
Predicting Concrete Pavement Condition for Sustainable Management: Unveiling the Development of Distresses through Machine Learning




Abstract
1. Introduction
2. Literature Review
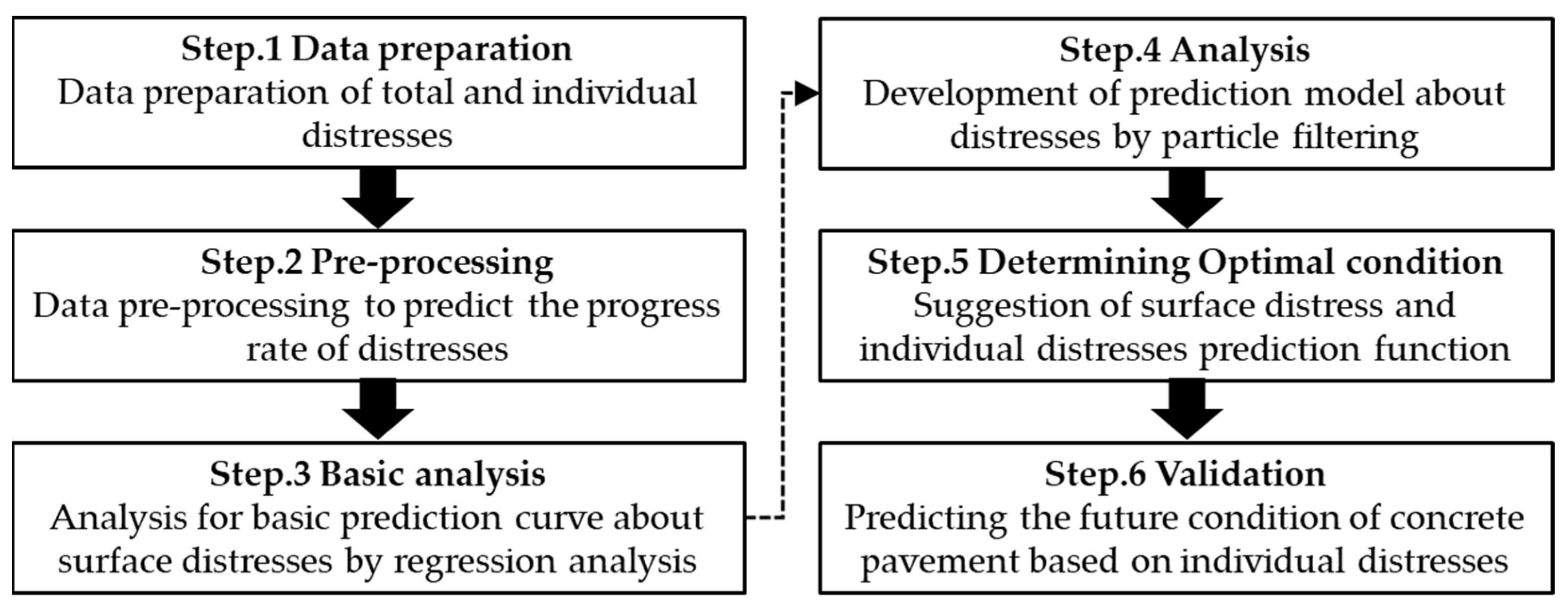
3. Methodology
4. Prediction of Individual Distresses Based on Particle Filtering
4.1. Concept of Analysis
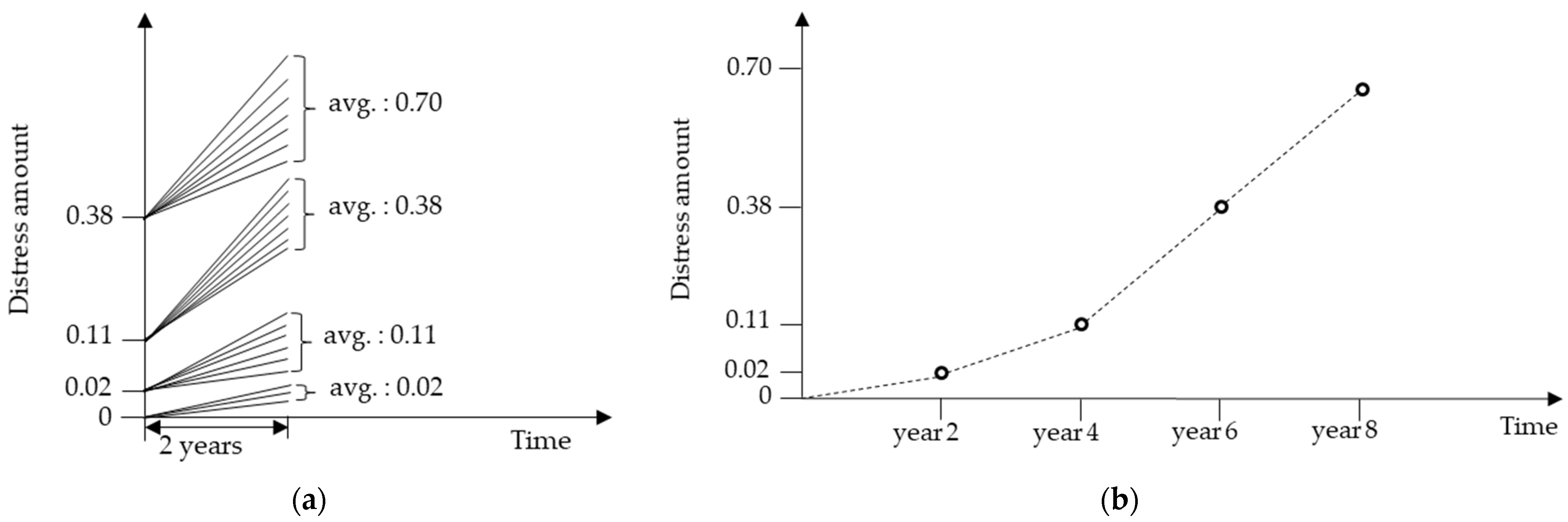
4.2. Data Preparation
4.3. Current State of the Survey Sections
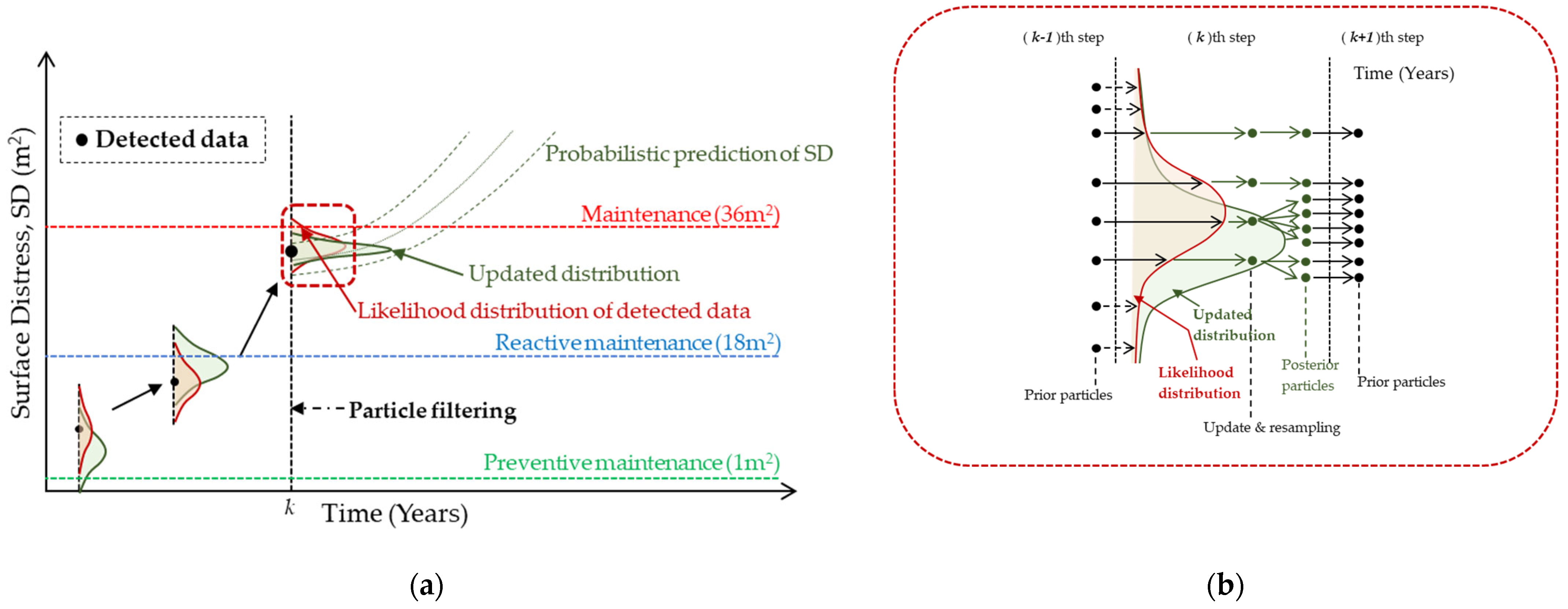
4.4. Particle Filter Model for Surface Distress Prediction
5. Results
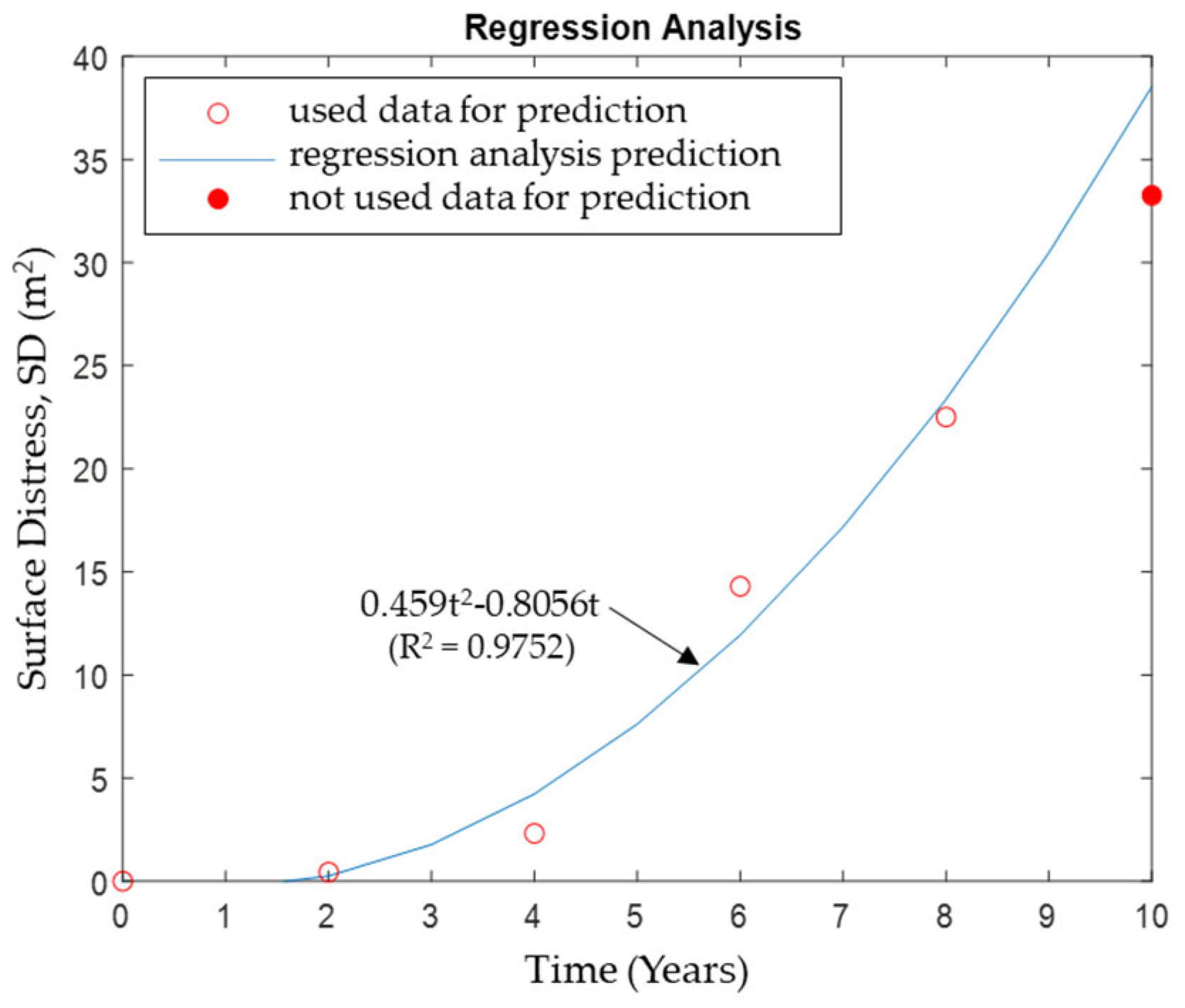
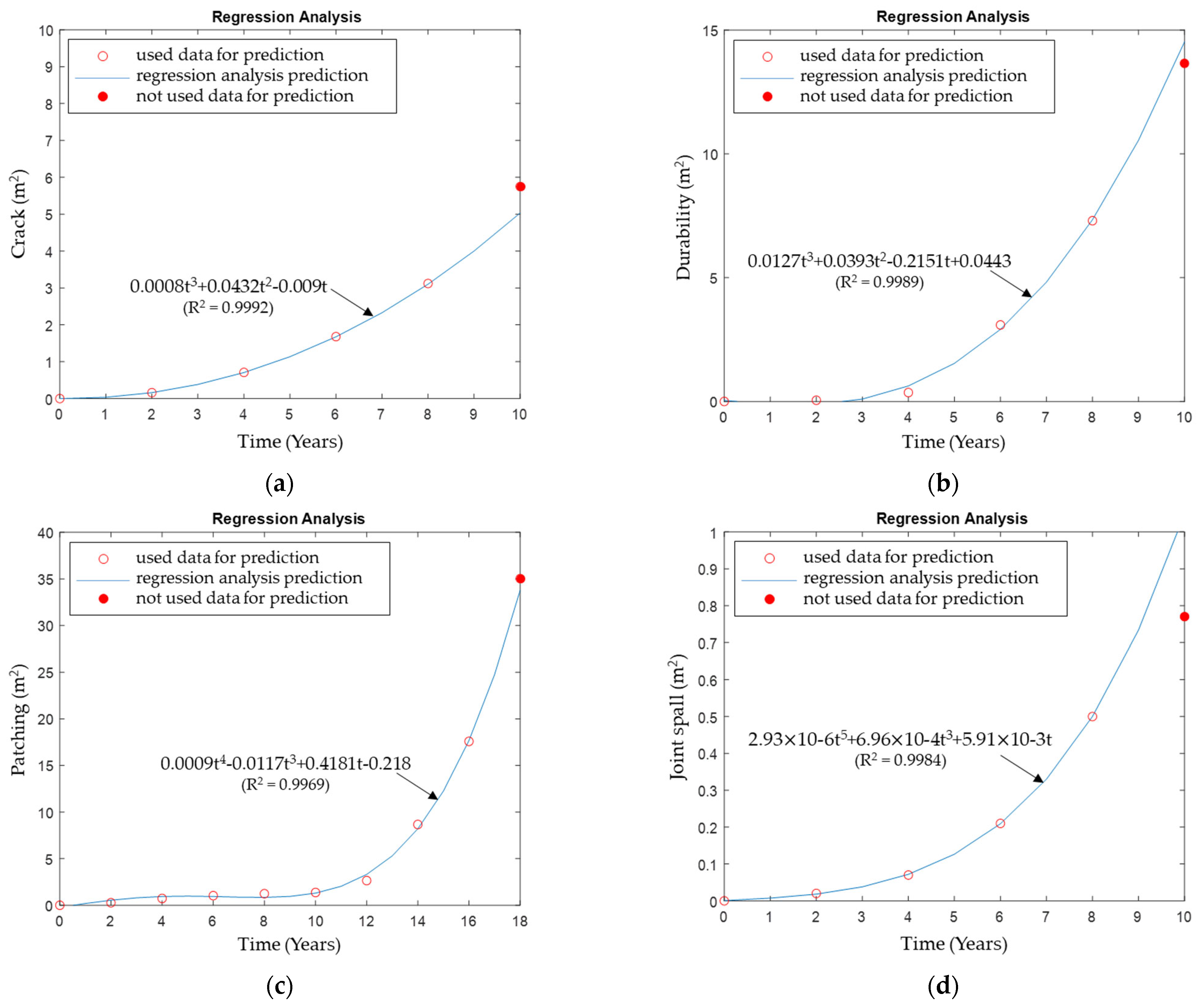
5.1. Suggestion of Surface Distress Prediction Model
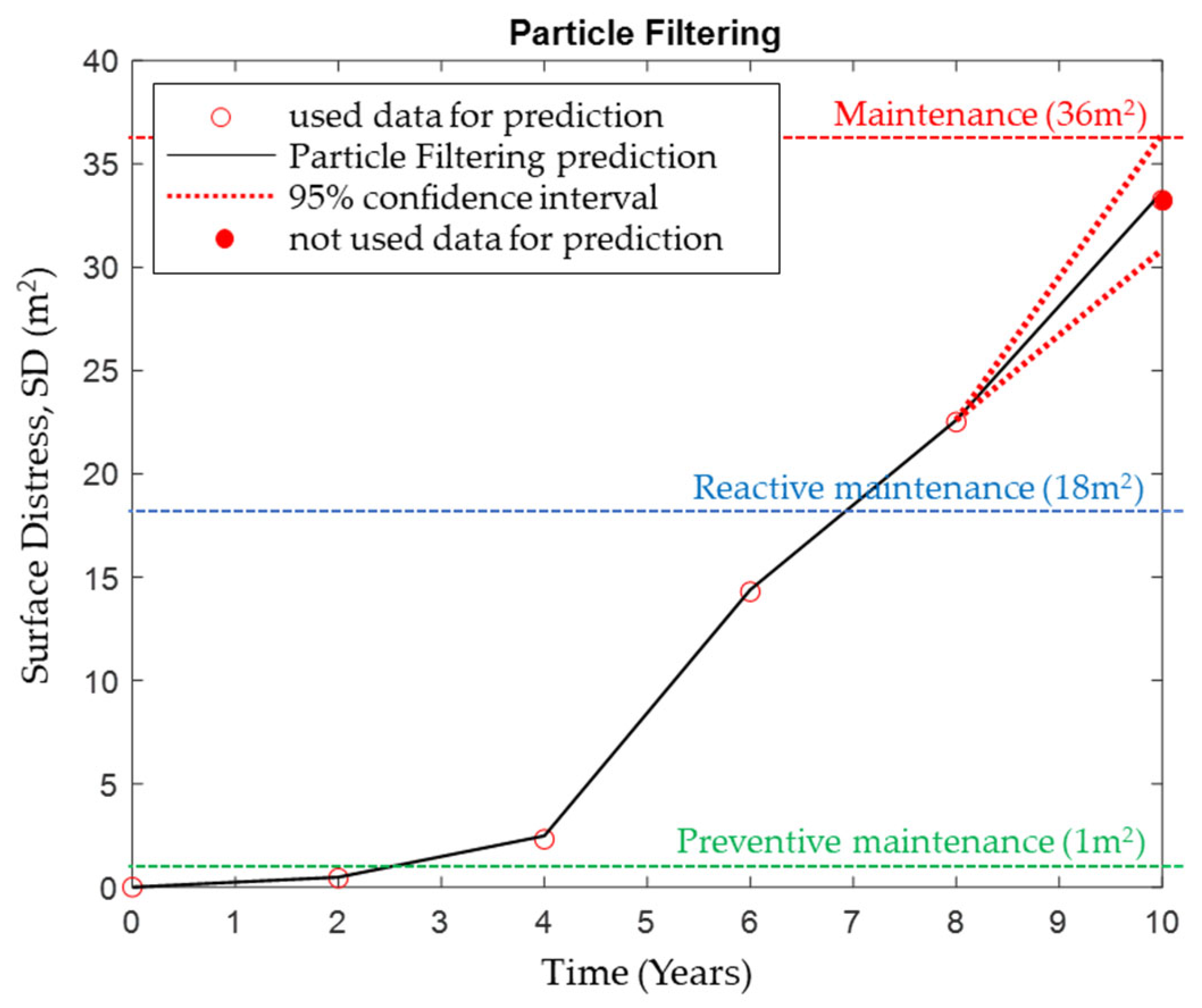
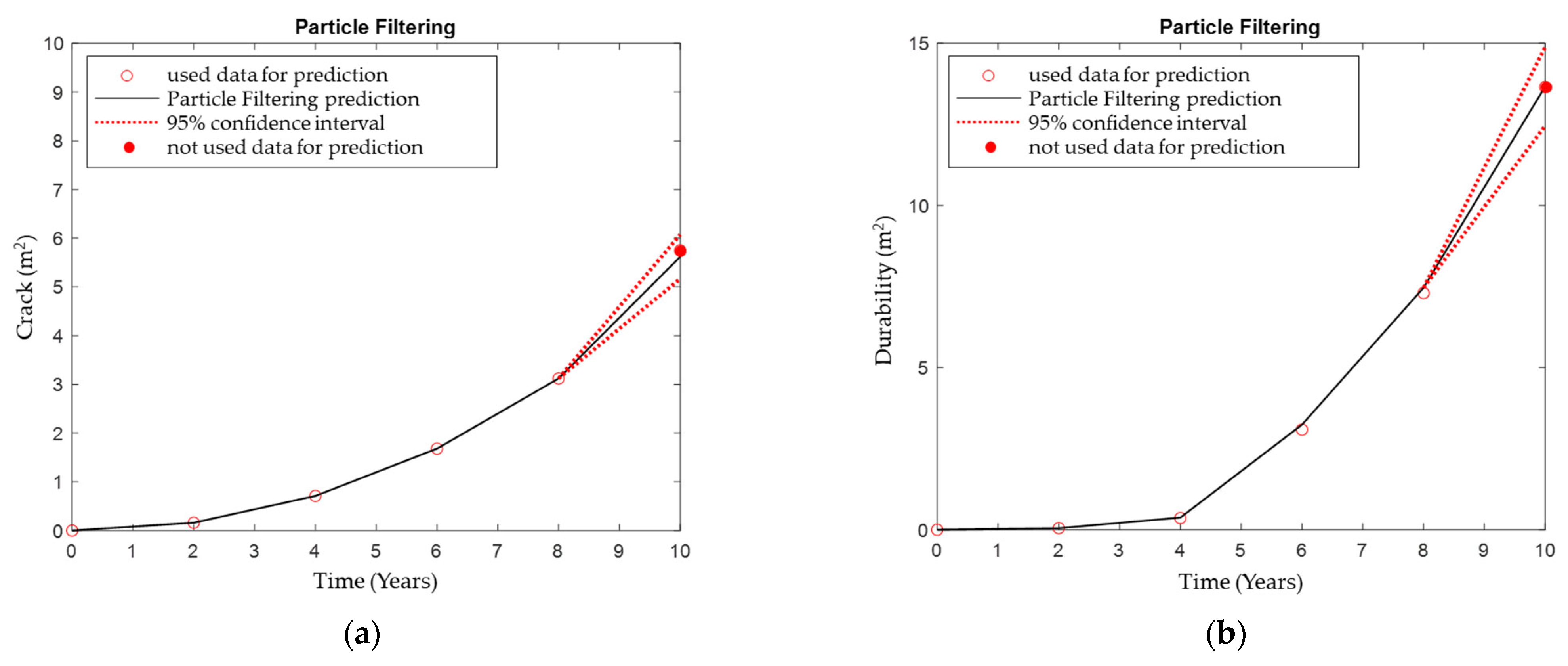
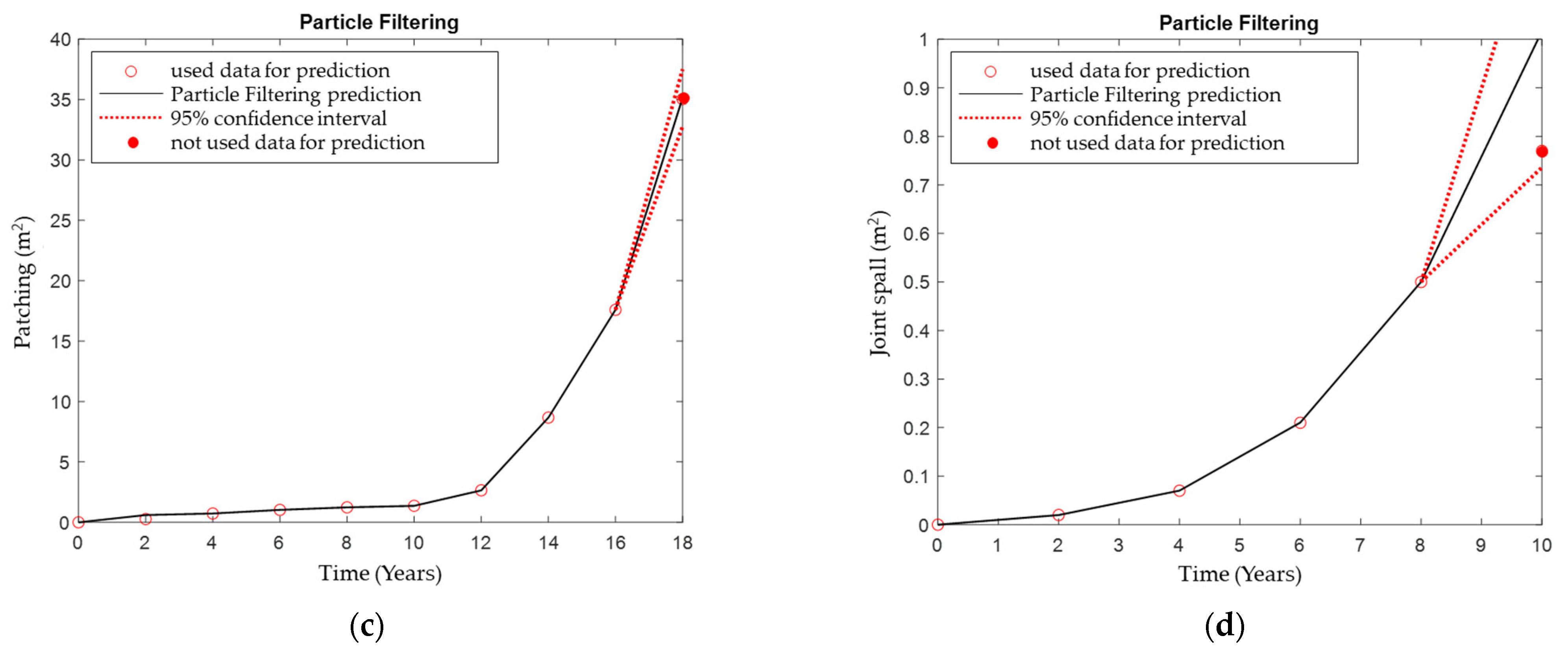
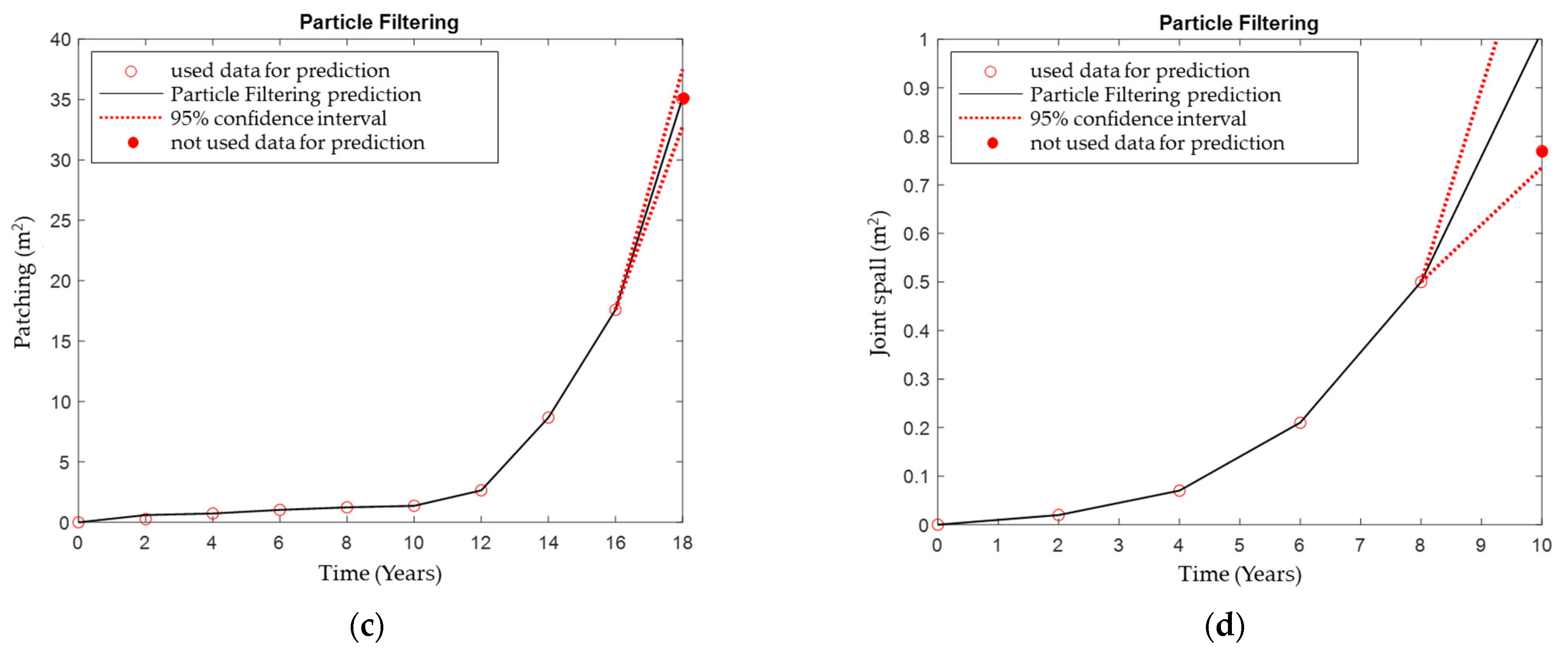
5.2. Application of Particle Filtering
6. Conclusions
- This study proposed a method to secure a high level of predictive power based on particle filtering, a machine learning technique, using long-term Korean pavement performance data collected nearly 30 years ago. This method was validated through a comparison with the existing regression modeling approach.
- The prediction accuracy for each variable is analyzed, revealing that particle filtering yielded a 3.3% to 14.67% higher prediction accuracy compared to general regression modeling. This allows for an analysis of the impact of individual distress or surface distress prediction accuracy on the maintenance budget for road pavement management in the future.
- Prediction accuracy using the particle filtering of crack, durability, and patching, except for joint spall, exhibits a prediction accuracy ranging from 97.72 and 99.86%. This indicates a quite high prediction power and considerable reliability.
- Particle filtering is found to be more suitable for deriving reliable results when predicting road pavement performance data compared to regression modeling with a single model, as it considers the probabilistic characteristics of all available training data in a time series manner.
- The low explanatory power of joint spall results from the distribution of the actual survey values at the prediction points failing to form a normal distribution. In this case, predictive power could be improved by normalizing the data distribution at each point, possibly by securing a longer extension (especially the Long-Term Performance Pavement database) compared to the one in this study, which covers a 76.72 km lane.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Choi, S.H.; Do, M.S.; You, S.H.; Cho, C.S. Determination of Visual Based Asphalt Pavement Crack Condition Using Deep Learning. Int. J. Highw. Eng. 2018, 20, 75–83. [Google Scholar] [CrossRef]
- Lee, Y.J.; Jeon, S.I.; Kim, R.E. A Computer-vision-based classification of road surface roughness grade using Machine Learning Techniques. Int. J. Highw. Eng. 2021, 23, 75–81. [Google Scholar] [CrossRef]
- Lee, J.S.; Kim, J.H.; Kim, J.R. Use of Deep Learning Image Classification Models and Vehicle Mounted Cameras for Automatic Pavment Pothole Detection. Int. J. Highw. Eng. 2021, 23, 25–34. [Google Scholar] [CrossRef]
- George, K.P.; Rajagopal, L.S.; Lim, L.K. Models for Predicting Pavement Deterioration. Trans. Res. Rec. 1989, 1215, 1–7. [Google Scholar]
- Johnson, K.D.; Cation, K.A. Performance Prediction Development Using Three Indexes for North Dakota Pavement Management System. Transp. Res. Rec. 1992, 1344, 22–30. [Google Scholar]
- Shah, Y.U.; Jain, S.S.; Tiwari, D.; Jain, M.K. Development of Overall Pavement Condition Index for Urban Road Network. Behav. Sci. 2013, 104, 332–341. [Google Scholar] [CrossRef]
- Jung, D.H.; Suh, Y.C.; Nam, J.H. Life of Asphalt Overlay over Old Concrete Pavements According to Time of Overlay. Int. J. Highw. Eng. 2019, 21, 69–76. [Google Scholar] [CrossRef]
- Lee, J.H.; Jung, D.H.; Lee, M.S.; Jeon, S.I. A Feasibility Study for the Prediction of Concrete Pavement Condition Index(CPCI) based on Machine Learning. Appl. Sci. 2022, 12, 8731. [Google Scholar] [CrossRef]
- Kulkarni, R.B.; Miler, R.W. Pavement Management System: Past, present, and future. Transp. Res. Rec. 2003, 1853, 65–71. [Google Scholar] [CrossRef]
- Dong, Q.; Chen, X.; Dong, S.; Ni, F. Data Analysis in Pavement Engineering: An Overview. IEEE Trans. Intell. Transp. Syst. 2021, 23, 22020–22039. [Google Scholar] [CrossRef]
- Deori, S.; Choudhary, R.; Tiwari, D.; Kumar, A. HDM-4 Deterioration Modelling: Validation and Adoption for Flexible Pavements with Modified Bituminous Road Surfacing. Balt. J. Road Bridge Eng. 2019, 14, 208–226. [Google Scholar] [CrossRef]
- Seyed, A.H. Data-Driven Framework for Modeling Deterioration of Pavements in the State of Iowa. Ph.D. Thesis, Iowa State University, Ames, IA, USA, 2020. [Google Scholar]
- Liu, H.; Li, Y.; Liu, C.; Shen, G.; Xiang, H. Pavement Distress Initiation Prediction by Time-Lag Analysis and Logistic Regression. Appl. Sci. 2022, 12, 11855. [Google Scholar] [CrossRef]
- Suh, Y.C.; Jung, D.H.; Park, K.W. Comparison of CRCP and JCP based on 30-year performance history. Int. J. Pavement Eng. 2021, 22, 1651–1658. [Google Scholar] [CrossRef]
- Al-Falahi, M.; Kassim, A. Automated Data Collection System of Pavement Distresses: Development, Evaluation & Validation of Distress Types and Severities. IOP Conf. Mater. Sci. Eng. 2019, 471, 062015. [Google Scholar]
- Arudi, R. Developing Pavement Performance Prediction Models and Decision Trees for the City of Cincinnati; Final Report, FHWA/OH-2006/14; Ohio Department of Transportation: Columbus, OH, USA, 2006. [Google Scholar]
- Ghassan, A.L.; Rick, L.; Gilbert, B.; Kamran, A. Development of Alternative Pavement Distress Index Models; Final Report; Department of Civil & Environmental Engineering, Michigan State University: Ann Arbor, MI, USA, 2003. [Google Scholar]
- Ahmed, K.; Abu-Lebdeh, G.; Lyles, R.W. Prediction of pavement distress index with limited data on causal factors: And auto-regression approach. Int. J. Pavement Eng. 2006, 7, 23–35. [Google Scholar] [CrossRef]
- Chen, D.; Cavalline, T.L. Development and Validation of Pavement Deterioration Models and Analysis Weight Factors for the NCDOT Pavement Management System; Final Report, NCDOT Project 2011-01, FHWA/NC/2011-01; Federal Highway Administration: Washington, DC, USA, 2011. [Google Scholar]
- Fatih, B.; Omar, S.; Mazin, A.Z. Pavement Management Performance Modeling: Evaluating the Existing PCI Equations; InTrans Project 13-455; Iowa Department of Transportation: Ames, IA, USA, 2014. [Google Scholar]
- Amir, S.; Sara, M.; Berthold, B.; Shahriar, R. An Overview of Pavement Degradation Prediction Models. J. Adv. Transp. 2022, 2022, 7783588. [Google Scholar]
- Justo-Silva, R.; Ferreira, A.; Flintsch, G. Review on Machine Learning Techniques for Developing Pavement Performance Prediction Models. Sustainability 2021, 13, 5248. [Google Scholar] [CrossRef]
- Mers, M.; Yang, Z.; Hsieh, Y.A.; Tsai, Y. Recurrent Neural Networks for Pavement Performance Forecasting: Review and Model Performance Comparison. Transporation Res. Rec. 2023, 2677, 610–624. [Google Scholar] [CrossRef]
- Sirhan, M.; Bekhor, S.; Sidess, A. Implementation of Deep Neural Networks for Pavement Condition Index Prediction, American Society of Civil Engineers. J. Transp. Eng. Part B Pavements 2022, 148, 04021070. [Google Scholar] [CrossRef]
- Haddad, A.J.; Chehab, G.R.; Saad, G.A. The use of deep neural networks for developing generic pavement rutting predictive models. Int. J. Pavement Eng. 2021, 23, 4260–4276. [Google Scholar] [CrossRef]
- Hosseini, S.A.; Alhasan, A.; Smadi, O. Use of Deep Learning to Study Modeling Deterioration of Pavements a Case Study in Iowa. Infrastructures 2020, 5, 95. [Google Scholar] [CrossRef]
- Garcia-Segura, T.; Montalban-Domigo, L.; Llopis-Castello, D.; Lepech, M.D.; Sanz, M.A.; Pellicer, E. Incorporating pavement deterioration uncertainty into pavement management optimization. Int. J. Pavement Eng. 2020, 23, 2062–2073. [Google Scholar] [CrossRef]
- Karimazadeh, A.; Shoghli, O. Predictive Analytics for Roadway Maintenance: A Review of Current Models, Challenges, and Opportunities. Civ. Eng. J. 2020, 6, 602–625. [Google Scholar] [CrossRef]
- Chopra, T.; Parida, M.; Kwatra, N.; Chopra, P. Development of pavement Distress Deterioration Prediction Models for Urban Road Network Using Genetic Programming. Adv. Civ. Eng. 2018, 2018, 1253108. [Google Scholar] [CrossRef]
- Issa, A.; Samaneh, H.; Ghanim, M. Predicting pavement condition index using an artificial neural networks approach. Ain Shams Eng. J. 2021, 13, 101490. [Google Scholar] [CrossRef]
- Yu, Q.; Sikai, C.; Majed, A.; Miltos, A.; Samuel, L. IRI Estimation Based on Pavement Distress Type, Density, and Severity: Efficacy of Machine Learning and Statistical Techniques. J. Infrastruct. Syst. 2022, 28, 4. [Google Scholar]
- Ali, A.A.; Heneash, U.; Hussein, A.; Ali, S.I.; Khan, S. Models Development for Asphalt Pavement Performance Index in Different Climate Regions Using Soft Computing Techniques. J. Soft Comput. Civ. Eng. 2022, 7, 20–42. [Google Scholar]
- Simon, D. Optimal State Estimation: Kalman, H-Infinity, and Nonlinear Approaches; John Willey & Sons: Hoboken, NJ, USA, 2006; pp. 461–483. [Google Scholar]
- Jeong, M.C.; Lee, S.J.; Cha, K.; Zi, G.; Kong, J.S. Probabilistic model forecasting for rail wear in Seoul metro based on Bayesian theory. Eng. Fail. Anal. 2019, 96, 202–210. [Google Scholar] [CrossRef]
- Lee, S.J.; Zi, G.; Mun, S.; Kong, J.S.; Choi, J.H. Probabilistic prognosis of fatigue crack growth for asphalt concretes. Eng. Fract. Mech. 2015, 141, 212–229. [Google Scholar] [CrossRef]
- Ristic, B.; Arulampalam, S.; Gordon, N. Beyond the Kalman Filter: Particle Filters for Tracking Applications; Artech House Publishers: Boston, UK; London, UK, 2004. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Content | Max. (m2) | Min. (m2) | Count (EA) | Summation of Distress Amount (m2) | Average Distress Amount (m2) | Average Except 0 (m2) | Distress Amount Standard Deviation (m2) | |
|---|---|---|---|---|---|---|---|---|
| SD | reference | 32.60 | 0.00 | 6288 | 1798.01 | 0.29 | 0.85 | 1.44 |
| after 2 yr. | 35.05 | 0.00 | 6288 | 6579.71 | 1.05 | 1.43 | 2.68 | |
| Crack | reference | 4.15 | 0.00 | 6771 | 599.04 | 0.09 | 0.56 | 0.33 |
| after 2 yr. | 9.50 | 0.00 | 6771 | 2366.18 | 0.35 | 0.69 | 0.76 | |
| Durability | reference | 2.33 | 0.00 | 7672 | 15.22 | 0.00 | 0.63 | 0.05 |
| after 2 yr. | 19.74 | 0.00 | 7672 | 452.46 | 0.06 | 2.41 | 0.67 | |
| Patching | reference | 32.45 | 0.00 | 7527 | 868.45 | 0.12 | 5.14 | 1.25 |
| after 2 yr. | 35.03 | 0.00 | 7527 | 3360.04 | 0.45 | 3.88 | 2.23 | |
| Joint spall | reference | 0.62 | 0.00 | 6261 | 60.56 | 0.01 | 0.11 | 0.04 |
| after 2 yr. | 4.13 | 0.00 | 6261 | 274.96 | 0.04 | 0.15 | 0.14 | |
| Division | Average Delta for Progression Rate of Distress in Time Intervals about Detected Data (Distress Delta Per 2 Years) | Number of Intervals Used in the Analysis (EA) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0~2 Years | 2~4 Years | 4~6 Years | 6~8 Years | 8~10 Years | 10~12 Years | 12~14 Years | 14~16 Years | 16~18 Years | ||
| SD | 0.44 | 1.88 | 11.98 | 8.21 | 10.74 | - | - | - | - | 6288 |
| Crack | 0.16 | 0.55 | 0.97 | 1.44 | 2.63 | - | - | - | - | 6771 |
| Durability | 0.05 | 0.31 | 2.73 | 4.21 | 6.35 | - | - | - | - | 7672 |
| Patching | 0.27 | 0.46 | 0.30 | 0.21 | 0.13 | 1.28 | 6.02 | 8.92 | 17.44 | 7527 |
| Joint spall | 0.02 | 0.05 | 0.14 | 0.29 | 0.27 | - | - | - | - | 6261 |
| Division | Actual Distress (m2) | Particle Filtering | Regression Analysis | LSTM | DNN | ||||
|---|---|---|---|---|---|---|---|---|---|
| Predicted Distress (m2) | Prediction Accuracy (%) | Predicted Distress (m2) | Prediction Accuracy (%) | Predicted Distress (m2) | Prediction Accuracy (%) | Predicted Distress (m2) | Prediction Accuracy (%) | ||
| SD | 33.25 | 33.65 | 98.78 | 38.53 | 84.11 | 29.64 | 89.14 | 28.91 | 86.95 |
| Crack | 5.75 | 5.62 | 97.72 | 5.03 | 87.47 | 4.81 | 83.48 | 4.56 | 79.31 |
| Durability | 13.65 | 13.67 | 99.86 | 14.52 | 93.59 | 12.44 | 91.14 | 11.17 | 81.83 |
| Patching | 35.03 | 35.14 | 99.69 | 33.76 | 96.39 | 28.84 | 82.33 | 26.64 | 76.05 |
| Joint spall | 0.77 | 1.02 | 67.96 | 1.05 | 63.87 | - | - | - | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, D.; Lee, J.; Baek, C.; An, D.; Yang, S. Predicting Concrete Pavement Condition for Sustainable Management: Unveiling the Development of Distresses through Machine Learning. Sustainability 2024, 16, 573. https://doi.org/10.3390/su16020573
Jung D, Lee J, Baek C, An D, Yang S. Predicting Concrete Pavement Condition for Sustainable Management: Unveiling the Development of Distresses through Machine Learning. Sustainability. 2024; 16(2):573. https://doi.org/10.3390/su16020573
Chicago/Turabian StyleJung, Donghyuk, Jinhyuk Lee, Cheolmin Baek, Deoksoon An, and Sunglin Yang. 2024. "Predicting Concrete Pavement Condition for Sustainable Management: Unveiling the Development of Distresses through Machine Learning" Sustainability 16, no. 2: 573. https://doi.org/10.3390/su16020573
APA StyleJung, D., Lee, J., Baek, C., An, D., & Yang, S. (2024). Predicting Concrete Pavement Condition for Sustainable Management: Unveiling the Development of Distresses through Machine Learning. Sustainability, 16(2), 573. https://doi.org/10.3390/su16020573