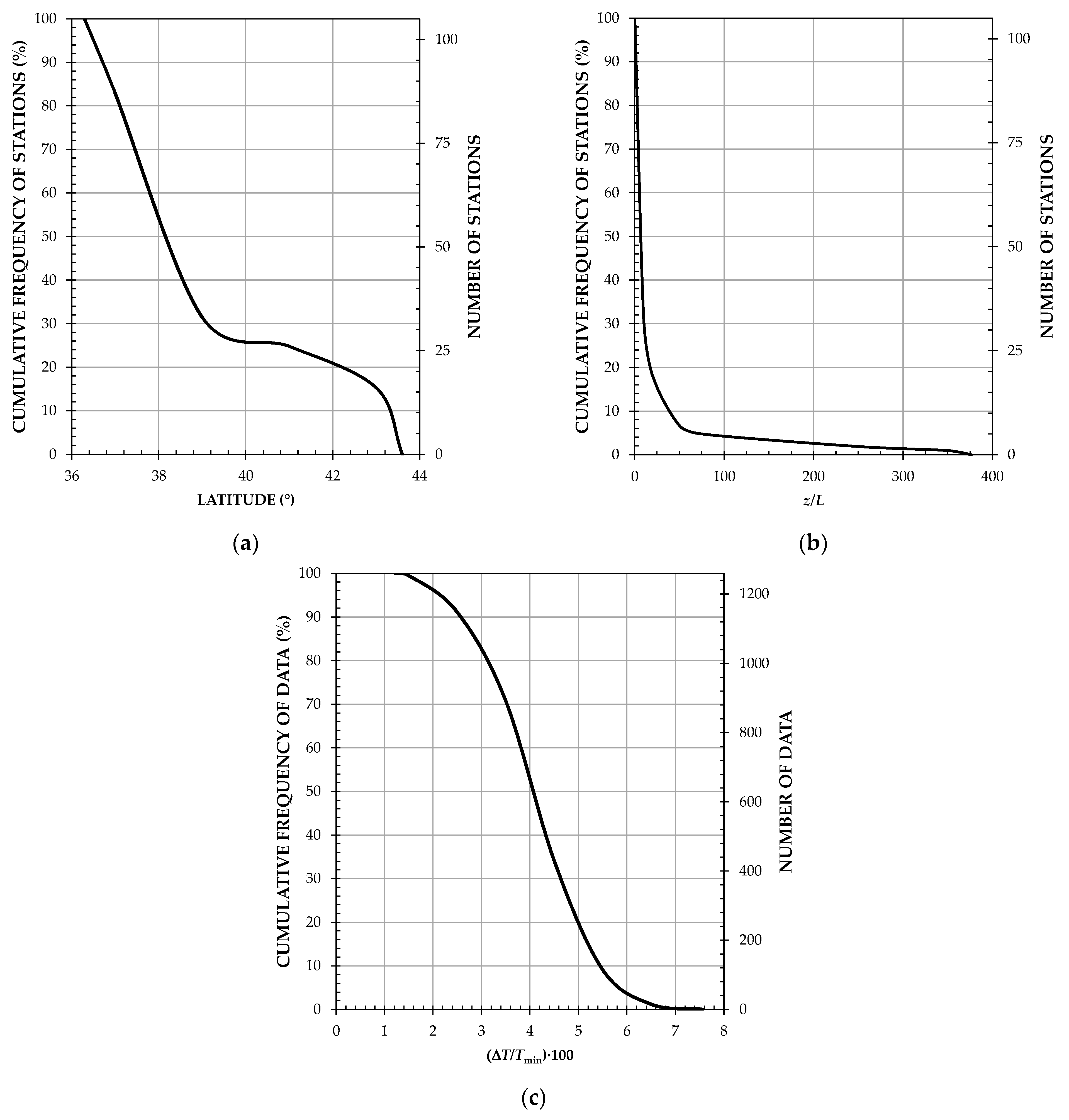
To investigate the first question, the scenario described in the previous paper is considered to be a starting point (Case 0), using 53 stations for ANN training and 52 for testing. Case 1 refers to the ANN trained with the same 53 stations as in Case 0, but using for validation the remaining 361 stations available after adding the SIAR database.
In the analysis of the second question, Case 2 refers to the behavior of the ANN re-trained with 206 stations and validated with the remaining 208 stations.
Finally, to address the third question and as a preliminary step for more comprehensive future work on the extension of the procedure to other countries, the ANN results for the Spanish stations are complemented with ANN results for 16 stations included in the Meteonorm database [
24].
Regarding the article’s structure, the Materials and Methods section contains descriptions of the physical and mathematical foundations of the model, the data, and the analysis procedure employed. In the Results section, it is considered an interesting contribution to show the statistical distribution of data in the cases analyzed, as well as the use of relative errors, both local and averaged over the total data set, as statistical indicators of the accuracy. After being previously described, the results are interpreted in the Discussion section in response to the research questions posed as objectives.
From a practical point of view, it is considered that the model procedure may be of interest for low-cost solar resource assessments at the microclimate scale, using data from secondary thermometric networks, terrain elevation maps, and GIS techniques once the model is validated on a wide range of input variables.
From an academic point of view, the article is an additional contribution to the scarce general GSR models, where the rare use of dimensionless variables is surprising despite being more orthodox from a physics point of view and more advantageous from a computational perspective.
4. Discussion
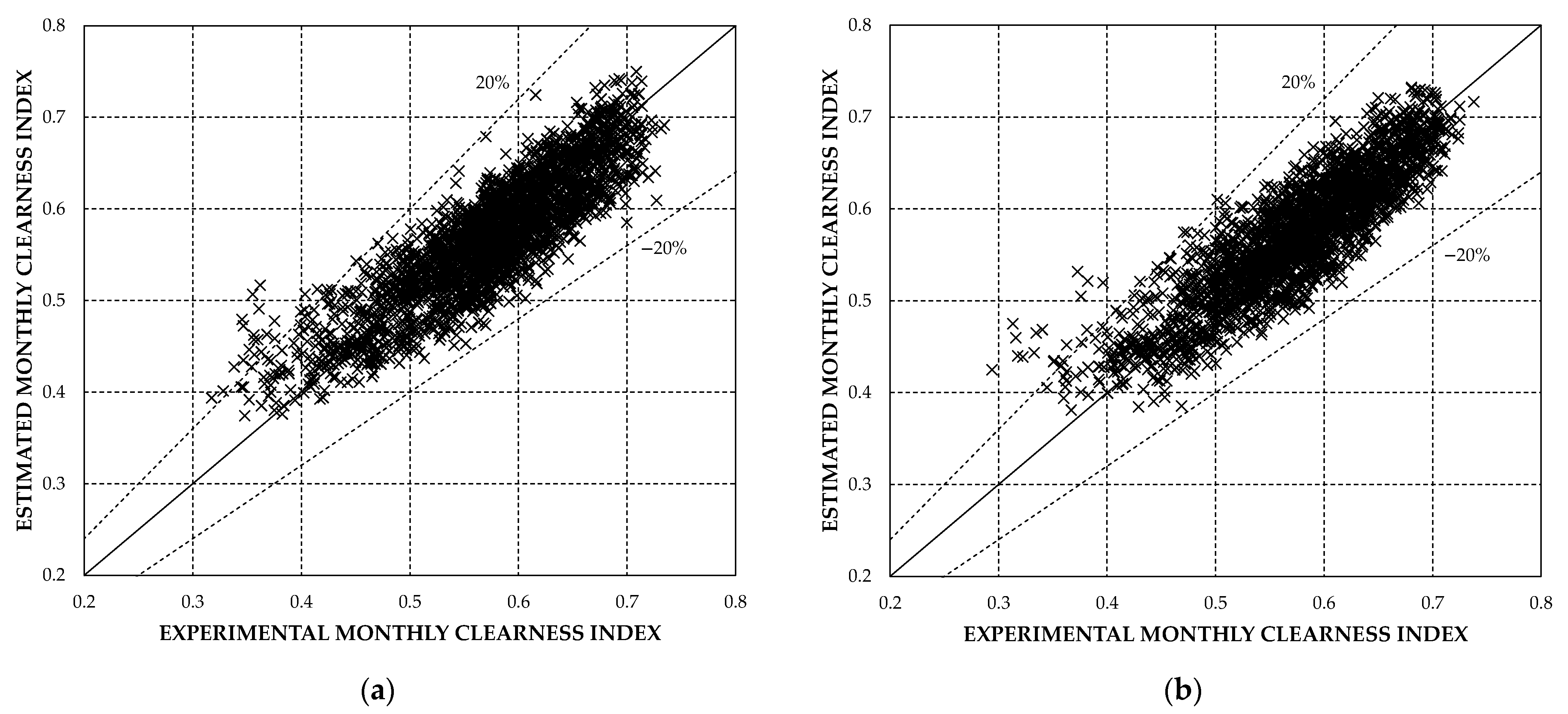
From the figures and tables, it can be deduced that the results are relatively satisfactory for Case 1, with an RRMSE value of 9.28% for the 4968 data set. In addition, with respect to the errors at each station, most of the monthly relative errors are within the range of ±20%, even though the network was trained in this case with less than 13% of the station set.
Table 4 shows the statistical distribution of the monthly relative errors, with only 92 values above 20%, equivalent to 1.85% of the total data. However, as
Figure 6 shows, it is evident that the neural network is biased for many stations in the SIAR network, providing estimates below the experimental data.
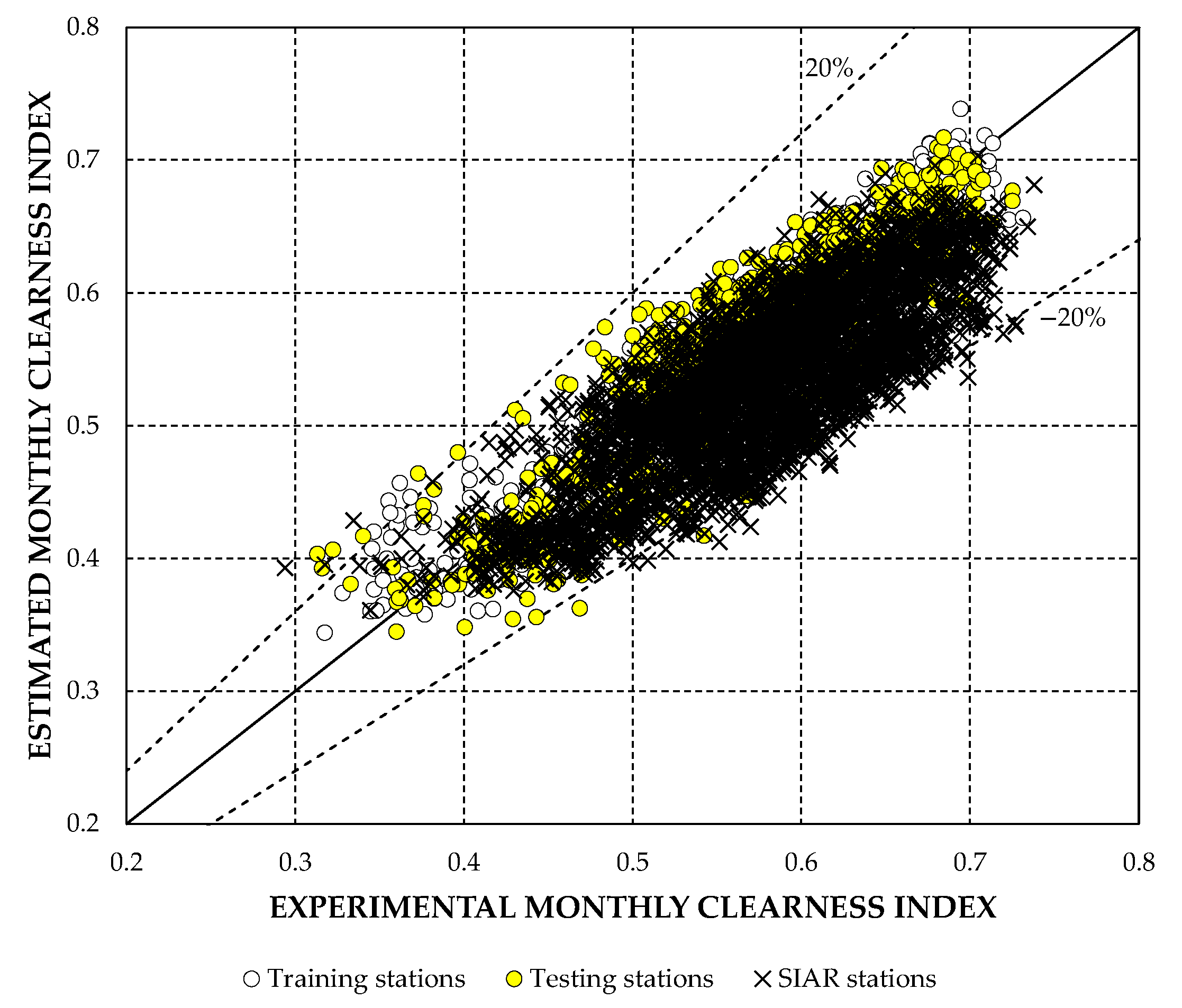
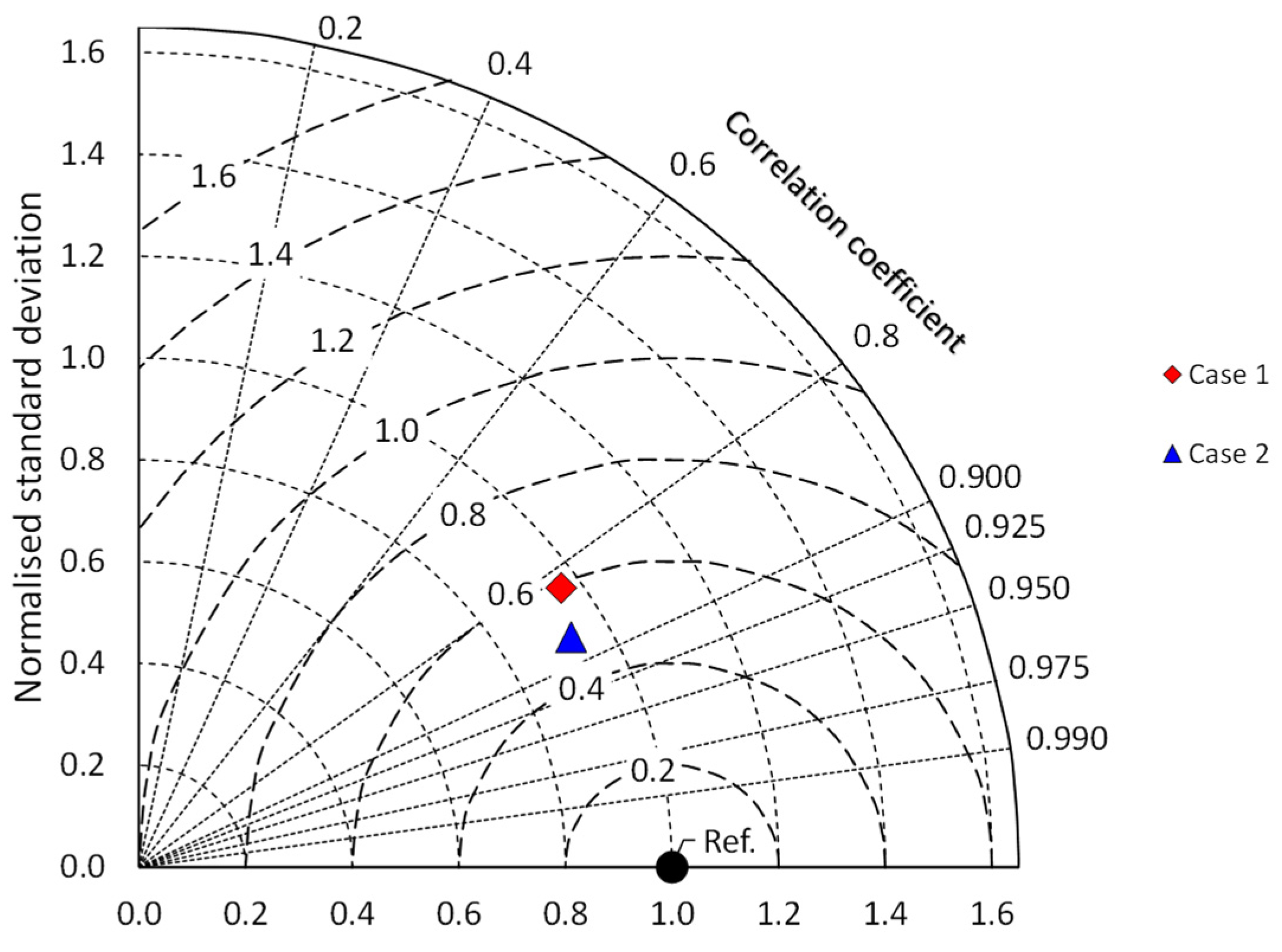
In Case 2, after re-clustering and selection of training stations, an RRMSE value of 6.89% is obtained for the data set.
Figure 8 highlights the best statistical indicators obtained in Case 2 for the set of stations. As for the monthly relative errors, the values above 20% are reduced to about half of Case 1, as can be seen from
Table 5.
Figure 9 provides a comparison between the monthly relative error distributions, with a noticeable improvement for Case 2. The comparison between
Figure 2a and
Figure 3a suggests that the main cause of such an improvement could be the higher percentage of stations used for training in mid-latitudes.
In Case 2 there are 49 values of monthly relative errors greater than 20%, spread over 16 stations.
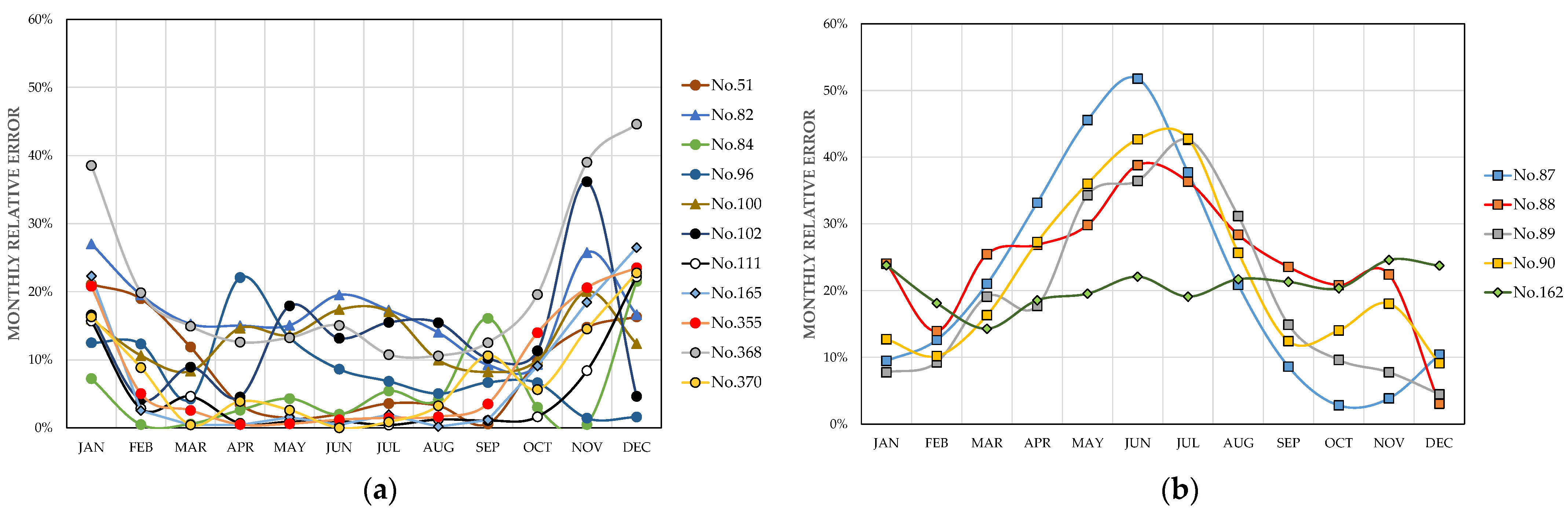
Figure 10a plots the values for the stations where the monthly relative errors are higher than 20% in 3 months at most, while
Figure 10b allows comparing the results for the remaining 5 stations where the monthly relative errors are higher than 20% in more than 3 months.
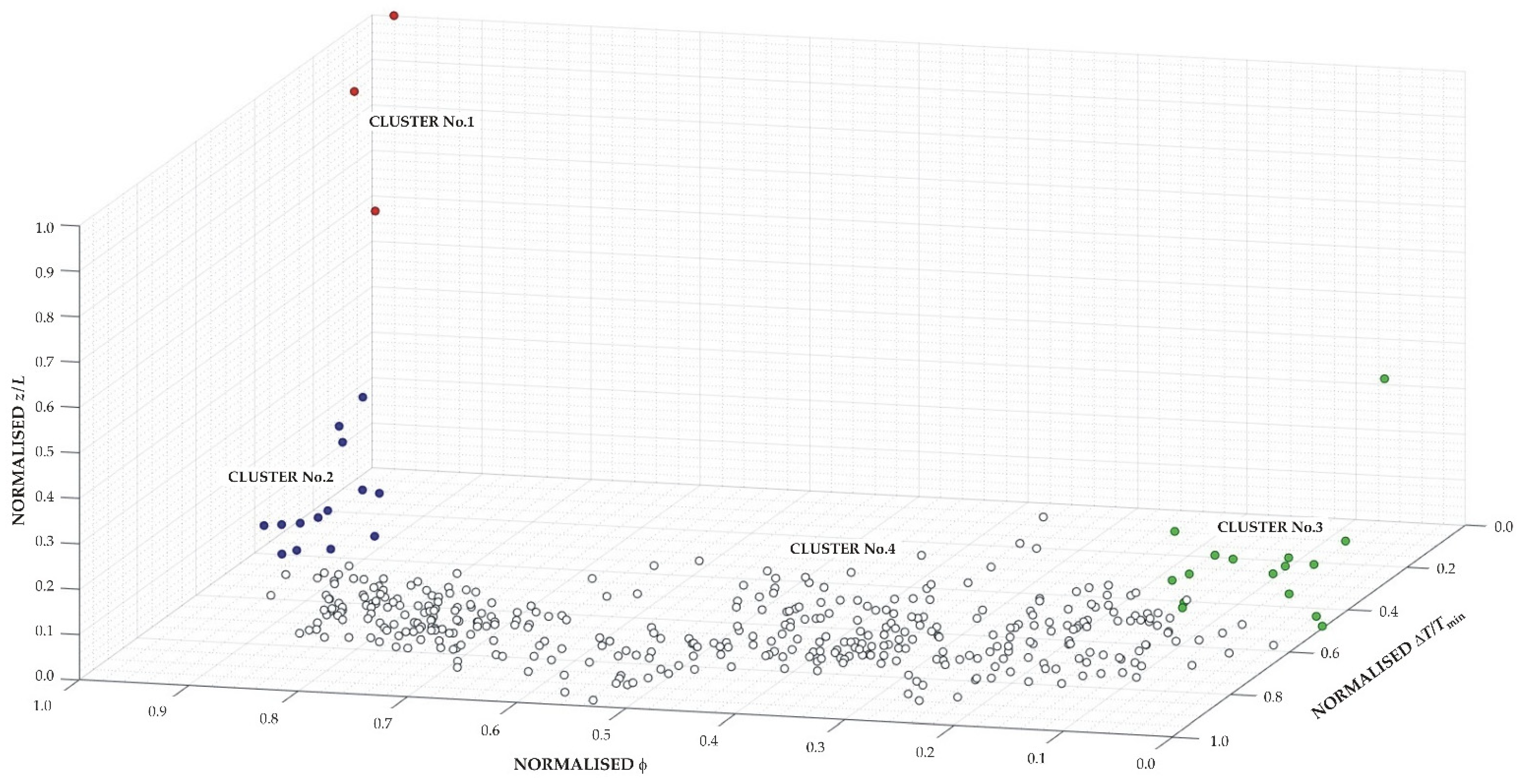
Figure 10a shows that relative error values are higher than 20% in three months at the most for 11 stations, which are included in Cluster No.4, except for station No.100, which belongs to Cluster No.2. For these stations, the least accurate estimates correspond practically to November, December, and January, with the least satisfactory results for station No.368.
Figure 10b shows that 25 monthly relative error values are higher than 20% in the spring and summer months for stations No.87–90, while for station No.162, the 7 values of monthly relative error higher than 20% are more moderate and do not have a marked seasonal character. All five stations are classified as Cfb-type climate. Stations No.87–90 are located in a coastal province of northern Spain and are included in Cluster No.2, where high values of latitude and, to a lesser degree of
are characteristic. However, station No.162 is located in the Castilian plateau and is included in Cluster No.4. Therefore, it is not evident that the largest errors are associated with high values of such variables since all stations of Cluster No.1 and most of Cluster No.2 present moderate monthly relative errors.
Figure 11a shows the low variability of the monthly clearness index measured for stations No.87–90, with the peculiarity that the difference between the clearness index values in June and December,
, is negative. This observation contrasts with the seasonal variability of the clearness index shown in
Figure 11b for the remaining 12 stations that also present some monthly error higher than 20%.
Among the 414 stations analyzed,
is negative at only 3 other stations, namely No.85, 91, and 98.
Figure 11c shows the variability of the monthly clearness index for these stations, as well as for station No.97, whose data have the lowest positive value of
, namely 0.005. This last station and the 7 already mentioned with
are included in clusters No.1 and 2, and all of them are in the Principality of Asturias, although managed by different official agencies.
It is interesting to note that in Case 1, stations No.87–90 and 162 also have the highest number of monthly relative errors above 20%.
Figure 12 shows that the trends are similar in both cases but with more moderate errors in Case 1.
Furthermore, it should be noted that data from stations No. 1–71, located in southern Spain, were used in previous work to compare 14 GSR models based on regression and temperatures [
12]. To evaluate their use as general models, the fit coefficients were replaced by functions of the
ratio. The best averages for the set of stations,
and
, were obtained using the modified Adaramola model [
12,
34], which expresses the clearness index by a linear function whose only variable is the monthly average daily mean temperature. This model predicted annual mean errors of less than 20% for all stations except for station No. 24, located in Cádiz, where the error was 50.32%, the most probable cause being that the
value at this location is notably higher than at the rest of the stations. Given that ANN predicts for station No.24 annual mean errors of 2.76% in Case 1 and 6.63% in Case 2, it can be concluded that the probability of obtaining unacceptable estimates at the local scale is lower using the neural network-based procedure.
As a complement to the analysis carried out for the Spanish stations and as a preliminary step to more comprehensive future work, the performance of the neural network has also been evaluated using data from stations located in other countries.
Table 6 shows the data of the monthly clearness index for 16 non-Spanish stations with input variables within the following ranges:
As shown in
Figure 13a, using the neural network trained in Case 2, the relative error of the clearness index is less than 20% for 12 stations during all months of the year. For the remaining four stations,
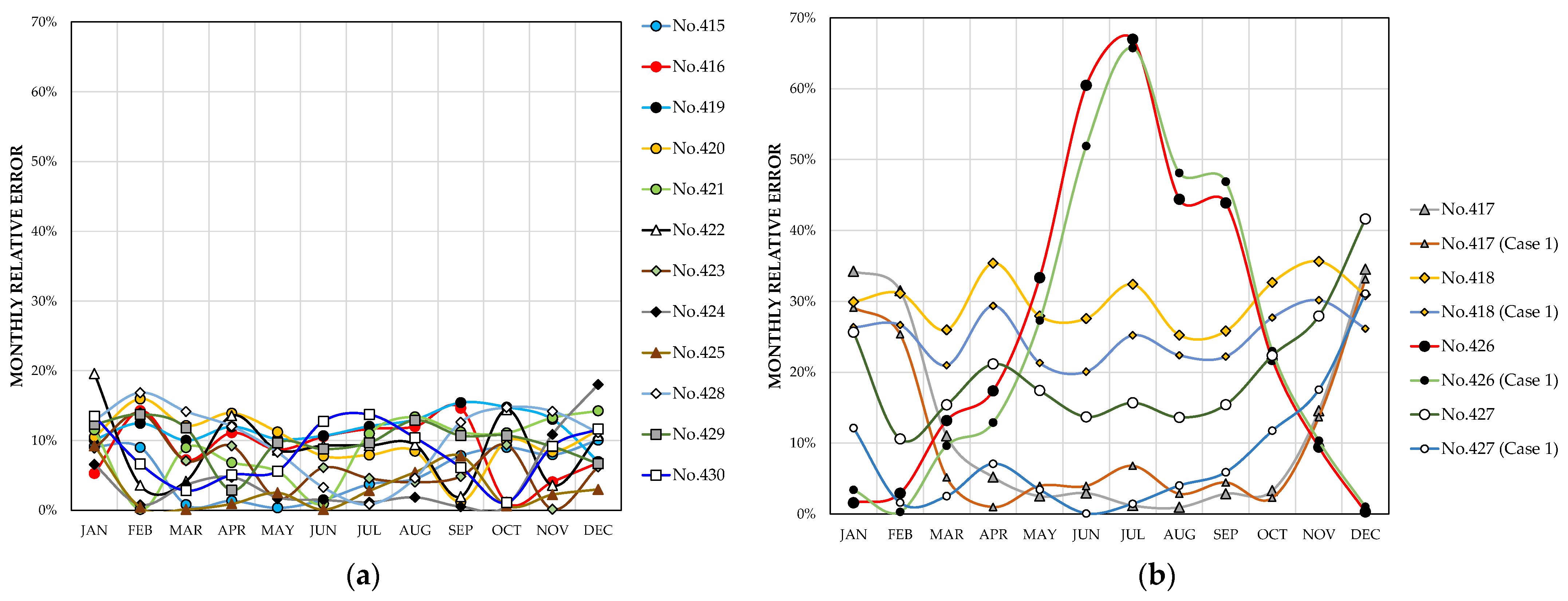
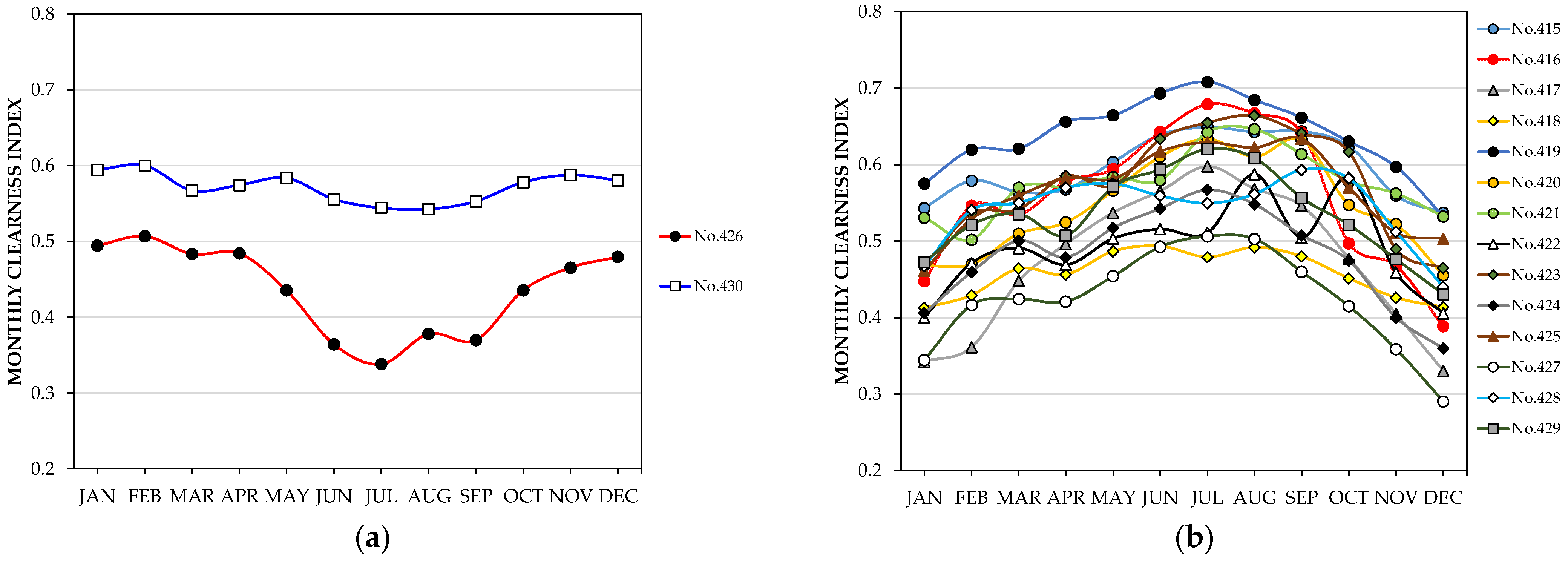
Figure 13b shows that the monthly relative errors are greater than 20% for station No.418 in all months of the year, with no appreciable seasonal differences. This result seems to be justified mainly because this station has a Dfa climate in the Köppen–Geiger classification and there are no stations of this class among the 414 Spanish stations analyzed. The errors are highest for station No.426 in the spring and summer months, while the highest errors are observed from December to February for station No.417 and from October to January for station No.427.
Figure 13b also shows that the same stations present the highest errors and with similar monthly trends when estimates are made using the neural network trained in Case 1, although the errors are more moderate except for station No.426. It can be interpreted that the remarkably high errors obtained at this station are related to the negative value of
, as
Figure 14a shows. On the contrary,
Figure 14b shows that stations No.417 and 427 have similar clearness index trends to the stations with lower errors, which is consistent with the fact that the errors at these stations only exceed 20% in 3 and 1 months, respectively, when using the network trained in Case 1.
The difference between the June and December clearness index is also negative for station No.430, located in Yinchuan, China, with some similarity to the behavior represented in
Figure 11c for stations No.85, 91, 97, and 98 on the Spanish north coast, and also with acceptable monthly errors. However, the ANN estimates for station No.430 are pending corroboration because, among the 414 Spanish stations analyzed, there is only one with the same BWk type climate, namely station No.1, located at the Plataforma Solar de Almería facilities, in the desert area of Tabernas.
In summary, it can be said that the choice of the best model is a matter of preference between objectives: The behavior of the ANN in Case 2 is more appropriate if the objective of obtaining the lowest mean error for the set of stations is a priority, but Case 1 leads to more moderate values of the maximum monthly relative errors, with a mean error for the set of stations that can be considered acceptable, especially if one takes into account that in this case the network has been trained with less than 13% of the set of stations.
In any case, the less accurate estimates seem to be related to climate types where the clearness index tends to be higher in winter than in summer, which is the case in few locations on the northern Spanish coast. This result is consistent with the estimates obtained for the Japanese locality of Sendai and suggests that the sign of the difference between the clearness indices in June and December may be a basic indicator of climatic variability as a complement to the Köppen–Geiger classification.
Future work is expected to improve the ANN model, designed to estimate GSR over large regions and based on temperature and geographic input data, using algorithms that incorporate climate variability as a variable for selecting training weather stations.
5. Conclusions
Hierarchical clustering, based on normalized values of relative temperature amplitude, latitude, and the ratio of elevation to distance to the sea, is suitable for the characterization of solar radiation data.
A simple ANN is capable of estimating GSR from temperature, orography and geography data with acceptable accuracy, both with respect to error averages for the input data set and with respect to local errors, which is interesting for low-cost solar resource assessments over wide areas.
The application of Buckingham’s theorem to the functional relation underlying the ANN simplifies the structure of the ANN, providing computational advantages due to the smaller number of variables and weights.
The percentage of data used for ANN training influences the quality of the results. In this work, with the same network structure, a lower average error was obtained for the set of 4968 data measured at 414 Spanish stations using 50% of the data for network training, but local errors were lower using 18% of the data for training.
The results of the article once again corroborate the usefulness of the ratio as a proxy for both elevation and thermal regulation of the sea.
The ANN trained with data from Spanish stations performs generally well for other places all around the world within the same ranges of input variables.
The difference between the clearness indices in June and December could be used in the hierarchical clustering of climate data as a complement to the Köppen–Geiger classification, which is suggested to be studied in future works.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}