
Leveraging AI and Data Visualization for Enhanced Policy-Making: Aligning Research Initiatives with Sustainable Development Goals

 , , , , , , and
, , , , , , and 
Abstract
1. Introduction
- How can BERT-based AI models be fine-tuned to classify research projects in alignment with the SDGs?
- In what ways can AI-powered data visualization tools improve decision-making in the allocation of public research funds to projects aligned with the SDGs?
2. Background
2.1. Large Language Models
2.2. Bidirectional Encoder Representations from Transformers (BERT)
3. Related Works
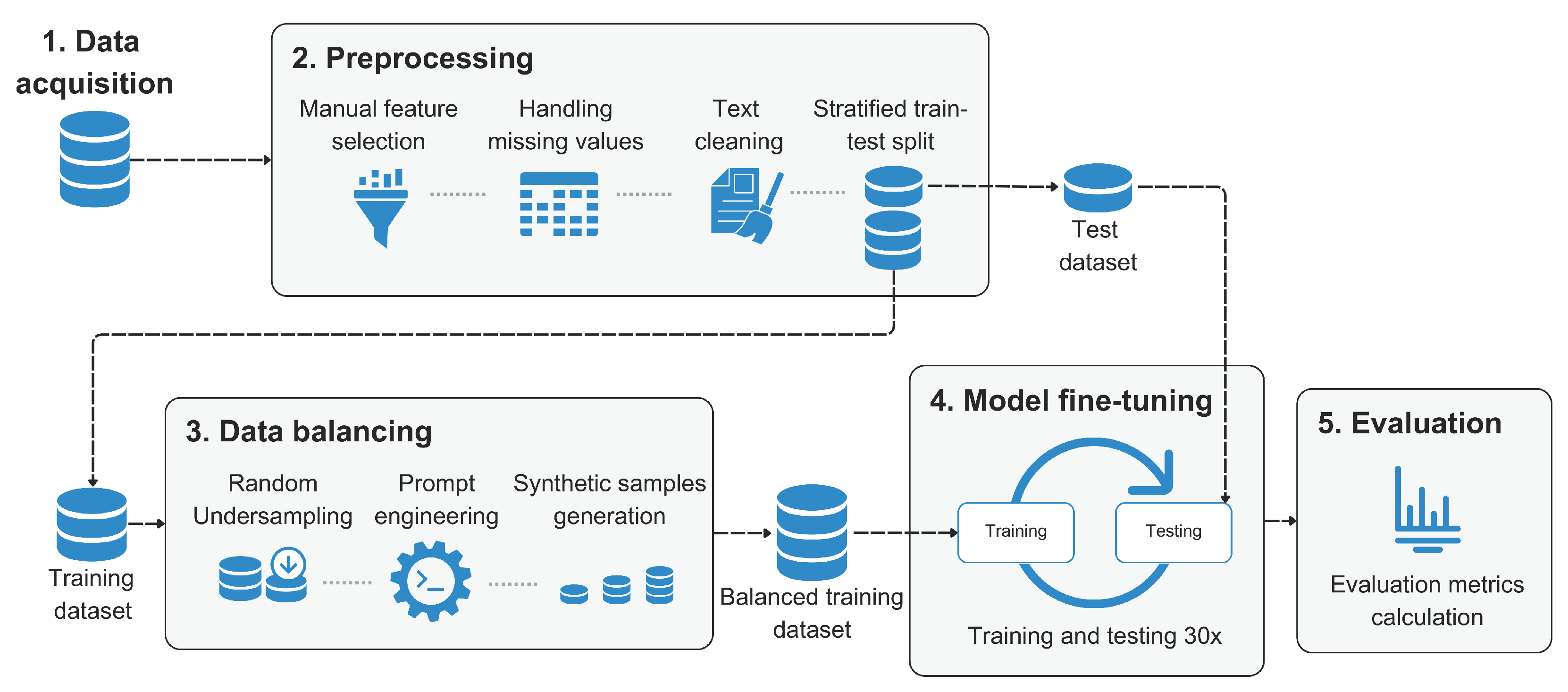
4. Material and Methods
4.1. Data Acquisition
4.2. Preprocessing
4.3. Data Balancing
Synthetic Sample Generation
4.4. Model Fine-Tuning
4.5. Evaluation
4.5.1. Precision
4.5.2. Recall
4.5.3. F1-Score
4.5.4. F1-Macro Average
5. Results
5.1. Classification of FACEPE Research Projects
5.2. Dashboard
6. Discussion
Limitations and Future Directions
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- United Nations. United Nations Sustainable Development Goals. 2024. Available online: https://sdgs.un.org/goals (accessed on 24 April 2024).
- Stevens, C.; Kanie, N. The Transformative Potential of the Sustainable Development Goals (SDGs). 2016. Available online: https://ideas.repec.org/a/spr/ieaple/v16y2016i3d10.1007_s10784-016-9324-y.html (accessed on 9 December 2024).
- The Sustainable Development Goals Report 2023: Special Edition Towards a Rescue Plan for People and Planet. 2023. Available online: https://unstats.un.org/sdgs/report/2023/ (accessed on 8 December 2024).
- Asadikia, A.; Rajabifard, A.; Kalantari, M. Navigating sustainability: Key factors in prioritising Sustainable Development Goals. Sustain. Sci. 2024, 19, 2041. [Google Scholar] [CrossRef]
- Morales-Hernández, R.C.; Jagüey, J.G.; Becerra-Alonso, D. A Comparison of Multi-Label Text Classification Models in Research Articles Labeled With Sustainable Development Goals. IEEE Access 2022, 10, 123534–123548. [Google Scholar] [CrossRef]
- Smith, T.B.; Vacca, R.; Mantegazza, L.; Capua, I. Natural language processing and network analysis provide novel insights on policy and scientific discourse around Sustainable Development Goals. Sci. Rep. 2021, 11, 22427. [Google Scholar] [CrossRef] [PubMed]
- Guisiano, J.E.; Chiky, R.; De Mello, J. SDG-Meter: A deep learning based tool for automatic text classification of the Sustainable Development Goals. In Proceedings of the Asian Conference on Intelligent Information and Database Systems, Ho Chi Minh City, Vietnam, 28–30 November 2022; pp. 259–271. [Google Scholar]
- Sashida, M.; Izumi, K.; Sakaji, H. Extraction SDGs-related sentences from Sustainability Reports using BERT and ChatGPT. In Proceedings of the 2023 14th IIAI International Congress on Advanced Applied Informatics (IIAI-AAI), Koriyama, Japan, 8–13 July 2023; pp. 742–745. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- dos Santos, V.G.; Santos, G.L.; Lynn, T.; Benatallah, B. Identifying Citizen-Related Issues from Social Media Using LLM-Based Data Augmentation. In Advanced Information Systems Engineering: CAiSE 2024; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2024; pp. 531–546. [Google Scholar]
- Chowdhary, K.; Chowdhary, K. Natural language processing. In Fundamentals of Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2020; pp. 603–649. [Google Scholar]
- Kang, M.; Jameson, N.J. Machine Learning: Fundamentals. In Prognostics and Health Management of Electronics: Fundamentals, Machine Learning, and the Internet of Things; John Wiley & Sons: Hoboken, NJ, USA, 2018; pp. 85–109. [Google Scholar]
- Das, K.; Behera, R.N. A survey on machine learning: Concept, algorithms and applications. Int. J. Innov. Res. Comput. Commun. Eng. 2017, 5, 1301–1309. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural language processing: State of the art, current trends and challenges. Multimed. Tools Appl. 2023, 82, 3713–3744. [Google Scholar] [CrossRef]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. GLUE: A multi-task benchmark and analysis platform for natural language understanding. arXiv 2018, arXiv:1804.07461. [Google Scholar]
- Chang, Y.; Wang, X.; Wang, J.; Wu, Y.; Yang, L.; Zhu, K.; Chen, H.; Yi, X.; Wang, C.; Wang, Y.; et al. A survey on evaluation of large language models. ACM Trans. Intell. Syst. Technol. 2024, 15, 1–45. [Google Scholar] [CrossRef]
- Kaddour, J.; Harris, J.; Mozes, M.; Bradley, H.; Raileanu, R.; McHardy, R. Challenges and applications of large language models. arXiv 2023, arXiv:2307.10169. [Google Scholar]
- Peng, Z.; Wang, Z.; Deng, D. Near-Duplicate Sequence Search at Scale for Large Language Model Memorization Evaluation. Proc. ACM Manag. Data 2023, 1, 1–18. [Google Scholar] [CrossRef]
- Wei, J.; Bosma, M.; Zhao, V.Y.; Guu, K.; Yu, A.W.; Lester, B.; Du, N.; Dai, A.M.; Le, Q.V. Finetuned language models are zero-shot learners. arXiv 2021, arXiv:2109.01652. [Google Scholar]
- Lukas, N.; Salem, A.; Sim, R.; Tople, S.; Wutschitz, L.; Zanella-Béguelin, S. Analyzing leakage of personally identifiable information in language models. In Proceedings of the 2023 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 22–25 May 2023; pp. 346–363. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Pukelis, L.; Puig, N.B.; Skrynik, M.; Stanciauskas, V. OSDG–Open-Source Approach to Classify Text Data by UN Sustainable Development Goals (SDGs). arXiv 2020, arXiv:2005.14569. [Google Scholar]
- Pukelis, L.; Bautista-Puig, N.; Statulevičiūtė, G.; Stančiauskas, V.; Dikmener, G.; Akylbekova, D. OSDG 2.0: A multilingual tool for classifying text data by UN Sustainable Development Goals (SDGs). arXiv 2022, arXiv:2211.11252. [Google Scholar]
- Guisiano, J.; Chiky, R. Automatic classification of multilabel texts related to Sustainable Development Goals (SDGs). In Proceedings of the TECHENV EGC2021, Montpellier, France, 26 January 2021. [Google Scholar]
- Matsui, T.; Suzuki, K.; Ando, K.; Kitai, Y.; Haga, C.; Masuhara, N.; Kawakubo, S. A natural language processing model for supporting sustainable development goals: Translating semantics, visualizing nexus, and connecting stakeholders. Sustain. Sci. 2022, 17, 969–985. [Google Scholar] [CrossRef]
- Center for World University Rankings. Center for World University Rankings. 2024. Available online: https://cwur.org/about.php (accessed on 8 October 2024).
- Bird, S. NLTK: The natural language toolkit. In Proceedings of the COLING/ACL 2006 Interactive Presentation Sessions, Sydney, Australia, 17–18 July 2006; pp. 69–72. [Google Scholar]
- Rosenblatt, M.; Tejavibulya, L.; Jiang, R.; Noble, S.; Scheinost, D. Data leakage inflates prediction performance in connectome-based machine learning models. Nat. Commun. 2024, 15, 1829. [Google Scholar] [CrossRef] [PubMed]
- Cai, X.; Xiao, M.; Ning, Z.; Zhou, Y. Resolving the imbalance issue in hierarchical disciplinary topic inference via llm-based data augmentation. In Proceedings of the 2023 IEEE International Conference on Data Mining Workshops (ICDMW), Shanghai, China, 1–4 December 2023; pp. 1424–1429. [Google Scholar]
- OpenAI. Prompt Engineering. 2022. Available online: https://platform.openai.com/docs/guides/prompt-engineering/six-strategies-for-getting-better-results (accessed on 15 May 2024).
- MistralAI. mistralai/Mixtral-8x7B-Instruct-v0.1. 2024. Available online: https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1 (accessed on 5 June 2024).
- Jiang, A.Q.; Sablayrolles, A.; Roux, A.; Mensch, A.; Savary, B.; Bamford, C.; Chaplot, D.S.; Casas, D.d.l.; Hanna, E.B.; Bressand, F.; et al. Mixtral of experts. arXiv 2024, arXiv:2401.04088. [Google Scholar]
- Xu, Q.S.; Liang, Y.Z. Monte Carlo cross validation. Chemom. Intell. Lab. Syst. 2001, 56, 1–11. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Samples | Labels | Timeframe | Source | |
|---|---|---|---|---|
| Total | 15,488 | 17 | 2013–2023 | Scopus |
| Preprocessed | 13,789 | |||
| Training | 11,030 | |||
| Balanced Training | 5100 | |||
| Testing | 2759 | |||
| Label | Abstract |
|---|---|
| Real | We studied the population dynamics of producers and parasites in a developing economy through the Lotka–Volterra model. Our baseline model found a cyclical equilibrium between these two groups of agents. When the equilibrium output is low, we propose that the economy is in a poverty trap, such that the only way to achieve superior equilibrium is through improvements in the institutional parameters (e.g., property rights). By adding expectations and time delays, the cyclical result may no longer hold. Nevertheless, institutional improvements promote development through an increase in the level of producers and a decrease in parasites. Still, such improvements positively affect the stability of the modified model. |
| Generated | This study investigates the population dynamics of producers and parasites in a developing economy using the Lotka-Volterra model. The baseline model indicates a cyclical equilibrium between the two agent groups. In conditions of low equilibrium output, the economy is suggested to be in a poverty trap, with the potential for superior equilibrium attainable solely through enhancements in institutional parameters, such as property rights. Incorporating expectations and time delays into the model disrupts the cyclical outcome, although institutional improvements continue to foster development by increasing producers and decreasing parasites. Notably, such improvements also positively impact the stability of the modified model. Further research is recommended to explore additional factors influencing the intricate relationship between producers, parasites, and institutional parameters in developing economies. |
| Parameter | Value |
|---|---|
| load_in_4bit | True |
| bnb_4bit_use_double_quant | True |
| bnb_4bit_quant_type | nf4 |
| bnb_4bit_compute_dtype | torch.bfloat16 |
| Parameter | Value |
|---|---|
| max_new_tokens | 280 |
| min_new_tokens | 264 |
| do_sample | True |
| temperature | Random (0.5, 0.7) |
| top_k | Random (5, 20) |
| top_p | 1 |
| exponential_decay_length_penalty | (264, 10) |
| encoder_repetition_penalty | 0.9 |
| pad_token_id | tokenizer.eos_token_id |
| bos_token_id | tokenizer.bos_token_id |
| eos_token_id | tokenizer.eos_token_id |
| Parameter | Value |
|---|---|
| Learning rate | |
| Batch size | 4 |
| Eval batch size | 4 |
| Epochs | 10 |
| Save strategy | “epoch” |
| Evaluation strategy | “epoch” |
| Load best model at end | True |
| Optimizer | AdamW |
| betas | 0.9, 0.999 |
| EPS | |
| Weight decay | 0 |
| Correct bias | True |
| Imbalanced | Train Records | Balanced | Train Records | |||||
|---|---|---|---|---|---|---|---|---|
| SDG | F1-Score | Precision | Recall | F1-Score | Precision | Recall | ||
| 1 | 0.00 (0.00) | 0.00 (0.00) | 0.00 (0.00) | 2 | 0.00 (0.00) | 0.00 (0.00) | 0.00 (0.00) | 300 |
| 2 | 60.87 (5.27) | 60.57 (0.06) | 61.86 (8.20) | 238 | 40.77 (2.05) | 29.66 (0.02) | 65.71 (4.99) | |
| 3 | 96.30 (0.46) | 95.80 (0.01) | 96.82 (0.62) | 6217 | 88.05 (1.29) | 93.95 (0.00) | 82.89 (2.55) | |
| 4 | 64.14 (9.23) | 65.09 (0.14) | 65.21 (9.53) | 65 | 36.55 (3.87) | 22.87 (0.03) | 93.33 (5.17) | |
| 5 | 0.00 (0.00) | 0.00 (0.00) | 0.00 (0.00) | 11 | 5.98 (2.00) | 3.09 (0.01) | 96.67 (18.26) | |
| 6 | 78.79 (3.99) | 76.54 (0.07) | 81.87 (5.28) | 293 | 75.25 (2.07) | 70.54 (0.04) | 80.82 (1.65) | |
| 7 | 88.99 (1.82) | 87.26 (0.03) | 90.92 (2.09) | 1045 | 65.94 (2.64) | 84.02 (0.02) | 54.32 (3.08) | |
| 8 | 0.00 (0.00) | 0.00 (0.00) | 0.00 (0.00) | 30 | 4.24 (1.64) | 2.48 (0.01) | 15.42 (7.10) | |
| 9 | 71.40 (4.27) | 70.26 (0.07) | 73.29 (5.78) | 277 | 59.29 (2.44) | 63.53 (0.04) | 56.04 (4.38) | |
| 10 | 44.22 (21.47) | 75.79 (0.33) | 34.29 (19.35) | 26 | 18.30 (4.09) | 10.67 (0.03) | 70.95 (2.61) | |
| 11 | 61.89 (7.25) | 66.90 (0.10) | 59.46 (11.23) | 123 | 56.12 (2.69) | 41.54 (0.03) | 86.77 (0.98) | |
| 12 | 16.21 (17.97) | 33.73 (0.33) | 11.85 (14.57) | 70 | 19.55 (2.63) | 12.04 (0.03) | 56.30 (6.64) | |
| 13 | 45.17 (23.37) | 72.35 (0.24) | 38.38 (24.24) | 138 | 43.24 (3.61) | 29.06 (0.03) | 85.33 (1.80) | |
| 14 | 75.74 (3.79) | 74.48 (0.04) | 77.42 (6.14) | 320 | 63.49 (1.85) | 49.68 (0.02) | 88.04 (1.76) | |
| 15 | 69.19 (3.95) | 75.65 (0.07) | 64.24 (5.38) | 234 | 42.35 (1.43) | 29.36 (0.02) | 76.33 (3.03) | |
| 16 | 34.69 (28.98) | 56.27 (0.43) | 27.27 (24.58) | 45 | 23.27 (2.69) | 14.52 (0.02) | 59.70 (5.17) | |
| 17 | 83.86 (1.13) | 82.21 (0.02) | 85.72 (3.25) | 1896 | 19.49 (3.82) | 85.10 (0.02) | 11.08 (2.65) | |
| Total | 11,030 | Total | 5100 | |||||
| SDG | Without Threshold | With Threshold |
|---|---|---|
| 0 | - | 6137 |
| 1 | 6 | 0 |
| 2 | 1074 | 49 |
| 3 | 1282 | 288 |
| 4 | 692 | 232 |
| 5 | 40 | 1 |
| 6 | 490 | 140 |
| 7 | 445 | 5 |
| 8 | 120 | 7 |
| 9 | 373 | 21 |
| 10 | 200 | 10 |
| 11 | 603 | 274 |
| 12 | 295 | 27 |
| 13 | 185 | 29 |
| 14 | 324 | 139 |
| 15 | 361 | 81 |
| 16 | 496 | 97 |
| 17 | 551 | 0 |
| Total | 7537 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lino Ferreira da Silva Barros, M.H.; Medeiros Neto, L.; Santos, G.L.; Leal, R.C.d.S.; Leal da Silva, R.C.; Lynn, T.; Dourado, R.A.; Endo, P.T. Leveraging AI and Data Visualization for Enhanced Policy-Making: Aligning Research Initiatives with Sustainable Development Goals. Sustainability 2024, 16, 11050. https://doi.org/10.3390/su162411050
Lino Ferreira da Silva Barros MH, Medeiros Neto L, Santos GL, Leal RCdS, Leal da Silva RC, Lynn T, Dourado RA, Endo PT. Leveraging AI and Data Visualization for Enhanced Policy-Making: Aligning Research Initiatives with Sustainable Development Goals. Sustainability. 2024; 16(24):11050. https://doi.org/10.3390/su162411050
Chicago/Turabian StyleLino Ferreira da Silva Barros, Maicon Herverton, Leonides Medeiros Neto, Guto Leoni Santos, Roberto Cesar da Silva Leal, Raysa Carla Leal da Silva, Theo Lynn, Raphael Augusto Dourado, and Patricia Takako Endo. 2024. "Leveraging AI and Data Visualization for Enhanced Policy-Making: Aligning Research Initiatives with Sustainable Development Goals" Sustainability 16, no. 24: 11050. https://doi.org/10.3390/su162411050
APA StyleLino Ferreira da Silva Barros, M. H., Medeiros Neto, L., Santos, G. L., Leal, R. C. d. S., Leal da Silva, R. C., Lynn, T., Dourado, R. A., & Endo, P. T. (2024). Leveraging AI and Data Visualization for Enhanced Policy-Making: Aligning Research Initiatives with Sustainable Development Goals. Sustainability, 16(24), 11050. https://doi.org/10.3390/su162411050