
Groundwater Quality Prediction and Analysis Using Machine Learning Models and Geospatial Technology

 , , and
, , and
Abstract
1. Introduction
2. Related Works
2.1. Groundwater Quality Assessment and Management
2.2. Wetland Mapping and ML-Based Water Quality Prediction
2.3. GIS-Based Water Quality Research
3. Materials and Methods
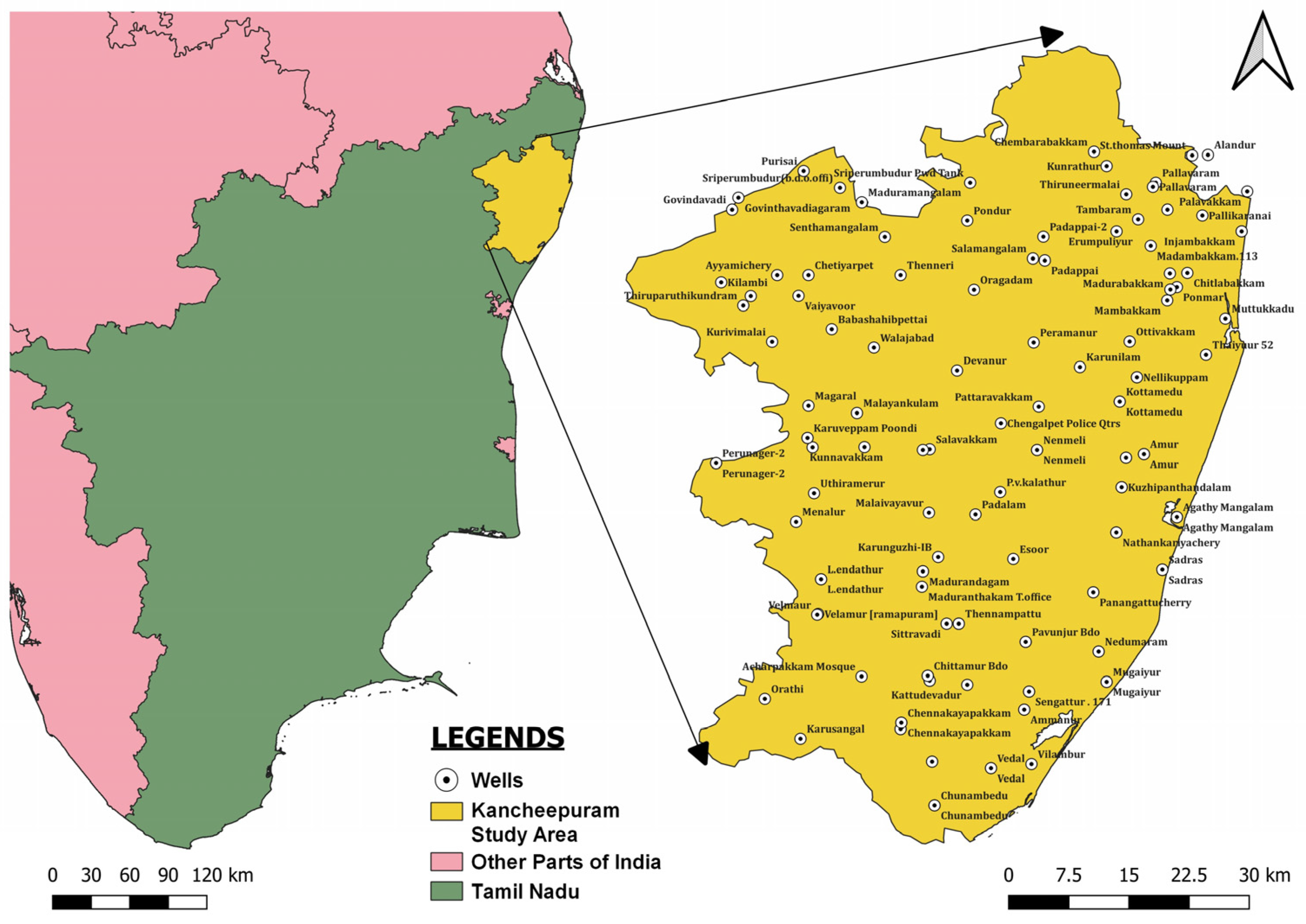
3.1. Study Area
3.2. Water Quality in the Study Area
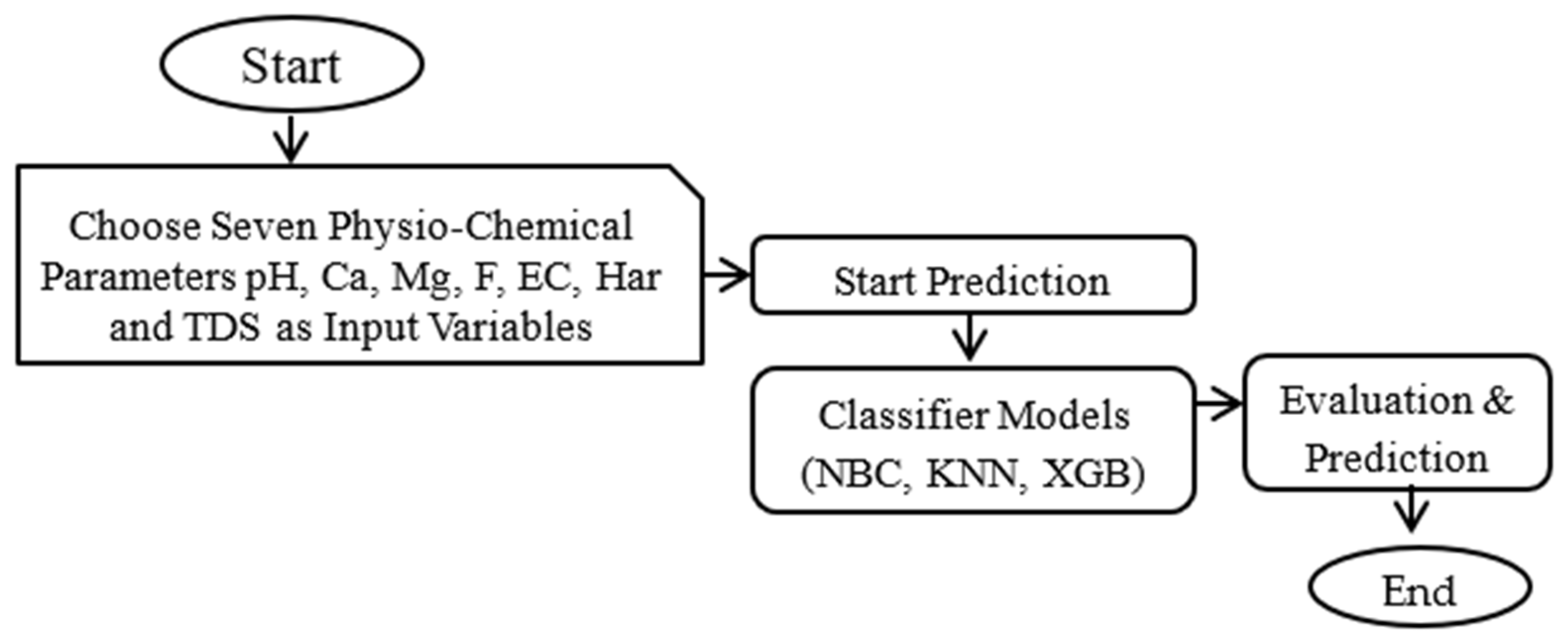
3.3. Research Methodology
3.4. Collection and Pre-Processing of Data Analysis
3.5. Description and Splitting of Dataset
3.6. The Proposed ML Model
3.6.1. Naïve Bayes Classifier
3.6.2. KNN Classifier
3.6.3. XGBoost Classifier
3.6.4. LSTM Network
4. Results and Discussion
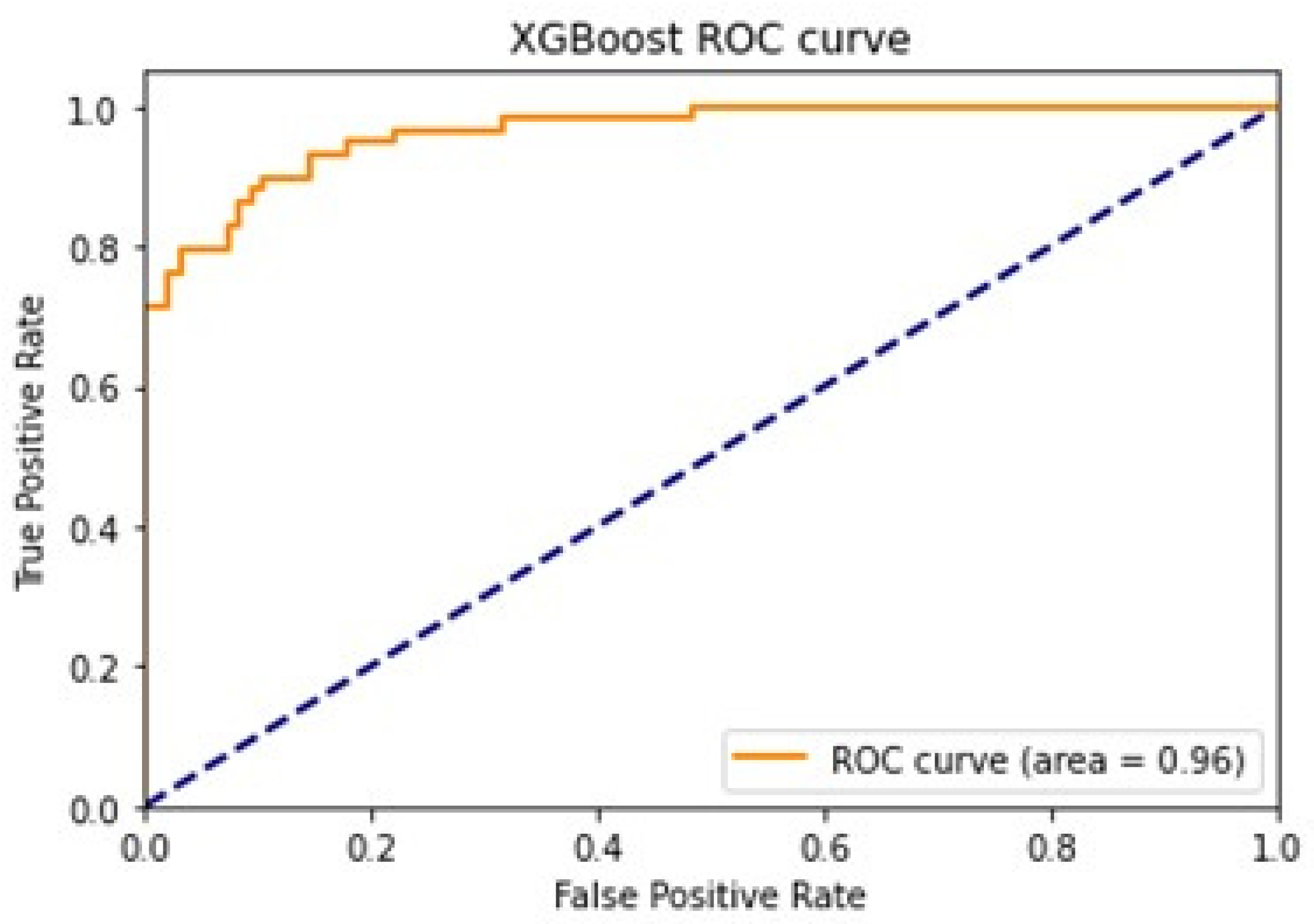
4.1. ML-Based Prediction Results
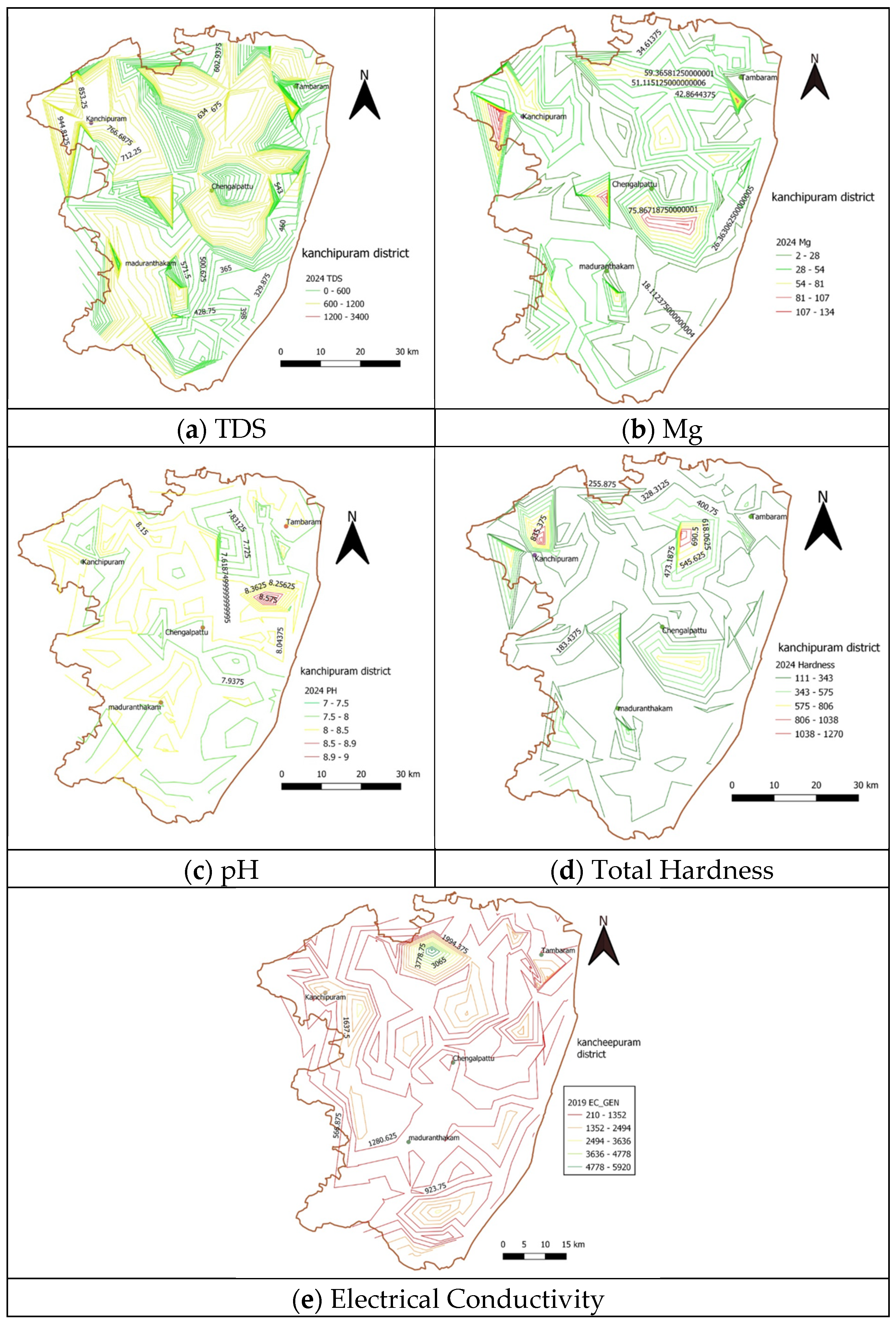
4.2. GIS-Based Water Quality Analysis
5. Conclusions
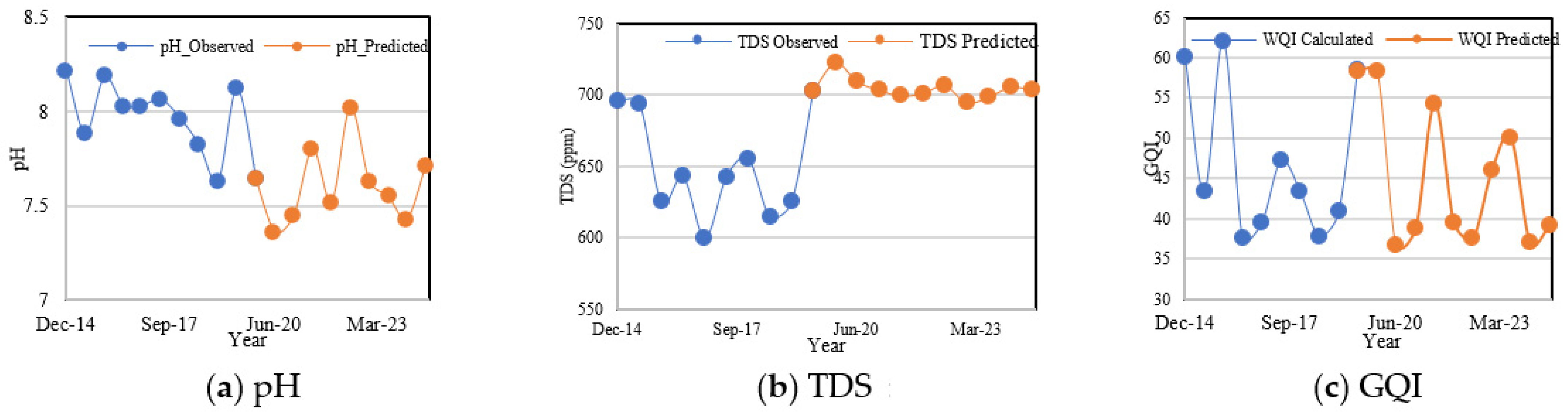
- First, machine learning algorithms, namely, naïve Bayes, KNN, and XGBoost, can be developed for the GQI. XGBoost outperforms KNN and naïve Bayes in the WQI. The results reveal that the XGBoost classifier model yielded the highest accuracy of about 94.6%, which surpassed the existing results. The predicted results using LSTM for the next five years indicate a reliable approach for forecasting the water quality.
- Thus, the proposed hybrid prediction model will identify any degradation in water quality before being planned for human consumption and can be used to notify the appropriate authorities. This research identifies the locations/places where water quality control measures or management measures are required in 2024.
- In the pre-monsoon season, the GQI is found to be poor in taluks such as Alandur, Tambaram, and Sriperumpudur. Compared to other taluks, these areas have the highest population density and urbanized areas. Cheyyur, Tirukalukundram, Chengalpattu, and Madurandagam taluks have excellent groundwater quality in the pre-monsoon season.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Aendo, P.; Netvichian, R.; Thiendedsakul, P.; Khaodhiar, S.; Tulayakul, P. Carcinogenic Risk of Pb, Cd, Ni, and Cr and Critical Ecological Risk of Cd and Cu in Soil and Groundwater around the Municipal Solid Waste Open Dump in Central Thailand. J. Environ. Public Health. 2022, 2022, 3062215. [Google Scholar] [CrossRef] [PubMed]
- Chapman, D.V.; World Health Organization; UNESCO & United Nations Environment Programme. Water Quality Assessments: A Guide to the Use of Biota, Sediments and Water in Environmental Monitoring; Chapman & Hall: London, UK, 1992. [Google Scholar]
- Li, W.; Chai, Y.; Khan, F.; Jan, S.R.U.; Verma, S.; Menon, V.G.; Kavita; Li, X. A Comprehensive Survey on Machine Learning-Based Big Data Analytics for IoT-Enabled Smart Healthcare System. Mob. Networks Appl. 2021, 26, 234–252. [Google Scholar] [CrossRef]
- Jha, M.K.; Shekhar, A.; Jenifer, M.A. Assessing groundwater quality for drinking water supply using hybrid fuzzy-GIS-based water quality index. Water Res. 2020, 179, 115867. [Google Scholar] [CrossRef] [PubMed]
- Chen, K.; Chen, H.; Zhou, C.; Huang, Y.; Qi, X.; Shen, R.; Liu, F.; Zuo, M.; Zou, X.; Wang, J.; et al. Comparative analysis of surface water quality prediction performance and identification of key water parameters using different machine learning models based on big data. Water Res. 2020, 171, 115454. [Google Scholar] [CrossRef] [PubMed]
- Shams, M.Y.; Elshewey, A.M.; El-kenawy, E.-S.M.; Ibrahim, A.; Talaat, F.M.; Tarek, Z. Water quality prediction using machine learning models based on grid search method. Multimed. Tools Appl. 2023, 83, 35307–35334. [Google Scholar] [CrossRef]
- Cheng, B.; Zhang, Y.; Xia, R.; Wang, L.; Zhang, N.; Zhang, X. Spatiotemporal analysis and prediction of water quality in the Han River by an integrated nonparametric diagnosis approach. J. Clean. Prod. 2021, 328, 129583. [Google Scholar] [CrossRef]
- Al-Adhaileh, M.H.; Alsaade, F.W. Modelling and prediction of water quality by using artificial intelligence. Sustainability 2021, 13, 4259. [Google Scholar] [CrossRef]
- Hejaz, B.; Al-khatib, I.A.; Mahmoud, N. Domestic Groundwater Quality in the Northern Governorates of the West Bank, Palestine. J. Environ. Public Health. 2020, 2020, 6894805. [Google Scholar] [CrossRef]
- Oberascher, M.; Rauch, W.; Sitzenfrei, R. Towards a smart water city: A comprehensive review of applications, data requirements, and communication technologies for integrated management. Sustain. Cities Soc. 2022, 76, 103442. [Google Scholar] [CrossRef]
- DeSimone, L.A.; Pope, J.P.; Ransom, K.M. Machine-learning models to map pH and redox conditions in groundwater in a layered aquifer system, Northern Atlantic Coastal Plain, eastern USA. J. Hydrol. Reg. Stud. 2020, 30, 100697. [Google Scholar] [CrossRef]
- Elubid, B.A.; Huang, T.; Ahmed, E.H.; Zhao, J.; Elhag, K.M.; Abbass, W.; Babiker, M.M. Geospatial Distributions of Groundwater Quality in Gedaref State Using Geographic Information System (GIS) and Drinking Water Quality Index (DWQI). Int. J. Environ. Res. Public Health. 2019, 16, 731. [Google Scholar] [CrossRef] [PubMed]
- Matsui, K.; Kageyama, Y. Water pollution evaluation through fuzzy c-means clustering and neural networks using ALOS AVNIR-2 data and water depth of Lake Hosenko, Japan. Ecol. Inform. 2022, 70, 101761. [Google Scholar] [CrossRef]
- Watershed, E.L.; Wang, X.; Zhang, F.; Ding, J. Evaluation of water quality based on a machine learning algorithm and water quality index for the. Sci. Rep. 2017, 7, 12858. [Google Scholar] [CrossRef]
- Malakar, P.; Mukherjee, A.; Bhanja, S.; Saha, D.; Ray, R.K.; Sarkar, S.; Zahid, A. Importance of spatial and depth-dependent drivers in groundwater level modeling through machine learning. Hydrol. Earth Syst. Sci. Discuss. 2020, 2020, 1–22. [Google Scholar] [CrossRef]
- Uddin, G.; Nash, S.; Olbert, A.I. A review of water quality index models and their use for assessing surface water quality. Ecol. Indic. 2021, 122, 107218. [Google Scholar] [CrossRef]
- Mallick, J.; Talukdar, S.; Pal, S.; Rahman, A. A novel classifier for improving wetland mapping by integrating image fusion techniques and ensemble machine learning classifiers. Ecol. Inform. 2021, 65, 101426. [Google Scholar] [CrossRef]
- Perez, J.; Attanasio, A.C.; Nechyporenko, N.; Sanz, P.J. A Deep Learning Approach for Underwater Image Enhancement. In Biomedical Applications Based on Natural and Artificial Computing: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2017, Corunna, Spain, 19–23 June 2017; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 183–192. [Google Scholar] [CrossRef]
- Babak, S.; Seyed, H.; Sharafati, A.; Motta, D.; Yaseen, Z.M. River Water Quality Index prediction and uncertainty analysis: A comparative study of machine learning models. Biochem. Pharmacol. 2020, 9, 104599. [Google Scholar] [CrossRef]
- Rajaee, T.; Khani, S.; Ravansalar, M. Chemometrics and Intelligent Laboratory Systems Arti fi cial intelligence-based single and hybrid models for prediction of water quality in rivers: A review. Chemom. Intell. Lab. Syst. 2020, 200, 103978. [Google Scholar] [CrossRef]
- Sobotka, A.; Sagan, J. Decision support system in management of concrete demolition waste. Autom. Constr. 2021, 128, 103734. [Google Scholar] [CrossRef]
- Hasan, M.M.; Lwin, K.; Imani, M.; Shabut, A.; Bittencourt, L.F.; Hossain, M.A. Dynamic multi-objective optimisation using deep reinforcement learning: Benchmark, algorithm and an application to identify vulnerable zones based on water quality. Eng. Appl. Artif. Intell. 2019, 86, 107–135. [Google Scholar] [CrossRef]
- Prasad, V.V.D.; Venkataramana, L.Y.; Perumal, S.K.; Gurunathan, P.; Kannan, S.; Poornema, A.J. Water quality analysis in a lake using deep learning methodology: Prediction and validation. Int. J. Environ. Anal. Chem. 2020, 102, 5641–5656. [Google Scholar] [CrossRef]
- Saikrishna, K.; Purushotham, D.; Sunitha, V.; Reddy, Y.S.; Linga, D.; Kumar, B.K. Data for the evaluation of groundwater quality using water quality index and regression analysis in parts of Nalgonda district, Telangana, Southern India. Data Br. 2020, 32, 106235. [Google Scholar] [CrossRef]
- Lu, H.; Ma, X. Chemosphere Hybrid decision tree-based machine learning models for short-term water quality prediction. Chemosphere 2020, 249, 126169. [Google Scholar] [CrossRef]
- Tien, D.; Khosravi, K.; Tiefenbacher, J.; Nguyen, H.; Kazakis, N. Science of the Total Environment Improving prediction of water quality indices using novel hybrid machine-learning algorithms. Sci. Total Environ. 2020, 721, 137612. [Google Scholar] [CrossRef]
- Hu, X.; He, C.; Peng, Z.; Yang, W. Analysis of ground settlement induced by Earth pressure balance shield tunneling in sandy soils with different water contents. Sustain. Cities Soc. 2019, 45, 296–306. [Google Scholar] [CrossRef]
- Ghasemlounia, R.; Sedaghat Herfeh, N. Study on Groundwater Quality Using Geographic Information System (GIS), Case Study: Ardabil, Iran. Civ. Eng. J. 2017, 3, 779–793. [Google Scholar] [CrossRef]
- Machiwal, D.; Jha, M.K.; Mal, B.C. GIS-based assessment and characterization of groundwater quality in a hard-rock hilly terrain of Western India. Environ. Monit. Assess. 2011, 174, 645–663. [Google Scholar] [CrossRef]
- Oseke, F.I.; Anornu, G.K.; Adjei, K.A.; Eduvie, M.O. Assessment of water quality using GIS techniques and water quality index in reservoirs affected by water diversion. Water-Energy Nexus 2021, 4, 25–34. [Google Scholar] [CrossRef]
- Panwar, H.; Gupta, P.K.; Siddiqui, M.K.; Morales-Menendez, R.; Bhardwaj, P.; Sharma, S.; Sarker, I.H. AquaVision: Automating the detection of waste in water bodies using deep transfer learning. Case Stud. Chem. Environ. Eng. 2020, 2, 100026. [Google Scholar] [CrossRef]
- Sagan, V.; Peterson, K.T.; Maimaitijiang, M.; Sidike, P.; Sloan, J.; Greeling, B.A.; Maalouf, S.; Adams, C. Monitoring inland water quality using remote sensing: Potential and limitations of spectral indices, bio-optical simulations, machine learning, and cloud computing. Earth-Sci. Rev. 2020, 205, 103187. [Google Scholar] [CrossRef]
- Mohammed, M.A.A.; Kaya, F.; Mohamed, A.; Alarifi, S.S.; Abdelrady, A.; Keshavarzi, A.; Szabó, N.P.; Szűcs, P. Application of GIS-based machine learning algorithms for prediction of irrigational groundwater quality indices. Front. Earth Sci. 2023, 11, 1274142. [Google Scholar] [CrossRef]
- Rawat, K.S.; Singh, S.K. Water Quality Indices and GIS-based evaluation of a decadal groundwater quality. Geol. Ecol. Landscapes. 2018, 2, 240–255. [Google Scholar] [CrossRef]
- Dhanasekar, K.; Partheeban, P. Numerical modeling of groundwater flow in Karayanchavadi region of Chennai, Tamilnadu, India. Ecol. Environ. Conserv. 2017, 23, 1564–1570. [Google Scholar]
- IS 10500-2012; Drinking Water-Specifications. Bureau of Indian Standard: New Delhi, India, 2012.
- HGlynn, P.D.; Plummer, L.N. Geochemistry and the understanding of ground-water systems. Hydrogeol. J. 2005, 13, 263–287. [Google Scholar] [CrossRef]
- Brown, R.M.; Mcclelland, N.I.; Deininger, R.A.; O’connor, M.F. A Water Quality Index–Crashing the Psychological Barrier; Pergamon Press Limited, n.d.: Oxford, UK, 1973. [Google Scholar] [CrossRef]
- Li, X.; Cheng, Z.; Yu, Q.; Bai, Y.; Li, C. Water-Quality Prediction Using Multimodal Support Vector Regression: Case Study of Jialing River, China. J. Environ. Eng. 2017, 143, 04017070. [Google Scholar] [CrossRef]
- Alomani, S.M.; Alhawiti, N.I.; Alhakamy, A. Prediction of Quality of Water According to a Random Forest Classifier. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 892–899. [Google Scholar] [CrossRef]
- Bayatvarkeshi, M.; Imteaz, M.A.; Kisi, O.; Zarei, M.; Yaseen, Z.M. Application of M5 model tree optimized with Excel Solver Platform for water quality parameter estimation. Environ. Sci. Pollut. Res. 2021, 28, 7347–7364. [Google Scholar] [CrossRef]
- Aljarah, F.; Çetin, A. Prediction of Water Quality with Ensemble Learning Algorithms. Adv. Artif. Intell. Res. 2023, 3, 36–44. [Google Scholar] [CrossRef]
- Nong, X.; Lai, C.; Chen, L.; Shao, D.; Zhang, C.; Liang, J. Prediction modelling framework comparative analysis of dissolved oxygen concentration variations using support vector regression coupled with multiple feature engineering and optimization methods: A case study in China. Ecol. Indic. 2023, 146, 109845. [Google Scholar] [CrossRef]
- Almadani, M.; Kheimi, M. Stacking Artificial Intelligence Models for Predicting Water Quality Parameters in Rivers. J. Ecol. Eng. 2023, 24, 152–164. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Annual Rainfall (mm) | Average Annual Rainfall (mm) | |||||||
|---|---|---|---|---|---|---|---|---|
| 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | |
| 905.2 | 907.9 | 2256.6 | 990.5 | 1191.7 | 712.73 | 1215.5 | 985.36 | 1252 |
| Parameters | WHO | Indian Standards [36] | ||
|---|---|---|---|---|
| Desirable | Excessive | Desirable | Excessive | |
| pH (no unit) | 7–8.5 | 6.5–9.2 | 6.5–8.5 | 6.5–9.2 |
| Turbidity (NTU) | 5 | 50 | 10 | 25 |
| Total Solids (mg/L) | 500 | 1500 | --- | --- |
| Total Hardness (mg/L) | 250 | 300 | 600 | |
| Calcium (mg/L) | 75 | 200 | 75 | 200 |
| Magnesium (mg/L) | 50 | 150 | 30 | 100 |
| Iron (mg/L) | 0.3 | 1 | 0.3 | 1 |
| Chlorides (mg/L) | 200 | 600 | 250 | 1000 |
| Alkalinity (mg/L) | --- | --- | 200 | 600 |
| Dissolved Solids (mg/L) | --- | --- | 500 | 2000 |
| GQI | Status |
|---|---|
| 0–25 | Excellent |
| 26–50 | Good |
| 51–75 | Poor |
| 76–100 | Very poor |
| Above 100 | Unsuitable for drinking |
| Parameter | Observed Values (vi) | Standard Values (Si) | Unit Weights (wt) | Quality Rating (qi) | Wiqi |
|---|---|---|---|---|---|
| pH | 8.4 | 6.5–8.5 | 0.116909012 | 93.33332 | 10.91150667 |
| Ca | 114 mg/L | 75 mg/L | 0.013249688 | 152 | 2.0139526 |
| Mg | 15.795 mg/L | 30 mg/L | 0.03312422 | 52.65 | 1.743990183 |
| F | 0.1 mg/L | 1.2 mg/L | 0.828105503 | 8.333333 | 6.900879192 |
| EC | 1610 mg/L | 300 mg/L | 0.003312422 | 536.6667 | 1.777666473 |
| Har | 350 mg/L | 300 mg/L | 0.003312422 | 116.6667 | 0.38644923 |
| TDS | 947 mg/L | 500 mg/L | 0.001987453 | 189.4 | 0.376423598 |
| Classifier | Rating | Excellent | Good | Poor | Unfit | Very Poor |
|---|---|---|---|---|---|---|
| Naïve Bayes classifier | Excellent | 54 | 11 | 0 | 0 | 0 |
| Good | 3 | 161 | 3 | 0 | 0 | |
| Poor | 0 | 18 | 57 | 0 | 4 | |
| Unfit | 0 | 0 | 0 | 10 | 7 | |
| Very Poor | 0 | 0 | 1 | 0 | 23 | |
| KNN classifier | Excellent | 64 | 1 | 0 | 0 | 0 |
| Good | 5 | 158 | 4 | 0 | 0 | |
| Poor | 0 | 7 | 72 | 0 | 0 | |
| Unfit | 0 | 0 | 0 | 16 | 1 | |
| Very Poor | 0 | 0 | 5 | 1 | 18 | |
| XGBoost classifier | Excellent | 63 | 2 | 0 | 0 | 0 |
| Good | 1 | 163 | 3 | 0 | 0 | |
| Poor | 0 | 7 | 72 | 0 | 0 | |
| Unfit | 0 | 0 | 0 | 16 | 1 | |
| Very Poor | 0 | 0 | 4 | 1 | 19 |
| Prediction Model Proposed by | ML Technique Used | Location | Data Collection Duration | Time Horizon | Performance Metrics |
|---|---|---|---|---|---|
| [39] | Support vector regression | Jialing River, China | One year | Weekly | MAE: 0.175 MAPE: 2.153% RMSE: 0.228 R2: 0.919 |
| [40] | Random forest classifier | - | - | - | Accuracy: 100% F1 score: 1.0 |
| [41] | M5 model | Hamedan (Iran) | Ten years | - | RMSE values is reduced by 18.95% |
| [42] | Stacking ensemble | - | - | - | Highest performance among all the other individual classifiers |
| [43] | Support vector regression | China | Four years | - | RMSE: 0.251, MSE: 0.063, MAE: 0.190, R2: 0.911 |
| [44] | ANFIS-PSO | Allen County, Indiana | - | - | RMSE: 1.284 |
| Proposed model | XGBoost KNN Naïve Bayes | Chennai, India | Five years | 6 months | Accuracy: 94.6% RMSE: 0.014 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rammohan, B.; Partheeban, P.; Ranganathan, R.; Balaraman, S. Groundwater Quality Prediction and Analysis Using Machine Learning Models and Geospatial Technology. Sustainability 2024, 16, 9848. https://doi.org/10.3390/su16229848
Rammohan B, Partheeban P, Ranganathan R, Balaraman S. Groundwater Quality Prediction and Analysis Using Machine Learning Models and Geospatial Technology. Sustainability. 2024; 16(22):9848. https://doi.org/10.3390/su16229848
Chicago/Turabian StyleRammohan, Bommi, Pachaivannan Partheeban, Ranihemamalini Ranganathan, and Sundarambal Balaraman. 2024. "Groundwater Quality Prediction and Analysis Using Machine Learning Models and Geospatial Technology" Sustainability 16, no. 22: 9848. https://doi.org/10.3390/su16229848
APA StyleRammohan, B., Partheeban, P., Ranganathan, R., & Balaraman, S. (2024). Groundwater Quality Prediction and Analysis Using Machine Learning Models and Geospatial Technology. Sustainability, 16(22), 9848. https://doi.org/10.3390/su16229848