
Development of a Cost Prediction Model for Design Changes: Case of Korean Apartment Housing Projects



Abstract
1. Introduction
2. Literature Review
2.1. Evaluate Effect Due to Design Changes in Construction Projects
2.2. Cost Predictions in Construction
- First, linear regression is a commonly used method for predicting construction project costs. Several studies have demonstrated the effectiveness of linear regression models in this area. Alshamrani (2017) [22] created linear regression models to predict the costs of building traditional and green college buildings in North America. In a similar way, Magdum and Adamuthe (2017) [23] used linear regression and Artificial Neural Networks to forecast costs for different construction projects. Petruseva et al. (2017) [24] tested how accurately linear regression models could predict construction costs, showing that these models are useful for forecasting costs. Surenth et al. (2019) [25] and Ahmed and Ali (2020) [26] also developed linear regression models to estimate the costs of specific projects in Sri Lanka and road projects, respectively. All these studies found a straightforward relationship between cost predictors and various cost indices using linear models. However, they did not consider non-linear relationships, which might be necessary for analyzing different types of data.
- Historical series analysis stands out as a popular method for modeling and predicting various cost indices, particularly in the construction industry, where forecasting costs based on historical data trends is crucial. Ashuri and Lu (2010) [27] applied four traditional time series models to the Construction Cost Index and found that these models performed well in stable, long-term datasets but faltered with data that showed high volatility. Expanding beyond traditional methods, the causal approach in time series analysis examines the impact of different economic indicators on cost indices. This method was tested by Aydınlı (2022) [28], who assessed the effectiveness of time series analysis in predicting construction costs in Turkey, emphasizing its potential in identifying cost trends. Furthermore, Isikdag et al. (2023) [29] delved into forecasting construction material indices using “Autoregressive Integrated Moving Average” models and optimized neural networks, demonstrating improved accuracy in cost predictability. These studies illustrate the benefits of causal time series analysis in offering insights into the factors driving Cost Index changes, presenting a significant improvement over a simplistic linear model. Nonetheless, despite its advantages in understanding and predicting cost dynamics, the causal time series method, much like its univariate counterparts, is primarily effective for short-term forecasting and may struggle with predicting large, sudden changes in the data.
- Third, ML algorithms offer a sophisticated approach to cost prediction, distinguishing themselves by learning from input data to make informed predictions about future costs. Unlike traditional static models, such as those used in time series analysis, ML algorithms adapt to data patterns to forecast outcomes more accurately [30]. For instance, Fan and Sharma (2021) [31] achieved a prediction accuracy within a 7% error margin using Support Vector Machine (SVM) and Least Squares SVM. Similarly, Meharie et al. (2021) [32] found that stacking ensemble ML algorithms surpassed traditional approaches like linear regression and neural networks in accuracy for highway construction cost predictions. Moreover, the research by Hsu et al. (2021) [33] and Ahn et al. (2017) [34] highlighted ML’s capability in forecasting various aspects of project performance and logistics costs. Cheng and Hoang (2014) [35] further demonstrated the use of LS-SVM for interval estimations in construction costs, underlining ML’s versatility in different predictive scenarios. Nonetheless, these successful applications underscore the dependence of ML models on the quality and structure of the data they are trained on, which could limit their effectiveness across different types of cost indices. Hashemi et al. (2020) [36] pointed out that the accuracy of ML-based cost forecasting is significantly influenced by the size and quality of the dataset, highlighting data availability and quality as potential challenges in applying ML techniques effectively in construction cost estimations.
2.3. Potential for Cost Increases Predictions of Design Changes
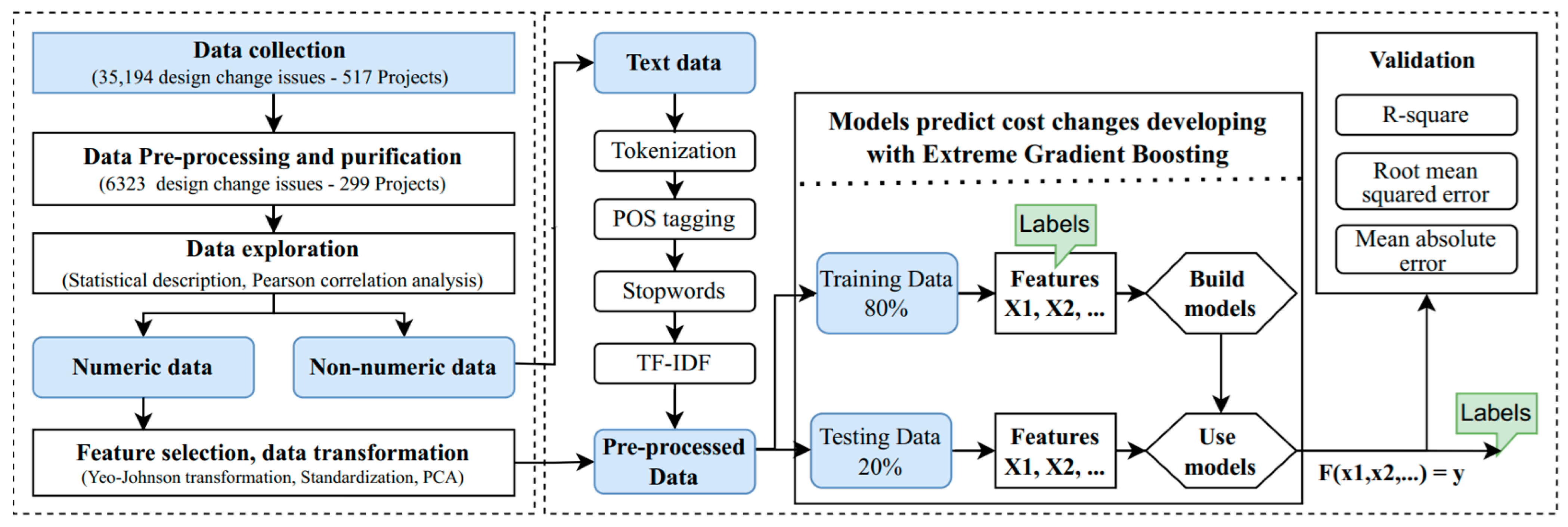
3. Data Collection and Preprocessing
4. ML-NLP Based Cost Prediction Model for Design Changes
- Tokenization to break the text into individual words.
- Parts-of-Speech tagging to assign grammatical labels to words in a sentence.
- Stop words to remove stop words from text data.
- TF-IDF vectorization converts a collection of documents into numerical representations based on the TF-IDF scores of terms.
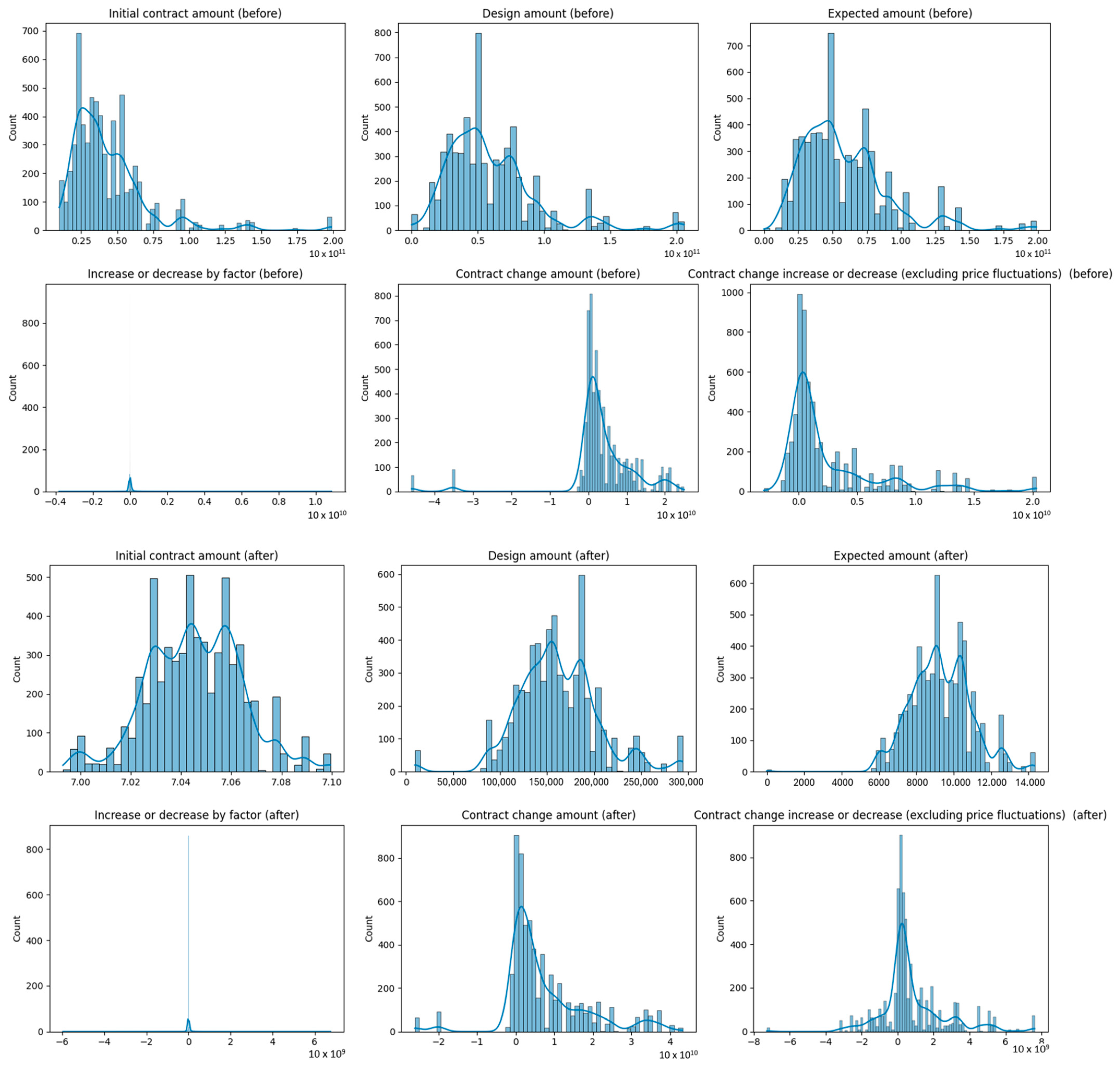
4.1. Data Description
4.2. Data Processing
4.2.1. Yeo-Johnson Transformation
4.2.2. Data Standardization
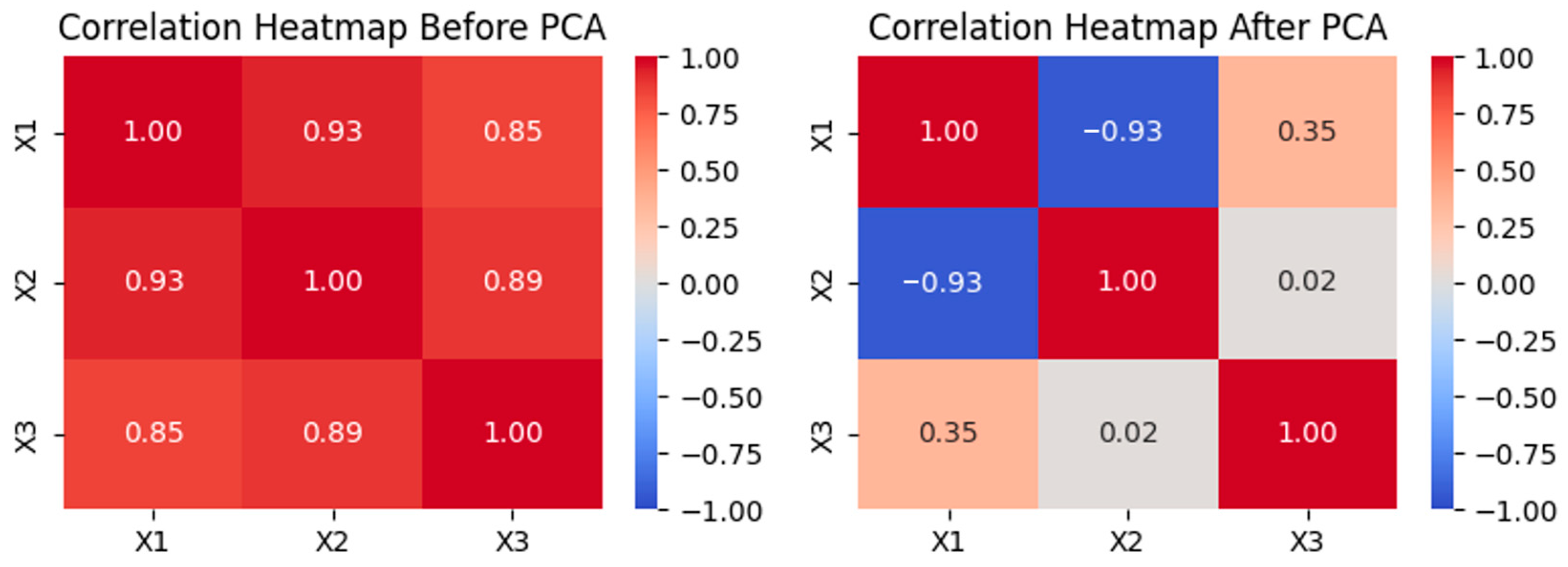
4.2.3. Principal Component Analysis (PCA)
4.2.4. Text Preprocessing Process
4.3. Model Development and Evaluation
4.3.1. ML Models Developing
Model for Output 1 (OP1)—Increase or Decrease by Factor
- MLR
- RF
- XGB
Model for Outputs 2 and 3 (OP2 and OP3)
- CatBoost
- Stacked models
4.3.2. Evaluation Metrics
- R-square (R)
- (Sum of Squares of Residuals) measures the variation of the observed data points from the fitted values.
- (Total Sum of Squares) quantifies the total variation in the dependent variable.
- Root mean squared error (RMSE)
- N is the number of observations or the total number of data points in the dataset.
- is the actual value for the ith observation.
- is the predicted value for the ith observation.
- MAE
- n is the number of observations or the total number of data points in the dataset.
- is the actual value for the ith observation.
- is the predicted value for the ith observation.
5. Prediction Performance
5.1. Increase or Decrease by Factor
5.2. Contract Change Amount
5.3. Contract Change Amount (Excluding Price Fluctuations)
6. Limitations and Discussion
- Firstly, the dataset, while extensive, is constrained to South Korean apartment projects. This project’s typical and geographical limitations may affect the generalizability of the findings to construction practices and market conditions in other regions. Future research could benefit from incorporating the data from a diverse set of locations to enhance the global applicability of the model.
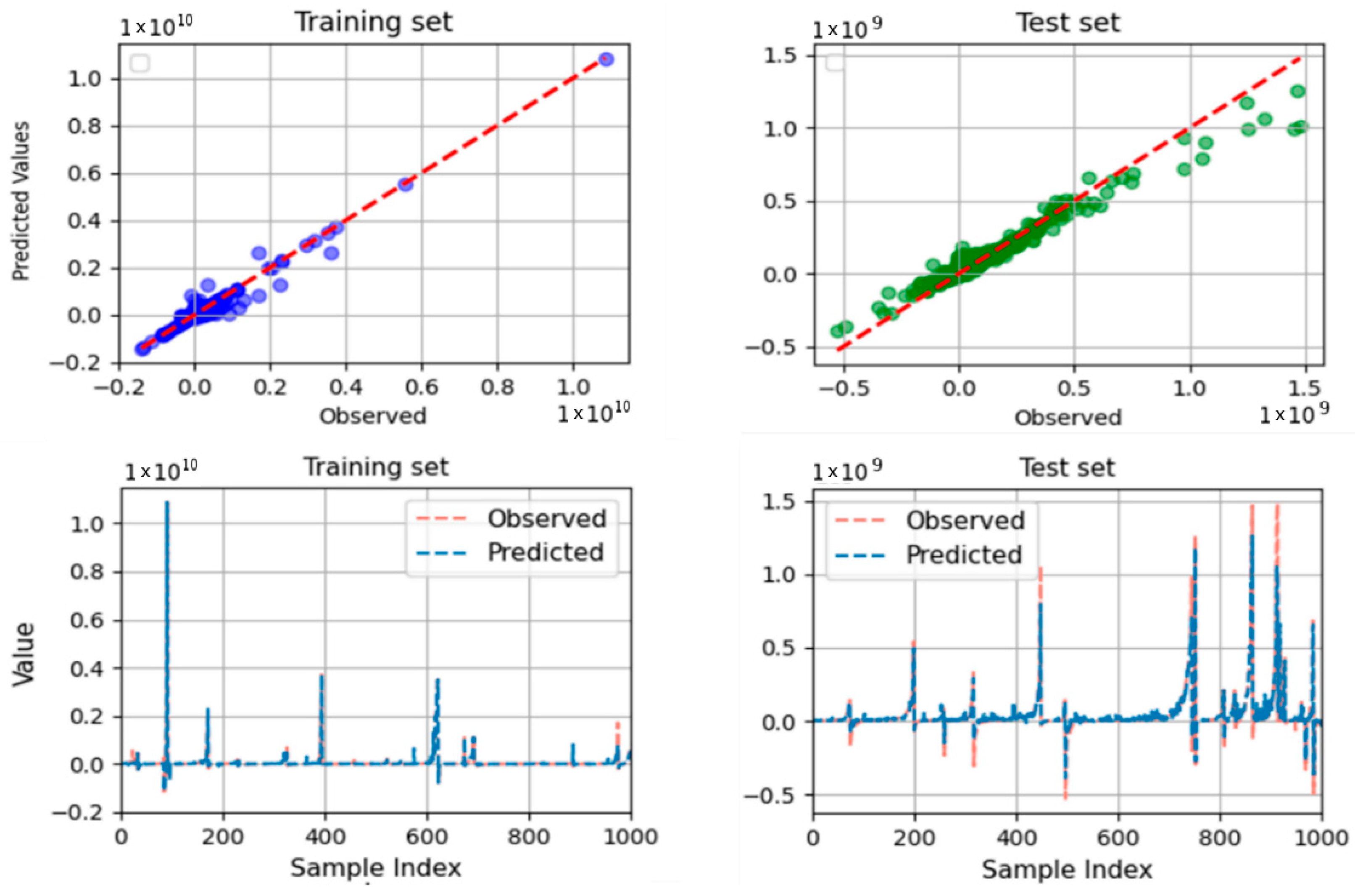
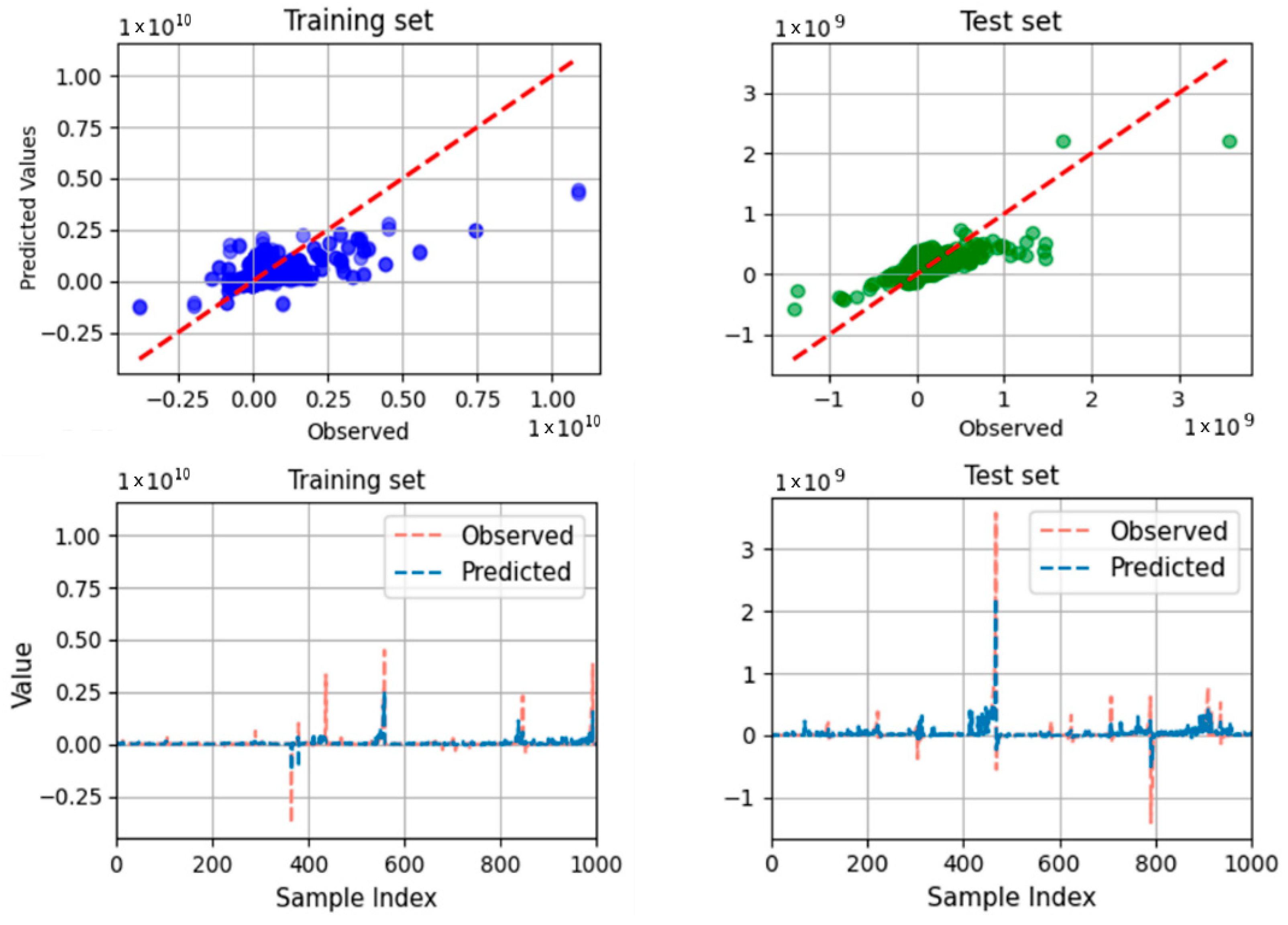
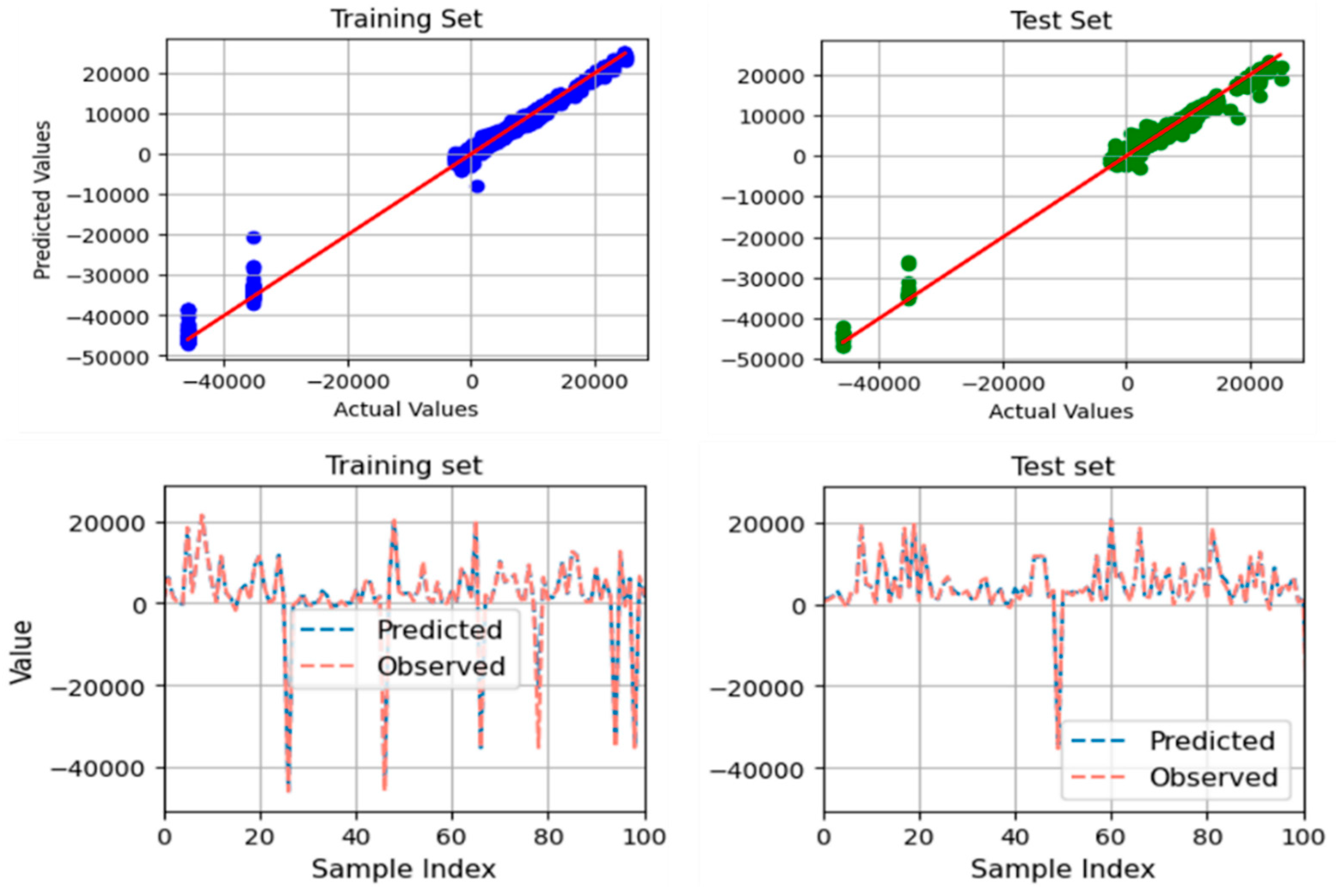
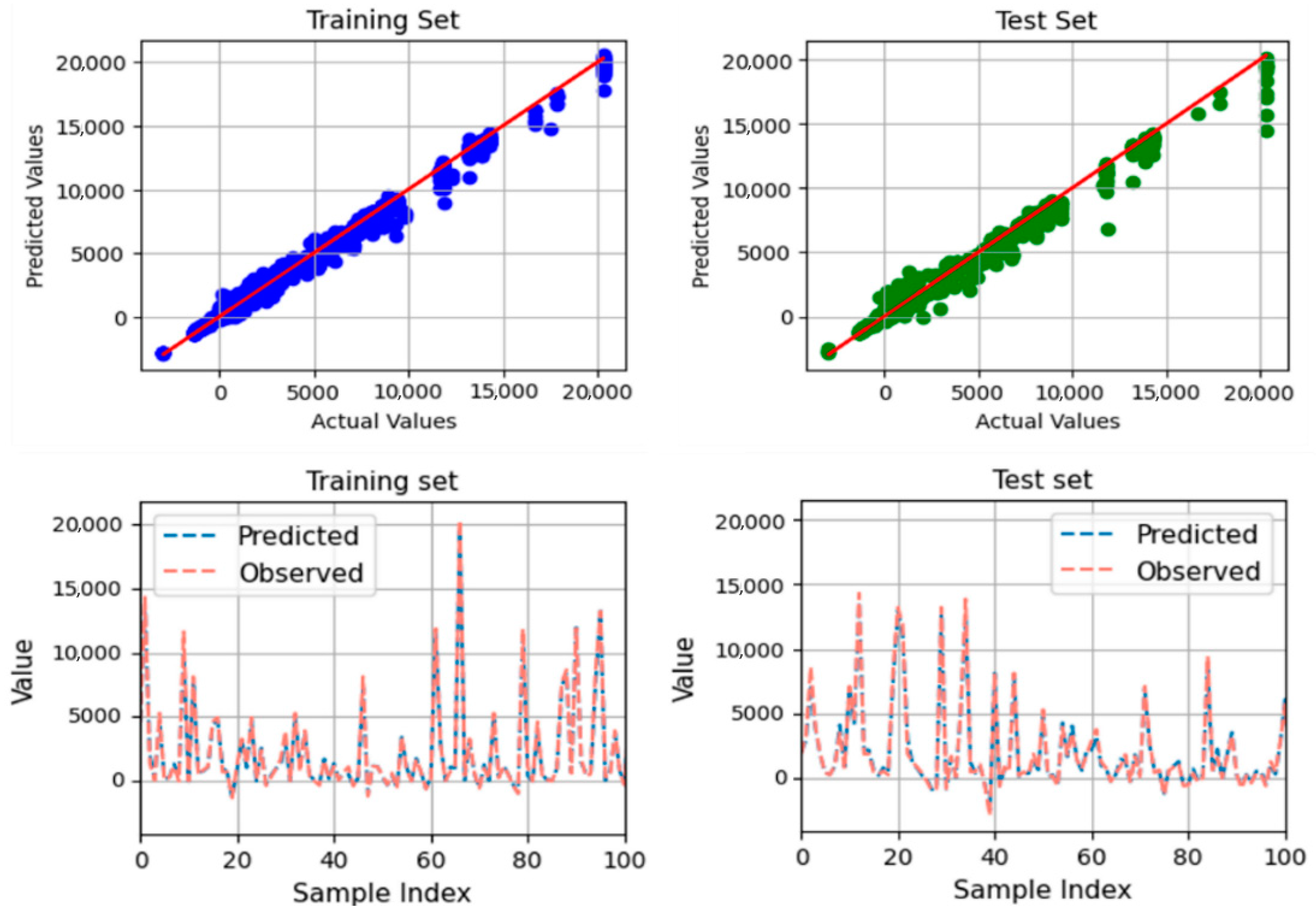
- Another limitation arises from the reliance on historical data, which may not fully capture the rapid advancements in construction technologies and methods. The prediction model is sequentially sampled based on project implementation time, using a training set from 2007 to 2010 and a test set from 2010 to 2011. Consequently, the model can effectively forecast future outputs. Additionally, Figure 5, Figure 6, Figure 7 and Figure 8 illustrate that the model demonstrates accurate predictions within a reasonable range, avoiding extremes that deviate significantly from the mean value. However, the construction industry is evolving, with new materials, techniques, and regulations emerging. These advancements could significantly alter the factors impacting cost adjustments, necessitating continuous updates to the model to maintain its accuracy and relevance.
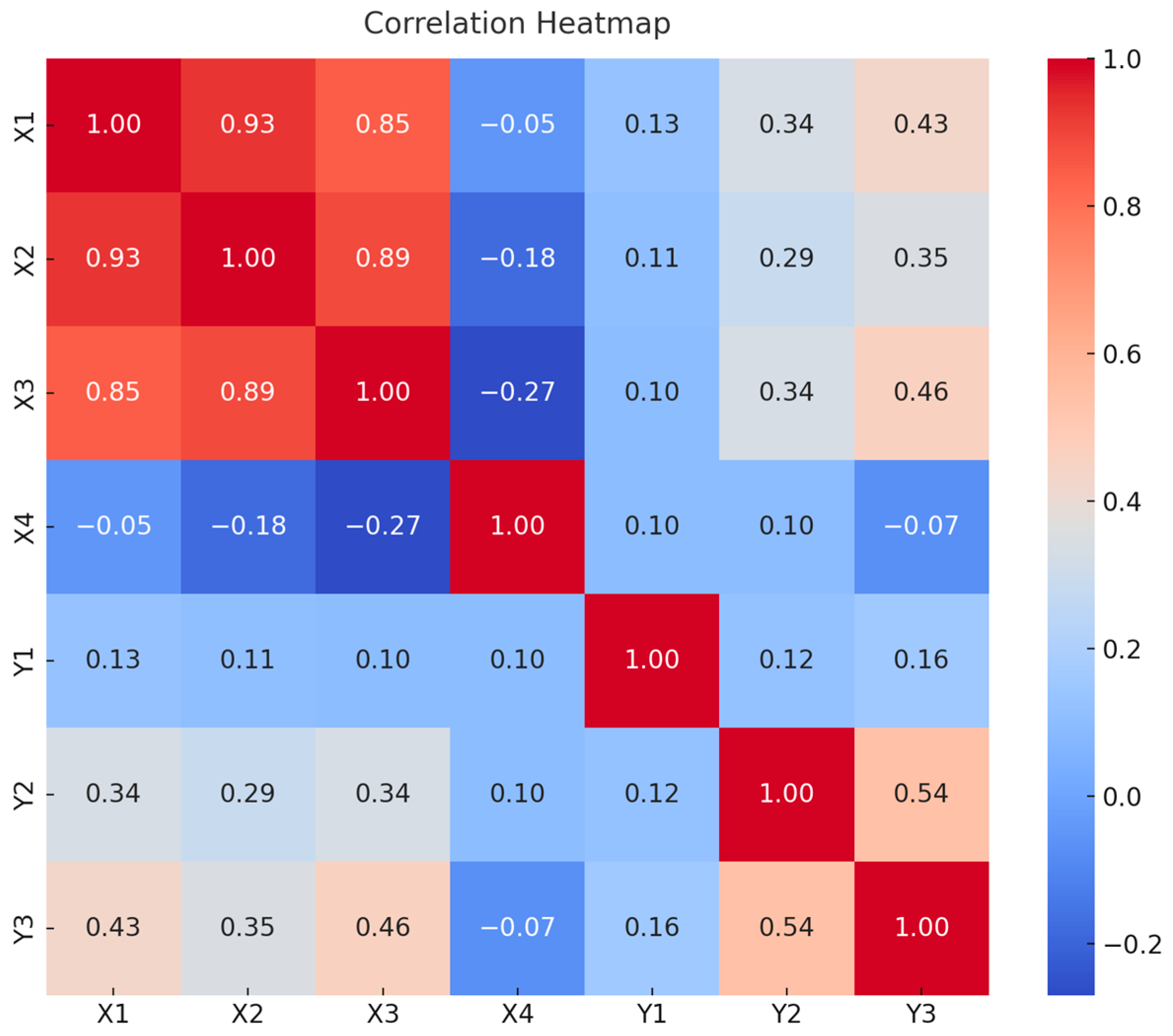
- Finally, the potential for multicollinearity among the variables, despite the application of PCA, suggests that some underlying relationships between predictors may not have been entirely addressed. Future studies could explore alternative or additional dimensionality reduction techniques to further mitigate this issue.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kim, G.H.; Shin, J.; Kim, S.Y.; Shin, Y. Comparison of School Building Construction Costs Estimation Methods Using Regression Analysis, Neural Network, and Support Vector Machine. J. Build. Constr. Plan. Res. 2013, 1, 29576. [Google Scholar] [CrossRef]
- Amoruso, F.M.; Dietrich, U.; Schuetze, T. Indoor thermal comfort improvement through the integrated BIM-parametric workflow-based sustainable renovation of an exemplary apartment in Seoul, Korea. Sustainability 2019, 11, 3950. [Google Scholar] [CrossRef]
- Kim, M.; Lee, J.; Kim, J. Analysis of Design Change Mechanism in Apartment Housing Projects Using Association Rule Mining (ARM) Model. Appl. Sci. 2022, 12, 11036. [Google Scholar] [CrossRef]
- Gharaibeh, L.; Matarneh, S.T.; Arafeh, M.; Sweis, G. Factors Leading to Design Changes in Jordanian Construction Projects. Int. J. Product. Perform. Manag. 2020, 70, 893–915. [Google Scholar] [CrossRef]
- Yap, J.B.H.; Abdul-Rahman, H.; Chen, W. A Conceptual Framework for Managing Design Changes in Building Construction. MATEC Web Conf. 2016, 66, 00021. [Google Scholar] [CrossRef]
- Khanh, H.D. Factors Causing Design Changes in Vietnamese Residential Construction Projects: An Evaluation and Comparison. J. Sci. Technol. Civ. Eng. (Stce)-Huce 2020, 14, 151–166. [Google Scholar] [CrossRef]
- Aslam, M.; Baffoe-Twum, E.; Saleem, F. Design Changes in Construction Projects—Causes and Impact on the Cost. Civ. Eng. J. 2019, 5, 1647–1655. [Google Scholar] [CrossRef]
- Jafari, P.; Al Hattab, M.; Mohamed, E.; AbouRizk, S. Automated extraction and time-cost prediction of contractual reporting requirements in construction using natural language processing and simulation. Appl. Sci. 2021, 11, 6188. [Google Scholar] [CrossRef]
- Sánchez, O.; Castañeda, K.; Herrera, R.; Pellicer, E. Benefits of Building Information Modeling in Road Projects for Cost Overrun Factors Mitigation. In Proceedings of the Construction Research Congress 2022, Arlington, VA, USA, 9–12 March 2022. [Google Scholar] [CrossRef]
- Plebankiewicz, E. Model of Predicting Cost Overrun in Construction Projects. Sustainability 2018, 10, 4387. [Google Scholar] [CrossRef]
- Williams, T.R.; Gong, J. Predicting Construction Cost Overruns Using Text Mining, Numerical Data and Ensemble Classifiers. Autom. Constr. 2014, 43, 23–29. [Google Scholar] [CrossRef]
- Babalola, N.A.J.; Aderogba, A.M.; Adetunji, O.O. Inflation and Cost Overrun in Public Sector Construction Projects in Nigeria. ECS Trans. 2022, 107, 16137. [Google Scholar] [CrossRef]
- Lee, J.; Yi, J.S. Predicting Project’s Uncertainty Risk in the Bidding Process by Integrating Unstructured Text Data and Structured Numerical Data Using Text Mining. Appl. Sci. 2017, 7, 1141. [Google Scholar] [CrossRef]
- Saravi, M.E.; Newnes, L.; Mileham, A.R.; Goh, Y.M. Estimating Cost at the Conceptual Design Stage to Optimize Design in Terms of Performance and Cost. In Collaborative Product and Service Life Cycle Management for a Sustainable World: Proceedings of the 15th ISPE International Conference on Concurrent Engineering (CE2008); Springer: London, UK, 2008. [Google Scholar] [CrossRef]
- Kikwasi, G.J. Claims in Construction Projects: How Causes Are Linked to Effects? J. Eng. Des. Technol. 2021, 21, 1710–1724. [Google Scholar] [CrossRef]
- Afelete, E.; Jung, W. Causes of Design Change Depending on Power Project-Types in Ghana. Energies 2021, 14, 6871. [Google Scholar] [CrossRef]
- Elmousalami, H.H. Artificial intelligence and parametric construction cost estimate modeling: State-of-the-art review. J. Constr. Eng. Manag. 2020, 146, 03119008. [Google Scholar] [CrossRef]
- Juszczyk, M.; Leśniak, A.; Zima, K. ANN Based Approach for Estimation of Construction Costs of Sports Fields. Complexity 2018, 2018, 7952434. [Google Scholar] [CrossRef]
- Koo, C.; Hong, T.; Hyun, C.-T. The Development of a Construction Cost Prediction Model With Improved Prediction Capacity Using the Advanced CBR Approach. Expert Syst. Appl. 2011, 38, 8597–8606. [Google Scholar] [CrossRef]
- Alqahtani, A.; Whyte, A. Artificial Neural Networks Incorporating Cost Significant Items Towards Enhancing Estimation for (Life-Cycle) Costing of Construction Projects. Constr. Econ. Build. 2013, 14, 1233–1243. [Google Scholar] [CrossRef]
- Fernando, N. An Artificial Neural Network (ANN) Approach for Early Cost Estimation of Concrete Bridge Systems in Developing Countries: The Case of Sri Lanka. J. Financ. Manag. Prop. Constr. 2023, 29, 23–51. [Google Scholar] [CrossRef]
- Alshamrani, O.S. Construction Cost Prediction Model for Conventional and Sustainable College Buildings in North America. J. Taibah Univ. Sci. 2017, 11, 315–323. [Google Scholar] [CrossRef]
- Magdum, S.K.; Adamuthe, A.C. Construction Cost Prediction Using Neural Networks. Ictact J. Soft Comput. 2017, 8, 1. [Google Scholar] [CrossRef]
- Petruseva, S.; Žileska-Pančovska, V.; Žujo, V.; Brkan-Vejzović, A. Construction Costs Forecasting: Comparison of the Accuracy of Linear Regression and Support Vector Machine Models. Teh. Vjesn.-Tech. Gaz. 2017, 24, 14311438. [Google Scholar] [CrossRef]
- Surenth, S.; Rajapakshe, R.M.P.P.V.; Muthumala, I.S.; Samarawickrama, M.N.C. Cost Forecasting Analysis on Bored and Cast-in-Situ Piles in Sri Lanka: Case Study at Selected Pile Construction Sites in Colombo Metropolis Area. Eng. J. Inst. Eng. Sri Lanka 2019, LII, 57–66. [Google Scholar] [CrossRef]
- Ahmed, S.F.; Ali, N.S. Pre-Design Cost Modeling of Road Projects. Tikrit J. Eng. Sci. 2020, 27, 6–11. [Google Scholar] [CrossRef]
- Ashuri, B.; Lu, J. Time series analysis of ENR construction cost index. J. Constr. Eng. Manag. 2010, 136, 1227–1237. [Google Scholar] [CrossRef]
- Aydınlı, S. Time Series Analysis of Building Construction Cost Index in Türkiye. J. Constr. Eng. Manag. Innov. 2022, 5, 218–227. [Google Scholar] [CrossRef]
- Isikdag, U.; Hepsağ, A.; Bıyıklı, S.İ.; Öz, D.; Bekdaş, G.; Geem, Z.W. Estimating Construction Material Indices With ARIMA and Optimized NARNETs. Comput. Mater. Contin. 2023, 74, 113. [Google Scholar] [CrossRef]
- Wang, J.; Ashuri, B. Predicting ENR construction cost index using machine-learning algorithms. Int. J. Constr. Educ. Res. 2017, 13, 47–63. [Google Scholar] [CrossRef]
- Fan, M.; Sharma, A. Design and Implementation of Construction Cost Prediction Model Based on SVM and LSSVM in Industries 4.0. Int. J. Intell. Comput. Cybern. 2021, 14, 145–157. [Google Scholar] [CrossRef]
- Meharie, M.G.; Mengesha, W.J.; Gariy, Z.A.; Mutuku, R.N. Application of Stacking Ensemble Machine Learning Algorithm in Predicting the Cost of Highway Construction Projects. Eng. Constr. Archit. Manag. 2021, 29, 2836–2853. [Google Scholar] [CrossRef]
- Hsu, M.-W.; Dacre, N.; Senyo, P.K. Identifying Inter-Project Relationships With Recurrent Neural Networks: Towards an AI Framework of Project Success Prediction. SSRN Electron. J. 2021. [Google Scholar] [CrossRef]
- Ahn, S.H.; Altaf, M.S.; Han, S.; Al-Hussein, M. Application of Machine Learning Approach for Logistics Cost Estimation in Panelized Construction. Modul. Offsite Constr. (Moc) Summit Proc. 2017. [Google Scholar] [CrossRef]
- Cheng, M.-Y.; Hoang, N.-D. Interval Estimation of Construction Cost at Completion Using Least Squares Support Vector Machine. J. Civ. Eng. Manag. 2014, 20, 223–236. [Google Scholar] [CrossRef]
- Hashemi, S.T.; Ebadati, O.M.; Kaur, H. Cost Estimation and Prediction in Construction Projects: A Systematic Review on Machine Learning Techniques. SN Appl. Sci. 2020, 2, 1703. [Google Scholar] [CrossRef]
- Sharma, S.; Ahmed, S.; Naseem, M.; Alnumay, W.S.; Singh, S.; Cho, G. A Survey on Applications of Artificial Intelligence for Pre-Parametric Project Cost and Soil Shear-Strength Estimation in Construction and Geotechnical Engineering. Sensors 2021, 21, 463. [Google Scholar] [CrossRef] [PubMed]
- Al Shalabi, L.; Shaaban, Z.; Kasasbeh, B. Data mining: A preprocessing engine. J. Comput. Sci. 2006, 2, 735–739. [Google Scholar] [CrossRef]
- Benavoli, A.; Corani, G.; Mangili, F. Should we really use post-hoc tests based on mean-ranks? J. Mach. Learn. Res. 2016, 17, 152–161. [Google Scholar]
- Walkowiak, T.; Gniewkowski, M. Evaluation of vector embedding models in clustering of text documents. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2019), Varna, Bulgaria, 2–4 September 2019; pp. 1304–1311. [Google Scholar]
- Bisandu, D.B.; Moulitsas, I.; Filippone, S. Social ski driver conditional autoregressive-based deep learning classifier for flight delay prediction. Neural Comput. Appl. 2022, 34, 8777–8802. [Google Scholar] [CrossRef]
- Kyriazos, T.; Poga, M. Dealing with multicollinearity in factor analysis: The problem, detections, and solutions. Open J. Stat. 2023, 13, 404–424. [Google Scholar] [CrossRef]
- Gwelo, A.S. Principal components to overcome multicollinearity problem. Oradea J. Bus. Econ. 2019, 4, 79–91. [Google Scholar] [CrossRef]
- Deshpande, N.; Londhe, S.; Kulkarni, S. Modeling compressive strength of recycled aggregate concrete by Artificial Neural Network, Model Tree and Non-linear Regression. Int. J. Sustain. Built Environ. 2014, 3, 187–198. [Google Scholar] [CrossRef]
- Lin, P.; Ding, F.; Hu, G.; Li, C.; Xiao, Y.; Tse, K.T.; Kwok, K.; Kareem, A. Machine learning-enabled estimation of crosswind load effect on tall buildings. J. Wind Eng. Ind. Aerodyn. 2022, 220, 104860. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Shah, S.F.A.; Chen, B.; Zahid, M.; Ahmad, M.R. Compressive strength prediction of one-part alkali activated material enabled by interpretable machine learning. Constr. Build. Mater. 2022, 360, 129534. [Google Scholar] [CrossRef]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient boosting with categorical features support. arXiv 2018, arXiv:1810.11363. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Contract Characteristic Indices | Description |
|---|---|---|
| X1 | Number of Contractors | Total number of main contractors involved. |
| X2 | Initial Contract Amount | Awarded bid price. |
| X3 | Design Amount | Maximum budget allocated for design. |
| X4 | Expected Amount | Estimated cost of the project. |
| X5 | Name of Project | Includes developer’s information and project name. |
| X6 | Regional | Encompasses South Korea’s 16 provinces. |
| X7 | Project type | Construction purpose (Renovation, Sale, Rental, Self-use). |
| X8 | Main Contractor | Lead contractor on the project. |
| X9 | How to Determine the Successful Bidder | Criteria for contractor selection (Eligibility, Lowest Bid, etc.). |
| X10 | Type (Construction Category) | Disciplines with design changes (e.g., Architectural, Structural). |
| X11 | Adjustment Factors (Reasons) | Main reasons for design changes (e.g., Design Change, Government Request). |
| X12 | Subcategory | Specific reasons for design alterations. |
| X13 | Part/Object | Elements subject to design changes (e.g., Toilets, Windows). |
| X14 | Detail | Detailed description of the design modifications. |
| X15 | Contractor’s Explanation | Detailed rationale for the changes. |
| X16 | Project Owner | Investing organization’s name. |
| X17 | Contract End Date | Contract finalization date. |
| X18 | Planned Completion Date | Publicly announced planned completion date. |
| X19 | Actual Completion Date | Actual date of completion. |
| Y1 | Increase or Decrease by Factor | Recorded cost variance per design change. |
| Y2 | Contract Change Amount (including price fluctuations) | Total adjustment to the contract value, accounting for both design changes and market price variations. |
| Y3 | Contract Change Amount (excluding price fluctuations) | Net change in contract cost due to design changes, not influenced by market price variations. |
| ID | Data Type | Detail | ||||
|---|---|---|---|---|---|---|
| Mean | STD | Min | Max | Skewness | ||
| X1 | Numeric | 1.82 | 0.95 | 1 | 6 | 1.01 |
| X2 | Numeric | 43.31 × 109 | 27.12 × 109 | 9.67 × 109 | 199.00 × 109 | 2.50 |
| X3 | Numeric | 59.87 × 109 | 35.11 × 109 | 0.10 × 109 | 205.71 × 109 | 1.63 |
| X4 | Numeric | 58.01 × 109 | 31.60 × 109 | 0.00 | 198.99 × 109 | 1.47 |
| X5 | String | e.g., “Wonju Musil District 3 1BL Apartment Construction Section 4” | ||||
| X6 | Categorical | Seoul, Chungbuk, Chungnam, Gangwon, Gyeonggi, Gyeongbuk, Gyeongnam, Jeollabuk, Jeollanam, Jeju. | ||||
| X7 | Categorical | housing/redevelopment; rental; sale; sales + rental; self-operation. | ||||
| X8 | String | e.g., “Samneung Construction Co., Ltd., Gwangju-si, Republic of Korea”. | ||||
| X9 | Categorical | Eligible; Lowest price; Lowest price review; Qualification review success system; Qualification screening; Turnkey. | ||||
| X10 | Categorical | Architectural; Structural; Mechanical; Outdoor Mechanical; Electrical; Communication; Firefighting; Earthwork; District Earthwork; Building Earthwork; Landscape; and Common. | ||||
| X11 | Categorical | Design changes: changes mandated by the head office; alterations requested by government agencies; design errors; design improvements; site conditions; cost reductions; schedule extensions; changes in finishing materials; compliance with permit requirements; project plan modifications; additional construction; cost savings; civil complaints; sales promotions; settlement at completion; and other factors (17 in total). | ||||
| X12 | String | e.g., “Settlement Change in construction method, Civil complaints around the site”. | ||||
| X13 | Categorical | PIT floor; living room; stairwell; common area; common facilities; machine room; balcony; rooms; corridors; firefighting equipment; elevator; indoor piping; indoor wiring; rooftop; outdoor areas; outdoor piping; exterior walls; bathroom; electrical room; kitchen; main entrance; underground spaces; underground water tank; underground parking; piloti; entrance; among others. | ||||
| X14 | String | e.g., “Machine room size (2400 × 2700) Overhead height H = 4550 Machine room height H = 2300 Door installation 9 × 21SD Equipment loading window 12 × 15 AGW” | ||||
| X15 | String | e.g., “Application for residents planning Basic (file/history)”. | ||||
| X16 | String | e.g., “L.H.” | ||||
| X17 | Date | Dd/mm/yyyy | ||||
| X18 | Date | Dd/mm/yyyy | ||||
| X19 | Date | Dd/mm/yyyy | ||||
| Mean | STD | Min | Max | Skewness | ||
| Y1 | Numeric | 0.04 × 109 | 0.29 × 109 | −3.80 × 109 | 10.86 × 109 | 16.01 |
| Y2 | Numeric | 3.63 × 109 | 9.04 × 109 | −45.94 × 109 | 24.96 × 109 | −2.37 |
| Y3 | Numeric | 2.50 × 109 | 4.07 × 109 | −2.96 × 109 | 20.33 × 109 | 2.12 |
| Output | Hyperparameter | ||||
|---|---|---|---|---|---|
| Bagging_Temperature | Learning_Rate | Depth | l2_Leaf_Reg | Iterations | |
| Contract change amount | 0.7 | 0.3 | 10 | 5 | 500 |
| Contract change increase or decrease | 0.7 | 0.3 | 10 | 5 | 500 |
| Model | Dataset | R2 | MAE | RMSE |
|---|---|---|---|---|
| XGB | train | 0.955 | 14.149 | 67.7 |
| test | 0.930 | 16.05 | 75.09 | |
| Multilinear Regression | train | 0.476 | 66.11 | 238.14 |
| test | 0.585 | 43.85 | 101.41 |
| Output (in Million Won) | Dataset | R2 | MAE | RMSE |
|---|---|---|---|---|
| Contract change amount | train | 0.994 | 422.3 | 701.8 |
| test | 0.985 | 605.1 | 1009.5 | |
| Contract change amount (excluding price fluctuations) | train | 0.9934 | 211.7 | 330.5 |
| test | 0.982 | 302.1 | 548.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahn, I.-S.; Kim, J.-J.; Lee, J.-S. Development of a Cost Prediction Model for Design Changes: Case of Korean Apartment Housing Projects. Sustainability 2024, 16, 4322. https://doi.org/10.3390/su16114322
Ahn I-S, Kim J-J, Lee J-S. Development of a Cost Prediction Model for Design Changes: Case of Korean Apartment Housing Projects. Sustainability. 2024; 16(11):4322. https://doi.org/10.3390/su16114322
Chicago/Turabian StyleAhn, Ie-Sle, Jae-Jun Kim, and Joo-Sung Lee. 2024. "Development of a Cost Prediction Model for Design Changes: Case of Korean Apartment Housing Projects" Sustainability 16, no. 11: 4322. https://doi.org/10.3390/su16114322
APA StyleAhn, I.-S., Kim, J.-J., & Lee, J.-S. (2024). Development of a Cost Prediction Model for Design Changes: Case of Korean Apartment Housing Projects. Sustainability, 16(11), 4322. https://doi.org/10.3390/su16114322